
Learning Two-View Correspondences and Geometry via Local Neighborhood Correlation

Abstract
:1. Introduction
- In our proposed LNCNet, the local neighborhood correlation block is proposed to filter outliers and cluster more accurate local neighborhood information into new feature vectors.
- In the proposed LNCNet, we construct the local neighborhood from coarse to fine, which can ensure we obtain a trade-off between time and precision.
- Our proposed LNCNet is able to accomplish outlier rejection and camera pose estimation tasks better even under complicated scenes.
2. Related Work
2.1. Traditional Outlier Rejection
2.2. Deep Learning-Based Outlier Rejection
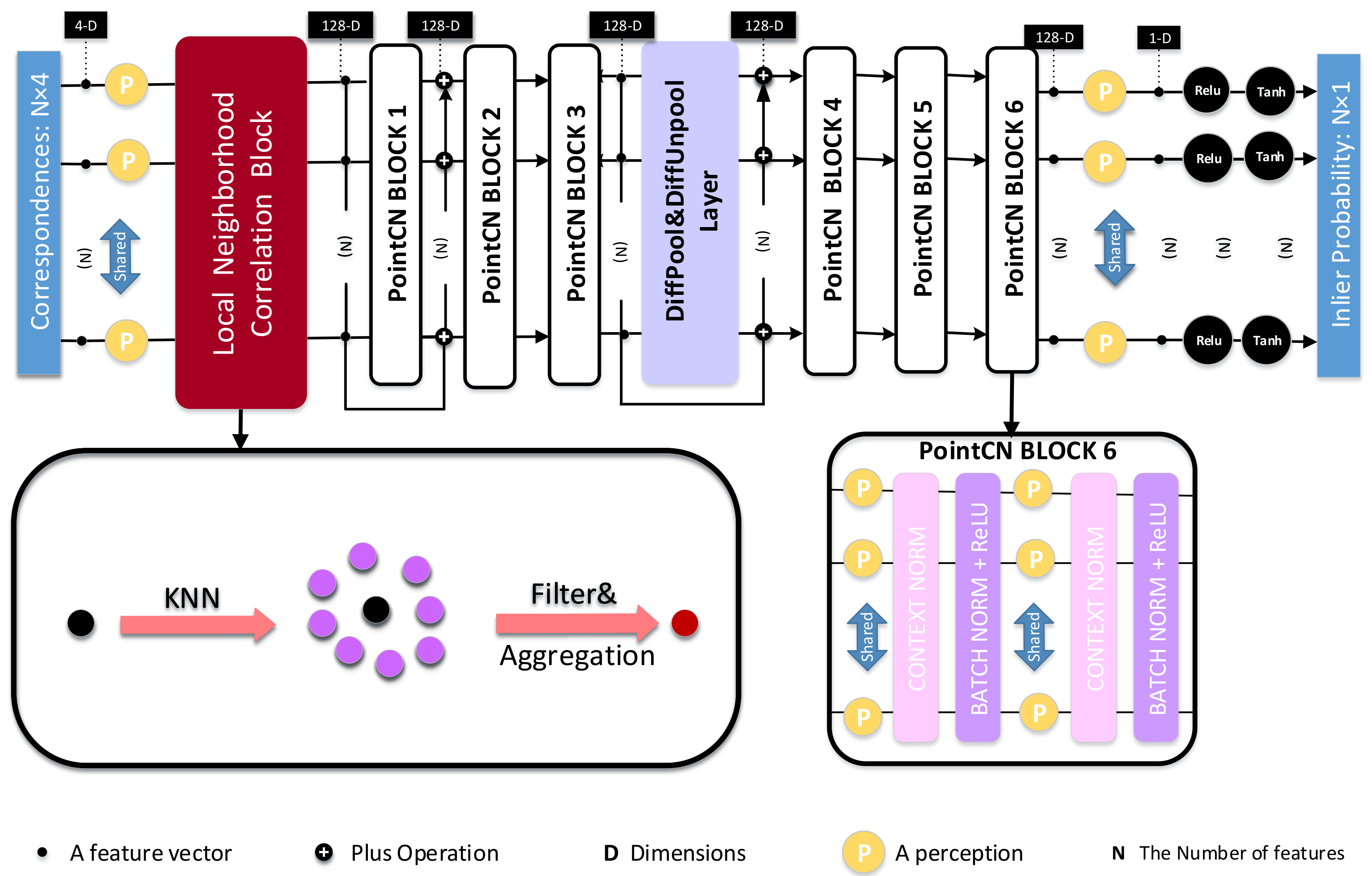
3. Method
3.1. Problem Formulation
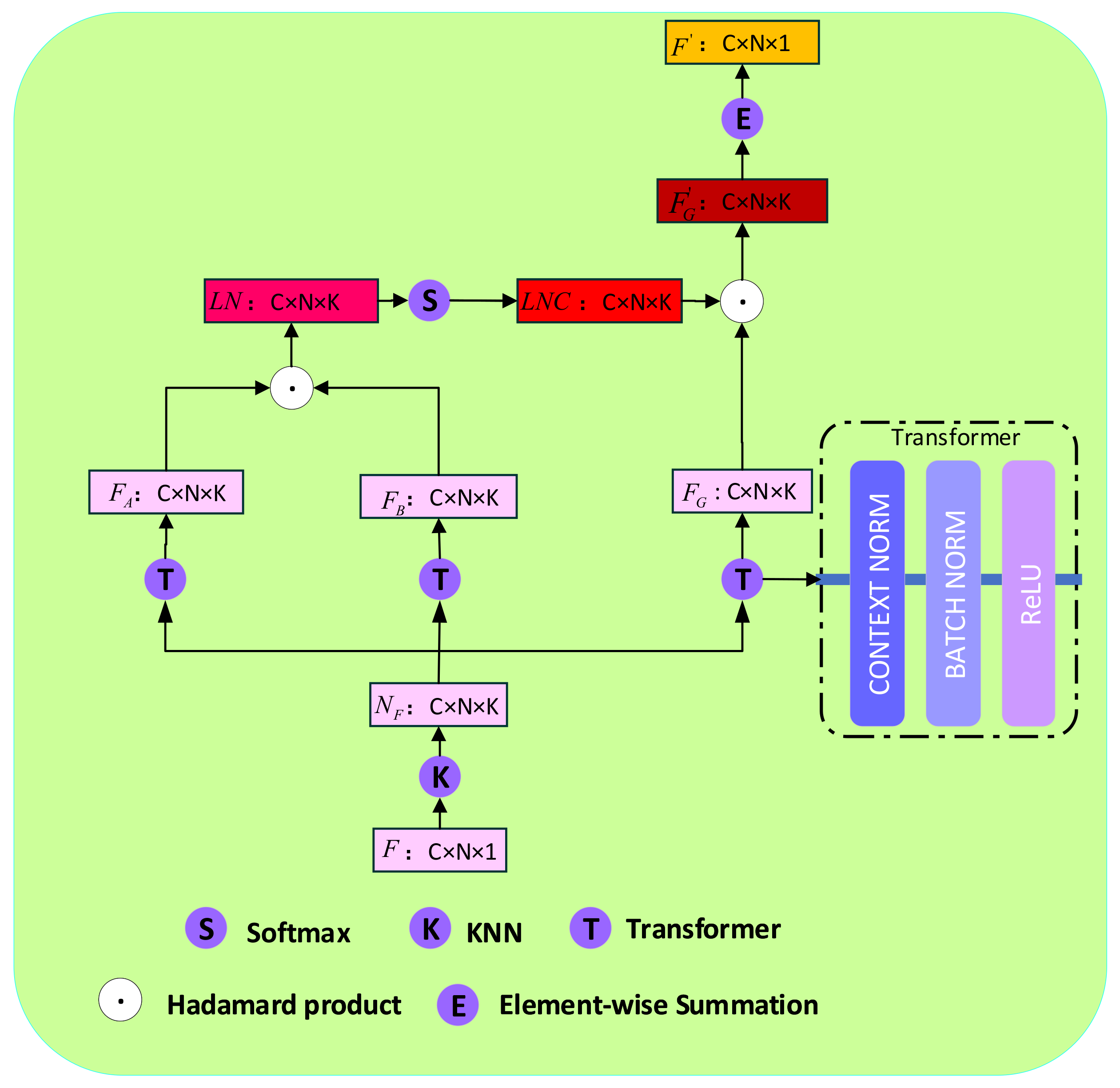
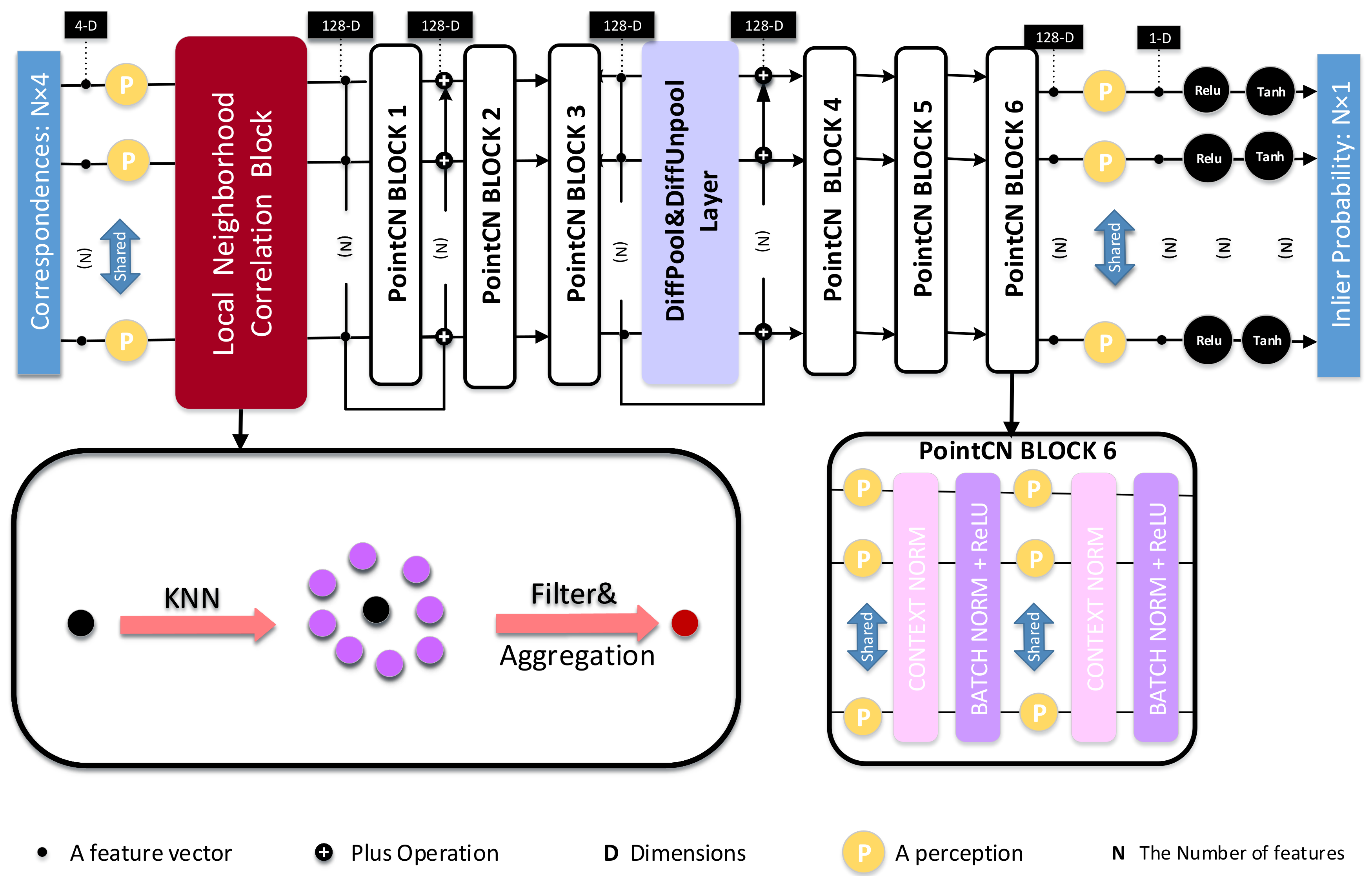
3.2. Local Neighborhood Correlation Block
3.3. Network Architecture
3.4. Loss Function
3.5. Implementation Details
4. Experiments
4.1. Datasets
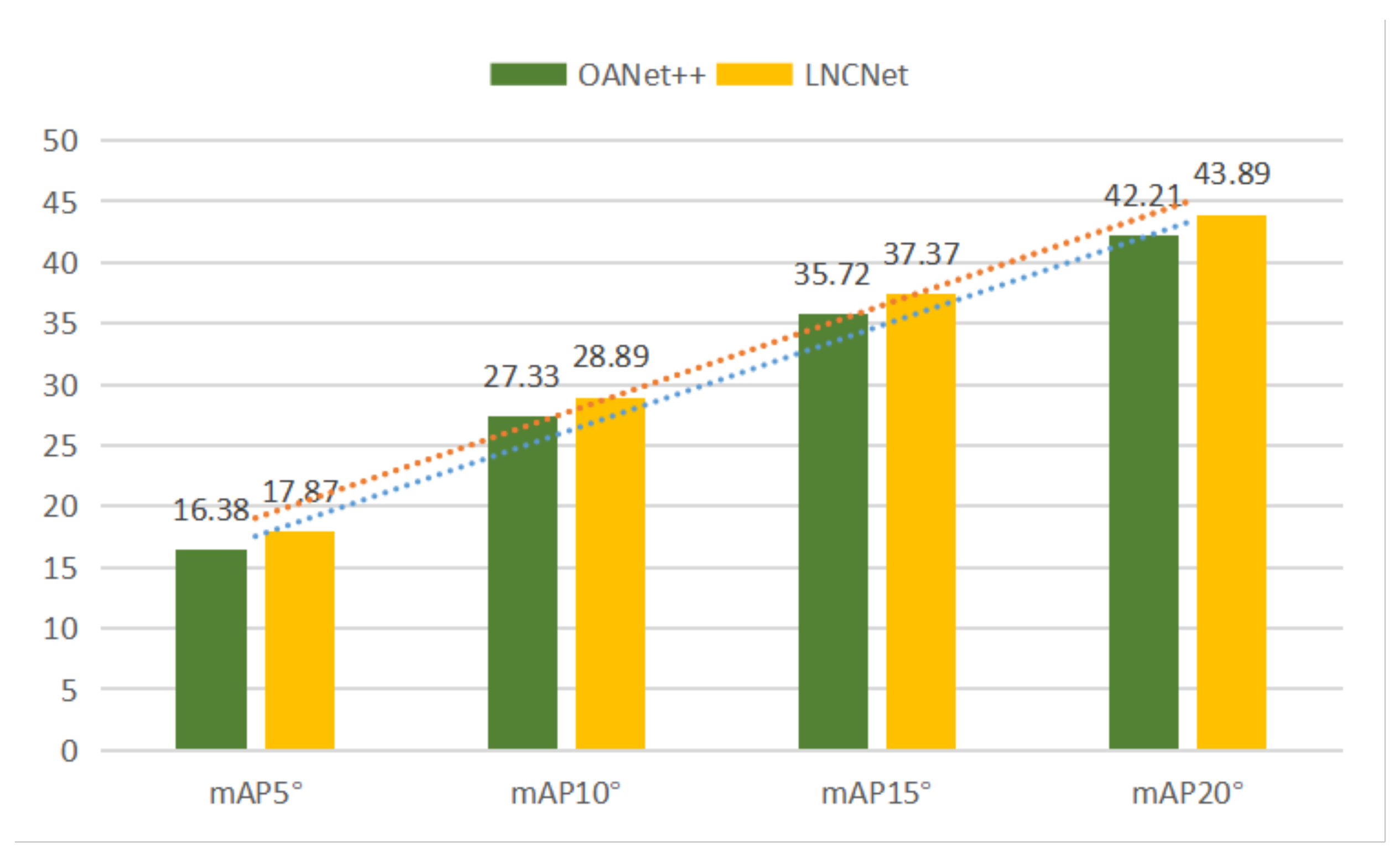
4.2. Evaluation Metrics and Comparative Results
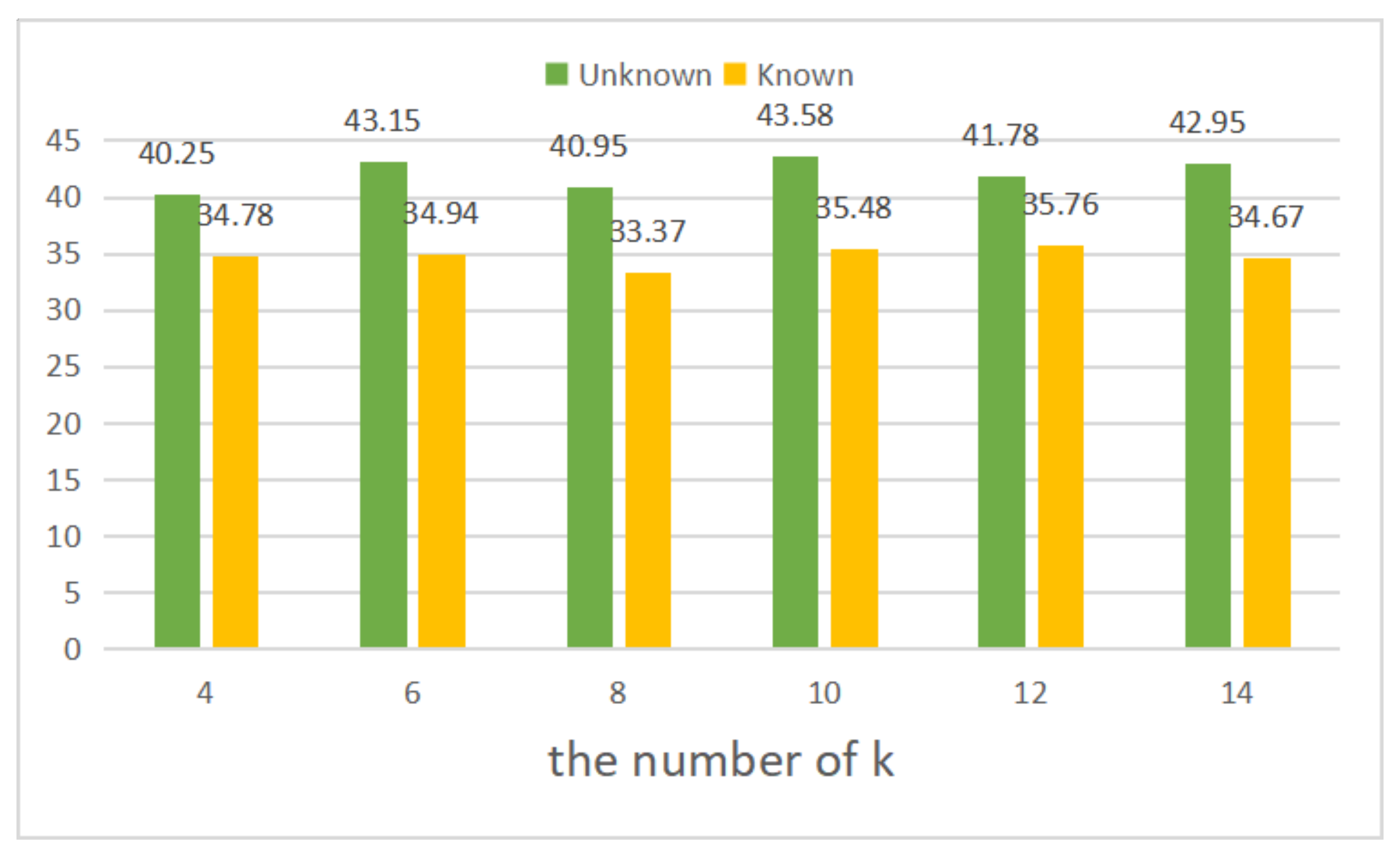
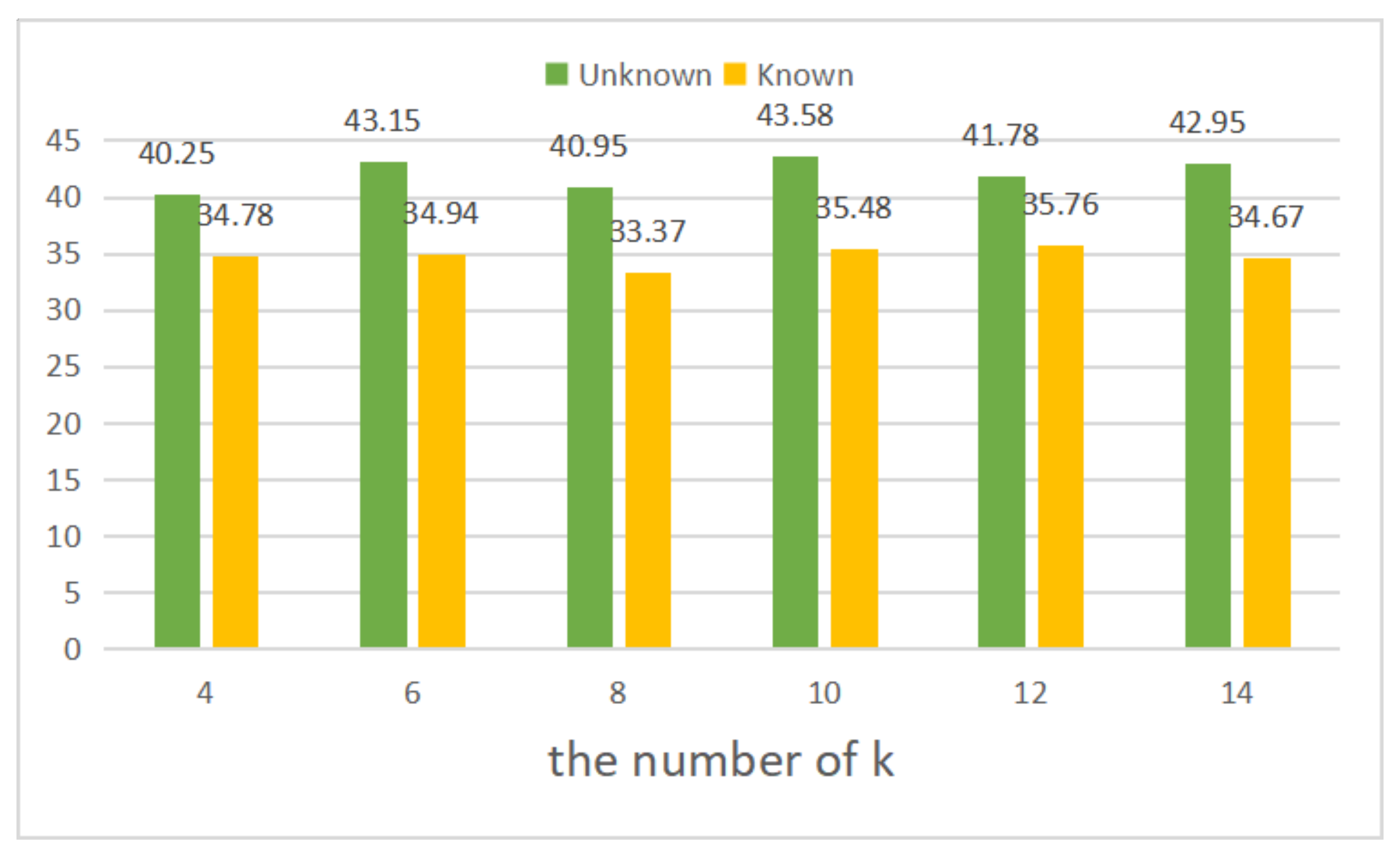
