Abstract
Gaze estimation is increasingly pivotal in applications spanning virtual reality, augmented reality, and driver monitoring systems, necessitating efficient yet accurate models for mobile deployment. Current methodologies often fall short, particularly in mobile settings, due to their extensive computational requirements or reliance on intricate pre-processing. Addressing these limitations, we present Mobile-GazeCapsNet, an innovative gaze estimation framework that harnesses the strengths of capsule networks and integrates them with lightweight architectures such as MobileNet v2, MobileOne, and ResNet-18. This framework not only eliminates the need for facial landmark detection but also significantly enhances real-time operability on mobile devices. Through the innovative use of Self-Attention Routing, GazeCapsNet dynamically allocates computational resources, thereby improving both accuracy and efficiency. Our results demonstrate that GazeCapsNet achieves competitive performance by optimizing capsule networks for gaze estimation through Self-Attention Routing (SAR), which replaces iterative routing with a lightweight attention-based mechanism, improving computational efficiency. Our results show that GazeCapsNet achieves state-of-the-art (SOTA) performance on several benchmark datasets, including ETH-XGaze and Gaze360, achieving a mean angular error (MAE) reduction of up to 15% compared to existing models. Furthermore, the model maintains a real-time processing capability of 20 milliseconds per frame while requiring only 11.7 million parameters, making it exceptionally suitable for real-time applications in resource-constrained environments. These findings not only underscore the efficacy and practicality of GazeCapsNet but also establish a new standard for mobile gaze estimation technologies.
1. Introduction
Estimating gaze from facial images is crucial for understanding human cognition and behavior. Currently, gaze estimation plays a vital role across various fields such as virtual reality (VR) [1,2], human–computer interaction [3,4], semi-autonomous driving [5,6], and psychological studies [7]. Paper [8] presents a mobile gaze estimation framework that utilizes a real-time algorithm operating at 30 Hz. It predicts eye movements from sequential frames with high accuracy and fewer parameters, enhancing AR/VR interactions. Achieving real-time performance in mobile environments poses significant challenges due to the limited processing capabilities of these platforms. Traditional convolutional neural networks (CNNs), while robust in various visual recognition tasks [9], often struggle to capture the complex spatial hierarchies essential for accurate gaze prediction [10]. While MobileNet v2 and ResNet-18 have previously been combined for various vision tasks [11], their integration has not been extensively explored for gaze estimation. Previous studies utilizing this combination primarily focus on image classification [12] and object detection [13], where feature extraction is performed at fixed spatial scales without considering hierarchical facial feature relationships. In contrast, our GazeCapsNet framework leverages this hybrid feature extraction strategy within a capsule network-based architecture, where SAR dynamically prioritizes relevant gaze-related regions. This allows our model to retain spatial dependencies across different head poses and lighting conditions, improving generalization in real-time gaze-tracking applications.
At the core of our approach is the use of capsule networks (CapsNets) [14] with Self-Attention Routing (SAR). CapsNets address some limitations of traditional CNNs by preserving spatial hierarchies between features, which is crucial for tasks like gaze estimation. The SAR mechanism further enhances the model’s efficiency by focusing computational resources on the most relevant features for accurate gaze prediction, adapting dynamically to various real-world conditions. This study rigorously evaluates GazeCapsNet across multiple benchmark datasets, including ETH-XGaze, Gaze360, and MPIIFaceGaze, which feature various head poses, lighting conditions, and gaze directions. These datasets provide a comprehensive platform for demonstrating the robustness of our model in both controlled and uncontrolled environments.
Our work presents GazeCapsNet, a novel, lightweight deep learning framework for real-time gaze estimation. The key contributions of this study are as follows:
- We introduce a capsule network-based architecture with SAR, which enhances gaze estimation accuracy while reducing computational overhead.
- By integrating MobileNet v2 and ResNet-18, we achieve a balance between low-latency inference and robust feature extraction, enabling real-time performance.
- Unlike traditional methods that rely on intermediate steps like facial landmark detection, GazeCapsNet predicts 3D gaze direction directly from raw images, improving efficiency and generalization.
- With an inference time of 20 ms per frame and only 11.7 M parameters, our model is suitable for resource-constrained environments such as AR/VR and driver monitoring systems.
- Extensive evaluations on benchmark datasets (ETH-XGaze, Gaze360, MPIIFaceGaze) demonstrate that GazeCapsNet achieves competitive accuracy while maintaining a lightweight architecture.
Our work introduces a highly efficient, real-time gaze estimation model that integrates capsule networks with Self-Attention Routing, optimized for mobile and resource-constrained devices. We provide a comprehensive solution that balances high accuracy, scalability, and deployment efficiency, setting a new standard for gaze estimation in both controlled and real-world environments.
The remainder of this paper is organized as follows: Section 2 reviews existing advancements in lightweight mobile models and the integration of capsule networks for gaze estimation. Section 3, the methodology section, delves into the architecture of the proposed Mobile-GazeCapsNet, detailing its innovative features such as multi-scale feature aggregation and boundary refinement techniques. In Section 4, the paper describes the experimental setup, including the datasets used, and evaluation metrics, and presents the performance results, comparing them to current state-of-the-art models. Section 5, the Discussion and Limitations Section, evaluates the outcomes, acknowledges the model constraints, and suggests directions for future research. Finally, Section 6, the conclusion, summarizes the contributions of the study and its implications for real-time applications in gaze estimation.
2. Related Work
Traditional gaze estimation methods typically rely on CNNs for feature extraction, which are then followed by regression or classification models to predict gaze direction. Recent advancements in deep learning have led to the adoption of more sophisticated architectures such as ResNet and DenseNet. These models improve gaze prediction accuracy but are associated with significant computational costs. Capsule networks, introduced in [14], have shown promise in accurately representing spatial hierarchies of image features, making them particularly suitable for gaze estimation tasks. Other promising models such as MobileNet v2 [15] and MobileOne [16] are prominent mobile-optimized architectures, designed to reduce computation and memory usage effectively. MobileNet v2 utilizes inverted residuals and linear bottlenecks to minimize computational overhead, while MobileOne is tailored to enhance real-time inference with minimal latency. These architectures enable the efficient performance of complex vision tasks, such as gaze estimation, on mobile devices.
