1. Introduction
Informational entropy, introduced by Shannon [
1] as an analogue of the thermodynamic concept developed by Boltzmann and Gibbs [
2], represents the expected information deficit prior to an outcome (or message) selected from a set or range of possibilities with known probabilities. Many modern applications using this concept have been developed, such as the so-called maximum entropy method for choosing the “best yet simplest” probabilistic model from amongst a set of parameterized models, which is statistically consistent with observed data. Informally, this can be stated as: “In order to produce a model which is statistically consistent with the observed results, model all that is known and assume nothing about that which is unknown. Given a collection of facts or observations, choose a model which is consistent with all these facts and observations, but otherwise make the model as ‘uniform’ as possible” [
3,
4]. Philosophically, this can be regarded as a quantitative version of “Occam’s razor” from the 14th Century - “Entities should not be multiplied without necessity”. Mathematically, this means that we find the parameter values which maximize the entropy of the model, subject to constraints that ensure the model is consistent with the observed data, and MacKay [
5] has given a Bayesian probabilistic explanation for the basis of Occam’s razor. This maximum entropy approach has found widespread applications in image processing to reconstruct images from noisy data [
6,
7] - for example, in Astronomy, where signal to noise levels are often extremely low - and in speech and language processing, including automatic speech recognition and automated translation [
3,
8].
This idea of informational entropy has been expanded and generalized. Tsallis [
9] proposed alternative definitions to embrace inter-message correlation [
10], though the information of a potential event remained solely dependent on its unexpectedness or “surprisal”. This is somewhat counterintuitive: “Man tosses 100 consecutive heads with coin” is very surprising but not important enough to justify a front-page headline. Conversely “Sugar rots your teeth” is of great importance but its lack of surprisal disqualifies it as news. “Aliens land in Trafalgar Square” is both surprising and important and we would expect it be a lead story. To reflect this, Guiaşu [
11] introduced the concept of “weighted entropy” whereby each possible outcome carried a specific informational importance, an idea expanded by Taneja and Tuteja [
12], Di Crescenzo and Longobardi [
13], and several others. Another modification considers the entropy of outcomes subject to specific constraints: for example, “residual entropy” was defined by Ebrahimi [
14] for lifetime distributions of components surviving beyond a certain minimum interval.
From the outset, Shannon identified two kinds of entropy: the “absolute” entropy of an outcome selected from amongst a set of discrete possibilities [
1] (p. 12) and the “differential” entropy of a continuous random variable [
1] (p. 36). The differential version of weighted entropy has found several applications: Pirmoradian et al. [
15] used it as a quality metric for unoccupied channels in a cognitive radio network and Tsui [
16] showed how it can characterize scattering in ultrasound detection. However, under Shannon’s definition the differential entropy of a physical variable requires the logarithm of a dimensioned quantity, an operation which necessitates careful interpretation [
17].
In this paper we examine the implications of this dimensioned logarithm argument to weighted entropy and show how an arbitrary choice of unit system can have profound effects on the nature of the results. We further propose and evaluate a potential remedy for this problem; namely a finite working granularity.
2. Absolute and Differential Entropies
Entropy may be regarded as the expected information gained by sampling a random variable (RV) with a known probability distribution. For example, if
is a discrete RV and
then outcome
occurs on average once every
observations and the mean information encoded as
bits. However, it is common to use natural logarithms for which the information unit is the “nat” (≈1.44 bits). Entropy can therefore be defined as
where
is the set of all possible
. (An implicit assumption is that
results from an independent identically distributed process: while Tsallis proposed a more generalized form to embrace inter-sample correlation [
9,
10], the current paper assumes independent probabilities.) Shannon extended (1) to cover continuous RVs as “differential” entropy
where
is the probability density function (PDF) of
. Two points may be noted: firstly, since in (2)
x only affects the integrand through
,
is “position-independent”, i.e.,
for all real
. Secondly
is not, as one might naïvely suppose, the limit of
as resolution tends to zero (see Theorem 9.3.1 in [
18]). Furthermore, while
is always positive (since
,
may be negative if most larger values of
are
. In the extreme case of a Dirac delta-function PDF, representing a deterministic—and therefore non-informative—outcome, the differential entropy would not be zero but minus infinity.
