Abstract
The paper suggests a model-dependent theoretical framework for designing optimal ranking algorithms to achieve desirable macroscopic opinion configurations. We consider an opinion formation process in which agents communicate through stochastic pairwise interactions, with the outcomes of these interactions being a function of the interacting agents’ opinions and individual attributes (types). For the model, we write a mean-field approximation (MFA)—a coarse-grained nonlinear ordinary differential equation—which accommodates network modularity and assortativity, agents’ activity heterogeneity, and the curation of a ranking system that can prohibit interactions with opinion- and type-dependent probabilities. Upon MFA, we formulate a control problem for dynamically adjusting the ranking algorithm’s parameters. The existence of a solution is proved, and certain properties of optimal controllers are derived. For the case of a two-element opinion alphabet, we obtain a solution to the control problem using finite-difference schemes. This solution holds for any number of agent types and does not depend on external factors, such as the influence of social bots. Numerical tests corroborate our findings and also enable us to investigate the control problem for high-dimension opinion spaces, wherein we consider two primary scenarios: depolarization of an initially polarized society and nudging a social system towards a fixed endpoint of an opinion spectrum.
1. Introduction
In the era of digitalization and information overload, it is extremely important to understand not only how individuals process new information but also how they acquire it. Despite the first question being the subject of analysis by scholars since the mid-20th century—beginning with the seminal work of French [1]—the second question has received relatively little attention in the literature. The problem is that, in the digital domain, individuals acquire new information under the curation of ranking algorithms (aka recommendation, personalization, or filtering systems) [2]. These algorithms leverage users’ data and provide them with content that aligns with their preferences, amplifies engagement, and perhaps subtly affects their opinions [3].
The mainstream of research on recommendation systems concerns how these technologies affect opinion polarization and the formation of echo-chambers on social platforms [4]. In general, the literature suggests that ranking algorithms contribute to polarization and information bubbles by forming feedback loops in which users are repeatedly exposed to content that confirms their views, thereby inducing positive reactions that are subsequently acknowledged by the system, and so on [5].
However, ranking systems can be applied to achieve completely opposite effects, such as depolarization [6]. In this article, we formulate, investigate, and solve, by means of analytical derivations and numerical experiments, a control problem in which one dynamically adjusts a ranking algorithm to sway the opinions of individuals according to a predefined objective. For instance, this objective can embrace the strive for depolarization. Our control problem is model-dependent. We build upon an opinion formation model [7,8], which effectively combines information on agents’ types, their activity heterogeneity, and the mesoscopic and macroscopic properties of the underlying networks. The model is able to span different mechanisms of social influence, such as assimilation or bounded confidence [9], thus providing a flexible framework for studying control over ranking algorithms.
2. Backgrounds
Our study lies at the intersection of two closely related areas of research: (i) opinion formation modeling and (ii) recommendation system modeling. To motivate the subject of our study, we begin by briefly reviewing opinion formation models.
2.1. Opinion Formation Models
Opinion formation (aka opinion dynamics) models consider a population of agents, possibly immersed in a social graph. These agents interact with each other according to a predefined set of rules and update their opinions following these microscopic interactions [10,11]. Agents’ opinions are typically described by numerical quantities, either discrete [12,13] or continuous [14]. In a typical case, these interactions lead to opinion assimilation, with more “distant” opinions ensuring greater assimilation [10]. However, psychological studies indicate that individuals with outlying opinions rarely listen to each other’s arguments, a phenomenon that is captured in bounded confidence models [15,16,17]. Finally, in some cases, communications between contrary opinions may give rise to opinion dissimilation, when opinions further diverge [9,18].
Empirical studies of social influence and opinion formation in social groups report rather mixed evidence. Laboratory experiments typically confirm the mechanism of opinion assimilation [19], whereas observational studies in online networks lend support for bounded confidence and dissimilation [20,21,22].
We refer the interested Reader to the excellent review articles in [16,17,23,24,25] for more information on the current state of the art in the field of modeling social influence and opinion formation in social networks.
What we would like to highlight here is that it was the opinion formation models underlying the analysis of ranking algorithms and their influence on society in the earliest studies [4,26]. The reason is that these models provide a flexible framework that can be easily adapted to incorporate the mechanics of recommendation systems into the models’ protocols.
2.2. Ranking Algorithms: A General View
Ranking algorithms are programs that curate the information users observe in their news feeds on social media platforms. Considering individuals’ limited cognitive and time resources [27], these algorithms help navigate users in the online domain by selecting the most relevant content. However, there are serious concerns that ranking algorithms, while addressing their own—essentially hidden—objectives, contribute to opinion polarization and the formation of echo chambers [2].
In fact, there are various forms of such algorithms that have slightly different purposes: some filter content in news feeds (filtering algorithms), while others recommend new acquaintances (recommendation algorithms). In turn, personalization typically refers to providing a user with content that aligns with that user’s individual preferences. To avoid any confusion, in what follows, we will use all these terms interchangeably whenever possible.
The four main principles of filtering are highlighted in the literature: (i) collaborative filtering (new recommendations are based on the preferences of users similar to a target one) [4,28]; (ii) popularity-based recommendation (more popular content is delivered to users primarily) [29,30]; (iii) a target user’s preferences (new content should align with the focal user’s stance or their previous actions on the platform) [5]; and (iv) nudging (recommendations follow certain objectives of exogenous actors who govern the algorithm) [2].
2.3. Research on Ranking Algorithms
The literature on recommendation algorithms can be roughly divided into two core research directions, which are relatively loosely bound: (i) theoretical direction and (ii) empirical direction. In the first one, the emphasis is on elaborating new insights concerning ranking systems and their societal outcomes by means of agent-based modeling (despite the fact that some of these studies were informed by empirical data) [4,26,30,31]. The empirical direction focuses on discerning specific biases and disparities [3,32,33] in real-world personalization systems, as well as some temporal changes in their functioning [34]. For instance, scholars have found that ranking algorithms may display ideological biases and facilitate a particular side of the ideological spectrum [32]. However, these studies face many guardrails and confounders. Among others, it is extremely difficult to distinguish individual choices on a platform from the platform’s own mechanics [35,36,37].
Considering the modeling of recommendation systems, we would like to start our review with the study by Anderson et al. [31], who analyzed the specific mechanics of certain platforms called badges. Badges acknowledge users’ contributions to a platform (such as those applied on Stack Overflow) and thus serve as incentives. The goal of [31] was to understand how badges affect users’ behaviors. On top of that, ref. [31] posed a control problem in which one should allocate badges in an optimal fashion to modify users’ behaviors.
Next, in their seminal paper [4], Dandekar et al. studied the polarizing effect of several naive recommender systems in the presence of biased assimilation. This research question—how recommendation affects polarization and the formation of echo-chambers—was then extensively investigated in a large number of studies and received considerable attention in the literature [2,26,28,30,38,39,40,41,42,43,44]. Most of these studies relied on an agent-based approach [26,38,39], but some departed from agent-based models and subsequently moved to various forms of mean-field descriptions [30,42,43,45]. Many models [5,42,45,46] were built upon linear opinion formation protocols—such as the DeGroot and Friedkin–Johnsen models [10,14]. However, in [41], a nonlinear—bounded confidence—model was considered as a workhorse description of opinion evolution. On top of that, in [47], the authors applied the classical Voter model [48,49].
2.4. Investigating the Effect of Ranking Algorithms on Polarization
Mäs and Bischofberger [26] delved into whether personalization should facilitate polarization in social systems. They found that the answer to the question largely depends on the underlying opinion dynamics model. Geschke et al. [38] considered individual, social, and technological levels of information processing. They obtained that echo-chambers are inevitable outcomes of our cognitive mechanisms, with technological filtering amplifying these effects.
Perra and Rocha analyzed [2] how various features of social network structure affect opinion dynamics in the presence of different types of algorithmic ranking. They found that network topologies with high levels of clustering, or those with spatial correlations, as well as an absence of shortcuts, generally facilitate the formation of echo-chambers. The study by Peralta et al. [50] generally supported the findings of [2] on the role of modular networks in facilitating polarization for personalization regimes. They also found that, in the case of content filtering, pairwise social interactions promote polarization more than group-level interactions [51,52].
The research of Cinus et al. [39] stands out here as it concerns a link recommendation algorithm that suggests new contacts on a social media platform based on structural or vertex-based similarities. They found that this sort of recommendation can give rise to an increase in echo chambers, provided that an initial network is homophilic enough. A similar finding was obtained in [53], where the authors showed that linking structurally similar nodes amplifies opinion polarization due to the reinforcement of network modularity [54]. In fact, this is also consistent with the results of Perra et al. [2].
2.5. Ranking Algorithms and Optimization
Generally speaking, the purpose of ranking algorithms relates to maximizing some objective. Of course, we do not know exactly the organization of these algorithms and the composition of the underlying functionals, as they are a commercial secret. However, we can hypothesize that they maximize users’ engagement [5] or some other relevant metrics. In this vein, one can think of these algorithms as an optimization problem and thus apply optimization theory in their analyses. This approach was successfully implemented in [5], where Rossi et al. elaborated on a formal model, in which a user interacts with a news aggregator and changes their opinion in accordance with the Friedkin–Johnsen model [14]. While the user is inclined to prefer information that aligns with their current views (confirmation bias), the aggregator filters information, attempting to maximize the user’s engagement. The authors proved that this feedback loop displays a tendency towards users having more extreme opinions.
This model was then extended in [46] by considering a network of users communicating with each other and with a recommendation system. The authors conceptualized the work of the recommendation system by formulating a control problem, in which agents’ engagement over an infinite time horizon is maximized, both in model-dependent and model-independent scenarios.
However, the objective of a ranking algorithm may not relate to engagement maximization. For example, one can try to use this technology to affect individuals’ behaviors, as suggested in [31]. This formulation is extremely close to our current research. In the current paper, we consider a population of agents that communicate in accordance with an opinion formation model [7], and these communications are governed by a ranking algorithm. The algorithm is dynamically adjusted to affect agents’ opinions according to a predefined objective. Among other things, we consider a depolarization problem, in which an initially polarized society should be moderated.
