Abstract
Point set registration is one of the basic problems in computer vision. When the overlap ratio between point sets is small or the relative transformation is large, local methods cannot guarantee the accuracy. However, the time complexity of the branch and bound (BnB) optimization used in most existing global methods is exponential in the dimensionality of parameter space. Therefore, seven-Degrees of Freedom (7-DoF) similarity transformation is a big challenge for BnB. In this paper, a novel rotation and scale invariant feature is introduced to decouple the optimization of translation, rotation, and scale in similarity point set registration, so that BnB optimization can be done in two lower dimensional spaces. With the transformation decomposition, the translation is first estimated and then the rotation is optimized by maximizing a robust objective function defined on consensus set. Finally, the scale is estimated according to the potential correspondences in the obtained consensus set. Experiments on synthetic data and clinical data show that our method is approximately two orders of magnitude faster than the state-of-the-art global method and more accurate than a typical local method. When the outlier ratio with respect to the inliers is up to 1.0, our method still achieves accurate registration.
1. Introduction
Point set registration is a fundamental problem in computer vision. It is widely used in three-dimensional reconstruction [,], medical image analysis [,,], mobile robots [,] and autonomous driving []. The goal of point set registration is to estimate a transformation to align two point sets, namely moving point set and reference point set. This paper focuses on the scenarios of estimating a similarity transformation between two 3D point sets.
A large body of methods have been proposed to solve the three-dimensional rigid point set registration problem [,]. Similarity point set registration has only increased a scale factor compared to rigid registration, so many studies have extended the rigid registration method to estimate similarity transformation. The iterative closest point (ICP) [] is the most typical rigid registration method; it has been extended for similarity point set registration in many researches [,,,,,,]. However, the optimization scheme of ICP is the expectation maximization (EM) [] type so it can only converge to a local optimum. Another line of research represents each point set with a probability density and registers the two point sets by aligning the two probability densities [,,]. Some methods use similar ideas to achieve non-rigid registration between two point sets []. Though these non-rigid point set registration methods can also be used for similarity registration, these methods can also only converge to a local optimum.
In recent years, some global point set registration methods have emerged, such as Go-ICP [], GOGMA [] and so on [,,,]. These methods parameterize rigid point set registration with the rigid transformation, which consists of a three-Degrees of Freedom (3-DoF) rotation and 3-DoF translation between the two point sets to be registered, but they cannot be simply extended to estimate 7-DoF similarity transformation, which consists of another DoF scale between the two point sets. In addition, most of these global methods use branch and bound (BnB) optimization framework, but the time complexity of BnB optimization is exponential in the dimensionality of the problem. It is already very slow for these global methods to perform 6-DoF rigid registration, and it will be very inefficient for them to do 7-DoF similarity registration. Asymmetric point matching (APM) [] parameterizes point set registration with the correspondence between points from each set and develops a deterministic global method to solve affine point set registration problem. APM can also be used to solve the similarity point set registration problem, but it assumes a point-to-point correspondence, which makes it difficult to register partially overlapping point sets or point sets with outliers.
In this paper, we propose a global similarity point set registration method by using BnB optimization framework. To avoid the inefficiency of the BnB-based method in solving high-dimensional problems, we introduce a transformation decomposition approach so that the translation, rotation and scale can be estimated separately. Two BnB-based algorithms are used to globally estimate the 3-DoF translation and the 3-DoF rotation, and the two algorithms are fast because the problem dimensionality is low. To the best of our knowledge, this is the first global similarity point set registration method. In addition, a consensus set-based objective function is used for the translation and rotation estimation, so the proposed method is robust to outlier and partial-overlap. Extensive experiments show that the proposed method is approximately two order of magnitudes faster than state-of-the-art global method and much more accurate than local methods in similarity point set registration.
2. Related Work
We review the works on the following three topics that are related to this paper: local methods for similarity point set registration, global point set registration methods and transformation decomposition method developed in point set registration.
