Amino Acid Composition in Various Types of Nucleic Acid-Binding Proteins





Abstract
1. Introduction
2. Amino Acid Composition of Nucleic Acid-Binding Proteins
2.1. History
2.2. Methods to Inspect the Amino Acid Composition of Proteins
2.3. Amino Acid Composition of Nucleic Acid-Binding Proteins
3. Closing Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| bZIP | Basic Leucine Zipper |
| CIRBP | Cold inducible RNA-binding protein |
| GNL1 | Guanine Nucleotide-Binding Protein-Like 1 |
| GO | Gene Ontology |
| bHLH | Helix-loop-helix |
| HTH | Helix-turn-helix |
| MAZ | Myc-associated zinc finger protein |
| SNRPA | Small Nuclear Ribonucleoprotein Polypeptide A |
| SRSF1 | Serine/arginine-rich splicing factor 1 |
| SVM | Support vector machine |
References
- Ghani, N.S.A.; Firdaus-Raih, M.; Ahmad, S. Computational Prediction of Nucleic acid-binding Residues From Sequence. In Encyclopedia of Bioinformatics and Computational Biology; Ranganathan, S., Gribskov, M., Nakai, K., Schönbach, C., Eds.; Academic Press: Oxford, UK, 2019; pp. 678–687. ISBN 978-0-12-811432-2. [Google Scholar]
- Jutras, B.L.; Verma, A.; Stevenson, B. Identification of Novel DNA-Binding Proteins Using DNA-Affinity Chromatography/Pull Down. Curr. Protoc. Microbiol. 2012, 24, 1F.1.1–1F.1.13. [Google Scholar] [CrossRef]
- Wang, I.X.; Grunseich, C.; Fox, J.; Burdick, J.; Zhu, Z.; Ravazian, N.; Hafner, M.; Cheung, V.G. Human Proteins That Interact with RNA/DNA Hybrids. Genome Res. 2018, 28, 1405–1414. [Google Scholar] [CrossRef] [PubMed]
- Ouwerkerk, P.B.; Meijer, A.H. Yeast one-hybrid screens for detection of transcription factor DNA interactions. In Plant Reverse Genetics; Springer: Basel, Switzerland, 2011; pp. 211–227. [Google Scholar]
- Gaudinier, A.; Tang, M.; Bågman, A.-M.; Brady, S.M. Identification of Protein–DNA Interactions Using Enhanced Yeast One-Hybrid Assays and a Semiautomated Approach. In Plant Genomics: Methods and Protocols; Busch, W., Ed.; Methods in Molecular Biology; Springer: New York, NY, 2017; pp. 187–215. ISBN 978-1-4939-7003-2. [Google Scholar]
- Hellman, L.M.; Fried, M.G. Electrophoretic Mobility Shift Assay (EMSA) for Detecting Protein–Nucleic Acid Interactions. Nat. Protoc. 2007, 2, 1849. [Google Scholar] [CrossRef] [PubMed]
- Seo, M.; Lei, L.; Egli, M. Label-Free Electrophoretic Mobility Shift Assay (EMSA) for Measuring Dissociation Constants of Protein-RNA Complexes. Curr. Protoc. Nucleic Acid Chem. 2019, 76, e70. [Google Scholar] [CrossRef] [PubMed]
- Carey, M.F.; Peterson, C.L.; Smale, S.T. Chromatin Immunoprecipitation (Chip). Cold Spring Harb. Protoc. 2009, 2009, pdb-prot5279. [Google Scholar] [CrossRef] [PubMed]
- de Barsy, M.; Herrgott, L.; Martin, V.; Pillonel, T.; Viollier, P.H.; Greub, G. Identification of New DNA-Associated Proteins from Waddlia Chondrophila. Sci. Rep. 2019, 9, 4885. [Google Scholar] [CrossRef]
- Kunová, N.; Ondrovičová, G.; Bauer, J.A.; Bellová, J.; Ambro, Ľ.; Martináková, L.; Kotrasová, V.; Kutejová, E.; Pevala, V. The Role of Lon-Mediated Proteolysis in the Dynamics of Mitochondrial Nucleic Acid-Protein Complexes. Sci. Rep. 2017, 7, 631. [Google Scholar] [CrossRef]
- Haronikova, L.; Coufal, J.; Kejnovska, I.; Jagelska, E.B.; Fojta, M.; Dvořáková, P.; Muller, P.; Vojtesek, B.; Brazda, V. IFI16 Preferentially Binds to DNA with Quadruplex Structure and Enhances DNA Quadruplex Formation. PLoS ONE 2016, 11, e0157156. [Google Scholar] [CrossRef]
- Liu, B.; Wang, S.; Wang, X. DNA-binding Protein Identification by Combining Pseudo Amino Acid Composition and Profile-Based Protein Representation. Sci. Rep. 2015, 5, 15479. [Google Scholar] [CrossRef]
- Fang, Y.; Guo, Y.; Feng, Y.; Li, M. Predicting DNA-Binding Proteins: Approached from Chou’s Pseudo Amino Acid Composition and Other Specific Sequence Features. Amino Acids 2008, 34, 103–109. [Google Scholar] [CrossRef]
