
Discriminant Analysis under f-Divergence Measures

Abstract
:1. Introduction
1.1. Motivation
1.2. Related Literature
1.3. Contributions
2. Preliminaries
- Kullback–Leibler (KL) divergence for :We also denote the KL divergence from to by .
- Symmetric KL divergence for :
- Squared Hellinger distance for :
- Total variation distance for :
- -divergence for :We also denote the -divergence from to by .
3. Problem Formulation
4. Main Results for Zero-Mean Gaussian Models
4.1. Kullback Leibler Divergence
4.1.1. Motivation
4.1.2. Connection between and
4.2. Symmetric KL Divergence
4.2.1. Motivation
4.2.2. Connection between and
4.3. Squared Hellinger Distance
4.3.1. Motivation
4.3.2. Connection between and
4.4. Total Variation Distance
4.4.1. Motivation
4.4.2. Connection between and
4.5. -Divergence
4.5.1. Motivation
4.5.2. Connection between and
4.6. Main Results
- For maximizing , set and select the eigenvalues of as
- Row of matrix is the eigenvector ofΣassociated with the eigenvalue .
- For maximizing , set and select the eigenvalues of as
- Row of matrix is the eigenvector ofΣassociated with the eigenvalue .
| Algorithm 1: Optimal Permutation When |
|
5. Zero-Mean Gaussian Models–Simulations
5.1. KL Divergence
5.2. Symmetric KL Divergence
5.3. Squared Hellinger Distance
5.4. Total Variation Distance
5.5. -Divergence
6. General Gaussian Models
6.1. Optimizing via Gradient Ascent
6.2. Results and Discussion
6.2.1. Schemes for Linear Map
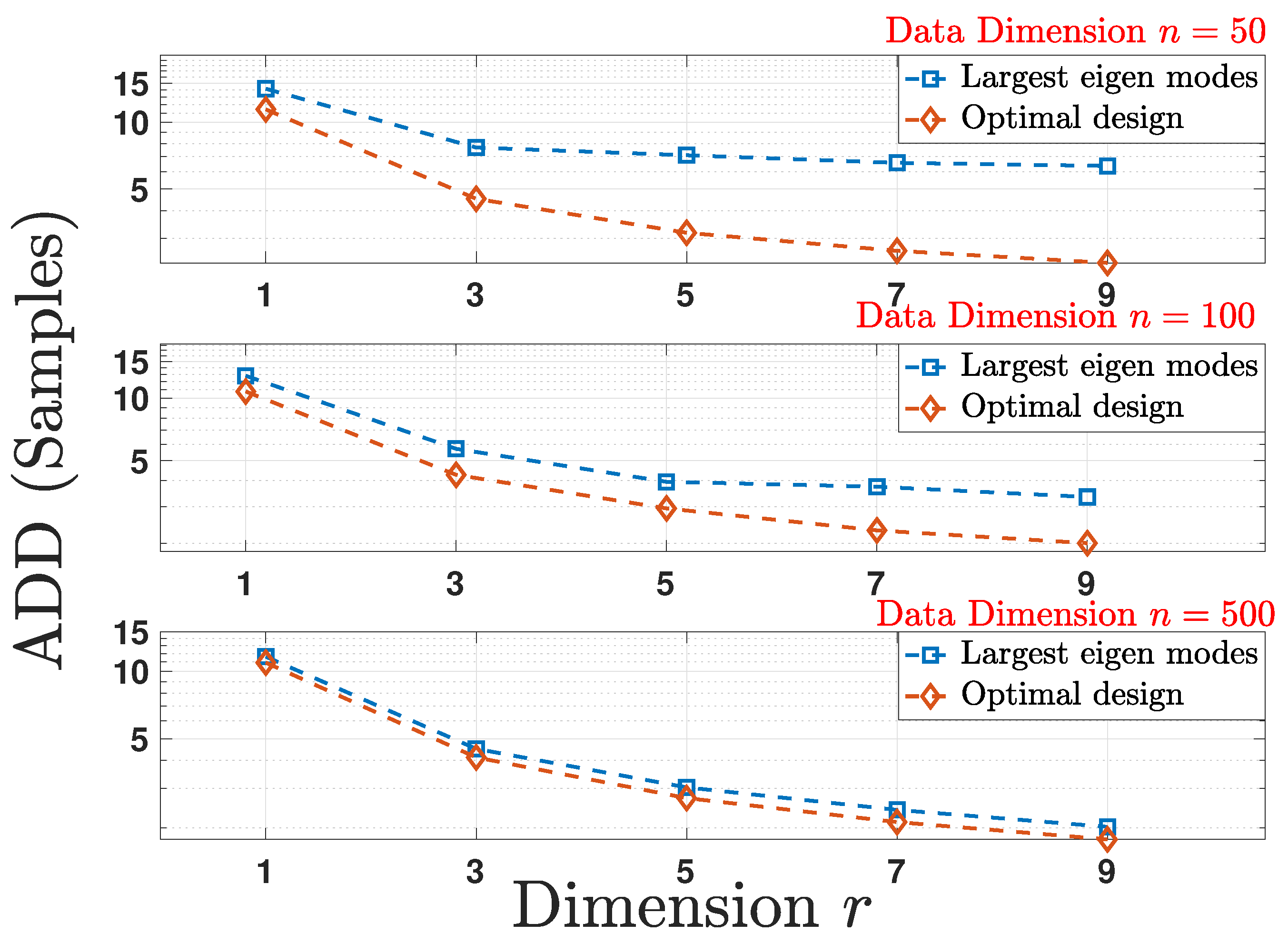
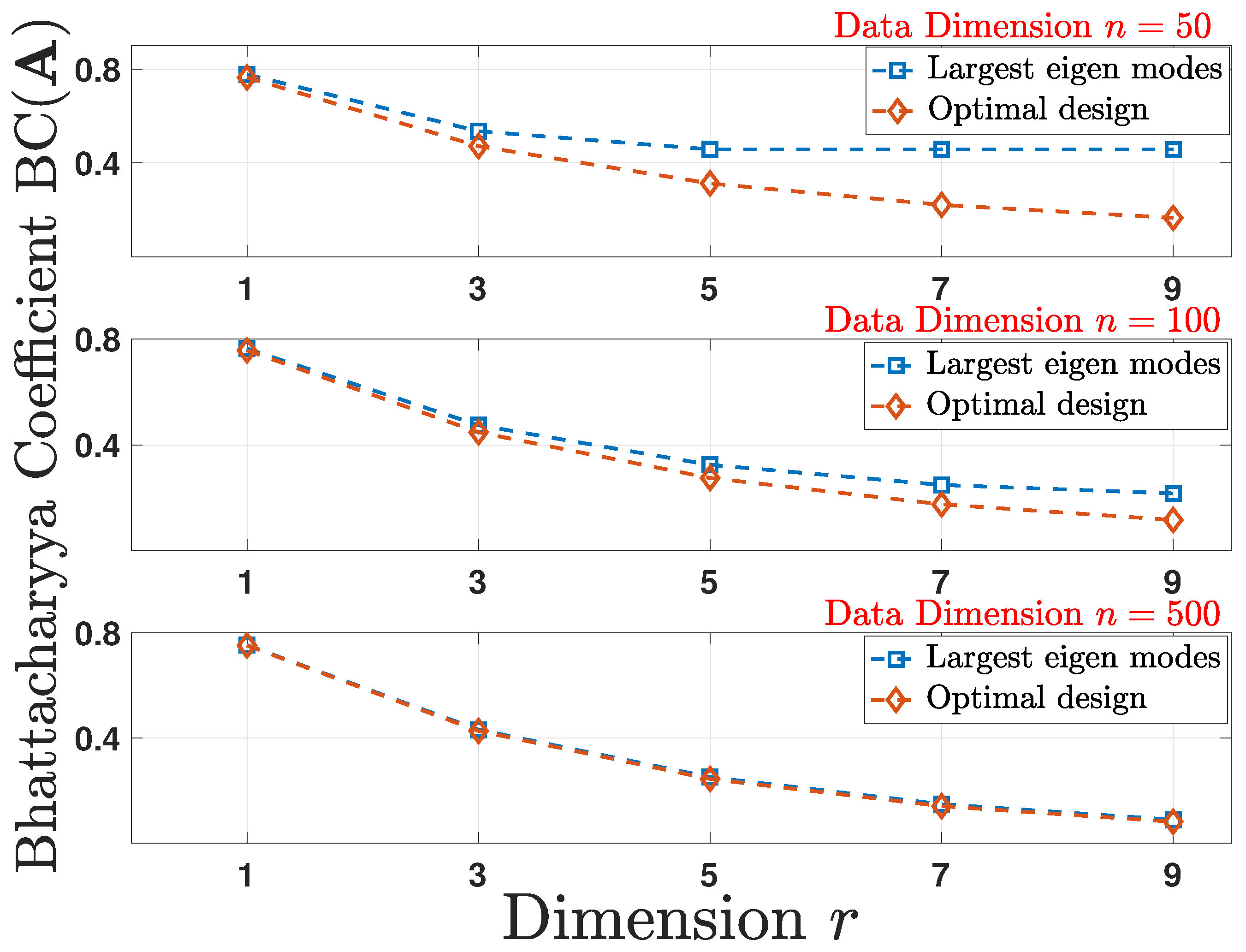
6.2.2. Performance Comparison
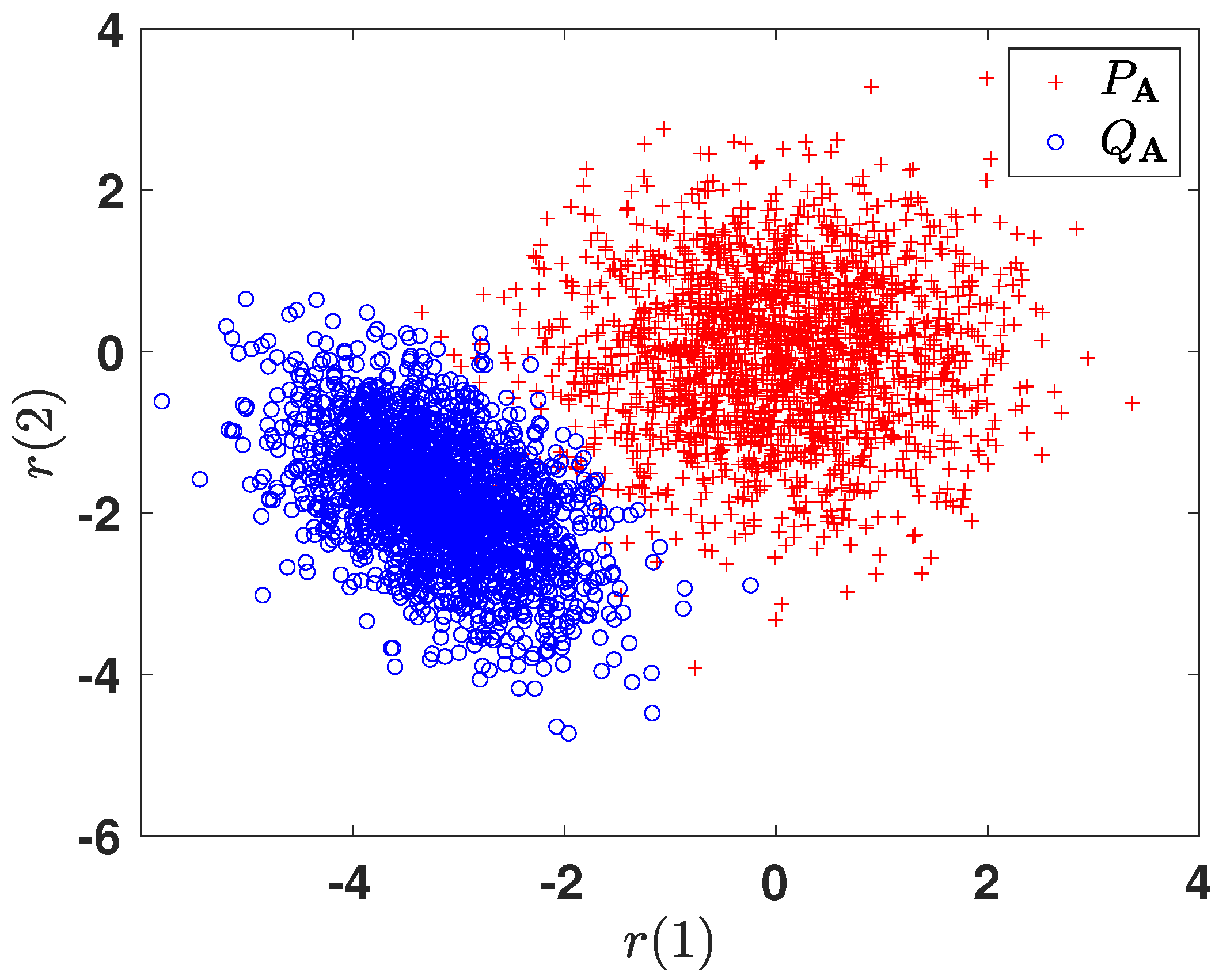
6.2.3. Subspace Representation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCA | Principal Component Analysis |
| MDS | Multidimensional Scaling |
| SDR | Sufficient Dimension Reduction |
| DA | Discriminant Analysis |
| KL | Kullback Leibler |
| TV | Total Variation |
| Average Detection Delay | |
| False Alarm Rate | |
| CuSum | Cumulative Sum |
