Abstract
We consider a two party network where each party wishes to compute a function of two correlated sources. Each source is observed by one of the parties. The true joint distribution of the sources is known to one party. The other party, on the other hand, assumes a distribution for which the set of source pairs that have a positive probability is only a subset of those that may appear in the true distribution. In that sense, this party has only partial information about the true distribution from which the sources are generated. We study the impact of this asymmetry on the worst-case message length for zero-error function computation, by identifying the conditions under which reconciling the missing information prior to communication is better than not reconciling it but instead using an interactive protocol that ensures zero-error communication without reconciliation. Accordingly, we provide upper and lower bounds on the minimum worst-case message length for the communication strategies with and without reconciliation. Through specializing the proposed model to certain distribution classes, we show that partially reconciling the true distribution by allowing a certain degree of ambiguity can perform better than the strategies with perfect reconciliation as well as strategies that do not start with an explicit reconciliation step. As such, our results demonstrate a tradeoff between the reconciliation and communication rates, and that the worst-case message length is a result of the interplay between the two factors.
1. Introduction
Consider a scenario in which two parties make a query over distributed correlated databases. Each party observes data from one database, whereas the query has to be evaluated over the data observed by both users separately. Suppose that one party knows all data combinations that may lead to an answer to some query, whereas the other party is missing some of these combinations. The parties are allowed to communicate with each other. The goal is to find the minimum amount of communication required so that both parties can retrieve the correct answer for any query. We model this scenario as interactive communication in which two parties interact to compute a function of two correlated discrete memoryless sources. Each source is observed by one party. One party knows the true joint distribution of the sources, whereas the other party is missing some source pairs that may occur with positive probability and assumes another distribution in which these missing pairs have zero probability. Communication takes place in multiple interactive rounds, at the end of which a function of the two correlated sources has to be computed at both parties with zero-error. We study the impact of this partial knowledge about the true distribution on the worst-case message length.
In a function computation scenario, one party observes a random variable X, whereas the other party observes a random variable Y, where each realization of is generated from some probability distribution . The two parties wish to compute a function by exchanging a number of messages in multiple rounds. Conventionally, the true distribution from which the sources are generated is available as common knowledge to both parties. This work extends this framework to the scenario in which the true distribution of the sources is available at one of the communicating parties only, while the distribution assumed at the other party has missing information compared to the true distribution. That is, the second party has only partial knowledge about the source pairs that are realized with positive probability according to the true distribution.
In order to identify the impact of partial information on the worst-case message length, we consider three interactive communication protocols. The first interactive protocol we consider is to reconcile the partial information between the two parties in a way to allow the second party to learn the true joint distribution, and then utilize the true distribution for function computation. The reconciliation stage transforms the problem into the conventional zero-error function computation problem with zero-error. Although this is a natural approach in that it ensures that both sides are in agreement about the true distribution, this protocol requires additional bits to be transmitted between the two parties for reconciling the distribution information, which, in turn may increase the overall message length. The second protocol we consider provides an alternative interaction strategy in which the two parties do not reconcile the true distribution, but instead use a function computation strategy that allows error-free computation under the distribution uncertainty. In doing so, this protocol alleviates the costs that may have incurred for reconciling the distributions. The message length for the function computation part, however, may be larger compared to that of the previous scheme. The last interaction protocol quantifies a trade-off between the two interaction protocols, by allowing the two parties to partially reconcile the distributions. In this protocol, each party learns the true distribution up to a class of distributions. The function computation step then ensures error-free computation under any distribution within the reconciled class of distributions. By doing so, we create different levels of common knowledge about the distribution to investigate the relation between the cost of various degrees of partial reconciliation and the resulting compression performance.
By leveraging the proposed interaction protocols, we identify the conditions under which it is better or worse to reconcile the partial information than to not reconcile the distributions, i.e., using a zero-error encoding scheme with possibly increased message length. Accordingly, we develop upper and lower bounds on the worst-case zero-error message length for computing the function at both parties under different reconciliation and communication strategies. Our results demonstrate that, reconciling the partial information, although often reducing the communication cost, may or may not reduce the overall worst-case message length. In effect, the worst-case message length results from an interplay between reconciliation and communication costs. As such, partial reconciliation of the true distribution is sometimes strictly better than the remaining two interaction strategies.
Related Work
For the setting when both parties know the true joint distribution of the sources, interactive communication strategies have been studied in [1] to enable both sides to learn the source observed by the other party with zero-error. Reference [2] has considered the impact of the number of interaction rounds on the worst-case message length, as well as upper and lower bounds on the worst-case message length. The optimal zero-error communication strategy for minimizing the worst-case message length, even for the setting in which the communicating parties know the exact true distribution of the sources, has since been an open problem. The zero-error communication problem has also been considered for communicating semantic information [3,4]. Our work is also related to the field of communication complexity, which studies the minimum amount of communication required to compute a function of two sources [5]. Known as the direct-sum theorem, it was shown in [6] that computing multiple instances of a function can reduce the minimum amount of communication required per instance. The main distinction between the communication-complexity approaches and the setups from [1,2] is that the models from [1,2] emphasize utilizing the source distribution and in particular its support set to reduce the amount of communication, which is also referred to as the computation of a partial function ([7], Section 4.7).
In addition to the zero-error setup, interactive communication has also been considered for computing a function at one of the communicating parties with vanishing error probability [8]. Subsequently, interactive communication has been considered for computing a function of two sources simultaneously at both parties with vanishing error probability [9]. The two-party scenario has been extended to a multi-terminal function computation setup in [10], in which each party observes an independent source and broadcasts its message to all the nodes in the network. A related study in [11] investigates the role of side information when communicating interactively a source known by one party to another with vanishing error. Interactive communication has also been leveraged in [11] for one-way recovery of a source known by one party at the other side with vanishing error in the presence of side information.
This work is also related to zero-error communication strategies in non-interactive data compression scenarios. In particular, we leverage graphical representations of the confusable source and distribution terms, which are reminiscent of characteristic graphs introduced in [12] to study the zero-error capacity of a channel. Subsequently, characteristic graphs have been utilized for zero-error compression of a source in the presence of decoder side information [13,14]. They have been utilized to characterize graph entropy and chromatic entropy in [15,16], respectively, in [8] to characterize the rate region for the lossless computation of a function, and in [17] to obtain achievable rates for lossy function computation. Such graphical representations have also been leveraged for non-interactive set reconciliation [18]. Another relevant application is zero-error source coding with compound decoder side information considered in [19].
Many existing and emerging network applications, e.g., sensor networks, cyber-physical systems, social media, and semantic networks, facilitate interaction between multiple terminals to share information towards achieving a common objective [20,21,22,23]. As such, it is essential for such systems to mitigate the ambiguities that may result from the imperfect knowledge available at the communicating parties. The case when the communicating parties assume different prior distributions while communicating a source from one party to another has recently been considered for the non-interactive setting. In [24], communicating a source with vanishing error is considered in the presence of side information when the joint probability distributions assumed at the encoder and the decoder are different. Reference [25] has incorporated shared randomness to facilitate compression when the source distribution assumed by the two parties are different from each other. Deterministic compression strategies are investigated in [26] for the case when no shared randomness is present. In this work, we study interactive function computation with partial priors for the asymmetric scenario when the true joint distribution of the sources is available at one party only [27].
