1. Introduction
SAR (synthetic aperture radar) is an active microwave remote sensing device that images an object by transmitting electromagnetic waves and receiving corresponding echoes from the object [
1]. SAR can work at night and in bad weather conditions, and can also penetrate the shallow surface and detect concealed targets. It has all-day and all-weather working capability [
2]. After decades of development, SAR has become an important method in remote sensing technologies, and it is widely used in military and civilian fields [
3].
SAR images are quite different from optical images, due to the mechanism of electromagnetic scattering and coherent imaging. SAR images are the mapping of the three-dimensional geometry and radiation information of the target into the two-dimensional images, which have overlap and shadow, and contain coherent speckle noise. This makes SAR images more difficult to interpret and understand visually than optical images, and thus has a greater impact on target detection and recognition. Therefore, SAR automatic target recognition (SAR ATR) has become a hot research topic.
ATR is used to identify the true attributes of the targets from SAR images. According to the different methods adopted by SAR ATR, the technology can be divided into two classes: classical methods and deep learning methods. Classical methods usually perform feature extraction manually, and then use template matching and machine learning methods for classification, the representative methods of which are given in [
4,
5,
6]. Deep learning methods usually use convolutional neural networks to extract the features of SAR images and then to classify them, the representative methods of which are given in [
7,
8,
9]. Comparing the two types of methods, because of powerful representation capabilities, the ATR methods based on deep learning often have stronger recognition performance. These methods have achieved some good results in target recognition based on single-angle SAR images.
In actual conditions, the performance of the SAR device will be affected by many factors, such as the attitude of platform, the parameters of the radar system, the environment, and the attitude angle of target, which will cause fluctuations to SAR image quality [
10]. Due to the side-view imaging geometry, SAR is very sensitive to elevation and azimuth angles of imaging [
11]. For the same target, even if the observation angle has a small change, the obtained SAR image of the target may be quite different. Meanwhile, for different targets under a certain observation angle, there may be greater similarity. This makes the target recognition of single-aspect SAR images quite difficult.
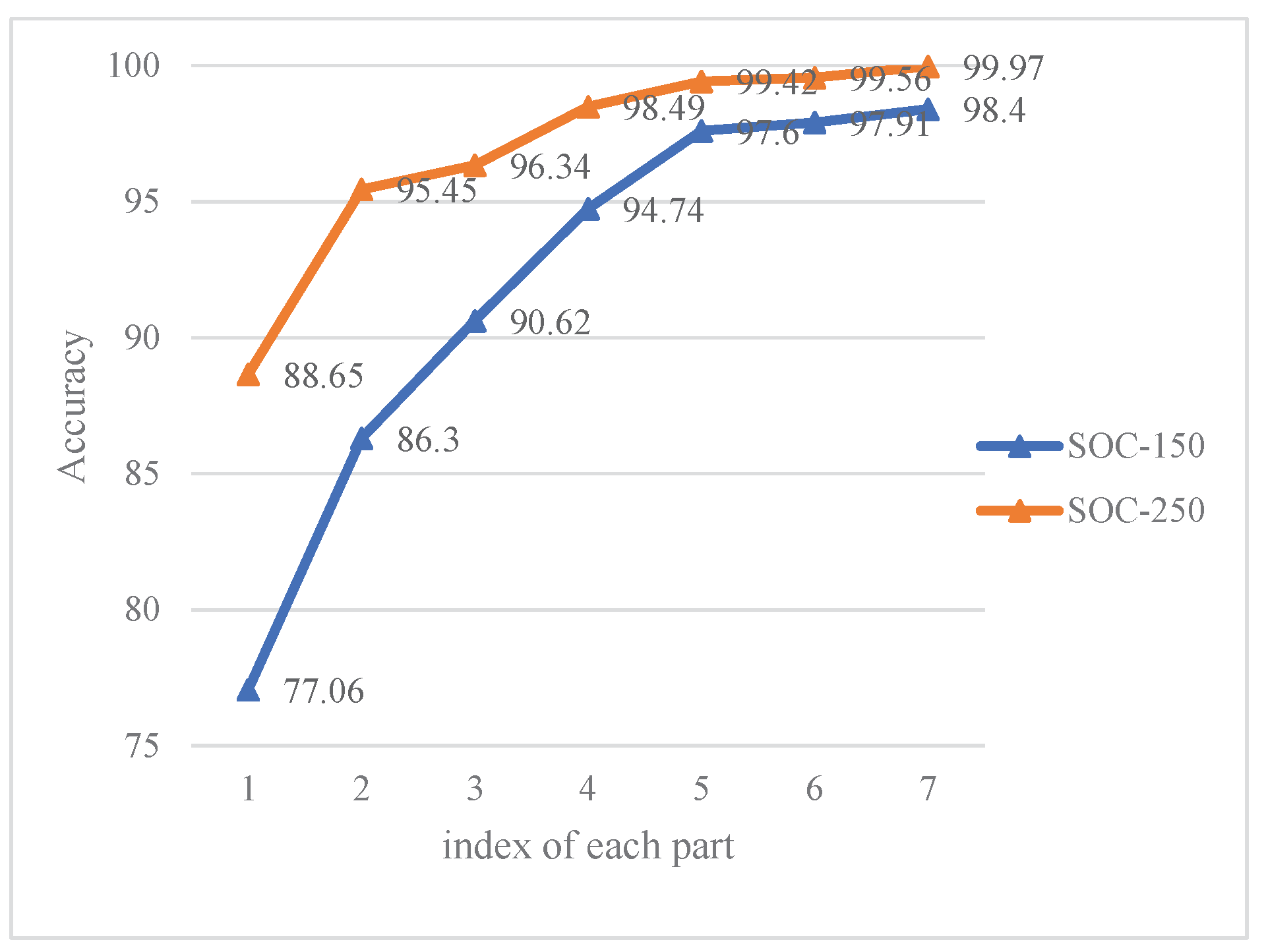
Figure 1 shows the images of the airborne SAR in MSTAR (Moving and Stationary Target Acquisition and Recognition) dataset [
12], observing the same target (T72 tank) at different azimuth angles.
Figure 1 (2),(6) can clearly show the barrel of T72, while other images are not observed or not obvious. Therefore, the single-aspect SAR target recognition method may fluctuate in performance as the azimuth angle changes, and it is often difficult to achieve the requirements of high-precision recognition.
With the development of SAR system technology, advanced SAR can continuously observe the same target at different azimuth angles. The SAR images of the same target at multiple azimuth angles have more information for identification [
13]. Multi-aspect SAR target recognition uses the image sequence of the same target at different azimuth angles, where the scattering characteristics of different angles are helpful for target recognition. Compared with single-aspect target recognition, it has some advantages [
14,
15]:
SAR image sequence with multiple azimuth angles can make up for the lack of information in a single image, and further increase the information for target recognition.
There is a certain correlation involved in multi-aspect SAR images, which provides another dimensional of information for target recognition.
In recent years, with the development of deep learning, multi-aspect SAR target recognition methods based on deep learning have also been developed. Pei et al. proposed the multi-view deep convolutional neural network (MVDCNN), which uses a parallel network to extract features from SAR images of different views, and further fuses these features through pooling [
16]. Zhao et al. proposed the multi-stream convolutional neural network (MS-CNN) and designed a Fourier feature fusion framework derived from kernel approximation based on random Fourier features to unravel the highly nonlinear relationship between images and classes [
17]. Zhang et al. proposed a multi-aspect ATR architecture based on ResNet and LSTM, which achieves good recognition performance [
18].
Although these methods have provided satisfactory results, they all require large-scale training data to train the deep learning model. Once the size of the dataset is reduced, the performance of target recognition will also decrease.
In addition, the SAR dataset of a specific target in a different azimuth angle is usually expensive to obtain and requires a lot of manpower and material resources to label sufficient samples for image annotation. Therefore, multi-aspect SAR target recognition under a small number of samples is the current development trend.
At present, single-apect SAR target recognition under the small number of training samples has been studied [
19,
20,
21]. However, there are relatively few studies on multi-apect SAR target recognition with a small number of training samples. Therefore, this paper proposes a recognition method based on a prototypical network [
22], which uses a deep learning model as a feature extraction module, and further uses methods such as multi-task learning and multi-level feature fusion based on attention mechanism.
The advantages of the method in this paper are as follows:
Experiments show that this method can significantly improve the recognition performance of the model with a small number of training samples.
This method can be applied to different deep learning feature extraction models.
The remainder of the paper is organized as follows.
Section 2 introduces the target recognition method under the small number of training samples proposed in this paper in detail;
Section 3 presents the experimental details and results;
Section 4 discusses the advantages and generality of the method in this paper;
Section 5 summarizes the full paper.
