1. Introduction
Integrated Information Theory (IIT) [
1,
2] is concerned with the study of natural or artificial systems formed by many interconnected micro-components. One of the key steps in this study is the identification of the “hidden” macro-components of the system, namely its
Minimum Information Partition (
MIP). The macro-components of the
MIP can be seen as distinct but interacting parts:
measures the added value provided by their integration/composition with respect to the plain sum of their contributions—how much the integrated whole is more than the sum of the separate parts.
In
Boolean Nets [
3]—the state transition model predominantly used for illustrating IIT—the integration/cooperation among the
MIP parts occurs via the directed edges that interconnect them: the parts influence one another by reading each other’s boolean variables—a form of
shared-variable cooperation.
In this paper, we contrast the above cooperation mechanism with an alternative one based on
shared transitions, that arises in
Process Algebras (or “
Calculi”) [
4,
5,
6,
7,
8]. Furthermore, viewing the interacting partners under the process algebraic perspective has suggested us to extend our analysis to
three execution modes for boolean nets:
synchronous,
asynchronous and “
hybrid” (although the second one is soon dropped).
We have three main objectives in mind.
The first is to put the interaction mechanisms of shared variables and shared transitions on an equal footing, and to obtain some numerical characterization of their “performance” with respect to the ability to produce integrated information.
The second is related to the central application area of IIT—the modeling and quantification of the emergence of consciousness from the complex structure of the brain. Given that the brain architecture is indeed intrinsically structured into macro-components, the investigation of alternative or additional mechanisms of cooperation among them, that explicitly reflect such higher-level structure, could be an interesting complement to the study of cooperation mechanism that only address micro-components.
The third objective is relevant to the areas from which these additional cooperation mechanisms are borrowed, namely Process Algebra and, more generally, formal methods for Software Engineering. Using informational measures from IIT appears as a completely novel and attractive approach to characterizing quantitatively these practically useful mechanisms and their associated operators.
The paper is organized as follows.
In
Section 2, we briefly recall the definition of Boolean Net and introduce the three execution modes:
synchronous,
asynchronous and
hybrid. The first, yielding deterministic behaviors, is the traditional mode; however, the nondeterministic asynchronous and hybrid modes appear more in line with the nondeterminism of the systems typically addressed by Process Algebra. Here, we also discuss the three modes with respect to the property of
conditional independence.
In
Section 3, we introduce the interaction mechanism adopted in process-algebraic calculi/languages, one based on shared labeled transitions (abbreviated “
sharTrans”) as opposed to shared variables (“
sharVar”). We in particular illustrate the flexible parametric operator of
parallel composition from the LOTOS language, denoted “
”: expression
P|
|
Q describes a system composed of two
processes P and
Q that cooperate by sharing some transitions, where
defines the degree of coupling between them.
In
Section 4, we show that the parallel composition operator
can be readily used also for composing two
boolean nets P and
Q—still written
P|
|
Q—provided these are enriched with transition labels, and regardless of the chosen execution mode. This enables us to put the newly considered form of composition/integration under the lens of IIT without need to import and discuss any other element of Process Algebras.
In
Section 5, we introduce notation
P<
>
Q and the idea to control the degree of coupling between two bool nets
P and
Q, under the
sharVar mechanism, by controlling the number
of edges crossing between them.
In
Section 6, we recall the notion of
integrated information, the central concept of IIT, both in its
state-dependent form and in its
averaged form, which we denote
. These definitions are based on a distance function
between two probabilistic state distributions, where
reflects inter-part cooperation while
corresponds to their independent operation. In IIT 2.0 [
1],
d is
Relative Entropy (or
Kullback–Liebler divergence, denoted
). We show that the definition of
for the
sharVar context is such to avoid the “
dkl-mismatch problem” that may arise when applying
to generic distributions. Then, we conduct a statistical analysis of
in order to study its dependency on
for the
and
execution modes of
P<
>
Q, using 10 pairs
of randomly generated bool nets. For facilitating the comparison of
P<
>
Q with
sharTrans compositions (in view of potential
-mismatch problems in the latter), we extend our statistical analysis by using a version of
in which
is replaced by
Manhattan distance.
In
Section 7, we address the problem of defining
in the very different context of
sharTrans bool net compositions
P|
|
Q. Here, we have to face two problems: the presence of deadlocks and the mentioned
-mismatches. The first problem is solved easily; a drastic way to bypass the second one is to switch to the
variant based on Manhattan distance.
Wishing to stick to the original,
-based definition of
, in
Section 8, we consider an alternative, process-algebraic cooperation mechanism, borrowed from CCS (Calculus of Communicating Systems) [
5], that avoids the
-mismatch problem. In fact, we combine CCS parallelism (“
”) and restriction (“\
”) into the convenient syntactic form
, where parameter
still expresses the degree of coupling between the interacting parties. This enables us to compare, by statistical experiments, the trends of
, in its original
-based definition [
1], for
P<
>
Q and
.
In
Section 9, we regroup the 15 plots introduced in the previous sections into a compact table that facilitates the comparison of mechanisms
,
and
.
2. Boolean Nets: Sync, Async and Hybrid Execution Modes
Boolean nets [
3] are discrete sequential dynamical systems. An
-
boolean net (“bool net” in the sequel) is a pair
where:
is a directed graph with n vertices , and edge set E; each vertex has exactly k incoming edges (this limitation on node in-degree is not essential; we adopt it only for convenience of implementation and notation): , so that .
is a set of n boolean functions of k arguments, one for each vertex in B.
Each vertex is a boolean variable controlled by boolean function from F, where the ordered k-tuple of arguments corresponds to the edges incident to . In the sequel, an -bool net P is sometimes denoted .
A bool net computation is a sequence of steps, assumed to take place in discrete time—one step at each clock tick. Each step consists of the instantaneous and simultaneous firing of a group of nodes, called the firing group. A firing group is a subset of B, which can be conveniently identified also by its characteristic function (i.e., characteristic function {1,1,0} indicates that only the first two nodes fire, out of three). When node fires, its value is updated according to boolean function .
- Notation.
Lower case letters x and y denote discrete random variables. In particular, x or is the current state at time t of an -bool net, consisting of an n-tuple of binary random variables . Similarly, y or is the next state at time . Upper case letters X and Y denote actual n-tuples of bits, i.e., the values that variables x and y may assume: and , where s and s are bits. Subscript i in is used when we want to range in a set of n-tuples, for example in the whole set —not for selecting an element inside the tuple! For example, writing , where , means . We consistently use identifiers x and X for predecessor states, and y and Y for successor states.
The densities of random variables x and y, often called here “distributions”, are denoted and , but sometimes also x and y, with symbol overloading; the meaning should be clear from the context. For example, the probability for variable y to assume value is written but also .
- tpm.
In the sequel, an essential role is played by the transition probability matrix (tpm), in which entry expresses the conditional probability obtained by counting all possible transitions that lead from state to state .
Given an -bool net, we consider three execution modes for it, which differ in the way we define , the set of firing groups possible at each step. (Note that does not depend on the current state.)
- Sync.
All nodes fire (update) simultaneously. In other words, consists of only one firing group, which includes all n nodes. For example, when , we have (using node sets), also represented as (using characteristic functions). Evolution is deterministic: each global state has only one successor. Sync boolean nets are a generalization of Cellular Automata.
- Async.
Nodes fire one at a time, the choice being made by a uniform random distribution. In other words, consists of n firing groups, each being a singleton. For , we have , or = {{1,0,0}, {0,1,0}, {0,0,1}}. Evolution is nondeterministic: each global state may have multiple successors—as many as n (note that, with fixed current state, the correspondence between firing groups and next states can be many-to-one).
- Hybrid.
(I am thankful to Larissa Albantakis for having drawn my attention to this execution mode and its conditional independence property.) Here, consists of firing groups—namely, all the subsets of the node set B. For , using characteristic functions, we have = {{0,0,0}, {0,0,1}, {0,1,0} …{1,1,1}}. The choice is made, again, by a uniform random distribution: the probability to pick any specific firing group is , where n is the number of nodes. Note that this is equivalent to firing each node with probability , independently node by node. Evolution is nondeterministic: each global state may have multiple distinct successors—as many as . Note that the empty firing group is also included.
We write for denoting the transition probability matrix of bool net S executed in mode m (sync, async or hybrid).
We soon deal with composite bool nets. The easiest way to compose two independent bool nets P and Q is to take their union, defined in the obvious way and denoted . P and Q are disconnected, and do not communicate. It is trivial to see that is itself a bool net, which can be executed in any of the three modes.
Let us then establish some simple facts about the relations between the set
of firing groups of
and sets
and
of firing groups of the components, in the three modes. In the equations below, firing groups are conceived as node sets.
In Equation (
1),
is a
singleton set—a set whose unique element is the set
of nodes. In
sync mode,
—be it referred to
P,
Q or
—has only one element, namely the firing group involving all available nodes. Thus,
and
. Symbol “
” denotes a Cartesian product that takes the union of the paired elements, which are node sets (e.g.,
.
Executing
in
async mode (Equation (
2)) means to fire (update) one node at a time. Thus, in this equation, we make use of singleton sets (e.g.,
or
) formed from the individual nodes of
P and
Q, where
and
. Set
is then the plain union of sets
and
.
Executing
in
hybrid mode (Equation (
3)) means to fire any possible subset of
, including the empty set. This set of firing groups can also be seen as the “special” Cartesian product
.
Note that the of the whole system is a Cartesian product only for the sync and hybrid modes, and that these results clearly hold also when P and Q are connected by some edges, i.e., are not independent, since firing groups are defined relative to node sets, regardless of node interconnections.
Conditional Independence in the Three Modes
Let denote the current global state of an bool net at time t, and be the next global state, at time .
Following Pearl [
9], we say that, for any
,
is
conditionally independent from ,
given x, if
Once
x is known, the additional knowledge of
does not add anything to what we already know about
(and vice versa). Note that the above equation means:
for all
s and
s such that
.
Two random variables
and
are
independent if and only if their
mutual information [
10] is null:
. Similarly, two random variables
and
are
conditionally independent, given
x, a third variable, if and only if their
conditional mutual information is null:
.
Recall that
mutual information , a symmetric quantity representing the information provided on average by one variable about the other, is:
where
is the joint distribution of the two variables, while
and
are the respective marginal distributions.
