Abstract
This paper aims to estimate an unknown density of the data with measurement errors as a linear combination of functions from a dictionary. The main novelty is the proposal and investigation of the corrected sparse density estimator (CSDE). Inspired by the penalization approach, we propose the weighted Elastic-net penalized minimal -distance method for sparse coefficients estimation, where the adaptive weights come from sharp concentration inequalities. The first-order conditions holding a high probability obtain the optimal weighted tuning parameters. Under local coherence or minimal eigenvalue assumptions, non-asymptotic oracle inequalities are derived. These theoretical results are transposed to obtain the support recovery with a high probability. Some numerical experiments for discrete and continuous distributions confirm the significant improvement obtained by our procedure when compared with other conventional approaches. Finally, the application is performed in a meteorology dataset. It shows that our method has potency and superiority in detecting multi-mode density shapes compared with other conventional approaches.
1. Introduction
Over the years, the mixture models have been extensively applied to model unknown distributional shapes in astronomy, biology, economics, and genomics (see [1] and references therein). The distributions of real data involving potential complex variables often show multi-mode and heterogeneity. Due to the flexibility, it also appears in various distribution-based statistical techniques, such as cluster analysis, discriminant analysis, survival analysis, and empirical Bayesian inference. Flexible mixture models can naturally represent how the data are generated as mathematical artifacts. Theoretical results show that the mixture can approximate any density in the Euclidean space well, and the amount of the mixture can also be finite (for example, a mixture of several Gaussian distributions). Although the mixture model is inherently attractive to the statistical modeling, it is well-known that it is difficult to infer (see [2,3]). From the computational aspect, the optimization problems of mixture models are non-convex. Although existing computational methods, such as EM and various MCMC algorithms, can make the mixture model fit the data relatively easily. It should be emphasized that the mixture problems are essentially challenging, even unrecognizable, and the number of components (says, the order selection) is hard to determine (see [4]). There is a large amount of literature on its approximation theory, and various methods have been proposed to estimate the components (see [5] and references therein).
The nonparametric method and combinatorial method in density estimation were well studied in [6,7], as well as [8]. These can consistently estimate the number of the mixture’s components when the components have known functional forms. When the number of candidate components is large, the non-parametric method becomes computationally infeasible. Fortunately, the high-dimensional inference would compensate for this gap and guarantee the corrected identification of the mixture components with a probability tending to one. With the advancement of technology, high-dimensional problems have been applied at the forefront of statistical research. The high-dimensional inference method has been applied to the infinite mixture models with a sparse mixture of components, which is an interesting and challenging problem (see [9,10]). We propose an improvement of the sparse estimation strategy proposed in [9], in which Bunea et al. propose a -type penalty [11] to obtain a sparse density estimate (SPADES). At the same time, we add a -type penalty and extend the oracle-inequality results to our new estimator.
In the real data, we often encounter the situation that the i.i.d. samples are contained by some zero-mean measurement errors ; see [12,13,14,15,16]. For density estimation of , if there exists orthogonal basis functions, the estimation method is quite easy. In the measurement errors setting, however, finding an orthogonal-based density function is not easy (see [17]). Ref. [17] suggests the assumption that the conditional distribution function of given is known. This condition is somewhat strong since most conditional distributions cannot obtain the explicit formula (except the Gaussian distribution). To address this predicament, particularly with nonorthogonal base functions, the SPADES model is attractive and makes the situation easier to deal with. Based on the SPADES method, our approach is an Elastic-net calibration approach, which is simpler and more interpreted than the conditional inference procedure proposed by [17]. In this paper, we proposed the corrected loss function to debiasing the measurement errors, and this is motivated by [18]. The main problem of considering measurement errors in various statistical models is that they are responsible for the bias of the classical statistical estimates; this is true, e.g., in linear regression, which has traditionally been the main focus of studies related to measurement errors. Debiasing represents an important task in various statistical models. In linear regression, it can be performed in the basic measurement errors (ME) model, which is also denoted as the Errors-in-variables (EIV or EV) model, if it is possible to estimate the variability of measurement errors (see [19,20]). We derive the real variable selection consistency based on weighted + penalty [21]. At the same time, some theoretical results of SPADES only contain the situation of the equal weights setting, which is not plausible in the sense of adaptive (data-dependent) penalized estimation. Moreover, we perform the Poisson mixture model to approximate the complex discrete distribution in the simulation part, while existing papers only emphasize the performance of continuous distribution models. Note that the multivariate kernel density estimator can only deal with a continuous distribution, and it requires a multivariate bandwidths section, while our method is dimensional-free (the number of the required tuning parameters is only two). There has been quite a lot of work in this area, starting with [22].
There are several differences between our article and [9]. The first point is that the upper bound of non-asymptotic oracle inequality in in our Theorems 1 and 2 is tighter than Theorems 1 and 2 in [9], and the optimal weighted tuning parameters are derived. The second point is that the -penalized techniques are applied in [9] to estimate the sparse density. Still, this paper considers the estimation of density functions in the presence of a classical measurement error. We opt to use an Elastic-net criterion function to estimate the density, which is taken to be approximated by a series of basis functions. The third point is that the tuning parameters are chosen by the coordinate descent algorithm in [9], and the mixture weights are calculated by the generalized bisection method (GBM). However, this paper directly calculates the optimal weights, so our algorithm is more accessible to implement than [9].