2. Problem Setup
This section introduces our two-party communication setup with asymmetric priors. The following notation is adopted in the sequel. We use for a set with cardinality , and define where [28]. The difference between defining a sequence vs. taking the power of a given number will be clear from context. We denote . The support set of a distribution over a set is represented as,
where
The chromatic number of a graph G is given by . represents the length (number of bits) of a bit stream. Finally, for a bipartite graph with vertex sets V, U and an edge set E, we let and denote the maximum degree of any node and , respectively.
2.1. System Model
Consider discrete memoryless correlated sources defined over a finite set . The sources are generated from a distribution where is a finite set of probability distributions. Nodes 1 and 2 observe and , respectively, with probability . The distribution is fixed over the course of n time instants. We refer to as the true distribution of sources as it represents nature’s selection for the distribution of sources . User 1 knows the true distribution . The source distribution known to user 2, however, may be different from the true distribution. In particular, user 2 assumes a distribution such that where is a finite set. The set of distributions is known by both users, but the actual selections for and are only known at the corresponding user. In that sense, provides some, although incomplete, information to user 2 about .
Each of the two parties is requested to compute a function for each term of the source sequence , which we represent as
where is a finite set. In particular, user 1 recovers some whereas user 2 recovers some such that zero-error probability condition
is satisfied, which is evaluated over the true distribution . Note that, whenever is a bijective function, Equation (4) reduces to the conventional zero-error interactive data compression where each source symbol is perfectly recovered at the other party [1].
The two users employ an interactive communication protocol, in which they send binary strings called messages at each round. A codeword represents a sequence of messages exchanged by the two users in multiple rounds. In particular, for an r round communication, the encoding function is given by some variable-length scheme for which the codeword is the sequence of messages exchanged for the pair , where represents the message transmitted by both parties at round i and denotes the sequence of messages exchanged through the first i rounds for . The encoding at each round is based only on the symbols known to the user and on the messages exchanged between the two users in the previous rounds, so that
where and are the messages transmitted from users 1 and 2 at round i, respectively. The encoding protocol is deterministic and agreed upon by both parties in advance. Accordingly, we define
and
as the sequences of messages transmitted from users 1 and 2, respectively, in r rounds. Another condition is the prefix-free message property to ensure that whenever one user sends a message, the other user knows when the message ends. This necessitates that for all , then for some requires that is not a proper prefix of . Same applies for user 1 when we interchange the roles of X and Y. In addition, we require the coordinated termination criterion to ensure both parties know when communication ends. In particular, given some , we require that is not a proper prefix of . Same condition applies when the roles of X and Y are interchanged. The last condition we require is the unique message property. In particular, if , then implies that . The same applies when the roles of X and Y are changed. Null transmissions are allowed at any round.
The worst-case codeword length for mapping is given by
where is the number of bits in a bit stream. The optimal worst-case codeword length is given by
The zero-error condition in Equation (4) ensures that, for any given function, the worst-case codeword length of the optimal communication protocol is the same for all distributions in , i.e., for any , as long as . We utilize this property for designing interactive protocols by constructing graphical structures as described next. It is useful to note that the results throughout the paper hold when the parties only know the support of the distributions and in the problem set up considered in this paper as described next. For each , we define a bipartite graph with vertex sets , , and an edge set . An edge exists if and only if .
Observe that we have for any with . One can therefore partition into groups of distributions that have the same support set, such that the set of distributions in each partition maps to a unique bipartite graph. We represent this set of resulting bipartite graphs by , and denote each element by . The bipartite graph structure used for partitioning the distributions in is related to the notion of ergodic decomposition from [29], in that each bipartite graph represents a class of distributions with the same ergodic decomposition. For each , we denote
and note that for any distribution whose support set can be represented by the bipartite graph G, one has .
Given , we define the following sets. For each , we define an ambiguity set
where each element is a sequence of function values, and denotes the number of distinct sequences of function values. Similarly, for each , we define an ambiguity set
with . Next, we let
and note that . Similarly, we define
and note that . We denote the maximum vertex degrees for graph G by
An illustrative example of the bipartite graph is given in Figure 1 for the function and the probability distribution
over the finite set and .
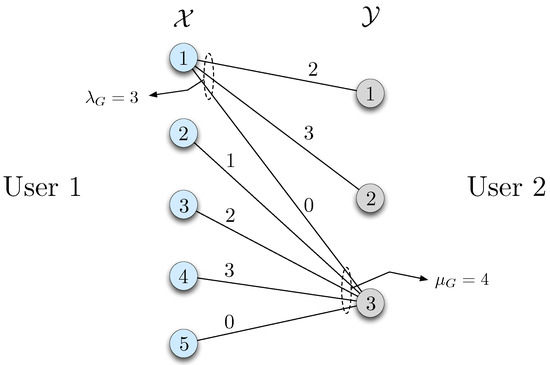
Figure 1.
Bipartite graph representation of the probability distribution from Equation (17). Edge labels represent the function values . Note that the maximum vertex degree is for and for whereas and .
Finally, we review a basic property of zero-error interactive protocols, which is key to our analysis in the sequel. The straightforward proof immediately follows, e.g., from ([1], Lemma 1, Corollary 2).
Proposition 1.
Let be the concatenation of all for . Then, for each , the set of sequences corresponding to the symbols in should be prefix-free.
Proof.
The proof follows from the following observation. Suppose for some , we have where is a prefix of . Then, from ([1], Lemma 1), we have . Now, if , then user 1 will not be able to distinguish between the two function values as the message sequences are the same for both. Similarly, if , then user 2 will not be able to distinguish between the two function values. Hence, cannot be a prefix of whenever . From the same argument, cannot be a prefix of whenever otherwise user 1 will not be able to recover the correct function value. The same applies to user 2 when the roles of X and Y are changed. Therefore, for any given , we need at least prefix-free sequences, one for each element of . Otherwise, one of the above three cases will occur and at least one user will not be able to distinguish the correct function value. ☐
2.2. Motivating Example
Consider two interacting users, user 1 observing and user 2 observing according to the distribution
where both users want to compute a function of
First, assume that users 1 and 2 both know the distribution ; we will call this the symmetric priors case. In this case, one can readily observe from Equations (18) and (19) that the function value will never occur, hence the two parties can discard that value beforehand. That is, in this case users 1 and 2 know beforehand that they only need to distinguish between two function values, , which occurs when , and , which occurs when . We now detail five interaction protocols as follows. The first one is a naïve protocol where user 1 sends x to user 2, and user 2 sends y to user 1, after which both users can compute . To do so, users 1 and 2 need bits each, i.e., a total of 6 bits is needed. Second, consider a protocol in which user 1 sends x to user 2, and user 2 calculates and sends the result back to user 1. To do so, user 1 needs to use bits. User 2 on the other hand needs to send only bit, since there are at most 2 possible function values. This protocol uses 4 bits in total in two rounds. Same applies to the third protocol where we exchange the roles of users 1 and 2. Since users 1 and 2 know the support set of , i.e., the pairs of for which , a fourth protocol would involve sending only bits in total, in which user 1 sends one of , whereas user 2 sends one of . Lastly, consider a different protocol where user 1 sends “0” if , and a “1” otherwise, which is sufficient for user 2 to infer whether or depending on the y he observes, since is not possible with these values. Therefore, user 2 computes and sends the result back to user 1 by using bit. This protocol requires only bits in two rounds and at the end both users learn . As is clear from this example, communicating all distinct pairs of symbols is not always the best strategy, and resources can be saved by using a more efficient strategy.