2. Methods
2.1. Prototypical Network
Prototypical network [
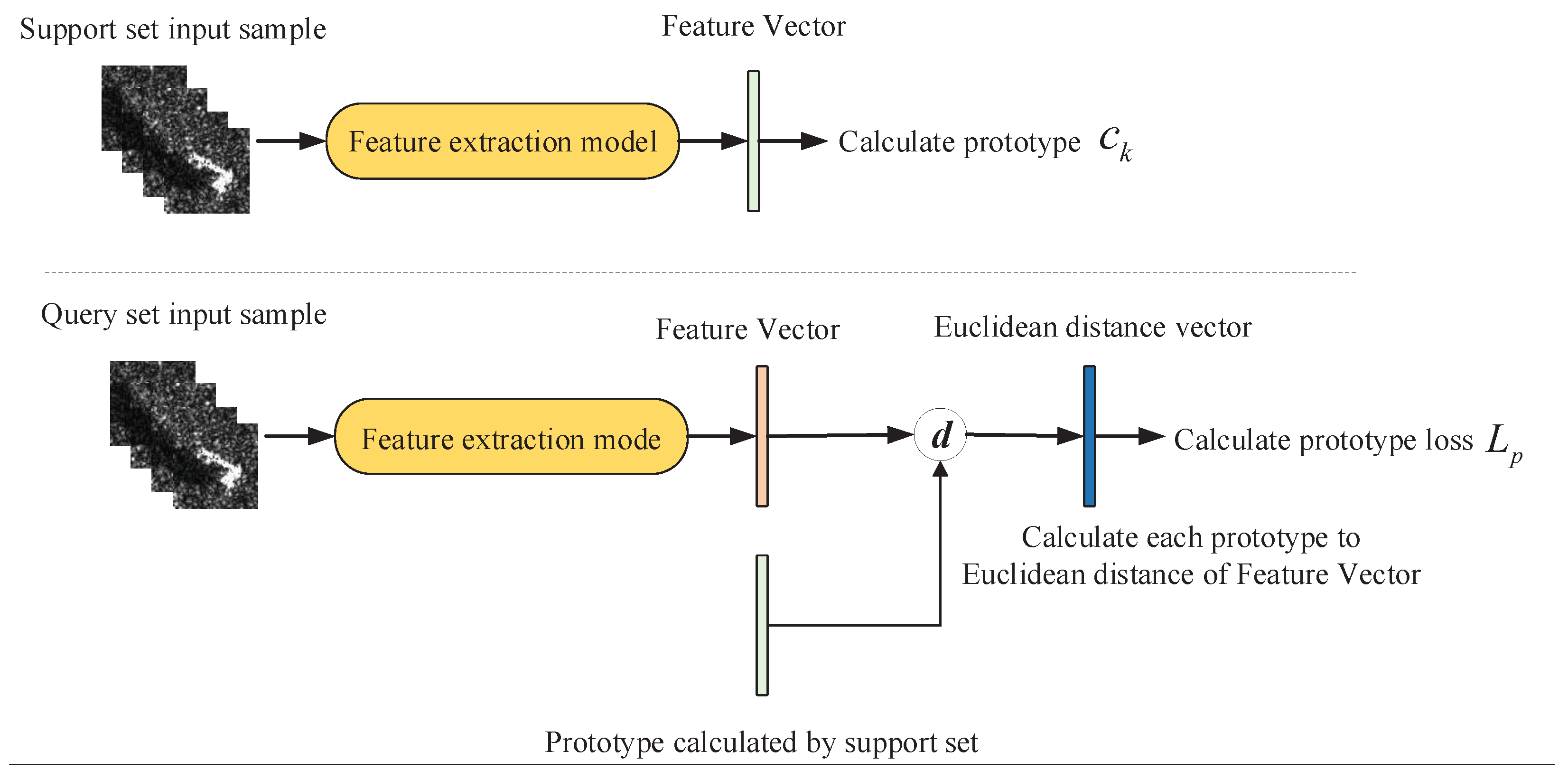
22] is a classical method for few-shot learning. The basic idea of the prototypical network is: For classification tasks, the prototypical network maps the samples of each class to a specific space, and uses the center point of each class in the specific space as the prototype of the class. The prototypical network uses the Euclidean distance to measure the distance between the sample and the prototype. During the training process, the sample is gathered in a specific mapping space, so that it is close to the prototype of its own class and far away from other prototypes. During the testing process, the Euclidean distance in the feature space from each test sample to each prototype is calculated, and the softmax classifier is used to classify the test samples according to the distance.
This paper has made some modifications to the prototypical network method, in which the classes of training set and test set are consistent.
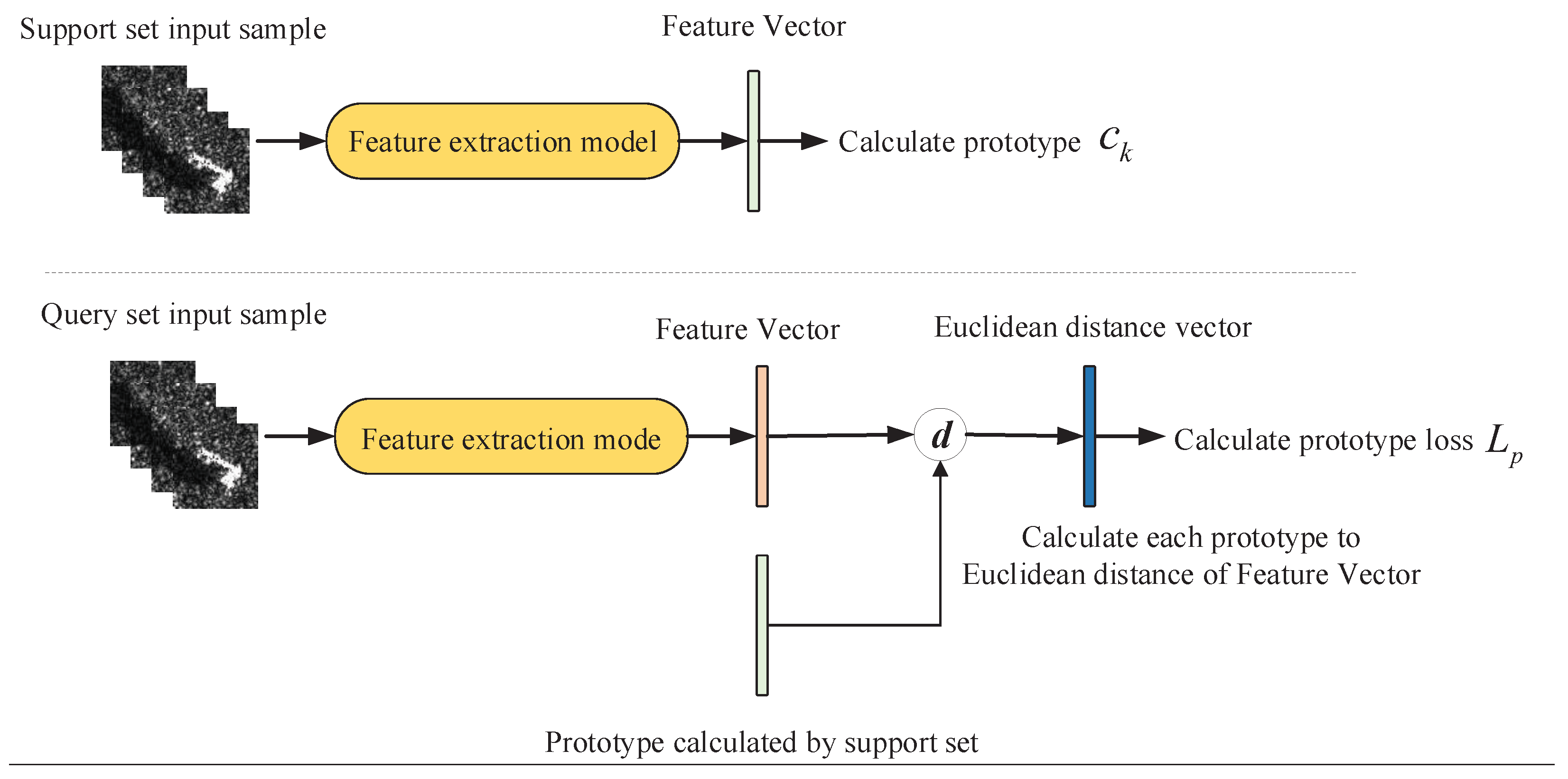
The training of the prototypical network method is shown in
Figure 2. There are
N classes of training set and test set. During training, each training episode randomly puts forward
samples from each of
N classes of training set as support set
, as well as randomly putting forward
samples as query set
, where
is the multi-aspect SAR images and
is the sample label. Through the deep learning feature extract model
, each D-dimensional training sample is mapped to a high-dimensional space of dimension M, and
is calculated by
, where
is the support set of class
k, and
is the prototype of class
k,
is obtained by taking the average value of all samples in
in the high-dimensional space, as in Formula (1).
After calculating the prototype, the prototypical network uses the Softmax function to calculate the distance between the samples in the query set
Q and each prototype, as shown in Formula (2), where it is the Euclidean distance, as shown in Formula (3).
The deep learning model is optimized by reducing the distance between the sample in the query set
Q and the center of the class prototype. The training loss is shown in Formula (4), where
k is the true label of training sample.
In the testing process, first we use all the training set samples to calculate the prototype of each class, and then calculate the distance from each test sample to each prototype through Formula (2). The test sample is divided into the class with the closest prototype.