Typically, scholars try to achieve such goals by solving an influence maximization problem [55], modifying the structure of the underlying network [56], or exposing agents to certain stimuli [57], which could be delivered to real users by bots or ads [8]. From this perspective, our approach to the problem is quite novel and has received relatively little attention in the literature.
3. Contributions
We depart from an opinion formation model that was first developed in [7] and then advanced in [8,58]. We have chosen this model because it provides a flexible framework to describe opinion evolution processes, as it is able to encode various forms of influence, such as assimilation, bounded confidence, or dissimilation [19]. For this model, we recall a mean-field approximation that takes the form of a nonlinear coarse-grained ordinary differential equation. In this equation, the state variables are the population-level parameters that represent the fractions of agents with a given opinion and a given type, while the ranking algorithm is operationalized as a set of time-dependent parameters that encode the probabilities that agents with given characteristics will be allowed to communicate with each other. The latter parameters appear linearly in the master equation.
We prove some properties of the mean-field description, such as the existence of a solution, its non-negativity, and continuation. Next, we set up a control problem in which the parameters of the ranking algorithm are dynamically adjusted to achieve a desirable opinion distribution, which is formalized by a linear objective functional.
We prove that this problem has a solution. Using the Pontryagin Maximum Principle, we derive some properties of optimal controllers. Applying finite-difference schemes, we solve the control problem for a simple scenario where the opinion alphabet consists of only two opinions—as in a two-party election. What is important is that the solution obtained in this case remains valid for any number of agent types and does not depend on external factors, such as the influence of social bots.
We perform extensive numerical tests to corroborate our findings. Comparing our controllers obtained through finite-difference schemes with open-loop controllers derived from numerical algorithms (the Forward–Backward Sweep method and the Direct method were applied as benchmarks), we conclude that the former performs as well as the latter.
Considering opinion spaces with more than two elements, we examine two generic scenarios: the depolarization of an initially polarized society and the nudging of a social system towards a given edge of an opinion spectrum. For these scenarios, we derive numerical solutions to the control problems and briefly discuss the resulting open-loop controllers.
4. Opinion Dynamics Model
4.1. Notations
By , we denote the set of natural numbers from 1 to , where is the whole set of natural numbers. stands for the set of real numbers. By , we denote the Kronecker delta: if and otherwise. Notation refers to the cardinality of set . We use both capital and lowercase letters to denote matrix objects. The inequality where A is a matrix, indicates that all the components of A are non-negative.
In our derivations, we will typically consider systems of differential equations in matrix form. That is, instead of a vector of phase velocity, we will investigate a phase velocity matrix. This is due to the fact that our phase space will admit a natural separation into two macro-dimensions that stand for (i) opinions and (ii) types (see the model description below). And because of this, instead of using the conventional non-negative orthant , we will harness the set of all matrices with non-negative components. Accordingly, shows all matrices with non-positive components. Analogously, the scalar product of two matrices A and B of the same shape is defined as follows:
where and are the components of A and B, respectively.
It is worth noting that a differential equation in matrix form can be reshaped into a differential equation in vector form. As such, we can safely apply all the known theoretical results and constructions (for example, the Hamiltonian–Pontryagin formalism)—which imply vector representation—using matrix representation.
4.2. Agents and Their Attributes
Our workhorse opinion dynamics model was first presented in [7] and then elaborated on in [8,58]. In this model, N agents are immersed in a social network , where shows agents and outlines edges between them. By , we denote the neighbors of agent i. Each agent i is characterized by an opinion from set and a type from set .
We assume that agents’ opinions can change, whereas their types are fixed. These types may stand for various human attributes, such as age, gender, education level, or combinations of these. For example, if we focus on two non-opinion characteristics—say age and education level—we can split the ranges of these two attributes into, say, and disjoint parts, respectively, and then derive possible types. By introducing types into the model, we rely on the body of literature that suggests non-opinion characteristics, such as gender or age, affect how individuals influence their peers and, conversely, how open they are to the influence of their peers [59,60]. Besides sociodemographics, one can make use of psychological attributes—for instance, the Big Five psychometric traits or other relevant psychometric scales.
Next, each agent i is characterized by an activity parameter , which shows how often the agent engages in conversations with their peers. This allows us to model heterogeneity in agents’ activity, which is frequently observed in real-world settings and may have a substantial effect on social dynamics [61]. For simplicity, we assume that activity parameters are functions of agents’ types: .
4.3. Opinion Dynamics Protocol
In the model, agents communicate in consecutive pairwise interactions. In each time step , an agent is randomly chosen as an influence object. This selection proceeds according to the activity distribution . Let us assume that an agent i has been picked. After that, an agent from is selected as an influence source. The probability that agent will be chosen is given by Let us assume that agent j has been selected.
After the agents i and j have been chosen, agent i is exposed to agent j’s opinion and has a chance to revise their current position. Let the opinions of i and j be and , respectively. Let the agents’ types be and , respectively. Now we are in a position to define how agent i’s opinion is revised. This revising procedure is derived from a Bernoulli trial with m possible outcomes that come with the probabilities , where shows the likelihood that agent i’s new opinion will become .
It is worth emphasizing here that the upper indices of are synchronized with those of the communicating agents’ types, whereas the first two lower indices of stand for the agents’ prior opinions. The third index k in triplet links to agent i’s potential opinion.
With these notations, indicates that agents with opinion and type do not change their opinions after being exposed to opinion of an agent with type . To the contrary, means that in the same situation, the focal agent always modifies their opinion to . The quantities necessarily fulfill the normalization condition
4.4. Transition Probability Tables
One can find it convenient to group quantities into a sequence of transition probability tables [7], where . Each transition probability table, , can be represented as a list of row-stochastic matrices, , with showing how agents with opinion and type perceive influence from agents with type :
We will return to the discussion of transition probability tables formalism in the ongoing Section 4.7, where we will exemplify this approach of opinion dynamics representation and demonstrate its efficacy.
4.5. Adding Social Bots
In our model setup, we consider a scenario where the social system is augmented by agents of an extra-type . These agents are invulnerable to social influence and do not update their opinions. One can think of these agents as social bots or marketing messages that appear in users’ news feeds on social media. These agents may be controlled by one or more malicious actors. Below, we will refer to these agents as social bots, while other agents will be referred to as native or authentic ones.
In the current study, we are not interested in optimizing the behavior of social bots (this control problem was considered in [8], and we refer the interested Reader to this paper for more detail). We only say that the behavior of bots is defined exogenously by some person(s) and is known (strict assumption). By saying “behavior”, we mean the setup of opinions and targets of bots. We will clarify these issues in more detail below.
4.6. Personalization Algorithm
We assume that communications are curated by a specific algorithm that mimics artificial intelligence-based recommendation systems on real-world online social platforms. These systems aim to mitigate information overload, which is frequently faced by users [2]. Recommendation algorithms rely on specific information and metrics, including content popularity, users’ attributes, and users’ most recent actions [5]. Despite having a priori fair and unbiased targets, personalization systems are frequently accused of exacerbating individual information isolation and facilitating polarization in social communities [30]. Scholars argue that commercial companies, seeking to maximize the time users spend on social media sites, may adjust personalization algorithm metrics so that information communications may fall into the trap of popularity-biased and ideologically coherent interactions, with no access to less popular and challenging content [2,32].
We follow a rather simplified and interpretable approach wherein the personalization algorithm decides whether the two agents chosen for communication will actually communicate or not in a Bernoulli trial. Mathematically, the communication act between agents with opinions and , and types and , will proceed with a probability of . This operationalization allows us to consider various personalization strategies, including homophily (when agents with similar characteristics have a greater chance of interaction) and heterophily (when dissimilar agents communicate more often) with respect to both opinion and non-opinion attributes.
To summarize, the sequence of parameters , where and formalizes the personalization algorithm. If we fix opinion-related parameters s and l (the lower indices of ), then we end up with values that can be orchestrated into an matrix, which shows the communication probabilities as functions of agents’ types. For example, the matrix
for indicates that (i) native agents with similar types always communicate after being selected, (ii) native agents with different types communicate in 75 out of 100 cases, and (iii) communications between native agents and bots are allowed with a probability of 0.5 (for example, the platform itself may try to prevent ordinary users from spam attacks). Such a regime corresponds to homophily personalization.
Conversely, one can fix the type-related indices (the upper indices of ) and examine how the opinions of interacting agents affect the probability that a communication will be allowed. In particular, for given and , the matrix
() tells us that the personalization algorithm is biased towards facilitating communications between agents with opposite opinions—a so-called opinion–heterophily personalization strategy.
We would like to highlight that the personalization parameters—in contrast to the components of transition probability tables—are only constrained to lie in the interval and do not follow any joint restrictions.
4.7. Interpreting Transition Probability Tables
In [8], it was systematically demonstrated how the transition probability table formalism may capture variant types of opinion formation mechanisms; therefore, we refer the interested Reader to [8] for a detailed inspection. For now, we will provide only a few examples to comprehend the organization of transition probability tables.
Let us start from a situation when there is only one agent type, so the upper indices of the transition probabilities can be safely omitted.
Example 1.
Let —such a situation may occur, say, in a two-party election system. Let us consider the following transition probability table:
One can notice that the transition probability table, (4), maps the dynamics of the Voter model [48,62] where agents simply copy the opinions of their conversation partners.
However, as it was documented in the empirical studies [21,63,64], in real-world settings, individuals rarely change their opinions. Because of this, in any matrix in Formula (1), the k-th column—a column that comprises the probabilities of keeping the current opinion unchanged—should dominate. This is perfectly illustrated in the ongoing example.
Example 2.
Now we consider a transition probability table that was derived from empirical data that were harvested from an online social network (see [7] for details):
The transition probability table, (5), shows three important takeaways that were confirmed in various (both laboratory and field) studies on social influence: (i) an individual may change their opinion even after communicating with a confederate [63,64]; (ii) after being exposed to the opposite opinion, an individual tends to change their opinion more often than if being exposed to the same opinion [21]; (iii) opinion evolution patterns are usually asymmetric [65]. In our case, the last point means that individuals with opinions and react differently to the opposite opinions (mathematically, matrix does not turn to after flipping the rows and columns).