The
conditional mutual information between variables
and
,
relative to variable x, is
which can be also formulated as the weighted sum of the mutual information relative to the individual values
of variable
x.
IIT attributes much importance to conditional independence: when the property is satisfied, each element , with its function , can be interpreted as an individual causal element within the system; when it is violated, a possibly undesirable form of instantaneous causal influence between and arises.
The three considered execution modes perform differently with respect to conditional independence.
The sync mode entails conditional independence for the simple reason that, due to transition determinism, knowledge of the current state X already provides complete information about (and ).
With the async mode, conditional independence is violated: knowing , in the case , reveals that has been the only firing (updating) node, which implies —a conclusion that we cannot draw from the pure knowledge of x.
The hybrid mode entails conditional independence. As already observed, picking a firing group with uniform probability is equivalent to firing each node with probability , independently node by node. Thus, finding that has fired does not provide additional information on whether or not has fired, thus on .
It is straightforward to see that the above definition of conditional independence, and the results for the three modes, are valid not only for individual nodes but also for groups of nodes, i.e., for parts of the net, such as P and Q in the sequel.
Two-Step Conditional Independence
It could be of some interest to see how conditional dependence/independence carries over to the case of two or more transitions, e.g., for analyzing behaviors under macro-transitions, or temporal coarse-graining. Somewhat surprisingly, the scenario changes as follows.
Let , , be a sequence of global states; we are now to compare with .
In sync mode, conditional independence is still valid, for the same argument of the case of one transition: is completely defined, once is known.
In async mode, conditional independence is still violated. If , we know that node j has fired at least once: this fact reduces the probability that node i has fired at time or , providing us additional information about .
The change occurs with respect to the hybrid mode: while the property is satisfied after one transition, it is violated after two. Informally, finding reveals that node j has fired at least once, which yields additional information about . This, in turn, may provide additional information about beyond what is already given by . Of course, knowing who fired in the first step still does not say anything about who fired in the second step: the point is that additional knowledge about the intermediate values of does refine our knowledge about the possible final values of .
3. Parallel Composition of LOTOS Processes: ||
In Process Algebras [
4,
5,
6,
7,
8], a distributed concurrent system is formally described as a set of interacting processes. Each of these formalisms offers its own set of
operators for specifying actions, interactions, concurrency, choice, nondeterminism, recursion, etc. By the
Structural Operational Semantics [
11], the syntactic expressions built by these operators, describing system structure and behavior, can be formally interpreted as
labeled transition systems.
Of crucial importance for specifying the macro-structure and interaction patterns of the system are the
parallel composition operators. We in particular refer to the flexible, parametric parallel composition operator of the process-algebraic language
(Language of Temporal Ordering Specification) [
8].
When two processes P and Q are composed by the parallel composition operator “”, where is the set of “synchronization labels”, the resulting labeled transition system is obtained by forcing the processes to proceed jointly—in synchrony—with the transitions with labels in , while proceeding independently—in “interleaving”—with their other transitions.
The Structural Operational Semantics provides one or more axioms or inference rules specifying the transitions associated with (the expressions formed by) each operator. The inference rules are usually written as “fractions”, and define the transitions of an expression formed by that operator, appearing in the “denominator” (the conclusion), in terms of the transitions of the operator arguments, appearing in the “numerator” (the premise).
Three inference rules define the semantics of the LOTOS parallel composition expression
, where
P and
Q are themselves expressions (processes):
For example, when two processes and , able to perform transitions with labels in, respectively, sets and , are composed by the expression “”, they will interleave their local transitions labeled a and d, and synchronize those labeled b and c.
When the set of synchronization labels is empty—
—we have the special case of
pure interleaving composition
, also denoted
, where “
” is called the
interleaving operator. In this case, it is clear that the rules in Equations (
8) and (
9) are still applicable while the rule in Equation (
10) is not; thus, in composition
, the components can only proceed one at a time.
In the next section, we discuss how to apply the above parallel composition operator to bool nets, and the way this operator performs with respect to the conditional independence property.
4. Parallel Compositions of Bool Nets: ||
Bool nets are state transition systems, and since the rules in Equations (
8)–(
10) for parallel composition are applicable to
labeled transition systems, it is perfectly feasible to apply them to the composition
P|
|
Q of boolean nets. The only missing elements are transitions labels!
For our investigations, we adopt pairs of nets with identical parameters; for the labels, we proceed as follows.
First, we choose the label alphabet, which consists of the set of natural numbers (the choice of size is justified below). We overload symbol to denote both a natural number, with , and the set of synchronization labels, so that is written . In particular, corresponds to the pure interleaving case mentioned in the previous section. As a natural number, represents the coupling factor between P and Q: the larger is , the more frequent will be the steps in which P and Q must synchronize.
Second, we turn
P and
Q into
labeled bool nets by adding two independent functions
and
that, respectively, assign a label to each transition
and
:
Aiming at maximum generality, our labels depend both on the source and on the target state, and are picked at random from set .
On this basis, the application of the rules in Equations (
8)–(
10) to
P|
|
Q becomes possible also when
P and
Q are labeled bool nets. Note that this can be done regardless of the mode—
sync,
async or
hybrid—in which
P and
Q are executed.
It is important not to confuse the concept of sync/async execution mode of P and Q with the (orthogonal) concept of synchronous/asynchronous transition of P||Q. The execution mode refers to the individual component P or Q, and when we attribute some execution mode to the whole P||Q we mean that both P and Q operate, internally, according to that mode; in principle, we could even imagine composing a P operating in sync mode with, e.g., a Q operating in async or hybrid mode (but in this paper we never do that). On the other hand, a synchronous transition of P||Q is one in which P and Q proceed jointly, each contributing with a local transition performed according to its own mode; furthermore, the two local and simultaneous transitions must have the same label , with . Conversely, an asynchronous transition of P||Q corresponds to a local, -labeled transition performed autonomously (and according to its own mode) by only one of the two components, where .
4.1. Conditional Dependence in Parallel Composition
We discuss the issue of conditional independence in
Section 2.1, relative to pure bool nets. How does parallel bool net composition
P|
|
Q perform with respect to this property?
The question involves comparing with where, as before, x and y are states at time t and , respectively, and the subscripts identify the relevant system components.
Regardless of the execution mode of the two components, parallel composition does violate conditional independence. The reason is that knowing and finding indicates that Q has indeed performed a local transition, whose label, e.g., , we can partly or completely deduce from labeling function , which is known. If , the system as a whole must have performed an asynchronous (interleaving) transition, in which P must have idled: we immediately deduce . If, conversely, , the system as a whole must have performed a synchronous transition, one in which P has performed a -labeled transition jointly with Q: this still tells us something about . In both cases, we acquire more information about than what alone can give.
In the area of formal methods for Software Engineering, to which Process Algebras belong, it is indeed conditional
dependence that plays an important role. Consider, for example, the
constraint-oriented specification style [
12,
13]. In this style, the parallel composition operator is used as a sort of logical conjunction: system behavior is specified by progressively accumulating constraints (processes) on the ordering of communication events and, possibly, on the exchanged data values. Each constraint reflects a different, partial view on the global system behavior, and all these views should agree on each global transition
. This agreement, governed by the inference rules in Equations (
8)–(
10), reflects a sort of on-the-fly communication between
P and
Q, as the global transition occurs. Overall, the effect of those rules is to introduce a mutual dependency among local transitions, which, in terms of conditional mutual information between local state components, means
.
4.2. Deadlocks
No matter which execution mode is considered, a bool net will always be able to perform transitions from any state. This is not the case for bool net
composition , when
. A
deadlock occurs at global state
, formed by the concatenation of local states
and
, when: (i) no
a-labeled local transitions are possible from state
or , with
(these would become global, interleaving, asynchronous transitions by the rule in Equation (
8) or Equation (
9)); and (ii) no pair of local
b-labeled transitions is possible from
and , with
(yielding global, synchronous transitions by the rule in Equation (
10)). In this case,
is a
deadlock state.
Each tpm row should be a probability vector: its total must be 1. However, when is a deadlock state there is no possible successor , and all elements of the corresponding row would be 0s, thus violating the probability vector property. One option sometimes adopted for restoring that property is to set , forcing the system to permanently remain in that state, and turning a static into a dynamic deadlock:
static deadlocks—some tpm rows, called null rows, only have 0s, and are not proper probability vectors;
dynamic deadlocks—all rows are probability vectors, with loop-edges added.
The introduction of dynamic deadlocks preserves the probabilistic nature of the , but does not discriminate between actual deadlocks and loop-transitions—those for which the source and target state coincide.
Deadlocks tend to increase as the coupling between the interacting parties becomes stronger:
Proposition 1. Let P and Q be two labeled bool nets, and be the set of deadlock states of system . Then, implies .
Proof. We prove by contradiction that if global state x is a deadlock for , it is also a deadlock for . Assume x is not a deadlock for . Then, can perform (at least) a labeled transition .
If
, the transition is a synchronization between
P and
Q, supported by the inference rule in Equation (
10): then, either
or
. In the first case, transition
would be feasible also for
(a contradiction); in the second case, the two component transitions
and
would enable, by the inference rules in Equations (
8) and (
9), two global, interleaving transitions of
(a contradiction).
If, on the other hand, , then is an interleaving transition for , which would be a fortiori a feasible interleaving transition for (a contradiction). □
Furthermore, given composition P||Q, we can establish the following relations among the deadlock sets for the different execution modes.
Proposition 2. Let P and Q be two labeled bool nets, let be system executed in the specified mode, and let D be the deadlock set function of Proposition 1. Then, (i) ; and (ii) .
Proof. Part (i). We show by contradiction that, if global state
x is a deadlock for
, it is also a deadlock for
. If
x were not a deadlock for
, then this system could escape state
x by some transition involving the simultaneous firing of all nodes of
and (by the inference rule in Equation (
10)), or the firing of all nodes of
or (by the inference rule in Equation (
8) or Equation (
9)). These three firing scenarios are feasible also under the
hybrid execution mode (see the definitions of the firing group sets
for the three modes in
Section 2), yielding a transition escaping state
x also for system
—a contradiction.
