1. Introduction
The technological progress in the field of spatial data management enables cities to better control the processing of spatial information. Geospatial applications enable people to access real-time maps to visualize spatial data, and this updated information can be used for decision-making. Spatial data, as widely collected and inexpensive geographical information systems on the internet, are frequently encountered in such diverse fields as real estate, finance, economics, geography, epidemiology, and environmetrics. The spatial autoregressive (SAR) model of Cliff and Ord [
1] has attracted a great deal of interest among the class of spatial models, and it has extensively been used to address spatial interaction effects among geographical units in cross-sectional or panel data. A number of early studies are summarized in Anselin [
2], Case [
3], Cressie [
4], LeSage [
5], and Kazar and Celik [
6], among others. These studies are mainly focused on the parametric SAR models, which are highly susceptible to model misspecification. However, the relationship between the covariates and the response variables are usually nonlinear effects in reality. Indeed, it has been proven in practice that many economic variables have highly nonlinear effects on response variables [
7]. Neglecting potential nonlinear relationships often leads to inconsistent parameter estimates in spatial models, and even misleading conclusions [
8]. Although fully nonparametric models possess the flexibility to capture underlying complex nonlinear effects, they may suffer from the “curse of dimensionality” [
9] with high dimensional covariates. Semiparametric SAR models are used as an alternative for processing spatial data to overcome the problems mentioned above. It not only offers greater flexibility than generalized linear models but also alleviates the “curse of dimensionality” inherent in nonparametric models.
Semiparametric models have garnered significant attention in econometrics and statistics due to their parametric interpretability combined with nonparametric flexibility. Among these, the partially linear varying coefficient (PLVC) model [
10] stands out as one of the most widely used. It provides a good tradeoff between the interpretation of a partially linear model and the adaptability of the varying coefficient model. In spatial data analysis, the partially linear varying coefficient spatial (PLVCS) model has been widely applied, improving the capacity of spatial analysis by exploring regression relationships. To approximate the varying coefficient functions in the PLVCS model, many authors have developed various methods, including the local smoothing method [
11], basis expansion technique [
12], Bayesian approach [
13], profile quasi-maximum likelihood estimation method [
14], etc. While much of the existing literature on PLVC models focuses on methodological developments and applications, rigorous theoretical analyses often assume data observed on grid points within a rectangular domain. To balance the interpretability and flexibility inherent in PLVC models while explicitly accounting for spatial dependence, we consider the PLVCSAR model.
It is well known that the basic spline [
15] approximation technique is a popular method for modeling nonlinearities in the semiparametric model [
7,
16]. Compared to the kernel estimate, the main advantage of the splines method is that its calculations are relatively simple and easily combined with classical spatial econometric estimates. However, it requires the user to choose the appropriate position and number of knots. If the number of knots is too large, the model may be seriously overfitted. Conversely, if the number of knots is too small, the splines may not fully reflect the nonlinearity of the modeling curve. Various approaches have been proposed to solve the problem mentioned above. A common approach could vary the number of knots to minimize some criteria, such as the form of information criteria including AIC and BIC. Moreover, Bayesian penalty splines [
17] offer an alternative approach through Bayesian shrinkage implemented via careful prior specification. In contrast, Bayesian free-knot splines ([
18,
19,
20], among others) offer a distinct advantage: by treating both the position and number of spline knots as random variables within the modeling framework, this approach achieves intrinsic spatial adaptivity. This approach enables the model to automatically determine optimal smoothing parameters and implement variable bandwidth selection, a critical capability for handling heterogeneous patterns in data [
19]. This adaptive capability constitutes the primary motivation for employing free-knot splines in our modeling framework, particularly when dealing with spatial or temporal processes exhibiting non-stationary characteristics.
The recent literature has increasingly focused on semiparametric SAR models. While quasi-likelihood estimation [
8,
21] remains prevalent, maximum likelihood-based approaches face computational challenges due to the need for repeated determinant calculations of large-dimensional matrices. Furthermore, these methods typically require homoscedastic error assumptions. Alternative estimators employing instrumental variables (IV) [
22], generalized method of moments (GMM) [
23], and Bayesian approach [
24] relax the homoscedasticity constraint but remain fundamentally limited to mean regression frameworks. Crucially, all existing approaches rely on the restrictive zero-mean error assumption, thereby failing to characterize potential heterogeneous covariate effects across response quantiles.
Quantile regression (QR), introduced by Koenker and Bassett [
25], offers significant advantages over traditional mean regression. It not only delivers robust estimations but also comprehensively delineates the fundamental relationship between covariates and the response variable throughout the entire conditional distribution. Crucially, QR captures heterogeneous covariate effects at different quantile levels of the response variable, thereby addressing a fundamental limitation of conventional approaches. For instance, Dai et al. [
26] considered the IV approach for the quantile regression of PLVCSAR models. As concerns the frequency method, the estimation strategy hinges on minimizing the sum of asymmetric absolute deviations. Particularly at the extreme quantile levels, not only is the estimation accuracy low, but it is also prone to instability in estimation. As a result, more and more scholars tend to use the Bayesian approach to estimate models. Pioneering work by Yu and Moyeed [
27] established a Bayesian QR paradigm utilizing an asymmetric Laplace error distribution as a working likelihood for inferential procedures, and sampling unknown quantities from its posterior distribution via the MCMC approach is feasible even under the most complex model specifications.
