Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting


Abstract
:1. Introduction
- This paper contributes an unsupervised driving anomaly detection and recounting (D&R) while performing an effective performance, which does not need any training data.
- A temporal-spatial-semantic (TSS) model is constructed to fulfill a coarse-to-fine focusing of the driving anomaly D&R. For each module, we design the procedure meticulously to find temporal, spatial, semantic cues for driving anomaly D&R.
- We validated the superiority of the proposed method by a dataset containing 106 video clips (100 frames/clip) temporal-spatial-semantically labeled by ourselves carefully.
2. Related Works
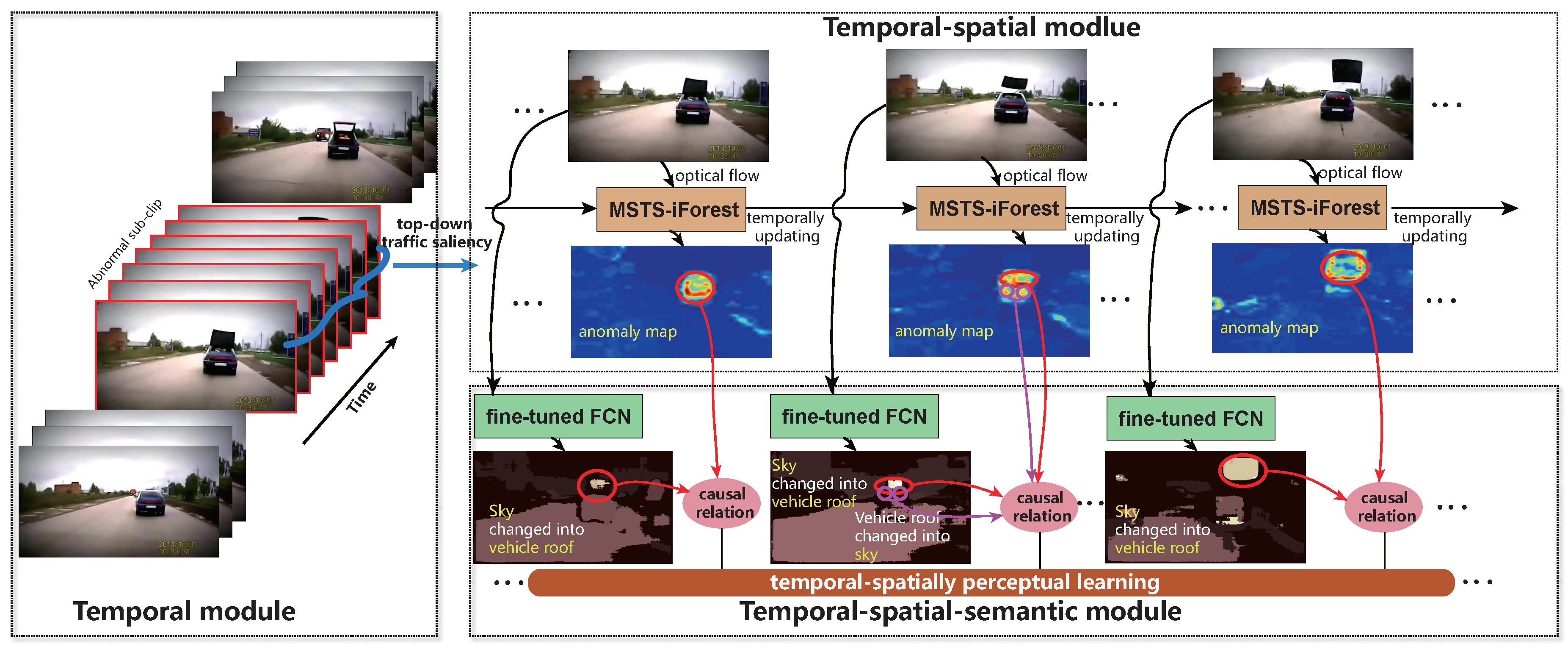
3. Driving Anomaly Detection and Recounting
3.1. Problem Formulation
3.2. Temporally Abnormal Sub-Clip Detection
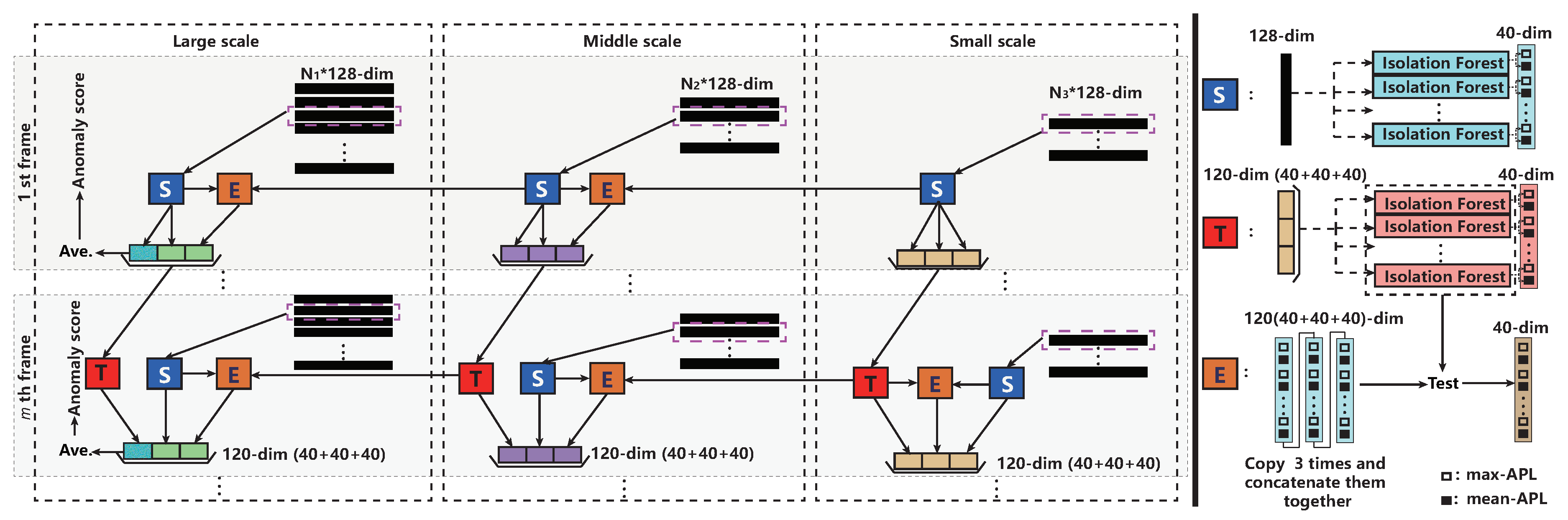
3.3. Temporal-Spatially Local Anomaly Detection
3.4. Temporal-Spatial-Semantical Anomaly Recounting
4. Experiments and Analysis
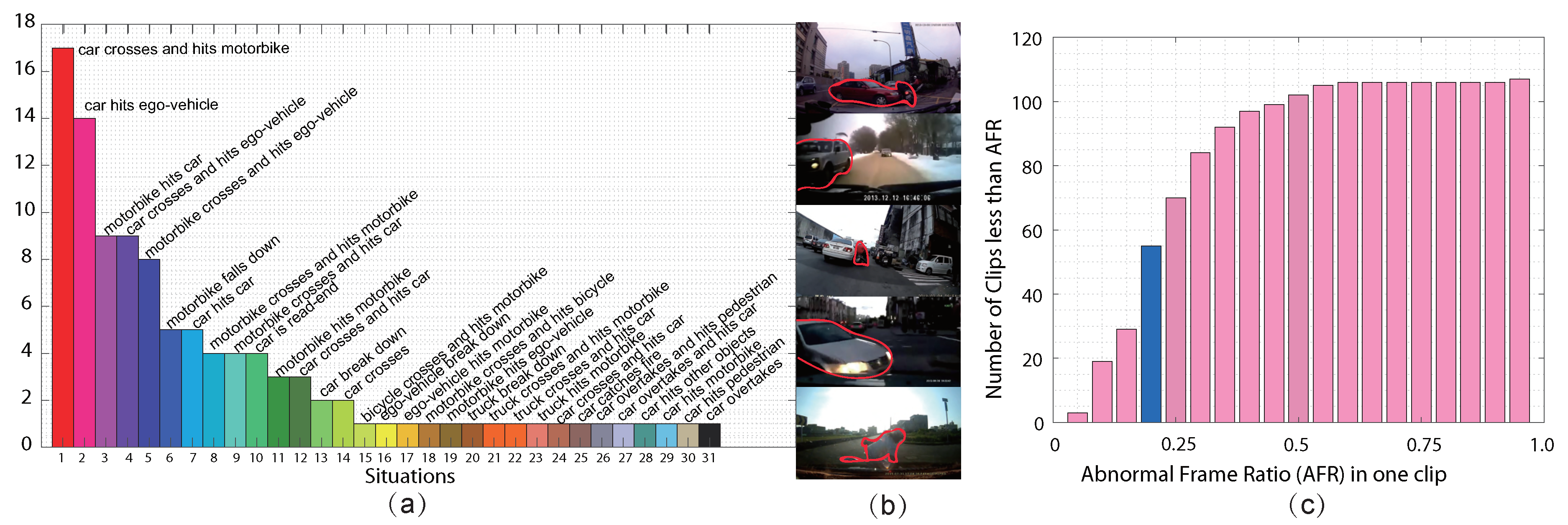
4.1. Dataset
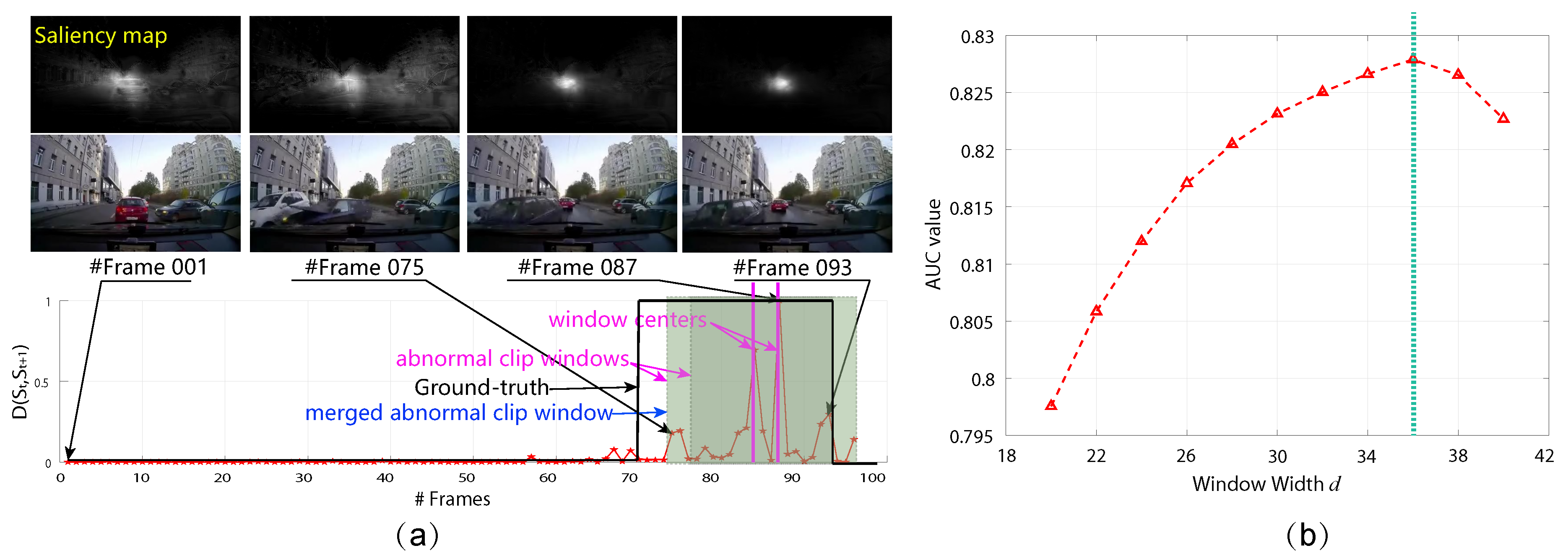
4.2. Implementation Details
- (1)
- iForest: We perform the iForest spatially on the large scale channel, with the same configuration for number of iForests, iTrees, and partitioning blocks;
- (2)
- OC-SVM: The partitioned optical flow field in each frame is used to train the boundaries with an RBF kernel, and the anomaly score of each sample is determined by the distance to the decision boundary;
