1. Introduction
Structural health monitoring (SHM) is a crucial process for engineering structures because it checks the correct behavior of the structure and determines whether it needs some type of maintenance. The healthy state of the structure has to remain between the specified limits or threshold, but these limits may change due to the aging of the structure and its use, or due to the environmental and operational conditions (EOC). Hence, in SHM systems, detection and classification of structural changes are essential in order to know the current state of the structure for security and to reduce costs of inspection and maintenance. If damage is detected and classified precisely at the time it occurs, some action may be taken before a human and/or economic disaster occurs, thus reducing the probability of accidents and the maintenance costs. SHM has been applied in many structures such as wind turbines [
1,
2,
3], buildings [
4,
5], and aircraft [
6,
7], among others, and a review of the state-of-the-art manifests that SHM is a very active research field.
With the goal of obtaining information about the state of the structure, data are collected by a sensor network, which is placed along the structure. The information obtained from multi-sensor signals creates a high-dimensional data set with a large volume of data due to continuous measurements of the monitoring system. Various methods have been proposed for the handling of high-dimensional, big, and complex data. Among these methods, plane or spatial representation techniques stick out as they offer a way to handle this type of data by means of an interface that allows an easy detection of natural clusters, identifying hidden patterns, et cetera [
8]. Plane or spatial representation techniques are also somehow related to dimensionality reduction. Dimensionality reduction is the mechanism of reducing the dimension of the original data, while keeping mostly the same intrinsic information [
9]. One of the proposed dimensionality reduction methods in the literature is
t-distributed stochastic neighbor embedding (
t-SNE), a technique developed by L. van der Maaten and G. Hinton [
10], which is able to represent the local structure of original high-dimensional data in a low-dimensional space (for example, a simple 2-D plot). This technique detects patterns by identifying clusters based on similarity of data points.
t-SNE is widely used in the literature as a dimensionality reduction technique, as a classification or pattern recognition method, or as a visualization and compression method of big data sets, but although
t-SNE has been applied in several applications, this is one of the first approaches of
t-SNE in the field of SHM [
11].
In the present approach,
t-SNE is applied in the frequency domain. In the field of SHM and condition monitoring (CM) this is sometimes common, and the combination of time-frequency domain is also used. Some examples are Tsogka et al. [
12], who propose a novel vibration-based SHM method for damage detection in the frequency domain, which illustrates its practical application in the case of a historic bell tower. Xu et al. [
13] propose a clustering method based on ensemble empirical mode decomposition and affinity propagation for bearing performance degradation assessment. To prove the superiority of the approach, the proposed methodology is compared to various popular clustering methods and commonly used time-domain indicators. The results show that the proposed method outperforms these popular clustering methods and time-domain indicators. Cheng et al. [
14] propose a multisensory data-driven health degradation monitoring system by using a generalized multiclass support vector machine. In this method, multidimensional feature extraction is implemented in the time domain, frequency domain, and time-frequency domain.