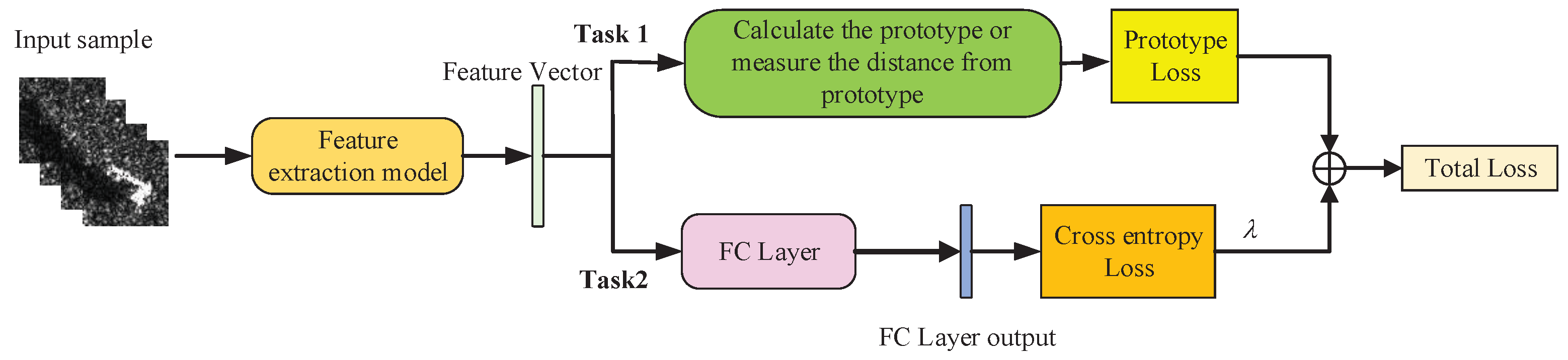
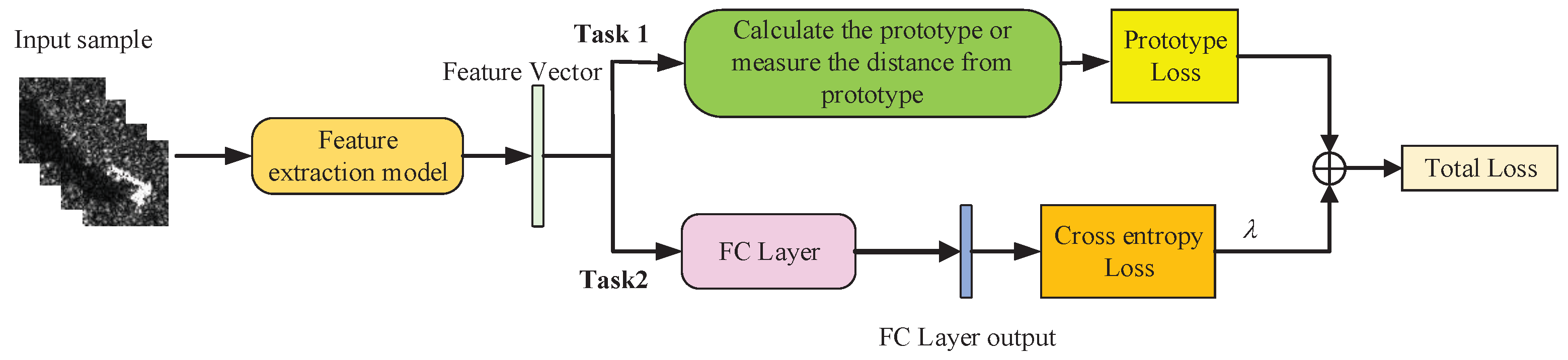
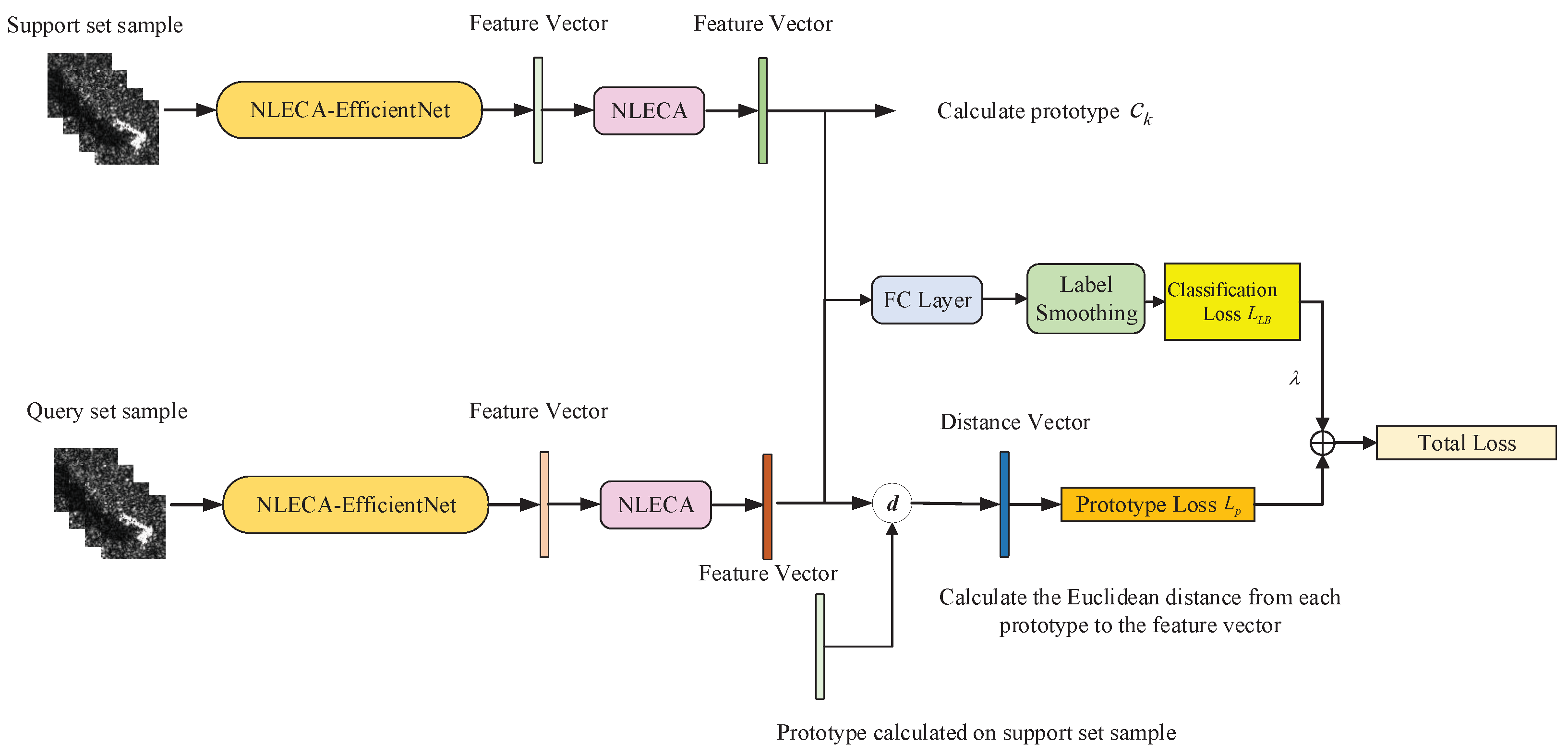
2.2. Multi-Task Learning
The prototypical network method proposed in
Section 2.1 can measure the distance between the test sample and the center of prototype, but cannot directly classify a single sample. Therefore, we try to add a fully connected layer after the deep learning model to classify the samples on the basis of the prototypical network method, and construct an additional classification task based on cross-entropy loss to form a multi-task learning model, as shown in
Figure 3.
Through the learning model shown in
Figure 3, the distance measurement task and the classification task of the prototypical network can assist each other, so that the model can learn effective information from the classification task that is helpful for the distance measurement task, and further improve the performance of prototypical network.
In addition, since each task has a different noise mode, the measurement task and classification task at the same time can average the impact of noise and share the overfitting risk of each task, thus improving the generalization performance of the model and reducing the impact of SAR image speckle noise on classification [
19].
The multi-task learning model includes a distance measurement task of prototypical network and a classification task. The classification task uses cross-entropy loss to optimize the model. Therefore, the joint loss of the model is shown in Formula (5), which is divided into two parts.
L is total loss,
represents the cross-entropy loss,
is the distance metric loss, and
is the hyperparameter.
2.3. Feature Extraction Model
The prototypical network method requires a feature extraction model to map the sample to a specific space. This paper uses a multi-channel convolutional neural network as a feature extraction model. That is, we use multiple weight-sharing CNNs to extract the features of a single SAR image, and then use the fully connected layer to classify the features of multiple SAR images.
This paper mainly inroduces the NLECA-EfficientNet model into the feature extraction model for experiments. The model uses multi-channel EfficientNet-B0 [
23] as the backbone network, and adds the NLECA channel attention module to recalibrate the multi-aspect SAR image features. It can enhance the more useful features for classification, so as to achieve high accuracy for multi-aspect SAR target recognition. In addition, this paper also uses multi-channel ResNet [
24], VGGNet [
25] and AlexNet [
26] as feature extraction models in experiments (
Section 4) to verify the generality of the method in this paper.
2.3.1. EfficientNet
The EfficientNet series model is one of the deep learning classification models with the best classification performance at present, and its basic network is obtained through neural network architecture search technology [
23]. In this paper, EfficientNet-B0 is selected. This model has the least parameters and the fastest inference speed among the EfficientNet series models. It is more suitable for small-scale datasets such as the SAR dataset. The structure of EfficientNet-B0 is shown in
Table 1,where
k is the number of classes.
2.3.2. NLECA Module
NLECA (Non-Local Efficient Channel Attention) module is a channel attention module improved from ECA (Efficient Convolution Attention) module [
27].
