1. Introduction
Large-scale data sets, where the number of predictors significantly exceeds the number of observations, become common in many practical problems from, among others, biology or genetics. Currently, the analysis of such data sets is a fundamental challenge in statistics and machine learning. High-dimensional prediction and variable selection are arguably the most popular and intensively studied topics in this field. There are many methods trying to solve these problems such as those based on penalized estimation [
1,
2]. The main representative of them is Lasso [
3], that relates to
-norm penalization. Its properties in model selection, estimation and prediction are deeply investigated, among others, in [
2,
4,
5,
6,
7,
8,
9,
10]. The results obtained in the above papers can be applied only if some specific assumptions are satisfied. For instance, these conditions concern the relation between the response variable and predictors. However, it is quite common that a complex data set does not satisfy these model assumptions or they are difficult to verify, which leads to the fact that the considered model is specified incorrectly. The model misspecification problem is the core of the current paper. We investigate this topic in the context of high-dimensional binary classification (binary regression).
In the classification problem we are to predict or to guess the class label of the object on the basis of its observed predictors. The object is described by the random vector
where
is a vector of predictors and
is the class label of the object. A classifier is defined as a measurable function
which determines the label of an object in the following way:
Otherwise, we guess that
The most natural approach is to look for a classifier
which minimizes the misclassification risk (probability of incorrect classification)
Let
It is clear that
minimizes the risk (
1) in the family of all classifiers. It is called the Bayes classifier and we denote its risk as
Obviously, in practice we do not know the function
, so we cannot find the Bayes classifier. However, if we possess a training sample
containing independent copies of
then we can consider a sample analog of (
1), namely the empirical misclassification risk
where
is the indicator function. Then a minimizer of (
2) could be used as our estimator.
The main difficulty in this approach lies in discontinuity of the function (
2). It entails that finding its minimizer is computationally difficult and not effective. To overcome this problem, one usually replaces the discontinuous loss function by its convex analog
, for instance the logistic loss, the hinge loss or the exponential loss. Then we obtain the convex empirical risk
In the high-dimensional case one usually obtains an estimator by minimizing the penalized version of (
3). Those tricks have been successfully used in the classification theory and have allowed to invent boosting algorithms [
11], support vector machines [
12] or Lasso estimators [
3]. In this paper we are mainly interested in Lasso estimators, because they are able to solve both variable selection and prediction problems simultaneously, while the first two algorithms are developed mainly for prediction.
Thus, we consider linear classifiers
where
For a fixed loss function
we define the Lasso estimator as
where
is a positive tuning parameter, which provides a balance between minimizing the empirical risk and the penalty. The form of the penalty is crucial, because its singularity at the origin implies that some coordinates of the minimizer
are exactly equal to zero, if
is sufficiently large. Thus, calculating (
5) we simultaneously select significant predictors in the model and we estimate their coefficients, so we are also able to predict the class of new objects. The function
and the penalty are convex, so (
5) is a convex minimization problem, which is an important fact from both practical and theoretical points of view. Notice that the intercept
is not penalized in (
5).
The random vector (
5) is an estimator of
where
In this paper we are mainly interested in minimizers (
6) corresponding to quadratic and logistic loss functions. The latter has a nice information-theoretic interpretation. Namely, it can be viewed as the Kullback–Leibler projection of unknown
on logistic models [
13]. The Kullback–Leibler divergence [
14] plays an important role in the information theory and statistics, for instance it is involved in information criteria in model selection [
15] or in detecting influenctial observations [
16].
In general, the classifier corresponding to (
6) need not coincide with the Bayes classifier. Obviously, we want to have a “good” estimator, which means that its misclassification risk should be as close to the risk of the Bayes classifier as possible. In other words, its excess risk
should be small, where
is the expectation with respect to the data
and we write simply
instead of
Our goal is to study the excess risk (
7) for the estimator (
5) with different loss functions
We do it by looking for the upper bounds of (
7).