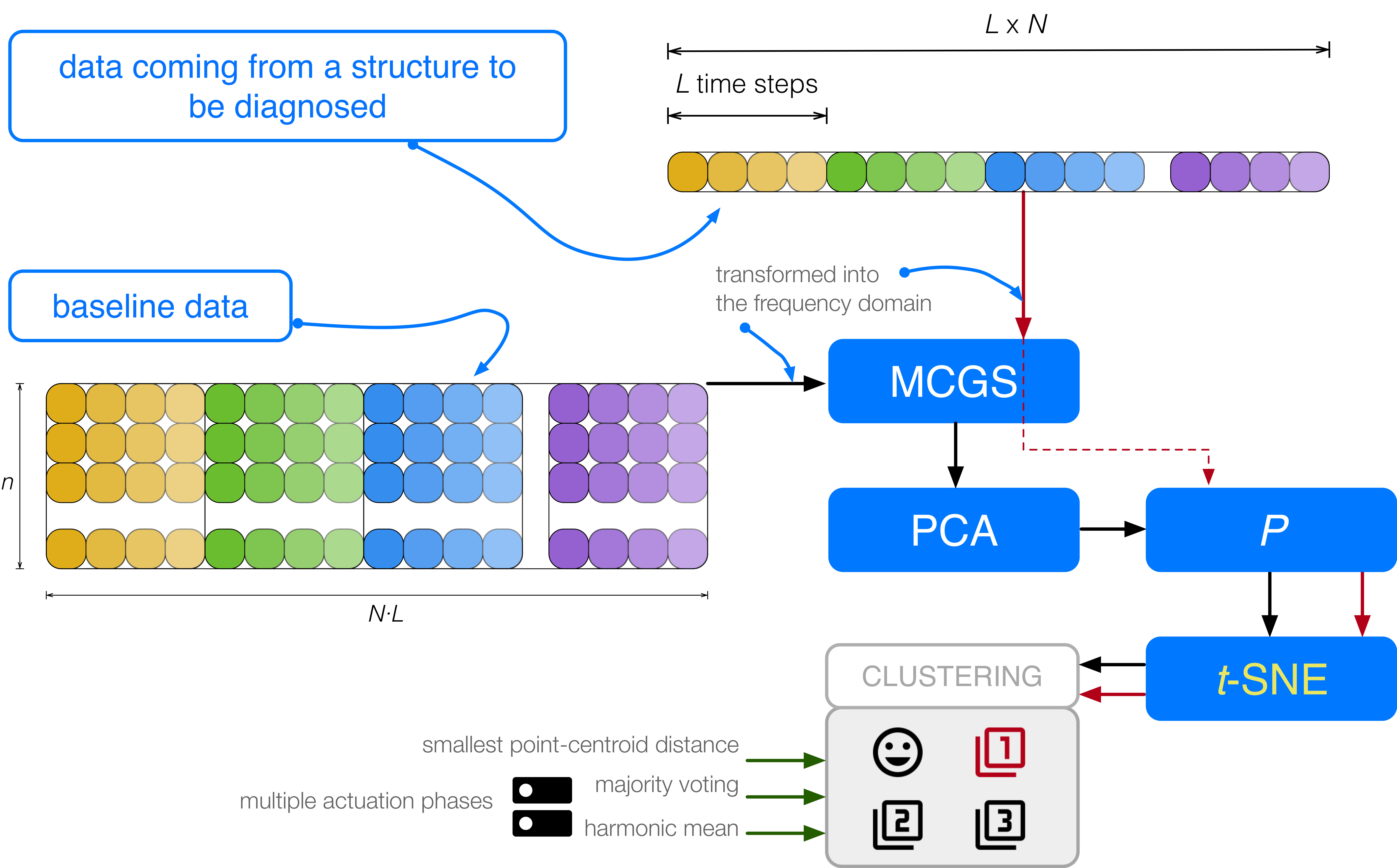
In this work, a SHM strategy for detection and classification of structural changes based on a two-step data integration (type
E unfolding [
15] and the so-called mean-centered group scaling (MCGS)), data transformation using PCA, and a two-step data reduction combining PCA and
t-SNE has been proposed. PCA is an extensively used technique that is mainly used for dimensionality reduction or feature extraction in the framework of pattern recognition [
16], and it can be applied differently to detect and classify structural changes or faults [
17]. In some cases, however, it can be observed that the projection into the first principal components does not allow a visual grouping, clustering, or separation. For this reason, we propose the damage or fault detection based on the combination of PCA and
t-SNE. As a consequence, the basic steps of the detection and classification procedure that we apply are: (i) the data collected, in the frequency domain, are first scaled using MCGS due to the different scales and magnitudes in the measurements; (ii) then PCA is applied to obtain a better representation of the original data, by reducing the dimensionality of the scaled data and projecting the scaled data into the vectorial space spanned by the principal components; and (iii)
t-SNE is finally applied to the projected data to represent these points as points in a plane. It will be shown that, with respect to the time domain, the quality of the clusters related to the different structural states is significantly improved. More precisely, the current structure to be diagnosed will then be associated with a structural state based on three different strategies: (i) the smallest point-centroid distance, i.e., when a single actuation phase is considered; (ii) majority voting; and (iii) sum of the inverse distances, i.e., when several actuation phases are combined. Therefore, in this work,
t-SNE is used, in combination with a particular data integration, data transformation, and data reduction, for the first time in the field of SHM in a frequency-based approach. In comparison to previous strategies found in the literature, this novel method is able to yield a best detection and classification of structural changes, thus leading to a best performance.
The proposed method for the detection and classification of structural changes is assessed using experimental data from a plate with four piezoelectric transducers (PZTs). Since guided wave propagation-based SHM strategies have proven their ability to adequately identify defects in structures [
18,
19,
20,
21], in the present work, we have also considered the paradigm of guided waves. In this paradigm, the structure is excited by a signal and the response is measured to create a baseline pattern. When a new structure has to be diagnosed, it has to be excited by the exact same signal and the response is measured and compared with the baseline pattern. Results reveal the high classification accuracy and the strong performance of this methodology, with a percentage of correct decisions of about
in various scenarios. In the present work, the environmental conditions were not considered, as it will be the topic for further developments.
The structure of the paper is as follows:
Section 2 describes the objective of
t-SNE and how the plane or spatial representation is obtained.
Section 3 includes how the baseline data are collected and pre-processed, how the global dimension of the data is reduced, and how the clusters are created using
t-SNE. The damage detection and classification procedure of a structure that has to be diagnosed is presented in
Section 4. The experimental case study is described in
Section 5. In
Section 6, the results are shown. Finally, in
Section 7, some conclusions are drawn.