If one considers opinion alphabets with more than two elements, then it becomes possible to capture more subtle forms of social influence. For example, the following transition probability table embraces a bounded confidence mechanism of opinion dynamics [19]:
Example 3.
Let us consider the following transition probability table:
For now, we are in a three-element ordinal opinion alphabet. By saying “ordinal”, we mean that opinions , , and are arranged, with and representing opposite standpoints, while shows a neutral stance. Having ordered opinions, we may appreciate assimilative opinion shifts (directed towards the opinion of an influence source) and dissimilative ones (directed outwards) [19]. (In our notations, assimilative opinion shifts are described by those components, , whose indices fulfill the equality ; the inequality in turn marks a dissimilative opinion shifts).
From (6), one can tell that if the opinion of an influence object is , then it changes to with a probability of 0.25 after communication with opinion (assimilative opinion shift) and with a probability of 0.05 after communication with opinion (dissimilative opinion shift). We would like to highlight that such patterns are not merely illustrative and imaginary, but were documented in empirical data [7].
Transition probability table (6) also demonstrates that agents with extreme opinions ( or ) can modify their opinions only to . On top of that, they do this more frequently when exposed to the neighboring opinion () than when exposed to the opposite opinion ( or , respectively)—a phenomenon that is usually referred to as bounded confidence [15,66].
If one wants to capture a scenario with more than one agent type and where individuals’ perceptions of influence change across in- and cross-type communications, then one should apply various transition probability tables depending on the types of the interacting agents. In particular, it stands to reason that for in-type communications, the level of conformity should be higher than that of cross-type communications—see, for example, Ref. [57]. This effect may be parameterized by increasing the probability of opinion assimilation at the expense of the probability of maintaining the current opinion for transition probability tables dedicated to in-type interactions. To be more specific, one can employ (6) to describe interactions between agents of different types, and the following transition probability table, which provides more room for conformity and assimilative shifts, can be employed in in-type communications:
5. Mean-Field Approximation
5.1. Assumptions and Notations
In the interest of notations, in what follows, we will refer to agents’ activity rates via the lower indices of their types. So, if , then instead of , we will simply write .
We depart from the assumption that the underlying social network is initiated by a stochastic block model [67]. This family of network generation algorithms takes a set of nodes divided into disjoint subsets (blocks) and then creates ties between nodes in an independent fashion. For each pair of nodes, the probability of a tie appearing is a function of the blocks to which the nodes pertain. These probabilities are the parameters of the model. As a result, one is given the opportunity to flexibly adjust various in- and inter-block tie appearance rates depending on the modeler’s purposes.
Let us now define how ties between native agents form. We assume that blocks correspond to agents’ types. We have M types of authentic agents in total, so we end up with M blocks. We denote the size of block f with . For each pair, , of blocks, we introduce the quantity that gives the probability that a randomly chosen pair of vertices of the corresponding types and will be connected. Note that leads to an in-type creation rate, whereas shows an inter-type creation rate (because the network is undirected by default, we have in this case). Following up on the empirical observations from real-world social networks, one can safely assume that should be greater than for a fixed pair such that —this phenomenon is usually referred to as the homophily or modularity of social networks [54].
Next, following the approach of [8], we assume that social bots act in a personalized fashion and can apply various manipulation strategies depending on the types of their targets. Bots are grouped into disjoint subsets (cohorts), and each cohort focuses on a specific type of authentic agent. In other words, the cohorts of bots and the corresponding blocks of native agents organize bipartite graphs. By , we denote the population of cohort f (which includes the bots that focus on the native agents of type ), and by , we denote the intensity of connections between the native agents of type and the social bots from the corresponding cohort f at time t. The time argument indicates that social bots may act adaptively, so the compositions of the cohorts, as well as the communication intensity rates, may change over time. For example, at some moment, all bots may find themselves in one cohort—meaning that all the bots exert influence on only one type of native agent. These agents may be, for instance, the most prone to conformity and thus are most vulnerable to influence.
As a result, we end up with a dynamic stochastic block model with blocks of sizes (some of them may be empty) and the following sequence of edge creation probabilities: Note that for any t, it holds that
Figure 1a schematically illustrates our assumptions about the network structure. Once again, we assume that connections between native agents are static, but ties between native agents and bots, as well as the cohort populations, may change over time. We would like to highlight that, despite bots acting strategically, the appearance of ties between authentic agents and bots does not depend on the agents’ opinions—only on their types. In principle, this modification can be incorporated into the model, but the computations will become more cumbersome.
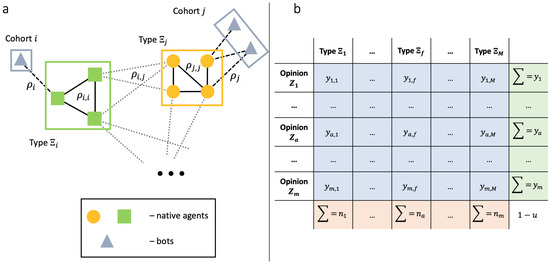
Figure 1.
(a) We showcase a sketch of the network structure. The network consists of M blocks of native agents and M cohorts of bots, for a total of blocks. In the interest of plot, we show only 4 blocks. Ties between native agents derive from their types. It means that in-type ties (solid lines) may be overrepresented, compared to cross-type connections (dashed pale). Bots organize bipartite graphs with their targets (dashed lines). (b) Our state variable is —the fraction of authentic agents with type that have opinion at a given time moment. If we sum this quantity over all possible opinions, then we end up with the number of agents of type —. The summation over all possible types lead us to the number of agents with opinion , which is given by . The total summation gives us the fraction of authentic agents .
5.2. Introducing Population-Level Variables
Let us define some macroscopic variables that we will make use of in our derivations. First, by (), we will denote the fraction of native agents having opinion and type at time t:
Next, denotes the total fraction of agents with type , , and denotes the total fraction of agents with opinion at time t, . The quantity shows the fraction of bots from cohort r with opinion at time t, represents the total fraction of bots in cohort r, and indicates the total fraction of bots in the system. Apparently, we have
This organization of our phase space is schematically illustrated in Figure 1b.
5.3. Master Equation
Having all these notations, we are now in a position to write the mean-field approximation. It was derived in [58], and we refer the interested Reader to this paper for detailed computations. Let be the scaled time: . Let , and
The following coarse-grained nonlinear ODE holds when applying the thermodynamic limit :
In the master Equation (8), quantities A and serve as normalization values—they appear after computing the probabilities of picking up an agent with a particular opinion and a particular type as an influence object (A) and then selecting an agent with a particular opinion and a particular type as an influence source (). In the latter case, a social bot can be chosen, and since the cohorts of bots change over time, the quantity has a time argument.
Remark 1.
Here, we would like to highlight that for Equation (8) to be correct, it is necessary to require that the opinions, cohorts, and ties change “no faster” than the speed at which the system evolves.
It is worth noting that the right-hand part of (8) is quadratic with respect to the populations of native agents and bots. This is due to the fact that communication events in the model are essentially pairwise. In this respect, (8) differs from many compartmental (epidemiological) models [68,69,70,71,72], such as the SIR model, whereby linear terms are frequently encountered. Next, one may notice that (8) is homogeneous with respect to the tie densities and : if introducing a simultaneous variable map and , where , then the equation remains the same.
As a final remark, we would also like to highlight that in (8), the parameters of the personalization algorithm are not static, but change over time.
5.4. Properties of the Master Equation
For ease of notation, we denote the right-hand side of (8) as . Next, we make use of the matrix functions defined as follows:
Using these notations, we rewrite (8) as
Let the functions and for be measurable. Let the personalization algorithm function be measurable. It is not a difficult task to show that, in this case, the Cauchy problem for Equation (9) with the initial condition
or, in matrix form
where the natural restrictions
on the initial point are fulfilled, has a unique solution that is defined on some interval . This solution is an absolutely continuous function and satisfies (9) almost everywhere [73,74].
Our current purpose is to show that is non-negative. In other words, we need to show that is an invariant set for (9). To prove this, we shall take an arbitrary point y at the boundary of and then check if the scalar product of the outer normal of in y and the right-hand part of (9) is non-positive for any [75]. Let us assume that for . For such pairs of a and f, we have
Next, under our assumptions, the set of the outer normals is given by , where if and is a negative value if . As such, the scalar product of and F would be less than or equal to zero. Thus far, we have obtained the following result.
Statement 1.
Next, one can straightforwardly notice that the functions for are the first integrals of (8), which reflects the fact that agents’ types remain unchanged. As such, given Statement 1, is bounded from above, and the following result is true.
Statement 2.
5.5. Simulation Examples
Before moving on to the setup of a control problem, we provide some illustrative examples that showcase the dynamics of the model and the accuracy of the mean-field description. We consider the case . We employ the transition probability tables in (6) and (7). The table in (6) covers interactions between agents of different types, while (7) describes in-type interactions. We assume that . Of these, agents have type , agents have type , and agents are bots. The initial joint distribution of opinions and types is given by
This said, we consider a polarized society wherein the agents with type are more inclined to opinion , and agents with type prefer .
We assume that bots apply a constant strategy: they target the first-type agents and influence them with opinion all the way. Mathematically, it means that . The stochastic block model parameters are as follows: , , and . The activity parameters are defined as follows: and . We assume that the first-type agents are more active than agents of type , but that the bots exhibit the highest activity rate, as is usually the case on social media platforms.
Three ranking algorithm specifications are considered. In the first one, no ranking is applied, and all the components of are equal to one. The second specification refers to type homophily. For each , matrix is defined by (2). Finally, the third specification facilitates opinion heterophily according to the matrix in (3).
Figure 2 shows direct simulations with the stochastic model and compares them against the solutions of the master equation, Equation (9). First, we notice that the mean-field description yields a reasonable level of accuracy in approximating the behavior of the stochastic system. We also appreciate the substantial effect of varying the ranking algorithm on opinion dynamics. One more interesting observation from Figure 2 is that in the absence of ranking, the social system features the highest level of polarization—the population of “neutral” agents reaches the smallest value of 0.38.
