1. Introduction
A “near miss” is considered to cause no property damage or personal injury, but is prone to damage or injury when there is a slight movement in time or location. In the field of traffic safety, near miss, also known as near accident, near collision, and so on, refers to an operation without personal or property loss but with high risk. It does not turn into an accident but from a probabilistic point of view the more near-miss events there are, the more likely it is that an accident occurs [
1]. Therefore, near-miss events, which are responsible for traffic safety, are a subject of increasing interest [
2]. Although near-miss events can be collected through telematics, modeling near-miss events allows us to evaluate the risk dynamically and predict potential accidents before they occur, thus enhancing preemptive safety measures. For example, a driver with a more aggressive driving style may not have a near-miss for a period of time, but the regression results of his driving data show that he does have near-miss events. In other words, regression analysis of telematics data can dig out risks hidden deep inside. In this study, a new driving risk assessment method is proposed, which uses the results of the near-miss event estimation model to calculate the driving risk of each driver. This method has been verified on datasets from China and Spain.
Vehicles and drivers are the main participants in traffic accidents, and their daily travel is inseparable from auto insurance, which provides security. Motor insurance is compulsory in most countries to protect those who should be compensated for losses caused by vehicles in motion. The premium calculation of auto insurance, which is based on the determination of claim risks and leads to insurance pricing, has always been the most concerned issue for both the policyholders and insurers. Historically, insurers have relied on the number of accidents during the insured period, in fact, insurers only consider the number of claims because policyholders may not report accidents when claiming implies that a penalization on the next term price is enforced. The reality is that, if a minor accident occurs, most of the drivers will avoid paying more premiums by not claiming [
3]. Policies with no claims for several years tend to be the majority in most portfolios, making it difficult to obtain useful information that truly reflects the risks of driving [
4]. With the development of telematics, usage-based insurance (UBI), a new type of vehicle insurance, can use more potential data attributes to complete the driving risk assessment and then complete the auto insurance premium determination [
5]. The method of scoring driving risk based on expected near-miss events proposed in this study is a new attempt in the field of UBI. It is crucial to develop UBI systems that can provide personalized insurance premiums based on real-time driving behavior.
Research on UBI has been ongoing for years. Initially, researchers included driving mileage alongside traditional auto insurance factors to assess driving risks and set premiums. This early mileage-based approach was known as pay-as-you-drive (PAYD) [
6,
7,
8]. Later, as data from the Internet of Vehicles became available, factors related to driving behavior and driving conditions were introduced into the rate-making model, which was called pay-how-you-drive (PHYD) [
9,
10,
11]. In the future, if 5G communication technology and in-car processors become widely used, UBI schemes will be called manage-how-you-drive (MHYD), which will enable drivers to analyze their competence at the wheel and allow for calculating insurance premiums in real-time [
12]. The driving risk assessment in this study is based on the near-miss event prediction model supported by telematics data. Still, the utilization rate of vehicles is also considered, so it should be regarded as a combination of PAYD and PHYD.
Driving risk scores are used in numerous contexts, primarily for pricing and risk analysis. This latter function can inform drivers about their performance or help insurance companies classify customers, though it is typically used internally or for marketing purposes. There are various methods for assessing driving risk. Many researchers advocate for methods based on the traditional generalized linear model (GLM), which is the most widely used in the insurance field. Linear regression [
12], logistic regression [
7,
13], quantile regression [
14], Poisson regression [
15,
16], zero-inflated Poisson regression [
3,
17], negative binomial regression [
18,
19], zero-inflated negative binomial regression [
18,
19], panel data regression [
19], generalized additive model [
20,
21], etc., are widely used in driving risk assessment due to their good interpretability. On the other hand, black-box algorithms in machine learning have also been used in UBI research, such as cluster analysis [
22,
23], decision tree [
7], support vector machine [
24], neural network [
25], gradient boosting method [
26], and other relevant models [
5,
27]. In recent years, scholars have combined the boosted generalized linear model with machine learning to study UBI by taking advantage of both [
28,
29,
30]. Nevertheless, the advent of these novel methodologies may encounter obstacles due to regulatory constraints in certain jurisdictions where the application of black-box predictive analysis is prohibited [
31].
The role of near-miss events in driving risk assessment and premium pricing is quite flexible and can be approached from multiple perspectives. Guillen et al. [
18] analyzed three types of near-miss events, i.e., cornering, braking, and accelerating, as independent variables and proved that both traditional and telematics variables are relevant to risk factors. Sun et al. [
19] employed Poisson regression and negative binomial regression to analyze four types of near-miss events as dependent variables in summary datasets and panel datasets, respectively. This not only confirmed the significant influence of certain driving risk variables but also identified specific driving risk factors for each driver. Guillen et al. [
4] proposed a new method for determining auto insurance rates, using historical claims as the dependent variable and near-miss events as the independent variable. They calculated influence coefficients via the log-link function and incorporated these into the pricing model to complete rate-making. Guillen et al. [
32] utilized telematics data from 19,214 drivers over 55 weeks to develop predictive models for weekly accident frequency. They demonstrated that incorporating behavioral and contextual factors significantly enhances risk assessment. This approach also highlights potential usage-based insurance schemes through Poisson regression-derived driving scores and personalized safety alerts. This paper builds on previous studies but uses data that lacks information on accidents or claims. Here, the frequency of each near-miss event is treated as a dependent variable to evaluate driving risk.