ICP is the most widely used local point set registration method. ICP first determines the correspondence using an initial guess of transformation between the two point sets to be registered and then iterates between updating transformation and determining correspondences. ICP was originally developed for rigid point set registration, and many works have been done to extend it for similarity point set registration. For example, Zha et al. [] used extended feature images to establish accurate correspondence, and then integrated the scale factor into an improved ICP algorithm to achieve precise image registration. Du et al. [] proposed an objective function based on bidirectional distance, introducing overlap ratio and scale factor. Furthermore, a new isotropic scale ICP algorithm is proposed, which can automatically calculate the scale transformation, correspondence and overlap ratio of each iteration. Although this method is very robust, it is time-consuming to establish a bidirectional correspondence. To speed up the isotropic scaling registration, Li et al. [] introduced a sparse-to-dense hierarchical model in ICP. Ying et al. [] proposed the Scale-ICP method. By adding a scale factor into ICP, the registration problem was transformed into a constraint optimization problem on a seven-dimensional nonlinear space, and then the singular value decomposition method was used for iterative solution. However, Scale-ICP may be affected by local dissimilarity, so Du et al. [] added the corner point constraint to the objective function and proposed a new isotropic scaling ICP algorithm. Wu et al. [] developed a robust scale ICP algorithm by using correntropy [] to substitute the mean square error (MSE) as the new similarity measure. Chen et al. [] proposed a robust algorithm based on correntropy and ICP. Yang et al. [] combined the kernel mean p-power error (KMPE) [] loss measure with ICP framework to model the similarity and affine registrations. The optimization scheme of ICP is the EM [] type so it can only converge to a local optimum. The similarity point set registration methods extended from ICP also have this drawback. To relieve the problem of local convergence, some researches model point sets as probability densities and achieve point set registration by aligning the two probability densities, such as the GMMReg method proposed by Jian et al. [], in which probability density is constructed by using Gaussian mixture model (GMM). Some other methods also use this idea to achieve non-rigid point set registration and they can also be used for similarity point set registration. A typical example of them is the coherent point drift (CPD) method proposed by Myronenko et al. []. The objective functions of these methods can be made smoother than that of ICP, so that they can have a larger basin of convergence, but a good initialization is still needed for them to achieve an accurate registration.
In recent years, there has been a series of work utilizing BnB to globally estimate the rigid transformation between two point sets, such as Go-ICP [], GOGMA [] and so on [,,]. However, these methods focus on rigid point set registration and they cannot be simply extended to solve the 7-DoF similarity registration problem. In addition, the time complexity of BnB is exponential in the dimensionality of the problem. It is already very slow to estimate the 6-DoF rigid transformation, and it will be even slower to use them to estimate the 7-DoF similarity transformation. APM [] is a global affine point set registration method, and it can be used to globally solve the similarity point set registration problem. In APM, the objective function of registration is defined on transformation and point corresponding matrix, and it assumes a point-to-point correspondence to achieve a theoretically global optimal solution, which makes it difficult to register partially overlapping point sets or point sets with outliers. Li et al. [] proposed an global affine point set registration method based on matching probability density and BnB. Though this method can also be used for similarity point set registration, it estimates the affine directly and the computation complexity of estimating a 12-DoF affine transformation is prohibitive.
An effective way of speeding up the BnB based global point set registration method is to decompose the transformation into components of lower dimensionality. For example, a rigid transformation in can be decomposed into a rotation in and a translation in . Here and are special Euclidean group and special orthogonal group in three dimensions, respectively, and they are the parameter space of 3D rigid transformation and 3D rotation []. Two studies utilize the idea of transformation decomposition for global rigid point set registration. Straub et al. [] constructed a surface normal distribution from the original point set, which is translation invariant, and used BnB to optimize rotation to align the two surface normal distributions first. Then it applied the obtained optimal rotation to the original point set, and used another BnB to optimize translation. Although this method decoupled the six-dimensional parameter space into two three-dimensional parameter spaces, it was time-consuming to construct translation-invariant features and required GPU acceleration. Liu et al. [] proposed a rotation invariant feature to decompose rigid transformation, but it cannot be used for similarity registration. Yang et al. [,] estimated scale, rotation and translation separately and proposed a polynomial time method, but putative correspondences between the two point sets to be registered are needed.
In this paper, we propose an efficient global method for similarity point set registration, in which the similarity transformation is decomposed into translation, rotation, and scale, and the three parameters are estimated sequentially. The transformation decomposition makes the registration very efficient. Concretely, our contribution in this paper includes two aspects:
- We propose a rotation and scale invariant feature (RSIF) utilizing the angle invariance in similarity transformation. Using this RSIF, we can first globally search for the translation between the two point sets to be registered. A BnB-based global optimal translation search algorithm is developed to match the RSIF sets constructed from the two original point sets.
- Then we propose a globally optimal rotation search algorithm, which is not influenced by the relative scale, to estimate the optimal rotation between the two original point sets after applying the relative translation obtained in the previous step. Finally, the scale is estimated according to the potential correspondences obtained in rotation estimation.
3. Method
Suppose there is a similarity transformation between the moving point set and the reference point set . For a pair of corresponding points and , we have
where and are the translation and rotation from to , respectively, and s is the scale.
Most existing BnB-based global methods jointly search every parameter. In this scenario, the 7-DoF similarity transformation is a big challenge for BnB, because the time complexity of BnB optimization is exponential in the dimensionality of the problem. In this paper, an efficient similarity point set registration method based on transformation decomposition is proposed. The RSIF is first introduced to decouple similarity transformation in Section 3.1. Then in Section 3.2, the BnB-based global optimal translation search algorithm is given to align the RSIF sets generated from the two original point sets to be registered. In Section 3.3, the complete similarity point set registration algorithm is given.