The proof for Part (ii) is analogous. □
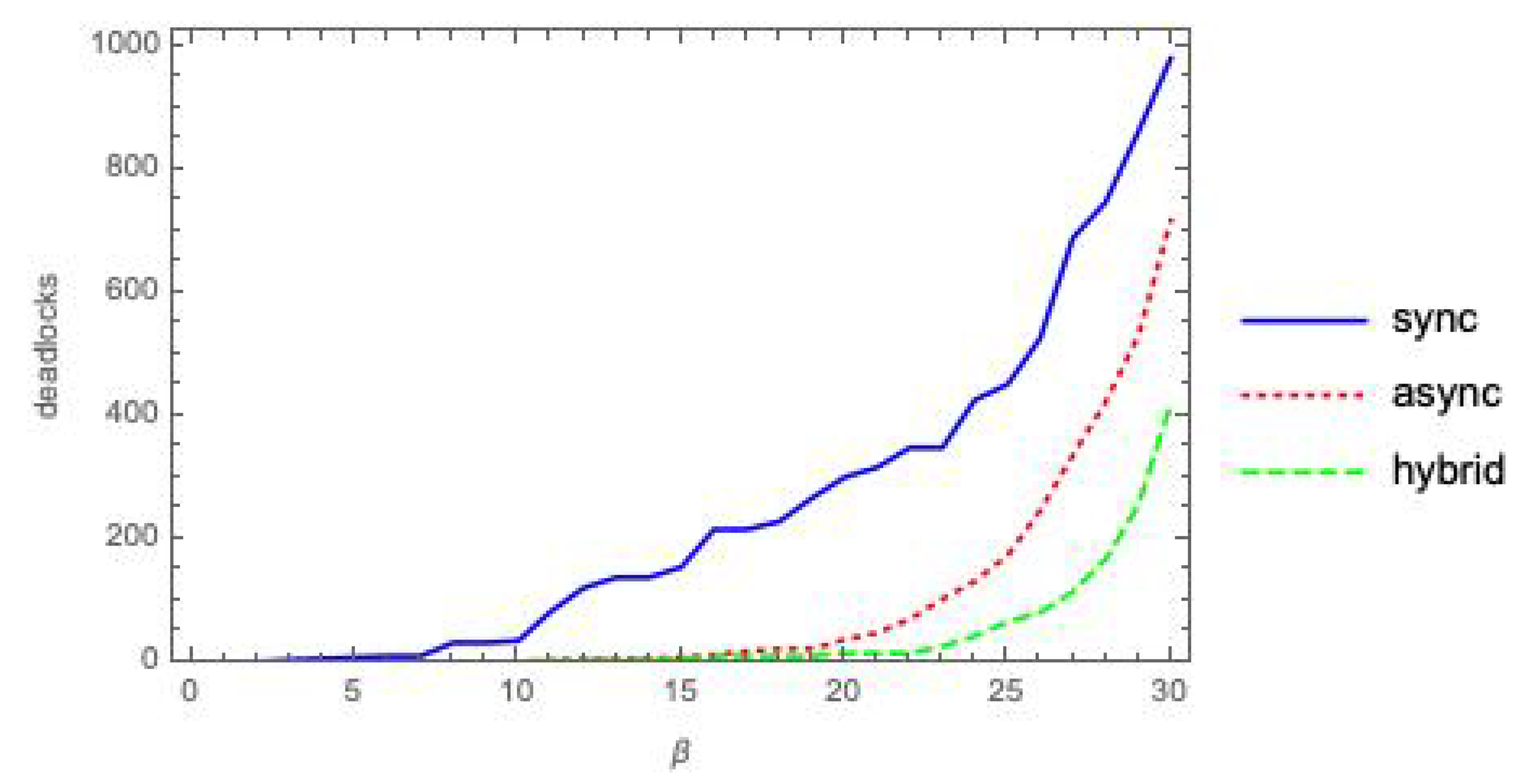
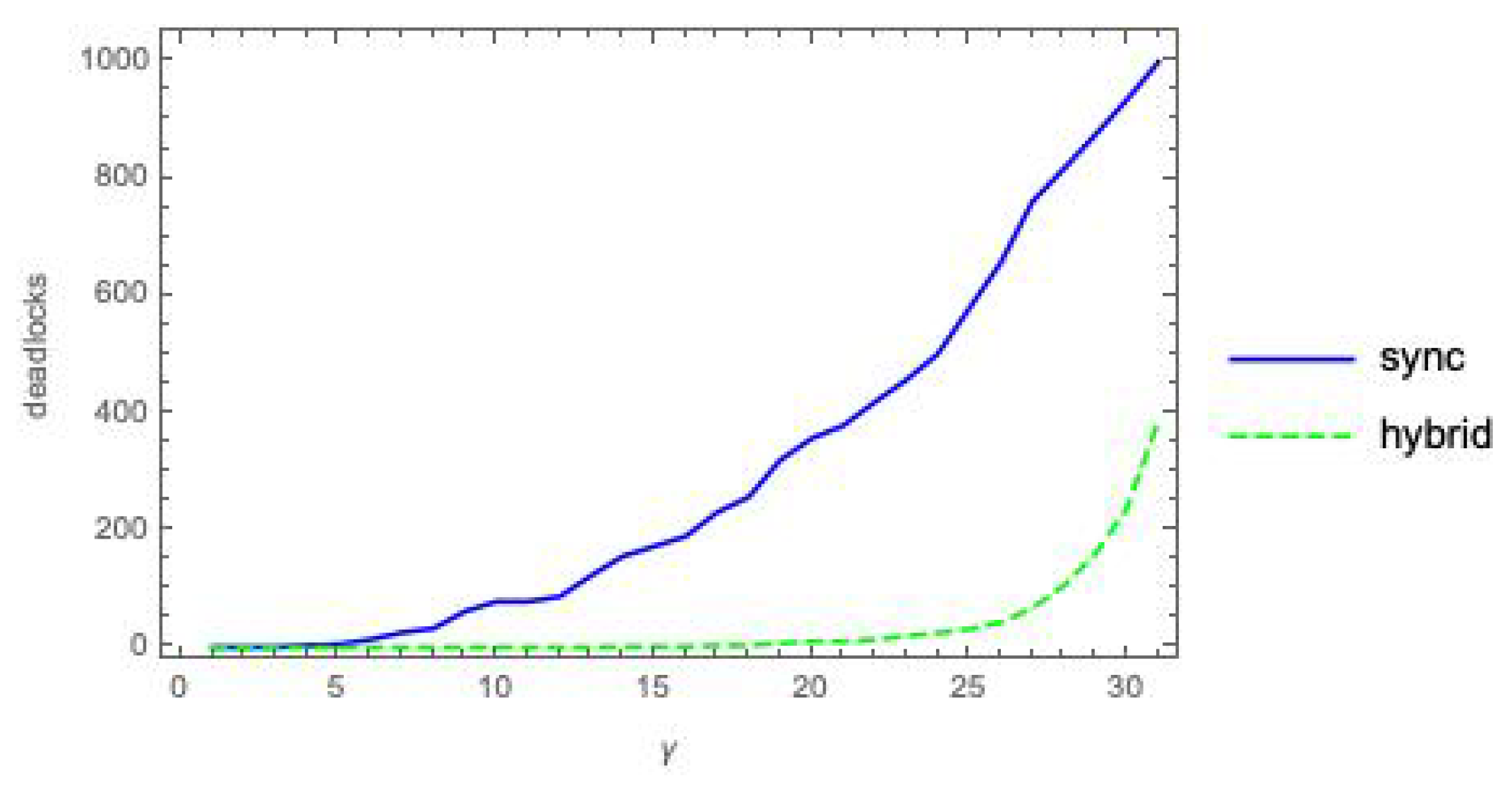
Figure 1 shows the count of deadlock states, out of
possible states, as a function of the coupling parameter
, for the parallel composition
of two randomly generated, labeled
-bool nets executed in mode
m =
sync,
async or
hybrid.
The plots in
Figure 1 provide experimental evidence for Propositions 1 and 2. Indeed, they might also suggest that a deadlock state
x for
must also be a deadlock state for
. However, this is not always the case, as shown by the following simple counterexample.
Assume P and Q are two labeled -bool nets with and . P and Q have identical topology—node 1 reads node 2 and vice versa—and all nodes are associated with the same bit-flip bool function. The label set is , Assume labeling functions and are defined so that
; and
.
Then, if we impose maximum synchronization between P and Q, by writing , we find that global state is a deadlock for (since can only perform local transitions and while can only offer and , with no label matching between P and Q) but it is not a deadlock for (since and can synchronize by performing local transitions ).
5. Bool Nets as <> sharVar Compositions
In analogy with the expression
P|
|
Q for the composition of two separate bool nets
P and
Q by shared transitions (
Section 4), we let
P<
>
Q denote a
single bool net whose nodes are partitioned into sets
and
, and where there are exactly
“
bridges”, i.e., directed edges with one endpoint in
and the other in
. Bridges allow the two bool net parts—called
P and
Q—to share and cross-read some of their variables; the other edges are “local” to
P or
Q. We take
as the
degree of coupling between
P and
Q. Furthermore,
and
, later equivalently denoted
and
, represent the two components
after separation: a bridge directed from
P to
Q (or vice versa) turns into a
dangling edge of
Q (or
P), with no specified source node (the notation
and
is meant to recall the presence of
bridges in the original, uncut bool net; however, it may still happen that one of the components, or both, when
, has no dangling edges after separation).
What if we are now given two independent bool nets P and Q and we want to derive from them some system P<>Q with target coupling factor ? This is done by some surgery: we turn local edges of P and/or Q into bridges between P and Q. The choice of which local edge to turn into a bridge is made at random, and so is the choice of a new source node for it.
Thus, while in building P||Q the two arguments of the composition are unaffected, except for the addition of the labeling functions and , for building P<>Q we do change the topology of the components, although the node sets and and the sets of boolean functions and are preserved. Strictly, <> should not be regarded as an algebraic operator, since the operation affects the operands. However, notations P<>Q and P||Q are useful for highlighting the system bipartition and the involved degree of coupling.
Let us now clarify a final, subtle point about execution modes for the two types of cooperation—<> and . While expression completely defines the behavior of the system, expression <> would not.
In the first case, execution mode m defines the individual behaviors of and in terms of their possible firing groups, while defines the possible transition pairings, i.e., whether or not, given current state , a firing group of P can fire simultaneously with one of Q, which depends on the involved transition labels. In other words, m defines the firing groups at the local level and controls them at the global level, by the mediation of transition labels.