The ECA module captures the local cross-channel interaction by considering each channel and its
k neighboring channels, this module implements the above operations through a one-dimensional convolution with the convolution kernel of
k. If the ECA module is directly added to the multi-channel CNN for multi-aspect SAR target recognition tasks, the current feature channel can only perform cross-channel information interaction with nearby
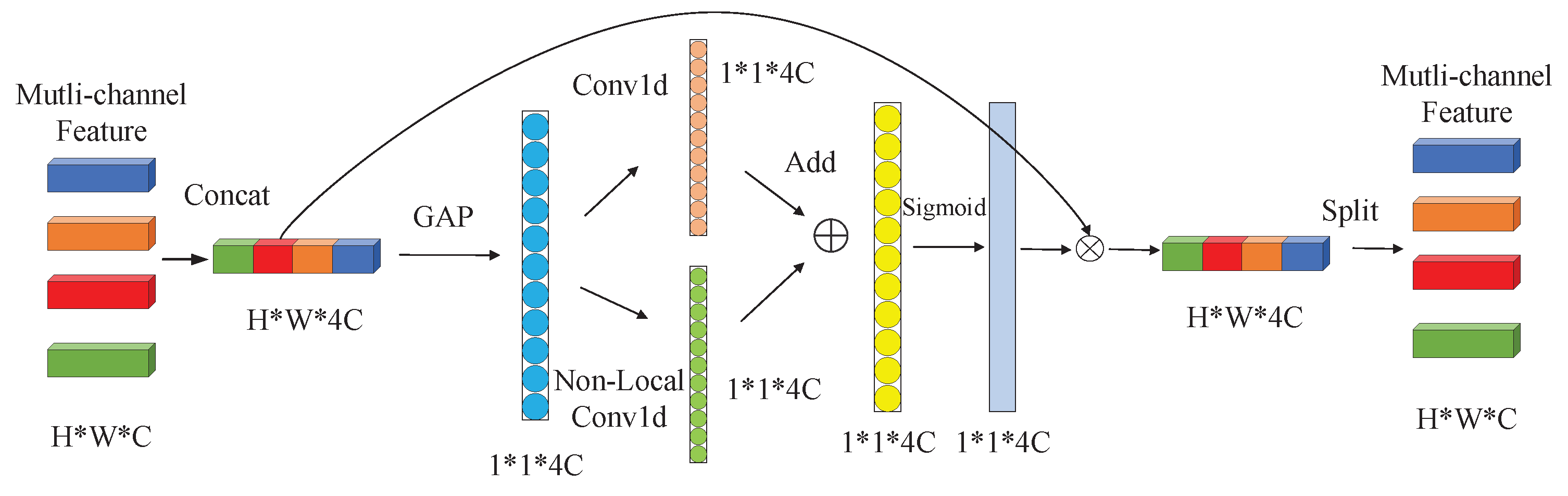
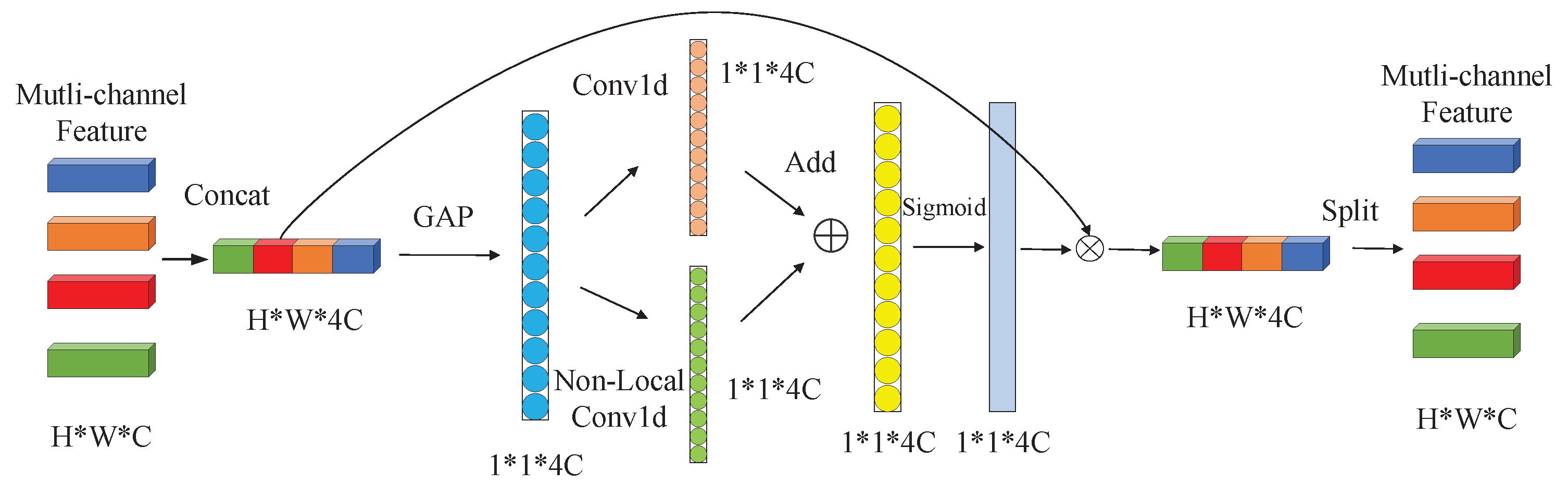
k feature channels, and these feature channels usually come from the same SAR target image, which cannot realize information interaction among multi-aspect SAR images. For example,
Figure 4 is a schematic diagram of the NLECA module with the number of input multi-aspect images is 4, the image features from 4 CNNs are concentrated and pooled to obtain a feature vector with a dimension of
, where
C is the number of feature channels and is usually much larger than the size of the convolution kernel
k. If only one-dimensional convolution is performed, the current
k convolution values usually come from the same input image. Therefore, the use of one-dimensional convolution cannot realize information interaction among different input images, and thus cannot make full use of multi-aspect SAR information.
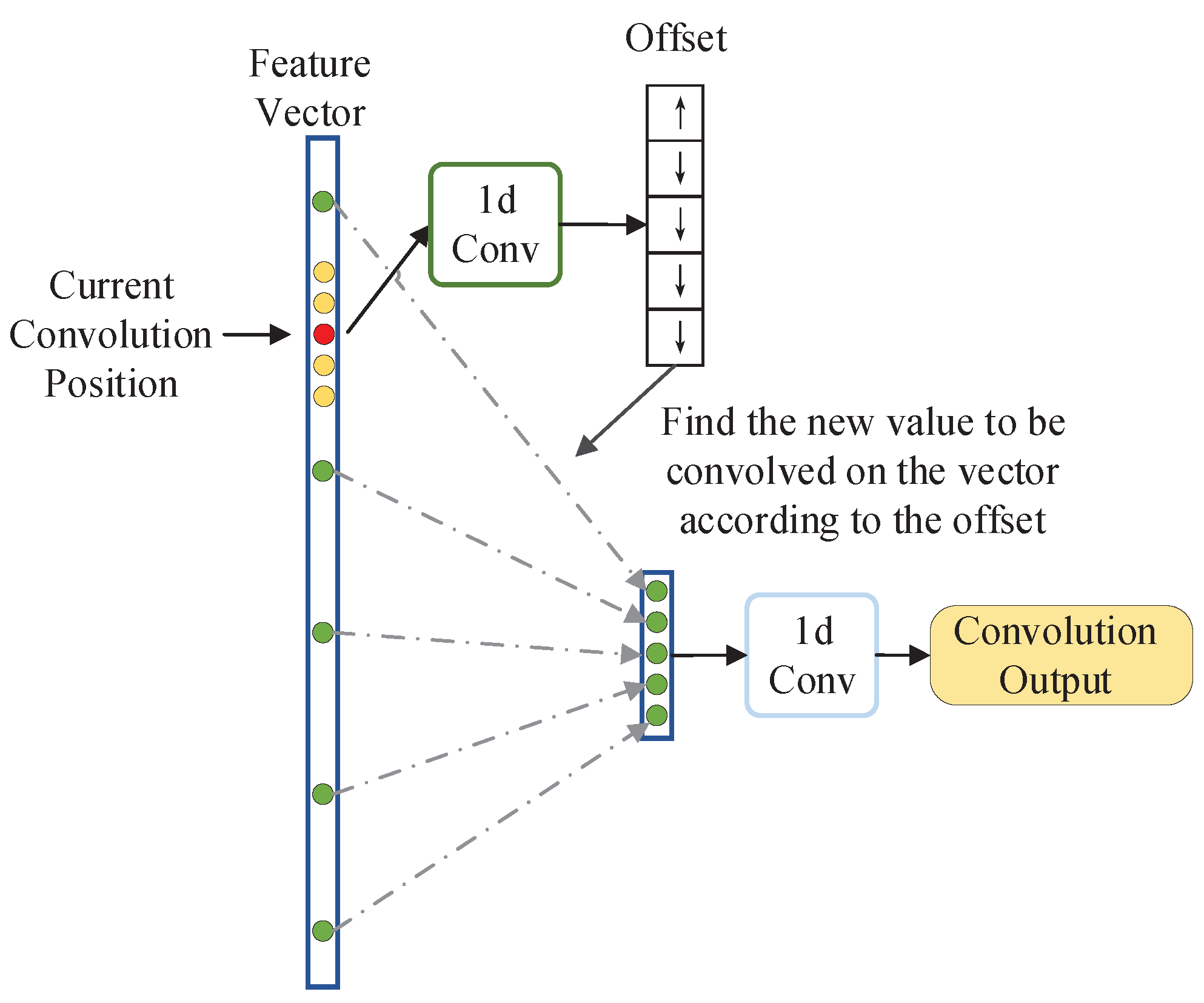
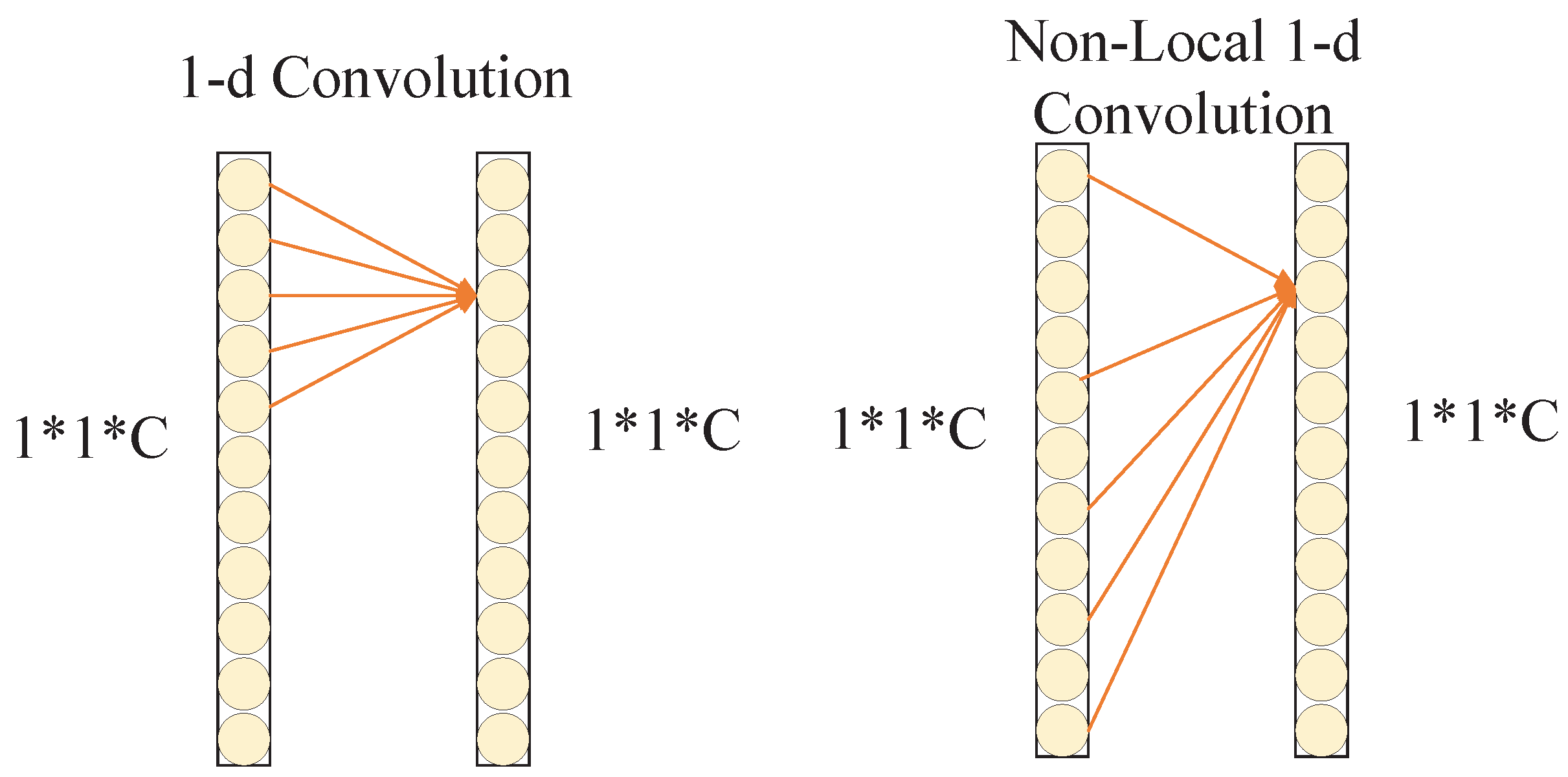
The NLECA module adopts non-local one-dimensional convolution (Non-Local Conv1d) to obtain non-local information. Non-local one-dimensional convolution is an one-dimensional implementation of Deformable Convolution Net [
28]. The diagram of one-dimensional convolution is shown on the left side of
Figure 5. If the size of the convolution kernel is
k, it can only perform convolution operations on local