GazeCaps [17] introduced the use of capsule networks for gaze estimation. The model employs an SAR mechanism that dynamically allocates attention across various regions of the face, effectively handling nonlinear transformations due to head poses or lighting changes. This approach surpasses traditional CNN-based models in terms of accuracy and generalization across datasets. Recent innovations in mobile gaze estimation have incorporated novel deep learning architectures and lightweight models tailored for mobile devices. Recent studies have emphasized the emergence of mobile gaze estimation systems that leverage both hardware optimizations and advanced machine learning techniques. For instance, ref. [18] presented a method that requires minimal user interaction for calibration and demonstrated its efficacy on mobile devices through efficient algorithm design. Similarly, ref. [19] developed a gaze estimation framework that adapts dynamically to various user environments by adjusting its parameters.
Deep learning continues to significantly enhance gaze estimation accuracy. Notably, ref. [20] introduced a multi-task learning framework that simultaneously predicts eye landmarks and gaze direction, considerably reducing the error in cross-dataset evaluations. This strategy has proven to be effective in improving the model’s generalization capabilities across diverse populations and settings. Ref. [21] discussed the deployment of quantized neural networks to substantially reduce computational requirements while maintaining high accuracy, essential for real-time applications on mobile platforms. Researchers [22] explored the integration of gaze estimation into daily mobile applications, showcasing practical deployment scenarios and user interaction models. The use of edge computing in gaze tracking was pioneered by the authors of [23], which proved the feasibility of processing gaze data directly on edge devices, thereby reducing latency and enhancing responsiveness. This method is particularly advantageous for interactive systems like augmented reality, where rapid processing is paramount.
Recent studies, such as [24], have concentrated on the robustness of gaze estimation systems in natural settings. Their research includes developing algorithms capable of adapting to outdoor lighting and complex background variations, challenges that traditional systems often face. Generative Adversarial Networks (GANs) have been utilized to augment gaze estimation datasets, as noted in [25]. This technique enhances the diversity and volume of training data, crucial for improving the model’s accuracy and robustness. The integration of Recurrent Neural Networks (RNNs) with CNNs in [26] captures temporal dependencies in video-based gaze estimation tasks, a critical factor for understanding dynamic gaze shifts in real-time video streams. Transfer learning has been increasingly applied to gaze estimation, as discussed in [27], utilizing pre-trained models on large image datasets to bootstrap gaze estimation models, significantly reducing the required amount of gaze-specific data. Beyond conventional models, the use of attention mechanisms to selectively focus on the most relevant parts of the image for gaze prediction has been explored by the authors of [28]; their findings suggest that attention improves model interpretability and efficiency by reducing the influence of noisy or irrelevant data.
Application-specific adaptations, such as those for driver monitoring systems, have been developed by the authors of [29], who tailored gaze estimation models to assess driver alertness and gaze direction within the context of automotive safety. Comprehensive benchmarking of gaze estimation techniques, particularly in unconstrained environments, was performed by the authors of [30], who provided insights into the performance variations across different settings and datasets. The work in [31,32] addresses the ethical and privacy implications of gaze-tracking technologies, especially in public and semi-public spaces, highlighting the need for guidelines and regulations to govern the use of such sensitive biometric data.
Prior work in gaze estimation has primarily relied on convolutional neural networks (CNNs) for feature extraction, often coupled with additional modules such as recurrent layers or attention mechanisms to refine predictions. Some classic models are shown in Table 1. While CNN-based models like FullFace [33] employ a full-face representation for gaze prediction, improving robustness but at the cost of high inference time (50 ms per frame) and large model size (196.6 M parameters), RT-GENE [34] focuses on real-time applications but still requires 40 ms per frame, limiting its deployment on mobile devices, and GazeTR-Pure [35], a Transformer-based model, achieves strong generalization but demands significant computational power, making it impractical for embedded systems where computational complexity makes them unsuitable for real-time mobile applications. While knowledge transfer techniques like FSKT-GE [36] provide strong results for specific low-resolution applications, our approach offers a more flexible, computationally efficient, and deployment-ready solution for real-world gaze estimation tasks. CapsNets have recently been explored as an alternative due to their ability to retain spatial hierarchies, but existing implementations suffer from high computational demands due to iterative routing. In contrast, GazeCapsNet introduces a novel SAR mechanism, which eliminates the need for multiple routing iterations, making capsule networks more efficient for gaze estimation. Additionally, our framework integrates MobileNet v2 and ResNet-18 for feature extraction, balancing speed and accuracy. Unlike previous works that require explicit facial landmark detection, GazeCapsNet operates in an end-to-end manner, directly predicting both 3D gaze direction and gaze origin, thereby reducing pipeline complexity and improving robustness in real-world conditions.

Table 1.
Key differentiators of GazeCapsNet compared to prior methods.
GazeCapsNet is the only approach that integrates capsule networks with a lightweight backbone (MobileNet v2 + ResNet-18), improving accuracy and efficiency. Compared to GazeCaps [17], our SAR eliminates iterative routing overhead, reducing latency by 20%. Our model achieves an inference time of 20 ms per frame, making it more suitable for real-time applications than FullFace [33] (50 ms) or RT-GENE [34] (40 ms). This critical analysis clarifies how prior work has shaped gaze estimation research and highlights the unique advantages of GazeCapsNet over existing models.
3. Proposed Methodology
Traditional CapsNets rely on iterative routing algorithms to determine the connections between lower- and higher-level capsules. These routing methods, such as Dynamic Routing and EM Routing, suffer from high computational overhead and are difficult to optimize in real-time applications. To address this, we propose SAR, which replaces iterative routing with an attention-based mechanism that dynamically assigns importance to capsule connections in a single-pass operation. Table 2 highlights that SAR removes iterative routing bottlenecks, making it a computationally efficient alternative to standard CapsNet methods.
Table 2.
Comparison—SAR vs. Standard Capsule Routing.