In the excess risk (
7) we compare two misclassification risks defined in (
1). In the literature one can also find a different approach, which replaces the misclassification risks
in (
7) by the convex risks
In that case the excess risk depends on the loss function
To deal with this fact one uses the results from [
17,
18], which state the relation between the excess risk (
7) and its analog based on the convex risk
In this paper we do not follow this way and work, right from the beginning, with the excess risk independent of
Only the estimator (
5) depends on the loss
In this paper we are also interested in variable selection. We investigate this problem in the following semiparametric model
where
,
is the true parameter and
g is unknown function. Thus, we suppose that predictors influence class probability through the function
g of the linear combination
. The goal of variable selection is the identification of the set of significant predictors
Obviously, in the model (
8) we cannot estimate an intercept
and we can identify the vector
only up to a multiplicative constant, because any shift or scale change in
can be absorbed by
g. However, we show in
Section 5 that in many situations the Lasso estimator (
5) can properly identify the set (
9).
The literature on the classification problem is comprehensive. We just mention a few references: [
12,
19,
20,
21]. The predictive quality of classifiers is often investigated by obtaining upper bounds for their excess risks. It is an important problem and was studied thoroughly, among others in [
17,
18,
22,
23,
24]. The variable selection and predictive properties of estimators in the high-dimensional scenario were studied, for instance, in [
2,
10,
13,
25,
26]. In the current paper we investigate the behaviour of classifiers in possibly misspecified high-dimensional classification, which appears frequently in practice. For instance, while working with binary regression one often assumes incorrectly that the data follow the logistic regression model. Then the problem is solved using the Lasso penalized maximum likelihood method. Another approach to binary regression, which is widely used due to its computational simplicity, is just treating labels
as they were numbers and applying standard Lasso. For instance, such method is used in ([
1], [Subsections 4.2 and 4.3]) or ([
2], Subsection 2.4.1). These two approaches to classification sometimes give unexpectedly good results in variable selection and prediction, but the reason of this phenomenon has not been deeply studied in the literature. Among the above mentioned papers only [
2,
13,
25] take up this issue. However, [
25] focuses mainly on the predictive properties of Lasso classifiers with the hinge loss. Bühlmann and van de Geer [
2] and Kubkowski and Mielniczuk [
13] study general Lipschitz loss functions. The latter paper considers only the variable selection problem. In [
2] one also investigates prediction, but they do not study classification with the quadratic loss.
In this paper we are interested in both variable selection and predictive properties of classifiers with convex (but not necessarily Lipschitz) loss functions. The prominent example is classification with the quadratic loss function, which has not been investigated so far in the context of the high-dimensional misspecified model. In this case the estimator (
5) can be calculated efficiently using the existing algorithms, for instance [
27] or [
28], even if the number of predictors is much larger than the sample size. It makes this estimator very attractive, while working with large data sets. In [
28] one provides also the efficient algorithm for Lasso estimators with the logistic loss in the high-dimensional scenario. Therefore, misspecified classification with the logistic loss plays an important role in this paper as well. Our goal is to study thoroughly such estimators and provide conditions, which guarantee that they are successful in prediction and variable selection.
The paper is organized as follows: in the next section we provide basic notations and assumptions, which are used in this paper. In
Section 3 we study predictive properties of Lasso estimators with different loss functions. We will see that these properties depend strongly on the estimation quality of estimators, which is studied in
Section 4. In
Section 5 we consider variable selection. In
Section 6 we show numerical experiments, which describe the quality of estimators in practice. The proofs and auxiliary results are relegated to
Appendix A.
2. Assumptions and Notation
In this paper we work in the high-dimensional scenario As usual we assume that the number of predictors p can vary with the sample size which could be denoted as However, to make notation simpler we omit the lower index and write p istead of The same refers to the other objects appearing in this paper.
In the further sections we will need the following notation:
- -
;
- -
is the -matrix of predictors;
- -
Let Then is a complement of A;
- -
is a submatrix of with columns whose indices belong to A;
- -
is a restriction of a vector to the indices from
- -
is the number of elements in
- -
so the set contains indices from A and the intercept;
- -
The -norm of a vector is defined as for
- -
For we denote
- -
is the matrix with the column of ones binded from the left side;
- -
are minimizers in (
5), (
6), respectively, with the quadratic loss function;
- -
are minimizers in (
5), (
6), respectively, with the logistic loss function;
- -
The Kullback–Leibler (KL) distance [
14] between two binary distributions with success probabilities
and
is defined as
Obviously, we have and if only if . Moreover, the distance need not be symmetric;
- -
the set of nonzero coefficients of
is denoted as
Notice that the intercept is not contained in (
11) even if it is nonzero.
