Abstract
This paper proposes an action recognition framework for depth map sequences using the 3D Space-Time Auto-Correlation of Gradients (STACOG) algorithm. First, each depth map sequence is split into two sets of sub-sequences of two different frame lengths individually. Second, a number of Depth Motion Maps (DMMs) sequences from every set are generated and are fed into STACOG to find an auto-correlation feature vector. For two distinct sets of sub-sequences, two auto-correlation feature vectors are obtained and applied gradually to -regularized Collaborative Representation Classifier (-CRC) for computing a pair of sets of residual values. Next, the Logarithmic Opinion Pool (LOGP) rule is used to combine the two different outcomes of -CRC and to allocate an action label of the depth map sequence. Finally, our proposed framework is evaluated on three benchmark datasets named MSR-action 3D dataset, DHA dataset, and UTD-MHAD dataset. We compare the experimental results of our proposed framework with state-of-the-art approaches to prove the effectiveness of the proposed framework. The computational efficiency of the framework is also analyzed for all the datasets to check whether it is suitable for real-time operation or not.
1. Introduction
Human action recognition is one of the most challenging tasks in the area of artificial intelligence and has obtained attention due to widespread real-life applications, which extend from robotics to human-computer interface, automated surveillance system, healthcare monitoring, etc. [1,2,3]. Human actions are composed of contemporary behaviors of human body parts. The objective of human action recognition is to recognize actions automatically from an unlabeled video [4,5]. To capture human actions, there are two broad categories of devices based on wearable sensors and video sensors. In the prior, using these apparatuses many research works have been completed in the area of action recognition. To recognize wearable sensor-based actions, multiple sensors are connected to the human body. To obtain action information, most of the researchers have used different sensors such as accelerometers, gyroscopes, and magnetometers [6,7,8]. These wearable sensors are used in the healthcare system, worker monitoring, interactive gaming, sports, etc. However, they are not acceptable in all the domains of action recognition, for example in the automatic surveillance system. It is far from convenient for humans (especially patients) to wear the sensors for a long time and relatively it is difficult in cases of energy costs. Wearable sensors can have health risks. For those carrying smartphones, laptops, and tablets, wearable sensor increases exposure to radio wave. Although the use of multiple sensors increases recognition accuracy, it has limitations for real-life applications because of increased associated complexity and the cost of the total procedure. Because of the difficulties of wearable sensors, video sensors such as RGB cameras are used to recognize the action. RGB images give restricted 2D data as grayscale or RGB intensity rate, motion illegibility (e.g., color and texture variations), inflexibility in the foreground or background segmentation, illumination variation, and low resolution which resist recognizing action accurately [9,10]. With the emergence of advanced technology, the redemption of accessible depth sensors is broadly used to achieve 3D action information. 3D information can be obtained through three approaches. The first approach is costly marker-based motion capture systems (MoCap) which uses visual sensing of markers settled in different parts of the human body and triangulation from several cameras to gain three-dimensional spatial information and the human skeleton. In the second approach, a stereo camera is used to acquire 3D depth information [11]. The stereo camera consists of two or more lenses with an individual image sensor or film frame for each lens. A stereo camera gives depth information by stereo matching and distance computation from lenses to object. The images captured by a stereo camera are sensitive to light changes and background clutter and action recognition from such images is a very challenging task [12]. The third approach involves the use of a depth sensor (for example Microsoft Kinect) that gives real-time 3D information for human body parts [11]. Unlike RGB camera, depth sensor camera gives overlapping multiple body portion information, it is insensitive to light changes that improve performance at dark, and in such data, it is easy to normalize the body orientation or its size variations [9]. This camera gives depth information from which skeleton data is obtained. The studies based on skeletal data often show high recognition performance, but where skeletal data is not available, the studies are not robust in terms of accuracy. These discussions encourage us to use depth information to establish an action recognition framework. However, DMMs based on the total depth frames of the entire video are not capable of obtaining the total motion information. To reduce this disability, in this paper, the depth map sequence of the entire video are partitioned into a set of overlapping portions. Each portion contains the same number of depth frames and DMMs sequences are constructed from DMMs of all portions. Then, the entire depth video is described through 3D auto-correlation features obtained from DMMs sequences. With the calculated features, the -regularized Collaborative Representation Classifier (-CRC) [13] and the Logarithmic Opinion Pool (LOGP) rule [14] work jointly to assign an action label of the video. The proposed framework is visualized in Figure 1.
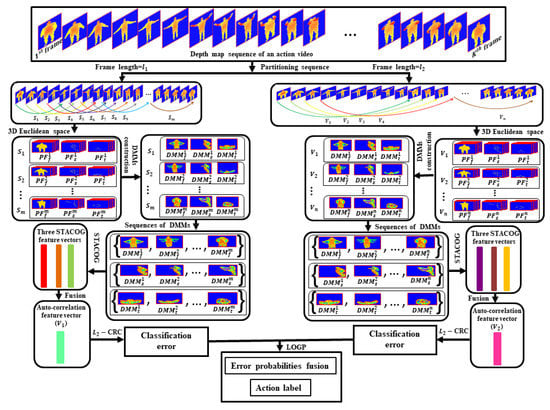
Figure 1.
Proposed action recognition framework.
- Motivation and Contributions:
The method proposed by Chen et al. [15], used 3D auto-correlation features from depth map sequences for action recognition; however, their framework has limited performance with the same data. They did not achieve significant results through their framework. Therefore, the objective of our work is to develop a framework to increase the recognition results as well as the overall performance by using the 3D auto-correlation gradient features.