Take for example the Johnson-Nyquist noise in an electrical resistor: if the noise potential is Gaussian with an RMS value volts it is easy to show that nats. (Position-independence makes the bias voltage irrelevant.) Suppose that ; working in microvolts we obtain nats but in millivolts nats. If differential entropy truly represented information then a noise sample in microvolts would increase our information but measured in millivolts would decrease it. Thus, must be regarded as a relative, not an absolute measure and consistent units must be used for different variables to be meaningfully compared.
“Residual” entropy, where only outcomes above some threshold
are considered, is given by [
14]
where
is called the “survival function” since in a life-test experiment it represents the proportion of the original component population expected to survive up to time
. Some authors call
the “hazard function” (a life-test metric equal to failure rate divided by surviving population) though this is only valid for the case of
; it is better interpreted as the PDF of
subject to the condition
. This somewhat eliminates the positional independence since a shift in
only produces the same entropy when accompanied by an equal shift in
, i.e.,
, but the contribution of each outcome to the total entropy still depends on rarity alone.
Guiaşu’s aforementioned weighted entropy [
11] introduces an importance “weighting”
to outcome
whose surprisal remains
: the overall information of this outcome is redefined
so entropy becomes
. It seems intuitively reasonable that the differential analogue should be
though if
is a monotonic function we could define this more compactly as [
13]:
and the residual weighted entropy
We have already noted that the logarithms of probability densities behave very differently from those of actual probabilities. Aside from the fact that may be greater than 1 (a negative entropy contribution) it is also typically a dimensioned quantity: for example if represents survival time then has dimension [Time]−1, leading to the importance of unit-consistency already noted. In the next section we explore more deeply the consequences of dimensionality.
3. Dimensionality
The underlying principle of dimensional analysis, sometimes called the “
-theorem”, was published in 1914 by Buckingham [
19] and consolidated by Bridgman in 1922 [
20]. In Bridgeman’s paraphrase [
20] (p. 37) an equation is “complete” if it retains the same form when the size of the fundamental units is changed. Newton’s Second Law for example states that
where
is the inertial force,
the mass and
the acceleration: if in SI units
kg and
ms
−2 then the resulting force
N, where the newton N is the SI unit of force. In the CGS system
g and
cms
−2 so the force is
dynes, the exact equivalent of four newtons. The equation is therefore “complete” under the
-theorem which requires that each term be expressible as a product of powers of the base units: in this case [Mass][Length][Time]
−2.
The problem of equations including logarithms (and indeed all transcendental functions) of dimensioned quantities has long been recognized. Buckingham opined that “… no purely arithmetic operator, except a simple numerical multiplier, can be applied to an operand which is not a dimensionless number, because we cannot assign any definite meaning to the result of such an operation” ([
19], p. 346). Bridgman was less dogmatic, citing as a counter-example the thermodynamic formula
where
is the absolute temperature,
is pressure, and
and
are other dimensioned quantities ([
20], p. 75). It is true that the logarithm returns the index to which the base (e.g.,
…) must be raised in order to obtain the argument: for example if
Pa (the Pa or pascal being the SI unit of pressure) then to what index must
be raised to in order to obtain that value? It is not simply a matter of obtaining 200 from the exponentiation but 200
pascals. Furthermore, the problem would change if we were to switch from SI to CGS where the pressure is 2000 barye (1 barye being 1 dyne cm
−2) though the physical reality behind the numbers would be the same.
However, in the current case it is the derivative of log pressure which is important, and since it has dimension [Temperature]−1 and the -theorem is therefore satisfied. Unfortunately, Shannon’s differential entropy has no such resolution since it is the absolute value of (not merely its derivative) which must have a numeric value. This kind of expression has historically provoked much debate and though there are several shades of opinion we confine ourselves to two competing perspectives:
Molyneux [
21] maintains that if
grams then
should be correctly interpreted as
and “log(gram)” should be regarded as a kind of “additive dimension” (he suggests the notation 2.303 <gram>).