- Wei, L.; Tang, J.; Zou, Q. Local-DPP: An Improved DNA-Binding Protein Prediction Method by Exploring Local Evolutionary Information. Inf. Sci. 2017, 384, 135–144. [Google Scholar] [CrossRef]
- Liu, B.; Xu, J.; Lan, X.; Xu, R.; Zhou, J.; Wang, X.; Chou, K.-C. IDNA-Prot|dis: Identifying DNA-Binding Proteins by Incorporating Amino Acid Distance-Pairs and Reduced Alphabet Profile into the General Pseudo Amino Acid Composition. PLoS ONE 2014, 9, e106691. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Han, K. Prediction of RNA-Binding Amino Acids from Protein and RNA Sequences. BMC Bioinform. 2011, 12, S7. [Google Scholar] [CrossRef] [PubMed]
- Brázda, V.; Coufal, J.; Liao, J.C.C.; Arrowsmith, C.H. Preferential Binding of IFI16 Protein to Cruciform Structure and Superhelical DNA. Biochem. Biophys. Res. Commun. 2012, 422, 716–720. [Google Scholar] [CrossRef] [PubMed]
- Čechová, J.; Coufal, J.; Jagelská, E.B.; Fojta, M.; Brázda, V. P73, like Its P53 Homolog, Shows Preference for Inverted Repeats Forming Cruciforms. PLoS ONE 2018, 13, e0195835. [Google Scholar] [CrossRef]
- Brázda, V.; Hároníková, L.; Liao, J.C.; Fojta, M. DNA and RNA Quadruplex-Binding Proteins. Int. J. Mol. Sci. 2014, 15, 17493–17517. [Google Scholar] [CrossRef]
- Helma, R.; Bažantová, P.; Petr, M.; Adámik, M.; Renčiuk, D.; Tichỳ, V.; Pastuchová, A.; Soldánová, Z.; Pečinka, P.; Bowater, R.P. P53 Binds Preferentially to Non-B DNA Structures Formed by the Pyrimidine-Rich Strands of GaA· TTC Trinucleotide Repeats Associated with Friedreich’s Ataxia. Molecules 2019, 24, 2078. [Google Scholar] [CrossRef]
- Lyons, S.M.; Kharel, P.; Akiyama, Y.; Ojha, S.; Dave, D.; Tsvetkov, V.; Merrick, W.; Ivanov, P.; Anderson, P. EIF4G Has Intrinsic G-Quadruplex Binding Activity That Is Required for TiRNA Function. Nucleic Acids Res. 2020, 48, 6223–6233. [Google Scholar] [CrossRef]
- Porubiaková, O.; Bohálová, N.; Inga, A.; Vadovičová, N.; Coufal, J.; Fojta, M.; Brázda, V. The Influence of Quadruplex Structure in Proximity to P53 Target Sequences on the Transactivation Potential of P53 Alpha Isoforms. Int. J. Mol. Sci. 2020, 21, 127. [Google Scholar] [CrossRef]
- Oyoshi, T.; Masuzawa, T. Modulation of Histone Modifications and G-Quadruplex Structures by G-Quadruplex-Binding Proteins. Biochem. Biophys. Res. Commun. 2020, 531, 39–44. [Google Scholar] [CrossRef]
- Bartas, M.; Brázda, V.; Bohálová, N.; Cantara, A.; Volná, A.; Stachurová, T.; Malachová, K.; Jagelská, E.B.; Porubiaková, O.; Červeň, J. In-Depth Bioinformatic Analyses of Nidovirales Including Human SARS-CoV-2, SARS-CoV, MERS-CoV Viruses Suggest Important Roles of Non-Canonical Nucleic Acid Structures in Their Lifecycles. Front. Microbiol. 2020, 11, 1583. [Google Scholar] [CrossRef] [PubMed]
- Tateishi-Karimata, H.; Sugimoto, N. Chemical Biology of Non-Canonical Structures of Nucleic Acids for Therapeutic Applications. Chem. Commun. 2020, 56, 2379–2390. [Google Scholar] [CrossRef] [PubMed]
- Cer, R.Z.; Donohue, D.E.; Mudunuri, U.S.; Temiz, N.A.; Loss, M.A.; Starner, N.J.; Halusa, G.N.; Volfovsky, N.; Yi, M.; Luke, B.T. Non-B DB v2. 0: A Database of Predicted Non-B DNA-Forming Motifs and Its Associated Tools. Nucleic Acids Res. 2012, 41, D94–D100. [Google Scholar] [CrossRef] [PubMed]
- Brazda, V.; Fojta, M.; Bowater, R.P. Structures and Stability of Simple DNA Repeats from Bacteria. Biochem. J. 2020, 477, 325–339. [Google Scholar] [CrossRef]
- Brázda, V.; Luo, Y.; Bartas, M.; Kaura, P.; Porubiaková, O.; Št’astnỳ, J.; Pečinka, P.; Verga, D.; Da Cunha, V.; Takahashi, T.S. G-Quadruplexes in the Archaea Domain. Biomolecules 2020, 10, 1349. [Google Scholar] [CrossRef] [PubMed]
- Rhodes, D.; Lipps, H.J. G-Quadruplexes and Their Regulatory Roles in Biology. Nucleic Acids Res. 2015, 43, 8627–8637. [Google Scholar] [CrossRef]