This paper is presented as follows. Section 2 introduces the density estimator, which can deal with measurement errors. This section introduces data-dependent weights for the Lasso penalty, and the weights are derived by the event of KKT conditions holding a high probability. In Section 3, we give a condition that can accurately estimate the weights of the mixture, with a probability tending to 1. We show that, in an increasing dimensional mixture model under the local coherence assumption, if the tuning parameter is higher than the noise level, the recovery of the mixture components can hold with a high probability. In Section 4, we study the performance of our approach on artificial data generated from mixture Gaussian or Poisson distributions compared with other conventional methods, which indeed shows the improvement by employing our procedures. Moreover, the simulation also demonstrates that our method is better than the traditional EM algorithm, even under a low-dimensional model. Considering the multi-modal density aspect of the meteorology dataset, our proposed estimator has a stronger ability to detect multiple modes for the underlying distribution compared with other methods, such as SPADES or un-weighted Elastic-net estimator. Section 5 is the summary, and the proof of theoretical results is delivered in the Appendix A.
2. Density Estimation
2.1. Mixture Models
Suppose that are independent random variables with a common unknown density h. However, the observations are contaminated with measurement errors as latent variables, the observed data are actually . Let be a series of density functions (such as Gaussian density or Poisson mass function), and are also called basis functions. Assume that the h belongs to the linear combination of . The is a function of n, which is particularly intriguing for us since there may be (the high-dimensional setting). Let be the unknown true parameter. Assume that
- (H.1): the is defined as
If the base is orthogonal and there are no measurement errors, a perfectly natural method is to estimate h by an orthogonal series of estimators in the form of , where has the coordinates (see [17]). However, this estimator depends on the choice of W, and a data-driven selection of W or the threshold needs to be adaptive. This estimator can only be applied to . Nevertheless, we want to solve more general problems for , and the base functions may not orthogonal.
We aim to achieve the best convergence for the estimator when the W is not necessarily less than n. Theorem 33.2 in [5] states that any smooth density can be well-approximated by a finite mixture of some continuous functions. However, Theorem 33.2 in [5] does not confirm how many components W are required for the mixture. Thus, the hypothesis of the increasing-dimensional W is reasonable. For discrete distributions, there is also a similar mixture density approximation—see Remark of Theorem 33.2 in [5].
2.2. The Density Estimation with Measurement Errors
This subsection aims to construct a sparse estimator for the density as a linear combination of known densities.
Recall the definition of the norm . For , let be the inner product. If two functions f and g satisfy , then we call these two functions are orthogonal. Note that if the density belongs to and assume that has the same distribution X, for any , we have . If is the density function for a discrete distribution, the integral is replaced by summation, and we can define the inner product as .
For true observations , we minimize the on to obtain the estimate of , i.e., minimizing
which implies that minimizing the is equivalent to minimizing
It is plausible to assign more constrains for the candidate set of in the optimization, for example, the constrains , where a is the tuning parameter. More adaptively, we prefer to use the weighted restriction , where the weights ’s are data-dependent and will be specified later. From [23], we add Elastic-net penality with tuning parameter c, which is in regards to the measurement errors (see [24,25]) for a similar purpose. We would have in the situation without measurement errors. The c indeed becomes larger if the measurement errors become more serious, i.e., we can say that the c is proportional to the increasing variability of the measurement errors. It is different from SPADES since adjusting for the measurement errors is important for accurately describing the relationship between the observed varables and the outcomes of interest.
From the discussion above, now we propose the following Corrected Sparse Density Estimator (CSDE):
where the c is the tuning parameter for -penalty, and the c also presents the correction for adjusting the measurement errors in our observations.
For CSDE, if is an orthogonal system, it can be clearly seen that the CSDE estimator is consistent with the soft thresholding estimator, and the explicit solution is , where and . In this case, we can see that is the threshold of the j-th component of the simplest mean estimator .
From the sub-differential of the convex optimization, the corresponding Karush–Kuhn–Tucker conditions (necessary and sufficient first-order condition) for the minimizer in Equation (3) is
Lemma 1
(KKT conditions, Lemma 4.2 of [26]). Let and . Then, a necessary and sufficient condition for CSDE to be a solution of Equation (3)
- if
- if
Since all values of are non-negative, when conducting minimization in Equation (3), we have to put a non-negative restriction for optimizing Equation (3).
Due to the computational feasibility and optimal first-order conditions, we prefer an adaptively weighted Lasso penalty as a convex adaptive penalization. We require that the larger weights are assigned to the coefficients of unimportant covariates, while significant covariates accompany the smaller weights. So, the weights represent the importance of the covariates. The larger (smaller) weights shrink to zero more easily (difficultly) than the unweighted Lasso, with appropriate or even optimal weights, leading to less bias and more efficient variable selection. The derivation of the weights will be given in Section 3.1.
