Abstract
To create normative scores for all CrossFit® Open (CFO) workouts and compare male and female performances, official scores were collected from the official competition leaderboard for all competitors of the 2011–2022 CFO competitions. Percentiles were calculated for athletes (18–54 years) who completed all workouts within a single year ‘as prescribed’ and met minimum scoring thresholds. Independent t-tests revealed significant (p < 0.05) sex differences for 56 of 60 workouts. In workouts scored by repetitions completed, men completed more repetitions in 18 workouts by small to large differences (d = 0.22–0.81), whereas women completed more repetitions in 6 workouts by small to medium differences (d = 0.36–0.77). When workouts were scored by time to completion, men were faster in 10 workouts by small to large differences (d = 0.23–1.12), while women were faster in 3 workouts by small differences (d = 0.46). In three workouts scored by load lifted, men lifted more weight by large differences (d = 2.00–2.98). All other differences were either trivial or not significant. Despite adjusted programming for men and women, the persistence of performance differences across all CFO workouts suggests that resultant challenges are not the same. These normative values may be useful for training and research in male and female CrossFit® athletes.
1. Introduction
The CrossFit® Open (CFO) has been the initial qualifying round for the CrossFit GamesTM competition since 2011 []. It has typically consisted of 3–6 workouts that variably challenge some aspect related to an athlete’s strength, endurance, sport-specific skill, or a combination of these [,]. Heading into the competition each year, athletes are aware of the number of weeks the CFO will last (3–5 weeks) but are unaware of each workout’s specific details until they are individually released via online broadcast each Thursday evening. Since competitors are only given four days to complete a given week’s workout and submit their best score to competition officials [], they should ideally be prepared for all possibilities.
It is known that each CFO battery will consist of a unique set of workouts, all formatted to produce a score that readily distinguishes performance [,]. Athletes have been challenged with completing a list of exercises as quickly as possible and were ranked by time to completion (TTC), and at times, the TTC of certain tie-breaking criteria. Approximately 90% of TTC-style workouts have also been assigned a time limit [,], and for these, athletes who did not finish all the workout when the time expired were scored by the number of repetitions they completed. The most common format, however, assigned a list of exercises to be completed for ‘as many repetitions as possible’ (AMRAP) within a time limit, and athletes were ranked by the total number of repetitions they completed. Out of the 60 scored CFO workouts programmed between 2011 and 2022, 35 have been AMRAP-style events. Very rarely (~5% of CFO workouts), athletes were tasked with finding their one-repetition maximum (1-RM) in a single exercise or complex within a time limit, and performance was based on load lifted.
Although CFO workouts might be limited in structure, and workouts have consistently included certain exercises from year to year, there are infinite possible exercise–prescription combinations. Each combination may uniquely challenge one or more energy systems and require different degrees of technical skill as well as strength and power. The CFO is indeed an accurate representation of the CrossFit® ideology which aims for simultaneous improvements in all areas of fitness []. In support of this, most investigated measures of body composition [,,], strength and power [,,,], and aerobic and anaerobic capacity [,,,,,,] have been related to performance. Athletes might use normative scores for many of these traditional physiological measures to estimate their ability to perform in competition []. However, the reported relationships have not demonstrated a hierarchal order of importance, and this is likely because they were not founded upon consistency. Sample populations, methods used for collecting physiological measures, and the workouts used to define performance have all varied across studies, leaving little clarity as to which laboratory-based measures should be monitored during training to predict competition performance. Further, it may not be practical or logistically feasible for non-researchers to acquire the expensive equipment (e.g., metabolic cart, cycle ergometers, force plates) needed to perform many traditional assessments. Standardized methods require varying degrees of expertise, are not always conducive for testing large groups, and are likely to impair movement and transitions if the desire is to measure responses during a typical CrossFit® workout.
Another solution may be to utilize CrossFit®-style workouts themselves to track progress and predict competition performance. Logically, performing well in these workouts during training or competition should be a strong predictor of future CFO performances. Indeed, past rankings at various stages of the CrossFit GamesTM competitions have been shown to be indicative of 2020 CFO performance [], and self-reported scores in benchmark workouts have also been shown to variably distinguish performance in 2016 [] and 2018 [] CFO competitors. Typically, any exercise and prescription combination could be programmed on any given training day [], and this lack of consistency is problematic for tracking progress. However, benchmark workouts are unique because they are readily identified by their name (e.g., Fran, Grace, Murph) and their prescription is standard. After their initial introduction, CFO workouts become benchmark workouts and may periodically be programmed into normal training and have even reappeared in later CFO competitions [,]. By monitoring their performance in these workouts, and relating it to a specific percentile rank, athletes might gauge how they would perform in future CFO competitions.