The rest of this paper is organized as follows. The data structure, data description, and variable availability of the datasets from China and Spain are presented in
Section 2.
Section 3 presents the generalized linear model and machine learning algorithm used in this research.
Section 4 presents the results of the two types of models on the two datasets. The similarities and differences are compared and discussed.
Section 5 summarizes the findings and shortcomings of this study.
2. Data Description
Different telematics datasets from China and Spain are included in this study. Although the sources of the two datasets are different, their data attributes have many similarities and differences (see details in
Table 1).
(
) and
(
), as common attributes of the two datasets, are selected as the dependent variables of this study. It is worth noting that there are no common attributes in the driving behavior category, but they are all taken into account because they have important information about driving risk. Similarly, in the driving duration category, while
and
in the dataset from China and
and
in the dataset from Spain do not appear in the other dataset, they should not be ignored because they contain key information. By the same token, in the driving distance category,
in the dataset from China and
,
kmh and
kmh in the dataset from Spain are retained.
The two datasets have their own data structures. The main feature is that neither dataset contains accidents or claims, while frequent near-miss events can serve as valuable indicators of driving risk. Unlike accidents and claims, which occur only a few times a year, near-miss events tend to occur more frequently and are easily captured by telematics sensors. The dataset from China contains telematics data from 261 vehicles over six days, as shown in
Table 2. Notice that the means of
and
are both non-negative integers, which suggests that Poisson regression models could be used. In contrast, the dataset from Spain consists of 285 connected vehicles with a period ranging from 1 to 194 days, see
Table 3. Notice that
and