In the end of this part, we will illustrate that in the mixture models, even without measurement errors, Equation (1) cannot be partially transformed into the linear model , where Y is the n-dimensional response variables, is the -dimensional fixed design matrix, is a W-dimensional vector of model parameters, the is a -dimensional vector for random error terms with zero mean and finite variance. Consider the least square objective function for estimating , Minimizing is equivalent to minimizing in Formula (4)
Comparing the objective function in Formula (4) with Equation (2), it is easy to obtain Substituting Y, and into a linear regression model, we obtain
Then,
It can be seen from Equation (5) that the value of is no longer random if was the fixed design matrix. Furthermore, even for a random design , take the expectation on both sides of Equation (5), and one can find that the left side is not equal to the right side, that is, It leads to an additional requirement , which is meaningless as , since all and are positive. This is a contradiction to for all n.
Both of the two situations above contradict the definition of the assumed linear regression model. Hence, we cannot convert the estimation of Equation (1) into the estimation problem of linear models. Thus, the existing oracle inequalities are not applicable anymore, and we will propose new ones later. However, we can transform the mixture models to a corrected score Dantzig selector, such as in [27]. Although [10] studies the oracle inequalities for adaptive Dantzig density estimation, their study does not contain the error-in-variables framework and the support recovery content.
3. Sparse Mixture Density Estimation
In this section, we will present the oracle inequalities for estimators and . The core of this section consists of five main results corresponding to the oracle inequalities for estimated density (Theorems 1 and 2), upper bounds on -estimation error (Corollaries 1 and 2) and support consistency (Theorem 3) as the byproduct of Corollary 2.
3.1. Data-Dependent Weights
The weights ’s are chosen adequately such that the KKT conditions for stochastic optimization problems have a high probability of being satisfied.
As mentioned before, the weights in Equation (3) rely on the observed data since we calculate the weights, ensuring the KKT conditions hold with a high probability. The weighted Lasso estimates could have less estimation error than Lasso estimates (see the simulation part and [28]). Next, we need to consider what kind of data-dependent weight configuration can enable the KKT conditions to be satisfied with a high probability. A way to obtain data-dependent weights is to apply a concentration inequality for a weighted sum of independent random variables. Moreover, the weights should be a known data function without any unknown parameters. A criterion can help obtain the weights grounded on McDiarmid’s inequality (see [29] for more details).
Lemma 2.
Suppose are independent random variables, and all values belong to a set A. Let be a function and satisfy the bounded difference conditions
then for all,
We define the KKT conditions of optimization evaluated at (it is from the sub-gradient of the optimization function evaluated at ) by the events below:
Assume that
- (H.2): s.t. ;
- (H.3): .
(H.2) is an assumption in sparse estimation, and the assumption (H.3) is a classical compact parameter space assumption in sparse high-dimensional regressions (see [9,25]).
Next, we check that the event is hold with high probability. Note that (which is free of ), we find
where the last inequality is due to .
Next, we apply the McDiarmid’s inequality on the event by (H.3). Then
Considering the previous line,
The weight in our paper is different from [9], which gives the un-shift version (), due to the Elastic-net penalty. Define the modified KKT conditions:
which hold with probability of at least .
3.2. Non-Asymptotic Oracle Inequalities
Introduced by [30], oracle inequality is a powerful non-asymptotic and analytical tool that seeks to provide the distance between the obtained estimator and a true estimator. The sharp oracle inequality connects the optimal convergence of an obtained estimator compared with the true parameter (see [31,32]).
For , let be the indices corresponding to the non-zero components of the vector , i.e., the support in mathematical jargon. If there is no ambiguity, we would like to write as for simplicity. Define as the number of its non-zero components, where represents the indicative function. Let .
Below, we will state the non-asymptotic oracle inequalities for (with the probability at least for any integer W and n), which measures the distance between and h. For , define the correlation for the two base densities: and , , Our results will be established under the local coherence condition, and we define the maximal local coherence as:
It is easy to see that measures the separation of the variables in the set from one another and the rest. The degree of separation is measured in terms of the size of the correlation coefficients. However, the regular condition introduced by this coherence may be too strong. It may exclude cases that the “correlation” can be relatively significant for a small number of pairs and almost zero otherwise. Thus, we consider the definition of the cumulative local coherence given by [9]: . Define where .
By using the definition of and the notations above, we present the main results of this paper, which lays the foundation for the oracle inequality of the estimated mixture coefficients.
Theorem 1.
Under (H.1)–(H.3), let and a given constant . If the true base functions conform to the cumulative local coherence assumption for all ,
then the of the optimization problem in Equation (3) has the following oracle inequality with a probability at least ,
where .
It is worthy to note that here we use instead of , and the latter is used in [9]. The upper bound of the oracle inequality by Theorem 1 is sharper than the upper bound of Theorem 1 in [9]. Further, we give the value of the optimal , but [9] did not give it. The reason for this phenomenon is quite clean actually: from the proof, it is due to ineuqality (A5). Now, let us address the sparse Gram matrix with a small number of non-zero elements in off-diagonal positions, define as the element -th of position . Condition (8) in Theorem 1 can be transformed to the condition
where the number S is called the sparse index of matrix , which is defined as , where is the number of elements of set A.
Sometimes the assumption in Condition (8) does not imply the positive definiteness of . Next, we give a similar oracle inequality that is valid under the hypothesis that the Gram matrix is positive definite.
Theorem 2.
Under the assumption of (H.1)–(H.3) and that the Gram matrix is positive definite with a minimum eigenvalue greater than or equal to . For all , the of the optimization problem in Equation (3) has the following oracle inequality with probability at least ,
whereand.
Remark 1.