Thus far, normative scores have only been published for five benchmark workouts (i.e., Grace, Fran, Helen, Fight-Gone-Bad, and Filthy-50) []. These were chosen because CFO athletes are able to self-report their performances for these specific workouts to their user profile on the official CrossFit GamesTM leaderboard []. However, because scores are self-reported, performances are not verified, and scores may be updated at any time, their veracity and timeliness are questionable. In contrast, CFO workout performances must meet specific criteria to appear on the leaderboard [,]. For instance, athletes must either complete the workout at a CrossFit®-affiliated gym or in front of a judge who has passed the judges’ certification course and who certifies that the athlete met all workout requirements and movement standards. Alternatively, athletes may submit a video recording of their performance using specific filming criteria and competition officials perform the judge’s task. Because submissions are only accepted, validated, and ranked if they are received within the 4-day window following each workout’s release, confidence in their accuracy and timeliness is much higher. While each competitor receives an official rank (absolute and percentile) for each validated submission, the separation between scores of neighboring percentile ranks is not made clear. Workout percentile ranks may also vary weekly for reasons other than differences in workout prescription, for example, as specialists, scaled athletes, and injured athletes join or leave the main competition (i.e., report or fail to submit their scores). Therefore, the purpose of this study was to create normative scores for all existing CFO workouts (i.e., from 2011 to 2022) using official scores of competitors who completed each workout as prescribed (i.e., Rx) within each respective competition year. Additionally, because workouts are most often programmed differently between men and women, a secondary aim was to examine sex differences in the performance of each workout.
2. Materials and Methods
2.1. Experimental Design
Performance data were collected for all athletes participating in CFO competitions from 2011 to 2022. All competition results were obtained from the JSON file located on the publicly available, official competition leaderboard []. Python3 was used to convert the data into a CSV format, and the data were treated in Microsoft Excel (v. 365, Microsoft Corporation, Redmond, VA, USA). Since these data were pre-existing and publicly available, the University’s Institutional Review Board classified this study as exempt, which did not require athletes to provide their informed consent (IRB #16-215). Treating the data involved removing all age-group athletes (e.g., teens and masters) and cases that did not meet study inclusion criteria. The retained data included each athlete’s age and final overall ranking (within a given year), as well as their rank and score for every CFO workout that they completed.
2.2. Participants
From 2011 to 2022, total CFO participation ranged between 13,127 and 399,538 combined male and female athletes []. The entire population for each year included all Rx, scaled, and adaptive athletes from each age grouping, as well as athletes who registered for the competition but did not submit scores for any workouts. For this study, age, rank, and workout performance data (rank and score) were retained for all athletes between the ages of 18 and 54 years (i.e., non-age-group athletes) who completed all CFO workouts as prescribed (i.e., as Rx with no within-sex scaling) within a specific competition year. To limit the inclusion of workout “specialists” and those who did not intend on completing or could not perform the exercises for the Rx workout (e.g., when an athlete completed only a few repetitions of an Rx workout to boost their overall ranking), cases were excluded if any of their scores did not surpass a minimum threshold within a single competition year. The minimum thresholds defined for this study required athletes to complete:
- At least one round (in AMRAP-style workouts);
- The first exercise couplet in workouts where couplets were repeated;
- All repetitions assigned for the first exercise in the list (TTC workouts) or when several rounds were not expected (in AMRAP-style workouts);
- Timed workouts within 60 min when no time limit was programmed (i.e., CFO 14.5, CFO 15.5, and CFO 16.5);
- A 1-RM with a load equal to or greater than the standard barbell used by men (45 lbs. (20.4 kg)) and women (35 lbs. (15.9 kg)).
Treating the data set with these criteria produced the total study population for each CFO year. Then, to minimize the effect of reporting or validation errors (intentional or non-intentional), random samples of approximately 68% of athletes from each study population (i.e., equal to approximately ± 1 standard deviation (SD)) [] were drawn and retained for statistical analyses. Table 1 provides a summary of the initial population of athletes for each year, the number of cases meeting study criteria, and the age and final competition ranking characteristics of each final sample.

Table 1.
Population and sample characteristics.