| Bhattacharyya Coefficient | |
| LEM | Largest Eigen Modes |
| SEM | Smallest Eigen Modes |
| LDA | Linear Discriminant Analysis |
| QDA | Quadratic Discriminant Analysis |
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 3
Appendix C. Proof for Theorem 4
Appendix D. Gradient Expressions for f-Divergence Measures
Appendix E. Proof for Lagrange Multipliers
References
- Kunisky, D.; Wein, A.S.; Bandeira, A.S. Notes on computational hardness of hypothesis testing: Predictions using the low-degree likelihood ratio. arXiv 2019, arXiv:1907.11636. [Google Scholar]
- Gamarnik, D.; Jagannath, A.; Wein, A.S. Low-degree hardness of random optimization problems. arXiv 2020, arXiv:2004.12063. [Google Scholar]
- van der Maaten, L.; Postma, E.; van den Herik, J. Dimensionality reduction: A comparative review. J. Mach. Learn. Res. 2009, 10, 66–71. [Google Scholar]
- Lee, J.A.; Verleysen, M. Nonlinear Dimensionality Reduction; Springer Science: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- DeMers, D.; Cottrell, G.W. Non-linear dimensionality reduction. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 3–6 November 1993; pp. 580–587. [Google Scholar]
- Cunningham, J.P.; Ghahramani, Z. Linear dimensionality reduction: Survey, insights, and generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Torgerson, W.S. Multidimensional scaling: I. Theory and method. Psychometrika 1952, 17, 401–419. [Google Scholar] [CrossRef]
- Cox, T.F.; Cox, M.A. Multidimensional scaling. In Handbook of Data Visualization; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Borg, I.; Groenen, P.J. Modern Multidimensional Scaling: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Izenman, A.J. Linear discriminant analysis. Modern Multivariate Statistical Techniques; Springer: New York, NY, USA, 2013; pp. 237–280. [Google Scholar]