The argument and result of Theorem 1 in this paper is more refined than the conclusion of Theorem 1 in [9] for Lasso by letting and . In addition, Theorems 1 and 2 of this paper, respectively, give the optimal α value of the density estimation oracle inequalities, namely , . It provides a potentially sharper bound for the -estimation error bound.
Next, we will present the -estimation error for the estimator by Equation (3), and the weights are defined by Equation (6). For the technical point, we consider that for all j in Equation (3), i.e., the base functions are normalized. This normalization mimics the covariates’ standardization procedure when doing penalized estimations in generalized linear models. For simplicity, we put .
For any other choice of greater than or equal to , the conclusions of Section 3 are valid with a high probability. It imposes a restriction on the predictive performance of CSDE. As pointed out in [33], for the -penalty in the regression, the adjusted sequence required for the corrected selection is usually larger than the adjusted sequence that produces a good prediction. The selection of the mixture density shown below is also true. Specifically, we will take the value and , then . Below, we give the Corollaries of Theorems 1 and 2.
Corollary 1.
Given the same conditions as Theorem 1 with for all j, let , then we have the following -estimation error oracle inequality:
with probability at least , where .
Corollary 2.
Given the same conditions as Theorem 2 with for all j, let , then we have the following oracle inequality, with probability at least ,
If the number of the mixture indicator elements is much smaller than , then inequality (9) guarantees that the estimated is close to the true , and the -estimation error will be presented in the numerical simulation in Section 4. Our results of Corollaries 1 and 2 are non-asymptotic for any W and n. The oracle inequalities are guiders for us to find an optimal tuning parameter with order for a sharper estimation error and better prediction performance. This is also an intermediate and crucial result, which leads to the main results of correctly identifying the mixture components in Section 3.3. In the following section, we turn to cope with the identification of . Corrected components are selected by the proposed oracle inequality for the weighted + penalty.
3.3. Corrected Support Identification of Mixture Models
In this section, we will study the results of the support recovery of our CSDE estimator. There are few results on support recovery, while most of the results are the consistency of the -error and prediction errors. Here, we borrow the framework of [25,33]. They give many proof techniques to deal with the corrected support identification in linear models by regularization. Let be the set of indicators consisting of non-zero elements of in the given Equation (3). In other words, is an estimate of the true support set . We will study for a given under some mild conditions.
To identify the consistently, we need more assumptions about some special correlation conditions than -error consistency.
Condition (A):
Moreover, we need an additional condition that the minimal signal should be higher than a threshold level and quantified by order of tuning parameter. Therefore, we state it as follows:
Condition (B): , where .
When performing simulation, Condition (B) is the theoretical guarantee that the minor magnitude of must be greater than a threshold value as a minimal signal condition. It is also called the Beta-min condition (see [26]).
Theorem 3.
Let and define . Assume that both conditions (A) and (B) are true and give the same conditions as Corollary 2, then
Under the Beta-min condition, the support estimation is very close to the true support of . The probability of the event is high when W is growing. The recovers the corrected support with probability at least . The result is non-asymptotic and it is true for any fixed W and n. There is a similar conclusion about support consistency (see Theorem 6 of [25]).
4. Simulation and Real Data Analysis
Ref. [9] proposes the SPADES estimation to deal with the samples for sparse mixture density, and they also derive an algorithm from complementing their theoretical result. Their findings successfully handle the high-dimensional adaptive density estimation to some degree. However, their algorithm is costly and unstable. In this section, we deal with the tuning parameter directly and compare our CSDE method with the SPADES method in [9] and other similar methods. In all cases here, we fix for , which is known as the dimension of the unknown parameter . The performance of each estimator is evaluated by the -estimation error and the total variation (TV) distance between the estimator and the true value of . The total variation (TV) error is defined as:
4.1. Tuning Parameter Selection
In [9], the is chosen by the coordinate descent method, while the mixture weights are detected by GBM. However, in our article, the optimal weights can be computed directly. Thus, it is much easier to carry out than [9]. The -penalty term with optimal weights are defined by , where , which usually can be computed easily for a continuous .
For a discrete base density , it can be estimated as the following approximation by using concentration inequalities from Exercise 4.3.3 of [34]: , where and represent the sample mean and sample median, respectively, in each simulation, then we only need to select the and , and they can be detected by the nesting coordinate descent method. Moreover, the precision level is assigned as in our simulation.
4.2. Multi-Modal Distributions
First, we examine our method in a multi-modal Gaussian model that is similar to the first model in [9]. However, our mixture Gaussian has a different variance, which leads the meaningful weights to our estimation. The density function for the i.i.d. sample is assigned as follows:
where is the density of . However, to estimate , we only observe i.i.d. data with density . Put and
with .
We replicate the simulation times. Simulation results are presented in Table 1, from which we can see our method has more and more excellent performances as the W increases, which matches the non-asymptotic results in the previous section. The best performance is far better than the other three methods when . It is worthy to note that the better approximation follows the increase in W, matching Equation (7) and Theorem 3 in our previous section.

Table 1.
The simulation results in Section 4.2. The mean and standard deviation of the errors in the four estimators of under simulations, with . The quasi-optimal is for Elastic-net, while is for the CSDE.