To sum up, Bayesian quantile regression (BQR) has emerged as a versatile framework, spanning diverse applications including longitudinal analysis [
28], risk measure [
29], variable selection [
30], empirical likelihood [
31], etc. In the progress of Bayesian spatial quantile regression methodology, Lee and Neocleous [
32] first proposed fixed effect model to process spatial counting data; King and Song [
33] then extended the framework to include random spatial effects. Related developments also include the spatial process multiple (or individual) quantile regression method proposed by Lum and Gelfand [
34] and the spatiotemporal trend joint (or simultaneous) quantile regression method established by Reich et al. [
35]. The former models each quantile independently, while the latter estimates all quantiles simultaneously. In the spatial context, Castillo et al. [
36] considered the multi-quantile regression of mixed effects autoregressive models, while Chen and Tokdar [
37] and Castillo et al. [
38] developed a joint quantile regression of spatial data. However, BQR, to the best of our knowledge, remains largely unexplored within semiparametric SAR models. Notably, Chen et al. [
39] proposed a Bayesian P-splines approach for the quantile regression of PLVCSAR models.
Building upon these collective results, we present a Bayesian free-knot splines method for the quantile regression of the PLVCSAR model to be applied to spatial dependent response. The contribution of this paper extends the traditional PLVCSAR models by allowing for quantile-specific effects and unknown heteroscedasticity. It can allow for varying degrees of spatial dependence in the response distributions at different quantiles. We develop an enhanced Bayesian approach that estimates unknown parameters and uses free-knot splines to approximate the nonparametric function. To enhance algorithmic convergence, we modify the movement step of the reversible-jump MCMC algorithm so that each iteration can relocate the positions of all knots instead of only one knot position. We develop a Bayesian sampling-based method that can be executed via the MCMC approach, and we design a Gibbs sampler to explore the joint posterior distributions. The computational tractability of MCMC methods in deriving posterior distributions through careful prior specification establishes Bayesian inference as a particularly attractive framework, even for complex modeling scenarios.
The remainder of this article is organized as follows.
Section 2 specifies the Bayesian quantile regression for the PLVCSAR model for spatial data, subsequently approximating the link function via B-splines to derive the likelihood function. To establish a Bayesian sampling-based analytical framework, we delineate the prior distributions and derive the full conditional posteriors of the latent variables and unknown parameters, and we describe the detailed sampling algorithms in
Section 3.
Section 4 reports Monte Carlo results for the finite sample performance of the BQR estimator, and for the comparisons with the QR and IVQR estimators at different quantile points.
Section 5 provides an empirical illustration, as well as the study results. Finally, we conclude the paper in
Section 6.
4. Monte Carlo Simulations
In this section, Monte Carlo simulations are used to assess the finite sample performance of the proposed model and estimation method. We assess the performance of the estimated varying-coefficient functions
using the mean absolute deviation error (MADE) and global mean absolute deviation error (GMADE), defined as
evaluated at
equidistant points
spanning
.
We conducted simulation studies using the date generated from the following model:
with covariates
where
with
for
, the scalar smoothing variable being
. The varying-coefficient functions
with
and
, the regression coefficients are
. The random error
with
being the standard normal CDF of
, ensuring
. By subtracting the
th quantile, we obtain a random error
for which the
th quantile is equal to zero. For comparison, we specify two types of matrices to study the impact of the spatial weight matrix
W on estimation performance, where
W is generated under two scenarios: the Rook weight matrix [
2] with
and the Case weight matrix [
3] with
, respectively. For each configuration, we consider spatial dependence parameters
at quantile levels
, capturing weak to strong spatial autocorrelation.
According to the aforementioned design, we conducted 1000 replications of each group of simulation results. We assigned hyperparameters
and apply a quadratic B-spline in our computation for
. The initial states of the Markov chain are derived from the respective prior distributions of unknown parameters. By adjusting the values of the tuning parameters,
and
for
are used such that the resultant acceptable rates of parameters can reach about 25%. We generated 6000 sampling values by running a Monte Carlo experiment, which removed the first 3000 values of each replication as a burn-in period. Based on the last 3000 sampling values, we computed the posterior mean (Mean), standard error (SE), and the 95% posterior credible intervals (95% CI) of the parameters across 1000 replications. Furthermore, we calculated the posterior standard deviation (SD) and compared it with the mean of the posterior SE. Following LeSage and Pace [
48], we employed scalar summary measures for the marginal effects, derived as
under the spatial specification in model (
21). Total effects comprised direct effects (mean of diagonal entries) and indirect effects (mean of column-wise or row-wise sums of off-diagonal entries, excluding diagonal entries).
