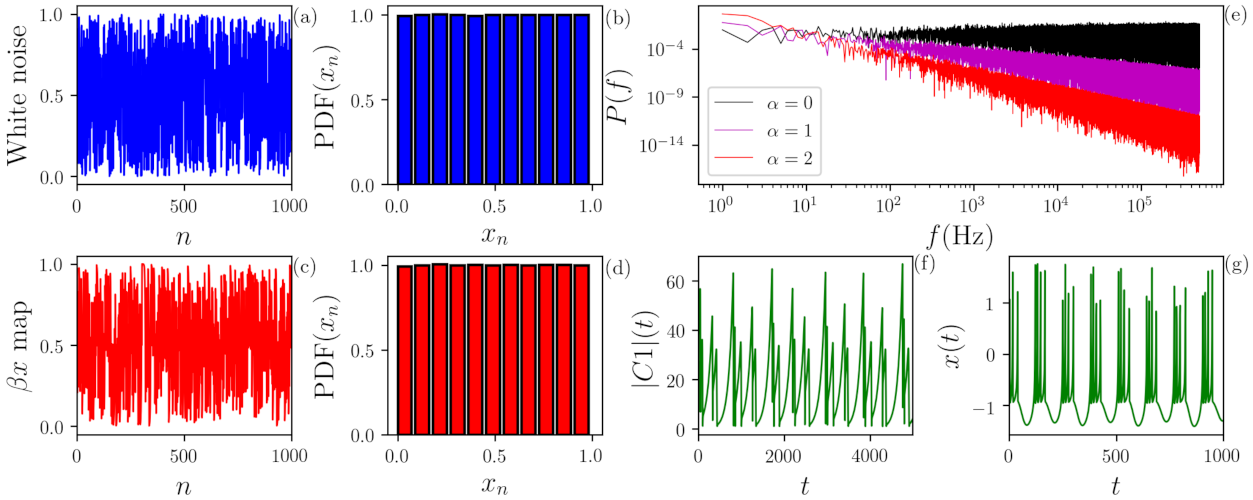
1. Introduction
Thanks to huge advances in data science and computing power, a wide repertoire of time series analysis methods [
1,
2,
3,
4,
5,
6,
7] are available for the quantitative characterization of time series and are routinely used in all fields of science and technology, social sciences, economy and finance, etc. Since different methods have different requirements and involve different approximations, no single method can be expected to perform well over all types of data. Therefore, despite huge advances, extracting reliable information from stochastic or high dimensional signals remains a challenge. As any algorithm will return, at least, a number (i.e., a “feature” that encapsulates some property of the time series), in order to interpret the information in the obtained features and to assess the performance of different algorithms, appropriate surrogates [
8] or a “reference model” (where the systems that generates the data are known) need to be used. The comparison of the features obtained from the time series of interest with those obtained from surrogate time series or from reference time series allows testing (and even quantifying) some particular property of the time series of interest.
We have recently proposed a new method for estimating the strength of the temporal correlations in a given time series, which uses flicker noise (FN), a fully stochastic process, as the reference model [
9]. A FN time series,
, is characterized by a power spectrum
, with
being a parameter that quantifies the temporal correlations present in the signal [
10]. The method proposed in [
9] combines the use of symbolic ordinal analysis [
11,
12] and machine learning (ML): We utilize the ordinal probabilities computed from FN time series generated with different
values as input features to a ML algorithm. The algorithm is trained to return the value of
, which estimates the real
value of a FN time series from the
probabilities of the ordinal patterns of length
D, calculated from the same time series. Then, after the training stage, the ordinal probabilities now computed from a time series of interest,
, are provided as input features to the ML algorithm that returns a value,
, which encapsulates reliable information about the strength of the temporal correlations present in
. By calculating the difference,
, between the permutation entropy (PE) of
and that of a FN time series generated with
,
, we were also able to identify determinism in
.
