
Exploring 3D Human Action Recognition Using STACOG on Multi-View Depth Motion Maps Sequences

 , , and
, , and
Abstract
1. Introduction
- Motivation and Contributions:
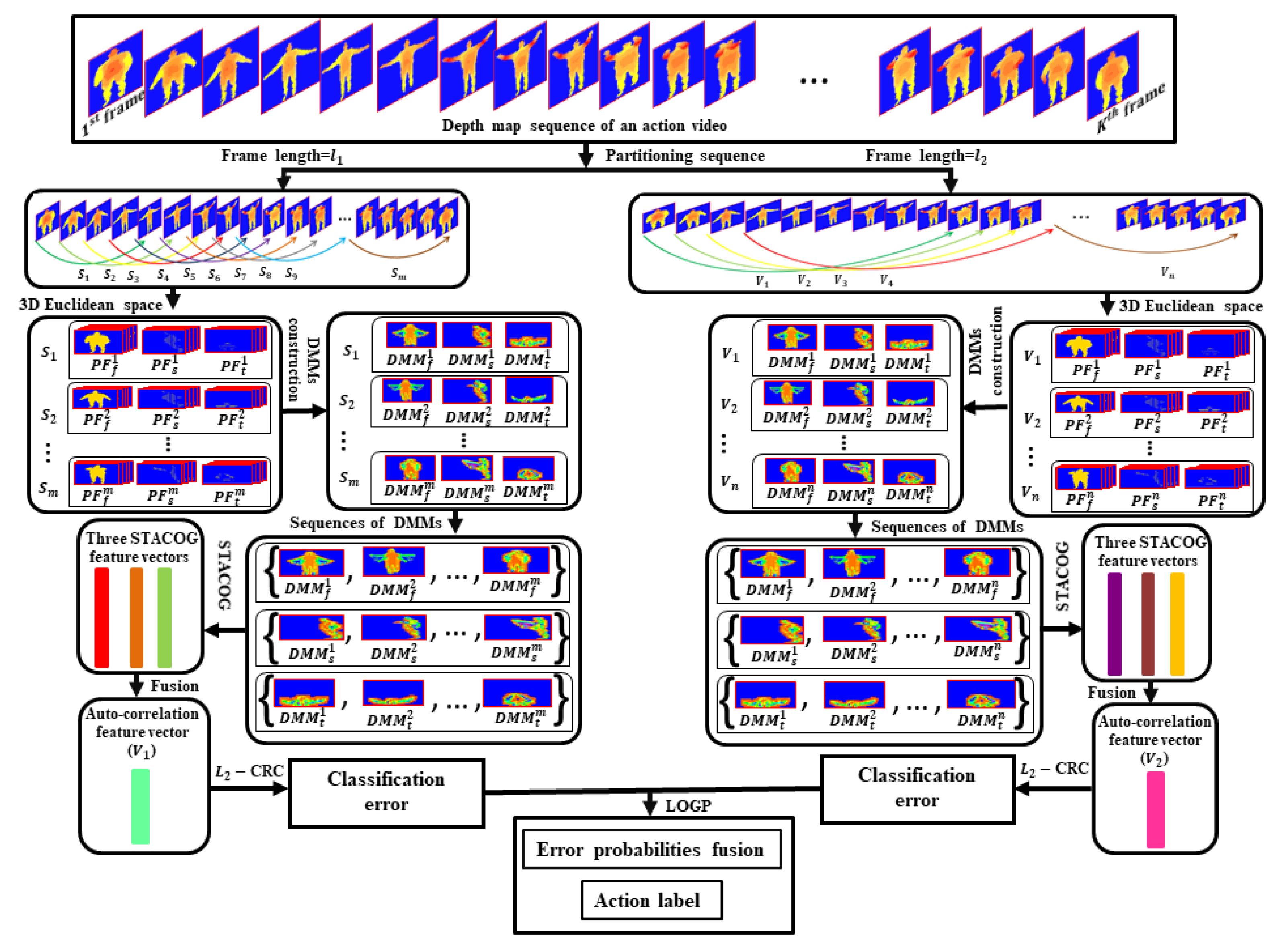
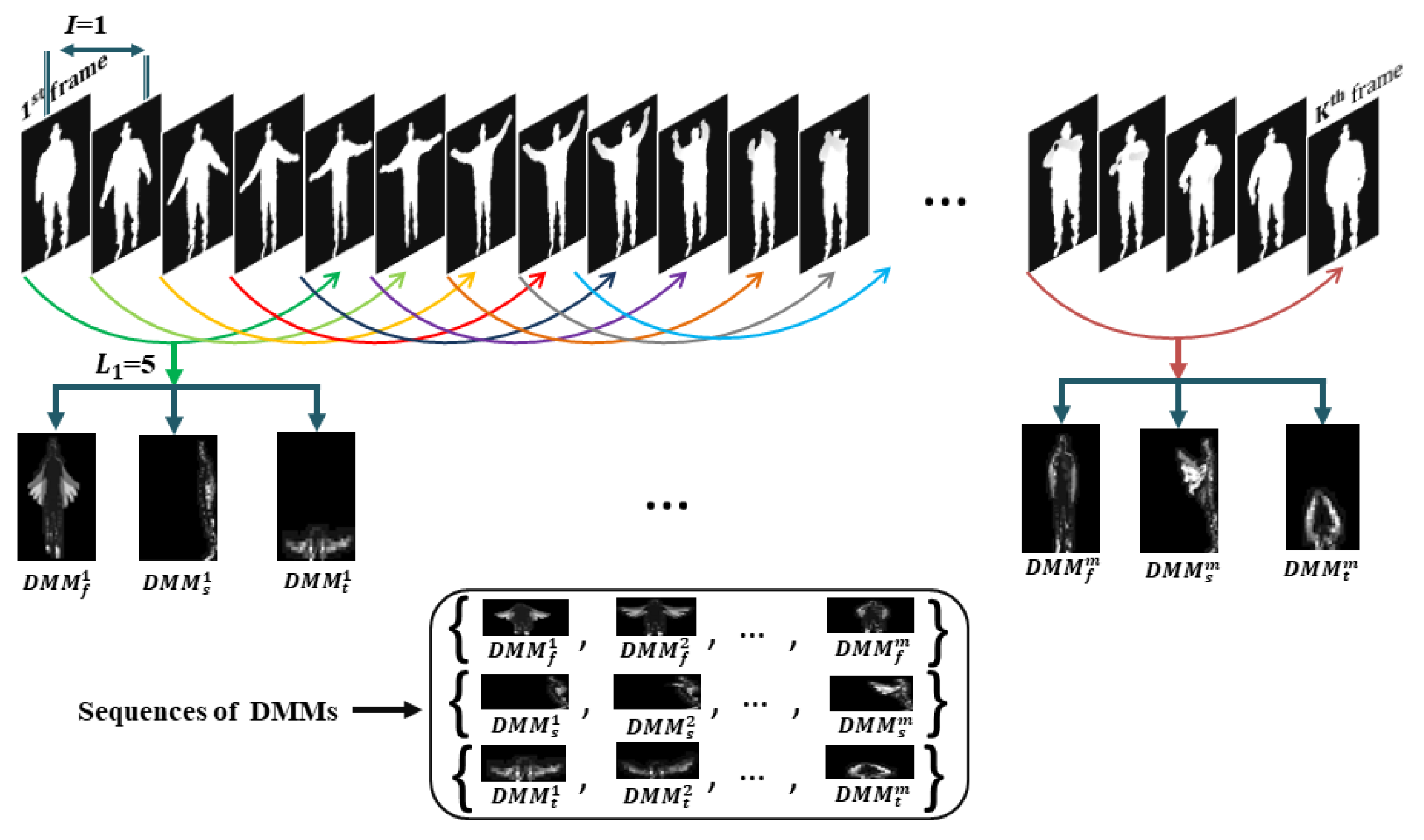
- The depth map sequences of each action video are partitioned into a set of sub-sequences of equal size. Afterward, DMMs are created from each sub-sequence corresponding to three projection views (front, side, and top) of 3D Euclidean space. Then, three