4.3. Ablation Studies
5. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Zhou, H.; Ma, J.; Tan, C.C.; Zhang, Y.; Ling, H. Cross-weather image alignment via latent generative model with intensity consistency. IEEE Trans. Image Process. 2020, 29, 5216–5228. [Google Scholar] [CrossRef]
- Brown, M.; Lowe, D.G. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust feature matching for remote sensing image registration via locally linear transforming. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Fan, A.; Xu, H.; Lin, G.; Lu, T.; Tian, X. Robust Feature Matching for Remote Sensing Image Registration via Linear Adaptive Filtering. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1577–1591. [Google Scholar] [CrossRef]
- Shah, R.; Srivastava, V.; Narayanan, P. Geometry-Aware Feature Matching for Structure from motion Applications. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 278–285. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Myronenko, A.; Song, X. Point set registration: Coherent point drift. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2262–2275. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust point matching via vector field consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Bian, J.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M. Gms: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar] [CrossRef]
- Moo Yi, K.; Trulls, E.; Ono, Y.; Lepetit, V.; Salzmann, M.; Fua, P. Learning to Find Good Correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2666–2674. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Jiang, W.; Trulls, E.; Tagliasacchi, A.; Yi, K.M. ACNe: Attentive Context Normalization for Robust Permutation-Equivariant Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11286–11295. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, D.; Luo, Z.; Yao, A.; Zhou, L.; Shen, T.; Chen, Y.; Quan, L.; Liao, H. Learning Two-View Correspondences and Geometry Using Order-Aware Network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5845–5854. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Mei, X.; Ma, Y.; Huang, J.; Fan, F.; Ma, J. Learning to find reliable correspondences with local neighborhood consensus. Neurocomputing 2020, 406, 150–158. [Google Scholar] [CrossRef]