The main contributions of our work are listed below:
- The depth map sequences of each action video are partitioned into a set of sub-sequences of equal size. Afterward, DMMs are created from each sub-sequence corresponding to three projection views (front, side, and top) of 3D Euclidean space. Then, three DMMs sequences are derived by organizing all the DMMs along the projection views. The video is fragmented by two times generating two sets of sub-sequences using two different frame lengths and thus there are two sets of three DMMs sequences are obtained.
- Our recognition framework mines the 3D auto-correlation gradient feature vectors from three DMMs sequences by using the STACOG feature extractor instead of mining from depth map sequences as shown in [15].
- A decision fusion scheme is applied to combine residual outcomes obtained for two 3D action representation vectors.
- The proposed framework achieved the highest results as compared to all the other work done by applying the STACOG descriptor on depth video.
The remainder of this paper is organized as follows. A couple of action recognition frameworks are reviewed in Section 2. The proposed framework is described in Section 3. In Section 4, experimental results and discussion of the proposed framework are reported. Finally, the conclusion and future research directions are presented in Section 5.
2. Related Work
This section describes current depth maps-based action recognition frameworks. Additionally, it also reviews skeleton, RGB, inertial, and fusion-based frameworks. Depending on depth data, Chen et al. [16] used local binary patterns (LBPs) to extract features. They represented two types of fusion levels and used the Kernel-based Extreme Learning Machine (KELM) for both levels. Ref. [17] introduced DMM-CT-HOG feature extractor that depends on Depth Motion Maps (DMMs), Contourlet Transform (CT), and Histogram of Oriented Gradients (HOGs). To improve accuracy, [18] used texture and dense shape information and combined them into DLE features that are fed to -regularized Collaborative Representation Classifier (-CRC). Ref. [19] proposed a method that fused classification results obtained by using multiple classifiers Kernel-based Extreme Learning Machine (KELM) through three types of features. A Bag-of-Map-Words (BoMW) method is introduced in [20] and feature vectors are extracted from Salient Depth Map (SDM) and Binary Shape Map (BSM) respectively and combined by the BoMW. Ref. [21] submitted a method using gradient local auto-correlations (GLAC) feature description algorithm based on spatial and orientational auto-correlations of local image. They introduced a fusion method depend on the Extreme Learning Machine classifier (ELM). Ji et al. [1], proposed a Spatio-Temporal Cuboid Pyramid (STCP) which subdivides the Depth Motion Sequence into spatial cuboids and temporal segments and used Histograms of Oriented Gradients (HOG) features. Chen et al. [22], used the texture feature descriptor Local Binary Pattern (LBP) and used the Kernel-based Extreme Learning Machine (KELM) classifier [19] to detect action. Again, in [23], DMMs are used as the feature descriptor. In their method, classification is accomplished by -CRC consisting of a distance-weighted Tikhonov matrix. A new feature named Global Ternary Image (GTI) was introduced in [24]. By a bag of GTI model, the authors in [24] obtained data from motion regions and motion directions. After that, Liang et al. [25], used multiscale HOG descriptors and extracted local STACOG features. Then actions were recognized by -CRC classifier. To improve accuracy, [15] fused 2D and 3D auto-correlation of gradients features which are extracted by Gradient Local Auto-Correlations (GLAC) and STACOG descriptors, respectively. Then, the action is classified by KELM with RBF kernel. Liu et al. [26] presented a method that used Adaptive Hierarchical Depth Motion Maps (AH-DMMs) and Gabor filter. Their method can extract motion and shape cues without decreasing temporal information and adopt the Gabor filter to encode the texture data of AH-DMMs. Jin et al. [27] split depth maps into a set of sub-sequences to create a vague boundary sequence (VB-sequence). They obtained dynamic features by combining all DMMs of VB-sequences. After that, Zhang et al. [28], presented low-cost 3D histograms of texture feature descriptors by which discriminant features are obtained. They also introduced a multi-class boosting classifier (MBC) to use different features for recognition. Furthermore, Chen et al. [29] introduced a multi-temporal DMMs descriptor in which a non-linear weighting function is used to assemble depth frames. They used a patch-based Local Binary Pattern (LBP) feature descriptor to obtain texture information. They used Fisher kernel representation and used the KELM classifier [19] for action classification. Li et al. [30], extracted texture features by discriminative completed LBP (disCLBP) descriptor and used a hybrid classifier associated with Extreme Learning Machine (ELM) and collaborative representation classifier (CRC). The authors in [31] used Histogram of Oriented Gradients (HOG) and Pyramid Histogram of Oriented Gradients (PHOG) as shape feature descriptors. They used -CRC classifier. Azad et al. [32], introduced a multilevel temporal sampling (MTS) scheme that depended on the motion energy of depth maps. They extracted histograms of gradient and local binary patterns from a weighted depth motion map (WDMM). In [33], an action recognition scheme based on two types of depth images (generated using 3D Motion Trail Model (3DMTM)) was introduced. They obtained two features by using the GLAC algorithm from the images respectively and the features were fused in a vector. In the same year, Weiyao et al. [34] submitted Multilevel Frame Select Sampling (MFSS) model to obtain temporal samples from depth maps. They also proposed motion and static maps (MSM) and extracted texture features by the block-based LBP feature extraction scheme. They used the fisher kernel representation method to fuse obtained features and the KLM classifier to detect action. After that, Shekar et al. [35] introduced Stridden DMMs from which effective information of actions can be obtained quickly. They Undecimated the Dual-Tree Complex Wavelet Transform algorithm to extract wavelet (UDTCWT) features from the proposed DMMs. They used a Sequential Extreme Learning Machine classifier. To improve results, [36] used two types of images that are obtained by using the 3D Motion Trail Model (3DMTM). In their method feature vectors are mined from MHIs and SHIs by the GLAC feature descriptor. Al-Faris et al. [37] presented the construction of a multi-view region-adaptive multi-resolution-in-time depth motion map (MV-RAMDMM). They trained several scenes and time resolutions of the region-adaptive depth motion maps (RA-DMMs) by multi-stream 3D convolutional neural networks (CNNs). They used a multi-class SVMs classifier to recognize human actions.