- Globerson, A.; Tishby, N. Sufficient dimensionality reduction. J. Mach. Learn. Res. 2003, 3, 1307–1331. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Rao, C.R. The utilization of multiple measurements in problems of biological classification. J. R. Stat. Soc. Ser. B 1948, 10, 159–203. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Suresh, B.; Ganapathiraju, A. Linear discriminant analysis- A brief tutorial. Inst. Signal Inf. Process. 1998, 18, 1–8. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Gelfand, I.M.; Kolmogorov, A.N.; Yaglom, A.M. On the general definition of the amount of information. Dokl. Akad. Nauk SSSR 1956, 11, 745–748. [Google Scholar]
- Csiszár, I. Eine Informationstheoretische Ungleichung und ihre Anwendung auf den Bewis der Ergodizität von Markhoffschen Ketten. Magy. Tudományos Akad. Mat. Kut. Intézetének Közleményei 1948, 8, 379–423. [Google Scholar]
- Ali, S.M.; Silvey, S.D. General Class of Coefficients of Divergence of One Distribution from Another. J. R. Stat. Soc. 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Morimoto, T. Markov Processes and the H-Theorem. J. Phys. Soc. Jpn. 1963, 18, 328–331. [Google Scholar] [CrossRef]
- Arimoto, S. Information-theoretical considerations on estimation problems. Inf. Control 1971, 19, 181–194. [Google Scholar] [CrossRef] [Green Version]
- Barron, A.R.; Gyorfi, L.; Meulen, E.C. Distribution estimation consistent in total variation and in two types of information divergence. IEEE Trans. Inf. Theory 1992, 38, 1437–1454. [Google Scholar] [CrossRef] [Green Version]
- Berlinet, A.; Vajda, I.; Meulen, E.C. About the asymptotic accuracy of Barron density estimates. IEEE Trans. Inf. Theory 1998, 44, 999–1009. [Google Scholar] [CrossRef]
- Gyorfi, L.; Morvai, G.; Vajda, I. Information-theoretic methods in testing the goodness of fit. In Proceedings of the IEEE International Symposium on Information Theory, Sorrento, Italy, 25–30 June 2000. [Google Scholar]
