1. Introduction
A Bayesian network (BN) is a graphical model that encodes probabilistic relationships among all variables, where nodes represent attributes, edges represent the relationships between the attributes, and directed arcs can be used to explicitly represent the joint probability distribution. Bayesian networks are often used for classification. Unfortunately, it has been proved that learning the optimal BN structure from an arbitrary BN search space of discrete variables is an non-deterministic polynomial-time hard (NP-hard) problem [
1].One of the most effective BN classifiers, in the sense that its predictive performance is competitive with state-of-the-art classifiers [
2], is the so-called naive Bayes (NB). NB is the simplest form of BN classifiers. It runs on labeled training instances and is driven by the conditional independence assumption that all attributes are fully independent of each other given the class. The NB classifier has the simple structure shown in
Figure 1, where every attribute
(every leaf in the network) is independent from the rest of the attributes, given the state of the class variable
C (the root in the network). However, it is obvious that the conditional independence assumption in NB is often violated in real-world applications, which will affect its performance with complex attribute dependencies [
3,
4].
In order to effectively mitigate the assumption of independent attributes for the NB classifier, appropriate structures and approaches are needed to manipulate independence assertions [
5,
6,
7]. Among the numerous Bayesian learning approaches, semi-naive Bayesian classifiers which utilize one-dependence estimators (ODEs) have been shown to be able to approximate the ground-truth attribute dependencies; meanwhile, the probability estimation in ODEs is effective, thus leading to excellent performance. Representative approaches include tree-augmented naive Bayesian (TAN) [
8], hidden naive Bayes (HNB) [
9], aggregating one-dependence estimators (AODE) [
10], weighted average of one-dependence estimators (WAODE) [
11].
To the best of our knowledge, few studies have focused on attribute value weighting in terms of Bayesian networks [
12]. The attribute value weighting approach is a more fine-grained weighting approach, e.g., when dealing with the pregnancy-related disease classification problem and trying to analyze the importance of gender attributes. It is obvious that the value of the male gender attribute has no effect on the class value (pregnancy-related disease), whereas the value of the female gender attribute has a great effect on the class value. It will be interesting to study whether a better performance can be achieved by combining attribute value weighting with the ODEs. The resulting model which combines attribute value weighting with the ODEs inherits the effectiveness of ODEs; meanwhile, this approach is a new paradigm of weighting approach in classification learning.
In this study, we propose a new paradigm based on a simple, efficient, and effective attribute value weighting approach, called attribute value weighted average of one-dependence estimators (AVWAODE). Our AVWAODE approach is well balanced between the ground-truth dependencies approximation and the effectiveness of probability estimation. We extend the current classification learning utilizing ODEs into the next level by introducing a new set of weight space to the problem. It is a new approach to calculating the discriminative weights for ODEs using the filter approach. We assume that the significance of each ODE can be decomposed, and in the structure of highly predictive ODE, the different root attribute value should be strongly associated with the class. Based on these assumptions, we assign a different weight to each ODE by computing the correlation between the root attribute value and the class. In order to correctly measure the amount of correlation between the root attribute value and the class, our approach uses two different attribute value weighting measures: the Kullback–Leibler (KL) measure and the information gain (IG) measure, and thus two different versions are created, which are simply denoted by AVWAODE-KL and AVWAODE-IG, respectively. We conducted two groups of extensive empirical comparisons with many state-of-the-art Bayesian classifiers using 36 University of California at Irvine (UCI) datasets published on the main website of the WEKA platform [
13,
14]. Extensive experiments show that both AVWAODE-KL and AVWAODE-IG can achieve better performance than these state-of-the-art Bayesian classifiers used to compare.
The rest of the paper is organized as follows. In
Section 2, we summarize the existing Bayesian networks learning utilizing ODEs. In
Section 3, we propose our AVWAODE approach. In
Section 4, we describe the experimental setup and results in detail. In
Section 5, we draw our conclusions and outline the main directions for our future work.
