1. Introduction
Image information entropy can be applied to the field of image processing. An image can be considered a two-dimensional array of pixels in image processing. Entropy can measure the complexity or the amount of information in an image, i.e., how much information is present in the image. For example, in a black-and-white image, if each pixel has only two possible values (black or white), the entropy value will be meager because the information in the image is elementary.
In recent years, with the development of computer technology, various intelligent applications are no longer limited to server-side deployment. The demand for deploying functions such as autonomous object detection, target tracking and positioning, and image captioning on embedded devices is increasing. However, embedded devices often need to consider power supply and consumption issues, making it difficult to directly deploy many large models. Therefore, it is necessary to find a method that is easy to deploy, requires less computing resources, and can maintain good performance.
Image captioning involves describing the contents of an image in sentences, bridging the gap between image processing and natural language processing. It is a critical component of intelligent applications. The encoder–decoder structure holds a dominant position in the field [
1,
2]. These methods consist of a cascade of convolutional layers that form an image encoder. The image is then passed through a pre-trained convolutional neural network to carry out the coding process, with the one-dimensional feature vector extracted at the network’s fully connected layer. A recurrent neural network then forms a decoder to fit the one-dimensional feature vector to the embedded annotated sentences.
In industrial applications, infrared sensors are preferred over visible light sensors, as they can capture images in all weather conditions and are resistant to meteorological interference. Infrared sensors measure physical characteristics and can capture images from any object emitting infrared light, provided it has a temperature higher than absolute zero. Unlike visible light sensors, they can be used in low-light conditions and at night, making them particularly useful in extreme weather conditions such as fog, rain, and snow [
3]. They have broad application prospects for night tasks. Therefore, studying image captioning based on infrared images is of significant importance, and has broad practical application value for the deployment of embedded devices. However, there are still many challenges to be addressed, which will be discussed in detail below.
Lacking precision relevant to the established object. In our preliminary experiments, we found that pre-trained models tend to describe the different content in an image, including the relationships and states between different objects. While the results generated in this way are diverse, it is difficult to obtain descriptive results that are highly relevant to the established object. For example, as can be seen from
Figure 1, when multiple objects are present, the annotation often describe the image from multiple perspectives, where the results of (3) are typically considered more complete and accurate for describing the behavior of the main object in the image. However, in actual tasks, there are always some objects that we focus on and some that can be ignored. Thus, different methods tend to generate varying results due to the uncertainty of global information. To achieve this effect, some researchers have utilized the semantic attention mechanism [
4] to align the feature map regions and embedded words. The attention modules tend to learn each word and corresponding image region; the low-level semantic features help the model to select the most essential and relevant image regions when generating a caption. However, for nouns, there are specific image areas that match them, but are inaccurate when directly corresponding verbs, prepositions, and adjectives to image areas. This may result in the generation of redundant information during feedback processing. Moreover, without the high-level information guidance, the model may prioritize visually appealing image regions that are semantically unrelated to the main subject of the image. Therefore, when considering the requirements of practical tasks, we usually want the model to focus on certain predefined objects. It is crucial to incorporate high-level information to guide the model in generating descriptions relevant to the predefined objects.