5. Case Study: Aluminum Plate with Four PZTs
5.1. Structure
In this section, a square aluminum plate with an area of 1600 cm
(40 cm
cm, and a thickness of
cm) and instrumented with four PZTs is considered to demonstrate the reliability of the damage detection and classification methodology introduced in
Section 3 and
Section 4. The piezoelectric transducer discs are attached to the surface and their location is shown in
Figure 3. Assuming that the lower left corner of the plate in
Figure 3 represents the origin of coordinates, the PZTs are installed at these positions (units in centimeters):
PZT1 at
PZT2 at
PZT3 at
PZT4 at
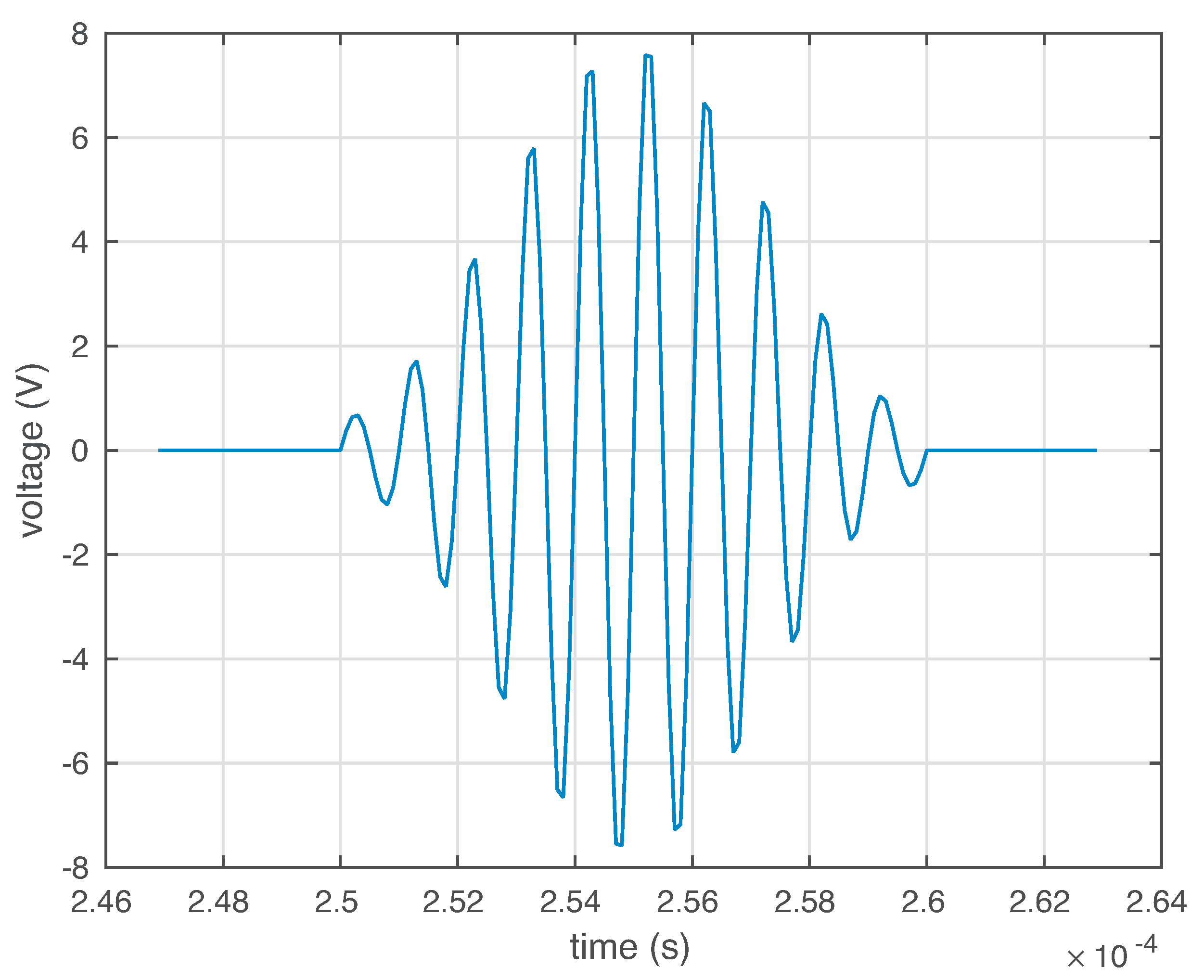
These PZTs are able to work both in actuator mode and in sensor mode. In actuator mode, the burst signal in
Figure 4 is applied to the PZTs, and they produce a mechanical vibration; and in sensor mode, they detect time varying mechanical response. It is worth keeping in mind that the distance between the four sensors is not the same. More precisely, for example, the distance between sensor 1 and sensor 2 and the distance between sensor 1 and sensor 4 is equal. However, the distance between sensor 1 and sensor 3 is relatively larger.