2. Related Work
Learning Bayesian networks from data is a rapidly growing field of research that has seen a great deal of activity in recent years [
15,
16]. The notion of x-dependence estimators (x-DE) was proposed by Sahami [
17]; x-DE allows each attribute to depend, at most, on only other x attributes in addition to the class. Webb et al. [
18] defined the averaged n-dependence estimators (AnDE) family of algorithms. AnDE further relaxes the independence assumption. Extensive experimental evaluation shows that the bias-variance trade-off for averaged 2-dependence estimators (A2DE) results in strong predictive accuracy over a wide range of data sets [
18]. A2DE proves to be a computationally tractable version of AnDE that delivers strong classification accuracy for large data without any parameter tuning.
To maintain efficiency, the Bayesian network appears desirable to restrict classifiers to ODEs [
19]. A comparative study of linear combination schemes for superparent-one-dependence estimators was proposed by Yang [
20]. Approaches which utilize ODEs have demonstrated remarkable performance [
21,
22]. Different from totally ignoring the attribute dependencies as naive Bayes or taking maximum flexibility for modelling dependencies as the Bayesian network, ODEs try to exploit attribute dependencies in moderate orders. By allowing one-order attribute dependencies, ODEs have been shown to be able to approximate the ground-truth attribute dependencies, whilst keeping the effectiveness of probability estimation, thus leading to excellent performance. In ODEs, directed arcs can be used to explicitly represent the joint probability distribution. The class variable is the parent of every attribute; meanwhile, every attribute has another attribute node as its parents; each attribute is independent of its nondescendants given the state of its parents. Using the independence statements encoded in ODEs, the joint probability distribution is uniquely determined by these local conditional distributions. These independencies are then used to reduce the number of parameters and to characterize the joint probability distribution.
ODEs restrict each attribute to depending only on one parent in addition to the class. If we assume that
are
m attributes, then a test instance
x can be represented by an attribute value vector
, where
denotes the value of the
i-th attribute
; under the attribute independence assumption, Equation (
1) is used to classify the test instance
x:
where
is the attribute value of
, which is the attribute parent of
.
Friedman et al. [
8] proposed tree-augmented naive Bayesian (TAN). The TAN algorithm builds a maximum weighted spanning tree; the conditional mutual information between each pair of attributes is computed, in which the vertices are the attributes; they finally transform the resulting undirected tree to a directed one by choosing a root variable and setting the direction of all edges to be outward from it. In TAN, the class variable has no parents and each attribute can only depend on another attribute parent in addition to the class; each attribute can have one augmenting edge pointing to it. The example of TAN is shown in