Our approach is, thus, based on reducing a large number of features (with
, we have
ordinal probabilities) to only two: the
value returned by the ML algorithm; and the permutation entropy,
, computed with the ordinal probabilities. Dimensionality reduction is a well known technique [
13,
14,
15] that has been used to tackle a variety of problems. With ordinal probabilities, for instance, it is possible to distinguish between noise and chaos by reducing the set of probabilities to only two features—the permutation entropy and the complexity; or the permutation entropy and the Fisher information—as demonstrated in [
16,
17,
18,
19]. In our methodology, we not only apply dimensionality reduction but also use a fully stochastic “reference” FN time series: we compare the value of
of the time series of interest with that of a FN time series generated with
. We have shown that the entropy difference,
, may provide good contrast for distinguishing fully stochastic time series from a time series with a degree of determinism [
9].
The method we proposed has in fact a large degree of flexibility because, instead of ordinal analysis and the permutation entropy, different symbolization rules [
20,
21] and different entropies [
22,
23,
24] could be tested. In addition, while we use a simple artificial neural network, other algorithms could be evaluated. Different combinations may provide different results and particular combinations may result in optimized performance for the analysis of particular types of time series.
We have shown that the algorithm returns meaningful information even from time series that are very short: for the synthetic examples considered in [
9], we could distinguish whether the dynamics is mainly chaotic or stochastic with only 100 data points. However, an open question is as follows: What are the limitations in terms of the level of chaos, the level of noise and the length of the time series? Here, we address this issue by using as examples the time series generated with the Logistic map, the
map and the Schuster map. We also address the following questions: Can we distinguish a highly chaotic time series from a stochastic one? Can we identify a periodic signal hidden by noise? In addition, to gain insight into the information encapsulated by
and
, we contrast them with well known quantifiers of chaos and complexity: the maximum Lyapunov exponent and the ordinal-based statistical complexity measure [
25].
The organization of the paper is as follows:
Section 2 describes the methodology,
Section 3 presents the datasets and systems analyzed,
Section 4 presents the results and
Section 5 presents the discussion and our conclusions.
2. Methodology
The methodology proposed in [
9] can be described in a few steps:
- 1.
Calculate the ordinal probabilities (OPs) of a large set of FN time series generated with different values of and use them as features to train a ML algorithm to return the (known) value of ;
- 2.
Calculate the OPs of the time series of interest,
, and use them as features to the trained ML algorithm, which returns a value
(see
Section 2.1);
- 3.
Generate a FN time series with
and calculate its permutation entropy (PE),
(see
Section 2.2);
- 4.
Calculate the relative difference,
, between the PE of
,
and
:
- 5.
Use the value of to quantify the strength of the temporal correlations in the time series of interest and use the value of to identify underlying determinism: if , is mainly stochastic, otherwise there is some determinism.
In the implementation proposed in [
9], the probabilities of the 720 ordinal patterns of length
(described in the next section) were used as input features to the ML algorithm. Then, these features were reduced to only two: the scalar value returned by the ML algorithm,
, which quantifies the temporal correlations presented in the time series of interest
; and the permutation entropy,
(Equation (
4)). Then, the value of
was compared with the PE of a FN time series generated with
and the relative difference,
(Equation (
1)), was found to provide contrast for identifying determinism in
. The value of
can be used to organize a set of time series according to their level of stochasticity (the lower the value of
, the larger the stochasticity level) and, by appropriately selecting a threshold value,
can be used to classify the time series into two categories: mainly stochastic and mainly deterministic.
2.1. Machine Learning Algorithm
A wide range of ML algorithms are available nowadays. Since we want to regress the information of the features (
probabilities) into one real value,
(a classical scalar regression problem), an appropriate simple option is a feed forward artificial neural network (ANN). Mathematically, the ANN can de described as follows. Considering a set of inputs
of
features with output
, the ANN can be sketched by the following:
where
and
are matrices of
weights,
and
are
biases column vectors,
f and
correspond to activation functions and the “*” symbols corresponds to a tensor product. In this sense,
is the result of the transformation
, which can be understood as a new representation of the inputs
. The elements of the tensors
are the parameters of the ANN, which are calibrated in the training state. ANNs are well known, and we refer the reader to our previous work [
9] for details about the network structure and the training procedure. We remark that our ANN is a fast and automatic tool and it performed well in all the cases we tested, with a computational time and in a standard notebook, of a few seconds for the analysis of time series with
data points. However, we do not claim that an ANN is an optimal choice, since different ML algorithms may be even more efficient. It is important to notice also that the optimal choice will likely depend on the characteristics of the time series (length, frequency content, level of noise, etc.).