- Liu, X.; Xiao, G.; Dai, L.; Zeng, K.; Yang, C.; Chen, R. SCSA-Net: Presentation of two-view reliable correspondence learning via spatial-channel self-attention. Neurocomputing 2021, 431, 137–147. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Torr, P.H.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Chum, O.; Matas, J.; Kittler, J. Locally optimized RANSAC. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2003; pp. 236–243. [Google Scholar] [CrossRef]
- Barath, D.; Ivashechkin, M.; Matas, J. Progressive NAPSAC: Sampling from gradually growing neighborhoods. arXiv 2019, arXiv:1906.02295. [Google Scholar]
- Barath, D.; Matas, J.; Noskova, J. MAGSAC: Marginalizing Sample Consensus. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10197–10205. [Google Scholar] [CrossRef] [Green Version]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a Fast, Reliable and Accurate Robust Estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar] [CrossRef]
- Ma, J.; Qiu, W.; Zhao, J.; Ma, Y.; Yuille, A.L.; Tu, Z. Robust L2E estimation of transformation for non-rigid registration. IEEE Trans. Signal Process. 2015, 63, 1115–1129. [Google Scholar] [CrossRef]
- Li, X.; Hu, Z. Rejecting mismatches by correspondence function. Int. J. Comput. Vis. 2010, 89, 1–17. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Tian, J.; Bai, X.; Tu, Z. Regularized vector field learning with sparse approximation for mismatch removal. Pattern Recognit. 2013, 46, 3519–3532. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Jiang, J.; Guo, X. Robust feature matching using spatial clustering with heavy outliers. IEEE Trans. Image Process. 2019, 29, 736–746. [Google Scholar] [CrossRef]
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. Dsac-Differentiable Ransac for Camera Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6684–6692. [Google Scholar]
- Ranftl, R.; Koltun, V. Deep Fundamental Matrix Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 284–299. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Jiang, J.; Zhao, J.; Guo, X. LMR: Learning a two-class classifier for mismatch removal. IEEE Trans. Image Process. 2019, 28, 4045–4059. [Google Scholar] [CrossRef]