DMMs sequences are derived by organizing all the DMMs along the projection views. The video is fragmented by two times generating two sets of sub-sequences using two different frame lengths and thus there are two sets of three DMMs sequences are obtained.
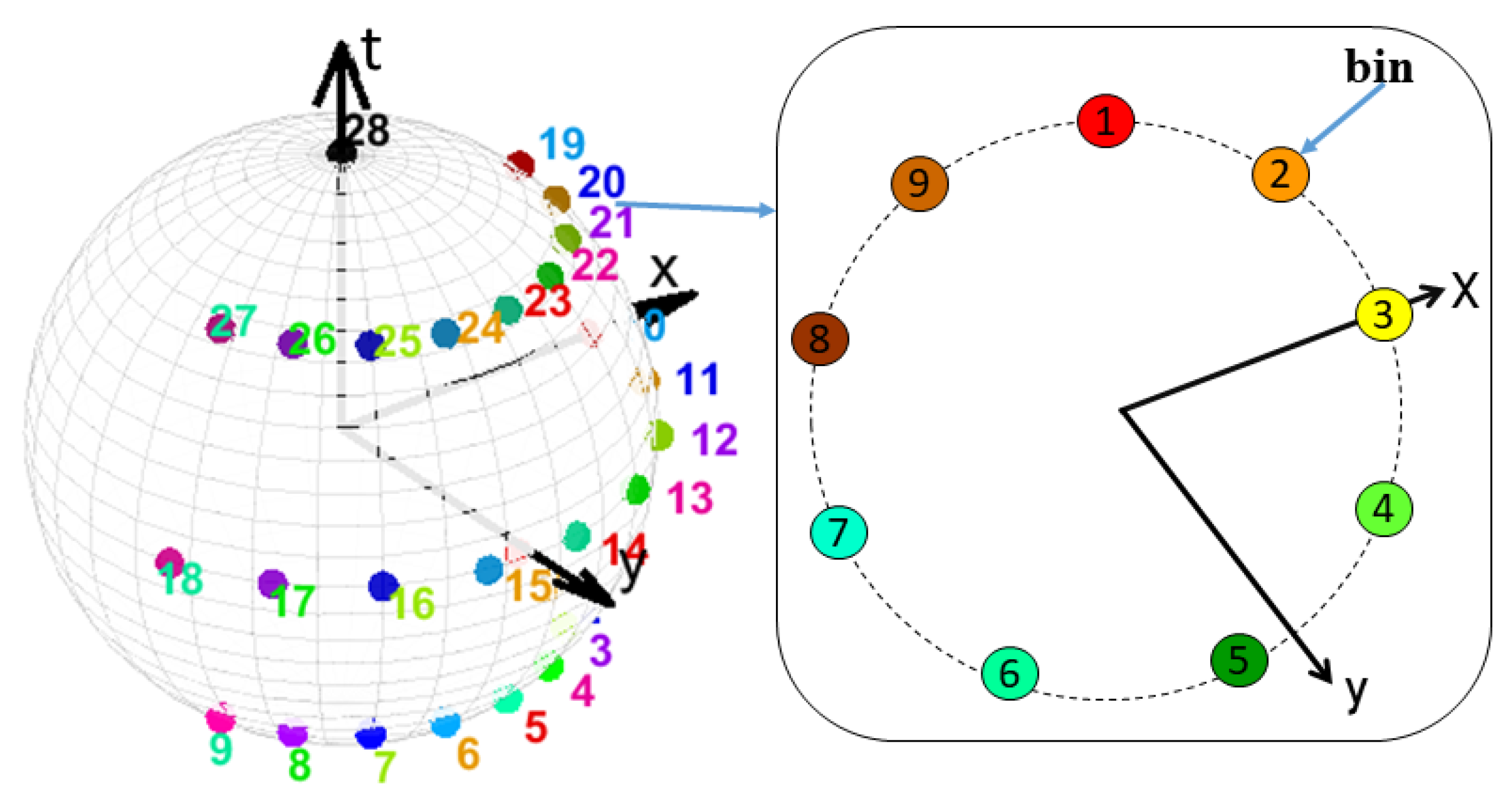
- Our recognition framework mines the 3D auto-correlation gradient feature vectors from three DMMs sequences by using the STACOG feature extractor instead of mining from depth map sequences as shown in [15].
