Efficient Similarity Point Set Registration by Transformation Decomposition


Abstract
1. Introduction
2. Related Work
- We propose a rotation and scale invariant feature (RSIF) utilizing the angle invariance in similarity transformation. Using this RSIF, we can first globally search for the translation between the two point sets to be registered. A BnB-based global optimal translation search algorithm is developed to match the RSIF sets constructed from the two original point sets.
- Then we propose a globally optimal rotation search algorithm, which is not influenced by the relative scale, to estimate the optimal rotation between the two original point sets after applying the relative translation obtained in the previous step. Finally, the scale is estimated according to the potential correspondences obtained in rotation estimation.
3. Method
3.1. Rotation and Scale Invariant Feature
- All the three-point combinations are screened from moving and reference point set. Each three-point combination can construct a RSIF. This paper chooses 300 RSIFs with the largest angular distance, and denotes them as and .
- For , it is constructed from a set . Take the difference between these three vectors and obtain a new vector . Take the angular distance for every two dimensions of , and we have .
- Without loss of generality, it assumes that is the corresponding RSIF of . Following the previous step, we have and .
- According to the previous steps, and should be equal when the data is clean, and the Euclidean distance between them is close to 0, if there exists noise in data.
- Finally, all the RSIFs that satisfy the condition are chosen from and , and denoted as and , respectively.
3.2. Global Translation Search
| Algorithm 1:Globally Optimal Translation Search Based on RSIFs. |
 |
3.3. Similarity Point Set Registration Algorithm
| Algorithm 2:Globally Optimal Rotation Search. |
 |
4. Results and Discussion
4.1. Synthetic Data
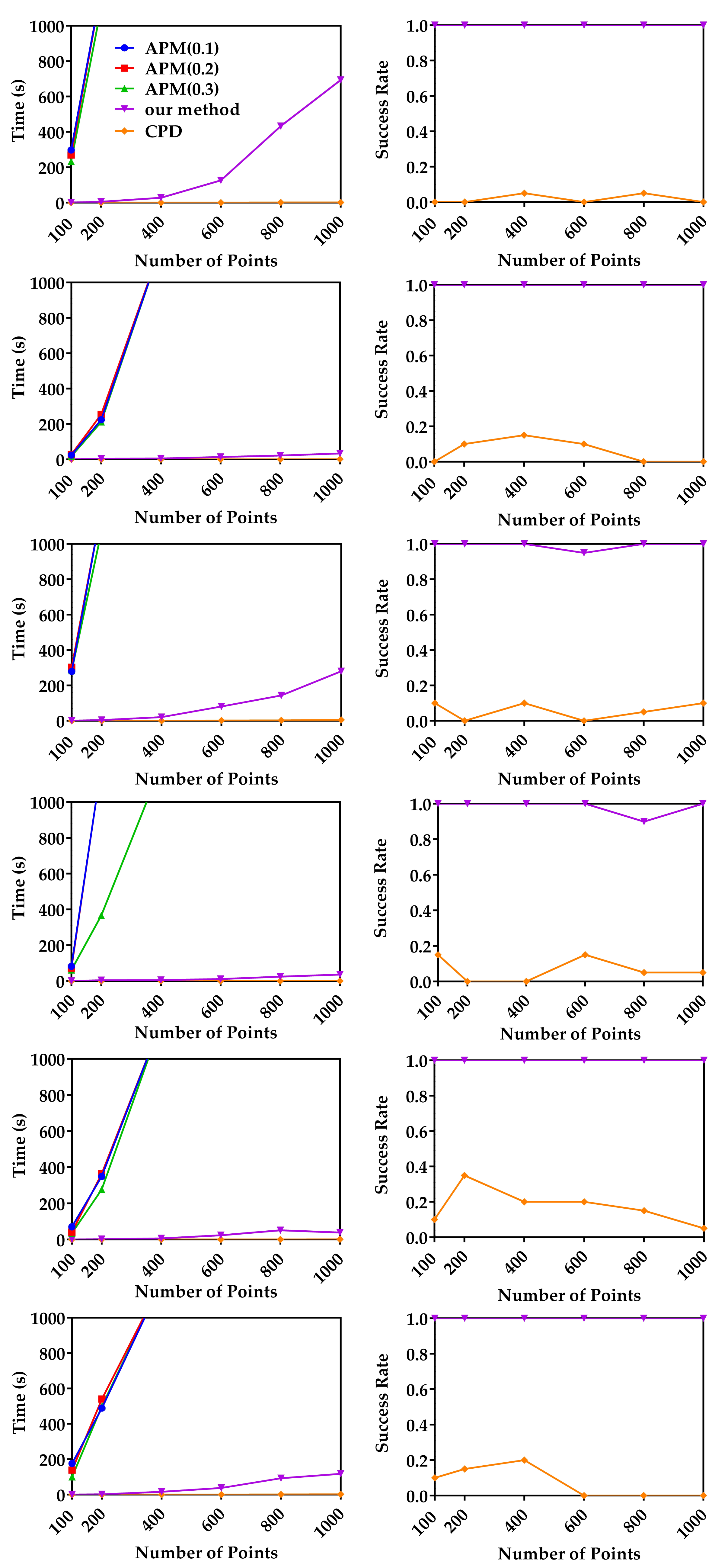
4.1.1. Runtime Comparison with APM and CPD