k values. Instead of non-local one-dimensional convolution, any
k values in the vector can be selected for convolution operation by learning, which makes up for the shortcomings of the ECA module and realizes the feature information interaction among multi-aspect SAR images.
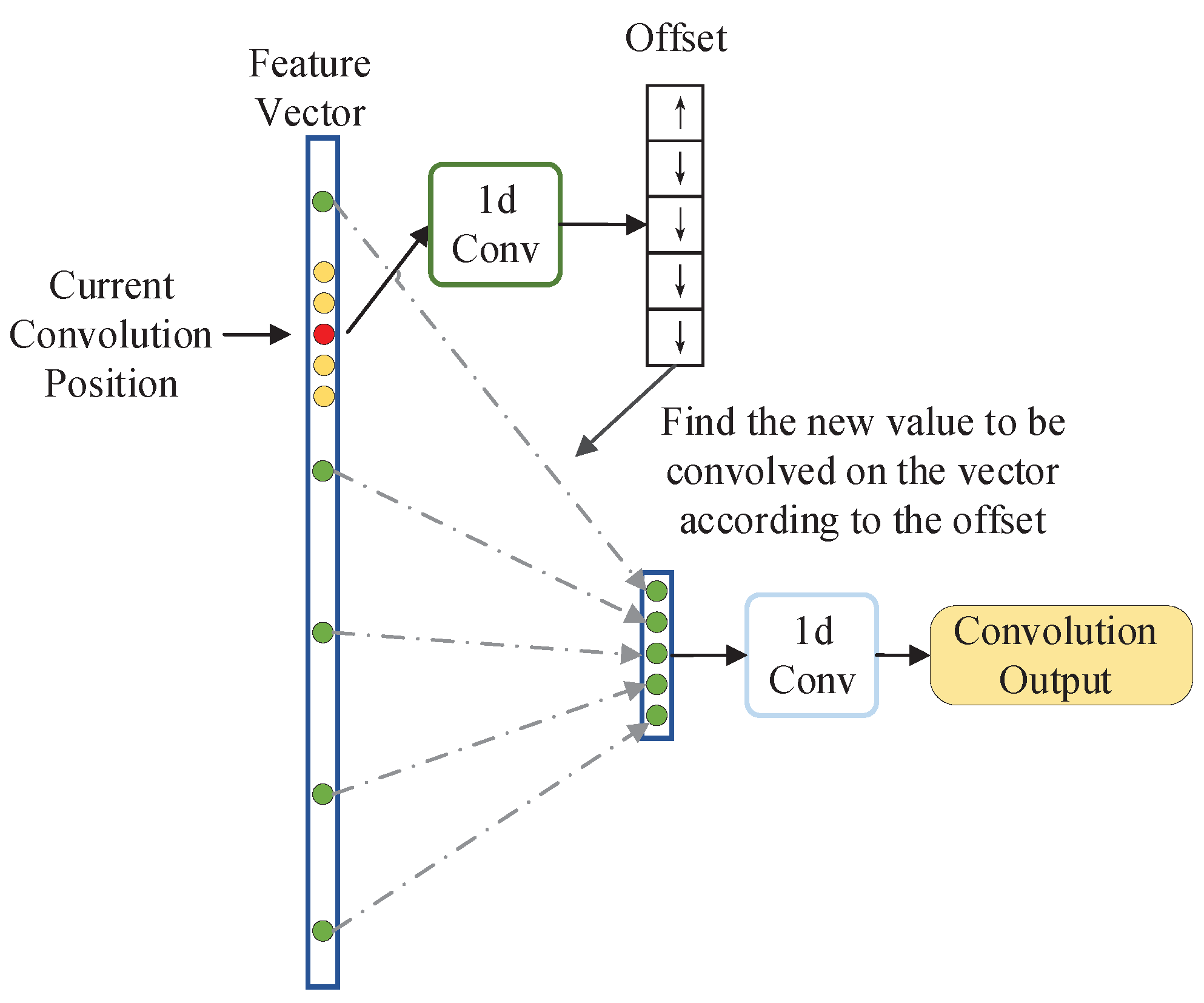
The structure of non-local one-dimensional convolution is shown in
Figure 6. It first obtains a set of offsets of the current convolution position through a one-dimensional convolution operation which kernel size is
k, and then uses this set of offsets to find
k non-local convolution values, thus realizing a non-local one-dimensional convolution operation.
About the calculation process of the NLECA module, first, the features of size obtained by 4 CNN channels are concatenated into feature F of size . Then, the global average pooling on the feature F is performed to obtain a global feature vector F, and one-dimensional convolution and non-local one-dimensional convolution on the feature vector V is performed to obtain two weight vectors and . The two weight vectors are added and normalized by the Sigmoid function to obtain the final weight vector W. After that, the feature F and the weight vector W are dotted to calculate the output feature . Finally, is split into feature vectors of size and sent back to the multi-channel CNN.
Through the combination of one-dimensional convolution and non-local one-dimensional convolution, the NLECA module not only has the ability of ECA module to improve classification performance from local channel information, but also has the ability of non-local information interaction. When NLECA module is inserted into a multi-channel CNN for multi-aspect SAR image recognition tasks, information interaction among multi-aspect SAR images can be further realized, thereby improving the recognition performance.