We also specify assumptions, which are used in this paper.
Assumption 1. We assume that are i.i.d. random vectors. Moreover, predictors are univariate subgaussian, i.e., for each and we have for positive numbers We also denote Finally, we suppose that the matrix is positive definite and for
Assumption 2. We suppose that the subvector of predictors is subgaussian with the coefficient , i.e., for each we have where The remaining conditions are as in Assumption 1. We also denote
Subgaussianity of predictors is a standard assumption while working with random predictors in high-dimensional models, cf. [
13]. In particular, Assumption 1 implies that
and
[
29].
3. Predictive Properties of Classifiers
In this part of the paper we study prediction properties of classifiers with convex loss functions. To do it we look for upper bounds of the excess risk (
7) of estimators.
As usual the excess risk in (
7) can be decomposed as
The second term in (
12) is the approximation risk and compares the predictive abilitity of the “best” linear classifier (
6) to the Bayes classifier. The first term in (
12) is called the estimation risk and describes how the estimation process influences the predictive property of classifiers.
In the next theorem we bound from above the estimation risk of classifiers. To make the result more transparent we use notations
and
in (
13), which indicate explicitly which probability we consider, i.e.,
is probability with respect to the data
D and
is with respect to the new object
X. In further results we omit these lower indexes and believe that it does not lead to confusion.
Theorem 1. For we consider an event We have In Theorem 1 we obtain the upper bound for the estimation risk. This risk becomes small, if we establish that probability of the event
is small and the sequence
which is involved in
and in the second term on the right-hand side of (
13), decreases sufficiently fast to zero. Therefore, Theorem 1 shows that to have a small estimation risk it is enough to prove that for each
there exists
c such that
Moreover, numbers
and
c should be sufficiently small. This property will be studied thoroughly in the next section. Notice that the first term on the right-hand side of (
13) relates to the fact, how well (
5) estimates (
6). Moreover, the second expression on the right-hand side of (
13) can be bounded from above, if predictors are sufficiently regular, for instance subgaussian.
So far, we have been interested in the estimation risk of estimators. In the next result we establish the upper bound for the approximation risk as well. This bound combined with (
13) enables us to bound from above the excess risk of estimators. We prove this fact for the quadratic loss
and the logistic loss
, which play prominent roles in this paper.
Theorem 2. Suppose that Assumption 1 is fulfilled. Moreover, a random variable has a density which is continuous on the interval and
where refers to the density h of
(b) Let Then we obtainwhere is the Kullback–Leibler distance defined in (10) and refers to the density h of Additionally, assuming that there exists such that and we have In Theorem 2 we establish upper bounds on the excess risks for Lasso estimators (
5). They describe predictive properties of these classifiers. In this paper we consider linear classifiers, so the misclassification risk of an estimator is close to the Bayes risk, if the “truth” can be approximated linearly in a satisfactory way. For the classifier with the logistic loss this fact is described by (18) and (
19), which measure the distance between true success probability and the one in logistic regression. In particular, when the true model is logistic, then (18) and (
19) vanish. The expression (16) relates to the approximation error in the case of the quadratic loss. It measures how well the conditional expectation
can be described by the “best” (with respect to the loss
) linear function
The right-hand sides of (
15) and (
17) relate to estimation risk. They have been already discussed after Theorem 1. Using subgaussianity of predictors we have made them more explicit. The main ingredient of bounds in Theorem 2, namely
is studied in the next section.
Results in Theorem 2 refer to Lasso estimators with quadratic and logistic loss functions. Similar results are given in ([
2], Theorem 6.4). They refer to the case that the convex excess risk is considered, i.e., the misclassification risks
are replaced by the convex risks
in (
7). Moreover, these results do not consider Lasso estimators with the quadratic loss applied to classification, which is an approach playing a key role in the current paper. Furthermore, in ([
2], Theorem 6.4) the estimation error
is measured in the
-norm, which is enough for prediction. However, for variable selection the
-norm gives better results. Such results will be established in
Section 4 and
Section 5. Finally, results of [
2] need more restrictive assumptions than ours. For instance, predictors should be bounded and a function
should be sufficiently close to
in the supremum norm.