A grams mass is added to simulate the damage, in a non-destructive way, in the aluminum plate. This mass is an attached magnet in both sides of the plate, since aluminum is non-magnetic metal. This kind of damage is used to change the properties of the structure and to produce changes in the propagated wave, therefore providing different scenarios for validating the proposed method. The location of the mass defines each damage. These locations are (units in centimeters):
damage 1 at
damage 2 at
damage 3 at
structural states are considered here:
the first structural state corresponds to the healthy state of the structure, that is, the square aluminum plate with no damage;
the second, third, and fourth structural states correspond to the plate with an added mass at the positions indicated in
Figure 3 as damage 1, damage 2, and damage 3, respectively.
The aluminum plate is isolated from the vibration and noise that could affect the laboratory, as can be observed in
Figure 5.
5.2. Scenarios and Actuation Phases
The experimental setup includes three different scenarios to determine the behavior of the methodology under the presence of white Gaussian noise, filters, and with respect to the length of the wire that is used from the digitizer to the sensors:
Scenario 1. The signals are obtained using a short wire (
m) from the digitizer to the PZTs, and these signals are filtered with a Savitzky–Golay (SG) [
25] filter algorithm after adding white Gaussian noise. The filter is applied for the intention of smoothing the data.
Scenario 2. The signals are obtained using a short wire ( m) from the digitizer to the PZTs, but these signals are not filtered.
Scenario 3. The signals are obtained using a long wire ( m) from the digitizers to the PZTs. Signals are also filtered with the SG algorithm.
In this manner, we can observe the effect of the attenuation with short and long wires, the effect of adding white Gaussian noise to the measured signals, and the effect of the use of a SG filter in the detection and classification procedure.
As stated in
Section 5.1, four PZTs (PZT1, PZT2, PZT3, and PZT4) are used to excite the aluminum plate and collect the measured response. This sensor network works in what we call
actuation phases. In each actuation phase, a single PZT is used as an actuator (active sensor: the PZT excites the structure with a given excitation signal), and the rest of the PZTs are used as sensors (passive sensors: PZTs measure signals). Therefore, we have as many
actuation phases as
sensors:
Actuation phase 1. PZT1 is used as the actuator, and PZT2, PZT3, and PZT4 are used as sensors.
Actuation phase 2. PZT2 is used as the actuator, and PZT1, PZT3, and PZT4 are used as sensors.
Actuation phase 3. PZT3 is used as the actuator, and PZT1, PZT2, and PZT4 are used as sensors.
Actuation phase 4. PZT4 is used as the actuator, and PZT1, PZT2, and PZT3 are used as sensors.
It is very common in the literature, when using a sensor data fusion as in J. Vitola et al. [
26,
27], to merge the data that come from the different actuation phases in a single data matrix. In this paper, the approach with a single data matrix is also considered, but the case where each actuation phase is used as a classifier is additionally examined in
Section 5.5.
5.3. Data Collection
Given a particular scenario, as the three defined in
Section 5.2, four matrices
, one for each actuation phase, are obtained. Each matrix
, is organized as follows:
experiments or realizations are performed for each structural state. Consequently, each matrix , consists of 100 rows, that is . More precisely, the first 25 rows represent the structure with no damage, the next 25 are realization where damage 1 is present in the structure, and so on.
For each actuation phase , we measure PZTs working as sensors during 60000 time instants. Then, these measurements are transformed into the frequency domain. Therefore, the number of columns of matrix , is equal to .
Therefore, the matrix that collects all the realizations under the four different structural states in the frequency domain is (see Equation (
6): here
and
):
The damage detection and classification procedure introduced in
Section 3 and
Section 4 can be applied to each one of the matrices
, in Equation (
17), thus leading to one classification per actuation phase. But we can also use the horizontal concatenation of the four matrices
, to obtain the matrix:
If matrix
in Equation (
18) is used for the damage detection and classification procedure introduced in
Section 3 and
Section 4, which this allows analyzation of the information of all the actuation phases at one time, a single classification is obtained that combines these four phases. Finally, we can also use the separate classification obtained for each actuation phase so that each actuation phase casts a vote thus leading to a final decision based on the four actuation phases. These strategies will be explained in detail in
Section 5.5.
5.4. Fold Non-Exhaustive Leave-p-Out Cross Validation
The analysis of the proposed approach is done by comparing test data, i.e., the new experiments in unknown state under the same conditions, with baseline data, which is data from the structure under different structural states. To this end, we use the fold non-exhaustive leave-p-out cross validation described in the subsequent paragraphs.
For the sake of clarity, let us write
to refer to both matrix
in Equation (
17) and matrix
in Equation (
18). Some of the rows in
will be used as the baseline data to build the model and the clusters, i.e.,
rows per structural state, and the rest of the rows are used for the validation. More precisely, we will perform five iterations (
) of a non-exhaustive leave-
p-out cross validation, where
, to estimate the overall accuracy and avoid overfitting. Let us define, for each structural state
, the permutation
:
In this particular case,
. Therefore, in the first iteration, the baseline data to build the model are the matrix:
where
is the
j-th element of the canonical basis of the real vector space
, and
is the
selector matrix. Basically, matrix
in Equation (
19) has been built by randomly selecting
rows per structural state. The
rows of matrix
that are not used to build the model are used for the validation.