Lacking domain adaptiveness. The performance of a model depends heavily on the support of datasets. Using pre-trained models and fine-tuning their parameters through transfer learning is a widely adopted technique. However, this approach often encounters overfitting caused by sample imbalancing. For instance, in object detection tasks, we frequently use certain object types as targets for transfer learning. The transfer results on the dataset usually exhibit good accuracy. However, during testing, we often observe high false positive rates, i.e., similar features are incorrectly identified as the designated targets. Image captioning faces similar problems. When the images and annotations in the dataset lack diversity, the training tends to favor specific high-frequency vocabulary, resulting in very similar descriptive results and overfitting issues. Introducing more diverse and comprehensive datasets can alleviate this problem. However, most open-source datasets are focused on visible light images. The same object has different features in visible light images and infrared images. In
Figure 2, some visible light and infrared images of the same scene and targets are presented, including daytime and nighttime. From the figure, it can be seen that the objects in the visible light images have relatively different textures and colors, while the infrared images contain the contour features of the objects. The different feature distributions of visible light and infrared lead to domain gaps, which seriously affect their performance. On the other hand, most pre-trained models are trained on massive visible light datasets with many instance-level annotations [
5]. When implementing these pre-trained models, it is important to follow a potential rule that ensures the testing and training images are distributed in the same feature space. For instance, if we set the infrared images as the target domain and visible-light images as the source domain, pre-trained models cannot be implemented directly. Certainly, we can also increase the amount of data in the target domain by re-labeling, but this is a very time-consuming and labor-intensive task. Therefore, in order to avoid overfitting caused by sample imbalancing in practical applications, existing open-source datasets should be used to expand the feature space in the target domain and achieve the knowledge transfer. It is essential to enhance the diversity and richness of the target domain data as much as possible.
Based on the above discussion, we followed the encoder–decoder structure and proposed an infrared image caption method. We extracted image features and high-level semantic information based on YOLOv6 [
6], and treated them as the encoder. Then, we used LSTM to implement decoding. The primary contributions of this paper are as follows:
(1) Firstly, we enhanced the knowledge transfer process by leveraging the approach outlined in reference [
7]. We refined the selection process for pseudo-labels, which has resulted in a more robust detector capable of effectively adapting to changes in images.
(2) Secondly, we introduced the object-oriented attention module, which combines high-level semantic information and image features to weigh the proportion of each component in the multi-level features during word generation. This approach guides the model to generate descriptions that are specifically related to the predefined object.
(3) We provided an infrared dataset of streets in both towns and cities and conducted extensive experiments across multiple datasets to validate the effectiveness of our proposed method. The results from our simulations demonstrate the efficacy of our approach.
2. Related Work
Image captioning refers to the task of generating natural language descriptions for images, and it has attracted significant attention in recent years. In this section, we will discuss several commonly used methods, which can be classified into two categories: Neural Network-Based and Transformer-Based image captioning.
2.1. Neural Network Based
Encoder–decoder models based on convolutional neural networks and recurrent neural networks are the most widely used structures in image captioning. Much of the research in this field has focused on improving the quality of generated text [
8], enhancing model robustness, and addressing challenges such as multilingualism and multimodality. To overcome these issues, researchers have proposed numerous innovative methods, such as utilizing attention mechanisms [
9,
10] to focus on different regions of an image. There are two main types of attention mechanisms used in image captioning: soft attention and hard attention. Soft attention assigns weights to all image regions at each decoding step, with weight values ranging between 0 and 1. On the other hand, hard attention attends to a specific region of the image at each decoding step, using one-hot encoding. Hard attention is computationally less expensive and typically employs Monte Carlo sampling to estimate gradients and perform backpropagation during training. The attention mechanism transforms the global image features extracted by CNNs into regional features. Before generating each word of the caption, the attention mechanism computes the relevance of each image region to the word to be generated. Then, the features of the highly relevant regions are selected and passed to the decoder to guide the generation of the next word.
The introduction of the attention mechanism enables image captioning models to focus on specific image regions. However, mechanically assigning each vocabulary word to a corresponding region in the image may not be the most effective approach for guiding sentence generation. This is because some words, such as “of” and “the”, do not necessarily correspond to specific regions in the image, and forcing them to do so can lead to unnecessary computational waste. Therefore, some researchers have studied the topic-guided method. Yu et al. [
11] proposed an image captioning framework based on the topic-oriented method, which uses a multi-label classifier to select the main topics and establish a hierarchy in the generated sentences. Similarly, Zhu et al. [
12] proposed the topic-guided attention method, in which the most frequent topic words are extracted from candidate sentences and used as the basis for sentence generation. Chen et al. [
13] proposed the topic words embedding method to represent the high-level semantic information. Image captioning methods based on the neural network have achieved good results. Researchers can further improve the model performance by using attention mechanisms or topic-oriented mechanisms. However, in practical applications, there is a need for further research investigating how to effectively guide the model to generate accurate descriptions of given objects.