Additionally, in [38], depth and inertial sensor-based features were extracted and fused to a single feature. The final feature set was passed to the collaborative representation classifier. Based on skeleton information, Youssef et al. [39], extracted normalized angles of local joints and used modified spherical harmonics (MSHs) to model the angular skeleton. They used MSH coefficients of the joints as the discriminative descriptor of the depth maps. Hou et al. [40], proposed a framework to convert Spatio-temporal data from skeleton sequence into color texture images. They used convolutional neural networks to obtain discriminative features. The authors in [41] created a Deep Convolutional Neural Network (3D2CNN) to acquire Spatio-temporal features from depth maps and calculated JointVectors from depth maps. The spatio-temporal features and JointVectors were passed individually to the SVM classifier and the outputs were combined into a single result. To improve accuracy [42] introduced a Spatially Structured Dynamic Depth Images DDI to represent an action video. To generate DDI, they presented a non-scaling method and approved a multiply score fusion scheme to increase accuracy. Using RGB image, Al-Obaidi et al. [43] presented a method to anonymize action video. Histograms of oriented gradients (HOG) features are extracted from anonymized video images. A Generative Multi-View Action Recognition (GMVAR) method is presented in [44], by which three discrete scenarios are managed at the same time. They introduced a View Correlation Discovery Network (VCDN) to concatenate multi-view data. Liu et al. introduced dynamic pose images (DPI) and attention-based dynamic texture images (att-DTIs) in [45] to obtain spatial and temporal cues. They combined DPI and att-DTIs through multi-stream deep neural networks and a late fusion scheme. Inertial sensor-based low-level and high-level features are used in [46] to categorize human actions acted by a performer in real time. Haider et al. [47] introduced balanced, imbalanced, and super-bagging methods to recognize volleyball action. They used four wearable sensors to evaluate their method. Using signals created by the inertial measurement unit [48] introduced a method based on 1D-CNN construction and consider the tractability of features in time and duration. Bai et al. [49], presented a Collaborative Attention Mechanism (CAM) to develop Multi-view action recognition (MVAR) performance. They also proposed Mutual-Aid RNN (MAR) cell to obtain multi-view sequential information. Ullah et al. [50] introduced a conflux long short-term memory (LSTMs) network. They used CNN model to extract features and used SoftMax for classification. A fusion technique called View-Correlation Adaptation (VCA) in feature and label space was presented in [51]. They generated a semi-supervised feature augmentation (SeMix) and introduced a label-level fusion network. In [52], a light-weight CNN model was used to detect humans and LiteFlowNet CNN was proposed to extract features. The deep skip connection gated recurrent unit (DS-GRU) was used to recognize the action.
3. Proposed Recognition Framework
In this segment, we introduced the proposed framework with a detailed discussion on the construction of DMMs sequences, 3D auto-correlation features extraction, and action recognition. Algorithms 1 and 2 describe the mechanism of feature extraction and action recognition, respectively.
| Algorithm 1 Algorithm for feature vector construction |
Input: A Depth action video D of frame length L Steps: 1. Split D and construct a set , where for all j 2. For all sub-sequences , calculate , and through Equation (1) 3. Use outcomes of Step2 and generate , and 5. Concatenate outcomes of Step4 6. Further split D and construct another set , where for all k 7. Follow Step2–Step5 for Output: Two auto-correlation feature vectors and |
| Algorithm 2 Algorithm for action recognition |
Input: The training feature set , test sample c, , K (number of action classes), class label (for class partitioning), Q is the number of classifiers. Steps: 1. Calculate using Equation (8) 2. for for ← two feature vectors are calculated for c using Algorithm 1 for all i do Partition , Calculate Calculate through Equation (11) end for end for end for 3. Calculate through Equation (12) 4. Decide through Equation (13) Output: |
3.1. Construction of DMMs Sequences
In our work, DMMs corresponding to three projection views (front, side, and top) are constructed for each sub-sequence of depth map sequence. To obtain DMMs, all the depth frames of each sub-sequence are projected onto 3D Euclidean space and projection frames corresponding to three projected views are generated. For each projected view, the addition of the utmost differences between sequential projection frames forms DMMs of front, side, and top.