Figure 2.
Jiang et al. [
9] proposed a structure extension-based algorithm (HNB), which is based on ODEs; each attribute in HNB has a hidden parent that is a mixture of the weighted influences from all other attributes. HNB uses conditional mutual information to estimate the weights directly from data, and establishes a novel model that can consider the influences of all the attributes; it avoids learning with intractable computational complexity. The structure of HNB is shown in
Figure 3.
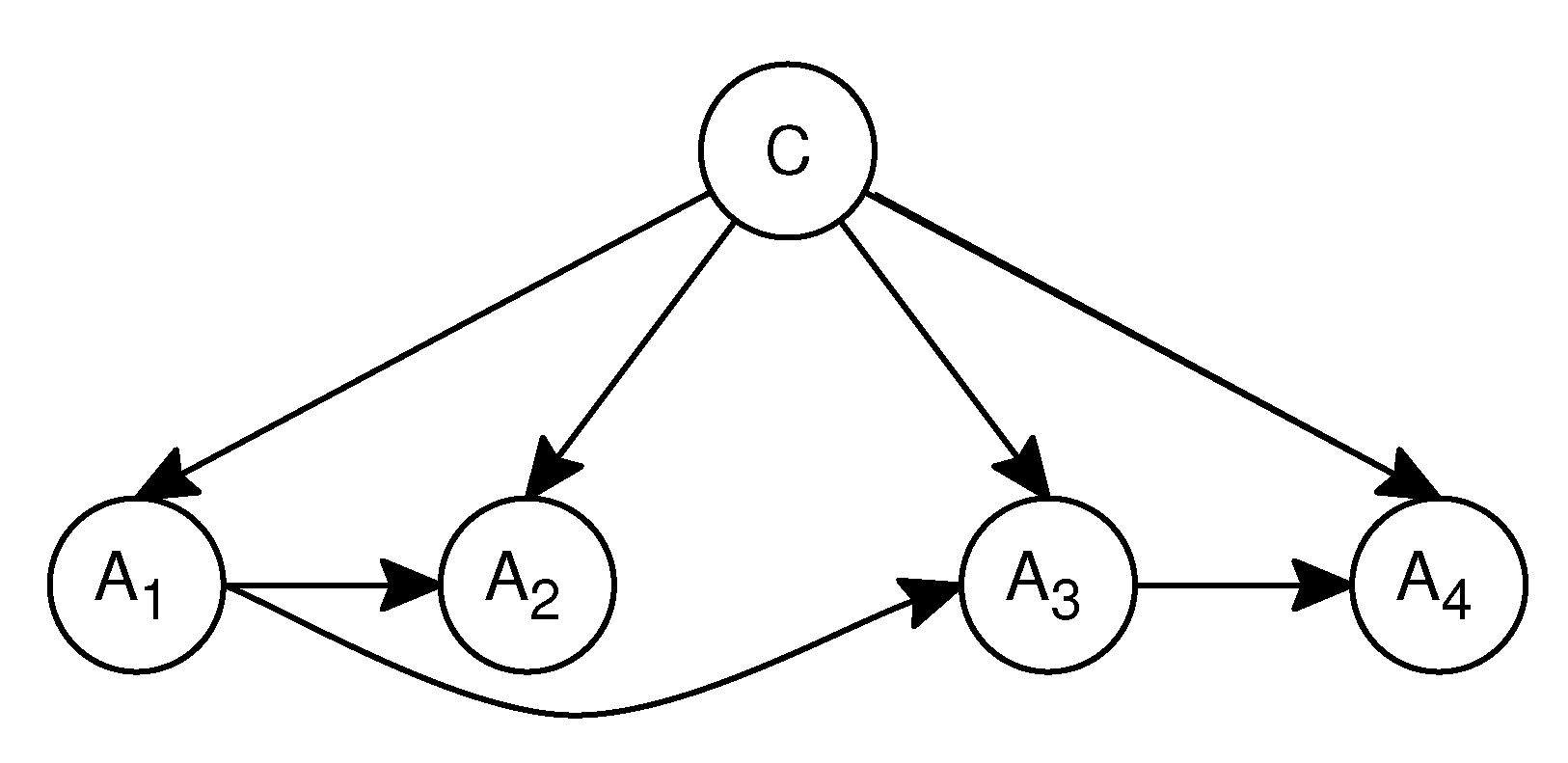
The approach of AODE [
10] is to select a limited class of ODE and to aggregate the predictions of all qualified classifiers where there is a single attribute that is the parent of all other attributes. In order to avoid including models for which the base probability estimates are inaccurate, the AODE approach excludes models where the training data contain fewer than 30 examples of the value for
of the parent attribute
. An example of the aggregate of AODE is shown in
Figure 4.
AODE classifies a test instance
x using Equation (
2).
where
is a count of the frequency of training instances having attribute value
, and is used to enforce the frequency limit;
is the number of the root attributes, which satisfy the condition that the training instances contain more than 30 instances with the value
for the parent attribute
.
However, all ODEs in AODE have the same weights and are treated equally. WAODE [
11] was proposed to assign different weights to different ODEs. In WAODE, a special ODE is built for each attribute. Namely, each attribute is set as the root attribute once and each special ODE is assigned a different weight. An example of the aggregate of WAODE is shown in
Figure 5.
WAODE classifies a test instance
x using the following Equation (
3).
where
is the weight of the ODE while the attribute
is set as the root attribute, which is the parent of all other attributes. The WAODE approach assigns weight to each ODE according to the relationship between the root attribute and the class; it uses the mutual information
between the root attribute
and the class variable
C to define the weight
. The detailed Equation is:
3. AVWAODE Approach
The remarkable performance of semi-naive Bayesian classifiers utilizing ODEs suggests that ODEs are well balanced between the attribute dependencies assumption and the effectiveness of probability estimation. To the best of our knowledge, few studies have focused on attribute value weighting in terms of Bayesian networks [
12]. Each attribute takes on a number of discrete values, and each discrete value has different importance with respect to the target. Therefore, the attribute value weighting approach is a more fine-grained weighting approach. It is interesting to study whether a better performance can be achieved by exploiting the ODEs while using the attribute value weighting approach. The resulting model which combines attribute value weighting with the ODEs inherits the effectiveness of ODEs; meanwhile, this approach is a new paradigm of weighting approach in Bayesian classification learning.