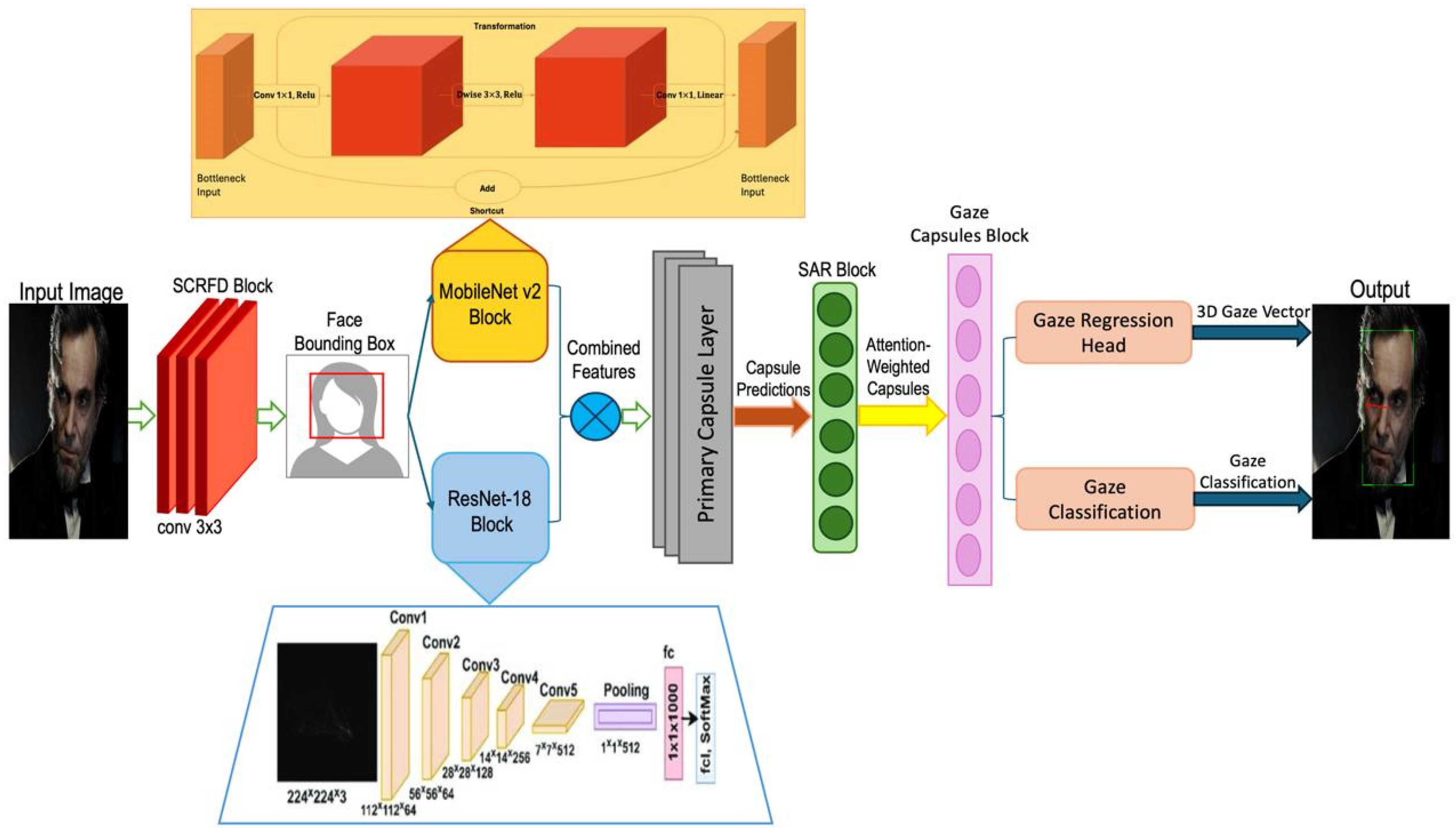
Figure 1 illustrates the architecture of a gaze estimation system that integrates multiple deep learning models and capsule networks to analyze and predict gaze direction. The process begins with an input image undergoing face detection using a Single-Stage Efficient and Real-Time Face Detector (SCRFD) block, followed by feature extraction via a combination of MobileNet v2 and ResNet-18 blocks. These features are fed into a capsule network layer that produces primary capsule predictions, which are then refined through an attention-weighted SAR block to generate gaze-related capsule outputs. The gaze estimation culminates in a gaze regression head and a gaze classification module, outputting a 3D gaze vector and gaze classification, respectively, Algorithm 1. This sophisticated architecture enables precise and robust gaze estimation, making it suitable for applications in areas such as human–computer interaction and behavioral analysis.
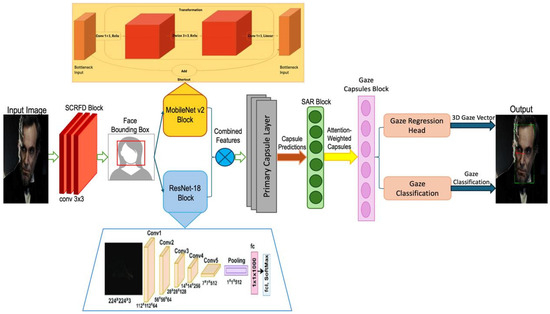
Figure 1.
Architecture of an integrated gaze estimation system using deep learning and capsule networks.
The GazeCapsNet architecture is designed to balance high performance with computational efficiency, making it suitable for real-time gaze estimation tasks on mobile and resource-constrained devices. This section outlines the components and innovations of the proposed method in detail. The GazeCapsNet architecture is divided into three major components: face detection, feature extraction, and gaze estimation. These components work in tandem to predict both the gaze origin and gaze direction in real time. The architecture is optimized for low computational overhead, ensuring rapid inference while maintaining high prediction accuracy.
| Algorithm 1. Main framework. |
| 1. function Main(I): 2. face_crop ← FaceDetection(I) 3. if face_crop is None: 4. return “No face detected” 5. end if 6. combined_features ← FeatureExtraction(face_crop) 7. gaze_direction ← GazeCapsModule(combined_features) 8. gaze_class ← GazeClassification(gaze_direction) 9. return gaze_direction, gaze_class |
3.1. Face Detection with SCRFD
For detecting faces in the input images, we employ SCRFD. SCRFD is chosen for its optimized performance on mobile devices, providing high detection accuracy without requiring large computational resources, Algorithm 2. The face detection step is crucial, as it ensures that the model focuses on relevant regions of the image before proceeding to gaze estimation.