- Zeraati, M.; Langley, D.B.; Schofield, P.; Moye, A.L.; Rouet, R.; Hughes, W.E.; Bryan, T.M.; Dinger, M.E.; Christ, D. I-Motif DNA Structures Are Formed in the Nuclei of Human Cells. Nat. Chem. 2018, 10, 631–637. [Google Scholar] [CrossRef]
- Brázdová, M.; Tichý, V.; Helma, R.; Bažantová, P.; Polášková, A.; Krejčí, A.; Petr, M.; Navrátilová, L.; Tichá, O.; Nejedlý, K.; et al. P53 Specifically Binds Triplex DNA In Vitro and in Cells. PLoS ONE 2016, 11, e0167439. [Google Scholar] [CrossRef]
- Chedin, F.; Benham, C.J. Emerging Roles for R-Loop Structures in the Management of Topological Stress. J. Biol. Chem. 2020, 295, 4684–4695. [Google Scholar] [CrossRef]
- Xu, P.; Pan, F.; Roland, C.; Sagui, C.; Weninger, K. Dynamics of Strand Slippage in DNA Hairpins Formed by CAG Repeats: Roles of Sequence Parity and Trinucleotide Interrupts. Nucleic Acids Res. 2020, 48, 2232–2245. [Google Scholar] [CrossRef]
- Fleming, A.M.; Zhu, J.; Jara-Espejo, M.; Burrows, C.J. Cruciform DNA Sequences in Gene Promoters Can Impact Transcription upon Oxidative Modification of 2′-Deoxyguanosine. Biochemistry 2020, 59, 2616–2626. [Google Scholar] [CrossRef] [PubMed]
- Bevilacqua, P.C.; Ritchey, L.E.; Su, Z.; Assmann, S.M. Genome-Wide Analysis of RNA Secondary Structure. Annu. Rev. Genet. 2016, 50, 235–266. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.-I.; Ham, S.; Park, J.; Seo, S.H.; Lim, C.H.; Jeon, H.; Huh, J.; Roh, T.-Y. Z-DNA-Forming Sites Identified by ChIP-Seq Are Associated with Actively Transcribed Regions in the Human Genome. DNA Res. 2016, 23, 477–486. [Google Scholar] [CrossRef] [PubMed]
- Spiegel, J.; Adhikari, S.; Balasubramanian, S. The Structure and Function of DNA G-Quadruplexes. Trends Chem. 2020, 2, 123–136. [Google Scholar] [CrossRef] [PubMed]
- Varshney, D.; Spiegel, J.; Zyner, K.; Tannahill, D.; Balasubramanian, S. The Regulation and Functions of DNA and RNA G-Quadruplexes. Nat. Rev. Mol. Cell Biol. 2020, 21, 459–474. [Google Scholar] [CrossRef]
- Kaushik, M.; Kaushik, S.; Roy, K.; Singh, A.; Mahendru, S.; Kumar, M.; Chaudhary, S.; Ahmed, S.; Kukreti, S. A Bouquet of DNA Structures: Emerging Diversity. Biochem. Biophys. Rep. 2016, 5, 388–395. [Google Scholar] [CrossRef][Green Version]
- Masai, H.; Tanaka, T. G-Quadruplex DNA and RNA: Their Roles in Regulation of DNA Replication and Other Biological Functions. Biochem. Biophys. Res. Commun. 2020, 531, 25–38. [Google Scholar] [CrossRef]
- Herbert, A. Z-DNA and Z-RNA in Human Disease. Commun. Biol. 2019, 2, 1–10. [Google Scholar] [CrossRef]
- Yuan, W.-F.; Wan, L.-Y.; Peng, H.; Zhong, Y.-M.; Cai, W.-L.; Zhang, Y.-Q.; Ai, W.-B.; Wu, J.-F. The Influencing Factors and Functions of DNA G-Quadruplexes. Cell Biochem. Funct. 2020, 38, 524–532. [Google Scholar] [CrossRef]
- Bacolla, A.; Cooper, D.N.; Vasquez, K.M.; Tainer, J.A. Non-B DNA Structure and Mutations Causing Human Genetic Disease. In eLS; American Cancer Society: Atlanta, GA, USA, 2018; pp. 1–15. ISBN 978-0-470-01590-2. [Google Scholar]
- Bacolla, A.; Tainer, J.A.; Vasquez, K.M.; Cooper, D.N. Translocation and Deletion Breakpoints in Cancer Genomes Are Associated with Potential Non-B DNA-Forming Sequences. Nucleic Acids Res. 2016, 44, 5673–5688. [Google Scholar] [CrossRef]
- Cammas, A.; Millevoi, S. RNA G-Quadruplexes: Emerging Mechanisms in Disease. Nucleic Acids Res. 2017, 45, 1584–1595. [Google Scholar] [CrossRef] [PubMed]
- Kharel, P.; Balaratnam, S.; Beals, N.; Basu, S. The Role of RNA G-Quadruplexes in Human Diseases and Therapeutic Strategies. Wiley Interdiscip. Rev. RNA 2020, 11, e1568. [Google Scholar] [CrossRef] [PubMed]
- Brázda, V.; Cerveň, J.; Bartas, M.; Mikysková, N.; Coufal, J.; Pečinka, P. The Amino Acid Composition of Quadruplex Binding Proteins Reveals a Shared Motif and Predicts New Potential Quadruplex Interactors. Molecules 2018, 23. [Google Scholar] [CrossRef] [PubMed]