In this study, we extend the current classification learning utilizing ODEs into the next level by introducing a new set of weight space to the problem. Therefore, this study proposes a new dimension of weighting approach by assigning weights according to attribute values. We propose a new paradigm based on a simple, efficient, and effective attribute value weighting approach, called attribute value weighted average of one-dependence estimators (AVWAODE). Our AVWAODE approach is well balanced between the ground-truth dependencies approximation and the effectiveness of probability estimation. It is a new method for calculating discriminative weights for ODEs using the filter approach. The basic assumption of our AVWAODE approach is that the root attribute value should be strongly associated with the class in the structure of highly predictive ODE, and in ODEs; when a certain root attribute value is observed, it gives a certain amount of information to the class. The more information a root attribute value provides to the class, the more important the root attribute value becomes.
In AVWAODE, a special ODE is built for each attribute. Namely, each attribute is set as the root attribute once and each special ODE is assigned a different weight. Different from the existing WAODE approach which assigns different weights to different ODEs according to the relationship between the root attribute and the class, our AVWAODE approach assigns discriminative weights to different ODEs by computing the correlation between the root attribute value and the class. Since the weight of each special ODE is associated with the root attribute value, AVWAODE uses Equation (
5) to classify a test instance
x.
where
is the weight of the ODE when the root attribute
has the attribute value
. The base probabilities
and
are estimated using the m-estimate as follows:
where
is the frequency with which a combination of terms appears in the training data,
n is the number of training instances,
is the number of values of the root attribute
,
is the number of values of the leaf attribute
, and
is the number of classes.
Now, the only question left to answer is how to use a proper measure which can correctly quantify the amount of correlation between the root attribute value and the class. To address this question, our approach uses two different attribute value weighting measures: the Kullback–Leibler (KL) measure and the information gain (IG) measure, and thus two different versions are created, which are simply denoted by AVWAODE-KL and AVWAODE-IG, respectively. Note that KL and IG are two widely used measures already presented in the existing literature; we just redefine them following our proposed methods.
3.1. AVWAODE-KL
The first candidate that can be used in our approach is the KL measure, which is a widely used method for calculating the correlation between the class variable and an attribute value [
23]. The KL measure calculates the distances of different posterior probabilities from the prior probabilities. The main idea is that the KL measure becomes more reliable as the frequency of a specific attribute value increases. It originally was proposed in the article [
24]. The KL measure calculates the average mutual information between the events
c and the attribute value
with the expectation taken with respect to a posteriori probability distribution of
C [
23]. The KL measure uses Equation (
8) to quantify the information content of an attribute value
:
where
represents the attribute value-class correlation.
