1. Introduction
Supply chain management (SCM) has been an important and extensively investigated topic since its appearance in the early 1980s. Due to the importance of supplier-customer relationships in guiding modern research and practice [
1], the main impacts of this research in the field of business management and operation research are apparent. An increasing interest in applying a network analysis approach to understand supply networks (SNs) instead of linear supply chains (SCs) has been observed [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14]. SNs have become a new analytic paradigm in SCM, and have been identified as regional clusters [
2,
3,
4,
6] or industrial sectors [
4,
7,
8], and are also well known as complex adaptive systems (CAS) [
5,
9,
10,
11,
12,
13,
14,
15,
16].
This new theory of SN is extremely valuable and more meaningful than traditional SCs, and both structural and relational characteristics in the SNs enable firms to activate existing partners and select appropriate cooperation partners [
6,
8,
17]. To assess the concepts surrounding structural and relational characteristics, the extension of network analysis to SN is natural, and represents the infrastructure of the social science of business [
18,
19]. SNs have been increasingly recognized to find new business partners, discover new opportunities, increase operational efficiency, inform strategic direction, and identify and develop new products and services [
20].
Previous studies have focused on geographical agglomeration and modularized SNs in regional clusters [
2,
3,
4,
6]. The regional clusters presented a dense inter-organizational network, which enhanced knowledge diffusion, regional learning and effective resource transfer. Due to the boundary strengths of regional clusters, the majority of the transactions were held within individual regional communities, and the bridges between different communities were much thinner. The analyses and results of the regional clusters were insufficient to reveal the cross-regional features to benefit community-based economics, accounting for the lack of transaction information. However, Takayasu et al. [
4,
5] investigated the community structure of a large-scale SN. Their studies only initiated possible applications of the visualization of the SN, and their results also showed the firms local closeness. Another similar study of SN focused on industrial sectors [
7,
8,
21,
22]. Kim et al. [
7] selected Honda and Daimler as the targets and constructed SNs that included raw materials suppliers to the final assemblers. Bellamy et al. [
8] also investigated several specific firms (e.g., Sandisk, Kodak and Intel) in the electronics industry and established an SN of 390 electronic firms. These studies well examined the structural properties of interfirm systems, and revealed that an interfirm system could be better modeled as an SN rather than a linear SC. However, they conducted the SNs starting from a focal firm with its directly connected suppliers and customers. Therefore, such SNs were egocentric networks and the analysis was only be extended from the vertex-level viewpoint.
Nevertheless, real-world SNs are complex systems containing numerous firms from multiple interrelated industries. In such systems, any tiny effect or change could cause a chain reaction, and diffuse the influence throughout the whole network. The merits of complexity theory supports a conceptual and methodological framework to identify the dynamic and complicated interfirm relationships between suppliers, manufacturers, assemblers, distributors, and retailers. Pathak et al. [
