Abstract
Censored data are frequently found in diverse fields including environmental monitoring, medicine, economics and social sciences. Censoring occurs when observations are available only for a restricted range, e.g., due to a detection limit. Ignoring censoring produces biased estimates and unreliable statistical inference. The aim of this work is to contribute to the modelling of time series of counts under censoring using convolution closed infinitely divisible (CCID) models. The emphasis is on estimation and inference problems, using Bayesian approaches with Approximate Bayesian Computation (ABC) and Gibbs sampler with Data Augmentation (GDA) algorithms.
1. Introduction
Observations collected over time or space are usually correlated rather than independent. Time series are often observed with data irregularities such as missing values or detection limits. For instance, a monitoring device may have a technical detection limit and it records the limit value when the true value exceeds/precedes the detection limit. Such data is called censored (type 1) data and are common in environmental monitoring, physical sciences, business and economics. In particular, in the context of time series of counts, censored data arise in call centers. In fact, the demand measured by the number of calls is limited by the number of operators. When the number of calls is higher than the number of operators the data is right censored and the call center incurs under-staffing and poor service to the costumers.
The main consequence of neglecting censoring in the time series analysis is the loss of information that is reflected in biased and inconsistent estimators and altered serial correlation. These consequences can be summarized as problems in inference that lead to model misspecification, biased parameter estimation, and poor forecasts.
These problems have been solved in regression settings (i.i.d.) and partially solved for Gaussian time series (see for instance [1,2,3,4,5,6,7]). However, the problem of modelling time series under censoring in the context of time series of counts has, as yet, received little attention in the literature even though its relevance for inference. Count time series occur in many areas such as telecommunications, actuarial science, epidemiology, hydrology and environmental studies where the modelling of censored data may be invaluable in risk assessment.
In the context of time series of counts, Ref. [8] deal with correlated under-reported data through INAR(1)-hidden Markov chain models. A naïve method of parameter estimation was proposed, jointly with the maximum likelihood method based on a revised version of the forward algorithm. Additionally, Ref. [9] propose a random-censoring Poisson model for under-reported data, which accounts for the uncertainty about both the count and the data reporting processes.
Here, the problem of modelling count data under censoring is considered under a Bayesian perspective. In this paper, we consider a general class of convolution closed infinitely divisible (CCID) models as proposed by [10].
We investigate two natural approaches to analyse censored convolution closed infinitely divisible models of first order, CCID(1), using the Bayesian framework: the Approximate Bayesian Computation (ABC) methodology and the Gibbs sampler with Data Augmentation (GDA).
Since the CCID(1) under censoring presents an intractable likelihood, we resort to the Approximate Bayesian Computation methodology for estimating the model parameters. The presupposed model is simulated by using sample parameters taken from the prior distribution, then a distance between the simulated dataset and the observations is computed and when the simulated dataset is very close to the observed, the corresponding parameter samples are accepted as part of the posterior.
In addition, a widely used strategy to deal with censored data is to fill in censored data in order to create a data-augmented (complete) dataset. When the data-augmented posterior and the conditional pdf of the latent process are both available in a tractable form, the Gibbs sampler allows us to sample from the posterior distribution of the parameters of the complete dataset. This methodology is called Gibbs sampler with Data Augmentation (GDA). Here, a modified GDA, in which the data augmentation is achieved by multiple sampling of the latent variables from the truncated conditional distributions (GDA-MMS), is adopted.
The Poisson integer-valued autoregressive models of first-order, PoINAR(1), is one of the most popular classes of CCID models. It was proposed by [11,12] and extensively studied in the literature and applied to many real-world problems because of its ease of interpretation. To motivate the proposed approaches, we present in Figure 1 a synthetic dataset with observations generated from a PoINAR(1) process with parameters and ( blue line) and the respective right-censored dataset ( red line), at corresponding to 30% of censoring. If we disregard the censoring, the estimates for the parameters (assuming an PoINAR(1) model without censoring) present a strong bias. For instance, in the frequentist framework, the conditional maximum likelihood estimates are and while in the Bayesian framework, the Gibbs sampler gives and On the other hand, if we assume a PoINAR(1) model under censoring, the parameter estimates given by the proposed approaches described in this work are, respectively, and and and Therefore, it is important to consider the censoring in data in order to avoid some inference issues that lead to a poor time series analysis.