- Bartas, M.; Bažantová, P.; Brázda, V.; Liao, J.; Červeň, J.; Pečinka, P. Identification of Distinct Amino Acid Composition of Human Cruciform Binding Proteins. Mol. Biol. 2019, 53, 97–106. [Google Scholar] [CrossRef]
- Consortium, G.O. Expansion of the Gene Ontology Knowledgebase and Resources. Nucleic Acids Res. 2017, 45, D331–D338. [Google Scholar]
- Consortium, G.O. Gene Ontology Consortium: Going Forward. Nucleic Acids Res. 2015, 43, D1049–D1056. [Google Scholar] [CrossRef]
- Carbon, S.; Ireland, A.; Mungall, C.J.; Shu, S.; Marshall, B.; Lewis, S.; Hub, A.; Group, W.P.W. AmiGO: Online Access to Ontology and Annotation Data. Bioinformatics 2009, 25, 288–289. [Google Scholar] [CrossRef]
- Mishra, S.K.; Tawani, A.; Mishra, A.; Kumar, A. G4IPDB: A Database for G-Quadruplex Structure Forming Nucleic Acid Interacting Proteins. Sci. Rep. 2016, 6, 38144. [Google Scholar] [CrossRef]
- Moccia, F.; Platella, C.; Musumeci, D.; Batool, S.; Zumrut, H.; Bradshaw, J.; Mallikaratchy, P.; Montesarchio, D. The Role of G-Quadruplex Structures of LIGS-Generated Aptamers R1.2 and R1.3 in IgM Specific Recognition. Int. J. Biol. Macromol. 2019, 133, 839–849. [Google Scholar] [CrossRef]
- Riccardi, C.; Napolitano, E.; Platella, C.; Musumeci, D.; Melone, M.A.B.; Montesarchio, D. Anti-VEGF DNA-Based Aptamers in Cancer Therapeutics and Diagnostics. Med. Res. Rev. 2021, 41, 464–506. [Google Scholar] [CrossRef]
- Brázda, V.; Laister, R.C.; Jagelská, E.B.; Arrowsmith, C. Cruciform Structures Are a Common DNA Feature Important for Regulating Biological Processes. BMC Mol. Biol. 2011, 12, 33. [Google Scholar] [CrossRef] [PubMed]
- Kim, C. How Z-DNA/RNA-binding Proteins Shape Homeostasis, Inflammation, and Immunity. BMB Rep. 2020, 53, 453–457. [Google Scholar] [CrossRef] [PubMed]
- Iwai, K.; Ishikawa, K.; Hayashi, H. Amino-Acid Sequence of Slightly Lysine-Rich Histone. Nature 1970, 226, 1056–1058. [Google Scholar] [CrossRef] [PubMed]
- Jukes, T.H.; Holmquist, R.; Moise, H. Amino Acid Composition of Proteins: Selection against the Genetic Code. Science 1975, 189, 50–51. [Google Scholar] [CrossRef] [PubMed]
- Aukerman, M.J.; Schmidt, R.J.; Burr, B.; Burr, F.A. An Arginine to Lysine Substitution in the BZIP Domain of an Opaque-2 Mutant in Maize Abolishes Specific DNA-binding. Genes Dev. 1991, 5, 310–320. [Google Scholar] [CrossRef]
- Lee, B.; Thirunavukkarasu, K.; Zhou, L.; Pastore, L.; Baldini, A.; Hecht, J.; Geoffrey, V.; Ducy, P.; Karsenty, G. Missense Mutations Abolishing DNA-binding of the Osteoblast-Specific Transcription Factor OSF2/CBFA1 in Cleidocranial Dysplasia. Nat. Genet. 1997, 16, 307–310. [Google Scholar] [CrossRef]
- Siomi, H.; Choi, M.; Siomi, M.C.; Nussbaum, R.L.; Dreyfuss, G. Essential Role for KH Domains in RNA-binding: Impaired RNA-binding by a Mutation in the KH Domain of FMR1 That Causes Fragile X Syndrome. Cell 1994, 77, 33–39. [Google Scholar] [CrossRef]
- Cheng, S.; Melkonian, M.; Smith, S.A.; Brockington, S.; Archibald, J.M.; Delaux, P.-M.; Li, F.-W.; Melkonian, B.; Mavrodiev, E.V.; Sun, W.; et al. 10KP: A Phylodiverse Genome Sequencing Plan. GigaScience 2018, 7. [Google Scholar] [CrossRef]
- Kriventseva, E.V.; Kuznetsov, D.; Tegenfeldt, F.; Manni, M.; Dias, R.; Simão, F.A.; Zdobnov, E.M. OrthoDB V10: Sampling the Diversity of Animal, Plant, Fungal, Protist, Bacterial and Viral Genomes for Evolutionary and Functional Annotations of Orthologs. Nucleic Acids Res. 2019, 47, D807–D811. [Google Scholar] [CrossRef]
- Vacic, V.; Uversky, V.N.; Dunker, A.K.; Lonardi, S. Composition Profiler: A Tool for Discovery and Visualization of Amino Acid Composition Differences. BMC Bioinform. 2007, 8, 211. [Google Scholar] [CrossRef]