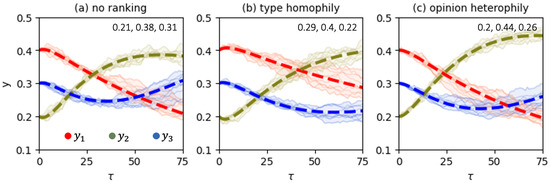
Figure 2.
Comparing the direct simulations with the stochastic opinion dynamics models (pale lines, each line corresponds to one of 10 independent experiments) against the corresponding solutions of the mean-field equation (bold dashed lines). Each trajectory marks the total fraction of agents with the corresponding opinion irrespective of their types. The values of the order parameters at the terminal time (that corresponds to 375,000 model iterations) are plotted in the upper right corner of each panel.
6. Control Problem
Let us assume that a person—say, an owner of a social media platform—also (in addition to the owner(s) of social bots) attempts to sway the native agents’ opinions. For instance, the platform owner may notice that the bots tear apart public opinion and polarize society. To this end, the owner may decide to apply a depolarization intervention in response. How can they do that? We assume that the platform owner is able to adjust the personalization algorithm. Mathematically, it means that the parameters are control variables and are subject to variation.
With this in mind, we formulate the following control problem:
where J is the following linear objective:
In (14), the value of T outlines a time horizon. The weight vector represents the objective of the platform owner. A larger value of indicates that opinion should be less represented in the population. As demonstrated in Ref. [8], because agents do not leave the system, we can safely assume that the weight vector is non-negative. Besides this, an algorithm for adjusting the values of the weight vector, given prior knowledge of the social system at hand, can also be found in [8]. Our final remark on (14) is that the parameter shows the relative importance of the integral term of the functional.
The class of admissible controllers includes all measurable functions such that
on . Parameter represents a floor value for personalization. This implies that all agents, regardless of their types and opinions, should have some minimal chance to communicate. The setting shows an extreme case in which the personalization algorithm can completely close communication channels. By default, we assume that .
7. Existence, Uniqueness, and Necessary Conditions for Optimality
We first reformulate our control problem by introducing one additional phase variable , which is defined as follows:
As a result, we end up with the following Mayer problem:
Control problem (15) has a convex compact set of admissible controls. Next, the control process of (15) is linear in control. This guarantees that for each , the set is compact and convex. As such, due to Filippov’s theorem, the reachable set is also compact. Because the cost functional in (15) includes only the terminal term, which is a continuous function depending solely on the phase variables, we arrive at the following result.
Statement 3.
Remark 2.
The uniqueness of this solution is not necessarily fulfilled. For example, there could be more than one controller that yields for control problems posed for “well-controlled” systems with .
Let us now write the Hamiltonian–Pontryagin function for the control problem in (13) (here, we account for the fact that the value of is not fixed):
From the Pontryagin Maximum Principle, we know that if a pair is optimal, then there exists a function that is the solution to the Cauchy problem:
and we have almost everywhere that
Since the Hamiltonian–Pontryagin function is linear with respect to the control variables, we can try to understand the organization of the optimal control in some specific cases by eliciting switching functions [71].
Statement 4.
Let be the solution to the Cauchy problem (16) for an optimal pair . Let us consider the quantity
for and , and . Let and either (if ), or and (if ). Then we have
Proof.
Let us first calculate the derivatives of with respect to the control variables:
for , and
for .
After that, we substitute these derivatives into the expressions for and and obtain:
It is worth noting that Statement 4 is not informed regarding the value of if . This is intuitively clear: indicates that agents with opinion and type are not sensitive to influence from agents with opinion and type . As such, these communications do not affect the state variable y and thus leave us in the dark as to how to accommodate them in optimal control finding.
These shortcomings fall under the more general umbrella of what one should do in the case when the derivatives of (19) and (20) are equal to zero on some interval . This could be the case because our Hamiltonian–Pontryagin function is linear with respect to —otherwise, one would try to estimate the control variables from the resulting equations [72]. In this case—referred to as singular control [76]—one can calculate the full derivatives from (19) or (20) with respect to on (in (21), we omit the arguments in the interest of space):
Note that the first equality in Equation (21) assumes that does not depend on . This is the case when the strategy of bots is constant over time.
After that, one should plug the expressions for and into (21). This will give us an equation that is linear in the control variables, allowing us to find all the singular control components of on . The resulting equation appears to be a bit too cumbersome, so we omit it in the interest of space. We make use of these calculations in the numerical solving of problem (13)—when applying the Forward–Backward Sweep method and maximizing the Hamiltonian–Pontryagin function pointwise (Our analysis showed that the use of singular control facilitates convergence of the FBS method. However, in most situations, it leads to boundary-bang controllers). Note that Statement 4 also informs our numerical algorithm.
We now turn to solving the target control problem using the finite-difference method.
8. Applying Finite-Difference Schemes: The Simplest Scenario
In this section, we consider the case when there are only two opinions in the system, and only one (authentic) agent type exists: . As such, we can safely omit all the indices that stand for agent types and bots cohorts. All we need is to separate the parameters of native agents from those of bots. We do this by applying the index “u”. As a result, we have the following master equation:
Because , Equation (22) describes the system completely.
Further, our control variables are given by
Finally, we have the following cost functional:
where or . We can safely focus on these two weight vectors because all other weight configurations can be reduced to one of these two. Indeed, let us consider a weight vector , where . As such, we can write , with . This leads us to
which means that from the perspective of the control problem at stake, a vector with is equivalent to . Analogously, the case can be boiled down to .
Let us focus on the case —that is, we want to decimate opinion in the system. The opposite case can be elaborated on analogously. Hence, we have
We approximate J using the trapezoidal rule:
where is small.
Considering , the minimization of J can be replaced by the maximization of
We now approximate Equation (22) using the Euler scheme:
We consider a finite-difference analogue of the control problem in (13) with the discrete process, (24), and the cost functional, (23), to be maximized:
We assert the following result.
Theorem 1.
Proof.
One can notice from the above expressions that each quantity contains exactly one component of the controller. And, conversely, this very component appears only in and nowhere else.
Let us consider —this corresponds to the last moment before the terminal time comes. With that being said, to maximize (and, correspondingly, to maximize the objective functional of (25)), the components of that appear in non-negative terms () should be set to the highest value possible (), and the components of that appear in non-positive terms () should be set to the minimal value possible (). As such, the following setup would be optimal if we were to start from :
Continuing this reasoning and moving backward, we notice that for an arbitrary , the control
maximizes the value of . With this in mind, and applying the Bellman principle of optimality, we end up with the controller in (26). □
Remark 3.
Intuitively, the controller in (26) is quite meaningful: if there are only two possible opinions, then it stands to reason that one should keep the agents holding a “desirable” opinion away from any contacts to prevent them from having any possibility of changing their opinion. And, on the contrary, one should facilitate communications between individuals with an “undesirable” opinion—to maximize the likelihood of opinion updating among these agents.
Remark 4.
One more interesting observation from the controller in (26) is that it does not depend on how the bots behave at all.
9. Applying Finite-Difference Schemes: The Scenario , Is Arbitrary
Now we turn to a more meaningful scenario in which the number of agent types is arbitrary, but the opinion alphabet still includes only two elements. The fact that the control parameters appear independently in the process enables us to generalize our findings from the previous section. Applying the Euler approximation scheme again and employing the trapezoidal rule, thus boiling down the continuous control problem (13) to its discrete counterpart, results in a controller that is similar to that of (25).
For an arbitrary , we have the following cost functional:
where is a weight vector. Without loss of generality, we consider , (the number of opinion holders is subject to minimization). We approximate the cost functional as follows:
where is small.
For the sake of convenience, instead of minimizing J, we will maximize :
Let . We now consider the differential equation for :
where
Applying the Euler approximation scheme to (28), one ends up with:
Let us consider a finite-difference counterpart of the problem in (13) with the discrete process, (29), and the cost functional, (27), to be maximized:
We assert the following result.
Theorem 2.
Proof.
Because we want to maximize the value of and because we can vary each of the terms – independently by tuning an appropriate control parameter (without changing the others), the following values of the control parameters will ensure the maximum of the state variable at time :
We also notice that our selection of the control parameters does not affect the values of the state variables at time for . This observation completes the proof of this theorem. □
10. Numerical Experiments
To corroborate our findings, we performed numerical tests. In these tests, we solved the control problem at stake using two well-established numerical algorithms: the Forward–Backward Sweep method and the Direct method [76], and compared—whenever it is possible—their outputs against controllers (26) and (31). All code necessary to replicate our experiments is available in the Supplementary Materials.
Starting from an initial guess control, the Forward–Backward Sweep method (henceforth referred to as the FBS method) consecutively repeats the following steps: (i) it solves the master equation, Equation (8), (ii) integrates the Euler–Lagrange Equation (16), thereby finding the adjoint function, and (iii) maximizes the resulting Hamiltonian–Pontryagin function pointwise. During these iterations, the method either converges—not necessarily to an optimal solution—or loops/diverges.
The Direct method simply boils down the control problem at stake to a constrained optimization problem, where all the values of the control function on a grid are subject to variation.
To investigate the effect of the initial guess on the output of these numerical algorithms, we used a multi-start approach, with the following constant uniform control functions as the inputs of the algorithms: and , where . For our tests, we set and . We applied to get a control function that lies “between” extreme controllers and . We also used this value as a default in situations when singular control components cannot be obtained by differentiating the partial derivatives of the Hamiltonian–Pontryagin function.
We also employed the controllers from (26) and (31) as starting guesses in simulations with a two-element opinion alphabet () to check whether the FBS method converges on them.
10.1. Some Details on Model Parameters Calibration
We orchestrate our experiments in accordance with the size m of the opinion alphabet. We consider the cases , , and .