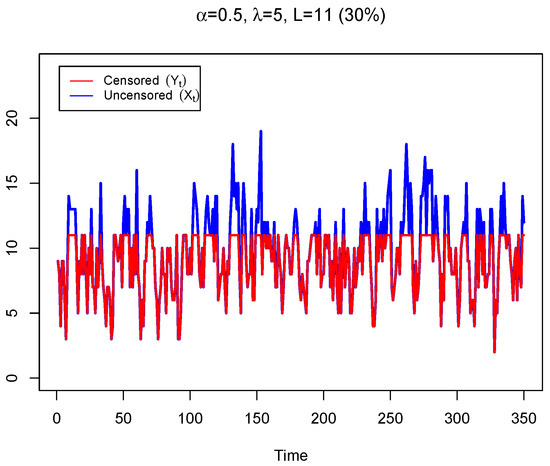
Figure 1.
Synthetic dataset with observations generated from a PoINAR(1) process with parameters and ( blue line) and the respective right censored dataset ( red line), at .
The remainder of this work is organized as follows. Section 2 presents a general class of convolution closed infinitely divisible (CCID) models under censoring. Two Bayesian approaches proposed to estimate the parameters of the censored CCID(1) model are described in Section 3. The proposed methodologies are illustrated and compared with synthetic data in Section 4. Finally, Section 5 concludes the paper.
2. A Model for Time Series of Counts under Censoring
This section introduces a class of models adequate for censored time series of counts based on the convolution closed infinitely divisible (CCID) models as proposed by [10].
2.1. Convolution Closed Models for Count Time Series
First we introduce some notation. Consider a random variable X with a distribution belonging to the convolution closed infinitely divisible (CCID) parametric family [10]. This means, in particular, that the distribution is closed under convolution, where * is the convolution operator. Let denote a random operator on X such that and the conditional distribution of given is As an example, consider a Poisson random variable, and a binomial thinning operation, Then is the Poisson distribution with parameter and is the Binomial distribution with parameters x and .
A stationary time series, with margin is called a convolution closed infinitely divisible process of order 1, CCID(1), if it satisfies the following equation
where the innovations are independently and identically distributed (i.i.d.) with distribution and are independent replications of the random operator [10]. Note that the above construction leads to time series with the same marginal distribution as that of the innovations.
Model (1) encompasses many AR(1) models proposed in the literature for integer valued time series. In particular, the Poisson INAR(1), PoINAR(1), the negative binomial INAR(1), NBINAR(1), and the generalised Poisson INAR(1), GPINAR(1) [13], summarized in Table 1 ( marginal distribution, random operation and its pmf , set of parameters ), have been widely used in the literature to model time series of counts, see inter alia [14,15], among others.

Table 1.
Methods for constructing integer valued AR(1) models with specified marginals and innovations denotes the beta function.
If one chooses as Poisson and the random operation as the usual binomial thinning operation (based on underlying Bernoulli random variables) then is Poisson and the Poisson integer-valued autoregressive model, PoINAR(1), as proposed by [11,12], is recovered with the familiar representation
Since model (1) is Markovian [10], given a time series the conditional likelihood is as follows
with
2.2. Modelling Censoring in CCID(1) Time Series
Given a model as in (1), a basic question is whether it properly describes all the observations of a given time series, or whether some observations have been affected by censoring. Here, we describe a model for dealing with censored observations in CCID(1) processes and study some of its properties.