2.2. Ordinal Analysis and Permutation Entropy
Ordinal analysis and the permutation entropy were proposed by Bandt and Pompe [
11] almost 20 years ago and they are now well-known. For their interdisciplinary applications, we refer the reader to a recent
Focus Issue [
12].
Here, we compute the ordinal patterns of length
with the algorithm proposed in [
26]. For
, there are
possible patterns. The patterns are calculated with an overlap of
data points, i.e., for a time series with
N data points,
ordinal patterns are obtained, which are then used to evaluate the ordinal probabilities
. Then, the normalized permutation entropy is calculated as follows.
2.3. Quantifiers of Chaos and Complexity
The Lyapunov exponents measure the local divergence of infinitesimally close trajectories, and positive exponents indicate chaos [
27]. While there are important challenges when calculating them from high-dimensional and/or noisy data [
3,
28], in the case of a one-dimensional dynamical system for which its governing equation is known, the Lyapunov exponent,
, can be straightforwardly calculated as follows.
A popular measure for characterizing complex systems is the statistical complexity measure [
25] that takes into account the distance to the most regular state and the most random states of the system. It is defined as follows:
where
is the entropy and
Q is the distance between the distribution that describes the state of the system,
, and the equilibrium distribution,
, that maximizes the entropy.
As we use the probabilities of the ordinal patterns [
16,
29],
is the normalized permutation entropy and
. The distance between
and
is calculated with the Jensen–Shannon divergence:
where
a normalization factor
.
4. Results
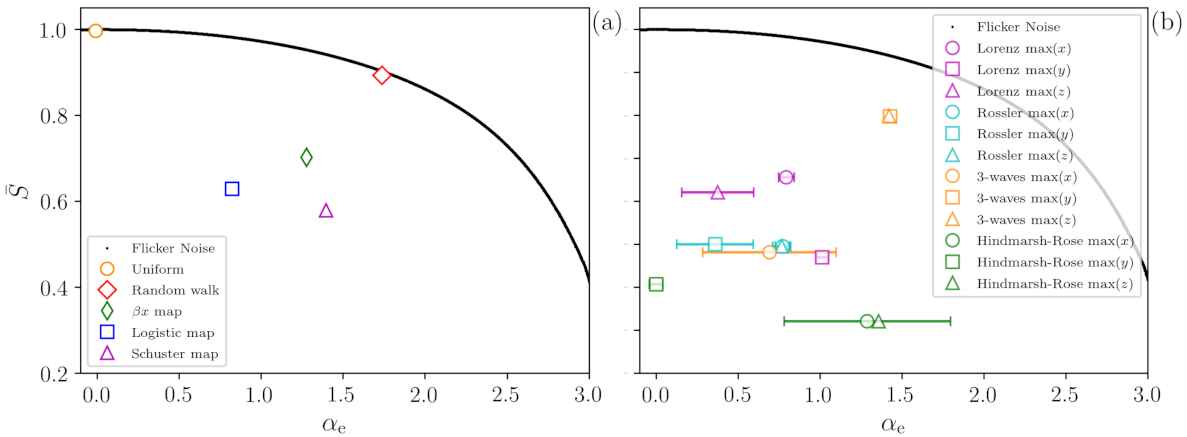
A demonstration of the methodology is presented in
Figure 2 that shows, in the plane (
,
), the values obtained from time series generated with the dynamical systems described in the previous section. All the time series analyzed possesses
points and the error bars represent the standard deviation over 1000 time series generated with different initial conditions or noise seeds.
Figure 2a presents results for discrete systems, while
Figure 2b, for continuous systems. In both panels the black line represents FN signals generated with different values of
, which are perfectly recovered by the ANN (that returns a value
equal to
). As expected, for
,
since the FN signal is white noise [
37]. For
, some ordinal patterns occur in the time series more frequently than others, and the value of
decreases.
In panel (a), the orange circle represents time series of uniform white noise, and the ANN returns the correct value (There is almost no dispersion in the returned value of , therefore, the error bar is not shown). The red diamond represents random walk signals; for them, the ANN returns (Again, there is almost no dispersion in the value of ). We observe that the red diamond is very close to the black line, providing a clear indication of the highly stochastic nature of a time series generated by a one-dimensional random walk.