2.2. Transformer Based
The Transformer [
14] was originally applied to natural language processing and has been widely used in the field of computer vision in recent years, achieving good results, such as Transformer-based object detection [
15] and classification [
16]. Based on the encoder–decoder structure, Wang et al. [
17] introduced the CapFormer, a method used to model historical words in image captioning tasks. CapFormer uses cross-focus layers to interact with image features and improve the accuracy of the generated captions. Liu et al. [
18] proposed the RS image captioning, which leverages the transformer architecture to enhance image features using the bitemporal feature differences from two temporal images. As for the decoder, the multilayer aggregated transformer [
19] has been proposed to utilize the extracted feature. Cornia et al. [
20] proposed an image captioning model based on a Meshed-Memory Transformer. Both the encoder and decoder of the model use transformer. The encoder encodes image regions and their relationships, while the decoder utilizes low-level and high-level visual relationships to generate the output. Zhou et al. [
21] proposed the Unified VLP based on the shared multi-layer transformer for both encoding and decoding.
Transformer-based models have demonstrated increasingly powerful performance. From neural networks to Transformers, researchers have been working hard to find better ways to improve the correlation between image and text features. Recently, some researchers have also been studying a unified framework for cross-modal learning, integrating tasks such as image captioning, image classification, and language modeling, such as mPLUG [
22] and OFA [
23]. To address the problem of Transformers requiring the flattening of grid features before being fed into the Encoder, which destroys the relative position information in the 2D grid, and the issue of some words (such as “with”) having little relevance to the image, RSTNet [
24] proposed the Grid-Augmented module and Adaptive Attention module to improve the visual representation of relative position information and measure the contribution of visual information to generating captions. Currently, the methods for improving model structure are becoming increasingly mature. However, due to the large amount of self-attention, its computational resource requirements are higher than those of convolutional neural networks and recurrent neural networks. Additionally, the Transformer requires a large amount of training data to achieve certain results, and is highly dependent on training data [
25]. Furthermore, as the Transformer does not have the hidden state of recurrent neural networks, it is very sensitive to the positional information of the input sequence.
The above content highlights that despite significant progress in research, there are still limitations and challenges in practical deployment.
One such challenge is the semantic diversity in images and description statements. Images are rich in semantic information, including various objects, scenes, and actions. It is challenging to convey all of this information in a single description result, and different descriptions of an image from different perspectives can lead to varying results. While most research focuses on guiding models to adapt to complex sentence content in Ground Truth, without clear object guidance, models often combine unrelated objects or content, leading to imprecise results. Therefore, there is a need for further research to improve the model’s ability to produce highly relevant results to the object.
Another significant challenge is how to enhance the adaptive domain of the model. While a good performance assumes that training and testing datasets share the same origin, real-world applications often have different data sources, especially in scenarios in which unmanned devices use dual-light devices for all-weather detection. Thus, further research should explore knowledge transfer methods that utilize existing resources to improve the model’s performance.
4. Experiment
In this section, we provide a detailed description of the experimental methodology used in our study. We evaluated our proposed method on three different datasets: Pascal VOC2012 [
5], KAIST [
27], and Infrared City and Town. Following the conventional image caption annotation method, we annotated the KAIST [
27] and Infrared City and Town. The datasets are described below:
Pascal VOC2012 [
5]: The dataset consists of 20 object categories, and the training and validation sets contain a total of 11,530 images with 27,450 ROI-annotated objects. This dataset has been widely used for object recognition and detection tasks.
KAIST [
27]: The dataset is a multispectral pedestrian dataset that contains visible-light and infrared images. The dataset has a total of 103,128 dense annotations and 1182 distinct objects. We annotated the infrared images in this dataset, and for each image, we provided five sentences of manual description.