Exogenous censoring can be modelled assuming (1) as a latent process and as the observed process, where L is a constant that is assumed to be known. For simplicity of exposition we assume exogenous right censoring but all the results are easily extended to left-censoring or interval censoring. Hence, for right exogenous censoring
Although a CCID(1) process is Markovian, the exogenous censoring implies that is not Markovian because depends on and Furthermore, is not CLAR (Conditionally Linear AutoRegressive). In fact,
The authors Zeger and Brookmeyer [1] established a procedure to obtain the likelihood of an observed time series under censoring, which becomes infeasible when the proportion of censoring is large. To overcome this issue, this work considers a Bayesian approach.
3. Bayesian Modelling
The Bayesian approach to the inference of an unknown parameter vector is based on the posterior distribution defined as
where is the likelihood function of the observed data and is the prior distribution of the model parameters.
When the likelihood is computationally prohibitive or even impossible to handle, but it is feasible to simulate samples from the model (bypass the likelihood evaluation), as is the case of censored CCID(1) processes, Approximate Bayesian Computation (ABC) algorithms are an alternative. This methodology accepts the parameter draws that produce a match between the observed and the simulated sample, depending on a set of summary statistics, a chosen distance and a selected tolerance. The accepted parameters are then used to estimate (an approximation of) the posterior distribution (conditioned on the summary statistics that afforded the match).
On the other hand, the idea of imputation arises naturally in the context of censored data. The Gibbs sampler with Data Augmentation (GDA) allows us to obtain an augmented dataset from the censored data by using a modified version of the Gibbs sampler, which samples not only the parameters of the model from its complete conditional but also the censored observations. The usual inference procedures may then be applied to the augmented data set.
3.1. Approximate Bayesian Computation
Approximate Bayesian Computation (ABC) is based on an acceptance–rejection algorithm. ABC is used to compute a draw from an approximation of the posterior distributions, based on simulated data obtained from the assumed model in situations where its likelihood function is intractable or numerically difficult to handle. Summary statistics from the synthetic data are compared with the corresponding statistics from the observed data and a parameter draw is retained when there is a match (in some sense) between the simulated sample and the observed time series observation.
Recently, Ref. [16] provided the asymptotic results pertaining to the ABC posterior, such as Bayesian consistency and asymptotic distribution of the posterior mean.
Let be the fixed (observed) data and the model from which the data is generated. The most basic approximate acceptance/rejection algorithm, based on the works of [17,18], is as follows:
- draw a value from the prior distribution,
- simulate a sample from the model
- accept if for some distance measure and some non-negative tolerance value where is a summary statistic and is a fixed value.
It is well known that, if we use a proper distance measure, then as tends to zero, the distribution of the accepted values tends to the posterior distribution of the parameter given the data. When the summary statistics are sufficient for the parameter, then the distribution of the accepted values tends to the true posterior as tends to zero, assuming a proper distance measure on the space of sufficient statistics. The latent structure of the thinning operator means that the reduction to a sufficient set of statistics of dimension smaller than the sample size is not feasible and, therefore, informative summary statistics are often used [19].
In this work, given the characteristics of the data under study to compare the observed data () and the synthetic (simulated ) data (), we consider two distinctive characteristics of CCID(1) time series which are affected by the censoring: (i) the empirical marginal distribution and (ii) lag 1 auto-correlation.
To measure the similarity between the empirical marginal distributions the Kullback-Leibler (Note that Kullback-Leibler distance measures the dissimilarity between two probability distributions.) distance is calculated as
where and denote the empirical marginal distribution of the observed time series and that of the simulated time series, respectively, estimated by the corresponding sample proportions, Whenever is zero, the contribution of the jth term is interpreted as zero because .
On the other hand, lag 1 sample autocorrelations, and are compared by their squared difference.
Additionally, we estimated the censoring rates, and which are also compared by their squared difference.
Thus, for each set of parameters, , a time series is generated from the model CCID(1) and right censored at L, yielding and the above statistics, and are computed. Combining these statistics in a metric leading to the choice of the parameters requires scaling. Thus, we propose the following metric
where and are the statistics obtained respectively from the observed and simulated data and and are the corresponding sample variances across the replications.