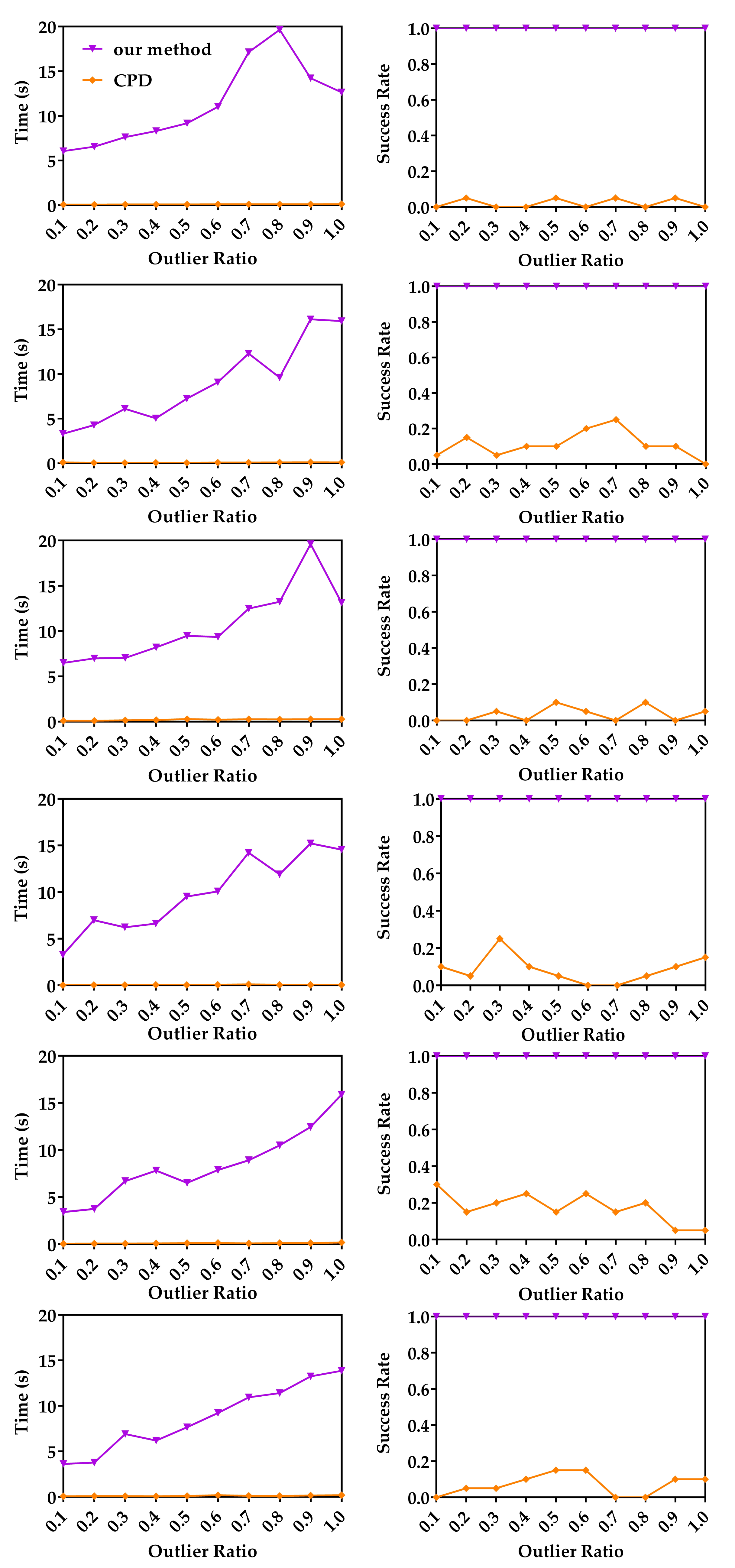
4.1.2. Robustness to Outliers
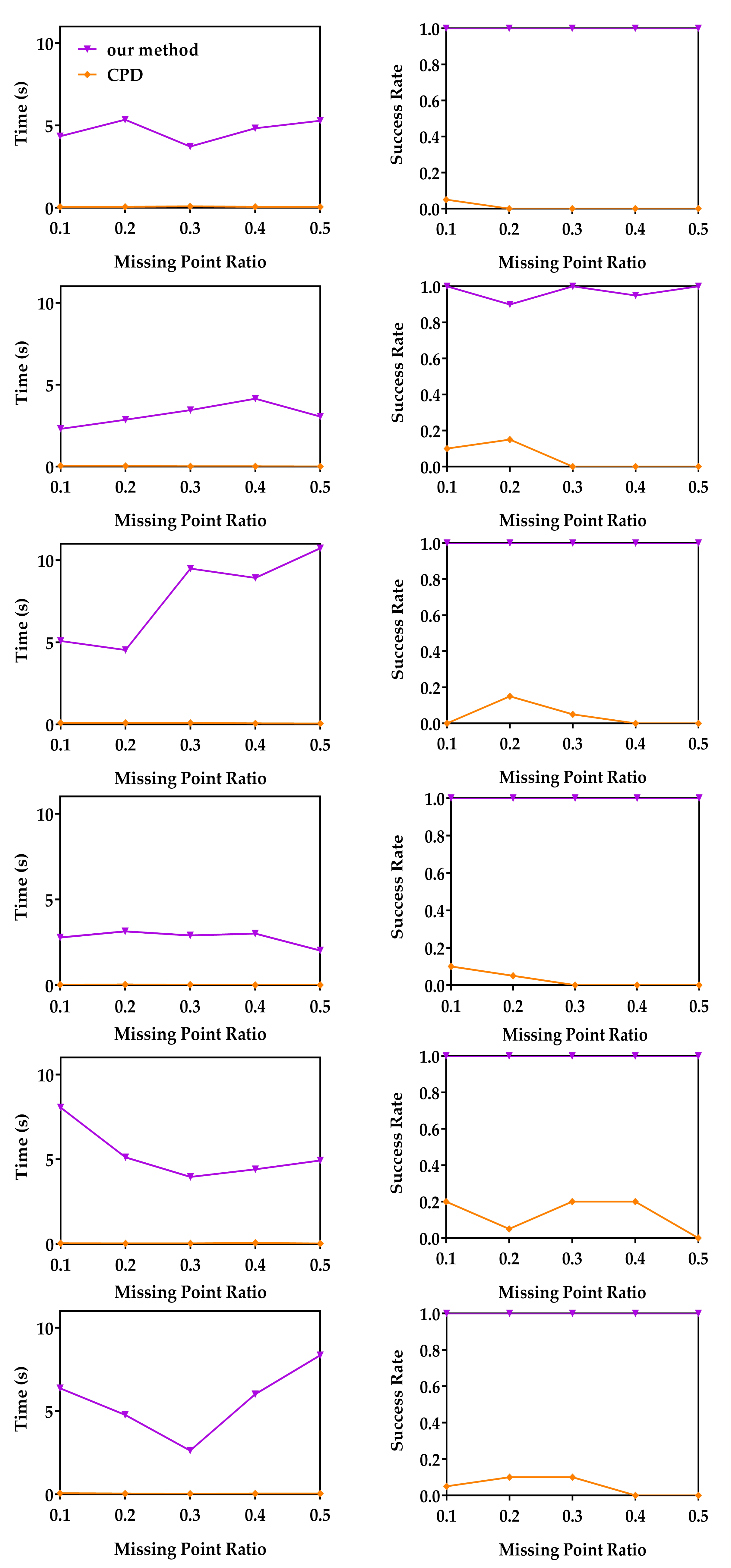
4.1.3. Robustness to Missing Points
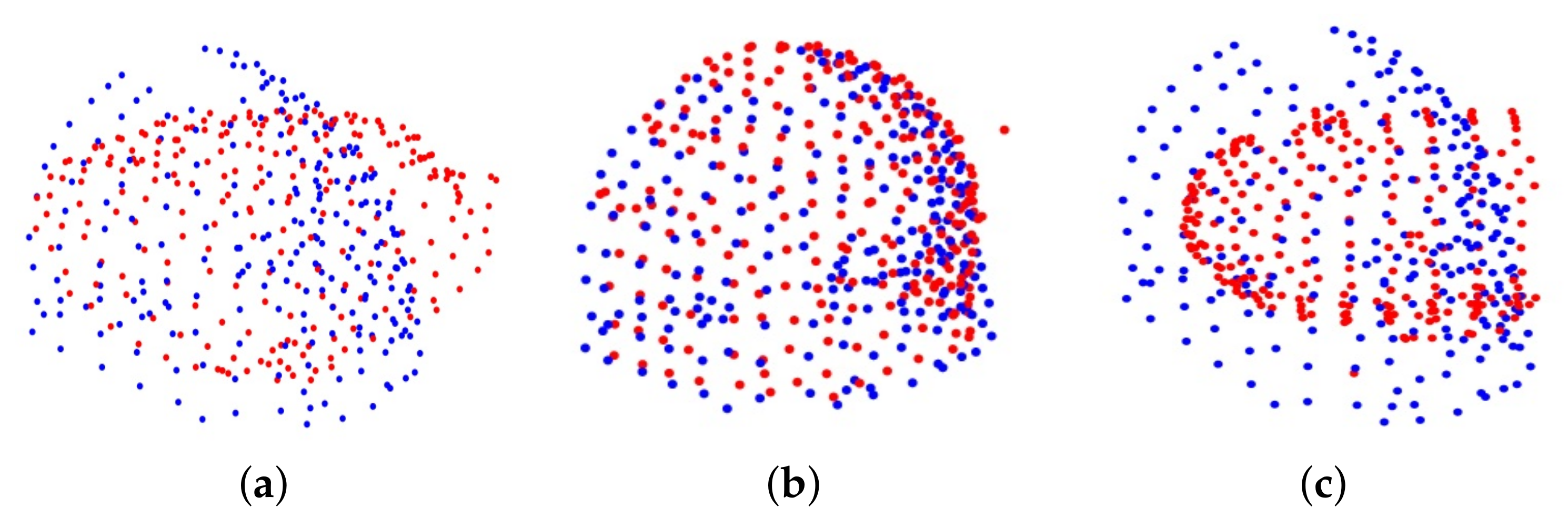
4.2. Clinical Data
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weiss, A.; Hirshberg, D.; Black, M.J. Home 3D Body Scans from Noisy Image and Range Data. In Proceedings of the 13th IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1951–1958. [Google Scholar]
- Zhu, J.; Zhu, L.; Jiang, Z.; Li, Z.; Li, C.; Zhang, F. Scaling registration of multiview range scans via motion averaging. J. Electron. Imaging 2016, 25, 43021. [Google Scholar] [CrossRef]
- Rasoulian, A.; Rohling, R.; Abolmaesumi, P. Group-Wise Registration of Point Sets for Statistical Shape Models. IEEE Trans. Med. Imaging 2012, 31, 2025–2034. [Google Scholar] [CrossRef]
- Shen, D.G.; Davatzikos, C. HAMMER: Hierarchical Attribute Matching Mechanism for Elastic Registration. IEEE Trans. Med. Imaging 2002, 21, 1421–1439. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Kim, M.; Wang, Q.; Shen, D. S-HAMMER: Hierarchical Attribute-Guided, Symmetric Diffeomorphic Registration for MR Brain Images. Hum. Brian Mapp. 2014, 35, 1044–1060. [Google Scholar] [CrossRef] [PubMed]
- Pomerleau, F.O.; Colas, F.; Siegwart, R. A Review of Point Cloud Registration Algorithms for Mobile Robotics. Found. Trends Robot. 2015, 4, 1–104. [Google Scholar] [CrossRef]
- Ma, L.; Zhu, J.; Zhu, L.; Du, S.; Cui, J. Merging grid maps of different resolutions by scaling registration. Robotica 2016, 34, 2516–2531. [Google Scholar] [CrossRef]
- Wang, R.; Xu, Y.; Sotelo, M.A.; Ma, Y.; Sarkodie-Gyan, T.; Li, Z.; Li, W. A Robust Registration Method for Autonomous Driving Pose Estimation in Urban Dynamic Environment Using LiDAR. Electronics 2019, 8, 43. [Google Scholar] [CrossRef]
- Maiseli, B.; Gu, Y.; Gao, H. Recent developments and trends in point set registration methods. J. Vis. Commun. Image Represent. 2017, 46, 95–106. [Google Scholar] [CrossRef]