- A decision fusion scheme is applied to combine residual outcomes obtained for two 3D action representation vectors.
- The proposed framework achieved the highest results as compared to all the other work done by applying the STACOG descriptor on depth video.
2. Related Work
3. Proposed Recognition Framework
| Algorithm 1 Algorithm for feature vector construction |
Input: A Depth action video D of frame length L Steps: 1. Split D and construct a set , where for all j 2. For all sub-sequences , calculate , and through Equation (1) 3. Use outcomes of Step2 and generate , and 5. Concatenate outcomes of Step4 6. Further split D and construct another set , where for all k 7. Follow Step2–Step5 for Output: Two auto-correlation feature vectors and |
| Algorithm 2 Algorithm for action recognition |
Input: The training feature set , test sample c, , K (number of action classes), class label (for class partitioning), Q is the number of classifiers. Steps: 1. Calculate using Equation (8) 2. for for ← two feature vectors are calculated for c using Algorithm 1 for all i do Partition , Calculate Calculate through Equation (11) end for end for end for 3. Calculate through Equation (12) 4. Decide through Equation (13) Output: |
3.1. Construction of DMMs Sequences
3.2. Action Vector Formation
3.3. Action Recognition
4. Experimental Results and Discussion
4.1. Datasets
4.1.1. MSR-Action 3D Dataset
4.1.2. DHA Dataset
4.1.3. UTD-MHAD Dataset
4.2. Parameter Setting
4.3. Classification on MSR-Action 3D Dataset
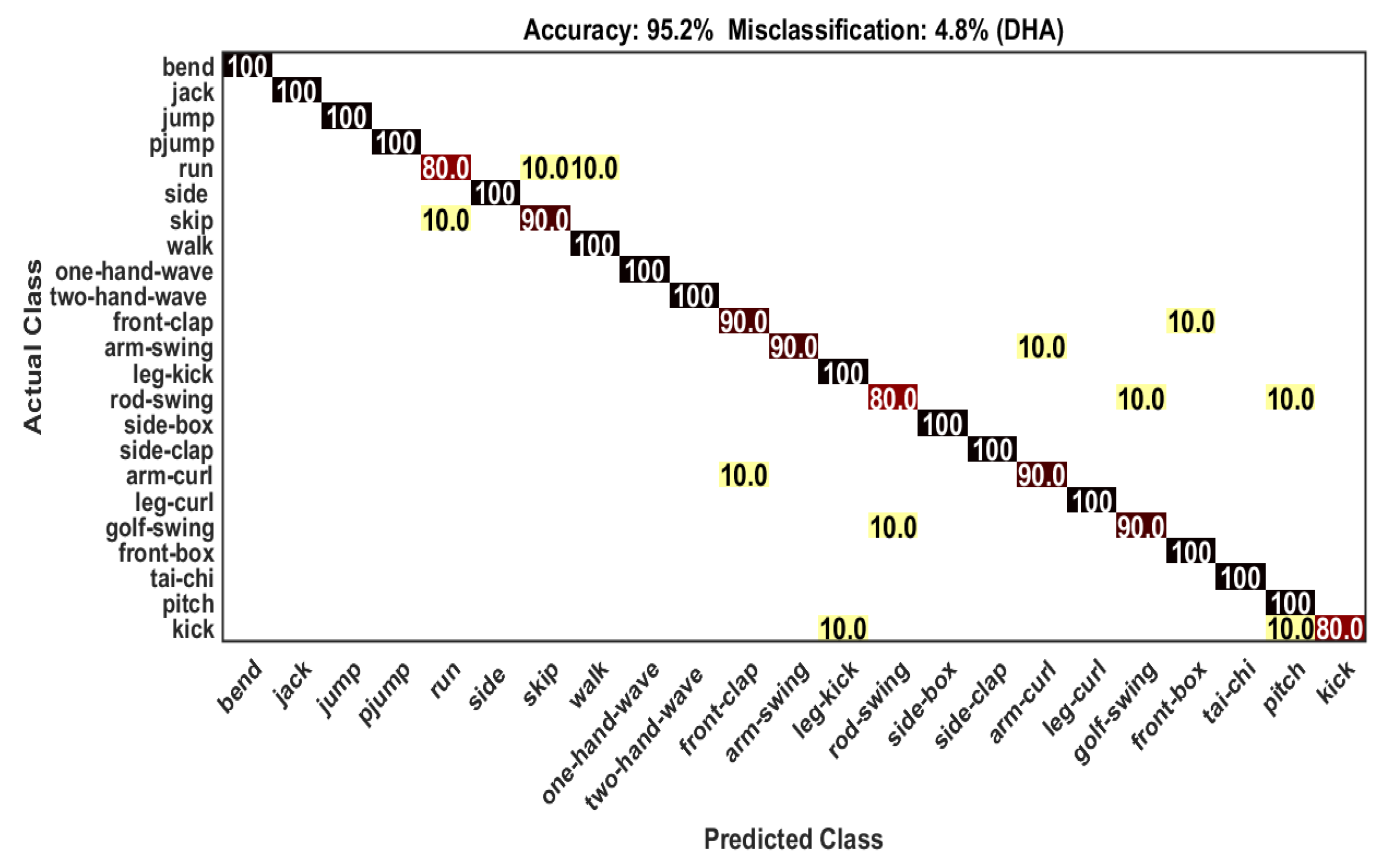
4.4. Classification on DHA Dataset
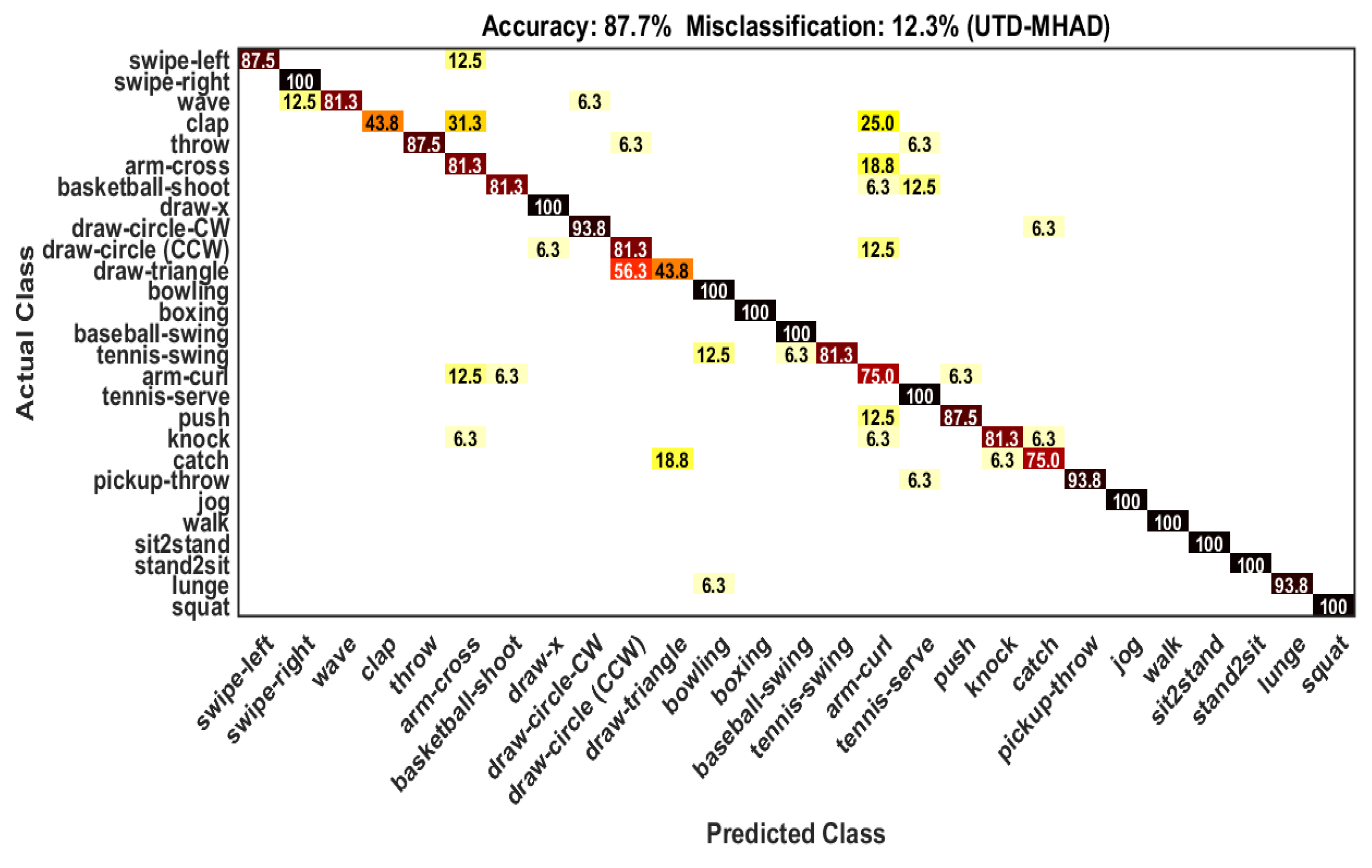
4.5. Classification on UTD-MHAD Dataset
4.6. Efficiency Evaluation
4.6.1. Execution Time
4.6.2. Space Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Ji, X.; Cheng, J.; Feng, W. Spatio-temporal cuboid pyramid for action recognition using depth motion sequences. In Proceedings of the 2016 Eighth International Conference on Advanced Computational Intelligence (ICACI), Chiang Mai, Thailand, 14–16 February 2016; pp. 208–213. [Google Scholar]
- Li, R.; Liu, Z.; Tan, J. Exploring 3D human action recognition: From offline to online. Sensors 2018, 18, 633. [Google Scholar]
- Fan, Y.; Weng, S.; Zhang, Y.; Shi, B.; Zhang, Y. Context-Aware Cross-Attention for Skeleton-Based Human Action Recognition. IEEE Access 2020, 8, 15280–15290. [Google Scholar] [CrossRef]
- Cho, S.; Maqbool, M.H.; Liu, F.; Foroosh, H. Self-Attention Network for Skeleton-based Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CA, USA, 1–5 March 2020; pp. 624–633. [Google Scholar]
- Ali, H.H.; Moftah, H.M.; Youssif, A.A. Depth-based human activity recognition: A comparative perspective study on feature extraction. Future Comput. Inform. J. 2018, 3, 51–67. [Google Scholar] [CrossRef]
- Tufek, N.; Yalcin, M.; Altintas, M.; Kalaoglu, F.; Li, Y.; Bahadir, S.K. Human action recognition using deep learning methods on limited sensory data. IEEE Sens. J. 2019, 20, 3101–3112. [Google Scholar] [CrossRef]
- Elbasiony, R.; Gomaa, W. A survey on human activity recognition based on temporal signals of portable inertial sensors. In International Conference on Advanced Machine Learning Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 734–745. [Google Scholar]