3.1. Rotation and Scale Invariant Feature
For a set of three points from the moving point set, a triple is constructed, where denotes the angular distance between two vectors. This triple is invariant with respect to scale and rotation of and around the origin. Thus,
where and . This triple is called a RSIF.
Let denote the RSIF constructed from a set of moving points and denote the RSIF constructed from a set of reference points . According to (1) and (2),
A function is defined to express that the two RSIFs are related by the translation .
is used to denote the set of RSIFs constructed from point sets , where and . is used to denote the set of RSIFs constructed from point sets , where and . The problem of finding the optimal translation from to is changed to be finding the optimal translation from to . In practice, the cardinalities of and are very large, so we match a subset of each of them as and . The steps to obtain the subsets to match are as follows.
- All the three-point combinations are screened from moving and reference point set. Each three-point combination can construct a RSIF. This paper chooses 300 RSIFs with the largest angular distance, and denotes them as and .
- For , it is constructed from a set . Take the difference between these three vectors and obtain a new vector . Take the angular distance for every two dimensions of , and we have .
- Without loss of generality, it assumes that is the corresponding RSIF of . Following the previous step, we have and .
- According to the previous steps, and should be equal when the data is clean, and the Euclidean distance between them is close to 0, if there exists noise in data.
- Finally, all the RSIFs that satisfy the condition are chosen from and , and denoted as and , respectively.
On the basis of the consensus set, our objective function of similarity transformation is defined by
where is an indicator function that returns 1 if the inner condition is true and 0 otherwise, denotes the Euclidean norm in , and is the translation search inlier threshold. The optimal translation is obtained by maximizing .
3.2. Global Translation Search
When BnB-based algorithm is used to globally solve the maximization problem (4), the key is to find a way to calculate the upper bound of in a branch of the parameter space of translation, which means we need to find a function satisfying
Define and if it is possible to find a lower bound function
then use as the upper bound of in the branch . Therefore, the problem becomes how to find given a translation cube . Here, this problem is addressed by natural interval extension [,], in which we need to first calculate the bound of each element of when . Since is computed identically for each dimension, the bounds used in this paper are described using the first dimension as an example.
For , without loss of generality, derive the bound of its first element , when falls in a branch . It turns out to be difficult to calculate a tight angular distance bound, but a simple yet loose bound can be directly obtained from previous studies [,].
When a point is translated by a translation in a cubic branch , the vector corresponding to the translated point falls in a confined range, which is called the uncertainty angle bound in []. The uncertainty angle bound is the maximum deviation of the vector in the range from the one corresponding to point translated by the center of . The bound proposed by [] is directly used in this paper. Given a 3D point and a cubic translation branch centered at with half space diagonal , then
The proof of (7) can be found in [].
Thus, the angular distance bound of when can be determined directly by using the results of (7):
After calculating the bounds of , where , the second and third elements of can also be obtained. Then obtain by natural interval extension and the upper bound for a translation branch . By utilizing the upper bound , we can search the translation space to find the globally optimal translation that maximizes the objective function (4) by BnB. The algorithm is outlined in Algorithm 1.
| Algorithm 1:Globally Optimal Translation Search Based on RSIFs. |
 |
After the global optimal translation has been found, the moving point set is translated to where . Thus, there are a relative rotation and scale between and . We first estimate the optimal .
3.3. Similarity Point Set Registration Algorithm
After the global optimal translation has been found, another BnB algorithm similar to the rotation search method in [,] is used to search the global optimal rotation about the origin. Again, define the objective function on the basis of the cardinality of the inlier set:
where is the inlier threshold. Please note that this objective function is not influenced by the relative scale between the two point sets, so the rotation can be calculated without considering the scale factor.
To maximize (9) with BnB, it is required to find an upper bound for a branch of its parameter space. Here, the axis-angle representation of the rotation is used, and then all rotations are contained in a ball of radius . As in many similar works [,], we enclose the ball with a cube with side length as the initial branch of BnB. Given two rotation vectors and in the parameter space of rotation and a 3D vector , it was established in [] that
where and are the matrix forms of rotation corresponding to and , respectively. Furthermore, given a cube in the parameter space of rotation, let and be points at two opposite corners of . Then, is the center of , and its corresponding rotation matrix is denoted as . For any rotation situated in the cube ,
Then, for ,
Then, the upper bound of the objective function can be defined as
Utilizing the upper bound given by Equation (13), we can search the rotation space to find the globally optimal rotation that maximizes the objective function (9). The algorithm is outlined in Algorithm 2.
| Algorithm 2:Globally Optimal Rotation Search. |
 |
By using Algorithm 2, the global optimal rotation can be obtained. At this point, there is only a scale relationship between the two sets, and the scale can be calculated according to the potential correspondences established in Algorithm 2. Concretely, apply the obtained rotation and translation to the original moving point set, and calculate the angle between any two points of the transformed moving point set and reference point set and the origin. For each point of the moving point set, find the point with the smallest angular distance in the reference point set, which is regarded as the corresponding point. Each pair of corresponding points calculates a scale, and takes the median of these scales as the scale factor estimated by our method.