In summary, we propose Algorithm 1 for ABC approach based on [20]:
| Algorithm 1 ABC for censored CCID(1) |
| For |
| Sample from the prior distribution |
| Generate a time series with n observations, from the CCID(1) model |
| Right truncate at L to obtain the simulated data |
| Compute and |
| Compute , |
| Select the values corresponding to the 0.1% quantile of |
Implementation issues regarding the prior distributions and the number of draws N for the CensPoINAR(1) model are addressed in Section 3.3 and Section 4.1.
3.2. Gibbs Sampler with Data Augmentation
Gibbs sampling is a Markov chain Monte Carlo (MCMC) algorithm that can generate samples of the posterior distribution from their full conditional distributions [21]. When the data are under censoring or there are missing values, both cases leading to an incomplete data set, Ref. [22] proposed to combine the Gibbs sampler with data augmentation. This methodology implies imputing the censored (or missing) data, thus obtaining a complete dataset, and then dealing with the posterior of the complete data through the iterative Gibbs sampler. Therefore, the Gibbs sampler is modified in order to sample not only the parameters of the model from their complete conditionals but also the censored observations, obtaining an augmented (complete) dataset where
where is the truncated marginal distribution of the CCID(1) model with support in Furthermore, we consider a modified sampling procedure for the imputation, designated as Mean of Multiple Simulation (MMS), proposed by [23] consisting in sampling from multiple times, say and then imputing with the (nearest integer value) median of the m samples. This procedure is designated by GDA-MMS.
The augmented dataset can be considered as a CCID(1) time series and with a conditional likelihood function given by Equation (3). The posterior distribution of is given by
where is the prior distribution of the parameters. In CCID(1) models the complexity of requires resorting to Markov Chain Monte Carlo (MCMC) techniques for sampling from the full conditional distributions. The procedure is summarized in Algorithm 2 and detailed for the CensPoINAR(1) case in Section 3.3 and Section 4.1.
| Algorithm 2 GDA-MMS for censored CCID(1) |
| Initialize with , , , and |
| Set |
| For |
| Sample ( represents the vector with the ith element |
| removed.), |
| For |
| If |
| For |
| Sample |
| Else |
| Return and . |
3.3. The Particular Case of CensPoINAR(1)
This section details the ABC and GDA-MMS procedures to estimate a censored CCID(1) with the binomial thinning operation and Poisson marginal distribution, the censored Poisson INAR(1), CensPoINAR(1), model.
Consider the censored observations from a PoINAR(1) time series defined as
with and Then and given , the conditional likelihood function is given by
Under a Bayesian approach, we need a prior distribution for In the absence of prior information, we use weakly informative prior distributions for detailed below.
3.3.1. ABC for Censored PoINAR(1)
The ABC procedure described in Algorithm 1 is now implemented for the censored PoINAR(1). For the parameter , we choose a non-informative prior while for the positive parameter , we choose a non-informative The former allows us to explore all the support space for The choice of as a prior for allows us to explore a restricted support for the parameter that is in accordance with small counts.
3.3.2. GDA-MMS for Censored PoINAR(1)
Under the GDA-MMS approach, we first need to obtain a complete data set by imputing the censored observations, see (8). In this work, we draw replicates of the right truncated at L Poisson distribution with parameter and set ( represents the integer ceiling of c), if Figure 2 shows an augmented dataset ( black line) from the synthetic data presented in Figure 1.
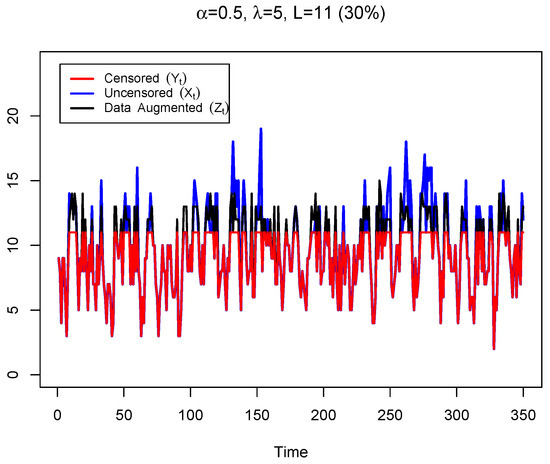
Figure 2.