We plot the solution path to compare the performance of the four estimators in for every W in Figure 1 (the result of Elastic-net in is not be shown due to its poor performance.). These figures also provide strong support for the above analysis. Meanwhile, we plot the probability densities of the several estimators and the true density to complement the visual sensory of the advantage in our method in Figure 2. The robust competency of detecting the multi-mode is shown (whereas other methods only find the most strongest signal, ignoring other meaningful but relatively weak signals).
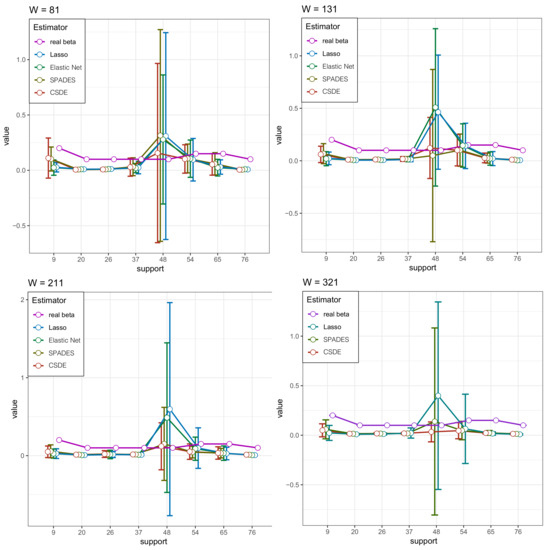
Figure 1.
The simulation result in Section 4.2. The estimated support of by the four types of estimators, and the W is varying. The circles represent the means of the estimators under the four specific approaches, while the half vertical lines mean the standard deviations.
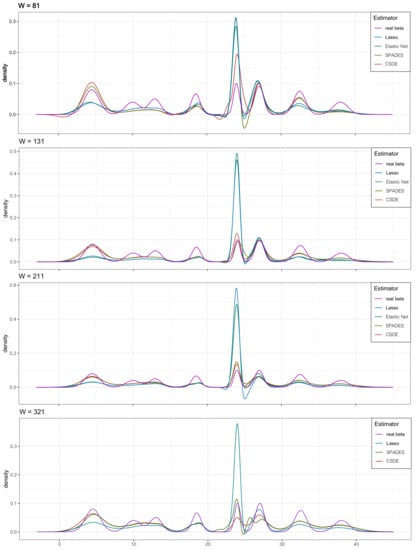
Figure 2.
The simulation results in Section 4.2. The density map of the four estimators. The result of Elastic-net in is not be shown due to its poor performance.
4.3. Mixture of Poisson Distributions
We study the mixture of discrete distribution: the mixture Poisson distribution
where is the probability mass function (p.m.f.) of the Poisson distribution with mean . We set and
The adjusted weights are calculated by Equation (3), and in discrete distributions, we define . Meanwhile, the Poisson random variable with measurement errors can be treated as a negative binomial random variable. Let be the p.m.f. of the Poisson distribution with the mean and dispersion parameter r. Suppose the observed data with sample size has the p.m.f.
where , which leads to an increment of variance from Poisson to the negative binomial distribution. Similarly, we replicate each simulation to estimate the parameter times with the sample from the mixture negative binomial distribution above. The result is shown in Table 2. The result is actually akin to that in the previous mixture Gaussian distribution, while the strong performance of our method is shown clearly when W is considerable.
Table 2.
The simulation result in Section 4.3. The mean and standard deviation of the errors in the four estimators of under simulations. The is chosen as for Elastic-net, while for the CSDE.
4.4. Low-Dimensional Mixture Model
Surprisingly, our method has more competitive efficacy than some popular methods (such as EM algorithm), even the dimension W is relatively small. To see this, we introduce the following numerical experiments to estimate the weights of the low-dimensional Gaussian mixture model: the samples come from the model: The updated equation for the EM algorithm in t-th step is:
Here, we consider two scenarios:
For each scenario , and the fitter levels (cessation level) in the EM approach and our method are both . A well-advised initial value in the EM approach is the equal weight.
We replicate the simulation times, and the optimal tuning parameters stem from the cross-validation (CV). Thus, under each simulation, they are not the same, albeit they are very close to each other. The result can be seen in Table 3.
Table 3.
The low-dimensional simulation result in Section 4.4.
4.5. Real Data Examples
Practically, we consider using our method to estimate some densities in the environmental science field. Wind, which is mercurial, has been an advisable object to study for a long time in meteorology. Please note that the wind’s speed at one specific location may not be diverse so we will use the wind’s azimuth angle with a more sparse density at two sites in China. Many types of research about the estimated density for wind exist, so there is a possibility of using our approach to cope with some difficulties in meteorology science.
There have been some very credible meteorological dataset. We used the ERA5 hourly data in [35] to continue our analysis. We want chose a continental area and a coastal area in China, so we chose Beijing Nongzhanguan and Qingdao Coast. The locations of these two areas are: (116.3125 E, 116.4375 E) × (39.8125 N, 39.8125 N). Take notice that the wind in one day may be highly correlated. Therefore, using the data at a specific time point of each day in a consecutive period as i.i.d. samples is reasonable. The sample histograms at 6 am in Beijing Nongzhanguan and at midnight on the Qingdao Coast are shown in Figure 3. Here, we used the data from 1 January 2013 to 12 December 2015.