To interpret computation of DMMs sequence [23], at first, a depth video D of length L is divided into a set of sub-sequences of uniform size as , where j represents the index of sub-sequence. Let us consider a depth frame sequence for each sub-sequence, where is the frame length of each sub-sequence, i.e., for all j. The projection of ith frame on 3D Euclidean space provides three projected frames (which are referred to as in Figure 1), where v designates front, side, and top projection views and . The DMMs corresponding to projection views are defined by the following equation:
For all , DMMs are represented by , , and . Therefore, , and sequences are formed from of D. In action datasets, the same actions are performed by different individuals with different speeds. To cope with action speed variations, the depth map sequence of D is further divided into another set of sub-sequences where frame length of each sub-sequence is , i.e., for all k (see Figure 1). As a result, more three new sets of DMMs sequences , and are obtained from . In our DMMs sequences constructing mechanism, numerical values of frame lengths and are experimentally chosen to 5 and 10 respectively. The frame length of a sub-sequence may vary and must be set to less than the length of total depth video, i.e., and . The DMMS sequences constructing scheme for frames length is displayed in Figure 2. The frame interval I in Figure 2 is set to 1 which is the number of frames from the first frame of a portion to the first frame of the neighboring portion which indicates how many frames between the two portions are overlapped. Please note that the frame interval must be less than the frame length of a sub-sequence, i.e., and .
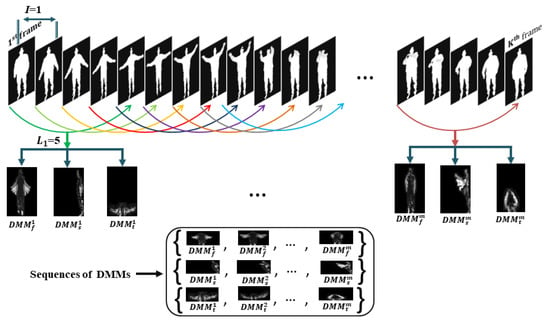
Figure 2.
Construction of DMMs sequences according to sub-sequences of 5 frames.
3.2. Action Vector Formation
STACOG was introduced in [53] for RGB video sequences to extract local relationships within the space-time gradients of three-dimensional motion by using auto-correlation functions to space-time orientations and the magnitudes of the gradients. In our work, this method is applied to all the DMMs sequences (calculated in the previous section) of a depth video D to extract 3D geometric features of human motion. At each space-time volume (in general, this volume stands for a DMMs sequence) around each space-time point in a DMMs sequence the space-time gradient vector is computed through the derivatives , , and to extract features. The space-time gradients can be described by angles = arctan() and = arcsin(), where the magnitude of gradient is defined by . By the two angles, space-time orientation of the gradient is coded into B orientation bins on a unit sphere by selecting weights to the nearest bins (see Figure 3). Finally, the orientation is represented by B-dimensional vector named space-time orientation coding (STOC) vector which is denoted by . By using the magnitude and the STOC vector of the gradients, the Nth order auto-correlation function for the space-time gradients is defined as follows:
where displacement are vectors from the reference point , f represents a weighting function and ⊗ is the tensor product of vector. In the tensor products, there are small numbers of non-zero components related to the gradient orientations of the neighboring vectors. The parameters are confined in the experiment. Where is the displacement interval along the spatial axis and is that of along the temporal axis. To inhibit the effect of isolated noise on surrounding auto-correlations, min is received regarding to weight function f.
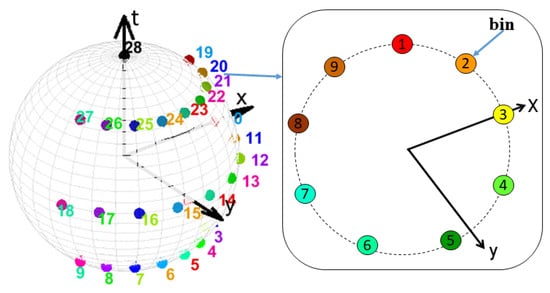
Figure 3.
28 orientation bins along latitude and longitude on a hemisphere. 4 orientation bin layers including a layer at pole are in two-dimensional plane. 9 orientation bins are located on each layer except at the pole (contains one bin).
For the 0th order and the 1st order STACOG features can be written as,
where and are 0th and 1st order auto-correlations which gives the 0th order and the 1st order STACOG features, and T is the transpose.
3.3. Action Recognition
By applying Algorithm 1, two auto-correlation feature vectors and are acquired corresponding to two different sets of sub-sequences, and , of the depth video D (see Figure 1). The dimension of and are reduced through Principal Component Analysis (PCA) [54]. Then the two vectors are passed separately to -regularized Collaborative Representation Classifier (-CRC) [13] and the relevant two distinct outcomes are fused by logarithmic opinion pool (LOGP) [14]. To explain -CRC, let us denote the class number by K. The set is the set of all training samples, where d is the-dimensionality of training samples, m is the number of training samples from K classes, is subset of training samples from class i and is any training sample of . Let, be any unknown test sample which is defined by the linear combination of all the training samples in Y:
where is a coefficients vector associated with the training samples of class i. In practice, Equation(5) cannot be solved directly because it is under determination [55]. By the solution of the following norm minimization problem, Equation(5) can be solved:
where denotes the regularization parameter and M is the Tikhonov regularization matrix [56], which is configured by the following diagonal matrix.
The coefficient vector can be calculated as [57],
Since the training samples are Y is given and is determined by these samples then Z can be simply calculated and thus Z is independent of c. It is clear when the test sample c is given, the corresponding vector can be easily computed from Equation (8). The coefficient vector is represented as by considering all the action classes. Now, the class-specific residual error can be obtained by
where, is the dictionary sample and is the coefficient of ith class, respectively.