The full similarity point set registration algorithm is composed of a translation search by Algorithm 1, a rotation search by Algorithm 2, and a final calculation of the scale factor. It should be noted that the decomposed problem is not exactly the same as the original problem formulated in Equation (1), but in practice, it is feasible to find the translation, the rotation and the scale separately.
4. Results and Discussion
In this section, we evaluate the performance of our method and compare it against state-of-the-art global and local methods in similarity point set registration. Because there are few new methods dedicated for similarity point set registration, we choose to compare to two recent methods, APM [] and CPD [], which can be used for similarity registration. APM and CPD are the state-of-the-art methods for global affine registration and local deformable registration, respectively. In this experiment, we study the runtimes and accuracy of these three methods on synthetic data and clinical data. Our method is implemented in MATLAB R2017b, except the parts of objective function calculation and collinear points screening, which were implemented in C. The code for the comparing methods was obtained from the authors. To avoid excessive runtimes, we set a limit for every method: if it was unable to converge and return a final solution within 1200 s, it will be terminated by force. In the experiment with synthetic data, the ground truth translation, rotation and scale between the moving point set and the reference point set are known. The accuracy of each method is mainly evaluated by success rate, where success means that the angle between the ground truth rotation and the output rotation is less than 0.1 radian and the translation error relative to the ground truth is less than 0.1, where is the estimated translation and is the ground truth translation, and the absolute error between the output scale and the ground truth scale is less than 0.1. All experiments were performed on a laptop with a 2.21 GHz Intel(R) Core(TM) i7-8750H CPU and 8 GB of RAM.
4.1. Synthetic Data
We experimented on point sets from four different data sets, which were Chef data set from University of Western Australia [,], Lucy data set from the Stanford 3D Scanning Repository [], Archer and Kids and Owl data sets from EPFL Computer Graphics and Geometry Laboratory [] and random point data uniformly distributed in . The original 3D models used in this experiment are shown in Figure 1. For our method, the inlier threshold of RSIFs screening was set to 0.01, the inlier threshold of translation search was set to 1, and the inlier threshold of rotation search was set to 10°. The iterations and tolerance error of CPD were set to 10,000 and 1 × , respectively. For APM, we used three different tolerance errors: 0.1, 0.2 and 0.3.

Figure 1.
The original 3D models. Archer, Chef, Kids, Lucy and Owl.
4.1.1. Runtime Comparison with APM and CPD
In this experiment, the runtimes of the three methods with respect to the number of points are studied. The original 3D models were first randomly down-sampled to different numbers of points, and then these points were uniformly scaled to fit in a cube . For random point data, different numbers of uniformly distributed 3D points from were randomly generated. The down-sampled model data sets and random points were used as moving point sets. For each moving point set, a random similarity transformation () (where ) was applied to generate a reference point set. For each number of points, we performed 20 registrations with different relative random transformations. Figure 2 shows the median runtime and success rate of APM, CPD and our method with respective to the number of points. We use five models and random data to evaluate our method, APM and CPD. The left column of Figure 2 shows the median runtime of APM, CPD and our method. We set three different tolerance errors, 0.1, 0.2 and 0.3, to APM as denoted APM(0.1), APM(0.2) and APM(0.3). APM exceeded 1200 s in most experiments. On the contrary, as a global method, ours can converge within 1200 s in all experiments. The median runtime of our method on Archer and Kids data sets are less than 40 s, which is 30 times faster than APM. This is because we decouple the translation, rotation, and scale, and we optimize the translation and rotation separately by using two BnB algorithms. The right column of Figure 2 shows the success rate of CPD and our method, and the success rate of APM is not plotted because it cannot terminate in the time limit in most cases. We can see our method achieved 100% success rate on random data (first row), Archer (2nd row), Lucy (5th row) and Owl (last row), although our method failed once in 20 registrations of Chef data with 600 points and twice in 20 registrations of Kids data with 800 points. Meanwhile, the success rate of CPD is very low, because it can only converge to a local optimum. From these results we can see that though the local method CPD is much faster than global methods, its success rate is very low without a proper initialization. Global methods tend to be slow, but our method is much faster than APM.