Infrared City and Town: This dataset was built by us, and contains three main object categories: airplane, car, and pedestrian. We captured the images using infrared equipment in the streets of both cities and towns, including various lighting and weather conditions such as sunny, cloudy, and rainy. We also annotated this dataset using five sentences per image.
Our experiments were divided into two parts:
(1) We validated the effectiveness of domain transfer method on the basis of two sets of experiments: Pascal VOC2012 [
5] to KAIST [
27] and Pascal VOC2012 [
5] to Infrared City and Town.
(2) Through combination with the detector, we validated the effectiveness of the infrared image caption method on KAIST [
27] and Infrared City and Town, respectively.
4.1. Experimental Details and Metrics
All models were implemented using Python 3.6 and PyTorch 1.9 and trained using an NVIDIA 2080Ti GPU.
For domain transfer evaluation, we used a pre-trained detector. The detector was optimized with SGD and included L2 regularization. The learning rate was set to 0.001. In addition, data augmentation techniques such as random crop, random flip, and random brightness adjustments were used. We evaluated the detector using Precision (
Pr), Recall (
Re), F1 score (
F1), and mean Average Precision (mAP), which are widely used in detection tasks. They can be calculated as follows:
where
TP,
FP and
FN represent the true positive, false positive and false negative, respectively.
For the infrared image caption experiments, we converted all annotations to lower case and removed function words, non-numeric, and non-alphabetic characters that did not provide information in the descriptions. We then counted the occurrences of the remaining words and used words that appeared more than three times to build a dictionary, which was converted to a one-hot vector. A total of 8532 words were used to train the image caption model. The learning rate was set to 0.001 and the batch size was set to 8. The input layer had a dimension of 2048 and the output layer had a dimension of 1024. The class features, region features, and word embedding vectors were set to 512 dimensions. The maximum length of a generated sentence was set to 15. We used publicly available metrics, including BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, and CIDEr. The BLEU-n score is widely used for machine translation, and can be calculated as follows:
where
refers to the reference annotation, and
refers to the candidate sentence.
and
are weights and precision of n-grams.
,
.
METEOR is based on word-to-word matching scores, and the calculation is as follows:
where
and
are caption precision and recall, respectively.
represents the number of matched words.
ch refers to chunk, a series of contiguous and identically ordered matches between the generated captions and the annotation.
CIDEr evaluates the consensus between a candidate sentence and annotation and calculates the frequency of n-grams in a candidate sentence based on term frequency–inverse document frequency (TF-IDF). The weighting processing can be formulated as follows:
where
refers to the reference annotation and
refers to the candidate’s sentence.
is the vector consisting of all n-grams of length
n.
4.2. Quantitative Results of the Domain Transfer Method
In our approach, we use detectors to extract image features and high-level semantic information. Therefore, in this section of the experiment, we began by validating the effectiveness of the domain transfer method. We selected widely used models such as FasterRCNN [
28], SSD [
29], YOLOv4 [
30], and YOLOv6 [
6] as comparison methods and chose the common categories “Car and pedestrian” in datasets as the transfer target. The backbone for FasterRCNN [
28] and SSD [
29] is Resnet50, and YOLOv4 [
30] and YOLOv6 [
6] both use the m-size.
First, we conducted the experiment of Pascal VOC2012 [
5] to KAIST [
27], where we used Pascal VOC2012 [
5] as the source domain and KAIST [
27] as the target domain to observe the performance changes.
Table 1 shows that YOLOv6m+DT (domain transfer) achieved precision, recall, F1, and mAP of 58.47%, 60.33%, 59.39%, and 62.47%, respectively. Compared to the method without domain transfer, precision, recall, F1, and mAP increased by 35.33%, 37.76%, 36.54%, and 38.90%, respectively. Similar improvements were observed in other detectors, such as YOLOv4m+DT and YOLOv4m, which increased mAP by 35.47%. The two-step detector also showed improvement, with FasterRCNN_Resnet50+DT achieving an mAP about 32.85% higher than FasterRCNN_Resnet50.