Matta et al. [
17] argue that “log(gram)” has no physical meaning; while Molyneux had dismissed this as pragmatically unimportant, they echo the views of Buckingham [
19] saying that dimensions are “… not carried at all in a logarithmic function”. According to Matta,
must be interpreted as
(the dimension of
cancelled out by the unit).
Since most opinions fall more or less into one or other of these camps it will be sufficient to consider a simple dichotomy: we refer to the first of these as “Molyneux” and the second as “Matta”. Under the Molyneux interpretation the differential entropy must be expressed
which has an additive (and physical) dimension of “log(second)” (or <second>) in addition to the multiplicative (and non-physical) dimension of nats. Pragmatically this is not important since entropies of variables governed by different probability distributions may still be directly compared (assuming
is always quantified in the same units). However, when we consider weighted entropy, we find that
where
is the expectation of
. Here Molyneux’s approach collapses since the expression has a multiplicative dimension nat-seconds and an additive dimension “
”. Since the latter depends on the specific distribution,
loses any independent meaning; comparing weighted entropies of two different variables would be like comparing the heights of two mountains in feet, defining a foot as 12 inches when measuring Everest and 6 when measuring Kilimanjaro.
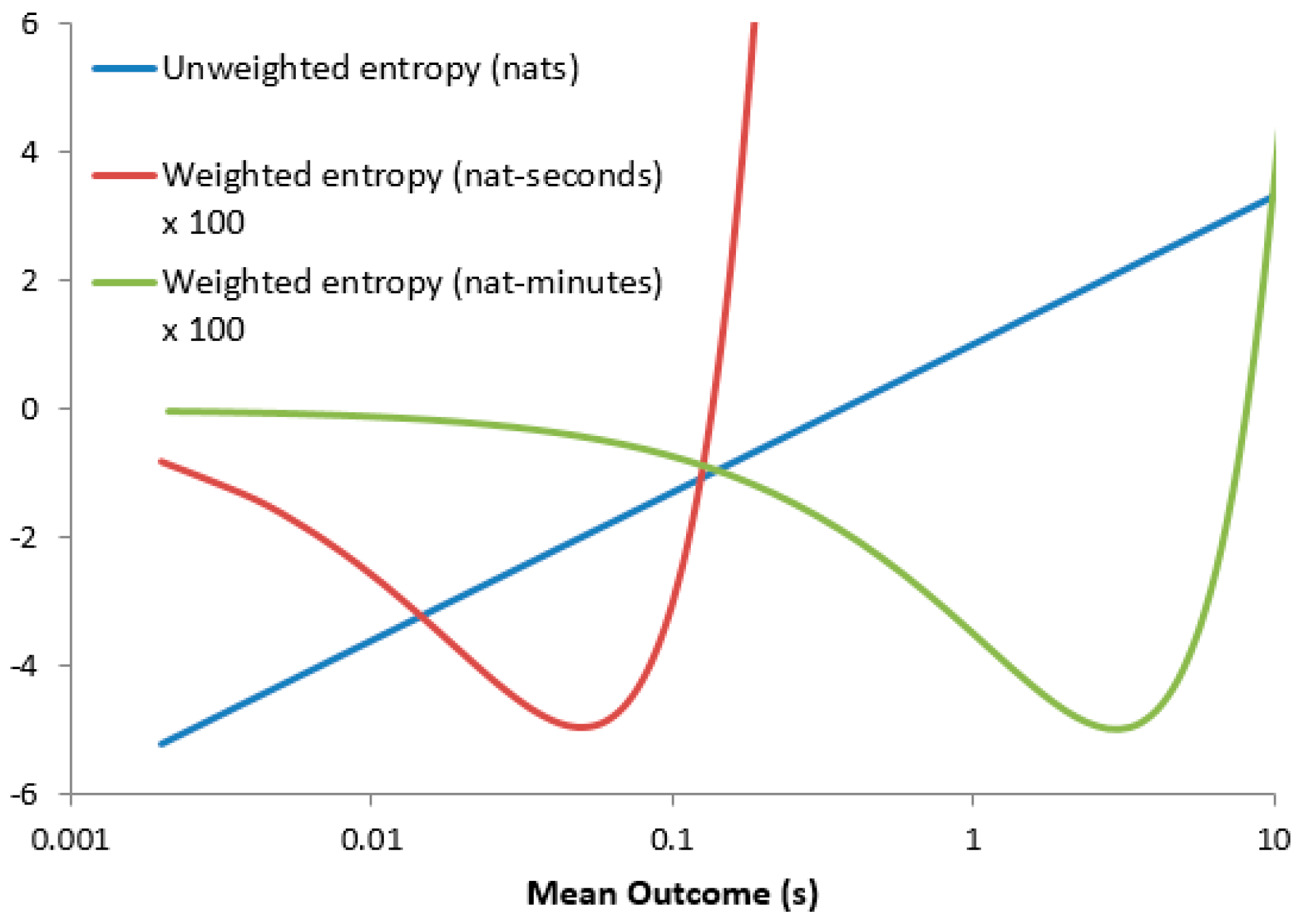
So, if Molyneux’s interpretation fails, does Matta’s fare any better? Since Matta requires the elimination of dimensional units, we introduce the symbol to represent one dimensioned unit of (for example, if represents time in seconds then s). The Shannon differential entropy now becomes and the corresponding weighted entropy . At first glance this appears hopeful since the logarithm arguments are now dimensionless, but let us consider a specific example: the exponential distribution where the mean outcome . This yields which is (as one would expect) a monotonically increasing function of tending to as .
However, the weighted entropy
which experiences a finite minimum when
. Though dimensionally valid, this creates a dependence on the unit-system used.