In the second case, the potential firing groups of and are well defined too, but we have no indication of how they should be combined to yield global transitions: should they act simultaneously or not? The solution is to understand the execution mode as applied to the net as a whole. Correspondingly, the correct, unambiguous notation for the sharVar cooperation mechanism would be <>, although this will often be left implicit.
6. Integrated Information for <> (sharVar)
In very abstract terms,
state-dependent integrated information , relative to a global system state
Y, reduces to the distance or difference
d between two
Y-dependent probabilistic distributions
and
:
Note the slight abuse of notation:
denotes here, and in similar contexts in the sequel, a distribution
x that depends,
as a whole, on some (state) value
Y;
elsewhere is used to select a specific element of distribution
x. The meaning should be clear from the context, and is facilitated by our consistent use of symbols
and
, for predecessor and successor states. In IIT terminology,
denotes a
cause repertoire, as is clear in Equation (
15); similarly,
would denote an
effect repertoire.
Furthermore,
,
and consequently
are defined with a system
partition in mind (we restrict to bipartitions) (strictly,
should refer to a specific partition, namely the
Minimum Information Partition (
MIP) [
1,
2], but we apply it to any (bi)partition). Distribution
refers to the system behavior in which parts
P and
Q cooperate according to the relevant interaction mechanism, e.g.,
sharVar or
sharTrans. With distribution
the parts are assumed to operate
independently. Hence, their difference
d is meant to measure the added value provided by cooperation over independent operation.
In IIT 2.0 [
1],
d is
relative entropy (Kullback–Leibler divergence):
where
and
are two distributions on the same discrete domain
. Note that
: the
of two equal distributions is null. Note also that, in light of Equation (
13), one can express the mutual information in Equation (
6) as follows:
where
and
are two random variables with joint distribution denoted
and respective marginal distributions
and
(we hope symbol overloading is no too confusing here!). Symbol “×” in Equation (
14) denotes distribution product, which is defined in the main text.
Consider an -bool net <> executed in mode m (sync, async or hybrid), denoted for short. The behavior of the net is fully defined by the transition probability matrix . It is easy to see that, regardless of the mode m, cannot have null-rows (all 0s), corresponding to deadlocks. Note, however, that one may find null-columns with the sync and async modes, corresponding to “Garden of Eden” states that have no predecessor state . This does not happen with the hybrid mode, since the firing groups for this mode include the empty firing group (no node fires), which creates a loop-edge: any state has itself as a predecessor.
For the subsequent definitions of integrated information for , we also need and : these are the s that characterize the independent behaviors, under mode m, of and , i.e., the two components P and Q after separation, when the data flowing across the bridges from one to the other are lost due to the cut, and replaced by white noise, i.e., uniformly distributed bit tuples.
We are finally ready to actualize the abstract definition of Equation (
12) into the concrete definition given in [
1]. The state-dependent integrated information
for global state
of
-bool net
=
P<
>
Q executed in mode
m is:
where:
is the distribution of the predecessors of state , obtained by normalizing —the -indexed column of ;
and are the P and Q components of state : (concatenation);
and are the distributions of the predecessors of, respectively, and , obtained as done for but using, respectively, and ; and
“×” is distribution multiplication: if and are probability distributions defined, respectively, over and —the sets of tuples of lengths and —and is the distribution product, then, for the generic -bit tuple , we have .
(The interested reader can find in [
14] a freely downloadable demonstration tool illustrating state-dependent
for bool nets executed in the standard,
mode, for generic partitions.)
The averaged form
of integrated information (subscript “
” is convenient in light of subsequent developments) is defined as a weighted sum over all states
of the state dependent
s—a weighted sum that we conveniently express as a dot product (“.”):
where:
denotes the uniform distribution of states (n-tuples of bits);
, expressing the weights of the sum, is the distribution of the successors of state distribution . Note that we conceive functions and to be applicable both to a specific state (some bit tuple X or Y) and to a distribution of such states, e.g., to . No ambiguity arises, since we always use lowercase to denote random variables or their distributions (x and y), and uppercase to denote specific state values (X and Y). (Using a distribution as argument of or is preferred, since a specific state, e.g., state of a three-bit bool net, can be represented as distribution assigning probability 1 to the second triple of bits, when these are presented in lexicographic order, and probability 0 to all other triples. In particular, .)
is the decimal representation of bit tuple .
is the list of values for all bit n-tuples , listed in lexicographic order.
In [
15], it is shown that
can also be computed as
, where the barred symbols denote uniform distributions (maximum entropy), and
M is mutual information between current and next state, both referred to the global system
and to the two noised components
and
. In our experiments, we took advantage of this alternative definition, which is computationally more efficient.
6.1. The dkl-Mismatch Problem for P<>Q
In light of its definition in Equation (
13),
is
undefined when
and
for some state
: this is what we call the “
-
mismatch problem”.
Proposition 3 establishes that this problem does not arise with the we are considering, at least relative to two execution modes.
Proposition 3. Given a partitioned bool net P<α>Q, the -mismatch problem does not arise for , when mode m is sync or hybrid.
Proof. In light of the definition in Equation (
15), we must prove that, when an element of distribution
is different from zero, so is the corresponding element of distribution
. For notational convenience, let these two distributions be called, respectively,
and
, as in Equation (
13). Then, we must prove that, for any state
:
implies
, in
sync and
hybrid mode. Now,
means that there exists (at least) one transition
triggered by some firing group
. Correspondingly,
.
Representing firing groups as node sets, and observing that the firing groups of the whole system
P<
>
Q and of its parts are independent from
, we can take advantage of Equations (
1)–(
3), which refer to
P<0>
Q, finding that a global firing group can be decomposed into two local firing groups, under the same mode—
—only for
and
(for
,
must include exactly
one node, while any
and any
must include one node each, so that
includes
two).
As a consequence, using a functional notation for transitions, for
and
we can write:
The fact that guarantees that : by definition, element of “noised” matrix is obtained by the cumulative contribution of all values , and we have assumed above that at least one of them, namely , gives a non-null contribution. Similarly, we find that . We conclude that the cut sub-systems and separately support transitions and , meaning that distribution (respectively, ) assigns a non-null probability to its -indexed (respectively, -indexed) element. Since was defined as , we conclude that . □
The “anomaly” of the
async mode already observed in Equations (
1)–(
3), and in
Section 2.1, is further highlighted in Proposition 3. For these reasons, we drop this execution mode, and in the sequel
m is only
sync or
hybrid.
The computation of
is not even affected by the presence of “Garden of Eden” states. If
is such a state, we might perhaps represent the predecessor distribution
as the null “probability vector”; then, regardless of the second argument
of
, we would obtain
. However, in any case, these null values are selected away in the weighted sum of the definition in Equation (
16), since state distribution
—providing the weights—assigns probability 0 to
since, by the definition of Garden of Eden state, none of the
s can transition to the latter.
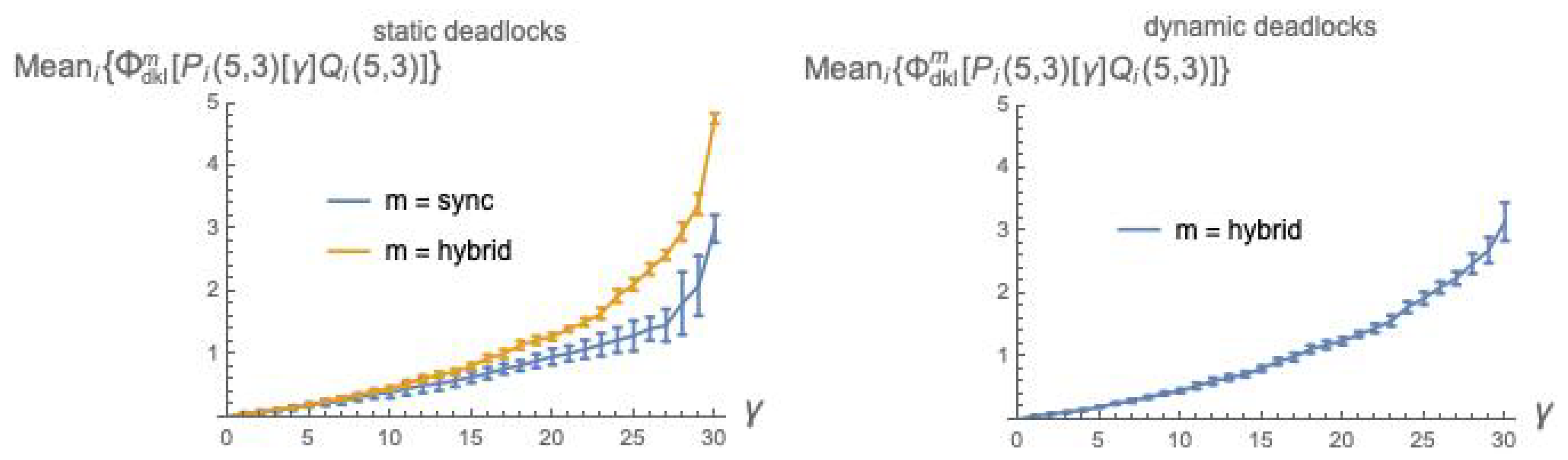
6.2. Statistical Results for
Having defined , we wish to investigate the dependence of this measure on , the degree of coupling between P and Q when they cooperate by shared variables.