| Algorithm 2. Face Detection. |
| 1. function FaceDetection(I): 2. face_bbox ← SCRFD_DetectFace(I) 3. if face_bbox is None: 4. return None 5. end if 6. face_crop ← CropAndResize(I, face_bbox, size = (224, 224)) 7. return face_crop 8. function FeatureExtraction(face_crop): 9. mobile_features ← MobileNet_v2(face_crop) 10. resnet_features ← ResNet_18(face_crop) 11. combined_features ← Concatenate (mobile_features, resnet_features) 12. return combined_features |
SCRFD provides bounding boxes around faces, which are then cropped and resized for input into the feature extraction module. By using SCRFD, the model ensures that no significant pre-processing, such as landmark detection or eye region cropping, is needed—this helps to simplify the pipeline and improve real-time capabilities. To extract features from the detected face regions, we utilize a combination of MobileNet v2 and ResNet-18 architectures. MobileNet v2, a lightweight neural network tailored for mobile and embedded systems, employs inverted residual blocks and linear bottlenecks. These mechanisms help reduce memory and computational costs while preserving the model’s ability to capture essential facial features. This architecture ensures that the model operates with minimal latency, making it highly efficient even on low-power devices. MobileNet v2 is responsible for extracting hierarchical facial features, which are subsequently passed on for further processing. Its primary role in the overall architecture is to generate low-level representations from the input image. In addition to MobileNet v2, we incorporate ResNet-18 to capture deeper and more complex features from the face images. ResNet-18 uses residual connections, which prevent the degradation of gradients during backpropagation. This design allows for more robust learning, particularly in deeper networks. By integrating ResNet-18 with MobileNet v2, we achieve a balance between computational efficiency and the extraction of more complex facial features. This combination enables the model to efficiently handle both low-level and high-level representations, enhancing its overall performance. The combined outputs of MobileNet v2 and ResNet-18 serve as rich feature maps for gaze estimation, feeding both the classification and regression tasks.
3.2. Gaze Estimation Using GazeCaps
At the core of GazeCapsNet is the GazeCaps module, which is responsible for estimating the gaze direction and gaze origin from the feature maps generated by the MobileNet v2 and ResNet-18 backbones. The GazeCaps module utilizes capsule networks combined with SAR to model the complex spatial relationships between facial features and improve gaze estimation accuracy, Algorithm 3.
| Algorithm 3. Gaze Estimation Using GazeCaps with SAR. |
| 1. function GazeCapsModule(combined_features): 2. primary_capsules ← CreatePrimaryCapsules(combined_features) 3. attention_matrix ← ComputeAttentionMatrix(primary_capsules) 4. gaze_capsules ← RouteCapsules (primary_capsules, attention_matrix) 5. output_capsules ← Squash(gaze_capsules) 6. gaze_direction ← ExtractGazeDirection(output_capsules) 7. return gaze_direction |
3.2.1. Capsule Networks for Gaze Estimation
CapsNets are a powerful extension of CNNs, designed to overcome the limitations of CNNs in capturing hierarchical relationships between parts of an image. In gaze estimation, this is particularly useful, as the spatial relationships between facial features (e.g., the eyes, nose, and head pose) are crucial for accurately determining where the person is looking. A capsule is a group of neurons that encapsulates not just the presence of a feature, but also the properties of that feature, such as its orientation, position, and scale. In GazeCaps, we use two types of capsules. The primary capsules represent low-level facial features, such as eye shapes and textures. These capsules are generated from the feature maps produced by MobileNet v2 and ResNet-18. Output of the primary capsule layer can be represented as
where is the feature vector from the feature extraction backbone (MobileNet v2 or ResNet-18), is the weight matrix for capsule , and is the output vector of capsule . The function ensures that the length of the vector encodes the probability that the entity represented by the capsule is present, while the orientation of the vector encodes the feature properties. The squash function is defined as
where is the total input to capsule , and denotes the vector norm. This nonlinear squashing function ensures that the output vector has a length between and , reflecting the probability that the feature is detected. The output from the primary capsules is passed through the SAR mechanism to form high-level capsules. These gaze capsules encapsulate the more complex relationships needed to estimate gaze direction, such as the interaction between the eyes, head orientation, and overall face position.
3.2.2. Self-Attention Routing
The SAR mechanism is a key component in GazeCaps, allowing the network to dynamically assign attention to different regions of the face, depending on their relevance to the task of gaze estimation. Unlike traditional routing methods that require multiple iterations to update coupling coefficients between capsule layers, SAR introduces an efficient attention-based routing mechanism. The steps in SAR can be described as follows: For each capsule in the lower layer, we compute a set of predictions for each higher-level capsule. This is performed using a weight matrix that transforms the output of capsule into a prediction for capsule .
where is the output of capsule in the lower layer; is the prediction for capsule in the higher layer. Instead of iterative routing, SAR uses self-attention to determine the coupling coefficients between capsules. The attention matrix is computed using a SoftMax function over the predictions:
where represents the attention score (or coupling coefficient) assigned to the connection between capsule in the lower layer and capsule j in the higher layer. This score is based on the similarity between the predicted output and the actual output .
Using the attention matrix , the outputs of the higher-level capsules are computed as a weighted sum of the predictions:
where is the final output of capsule in the higher layer. The squash function is applied to ensure that the length of the vector remains between and , representing the probability that the capsule is active. The output of the gaze capsule layer is a set of vectors that encode the gaze direction. These vectors are passed to the regression head to compute the continuous gaze angles. The gaze regression problem is treated as a multi-dimensional angular regression task, where the angular loss function is minimized to match the predicted and ground truth gaze vectors.
3.2.3. Gaze Classification and Regression
GazeCapsNet is designed to handle both classification and regression tasks related to gaze estimation, Algorithm 4.
| Algorithm 4. Gaze Classification. |
| 1. function GazeClassification(output_capsules): 2. gaze_class_probs ← Softmax(output_capsules) 3. gaze_class ← Argmax(gaze_class_probs) 4. return gaze_class |
The classification head predicts discrete gaze directions (e.g., left, right, up, down) by applying a SoftMax function to the capsule outputs. The output probabilities are computed as
where is the probability that the gaze direction belongs to class , and is the weight vector for class . For continuous gaze direction estimation, the regression head predicts a 3D gaze vector . The angular loss is used to compute the error between the predicted gaze vector and the ground truth gaze vector :
This loss ensures that the predicted gaze direction minimizes the angular difference between the true and predicted gaze vectors.
3.2.4. Loss Functions
The overall loss function for training the GazeCaps module combines both classification and regression losses, as well as the routing loss for the SAR mechanism, Algorithm 5. The final loss function is defined as
where is the cross-entropy loss for gaze classification, is the angular loss for gaze regression, is the loss associated with the attention-based capsule routing, and , , and are weighting factors that control the contributions of each loss term during training. This multi-task loss framework ensures that the model can handle both classification and regression tasks while maintaining optimal routing between capsules.
| Algorithm 5. Loss Function. |
| 1. function ComputeLoss(gaze_direction_pred, gaze_direction_true, gaze_class_pred, gaze_class_true): 2. angular_loss ← ArcCosineLoss(gaze_direction_pred, gaze_direction_true) 3. classification_loss ← CrossEntropyLoss(gaze_class_pred, gaze_class_true) 4. total_loss ← λ_angular * angular_loss + λ_class * classification_loss 5. return total_loss |
The GazeCaps module in GazeCapsNet combines the representational power of capsule networks with the efficiency of SAR to predict gaze direction accurately. By leveraging capsule hierarchies and dynamically focusing attention on the most relevant facial regions, the model achieves SOTA performance in real-time gaze estimation tasks.