From Equation (9), an error vector is obtained about an input feature vector. In our case, there are two error vectors and since we input two feature vectors and obtained by Algorithm 1 for the test sample c. A decision fusion scheme logarithmic opinion pool (LOGP) [14] rule is used to concatenate the probabilities of those errors and to output the class label. In this scheme, the following global membership function is calculated through the posterior probability of each classifier.
where denotes class label, and denotes the number of classifiers.
Then a Gaussian mass function corresponding to the residual error is represented by the following equation.
Equation (11) defines the higher posterior probability for a smaller residual error . Therefore, the combined probability from the two classifiers is defined as:
where and are normalized to .
4. Experimental Results and Discussion
This section discusses three sets of experiments on three datasets to evaluate the performance of the proposed framework. First, the datasets are introduced along with their challenges. Secondly, the setup of STACOG parameters is then discussed to evaluate the proposed framework. Finally, experimental results on three datasets are described.
4.1. Datasets
Our proposed framework is greatly appraised on depth-based actions datasets named MSR-action 3D dataset [58], DHA dataset [59], and UTD-MHAD dataset [38].
4.1.1. MSR-Action 3D Dataset
MSR-Action 3D dataset is captured by a depth camera which represents action data of depth map sequences. The resolution of each map is . This dataset has 20 types of action categories. All the actions are acted by 10 different persons and every subject act in each action 2 or 3 times. In this dataset, the number of depth map sequences is 557 [58]. This dataset is a challenging because of the correspondence between some actions (e.g., “Draw x” and “Draw tick”).
4.1.2. DHA Dataset
DHA dataset was introduced in [59] which contains some actions extended from the Weizmann dataset [60]. The Weizmann dataset is used in action recognition based on RGB sequences. The DHA dataset involves 23 action types among which 1 to 10 actions are adopted from Weizmann dataset [61]. All the actions are performed by 21 subjects (12 males and nine females) and the total number of depth map sequences is 483. Because of the inter-similarity between action classes (e.g., “rod-swing” and “golf swing”), the DHA dataset is challenging.
4.1.3. UTD-MHAD Dataset
In the UTD-MHAD dataset [38], RGB videos, depth videos, skeleton positions, and inertial signals are captured by a video sensor and a wearable inertial sensor. All the actions of this dataset contain 27 actions and all the actions are performed by eight subjects (four females and four males). Each performer repeats each action four times. This dataset includes 861 depth action sequences, after eliminating three inappropriate sequences.
4.2. Parameter Setting
The proposed framework is evaluated on the datasets discussed above and compared with the other state-of-the-art approaches. Of all the samples of each dataset, some samples are used as training samples and the remaining samples are used as test samples. Depending on the test samples, results on all datasets are obtained. Each depth action video of all datasets is partitioned into sub-sequences using the same frame lengths. The frame interval between two consecutive sub-sequences is set to 1 which indicates the number of overlapping frames. Thus, for two different frame lengths 5 and 10, the overlapping frames 4 and 9 are obtained, respectively. Additionally, for all action datasets, we used the same values of parameters. At first, all parameter values are tuned for a dataset to query which values give the highest recognition accuracy. Then, the values of parameters set for the highest result are used in all other datasets to verify the superiority of the framework. To extract STACOG features, orientation bins in the plane and orientation bin layers are set to 9 and 4, respectively. According to [15], the temporal interval is set to 1 and the spatial interval is fixed to 8. The -CRC parameter is tuned to .
4.3. Classification on MSR-Action 3D Dataset
In the experimental arrangement, we used all action categories of MSR-Action 3D dataset instead of dividing them into different action subsets. The action samples acted through persons of the odd number are employed as training samples (284) and the samples of the remaining persons of even number are used as test samples(273). Our proposed framework gives % recognition accuracy which is compared with other frameworks on depth data as shown in Table 1. Among 20 actions, the classification accuracy is 100% for 14 actions. The remaining 6 actions have some confusion with other actions because of some inter-class similarities. For example, the confusion of an action “Side kick” with an action “Hand catch” is % (see Figure 4). The accuracy including confusion information of each class is further clarified in Table 2.

Table 1.
Comparison of action recognition accuracy (%) with state-of-the-art frameworks on the MSR-Action 3D dataset.
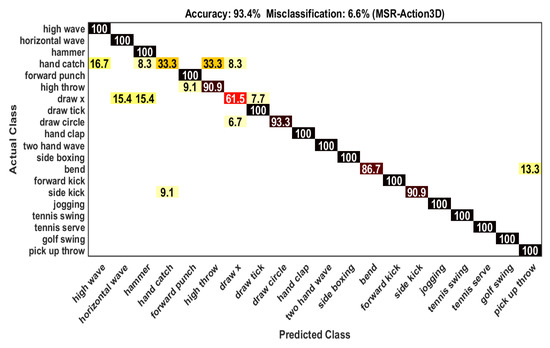
Figure 4.
Confusion matrix on MSR-Action 3D dataset.
Table 2.
Class-specific accuracy on MSR-Action3D dataset.
4.4. Classification on DHA Dataset
In the DHA dataset, samples of the odd subjects are used as training samples and the samples of the even subjects are used as test samples. There are 253 samples are used as training samples and 230 samples are used as test samples. Our proposed framework achieves % accuracy which shows the effectiveness of the recognition framework. From Table 3, we can observe that 15 out of 23 actions are recognized with 100% accuracy. The remaining 8 actions are confused with other actions shown in Figure 5. The action “golf swing” gives 10% confusion with “rod-swing”. The comparison of our recognition framework with other state-of-the-art methods is shown in Table 3. It is clear from the table that our proposed framework beats other existing frameworks considerably. The class-wise classification accuracy (for right and wrong classification) is shown in Table 4.