Next, consider the following variation on the example. Users 1 and 2 again wish to compute given in Equation (19), but this time the joint distribution of the sources is selected from a set of distributions where is defined as in Equation (18), and we have
and
As described in the beginning of Section 2.1, one can represent the structure of these distributions and the corresponding function values via bipartite graphs. Such a bipartite graph for the probability distribution in Equation (20) is given in Figure 2.
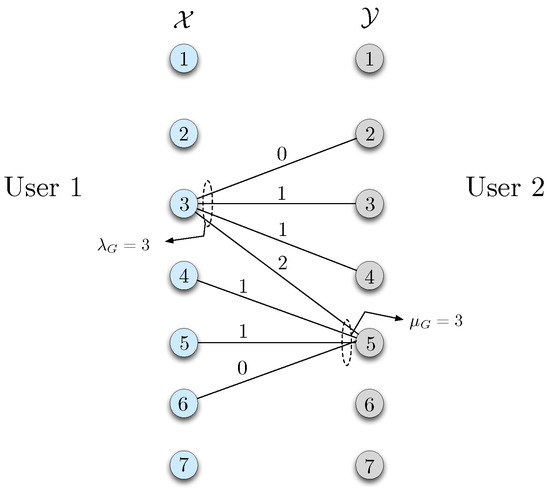
User 1 observes , i.e., the true distribution. User 2 knows the set , but not the specific choice in . User 2 instead observes a distribution from a set .
User 1 does not know the distribution observed at user 2. In addition, the set is unknown to both users. The only requirement we have is that this distribution be consistent with . That is to say that the support of is contained in the support of , i.e., does not have a positive probability for a source pair whose probability is zero in , i.e., . Note that this is side information in that users 1 and 2 can infer which of the or distributions are possible at the other party, respectively, given their own distribution.
In order to interact in this setup, users 1 and 2 may initially agree to reconcile the distribution and then use it as in the previous case. To do so, user 1 informs user 2 of the true distribution. She assigns an index “0” if , and a “1” if , and sends it to user 2 by using bit. User 2 can infer the true distribution by using the received index as well as his own distribution q. If the received index is “0”, then it immediately follows that the true distribution is . However, if the received index is “1”, then user 2 needs to decide between and . To do so, he utilizes q: (i) whenever , he declares that the true distribution is , since , (ii) whenever , he decides that the true distribution is , since in this case . After this step, both users know the true distribution, and can compute by exchanging no more than a total number of bits, as detailed next. The case where is the true distribution requires 2 bits for interaction as noted earlier. If the true distribution is , user 1 can send user 2 an index “0” if , a “1” if , or a “2” otherwise. User 2 can compute and send the result back to user 1 by using at most bits, since in the worst-case all three function values may occur, which happens when . Therefore, this case requires 4 bits for communication. If instead the true distribution is , user 1 can send user 2 an index “0” if , a “1” if , or a “2” otherwise. User 2 can compute and send it back to user 1 by using bits, since all three function values are again possible for . Hence, this scheme requires 5 bits to be communicated in total, 1 bit for reconciliation and 4 bits for communication.
An alternative scheme is one in which users 1 and 2 do not reconcile the true distribution, but instead use an encoding scheme that allows error-free communication under any distribution uncertainty. To do so, user 1 sends an index “0” if , a “1” if , and a “2” otherwise. Describing 3 indices requires user 1 to use bits. After receiving the index value, user 2 can recover perfectly, whether the true distribution p is equal to , , or , and then send it to user 1 by using no more than bits, since there are at most 3 distinct values of for each . Both users can then learn . Not reconciling the partial information therefore takes 4 bits, which is less then the previous two stage reconciliation-communication protocol.
3. Communication Strategies with Asymmetric Priors
In this section, we propose three strategies for zero-error communication by mitigating the ambiguities resulting from the partial information about the true distribution.
3.1. Perfect Reconciliation
For the communication model described in Section 2.1, a natural approach to tackle the partial information is by first sending the missing information to user 2 so that both sides know the source pairs that may be realized with positive probability with respect to the true distribution, which can then be utilized for communication. This setup consists of two stages. In the first stage, user 2 learns the support set of the true distribution , or equally the bipartite graph G corresponding to , from user 1. We call this the reconciliation stage. After this stage, both parties use graph G for zero-error interactive communication. We refer to this two-stage protocol as perfect reconciliation in the sequel. The worst-case message length under this setup is referred to as .
For the reconciliation stage, we first partition into groups of distributions with distinct support sets, and denote by the set of distinct bipartite graphs that correspond to the support sets of the distributions in . This process is similar to the one described for in Section 2.1. Next, we find a lower bound for the minimum number of bits required for user 2 to learn the graph G, i.e., all pairs that may occur with positive probability under the true distribution .
Definition 1.
(Reconciliation graph) Define a characteristic graph , in which each vertex represents a graph . Recall that is a set of bipartite graphs as we define in Section 2.1. An edge is defined between vertices G and if and only if there exists a such that and .
The minimum number of bits required for user 2 to perfectly learn G is then , where denotes the chromatic number of a graph. This can be observed by noting that in the reconciliation phase, any two nodes in the reconciliation graph with an edge in between has to be assigned to distinct bit streams, otherwise user 2 will not be able to distinguish them, which requires a minimum of number of bits to be transmitted from user 1 to user 2. It is useful to note that perfect reconciliation incurs a negligible cost for large blocklengths.
Proposition 2.
Perfect reconciliation is an asymptotically optimal strategy.
Proof.
Since the distributions and are fixed once chosen, reconciliation requires at most bits for any class of graphs . Therefore its contribution on the codeword length per symbol is , which vanishes as . Since the communication cost for not reconciling the graphs can never be lower than reconciling them, we can conclude that reconciling the graphs first, and then using the reconciled graphs for communication, cannot perform worse than not reconciling them. We note, however, that this statement may no longer hold if the joint distribution is arbitrarily varying over the course of n symbols, since correct recovery in this case may require the graphs to be repeatedly reconciled. ☐
In the following, we demonstrate a lower bound on the worst-case message length for this two-stage reconciliation-communication protocol.