2.3. Workout Descriptions
Changes to the competition format have occurred throughout the CFO’s history []. The competition has always released 1–2 workouts each week on Thursday evenings via live online broadcast, and competitors have always been allotted four days to complete the workout at their normal training facility and upload their best score to the online leaderboard []. With a few exceptions, competitors have always been given different instructions for completing Rx (i.e., ‘as prescribed’) and scaled versions of each workout, as well as those prescribed to teen and masters athletes [,]. Additional workout versions were programmed in more recent years with the introduction of the adaptive, foundations, and equipment-free divisions. In each instance, the modified workout typically programmed variants of Rx exercises, prescribed different repetition counts (per exercise), and/or different intensity loads when applicable []. Because these differences alter the assigned workload, equating different CrossFit®-style workouts is inherently difficult [], and verifying modified workloads may not be possible, only Rx performances were considered for this study. Cases were also excluded if the reported age was not between 18 and 54 years due to the lack of clarity on the leaderboard about which workout version these athletes completed. Otherwise, all retained scores were assumed to have been representative of attempts made using Rx standards.
The data retained for analysis included the athlete’s official rank for each workout and score, recorded as TTC (in minutes), repetitions, or load (in lbs. (kg)). Whenever the score could be officially quantified in multiple units (e.g., CFO 17.1 could be quantified as TTC or repetitions if the workout was not completed within the time limit), all scores were converted into a repetition completion rate (i.e., repetitions completed divided by TTC or workout duration; repetitions · minute−1) as previously described [,]. In these instances, the calculated repetition completion rate was used for all statistical analyses and to present sex differences, whereas the original scoring format was used to present normative scores.
2.4. Statistical Analysis
Statistical software (SPSS, v.28.0, SPSS Inc., Chicago, IL, USA) was used for random sampling, as well as to calculate means, SDs, and percentiles for men and women separately. Independent t-tests were used to examine sex differences for each workout. Significance was accepted at an alpha level of p ≤ 0.05. Effect sizes (d) were also used to quantify the magnitude of any observed differences []. Interpretations of effect size were evaluated at the following thresholds: trivial (d < 0.20), small (d = 0.20), medium (d = 0.50), and large (d ≥ 0.80). All data are reported as mean ± standard error (SE).
3. Results
The specific programming details for each workout included in this study are provided alongside their respective normative scores throughout Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7.
Table 2.
Programming and normative scores for 2011–2012 CFO workouts.
Table 3.
Programming and normative scores for 2013–2014 CFO workouts.
Table 4.
Programming and normative scores for 2015–2016 CFO workouts.
Table 5.
Programming and normative scores for 2017–2018 CFO workouts.
Table 6.
Programming and normative scores for 2019–2020 CFO workouts.
Table 7.
Programming and normative scores for 2021–2022 CFO workouts.
Sex Differences
In AMRAP-style workouts, significant (p < 0.05) differences between men and women in repetitions completed were observed in 33 (out of 35) workouts. Men outperformed women in 24 of these workouts with 1 by a large difference (CFO 19.1, p < 0.001, d = 0.81), 7 by medium differences (p < 0.001, d = 0.52–0.78), and 10 by small differences (p < 0.001, d = 0.22–0.48). Women completed more repetitions than men in nine workouts with four by medium differences (p < 0.001, d = 0.51–0.77) and two by small differences (CFO 16.2, p < 0.001, d = 0.36; CFO 12.2, p < 0.001, d = 0.46). Sex differences in all remaining AMRAP-style workouts were either trivial or not significant. Mean differences (± SE) between sexes in AMRAP-style workouts are illustrated in Figure 1.
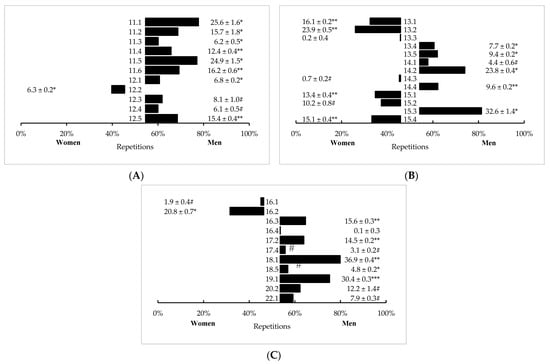
Figure 1.
Sex differences in AMRAP-style CFO workouts programmed from (A) 2011–2012, (B) 2013–2015, and (C) 2016–2022 (mean difference ± SE). # = Trivial, significant (p < 0.05) difference between men and women. * = Small, significant (p < 0.05) difference between men and women. ** = Medium, significant (p < 0.05) difference between men and women. *** = Large, significant (p < 0.05) difference between men and women.