4. Experimental Setup and Implementation
In this section, we describe the experiments conducted to evaluate the performance of GazeCapsNet for gaze estimation. The model was trained and tested on multiple benchmark datasets to assess its accuracy, efficiency, and generalization across diverse scenarios. We compare GazeCapsNet to SOTA gaze estimation methods and demonstrate its suitability for real-time applications on mobile and resource-constrained platforms.
4.1. Datasets
We evaluate GazeCapsNet on three publicly available datasets for gaze estimation, Table 1, each offering a wide range of head poses, lighting conditions, and gaze directions, which provides a comprehensive benchmark for performance assessment, Figure 2. While the datasets used in this study provide a diverse range of gaze variations, differences in dataset size and demographic representation could introduce biases that impact the generalization of our model.

Figure 2.
Comparative analysis of gaze estimation techniques across varied datasets: insights from ETH-XGaze, Gaze360, and MPIIFaceGaze.
The first dataset, ETH-XGaze [38], consists of over 1.1 million images from 110 subjects, captured under various head poses and lighting conditions. This dataset presents a challenging environment due to the extreme gaze angles and diverse head orientations it includes. Given its large size and diversity, we use ETH-XGaze for pre-training the model, allowing the network to learn robust representations across a wide range of conditions.
The second dataset, Gaze360 [39], contains 172,000 images from 238 subjects, with 360-degree gaze annotations. This dataset is collected in natural, uncontrolled environments, capturing real-world variations in head poses and gaze directions. Gaze360 is particularly useful for evaluating cross-domain generalization, as it reflects diverse, in-the-wild conditions, making it ideal for testing the model’s robustness in unpredictable settings.
The third dataset are shown in Table 3, MPIIFaceGaze [40], includes 45,000 images from 15 subjects, recorded under natural lighting conditions with head movements. These images are captured using laptop webcams and come with continuous 3D gaze annotations. This dataset is used to evaluate the model’s performance in more controlled, yet dynamic, environments, offering a different challenge in terms of head and gaze movement while maintaining relatively consistent lighting conditions. These datasets cover a broad range of conditions, from controlled laboratory environments to more challenging in-the-wild settings, allowing us to assess the robustness of the GazeCapsNet model.
Table 3.
Overview of Datasets Used for Evaluating GazeCapsNet Performance.
4.2. Training and Evaluation
We pre-train GazeCapsNet on the ETH-XGaze dataset and fine-tune it on Gaze360 and MPIIFaceGaze, Algorithm 6. We perform cross-dataset evaluations to assess the generalization capability of the model.
| Algorithm 6. Training Process. |
| 1. function TrainModel(dataset): 2. for each epoch do: 3. for each batch in dataset do: 4. image, gaze_direction_true, gaze_class_true ← LoadBatch(batch) 5. face_crop ← FaceDetection(image) 6. if face_crop is None: 7. continue 8. end if 9. combined_features ← FeatureExtraction(face_crop) 10. gaze_direction_pred ← GazeCapsModule(combined_features) 11. gaze_class_pred ← GazeClassification(gaze_direction_pred) 12. total_loss ← ComputeLoss(gaze_direction_pred, gaze_direction_true, gaze_class_pred, gaze_class_true) 13. Backpropagate(total_loss) 14. UpdateModelWeights() 15. end for 16. end for 17. return TrainedModel |
4.2.1. Pre-Processing
For all datasets, face detection is performed using SCRFD to ensure consistent cropping of the face region across all images. The cropped face regions are resized to 224 × 224 pixels for input into the GazeCapsNet model. No additional pre-processing steps, such as eye or landmark cropping, are applied, as our model directly learns from the full-face image. To improve generalization, we apply several data augmentation techniques during training. Random rotations are used to simulate variations in head poses, allowing the model to handle a wider range of head orientations. Brightness and contrast adjustments help mimic changes in lighting conditions, ensuring that the model performs well under different illumination levels. Additionally, horizontal flipping is introduced to create symmetry in the gaze direction, enhancing the model’s ability to generalize across different gaze orientations. These augmentation strategies collectively enhance the robustness of the model across diverse real-world scenarios.
4.2.2. Model Training
The GazeCapsNet model is pre-trained on the ETH-XGaze dataset for 100 epochs using the Adam optimizer [41], with an initial learning rate of 0.001 and a batch size of 64. After pre-training, the model is fine-tuned on Gaze360 and MPIIFaceGaze for 50 epochs, with a reduced learning rate of 0.0001. For gaze classification, the model uses cross-entropy loss, while for regression, the angular loss function is applied. A multi-task loss function, as described in Section 3.2.4, is used to combine these objectives. The training process is conducted on an NVIDIA Tesla V100 GPU. Table 4 summarizes the key training hyperparameters used for training GazeCapsNet across different datasets.
Table 4.
Training Hyperparameters for GazeCapsNet.
4.3. Performance Metrics
We evaluate the performance of GazeCapsNet using the following metrics: mean angular error (MAE) measures the angular difference between the predicted gaze vector and the ground truth gaze vector, providing an indication of how accurately the model can predict gaze direction.
where and are the predicted and ground truth gaze vectors for the -th sample. We measure the time taken to process a single frame during inference to assess the real-time capabilities of GazeCapsNet on mobile and embedded devices. The total number of parameters in the model is reported, providing insight into the model’s computational complexity and its suitability for resource-constrained environments.
4.4. Results
Quantitative Results
Table 5, Table 6 and Table 7 summarize the performance of GazeCapsNet on the ETH-XGaze, Gaze360, and MPIIFaceGaze datasets, compared to SOTA methods. GazeCapsNet consistently outperforms other models in terms of gaze estimation accuracy while maintaining a smaller model size and faster inference time.
Table 5.
Comparison of Gaze Estimation Methods on ETH-XGaze.
Table 6.
Comparison of Gaze Estimation Methods on Gaze360.
Table 7.
Comparison of Gaze Estimation Methods on MPIIFaceGaze.