- Tam, G.K.L.; Cheng, Z.; Lai, Y.; Langbein, F.C.; Liu, Y.; Marshall, D.; Martin, R.R.; Sun, X.; Rosin, P.L. Registration of 3D Point Clouds and Meshes: A Survey from Rigid to Nonrigid. IEEE Trans. Vis. Comput. Graph. 2013, 19, 1199–1217. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method For Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, X.; Du, S.; Wu, Z.; Zheng, N. A Correntropy-based Affine Iterative Closest Point Algorithm for Robust Point Set Registration. IEEE-CAA J. Autom. Sin. 2019, 6, 981–991. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, H.; Du, S.; Fu, M.; Zhou, N.; Zheng, N. Correntropy Based Scale ICP Algorithm for Robust Point Set Registration. Pattern Recogn. 2019, 93, 14–24. [Google Scholar] [CrossRef]
- Yang, Y.; Fan, D.; Du, S.; Wang, M.; Chen, B.; Gao, Y. Point Set Registration With Similarity and Affine Transformations Based on Bidirectional KMPE Loss. IEEE Trans. Cybern. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Du, S.; Cui, W.; Wu, L.; Zhang, S.; Zhang, X.; Xu, G.; Xu, M. Precise Iterative Closest Point Algorithm with Corner Point Constraint for Isotropic Scaling Registration. Multi-Media Syst. 2019, 25, 119–126. [Google Scholar] [CrossRef]
- Li, C.; Xue, J.; Zheng, N.; Du, S.; Zhu, J.; Tian, Z. Fast and Robust Isotropic Scaling Iterative Closest Point Algorithm. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1485–1488. [Google Scholar]
- Ying, S.; Peng, J.; Du, S. A Scale Stretch Method Based on ICP for 3D Data Registration. IEEE Trans. Autom. Sci. Eng. 2009, 3, 559–565. [Google Scholar] [CrossRef]
- Zha, H.B.; Ikuta, M.; Hasegawa, T. Registration of range images with different scanning resolutions. In Proceedings of the IEEE International Conference on Systems Man and Cybernetics Conference, Nashville, TN, USA, 8–11 October 2000; pp. 1495–1500. [Google Scholar]
- Li, H.; Hartley, R. The 3D-3D Registration Problem Revisited. In Proceedings of the IEEE International Conference on Computer Vision, Minneapolis, MN, USA, 18–23 June 2007; pp. 1947–1954. [Google Scholar]