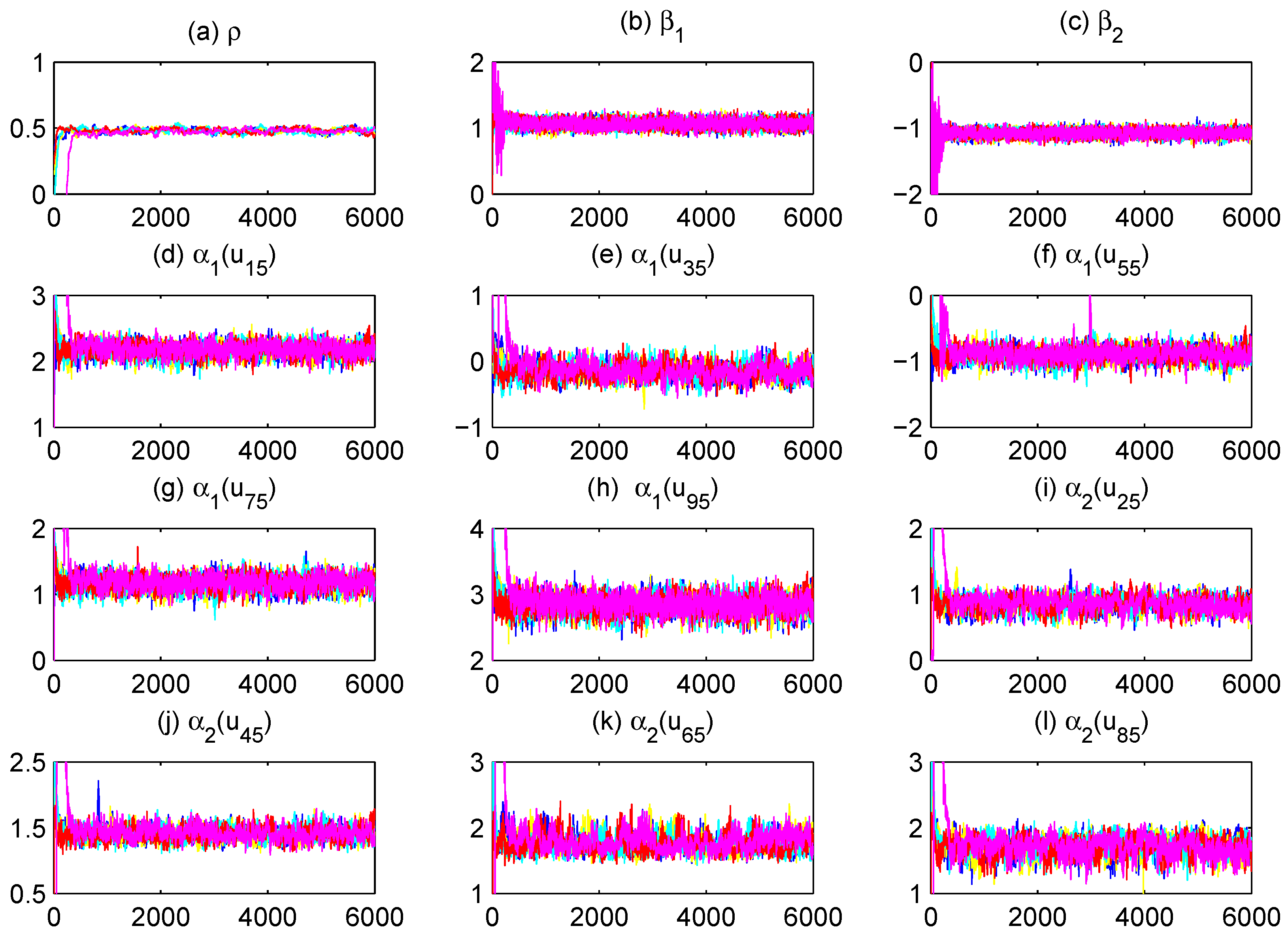
To assess MCMC convergence, we conducted five parallel Markov chains with distinct initial values through Monte Carlo experiments using an arbitrarily selected replication. The sampled traces of parts of unknown quantities, including model parameters and fitted varying-coefficient functions evaluated at grid points, are plotted in
Figure 1 (only a replication with
and
at
quantile is displayed). It is obvious that the five parallel MCMC chains are adequately mixed. We further calculated the “potential scale reduction factor”
for all model parameters and fitted varying-coefficient functions at 10 equidistant grid points based on the five parallel sequences.