Letting
and
, we have built ten pairs
,
, of randomly generated
-bool nets and have derived, for each pair, the sequence of
<
>
systems for values
(with
= 30), as described at the beginning of
Section 5. Then, for each
, we have computed
<
>
and associated standard deviation, for
and
. The results of the simulation are shown in the plots of
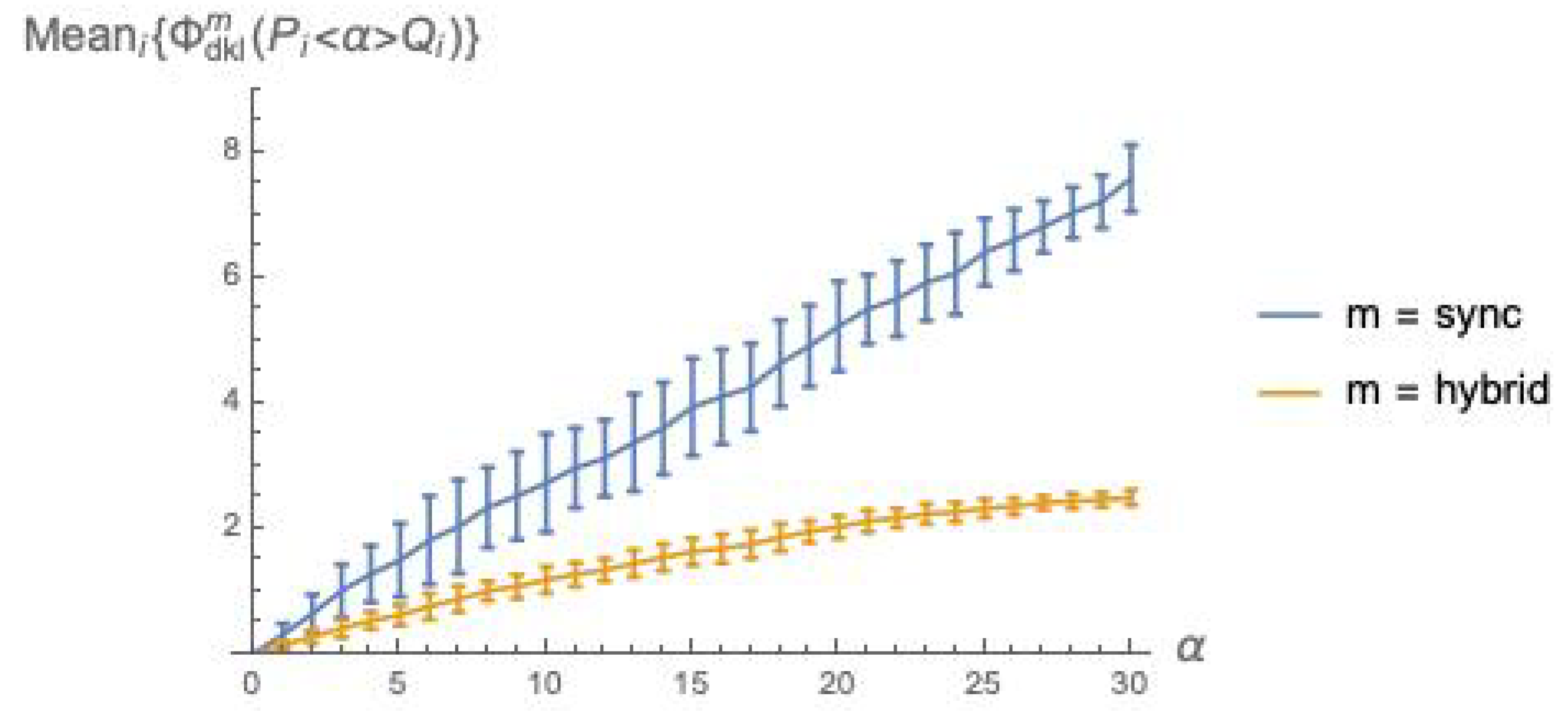
Figure 2.
The plots in
Figure 2 confirm the intuitive expectation that integrated information grows with the coupling factor
between
P and
Q. Recall that
is a weighted sum of
(Equation (
16)), and that
is a
“distance” between an
and an
distribution (Equation (
15)). As
grows, it is to be expected that
and
drift apart, since a larger
means a stronger mutual influence between the behaviors of
P and
Q, thus a more marked departure from the behaviors they exhibit when acting independently.
The fact that
can be intuitively explained as follows. Due to the different sizes of the involved firing group sets—
and
—in
mode the
successor distribution
is “punctual” (one element has probability 1, the others have probability 0), while
is much more spread over the states. An analogous difference in spread can be observed also when looking backward, with
predecessor distributions
and
. The local
post and
pre distributions for
P and
Q follow a similar pattern with respect to
sync vs.
hybrid. Then, in
the two argument distributions are closer to each other for
than for
, due to the higher spread of the distributions for the
mode. Note that the local distributions are also affected by noise injection, which cannot but amplify their spread, pushing them closer to the global distribution with higher spread, namely the distribution for the
hybrid mode, and smaller distance means smaller
.
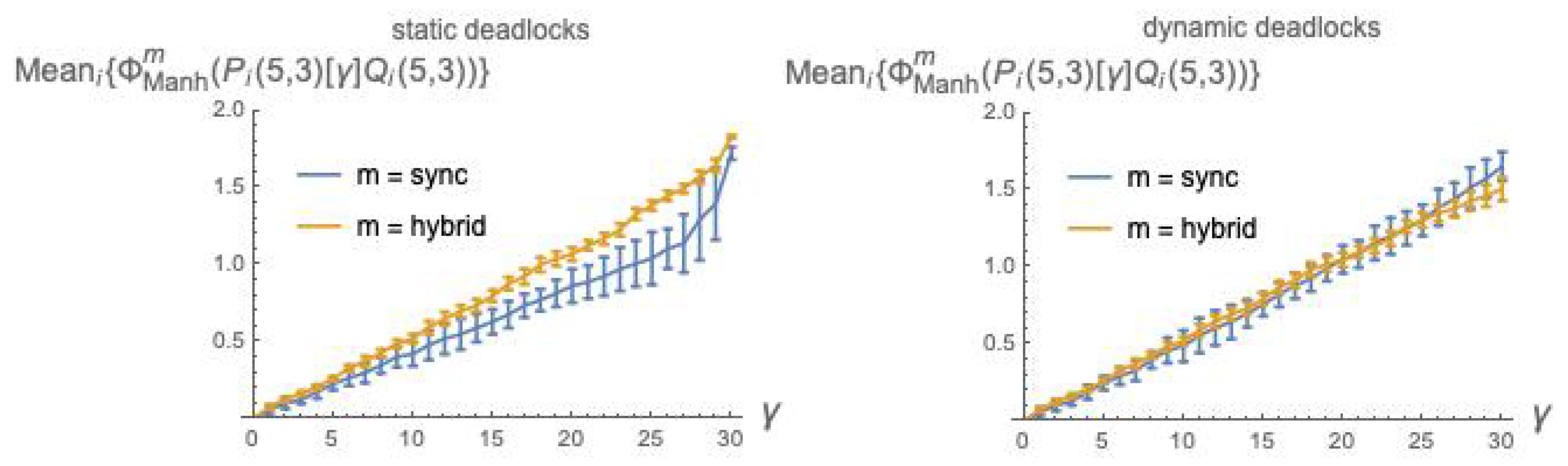
6.3. Statistical Results for Using Manhattan Distance
We show that, for the
cooperation mechanism
, the
-mismatch problem becomes pervasive. Thus, for enabling comparisons between
and
cooperation in terms of integrated information, we consider also a state-dependent version
of this measure in which the
of Equation (
15) is replaced by Manhattan distance (
Manh):
is then used, as in Equation (
16), for obtaining the corresponding state-independent
:
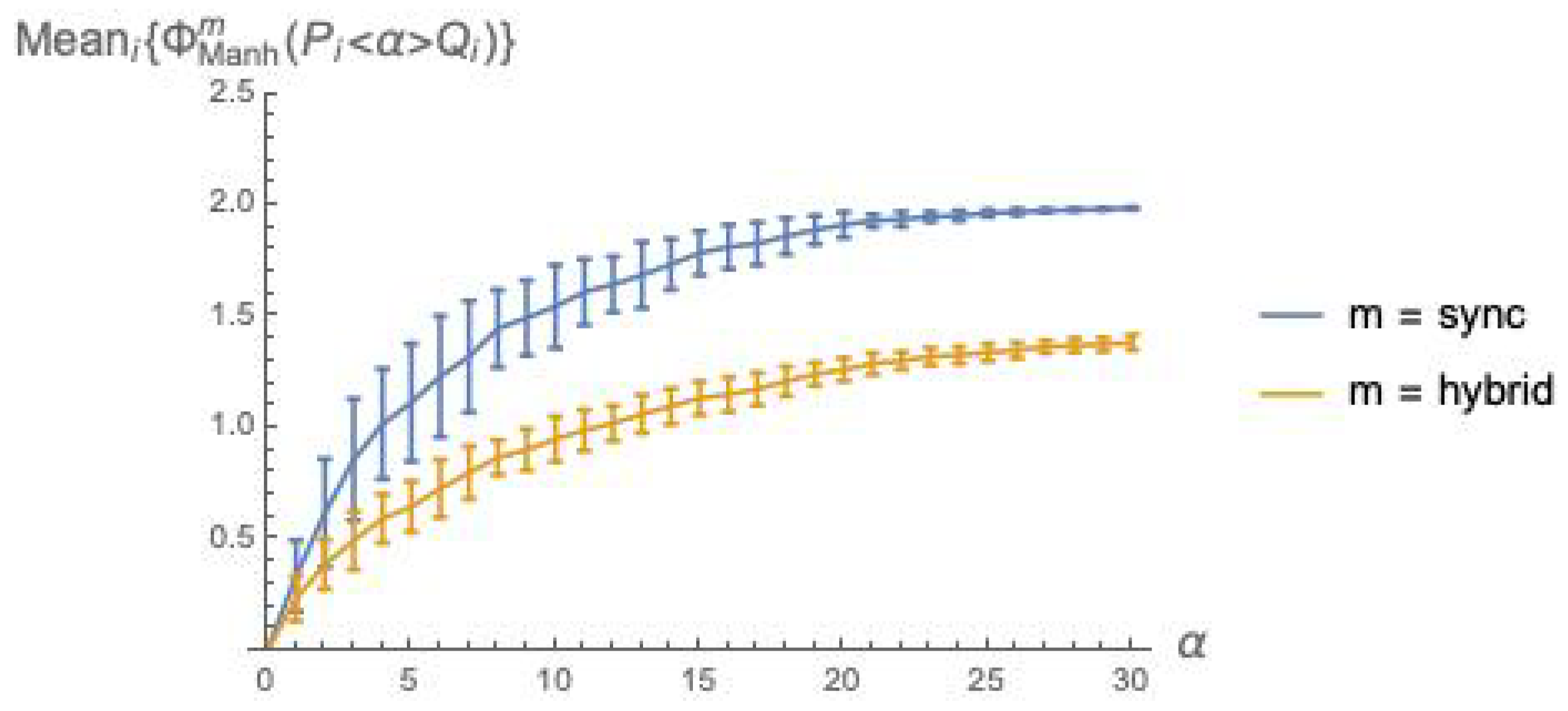
We have conducted a statistical analysis for
analogous to that presented in
Section 6.2. The results are illustrated in
Figure 3. This figure indicates that Manhattan distance broadly agrees with
dkl (while not suffering from the mismatch problem), and confirms the two general facts already established with
Figure 2: integrated information grows with the coupling factor
, and is higher for the
sync than for the
hybrid execution mode.