- (3)
- RDA: RDA aims to find the principal component with a detection of outlier using a multi-layer structure. This work introduces the penalty, and compared several parameter combinations and used parameters that performed best ( = 0.00056 and layer size is 128, 80, and 100). The anomaly is determined by checking the reconstruction error of the partitioned blocks of optical flow field, where the instance dimension (HOF feature) is 128, the same as the proposed method;
- (4)
- iGRLSS: Strictly speaking, iGRLSS is a weak-supervised method, which first segmented the frame into many superpixels, and treated the first 10 frames of each clips as normal. Then, the temporal consistency with the pre-defined normal patterns in each clip was examined. This paper sets the superpixel number as 125 following its setting of [37], and adopts five frames to update the dictionaries in iGRLSS.
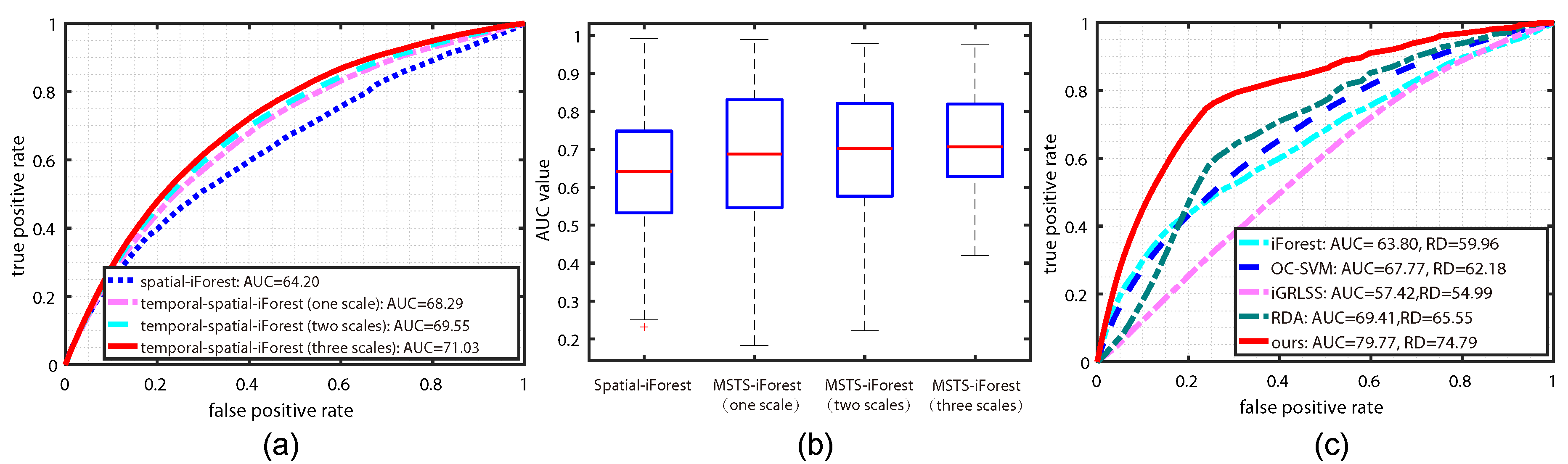
4.3. Evaluation on Different Detection Components
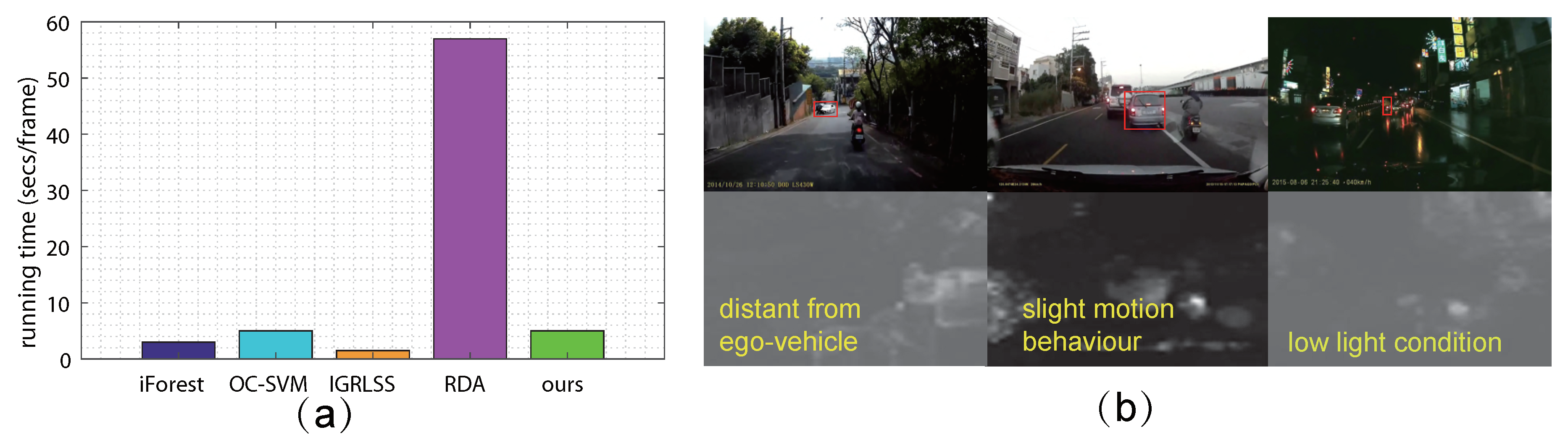
4.4. Comparison with the State-Of-The-Art
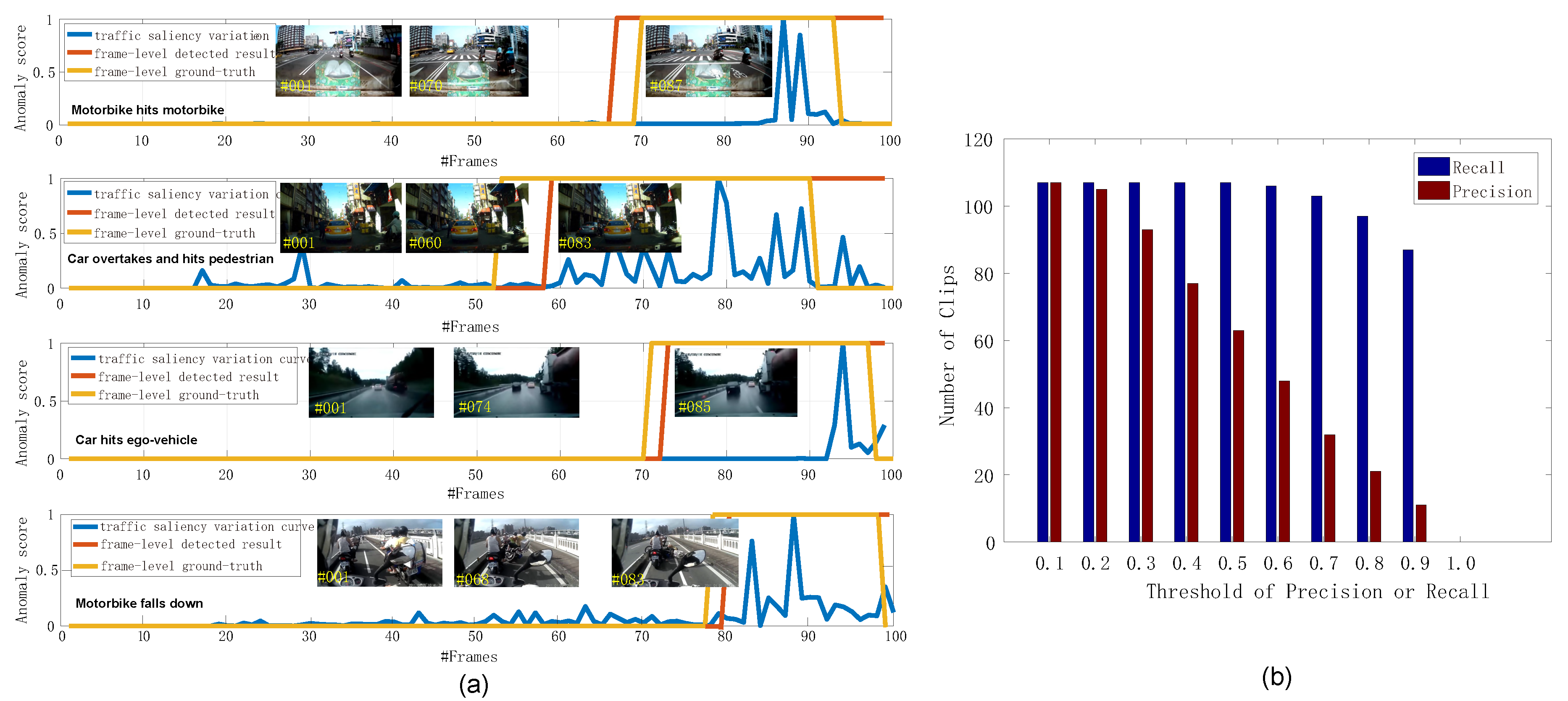
4.5. Evaluation on Driving Anomaly Recounting
4.6. Discussion
5. Conclusions
Supplementary Materials
Supplementary File 1Author Contributions
Funding
Conflicts of Interest
References
- Luo, W.; Liu, W.; Gao, S. A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 341–349. [Google Scholar]