- Sivashankari, S.; Shanmughavel, P. Functional Annotation of Hypothetical Proteins – A Review. Bioinformation 2006, 1, 335–338. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Lin, S.L. Support Vector Machines for Predicting RRNA-, RNA-, and DNA-Binding Proteins from Amino Acid Sequence. Biochim. Et Biophys. Acta (Bba) - Proteins Proteom. 2003, 1648, 127–133. [Google Scholar] [CrossRef]
- Kumar, M.; Gromiha, M.M.; Raghava, G.P. Identification of DNA-Binding Proteins Using Support Vector Machines and Evolutionary Profiles. BMC Bioinform. 2007, 8, 463. [Google Scholar] [CrossRef] [PubMed]
- Standing, K.G. Peptide and Protein de Novo Sequencing by Mass Spectrometry. Curr. Opin. Struct. Biol. 2003, 13, 595–601. [Google Scholar] [CrossRef] [PubMed]
- Vitorino, R.; Guedes, S.; Trindade, F.; Correia, I.; Moura, G.; Carvalho, P.; Santos, M.A.S.; Amado, F. De Novo Sequencing of Proteins by Mass Spectrometry. Expert Rev. Proteom. 2020, 17, 595–607. [Google Scholar] [CrossRef] [PubMed]
- Gasteiger, E.; Hoogland, C.; Gattiker, A.; Wilkins, M.R.; Appel, R.D.; Bairoch, A. Protein identification and analysis tools on the ExPASy server. In The proteomics protocols handbook; Springer: Basel, Switzerland, 2005; pp. 571–607. [Google Scholar]
- Cao, D.-S.; Xu, Q.-S.; Liang, Y.-Z. Propy: A Tool to Generate Various Modes of Chou’s PseAAC. Bioinformatics 2013, 29, 960–962. [Google Scholar] [CrossRef]
- Vishnoi, S.; Garg, P.; Arora, P. Physicochemical N-Grams Tool: A Tool for Protein Physicochemical Descriptor Generation via Chou’s 5-Step Rule. Chem. Biol. Drug Des. 2020, 95, 79–86. [Google Scholar] [CrossRef]
- Zuo, Y.; Li, Y.; Chen, Y.; Li, G.; Yan, Z.; Yang, L. PseKRAAC: A Flexible Web Server for Generating Pseudo K-Tuple Reduced Amino Acids Composition. Bioinformatics 2017, 33, 122–124. [Google Scholar] [CrossRef]
- Hudson, W.H.; Ortlund, E.A. The Structure, Function and Evolution of Proteins That Bind DNA and RNA. Nat. Rev.. Mol. Cell Biol. 2014, 15, 749–760. [Google Scholar] [CrossRef]
- Terribilini, M.; Lee, J.-H.; Yan, C.; Jernigan, R.L.; Honavar, V.; Dobbs, D. Prediction of RNA-binding Sites in Proteins from Amino Acid Sequence. RNA 2006, 12, 1450–1462. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, Z.; Kurgan, L. Comprehensive Review and Empirical Analysis of Hallmarks of DNA-, RNA-and Protein-Binding Residues in Protein Chains. Brief. Bioinform. 2019, 20, 1250–1268. [Google Scholar] [CrossRef]
- Michalek, J.L.; Besold, A.N.; Michel, S.L.J. Cysteine and Histidine Shuffling: Mixing and Matching Cysteine and Histidine Residues in Zinc Finger Proteins to Afford Different Folds and Function. Dalton Trans. 2011, 40, 12619–12632. [Google Scholar] [CrossRef]
- Laity, J.H.; Lee, B.M.; Wright, P.E. Zinc Finger Proteins: New Insights into Structural and Functional Diversity. Curr. Opin. Struct. Biol. 2001, 11, 39–46. [Google Scholar] [CrossRef]
- Yesudhas, D.; Batool, M.; Anwar, M.A.; Panneerselvam, S.; Choi, S. Proteins Recognizing DNA: Structural Uniqueness and Versatility of DNA-Binding Domains in Stem Cell Transcription Factors. Genes 2017, 8, 192. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Xu, D.; Wang, W. Type IA Topoisomerases Can Be “Magicians” for Both DNA and RNA in All Domains of Life. RNA Biol. 2017, 14, 854–864. [Google Scholar] [CrossRef] [PubMed]
- Aravind, L.; Anantharaman, V.; Balaji, S.; Babu, M.M.; Iyer, L.M. The Many Faces of the Helix-Turn-Helix Domain: Transcription Regulation and Beyond. FEMS Microbiol Rev 2005, 29, 231–262. [Google Scholar] [CrossRef]
- Atchley, W.R.; Fitch, W.M. A Natural Classification of the Basic Helix–Loop–Helix Class of Transcription Factors. Proc. Natl. Acad. Sci. USA 1997, 94, 5172–5176. [Google Scholar] [CrossRef]
- Casey, B.H.; Kollipara, R.K.; Pozo, K.; Johnson, J.E. Intrinsic DNA-binding Properties Demonstrated for Lineage-Specifying Basic Helix-Loop-Helix Transcription Factors. Available online: http://genome.cshlp.org (accessed on 2 January 2021).