- Tsin, Y.; Kanade, T. A Correlation-Based Approach to Robust Point Set Registration. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 558–569. [Google Scholar]
- Chui, H.L.; Rangarajan, A. A Feature Registration Framework using Mixture Models. In Proceedings of the IEEE Workshop on Mathematical Methods in Biomedical Image Analysis, Hilton Head Island, SC, USA, 11–12 June 2000; pp. 190–197. [Google Scholar]
- Jian, B.; Vemuri, B.C. Robust Point Set Registration Using Gaussian Mixture Models. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1633–1645. [Google Scholar] [CrossRef]
- Myronenko, A.; Song, X. Point Set Registration: Coherent Point Drift. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 2262–2275. [Google Scholar] [CrossRef]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2241–2254. [Google Scholar] [CrossRef]
- Campbell, D.; Petersson, L. GOGMA: Globally-Optimal Gaussian Mixture Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5685–5694. [Google Scholar]
- Olsson, C.; Kahl, F.; Oskarsson, M. Branch-and-Bound Methods for Euclidean Registration Problems. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 783–794. [Google Scholar] [CrossRef]
- Straub, J.; Campbell, T.; How, J.P.; Fisher, J.W.I. Efficient Global Point Cloud Alignment using Bayesian Nonparametric Mixtures. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 September 2017; pp. 2403–2412. [Google Scholar]
- Liu, Y.; Wang, C.; Song, Z.; Wang, M. Efficient Global Point Cloud Registration by Matching Rotation Invariant Features Through Translation Search. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 460–474. [Google Scholar]
- Bustos, A.P.; Chin, T.; Eriksson, A.; Li, H.; Suter, D. Fast Rotation Search with Stereographic Projections for 3D Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2227–2240. [Google Scholar] [CrossRef]
- Lian, W.; Zhang, L.; Yang, M. An Efficient Globally Optimal Algorithm for Asymmetric Point Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 7, 1281–1293. [Google Scholar] [CrossRef]