Synthetic dataset with observations generated from a PoINAR(1) process with parameters and ( blue line), the respective right-censored dataset ( red line), at and an example of data augmentation ( black line).
As remarked above, given the complexity of the posterior distribution, Markov Chain Monte Carlo techniques are required for sampling from the full conditional distributions. Thus, the Adaptive Rejection Metropolis Sampling (ARMS) is used inside the Gibbs sampler [24]. Also in this approach, in the absence of prior information, we use weakly informative prior distributions for . Thus, for the parameter , we choose a non-informative beta prior, conjugate of the binomial distribution, with parameters while for the positive parameter , we choose a non-informative Gamma (shape, rate) prior, conjugate of the Poisson distribution, with parameters The full conditional of is given by
where
The full conditional distribution of is given by
where
The parameters and are computed as the posterior mean.
The GDA-MMS procedure to estimate a censored PoINAR(1) process is detailed in Algorithm 3.
| Algorithm 3 GDA-MMS for CensPoINAR(1) |
| Initialize with , , , and |
| Set |
| For |
| Using ARMS |
| Sample |
| Sample |
| For |
| If |
| For |
| Sample |
| Else |
| Return and . |
4. Illustration
This section illustrates the procedures proposed above to model CCID(1) right-censored time series in the particular case of Poisson distribution and binomial thinning operation.
4.1. Illustration with CensPoINAR(1)
In this section, the performance of the Bayesian approaches previously proposed is illustrated via synthetic data. Thus, realizations with observations of CensPoINAR(1) models were simulated, with parameters and considering for each case two levels of censorship, namely 30% and 5%.
For the ABC estimates, we run replications and choose the pairs corresponding to the 0.1% lower quantile of Equation (7), in total of 1000 values from which the estimates are computed as the mean value. Software R [25] was used to implement the ABC algorithm.
To implement GDA-MMS algorithm we consider the initial values given by the Conditional Least squares estimates of and [24]. The hyper-parameters for the prior distributions of and are the following and In this work, the function armspp was used from the package armspp [26] in R to sample from the full conditional distributions. Several experiments were carried out to analyse the size that the chain should have in order to be stable and, thus, the number of Gibbs sampler iterations used in this work is N = 15,000. Among these, we ignored the first 5000 simulations as burn-in time and, to reduce autocorrelation between MCMC observations, we considered only simulations from every 30 iterations. Therefore, we use a simulated sample with size 323 to obtain the Bayesian estimates. A convergence analysis with the usual diagnostic tests was performed with the package coda [27] in R [25].
Table 2 and Table 3 summarize ABC and GDA-MMS results for the several scenarios described above: point estimates, and obtained as sample means, the corresponding bias, standard deviation and the coefficient of variation. The results indicate that the bias tends to decrease for large sample sizes and small censoring rates. The results also indicate that overall ABC presents estimates with smaller bias but larger variability when compared with GDA-MMS.
Table 2.
ABC and GDA-MMS results for parameter (sample mean, and the corresponding bias, standard deviation and coefficient of variation) for synthetic data generated from CensPoINAR(1) models.
Table 3.
ABC and GDA-MMS results for the parameter (sample mean, and the corresponding bias, standard deviation and coefficient of variation) for synthetic data generated from CensPoINAR(1) models.
Additionally, Figure 3 and Figure 4 represent the corresponding posterior densities. The plots show unimodal and approximately symmetric distributions, with a dispersion that clearly decreases with increasing sample size and smaller censoring rate. The posterior densities indicate that the ABC approach produces posteriors that are flatter but with modes very close to the true value, while the corresponding GDA-MMS approach, despite producing posteriors which are more concentrated also evidence higher bias. However, the behaviour of GDA-MMS estimates varies with the parameters and even the sample sizes. These results are representative of the properties of GDA-MMS estimates across a large number of experiments, not reported here for conciseness.