9] firstly adopted a complex adaptive systems (CAS) perspective to gain insights into SN issues and suggested dozens of potential CAS research questions. Their work has familiarized us with the existence of SN theory, and brought the applicability of CAS properties to enrich the SN discipline. Edward and Wilson [
10] further advanced SN theory by embracing the CAS perspective by synthesizing the advances of CAS and demonstrating the small-world (SW) property [
23] and scale-free (SF) nature [
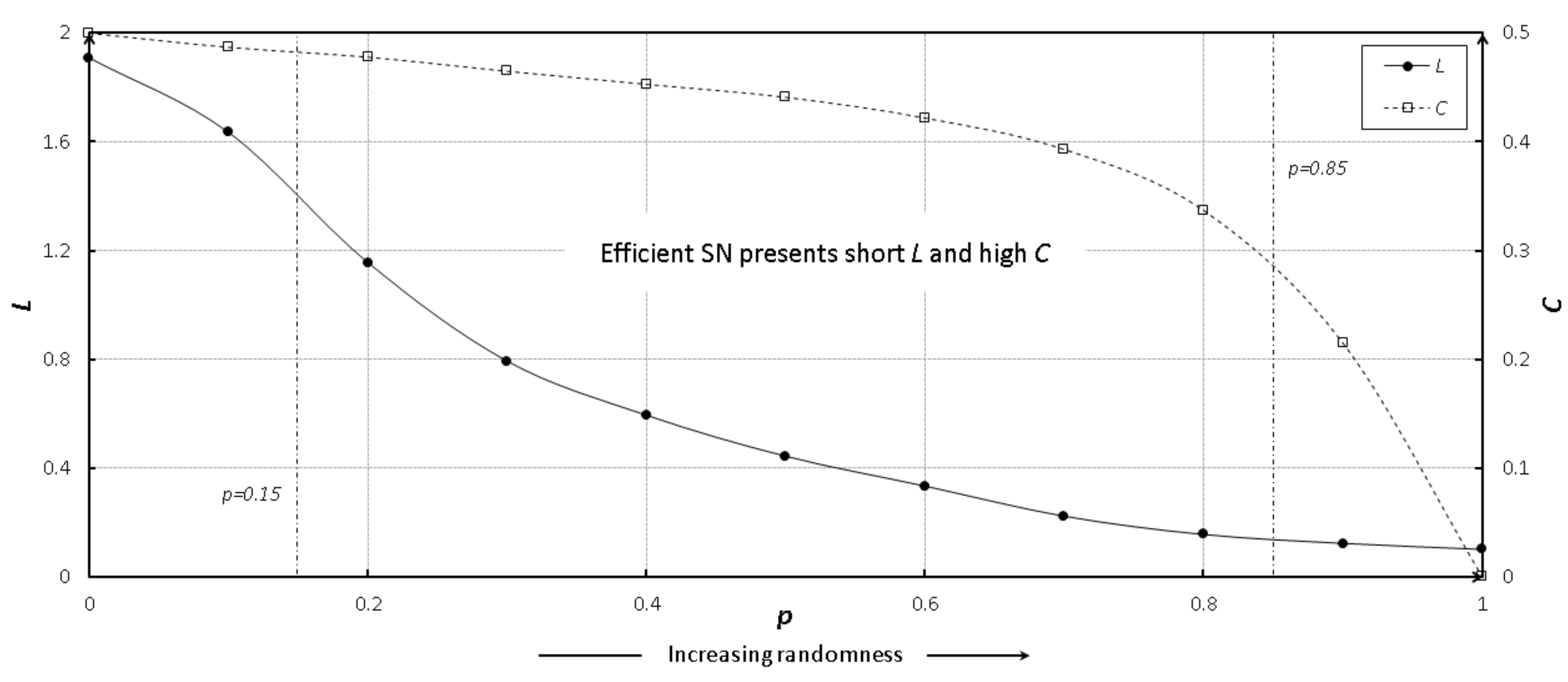
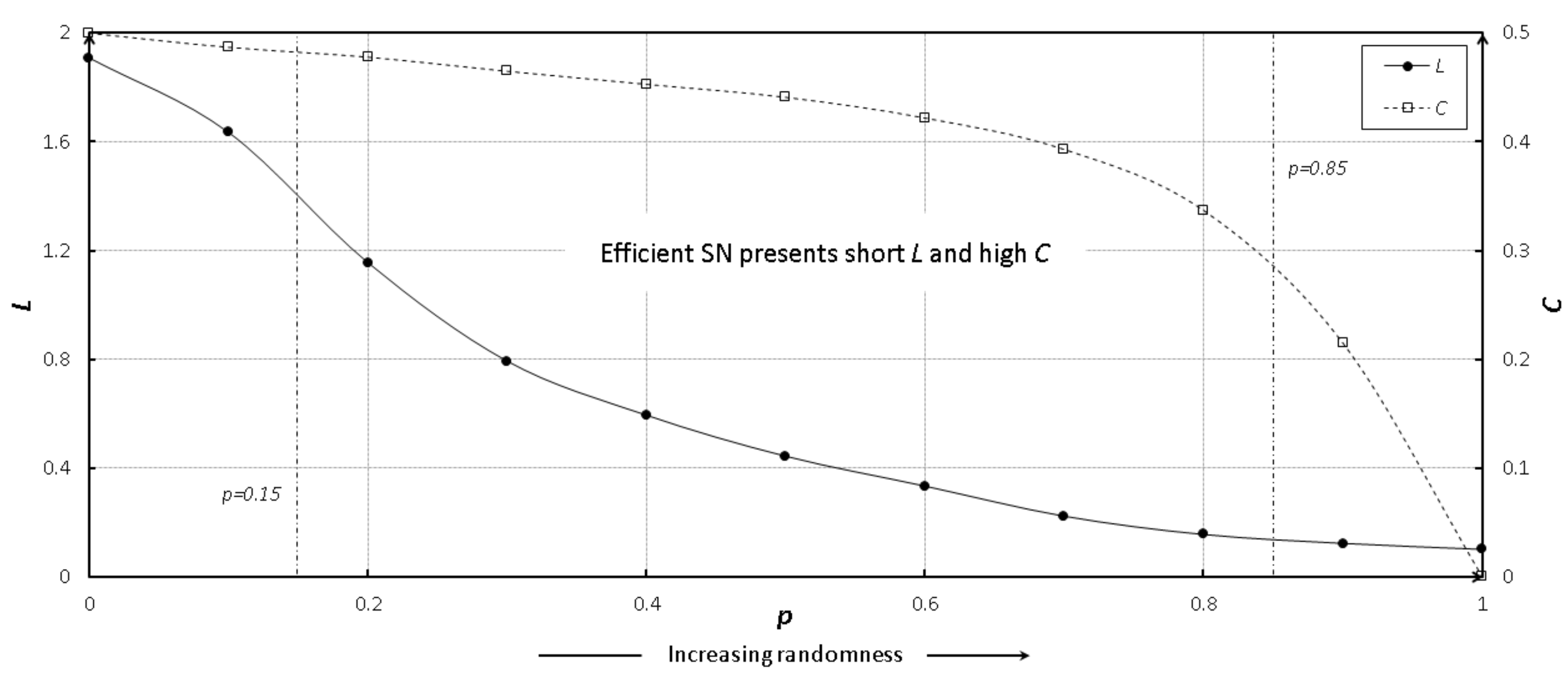
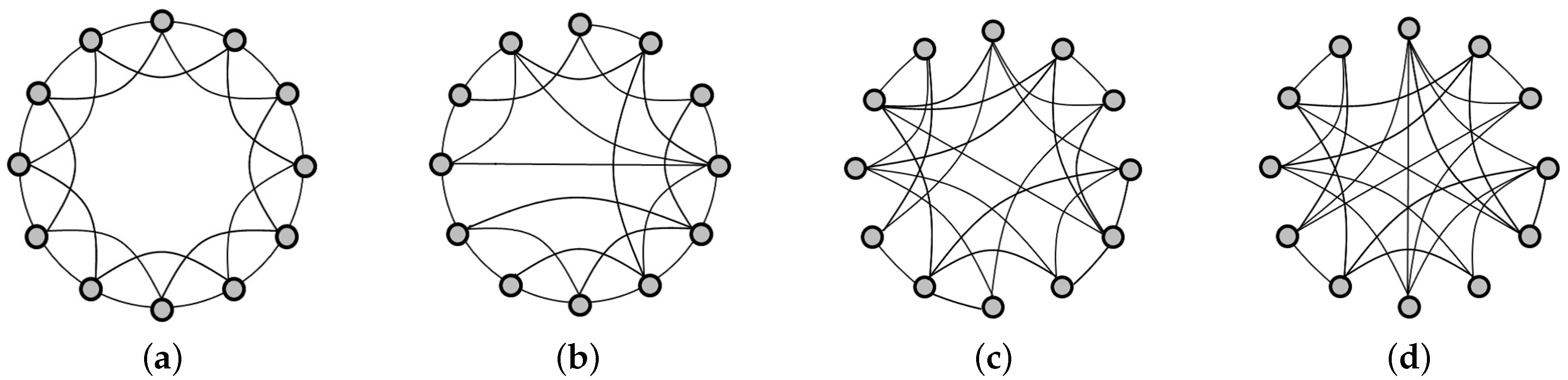
24] of SNs. The SW property suggested that an efficient SN should present a short average path length and high clustering coefficient, which means that the SW network could efficiently transfer the flows throughout the entire system. The SF nature suggested that an efficient SN should present a power law connectivity distribution, accounting for SN resilience derived by hub firms. Ohnishi et al. [
15] also identified the SNs as complex networks with directed links. By comparing them with random networks, they revealed that the firms with a large firm-size in the SN tended to have a large PageRank [
25], and small authority and hub scores [
26]. Giannoccaro [
11] characterized SN as a CAS, and used the NK simulation model [
27,
28] to exhibit SN properties, which demonstrated that the effects of capacity, efficiency and stability on the SN performance. In future studies, Giannoccaro et al. [
12,
13,
14] conceptualized the SN theory from a CAS perspective, and performed several computational analyses such as Tobit regression [