- Tran, H.T.; Hogg, D. Anomaly Detection using a Convolutional Winner-Take-All Autoencoder. In Proceedings of the 2017 British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Deep-Cascade: Cascading 3D Deep Neural Networks for Fast Anomaly Detection and Localization in Crowded Scenes. IEEE Trans. Image Process. 2017, 26, 1992–2004. [Google Scholar] [CrossRef] [PubMed]
- Giorno, A.D.; Bagnell, J.A.; Hebert, M. A Discriminative Framework for Anomaly Detection in Large Videos. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 334–349. [Google Scholar]
- Kratz, L.; Nishino, K. Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1446–1453. [Google Scholar]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Patten Anal. Mach. Intell. 2014, 36, 18–32. [Google Scholar]
- Hu, J.; Zhu, E.; Wang, S.; Liu, X.; Guo, X.; Yin, J. An Efficient and Robust Unsupervised Anomaly Detection Method Using Ensemble Random Projection in Surveillance Videos. Sensors 2019, 19, 4145. [Google Scholar] [CrossRef] [PubMed]
- Basan, E.; Basan, A.; Nekrasov, A. Method for Detecting Abnormal Activity in a Group of Mobile Robots. Sensors 2019, 19, 4007. [Google Scholar] [CrossRef]
- Venskus, J.; Treigys, P.; Bernatavičienė, J.; Tamulevičius, G.; Medvedev, V. Real-time maritime traffic anomaly detection based on sensors and history data embedding. Sensors 2019, 19, 3782. [Google Scholar] [CrossRef]