In the
i-th iteration,
, the baseline data to build the model are the matrix:
where, as in Equation (
19),
is the
j-th element of the canonical basis of the real vector space
and, as in Equation (20),
is the
selector matrix. Since
rows of matrix
will be used for the validation step and with respect to
iterations, the sum of all the elements in the
confusion matrices that we will present in
Section 6 is equal to
.
5.5. Application of the Damage Detection and Classification Procedure
In this section, two strategies are presented to apply the damage detection and classification procedure. These two strategies are:
- (1)
the classification is based on a single matrix:
or
, as defined in Equations (
17) and (
18), respectively, with
fold non-exhaustive leave-
p-out cross validation;
- (2)
the classification is based on the four matrices
and
, defined in Equation (
17), with respect to the four actuation phases, with
fold non-exhaustive leave-
p-out cross validation. Each actuation phase will cast a vote and a final decision is taken.
In the first case, in a succinct way, the following seven steps are performed:
Step 1. The data in matrix are scaled using MCGS to define a new matrix .
Step 2. PCA is applied to to obtain the PCA model .
Step 3. The number of principal components is chosen so that the proportion of variance explained is greater than or equal to . Therefore, the reduced PCA model is .
Step 4. A realization
—for
and
— or
—for
— of the current structure to diagnose is needed. Then, vector
is scaled as in Equation (
14) to define
.
Step 5. The data points set
is defined as:
where
Subsequently,
t-SNE is applied to this
dimensional data set
to find a collection of
dimensional map points:
Step 6.
clusters are obtained, that are related to the
different structural states. These clusters are formed by the map points:
The centroid
, associated with the
l-th structural state is computed as in Equation (
16).
Step 7. Finally, the current structure to diagnose is associated to the
l-th structural state if
In the second case, we follow
Step 1 to
Step 6 above for the four matrices
, related to the four actuation phases. With the information provided by the four actuation phases, several approaches can be considered to finally classify the structure that has to be diagnosed. One of these approaches, majority voting, is widely used in standard fusion schemes [
28], as well as weighted majority vote or soft voting. For our case of the small aluminum plate, the majority voting will be used, as well as an approach based on the sum of the inverse distances between the centroids and the map point, which is somehow related to a weighted majority vote. Here are the details of both approaches:
Majority voting. In this case, the strategy of the smallest point-centroid distance is performed four times, one per actuation phase. Therefore, four classifications are obtained for a single structure to diagnose. More precisely, each actuation phase acts as a
classifier.
Figure 6 illustrates this idea with respect to three actuation phases.
The current structure to diagnose, in the
-th actuation phase,
, is associated to the
-th structural state if
It is worth remembering that
is the map point associated to the realization of the current structure to diagnose. The structure is finally classified according to the most repeated classification. That is, the current structure to diagnose is associated to the
l-th structural state if
in the case of a unimodal set. In the case of a bi-modal set, if the two modal values are
and
, the current structure to diagnose is associated to the
l-th structural state if
Finally, if the set
is a set with no mode, the structure is associated to the
l-th structural state if
Sum of the inverse distances. In this case, for a given structural state, we sum the inverse of the distances between the centroids
and the map point
, for all the actuation phases
. The assigned structural state is the one that obtains the highest sum. More precisely, the current structure to diagnose is associated to the
l-th structural state if
It is worth remarking that the arguments of the maxima of the sum of the inverse distances is equivalent to the arguments of the minima of the harmonic mean of these distances. More precisely, for a given structural state, the harmonic mean of the distances between the centroids
and the map point
, for all the actuation phases
is
Therefore,
S. Mehta et al. [
29] also uses the harmonic distance to define a pattern classification technique similar to
k-nearest neighbors classifier.
6. Results
In this section, the results of the application of the damage detection and classification procedure, introduced in
Section 3 and
Section 4 and detailed in
Section 5.3,
Section 5.4 and
Section 5.5, to the aluminum plate are presented in terms of the confusion matrices and with respect to the scenarios defined in
Section 5.2. The results for each scenario are presented in a different section. More precisely, in
Section 6.1 the results with respect to
Scenario 1 are presented. Equivalently,
Section 6.2 and
Section 6.3 present the results with respect to
Scenario 2 and
Scenario 3, respectively. In the three scenarios, four different structural states have been considered:
the first structural state corresponds to the healthy state of the structure, that is, the square aluminum plate with no damage, noted as ;
the second, third, and fourth structural states correspond to the plate with an added mass at the positions indicated in
Figure 3 and
Figure 5, noted as
,
, and
, respectively.