12], fitness landscape [
13], and agent-based simulation [
14]. These studies argued that CAS provided a conceptual and methodological framework to pursue the network-level issues of SNs, such as SN efficiency, SN resilience and SN interdependence. Zachariou et al. [
16] also investigated directed inter-firm networks such as SN, and generalized sandpile dynamics of an SN from a network-level study of complex interactions. They pointed out that characterization of CASs and their measurements was still a developing field that is relevant for a variety of research issues from different viewpoints. Therefore, following a review of SNs literature drawn from the regional clusters, industrial sectors and CAS, a combination of multiple approaches is necessary to adequately explore these multi-level issues in SNs.
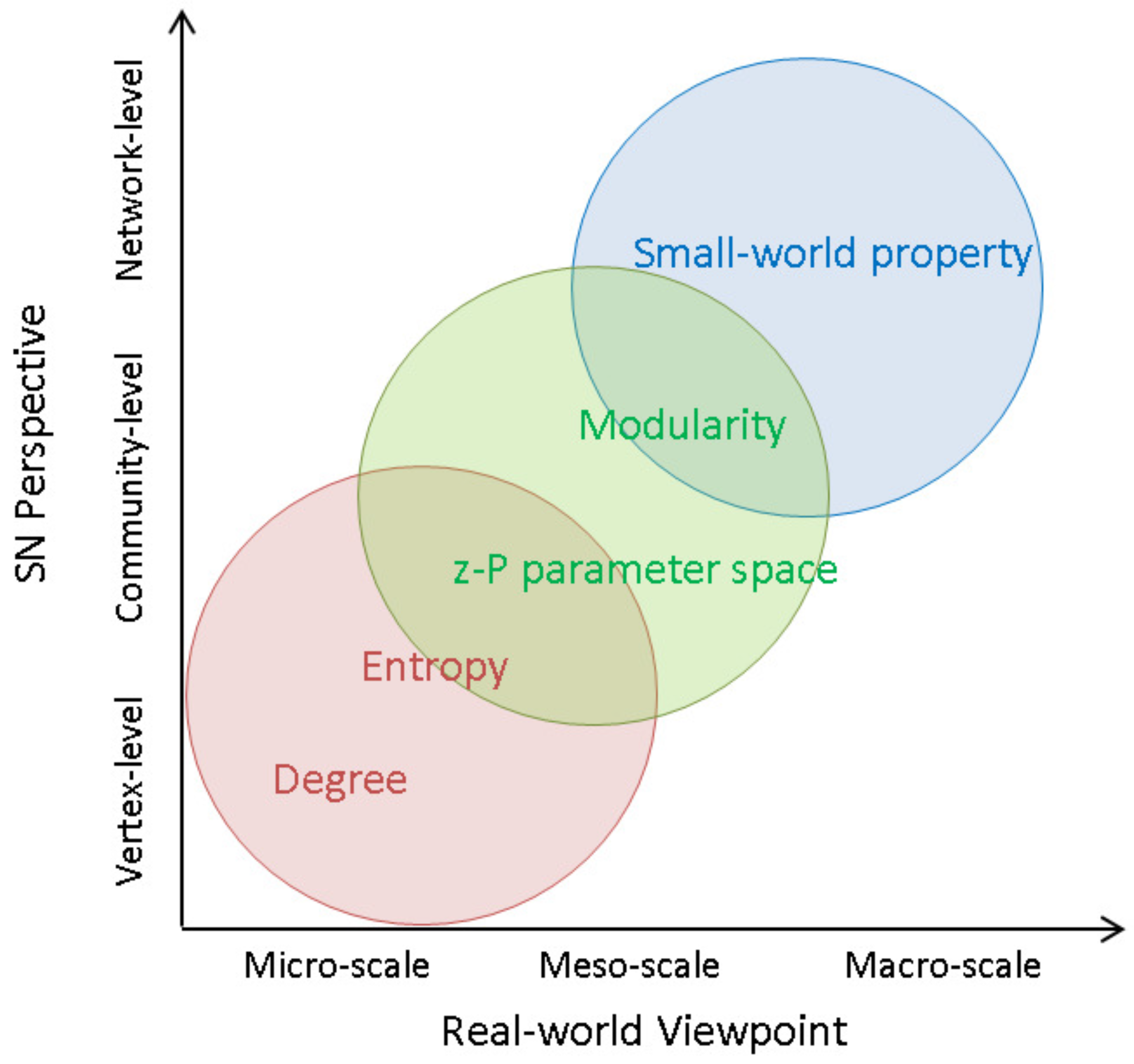
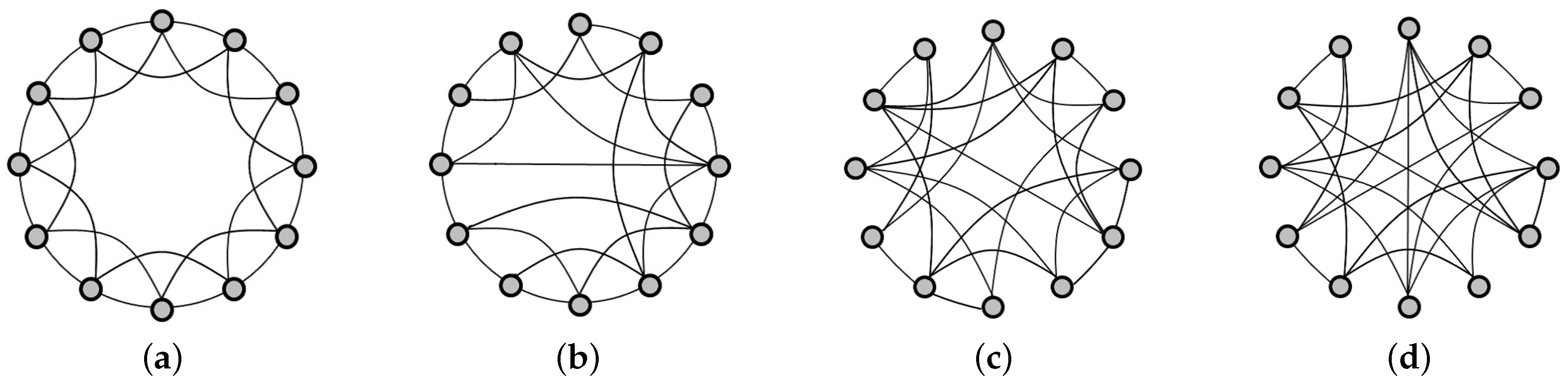
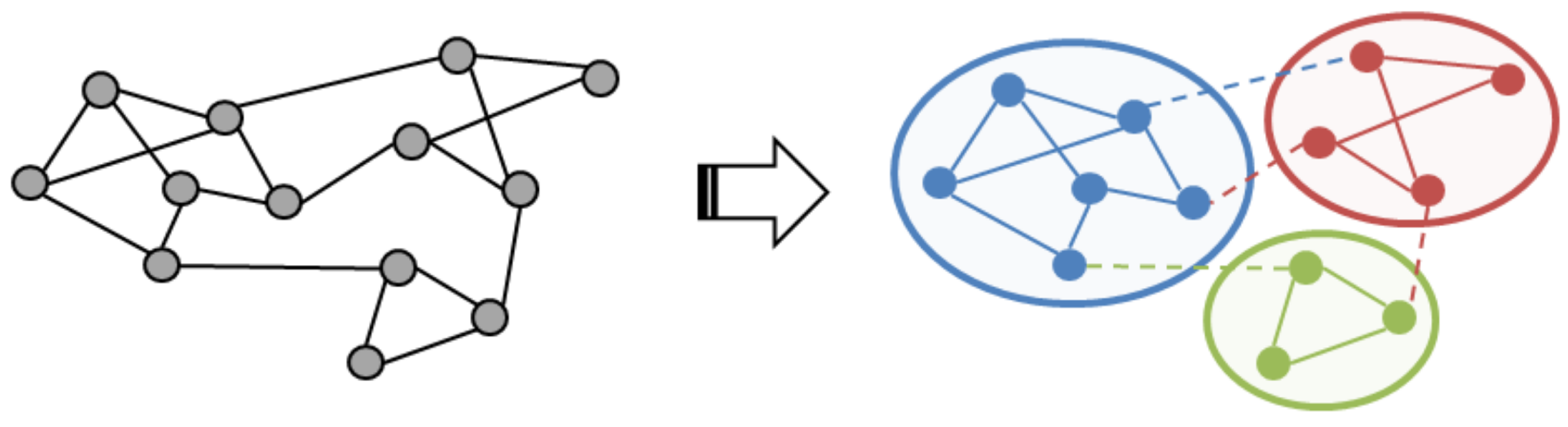
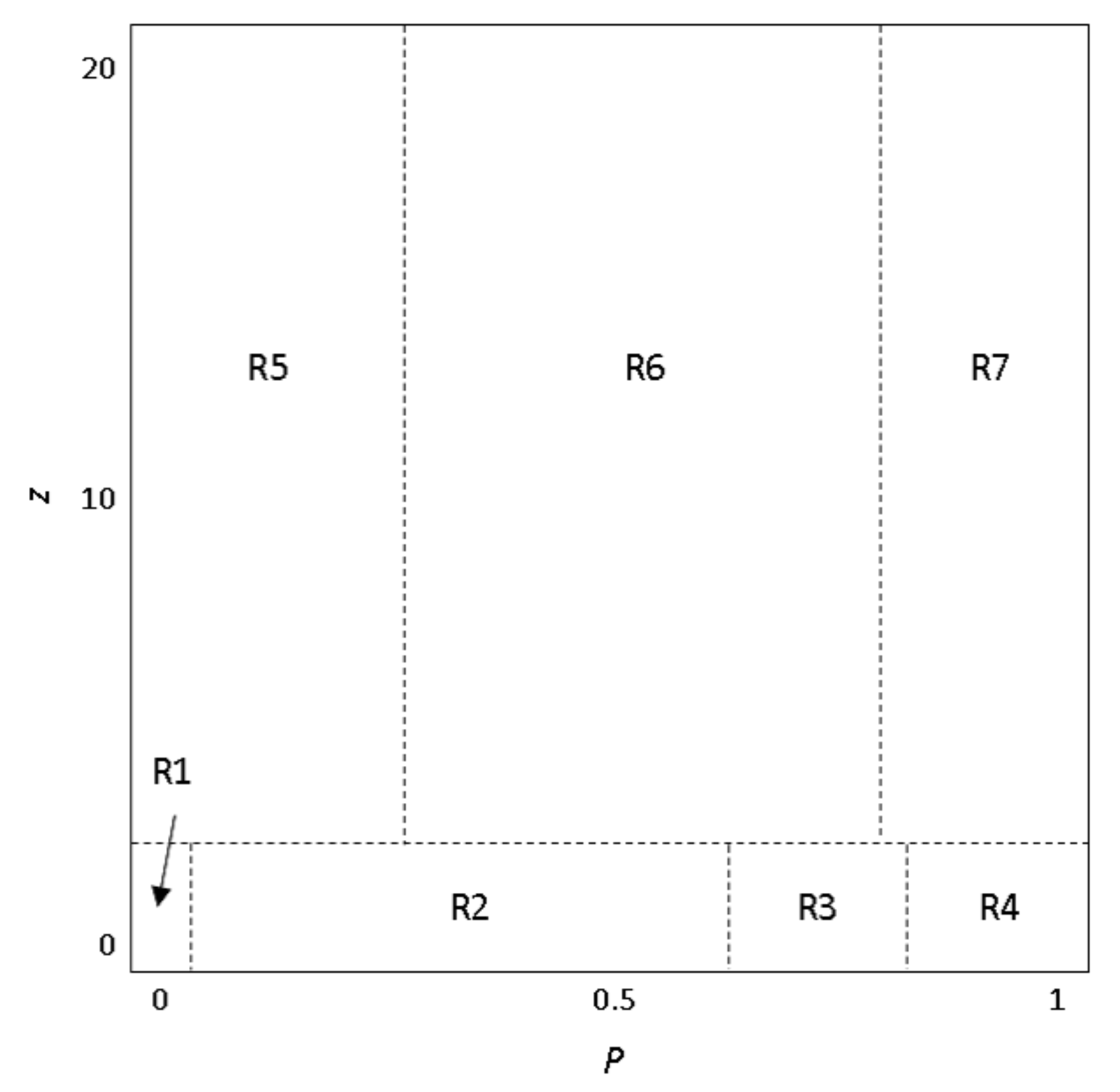
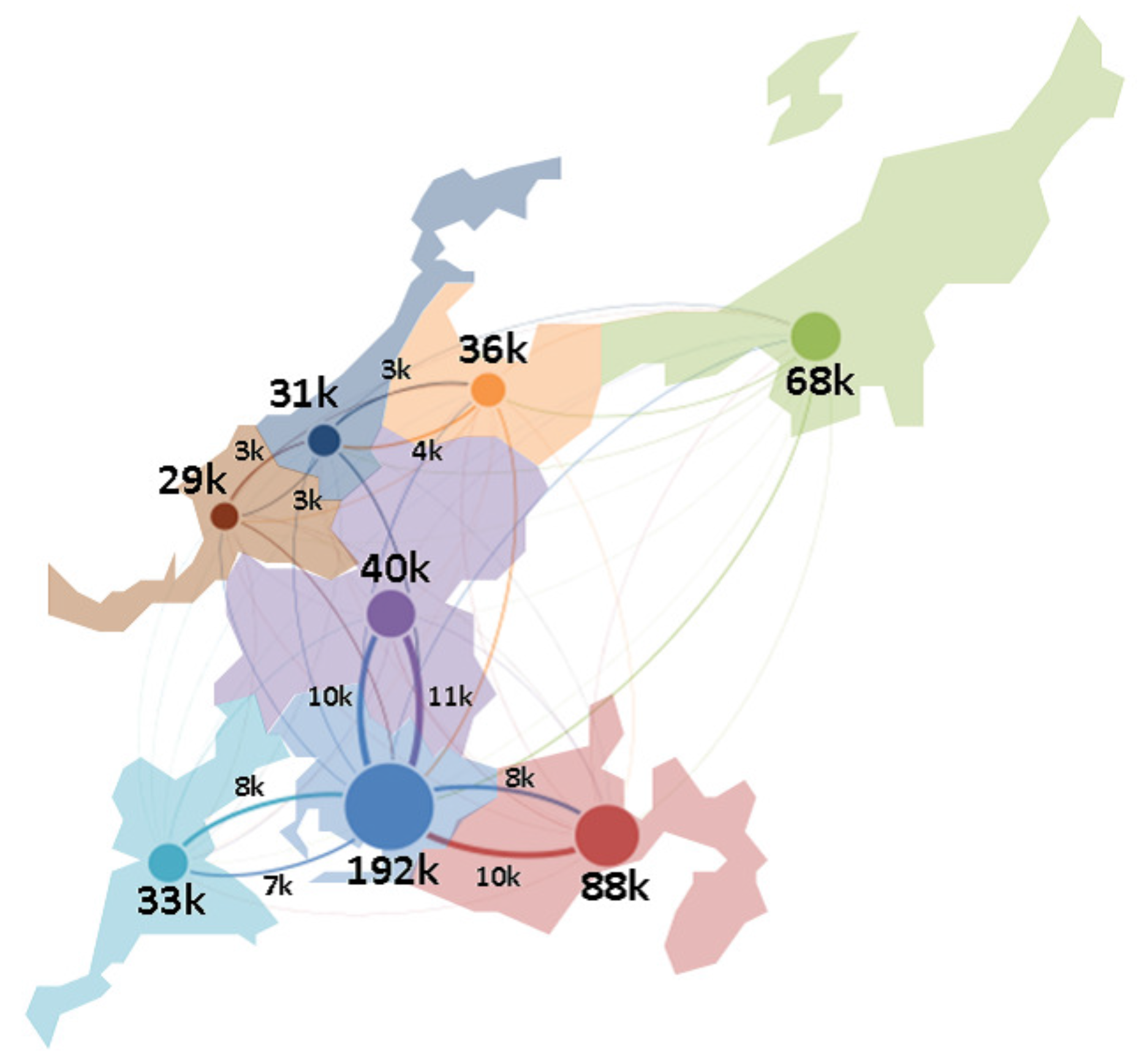
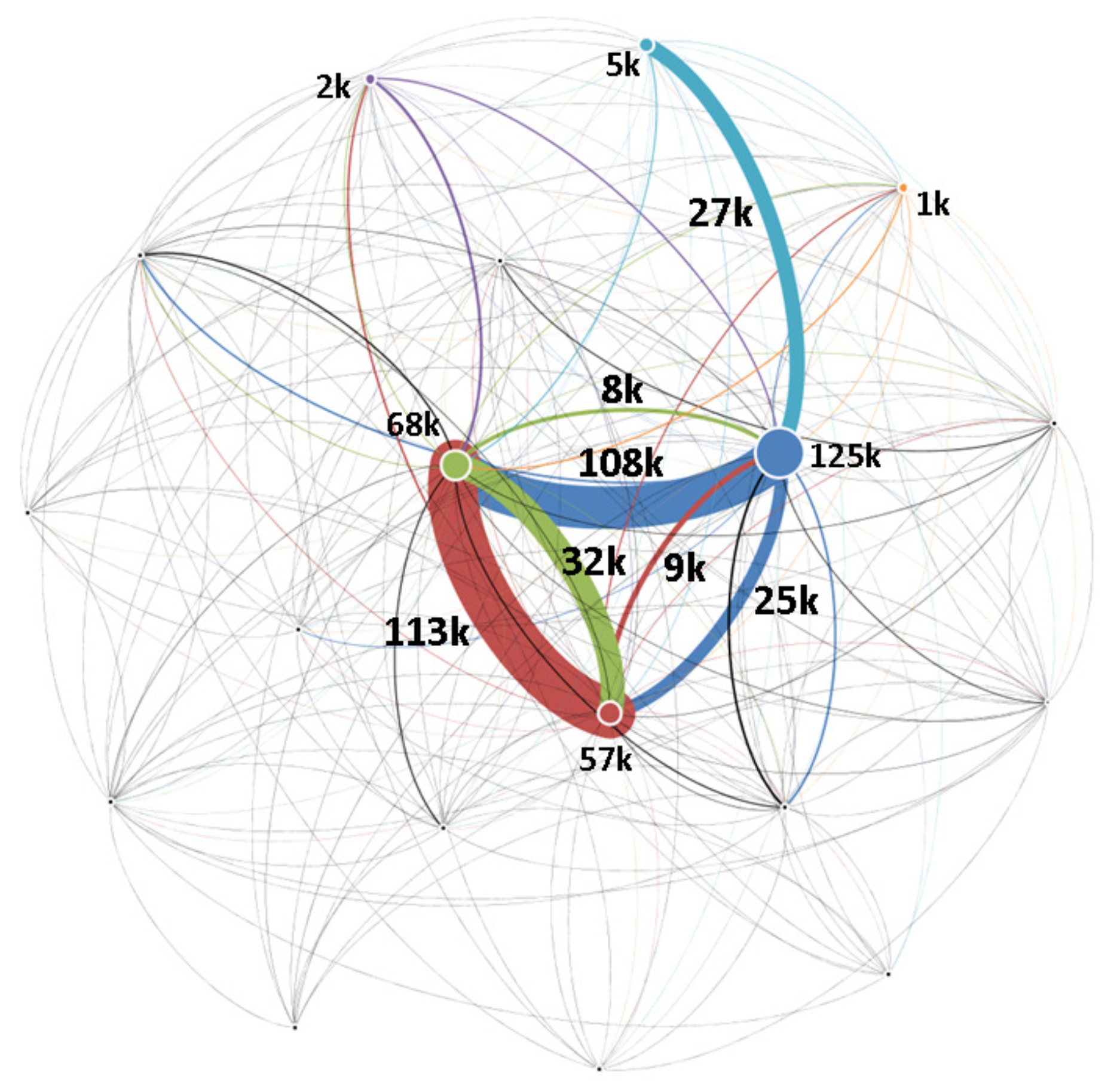
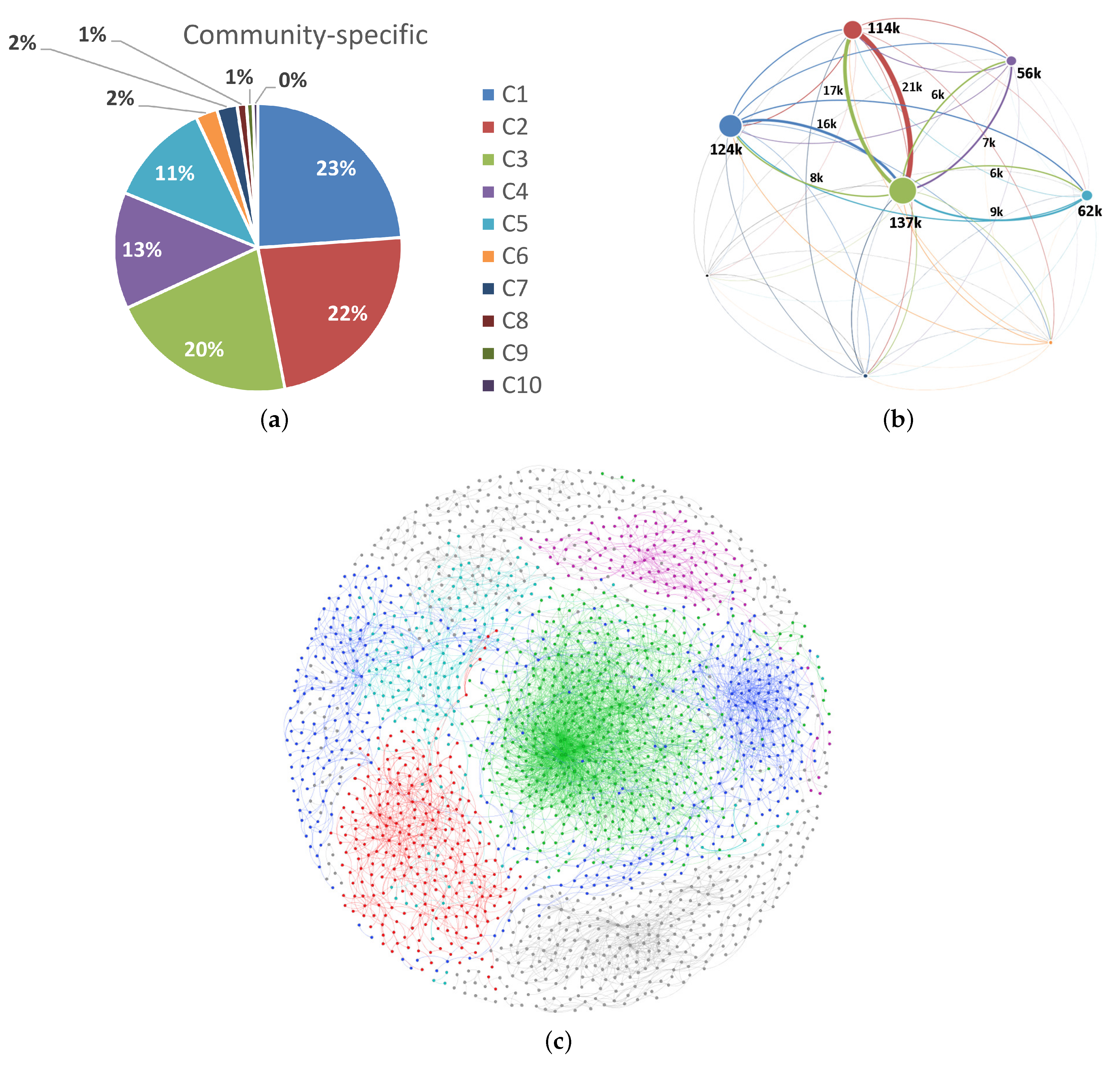
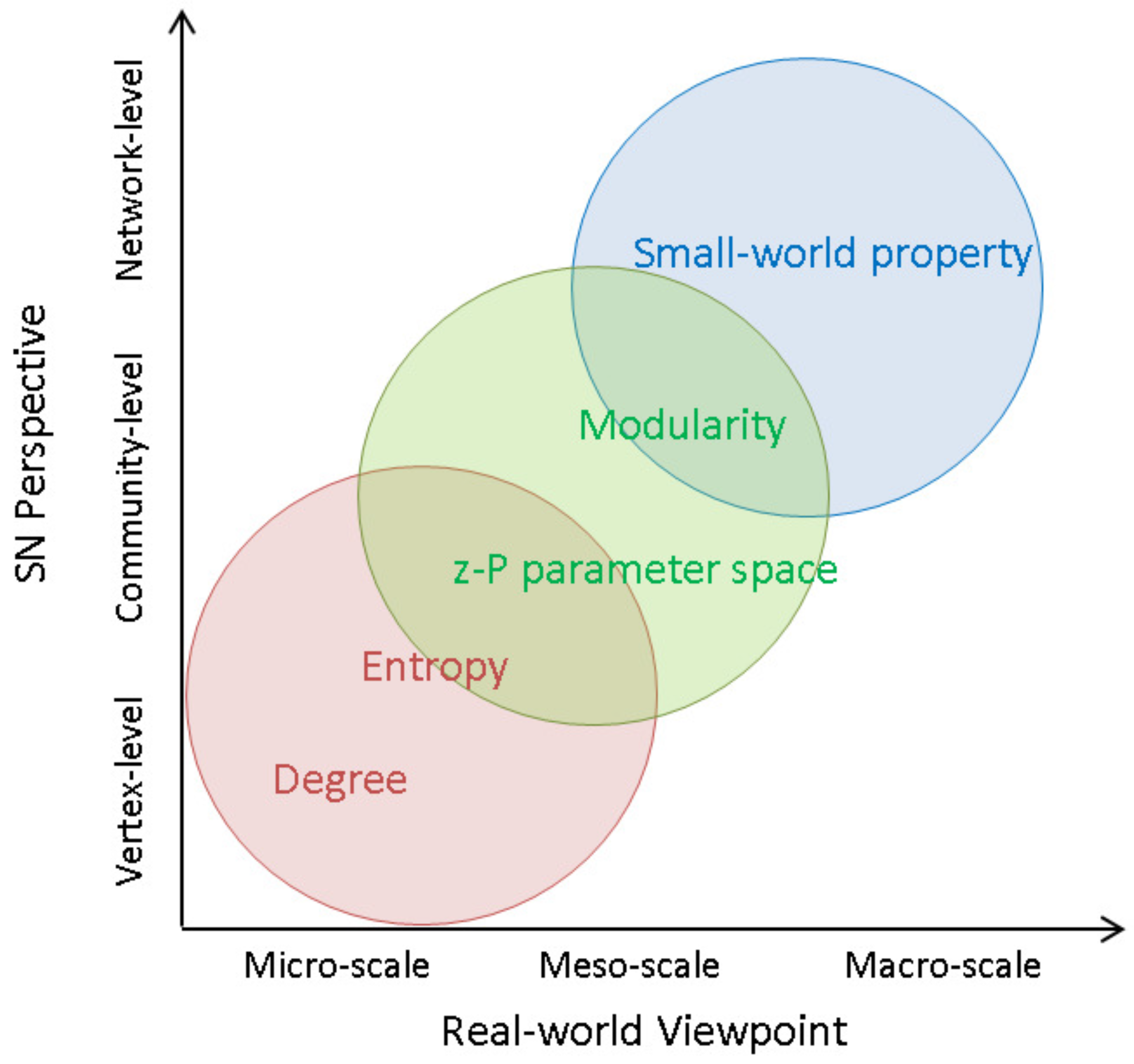
To enrich the SN theory relevant to such difficult issues, this paper presents an integrated investigation of multi-level network analysis from a network-, community- and vertex-perspective. For the network-perspective analysis, we re-emphasized the effects of SW properties (i.e., average shortest path length
L and average clustering coefficient
C) presented in [
23] as to how to evaluate SN efficiency. However, Capaldo and Giannoccaro [