- Masum, A.K.M.; Bahadur, E.H.; Shan-A-Alahi, A.; Chowdhury, M.A.U.Z.; Uddin, M.R.; Al Noman, A. Human Activity Recognition Using Accelerometer, Gyroscope and Magnetometer Sensors: Deep Neural Network Approaches. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Farooq, A.; Won, C.S. A survey of human action recognition approaches that use an RGB-D sensor. IEIE Trans. Smart Process. Comput. 2015, 4, 281–290. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A survey of depth and inertial sensor fusion for human action recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3d data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Zhou, Y.; Ali, H. Improving Human Action Recognition Using Hierarchical Features And Multiple Classifier Ensembles. Comput. J. 2019. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Sveinsson, J.R. Multisource remote sensing data classification based on consensus and pruning. IEEE Trans. Geosci. Remote Sens. 2003, 41, 932–936. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Hou, Z.; Jiang, J.; Liu, M.; Yang, Y. Action recognition from depth sequences using weighted fusion of 2D and 3D auto-correlation of gradients features. Multimed. Tools Appl. 2017, 76, 4651–4669. [Google Scholar] [CrossRef]
- Chen, C.; Hou, Z.; Zhang, B.; Jiang, J.; Yang, Y. Gradient local auto-correlations and extreme learning machine for depth-based activity recognition. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 613–623. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. Human action recognition based on DMMs, HOGs and Contourlet transform. In Proceedings of the 2015 IEEE International Conference on Multimedia Big Data, Beijing, China, 20–22 April 2015; pp. 389–394. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. Real-time human action recognition using DMMs-based LBP and EOH features. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 271–282. [Google Scholar]
- Bulbul, M.F.; Jiang, Y.; Ma, J. DMMs-based multiple features fusion for human action recognition. Int. J. Multimed. Data Eng. Manag. 2015, 6, 23–39. [Google Scholar] [CrossRef]
- Liu, H.; Tian, L.; Liu, M.; Tang, H. Sdm-bsm: A fusing depth scheme for human action recognition. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4674–4678. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 1092–1099. [Google Scholar]
- Chen, C.; Liu, M.; Zhang, B.; Han, J.; Jiang, J.; Liu, H. 3D Action Recognition Using Multi-Temporal Depth Motion Maps and Fisher Vector. In Proceedings of the International Joint Conference On Artificial Intelligence IJCAI, New York, NY, USA, 9–15 July 2016; pp. 3331–3337. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time human action recognition based on depth motion maps. J. Real-Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Liu, M.; Liu, H.; Chen, C.; Najafian, M. Energy-based global ternary image for action recognition using sole depth sequences. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 47–55. [Google Scholar]
- Liang, C.; Qi, L.; Chen, E.; Guan, L. Depth-based action recognition using multiscale sub-actions depth motion maps and local auto-correlation of space-time gradients. In Proceedings of the 2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems (BTAS), Niagara Falls, NY, USA, 6–9 September 2016; pp. 1–7. [Google Scholar]