- Brachmann, E.; Rother, C. Neural-Guided RANSAC: Learning where to Sample model Hypotheses. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4322–4331. [Google Scholar] [CrossRef] [Green Version]
- Kluger, F.; Brachmann, E.; Ackermann, H.; Rother, C.; Yang, M.Y.; Rosenhahn, B. Consac: Robust Multi-Model Fitting by Conditional Sample Consensus. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4634–4643. [Google Scholar] [CrossRef]
- Swinburne, R. Bayes’ Theorem. Rev. Philos. Fr. 2004, 194. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef] [Green Version]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.J. YFCC100M: The new data in multimedia research. Commun. ACM 2016, 59, 64–73. [Google Scholar] [CrossRef]
- Xiao, J.; Owens, A.; Torralba, A. Sun3d: A Database of Big Spaces Reconstructed Using SFM and Object Labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1625–1632. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5099–5108. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | YFCC100M(%) | SUN3D(%) | ||||
|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |
| RANSAC [7] | 41.83 | 57.08 | 48.28 | 44.11 | 46.42 | 45.24 |
| LPM [10] | 43.75 | 65.65 | 51.72 | 44.28 | 55.42 | 50.63 |
| PointNet++ [39] | 48.42 | 61.16 | 54.05 | 45.64 | 83.43 | 59.00 |
| DFE [31] | 51.68 | 83.49 | 63.84 | 44.09 | 84.00 | 57.82 |
| LMR [32] | 50.73 | 66.12 | 55.19 | 44.88 | 58.21 | 52.71 |
| ACNe [13] | 54.56 | 86.92 | 67.04 | 46.44 | 84.23 | 59.87 |
| LFGC [12] | 53.12 | 85.51 | 65.53 | 47.24 | 83.45 | 60.32 |
| LFGC++ | 53.71 | 85.57 | 66.00 | 45.82 | 84.28 | 59.36 |
| OANet [14] | 55.65 | 85.80 | 67.51 | 46.54 | 83.43 | 59.74 |
| OANet++ | 54.55 | 86.67 | 66.96 | 46.95 | 83.77 | 60.17 |
| LNCNet | 57.67 | 86.21 | 69.11 | 48.37 | 83.49 | 61.25 |
| Algorithm | YFCC100M (%) | SUN3D (%) | ||
|---|---|---|---|---|
| Known | Unknown | Known | Unknown | |
| RANSAC [7] | 5.82/- | 9.08/- | 4.38/- | 2.86/- |
| PointNet++ [39] | 34.69/11.49 | 45.85/15.75 | 21.00/11.80 | 18.79/10.29 |
| DFE [31] | 35.17/12.52 | 49.80/21.78 | 20.34/10.08 | 15.68/08.81 |
| ACNe [13] | 39.08/25.55 | 51.62/35.40 | 21.08/13.44 | 16.40/11.62 |
| LFGC [12] | 37.19/16.77 | 49.93/26.13 | 20.85/13.62 | 16.35/11.96 |