are also non-negative integers but their variances are much higher than the mean, which suggests that Poisson regression may not be as good as negative binomial regression in modeling the frequency of near misses. In general, negative binomial regression would be more appropriate when there is excessive dispersion in the count data, but if this dispersion is mainly caused by a few outliers, the Poisson regression model may be more robust. In other words, the negative binomial regression model may be affected by outliers, leading to biased parameter estimates and, thus, affecting predictive performance. Note that the median, 75% quantile, and maximum value of the
variable are equal, which might indicate repeated values caused by sensor errors. Consequently, this variable has been ignored in this study.
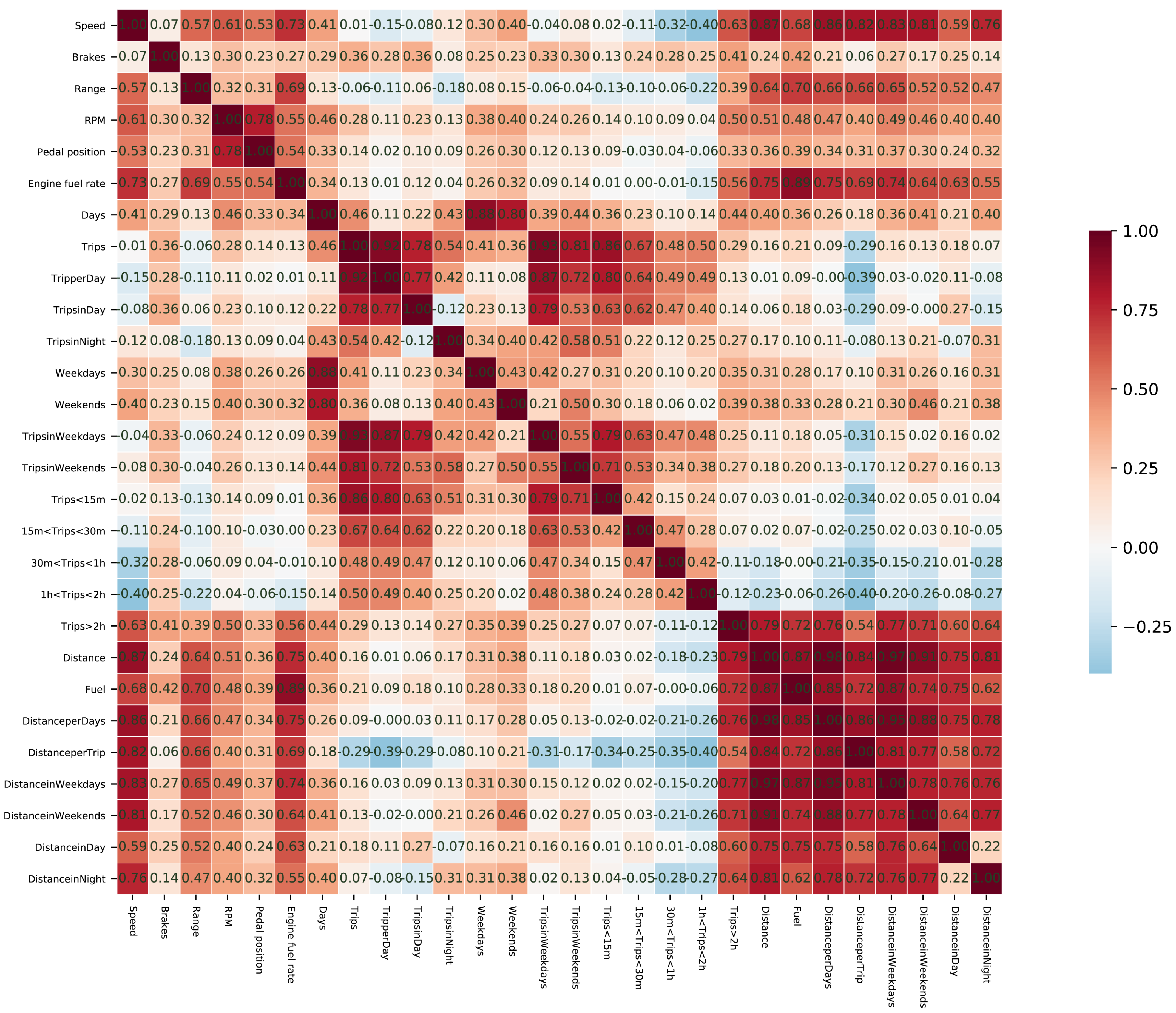
Given the large number of data attributes, a correlation analysis of the variables was also conducted prior to modeling and before examining the regression results. In the dataset from China, as shown in
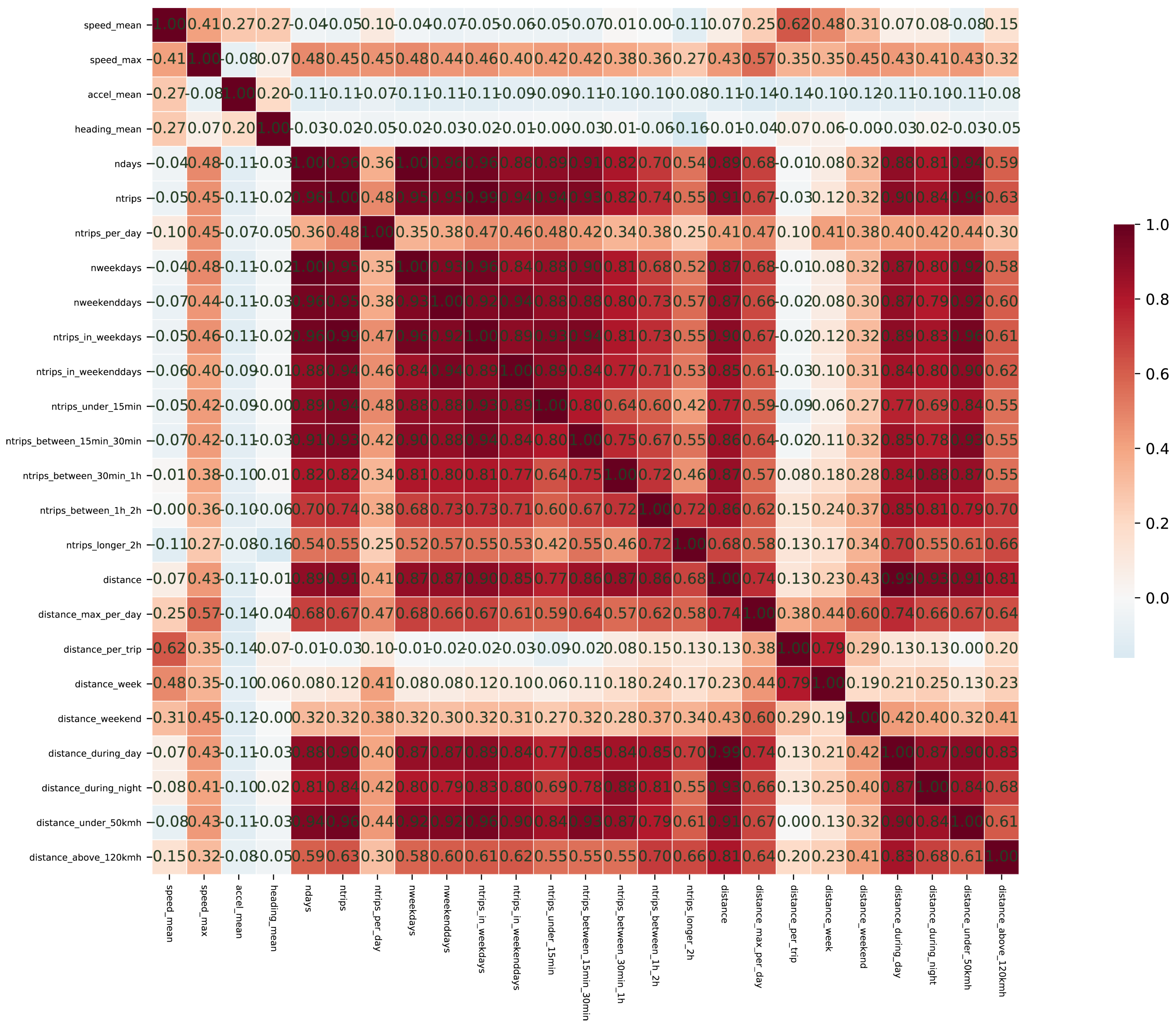
Figure 1, each type of variable exhibits a certain degree of internal correlation. Notably, the driving distance variables demonstrate the strongest correlation. There is a positive correlation between driving behavior variables and driving distance variables, whereas the correlation between driving duration variables and the other two types of variables is weak or even negative. In the dataset from Spain (see
Figure 2), driving distance variables and driving duration variables show an obvious positive correlation, while driving behavior variables have no obvious correlation with other variables. Interestingly, the linear correlation between dependent variables and independent variables in the dataset from China is not strong, but the correlation between dependent variables and independent variables in the dataset from Spain is strong. Since the correlation between independent variables can affect model parameter identification and the assessment of causality, it is necessary to conduct multicollinearity tests and make trade-offs before modeling. Alternatively, regularization terms can be added to eliminate the bad effects of multicollinearity during modeling. As shown in
Table 4 and
Table 5, after eliminating variables with the excessive variance inflation factor (VIF), the remaining variables passed the multicollinearity test. Although, this work is not limited to generalized linear models, the number of variables involved in this study can be easily handled by a machine learning algorithm, which is good at processing multidimensional data.