In TTC-style workouts that did not have a time limit, small sex differences were noted where women completed CFO 14.5 (mean difference = 1.1 ± 0.1 min, p < 0.001, d = 0.23) and CFO 16.5 (mean difference = 1.3 ± 0.1 min, p < 0.001, d = 0.40) faster than men. A significant but trivial difference (p < 0.001, d = 0.08) was seen between women (10.9 ± 0.1 min) and men (11.1 ± 0.1 min) for CFO 15.5.
In time-limited TTC-style workouts, significant (p < 0.05) differences between men and women in repetition completion rate were observed in 17 (out of 19) workouts. Men completed 12 of these workouts at a faster rate than women, with 2 by large differences (CFO 21.1, p < 0.001, d = 0.92; CFO 21.3, p < 0.001, d = 1.12), 4 by medium differences (p < 0.001, d = 0.61–0.76), and 4 by small differences (p < 0.001, d = 0.23–0.46). Women completed CFO 20.4 at a faster rate than men, but by a small difference (p < 0.001, d = 0.46). Sex differences in all remaining time-limited TTC-style workouts were either trivial or not significant. Mean differences (±SE) between sexes in time-limited TTC-style workouts are illustrated in Figure 2.
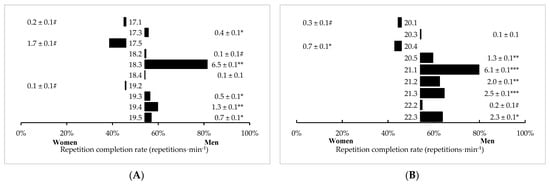
Figure 2.
Sex differences in timed TTC-style CFO workouts programmed from (A) 2017–2019 and (B) 2020–2022 (mean difference ± SE). # = Trivial, significant (p < 0.05) difference between men and women. * = Small, significant (p < 0.05) difference between men and women. ** = Medium, significant (p < 0.05) difference between men and women. *** = Large, significant (p < 0.05) difference between men and women.
In workouts scored by load lifted, large sex differences (p < 0.001, d = 2.00–2.98) where men lifted more weight than women were seen for CFO 15.1a (mean difference = 13.7 ± 0.1 kg), CFO 18.2a (mean difference = 35.4 ± 0.1 kg), and CFO 21.4 (mean difference = 37.3 ± 0.1 kg). Body mass and height were not reported by all participants each year, and due to concerns about the accuracy and timeliness of available information, strength performance differences were not assessed relative to body size.
4. Discussion
The purpose of this study was to create normative scores for workouts programmed for the men’s and women’s divisions for the 2011 through 2022 CFO competitions. Objectively tracking progress with CrossFit® training is difficult because workouts vary daily to simultaneously stimulate adaptations in all relevant parameters of fitness []. Although any targeted physiological trait can be assessed by a variety of commonly accepted field and laboratory tests [], the relevance of specific tests appears to vary [,,,,,,,] and evidence is not clear on which assessments are most insightful. It may also be impractical for non-researchers to acquire the more expensive, research-grade equipment needed to run traditional physiological assessments (e.g., metabolic cart, cycle ergometer, force plates). Instead, it may be easier to use standardized CrossFit® workouts to monitor improvements. The annual CrossFit GamesTM competition sets out to find the fittest men and women through a series of stages, beginning with the CFO, and each stage features a unique battery of CrossFit®-style workouts [,,]. Like the training style, each workout is designed to differentially challenge some combination of each athlete’s strength, endurance, and sport-specific skill [,]. After their introduction, CFO workouts become benchmarks that may be incorporated into training. Unlike everyday workouts, the standard requirements of each benchmark workout allow trainees to relate changes in their score to improvements in either the physiological traits or skills associated with the specific workout. Additionally, because CFO competitors are ranked by their performance in each workout [], trainees might use their improvements in benchmark workouts to gauge how they might place in future CFO competitions.
Although workout performances are ranked in the CFO [], several inherent flaws in the ranking process could lead to misinterpretation of where one truly ranks and in the degree of improvement needed to advance in rank. Within a specific CFO competition, athletes who complete a workout ‘as prescribed’ (i.e., Rx) are ranked, albeit higher, on the same scale as athletes who completed a scaled version []. That is, completing only a single repetition of the Rx workout will earn a higher rank than a record-setting performance in a scaled version of the same workout. Because this can improve their rank by several thousand places, athletes may attempt the Rx version knowing that they do not possess the skill or capacity to complete the entire workout or some of its components. Regardless, the inclusion of these well-below-average performances skews the calculation of a score’s associated percentile rank. Percentile ranks may also be skewed by the inclusion of “specialist” performances by athletes who only complete or submit scores for workouts that suit their strengths. While their performance in the specific workout that suited their skills may not be objectionable in itself, their extremely poor or non-existent performances in all other workouts make it difficult to affirm that they are part of the main competition’s population (i.e., athletes who capably completed all workouts within a single competition). Rather, because they could (or did) not complete all workouts, these athletes should be more closely associated with the scaled division populations. Likewise, athletes who intentionally (or unintentionally) fail to meet movement standards, miscount repetitions, or outright cheat, and still manage to successfully validate their score, cannot be viewed as being part of the main competition population. The presence of these scores adds too much variability to produce precise ranking thresholds from the entire pool of scores. Consequently, this study used very specific and standardized criteria to limit their inclusion before calculating any normative scores.