Lemma 1.
A lower bound on the worst-case message length for the two-stage reconciliation-communication protocol is,
Proof.
We prove Equation (24) by obtaining a lower bound on the message length for the reconciliation and communication parts separately. The lower bound for the reconciliation part is determined by bounding the minimum number of bits to be transmitted from user 1 to user 2 using Definition 1. As a result, both sides learn the support set of the true distribution . The lower bound in Equation (24) then follows from
where Equation (26) follows from the min-max inequality and Equation (28) from Proposition 1. ☐
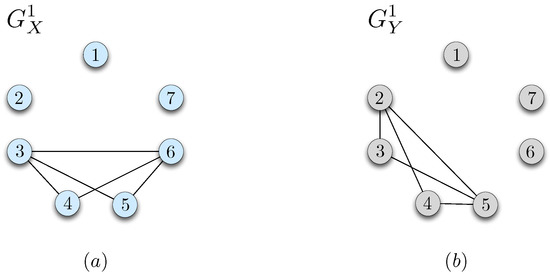
We next demonstrate an upper bound for the minimum worst-case message length. Consider the distribution and the corresponding bipartite graph . Let denote a characteristic graph for user 1 with a vertex set . Vertices of are the n-tuples . An edge exists between and whenever some exists such that , and . Similarly, define a characteristic graph for user 2 whose vertices are the n-tuples . An edge exists between and whenever some exists such that , , and .
The characteristic graphs defined above are useful in that any valid coloring over the characteristic graphs will enable the two parties to resolve the ambiguities in distinguishing the correct function values. Figure 3 illustrates the characteristic graphs and , respectively, constructed by using from Equation (20) and from Equation (19) in the example discussed in Section 2.2. In the following, we follow the notation and .
Theorem 1.
The worst-case message length for the two-stage separate reconciliation and communication strategy satisfies
Proof.
Consider a minimum coloring for and using and colors. Note that and can be colored with at most and colors, respectively. Hence, users 1 and 2 can simultaneously send the index of the color assigned to their symbols by using at most and bits, respectively. Then, users can utilize the received color index and their own symbols for correct recovery of the function values. ☐
3.2. Protocols that Do Not Explicitly Start with a Reconciliation Procedure
Instead of the reconciliation-based strategy described in Section 3.1, the two users may choose not to reconcile the distributions, but instead utilize a robust communication strategy that ensures zero-error communication under any distribution in set . Specifically, they can agree on a worst-case communication strategy that always ensures zero-error communication for both users. In this section, we study two specific protocols that do not explicitly start with a reconciliation procedure. We denote the worst case message length in this setting as .
As an example of such a robust communication strategy, consider a scenario in which user 1 enumerates each by using bits whereas user 2 enumerates each by using bits. Then, by using no more than bits in total, the two parties can communicate their observed symbols with zero-error under any true distribution, and evaluate . In that sense, this setup does not require any additional bits for learning about the distribution from the other side either perfectly or partially, but the message length for communicating the symbols is often higher. In the following, we derive an upper bound on the worst-case message length based on two achievable protocols that do not start with a reconciliation procedure.
The first achievable strategy we consider is based on graph coloring. Let be a characteristic graph for user 1 whose vertex set is . Define an edge between nodes and whenever there exists some such that and whereas . Similarly, define a characteristic graph for user 2 whose vertex set is . Define an edge between vertices and whenever there exists some such that and for some but . We note the difference between the conditions for constructing and in that the former is based on the union whereas the latter is based on the existence for some . This difference results from the fact that user 2 does not know the true distribution, hence needs to distinguish the possible symbols from a group of distributions, whereas user 1 has the true distribution, and can utilize it for eliminating the ambiguities for correct function recovery. We note however that both and depend on . Lastly, we let and denote the chromatic number of and , respectively.
Then, under any true distribution , the following communication protocol ensures zero error. Suppose user 1 observes and user 2 observes from some distribution . For each where , user 1 sends the color of by using no more than bits. After this step, user 2 can recover by using as follows. Given , user 2 considers the set of all such that for some . Note that within this set, each color represents a group of for which is equal. Therefore, under any true distribution , user 2 will be able to recover the correct value solely by using the received color along with . Similarly, for each , user 2 sends the color of by using no more than bits, after which user 1 recovers by using the received color and the true distribution . Since user 1 knows the true distribution, it can distinguish any function value correctly as long as no two are assigned to the same codeword for which such that and when .
We then have the following upper bound on the worst-case message length,
where user 1 sends bits to user 2 whereas user 2 sends bits to user 1. After this step, both users can recover the correct function values for any source pair under any .
The second achievable strategy we consider is based on perfect hash functions. A function is called a perfect hash function for a set if for all such that , one has . Define a family of functions such that for all . If
for some , then, there exists a family of functions such that for every with , there exists a function that is injective (one-to-one) over ([30], Section III.2.3). Perfect hash functions have been proved to be useful for constructing zero-error interactive communication protocols when the true distribution of the sources are known by both parties [7]. In the following, we extend the interactive communication framework from [7] to the setting when the true distribution is unknown by the communicating parties.
Initially, we construct a graph for user 2 with a vertex set . In that sense, each vertex of the graph is an n-tuple . Define an edge between vertices and if for some n-tuple that there exists some for which and for all . Define a minimum coloring of this graph and let denote the minimum number of required colors, i.e., the chromatic number of . In that sense, any valid coloring over this graph will enable user 1 to resolve the ambiguities in distinguishing the correct n-tuple observed by user 2, under any true distribution .
We next define the following ambiguity set for each ,
as the set of distinct sequences that may occur with respect to the support set under the given sequence . We denote the size of the largest single-term ambiguity set as,
and note that . Lastly, we define an ambiguity set for each ,
as the set of distinct function values that may appear for the given sequence and with respect to the support set . We denote the size of the largest single-term ambiguity set as
and note that .
The interaction protocol is then given as follows. From Equation (31), there exists a family of
functions such that for all and for each of size , there exists an that is injective over . In that sense, the colors assigned to an ambiguity set for some will correspond to some . Both users initially agree on such a family of functions and a minimum coloring of graph with colors. Suppose user 1 observes and user 2 observes . User 1 finds a function that is injective over the colors assigned to vertices from Equation (32) and sends its index to user 2 by using no more than
bits in total. After this step, user 2 evaluates the corresponding function for the assigned color of and sends the evaluated value back to user 1 by using no more than bits. After this step, user 1 will learn the color of , from which it can recover by using the observed . This is due to the fact that from the definition of an ambiguity set in Equation (32), every n-tuple for a given will receive a different color in the minimum coloring of the graph . Since the selected perfect hash function is one-to-one over the colors assigned to , it will allow user 1 to recover the color of from the evaluated hash function value. In the last step, user 1 evaluates the function , and sends it to user 2 by using no more than bits. In doing so, she assigns a distinct index for each sequence of function values in the ambiguity set from Equation (34). User 2 can then recover the function by using and the received index. Overall, this protocol requires no more than
bits to be transmitted in total, therefore
where Equation (42) follows from the fact that , and Equation (44) holds since . This is due to the fact that any coloring over the nth order strong product of is also a valid coloring for , since by construction of , any edge that exists in also exists in the nth order strong product of . Therefore, the chromatic number of is no greater than the chromatic number of the nth order product of , which is no greater than .