- Liu, H.; He, Q.; Liu, M. Human action recognition using adaptive hierarchical depth motion maps and Gabor filter. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1432–1436. [Google Scholar]
- Jin, K.; Jiang, M.; Kong, J.; Huo, H.; Wang, X. Action recognition using vague division DMMs. J. Eng. 2017, 2017, 77–84. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action recognition using 3D histograms of texture and a multi-class boosting classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, M.; Liu, H.; Zhang, B.; Han, J.; Kehtarnavaz, N. Multi-temporal depth motion maps-based local binary patterns for 3-D human action recognition. IEEE Access 2017, 5, 22590–22604. [Google Scholar] [CrossRef]
- Li, W.; Wang, Q.; Wang, Y. Action Recognition Based on Depth Motion Map and Hybrid Classifier. Math. Probl. Eng. 2018. [Google Scholar] [CrossRef]
- Bulbul, M.F. Searching Human Action Recognition Accuracy from Depth Video Sequences Using HOG and PHOG Shape Features. Eur. J. Appl. Sci. 2018, 6, 13. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Kasaei, S.; Escalera, S. Dynamic 3D hand gesture recognition by learning weighted depth motion maps. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 1729–1740. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Ali, H. Human action recognition using MHI and SHI based GLAC features and collaborative representation classifier. J. Intell. Fuzzy Syst. 2019, 36, 3385–3401. [Google Scholar] [CrossRef]
- Weiyao, X.; Muqing, W.; Min, Z.; Yifeng, L.; Bo, L.; Ting, X. Human action recognition using multilevel depth motion maps. IEEE Access 2019, 7, 41811–41822. [Google Scholar] [CrossRef]
- Shekar, B.; Rathnakara Shetty, P.; Sharmila Kumari, M.; Mestetsky, L. Action recognition using undecimated dual tree complex wavelet transform from depth motion maps/depth sequences. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Bulbul, M.F.; Islam, S.; Ali, H. 3D human action analysis and recognition through GLAC descriptor on 2D motion and static posture images. Multimed. Tools Appl. 2019, 78, 21085–21111. [Google Scholar] [CrossRef]
- Al-Faris, M.; Chiverton, J.P.; Yang, Y.; Ndzi, D. Multi-view region-adaptive multi-temporal DMM and RGB action recognition. Pattern Anal. Appl. 2020, 23, 1587–1602. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Youssef, C. Spatiotemporal representation of 3d skeleton joints-based action recognition using modified spherical harmonics. Pattern Recognit. Lett. 2016, 83, 32–41. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 807–811. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based deep convolutional neural network for action recognition with depth sequences. Image Vis. Comput. 2016, 55, 93–100. [Google Scholar] [CrossRef]
- Wang, P.; Wang, S.; Gao, Z.; Hou, Y.; Li, W. Structured images for RGB-D action recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1005–1014. [Google Scholar]
- Al-Obaidi, S.; Abhayaratne, C. Privacy Protected Recognition of Activities of Daily Living in Video. In Proceedings of the 3rd IET International Conference on Technologies for Active and Assisted Living (TechAAL 2019), London, UK, 25 March 2019; pp. 1–6. [Google Scholar]