- Du, S.Y.; Zhu, J.H.; Zheng, N.N.; Zhao, J.Z.; Li, C. Isotropic Scaling Iterative Closest Point Algorithm for Partial Registration. Electron. Lett. 2011, 47, 784–799. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and Applications in Non-Gaussian Signal Processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Wang, X.; Qin, J.; Zheng, N. Robust Learning with Kernel Mean p-Power Error Loss. IEEE Trans. Cybern. 2018, 48, 2101–2113. [Google Scholar] [CrossRef] [PubMed]
- Consolini, L.; Laurini, M.; Locatelli, M.; Rizzini, D.L. Globally Optimal Registration based on Fast Branch and Bound. arXiv 2019, arXiv:1901.09641. [Google Scholar]
- Dym, N.; Kovalsky, S.Z. Linearly Converging Quasi Branch and Bound Algorithms for Global Rigid Registration. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1628–1636. [Google Scholar]
- Yu, C.; Da, J. A Maximum Feasible Subsystem for Globally Optimal 3D Point Cloud Registration. Sensors 2018, 18, 544. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, Y.; Wang, M.; Song, Z. GO-APSR: A Globally Optimal Affine Point Set Registration Method. IEEE Access 2019, 7, 137232–137240. [Google Scholar] [CrossRef]
- Hartley, R.I.A.Z. Multi-View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Yang, H.; Carlone, L. A Polynomial-time Solution for Robust Registration with Extreme Outlier Rates. In Proceedings of the Robotics: Science and Systems, Breisgau, Germany, 22–26 June 2019. [Google Scholar]
- Yang, H.; Shi, J.; Carlone, L. TEASER: Fast and Certifiable Point Cloud Registration. arXiv 2020, arXiv:2001.07715. [Google Scholar]
- Moore, R.E.; Kearfott, R.B.; Cloud, M.J. Introduction to Interval Analysis; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009. [Google Scholar]
- Moore, R.E. Methods and Applications of Interval Analysis; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1979. [Google Scholar]
- Brown, M.; Windridge, D.; Guillemaut, J. Globally Optimal 2D-3D Registration from Points or Lines Without Correspondences. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 8–12 June 2015; pp. 2111–2119. [Google Scholar]