In another set of experiments, we employed Pascal VOC2012 [
5] on the Infrared City and Town dataset. We used Pascal VOC2012 [
5] as the source domain and Infrared City and Town as the target domain, and we observed similar patterns. As shown in
Table 2, we obtained precision, recall, F1, and mAP of 81.64%, 80.93%, 81.28%, and 83.16%, respectively. Compared to the method without domain transfer, precision, recall, F1, and mAP increased by 50.82%, 49.76%, 50.29%, and 48.19%, respectively. The SSD_Resnet50 had poorer performance, but also achieved an improvement of 47.11% of mAP. The detectors performed better in Infrared City and Town than in KAIST [
27]. After analyzing the results, we found that many objects in Infrared City and Town have a relatively transparent background compared to KAIST [
27]. Therefore, it is easier to distinguish the foreground from the background.
In both experiments, both single-step and two-step detectors improved when combined with the domain transfer method. The feature distribution of the detectors switched from visible light to infrared after domain transfer using transfer learning, making the detectors more adaptable to infrared object features. Based on the above discussion, the experimental results demonstrate the effectiveness of our domain transfer method. We achieved domain adaptation through the adversarial model and fine-tuned the detectors through pseudo-learning. Ultimately, the detector trained on visible-light datasets demonstrated good domain adaptability on infrared datasets.
4.3. Quantitative Evaluation Results for Infrared Image Caption on KAIST
In this section of the experiment, we compare our method with several existing image caption models. We divided them into four types: (1) Neural network-based methods, such as Vgg16+RNN, Vgg16+LSTM, Neural Baby Talk [
2], Google NIC [
1], and Noc [
8]; (2) Transformer-based methods, such as M2 Transformer [
20], Unified VLP [
21] and RSTNet [
24]; (3) Attention-based methods, such as soft attention [
9], semantic attention [
10], Yu et al. [
11], OGA [
12], C-LSTM [
24], and our proposed method; and (4) Multimodal-based methods, such as mPLUG [
22] and OFA [
23]. The structural composition of the model in each of the methods described above is presented in
Table 3. All methods were set up with consistent basic settings. All experiments were conducted offline using two NVIDIA 2080ti GPUs. The learning rate for the encoder was set to 0.001, and the learning rate for the decoder was set to 0.004. Both the encoder and decoder were optimized using the Adam method, and training was conducted for 150 epochs. The same training set was used for all experiments, and no data augmentation was performed in this part. The maximum length for generating words was set to 15.
Table 4 shows the corresponding infrared image captioning performances on KAIST [
27]. Our proposed method obtained BLUE-4, METEOR and CIDEr scores of 32.6%, 26.8%, 111.2%, respectively. These were the highest scores on both datasets for all metrics. Our method outperformed neural network-based methods such as Google NIC [
1] and Noc [
8] by 6.5% and 4.7% in BLUE-4. Moreover, compared to other attention-based methods such as soft attention [
9], semantic attention [
10], Yu et al. [
11], and OGA [
12], our object-oriented attention method performed better, utilizing local object regions and high-level information fully, and demonstrating more than 3.0%, 2.1%, 6.1%, and 6.7% improvements in METEOR, respectively. While our method achieved significant advantages compared to the Neural network- and Attention-based methods, it achieved relatively similar results to those achieved by the Transformer-based methods and the Multimodal-based methods. For instance, compared to RSTNet [
24] (ResNext152), our method achieved an improvement of 3.7% and 2.9% for BLEU-4 and METEOR, respectively. In addition, our method outperformed M2 Transformer [
20] and Unified VLP [
21] by 4.0% and 3.4% in BLUE-4, respectively. Additionally, compared to mPLUG [
22] and OFA [
23], our method scored 1.2% and 2.1% higher in METEOR. Although the performance of the transformer-based methods and the multimodal-based methods was very close to ours, our method has a simpler structure, requires less computational resources, has faster inference speed, and is more compatible with deployment on embedded platforms. Our proposed method also achieved a higher score than the others in terms of CIDEr, illustrating the similarity of the sentence to the ground truth. This suggests that our method can clearly state the objects in an image. These observations indicate that image captioning based on object regions’ semantics improves model performance significantly compared to describing global semantics. Our proposed method eliminates redundant information from other image areas and focuses more on the object.