On the other hand, when we analyze chaotic signals (time series from map with , from logistic map with and from Schuster map with ), we observe that the distance between the symbols and the FN noise curve (black line) allows identifying the signals as not fully stochastic, i.e., the distance to the FN curve uncovers determinism in the signals.
For continuous dynamical systems, the results obtained with ordinal analysis strongly depend on the lag time between the data points, which can be performed in multiple ways, for instance using the maxima of each variable or even the first minimum of the mutual information [
38]. While this dependence with the lag allows identifying different time scales in a complex signal [
39,
40], it renders it difficult to compare different signals. Therefore, for the continuous dynamical systems considered (Lorenz, Rossler, 3-waves and Hindmarsh–Rose), the time series analyzed here are the sequence of maxima of each variable of the system. Due to the fact that the variables obey different equations and have oscillations with different properties, we can expect obtaining different values of
. Despite a large dispersion in the values obtained, it can be observed in
Figure 2b that all the systems depict a substantial distance to the FN curve, clearly revealing that they are not fully stochastic. The dispersion in the permutation entropy values is of the order of 1%; therefore, vertical error bars are not shown.
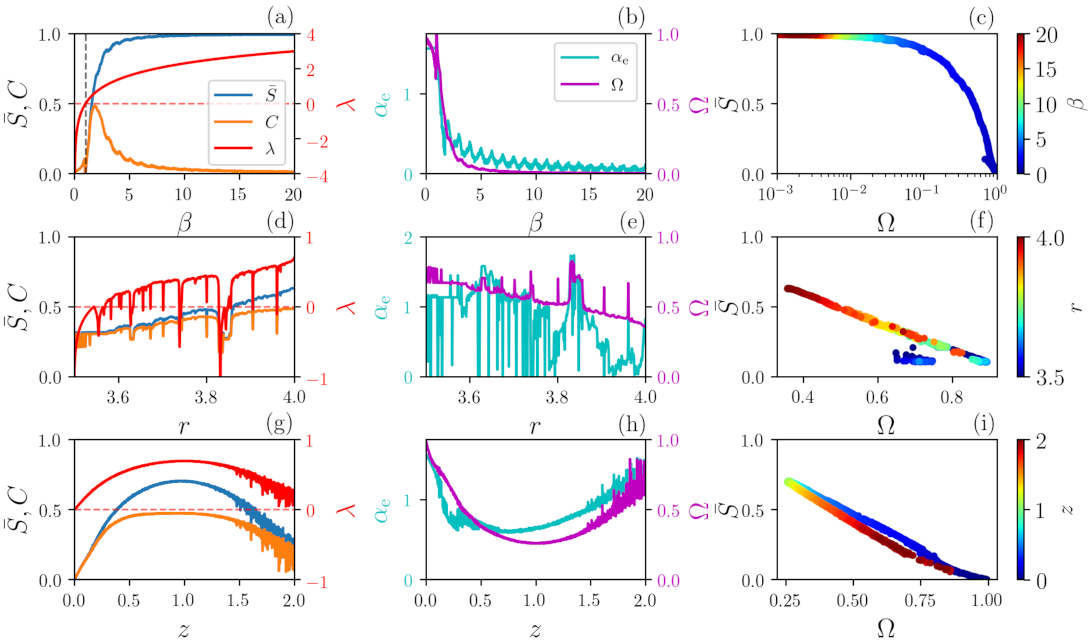
4.1. Comparison with Standard Quantifiers
Next, we compare, for the three chaotic maps, the quantifiers obtained with our approach,
and
, with well-known quantifiers of chaos and complexity including the Lyapunov exponent,
and the ordinal statistical complexity,
C (described in
Section 2.3).
The results are depicted in
Figure 3. Panels (a), (b) and (c) show results for the
map. For
, the map is not chaotic since
. In this range,
decreases while
remains constant. The
map is chaotic for
, since
. At
,
and
vary abruptly and both decreases as
increases. There is negative correlation between
and
and also between
and
. If
is too large,
and
determinism can no longer be identified. We note that the small oscillations of
capture the changes in dynamics when
approaches an integer number since the PDF of
is homogeneous for integer
but becomes inhomogeneous for non-integer values [
41], which is not clearly observed in the other quantifiers.