- Campbell, D.J.; Petersson, L.; Kneip, L.; Li, H. Globally-Optimal Inlier Set Maximisation for Camera Pose and Correspondence Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 328–342. [Google Scholar] [CrossRef]
- Hartley, R.I.; Kahl, F. Global Optimization through Rotation Space Search. Int. J. Comput. Vision 2009, 82, 64–79. [Google Scholar] [CrossRef]
- Mian, A.S.; Bennamoun, M.; Owens, R.A. A Novel Representation and Feature Matching Algorithm for Automatic Pairwise Registration of Range Images. Int. J. Comput. Vision 2006, 66, 19–40. [Google Scholar] [CrossRef]
- Mian, A.S.; Bennamoun, M.; Owens, R. Three-Dimensional Model-Based Object Recognition and Segmentation in Cluttered Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1584–1601. [Google Scholar] [CrossRef] [PubMed]
- Available online: http://graphics.stanford.edu/data/3Dscanrep/ (accessed on 1 June 2020).
- Available online: https://lgg.epfl.ch/statues_dataset.php (accessed on 1 June 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Time [s] | TRE | Mean | Standard Deviation | ||
|---|---|---|---|---|---|---|
| Target No.1 | Target No.2 | Target No.3 | ||||
| Our method | 18.568 | 0.109 | 0.092 | 0.090 | 0.097 | 0.009 |
| CPD | 0.416 | 0.423 | 0.782 | 0.472 | 0.559 | 0.159 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Chen, X.; Wang, M. Efficient Similarity Point Set Registration by Transformation Decomposition. Sensors 2020, 20, 4103. https://doi.org/10.3390/s20154103
Wang C, Chen X, Wang M. Efficient Similarity Point Set Registration by Transformation Decomposition. Sensors. 2020; 20(15):4103. https://doi.org/10.3390/s20154103
Chicago/Turabian StyleWang, Chen, Xinrong Chen, and Manning Wang. 2020. "Efficient Similarity Point Set Registration by Transformation Decomposition" Sensors 20, no. 15: 4103. https://doi.org/10.3390/s20154103
APA StyleWang, C., Chen, X., & Wang, M. (2020). Efficient Similarity Point Set Registration by Transformation Decomposition. Sensors, 20(15), 4103. https://doi.org/10.3390/s20154103