- Hakoshima, T. Leucine Zippers. In eLS; American Cancer Society: Atlanta, GA, USA, 2014; ISBN 978-0-470-01590-2. [Google Scholar]
- Miller, M. The Importance of Being Flexible: The Case of Basic Region Leucine Zipper Transcriptional Regulators. Curr. Protein Pept. Sci. 2009, 10, 244–269. [Google Scholar] [CrossRef]
- Yagi, R.; Miyazaki, T.; Oyoshi, T. G-Quadruplex Binding Ability of TLS/FUS Depends on the β-Spiral Structure of the RGG Domain. Nucleic Acids Res. 2018, 46, 5894–5901. [Google Scholar] [CrossRef]
- Ishiguro, A.; Kimura, N.; Noma, T.; Shimo-Kon, R.; Ishihama, A.; Kon, T. Molecular Dissection of ALS-Linked TDP-43 – Involvement of the Gly-Rich Domain in Interaction with G-Quadruplex MRNA. FEBS Lett. 2020, 594, 2254–2265. [Google Scholar] [CrossRef]
- Takahama, K.; Oyoshi, T. Specific Binding of Modified RGG Domain in TLS/FUS to G-Quadruplex RNA: Tyrosines in RGG Domain Recognize 2′-OH of the Riboses of Loops in G-Quadruplex. J. Am. Chem. Soc. 2013, 135, 18016–18019. [Google Scholar] [CrossRef] [PubMed]
- Bartas, M.; Červeň, J.; Pečinka, P. Identification of Distinct Amino Acid Composition of Z-DNA/RNA and Triplex-Binding Proteins. Mol. Bio. 53, 97–106.
- Ribeiro de Almeida, C.; Dhir, S.; Dhir, A.; Moghaddam, A.E.; Sattentau, Q.; Meinhart, A.; Proudfoot, N.J. RNA Helicase DDX1 Converts RNA G-Quadruplex Structures into R-Loops to Promote IgH Class Switch Recombination. Mol. Cell 2018, 70, 650–662.e8. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.-H.; Chao, C.-F.; Huang, H.-C.; Lee, H.-Y.; Kannagi, R.; Chen, J.-Y. Roles of P53 Family Structure and Function in Non-Canonical Response Element Binding and Activation. Int. J. Mol. Sci. 2019, 20, 3681. [Google Scholar] [CrossRef] [PubMed]
- Bossone, S.A.; Asselin, C.; Patel, A.J.; Marcu, K.B. MAZ, a Zinc Finger Protein, Binds to c-MYC and C2 Gene Sequences Regulating Transcriptional Initiation and Termination. Proc. Natl. Acad. Sci. USA 1992, 89, 7452–7456. [Google Scholar] [CrossRef] [PubMed]
- Cogoi, S.; Zorzet, S.; Rapozzi, V.; Géci, I.; Pedersen, E.B.; Xodo, L.E. MAZ-Binding G4-Decoy with Locked Nucleic Acid and Twisted Intercalating Nucleic Acid Modifications Suppresses KRAS in Pancreatic Cancer Cells and Delays Tumor Growth in Mice. Nucleic Acids Res. 2013, 41, 4049–4064. [Google Scholar] [CrossRef] [PubMed]
- Dominguez, D.; Freese, P.; Alexis, M.S.; Su, A.; Hochman, M.; Palden, T.; Bazile, C.; Lambert, N.J.; Van Nostrand, E.L.; Pratt, G.A.; et al. Sequence, Structure, and Context Preferences of Human RNA-binding Proteins. Mol. Cell 2018, 70, 854–867. [Google Scholar] [CrossRef]
- Laptenko, O.; Tong, D.R.; Manfredi, J.; Prives, C. The Tail That Wags the Dog: How the Disordered C-Terminal Domain Controls the Transcriptional Activities of the P53 Tumor-Suppressor Protein. Trends Biochem. Sci. 2016, 41, 1022–1034. [Google Scholar] [CrossRef]
- Petr, M.; Helma, R.; Polášková, A.; Krejčí, A.; Dvořáková, Z.; Kejnovská, I.; Navrátilová, L.; Adámik, M.; Vorlíčková, M.; Brázdová, M. Wild-Type P53 Binds to MYC Promoter G-Quadruplex. Biosci. Rep. 2016, 36. [Google Scholar] [CrossRef]
- Inukai, S.; Kock, K.H.; Bulyk, M.L. Transcription Factor–DNA-binding: Beyond Binding Site Motifs. Curr. Opin. Genet. Dev. 2017, 43, 110–119. [Google Scholar] [CrossRef]