In panels (d), (e) and (f) for the logistic map, periodic windows embedded in chaotic regions are detected in the Lyapunov exponent, and the quantifiers , C and also show abrupt variations. We note that identifies the deterministic nature of the signals since, for the entire interval of r, remains well above zero and remains well below one.
Similar results are found for the Schuster map, panels (g), (h) and (i):
is anti-correlated with
and confirms that the signal is always deterministic since relatively large
values are observed for the entire interval of
z. Even though a signal generated by the Schuster map has the same power spectrum as Flicker noise, its
value varies non-monotonically with
z [
32], contrary to the line
that is obtained from FN signals. This is due to the fact that signals generated by the Schuster map and FN signals have different sets of ordinal probabilities.
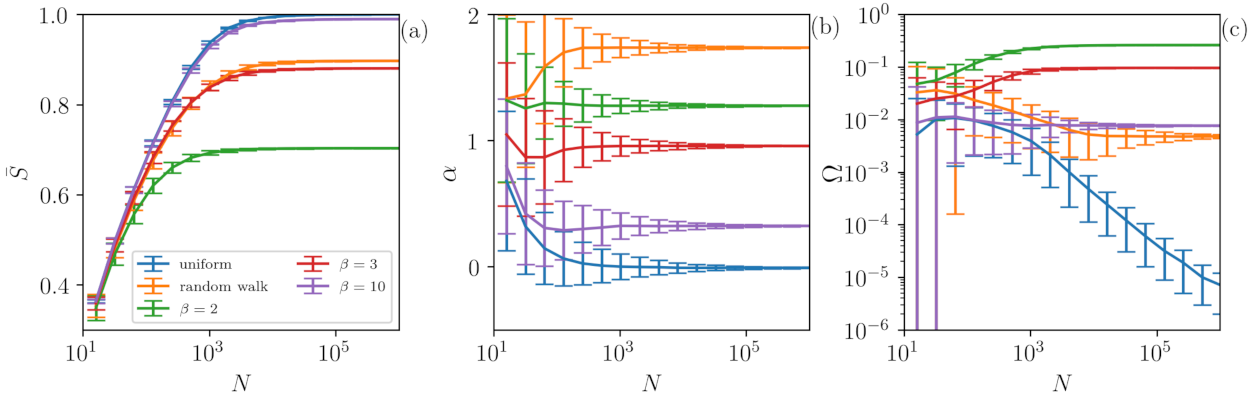
4.2. Influence of the Length of the Time Series
The results so far indicate that our methodology is very precise for characterizing chaotic and stochastic signals when long times series are analyzed (in
Figure 2 and
Figure 3 ). However, an important question is the following: What is the role of the time series size in the analysis? In order to address this issue, we investigate both stochastic and chaotic time series with different lengths
N.
Figure 4 displays the role of time series length
N in
(a), in the output of the ANN
(b) and in
(c) for chaotic and for stochastic signals. Here, chaotic time series are represented by signals generated with the
map, while stochastic ones are given by uniform white noise and a random walk.