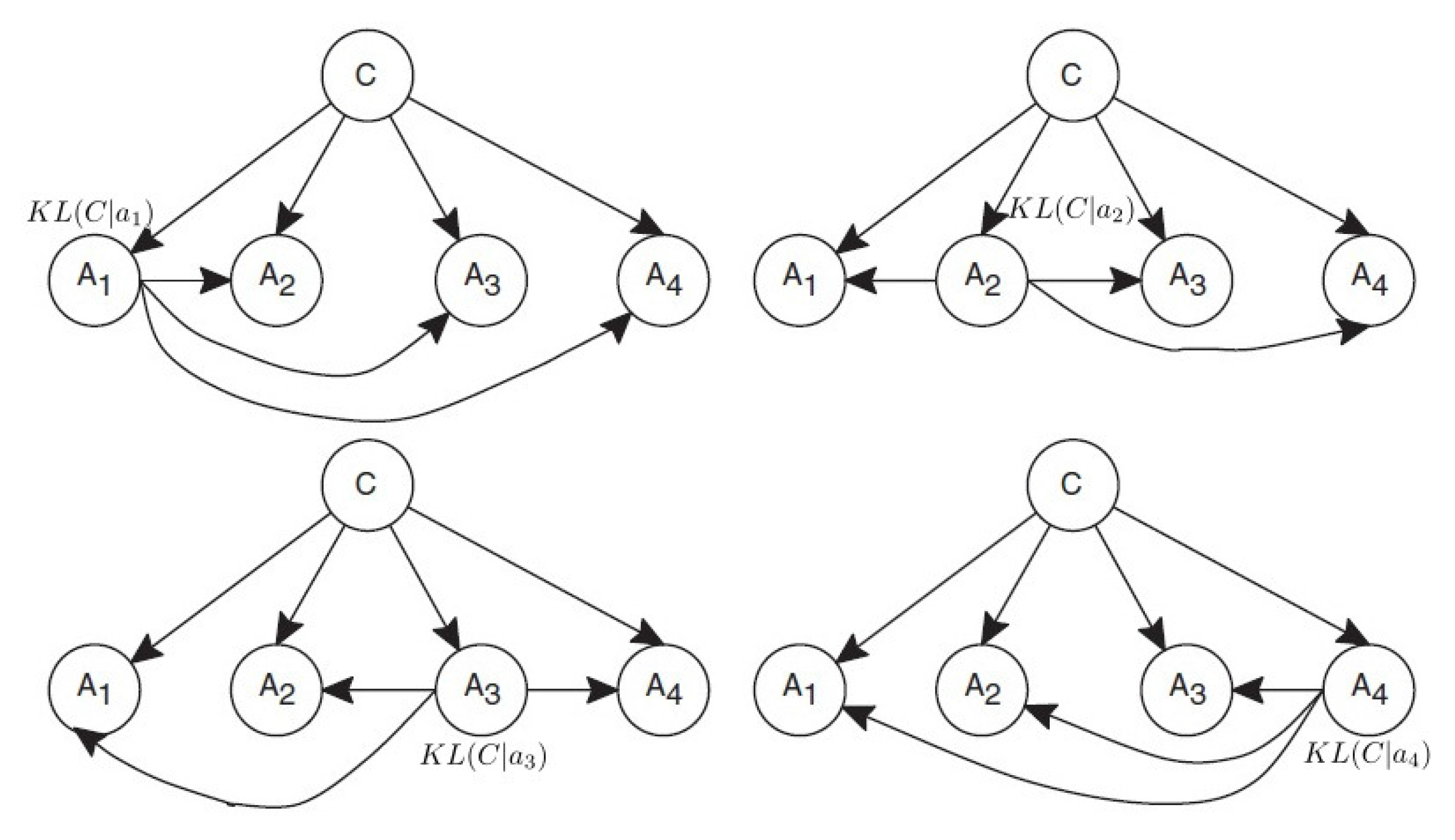
It is quite an intuitive argument that if the root attribute value
gets a higher KL value, the ODE will deserve a higher weight. Therefore, we use the
between the root attribute value
and the class
C to define the weight
of the ODE as:
where
is the attribute value of the root attribute, which is the parent of all other attributes. An example of AVWAODE-KL is shown in
Figure 6.
The detailed learning algorithm for our AVWAODE approach using the KL measure (AVWAODE-KL) is described briefly as Algorithm 1.
| Algorithm 1: AVWAODE-KL (D, x) |
Input: A training dataset D and a test instance x
Output: Class label of x |
| 1. | For each class value c |
| 2. | Compute from D |
| 3. | For each attribute value |
| 4. | Compute from D |
| 5. | Compute by Equation (6) |
| 6. | For each attribute value () |
| 7. | Compute from D |
| 8. | Compute by Equation (7) |
| 9. | For each attribute value |
| 10. | Compute from D |
| 11. | Compute by Equation (9) |
| 12. | Estimate the class label for x using Equation (5) |
| 13. | Return the class label for x |
Compared to the well-known AODE, AVWAODE-KL requires some additional training time to compute the weights of all the attribute values. According to the algorithm given above, the additional training time complexity for computing these weights is only ; where is the number of classes, m is the number of attributes, and v is the average number of values for an attribute. Therefore, AVWAODE-KL has only a training time complexity of , where n is the number of training instances. Note that is generally much less than in reality. If we only take the highest order term, the training time complexity is still , which is the same as AODE. In addition, the classification time complexity of AVWAODE-KL is , which is also the same as AODE. All of this means that AVWAODE-KL is simple and efficient.