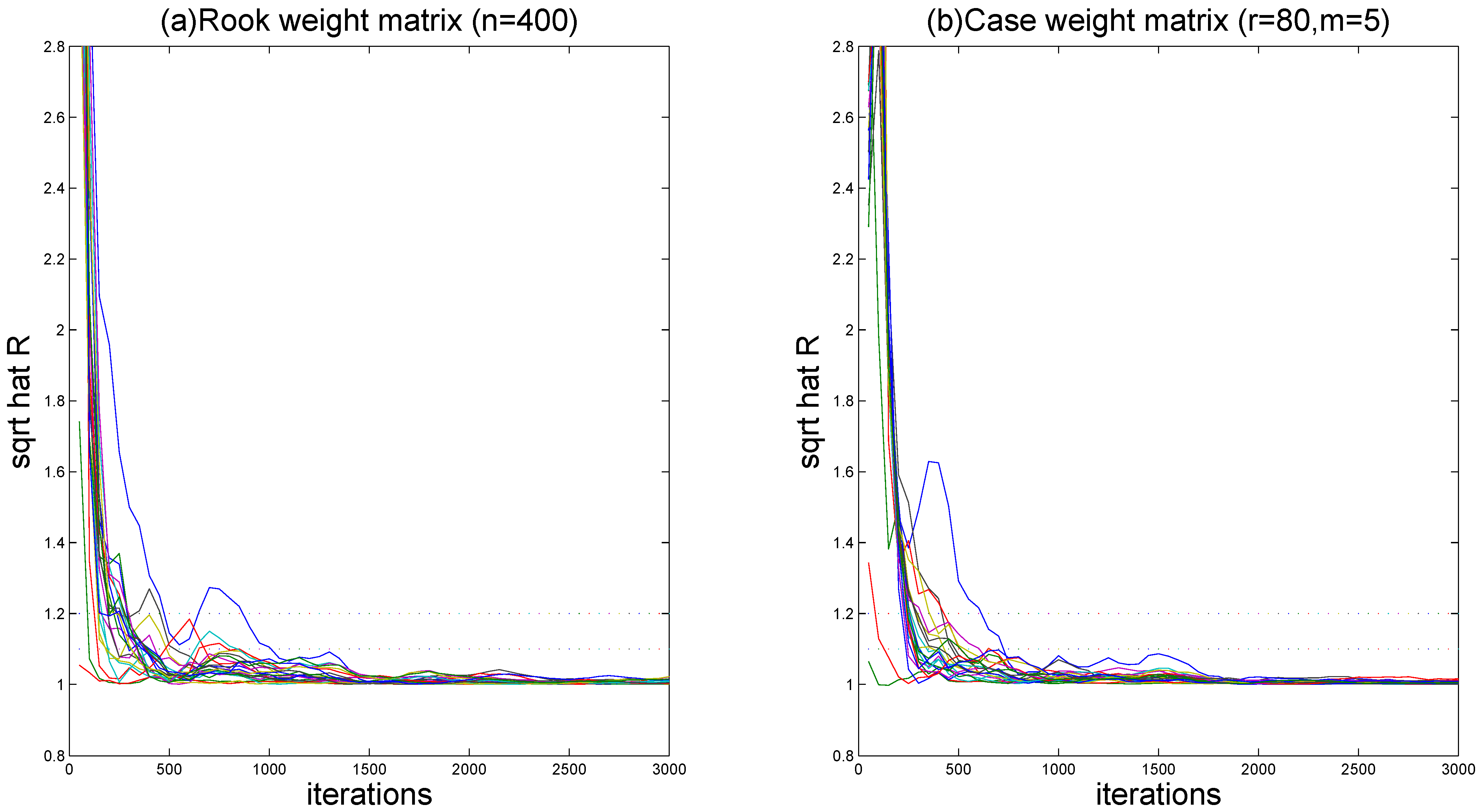
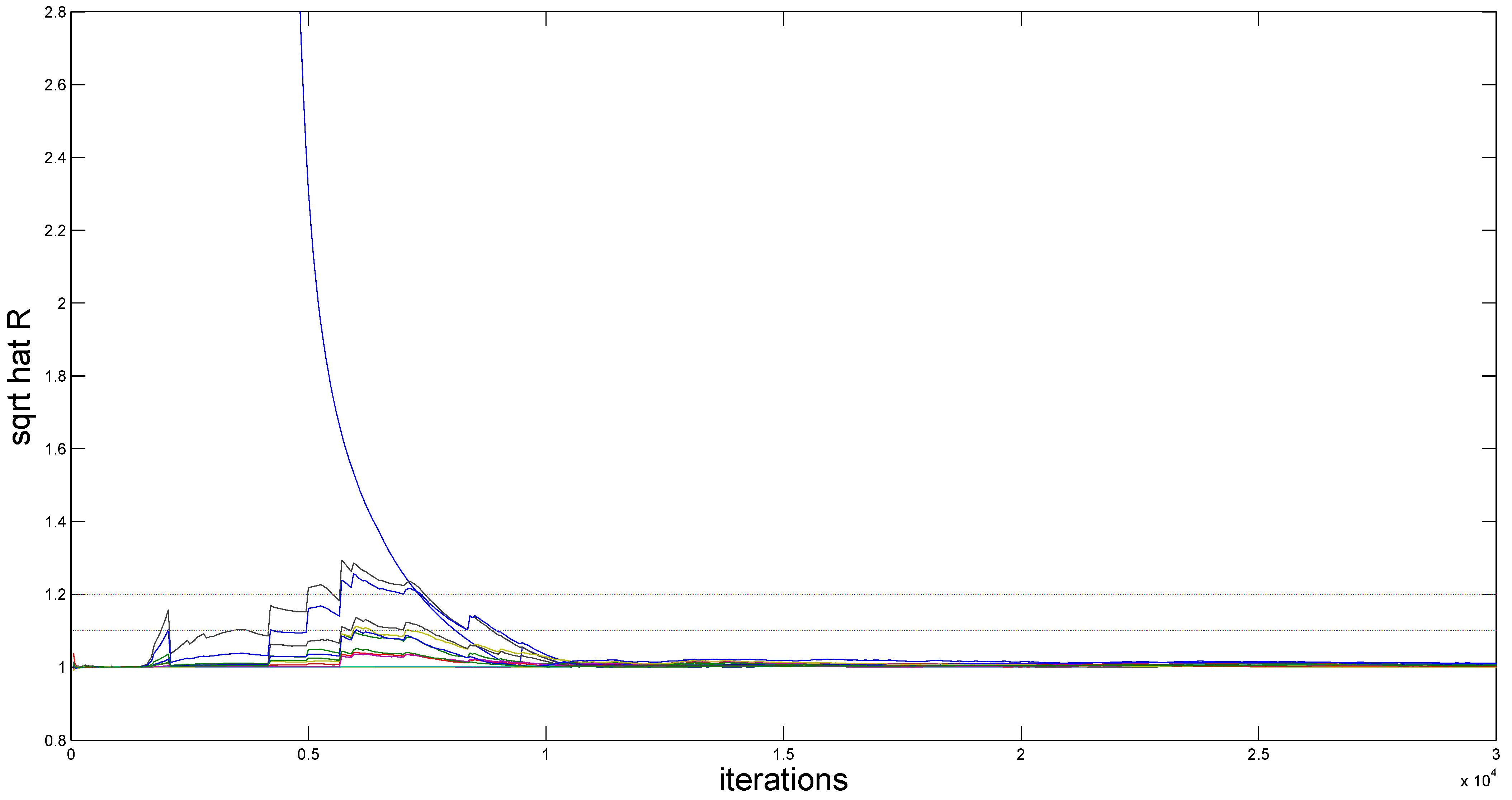
Figure 2 (for
) demonstrates the evolution of
values throughout iterations. It is easy to see that convergence is achieved within 2000 burn-in iterations, as all
estimates stabilize below the recommended threshold of 1.2, following the suggestion of Gelman and Rubin [
49].
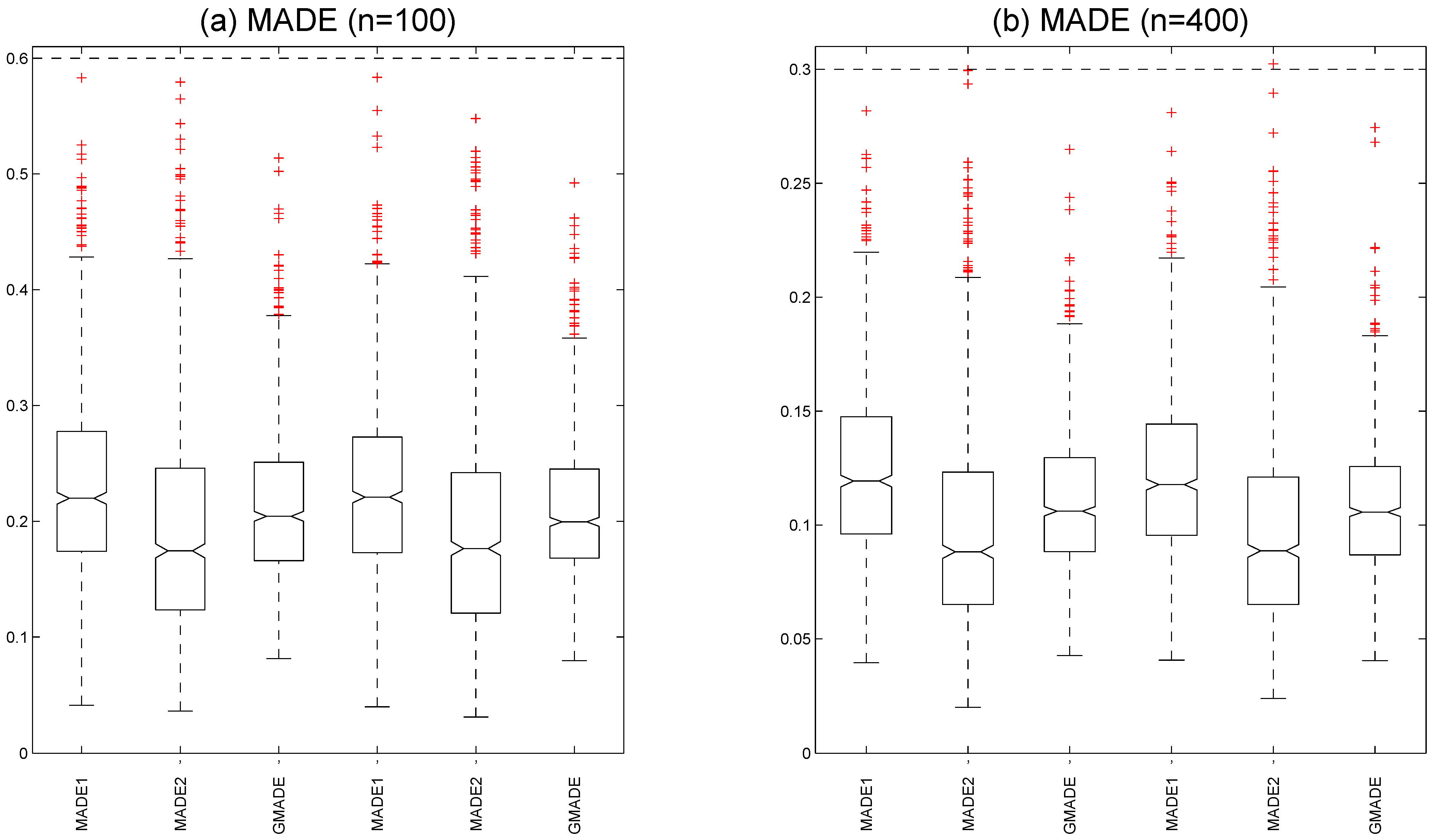
Figure 3a shows the boxplots of the MADE and GMADE values with a
at
quantile under sample size
. We calculated the medians
,
, and
under a Rook weight matrix and the medians
,
, and
under a Case weight matrix. The boxplots of the MADE and GMADE with a
at
quantile under sample size
are displayed
Figure 3b. We also computed the medians
,
, and
under a Rook weight matrix and the medians
,
, and
under a Case weight matrix. These results indicate that the MADE and GMADE values of the varying-coefficient functions decrease as the sample size increases, which suggests that the estimated performance of the unknown varying-coefficient functions improves as the sample size grows. It is evident that both the Case weight matrix and Rook weight matrix yield reasonable estimates in fitting varying-coefficient functions.