4. Results and Discussions
Assuming that each near-miss event (as a dependent variable) obeys the Poisson distribution, the Kolmogorov–Smirnov test was conducted on them, respectively, and the test results (seeing
Table 6) showed that none of the four near-miss events conformed to the standard Poisson distribution. This may bring about the estimation results of Poisson regression bias. In order to compare the effects of the two regressions, Poisson regression and negative binomial regression were estimated on the dataset from China and the dataset from Spain, respectively, and their coefficient estimations and significance results are shown in
Table 7 and
Table 8. It is worth noting that prior to undertaking the regressions, the independent variables were subjected to standardization. This process entailed the division of the total number of variables such as brakes, trips, and distance by the exposure period, thereby converting them into average daily rates (with the “
” suffix). This modification was implemented to ensure that the values of the independent variables were comparable across insureds with varying exposure periods, thereby enhancing the robustness and interpretability of the model. From the regression results, whether in the dataset from China or Spain, most of the independent variables in the Poisson regression demonstrate significant effects, regardless of which near-miss event is used as the dependent variable. However, it seems to mean that the variances of the estimators are probably understated. Furthermore, the Akaike information criterion (AIC) and Bayesian information criterion (BIC) of negative binomial regressions are smaller than Poisson regressions for the same variables. The log-likelihood of the negative binomial regression is higher than that of the Poisson regression. And the discrete parameter
is significantly greater than zero. These all imply that the negative binomial regression performs more convincingly at the parameter estimation level relative to Poisson regression. Since this study focuses more on obtaining an accurate prediction model, further validation is needed to compare the accuracy of the two predictions.
According to the negative binomial regression results for the dataset from China (see
Table 7), driving behavior variables, especially
, have significant positive effects on near-miss events. The positive impacts of
and the
on
show that the more aggressive the driving behavior, the more near-miss events will be observed, which is consistent with the common sense of daily driving. The positive effect of
shows that the more frequent the driving, the more near-miss events are generated, while the negative impacts of
on
and
on
indicate that driving in a specific environment will reduce dangerous driving. For example, driving on weekends can make drivers more cautious due to changes in the driving environment, both inside and outside the vehicle. Another example is the driver is less frequently involved in other vehicles’ trajectories due to low traffic flow at night. The strong negative effects of
(under 15 min) and
(between 15 min and half an hour) indicate that short-term driving will produce less dangerous driving. Correspondingly, the negative effects of
(between one hour and two hours) and
(over 2 h) are believed to be caused by the fact that driving fatigue leads to less intense driving.
In contrast, the negative binomial regression results for the dataset from Spain are, in many respects, identical yet still slightly different than those from the dataset from China. As
Table 8 shows, the biggest similarity is that
shows a strong positive effect for near-miss events. In a similar vein,
,
,
and
, have a negative effect on both types of near-miss events. However, trips between 30 min and 1 h also show significant negative effects on near-miss events, which is different from the results of the above model for China. The biggest difference is that
and
do not show significant effects on near-miss events in the dataset from Spain, which is probably related to the different driving conditions and different driving habits of drivers. In addition, driving behavior variables such as
do not show a significant effect on near-miss events. This lack of significance is likely related to differences in variable definition methods, data collection methods, and data collection channels between the two datasets [
12,
32].
In the prediction process, factors such as model complexity, generalization capability, and adaptability to data characteristics need to be considered to select the most suitable model. To validate the prediction capability, the evaluation of the GLM model and the HGBR model are presented in
Table 9. Here, all three models were run with default maximum iterations set at 100 on both a train set and a test set to prevent overfitting from affecting model judgment. The results show that the Poisson regression model has the poorest performance on the test set, indicating weak generalization. Conversely, while the negative binomial regression did not perform exceptionally well on the training set, it outperformed Poisson regression on the test set. This suggests that it is more sensitive and adaptable to the overly discrete data characteristic of this study. This aligns with previous evaluations of parameter estimation and model comparison. Therefore, negative binomial regression has been chosen as the comparison group in subsequent studies for HGBRs, which consistently demonstrate superior model evaluation metrics over GLMs across all datasets and dependent variables. Although most of the hyperparameters remain default without tuning (loss = ’poisson’, max_iter = 100, max_depth = 2, random_state = 0, and other defaults), the HGBR’s performance is exceptional. In practice, the optimal model hyperparameters can be further selected by using cross-validation and grid search to obtain the best model performance with the best data characterization capabilities.