We departed from the case , for which we have the controllers in (26) and (31). For our tests, we employed two collections of transition probability tables. The first one was motivated by the empirically calibrated transition probability table in (5) (see Section 4.7). To be more specific, we preserved the main patterns of (5) and created two new transition probability tables:
so that the table in (32) gives rise to higher (vs. (33)) levels of conformity (copying the opinion of a partner) and lower levels of anti-conformity (changing the opinion after a conversation with a like-minded individual) [63]. In accordance with previous empirical studies on influence in social groups [57], we employed (32) in in-type interactions and (33) in out-type interactions.
The second collection of transition probability tables was created artificially, with no direct reference to any empirical data, but indicating two well-known tendencies of people—the tendency for conformity [77] and the tendency to incline towards the current opinion [64]:
It is worth noting that, in contrast to (32) and (33), the tables in (34) and (35) are symmetric. The table in (34), which exhibits higher conformity rates, was applied to in-type interactions, and (35) was applied to out-type interactions.
To investigate the control problem in the case of a three-element opinion alphabet (), we considered variant transition probability tables that encode different social influence mechanisms established in the literature, such as assimilative influence or bounded confidence (see [7,8,19] for details). Since our findings on the performances of the numerical methods were virtually the same, we would like to focus on a collection of two transition probability tables that were generated using the large language model Perplexity, for which we obtained the effect of varying the initial guess on the output of the Direct method. The resulting tables are provided in Appendix A.3. Note that these tables, as well as those obtained for , regard opinions as ordinal social objects. Therefore, we can speak about the underlying opinion alphabet as a one-dimensional opinion spectrum, with and representing its extremes.
While dealing with a five-element opinion alphabet (), we harnessed the transition probability table from [7], which was calibrated using empirical longitudinal data from an online social network ( 1,500,000). This allowed us to optimize the ranking algorithm in real-world settings. Due to the large size of the corresponding transition table, we portray it in a separate figure—see Figure A1 in Appendix B. We refer the interested Reader to Refs. [7,21] for a detailed analysis of the social influence patterns encoded by this table and the underlying social data. We also made use of the empirical data from [78]. This longitudinal dataset describes the opinion dynamics of a large sample of users 30,000 and includes information about individual characteristics other than opinion, such as gender. This allowed us to investigate the role of gender in recommendations.
In the results presented below, one cell of the grid corresponds to one Monte Carlo step (one unit of time ), which, in turn, refers to N steps in the initial discrete time t.
We are now in a position to present the results of our numerical experiments. We start from the case .
10.2. Results:
Figure 3 indicates that our solution in (26) yields the best performance in the case , as do the FBS and Direct methods. We report that, for synthetic transition probability tables (panels (b), (d), and (f)), a singular control appears in the iterations of the FBS method. In the experiments presented in these three panels, we found that the outcomes of the numerical methods depend on the initial guess and deviate from the controller in (26), as shown in panels (d) and (f). We should say here that the Direct method is quite sensitive to the grid size, and on a grid of 20 points, depending on the initial guess, it may require ∼4 min to converge (all experiments were performed on Dell PowerEdge R740, 2× Intel Xeon Gold 5218R, 320 Gb RAM), whereas the FBS method consistently converges in two iterations, and it usually takes ∼0.01 s.
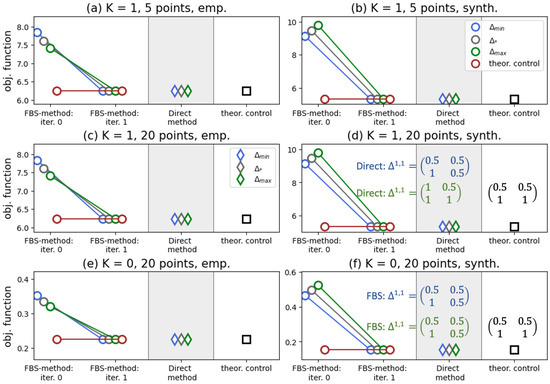
Figure 3.
We investigate the performances of the FBS method and the Direct method against our analytically derived controller, (26). The opinion weight vector is (we minimize the presence of opinion in the system). We test two collections of transition probability tables: (i) (32) and (33) (left panels) and (ii) (34) and (35) (right panels). We also vary the size of the grid and the value of K. In this figure and in the ongoing ones, various colors signify different initial guesses, as marked in the legend. In panels (d,f), we plot controllers derived by the numerical algorithms for initial guesses and (the colors are aligned with the legend). Simulation issues are detailed in Appendix A.1.
The aforementioned findings generally remain valid when considering the case of more than one type of native agent. In Figure 4, we show the results of numerical tests for of such types. From this figure, one can observe the absence of any effect of varying the activity parameters on the performance of the algorithms. Again, we see that the FBS method, the Direct method, and our controller yield the same value of the objective functional, with the FBS method requiring two iterations for convergence.
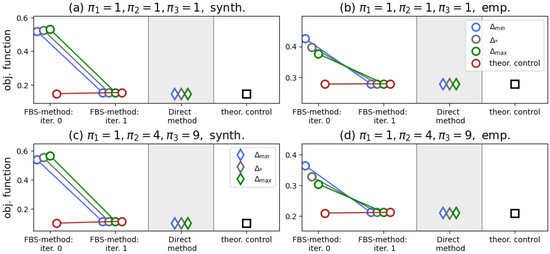
Figure 4.
We consider a system with opinions and types of authentic agents, with in-type interactions being described by the table in (34) (left panels) or (32) (right panels), and out-type communications being defined by the table in (35) (left panels) or (33) (right panels). All simulations were performed on a grid of 5 points, with . In these simulations, we also varied the values of the activity parameters, as shown in the panel titles. Simulation issues are detailed in Appendix A.2.
10.3. Results:
For the case of a three-element opinion alphabet, our analytically derived controllers are meaningless and cannot be applied. However, we can still make use of the FBS method and the Direct method. As well, we can try to find any similarities between the outputs of the numerical algorithms and the controllers from (26) and (31) (see Remark 3).
Our current foci are two core scenarios (). In the first one, the system starts from the state of
which indicates that opinions and types are strongly correlated: agents with type tend to have opinion , and agents with type are inclined to opinion . To the contrary, in the second scenario, the starting state is given by
which shows no correlation between opinions and types. Both of these scenarios concern an initially polarized population, and we set the opinion weight vector as —thus said, the goal of stewardship is to depolarize the community.
We present our results in Figure 5. In contrast to the case , we now see that the Direct method slightly outperforms the FBS method, which now takes much more than two iterations to converge. All the iterations of the FBS method depicted in Figure 5 were accompanied by the presence of singular control components.
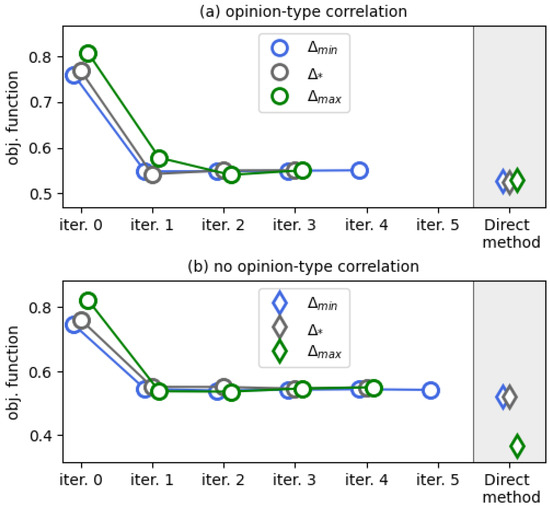
Figure 5.
Results of numerical experiments for a system with opinions and types being correlated (a) and for an uncorrelated system (b). The ticks “iter. i” show the working of the FBS method. Simulation issues are detailed in Appendix A.3.
The interesting point of Figure 5b is that we acknowledge the effect of the initial guess on the performance of the Direct method: when starting from , the numerical method yields the lowest value of the objective functional. In Figure 6, we show the corresponding control function. If this controller were to follow the principles of the controllers of Theorems 1 and 2 (see Remark 3), then one would expect that each slice has the following organization: the components in the second row of are equal to (because we would like to maximize the presence of opinion ), whereas the components of the first and third rows are equal to (as we would like to suppress radical opinions and from the system). However, this seems to be the case only for a few of the panels, and even then only partially.
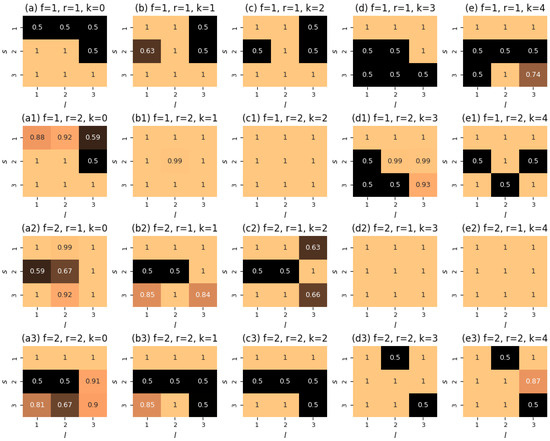
Figure 6.
Organization of the controller obtained by the Direct method with the starting guess in the no-correlation scenario (see Figure 5b). Each panel shows a slice (the indices are provided in the titles) of the function defined on a 5-point grid (marked by k).
However, the controller derived by the Direct method with as a starting guess is much closer to this intuition—see Figure A3 (Appendix B). At least, most of its slices have zero-valued second rows. Nonetheless, one can notice a reasonable level of asymmetry in this control function, which is manifested in opinion being closed for contacts. The output derived from the FBS method displays an opposite asymmetry pattern, where opinion is underrepresented in interactions (see Figure A4 in Appendix B). Comparing this controller with the one obtained by the FBS method in the no-correlation setting (plotted in Figure A5, Appendix B), we see that the presence of opinion-type correlations sufficiently affects the organization of the controller and makes it more inclined to prohibit any contacts with opinion .
10.4. Results:
We finalize our analysis with the case . Because the number of control parameters to estimate at each grid point grows quadratically with both m and M, we focused on scenarios with and types of native agent.
For , we investigated two stylized scenarios: (i) (depolarization of the system) and (ii) (agents’ opinions are steered towards the right endpoint of the opinion spectrum—opinion nudging [2]). In the case of the first scenario, the initial system state was
(a perfectly symmetric polarized social system).