4.4. Quantitative Evaluation Results for Infrared Image Caption on Infrared City and Town
Similar to the previous section, we continued to use the methods mentioned earlier for testing on the self-built dataset.
Table 5 shows the comparison experiment results on Infrared City and Town. The performance of each evaluation metric improved. Our proposed method obtained BLUE-4, METEOR and CIDEr scores of 42.2%, 36.9%, 127.3%, respectively. Compared to C-LSTM [
24], BLUE-1, BLEU-2, BLEU-3 and BLEU-4 increased by 2.4%, 3.6%, 2.8% and 4.6%, respectively. Additionally, compared to Google NIC [
1], our method outperformed it by 7.4%, 9.8%, 6.4% and 7.0% (BLUE-1, BLEU-2, BLEU-3, and BLEU-4, respectively). For the classical Neural Talk method [
2], our method outperformed the other models by almost 11.3% and 16.0% in terms of METEOR and CIDEr, respectively. The proposed object-oriented attention method also obtained a better performance than other attention methods, such as soft attention [
9] and semantic attention [
10]: by more than 7.3% and 5.1% for BLUE-4 and more than 7.8% and 6.2 for METEOR. As in the previous section, the results achieved by the methods based on the transformer and the multimodal were very close to those achieved using our method. For example, our method outperformed mPLUG [
22] and Unified VLP [
21] by 1.6% and 2.6% for BLUE-4, and 1.3% and 2.2% for METEOR, respectively. In addition, compared to RSTNet [
24] (ResNext101) and RSTNet [
24] (ResNext152), METEOR improved by 3.0% and 2.3%, and BLEU-4 improved by 3.6% and 2.8%, respectively. However, our method still maintained a good performance in terms of CIDEr. The adaptive weighting module can fully exploit the potential relevance of the class feature, region feature, and embedded word vector, and can improve the performance of image captioning by enabling interaction between each component of the visual region feature. The introduction of this module breaks down the isolation of object regions and high-level information in the image, revealing the semantic relevance of each image region by comprehensively considering the location and content relevance. Regions with high semantic relevance can assist each other in generating words, which effectively improves the model’s ability to understand the image content. Based on the above analysis, the object-oriented attention method can guide the allocation of weights and provide more useful information for the text generation model. It is easy to conclude that the image captioning method based on object-oriented attention can enhance the model’s ability to understand regional relationships and improve the description generation performance.