Table 3.
Comparison of action recognition accuracy (%) with state-of-the-art frameworks on the DHA dataset.
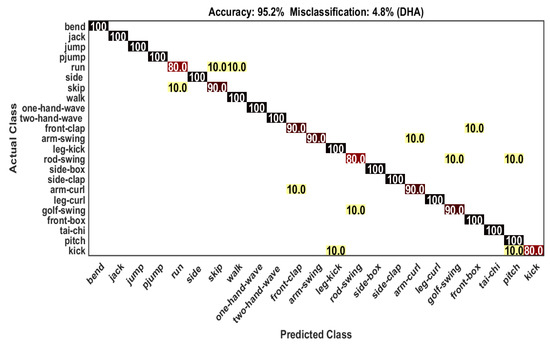
Figure 5.
Confusion matrix on DHA dataset.
Table 4.
Class-specific accuracy on DHA dataset.
4.5. Classification on UTD-MHAD Dataset
In the UTD-MHAD dataset, samples of the odd subjects are used as training samples (431) and the samples of the even subjects are used as test samples (430). The evaluation result of our framework on this dataset gives % recognition accuracy (see Table 5) because of using varieties actions. The result in our recognition framework gives 100% accuracy for 11 actions and the remaining 16 actions show confusion with other actions (see Figure 6). The individual class recognition performance is reported in Table 6.
Table 5.
Comparison of action recognition accuracy (%) with state-of-the-art frameworks on the UTD-MHAD dataset.
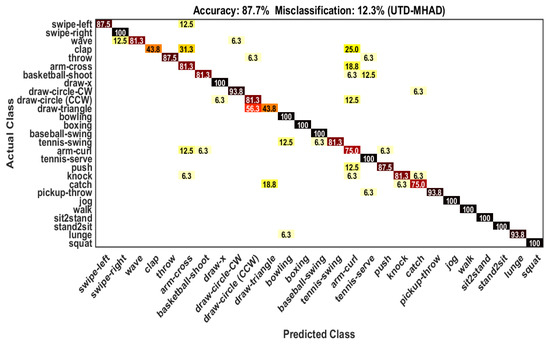
Figure 6.
Confusion matrix on the UTD-MHAD dataset.
Table 6.
Class-specific accuracy on UTD-MHAD dataset.
4.6. Efficiency Evaluation
The execution time and the space complexity of key factors are deliberated to show the efficiency of our system.
4.6.1. Execution Time
The system is executed by using MATLAB on CPU platform with an Intel i5-7500 Quad-core processor of 3.41 GHz frequency and a RAM of 16 GB. There are seven major components in the proposed approach: DMMs sequences construction for frame length 5, DMMs sequences construction for frame length 10, feature vector generation, feature vector generation, PCA on , PCA on , Action label. The execution time of these components is determined to assess the time efficiency of the system on three datasets as MSR-Action 3D, DHA, and UTD-MHAD dataset. Table 7 showed the execution time (in milliseconds) of the seven components on those datasets and compared the total execution time on the datasets. In the case of the MSR-Action 3D dataset, execution times are calculated for each action sample with 40 frames on average. As can be seen from Table 7, 40 frames are processed in less than one second (i.e., 252.6 ± 74.8 milliseconds). Therefore, our proposed recognition framework can be used for real-time action recognition on the MSR-Action 3D dataset. The execution times on the DHA dataset are calculated for each action sample with 29 frames on average. Table 7 showed that the 29 frames are processed in less than one second (i.e., 379.1 ± 90.7 milliseconds) which proves our framework can be used for real-time action recognition on the DHA dataset. Table 7 also presented the execution times (in milliseconds) on the UTD-MHAD dataset for each action sample with 68 frames on average. To process 68 frames, the system requires less than one second (i.e., 508.9 ± 100.9 milliseconds) which showed the capability of the real-time action recognition of our proposed framework.
Table 7.
Comparison of execution time (mean ± std) of the key factors on three datasets.
4.6.2. Space Complexity
The components PCA and -CRC are the key components for the calculation of space complexity of the proposed system. PCA and -CRC are adopted for both frame lengths 5 and 10. Therefore, the complexity of PCA is [23] and the complexity of -CRC is [62]. Thus, the total complexity of the system can be expressed as . Table 8 describes the computed complexity and compared it with the complexities of other existing frameworks. The table shows that our framework delivers lower complexity and recognizes actions better than other existing frameworks.
Table 8.
Comparison of computational complexity of the proposed approach with other existing approaches.
5. Conclusions
In this paper, we present an effective action recognition framework that is based on 3D Auto-Correlation features. In fact, the Depth Motion Maps (DMMs) sequence representation is firstly introduced to obtain additional temporal motion information from depth map sequences which can distinguish similar actions. The space-time auto-correlation of gradients features description algorithm is then used to extract motion cues from the sequences of DMMs according to different projection views. At last, the Collaborative representation classifier (CRC) and the decision fusion scheme are used for detecting action class. Experimental results on three benchmark datasets shows that the proposed framework is better than the state-of-the-art methods. Moreover, the framework outperforms other existing techniques that are based on space-time auto-correlation of gradients feature. Furthermore, the space-time complexity analysis of the proposed framework indicates that it can be used for the real-time human action recognition.