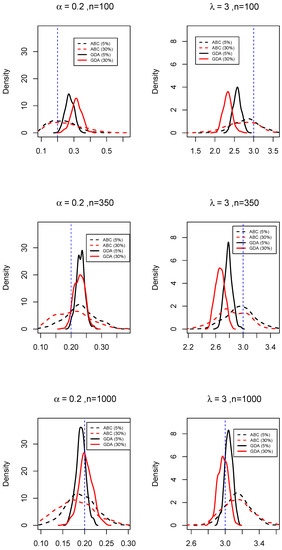
Figure 3.
ABC and GDA-MMS posterior densities of the parameters for a realization of 100, 350 and 1000 observations of a CensPoINAR(1) model with , considering two levels of censoring. Note that the scale of x-axis of the six plots are different.
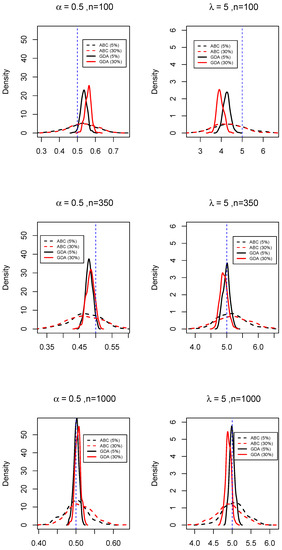
Figure 4.
ABC and GDA-MMS posterior densities of the parameters for a realization of 100, 350 and 1000 observations of a CensPoINAR(1) model with , considering two levels of censoring. Note that the scale of x-axis of the six plots are different.
4.2. Simulation Study for GDA-MMS
This section presents the results of a simulation study designed to further analyse the sample properties of GDA-MMS, in particular the bias of the resulting Bayesian estimates.
For that purpose, realizations with sample sizes and of CensPoINAR(1) models with parameters and are generated, considering two levels of censorship, namely 30% and 5%. To analyse the performance of the procedure, the sample posterior mean, standard deviation and mean squared error were calculated over 50 repetitions.
Boxplots of the sample bias for the 50 repetitions of GDA-MMS methodology are presented in Figure 5 and Figure 6. The bias increases with the rate of censoring and the variability decreases with the sample size. Furthermore, in general, the estimates for presents positive sample mean biases, indicating that is overestimated, whilst the estimates for shows negative sample biases, indicating underestimation for Both bias and dispersion seem larger for
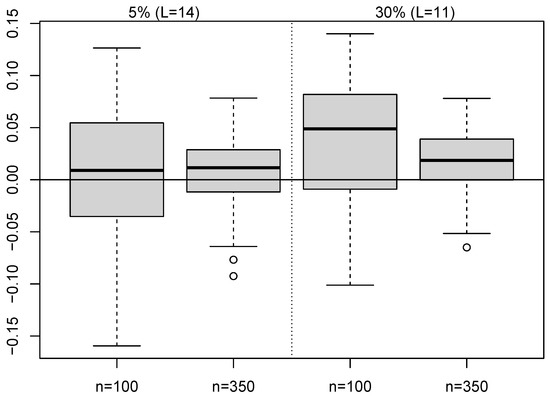
Figure 5.
Boxplots of bias for GDA-MMS estimates of when .
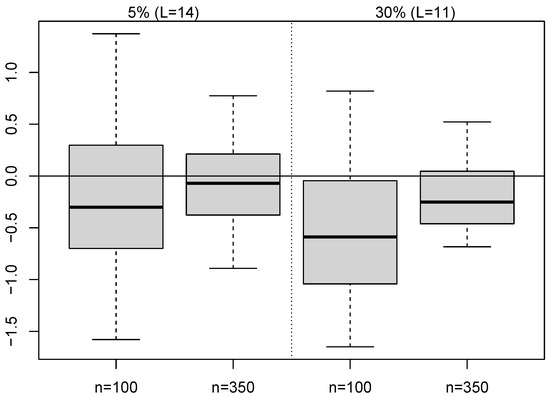
Figure 6.