- Wang, H.; Wen, H.; Yi, F.; Zhu, H.; Sun, L. Road traffic anomaly detection via collaborative path inference from GPS snippets. Sensors 2017, 17, 550. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Deng, T.; Yang, K.; Li, Y.; Yan, H. Where Does the Driver Look? Top-Down-Based Saliency Detection in a Traffic Driving Environment. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2051–2062. [Google Scholar] [CrossRef]
- Palazzi, A.; Solera, F.; Calderara, S.; Alletto, S.; Cucchiara, R. Where Should You Attend While Driving? arXiv 2016, arXiv:1611.08215. [Google Scholar]
- Fang, J.; Yan, D.; Qiao, J.; Xue, J.; Wang, H.; Li, S. DADA-2000: Can Driving Accident be Predicted by Driver Attention? Analyzed by A Benchmark. arXiv 2019, arXiv:1904.12634. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Horrey, W.J.; Lesch, M.F.; Dainoff, M.J.; Robertson, M.M.; Noy, Y.I. On-board safety monitoring systems for driving: Review, knowledge gaps, and framework. J. Saf. Res. 2012, 43, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Pascale, A.; Nicoli, M.; Deflorio, F.; Dalla Chiara, B.; Spagnolini, U. Wireless sensor networks for traffic management and road safety. Intell. Transp. Syst. 2012, 6, 67–77. [Google Scholar] [CrossRef]
- Battiato, S.; Farinella, G.M.; Gallo, G.; Giudice, O. On-board monitoring system for road traffic safety analysis. Comput. Ind. 2018, 98, 208–217. [Google Scholar] [CrossRef]