14] investigated 10 patterns of SN forms. Fewer studies have been devoted to this organizational issue by comparing SW properties between distinctive real-world communities with regard to geographic proximity and industrial affinity. Therefore, in the community-perspective analysis, we employed a network clustering algorithm known as the Newman method to optimize the modularity of the real-world SN [
29,
30,
31]. The Newman method employs a hierarchical search by the maximizing modularity
Q, which measures the fraction of connectedness among the communities of the original network from the edge betweenness. Based on the results of the experiment, five main business communities were extracted from the cross-industry and cross-region economies. After clustering, we employed a topological measure of
z-
P parameter space [
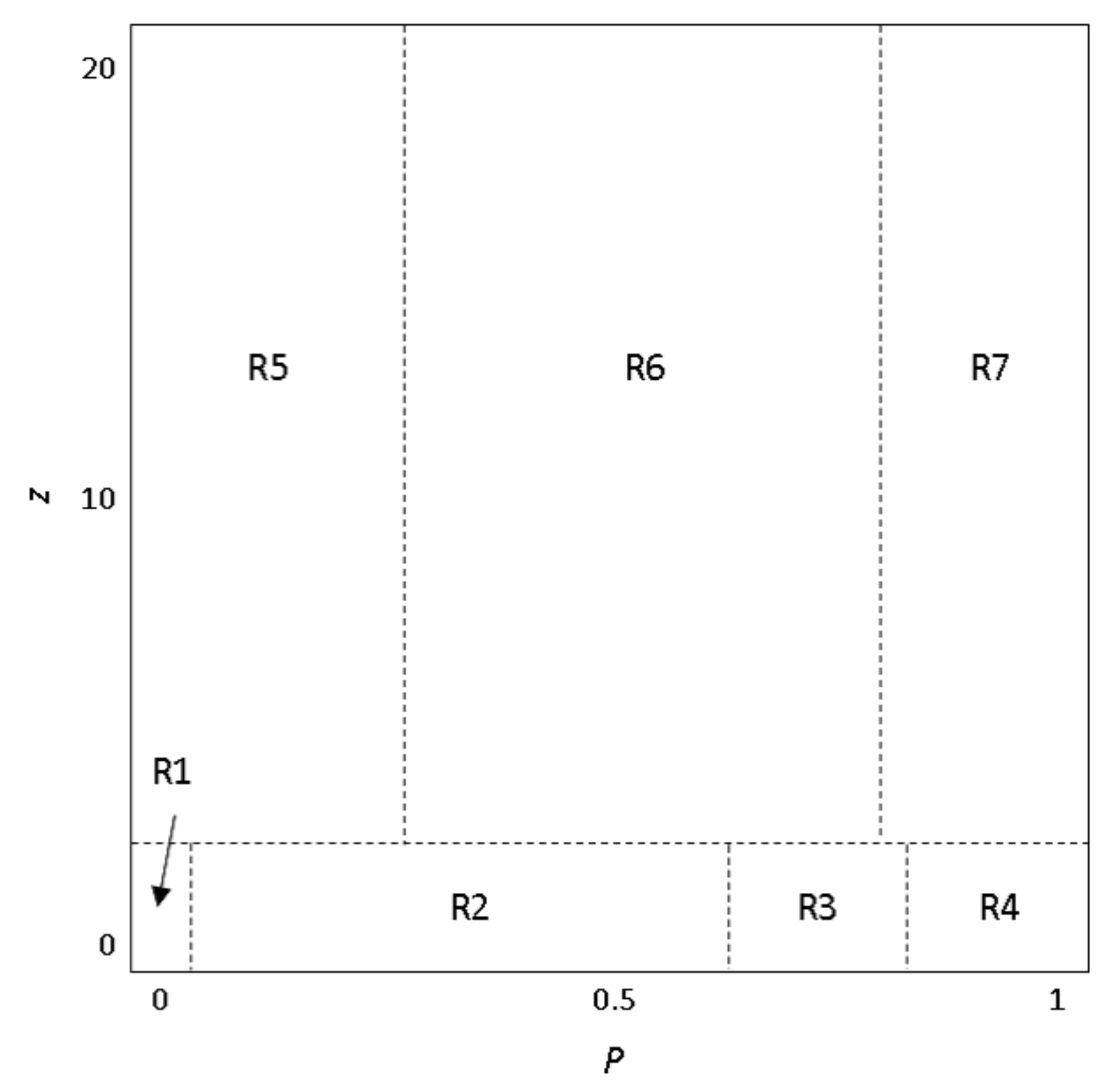
32] to re-define the hub firms instead of degree. The
z-
P parameter space uses a multi-criteria where one is the within-module degree
z in its own community and the other one is the participation coefficient
P between other communities. This measure separates nodes into seven different roles, where we focused on the “connector hubs”. Due to the existence of such connector hub firms, different communities can overlap boundaries for their flows of information [
10], improve the SM properties of SN efficiency, and SN interdependence [
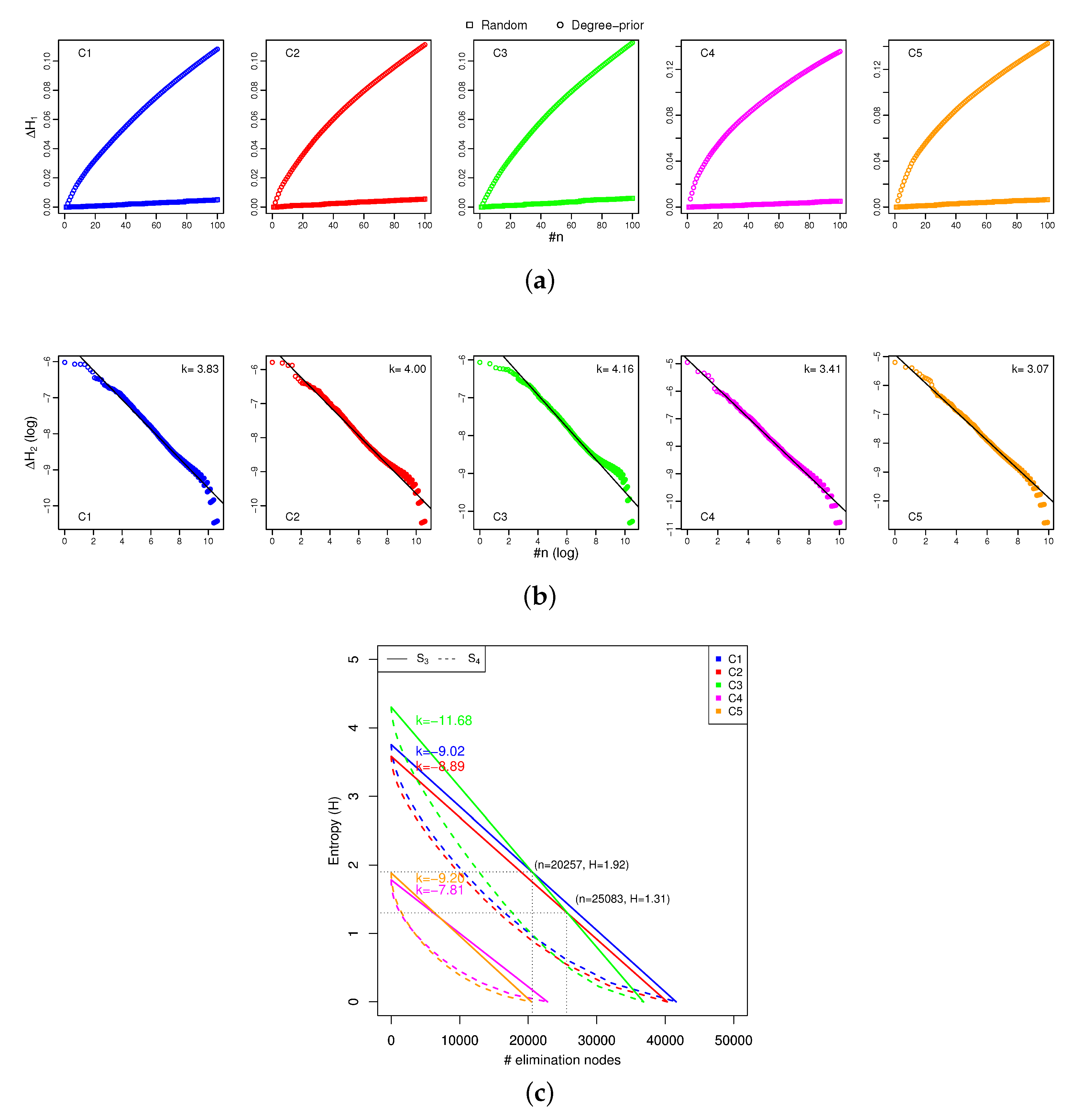
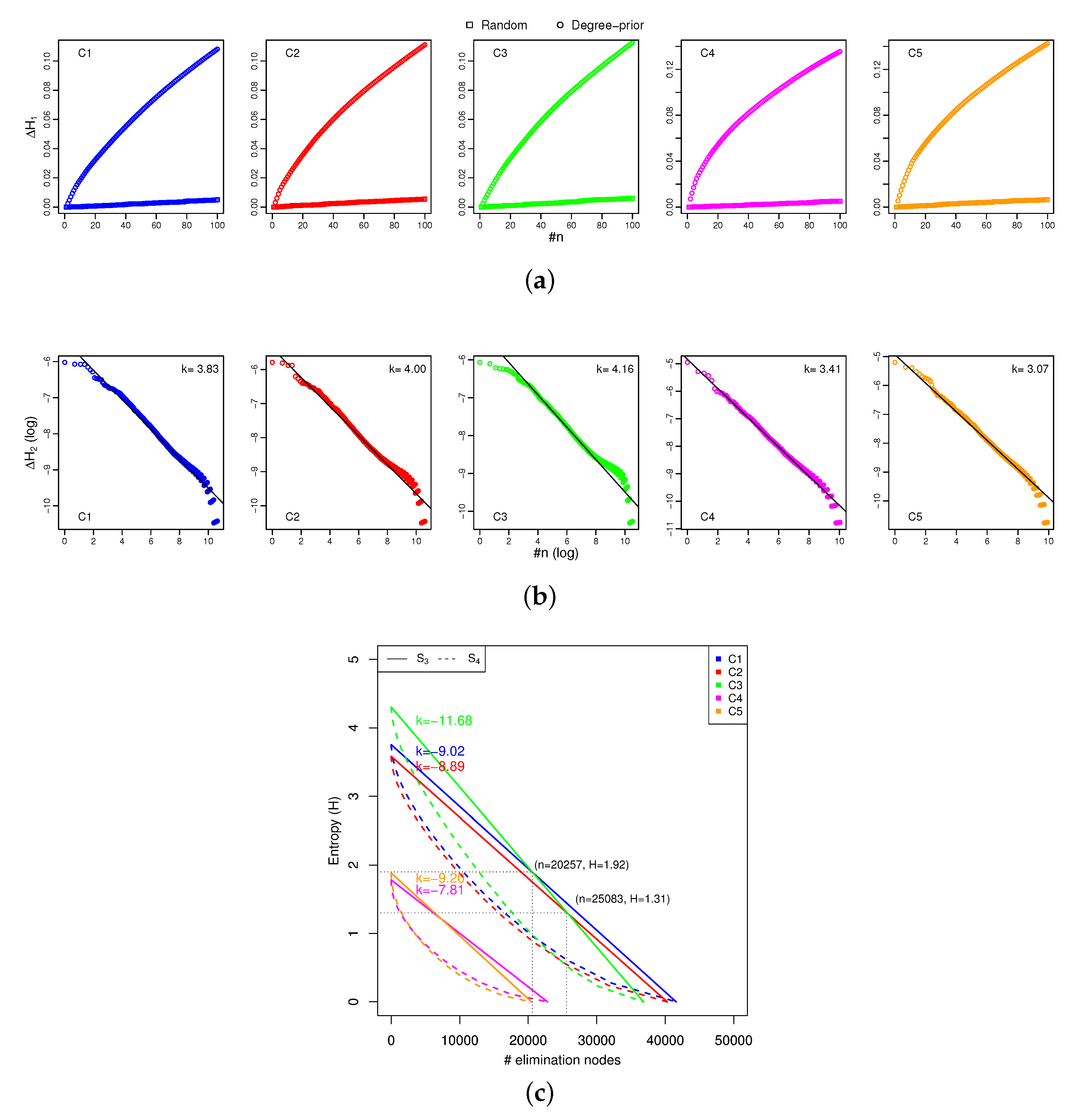
3]. Finally, we evaluated the SN resilience of distinctive communities from a vertex-level perspective. This paper employed the entropy [
33,
34,
35,
36,
37,
38,
39,
40], which is generated by node degree [
41]. Several elimination scenarios of random failures and targeted attacks (i.e., degree-prior and
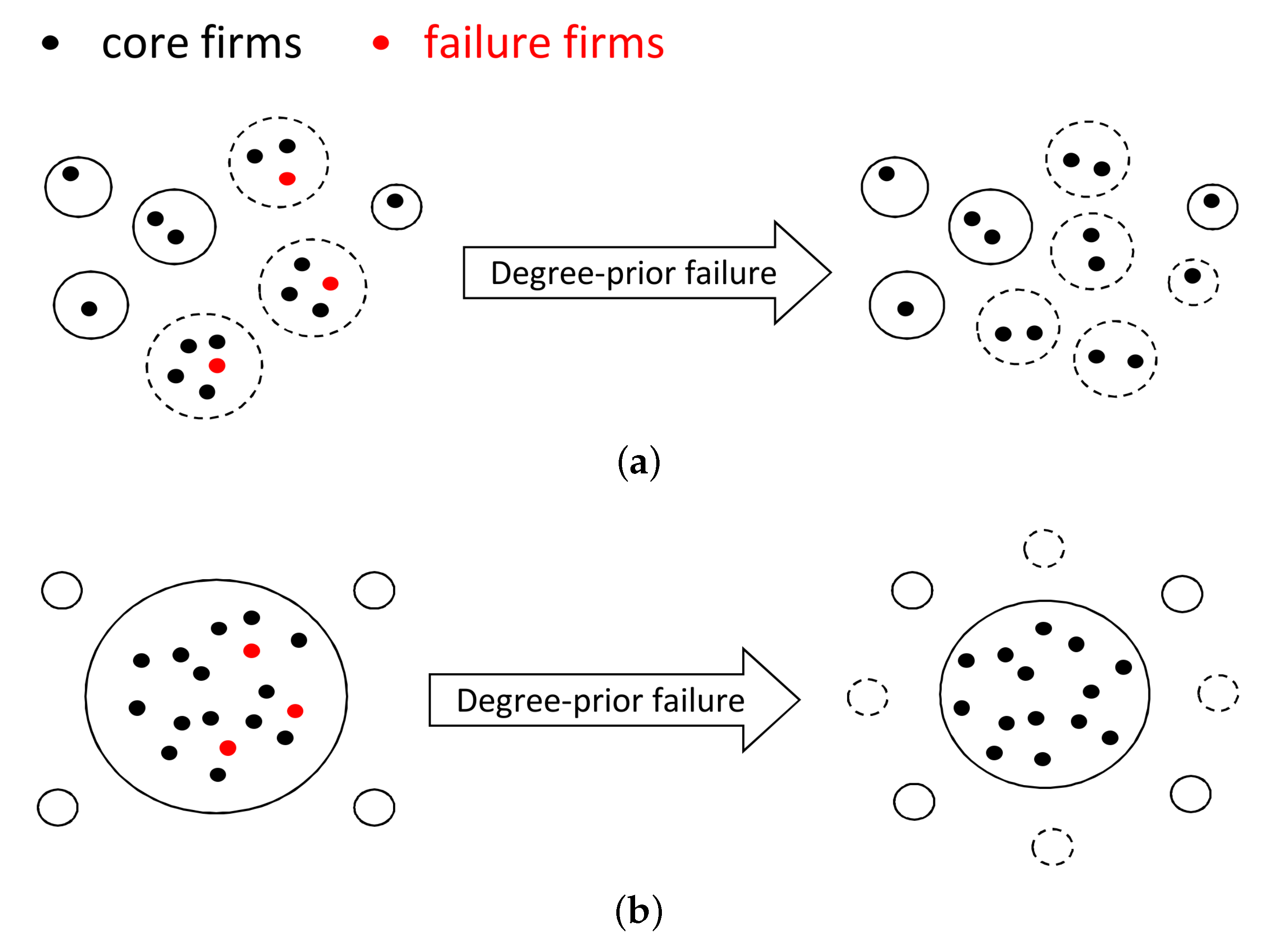
P-prior) were simulated to investigate the complexity and robustness of the SN by sequentially removing the firms [