Figure 1 shows the entropy values plotted against the expectation for calculation in seconds and minutes, showing the shift in the minimum weighted entropy between the two unit systems. The absurdity of this becomes apparent when one considers two exponentially distributed random variables
and
with
= 9 s and
= 15 s:
Table 1 shows that
when computed in nat-hours but
when computed in nat-seconds.
The underlying problem is as follows: since logarithm polarity depends on whether or not
exceeds
, different sections of the PDF may exert opposing influences on the integral (
Figure 2). While this is unimportant for
which has no finite minimum,
is forced towards zero with decreasing
, which ultimately counteracts the negative-going influence of the logarithm. The two factors therefore operate contrarily: zero surprisal appears as entropy minus infinity and zero importance as entropy zero. Two solutions suggest themselves: (i) combine
and
in an expression to which they both always contribute positively (e.g., a weighted sum, which in fact yields a weighed sum of expectation and unweighted entropy) and (ii) retain the product but redefine the logarithm argument such that surprisal is always positive. With this in mind, the following section considers the fundamental relationship between absolute and differential entropies.
4. Granularity
All physical quantities are ultimately quantified by discrete units; time for example as a number of regularly-occurring events (e.g., quartz oscillations) between two occurrences, which is ultimately limited by the Planck time (
s), though the smallest temporal resolution ever achieved is around
s [
22]. Finite granularity therefore exists in all practical measurements: if the smallest incremental step for a given system is
then
is really an approximation of a discrete distribution, outcomes 0,
,
…. having probabilities
,
,
…etc., so
which may be expanded into two terms (in the manner of [
18])
and if
is sufficiently small
where the logarithm argument in
is “undimensionalised” (as per Matta et al. [
17]) and
is the information (in nats) needed to represent one dimensioned base-unit in the chosen measurement system: this provides the correctional “shift” needed when the unit-system is changed and thus makes (8) comply exactly with the
-theorem.