The simulation results of parameter estimation are reported in
Table 1 and
Table 2. The simulation results demonstrate both minimal bias in parameter estimates (mean estimates closely align with true values) and robust uncertainty quantification (SE approximate empirical SD), confirming a high estimation accuracy. Moreover, the covariates affecting the response are different at different quantile points of the response distribution. Estimation precision improves with a larger sample sizes under identical spatial weight matrices. By comparing the estimates of spatial coefficient
at the same quantile level with the same sample sizes, we observe that the estimation performances of
becomes more and more accurate along with the increase in
, and the Case weight matrices are slightly better than that with the Rook weight matrix. Furthermore,
Table 1 and
Table 2 indicate that all parameter estimators produce larger estimation errors for total effects under conditions of strong positive spatial dependence, regardless of comparable sample sizes. The results of repeating the above experiments with different starting values were similar, confirming the robustness of the proposed Gibbs sampler.
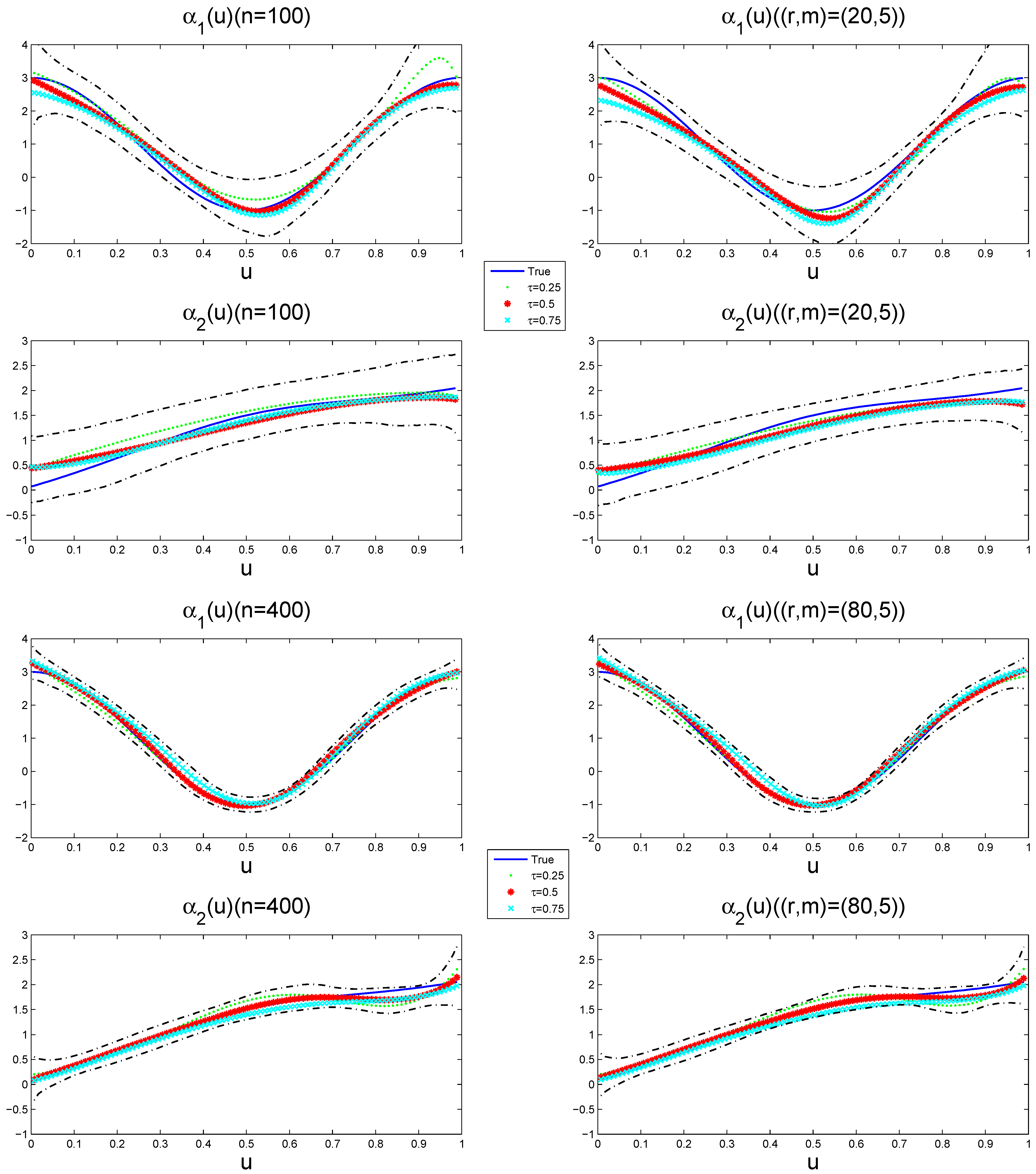
Figure 4 depicts the estimated varying-coefficient functions at different quantile points, together with its 95% pointwise posterior credible intervals from a typical sample under
when the sample size is
and
, respectively. The way to select a typical sample is to make its GMADE value equal to the median of the 1000 replicates. The results show that the estimation performance of the variable coefficient function improves with the increase in the sample size, while the effects exhibit quantile-specific heterogeneity across the response distribution.