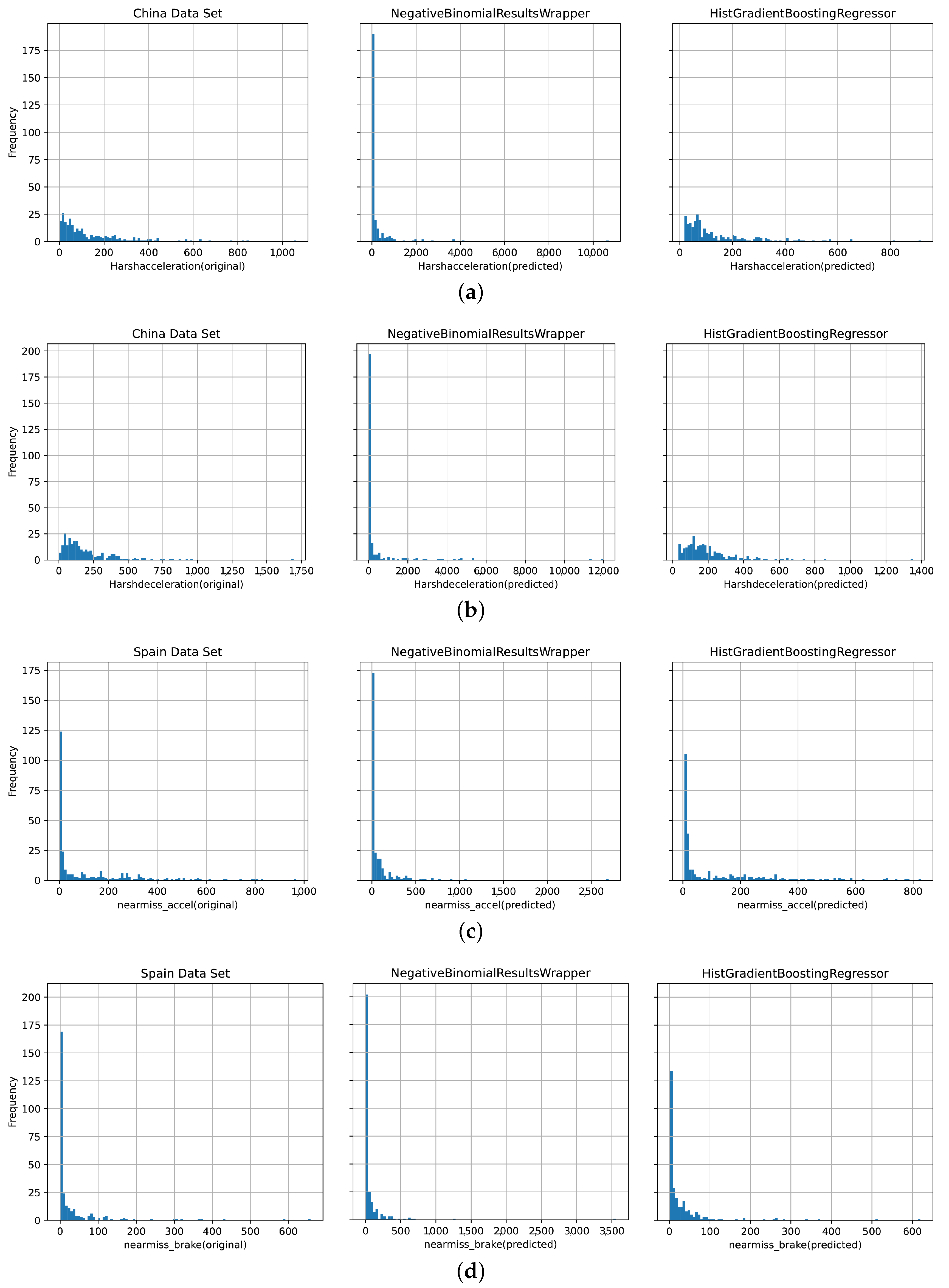
As illustrated in
Figure 3, the HGBR exhibits superior predictive capabilities and more accurately simulates the data distribution of the two types of near-miss events in comparison to the negative binomial model across both datasets (from China and Spain). It has been observed that the negative binomial model’s predictions for zero values sometimes do not align with reality, unlike the HGBR, which demonstrates a good fit to actual data. This discrepancy may be attributed to the failure of the GLM to account for non-linear relationships among variables. There is also the fact that the prediction process of the GLM is actually an approximation to a hypothetical distribution, and once the actual situation is not a standard distribution, its predictive power is weakened. In contrast, the HGBR’s strength lies in its capacity to incorporate diverse data types and variable dependencies, which contributes to its exceptional predictive power.