Combining the bounds obtained from the two protocols from Equations (30) and (45), we have the following upper bound on the worst-case message length.
Proposition 3.
The worst-case message length for the two strategies that do not explicitly start with a reconciliation procedure can be upper bounded as,
3.3. Partial Reconciliation
In order to understand the impact of level of reconciliation on the worst-case message length, we consider a third scheme called partial reconciliation, which allows user 2 to distinguish the true distribution up to a class of distributions, after which the two users use a robust worst-case communication protocol that allows for zero-error communication in the presence of any distribution within the class. In that sense, partial reconciliation allows some ambiguity in the reconciled set of distributions. Accordingly, the schemes considered in Section 3.1 and Section 3.2 are special cases of the partial reconciliation scheme. We denote as the per-symbol worst-case message length for a finite block of n source symbols under the partial reconciliation scheme. In the following, we demonstrate two protocols for interactive communication with partial reconciliation. The first protocol is based on coloring characteristic graphs, whereas the second protocol is based on perfect hash functions. We then derive an upper bound on the worst-case message length with partial reconciliation.
For the first partial reconciliation protocol, consider the set of bipartite graphs constructed by using the distributions as described in Section 2.1. Define a partition of the set as such that and for all , where is non-empty for . Define as the set of all such partitions of .
Fix a partition . For each , define a graph for user 1 with the vertex set . Define an edge between nodes and if there exists some such that and whereas . Next, construct a graph for user 2 with the vertex set . Define an edge between nodes and if there exists some such that and for some but . Let and denote the chromatic number of and , respectively.
Then, under any true distribution , the following communication protocol ensures zero error. The two users agree on a partition before communication starts. Suppose users 1 and 2 observe and , respectively, under the true distribution . Let denote the bipartite graph corresponding to the distribution . Initially, user 1 sends the index i of the set for which , by using no more than bits. After this step, user 1 sends the color of each symbol in according to the minimum coloring of graph by using no more than bits in total. By using the sequence of colors received from user 1, user 2 can determine the correct function values . In the last step, user 2 sends the color of each symbol in according to graph by using no more than bits. After this step, user 1 can recover the function values . Overall, this protocol requires no more than
bits to be transmitted. Since one can leverage any partition within for constructing the communication protocol, we conclude that the worst-case message length for partial reconciliation is bounded above by,
For the second partial reconciliation protocol, we again leverage perfect hash functions from Equation (31). As in the first protocol, we define a partition of the set as such that and for all . We let be the set of all such partitions of .
We fix a partition of . For each , we define a graph with the vertex set . We define an edge between two vertices and if there exists some such that and for . We denote the chromatic number of by .
We define an ambiguity set for each ,
where the size of the largest single-term ambiguity set is given as,
and note that . Next, we define an ambiguity set for each ,
and define the size of the largest single-term ambiguity set as,
where . Given , from Equation (31), there exists a family of
functions such that for all and for each of size , there exists an injective over . For each , the two users agree on a family of functions and a coloring of graph with colors. Suppose user 1 observes and user 2 observes . User 1 sends the index of the partition for p to user 2 by using no more than bits. User 1 then finds a function that is injective over the colors of the vertices from Equation (49) and sends its index to user 2 by using no more than
bits. User 2 then evaluates the corresponding function for the assigned color of and sends it back to user 1 by using no more than bits. After this step, user 1 learns the color of , from which it recovers by using the observed . User 1 then evaluates the function , and sends it to user 2 by using no more than bits. In doing so, she assigns a distinct index for each sequence of function values in the ambiguity set from Equation (34). User 2 can then recover the function by using and the received index. Overall, this protocol requires no more than
bits to be transmitted in total, therefore
Combining the bounds obtained from the two protocols in Equations (48) and (57), we have the following upper bound on the worst-case message length with partial reconciliation,
At the outset, partial reconciliation characterizes the interplay between reconciliation and communication costs. In order to understand this inherent reconciliation-communication trade-off, we next identify the cases for which reconciling the missing information is better or worse than not reconciling them. To do so, we provide sufficient conditions under which reconciliation-based strategies can outperform the strategies that do not start with a reconciliation procedure, and vice versa, and show that either strategy can outperform the other. Finally, we demonstrate that partial reconciliation can strictly outperform both.
4. Cases in which Strategies that Do Not Start with a Reconciliation Procedure is Better than Perfect Reconciliation
In this section, we demonstrate that strategies with no explicit reconciliation step can be strictly better than perfect reconciliation.
Proposition 4.
Strategies that do not start with an explicit reconciliation procedure is better than perfect reconciliation if
Proof.
Corollary 1.
Strategies with no explicit reconciliation step can strictly outperform perfect reconciliation.
Proof.
Consider a scenario in which there exists a parent distribution such that for all , then, reconciliation cannot perform better than the strategies with no explicit reconciliation step. This immediately follows from: (i) any zero-error communication strategy for is a valid strategy with no explicit reconciliation step, since , (ii) any perfect reconciliation scheme should ensure a valid zero-error communication strategy for , as it may appear as the true distribution. Therefore, reconciling distributions cannot decrease the overall message length. Suppose that there exists some for which for all . Then, Corollary 1 holds whenever . ☐
We next consider the following example to elaborate on the impact of overlap between the edges of bipartite graphs on the worst-case message length. To do so, we let and investigate the following class of graphs.
Definition 2.
(Z-Graph) Consider a class of graphs for which there exists a single such that for all . Additionally, assume that for any such that for some , then either or . In that sense, the structure of these graphs resemble a Z shape, hence we refer to them as Z-graphs. For this class of graphs, and for any .
Lemma 2.
Consider the class of graphs defined in Definition 2. For this class of graphs, the worst-case message length for strategies with no explicit reconciliation step satisfies,
where is defined in Section 3.2 and such that is as given in Equation (12).
Proof.
Consider the following encoding scheme. Group all the neighbors of y in that lead to the same function value . Assign a single distinct codeword to each of these groups. User 1 sends the corresponding codeword to user 2, which requires no more than bits, after which user 2 can recover the correct function value. Next, construct the graph as defined in Section 3.2. Find the minimum coloring of , and assign a distinct codeword to each of the colors. User 2 then sends the corresponding codeword to user 1, by using no more than bits. Note that user 1 can infer the correct function value after this step, as she already knows the bipartite graph G that corresponds to the true distribution and given x and G, each color represents a distinct function value. ☐
Example 1.