Rank-boosting performances skew the final population of scores [] and lead to reduced thresholds distinguishing performance among higher percentile ranks. Previously, normative values were established from the self-reported scores for the five benchmark workouts that CFO competitors may upload to their user profiles []. In that study, exaggerated scores were addressed by uniform removal of all cases exceeding four SDs from the mean. This was problematic because SD is calculated from all scores [] and uniformly removing scores based on its position on the normal curve will necessarily lead to illegitimate attempts causing a portion of valid attempts to be removed from both tails. Therefore, the present study used a different approach and only removed cases when the reported score did not exceed the minimum expectation for a legitimate attempt. This process still produced limitations because the minimum expectations were subjective creations and varied in degree of stringency depending on each workout’s programming. For instance, completing “one round” in AMRAP-style workouts resulted in the minimum expectation being as few as two repetitions (e.g., CFO 11.3 and CFO 12.1) to as many as 157 repetitions (i.e., CFO 15.3). When the threshold required athletes to complete the first exercise or exercise couplet, no greater ambiguity existed than when deciding what this criterion meant for CFO 20.5. In that workout, athletes could partition the workload (120 wall ball shots, 80 calories of rowing, and 40 ring muscle-ups) any way. Fortunately, pilot work suggested that within the top 10,000 competitors, legitimate attempts accumulated at least 80 repetitions between the rowing and wall ball shots but not necessarily both, and 40 muscle-ups would be the performance distinguishing factor []. These criteria still do not prevent legitimate attempts from being removed, and greater reliance is placed on the authors’ familiarity with the sport. Nevertheless, these criteria were consistently applied across all workouts and eliminated the arbitrary removal of elite performances, and it seems reasonable to assume that the resultant normative scores would still accurately place any valid, low-ranking (i.e., <1%) performances that were removed by this process.
Cases involving “specialists”, systematic reporting errors, and outright cheating also skew performances and lead to inflated thresholds distinguishing higher percentile ranks []. Like the previous normative study [], these were dealt with by random athlete selection of the remaining cases []. This process does not guarantee the elimination of these cases but helps to reduce any systematic appearances to produce normative scores that are not artificially pulled in either direction. Although the success of these criteria can only be verified by a costly, international-scale, in-person study to repeat 11 years of CFO workouts, this does not seem to be necessary. The study criteria were designed to produce percentile scores that were relevant to and in line with the definition of the overall CrossFit® ideology [].
A secondary aim of this study was to compare performances by men and women across each CFO workout. The sport emphasizes gender equity in the number of male and female competitors invited to compete at the CrossFit GamesTM, the monetary compensation [], and the design of each workout [,]. Regarding the latter, CFO workouts are often scaled between sexes, presumably to elicit a similar challenge and account for known physiological differences. Theoretically, appropriate scaling should yield no differences between men and women in repetitions completed or TTC. CFO programming accomplished this by adjusting prescribed weight training exercise loads for women to be approximately 66.9 ± 4.4% of the weight assigned to men, or uniformly reducing women’s box height (for jumps, jump-overs, or step-ups) by ~17%, medicine ball weight by 30%, and wall ball shot target height by 10% from their respective prescriptions in men []. Such adjustments were present for at least one exercise in 55 (out of 60) CFO workouts. Still, sex differences were observed in 51 (of the 55 scaled workouts) and in all unscaled workouts (i.e., sex differences were noted in a total of 56 workouts).