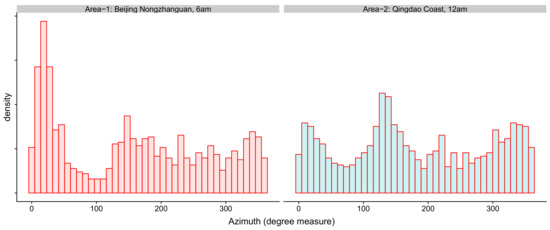
Figure 3.
The sample histogram of the azimuth in Beijing Nongzhanguan at 6am and Qingdao Coast at 12 am.
As we can see, their density does multi-peak (we used 1095 samples). Now, we can use our approach to estimate the multi-mode densities based on a relatively small size of samples, which is only a tiny part of the whole data from 1 January 2013 to 12 December 2015. Because one year has about 360 days, we may assume that every day is a latent factor that forms the base density. Thus, the model is designed as with the mean and variance parameters , , where t is the bandwidth (or tuning parameter). With the different sub-samples, the computed values are different.
Another critical issue is how to choose the tuning parameters and . Then, we apply the cross-validation criterion, namely choosing , to minimize the difference between the two estimators derived from the separated samples in a random dichotomy.
Now, start to construct the samples for the estimating procedure. Assume that an observatory wants to figure out some information about the two areas’ wind. However, it does not have intact data due to the limited budget at its inception. The only samples it has are several days’ information each month for the two areas, and these days scatter randomly. Furthermore, sample size exactly. These imperfect data increase the challenge of estimating a trustworthy density. We compared our method with other previous methods, in which appraising the difference between the complete data sample histogram and the estimated density under each method is for the evaluation. Notice that the samples are only a tiny part of the data, so the is relatively small. The small sample and large dimension setting coincide with the non-asymptotic theory provided in the previous section. The estimated density has been shown in Figure 4.
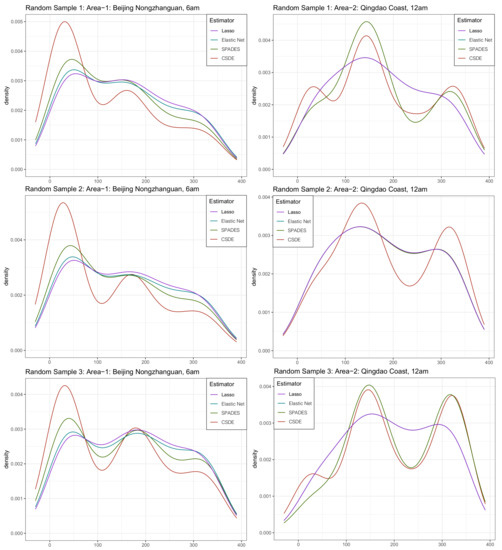
Figure 4.
The density map of the four estimators’ approaches for the three random sub-samples from the real-world data in Section 4.5.
In this practical application, our method vindicates its more efficient estimating performance and stability from its propinquity of the complete sample histogram, namely the productive capacity of detecting the shape of the multi-mode density and the stronger inclination to bear a resemblance to each other sub-sample (although some subtle nuances do exist because of the different sub-sample). An alternative approach can be to consider principles and tools of circular statistics, which has been reviewed in [36].
5. Summary and Discussions
The paper deals with the deconvolution problem using Lasso-type methods: the observations are independent and generated from , and the goal is to estimate the unknown density h of the . We assume that the function h can be written as based on some functions from a specific dictionary and propose estimating the coefficients of this decomposition with the Elastic-net method. For this estimator, we show that under some classical assumptions of the model, such as coherence of the Gram matrix, finite sample bounds for the estimation and the prediction errors valid with a relatively high probability can be obtained. Moreover, we prove a variable selection consistency result under a beta-min condition and conduct an extensive numerical study. The following estimation problem is also similar to the CSDE.
For future study, it is also interesting and meaningful to do hypothesis testing about the coefficients in sparse mixture models. For a general function and a nonempty closed set , we can consider
It is possible to use [37] as a general approach to hypothesis testing within models with measurement errors.
Author Contributions
Conceptualization, H.Z.; Data curation, X.Y.; Formal analysis, X.Y. and S.Z.; Funding acquisition, X.Y.; Investigation, X.Y. and S.Z.; Methodology, X.Y., H.Z., H.W. and S.Z.; Project administration, H.Z.; Resources, H.W.; Software, H.W.; Supervision, X.Y. and H.Z.; Visualization, H.W.; Writing—original draft, X.Y., H.Z., H.W. and S.Z.; Writing—review and editing, H.Z. and H.W. All authors have read and agreed to the published version of the manuscript.
Funding
Xiaowei Yang is supported in part by the General Research Project of Chaohu University (XLY-201906), Chaohu University Applied Curriculum Development Project (ch19yykc21), Key Project of Natural Science Foundation of Anhui Province Colleges and Universities (KJ2019A0683), Key Scientific Research Project of Chaohu University (XLZ-202105). Huiming Zhang is supported in part by the University of Macau under UM Macao Talent Program (UMMTP-2020-01). This work also is supported in part by the National Natural Science Foundation of China (Grant No. 11701109, 11901124) and the Guangxi Science Foundation (Grant No. 2018GXNSFAA138164).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The authors would like to thank Song Xi Chen’s Group https://songxichen.com/(accessed on 20 December 2021) for sharing the meteorological dataset.