| LFGC++ | 37.76/19.78 | 49.92/30.28 | 21.08/14.33 | 15.77/12.59 |
| OANet [14] | 41.40/31.00 | 51.45/35.07 | 22.29/19.22 | 16.95/13.69 |
| OANet++ | 42.06/34.04 | 51.65/38.95 | 22.76/21.19 | 17.48/16.38 |
| LNCNet | 43.75/35.48 | 54.30/43.58 | 23.05/23.49 | 18.00/17.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, L.; Liu, X.; Wang, J.; Yang, C.; Chen, R. Learning Two-View Correspondences and Geometry via Local Neighborhood Correlation. Entropy 2021, 23, 1024. https://doi.org/10.3390/e23081024
Dai L, Liu X, Wang J, Yang C, Chen R. Learning Two-View Correspondences and Geometry via Local Neighborhood Correlation. Entropy. 2021; 23(8):1024. https://doi.org/10.3390/e23081024
Chicago/Turabian StyleDai, Luanyuan, Xin Liu, Jingtao Wang, Changcai Yang, and Riqing Chen. 2021. "Learning Two-View Correspondences and Geometry via Local Neighborhood Correlation" Entropy 23, no. 8: 1024. https://doi.org/10.3390/e23081024
APA StyleDai, L., Liu, X., Wang, J., Yang, C., & Chen, R. (2021). Learning Two-View Correspondences and Geometry via Local Neighborhood Correlation. Entropy, 23(8), 1024. https://doi.org/10.3390/e23081024