3.2. AVWAODE-IG
The second candidate that can be used in our approach is the IG measure, which is a widely used method for calculating the importance of attributes [
5,
25]. The C4.5 approach [
2] uses the IG measure to construct the decision tree for classifying objects. The information gain used in the C4.5 approach [
2] is defined as:
Equation (
10) computes the difference between the entropy of a priori distribution and the entropy of a posteriori distribution of the class, and the C4.5 approach uses the difference value as the metric for deciding the branching node. The value of the IG measure can represent the significance of the attribute; the bigger the value is, the greater impact of the attribute when classifying the test instance. The correlation between the attribute
and the class
C can be measured by Equation (
10). Since we require discriminative power for an attribute value, we cannot use Equation (
10) directly as the measure of the discriminative power for an attribute value. The IG measure calculates the correlation between an attribute value
and the class variable
C by:
It is quite an intuitive argument that if the root attribute value
gets a higher IG value, the ODE will deserve a higher weight. Therefore, we use the
between the root attribute value
and the class
C to define the weight
of the ODE as:
where
is the attribute value of the root attribute, which is the parent of all other attributes. An example of AVWAODE-IG is shown in
Figure 7.
The training time complexity and the classification time complexity of AVWAODE-IG is the same as AVWAODE-KL. In order to save space, we do not repeat the detailed analysis here.
4. Experiments and Results
In order to validate the classification performance of AVWAODE, we ran our experiments on all the 36 UCI datasets [
26] published on the main web site of Weka platform [
13,
14]. In our experiments, missing values are replaced with the modes and means of the corresponding attribute values from the available data. Numeric attribute values are discretized using the unsupervised ten-bin discretization implemented in Weka platform. Additionally, we manually delete three useless attributes: the attribute “Hospital Number” in the dataset “colic.ORIG”, the attribute “instance name" in the dataset “splice”, and the attribute “animal” in the dataset “zoo”.
We compare the performance of AVWAODE with some state-of-the-art Bayesian classifiers: TAN [
8], HNB [
9], AODE [
10], WAODE [
11], NB [
2] and A2DE [
18]. We conduct extensive empirical comparisons in two groups with these state-of-the-art models in terms of the classification accuracy. In the first group, we compared AVWAODE-KL with all of these models, and in the second group, we compared AVWAODE-IG with these competitors.
Table 1 and
Table 2 show the detailed results of the comparisons in terms of the classification accuracy. All of the classification accuracy estimates were obtained by averaging the results from 10 separate runs in a stratified ten-fold cross-validation. We then conducted corrected paired two-tailed
t-tests at the 95% significance level [
27] in order to compare our AVWAODE-KL and AVWAODE-IG with each of their competitors: TAN, HNB, AODE, WAODE, NB, and A2DE. The averages and the
/
/
(
W/
T/
L) values are summarized at the bottom of the tables. Each entry’s
W/
T/
L in the tables implies that, compared to their competitors, AVWAODE-KL and AVWAODE-IG win on
W datasets, tie on
T datasets, and lose on
L datasets. The average (arithmetic mean) of each algorithm across all datasets provides a gross indicator of the relative performance in addition to the other statistics.
Then, we employ a corrected paired two-tailed
t-test with the
significance level [
27] to compare each pair of algorithms.
Table 3 and
Table 4 show the summary test results with regard to AVWAODE-KL and AVWAODE-IG, respectively. In these tables, for each entry
,
i is the number of datasets on which the algorithm in the column achieves higher classification accuracy than the algorithm in the corresponding row, and
j is the number of datasets on which the algorithm in the column achieves significant wins with the
significance level [
27] with regard to the algorithm in the corresponding row.
Table 5 and
Table 6 show the ranking test results with regard to AVWAODE-KL and AVWAODE-IG, respectively. In these tables, the first column is the difference between the total number of wins and the total number of losses that the corresponding algorithm achieves compared with all the other algorithms, which is used to generate the ranking. The second and third columns represent the total numbers of wins and losses, respectively.