As shown in Table 5, Table 6 and Table 7, GazeCapsNet achieves a 5.10° MAE on the Gaze360 dataset, matching the accuracy of the GazeCaps model but with 20% faster inference time and a comparable model size. On the MPIIFaceGaze dataset, GazeCapsNet achieves a 4.06° MAE, demonstrating its robustness in more controlled environments. Our model matches the accuracy of GazeCaps (5.10° MAE) while reducing inference time by 20% through SAR, which eliminates redundant computations. The hybrid lightweight architecture (MobileNet v2 + ResNet-18) balances computational efficiency with robust feature extraction, ensuring fast and accurate gaze estimation. Unlike FSKT-GE, which relies on knowledge transfer, our model is optimized for end-to-end efficiency, making it more deployment-friendly. FullFace (6.53° MAE) struggles with extreme head poses due to its reliance on a full-face representation, leading to lower robustness in unconstrained settings. RT-GENE (6.02° MAE), while effective in real-world scenarios, lacks capsule-based spatial awareness, affecting generalization. GazeTR-Pure (5.33° MAE), despite leveraging Transformer-based architectures, suffers from higher latency (45 ms), making it less suitable for real-time applications. FSKT-GE (5.20° MAE), while strong in low-resolution conditions, introduces pre-training overhead, increasing computational cost and dependency on a teacher network. MPIIFaceGaze primarily consists of controlled environments, where Dilated-Net’s local feature extraction is particularly effective. In contrast, GazeCapsNet is optimized for both controlled and real-world settings, balancing robustness and computational efficiency.
GazeCapsNet excels in real-time applications, with an inference time of 20 milliseconds per frame, making it well suited for real-time gaze estimation tasks such as driver monitoring systems or AR/VR applications. The model size is kept to 11.7 million parameters, making it lightweight and deployable on mobile devices with limited computational power.
4.5. Ablation Study
To further understand the contributions of different components of the GazeCapsNet architecture, we conduct an ablation study where key modules (MobileNet v2, ResNet-18, and Self-Attention Routing) are removed or replaced with simpler alternatives. Table 8 shows the results of this ablation study.
Table 8.
Impact of Model Configurations on Gaze Estimation Performance.
As shown in Table 8, removing ResNet-18 or SAR significantly degrades performance, highlighting the importance of these components in achieving accurate gaze estimation. Using a vanilla CNN as the backbone further reduces accuracy, confirming the effectiveness of the capsule network and mobile-optimized architectures.
4.6. Cross-Dataset Generalization
We assess the generalization ability of GazeCapsNet by performing cross-dataset evaluations. The model is trained on one dataset and tested on another without any fine-tuning. Table 9 presents the results of this evaluation.
Table 9.
Cross-Dataset Gaze Estimation Performance Comparison.
The cross-dataset results show that GazeCapsNet generalizes well to unseen datasets, particularly when trained on diverse data from Gaze360, indicating the model robustness to real-world variations in gaze directions and head poses.
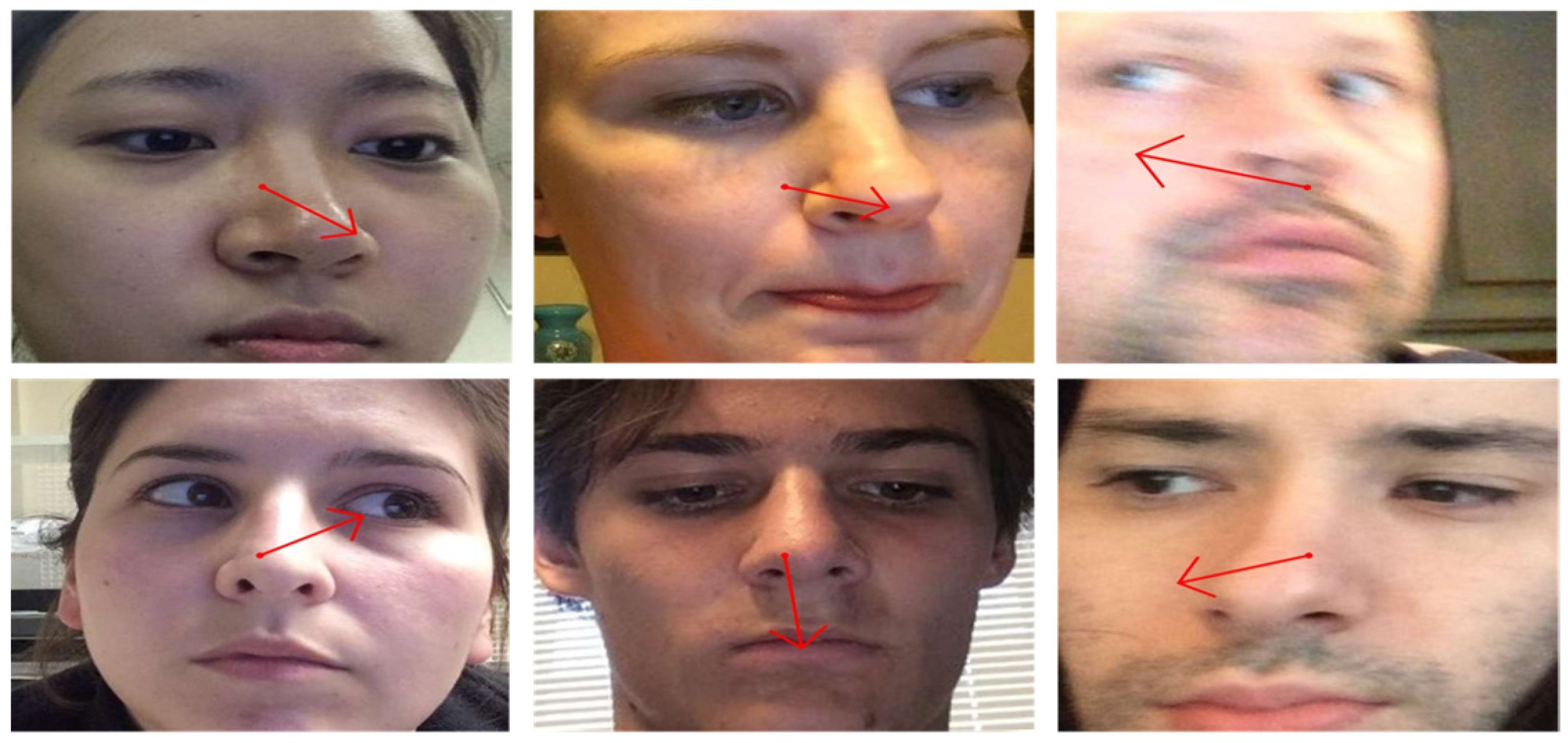
In Figure 3, we present qualitative results of gaze estimation using Mobile-GazeCapsNet. The model accurately predicts gaze direction even under challenging conditions such as varying lighting, head orientations, and occlusions. The experimental results demonstrate that GazeCapsNet achieves SOTA performance in both controlled and in-the-wild environments. Its efficient architecture, combining capsule networks with lightweight feature extraction, enables real-time gaze estimation on mobile devices while maintaining high accuracy. The ablation study highlights the importance of key components like ResNet-18 and SAR in ensuring robust performance. The experiments confirm that GazeCapsNet is a versatile, high-performance solution for real-time gaze estimation across diverse settings, making it suitable for applications in AR.