4.5. Quantitative Evaluation Results and Embedded Platform Porting
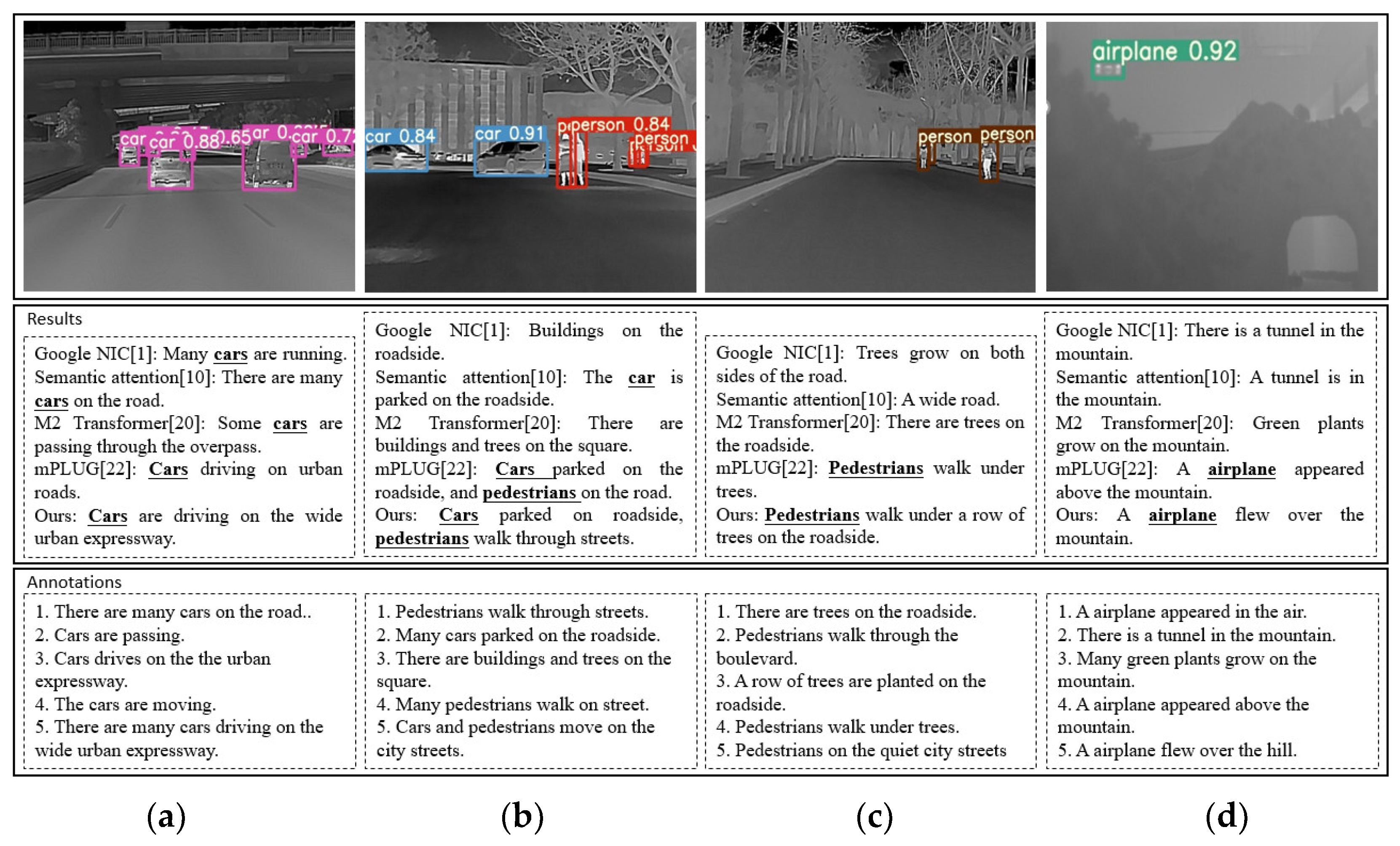
Figure 7 displays examples of image caption results with their corresponding annotations. We selected methods from each of the four types as the object of comparative simulation testing, and these are: Google NIC [
1], Semantic attention [
10], M2 Transformer [
20] and mPLUG [
22]. Our method generates descriptions that are relevant to the objects in the images. The annotations attempt to describe the image’s complex semantic content. For instance, in the second infrared image from left to right, the annotations include “pedestrians”, “cars”, “trees”, and “buildings”. The sentences describe these objects separately, but the crucial aspects of the foreground are the “pedestrians” and “cars”. The other elements can be considered as background. In our opinion, the description of an image’s content should prioritize the foreground. Our method can describe both objects based on the domain-transferred detector and object-oriented attention.
Moreover, for the last image from left to right, the annotations contain different topic sentences, such as “mountain”, “tunnel”, and “airplane”. Our method focuses on the object itself, accurately generating the most relevant description of the “airplane”. These examples demonstrate that our method can accurately describe the complex semantic information of an infrared image, and we have achieved similar performances on both examination datasets. Based on the above discussion, the qualitative results further support the effectiveness of the proposed method.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}