Analogous bounds to those in Theorem 2 can be obtained for other loss functions, if we combine Theorem 1 with results of [
17]. Finally, we should stress that the estimator
need not rely on the Lasso method. All we require is that the bound (
14) can be estiblished for this estimator.
4. On the Event
In this section we show that probability of the event
can be close to one. Such results for classification models with Lipschitz loss functions were established in [
2,
13]. Therefore, we focus on the quadratic loss function, which is obviously non-Lipschitz. This loss function is important from the practical point of view, but was not considered in these papers. Moreover, in our results the estimation error in
can be measured in the
-norms,
not only in the
-norm as in [
2,
13]. Bounds in the
-norm lead to better results in variable selection, which are given in
Section 5.
We start with introducing the cone invertibility factor (CIF), which plays a significant role in investigating properties of estimators based on the Lasso penalty [
9]. In the case
one usually uses the minimal eigenvalue of the matrix
to express the strength of correlations between predictors. Obviously, in the high-dimensional scenario this value is equal to zero and the minimal eigenvalue needs to be replaced by some other measure of predictors interdependency, which would describe the potential of consistent estimation of model parameters.
For
we define a cone
where we recall that
In the case when
three different characteristics measuring the potential for consistent estimation of the model parameters have been introduced:
- -
The restricted eigenvalue [
8]:
- -
The compatibility factor [
7]:
- -
The cone invertibility factor (CIF, [
9]): for
In this article we will use CIF, because this factor allows for a sharp formulation of convergency results for all
norms with
see ([
9], Section 3.2). The population (non-random) version of CIF is given by
where
The key property of the random and the population versions of CIF,
and
, is that, in contrast to the smallest eigenvalues of matrices
and
they can be close to each other in the high-dimensional setting, see ([
30], Lemma 4.1) or ([
31], Corollary 10.1). This fact is used in the proof of Theorem 3 (given below).
Next, we state the main results of this section.
Theorem 3. Let and be arbitrary. Suppose that Assumption 2 is satisfied and andwhere are universal constants. Then there exists a universal constant such that with probability at least we have In Theorem 3 we provide the upper bound for the estimation error of the Lasso estimator with the quadratic loss function. This result gives the conditions for estimation consistency of
in the high-dimensional scenario, i.e., the number of predictors can be significantly greater than the sample size. Indeed, consistency in the
-norm holds e.g., when
where
Moreover,
is taken as the right-hand side of the inequality (
21) and finally
is bounded from below (or slowly converging to 0) and
is bounded from above (or slowly diverging to
∞).
The choice of the
parameter is difficult in practice, which is a common drawback of Lasso estimators. However, Theorem 3 gives us a hint how to choose
. The “safe” choice of
is the right-hand side of the inequality (
21), so, roughly speaking,
should be proportional to
In the experimental part of the paper the parameter
is chosen using the cross-validation method. As we will observe it gives satisfatory results for the Lasso estimators in both prediction and variable selection.
Theorem 3 is a crucial fact, which gives the upper bound for (
15) in Theorem 2. Namely, taking
and
equal to the right-hand side of the inequality (
21), we obtain the following consequence of Theorem 3.
Corollary 1. Suppose that Assumptions 2 is satisfied. Moreover, assume that there exist and constants and such that and . If thenwhere the constants and depend only on and is a universal constant provided in Theorem 3. The above result works for Lasso estimators with the quadratic loss. In the case of the logistic loss analogous result is obtained in ([
13], Theorem 1). In fact, their results relate to the case of quite general Lipschitz loss functions, which can be useful in extending Theorem 2 to such cases.
5. Variable Selection Properties of Estimators
In
Section 3 we are interested in predictive properties of estimators. In this part of the paper we focus on variable selection, which is another important problem in high-dimensional statistics. As we have already noticed upper bounds for probability of the event
are crucial in proving results concerning prediction. It also plays a key role in establishing results relating to variable selection. In this section we again focus on the Lasso estimators with the quadratic loss functions. The analogous results for Lipschitz loss functions were considered in ([
13], Corollary 1).