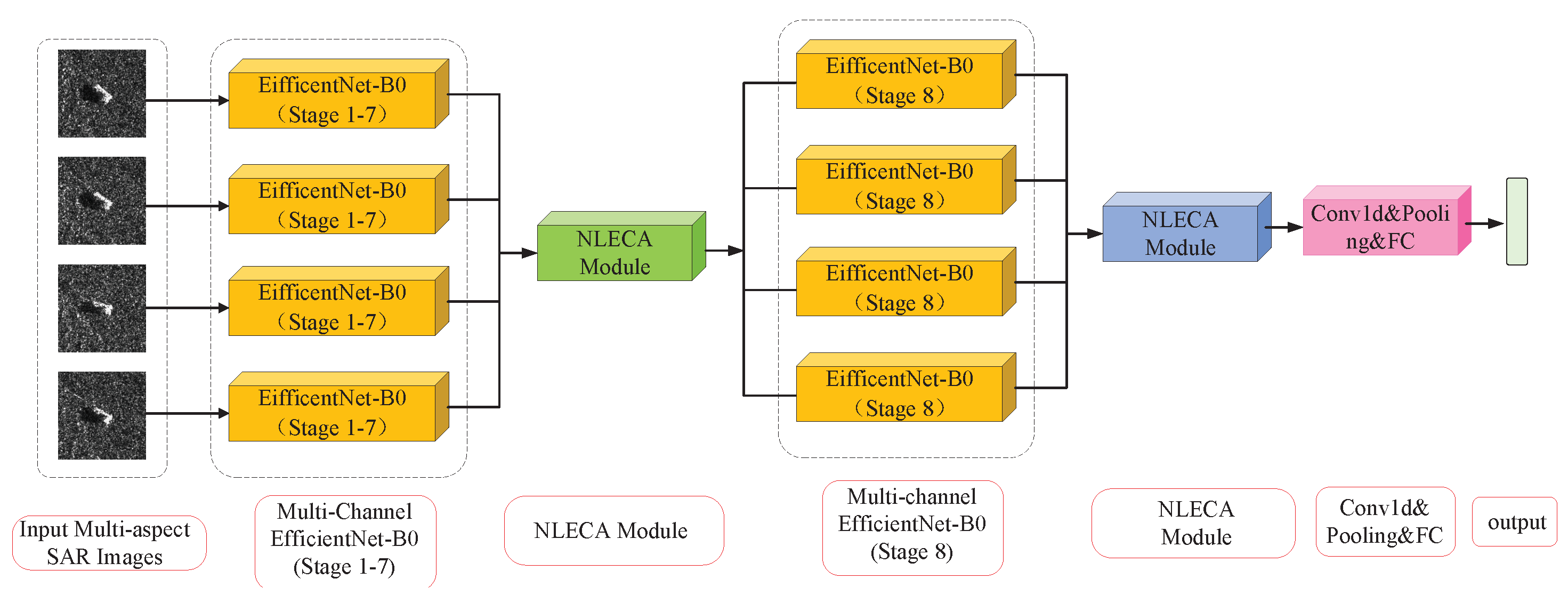
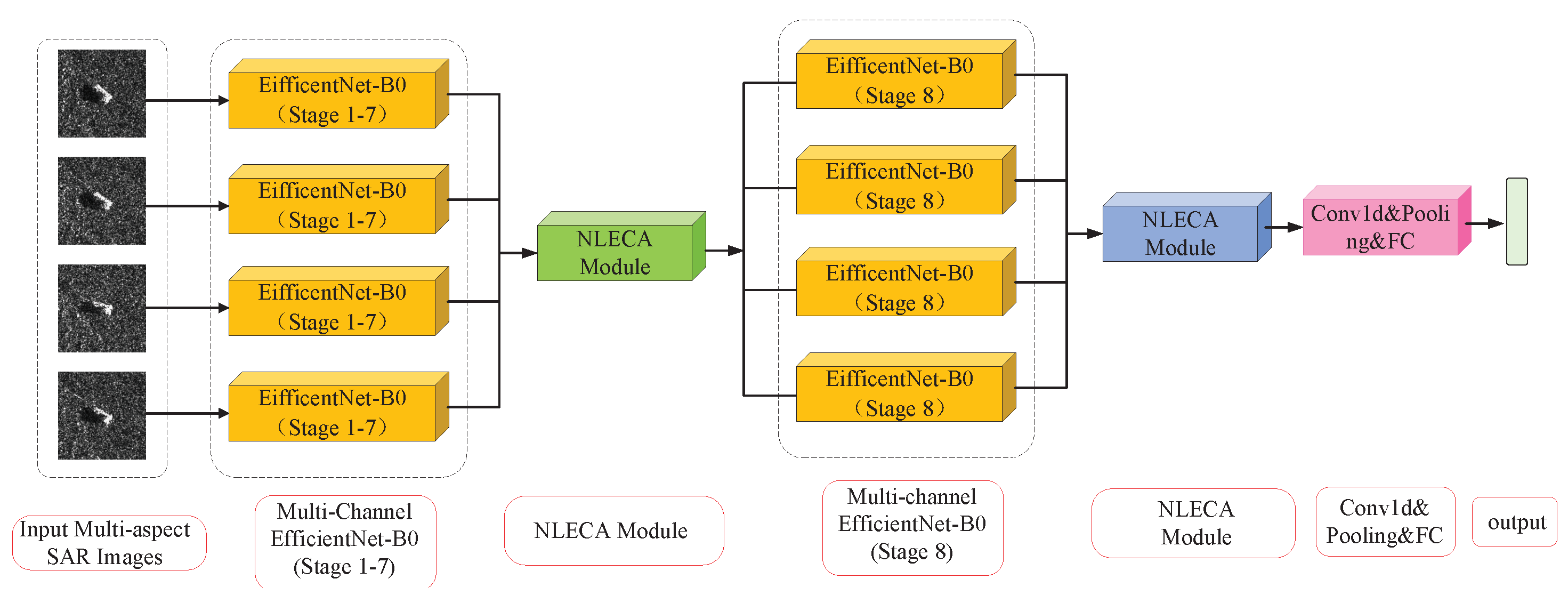
2.3.3. NLECA-EfficinentNet
The NLECA-EfficienctNet model used in the experiment is shown in
Figure 7. The NLECA module is inserted before and after the last MBConv stage of EfficientNet-B0 at the same time. The model uses the channel attention mechanism to re-calibrate the features of the multi-channel image, by enhancing the information useful for classification among the global information, as well as suppressing the information useless for classification, so as to achieve high accuracy in multi-aspect SAR target recognition. The recognition performance of the method under the MSTAR dataset is shown in
Section 3.
When used as a feature extraction model, this paper removes the fully connected layer part of the model.
2.4. Multi-Level Feature Fusion
In deep convolutional neural networks, low-level image features have high resolution and more detailed information, but low-level image features are more noisy and have poor semantics; while high-level image features have higher-level semantics, but its resolution is lower, the detailed information are less, and the high-level features are more prone to over-fitting; the middle-level image features are in-between the high-level and low-level features [
20,
21]. Effective fusion of these three features can improve the classification performance and make the model more robust.
This paper uses multi-level feature fusion to improve the accuracy of multi-aspect SAR target recognition under a small number of samples. Thus, the low-, medium- and high- levels image features of the multi-aspect SAR images are integrated to classify.
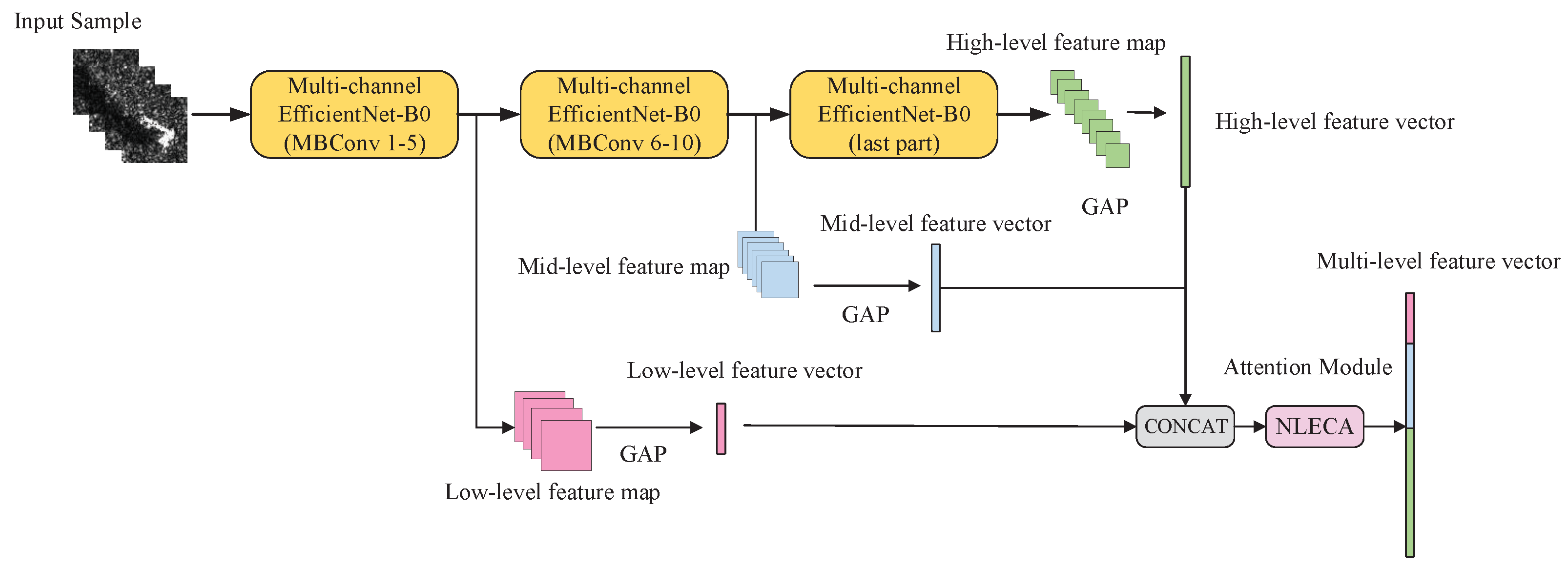
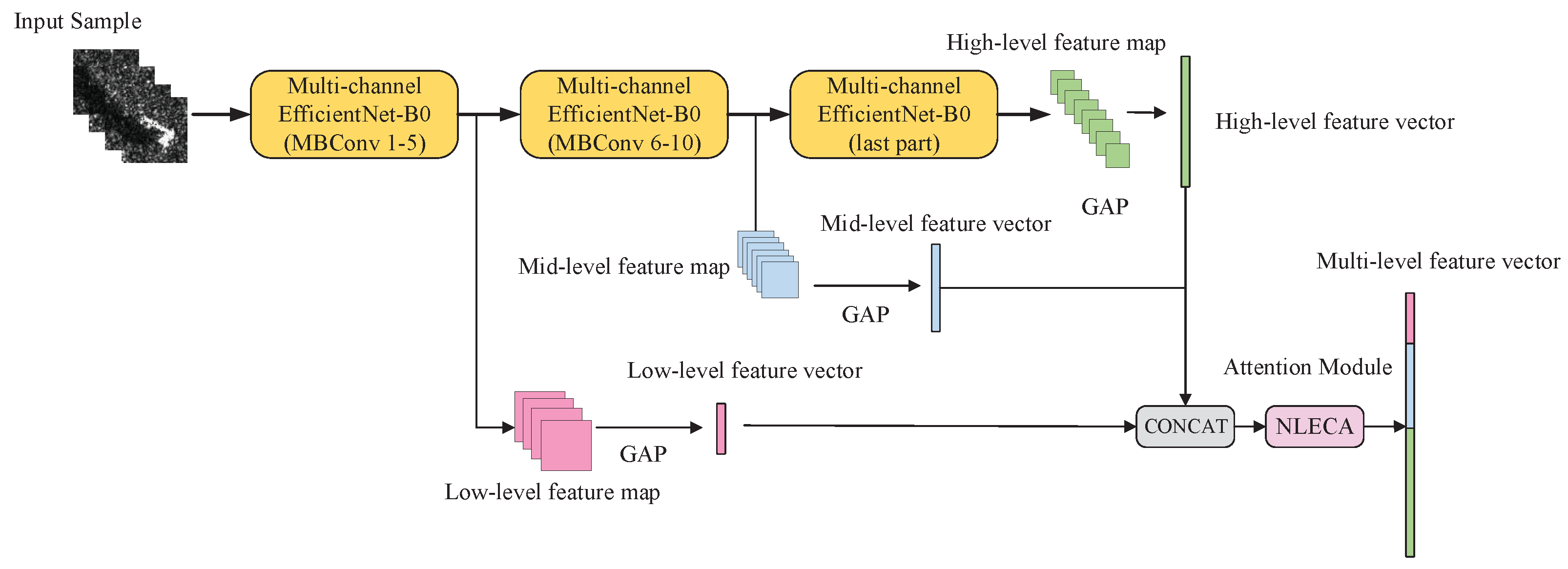
As shown in
Figure 8, NLECA-EfficientNet is used as a feature extraction model, and its backbone network is EfficientNet-B0. The feature maps output from the 5th MBConv Stage, the 10th MBConv Stage, and the last layer of EfficientNet-B0 are low-, middle-, and high-level features separately. The dimensions of the low-level, middle-level, and high-level feature maps, which are given by
,
, and
, are
,
, and
, respectively.