- Liese, F.; Vajda, I. On Divergences and Informations in Statistics and Information Theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Kailath, T. The Divergence and Bhattacharyya Distance Measures in Signal Selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Poor, H. Robust decision design using a distance criterion. IEEE Trans. Inf. Theory 1980, 26, 575–587. [Google Scholar] [CrossRef]
- Clarke, B.S.; Barron, A.R. Information-theoretic asymptotics of Bayes methods. IEEE Trans. Inf. Theory 1990, 36, 453–471. [Google Scholar] [CrossRef] [Green Version]
- Harremoes, P.; Vajda, I. On Pairs of f-divergences and their joint range. IEEE Trans. Inf. Theory 2011, 57, 3230–3235. [Google Scholar] [CrossRef]
- Sason, I.; Verdú, S. f-Divergence Inequalities. IEEE Trans. Inf. Theory 2016, 62, 5973–6006. [Google Scholar] [CrossRef]
- Sason, I. On f-divergence: Integral representations, local behavior, and inequalities. Entropy 2018, 20, 383. [Google Scholar] [CrossRef] [Green Version]
- Rao, C.R.; Statistiker, M. Linear Statistical Inference and Its Applications; Wiley: New York, NY, USA, 1973. [Google Scholar]
- Poor, H.V.; Hadjiliadis, O. Quickest Detection; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Cavanaugh, J.E. Criteria for linear model selection based on Kullback’s symmetric divergence. Aust. N. Z. J. Stat. 2004, 46, 257–274. [Google Scholar] [CrossRef]
- Devroye, L.; Mehrabian, A.; Reddad, T. The total variation distance between high-dimensional Gaussians. arXiv 2020, arXiv:1810.08693. [Google Scholar]
- Pollak, M. Optimal detection of a change in distribution. Ann. Stat. 1985, 13, 206–227. [Google Scholar] [CrossRef]
- Carter, K.M.; Raich, R.; Finn, W.G.; Hero, A.O. Information preserving component analysis: Data projections for flow cytometry analysis. IEEE J. Sel. Top. Signal Process. 2009, 3, 148–158. [Google Scholar] [CrossRef] [Green Version]
- Wen, Z.; Yin, W. A feasible method for optimization with orthogonality constraints. Math. Program. 2013, 142, 397–434. [Google Scholar] [CrossRef] [Green Version]