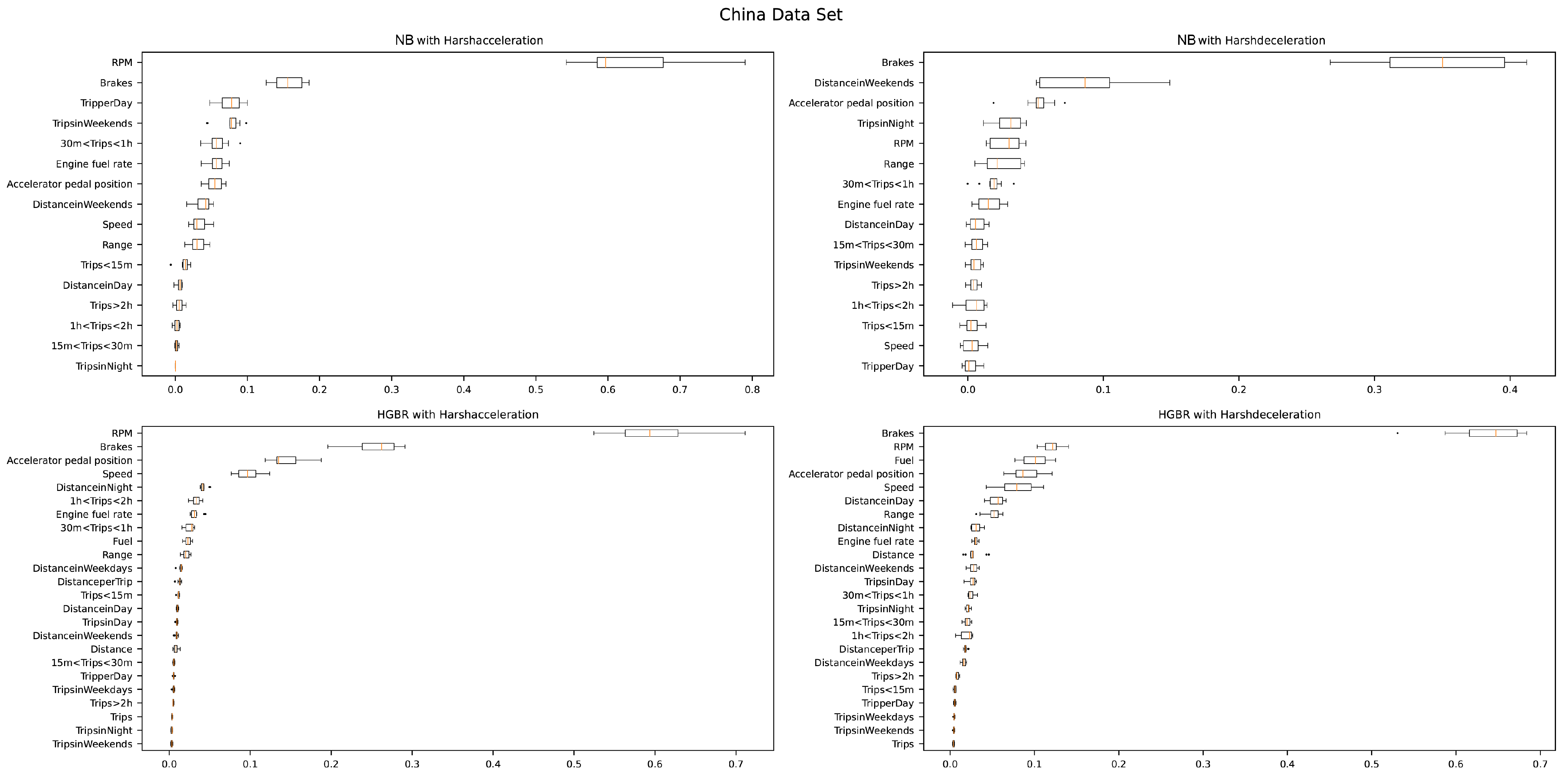
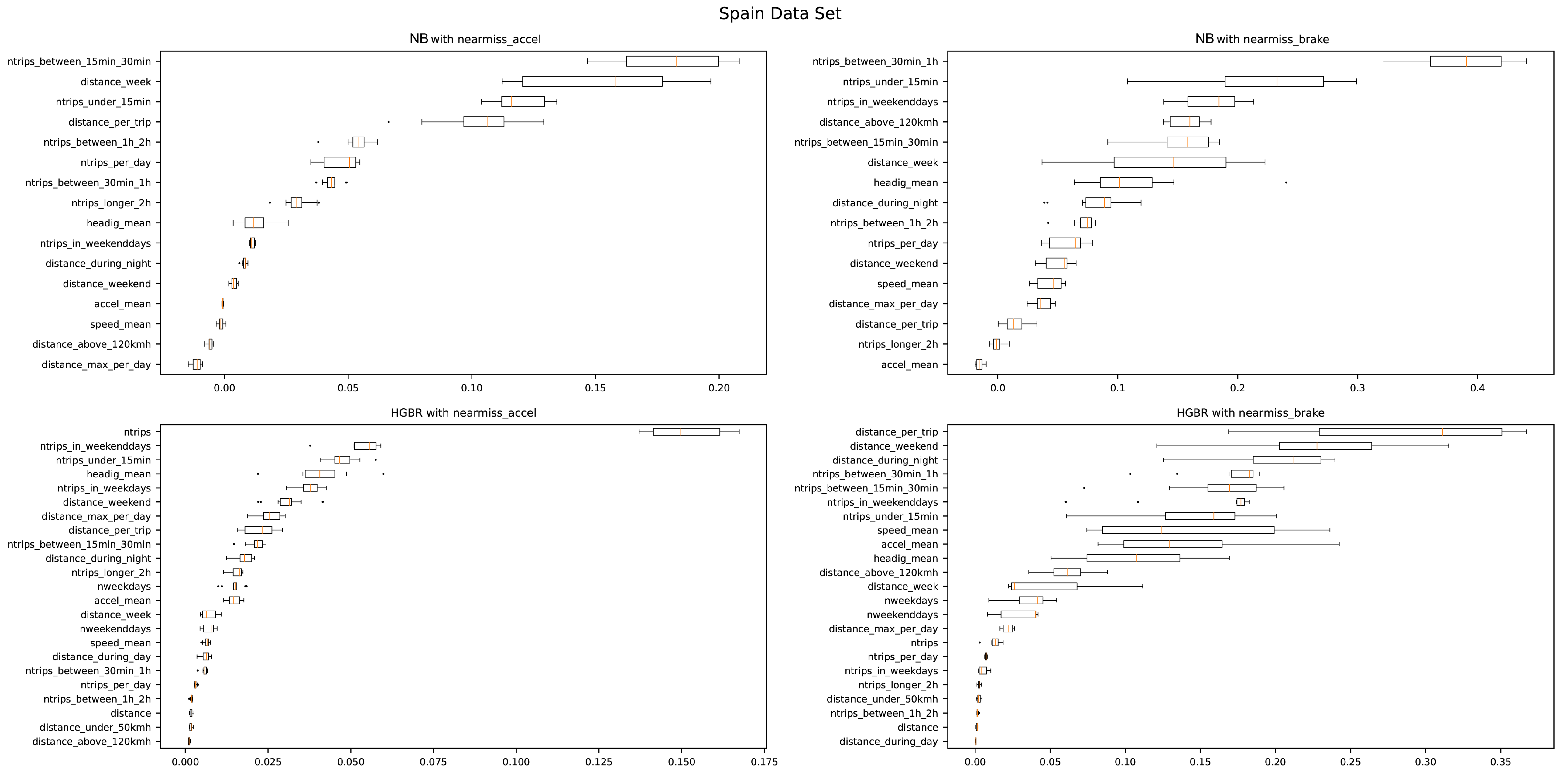
Permuted feature importance, one of the explanation tools of machine learning, could be derived from changes in model prediction errors following the disruption of eigenvalues [
35]. To understand the contribution of features to model prediction, permuted feature importance tests are performed on the Poisson regression model and HGBR model, respectively. It can be seen from
Figure 4 that the two models of the two near-miss event labels in the dataset from China are more sensitive to driving behavior variables. The same is true for the dataset from Spain, except that the model from the dataset from Spain is more sensitive to distance and duration variables, as shown in
Figure 5. However, the characteristics of the same model do not contribute to the prediction of different labels. Due to the different features selected among different models, the comparison of feature contributions is meaningless. It is worth mentioning that the permuted feature importance of the negative binomial regression model is partially consistent with the variable significance shown in
Table 7 and
Table 8, but there are also contradictions. This means that this method can only be used as an aid to understanding the contribution of variables, and its reliability and interpretability need to be improved.