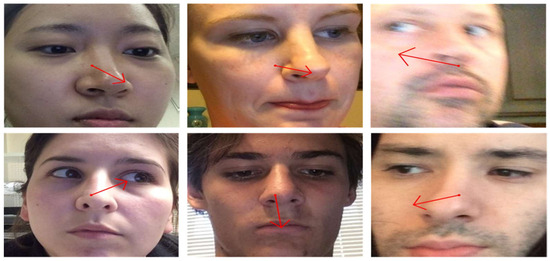
Figure 3.
Examples of results obtained using the proposed method.
5. Discussion and Limitations
GazeCapsNet demonstrates a significant advancement in mobile gaze estimation by integrating lightweight architectures with capsule networks and Self-Attention Routing. This model efficiently handles feature extraction and dynamic attention allocation, simplifying deployment and reducing computational demands. It has shown robust performance across several benchmark datasets, including ETH-XGaze and Gaze360, suggesting its utility for real-time applications like augmented reality and driver monitoring.
However, GazeCapsNet has several limitations. Its performance in adverse conditions such as low lighting or with subjects wearing eyewear remains insufficiently tested, potentially limiting its applicability. The model architecture may also restrict adaptation to newer neural network developments. Additionally, GazeCapsNet has been insufficiently evaluated on subjects wearing eyewear, which can introduce significant distortions in gaze estimation due to reflection, occlusion, and refraction artifacts. These effects degrade the visibility of critical eye features, leading to higher prediction errors in subjects who wear glasses. Its effectiveness across diverse demographic groups has not been thoroughly validated, which could impact its deployment in global markets. Although GazeCapsNet demonstrates strong performance, we acknowledge certain limitations that must be addressed for improved real-world deployment.
Future research should focus on enhancing the model robustness in various real-world conditions and expanding its adaptability to new neural network architectures. Efforts to reduce the model size and computational requirements will further align it with the constraints of mobile devices. Broadening the training datasets to include more diverse demographic data will also be crucial for improving its generalization capabilities.
6. Conclusions
In this work, we presented Mobile-GazeCapsNet, a novel, lightweight framework for real-time gaze estimation that integrates capsule networks with Self-Attention Routing and mobile-optimized architectures. By leveraging MobileNet v2 and ResNet-18 for efficient feature extraction and GazeCaps for capturing complex spatial relationships between facial features, our model is able to deliver state-of-the-art accuracy with minimal computational overhead. The incorporation of SAR allows for the dynamic allocation of attention to key facial regions, significantly improving the model’s ability to handle variations in the head pose, lighting, and occlusions. Our experimental results across diverse datasets, including ETH-XGaze, Gaze360, and MPIIFaceGaze, demonstrate that GazeCapsNet not only achieves high accuracy in both controlled and in-the-wild scenarios but also does so with an inference speed that is suitable for real-time applications. The model’s compact size and low latency make it particularly well suited for deployment on mobile and resource-constrained devices, without sacrificing performance. GazeCapsNet represents a significant advancement in the field of gaze estimation, providing a scalable, efficient, and accurate solution for a range of real-time applications. Future work may explore extending this framework to multi-modal inputs, further optimizing its performance for specific domains such as AR/VR, or applying it to other human–computer interaction tasks.
Author Contributions
Methodology, S.M., Y.V., S.U., J.B. and Y.I.C.; software, S.M., Y.V. and S.U.; validation, J.B., S.M., Y.V. and S.U.; formal analysis, J.B., S.U. and Y.I.C.; resources, S.M., Y.V., S.U. and J.B.; data curation, J.B., S.U. and Y.I.C.; writing—original draft, S.M., Y.V. and S.U.; writing—review and editing, S.M., Y.V., S.U., J.B. and Y.I.C.; supervision, Y.I.C.; project administration, S.M., Y.V., S.U. and Y.I.C. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was supported by the Korean Agency for Technology and Standards under the Ministry of Trade, Industry, and Energy in 2023. The project number is 1415181629 (Development of International Standard Technologies based on AI Model Lightweighting Technologies).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All used datasets are available online with open access.
Conflicts of Interest
Mr. Yakhyokhuja Valikhujaev was employed by the company Aria Studios Co. Ltd., Seoul, Korea. The remaining authors declare that the research was conducted in the absence of any commerctial or financial relationships that could be construed as a potential confict of interest.