- St-Aubin, P.; Saunier, N.; Miranda-Moreno, L. Large-scale automated proactive road safety analysis using video data. Transp. Res. Part C Emerg. Technol. 2015, 58, 363–379. [Google Scholar] [CrossRef]
- Jackson, S.; Miranda-Moreno, L.F.; St-Aubin, P.; Saunier, N. Flexible, mobile video camera system and open source video analysis software for road safety and behavioral analysis. Transp. Res. Rec. 2013, 2365, 90–98. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, C.; Wo, T.; Xie, T.; Bhuiyan, M.Z.A.; Lin, X. SafeDrive: Online Driving Anomaly Detection From Large-Scale Vehicle Data. IEEE Trans. Ind. Inform. 2017, 13, 2087–2096. [Google Scholar] [CrossRef]
- Laxhammar, R.; Falkman, G. Online Learning and Sequential Anomaly Detection in Trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1158–1173. [Google Scholar] [CrossRef]
- Jiang, F.; Wu, Y.; Katsaggelos, A.K. A dynamic hierarchical clustering method for trajectory-based unusual video event detection. IEEE Trans. Image Process. 2009, 18, 907–913. [Google Scholar] [CrossRef]
- Cheng, K.W.; Chen, Y.T.; Fang, W.H. Gaussian Process Regression-Based Video Anomaly Detection and Localization With Hierarchical Feature Representation. IEEE Trans. Image Process. 2015, 24, 5288–5301. [Google Scholar] [CrossRef]
- Zhao, B.; Li, F.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3313–3320. [Google Scholar]