The corresponding weighted entropy may be dealt with in the same manner
While the second term in (9) corresponds to the enigmatic
“dimension” of (7), it now has an interpretation independent of the measurement system and allows weighted entropies from different distributions to be compared. However, a suitable
must be chosen; while this need not correspond to the
actual measurement resolution, it is necessary (in order for all entropy contributions to be non-negative) that
across all random variables
,
…
whose weighted entropies are to be compared. It must therefore not exceed
Similarly, the residual weighted entropy can be shown to be
where
is the expectation of
given
. The maximum granularity now becomes
where
is the
-value pertinent to the random variable
and
is the corresponding survival function. Equations (9) and (11) also provide a clue as to the lower acceptable limit of the granularity: if
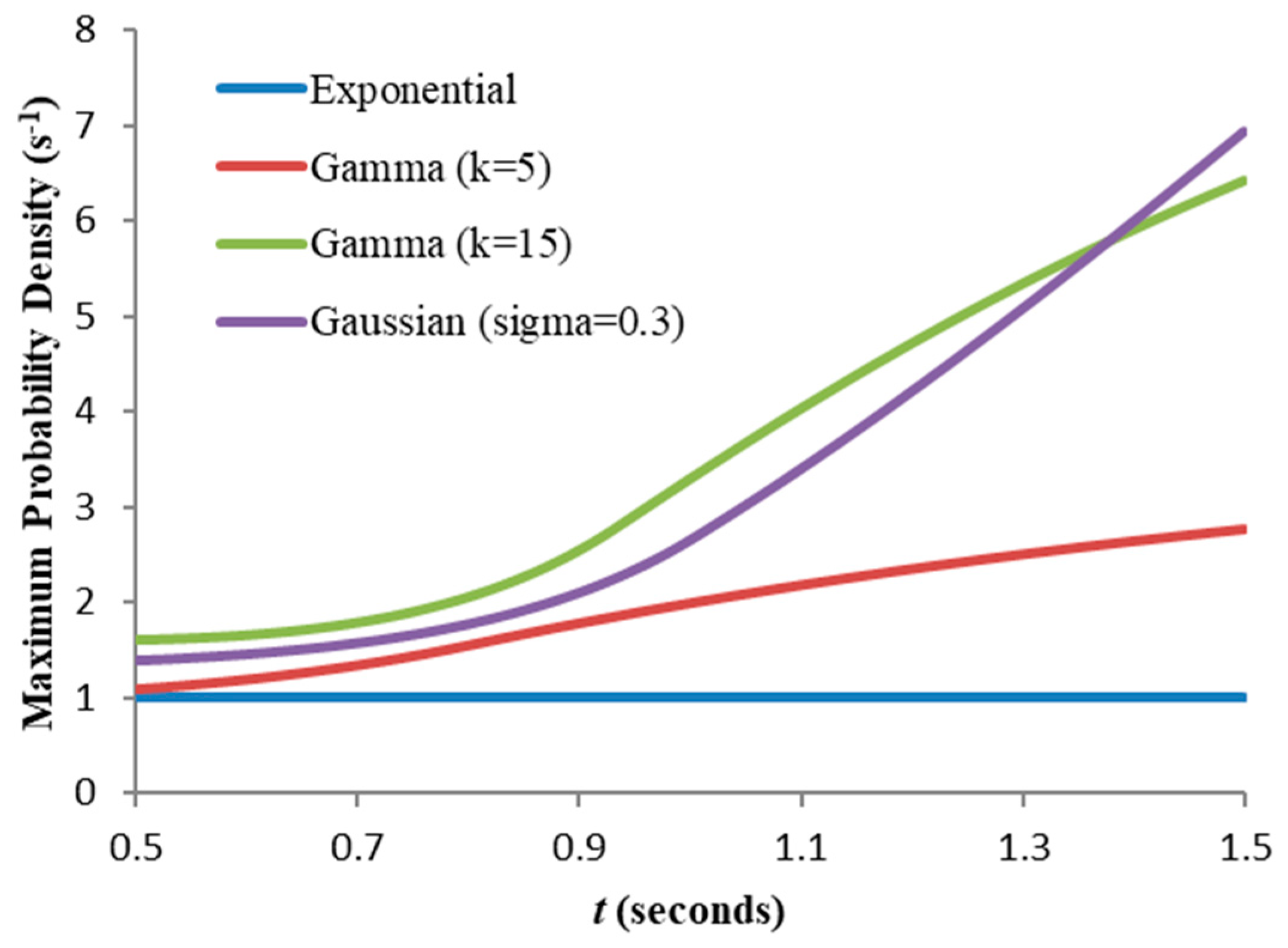
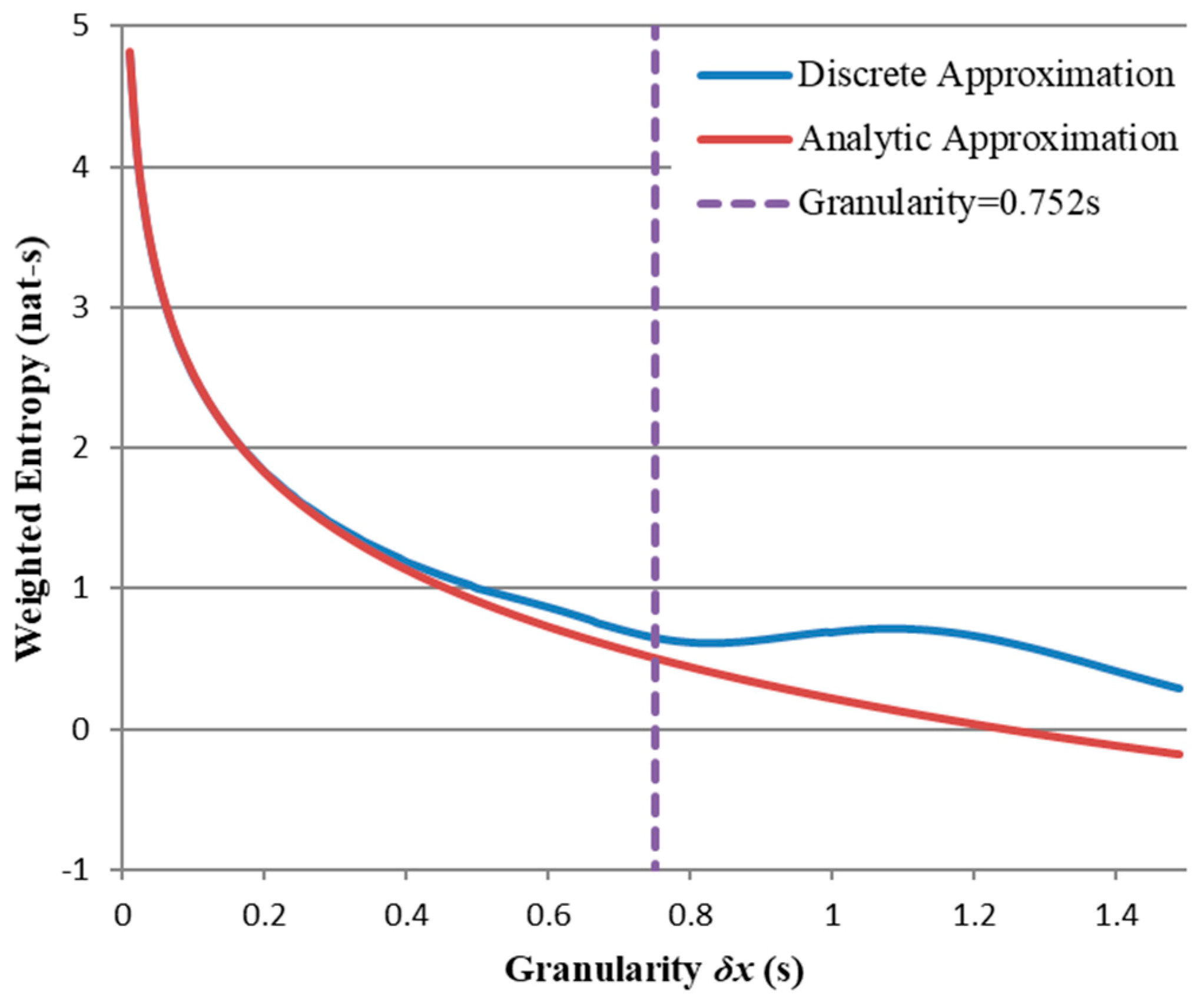
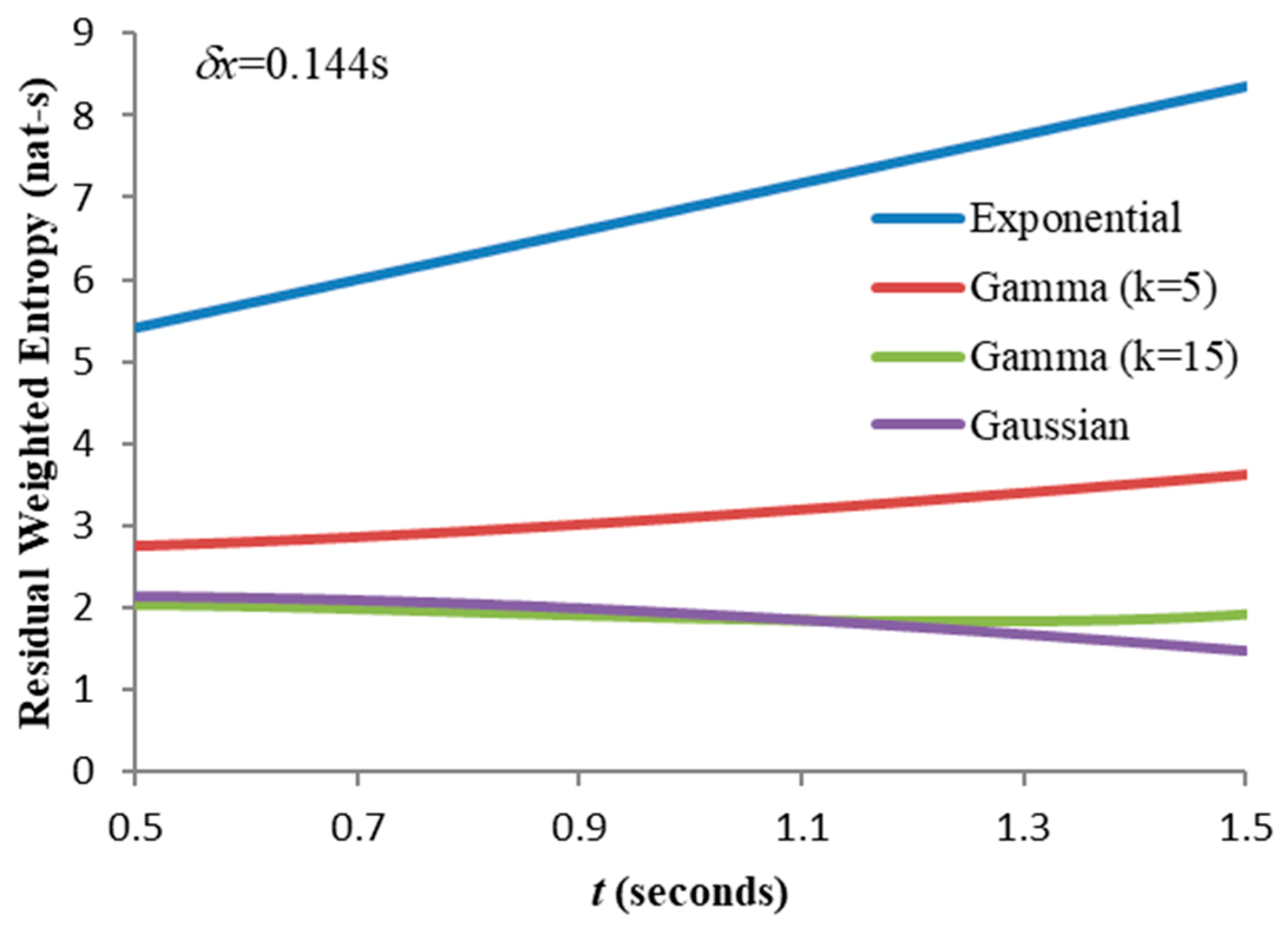
were too small then the second terms in these expressions would dominate, making “weighted entropy” merely an overelaborate measure of expectation. Within this window of acceptable values, a compromise “working granularity” must be found. This will be addressed later.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}