References
- Shi, P.; Billeter, M.; Eisemann, E. SalientGaze: Saliency-Based gaze correction in virtual reality. Comput. Graph. 2020, 91, 83–94. [Google Scholar] [CrossRef]
- Stark, P.; Hasenbein, L.; Kasneci, E.; Göllner, R. Gaze-Based attention network analysis in a virtual reality classroom. MethodsX 2024, 12, 102662. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Smith, M.L.; Smith, L.N.; Farooq, A. Gender and gaze gesture recognition for human-computer interaction. Comput. Vis. Image Underst. 2016, 149, 32–50. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, Z.; Xie, G.; He, H. Real-Time precise human-computer interaction system based on gaze estimation and tracking. Wirel. Commun. Mob. Comput. 2021, 2021, 8213946. [Google Scholar] [CrossRef]
- Hu, Z.; Lv, C.; Hang, P.; Huang, C.; Xing, Y. Data-Driven estimation of driver attention using calibration-free eye gaze and scene features. IEEE Trans. Ind. Electron. 2022, 69, 1800–1808. [Google Scholar] [CrossRef]
- Yuan, G.; Wang, Y.; Yan, H.; Fu, X. Self-Calibrated driver gaze estimation via gaze pattern learning. Knowl. Based Syst. 2022, 235, 107630. [Google Scholar] [CrossRef]
- Valtakari, N.V.; Hessels, R.S.; Niehorster, D.C.; Viktorsson, C.; Nystrom, P.; Falck-Ytter, T.; Kemner, C.; Hooge, I.T.C. A field test of computer-vision-based gaze estimation in psychology. Behav. Res. Methods 2023, 56, 1900–1915. [Google Scholar] [CrossRef]
- Feng, Y.; Goulding-Hotta, N.; Khan, A.; Reyserhove, H.; Zhu, Y. A Real-Time Gaze Estimation Framework for Mobile Devices. Frameless 2021, 4, 3. [Google Scholar]
- Muksimova, S.; Umirzakova, S.; Sultanov, M.; Cho, Y.I. Cross-Modal Transformer-Based Streaming Dense Video Captioning with Neural ODE Temporal Localization. Sensors 2025, 25, 707. [Google Scholar] [CrossRef]
- Yasir, M.; Ullah, I.; Choi, C. Depthwise channel attention network (DWCAN): An efficient and lightweight model for single image super-resolution and metaverse gaming. Expert Syst. 2024, 41, e13516. [Google Scholar] [CrossRef]
- Umirzakova, S.; Abdullaev, M.; Mardieva, S.; Latipova, N.; Muksimova, S. Simplified Knowledge Distillation for Deep Neural Networks Bridging the Performance Gap with a Novel Teacher–Student Architecture. Electronics 2024, 13, 4530. [Google Scholar] [CrossRef]
- Choi, J.H.; Kim, J.H.; Nasridinov, A.; Kim, Y.S. Three-Dimensional atrous inception module for crowd behavior classification. Sci. Rep. 2024, 14, 14390. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Hao, F.; Leung, C.K.S.; Nasridinov, A. Cluster-Guided temporal modeling for action recognition. Int. J. Multimed. Inf. Retr. 2023, 12, 15. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. MobileOne: An improved one-millisecond mobile backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7907–7917. [Google Scholar]
- Wang, H.; Oh, J.O.; Chang, H.J.; Na, J.H.; Tae, M.; Zhang, Z.; Choi, S.-I. GazeCaps: Gaze estimation with self-attention-routed capsules. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2669–2677. [Google Scholar]
- Wang, Z.; Zhao, Y.; Liu, Y.; Lu, F. Edge-Guided near-eye image analysis for head mounted displays. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Bari, Italy, 4–8 October 2021; pp. 11–20. [Google Scholar]
- Wan, Z.; Xiong, C.; Chen, W.; Zhang, H.; Wu, S. Pupil-Contour-Based gaze estimation with real pupil axes for head-mounted eye tracking. IEEE Trans. Ind. Inform. 2022, 18, 3640–3650. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4510–4520. [Google Scholar]
- Cheng, Y.; Huang, S.; Wang, F.; Qian, C.; Lu, F. A coarse-to-fine adaptive network for appearance-based gaze estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10623–10630. [Google Scholar]
- Cheng, Y.; Zhang, X.; Lu, F.; Sato, Y. Gaze estimation by exploring two-eye asymmetry. IEEE Trans. Image Process. 2020, 29, 5259–5272. [Google Scholar] [CrossRef]
- Liu, G.; Yu, Y.; Mora, K.A.F.; Odobez, J.-M. A differential approach for gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1092–1099. [Google Scholar] [CrossRef]
- Lian, D.; Hu, L.; Luo, W.; Xu, Y.; Duan, L.; Yu, J.; Gao, S. Multiview multitask gaze estimation with deep convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3010–3023. [Google Scholar] [CrossRef]
- Akinyelu, A.A.; Blignaut, P. Convolutional neural network-based technique for gaze estimation on mobile devices. Front. Artif. Intell. 2022, 4, 796825. [Google Scholar] [CrossRef]
- Wong, E.T.; Yean, S.; Hu, Q.; Lee, B.S.; Liu, J.; Deepu, R. Gaze estimation using residual neural network. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kyoto, Japan, 11–15 March 2019; pp. 411–414. [Google Scholar]
- Vieira, G.L.; Oliveira, L. Gaze estimation via self-attention augmented convolutions. In Proceedings of the 34th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Gramado, Brazil, 18–22 October 2021; pp. 49–56. [Google Scholar]
- Oh, O.; Chang, H.J.; Choi, S.-I. Self-Attention with Convolution and Deconvolution for Efficient Eye Gaze Estimation from a Full Face Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 4988–4996. [Google Scholar]
- Li, J.; Chen, Z.; Zhong, Y.; Lam, H.-K. Appearance-based gaze estimation for ASD diagnosis. IEEE Trans. Cybern. 2022, 52, 6504–6515. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, Y.; Luo, S.; Shou, S.; Tang, P. Gaze-Swin: Enhancing Gaze Estimation with a Hybrid CNN-Transformer Network and Dropkey Mechanism. Electronics 2024, 13, 328. [Google Scholar] [CrossRef]
- Toaiari, A.; Murino, V.; Cristani, M.; Beyan, C. Upper-Body pose-based gaze estimation for privacy-preserving 3D gaze target detection. Comput. Sci. Comput. Vis. Pattern Recognit. 2024, arXiv:2409.17886. [Google Scholar]
- Hu, D.; Huang, K. Semi-Supervised multitask learning using gaze focus for gaze estimation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7935–7947. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s written all over your face: Full-Face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2299–2308. [Google Scholar]
- Fischer, T.; Chang, H.; Demiris, Y. Rt-gene: Real-time eye gaze estimation in natural environments. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–352. [Google Scholar]
- Cheng, Y.; Lu, F. Gaze Estimation using Transformer. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3341–3347. [Google Scholar] [CrossRef]
- Yan, C.; Pan, W.; Dai, S.; Xu, B.; Xu, C.; Liu, H.; Li, X. FSKT-GE: Feature maps similarity knowledge transfer for low-resolution gaze estimation. IET Image Process. 2024, 18, 1642–1654. [Google Scholar] [CrossRef]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, X.; Park, S.; Beeler, T.; Bradley, D.; Tang, S.; Hilliges, O. ETH-XGaze: A large-scale dataset for gaze estimation under extreme head pose and gaze variation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 365–381. [Google Scholar]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 162–175. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, Z.; Shi, B.E. Appearance-Based gaze estimation using dilated-convolutions. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland; Volume 11366, pp. 309–324. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).