- Wang, L.; Ding, Z.; Tao, Z.; Liu, Y.; Fu, Y. Generative multi-view human action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6212–6221. [Google Scholar]
- Liu, M.; Meng, F.; Chen, C.; Wu, S. Joint dynamic pose image and space time reversal for human action recognition from videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8762–8769. [Google Scholar]
- Lopez-Nava, I.H.; Muñoz-Meléndez, A. Human action recognition based on low-and high-level data from wearable inertial sensors. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719894532. [Google Scholar] [CrossRef]
- Haider, F.; Salim, F.A.; Postma, D.B.; Delden, R.v.; Reidsma, D.; van Beijnum, B.J.; Luz, S. A super-bagging method for volleyball action recognition using wearable sensors. Multimodal Technol. Interact. 2020, 4, 33. [Google Scholar] [CrossRef]
- Lemieux, N.; Noumeir, R. A hierarchical learning approach for human action recognition. Sensors 2020, 20, 4946. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Tao, Z.; Wang, L.; Li, S.; Yin, Y.; Fu, Y. Collaborative Attention Mechanism for Multi-View Action Recognition. arXiv 2020, arXiv:2009.06599. [Google Scholar]
- Ullah, A.; Muhammad, K.; Hussain, T.; Baik, S.W. Conflux LSTMs network: A novel approach for multi-view action recognition. Neurocomputing 2020, 414, 90–100. [Google Scholar]
- Liu, Y.; Wang, L.; Bai, Y.; Qin, C.; Ding, Z.; Fu, Y. Generative View-Correlation Adaptation for Semi-supervised Multi-view Learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 318–334. [Google Scholar]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Kobayashi, T.; Otsu, N. Motion recognition using local auto-correlation of space-time gradients. Pattern Recognit. Lett. 2012, 33, 1188–1195. [Google Scholar] [CrossRef]
- Liu, K.; Ma, B.; Du, Q.; Chen, G. Fast motion detection from airborne videos using graphics processing unit. J. Appl. Remote Sens. 2012, 6, 061505. [Google Scholar]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of ill-posed problems. N. Y. 1977, 1, 30. [Google Scholar]
- Golub, G.H.; Hansen, P.C.; O’Leary, D.P. Tikhonov regularization and total least squares. SIAM J. Matrix Anal. Appl. 1999, 21, 185–194. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Lin, Y.C.; Hu, M.C.; Cheng, W.H.; Hsieh, Y.H.; Chen, H.M. Human action recognition and retrieval using sole depth information. In Proceedings of the 20th ACM international conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1053–1056. [Google Scholar]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar]
- Vieira, A.W.; Nascimento, E.R.; Oliveira, G.L.; Liu, Z.; Campos, M.F. Stop: Space-time occupancy patterns for 3d action recognition from depth map sequences. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 252–259. [Google Scholar]
- Bulbul, M.F.; Ali, H. Gradient local auto-correlation features for depth human action recognition. SN Appl. Sci. 2021, 3, 1–13. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Accuracy (%) |
|---|---|
| Decision-level Fusion (MV) [19] | 91.9 |
| DMM-GLAC-FF [16] | 89.38 |
| DMM-GLAC-DF [16] | 92.31 |
| DMM-LBP-FF [21] | 91.9 |
| DMM-LBP-DF [21] | 93.0 |
| CNN [41] | 84.07 |
| Skeleton-MSH [39] | 90.98 |
| 3DHoT_S [28] | 91.9 |