10,
18,
42,
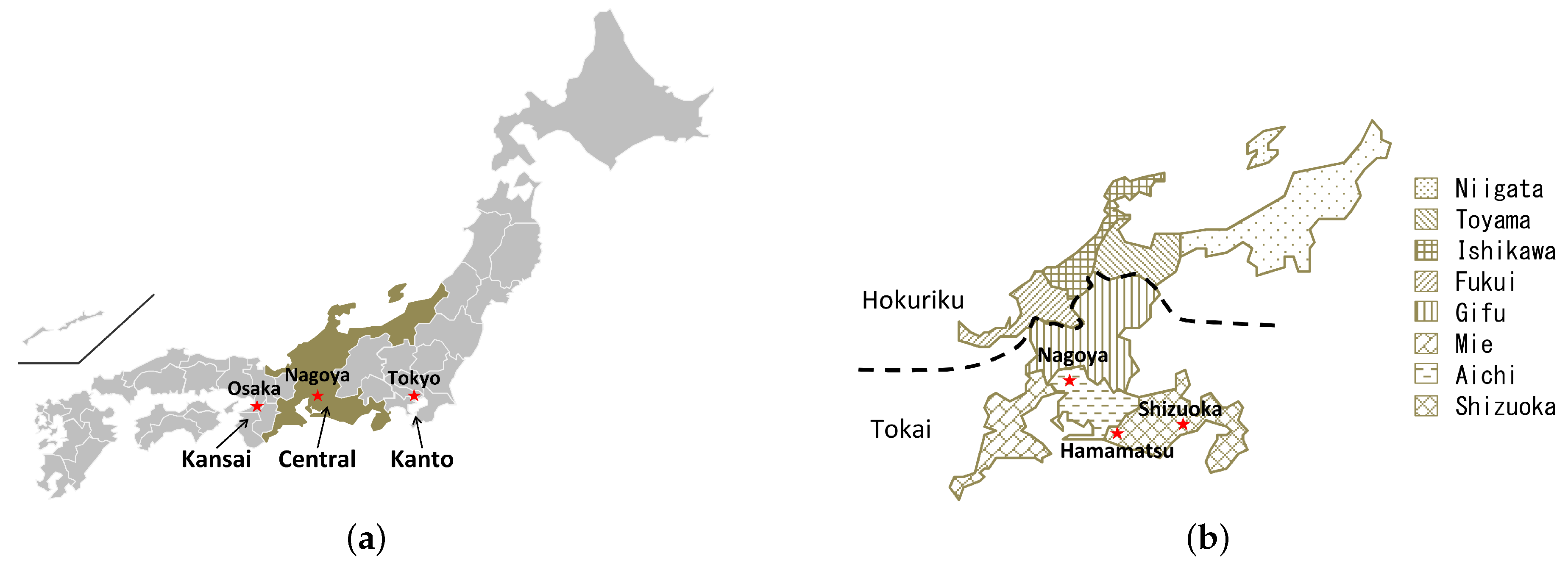
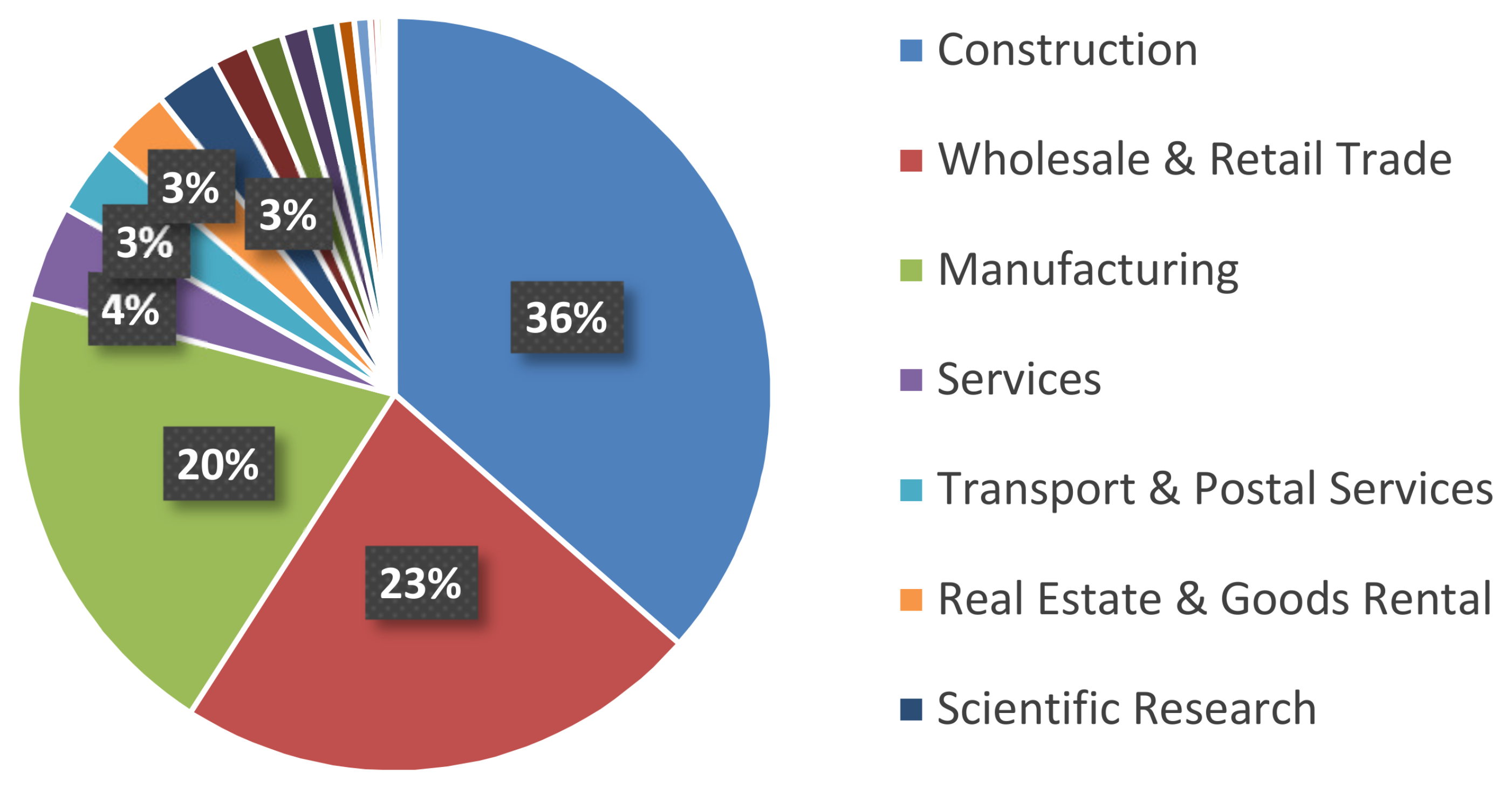
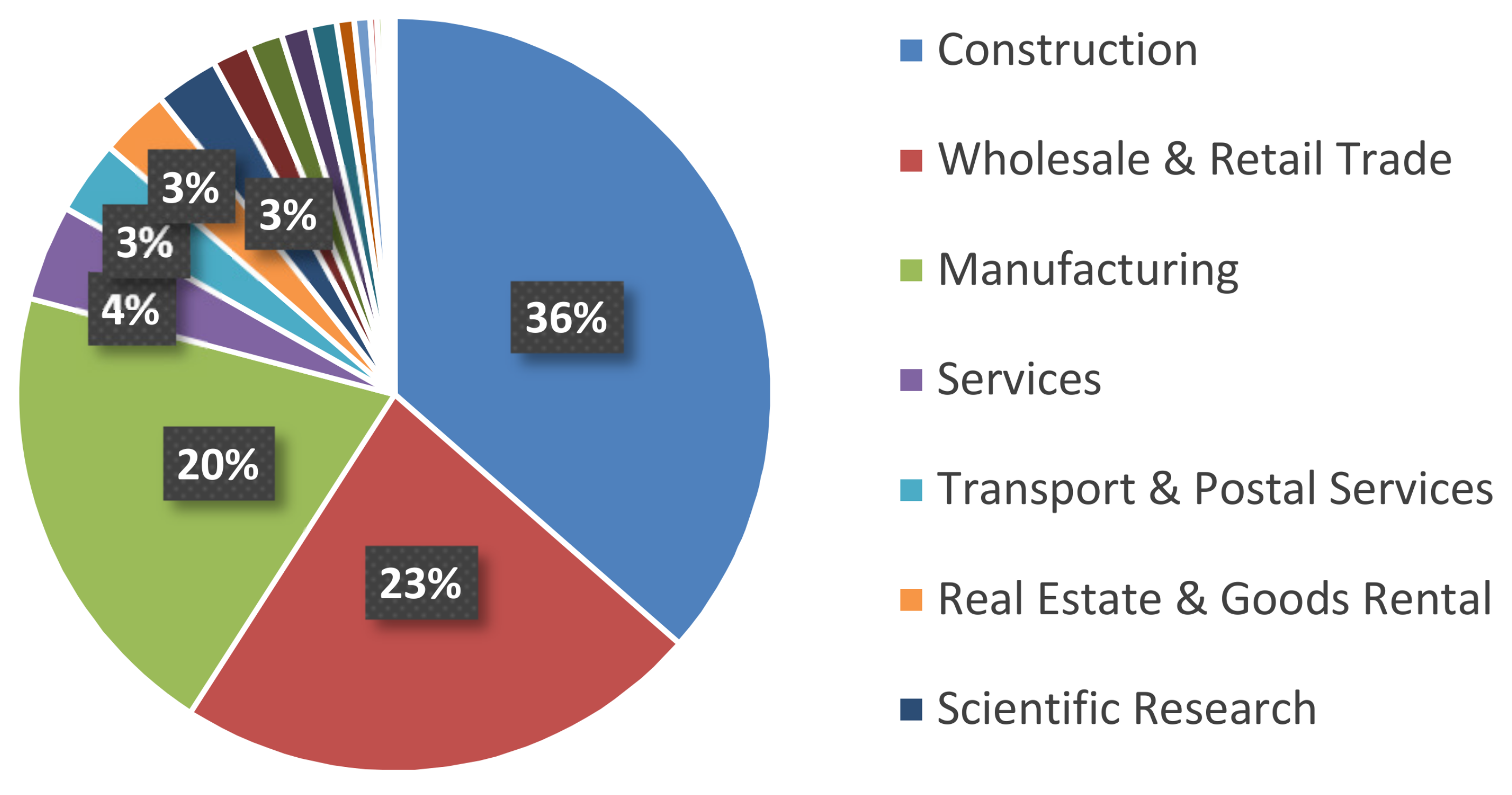
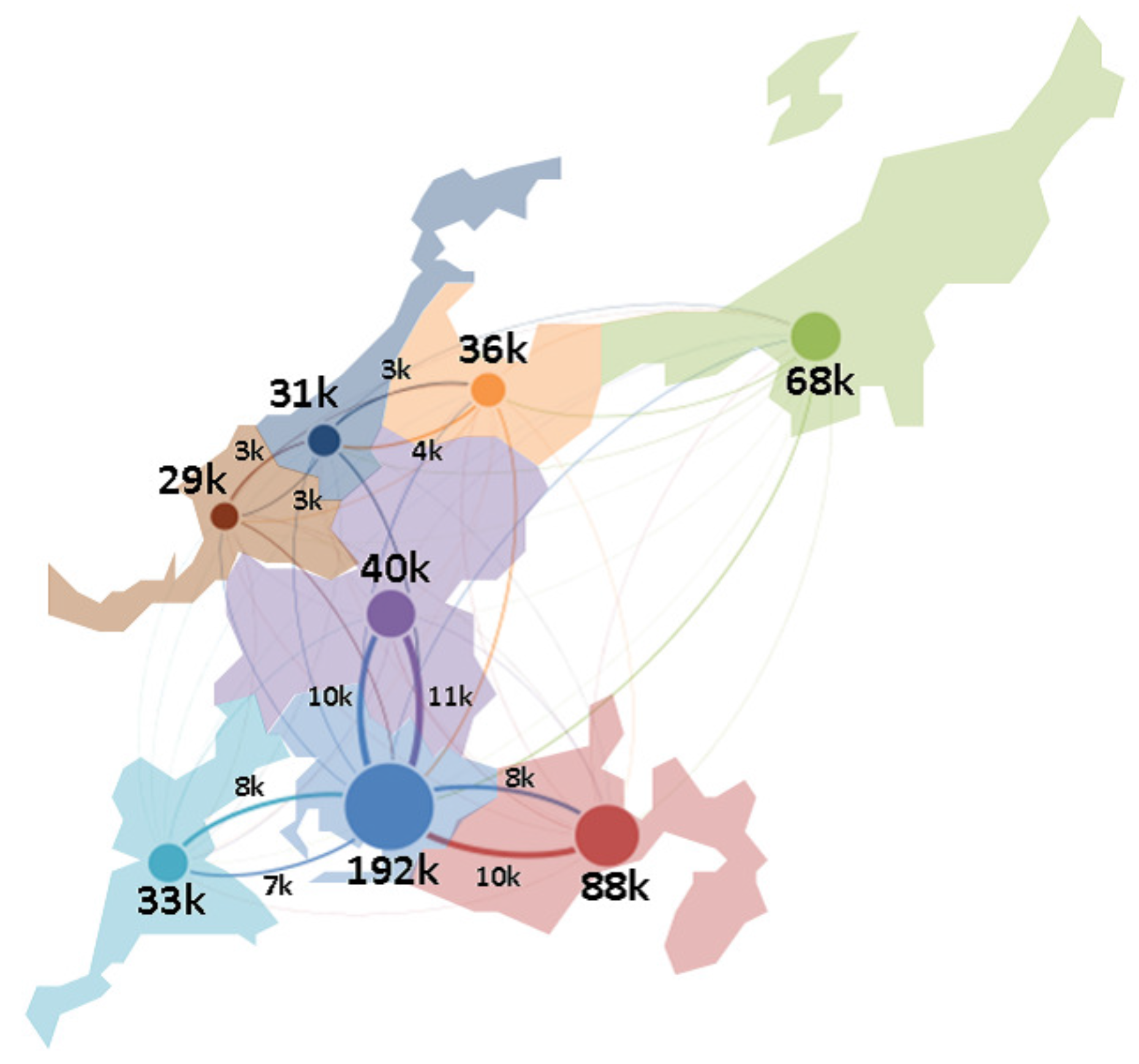
43]. We found that the network entropy showed a strongly correlation with the SN interdependence, and also moderated the correlation between SN efficiency and SN resilience. The objective of this paper was to present not only our structural outcomes concerning the SN, but also the finding that our structural analysis was significantly related to delivering efficient and effective support to SN design and management. Therefore, we introduced a real-world SN in the central area of Japan, which contained more than 180,000 firms, approximately 600,000 business relationships across all industrial categories. In the experiments, we measured the applicability of the proposed SN theory in a real-world case study and demonstrated several managerial implications based on the scenario analysis. Furthermore, this paper familiarized the researchers and managers in the SC discipline with an integrated SN theory, which can also be supported by public institutes or policy development.
In
Section 2, we briefly describe the data sources, which were related to geography, industry and transaction information. In
Section 3, we describe the network analysis techniques from network-, community- and vertex-level perspectives. In
Section 4, we introduce the network analysis methods from the three perspectives and present the experiments, results and discussion based on them. In
Section 5, we conclude and summarize the paper.
5. Conclusions
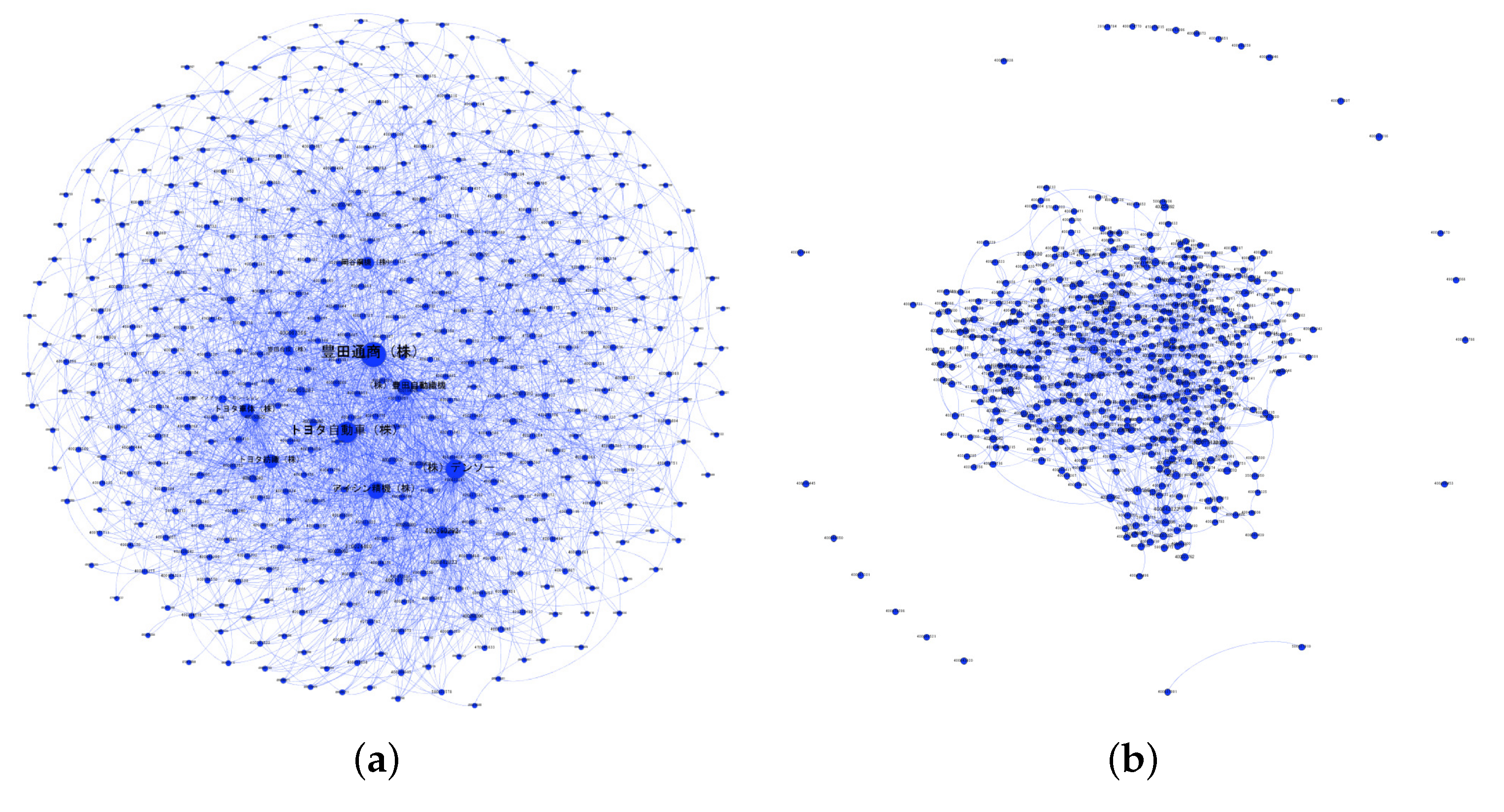