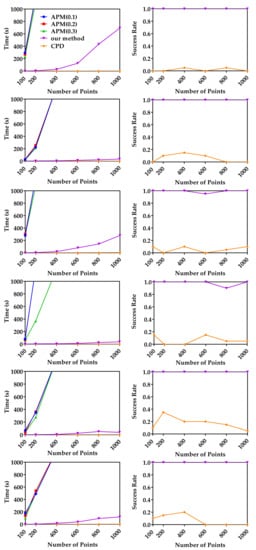
Figure 2.
Median runtime and success rate with respective to the number of points. Random data (first row), Archer (2nd row), Chef (3rd row), Kids (4th row), Lucy (5th row) and Owl (last row). Left column: The median runtimes of our method, asymmetric point matching (APM) and coherent point drift (CPD) with respect to the number of points. Right column: The mean success rates of our method and CPD with respect to the number of points.
4.1.2. Robustness to Outliers
In this experiment, we compare the robustness of our method, APM and CPD to outliers using the same raw data as in Section 4.1.1. These original model data sets were first randomly down-sampled to 200 points, and then each model was scaled uniformly to make it fit in a cube of . For random point data, 200 points uniformly distributed in were randomly generated. The down-sampled model data sets and random points were used as moving point sets. For each moving point set, a random similarity transformation (where ) was applied and random gross outlier points with different outlier percentages with respect to the inliers were added to obtain the reference point sets. For each outlier ratio, 20 registrations under different random transformations were performed. Figure 3 shows the median runtime and success rate of CPD and our method. Please note that the results of APM are not shown in Figure 3, because APM was unable to terminate within 1200 s in most experiments. The left column of Figure 3 shows the median runtime of CPD and our method. The right column of Figure 3 shows the success rate of CPD and our method. Just as mentioned above, global method APM is very slow, while our method can converge within 20 s in all experiments. Although CPD is fast, it cannot return an accurate result in most cases. Our method achieved 100% success rate, which indicates that our method is very robust to gross outliers. From Figure 3, we can see our method is much faster than the global method APM and more accurate than local method CPD. The reason is that our method uses BnB to optimize the translation and rotation separately, which can guarantee the global optimal, and the decomposition strategy greatly improve the efficiency of BnB.
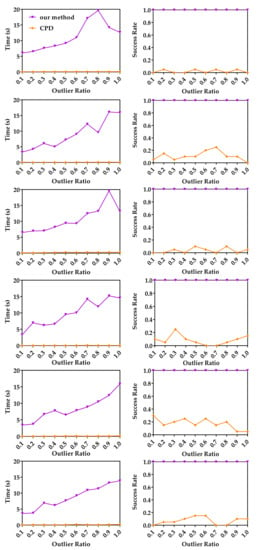
Figure 3.
Median runtime and success rate with respective to the outlier ratio. Random data (first row), Archer (2nd row), Chef (3rd row), Kids (4th row), Lucy (5th row) and Owl (last row). Left column: The median runtimes of our method and CPD with respect to the outlier ratio. Right column: The mean success rates of our method and CPD with respect to the outlier ratio.
4.1.3. Robustness to Missing Points
In this experiment, we study the robustness of the three methods with respect to the missing point ratio using the same raw data as in Section 4.1.1. These original model data sets were first randomly down-sampled to 200 points, and then each model was scaled uniformly to make it fit in a cube of . For random point data, 200 points uniformly distributed in were randomly generated. Different ratios of data points were deleted from the down-sampled model data sets and random points to generate the moving point sets, while the reference point sets were constructed by applying random similarity transformation (where ) to the entire down-sampled model data sets and random points. For each missing point ratio, 20 registrations under different random transformations were performed. Figure 4 shows the median runtime and success rate of CPD and our method. Please note that the results of APM are not shown in Figure 4, because APM was unable to terminate within 1200 s in most experiments. The left column of Figure 4 shows the median runtime of CPD and our method. The right column of Figure 4 shows the success rate of CPD and our method. From Figure 4, we can see the median runtime of our method is less than 10 s in most cases, which is much faster than the global method APM. The reason may be that the assumption of one-to-one correspondence adopted by APM is not valid in these experiments and transformation decomposition in our method can greatly improve the efficiency of BnB. Our method could successfully register the moving and reference point sets except two failed cases in 20 registrations of the Archer data with 0.2 missing point ratio and one failed case in 20 registrations of the Archer data with 0.4 missing point ratio. Although CPD is fast, it cannot return an accurate result in most cases.
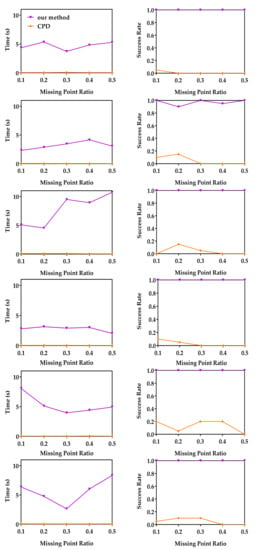
Figure 4.