Men are generally stronger than women []. Indeed, the largest performance differences were noted in the three workouts that required athletes to find their 1-RM (CFO 15.1a, CFO 18.2a, and CFO 21.4). CFO workouts presumably attempt to account for expected strength differences by adjusting weight training exercise loads (50 out of 60 workouts) and box height and wall ball shot criteria (18 out of 60 workouts). Even when the workout contained no purposefully scaled component, it may be argued that the design naturally accounted for strength differences. Body mass, which typically differs between men and women [,], altered the intensity of the only “unscaled” workouts that did not program 1-RMs (i.e., CFO 12.1 and CFO 21.1). Nevertheless, persistent differences in performance suggest that scaling was not sufficient to equate the challenge for most athletes. Without counting 1-RM workouts, ties were only noted in 7% (n = 4) of CFO workouts. Otherwise, men or women outperformed the other sex ~63% (n = 36) or ~30% (n = 17) of the time, respectively. Interestingly, average relative loads assigned to women varied from the average prescribed across all CFO workouts whenever either sex performed better. When men scored better than women, the loads assigned to women were slightly higher (68.3 ± 2.7% of loads assigned to men), and then slightly less (64.7 ± 4.0% of loads assigned to men) when women scored better than men. When men and women tied and the workouts involved a resistance training exercise (i.e., CFO 16.4, CFO 18.4, and CFO 20.3), relative loads prescribed to women (67.4 ± 2.1% of loads assigned to men) was closer to the average. However, the workouts only needed to adjust loads for one exercise, the deadlift. Thus, it may be hypothesized that the absolute loads assigned to men and women played a role in the observed performance differences and that ideal load scaling may vary based on the specific exercise.
Another programming aspect to consider is the lack of scaling for either the number of repetitions assigned to gymnastic–calisthenic exercises or the duration of traditional aerobic modalities. Besides the 1-RM workouts, men outperformed women by large differences in CFO 19.1, CFO 21.1, and CFO 21.3. While CFO 19.1 scaled wall ball shots and CFO 21.3 scaled front squat and thruster loads, all three workouts were 15 min long and involved unscaled, high-volume prescription for exercises that required upper-body muscular endurance (e.g., rowing, wall walks, muscle-ups, etc.). Likewise, in 7 of the 11 workouts where men scored better than women by a medium difference, the workout duration was between 10 and 20 min and included at least one high-volume, upper-body gymnastic exercise. Men are also known to possess greater aerobic and anaerobic capacity and more upper-body strength endurance than women [,,], and not scaling these components may have contributed to them performing better. That said, there were two instances (CFO 15.1 and CFO 15.4) where unscaled, upper-body gymnastic exercises were programmed, and women outperformed men. However, both workouts also programmed 1–2 scaled, resistance training exercises that could have helped to offset any disadvantage they may have had from the toes-to-bar or handstand push-up exercises.
Men will typically outperform women whenever absolute values for traditional measures of strength and endurance are used, but not when these measures are standardized (e.g., percentage of 1-RM, per kilogram of body mass) [,,]. Though it is beyond the scope of this study to speculate on the feasibility of relative programming or scaling gymnastic and aerobic components, these findings suggest CFO programming is regularly providing a different challenge to men and women. A counter argument is that it may be unnecessary, excessively tedious, and nearly impossible to equate CFO workout difficulty between sexes on an annual basis. Men and women do not directly compete, and a better performance from either sex will not impact their rankings []. Complicating prescription by assigning relative loads (e.g., percentages of established 1-RM) might create additional opportunities for cheating, and this would still not address traditionally unscaled components. It may also only be a matter of time before existing scaling methods naturally become regularly sufficient. Further analyses of data previously presented by Mangine [] showed that women have experienced an ~8.3% improvement across all repeated CFO workouts compared with ~2.8% in similarly ranked men. Additionally, representation by women in the CFO has grown from 34.3% to 44.1% of all competitors in 2011 and 2022, respectively [], and from 30.2% to 36.2% of all competitors meeting this study’s criteria. The combination of improved fitness and greater participation may naturally eliminate any regularity seen between sexes in CFO performance. Meanwhile, the purpose of the CFO is to identify the athletes who will be able to be competitive at later rounds (i.e., currently the top 10%) []. Manipulating prescription to equate the challenge when differences were predominantly (39 of 60 CFO workouts) small, trivial, or non-existent might be irrelevant to that purpose.
5. Conclusions
The present study created normative values for men and women in all CFO workouts. These data provide a current representation of the standards that distinguish performance in an ever-growing list of benchmark workouts. Periodic updates to account for changes in the population and new CFO workouts will undoubtedly be needed in the future. However, it is foreseeable that the list, currently at 60, will easily surpass 100 in the next decade and beyond, especially if traditional benchmark and “Hero” workouts are also considered. Such efforts may ultimately prove to be redundant and unnecessary. Recently, it was suggested that relationships might exist amongst workouts and/or workout components (e.g., the pull-up component of “Fran”) []. If true, workout components or entire workouts might be classified, and normative scores may only be necessary for symbolic representations of workout types or classifications. Currently, however, fair associations are impossible without the development of a simple and universal method for quantifying and equating workloads in any CrossFit®-style workout.