Author Contributions
M.F.B.: Conceptualization, methodology, software, data curation, validation, formal analysis, investigation, writing—original draft preparation; S.T.: Validation, Implementation, formal analysis, writing—original draft preparation; H.A.: Conceptualization, writing—original draft preparation, writing—review and editing; W.Z.: Writing—review and editing, funding acquisition, data collection and analysis; M.Y.L.: Methodology, formal analysis, revision—draft preparation and critical revision, funding acquisition, project administration; A.U.: investigation, visualization, writing—review and editing, supervision. All authors have read and agreed to the published version of the manuscript, please turn to the http://img.mdpi.org/data/contributor-role-instruction.pdf CRediT taxonomy for the term explanation. Authorship must be limited to those who have contributed substantially to the work reported.
Funding
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2018R1D1A1B07043302).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ji, X.; Cheng, J.; Feng, W. Spatio-temporal cuboid pyramid for action recognition using depth motion sequences. In Proceedings of the 2016 Eighth International Conference on Advanced Computational Intelligence (ICACI), Chiang Mai, Thailand, 14–16 February 2016; pp. 208–213. [Google Scholar]
- Li, R.; Liu, Z.; Tan, J. Exploring 3D human action recognition: From offline to online. Sensors 2018, 18, 633. [Google Scholar]
- Fan, Y.; Weng, S.; Zhang, Y.; Shi, B.; Zhang, Y. Context-Aware Cross-Attention for Skeleton-Based Human Action Recognition. IEEE Access 2020, 8, 15280–15290. [Google Scholar] [CrossRef]
- Cho, S.; Maqbool, M.H.; Liu, F.; Foroosh, H. Self-Attention Network for Skeleton-based Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CA, USA, 1–5 March 2020; pp. 624–633. [Google Scholar]
- Ali, H.H.; Moftah, H.M.; Youssif, A.A. Depth-based human activity recognition: A comparative perspective study on feature extraction. Future Comput. Inform. J. 2018, 3, 51–67. [Google Scholar] [CrossRef]
- Tufek, N.; Yalcin, M.; Altintas, M.; Kalaoglu, F.; Li, Y.; Bahadir, S.K. Human action recognition using deep learning methods on limited sensory data. IEEE Sens. J. 2019, 20, 3101–3112. [Google Scholar] [CrossRef]
- Elbasiony, R.; Gomaa, W. A survey on human activity recognition based on temporal signals of portable inertial sensors. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 734–745. [Google Scholar]
- Masum, A.K.M.; Bahadur, E.H.; Shan-A-Alahi, A.; Chowdhury, M.A.U.Z.; Uddin, M.R.; Al Noman, A. Human Activity Recognition Using Accelerometer, Gyroscope and Magnetometer Sensors: Deep Neural Network Approaches. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Farooq, A.; Won, C.S. A survey of human action recognition approaches that use an RGB-D sensor. IEIE Trans. Smart Process. Comput. 2015, 4, 281–290. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3d data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Zhou, Y.; Ali, H. Improving Human Action Recognition Using Hierarchical Features And Multiple Classifier Ensembles. Comput. J. 2019. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Sveinsson, J.R. Multisource remote sensing data classification based on consensus and pruning. IEEE Trans. Geosci. Remote Sens. 2003, 41, 932–936. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Hou, Z.; Jiang, J.; Liu, M.; Yang, Y. Action recognition from depth sequences using weighted fusion of 2D and 3D auto-correlation of gradients features. Multimed. Tools Appl. 2017, 76, 4651–4669. [Google Scholar] [CrossRef]
- Chen, C.; Hou, Z.; Zhang, B.; Jiang, J.; Yang, Y. Gradient local auto-correlations and extreme learning machine for depth-based activity recognition. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 613–623. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. Human action recognition based on DMMs, HOGs and Contourlet transform. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 389–394. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. Real-time human action recognition using DMMs-based LBP and EOH features. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 271–282. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. DMMs-based multiple features fusion for human action recognition. Int. J. Multimed. Data Eng. Manag. 2015, 6, 23–39. [Google Scholar] [CrossRef]
- Liu, H.; Tian, L.; Liu, M.; Tang, H. Sdm-bsm: A fusing depth scheme for human action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4674–4678. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 1092–1099. [Google Scholar]
- Chen, C.; Liu, M.; Zhang, B.; Han, J.; Jiang, J.; Liu, H. 3D Action Recognition Using Multi-Temporal Depth Motion Maps and Fisher Vector. In Proceedings of the International Joint Conference On Artificial Intelligence IJCAI, New York, NY, USA, 9–15 July 2016; pp. 3331–3337. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Liu, M.; Liu, H.; Chen, C.; Najafian, M. Energy-based global ternary image for action recognition using sole depth sequences. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 47–55. [Google Scholar]
- Liang, C.; Qi, L.; Chen, E.; Guan, L. Depth-based action recognition using multiscale sub-actions depth motion maps and local auto-correlation of space-time gradients. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–7. [Google Scholar]
- Liu, H.; He, Q.; Liu, M. Human action recognition using adaptive hierarchical depth motion maps and Gabor filter. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1432–1436. [Google Scholar]