To validate the damage detection and classification detailed in
Section 5.3,
Section 5.4 and
Section 5.5, we will perform five iterations (
) of a non-exhaustive leave-
p-out cross validation, where
, as described in
Section 5.4. At each iteration, a total of 80 realizations have been considered, according to the following distribution: 20 realization per structural state (
, and
). Since 80 realizations have been used for the validation step and with respect to
iterations, the sum of all the elements in the confusion matrices that we will present in
Section 6.1,
Section 6.2 and
Section 6.3 is equal to
.
Again, for the three scenarios, seven different confusion matrices are presented:
Actuation phase 1. The damage detection and classification procedure is applied to a single matrix,
, as in Equation (
17), using the smallest point-centroid distance.
Actuation phase 2. The damage detection and classification procedure is applied to a single matrix,
, as in Equation (
17), using the smallest point-centroid distance.
Actuation phase 3. The damage detection and classification procedure is applied to a single matrix,
, as in Equation (
17), using the smallest point-centroid distance.
Actuation phase 4. The damage detection and classification procedure is applied to a single matrix,
, as in Equation (
17), using the smallest point-centroid distance.
Actuation phases 1–4. The damage detection and classification procedure is applied to a single matrix, i.e., the horizontal concatenation of the four matrices
,
, as in Equation (
18), using the smallest point-centroid distance.
Majority voting. The damage detection and classification procedure is applied to the four
. Each actuation phase casts a vote, and a final decision is taken based on majority voting (
Section 5.5).
Sum of the inverse distances. The damage detection and classification procedure is applied to the four
. Each actuation phase casts a vote and a final decision is taken based on the maximum sum of the inverse distances (
Section 5.5).
Finally, in some cases, and with the purpose of comparing the performance of the current damage detection and classification approach, confusion matrices in the frequency and time domains have been included.
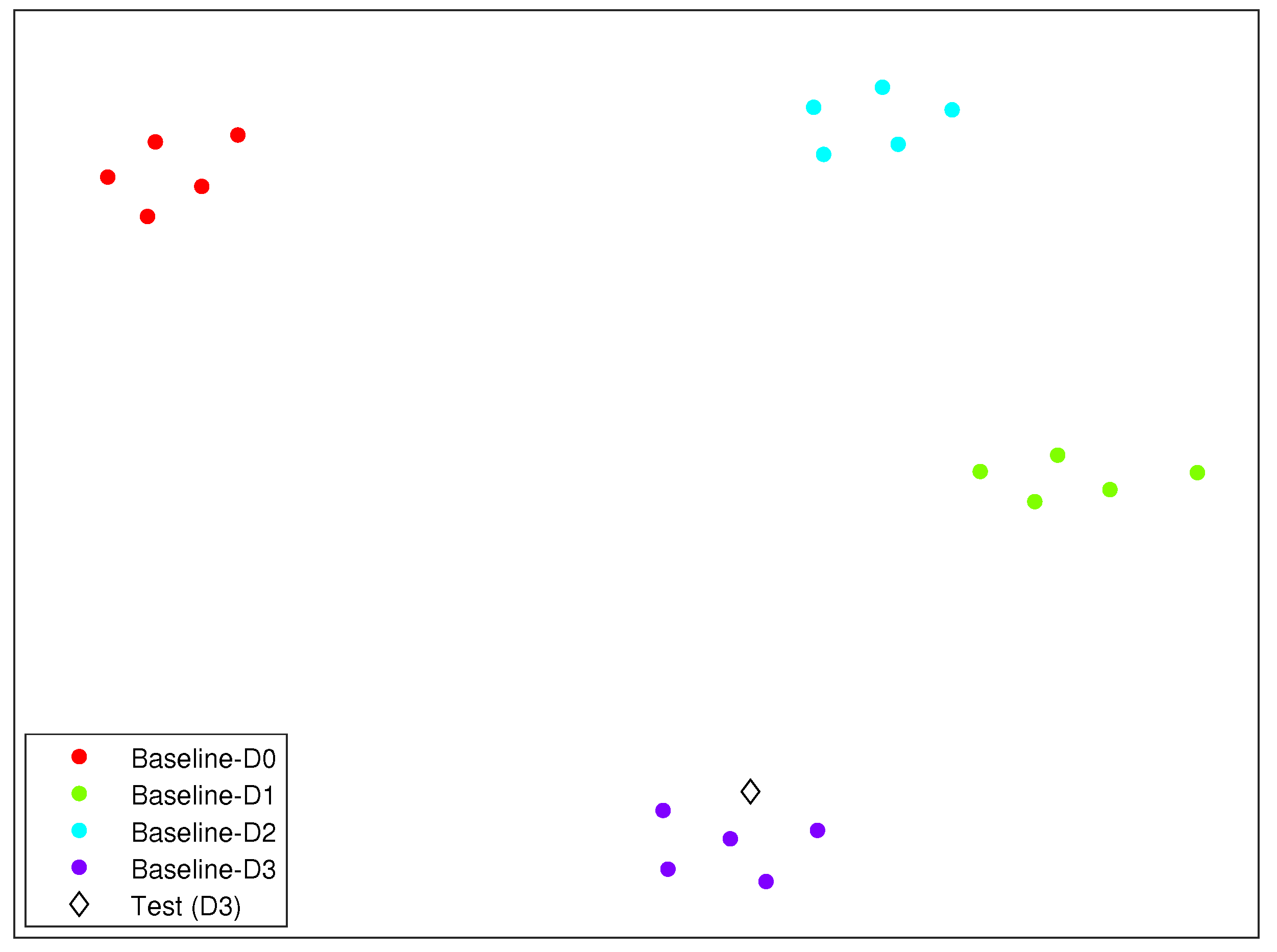
As an illustrating example, we have included in
Figure 7 the clusters formed by the different structural states described in this section and in the case of Scenario 3. In this figure, the diamond represents the structure to diagnose. It can be clearly observed how the diamond is close to the cluster related to damage 3.