For the time being, the normative scores calculated in this study may be useful to CrossFit® trainees and athletes for identifying strengths and weaknesses, assessing progress, and establishing realistic training goals. As research on this training strategy continues to grow, these values may help researchers to better identify individuals who are most representative of a targeted population. Existing studies have typically relied on the presence (or lack of) training experience (i.e., years of participation) to define a participant’s familiarity with CrossFit® or high-intensity functional training. However, proficiency with the massive array of exercises that could potentially appear during a workout, as well as capability in regularly selecting appropriate pacing strategies, cannot be inferred simply from years of experience. In contrast, each year’s battery of CFO workouts was meant to, albeit variably, challenge aptitude across a broad range of sport-related traits and skills [,]. Not only are the selected exercises, movement standards, and prescriptions commonly incorporated into training, but standardized equipment makes it easier for most training facilities and laboratories to be adequately equipped for these workouts. Moreover, because CFO workouts are all designed to produce a score that distinguishes performance, these normative values can readily quantify individual skill in a single CFO workout or battery of workouts. Athletes, coaches, and researchers need only select the workouts that most closely resemble the needs of their training or study.
Author Contributions
Conceptualization, G.T.M., N.G. and Y.F.; methodology, G.T.M. and N.G.; formal analysis, G.T.M.; resources, N.G.; writing—original draft preparation, G.T.M.; writing—review and editing, N.G. and Y.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki and approved by the Institutional Review Board of Kennesaw State University (IRB #16-216, December 2015).
Informed Consent Statement
Since these data were pre-existing and publicly available, the University’s Institutional Review Board classified this study as exempt, which did not require athletes to provide their informed consent.
Data Availability Statement
All data are publicly available at: https://games.crossfit.com/leaderboard/open/ (accessed on 1 December 2022).
Conflicts of Interest
The authors declare no conflict of interest. The views presented herein are those of the authors and do not represent the views of the American College of Sports Medicine, its executive leadership, or any of its members. Statements contained in this document should not be considered endorsements of the American College of Sports Medicine and/or any of its sponsors.
References
- CrossFit. Finding the Fittest on Earth. In CrossFit Games; CrossFit: Washington, DC, USA, 2021; Available online: https://games.crossfit.com/history-of-the-games (accessed on 1 November 2022).
- CrossFit. Open Workouts. In CrossFit Games; CrossFit: Washington, DC, USA, 2021. [Google Scholar]
- CrossFit. Games Competition Rulebook. CrossFit J. 2022. [Google Scholar]
- Glassman, G. CrossFit training guide level 1. CrossFit J. 2011. [Google Scholar]
- Carreker, J.D.D.; Grosicki, G.J. Physiological predictors of performance on the CrossFit® “Murph” challenge. Sports 2020, 8, 92. [Google Scholar] [CrossRef] [PubMed]
- Mangine, G.T.; Tankersley, J.E.; McDougle, J.M.; Velazquez, N.; Roberts, M.D.; Esmat, T.A.; VanDusseldorp, T.A.; Feito, Y. Predictors of CrossFit Open performance. Sports 2020, 8, 102. [Google Scholar] [CrossRef] [PubMed]
- Mangine, G.T.; Mcdougle, J.M.; Feito, Y. Relationships Between Body Composition and “Fran” Performance are Modulated by Competition Class and Skill. Front. Physiol. 2022, 13, 893771. [Google Scholar] [CrossRef]
- Butcher, S.J.; Neyedly, T.J.; Horvey, K.J.; Benko, C.R. Do physiological measures predict selected CrossFit® benchmark performance? Open Access J. Sport. Med. 2015, 6, 241. [Google Scholar] [CrossRef]
- Dexheimer, J.D.; Schroeder, E.T.; Sawyer, B.J.; Pettitt, R.W.; Aguinaldo, A.L.; Torrence, W.A. Physiological Performance Measures as Indicators of CrossFit® Performance. Sports 2019, 7, 93. [Google Scholar] [CrossRef]