This paper presents an exploratory study of a supply network (SN) using network analysis techniques to analyze SN theory from multi-level perspectives of the whole network. Compared with existing studies in the complex system discipline, most of them identify the SNs as complex adaptive systems (CASs), and hence complex system theory can be widely used to generate, validate, and refine the SNs properties from a network-level perspective. On the other hand, compared with existing studies in the SCM discipline, most of them identify SNs as regional clusters or industrial sectors, and analyze the specific firms considering geographic proximity or industrial affinity from a vertex-level perspective. For these multi-level issues in SN theory, this paper proposed an integrated framework to enrich the SN theory from a network-level perspective to a vertex-level perspective. One of the most important contributions of this framework is to introduce community-level analysis, which can bury the structural analysis hole between network-level analysis and vertex-level analysis.
In the network-level analysis, we applied the small-world properties to the SNs, and found that SN efficiency depended on a short average path length and high clustering coefficient. In the community-level analysis, we employed a network clustering method to detect communities of SN interdependence, and found that better community structures could benefit SN efficiency, namely community economics. As community economics has also been identified as connector hub business, we extracted such hub firms by using z-P parameter space and found that the number of hub firms could moderate the relationship between SN interdependence and SN efficiency. Finally, in the vertex-level analysis, we introduced network entropy to measure the SN resilience, and applied several scenarios to conduct analysis against random failures and targeted attacks. The results revealed that SN resilience was dependent on SN interdependence. In the experiment, we constructed an SN from the real-world case of the central region of Japan, which contains over 180,000 nodes and approximately 600,000 links. Compared with existing studies, our SN contained eight prefectures and a full-scale sample of industries from 20 categories. Therefore, another most important contributions of this paper was to apply and investigate the SN theory in a real-world large-scale supply chain. This paper not only familiarizes researchers and managers in the SCM field with the existence of the integrated SN theory, but also delivers several managerial implications to support SN design and management. We also hope that SN theory can be supported by public institutions in policy development.
Our study had two limitations that will be addressed in future research. First, we did not identify the SN as a directed networks. In our SN theory, the measures of CAS (such as clustering coefficient, the shortest path length, and others) were used for undirected networks and ignoring link directions although the real-world SN represented supplier-customer relationships with directed links [
15,
16]. Therefore, a future extension of SN theory will conduct a directed network, and frame SN as a directed CAS. Second, this study also ignored the firm’s attributes. Real-world firms contain rich attributes such as sales, number of employees, location, and industry sector, which are very useful for community detection [
5,
45]. Therefore, we propose an attribute-associated network clustering method to enrich current SN theory.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}