- Chen, Y.; Qian, J.; Saligrama, V. A new one-class SVM for anomaly detection. In Proceedings of the 2013 International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3567–3571. [Google Scholar]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-Based Anomaly Detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Klette, R. Fully Convolutional Neural Network for Fast Anomaly Detection in Crowded Scenes. arXiv 2016, arXiv:1609.00866. [Google Scholar] [CrossRef]
- Chan, F.; Chen, Y.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Proceedings of the 2016 Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 136–153. [Google Scholar]
- Kiran, B.; Thomas, D.; Parakkal, R. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos. J. Imaging 2018, 4, 36. [Google Scholar] [CrossRef]
- Medel, J.R.; Savakis, A.E. Anomaly Detection in Video Using Predictive Convolutional Long Short-Term Memory Networks. arXiv 2016, arXiv:1612.00390. [Google Scholar]
- Basharat, A.; Gritai, A.; Shah, M. Learning object motion patterns for anomaly detection and improved object detection. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Yuan, Y.; Fang, J.; Wang, Q. Online Anomaly Detection in Crowd Scenes via Structure Analysis. IEEE Trans. Cybern. 2015, 45, 548–561. [Google Scholar] [CrossRef]
- Yuan, Y.; Fang, J.; Wang, Q. Incrementally perceiving hazards in driving. Neurocomputing 2018, 282, 202–217. [Google Scholar] [CrossRef]