N,
H,
W, and
C are the batch sizes of the input samples, the height, the width, and the channel number of the feature map. However, due to the different heights, widths, and channel numbers of low, medium, and high-level feature maps, they cannot be directly concatenated.Therefore, we perform global average pooling on
,
, and
to obtain feature vectors
,
and
with dimensions
,
and
respectively. Then we concatenate the feature vectors to obtain a vector
V whose dimension is
,
. The calculation process is given in Formulas (6) and (7), where GAP means global average pooling, and CONCAT means vector concatenation.
It should be noted that the vector V contains not only the features of multi-aspect SAR images, but also the three-level features of high-, medium- and low- levels. These types of features have different effects on classification results, so we use the NLECA module to recalibrate the vector V to enhance the useful features, and thus obtain the final output .
After passing through the NLECA module, is further used for direct classification, calculation, and measurement of the prototype. The operation of the attention mechanism here not only realizes the information interaction of low-, medium-, and high-levels, but also realizes the information interaction among multi-aspect SAR images, which makes full use of the feature information and thus improves the performance and the generality of the model.
2.5. Training and Testing Tricks
In addition, this paper also uses some tricks to improve the performance of multi-aspect SAR ATR under the small number of training samples.
2.5.1. Image Preprocessing
Since the SAR imaging angle of target has a great influence on the image feature, it is not proper to use large-angle rotation, mirroring and other optical image augmentation methods to augment the SAR samples. With reference to the method in [
19], after constructing a multi-aspect SAR images dataset, each image of the training set is rotated by
, hereby increasing the training set by three times. In addition, for coherent speckle noise reduction, this paper also uses the refined Lee filter [
29] for preprocessing.
2.5.2. Label Smoothing
Label smoothing is a regularization method in machine learning. It changes the one hot encoding of the label vector
y into soft one-hot encoding, thereby adding some noise to the label, reducing the weight of the correct class and the overfitting problem of the model. After using label smoothing, the classification loss changes from cross-entropy
to
, as shown in Formula (8), where
is a small hyperparameter, the value of
is usually 0.1, and
represents the class of current samples [
30].
2.5.3. Test Time Augmentation
The same augmentation method for testing dataset, as that for training dataset, can also effectively improve the test accuracy.
Each test sample is first rotated by to add up one sample to three samples. Then, the three samples are produced by feature extraction model to obtain three corresponding feature vectors. These three vectors are averaged to obtain a new vector, which is then used to measure the distance from test sample to the prototype.
This method is similar to the bagging method in machine learning. It can effectively generalize the model.
2.6. Multi-Aspect SAR ATR Method with Small Number of Training Samples
Combining the above methods and using NLECA-EfficientNet as the feature extraction model, the multi-aspect SAR ATR training framework proposed in this paper under the small number of samples is shown in
Figure 9.
The training process has multiple epochs, and each epoch is divided into multiple episodes, as shown in
Figure 9. The training steps for each episode are as follows:
Randomly select samples from each of the N classes in the training set as the support set , and select samples as the query set , where is the multi-aspect SAR images, is the sample label, and there are a total of training samples participate in each training episode.
Use the training samples in the support set to calculate the prototype of each class.That is, the support set samples of each class are used to obtain multi-level feature vectors through the multi-aspect SAR feature extraction model, and the multi-level feature vectors of each class are averaged to obtain the prototype.
The samples of the query set are used to obtain the feature vector through the feature extraction model, which is used to calculate the Euclidean distance from each prototype. The loss is calculated using Formulas (2) and (4).
Use the multi-level feature vectors of all samples in the support set and the query set to perform the classification task, and obtain the classification loss by Formula (8).
Perform a weighted addition on the prototype loss and the classification loss to get the total loss, while backpropagates to adjust the model parameters.
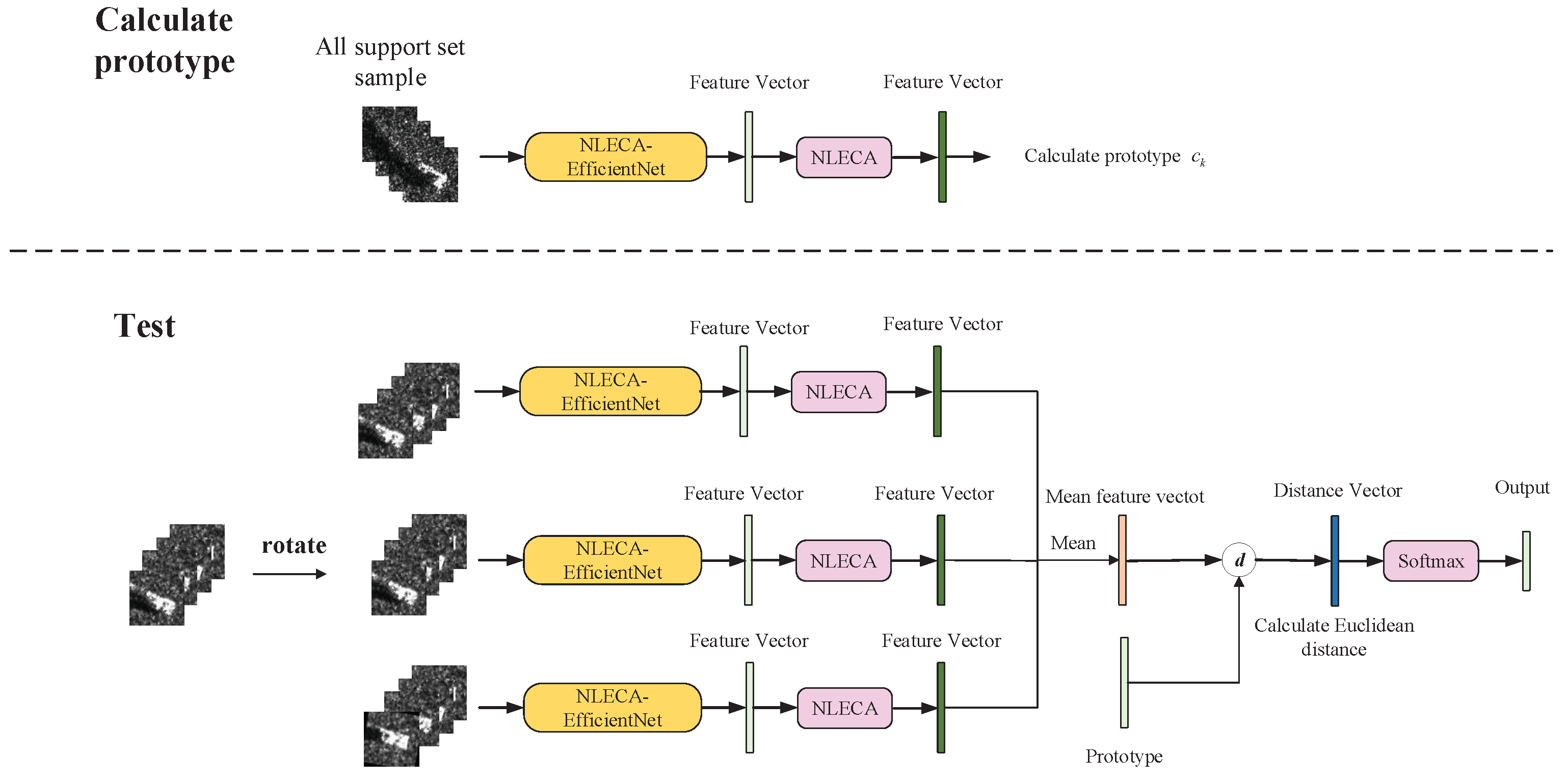
The test method is shown in
Figure 10. The test steps for a single sample are as follows:
Use the trained feature extraction model and use the entire training set to calculate the prototype of each class.