6.1. Scenario 1
In this section, the results with respect to
Scenario 1 are presented. It is worth noting that, in this scenario, a short wire has been used, and the measured signals are filtered with a SG algorithm. The seven confusion matrices can be found in
Table 1 and
Table 2. When the decision is based on a single actuation phase (
Table 1), the overall accuracy is quite good. More precisely, with 397 in the actuation phase 1, 399 in the actuation phase 2, 395 in the actuation phase 3, and 397 in the actuation phase 4, realizations have been correctly classified out of 400 cases, which represents an overall accuracy of
,
,
, and
, respectively. When the four actuation phases are used at the same time (actuation phases 1–4, Equation (
18), majority voting, and sum of the inverse distances), an overall accuracy of 99–100% is achieved, as it can be observed from
Table 2.
6.2. Scenario 2
In this section, the results with respect to
Scenario 2 are presented. In this case, a short wire has been used but the measured signals are not filtered. The seven confusion matrices can be found in
Table 3 and
Table 4. When the decision is based on a single actuation phase (
Table 3), the overall accuracy is very remarkable. More precisely, with respect to actuation phase 1, 2, and 3, 400 realizations have been correctly classified out of 400 cases, which represents an overall accuracy of
. With respect to actuation phase 4, 399 realizations have been correctly classified out of 400 cases, that is to say, an overall accuracy of
. When the four actuation phases are used at the same time (actuation phases 1–4, Equation (
18), majority voting, and sum of the inverse distances), an overall accuracy of
is achieved, as it can be observed from
Table 4.
6.3. Scenario 3
The results with respect to
Scenario 3 are finally presented in this section. In the two previous scenarios, a short wire was used. However, in this case, the signals are acquired using a
m long wire.
Table 5 and
Table 6 include the seven confusion matrices. When the decision is based on a single actuation phase (
Table 5), the overall accuracy is quite good, too. More precisely, with 384 in the actuation phase 1, 395 in the actuation phase 2, 395 in the actuation phase 3, and 398 in the actuation phase 4, realizations have been correctly classified, which represents an overall accuracy of
,
,
, and
, respectively. When the four actuation phases are used at the same time (actuation phases 1–4, Equation (
18), majority voting, and sum of the inverse distances), an overall accuracy of 99.5–100% is achieved, as it can be observed from
Table 6.
The potential of the approaches where the four actuation phases are used can be observed in this last scenario, see
Table 6:
When the four actuation phases are merged in a single matrix as in Equation (
18), 398 realizations have been correctly classified out of 400 cases, which represents an overall accuracy of
.
When each actuation phase casts a vote and a final decision is taken based on majority voting, the overall accuracy is increased to .
Finally, when each actuation phase casts a vote and a final decision is taken based on the maximum sum of the inverse distances, the overall accuracy is increased to , too.
In addition, in this scenario, the results in the frequency domain are compared to those in the time domain [
11]. In the time domain, when the decision is based on a single actuation phase (
Table 7), with 244 in the actuation phase 1, 398 in the actuation phase 2, 280 in the actuation phase 3, and 277 in the actuation phase 4, realizations have been correctly classified out of 400 cases. This represents an overall accuracy of
,
,
, and
, respectively. Clearly, the strategy in the frequency domain, i.e., the overall accuracy fluctuates between
and
, outperforms the approach in the time domain. In addition, the false positive rate (FPR), i.e., the number of false positives with respect to the total number of negatives, and the false negative rate (FNR), i.e., the number of false negatives with respect to the total number of positives, are clearly unsatisfactory in the time domain. However, FPR and FNR are significantly reduced to values close to
in the frequency domain. It is worth noting that in the computation of the FNR, the three different types of damage
, and
are considered as a single category, just the opposite of the healthy state of the structure. In the time domain, when the four actuation phases are used at the same time (
Table 8), the overall accuracy is of
in actuation phases 1–4, of
in majority voting, and of
in sum of the inverse distances, whereas the overall accuracy is increased to
,
, and
, respectively, in the frequency domain. At the same time, FPR and FNR are reduced to
in the frequency domain, while they are slightly increased in the time domain. All this is an indication of the better quality of the clusters created in the frequency domain than the ones created in the time domain.