In the variable selection problem we want to find significant predictors, which, roughly speaking, give us some information on the observed phenomenon. We consider this problem in the semiparametric model, which is defined in (
8). In this case the set of significant predictors is given by (
9). As we have already mentioned vectors
and
need not be the same. However, in [
32] one proved that for a real number
the following relation
holds under Assumption 3, which is now stated.
Assumption 3. Let We assume that for each the conditional expectation exists and for a real number
The coefficient
in (
24) can be easily calculated. Namely, we have
Standard arguments [
33] show that
is nonzero, if
g is monotonic. In this case we have that the set
defined in (
9) equals to
T defined in (
11).
Assumption 3 is a well-known condition in the literature, see e.g., [
13,
32,
34,
35,
36]. It is always satisfied in the simple regression model (i.e., when
), which is often used for initial screening of explanatory variables, see, e.g., [
37]. It is also satisfied when
X comes from the
elliptical distribution, like the multivariate normal distribution or multivariate
t-distribution. In the interesting paper [
38] one advocates that Assumption 3 is a nonrestrictive condition, when the number of predictors is large, which is the case that we focus on in this paper.
Now, we state the results of this part of the paper. We will use the notation
Corollary 2. Suppose that conditions of Theorem 3 are satisfied for If then where is the universal constant from Theorem 3.
In Corollary 2 we show that the Lasso estimator with the quadratic loss is able to separate predictors, if the nonzero coefficients of
are large enough in absolute values. In the case that
T equals (
9) (i.e.,
T is the set of significant predictors) we can prove that the thresholded Lasso estimator is able to find the true model with high-probability. This fact is stated in the next result. The thresholded Lasso estimator is denoted by
and defined as
where
is a threshold. We set
and denote
Corollary 3. Let g in (8) be monotonic. We suppose that Assumption 3 and conditions of Theorem 3 are satisfied for If thenwhere is the universal constant from Theorem 3. Corollary 3 states that the Lasso estimator after thresholding is able to find the true model with high probability, if the threshold is appropriately chosen. However, Corollary 3 does not give a constructive way of choosing the threshold, because both endpoints of the interval
are unknown. It is not a surprising fact and has been already observed, for instance, in linear models ([
9], Theorem 8). In the literature we can find methods, which help to choose a threshold in practice, for instance the approach relying on information criteria developed in [
39,
40].
Finally, we discuss the condition of Corollary 3 that
cannot be too small, i.e.,
. We know that
for
so the considered condition requires that
Compared to the similar condition for the Lasso estimators in the well-specified models, we observe that the denominator in (
26) contains an additional factor
. This number is usually smaller than one, which means that in the misspecified models the Lasso estimator needs larger sample size to work well. This phenomenon is typical for misspecified models and the similar restrictions hold for competitors [
13].
6. Numerical Experiments
In this section we present simulation study, where we compare the accuracy of considered estimators in prediction and variable selection.
We consider the model (
8) with predictors generated from the
p-dimensional normal distribution
, where
and
for
. The true parameter is
where signs are chosen at random. The first coordinate in (
27) corresponds to the intercept and the next ten coefficients relate to significant predictors in the model. We study two cases:
- -
Scenario 1:
- -
Scenario 2:
In each scenario we generate the data
for
The corresponding numbers of predictors are
so the number of predictors exceeds significantly the sample size in the experiments. For every model we consider two Lasso estimators with unpenalized intercepts (
5): the first one with the logistic loss and the second one with the quadratic loss. They are denoted by “logistic” and “quadratic”, respectively. To calculate them we use the “glmnet” package [
28] in the “R” software [
41]. The tuning parameters
are chosen on the basis of 10-fold cross-validation.
Observe that applying the Lasso estimator with the logistic loss function to Scenario 1 leads to a well-specified model, while using the quadratic loss implies misspecification. In Scenario 2 both estimators work in misspecified models.
Simulations for each scenario are repeated 300 times.