Rotate each image of the test sample by , and extend the test sample by three times, obtain three feature vectors by the trained feature extraction model, and average the three feature vectors to obtain a new feature vector.
Use the feature vector in step 2 and the prototype in step 1 to calculate the Euclidean distance and obtain the distance vector, and then use the Softmax classifier to classify the distance vector.
5. Conclusions
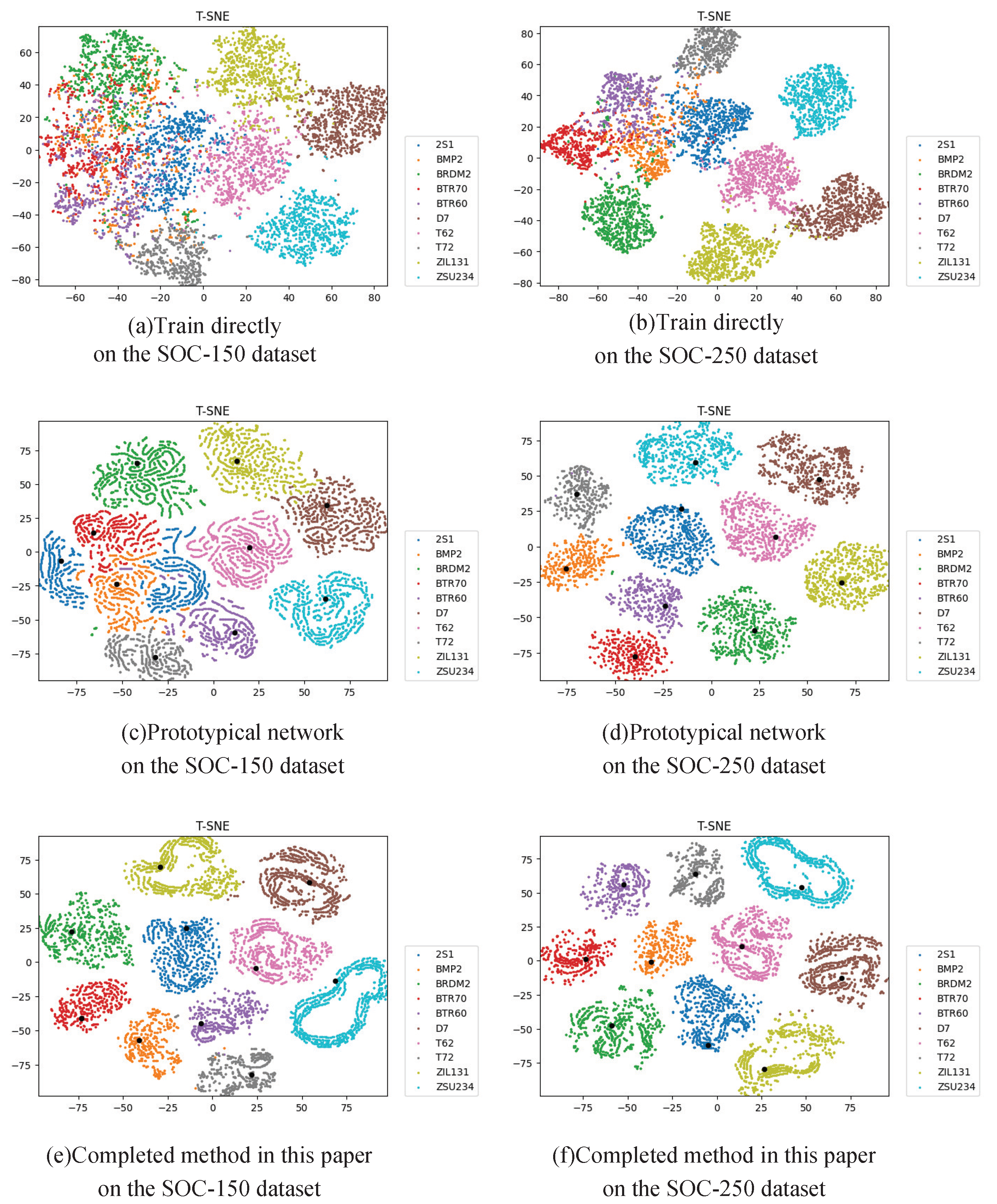
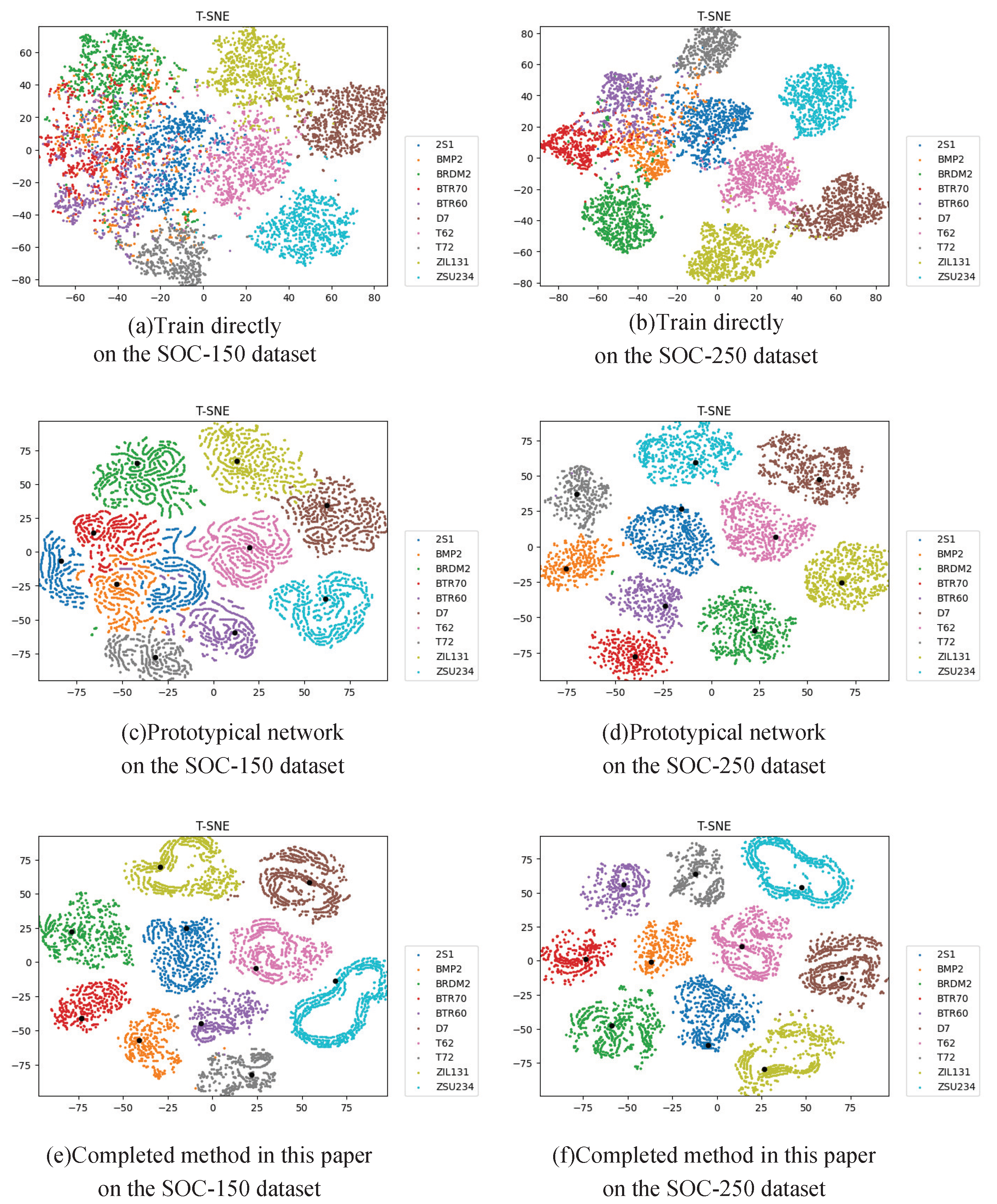
Aimed at the problems of the multi-aspect SAR target recognition issue based on deep learning model under the small number of training samples, this paper proposes a small training dataset learning method based on the prototypical network. This method is classified by calculating the distance between the test sample and the prototype, and on this basis, methods such as multi-task learning, multi-level feature fusion and attention mechanism are added.
Experiments based on the MSTAR dataset show that this method can significantly improve the recognition performance of the deep learning model under a small number of samples, and thus the recognition accuracy can be close to that under the complete training set. In addition, the experiments also prove that this method has a certain generality and can be applied to a lot of deep learning feature extraction models. Therefore, this method is very meaningful and can be generally used for multi-aspect SAR target recognition issues with a small number of training samples.
Subsequent research can be carried out in the future. This method uses the amplitude SAR images for training and testing. The complex SAR images may make up for the lack of information in the case of a small number of training samples. Here, we refer to the CV-CNN method proposed in [
33] to extend CNN to the complex domain, so as to make full use of SAR image information, and try to further improve the recognition accuracy under a small number of training samples.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}