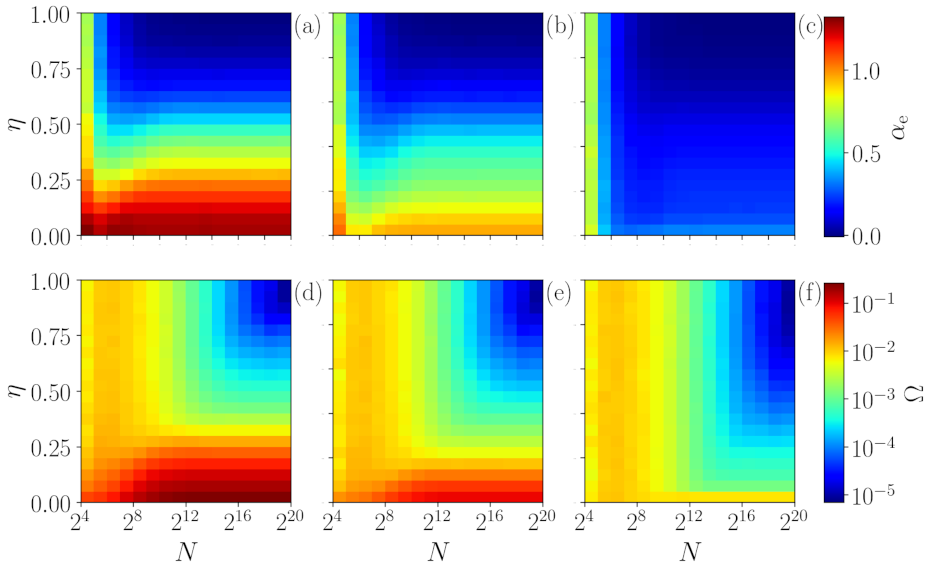
One can observe that, in general, for a small number of data points (), our method is unable to distinguish the signals as all of them are overlapping. Interestingly, for , our method is able to distinguish the chaotic signal generated by the map with (green lines), since depicts values that are higher than those of the other signals. As N is increased, the signal of is also separated and characterized as chaotic. Surprisingly, for (the number of features), we are already able to distinguish the chaotic signals of and from the stochastic ones (uniform and random walk) by using the quantifier . The results improve as the number of points increases and, for , the analysis stabilizes. Here, an important point is that even if the chaotic and stochastic signals have similar permutation entropy values (), is able to capture their difference. On the other hand, if the chaoticity of the signal is too high, as observed for (purple lines), . In this case the ordinal probabilities of the signal are as uniform as those of white noise, which means that we are unable to identify determinism.
Figure 5 shows that the above observations remain robust when noise is added to the chaotic signal. As explained in
Section 3.4, we control the amount of noise in the analyzed time series by varying the parameter
. If the time series is too long and has too much noise,
does not identify determinism (blue region). On the other hand, if the time series is not long,
identifies determinism even when there is no determinism for
(orange region). Therefore, for a correct interpretation of the information contained in the value of
, we need to compare it with the value of
obtained from “reference” time series of the same length as the time series of interest, generated by a known stochastic process such as Flicker noise.
4.3. Analysis of Periodic Signals Contaminated by Noise
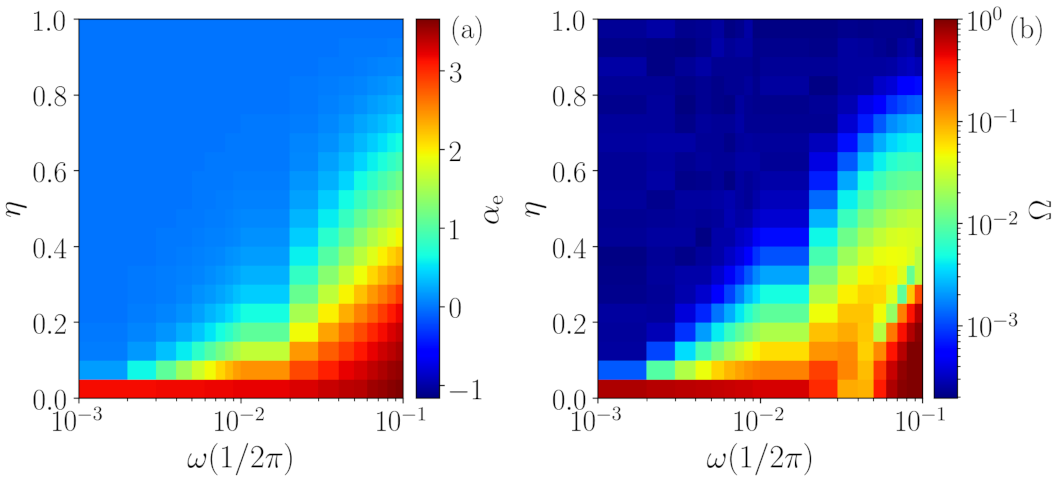
Another challenge to our methodology is the identification of periodic signals with added noise. The results obtained when varying the parameter
(see
Section 3.4) are depicted in
Figure 6, where panel (a) shows the temporal correlation
returned by the ANN and panel (b) shows the quantifier
, both as a function of
. Here, the periodic signals with
points and different frequencies
are analyzed.