- Rao, A.S.; Gubbi, J.; Marusic, S.; Palaniswami, M. Crowd Event Detection on Optical Flow Manifolds. IEEE Trans. Cybern. 2016, 46, 1524–1537. [Google Scholar] [CrossRef]
- Cong, Y.; Yuan, J.; Tang, Y. Video Anomaly Search in Crowded Scenes via Spatio-Temporal Motion Context. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1590–1599. [Google Scholar] [CrossRef]
- Thida, M.; Eng, H.L.; Remagnino, P. Laplacian eigenmap with temporal constraints for local abnormality detection in crowded scenes. IEEE Trans. Cybern. 2013, 43, 2147–2156. [Google Scholar] [CrossRef]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Gan, C.; Wang, N.; Yang, Y.; Yeung, D.Y.; Hauptmann, A.G. DevNet: A Deep Event Network for multimedia event detection and evidence recounting. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2568–2577. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Hinami, R.; Mei, T.; Satoh, S.I. Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3639–3647. [Google Scholar]
- Alletto, S.; Palazzi, A.; Solera, F.; Calderara, S.; Cucchiara, R. DR(eye)VE: A Dataset for Attention-Based Tasks with Applications to Autonomous and Assisted Driving. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 54–60. [Google Scholar]
- Hawkins, D.M. Identification of Outliers; Chapman and Hall: London, UK, 1980; pp. 321–328. [Google Scholar]
- Liu, C. Beyond Pixels: Exploring New Representations and Applications for Motion Analysis; Massachusetts Institute of Technology: Cambridge, MA, USA, 2009. [Google Scholar]