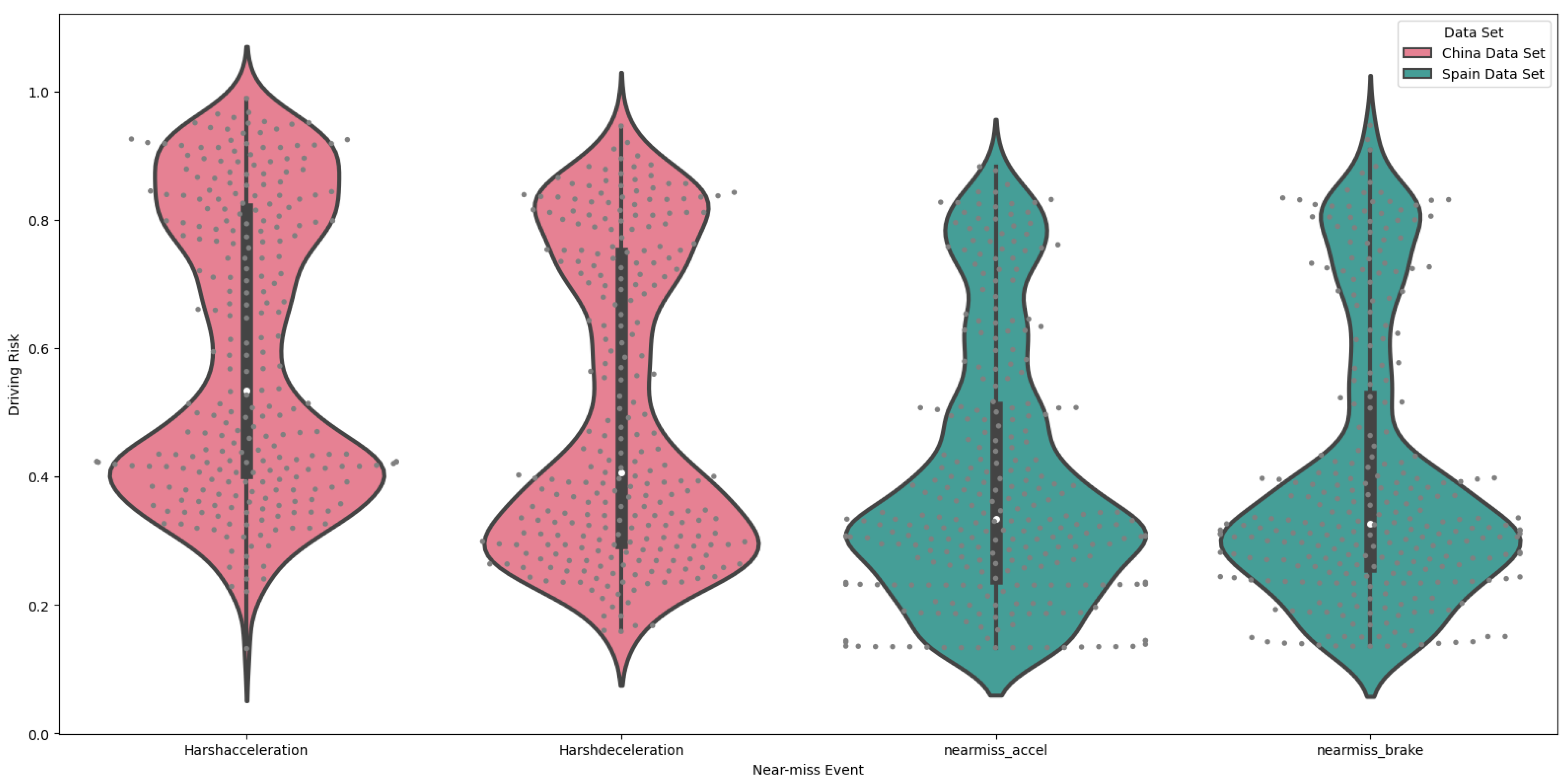
Once the aforementioned risk factor calculation method was employed to derive driving risks, the predicted outcomes from the HGBR were combined with the actual values of near-miss events from the two datasets. This process yielded four groups of driving risk factors, as detailed in
Table 10. Due to the limited number of drivers, all these metrics were derived from the full sample. The distribution maps in
Figure 6 illustrate the distribution of driving risks for each near-miss event. In each group, a point represents an observation’s driving risk factor, while the shaded areas and box plots represent the kernel density and distribution of observed driving risks. In the dataset from China, either in the
group or in the
group, the driving risk for each near-miss event group is primarily concentrated into two clusters. The first cluster, comprising observations with a value above 0.6, indicates a high-risk group, while the second cluster, comprising observations with a value below 0.6, indicates a low-risk group. In the dataset from Spain, both the
acceleration and
braking groups indicate that the majority of drivers’ risks are distributed approximately normally around 0.3, whereas a minority are distributed approximately normally around 0.8.