First, one can observe that, for , all signals are characterized as deterministic (high value of ) with a high temporal correlation (high value of ), which is expected from a periodic signal. Secondly, as we can also expect for , all signals are identified as stochastic and memory-less (zero temporal correlation), since the added noise is white. However, for intermediate values of , an interesting behavior is observed. The frequency of the signal is indeed important, because periodic signals with low frequencies are characterized as stochastic time series for lower values of (panel (b)). For instance, for , the signal is characterized as noisy even for very small values of , while for signals with , the deterministic nature of the original time series is kept for . As expected, the temporal correlation of the signals (panel (a)) also depends on the frequency . As is increased, the higher the frequency of the signal, the slower the way (i.e., high-frequency signals loss memory slower than low-frequency signals). Since the noise being added is white and thus, is memory-less, one can expect that and for . However, we see that the temporal correlation can be high even when is very small. Therefore, these signals are first identified as noisy with non-zero time correlation, and, subsequently, they are identified as noisy with no time correlation.
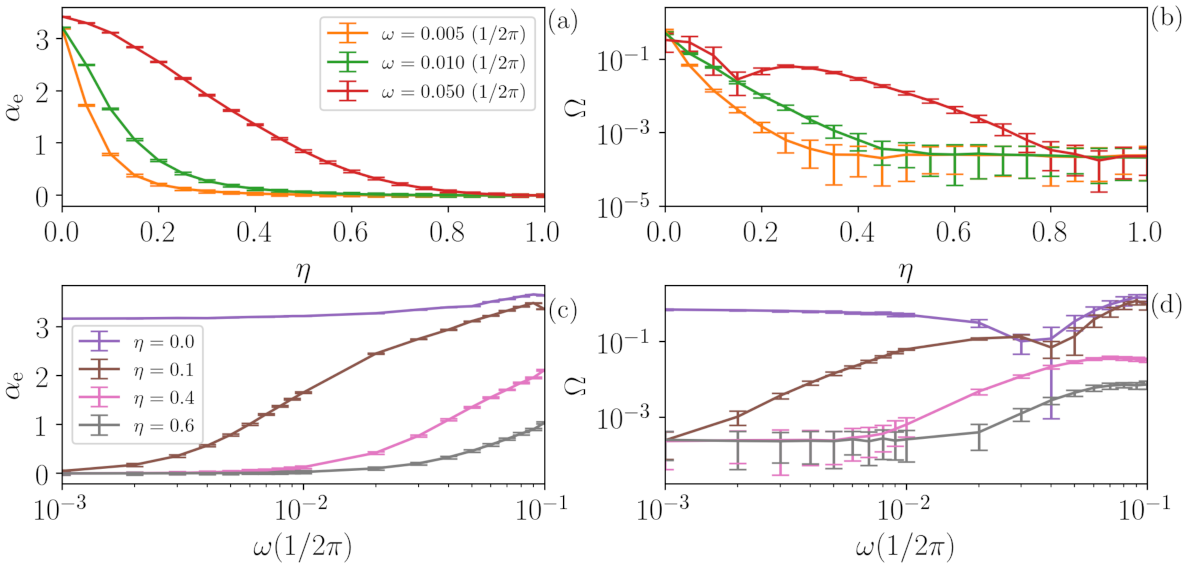
These results and conclusions are robust for different realizations of the noise, as is shown in
Figure 7, which depicts curves with fixed values of
(upper row) as a function of
. Panel (a) shows the temporal correlation coefficient
, while panel (b) shows the quantifier
. Following the same idea, the lower row shows three examples with fixed
values as a function of the periodic signal frequency
. In all cases, the error bars represent the dispersion over 1000 different noise realizations, and we can observe that the trends discussed previously persist over different noise realizations.