7. Integrated Information for || (LOTOS sharTrans)
How can one define integrated information
for
sharTrans composition
P|
|
Q? The problem reduces to one of adapting to the new context the state-dependent measure
of Equation (
12), which is given a concrete form in Equation (
15).
In fact, in
, the first argument is readily defined even in the new setting, since it refers to the “cooperative” behavior of
P|
|
Q in which
P and
Q interact as specified by operator
—a behavior that is fully defined by
—which is, in turn, fully defined by the inference rules in Equations (
8)–(
10). The difficulty arises with the definition of
: what does it mean, in the
sharTrans context, for
P and
Q to
operate independently?
Our proposed solution to this problem stems from the observation that, while under
sharVar the cooperating parts share knowledge about each other’s variables, under
sharTrans they share
knowledge about the order of transitions in time, since each part must follow the ordering of transitions of the other, at least limited to the transitions whose labels are in the synchronization set
. We must then conclude that the
absence of cooperation occurs when there is no shared knowledge about local transition ordering, and no concern to agree on it. This immediately suggests to identify independent behavior—and
in expression
—with the pure interleaving composition
(see
Section 3). The resulting definition of state-dependent integrated information for the
mechanism is then:
Note that the above definition is conceptually (and computationally) simpler than the corresponding definition for <
> (Equation (
15)): no input noise for the cut components (
and
) is involved, and the second argument of
is not a distribution product but simply the first element of the sequence
P|
|
Q for
.
Then, the definitions of
state-independent integrated information
for
P|
|
Q and for
P<
>
Q are essentially the same (compare with Equation (
16)):
Note that n is now the number of nodes in P, which has the same size as Q, yielding a total of nodes.
7.1. The dkl-Mismatch Problem for P||Q
As anticipated, the
-mismatch problem becomes pervasive with systems of type
P|
|
Q. Let state
be fixed and consider distributions
and
in Equation (
19). The mismatch occurs when
and
for some
. In
sync mode, it is easy to imagine a transition
of system
P|
|
Q such that the two bit tuples
and
differ both in their
P and in their
Q component: this may happen when the transition is a synchronization. Since
is a predecessor state of
, we have
. On the contrary, no predecessor of
under system
can differ from
in both state components, since system
must fire one component at a time, as explained at the end of
Section 3. Thus, necessarily,
: this yields the mismatch. The argument for the
mode is analogous, the key point being that a firing group of
P|
|
Q may involve nodes from both
P and
Q, while a firing group of
involves nodes exclusively from one component, by the definition of “
”.
To give an idea of how severe the
-mismatch problem is for
P|
|
Q, we have counted the number of states
yielding a
-mismatch for each of the 310 systems
<
>
, for
and
, where the
pairs are those already used in
Section 6 (
Figure 2). These numbers are collected in the
grey-level matrix of
Figure 4.
7.2. Statistical Results for Using Manhattan Distance
In light of the impossibility to use the
-based definition of
(Equation (
19)) for
cooperation, we switch, again, to a “hat” version
in which
is replaced by
Manhattan distance:
and use it, in turn, for defining the state-independent
, as in Equation (
20):
Analogous to
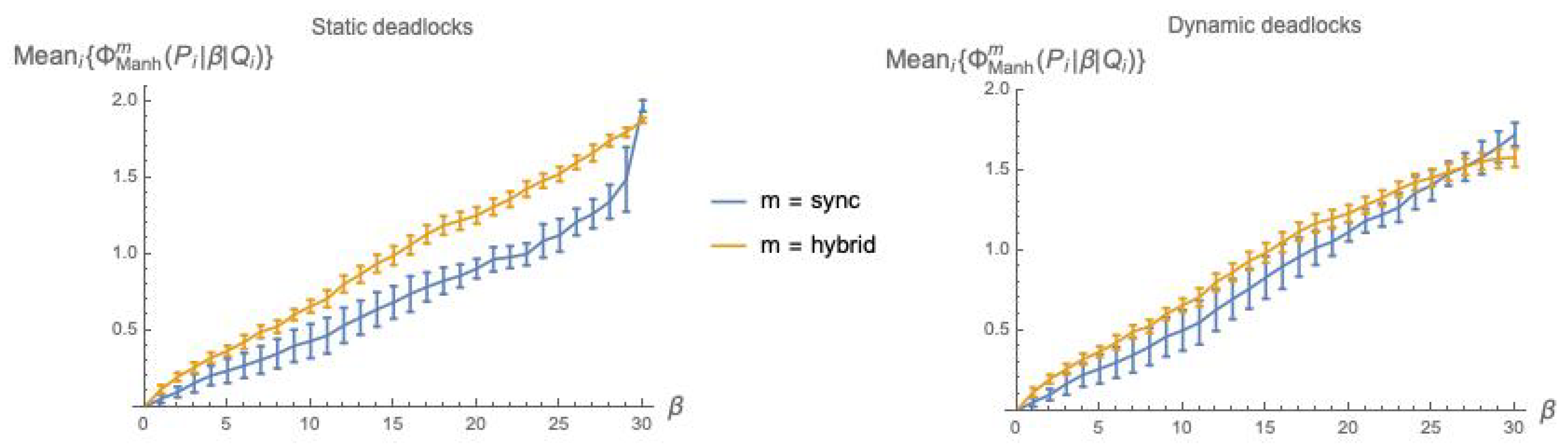
Figure 3, in
Figure 5, we plot the values of
as a function of the coupling factor
, each point obtained by averaging over 10
pairs, both using static deadlocks (
Figure 5, left) and dynamic deadlocks (
Figure 5, right).
The distinction between static and dynamic deadlocks was introduced in
Section 4.2. Note that when using static deadlocks—no 1s added on the diagonal of
—the weights
in Equation (
22) will in general not total 1,
and must be re-normalized.
8. Integrated Information for (CCS sharTrans)
Kullback–Leibler divergence
is a central element of Integrated Information Theory 2.0 [
1], thua it is indeed desirable to apply it in the new
sharTrans context without incurring the
-mismatch problem. In this section, we propose a slightly different version of
sharTrans cooperation, directly inspired to Robin Milner’s seminal process algebra
(Calculus of Communicating Systems) [
5], that precisely avoids that problem.
Consider the abstract expression:
How can we conceive the cooperative and independent behaviors of bipartite system (as defined by matrices and , from which and are derived) so that the -mismatch problem is ruled out?
Clearly, a sufficient condition for avoiding -mismatches is the following:
The existence of a transition implies the existence of transition between the same states.
The two CCS behavioral operators of (non-parametric) parallel composition (“”) and (parametric) restriction (“\”), where is a label set (using the same convention as for ), offer us a way to define cooperation and independence so that they satisfy the above condition.
In CCS, symbol
denotes a special
internal,
not observable transition label: no synchronization is possible with a process that performs a
-labeled transition. Let
A be the set of observable labels and define
. Symbol
a ranges in
A and symbol
x ranges in
. We provide below the four inference rules of the Structural Operational Semantics of CCS for the two mentioned operators (we depart from the standard definition of Milner [
5] only in one aspect: we drop the idea of a synchronization based on the matching between a label
a and its corresponding “co-label”
, and revert to the LOTOS requirement that the two labels be simply equal).
The “interleaving” rules in Equations (
23) and (
24) establish that any transition that
P or
Q could perform
locally—in itself—can be performed
globally by composite system
. Additionally, the rule in Equation (
25) establishes that parallel composition
can also perform synchronization transitions whenever two equally labeled observable transitions are available at the two sides. The rule in Equation (
26) defines the restriction
as a filter that enables
P (which can be itself a two-process composition) to perform a transition only if its label is not in the specified set
of
forbidden labels (thus,
is always admitted), pruning away all other transitions.
We now combine CCS
parallel composition and
restriction into the convenient syntactic form
where parameter
is enclosed in square brackets to distinguish it from the LOTOS form “
”, and use it for actualizing the cooperation and independence relations between
P and
Q:
Note that no deadlock can occur in
. With the LOTOS-based
sharTrans composition, we had assumed
, a form of independence by which
P and
Q will never deadlock
and will
never synchronize: their respective transitions can only interleave. This is not the case for the CCS-based approach, where
: the two independent systems, by the rule in Equation (
25), can indeed synchronize any pair of transitions
and
with the same observable label. However, by the rules in Equations (
23) and (
24), these same transitions can be executed separately, in interleaving—in
independence. Cooperation
, then, consists in ruling out these independent transitions—at least those specified in set
—while preserving their synchronizations.
One could argue that already entails a sort of cooperation, via all the synchronization transitions it supports, and that pure LOTOS interleaving is a more appropriate form of independence. This is true only in part. The “cooperation” that takes place in is not private: the transition that P shares with Q, forming a -labeled synchronization, is also “offered” separately by P (and by Q too) for further two-way synchronizations with other potential partners. When we apply restriction to the composition——we rule out this possibility, and cooperation via joint transitions with labels in becomes exclusive of the pair, occurring via a global, -labeled transition. In other words, in , the parties are not forced to wait for each other at specific transitions, as in P||Q, while this effect of mutual influence on transition ordering is enforced in , when restriction is in action.
It is clear that the above sufficient condition for ruling out
-mismatches is satisfied by our newly adopted CCS-based definitions:
since, by the definition of the restriction operator, the transitions of
are a subset of those of
.
8.1. Deadlocks in
While deadlocks can never occur in , they may occur in : this happens when P and Q offer disjoint sets of labels, thus preventing any synchronization between them, and when all these labels are members of , the set of forbidden labels.
In
Figure 6, we show the count of deadlock states, out of 1024 possible states, as a function of the coupling parameter
, for the composition
of two randomly generated labeled (5,3)-bool nets executed in modes
sync and
hybrid.