Acknowledgments
The Appendix includes the proofs of the lemmas, corollaries and theorems in the main body.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
For convenience, we first give a preliminary lemma and proof. Define the random variables Consider the event by , where . Then, we have the following lemma, which is cornerstone for the proofs in below.
Lemma A1.
Suppose and , for any on the event , we have
Appendix A.1. Proof of Lemma A1
According to the definition of , for any , we find Then
Note that
Combining the two result above, we obtain
According to the definition of , it gives with . For the three terms in Equation (A1), we have
Then
Conditioning on , we have We add to both sides of the inequality, it gives
Note that
where the last inequality is due to the assumption . Thus, we obtain
where the last inequality follows from for all j.
We know if , and if . Considering for all j, we have Then
Appendix A.2. Proof of Theorems
According to in Equation (6), the sum of the independent random variables is determined by Hoeffding’s inequality, and . We obtain
Appendix A.3. Proof of Theorem 1
By Lemma A1, we need an upper bound on . For easy notation, let According to the definition of , that is, , we have
Let . Using the definition of , we obtain As , , it is easy to see . Observe that
By the definitions of and , then
By ,
By Equation (A3), we can obtain
To find the upper bound of , applying the properties of the quadratic inequality to the above formula, we obtain that
Note that , employing the Cauchy–Schwarz inequalities, we have
Then, In combination with Equation (A4), we can obtain . Therefore,
By Lemma A1 and Equation (A2), we have the following inequality with probability exceeding ,
where the second last inequality follows from the definition of , and the last inequality is derived by the assumption
Further, we can find that, with probability at least ,
Using the elementary inequality to the last two terms of the above inequality, it yields
Thus,
Simplifying, we have
Optimizing to obtain the sharp upper bounds for the above oracle inequality
by the first order condition. To date, Theorem 1 is proved by substituting into Equation (A6).
Appendix A.4. Proof of Theorem 2
By the minimal eigenvalue assumption for , we have
Using the definition of and assumption ,
Since and , we have
Let , by the Cauchy–Schwartz inequality, we obtain
where the last inequality above is from Equation (A7) due to
Let , Lemma 2 implies
Using the inequality for the last two terms on the right side of the above inequality, we find
Thus,
gives . Therefore,
To obtain the sharp upper bounds for the above oracle inequality, we optimize
by the first-order condition. This completes the proof of Theorem 2.
Appendix A.5. Proof of Corollory 1
Let . We replace in Theorem 1 by the larger value . Substituting in Theorem 1, we have
by . Since for all j, we obtain
In this case, , and ; thus,
from and
This completes the proof of Corollary 1.
Appendix A.6. Proof of Corollary 2
Let in Theorem 2, with , we replace in Theorem 2 by the larger value , then By the definition of , we can obtain
This concludes the proof of Corollary 2.
Appendix A.7. Proof of Theorem 3
The following lemma is by virtue of the KKT conditions. It derives a bound of , which is easily analyzed.
Lemma A2
(Proposition 3.3 in [33]).
To present the proof of Theorem 3, we first notice that Next, we control the probability on the right side of the above inequality.
For the control of , by Lemma A2, it remains to bound .
Below, we will use the conclusion of Lemma 2 (KKT conditions). Recall that . Since we assume that the density of is the mixture density . Therefore, for , we have,
Similar to Lemma 2, for Equation (A9), we use Hoeffding’s inequality. Since for all k. Put . Consider Condition (B), and , then we have
For the upper bound of Equation (A10), using Condition (A) and Condition (B), by the definitions of and , we obtain
where the second last inequality is by Condition (A), and the last inequality above is by using the -estimation oracle inequality in Corollary 2.
Therefore, by the definition of , , we find
For the control of , let
where Consider the following random event
Let be a vector corresponding to the component of the index set having given by Equation (A12), and the component at other corresponding positions is 0. By Lemma 1, we know that is a solution of Equation (3) on the event . It is recalled that , which is also a solution of Equation (3). Through the definition of the indicator set , we have for . By construction, we obtain for some subset . The KKT conditions indicate that any two solutions have non-zero components at the same positions. Therefore, on the event . Further, we can write
According to the previously proven Formula (A11), we find
For the upper bound of Equation (A15), observe Theorem 2, we can use a larger instead of . Consider the construction of in Equation (A12), we obtain
Similarly, we have
Combining all the bounds above, we can obtain
This completes the proof of Theorem 3.