According to these comparisons, we can see that both AVWAODE-KL and AVWAODE-IG perform better than TAN, HNB, AODE, WAODE, NB, and A2DE. We summarize the main features of these comparisons as follows.
Both AVWAODE-KL and AVWAODE-IG significantly outperform NB with 16 wins and one loss, and they also outperform TAN with 11 wins and zero losses.
Both AVWAODE-KL and AVWAODE-IG perform notably better than HNB on six datasets and worse on zero datasets, and also better than A2DE on five datasets and worse on one dataset.
Both AVWAODE-KL and AVWAODE-IG are markedly better than AODE with nine wins and zero losses.
Both AVWAODE-KL and AVWAODE-IG perform substantially better than WAODE on two datasets and one datset, respectively.
Seen from the ranking test results, our proposed algorithms are always the best ones, and NB is the worst one. The overall ranking (descending order) is AVWAODE-KL (AVWAODE-IG), WAODE, A2DE, HNB, AODE, TAN and NB, respectively.
The results of these comparisons suggest that assigning discriminative weights to different ODEs by computing the correlation between the root attribute value and the class is highly effective when setting weights for ODEs.
Yet at the same time, based on the accuracy results presented in
Table 1 and
Table 2, we take advantage of KEEL Data-Mining Software Tool [
28,
29] to complete the Wilcoxon signed-ranks test [
30,
31] to thoroughly compare each pair of algorithms. The Wilcoxon signed-ranks test is a non-parametric statistical test, which ranks the differences in performances of two algorithms for each dataset, ignoring the signs, and compares the ranks for positive and negative differences.
Table 7,
Table 8,
Table 9 and
Table 10 summarize the detailed results of the nonparametric statistical comparisons based on the Wilcoxon test. According to the table, for the exact critical values in the Wilcoxon test at a confidence level of
(
) and with datasets where
, two algorithms are considered “significantly different" if the smaller of
and
is equal to or less than 208 (227), and thus we could reject the null hypothesis. ∘ indicates that the algorithm in the column improves the algorithm in the corresponding row, and • indicates that the algorithm in the row improves the algorithm in the corresponding column. According to these comparisons, we can see that both AVWAODE-KL and AVWAODE-IG performed significantly better than NB, and TAN, and AVWAODE-IG performed even significantly better than A2DE at a confidence level of
.
Additionally, in our experiments, we have also observed the performance of our proposed AVWAODE in terms of the area under the Receiver Operating Characteristics (ROC) curve (AUC) [
25,
32,
33,
34].
Table 11 and
Table 12 show the detailed comparison results in terms of AUC. From these comparison results, we can find that our proposed AVWAODE is also very promising in terms of the area under the ROC curve. Please note that, in order to save space, we do not present the detailed summary test results, the ranking test results, and the Wilcoxon test results.
5. Conclusions and Future Work
Of numerous proposals to improve the accuracy of naive Bayes by weakening its attribute independence assumption, semi-naive Bayesian classifiers which utilize one-dependence estimators (ODEs) have been shown to be able to approximate the ground-truth attribute dependencies; meanwhile, the probability estimation in ODEs is effective. In this study, we propose a new paradigm based on a simple, efficient, and effective attribute value weighting approach, called attribute value weighted average of one-dependence estimators (AVWAODE). Our AVWAODE approach is well balanced between the ground-truth dependencies approximation and the effectiveness of probability estimation. We assign discriminative weights to different ODEs by computing the correlation between the root attribute value and the class. Two different attribute value weighting measures, which are called the Kullback–Leibler (KL) measure and the information gain (IG) measure, are used to quantify the correlation between the root attribute value and the class, and thus two different versions are created, which are simply denoted by AVWAODE-KL and AVWAODE-IG, respectively. Extensive experiments show that both AVWAODE-KL and AVWAODE-IG achieve better performance than some other state-of-the-art ODE models used for comparison.
How to learn the weights is a crucial problem in our proposed AVWAODE approach. An interesting future work will be the exploration of more effective methods to estimate weights to improve our current AVWAODE versions. Furthermore, applying the proposed attribute value weighting approach to improve some other state-of-the-art classification models is another topic for our future work.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}