- Wang, C.; Uversky, V.N.; Kurgan, L. Disordered Nucleiome: Abundance of Intrinsic Disorder in the DNA- and RNA-Binding Proteins in 1121 Species from Eukaryota, Bacteria and Archaea. Proteomics 2016, 16, 1486–1498. [Google Scholar] [CrossRef]
- Watson, M.; Stott, K. Disordered Domains in Chromatin-Binding Proteins. Essays Biochem. 2019, 63, 147–156. [Google Scholar] [CrossRef] [PubMed]
- Turner, A.L.; Watson, M.; Wilkins, O.G.; Cato, L.; Travers, A.; Thomas, J.O.; Stott, K. Highly Disordered Histone H1−DNA Model Complexes and Their Condensates. Proc. Natl. Acad. Sci. USA 2018, 115, 11964–11969. [Google Scholar] [CrossRef] [PubMed]
- Serrano, P.; Aubol, B.E.; Keshwani, M.M.; Forli, S.; Ma, C.-T.; Dutta, S.K.; Geralt, M.; Wüthrich, K.; Adams, J.A. Directional Phosphorylation and Nuclear Transport of the Splicing Factor SRSF1 Is Regulated by an RNA Recognition Motif. J. Mol. Biol. 2016, 428, 2430–2445. [Google Scholar] [CrossRef] [PubMed]
- Von Hacht, A.V.; Seifert, O.; Menger, M.; Schütze, T.; Arora, A.; Konthur, Z.; Neubauer, P.; Wagner, A.; Weise, C.; Kurreck, J. Identification and Characterization of RNA Guanine-Quadruplex Binding Proteins. Nucleic Acids Res. 2014, 42, 6630–6644. [Google Scholar] [CrossRef]
- Huang, Z.-L.; Dai, J.; Luo, W.-H.; Wang, X.-G.; Tan, J.-H.; Chen, S.-B.; Huang, Z.-S. Identification of G-Quadruplex-Binding Protein from the Exploration of RGG Motif/G-Quadruplex Interactions. J. Am. Chem. Soc. 2018, 140, 17945–17955. [Google Scholar] [CrossRef]
- Rigo, R.; Palumbo, M.; Sissi, C. G-Quadruplexes in Human Promoters: A Challenge for Therapeutic Applications. Biochim. Et Biophys. Acta (Bba)-Gen. Subj. 2017, 1861, 1399–1413. [Google Scholar] [CrossRef]
- Poggi, L.; Richard, G.-F. Alternative DNA Structures In Vivo: Molecular Evidence and Remaining Questions. Microbiol. Mol. Biol. Rev. 2020, 85. [Google Scholar] [CrossRef]
- Sissi, C.; Gatto, B.; Palumbo, M. The Evolving World of Protein-G-Quadruplex Recognition: A Medicinal Chemist’s Perspective. Biochimie 2011, 93, 1219–1230. [Google Scholar] [CrossRef]
- Brázda, V.; Coufal, J. Recognition of Local DNA Structures by P53 Protein. Int. J. Mol. Sci. 2017, 18, 375. [Google Scholar] [CrossRef]
- Sun, Z.-Y.; Wang, X.-N.; Cheng, S.-Q.; Su, X.-X.; Ou, T.-M. Developing Novel G-Quadruplex Ligands: From Interaction with Nucleic Acids to Interfering with Nucleic Acid–Protein Interaction. Molecules 2019, 24, 396. [Google Scholar] [CrossRef] [PubMed]
- Kharel, P.; Becker, G.; Tsvetkov, V.; Ivanov, P. Properties and Biological Impact of RNA G-Quadruplexes: From Order to Turmoil and Back. Nucleic Acids Res. 2020, 48, 12534–12555. [Google Scholar] [CrossRef] [PubMed]
- Lee, T.; Pelletier, J. The Biology of DHX9 and Its Potential as a Therapeutic Target. Oncotarget 2016, 7, 42716–42739. [Google Scholar] [CrossRef] [PubMed]
- Turcotte, M.-A.; Garant, J.-M.; Cossette-Roberge, H.; Perreault, J.-P. Guanine Nucleotide-Binding Protein-Like 1 (GNL1) Binds RNA G-Quadruplex Structures in Genes Associated with Parkinson’s Disease. RNA Biol. 2020, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Bolduc, F.; Turcotte, M.-A.; Perreault, J.-P. The Small Nuclear Ribonucleoprotein Polypeptide A (SNRPA) Binds to the G-Quadruplex of the BAG-1 5′UTR. Biochimie 2020, 176, 122–127. [Google Scholar] [CrossRef]