References
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite mixture models. Ann. Rev. Stat. Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Balakrishnan, S.; Wainwright, M.J.; Yu, B. Statistical guarantees for the EM algorithm: From population to sample-based analysis. Ann. Stat. 2017, 45, 77–120. [Google Scholar] [CrossRef]
- Wu, Y.; Zhou, H.H. Randomly initialized EM algorithm for two-component Gaussian mixture achieves near optimality in O() iterations. arXiv 2019, arXiv:1908.10935. [Google Scholar]
- Chen, J.; Khalili, A. Order selection in finite mixture models with a nonsmooth penalty. J. Am. Stat. Assoc. 2008, 103, 1674–1683. [Google Scholar] [CrossRef] [Green Version]
- DasGupta, A. Asymptotic Theory of Statistics and Probability; Springer: New York, NY, USA, 2008. [Google Scholar]
- Devroye, L.; Lugosi, G. Combinatorial Methods in Density Estimation; Springer: New York, NY, USA, 2001. [Google Scholar]
- Biau, G.; Devroye, L. Density estimation by the penalized combinatorial method. J. Multivar. Anal. 2005, 94, 196–208. [Google Scholar] [CrossRef] [Green Version]
- Martin, R. Fast Nonparametric Estimation of a Mixing Distribution with Application to High Dimensional Inference. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2009. [Google Scholar]
- Bunea, F.; Tsybakov, A.B.; Wegkamp, M.H.; Barbu, A. Spades and mixture models. Ann. Stat. 2010, 38, 2525–2558. [Google Scholar] [CrossRef]
- Bertin, K.; Le Pennec, E.; Rivoirard, V. Adaptive Dantzig density estimation. Annales de l’IHP Probabilités et Statistiques 2011, 47, 43–74. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodological 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hall, P.; Lahiri, S.N. Estimation of distributions, moments and quantiles in deconvolution problems. Ann. Stat. 2008, 36, 2110–2134. [Google Scholar] [CrossRef]
- Meister, A. Density estimation with normal measurement error with unknown variance. Stat. Sinica 2006, 16, 195–211. [Google Scholar]
- Cheng, C.L.; van Ness, J.W. Statistical Regression with Measurement Error; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Zhu, H.; Zhang, R.; Zhu, G. Estimation and Inference in Semi-Functional Partially Linear Measurement Error Models. J. Syst. Sci. Complex. 2020, 33, 1179–1199. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, R.; Yu, Z.; Lian, H.; Liu, Y. Estimation and testing for partially functional linear errors-in-variables models. J. Multivar. Anal. 2019, 170, 296–314. [Google Scholar] [CrossRef]
- Bonhomme, S. Penalized Least Squares Methods for Latent Variables Models. In Advances in Economics and Econometrics: Volume 3, Econometrics: Tenth World Congress; Cambridge University Press: Cambridge, UK, 2013; Volume 51, p. 338. [Google Scholar]
- Nakamura, T. Corrected score function for errors-in-variables models: Methodology and application to generalized linear models. Biometrika 1990, 77, 127–137. [Google Scholar] [CrossRef]
- Buonaccorsi, J.P. Measurement error. In Models, Methods, and Applications; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Carroll, R.J.; Ruppert, D.; Stefanski, L.A.; Crainiceanu, C.M. Measurement error in nonlinear models. In A Modern Perspective, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Zou, H.; Zhang, H. On the adaptive elastic-net with a diverging number of parameters. Ann. Stat. 2009, 37, 1733–1751. [Google Scholar] [CrossRef] [Green Version]
- Aitchison, J.; Aitken, C.G. Multivariate binary discrimination by the kernel method. Biometrika 1976, 63, 413–420. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Rosenbaum, M.; Tsybakov, A.B. Sparse recovery under matrix uncertainty. Ann. Stat. 2010, 38, 2620–2651. [Google Scholar] [CrossRef]
- Zhang, H.; Jia, J. Elastic-net regularized high-dimensional negative binomial regression: Consistency and weak signals detection. Stat. Sinica 2022, 32. [Google Scholar] [CrossRef]
- Buhlmann, P.; van de Geer, S. Statistics for High-Dimensional Data: Methods, Theory and Applications; Springer: New York, NY, USA, 2011. [Google Scholar]
- Belloni, A.; Rosenbaum, M.; Tsybakov, A.B. Linear and conic programming estimators in high dimensional errors-in-variables models. J. R. Stat. Soc. Series B Stat. Methodol. 2017, 79, 939–956. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Gao, Y.; Zhang, H.; Li, B. Weighted Lasso estimates for sparse logistic regression: Non-asymptotic properties with measurement errors. Acta Math. Sci. 2021, 41, 207–230. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, S.X. Concentration Inequalities for Statistical Inference. Commun. Math. Res. 2021, 37, 1–85. [Google Scholar]
- Donoho, D.L.; Johnstone, J.M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Deng, H.; Chen, J.; Song, B.; Pan, Z. Error bound of mode-based additive models. Entropy 2021, 23, 651. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.A.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Bunea, F. Honest variable selection in linear and logistic regression models via ℓ1 and ℓ1 + ℓ2 penalization. Electron. J. Stat. 2008, 2, 1153–1194. [Google Scholar] [CrossRef]
- Chow, Y.S.; Teicher, H. Probability Theory: Independence, Interchangeability, Martingales, 3rd ed.; Springer: New York, NY, USA, 2003. [Google Scholar]
- Hersbach, H.; de Rosnay, P.; Bell, B.; Schepers, D.; Simmons, A.; Soci, C.; Abdalla, S.; Alonso-Balmaseda, M.; Balsamo, G.; Bechtold, P.; et al. Operational Global Reanalysis: Progress, Future Directions and Synergies with NWP; European Centre for Medium Range Weather Forecasts: Reading, UK, 2018. [Google Scholar]
- Fisher, N.I. Statistical Analysis of Circular Data; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Broniatowski, M.; Jureckova, J.; Kalina, J. Likelihood ratio testing under measurement errors. Entropy 2018, 20, 966. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).