- Fire, A.; Zhu, S.C. Learning Perceptual Causality from Video. ACM Trans. Intell. Syst. Technol. 2015, 7, 1–22. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.; Shawe-Taylor, J.; Smola, A. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Zhou, C.; Paffenroth, R.C. Anomaly Detection with Robust Deep Autoencoders. In Proceedings of the 2017 ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 665–674. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Conditions | Number of Sequences | Proportion (%) | AUC (%) |
|---|---|---|---|
| Nocturne Driving | 16 | 15.09 | 83.24 |
| Heavy Traffic | 22 | 20.75 | 79.10 |
| Bad Weather | 20 | 18.87 | 82.25 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Fang, J.; Xu, H.; Xue, J. Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting. Sensors 2019, 19, 5098. https://doi.org/10.3390/s19235098
Zhu R, Fang J, Xu H, Xue J. Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting. Sensors. 2019; 19(23):5098. https://doi.org/10.3390/s19235098
Chicago/Turabian StyleZhu, Rixing, Jianwu Fang, Hongke Xu, and Jianru Xue. 2019. "Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting" Sensors 19, no. 23: 5098. https://doi.org/10.3390/s19235098
APA StyleZhu, R., Fang, J., Xu, H., & Xue, J. (2019). Progressive Temporal-Spatial-Semantic Analysis of Driving Anomaly Detection and Recounting. Sensors, 19(23), 5098. https://doi.org/10.3390/s19235098