- Clemo, N.K.; Collard, T.J.; Southern, S.L.; Edwards, K.D.; Moorghen, M.; Packham, G.; Hague, A.; Paraskeva, C.; Williams, A.C. BAG-1 Is up-Regulated in Colorectal Tumour Progression and Promotes Colorectal Tumour Cell Survival through Increased NF-ΚB Activity. Carcinogenesis 2008, 29, 849–857. [Google Scholar] [CrossRef][Green Version]



{kind=link}
{kind=link}
| Important Notes | References | |
|---|---|---|
| DNA-binding | Arginine, tryptophan, tyrosine, histidine, phenylalanine, and lysine residues enrichment. Glutamate, aspartate, and proline depletion in the protein-DNA interface. | [76,79] |
| RNA-binding | Arginine, methionine, histidine, and lysine residues enrichment. Glutamate, aspartate residues depletion in protein-RNA interface. | [75,76] |
| DNA and RNA-binding | Proteins that are able to bind both DNA and RNA. | [74,80] |
| Sequence-specific | ||
| Zinc finger proteins | Cysteine and histidine amino acid residues are crucially important to coordinate Zn2+ binding in the Cys2His2 subgroup of zinc-finger proteins | [77,78] |
| Helix-turn-helix (HTH) | Conserved “shs” and “phs” patterns, where ‘s’ is a small residue, most frequently glycine in the first position, ‘h’ is a hydrophobic residue, and ‘p’ is a charged residue, most frequently glutamate. “shs” pattern lies in the turn between helix-2 and helix-3 of the core HTH structure, and “phs” is present in helix-2. | [81] |
| Basic Helix-loop-helix (bHLH) | Mostly arginine, lysine or histidine amino acid residues are present within conserved positions of this motif | [82,83] |
| Leucine zipper proteins | Leucine amino acid residues are crucial for leucine zipper motifs | [84,85] |
| Structure specific | ||
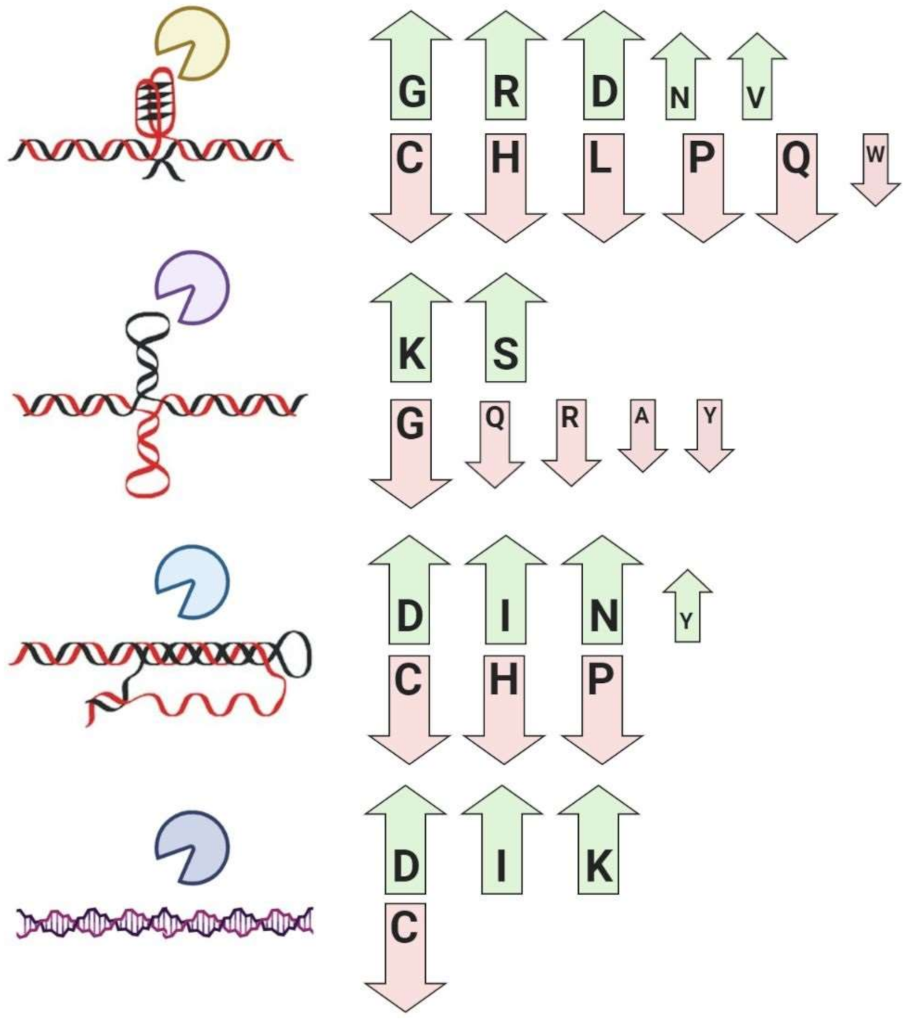
| G-quadruplex binding proteins | Global enrichment for glycine, arginine, aspartic acid, asparagine, valine, and depletion for cysteine, histidine, leucine, proline, glutamine, and tryptophan residues | [47,86,87,88] |
| Cruciform binding proteins | Global enrichment for lysine and serine, and depletion for alanine, glycine, glutamine, arginine, tyrosine, and tryptophan residues | [48,55] |
| Triplex binding proteins | Global enrichment for asparagine, aspartic acid, isoleucine, tyrosine, and depletion for cysteine, histidine, and proline residues | [89] |
| Z-DNA/RNA-binding proteins | Global enrichment for isoleucine, aspartic acid, lysine, and depletion for cysteine residues | [89] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bartas, M.; Červeň, J.; Guziurová, S.; Slychko, K.; Pečinka, P. Amino Acid Composition in Various Types of Nucleic Acid-Binding Proteins. Int. J. Mol. Sci. 2021, 22, 922. https://doi.org/10.3390/ijms22020922
Bartas M, Červeň J, Guziurová S, Slychko K, Pečinka P. Amino Acid Composition in Various Types of Nucleic Acid-Binding Proteins. International Journal of Molecular Sciences. 2021; 22(2):922. https://doi.org/10.3390/ijms22020922
Chicago/Turabian StyleBartas, Martin, Jiří Červeň, Simona Guziurová, Kristyna Slychko, and Petr Pečinka. 2021. "Amino Acid Composition in Various Types of Nucleic Acid-Binding Proteins" International Journal of Molecular Sciences 22, no. 2: 922. https://doi.org/10.3390/ijms22020922
APA StyleBartas, M., Červeň, J., Guziurová, S., Slychko, K., & Pečinka, P. (2021). Amino Acid Composition in Various Types of Nucleic Acid-Binding Proteins. International Journal of Molecular Sciences, 22(2), 922. https://doi.org/10.3390/ijms22020922