| 3DHoT_M [28] | 88.3 |
| Depth-STACOG [15] | 75.82 |
| DMM-GLAC [15] | 89.38 |
| WDMM [32] | 90.0 |
| DMM-UDTCWT [35] | 92.67 |
| Proposed Approach | 93.4 |
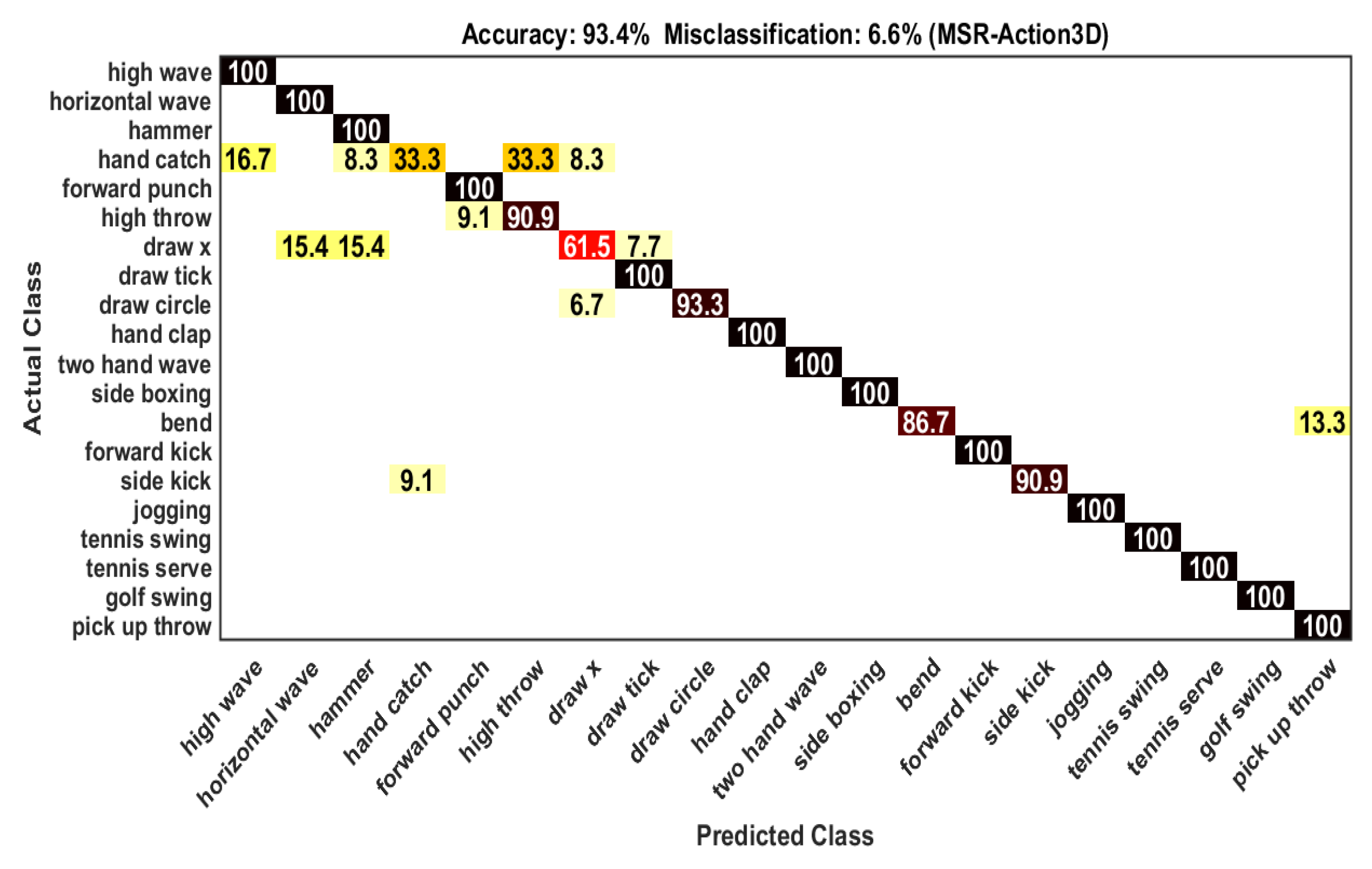
| Actions | Classification (%) | Confusion (%) |
|---|---|---|
| High wave | 100 | No confusion |
| Horizontal wave | 91.7 | Hammer (8.3) |
| Hammer | 100 | No confusion |
| Hand catch | 33.3 | High wave (16.7), Hammer (8.3), High throw (33.3), Draw x (8.3) |
| Forward punch | 100 | No confusion |
| High throw | 90.9 | Forward punch (9.1) |
| Draw x | 61.5 | Horizontal wave (15.4), Hammer (15.4), Draw tick (7.7) |
| Draw tick | 100 | No confusion |
| Draw circle | 93.3 | Draw X (6.7) |
| Hand clap | 100 | No confusion |
| Two hand wave | 100 | No confusion |
| Side boxing | 100 | No confusion |
| Bend | 86.7 | Pick up and throw (13.3) |
| Forward kick | 100 | No confusion |
| Side kick | 90.9 | Hand catch (9.1) |
| Jogging | 100 | No confusion |
| Tennis swing | 100 | No confusion |
| Tennis serve | 100 | No confusion |
| Golf swing | 100 | No confusion |
| Pick up and throw | 100 | No confusion |
| Approach | Accuracy (%) |
|---|---|
| SDM-BSM [20] | 89.50 |
| GTI-BoVW [24] | 91.92 |
| Depth WDMM [32] | 81.05 |
| RGB-VCDN [44] | 84.32 |
| VCDN [44] | 88.72 |
| Binary Silhouette [43] | 91.97 |
| DMM-UDTCWT [35] | 94.2 |
| Stridden DMM-UDTCWT [35] | 94.6 |
| VCA [51] | 89.31 |
| CAM [49] | 87.24 |
| Proposed Approach | 95.2 |
| Actions | Classification (%) | Confusion (%) |
|---|---|---|
| Bend | 100 | No confusion |
| Jack | 100 | No confusion |
| Jump | 100 | No confusion |
| Pjump | 100 | No confusion |
| Run | 80.0 | Skip (10.0), Walk (10.0) |
| Side | 100 | No confusion |
| Skip | 90.0 | Run (10.0) |
| Walk | 100 | No confusion |
| One-hand-wave | 100 | No confusion |
| Two-hand-wave | 100 | No confusion |
| Front-clap | 90.0 | Front-box (10.0) |
| Arm-swing | 90.0 | Arm-curl (10.0) |
| Leg-kick | 100 | No confusion |
| Rod-swing | 80.0 | Golf-swing (10.0), Pitch (10.0) |
| Side-box | 100 | No confusion |
| Side-clap | 90.0 | Side-box (10.0) |
| Arm-curl | 90.0 | Front-clap (10.0) |
| Leg-curl | 100 | No confusion |
| Golf-swing | 90.0 | Rod-swing (10.0) |
| Front-box | 100 | No confusion |
| Tai-chi | 100 | No confusion |
| Pitch | 100 | No confusion |
| Kick | 90.0 | Pitch (10.0) |
| Approach | Accuracy (%) |
|---|---|
| Kinect [38] | 66.10 |
| Inertial [38] | 67.20 |
| Kinect+Inertial [38] | 79.10 |
| DMM-EOH [19] | 75.3 |
| DMM-LBP [19] | 84.20 |
| CNN-Top [40] | 74.65 |
| CNN-Fusion [40] | 86.97 |
| 3DHOT-MBC [28] | 84.40 |
| VDDMMs [27] | 85.10 |
| Structured body DDI [42] | 66.05 |
| Structured part DDI [42] | 78.70 |
| RGB DTIs [45] | 85.39 |
| Inertial [48] | 85.35 |
| Proposed Approach | 87.7 |
| Actions | Classification (%) | Confusion (%) |
|---|---|---|
| Swipe-lift | 87.5 | Arm-cross (12.5) |
| Swipe-right | 100 | No confusion |
| Wave | 81.3 | Swipe-right (12.5), Draw-circle-CW (6.3) |
| Clap | 43.8 | Arm-cross (31.3), Arm-curl (25.0) |
| Throw | 87.5 | Draw-circle (CCW) (6.3), Tennis-serve (6.3) |
| Arm-cross | 81.3 | Arm-curl (18.8) |
| Basketball-shoot | 81.3 | Arm-curl (6.3), Tennis-serve (12.5) |
| Draw-x | 100 | No confusion |
| Draw-circle CW | 93.8 | Catch (6.3) |