Recall that we have dropped the
mode for its various anomalies. For the remaining two modes, deadlocks under the
and
interaction mechanisms seem to behave quite similarly (compare with
Figure 1).
8.2. Statistical Results for
Before presenting the plots, we need to deal again with static vs. dynamic deadlocks (
Section 4.2). Referring to the
sync mode,
s with dynamic deadlocks turn out to be inappropriate for computing
, since they would re-introduce the
-mismatch problem that we have managed to rule out by switching to the
cooperation mechanism! The reason is that a static deadlock is made dynamic by adding a “1” on the diagonal of
, at an otherwise null row. This entry is unlikely to find a non-zero counterpart in
, since
(i.e.,
) has no deadlocks—no 1s added on the diagonal—and the only possibility to have a non-zero entry on the diagonal is that an actual loop-transition
be possible for that system. However, when
P and
Q are executed in
sync mode, this is unlikely, both when they operate in interleaving (i.e., when only one of them updates all its nodes) and, even worse, when they synchronize (i.e., when all nodes of
P and
Q are updated). Thus, for the
mode, the option is to use static deadlocks—no 1s added on the diagonal of
. As observed above for the
composition, the weights
in Equation (22), will in general not total 1, and must be re-normalized.
The -mismatch problem does not arise with the hybrid mode since, using the empty firing group, a loop edge is always possible for system , for any state , so the elements on the diagonal of are all different from 0. In this case, we can then safely use both dynamic deadlocks and static deadlocks with re-normalization.
In
Figure 7, we plot the values of
as a function of the coupling factor
, each point obtained by averaging over 10
pairs, using static deadlocks (for the
sync and
hybrid modes) and dynamic deadlocks (only for the
hybrid mode).
8.3. Statistical Results for Using Manhattan Distance
The potential mismatch between distributions and in is not a concern when using Manhattan distance for defining (by equations analogous to Equations (30) and (31)). Thus, we can handle both static deadlocks, with renormalization of the weights, and dynamic deadlocks.
Figure 8 is analogous to
Figure 7, except that Manhattan distance is used in place of
.
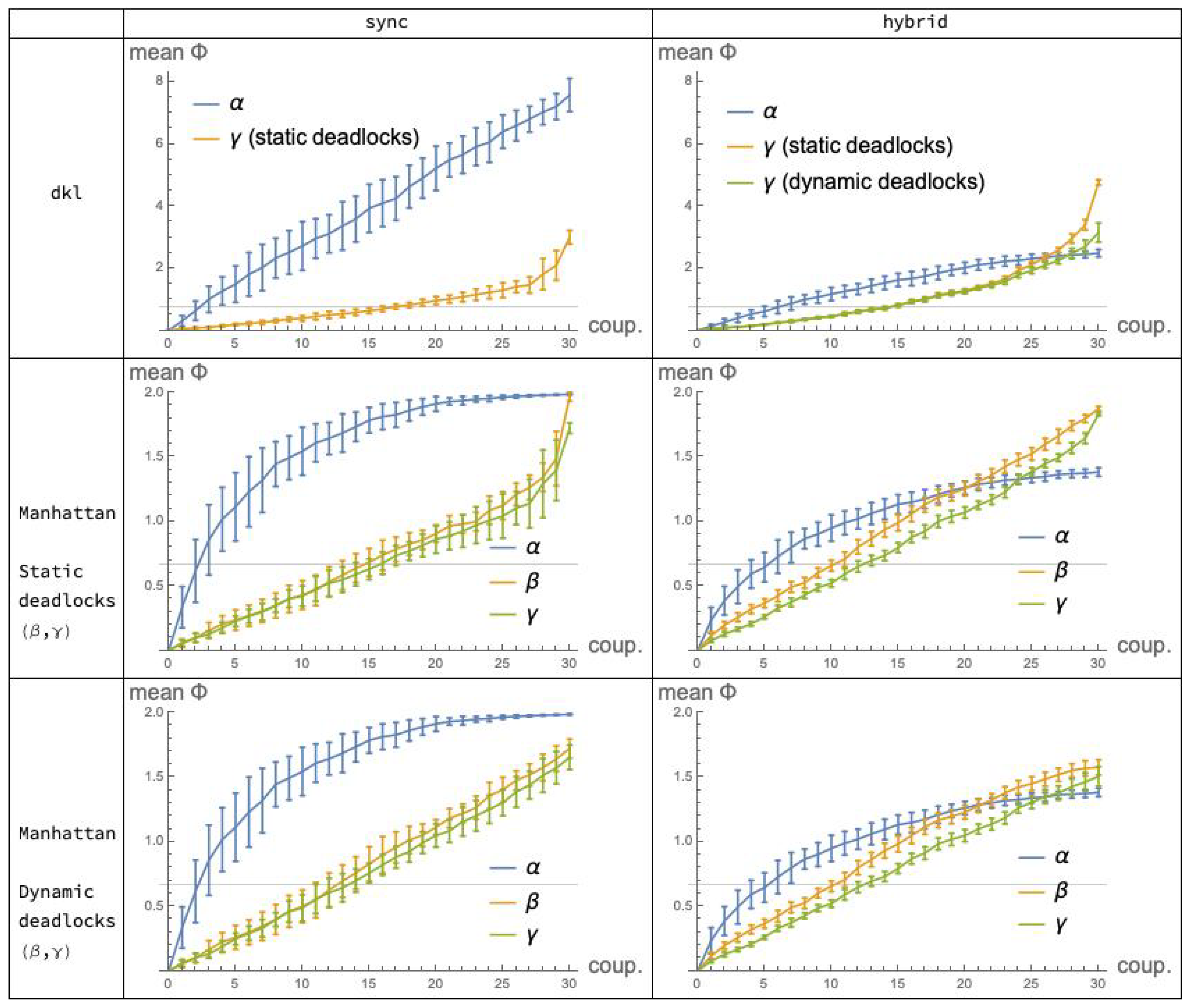
9. Comparisons
Our experimental analysis has involved three dimensions, or degrees of freedom:
(i) bool net cooperation mechanism (//);
(ii) bool net execution mode (/); and
(iii) “distance” function for probabilistic distributions (/Manhattan distance).
As stated initially, our interest is primarily in the comparison of cooperation mechanisms (i). It is then useful to aggregate the statistical data collected in the previous sections so that the plots for
,
and
appear in the same diagram. This is done in
Figure 9 which shows, for each fixed choice of execution mode (the columns) and distance function (the rows), the “performance” of the applicable mechanisms in terms of integrated information, as a function of the coupling factor (“coup”). Note that Manhattan distance is represented in Rows 2
and 3, corresponding to systems implementing, respectively, static and dynamic deadlocks: this distinction only affects the
and
plots, since the
mechanism is immune to deadlocks. For convenience, the
plots in Row 2 are replicated in Row 3. (Recall also that the
dkl-mismatch problem prevented us from applying distance
to the
mechanism.)
In the following subsections, we consider all three “dimensions” (iii), (ii) and (i), precisely in this order, with (i) being the dominant one.
9.1. Distribution Distances: Kullback–Leibler Divergence dkl vs. Manhattan
It is not our goal here to assess the various (pseudo-)distances used for defining
: the interested reader can find an accurate study involving
seven options for this metric in [
16]. However, we are interested in checking whether, despite the different ranges of values and plot shapes that they yield, the two alternative distances give analogous indications about the
mutual relations among the
,
and
mechanisms.
A quick look at the grid of
Figure 9 suggests that the relations between the plots for
and
are not “qualitatively” different under
dkl (Row 1) and under Manhattan distance (Rows 2 and 3). By this, we mean that the
relative order between
values for the different mechanisms and modes, as the coupling factor moves in its range, is substantially the same for the two distances.
More precisely, we can split the comparisons in two steps.
Fix the mode and vary the mechanism. In mode
(Column 1 of
Figure 9), the relation between the
and
plots is qualitatively the same for
and for
Manhattan distance. A similar observation applies relative to mode
(Column 2).
Fix the mechanism and vary the mode. Consider the
mechanism: under
, the relation between
and
is depicted in
Figure 2; under Manhattan distance, the relation between
and
is qualitatively the same, and is depicted in
Figure 3. For mechanism
, the comparison
/
Manhattan distance does not apply. For mechanism
, under
the relation between
and
is depicted in
Figure 7 (left), where static deadlocks are assumed. An analogous relationship is observed between
and
in
Figure 8 (left) that also assumes static deadlocks.
In conclusion, the choice to use Manhattan distance as an alternative to , for comparing the , and mechanisms appears, a posteriori, convenient and fully legitimate.
9.2. Modes: Sync vs. Hybrid
Having found that the choice of distribution distance does not affect the picture of the relations among
,
and
, we may wonder whether the same happens with the choice between
sync and
hybrid mode. It turns out that this is
not the case: the pictures that emerge under the two modes are different, as a quick comparison of the two columns of
Figure 9 reveals. In light of the findings of the previous subsection, it is sufficient, convenient and safe to focus on Manhattan distance—Tows 2 and 3. Indeed, given the minimal differences between these two rows, choosing one or the other is irrelevant: implementing static or dynamic deadlocks in the
s does not significantly affect our comparisons.
In
sync mode, the
plot is constantly higher than the
and
plots, which are close to each other; in
hybrid mode, the
plot crosses the other two. This crossing is mainly due to a substantial
decrement of the values of the
plots, when switching from
to
(
Figure 3)—a justification of this is given in
Section 6.2—whereas for the
mechanism the effect of the mode switch is reversed, with a moderate
increase of the values of the
hybrid over the
sync plot (
Figure 5). For the
mechanisms (
Figure 8) the effect of switching from
to
is similar.
Why does this happen? Why do the arguments related to distributions spread in
Section 6.2 not apply here? Our conjecture is as follows. Under the
mechanism, the much higher abundance of transition possibilities provided by the
hybrid over the
sync mode for system
<
>
causes a
reduction of the distance between distributions
and
in
, as discussed. On the contrary, in system
, written more accurately
, the higher abundance of transitions in
and
, with respect to those in
and
, offers
more opportunities to
than to
to perform
synchronization transitions involving
P and
Q (the reader is invited to recall the discussed difference between
sync execution mode of a bool net and
synchronization transition for parallel composition
P|
|
Q). More synchronization transitions for
yield a
bigger gap between distributions
and
(
cannot perform any synchronization transition), or between distributions
and
(switching from forward to backward reasoning), the latter being the distributions that feature in the definition of
in Equation (
19).