- Edelman, A.; Arias, T.; Smith, S. The geometry of algorithms with orthogonality constraints. SIAM J. Matrix Anal. Appl. 1998, 20, 303–353. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fisher’s QDA | SEM | LEM | ||||
|---|---|---|---|---|---|---|
| 331/2000 | 331/2000 | 331/2000 | 331/2000 | 337/2000 | 915/2000 | |
| 1226/2000 | 63/2000 | 63/2000 | 63/2000 | 64/2000 | 811/2000 | |
| Total Error | 1557/4000 | 394/4000 | 394/4000 | 394/4000 | 401/4000 | 1726/4000 |
| Fisher’s QDA | SEM | LEM | ||||
|---|---|---|---|---|---|---|
| 344/2000 | 344/2000 | 344/2000 | 345/2000 | 347/2000 | 782/2000 | |
| 594/2000 | 63/2000 | 63/2000 | 63/2000 | 64/2000 | 739/2000 | |
| Total Error | 938/4000 | 407/4000 | 407/4000 | 408/4000 | 411/4000 | 1521/4000 |
| Fisher’s QDA | SEM | LEM | ||||
|---|---|---|---|---|---|---|
| 326/2000 | 326/2000 | 335/2000 | 318/2000 | 335/2000 | 638/2000 | |
| 137/2000 | 55/2000 | 108/2000 | 57/2000 | 61/2000 | 669/2000 | |
| Total Error | 463/4000 | 381/4000 | 443/4000 | 375/4000 | 396/4000 | 1307/4000 |
| Fisher’s QDA | SEM | LEM | ||||
|---|---|---|---|---|---|---|
| 264/2000 | 264/2000 | 159/2000 | 255/2000 | 307/2000 | 561/2000 | |
| 25/2000 | 53/2000 | 64/2000 | 55/2000 | 60/2000 | 580/2000 | |
| Total Error | 289/4000 | 317/4000 | 214/4000 | 310/4000 | 367/4000 | 1141/4000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dwivedi, A.; Wang, S.; Tajer, A. Discriminant Analysis under f-Divergence Measures. Entropy 2022, 24, 188. https://doi.org/10.3390/e24020188
Dwivedi A, Wang S, Tajer A. Discriminant Analysis under f-Divergence Measures. Entropy. 2022; 24(2):188. https://doi.org/10.3390/e24020188
Chicago/Turabian StyleDwivedi, Anmol, Sihui Wang, and Ali Tajer. 2022. "Discriminant Analysis under f-Divergence Measures" Entropy 24, no. 2: 188. https://doi.org/10.3390/e24020188
APA StyleDwivedi, A., Wang, S., & Tajer, A. (2022). Discriminant Analysis under f-Divergence Measures. Entropy, 24(2), 188. https://doi.org/10.3390/e24020188