| Draw-circle (CCW) | 81.3 | Draw X (6.3), Arm-curl (15.5) |
| Draw-triangle | 43.8 | Draw-circle (CCW) (56.3) |
| Bowling | 100 | No confusion |
| Boxing | 100 | No confusion |
| Baseball-swing | 100 | No confusion |
| Tennis-swing | 81.3 | Bowling (12.5), Baseball-swing (6.3) |
| Arm-curl | 75.0 | Arm-cross (12.5), Basketball-shoot (6.3), Push (6.3) |
| Tennis-serve | 100 | No confusion |
| Push | 87.5 | Arm-curl (12.5) |
| Knock | 81.3 | Arm-cross (6.3), Arm-curl (6.3), Catch (6.3) |
| Catch | 75.0 | Draw-triangle (18.8), Knock (6.3) |
| Pickup-throw | 93.8 | Tennis-serve (6.3) |
| Jog | 100 | No confusion |
| Walk | 100 | No confusion |
| Sit2stand | 100 | No confusion |
| Stand2sit | 100 | No confusion |
| Lunge | 93.8 | Bowling (6.3) |
| Squat | 100 | No confusion |
| Main Components | MSR-Action3D Dataset | DHA Dataset | UTD-MHAD Dataset |
|---|---|---|---|
| DMMs sequences construction for frame length 5 | 11.3 ± 0.7 | 80.7 ± 6.2 | 36.6 ± 3.0 |
| DMMs sequences construction for frame length 10 | 18.8 ± 1.3 | 155.6±12.0 | 67.9 ± 5.5 |
| feature vector generation | 108.5 ± 35.0 | 69.9 ± 35.0 | 197.7 ± 45.6 |
| feature vector generation | 95.6 ± 36.7 | 57.2 ± 36.7 | 180.9 ± 45.9 |
| PCA on | 8.5 ± 0.4 | 7.3 ± 0.3 | 10.7 ± 0.3 |
| PCA on | 8.4 ± 0.3 | 7.2 ± 0.3 | 10.7 ± 0.3 |
| Action label | 1.5 ± 0.4 | 1.2 ± 0.2 | 4.4 ± 0.3 |
| Total execution time | 252.6 ± 74.8/action sample (40 frames) | 379.1 ± 90.7/action sample (29 frames) | 508.9 ± 100.9/action sample (68 frames) |
| Approach | Components | Space Complexity |
|---|---|---|
| DMM [23] | PCA, -CRC | l = size of action vector, m = number of training samples, = number of action classes |
| DMM-LBP-DF [21] | PCA, Kernel-based Extreme Learning Machine (KELM) | l = size of action vector, m = number of training samples |
| MHF+SHF+KELM [13] | PCA, KELM | l = size of action vector, m = number of training samples |
| GMSHI+GSHI+CRC [36] | PCA, -CRC | l = size of action vector, t = number of training samples, = number of action classes |
| Enhanced auto-correlation [63] | PCA, KELM ensemble | l = size of action vector, m = number of action classes |
| Proposed Approach | PCA, -CRC | l = size of action vector, m = number of training samples, = number of action classes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulbul, M.F.; Tabussum, S.; Ali, H.; Zheng, W.; Lee, M.Y.; Ullah, A. Exploring 3D Human Action Recognition Using STACOG on Multi-View Depth Motion Maps Sequences. Sensors 2021, 21, 3642. https://doi.org/10.3390/s21113642
Bulbul MF, Tabussum S, Ali H, Zheng W, Lee MY, Ullah A. Exploring 3D Human Action Recognition Using STACOG on Multi-View Depth Motion Maps Sequences. Sensors. 2021; 21(11):3642. https://doi.org/10.3390/s21113642
Chicago/Turabian StyleBulbul, Mohammad Farhad, Sadiya Tabussum, Hazrat Ali, Wenli Zheng, Mi Young Lee, and Amin Ullah. 2021. "Exploring 3D Human Action Recognition Using STACOG on Multi-View Depth Motion Maps Sequences" Sensors 21, no. 11: 3642. https://doi.org/10.3390/s21113642
APA StyleBulbul, M. F., Tabussum, S., Ali, H., Zheng, W., Lee, M. Y., & Ullah, A. (2021). Exploring 3D Human Action Recognition Using STACOG on Multi-View Depth Motion Maps Sequences. Sensors, 21(11), 3642. https://doi.org/10.3390/s21113642