For the second scenario, the starting point was
which represents a social system inclined to the left side of the opinion spectrum.
Our results are summarized in Figure 7. We see that the Direct method yields the same quality as the FBS method in both scenarios, with no effects of the initial guess on the outputs of the algorithms. The resulting outputs of the Direct method are also presented in the figure. One can notice that they largely follow the intuition of Theorems 1 and 2: an opinion to be minimized should communicate more often, whereas a desirable opinion should avoid any interactions.
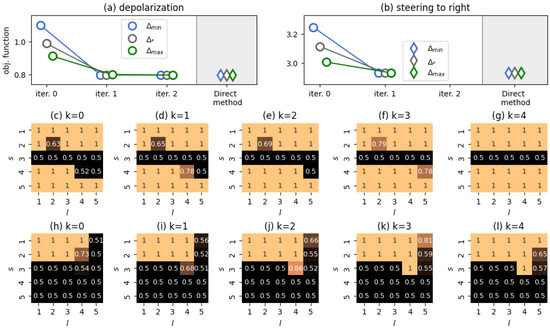
Figure 7.
Plotted are the results of our numerical experiments for . The ticks “iter. i” in panels (a,b) show the workings of the FBS method. Panels (c–g) show the controller derived by the Direct method (starting guess ) for the depolarization scenario (a). Panels (h–l) show the controller derived by the Direct method (starting guess ) for the opinion nudging scenario (b). Simulation issues are detailed in Appendix A.4.
The case was explored under the setting that agents’ opinions should shift to the left, as indicated by . The initial state of the system was
which shows a general bias towards the right end of the opinion spectrum, with females () being more inclined than males (). The results of our experiments are shown in Figure 8. We see that the FBS-derived controller hinders communications in which the influence source has an opinion that is more to the right of the influence target, thus preventing the target’s opinion from moving towards the right. We also notice that this pattern is more pronounced for interactions in which male agents are influenced. This can be explained by the observation that female agents with left-leaning opinions tend to be less susceptible to influence than male agents with the same opinions, as shown in Figure A2 (Appendix B). As such, we conclude that the ranking algorithm—which strives for the left side of the opinion spectrum—should shield such male agents from the influence of right-leaning opinions.
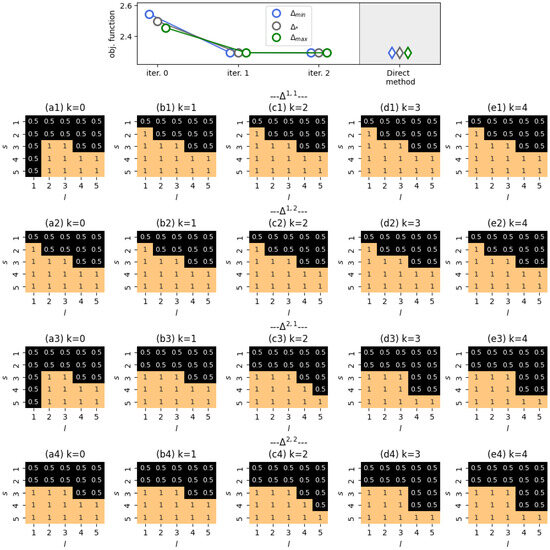
Figure 8.
Plotted are the results of our numerical experiments for . The upper panel shows the convergence of the FBS method across various initial guesses, indicating that the resulting controllers are as optimal as those obtained using the Direct method, though they differ slightly. The subsequent panels demonstrate the control achieved by the FBS method. Simulation issues are detailed in Appendix A.5.
From panels (a1) and (a3) of Figure 8, one can notice that if a female agent is the source of influence, then, in the beginning of the system’s evolution, agents with opinion should not influence other agents. This is simply due to the absence of any female agents with opinion at , as specified by the initial state q.
11. Conclusions
This paper proposes a model-dependent theoretical framework for finding an optimal design of a ranking algorithm to affect individuals’ opinions. Building upon the mean-field approximation of a nonlinear opinion dynamics model [58], we formulated a control problem in which the time-dependent parameters of a ranking algorithm are dynamically adjusted to achieve a desirable opinion distribution.
We proved that the control problem at stake has a solution. Using the Pontryagin Maximum Principle, we characterized certain properties of optimal controllers. After applying finite-difference schemes to the control problem, we solved it for the case of a two-element opinion alphabet and an arbitrary number of agent types. The resulting solution is intuitive: if there are only two possible opinions, then one should keep the agents holding a “desirable” opinion away from any contacts to prevent them from having any possibility of changing their opinion. And, on the contrary, one should facilitate communications between individuals with an “undesirable” opinion—to maximize the likelihood of opinion updating among these agents. What is important here is that this control does not depend on external factors, such as social bots and their attacks.
We conducted extensive numerical tests to bolster our theoretical findings. We found that the finite-difference scheme controllers yield the same quality as those derived from several established numerical methods. Our experiments also spanned the cases of three- and five-element opinion alphabets. We examined two stylized scenarios: the depolarization of an initially polarized society and the nudging of a social system towards a given edge of an opinion spectrum. Social systems with node-level and edge-level correlations were covered in our simulations, and we acknowledge the effect of such correlations on the outputs of the numerical algorithms. The obtained controllers tended to be of a boundary-bang type [71], which is due to the fact that our model is linear with respect to the control variables.
We recognize that our approach is not without limitations. Our operationalization of the ranking algorithm involves agents avoiding interactions with certain probabilities. However, in a real setting, a user who is deprived of a piece of content by an algorithm will replace it with a different piece of content. Next, we assume that the parameters of the ranking algorithm are adjusted independently: the lower and upper bounds are the only constraints we impose on them. However, it is likely not the case for real-world online platforms. Effectively, it would be more realistic to assume that there is a total constraint on the number of interactions blocked by the system, with the constraint stemming from hardware capabilities. Therefore, the set of admissible controls should be a simplex, rather than a hyperrectangle. It is also worth noting that our model omits one of the key aspects of platform behavior: the pursuit of increased user engagement alongside opinion nudging [5].
Nonetheless, the theoretical framework proposed is flexible enough to embrace information on agents’ attributes, their activity heterogeneity, and the mesoscopic and macroscopic properties of the underlying networks, including modularity patterns. Our control model covers different mechanisms of social influence, thus providing an opportunity to exert control over ranking algorithms in the presence of inevitable uncertainty regarding the true nature of social influence [25].
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/e28030333/s1.
Author Contributions
Conceptualization, I.K.; methodology, I.K. and V.G.; software, V.G.; validation, V.G. and I.K.; formal analysis, V.G. and I.K.; investigation, V.G. and I.K.; resources, I.K.; data curation, V.G.; writing—original draft preparation, I.K.; writing—review and editing, V.G. and I.K.; visualization, V.G. and I.K.; supervision, I.K.; project administration, I.K.; funding acquisition, I.K. All authors have read and agreed to the published version of the manuscript.
Funding
The research is supported by a grant from the Russian Science Foundation (project no. 24-71-00070).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Simulation Details
Appendix A.1. Simulation Details for Figure 3
The case is considered. The starting point of the dynamical system is given by , the bots’ behavior (whose population is 0.1) is described by . That is, bots consistently disseminate opinion all the time. The network configuration is given by (ties between authentic agents appear twice as often as those between authentic agents and bots). The activity parameters are , which means that bots are more active than native agents. The opinion weight vector is : the presentation of opinion —which is disseminated by bots—should be minimized. Interactions between native agents are described either by table (32) (see the left panels of the figure), or by table (34) (right panels). Interactions between native agents and bots are portrayed by transition probability tables (33) (left panels) and (35) (right panels).
Appendix A.2. Simulation Details for Figure 4
In this figure, the scenario is presented. The starting point of the dynamical system is
which means that there are no bots in the system. The network configuration is given by
The parameters of the stochastic block model reflect the phenomenon of homophily in social networks—the tendency of individuals to contact those who are similar [79]. In our case, we refer to similarity in terms of agent types—agents with the same type have more chances to be connected by an edge. The parameters in (A1) also indicate that such a tendency is more pronounced among the agents of type and, especially, . The activity parameters are varied in experiments, as shown in the captions of the panels of Figure 4. The opinion weight vector is . The transition probability tables employed in the referenced experiments are the same as those listed in the previous subsection of the appendix.
Appendix A.3. Simulation Details for Figure 5
Here, we present a transition probability table calibrated by the large language model Perplexity for . As a focal question, we considered attitudes towards anime. Three opinion values were introduced (a three-point Likert scale):
- —positive attitude;
- —neutral attitude;
- —negative attitude.
Using prompt-engineering, we asked Perplexity to evaluate its opinion on the focal question, given that the following information is provided:
- The model’s previous opinion (measured on the same scale);
- The opinion of its “friend” (measured on the same scale);
- The model’s “gender”—we asked the model to roleplay either a male person () or a female person ().
With this information being digested by Perplexity via in-context learning, the model outputs its “new” opinion, which can then be employed in the calibration of transition probability tables.
We obtained the following tables:
From these tables, one can notice a sufficient level of asymmetry, a presence of dissimilative opinion shifts (see matrices ), and the absence of bounded confidence patterns—for a fixed non-central opinion ( or ), the probability of the opinion being unchanged exhibits a monotonic decay with opinion distance and shows no tendency to increase in the case of communications with the opposite opinion (see matrices and —the components and , respectively). Generally, these tables display a strong tendency towards assimilation, in line with research on the behavior of large language models [80].
Appendix A.4. Simulation Details for Figure 7
The case is considered. The starting point of the dynamical system is either
(panel (a)), or
(panel (b)). In both cases, there are no bots in the system
In panel (a), we show a depolarization scenario, which is given by the weight-vector . In panel (b), the purpose of stewardship is to steer the system towards the right end-point of the opinion scale (). We set and consider a five-point grid. Figure A1 plots the underlying transition probability table (see the next subsection of the appendix). This table was calibrated on the empirical data from [21], as described in Ref. [7].