- Zeitz, E.K.; Cook, L.F.; Dexheimer, J.D.; Lemez, S.; Leyva, W.D.; Terbio, I.Y.; Tran, J.R.; Jo, E. The relationship between Crossfit® performance and laboratory-based measurements of fitness. Sports 2020, 8, 112. [Google Scholar] [CrossRef]
- Bellar, D.; Hatchett, A.; Judge, L.; Breaux, M.; Marcus, L. The relationship of aerobic capacity, anaerobic peak power and experience to performance in CrossFit exercise. Biol. Sport 2015, 32, 315–320. [Google Scholar] [CrossRef]
- Feito, Y.; Giardina, M.J.; Butcher, S.; Mangine, G.T. Repeated anaerobic tests predict performance among a group of advanced CrossFit-trained athletes. Appl. Physiol. Nutr. Metab. 2018, 44, 727–735. [Google Scholar] [CrossRef]
- Hoffman, J.R. Norms for Fitness, Performance, and Health; Human Kinetics: Champaign, IL, USA, 2006. [Google Scholar]
- Mangine, G.T.; McDougle, J.M. CrossFit® open performance is affected by the nature of past competition experiences. BMC Sport. Sci. Med. Rehabil. 2022, 14, 46. [Google Scholar] [CrossRef] [PubMed]
- Serafini, P.R.; Feito, Y.; Mangine, G.T. Self-reported measures of strength and sport-specific skills distinguish ranking in an international online fitness competition. J. Strength Cond. Res. 2018, 32, 3474–3484. [Google Scholar] [CrossRef]
- Mangine, G.T. Sex differences and performance changes over time in a repeated fitness competition workout containing thrusters and chest-to-bar pull-ups. In Proceedings of the National Strength & Conditioning Association National Conference, New Orleans, LA, USA, 6–9 July 2022. [Google Scholar]
- Mangine, G.T.; Cebulla, B.; Feito, Y. Normative values for self-reported benchmark workout scores in CrossFit® practitioners. Sport. Med.-Open 2018, 4, 39. [Google Scholar] [CrossRef]
- CrossFit. Athlete Profile. Available online: https://athlete.crossfit.com/profile (accessed on 25 April 2022).
- Leaderboard. Leaderboard. Available online: http://games.crossfit.com/leaderboard (accessed on 31 August 2022).
- Weir, J.P.; Vincent, W.J. The Normal Curve. In Statistics in Kinesiology, 5th ed.; Human Kinetics: Champaign, IL, USA, 2021; pp. 55–65. [Google Scholar]
- Mangine, G.T.; Seay, T.R. Quantifying CrossFit®: Potential solutions for monitoring multimodal workloads and identifying training targets. Front. Sport. Act. Living 2022, 4, 949429. [Google Scholar] [CrossRef] [PubMed]
- Mangine, G.T.; Feito, Y.; Tankersley, J.E.; McDougle, J.M.; Kliszczewicz, B.M. Workout Pacing Predictors of Crossfit Open Performance: A Pilot Study. J. Hum. Kinet. 2021, 78, 89–100. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences; Lawrence Erlbaum Associates, Publishers: Hillsdale, NJ, USA, 1988; pp. 284–288. [Google Scholar]
- Mangine, G.T.; Dexheimer, J.D.; Zeitz, E.K.; Tankersley, J.E.; Kliszczewicz, B.M. Pacing strategies for women in a 20 minute high intensity functional training competition workout containing muscle ups, rowing, and wall balls. In Proceedings of the National Conference, Orlando, FL, USA, 9–12 December 1984. [Google Scholar]
- Laxton, K. Closing the gender gap—Empowering women in sport. In CrossFit Journal; CrossFit Games: Washington, DC, USA, 2022. [Google Scholar]
- Sandbakk, Ø.; Solli, G.S.; Holmberg, H.-C. Sex differences in world-record performance: The influence of sport discipline and competition duration. Int. J. Sports Physiol. Perform. 2018, 13, 2–8. [Google Scholar] [CrossRef] [PubMed]
- Huebner, M.; Perperoglou, A. Sex differences and impact of body mass on performance from childhood to senior athletes in Olympic weightlifting. PLoS ONE 2020, 15, e0238369. [Google Scholar] [CrossRef] [PubMed]
- Hunter, S.K. The relevance of sex differences in performance fatigability. Med. Sci. Sports Exerc. 2016, 48, 2247. [Google Scholar] [CrossRef]
- Frontera, W.R.; Hughes, V.A.; Lutz, K.J.; Evans, W.J. A cross-sectional study of muscle strength and mass in 45-to 78-yr-old men and women. J. Appl. Physiol. 1991, 71, 644–650. [Google Scholar] [CrossRef]
- Doherty, T.J. The influence of aging and sex on skeletal muscle mass and strength. Curr. Opin. Clin. Nutr. Metab. Care 2001, 4, 503–508. [Google Scholar] [CrossRef]
- Bishop, P.; Cureton, K.; Collins, M. Sex difference in muscular strength in equally-trained men and women. Ergonomics 1987, 30, 675–687. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).