While there is no inherent correlation between the four sets of driving risk factor outcomes, they do exhibit certain similarities. These include the magnitude of individual driving risks and how they are aggregated. The results demonstrate that—regardless of the dimension used to assess a driver’s risk-taking behavior—two distinct groups emerge: one with lower driving risk and another with higher driving risk. These groups exhibit a clear divergence, with the majority of ambiguous drivers occupying a relatively minor position. In general, the lower-risk drivers constitute the majority, yet it is not implausible that the majority of drivers may engage in more aggressive driving under certain circumstances. This result also proves that the driving risk scoring algorithm proposed in this study can effectively distinguish the driving risk levels. In addition, although laws and regulations in Spain differ from those in China, and neither auto insurance market currently offers a near-miss-based premium calculation product, this method demonstrates a straightforward way to show that near-miss events can be used as corrections to the price of subsequent periods. Furthermore, the same approach can be applied across different countries.
5. Conclusions
Near-miss events have been shown to be effective for assessing driving risks. Most independent variables in the GLM model are statistically significant, indicating that the model effectively captures the distribution pattern of near-miss events as dependent variables. The HGBR model demonstrates exemplary predictive capacity, ensuring accurate output variables derived from input variables. The values and distribution of driving risk factors align with prevailing expectations and understanding. This study’s findings suggest that near-miss events have the potential to serve as independent variables, providing valuable information for driving risk regression analysis. Furthermore, near-miss events may be utilized as substitutes for accidents or claims when scoring driving risks [
36]. Additionally, driving risks can be leveraged to adjust premiums. However, the actuarial implications of such adjustments for insurance companies require analysis. In particular, issues such as the equilibrium of premiums and the distribution of payouts remain beyond the scope of this paper and necessitate further examination.
The aforementioned study raises an intriguing question about the potential benefits of employing driving risk predictors instead of directly using near-miss frequencies. We contend that predictive models offer an effective methodology for generating a risk score that incorporates contextual data beyond near-miss information. This data can be influenced by external factors unrelated to the driver, such as the hazardous actions of other drivers. Consequently, the risk score or predictive value provides a more accurate approximation of the expected number of near-miss events and, ultimately, the projected number of accidents.
Both conventional generalized linear models and machine learning algorithms have their own respective merits and limitations. The outcomes of Poisson regression and negative binomial regression indicate the effect size and statistical significance of each independent variable on the dependent variable. They also highlight the causal impact of telematics attributes on near-miss events. The high accuracy of the HGBR in predicting near-miss events demonstrates its robust capability in handling telematics data with multiple driving-related variables. In the context of applying driving risk to rate-making, the interpretability of the calculation method is highly valuable to policyholders. Meanwhile, the efficiency and precision of the algorithm enable insurers to process large volumes of driver data in an effective and precise manner.
It needs to be recognized that the findings of this study are constrained by a number of limitations pertaining to the availability of relevant data. Firstly, the dataset from China covers a duration of less than seven days, which precludes essential analyses such as comparisons between weekdays and weekends. This limited timeframe may not accurately represent annual driving behavior, particularly as it may be influenced by seasonal variations. Additionally, the restricted temporal range could contribute to inconsistencies in the reported significance of variables. Moreover, the dataset from Spain is insufficiently comprehensive, and the types and number of variables included are not as large as those in the dataset from China, which renders the results less interpretable. Furthermore, the lack of traditional insurance data and driving condition data represents a substantial limitation. Including factors that capture the characteristics of drivers is crucial for providing a comprehensive evaluation of the risks associated with driving.
Given the good performance of the ensemble learning algorithms used in this study, future research will explore the use of more interpretable machine learning algorithms for modeling and predicting large amounts of telematics data, and for car insurance pricing. While artificial neural networks are not inherently interpretable, they can nonetheless be explained using secondary tools or methods [
37,
38]. Thus, future research will explore how state-of-the-art artificial neural networks can be applied to auto insurance to change the persistent perception among insurers and administrators that such algorithms are completely black-box systems. Exploring and analyzing telematics data using AI methods is important for shifting our perceptions and decision-making processes from non-autonomous to semi-autonomous to fully autonomous driving.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}