Consider the framework of Section 3.1 along with a class of Z-graphs and . That is, share an edge such that . Moreover, for any other edge , either or . Assume that is distinct for each edge in . Let
represent the number of common edges, i.e., overlap, between and , where . Note that the overlap between and can only consist of the edges that share the endpoint y. We consider the following four cases that may occur for the relations between the structures of the graphs .
- , , , . In this case, no reconciliation is always better than reconciliation, because whenever user 2 observes (respectively ), he can infer that user 1 knows (respectively ).
- , , , . In this case, no reconciliation is again optimal as user 2 can infer that user 1 is knows whenever he observes or .
- , , , . Then, no reconciliation is again optimal as user 2 can infer that user 1 knows if she observes or .
- , , , . In this case, the chromatic number of the reconciliation graph is given by from Definition 1. Then the worst-case message length for the perfect reconciliation scheme satisfies,which follows from Lemma 1. On the other hand, we find that the worst-case message length for the no reconciliation scheme satisfieswhich follows from Lemma 2 and the following coloring scheme. Suppose . Using colors, assign each that is connected to x in a distinct color. Next, take of these colors excluding the color assigned to node y, and color each that is connected to x in with a distinct color. Note that this is a valid coloring since there are only two bipartite graphs and , corresponding to two cliques whose sizes are and in the characteristic graph and the only common node between these two cliques is y. Furthermore, no edge exists across the two cliques. Hence, no reconciliation is better than perfect reconciliation wheneverAs an example, consider the graphs illustrated in Figure 4 for which and . The corresponding characteristic graph and coloring of is illustrated in Figure 5. For this case, we observe that no reconciliation is always better than reconciliation.
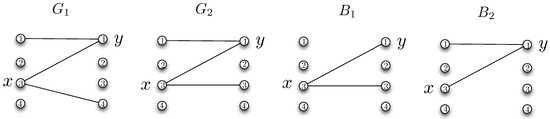 Figure 4. Example graphs and , where .
Figure 4. Example graphs and , where .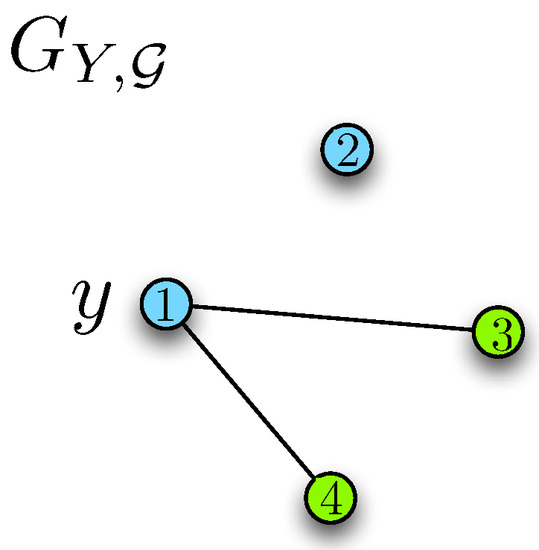 Figure 5. Coloring of the characteristic graph .
Figure 5. Coloring of the characteristic graph .
We note that the performance of a particular communication strategy with respect to others greatly depends on the structure of the partial information as well as the true probability distribution of the observed symbols. In the following section, we show that there exist cases for which reconciling the true distribution only partially can lead to better worst-case message length then both the strategies from Section 3.1 and Section 3.2, indicating that the best communication strategy under partial information may result from a balance between reconciliation and communication costs.
5. Cases in Which Partial Reconciliation is Better
We now investigate the conditions under which partially reconciling the graph information is better than perfect reconciliation. To do so, we initially compare the perfect and partial reconciliation strategies.
Proposition 5.
Partial reconciliation is better than perfect reconciliation if
Proof.
We next show that there exist cases for which partial reconciliation strictly outperforms the strategies from Section 3.1 and Section 3.2. To do so, we let and again focus on the class of graphs introduced in Definition 2. First, we present an upper bound on the worst-case message length with partial reconciliation for Z-graphs.
Lemma 3.
The worst-case message length with partial reconciliation for the class of graphs from Definition 2 can be upper bounded by,
where is as defined in Section 3.3 and with as described in Equation (12).
Proof.
To prove achievability, note that for a given partition , at least bits are necessary for sending the partition index, which reconciles each graph up to the class of graphs in the partition it is assigned to. After reconciliation, zero-error communication requires no more than in the worst-case. We show this by considering an encoding scheme that ensures zero-error communication for any graph in by using bits. Group all the neighbors of y in that lead to the same function value . Assign a single distinct codeword to each of these groups. Note that this requires no more than bits in total. Next, for a given partition , construct the graph as defined in Section 3.3. Find the minimum coloring of , and assign a distinct codeword to each of the colors, which requires no more than bits in total. Then, fix a partitioning of and use the following communication scheme. User 1, using the partition , sends the index of the group in which her graph G resides. Then, users 1 and 2 use a robust communication scheme for all the graphs contained in this group. To do so, user 1 sends the codeword assigned to by using no more than bits, after which user 2 can recover the correct function value. Then, user 2 sends the color assigned to using no more than bits, after which user 1 can learn the correct function value. ☐
Proposition 6.
Partial reconciliation can strictly outperform the strategies from Section 3.1 and Section 3.2.
Proof.
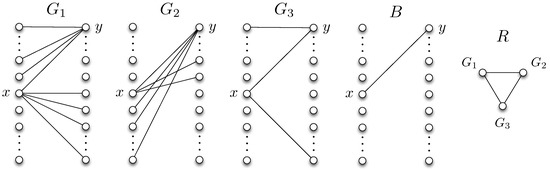
Consider the set of Z-graphs and in Figure 6. The edge sets satisfy , , and .
Figure 6.
Bipartite graphs , , and the corresponding reconciliation graph R.
Let be distinct for each edge in , and that for some .
First, consider the protocol from Section 3.2. It can be shown that this protocol satisfies
which results from the following observation. From Proposition 1, it follows that if for some , then cannot be a prefix of , where is the sequence of bits sent by user 1 in r rounds. Next, suppose that for some and where , and is a prefix of . Since user 2 does not know the true distribution, she cannot distinguish between and , causing an error since and lead to different function values. This in turn violates the zero-error condition. As a result, should be prefix free for all defined in Equation (34) whose size is . Therefore, user 1 needs to send at least bits to user 2. Next, we demonstrate that user 2 needs to send at least 1 bit to user 1. Suppose that this is not true, i.e., user 2 does not send anything. Since for some , in this case user 1 will not be able to distinguish between two distinct function values for at least one graph that may occur at user 1. Therefore, by contradiction, Equation (67) provides a lower bound for Z-graphs for the protocols that do not start with a reconciliation strategy considered in Section 3.2.
Next, consider the perfect reconciliation protocol. For this scheme, we construct the reconciliation graph R as given in Figure 6, and observe that any encoding strategy that allows user 2 to distinguish the graph of user 1 requires 3 colors (distinct codewords). After this step, both users consider one of , , or . Then,
which follows from Lemma 1 with the observation that for .