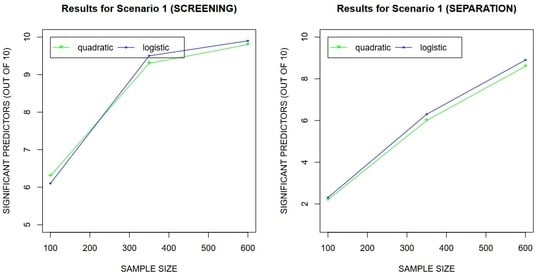
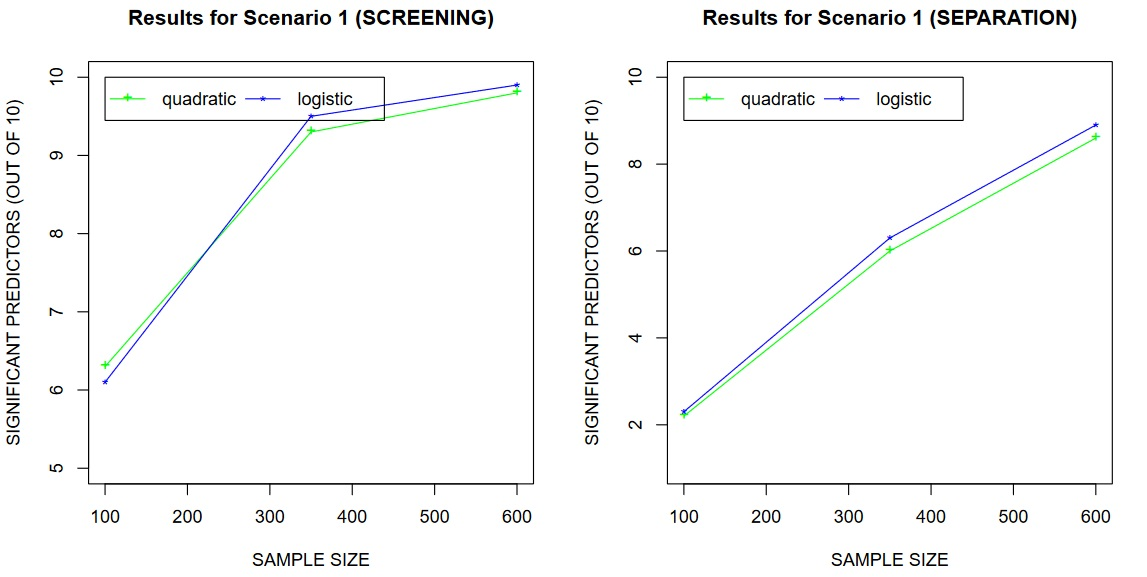
To describe the quality of estimators in variable selection we calculate two values:
- -
TD—the number of correctly selected relevant predictors;
- -
sep—the number of relevant predictors, whose Lasso coefficients are greater in absolute value than the largest in absolute value Lasso coefficient corresponding to irrelevant predictors.
So, we want to confirm that the considered estimators are able to separate predictors, which we establish in
Section 5. Using TD we also study “screening” properties of estimators, which are easier than separability.
The classification accuracy of estimators is measured in the following way: we generate a test sample containg 1000 objects. On this set we calculate
- -
pred—the fraction of correctly predicted classes of objects for each estimator.
The results of experiments are collected in
Table 1 and
Table 2. By the “oracle” we mean the classifier, which works only with significant predictors and uses the function
g from the true model (
8) in the estimation process.
Finally, we also compare execution time of both algorithms. In
Table 3 we show the averaged relative time difference
where
and
is time of calculating Lasso with quadratic and logistic loss functions, respectively.
Looking at the results of experiments we observe that both estimators perform in a satisfactory way. Their predictive accuracy is relatively close to the oracle, especially when the sample size is larger. In variable selection we see that both estimators are able to find significant predictors and separate predictors in both scenarios. Again we can notice that properties of estimators become better, when n increases.
In Scenario 2 the quality of both estimators in prediction and variable selection is comparable. In Scenario 1, which is well-specified for Lasso with the logistic loss, we observe its dominance over Lasso with the quadratic loss. However, this dominance is not large. Therefore, using Lasso with the quadratic loss we obtain slightly worse accuracy of the procedure, but this algorithm is computationally faster. The computational efficiency is especially important, when we study large data sets. As we can see in
Table 3 execution time of estimators is almost the same for
, but for
the relative time difference becomes greater than



{kind=link}