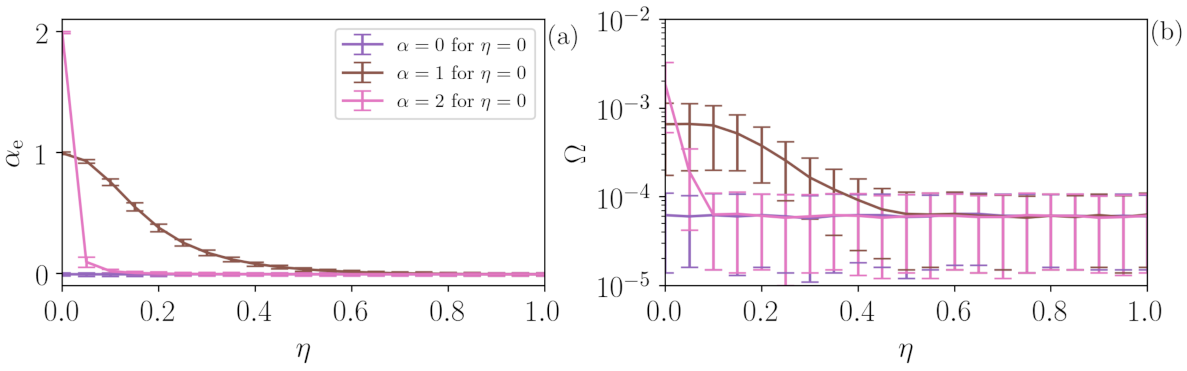
4.4. Analysis of Two Stochastic Processes
In experimental stochastic systems, two (or more) stochastic dynamics are often present. In order to test the performance of the algorithm in this situation, we consider the same approach as in the previous section,
, but now
is not a periodic signal but a Flicker noise. The results are depicted in
Figure 8, where panels (a) and (b) present
and
, respectively, and are calculated from 1000 FN time series with
(purple),
(brown) and
(pink). For
(FN noise)
, as
increases due to the influence of the uniform white noise,
decreases to 0 and
(pink line) decays faster due to the slower dynamics, while
(purple) does not change since there is no time correlation in both
and
.
is extremely low for all cases (
) identifying the full stochasticity of the time series.
5. Discussions and Conclusions
We have analyzed stochastic and deterministic time series using an algorithm [
9] that automatically reduces the dimensionality of the feature space from 720 probabilities of ordinal patterns to 2 features: the degree of stochasticity (
) and the strength of the temporal correlations (
). We have analyzed the performance and limitations of the algorithm, presenting applications to different datasets, including highly chaotic and periodic signals with added white noise.
For the analysis of chaotic time series, we have shown that and are able to capture the rich dynamics that chaotic systems can depict, where the transitions between periodic windows and chaos are evident. In general, negative correlation between the Lyapunov exponent and and between the permutation entropy and were found. For highly chaotic signals, when the time evolution of the system is very similar to a stochastic process, and and our methodology characterizes highly chaotic signals as stochastic ones.
In addition, we have studied periodic signals contaminated with noise. In this case, our method captures the transition from deterministic time series to stochastic ones. However, we have shown that the period of the signal is indeed important, with fast signals being identified as deterministic even with large noise. We have found that when the noise contamination increases, periodic signals lose their deterministic feature but preserve a nonzero temporal correlation.
For future work, it will be interesting to analyze whether the performance of our methodology can be improved by using different lengths of the ordinal pattern,
D, or different lags between the data points that define the ordinal patterns. It is well known that the ordinal patterns distribution varies with the time scale of the analysis [
19] and it will also be interesting, for future work, to address the relevant question of whether our method is able to estimate, from the same time series, different values of
by using different lags.
We remark that the automatic and easy-to-use time series analysis tool that we propose is here is freely available at [
42]. We believe that it will be a valuable contribution to the wide repertoire of time series analysis tools that are available nowadays. Many applications are foreseen. As an example, for ultra-fast optical random number generation [
43,
44,
45], it is crucial to generate optical chaotic signals that are as uncorrelated and as ‘‘pseudorandom’’ as possible, for which its deterministic nature is hidden by noise-like properties. Many different setups have been proposed to generate such broad-band, high-entropy optical signals [
46,
47,
48,
49,
50]. Our algorithm allows an automatic comparison of the strength of the correlations and the level of randomness of signals generated by different setups. Moreover, the algorithm may be used to identify, in a given experimental setup, the optimal operation conditions and parameters that produce optical signals with the lowest temporal correlations (lowest
) or with highest level of randomness (lowest
).


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}