Median runtime and success rate with respective to the missing point ratio. Random data (first row), Archer (2nd row), Chef (3rd row), Kids (4th row), Lucy (5th row) and Owl (last row). Left column: The median runtimes of our method and CPD with respect to the missing point ratio. Right column: The mean success rates of the our method and CPD with respect to the missing point ratio.
4.2. Clinical Data
In this section, we compare our method, APM and CPD in registering clinical data. Two scans from 3D MRI volume data and a laser range scanner were used. The point clouds used in these experiments are very dense, and they were down-sampled by using the pcdownsample function of MATLAB with a specified gridsize 20 to 223 and 241 points, respectively. Then these points were scaled uniformly to make it fit in a cube of . Since there is no ground truth for transformation, in order to calculate the registration error, three targets were selected from the data to calculate the target registration error (TRE). It should be noted that due to the manual selection of the target and the weak correspondence between the data, there is a certain error between the corresponding targets. For our method, the inlier threshold of RSIFs screening was set to 0.1, the inlier threshold of translation search was set to 1, and the inlier threshold of rotation search was set to 10. The iterations and tolerance error of CPD were set to 10,000 and 1 × , respectively. For APM, we used three different tolerance errors: 0.1, 0.2 and 0.3. Since APM requires that the number of moving points to be less than the number of reference points, two point sets were exchanged and input into APM. However, APM cannot converge within 1200 s. Then we randomly delete 18 points from the moving point set so that the number of moving points is the same as the number of reference points, but APM still cannot converge in 1200 s. Figure 5 shows the clinical data before and after registration. There is approximately relative rotation of 90 degrees between two point sets in Figure 5a. The result of our method is shown in Figure 5b, and our method could successfully register two point sets. Figure 5c shows the result of CPD. The running time of each method, TRE, mean, and standard deviation are listed in Table 1. The scale of CPD is 0.893, and ours is 1.040. CPD is much faster than our method, but it failed, while our method succeeded in 19 s.
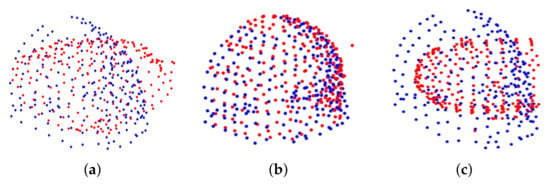
Figure 5.
Clinical data before and after registration. (a) The initial relative position of the two point sets to be registered. (b) The result of our method. (c) The result of CPD.

Table 1.
The results of registration on the clinical data.
5. Conclusions
This paper focuses on the similarity point set registration problem and proposes an efficient global method by using BnB and transformation decomposition. Because the time efficiency of BnB optimization is exponential in the dimensionality of the problem, a novel rotation and scale invariant feature is proposed to decouple the optimization of translation, rotation and scale. The optimal translation is first globally optimized based on the two sets of rotation and scale invariant features constructed from the original point sets. Then, the optimal rotation between the original point sets is calculated after applying the obtained optimal translation to the moving point set. Finally, the scale is estimated through potential correspondences. Decoupling the optimization of the translation, the rotation and the scale makes the proposed algorithm much more efficient than the existing global method. When the outlier ratio with respect to inliers is up to 1.0 or missing point ratio is 0.5, our method still successfully registers the moving point set and reference point set. Extensive experiments show that the proposed method is approximately two orders of magnitude faster than state-of-the-art global method and much more accurate than local methods in similarity point set registration.
There are several limitations of this study. First of all, we have to admit that the decomposed problem is not exactly the same as the original problem. However, in practice, it is feasible to find the translation, the rotation and the scale separately. Secondly, when the outlier ratio is higher, the method may fail. Finally, the application experiment is relatively simple. In the future, we will further optimize the algorithm and enhance its applicability.
Overall, this paper proposes an efficient global similarity point registration algorithm based on transformation decomposition and BnB optimization framework. Two BnB-based algorithms are used to globally estimate translation and rotation in two three-dimensional spaces, which improve the efficiency of BnB. Thus, our method is faster than the state-of-the-art global method. At the same time, our method uses BnB optimization framework to guarantee the global optimality, which makes it more accurate than local method in similarity point set registration.