Table 9 summarizes the values for the overall accuracy, the FPR, and the FNR in this scenario and in the time and frequency domains.
6.4. General Comments
The results presented in
Section 6.1,
Section 6.2 and
Section 6.3 reveal that it is better to make a decision considering all of the actuation phases (assembling theses phases or using them to cast a vote) rather than working with the phases separately. On the other hand, the results also show that both strategies majority voting and sum of the inverse distances slightly outperform the horizontal concatenation of the four actuation phases in the frequency domain. However, in the time domain (
Scenario 3,
Table 8), the results reveal (i) the strong performance of the sum of the inverse distances strategy, which clearly classifies the practical totality of the kinds of damage that we have considered, compared to majority voting or the horizontal concatenation of the four actuation phases; and (ii) that the majority voting outperforms the horizontal concatenation of the four actuation phases, but it cannot completely classify damage
.
It is worth noting that, in general, the healthy state of the structure is confused with the structure with damage in just a few cases. Similarly, the structure with damage is identified as a structure with no damage in a very limited number of realizations.
In general, the performance of the proposed methodology is very satisfactory when the signals are acquired using a short wire, with or without adding white Gaussian noise. In these two cases, using PCA as a pre-processing step, the noise is canceled. The third scenario presents the worst case because it used a long cable ( m) from the digitizers to the sensors. In this scenario, the signals were badly digitized due to the impedance of the cable, the low voltage of the stimulus, and other experimental features. Therefore, it can be observed that the use of a long cable from the digitizer to the sensors affects in the detection and classification method. However, combining the four actuation phases with
- (i)
the sum of the inverse distances strategy, in the time domain; or
- (ii)
the majority voting strategy or the sum of the inverse distances strategy, in the frequency domain,
very accurate results can be obtained.
It should be noted that, in general, it is better to work in the frequency domain than in the time domain because the obtained results are significantly improved, as it can be clearly observed in the third scenario.
7. Conclusions
In this work, a SHM strategy for detection and classification of structural changes based on a two-step data integration (type E unfolding and MCGS), data transformation using PCA, and a two-step data reduction combining PCA and t-SNE has been proposed. The proposed approach is evaluated using experimental data. In general, the results obtained show that the performance of the proposed methodology is very satisfactory, given its high classification accuracy; and its behavior is very good and similar in all the data sets.
In the case study, very accurate results are obtained with or without adding white Gaussian noise, since PCA cancels the noise. However, the use of a long wire ( m) from the digitizers to the sensors negatively affects the detection and classification method. But combining the four actuation phases with the sum of the inverse distances strategy, in the time domain, and with the majority voting strategy or the sum of the inverse distances strategy, in the frequency domain, accurate results can be obtained. Results also show that the quality of the two-dimensional clusters created with t-SNE in the frequency domain is better than the quality of the two-dimensional clusters created with t-SNE in the time domain, thus leading to a better classification. Therefore, the strategy in the frequency domain significantly outperforms the approach in the time domain.
Some aspects to highlight in the proposed methodology are: the t-SNE technique has been extended and adapted to the field of SHM, in the detection and classification of structural changes; the method classifies the current state of the structure by means of a data-driven analysis, that is, using collected data from the structure under different structural states and without the use of complex mathematical models; it is better to make a decision considering all of the actuation phases (assembling theses phases or using them to cast a vote) rather than working with the phases separately; both strategies, majority voting and sum of the inverse distances, slightly outperform the horizontal concatenation of the four actuation phases in the frequency domain; in the time domain, sum of the inverse distances strategy outperforms majority voting, and this last strategy outperforms the horizontal concatenation of the four actuation phases; it is better to work in the frequency domain than in the time domain because better results are obtained; and finally, in general, the healthy state of the structure is confused with the structure with damage in just a few cases, and similarly, the structure with damage is identified as a structure with no damage in a very limited number of realizations. With respect to the possible fields of application, similar aluminum plates have been used to represent parts of a plane (wings or fuselage). We think that we can also apply this approach for the damage and fault detection of wind turbines. In general, there is no a prescribed field of application: if a sensor network can be installed in a structure, and several actuation phases can be considered, the proposed approach can be implemented a priori.
As a future work, we plan to develop further the proposed method for different EOC to determine its effectiveness, as well as to handle imbalanced data. In addition, we aim to investigate the parametric version of t-SNE.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}