The conclusion is that the comparison among , and cannot be done independently of the execution mode.
9.3. Mechanisms: vs. vs
We come finally to the comparison among cooperation mechanisms, one that we must contextualize to one or the other execution modes, as just established.
For further assessment of the data in
Figure 9, we have included in the plots of Row 1, relative to the
distance, a gridline corresponding to the expected relative entropy
, where
and
are two
random distributions. Similarly, in the plots of Rows 2 and 3, relative to Manhattan distance, gridlines indicate the expected Manhattan distance
. These expected values are established by the next two propositions.
Proposition 4. If and are random discrete distributions over the same domain of size N, where each element (respectively, ) is obtained by picking a real number (respectively, ) at random in (0, 1] and normalizing it so that p (respectively, q) is a probability vector, then as the expected KL-divergence between p and q is: Proof. For Equation (34), we use the definitions of and , and . For Equation (35), we swap Mean and summation and use the fact that is the same for all is. In Equation (36), we express the Mean as an integral on the unit square. The integral is routinely solved by parts, yielding Equations (37) and (38), where “ln” is the natural logarithm. □
Proposition 5. If p and q are random distributions of length N as defined in Proposition 4, then as the expected Manhattan distance between p and q is: Proof. The easy proof is analogous to that of Proposition 4, and is omitted. □
9.3.1. Comparing Mechanisms under the sync Mode
The relevant plots for this comparison are those in Column 1 of the grid in
Figure 9, Row 2 or 3.
values for the
mechanism are remarkably higher than those attained by the
and
mechanisms, which are very close to each other.
Bool nets executing in the sync mode exhibit a fully deterministic behavior, and, due to their simplicity, are probably the model most widely used in the literature for illustrating the basic concepts of IIT. If we were to accept them as a sufficiently realistic model for consciousness phenomena, then, according to our findings, we would conclude that the traditional, simple cooperation mechanism, outperforms the alternative and, in a way, more sophisticated process-algebraic mechanisms and in achieving high values of integrated information and, potentially, consciousness. This gap is particularly marked in the central segment of the range of coupling values, where P and Q show an even balance of cooperation and independence. However, the ever-lasting debate on determinism vs. nondeterminism in the natural sciences must invest also the neurosciences, and, although we cannot provide an accurate picture of the status of this discussion in this field, we believe that the assumption of a fully deterministic model for the brain appears too restrictive, if not naive. The hybrid mode may then be a better option. (Of course, the nondeterministic hybrid mode appears a better option if we restrict ourselves to the relatively small family of models investigated in the paper, but there may well be other nondeterministic models that lend themselves to interesting and perhaps more appropriate and realistic applications to neuroscience. For example, an option that seems to have gained attention inside the IIT community (as emerged in a private communication) is that of noisy mechanisms run in sync mode, e.g., the idea that the computations performed by the boolean functions associated with bool net nodes are affected by some percentage of error.)
9.3.2. Comparing Mechanisms under the Hybrid Mode
The hybrid mode produces nondeterministic behavior. Nondeterminism may appear as a desirable feature, when dealing with complex systems and models in neuroscience; however, it is certainly a must for system models in Software Engineering. In the early phases of software development, for example, nondeterminism is typically used to prevent premature design choices that are postponed to later phases, down to the final implementation—a convenient way to offer implementation freedom. Then, if we set up to assess the three cooperation mechanisms in the context of formal models for Software Engineering, or system engineering in general, we believe that it is much more appropriate to refer to the execution mode.
Here, the relevant plots are those in the last column of
Figure 9, Row 2 or 3. The
plots for the LOTOS-inspired mechanisms
and the CCS-inspired mechanism
end up performing in a similar way, as it happens under the
mode. However, the difference between
, on the one hand, and
-
, on the other hand, is now considerably reduced, and a faster growth of the
plot in the lower part of the
coup range is counterbalanced by the slightly higher values of the
-
plots in the upper part.
It seems arduous, and perhaps even pointless, to speculate on the detailed differences among those three plots, trying to justify them formally—detailed differences that one may well expect, given the substantial difference between the sharVar and the sharTrans mechanisms. On the other hand, by taking a coarser look at the mentioned plots, we can reasonably conclude that, in terms of integrated information, the performances of the three mechanisms are roughly equivalent. Furthermore, by comparing their plots with the reference values (the gridlines) that derive from purely random distributions, we can additionally claim that all three methods of coupling two systems P and Q for them to interact, do their jobs quite well: in their highest values, all of them roughly double those reference values.
10. Conclusions
In this paper, we have addressed the scenario of two state transition systems P and Q that exhibit different types of cooperation and a variable degree of coupling. We have applied the informational measure of averaged Integrated Information for the assessment and comparison of two fundamentally different cooperation mechanisms: (i) the standard shared variables mechanism associated to bool nets and very often adopted in the IIT literature, expressed as P<>Q; and (ii) the shared transitions mechanism typical of process algebras, which we have studied in the two forms P||Q and . In each case, , and control and measure the degree of coupling between P and Q. Having been able to export from its standard application context and to adapt it to a completely novel field, re-defining what cooperation and independence mean in the new setting, is, in our opinion, one of the interesting and original contributions of our work, on the conceptual side.
We have modeled
P and
Q as boolean nets, and have considered three possible
execution modes, namely
synchronous,
asynchronous and
hybrid, although the anomalies of the second mode soon suggested to drop it. Furthermore, we have considered two variants of Integrated Information, based on two distinct measures of
distribution distance, namely Kullback–Leibler divergence “
dkl” and Manhattan distance, which avoids some limitations of
. With the main objective to compare the
,
and
cooperation mechanisms (
coop), the idea to articulate our experimental analysis along those two additional dimensions—execution modes (
m) and distribution distances (
dd)—has been useful for obtaining a sufficiently large set of plots for
on which to ponder.
In summary, the inspection of these plots has led us to the following main conclusions.
Adopting a definition of
based on Manhattan distance rather than
makes averaged integrated information more widely applicable; furthermore, when both variants apply, they yield nicely compatible indications. For our purposes, Manhattan distance is therefore more convenient, and safe. It is worth noting that the Earth Mover’s Distance (EMD) [
17], adopted in IIT 3.0 [
2] but computationally more costly that Manhattan distance, would also avoid the mismatch problem arising with
.
Under the deterministic, execution mode, the IIT-standard cooperation mechanism performs considerably better than and , especially for bipartite systems structured so that the two parts exhibit an intermediate degree of coupling. Conversely, under the nondeterministic mode, which may be more appropriate for cognitive system models, but is definitely more appropriate for Software Engineering models, the three mechanisms exhibit roughly equivalent performances, and good ones, at least compared with those achieved by using randomized state distributions.
Could the latter approximate equivalence be intuitively expected a priori? For the author, this was not the case. Let us explain.
In the general context of discrete state-transition models for distributed, concurrent systems, it seems reasonable to consider a cooperation mechanism as effective when the cooperating parts can produce state distributions—successor or predecessor state distributions, corresponding to effect- or cause-reasoning—that are markedly different from those achieved when the parts work independently. The reason one might expect, at least for the mode, higher values for the sharTrans than for the sharVar mechanism has to do with the difference in intrinsic complexity of the two mechanisms.
For simplicity, let us refer to effect reasoning, i.e., successor state distributions. For finding the next state under -cooperation, we only need to evaluate the n boolean functions of the bool net, where n is the overall number of nodes; the interactivity between P and Q comes “for free”, depending only on the fact that, for intermediate values of , both P and Q read a mix of local and remote nodes.
Under
- and
-cooperation, boolean function evaluation is still necessary, but then the possible local transition labels must be computed, and these depend both on current local states
and
and on next states
and
, according to our labeling policy. Then, transition
is determined after a sort of negotiation between
P and
Q, based both on the locally available labeled transitions and on the set
of synchronization labels. It is clear that mechanisms
and
are intrinsically more complex than
: they manipulate more information and do more work. It seemed then plausible that these mechanisms were able to exploit this additional information and machinery for creating next state distributions
that can depart more markedly from the reference distribution
, thus achieving higher
values. (We also expected that the noise injected in
and
for computing the distribution product
in Equation (
15) could act as a limiting factor for the gap between this distribution and distribution
, thus limiting the growth of
, and keeping it well below
and
.)
Experimental evidence has shown that this expectation was wrong.
The combination of measure with mechanisms and may appear bizarre to the IIT expert (“why and ”) as well as to the expert in process algebra (“why ”).
The first expert may criticize the adoption of additional interaction mechanisms for modeling brain-like systems, when several phenomena related to consciousness have already been successfully investigated by the plain bool net model without super-imposed features, and given that parallel compositions and fail to satisfy conditional independence. Nevertheless, flat bool nets using the basic mechanism suffer from serious scalability problems. The state space of an -bool net has size and the associated is a matrix: given this exponential growth, standard computers and algorithms can successfully deal only with “toy” models (such as those investigated in this paper), while there is no hope to handle realistic systems whose size n is, e.g., 5 or 10 orders of magnitude larger. We still believe that exploring macro-structured bool nets and higher-level interaction mechanisms—, or others—may help alleviate those problems.
The process-algebra expert, in turn, may be puzzled by the fact that
is defined in terms of just
one-step of system behavior, but considers the full repertoire of conceivable system states,
including those unreachable from the initial state (in this respect,
, especially in the state-independent form, reflects the “counterfactual-reasoning” that informs J. Pearl’s Do-Calculus of intervention [
9])
may then appear: (i) inadequate to cope with systems in which the existence and importance of an initial state is out of question—as in Process Algebra and Software Engineering; and (ii) insensitive to phenomena that emerge only with longer transition sequences, e.g., attractors (the interested reader may look at the demonstration in [
18], where attractors play a role for the analysis of
asymptotic mutual information between boolean net components
P and
Q). With respect to this objection, we do agree that the two analytical approaches of
one-step-from-all-states and
all-steps-from-one-state may address and reveal different system properties, but, of course, we can take them as
complementary techniques and explore their potential synergy. In any case, using
in the context of formal models and languages for software engineering is, to our knowledge, a radically novel way to assess the “power” of their structuring principles and operators.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