The simulations were implemented in C++ on an Intel(R) Core(TM) i7-8750H processor (2.20 GHz PC). The mean CPU times per replication reached 5 s () and 25 s (). The implementation code is available from the authors upon request.
In addition, in order to compare the performance between our Bayesian quantile regression estimator (BQRE) and the instrumental variable quantile regression estimator (IVQRE) [
26], the following [
26] spatial weight matrix
was generated based on a mechanism that
for
, and then row normalization.
Example 1. The samples were generated as follows:where , , , and . The error term is specified as with Φ being the standard normal CDF of . Independent covariates are simulated such that , , and bivariate with and . For each configuration, 1000 simulation replications yield a bias and an RMSE (in parentheses) for parameter estimators, along with MADE [in brackets] for varying-coefficient function accuracy. Table 3 compares the QR, IVQR, and BQR methods under homoscedastic errors. Example 2. The samples were generated as follows:where , , , and . The error term follows , where Φ denotes the standard normal CDF of . and , are bivariates, where and are generated independently. Table 4 reports the comparison results of the QR, IVQR, and BQR estimation methods with a heteroscedastic error term. The results in
Table 3 and
Table 4 indicate that all estimators exhibit a decreasing bias, RMSE, and MADE with an increasing sample size. Simultaneously, the influence of explanatory variables on the response differs significantly across quantile levels of the conditional distribution. Moreover, the BQR estimator yields a marginally lower bias, RMSE, and MADE for both parameters and the varying-coefficient functions compared to the QR and IVQR estimators at the same quantile level under the same sample size. It is evident that BQR has superior relative performance, though QR and IVQR still produce statistically reasonable estimates. This comparative advantage persists despite QR/IVQR maintaining estimation feasibility, further reinforcing BQR’s methodological superiority in spatial quantile regression.
5. Application
To demonstrate our proposed method, we analyzed a real data set collected from the well-known Boston housing data. The data set was collected in the Boston Standard Meteropolitan Statistical Area of 1970. It contains about 506 different houses’ information from a variety of locations, and it is available from the spData package in R developed by Bivand et al. [
50]. Since our model and method investigate not only the influencing effects of covariates but also the spatial effects of response variable at different quantile points, it is interesting to examine the socioeconomic drivers of housing price variation.
In this application, we mainly considered the influencing factors of the median value of owner-occupied homes (MEDV) from the aspects of pupil–teacher ratio by town school district (PTRATIO), full value property tax rate (TAX), the percentage of lower status proportion (LSTAT), per capita crime rate by town (CRIM), and nitric oxides concentration parts per 10 million (NOX) in Boston. In order to perform fitting at different lower status percentages in our model, we took LSTAT as the index variable. Meanwhile, log-transformed MEDV, PTRATIO, and TAX mitigate scale disparities induced by domain magnitude variations. This theoretical foundation motivated the specification of the PLVCSAR model:
where the response variable
,
,
,
,
,
. We adopted the Sun et al. [
21] approach: constructing spatial weights via spherical Euclidean distances between housing coordinates (longitude, latitude). That is, the spatial weight
where
, and
is the Euclidean norm. Based on the above designs, we conducted 1000 replications of each experiment. We executed five independent runs of the proposed Gibbs sampler with different initial states and generated 10,000 sampled values after a burn-in of 20,000 iterations in each experiment. Part traces of parameters are plotted in
Figure 5 (only a replication at the median quantile (
) is displayed), showing satisfactory mixing across parallel sequences. Using the five parallel sequences, we computed the “potential scale reduction factor”
, which is plotted in
Figure 6 (the case of
quantile). These diagnostics confirm Markov chain convergence within the 20,000-iteration burn-in period.