Appendix A.5. Simulation Details for Figure 8
The case was considered. The starting point of the dynamical system was
The network configuration is given by
We used transition tables obtained by virtue of the empirical longitudinal data from Ref. [78], see Figure A2 (the medium and bottom panels). These tables show how female () and male () users respond to influence, regardless of the gender of the influence source (this covariate was found to be statistically insignificant in [78]). We used the middle table to calibrate and and the bottom table to calibrate and , respectively.
Appendix B. Supporting Figures

Figure A1.
Transition probability table for a 5-element opinion alphabet derived from the empirical data of [21].
Figure A1.
Transition probability table for a 5-element opinion alphabet derived from the empirical data of [21].


Figure A2.
Transition probability tables for a 5-element opinion alphabet derived from the empirical data from [78]. The upper table was calibrated using the entire dataset and is not informed about individual characteristics. The middle table was calibrated using a subset of the data where female individuals were influenced. The lower table was created for the subsample where male individuals were influence objects. For each table, we provide the rates of resistance to influence as averages of over for fixed s (each value is depicted under the corresponding column). From these rates, one of the main findings of Ref. [78] can be seen: women with conservative opinions are more resistant to influence than men with conservative views.
Figure A2.
Transition probability tables for a 5-element opinion alphabet derived from the empirical data from [78]. The upper table was calibrated using the entire dataset and is not informed about individual characteristics. The middle table was calibrated using a subset of the data where female individuals were influenced. The lower table was created for the subsample where male individuals were influence objects. For each table, we provide the rates of resistance to influence as averages of over for fixed s (each value is depicted under the corresponding column). From these rates, one of the main findings of Ref. [78] can be seen: women with conservative opinions are more resistant to influence than men with conservative views.


Figure A3.
We plot the open-loop controller obtained by the Direct method with the starting guess in the no-correlation scenario (see Figure 5b).
Figure A3.
We plot the open-loop controller obtained by the Direct method with the starting guess in the no-correlation scenario (see Figure 5b).


Figure A4.
We plot the open-loop controller obtained by the FBS method with the starting guess in the no-correlation scenario (see Figure 5b).
Figure A4.
We plot the open-loop controller obtained by the FBS method with the starting guess in the no-correlation scenario (see Figure 5b).


Figure A5.
We plot the open-loop controller obtained by the FBS method with the starting guess in the opinion-type correlation scenario (see Figure 5a).
Figure A5.
We plot the open-loop controller obtained by the FBS method with the starting guess in the opinion-type correlation scenario (see Figure 5a).

References
- French, J.R., Jr. A formal theory of social power. Psychol. Rev. 1956, 63, 181. [Google Scholar] [CrossRef] [PubMed]
- Perra, N.; Rocha, L.E. Modelling opinion dynamics in the age of algorithmic personalisation. Sci. Rep. 2019, 9, 7261. [Google Scholar] [CrossRef]
- Epstein, R.; Huang, Y.; Megerdoomian, M.; Zankich, V.R. The “opinion matching effect”(OME): A subtle but powerful new form of influence that is apparently being used on the internet. PLoS ONE 2024, 19, e0309897. [Google Scholar] [CrossRef] [PubMed]
- Dandekar, P.; Goel, A.; Lee, D.T. Biased assimilation, homophily, and the dynamics of polarization. Proc. Natl. Acad. Sci. USA 2013, 110, 5791–5796. [Google Scholar] [CrossRef] [PubMed]
- Rossi, W.S.; Polderman, J.W.; Frasca, P. The closed loop between opinion formation and personalized recommendations. IEEE Trans. Control Netw. Syst. 2021, 9, 1092–1103. [Google Scholar] [CrossRef]
- Borges, H.M.; Vasconcelos, V.V.; Pinheiro, F.L. How social rewiring preferences bridge polarized communities. Chaos Solitons Fractals 2024, 180, 114594. [Google Scholar] [CrossRef]
- Kozitsin, I.V. A general framework to link theory and empirics in opinion formation models. Sci. Rep. 2022, 12, 5543. [Google Scholar] [CrossRef]
- Kozitsin, I.V. Optimal control in opinion dynamics models: Diversity of influence mechanisms and complex influence hierarchies. Chaos Solitons Fractals 2024, 181, 114728. [Google Scholar] [CrossRef]
- Flache, A.; Mäs, M. How to get the timing right. A computational model of the effects of the timing of contacts on team cohesion in demographically diverse teams. Comput. Math. Organ. Theory 2008, 14, 23–51. [Google Scholar] [CrossRef]
- DeGroot, M.H. Reaching a consensus. J. Am. Stat. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Galam, S. Opinion dynamics and unifying principles: A global unifying frame. Entropy 2022, 24, 1201. [Google Scholar] [CrossRef] [PubMed]
- Abramiuk-Szurlej, A.; Lipiecki, A.; Pawłowski, J.; Sznajd-Weron, K. Discontinuous phase transitions in the q-voter model with generalized anticonformity on random graphs. Sci. Rep. 2021, 11, 17719. [Google Scholar] [CrossRef]
- Javarone, M.A.; Galam, S. Emergence of extreme opinions in social networks. In International Conference on Social Informatics; Springer: Cham, Switzerland, 2014; pp. 112–117. [Google Scholar]
- Friedkin, N.E.; Johnsen, E.C. Social influence and opinions. J. Math. Sociol. 1990, 15, 193–206. [Google Scholar] [CrossRef]
- Deffuant, G.; Neau, D.; Amblard, F.; Weisbuch, G. Mixing beliefs among interacting agents. Adv. Complex Syst. 2000, 3, 87–98. [Google Scholar] [CrossRef]
- Liu, S.; Mäs, M.; Xia, H.; Flache, A. Job done? New modeling challenges after 20 years of work on bounded-confidence models. J. Artif. Soc. Soc. Simul. 2023, 26, 8. [Google Scholar] [CrossRef]
- Bernardo, C.; Altafini, C.; Proskurnikov, A.; Vasca, F. Bounded confidence opinion dynamics: A survey. Automatica 2024, 159, 111302. [Google Scholar] [CrossRef]
- Razaq, M.A.; Altafini, C. Signed Friedkin-Johnsen Models: Opinion Dynamics With Stubbornness and Antagonism. IEEE Trans. Autom. Control 2025, 70, 5037–5051. [Google Scholar] [CrossRef]
- Takács, K.; Flache, A.; Mäs, M. Discrepancy and disliking do not induce negative opinion shifts. PLoS ONE 2016, 11, e0157948. [Google Scholar] [CrossRef]
- Bail, C.A.; Argyle, L.P.; Brown, T.W.; Bumpus, J.P.; Chen, H.; Hunzaker, M.F.; Lee, J.; Mann, M.; Merhout, F.; Volfovsky, A. Exposure to opposing views on social media can increase political polarization. Proc. Natl. Acad. Sci. USA 2018, 115, 9216–9221. [Google Scholar] [CrossRef]
- Kozitsin, I.V. Opinion dynamics of online social network users: A micro-level analysis. J. Math. Sociol. 2023, 47, 1–41. [Google Scholar] [CrossRef]
- Keijzer, M.A.; Mäs, M.; Flache, A. Polarization on social media: Micro-level evidence and macro-level implications. J. Artif. Soc. Soc. Simul. 2024, 27, 7. [Google Scholar] [CrossRef]
- Flache, A.; Mäs, M.; Feliciani, T.; Chattoe-Brown, E.; Deffuant, G.; Huet, S.; Lorenz, J. Models of social influence: Towards the next frontiers. J. Artif. Soc. Soc. Simul. 2017, 20, 2. [Google Scholar] [CrossRef]
- Proskurnikov, A.V.; Tempo, R. A tutorial on modeling and analysis of dynamic social networks. Part I. Annu. Rev. Control 2017, 43, 65–79. [Google Scholar] [CrossRef]
- Proskurnikov, A.V.; Tempo, R. A tutorial on modeling and analysis of dynamic social networks. Part II. Annu. Rev. Control 2018, 45, 166–190. [Google Scholar] [CrossRef]
- Maes, M.; Bischofberger, L. Will the personalization of online social networks foster opinion polarization? SSRN 2015, 2553436. [Google Scholar] [CrossRef]
- Dunbar, R.I.; Arnaboldi, V.; Conti, M.; Passarella, A. The structure of online social networks mirrors those in the offline world. Soc. Netw. 2015, 43, 39–47. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Buss, M.; Liu, F. Coevolution of opinion dynamics and recommendation system: Modeling analysis and reinforcement learning based manipulation. IEEE Trans. Comput. Soc. Syst. 2025, 13, 971–983. [Google Scholar] [CrossRef]
- Zhang, S.; Medo, M.; Lü, L.; Mariani, M.S. The long-term impact of ranking algorithms in growing networks. Inf. Sci. 2019, 488, 257–271. [Google Scholar] [CrossRef]
- Bellina, A.; Castellano, C.; Pineau, P.; Iannelli, G.; De Marzo, G. Effect of collaborative-filtering-based recommendation algorithms on opinion polarization. Phys. Rev. E 2023, 108, 054304. [Google Scholar] [CrossRef] [PubMed]
- Anderson, A.; Huttenlocher, D.; Kleinberg, J.; Leskovec, J. Steering user behavior with badges. In 22nd International Conference on World Wide Web; Association for Computing Machinery: New York, NY, USA, 2013; pp. 95–106. [Google Scholar]
- Ibrahim, H.; AlDahoul, N.; Lee, S.; Rahwan, T.; Zaki, Y. YouTube’s recommendation algorithm is left-leaning in the United States. PNAS Nexus 2023, 2, pgad264. [Google Scholar] [CrossRef]