Boxplots of bias for GDA-MMS estimates of when .
Table 4 and Table 5 present the sample posterior measures for and respectively. We can see improvement of the estimation methods performance when the sample size increases. Additionally, the higher the censoring percentage, the worse the behavior of the proposed methods.
Table 4.
Sample posterior mean, standard errors (in brackets) and root mean square error for GDA-MMS estimates of .
Table 5.
Sample posterior mean, standard errors (in brackets) and root mean square error for GDA-MMS estimates of .
5. Final Comments
This work approaches the problem of estimating CCID(1) models for time series of counts under censoring from a Bayesian perspective. Two algorithms are proposed: one is based on ABC methodology and the second a Gibbs Data Augmentation modified with multiple sampling. Experiments with synthetic data allow us to conclude that both approaches lead to estimates that present less bias than those obtained neglecting the censoring. Moreover, the GDA-MMS approach allows us to obtain a complete data set, making it a valuable method in other situations such as missing data.
In this study, we focus on the most popular CCID(1) model, the Poisson INAR(1). However, if the data under study present over- or under-dispersion, other CCID(1) models with appropriate distributions for the innovations, such as Generalised Poisson or Negative Binomial, can easily be entertained. Furthermore, one can consider different models for time series of counts under censoring, based on INGARCH models, ([28,29] using a switching mechanism) if they are more suitable to the data set to be modeled. These issues are beyond the scope of this paper and are a topic for a future research project.
Author Contributions
The authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
The first and third authors were partially supported by The Center for Research and Development in Mathematics and Applications (CIDMA) through the Portuguese Foundation for Science and Technology (FCT—Fundação para a Ciência e a Tecnologia), reference UIDB/04106/2020. The second author is partially financed by National Funds through the Portuguese funding agency, FCT, within project UIDB/50014/2020.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zeger, S.; Brookmeyer, R. Regression Analysis with Censored Autocorrelated Data. J. Am. Stat. Assoc. 1986, 81, 722–729. [Google Scholar] [CrossRef]
- Hopke, P.K.; Liu, C.; Rubin, D.R. Multiple imputation for multivariate data with missing and below-threshold measurements: Time-series concentrations of pollutants in the arctic. Biometrics 2001, 57, 22–33. [Google Scholar] [CrossRef] [PubMed]
- Park, J.W.; Genton, M.G.; Ghosh, S.K. Censored time series analysis with autoregressive moving average models. Can. J. Stat. 2007, 35, 151–168. [Google Scholar] [CrossRef]
- Mohammad, N.M. Censored Time Series Analysis. Ph.D. Thesis, The University of Western Ontario, London, ON, Canada, 2014. [Google Scholar]
- Schumacher, F.L.; Lachos, V.H.; Dey, D.K. Censored regression models with autoregressive errors: A likelihood-based perspective. Can. J. Stat. 2017, 45, 375–392. [Google Scholar] [CrossRef]
- Wang, C.; Chan, K.S. Carx: An R Package to Estimate Censored Autoregressive Time Series with Exogenous Covariates. R J. 2017, 9, 213–231. [Google Scholar] [CrossRef]
- Wang, C.; Chan, K.S. Quasi-Likelihood Estimation of a Censored Autoregressive Model with Exogenous Variables. J. Am. Stat. Assoc. 2018, 113, 1135–1145. [Google Scholar] [CrossRef]