Author Contributions
Conceptualization, C.W.; Methodology, C.W. and M.W.; Software, C.W.; Validation, X.C. and M.W.; Formal analysis, C.W.; Investigation, M.W.; Resources, X.C. and M.W.; Data curation, C.W.; Writing–original draft preparation, C.W. and M.W.; Visualization, C.W.; Supervision, X.C. and M.W.; Project administration, M.W.; Funding acquisition, X.C. and M.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (grants 81701795).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Weiss, A.; Hirshberg, D.; Black, M.J. Home 3D Body Scans from Noisy Image and Range Data. In Proceedings of the 13th IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1951–1958. [Google Scholar]
- Zhu, J.; Zhu, L.; Jiang, Z.; Li, Z.; Li, C.; Zhang, F. Scaling registration of multiview range scans via motion averaging. J. Electron. Imaging 2016, 25, 43021. [Google Scholar] [CrossRef]
- Rasoulian, A.; Rohling, R.; Abolmaesumi, P. Group-Wise Registration of Point Sets for Statistical Shape Models. IEEE Trans. Med. Imaging 2012, 31, 2025–2034. [Google Scholar] [CrossRef]
- Shen, D.G.; Davatzikos, C. HAMMER: Hierarchical Attribute Matching Mechanism for Elastic Registration. IEEE Trans. Med. Imaging 2002, 21, 1421–1439. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Kim, M.; Wang, Q.; Shen, D. S-HAMMER: Hierarchical Attribute-Guided, Symmetric Diffeomorphic Registration for MR Brain Images. Hum. Brian Mapp. 2014, 35, 1044–1060. [Google Scholar] [CrossRef] [PubMed]
- Pomerleau, F.O.; Colas, F.; Siegwart, R. A Review of Point Cloud Registration Algorithms for Mobile Robotics. Found. Trends Robot. 2015, 4, 1–104. [Google Scholar] [CrossRef]
- Ma, L.; Zhu, J.; Zhu, L.; Du, S.; Cui, J. Merging grid maps of different resolutions by scaling registration. Robotica 2016, 34, 2516–2531. [Google Scholar] [CrossRef]
- Wang, R.; Xu, Y.; Sotelo, M.A.; Ma, Y.; Sarkodie-Gyan, T.; Li, Z.; Li, W. A Robust Registration Method for Autonomous Driving Pose Estimation in Urban Dynamic Environment Using LiDAR. Electronics 2019, 8, 43. [Google Scholar] [CrossRef]
- Maiseli, B.; Gu, Y.; Gao, H. Recent developments and trends in point set registration methods. J. Vis. Commun. Image Represent. 2017, 46, 95–106. [Google Scholar] [CrossRef]
- Tam, G.K.L.; Cheng, Z.; Lai, Y.; Langbein, F.C.; Liu, Y.; Marshall, D.; Martin, R.R.; Sun, X.; Rosin, P.L. Registration of 3D Point Clouds and Meshes: A Survey from Rigid to Nonrigid. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1199–1217. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method For Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, X.; Du, S.; Wu, Z.; Zheng, N. A Correntropy-based Affine Iterative Closest Point Algorithm for Robust Point Set Registration. IEEE-CAA J. Autom. Sin. 2019, 6, 981–991. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, H.; Du, S.; Fu, M.; Zhou, N.; Zheng, N. Correntropy Based Scale ICP Algorithm for Robust Point Set Registration. Pattern Recogn. 2019, 93, 14–24. [Google Scholar] [CrossRef]
- Yang, Y.; Fan, D.; Du, S.; Wang, M.; Chen, B.; Gao, Y. Point Set Registration With Similarity and Affine Transformations Based on Bidirectional KMPE Loss. IEEE Trans. Cybern. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Du, S.; Cui, W.; Wu, L.; Zhang, S.; Zhang, X.; Xu, G.; Xu, M. Precise Iterative Closest Point Algorithm with Corner Point Constraint for Isotropic Scaling Registration. Multi-Media Syst. 2019, 25, 119–126. [Google Scholar] [CrossRef]
- Li, C.; Xue, J.; Zheng, N.; Du, S.; Zhu, J.; Tian, Z. Fast and Robust Isotropic Scaling Iterative Closest Point Algorithm. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1485–1488. [Google Scholar]
- Ying, S.; Peng, J.; Du, S. A Scale Stretch Method Based on ICP for 3D Data Registration. IEEE Trans. Autom. Sci. Eng. 2009, 3, 559–565. [Google Scholar] [CrossRef]
- Zha, H.B.; Ikuta, M.; Hasegawa, T. Registration of range images with different scanning resolutions. In Proceedings of the IEEE International Conference on Systems Man and Cybernetics Conference, Nashville, TN, USA, 8–11 October 2000; pp. 1495–1500. [Google Scholar]
- Li, H.; Hartley, R. The 3D-3D Registration Problem Revisited. In Proceedings of the IEEE International Conference on Computer Vision, Minneapolis, MN, USA, 18–23 June 2007; pp. 1947–1954. [Google Scholar]
- Tsin, Y.; Kanade, T. A Correlation-Based Approach to Robust Point Set Registration. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 558–569. [Google Scholar]
- Chui, H.L.; Rangarajan, A. A Feature Registration Framework using Mixture Models. In Proceedings of the IEEE Workshop on Mathematical Methods in Biomedical Image Analysis, Hilton Head Island, SC, USA, 11–12 June 2000; pp. 190–197. [Google Scholar]