Lastly, consider the partial reconciliation protocol. In particular, consider a partial reconciliation scheme achieved by the partitioning such that , and . Then, from Equation (66), we obtain
Therefore, whenever satisfy
then, partial reconciliation outperforms the strategies from Section 3.2. On the other hand, whenever satisfy
then, partial reconciliation outperforms the perfect reconciliation scheme. By setting , , , , we observe that whereas and and both Equations (70) and (71) are satisfied, from which Proposition 6 follows. ☐
Therefore, under certain settings, it is strictly better to design the interaction protocols to allow the communicating parties to agree on the true source distribution only partially, than to learn it perfectly or not learn it at all, pointing to an inherent reconciliation-communication tradeoff.
6. Communication Strategies with Symmetric Priors
In this section we let and and specialize the communication model to the conventional function computation scenario where the true distribution of the sources is known by both users. Users thus share a common bipartite graph which they can leverage for interactive communication. We first state a simple lower bound on the worst-case message length.
Proposition 7.
A lower bound on the worst-case message length when the true distribution is known by both parties is,
Proof.
We next consider the upper bounds on the worst-case message length for this scenario. A simple upper bound can be obtained via the graph coloring approach in Theorem 1,
where the characteristic graphs and are constructed as in Theorem 1 using the bipartite graph corresponding to the true distribution . We note that Equation (76) implies that
The above approach may yield limited gains for compression for large values of and , and another round of interaction may help reduce the compression rate. We next provide another upper bound that combines graph coloring and hypergraph partitioning. To do so, we first review the following notable results. The first one is a technical result regarding partitioning hypergraphs.
Lemma 4 ([1]).
Define to be a hypergraph with a vertex set of size , and the hyperedges with . Assume that each hyperedge has at most κ elements, i.e., . Then for any given , there exists a constant such that and , a partition of V can be found with for all and .
We can now state the second useful result.
Lemma 5 ([1]).
The following worst-case codeword length can be achieved in three rounds for ,
where each person makes two non-empty transmissions.
We next derive an upper bound based on Lemma 5 by increasing the number of interaction rounds and following a sequential hypergraph partitioning approach. This allows the proposed scheme to work in low-rate communication environments when parties do not mind having extra rounds of interaction.
Theorem 2.
Given a joint probability distribution , consider the corresponding bipartite graph . Consider a partition of into groups such that for each group ,
where . Then, the worst-case codeword length with four total rounds can be bounded by using sequential hypergraph partitioning as
where .
Proof.
where , and . User 1 can also determine this set by using the group index for her symbol and the relations between the function values of both parties. Let
Our proof builds upon [1] as follows. The set of symbols in the first round are from and for users 1 and 2, respectively. We assume without loss of generality. Let . From Lemma 4, can be partitioned into groups such that for each group ,
where . In this round, user 1 sends the index of the group that her symbol resides in by using no more than bits, and user 2 makes a null transmission. Let be the index of the group sent by user 1 in the first round. In the second round, the following set is considered by user 2 after receiving the index from user 1
Note that . Next, consider a hypergraph with the vertex set and define a hyperedge for each as follows.
User 2 then partitions into groups and sends the group index for his symbol, which requires no more than bits. After receiving the group index, user 1 has to decide from at most possible symbols from user 2.
In the third round, symbols are now restricted to a subspace of with at most possible symbols from user 1 for each symbol from user 2 and at most possible symbols from user 2 for each one of the symbols of user 1. Then, by using ([1], Lemma 2), one can find that no more than bits are required.
This scheme requires four rounds of interaction in total; each person makes two non-empty transmissions. The total number of bits required in the worst-case satisfies
where . ☐
Corollary 2.
In the limit of large block lengths, the upper bound of Theorem 2 satisfies
Proof.
As and for all partitions u of and , from Theorem 2,
☐
Lemma 5 and Theorem 2 apply the hypergraph partitioning technique to the bipartite graph of the joint distribution , but provide achievable rates by first performing source reconstruction at the two ends, after which both users can compute the correct function value. The next theorem takes the function values into account while constructing the hypergraph partitioning algorithm, with the use of characteristic graphs.
Consider any valid coloring of the characteristic graphs and defined in Section 3.1. Note that by using their own symbols, each user can recover the correct function values upon receiving the color from the other user. The problem now reduces to sharing the colors between the two parties correctly, for which we apply sequential hypergraph partitioning to the colors of the graphs and .
Theorem 3.
Define a coloring for with colors, and a coloring for with colors. Let and denote the colors assigned to and by the colorings α and β, respectively. Define the ambiguity set for color as
with the size bound , and the ambiguity set for color as
with the size bound . Consider a partition of into groups such that for each group ,
and
where . Then, the worst-case message length can be upper bounded as,
where .
Proof.
Assume without loss of generality. Choose . Partition into groups such that in each partition the number of colors from the ambiguity set is no greater than . Hence, for any ,
for . In the first round, user 1 sends the index of the partition the color of her symbols lies in. This requires at most bits, whereas user 2 makes an empty transmission. Denote as the index of the partition sent from user 1. In the second round, upon receiving from user 1, user 2 considers a set given as in Equation (93), where . Define a hypergraph with a vertex set and a hyperedge for each such that , and for every . Define and partition into to groups so that user 2 can send the index of his symbols with at most bits. Upon receiving the index, user 1 can reduce the number of possible symbols from user 2 to at most . Colors in the third round are restricted to a subset of such that for every color from user 1 (user 2), there are at most () possible colors exist from user 2 (user 1). Then Equation (94) follows from ([1], Lemma 2).
It can be observed from Equation (94) that different codeword lengths are obtained by different colorings, since they lead to different color and ambiguity set sizes. In general, there exists a trade-off between the ambiguity set sizes and the number of colors, such that using a smaller number of colors may in turn increase the ambiguity set sizes. The exact nature of the bound depends on the graphical structures such as degree and connectivity, however, any valid coloring allows error-free recovery. For instance, assigning a distinct color to each element of and is a valid coloring scheme. If one restricts oneself to such set of colorings, the coding scheme of Theorem 3 will reduce to that of Theorem 2, hence the bound in Theorem 3 generalizes the achievable protocols in Theorem 2.
7. Conclusions
In this paper, we have considered a communication scenario in which two parties interact to compute a function of two correlated sources with zero error. The prior distribution available at one of the communicating parties is possibly different from the true distribution of the sources. In this setting, we have studied the impact of reconciling the missing information about the true distribution prior to communication on the worst-case message length. We have identified sufficient conditions under which reconciling the partial information is better or worse than not reconciling it but instead using a robust communication protocol that ensures zero-error recovery despite the asymmetry in the knowledge of the distribution. Accordingly, we have provided upper and lower bounds on the worst-case message length for computing multiple descriptions of the given function. Our results point to an inherent reconciliation-communication tradeoff, in that an increased reconciliation cost often leads to a lower communication cost. A number of interesting future directions remain. In this paper, we do not consider additional strategies which consider further information that may be revealed by the function realizations on the support set. Developing interaction strategies that leverage this information is another interesting future direction. A second one is finding the optimal joint reconciliation-communication strategy in general and the study of alternative upper bounds that take into account the specific structure of the function and input distributions. Another interesting direction is to model the case where knowledge asymmetry is due to one party having superfluous information.