- Jin, K.; Jiang, M.; Kong, J.; Huo, H.; Wang, X. Action recognition using vague division DMMs. J. Eng. 2017, 2017, 77–84. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action recognition using 3D histograms of texture and a multi-class boosting classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, M.; Liu, H.; Zhang, B.; Han, J.; Kehtarnavaz, N. Multi-temporal depth motion maps-based local binary patterns for 3-D human action recognition. IEEE Access 2017, 5, 22590–22604. [Google Scholar] [CrossRef]
- Li, W.; Wang, Q.; Wang, Y. Action Recognition Based on Depth Motion Map and Hybrid Classifier. Math. Probl. Eng. 2018. [Google Scholar] [CrossRef]
- Bulbul, M.F. Searching Human Action Recognition Accuracy from Depth Video Sequences Using HOG and PHOG Shape Features. Eur. J. Appl. Sci. 2018, 6, 13. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Kasaei, S.; Escalera, S. Dynamic 3D hand gesture recognition by learning weighted depth motion maps. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1729–1740. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Ali, H. Human action recognition using MHI and SHI based GLAC features and collaborative representation classifier. J. Intell. Fuzzy Syst. 2019, 36, 3385–3401. [Google Scholar] [CrossRef]
- Weiyao, X.; Muqing, W.; Min, Z.; Yifeng, L.; Bo, L.; Ting, X. Human action recognition using multilevel depth motion maps. IEEE Access 2019, 7, 41811–41822. [Google Scholar] [CrossRef]
- Shekar, B.; Rathnakara Shetty, P.; Sharmila Kumari, M.; Mestetsky, L. Action recognition using undecimated dual tree complex wavelet transform from depth motion maps/depth sequences. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Ali, H. 3D human action analysis and recognition through GLAC descriptor on 2D motion and static posture images. Multimed. Tools Appl. 2019, 78, 21085–21111. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.P.; Yang, Y.; Ndzi, D. Multi-view region-adaptive multi-temporal DMM and RGB action recognition. Pattern Anal. Appl. 2020, 23, 1587–1602. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Youssef, C. Spatiotemporal representation of 3d skeleton joints-based action recognition using modified spherical harmonics. Pattern Recognit. Lett. 2016, 83, 32–41. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 807–811. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based deep convolutional neural network for action recognition with depth sequences. Image Vis. Comput. 2016, 55, 93–100. [Google Scholar] [CrossRef]
- Wang, P.; Wang, S.; Gao, Z.; Hou, Y.; Li, W. Structured images for RGB-D action recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1005–1014. [Google Scholar]
- Al-Obaidi, S.; Abhayaratne, C. Privacy Protected Recognition of Activities of Daily Living in Video. In Proceedings of the 3rd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2019), London, UK, 25 March 2019; pp. 1–6. [Google Scholar]
- Wang, L.; Ding, Z.; Tao, Z.; Liu, Y.; Fu, Y. Generative multi-view human action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6212–6221. [Google Scholar]
- Liu, M.; Meng, F.; Chen, C.; Wu, S. Joint dynamic pose image and space time reversal for human action recognition from videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8762–8769. [Google Scholar]
- Lopez-Nava, I.H.; Muñoz-Meléndez, A. Human action recognition based on low-and high-level data from wearable inertial sensors. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719894532. [Google Scholar] [CrossRef]
- Haider, F.; Salim, F.A.; Postma, D.B.; Delden, R.v.; Reidsma, D.; van Beijnum, B.J.; Luz, S. A super-bagging method for volleyball action recognition using wearable sensors. Multimodal Technol. Interact. 2020, 4, 33. [Google Scholar] [CrossRef]
- Lemieux, N.; Noumeir, R. A hierarchical learning approach for human action recognition. Sensors 2020, 20, 4946. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Tao, Z.; Wang, L.; Li, S.; Yin, Y.; Fu, Y. Collaborative Attention Mechanism for Multi-View Action Recognition. arXiv 2020, arXiv:2009.06599. [Google Scholar]
- Ullah, A.; Muhammad, K.; Hussain, T.; Baik, S.W. Conflux LSTMs network: A novel approach for multi-view action recognition. Neurocomputing 2020, 414, 90–100. [Google Scholar]
- Liu, Y.; Wang, L.; Bai, Y.; Qin, C.; Ding, Z.; Fu, Y. Generative View-Correlation Adaptation for Semi-supervised Multi-view Learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 318–334. [Google Scholar]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Kobayashi, T.; Otsu, N. Motion recognition using local auto-correlation of space-time gradients. Pattern Recognit. Lett. 2012, 33, 1188–1195. [Google Scholar] [CrossRef]
- Liu, K.; Ma, B.; Du, Q.; Chen, G. Fast motion detection from airborne videos using graphics processing unit. J. Appl. Remote Sens. 2012, 6, 061505. [Google Scholar]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of ill-posed problems. N. Y. 1977, 1, 30. [Google Scholar]
- Golub, G.H.; Hansen, P.C.; O’Leary, D.P. Tikhonov regularization and total least squares. SIAM J. Matrix Anal. Appl. 1999, 21, 185–194. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Lin, Y.C.; Hu, M.C.; Cheng, W.H.; Hsieh, Y.H.; Chen, H.M. Human action recognition and retrieval using sole depth information. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1053–1056. [Google Scholar]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar]
- Vieira, A.W.; Nascimento, E.R.; Oliveira, G.L.; Liu, Z.; Campos, M.F. Stop: Space-time occupancy patterns for 3d action recognition from depth map sequences. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 252–259. [Google Scholar]
- Bulbul, M.F.; Ali, H. Gradient local auto-correlation features for depth human action recognition. SN Appl. Sci. 2021, 3, 1–13. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).