- Cakmak, M.C.; Okeke, O.; Onyepunuka, U.; Spann, B.; Agarwal, N. Analyzing Bias in Recommender Systems: A Comprehensive Evaluation of YouTube’s Recommendation Algorithm. In International Conference on Advances in Social Networks Analysis and Mining; Association for Computing Machinery: New York, NY, USA, 2023; pp. 753–760. [Google Scholar]
- Talaga, S.; Wertz, E.; Batorski, D.; Wojcieszak, M. Changes to the Facebook Algorithm Decreased News Visibility Between 2021–2024. arXiv 2025, arXiv:2507.19373. [Google Scholar]
- Bakshy, E.; Messing, S.; Adamic, L.A. Exposure to ideologically diverse news and opinion on Facebook. Science 2015, 348, 1130–1132. [Google Scholar] [CrossRef]
- Robertson, R.E.; Green, J.; Ruck, D.J.; Ognyanova, K.; Wilson, C.; Lazer, D. Users choose to engage with more partisan news than they are exposed to on Google Search. Nature 2023, 618, 342–348. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Ghasemian, A.; Rivera-Lanas, M.; Horta Ribeiro, M.; West, R.; Watts, D.J. Causally estimating the effect of YouTube’s recommender system using counterfactual bots. Proc. Natl. Acad. Sci. USA 2024, 121, e2313377121. [Google Scholar] [CrossRef] [PubMed]
- Geschke, D.; Lorenz, J.; Holtz, P. The triple-filter bubble: Using agent-based modelling to test a meta-theoretical framework for the emergence of filter bubbles and echo chambers. Br. J. Soc. Psychol. 2019, 58, 129–149. [Google Scholar] [CrossRef] [PubMed]
- Cinus, F.; Minici, M.; Monti, C.; Bonchi, F. The effect of people recommenders on echo chambers and polarization. Int. AAAI Conf. Web Soc. Media 2022, 16, 90–101. [Google Scholar] [CrossRef]
- de Arruda, H.F.; Cardoso, F.M.; de Arruda, G.F.; Hernández, A.R.; da Fontoura Costa, L.; Moreno, Y. Modelling how social network algorithms can influence opinion polarization. Inf. Sci. 2022, 588, 265–278. [Google Scholar] [CrossRef]
- Pansanella, V.; Sîrbu, A.; Kertesz, J.; Rossetti, G. Mass media impact on opinion evolution in biased digital environments: A bounded confidence model. Sci. Rep. 2023, 13, 14600. [Google Scholar] [CrossRef] [PubMed]
- Galante, F.; Vassio, L.; Garetto, M.; Leonardi, E. Modeling communication asymmetry and content personalization in online social networks. Online Soc. Netw. Media 2023, 37, 100269. [Google Scholar] [CrossRef]
- Piao, J.; Liu, J.; Zhang, F.; Su, J.; Li, Y. Human–AI adaptive dynamics drives the emergence of information cocoons. Nat. Mach. Intell. 2023, 5, 1214–1224. [Google Scholar] [CrossRef]
- Chavalarias, D.; Bouchaud, P.; Panahi, M. Can a single line of code change society? The systemic risks of optimizing engagement in recommender systems on global information flow, opinion dynamics and social structures. J. Artif. Soc. Soc. Simul. 2024, 27, 1–9. [Google Scholar] [CrossRef]
- Peralta, A.F.; Kertész, J.; Iñiguez, G. Opinion formation on social networks with algorithmic bias: Dynamics and bias imbalance. J. Phys. Complex. 2021, 2, 045009. [Google Scholar] [CrossRef]
- Sprenger, B.; De Pasquale, G.; Soloperto, R.; Lygeros, J.; Dörfler, F. Control strategies for recommendation systems in social networks. IEEE Control Syst. Lett. 2024, 8, 634–639. [Google Scholar] [CrossRef]
- De Marzo, G.; Zaccaria, A.; Castellano, C. Emergence of polarization in a voter model with personalized information. Phys. Rev. Res. 2020, 2, 043117. [Google Scholar] [CrossRef]
- Clifford, P.; Sudbury, A. A model for spatial conflict. Biometrika 1973, 60, 581–588. [Google Scholar] [CrossRef]
- Kononovicius, A. Compartmental voter model. J. Stat. Mech. Theory Exp. 2019, 2019, 103402. [Google Scholar] [CrossRef]
- Peralta, A.F.; Neri, M.; Kertész, J.; Iñiguez, G. Effect of algorithmic bias and network structure on coexistence, consensus, and polarization of opinions. Phys. Rev. E 2021, 104, 044312. [Google Scholar] [CrossRef] [PubMed]
- Galam, S. Sociophysics: A review of Galam models. Int. J. Mod. Phys. C 2008, 19, 409–440. [Google Scholar] [CrossRef]
- Galam, S. Democratic Thwarting of Majority Rule in Opinion Dynamics: 1. Unavowed Prejudices Versus Contrarians. Entropy 2025, 27, 306. [Google Scholar] [CrossRef]
- Santos, F.P.; Lelkes, Y.; Levin, S.A. Link recommendation algorithms and dynamics of polarization in online social networks. Proc. Natl. Acad. Sci. USA 2021, 118, e2102141118. [Google Scholar] [CrossRef]
- Newman, M.E. Mixing patterns in networks. Phys. Rev. E 2003, 67, 026126. [Google Scholar] [CrossRef]
- Romero Moreno, G.; Chakraborty, S.; Brede, M. Shadowing and shielding: Effective heuristics for continuous influence maximisation in the voting dynamics. PLoS ONE 2021, 16, e0252515. [Google Scholar] [CrossRef] [PubMed]
- Rácz, M.Z.; Rigobon, D.E. Towards consensus: Reducing polarization by perturbing social networks. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3450–3464. [Google Scholar] [CrossRef]
- Balietti, S.; Getoor, L.; Goldstein, D.G.; Watts, D.J. Reducing opinion polarization: Effects of exposure to similar people with differing political views. Proc. Natl. Acad. Sci. USA 2021, 118, e2112552118. [Google Scholar] [CrossRef] [PubMed]
- Gezha, V.N.; Kozitsin, I.V. Macroscopic Description of Structured Heterogeneous Online Social Systems with Dynamical Opinions. In 2024 6th International Conference on Control Systems, Mathematical Modeling, Automation and Energy Efficiency (SUMMA); IEEE: Piscataway, NJ, USA, 2024; pp. 133–138. [Google Scholar]
- Steinberg, L.; Monahan, K.C. Age differences in resistance to peer influence. Dev. Psychol. 2007, 43, 1531–1543. [Google Scholar] [CrossRef] [PubMed]
- Rosenfeld, D.L.; Tomiyama, A.J. Gender differences in meat consumption and openness to vegetarianism. Appetite 2021, 166, 105475. [Google Scholar] [CrossRef]
- Li, G.J.; Porter, M.A. Bounded-confidence model of opinion dynamics with heterogeneous node-activity levels. Phys. Rev. Res. 2023, 5, 023179. [Google Scholar] [CrossRef]
- Zimmaro, F.; Contucci, P.; Kertész, J. Voter-like dynamics with conflicting preferences on modular networks. Entropy 2023, 25, 838. [Google Scholar] [CrossRef]
- Krueger, T.; Szwabiński, J.; Weron, T. Conformity, anticonformity and polarization of opinions: Insights from a mathematical model of opinion dynamics. Entropy 2017, 19, 371. [Google Scholar] [CrossRef]
- Carpentras, D.; Maher, P.J.; O’Reilly, C.; Quayle, M. Deriving an opinion dynamics model from experimental data. J. Artif. Soc. Soc. Simul. 2022, 25, 4. [Google Scholar] [CrossRef]
- Soares, F.B.; Recuero, R.; Zago, G. Asymmetric polarization on Twitter and the 2018 Brazilian presidential elections. In 10th International Conference on Social Media and Society; Association for Computing Machinery: New York, NY, USA, 2019; pp. 67–76. [Google Scholar]
- Hegselmann, R. Opinion dynamics and bounded confidence: Models, analysis and simulation. J. Artif. Soc. Soc. Simul. 2015, 5, 2. [Google Scholar]
- Lee, C.; Wilkinson, D.J. A review of stochastic block models and extensions for graph clustering. Appl. Netw. Sci. 2019, 4, 1–50. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G. A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. Ser. A Contain. Pap. A Math. Phys. Character 1927, 115, 700–721. [Google Scholar] [CrossRef]
- Kendall, D.G. Deterministic and stochastic epidemics in closed populations. In Third Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1956; Volume 4, pp. 149–165. [Google Scholar]
- Shiller, R.J. Narrative economics: How stories go viral and drive major economic events. Q. J. Austrian Econ. 2020, 22, 620–627. [Google Scholar] [CrossRef]
- Balderrama, R.; Prieto, M.I.; de la Vega, C.S.; Vazquez, F. Optimal control for an SIR model with limited hospitalised patients. Math. Biosci. 2024, 378, 109317. [Google Scholar] [CrossRef]
- Sha, H.; Zhu, L. Dynamic analysis of pattern and optimal control research of rumor propagation model on different networks. Inf. Process. Manag. 2025, 62, 104016. [Google Scholar] [CrossRef]
- Lee, E.B.; Markus, L. Foundations of Optimal Control Theory; Wiley: New York, NY, USA, 1967. [Google Scholar]
- Vasil’Ev, F. Numerical Methods for Solving Extremal Problems; Nauka: Moscow, Russia, 1988; 552p. [Google Scholar]
- Prüss, J.W.; Schnaubelt, R.; Zacher, R. Mathematische Modelle in der Biologie: Deterministische Homogene Systeme; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Lenhart, S.; Workman, J.T. Optimal Control Applied to Biological Models; Chapman and Hall/CRC: Boca Raton, FL, USA, 2007. [Google Scholar]
- Franzen, A.; Mader, S. The power of social influence: A replication and extension of the Asch experiment. PLoS ONE 2023, 18, e0294325. [Google Scholar] [CrossRef] [PubMed]
- Gezha, V.N.; Kozitsin, I.V. The effects of individuals’ opinion and non-opinion characteristics on the Organization of Influence Networks in the online domain. Computers 2023, 12, 116. [Google Scholar] [CrossRef]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a feather: Homophily in social networks. Annu. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Chuang, Y.S.; Goyal, A.; Harlalka, N.; Suresh, S.; Hawkins, R.; Yang, S.; Shah, D.; Hu, J.; Rogers, T.T. Simulating opinion dynamics with networks of llm-based agents. arXiv 2023, arXiv:2311.09618. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.