Table 5 lists the estimated parameters, their standard errors, and the 95% posterior credible intervals at different quantile points. The results reveal significant spatial autocorrelation
(
) at
, confirming statistically significant positive spatial spillover effects in housing markets. More interestingly, we see that the spatial effect slightly increases with the increase in quantiles. That is, the spatial effect changes across the quantile points. On the other hand, we observe that the regression coefficients of two explanatory variables PTRATIO and TAX are
and
at a
quantile, respectively. It implies that PTRATIO and TAX have a positive and significant effect on the housing price. That is, the effect of PTRATIO increased with the increase in quantiles, while the effect of TAX decreased with the increase in quantiles. Therefore, we can observe the way that this quantile-dependent heterogeneity demonstrates differential mechanisms through which covariates influence housing markets along the price distribution.
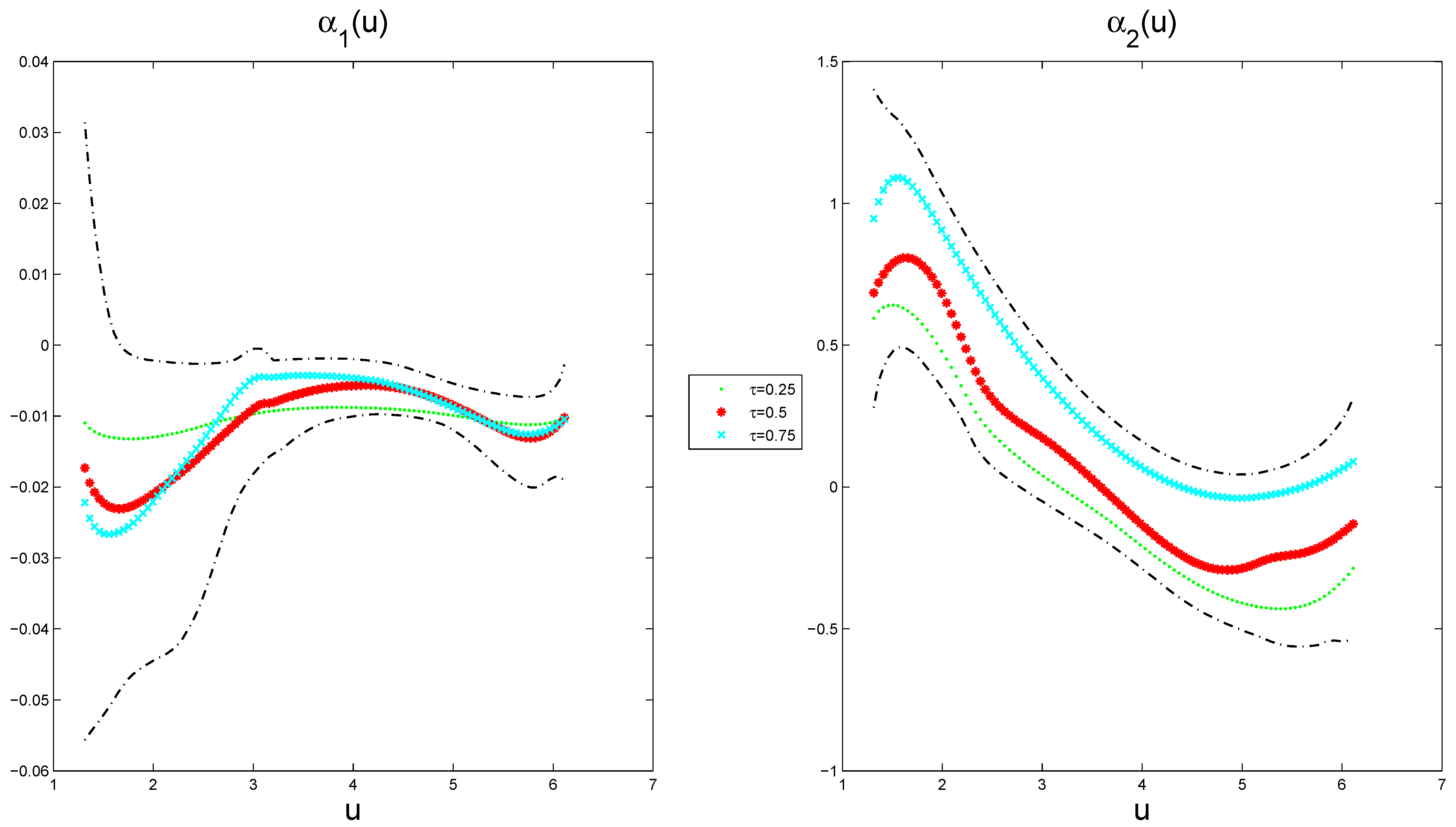
The estimated varying-coefficient functions at different quantile points, along with their corresponding 95% pointwise posterior credible intervals, are presented in
Figure 7, exhibiting nonlinear characteristics. The results indicate that
reaches a local maximum of
at around
at a
quantile, and
attains a local maximum of 0.8079 at around
and a local minimum of
at around
at a
quantile. This provides evidence that the analysis reveals significant nonlinear relationships: CRIM exhibits an inverted U-shaped effect, whereas NOX demonstrates a U-shaped pattern in housing prices. Furthermore, the varying-coefficient functions show distinct quantile-specific modulation across the price distribution, indicating differential response mechanisms at varying market valuation tiers.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}