- Jian, B.; Vemuri, B.C. Robust Point Set Registration Using Gaussian Mixture Models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1633–1645. [Google Scholar] [CrossRef]
- Myronenko, A.; Song, X. Point Set Registration: Coherent Point Drift. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2262–2275. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2241–2254. [Google Scholar] [CrossRef]
- Campbell, D.; Petersson, L. GOGMA: Globally-Optimal Gaussian Mixture Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5685–5694. [Google Scholar]
- Olsson, C.; Kahl, F.; Oskarsson, M. Branch-and-Bound Methods for Euclidean Registration Problems. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 783–794. [Google Scholar] [CrossRef]
- Straub, J.; Campbell, T.; How, J.P.; Fisher, J.W.I. Efficient Global Point Cloud Alignment using Bayesian Nonparametric Mixtures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 September 2017; pp. 2403–2412. [Google Scholar]
- Liu, Y.; Wang, C.; Song, Z.; Wang, M. Efficient Global Point Cloud Registration by Matching Rotation Invariant Features Through Translation Search. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 460–474. [Google Scholar]
- Bustos, A.P.; Chin, T.; Eriksson, A.; Li, H.; Suter, D. Fast Rotation Search with Stereographic Projections for 3D Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2227–2240. [Google Scholar] [CrossRef]
- Lian, W.; Zhang, L.; Yang, M. An Efficient Globally Optimal Algorithm for Asymmetric Point Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 7, 1281–1293. [Google Scholar] [CrossRef]
- Du, S.Y.; Zhu, J.H.; Zheng, N.N.; Zhao, J.Z.; Li, C. Isotropic Scaling Iterative Closest Point Algorithm for Partial Registration. Electron. Lett. 2011, 47, 784–799. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and Applications in Non-Gaussian Signal Processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Wang, X.; Qin, J.; Zheng, N. Robust Learning with Kernel Mean p-Power Error Loss. IEEE Trans. Cybern. 2018, 48, 2101–2113. [Google Scholar] [CrossRef] [PubMed]
- Consolini, L.; Laurini, M.; Locatelli, M.; Rizzini, D.L. Globally Optimal Registration based on Fast Branch and Bound. arXiv 2019, arXiv:1901.09641. [Google Scholar]
- Dym, N.; Kovalsky, S.Z. Linearly Converging Quasi Branch and Bound Algorithms for Global Rigid Registration. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1628–1636. [Google Scholar]
- Yu, C.; Da, J. A Maximum Feasible Subsystem for Globally Optimal 3D Point Cloud Registration. Sensors 2018, 18, 544. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, Y.; Wang, M.; Song, Z. GO-APSR: A Globally Optimal Affine Point Set Registration Method. IEEE Access 2019, 7, 137232–137240. [Google Scholar] [CrossRef]
- Hartley, R.I.A.Z. Multi-View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Yang, H.; Carlone, L. A Polynomial-time Solution for Robust Registration with Extreme Outlier Rates. In Proceedings of the Robotics: Science and Systems, Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Yang, H.; Shi, J.; Carlone, L. TEASER: Fast and Certifiable Point Cloud Registration. arXiv 2020, arXiv:2001.07715. [Google Scholar]
- Moore, R.E.; Kearfott, R.B.; Cloud, M.J. Introduction to Interval Analysis; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009. [Google Scholar]
- Moore, R.E. Methods and Applications of Interval Analysis; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1979. [Google Scholar]
- Brown, M.; Windridge, D.; Guillemaut, J. Globally Optimal 2D-3D Registration from Points or Lines Without Correspondences. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 8–12 June 2015; pp. 2111–2119. [Google Scholar]
- Campbell, D.J.; Petersson, L.; Kneip, L.; Li, H. Globally-Optimal Inlier Set Maximisation for Camera Pose and Correspondence Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 328–342. [Google Scholar] [CrossRef]
- Hartley, R.I.; Kahl, F. Global Optimization through Rotation Space Search. Int. J. Comput. Vision 2009, 82, 64–79. [Google Scholar] [CrossRef]
- Mian, A.S.; Bennamoun, M.; Owens, R.A. A Novel Representation and Feature Matching Algorithm for Automatic Pairwise Registration of Range Images. Int. J. Comput. Vision 2006, 66, 19–40. [Google Scholar] [CrossRef]
- Mian, A.S.; Bennamoun, M.; Owens, R. Three-Dimensional Model-Based Object Recognition and Segmentation in Cluttered Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1584–1601. [Google Scholar] [CrossRef] [PubMed]
- Available online: http://graphics.stanford.edu/data/3Dscanrep/ (accessed on 1 June 2020).
- Available online: https://lgg.epfl.ch/statues_dataset.php (accessed on 1 June 2020).
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).