- Fernández-Fontelo, A.; Cabaña, A.; Puig, P.; Moriña, D. Under-reported data analysis with INAR-hidden Markov chains. Stat. Med. 2016, 35, 4875–4890. [Google Scholar] [CrossRef]
- De Oliveira, G.L.; Loschi, R.H.; Assunção, R.M. A random-censoring Poisson model for underreported data. Stat. Med. 2017, 36, 4873–4892. [Google Scholar] [CrossRef]
- Joe, H. Time series model with univariate margins in the convolution-closed infinitely divisible class. Appl. Probab. 1996, 33, 664–677. [Google Scholar] [CrossRef]
- Al-Osh, M.A.; Alzaid, A.A. First-order integer-valued autoregressive (INAR(1)) process. J. Time Ser. Anal. 1987, 8, 261–275. [Google Scholar] [CrossRef]
- McKenzie, E. Some ARMA models for dependent sequences of Poisson counts. Adv. Appl. Probab. 1988, 20, 822–835. [Google Scholar] [CrossRef]
- Alzaid, A.A.; Al-Osh, M.A. Some autoregressive moving average processes with generalized Poisson marginal distributions. Ann. Inst. Stat. Math. 1993, 45, 223–232. [Google Scholar] [CrossRef]
- Han, L.; McCabe, B. Testing for parameter constancy in non-Gaussian time series. J. Time Ser. Anal. 2013, 34, 17–29. [Google Scholar] [CrossRef]
- Jung, R.C.; Tremayne, A.R. Useful models for time series of counts or simply wrong ones? AStA Adv. Stat. Anal. 2011, 95, 59–91. [Google Scholar] [CrossRef]
- Frazier, D.T.; Martin, G.M.; Robert, C.P.; Rousseau, J. Asymptotic properties of approximate Bayesian computation. Biometrika 2018, 105, 593–607. [Google Scholar] [CrossRef]
- Plagnol, V.; Tavaré, S. Approximate Bayesian computation and MCMC. In Monte Carlo and Quasi-Monte Carlo Methods; Niederreiter, H., Ed.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 99–113. [Google Scholar]
- Wilkinson, R.D. Approximate Bayesian computation (ABC) gives exact results under the assumption of model error. Stat. Appl. Genet. Mol. Biol. 2013, 12, 129–141. [Google Scholar] [CrossRef]
- Frazier, D.T.; Maneesoonthorn, W.; Martin, G.M.; McCabe, B. Approximate Bayesian forecasting. Int. J. Forecast. 2019, 35, 521–539. [Google Scholar] [CrossRef]
- Biau, G.; Cérou, F.; Guyader, A. New Insights into Approximate Bayesian Computation. Ann. Henri Poincaré (B) Probab. Stat. 2015, 51, 376–403. [Google Scholar] [CrossRef]
- Gelfand, A.; Smith, A. Sampling-based approaches to calculating marginal densities. J. R. Stat. Soc. Ser. B 1990, 85, 398–409. [Google Scholar] [CrossRef]
- Chib, S. Bayes Inference in the Tobit Censored Regression Model. J. Econom. 1992, 51, 79–99. [Google Scholar] [CrossRef]
- Sousa, R.; Pereira, I.; Silva, M.E.; McCabe, B. Censored Regression with Serially Correlated Errors: A Bayesian approach. arXiv 2023, arXiv:2301.01852. [Google Scholar]
- Silva, I.; Silva, M.E.; Pereira, I.; Silva, N. Replicated INAR(1) Processes. Methodol. Comput. Appl. Probab. 2005, 7, 517–542. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 20 March 2023).
- Bertolacci, M. Armspp: Adaptive Rejection Metropolis Sampling (ARMS) via ‘Rcpp’. R Package Version 0.0.2. 2019. Available online: https://CRAN.R-project.org/package=armspp (accessed on 20 March 2023).
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence Diagnosis and Output Analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Chen, C.W.S.; Lee, S. Generalized Poisson autoregressive models for time series of counts. Comput. Stat. Data Anal. 2016, 99, 51–67. [Google Scholar] [CrossRef]
- Ferland, R.; Latour, A.; Oraichi, D. Integer-Valued GARCH Process. J. Time Ser. Anal. 2006, 27, 923–942. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).