Acknowledgments
This research was sponsored by the U.S. Army Research Laboratory and was accomplished under Cooperative Agreement Number W911NF-09-2-0053 (the ARL Network Science CTA). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation here on. Earlier versions of this work have partially appeared at the IEEE GlobalSIP Symposium on Network Theory, December 2013, IEEE Data Compression Conference (DCC’14), March 2014, and IEEE Data Compression Conference (DCC’16), March 2016. This document does not contain technology or technical data controlled under either the U.S. International Traffic in Arms Regulations or the U.S. Export Administration Regulations.
Author Contributions
The ideas in this work were formed by the discussions between Basak Guler and Aylin Yener with Prithwish Basu and Ananthram Swami. Basak Guler is the main author of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- El Gamal, A.; Orlitsky, A. Interactive data compression. In Proceedings of the IEEE Symposium on Foundations of Computer Science (FOCS’84), West Palm Beach, FL, USA, 24–26 October 1984; pp. 100–108. [Google Scholar]
- Orlitsky, A. Worst-case interactive communication I: Two messages are almost optimal. IEEE Trans. Inf. Theory 1990, 36, 1111–1126. [Google Scholar] [CrossRef]
- Guler, B.; Yener, A.; Basu, P. A study of semantic data compression. In Proceedings of the IEEE Global Conference on Signal and Information Processing (GlobalSIP’13), Austin, TX, USA, 3–5 December 2013; pp. 887–890. [Google Scholar]
- Guler, B.; Yener, A. Compressing semantic information with varying priorities. In Proceedings of the IEEE Data Compression Conference (DCC’14), Snowbird, UT, USA, 26–28 March 2014; pp. 213–222. [Google Scholar]
- Yao, A.C. Some complexity questions related to distributed computing. In Proceedings of the 11th Annual ACM Symposium on Theory of Computing (STOC’79), Atlanta, GA, USA, 30 April–2 May 1979; pp. 209–213. [Google Scholar]
- Feder, T.; Kushilevitz, E.; Naor, M.; Nisan, N. Amortized communication complexity. SIAM J. Comput. 1995, 24, 736–750. [Google Scholar] [CrossRef]
- Kushilevitz, E.; Nisan, N. Communication Complexity; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Orlitsky, A.; Roche, J.R. Coding for computing. IEEE Trans. Inf. Theory 2001, 47, 903–917. [Google Scholar] [CrossRef]
- Ma, N.; Ishwar, P. Some results on distributed source coding for interactive function Computation. IEEE Trans. Inf. Theory 2011, 57, 6180–6195. [Google Scholar] [CrossRef]
- Ma, N.; Ishwar, P.; Gupta, P. Interactive source coding for function computation in collocated networks. IEEE Trans. Inf. Theory 2012, 58, 4289–4305. [Google Scholar] [CrossRef]
- Yang, E.H.; He, D.K. Interactive encoding and decoding for one way learning: Near lossless recovery with side information at the decoder. IEEE Trans. Inf. Theory 2010, 56, 1808–1824. [Google Scholar] [CrossRef]
- Shannon, C. The zero error capacity of a noisy channel. IRE Trans. Inf. Theory 1956, 2, 8–19. [Google Scholar] [CrossRef]
- Witsenhausen, H.S. The zero-error side information problem and chromatic numbers. IEEE Trans. Inf. Theory 1976, 22, 592–593. [Google Scholar] [CrossRef]
- Simonyi, G. On Witsenhausen’s zero-error rate for multiple sources. IEEE Trans. Inf. Theory 2003, 49, 3258–3260. [Google Scholar] [CrossRef]
- Körner, J. Coding of an information source having ambiguous alphabet and the entropy of graphs. In Proceedings of the Sixth Prague Conference on Information Theory, Prague, Czech Republic, 19–25 September 1973; pp. 411–425. [Google Scholar]
- Alon, N.; Orlitsky, A. Source coding and graph entropies. IEEE Trans. Inf. Theory 1995, 42, 1329–1339. [Google Scholar] [CrossRef]
- Doshi, V.; Shah, D.; Médard, M.; Effros, M. Functional compression through graph coloring. IEEE Trans. Inf. Theory 2010, 56, 3901–3917. [Google Scholar] [CrossRef]
- Minsky, Y.; Trachtenberg, A.; Zippel, R. Set reconciliation with nearly optimal communication complexity. IEEE Trans. Inf. Theory 2003, 49, 2213–2218. [Google Scholar] [CrossRef]
- Nayak, J.; Rose, K. Graph capacities and zero-error transmission over compound channels. IEEE Trans. Inf. Theory 2005, 51, 4374–4378. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic Web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Sheth, A.; Bertram, C.; Avant, D.; Hammond, B.; Kochut, K.; Warke, Y. Managing semantic content for the Web. IEEE Internet Comput. 2002, 6, 80–87. [Google Scholar] [CrossRef]
- Lee, E.A. Cyber physical systems: Design challenges. In Proceedings of the IEEE International Symposium on Object Oriented Real-Time Distributed Computing (ISORC’08), Orlando, FL, USA, 5–7 May 2008; pp. 363–369. [Google Scholar]
- Sheth, A.; Henson, C.; Sahoo, S. Semantic sensor Web. IEEE Internet Comput. 2008, 12, 78–83. [Google Scholar] [CrossRef]
- Chen, J.; He, D.K.; Jagmohan, A. On the duality between Slepian–Wolf coding and channel coding under mismatched decoding. IEEE Trans. Inf. Theory 2009, 55, 4006–4018. [Google Scholar] [CrossRef]
- Juba, B.; Kalai, A.T.; Khanna, S.; Sudan, M. Compression without a common prior: An information-theoretic justification for ambiguity in language. In Proceedings of the Second Symposium on Innovations in Computer Science (ICS 2011), Beijing, China, 7–9 January 2011. [Google Scholar]
- Haramaty, E.; Sudan, M. Deterministic compression with uncertain priors. Algorithmica 2016, 76, 630–653. [Google Scholar] [CrossRef]
- Guler, B.; Yener, A.; MolavianJazi, E.; Basu, P.; Swami, A.; Andersen, C. Interactive Function Compression with Asymmetric Priors. In Proceedings of the IEEE Data Compression Conference (DCC’16), Snowbird, UT, USA, 30 March–1 April 2016; pp. 379–388. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, 2012. [Google Scholar]
- Gács, P.; Körner, J. Common information is far less than mutual information. Probl. Control Inf. Theory 1973, 2, 149–162. [Google Scholar]
- Mehlhorn, K. Data Structures and Algorithms 1: Sorting and Searching; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).