Abstract
Timely status updates are critical in remote control systems such as autonomous driving and the industrial Internet of Things, where timeliness requirements are usually context dependent. Accordingly, the Urgency of Information (UoI) has been proposed beyond the well-known Age of Information (AoI) by further including context-aware weights which indicate whether the monitored process is in an emergency. However, the optimal updating and scheduling strategies in terms of UoI remain open. In this paper, we propose a UoI-optimal updating policy for timely status information with resource constraint. We first formulate the problem in a constrained Markov decision process and prove that the UoI-optimal policy has a threshold structure. When the context-aware weights are known, we propose a numerical method based on linear programming. When the weights are unknown, we further design a reinforcement learning (RL)-based scheduling policy. The simulation reveals that the threshold of the UoI-optimal policy increases as the resource constraint tightens. In addition, the UoI-optimal policy outperforms the AoI-optimal policy in terms of average squared estimation error, and the proposed RL-based updating policy achieves a near-optimal performance without the advanced knowledge of the system model.
1. Introduction
With the development of 5G and the Internet of Things (IoT), requirements for wireless communication have shifted from merely providing communication channels to covering the entire process of various IoT applications, e.g., autonomous vehicle [1] and virtual reality (VR) [2], where sensing, communication, computation, and control form a closed loop. Therefore, in addition to the communication delay, it is necessary to consider the information delay counted from the generation of the state information to the execution, namely the timeliness of information. For this purpose, Age of Information (AoI) has been proposed, which is defined as the time elapsed since the generation time of the latest received packets [3]. Due to its concise definition and clear physical meaning, AoI has been widely used for the design of scheduling and updating policies in remote estimation [4,5,6] and wireless communication networks [7,8,9,10,11,12]. Most existing works focus on optimizing average AoI or peak age. In [13], the authors claim that minimizing average age cannot satisfy the requirements for ultra-reliable low-latency communication (URLLC) and study the tail distribution of AoI. The violation probability for peak age is derived in [14] and the stationary distribution of AoI is studied in [15].
Nevertheless, the AoI still has some limitations. First, it fails to measure the nonlinear performance degradation caused by information staleness. In [16,17,18,19], nonlinear age penalty functions were introduced to solve this problem. Meanwhile, the Age of Synchronization (AoS) [20] and Age of Incorrect Information (AoII) [21] are defined to associate information freshness with the content of information. AoS is the time elapsed since the information at the receiver becomes desynchronized with the actual status of the monitored process. AoII is defined as the product of an increasing time penalty function and a penalty function of the estimation error. In addition, the status of heterogeneous data sources may change at different rates. A fast-changing process may require information with a lower age. However, age is independent of the changing rate and thus is not proper in the cases when heterogeneous data sources are jointly considered. To solve this problem, weighted age was introduced in [22,23] to distinguish important monitored processes. In [24], the metric based on information theory is proposed as a replacement of the time-based metric, AoI, to characterize the changing rate. In [5], the authors claim that minimizing age is not equivalent to minimizing the estimation error in a remote estimation problem and propose an effective age to solve this problem [25].
Practical systems (e.g., V2X-communication systems) may have different requirements for information freshness with different contexts. The context refers to all environmental factors that affect the requirement for information freshness. Therefore, resources should be reserved for frequent status updates in emergency to ensure safety.
However, the timeliness metrics mentioned above pay no attention to the significance of context information. To solve this problem, Urgency of Information (UoI) has been proposed in [26,27,28] to measure the influence of inaccurate information on performance under different contexts. To be specific, UoI uses a time-variant context-aware weight to distinguish different contexts. A higher indicates that the system is in more urgent situations (e.g., when a vehicle is approaching an intersection or overtaking) and therefore requires frequent updates. For example, when a vehicle passes through an intersection, the context-aware weight increases as the distance between the vehicle and the center of the intersection decreases. Meanwhile, the estimation error is introduced to measure the information inaccuracy, which is defined as the difference between the actual status and the estimated status at the receiver. The larger the absolute value of is, the less accurate the estimated status is. Therefore, UoI is defined as the product of context-aware weight and a cost function of the estimation error :
In discrete-time systems, the estimation error is:
where is the generation time of the latest status update at the receiver and is the increment in estimation error in time slot t. Specifically, if the context-aware weight is time-invariant (i.e., ), and as well as , UoI is the same as AoI. If the context-aware weight is process-dependent, UoI can represent weighted age. If the cost function is nonlinear, UoI can represent the nonlinear age penalty function. For example, when the outdated information is worthless, e.g., the information is about sales that expire after some time [29], then the shifted unit step cost function , is recommended. For the unit step function, when and otherwise .
In this work, we considered a single-user remote monitoring system, and the objective was to find an updating policy minimizing the average UoI over time under the constraint on average update frequency. To solve this problem, Refs. [27,30] proposed update-index-based adaptive schemes with Lyapunov optimization but did not conduct a theoretical analysis of their optimality. In addition, the constrained Markov decision process (CMDP) formulation was only used in the simulation for a numerically solved benchmark. Based on the existing works, in this paper, we theoretically analyzed the structure of the UoI-optimal policy and focused on how to derive an updating policy in an unknown environment.
The main contributions of this paper are summarized as follows.
- In contrast to [27,30], we assumed that the context-aware weight is a first-order irreducible positive recurrent Markov process or independent and identically distributed (i.i.d.) over time. We formulated the updating problem as a CMDP problem and proved the single threshold structure of the UoI-optimal policy. We then derived the policy through LP with the threshold structure and discussed the conditions that the monitored process needs to satisfy for the threshold structure.
- When the distributions of the context-aware weight and the increment in estimation error were unknown, we used model-based RL method to learn the state transitions of the whole system and derive a near-optimal RL-based updating policy.
- Simulations were conducted to verify the theoretical analysis of the threshold structure and show the near-optimal performance of the RL-based updating policy. The results indicate that: (i) the update thresholds decrease when the maximum average update frequency becomes large; (ii) the update threshold for emergency can actually be larger than that for ordinary states when the probability of transferring from emergency to ordinary states tends to 1.
The rest of this paper is organized as follows. The system model and the problem formulation are described in Section 2. In Section 3, we obtain the CMDP formulation of the problem with the given distribution of context-aware weight and prove the threshold structure of the UoI-optimal policy. The proposed model-based RL updating policy is obtained in Section 4. In Section 5, the simulation results are shown and discussed while the conclusions are drawn in Section 6.
2. System Model and Problem Formulation
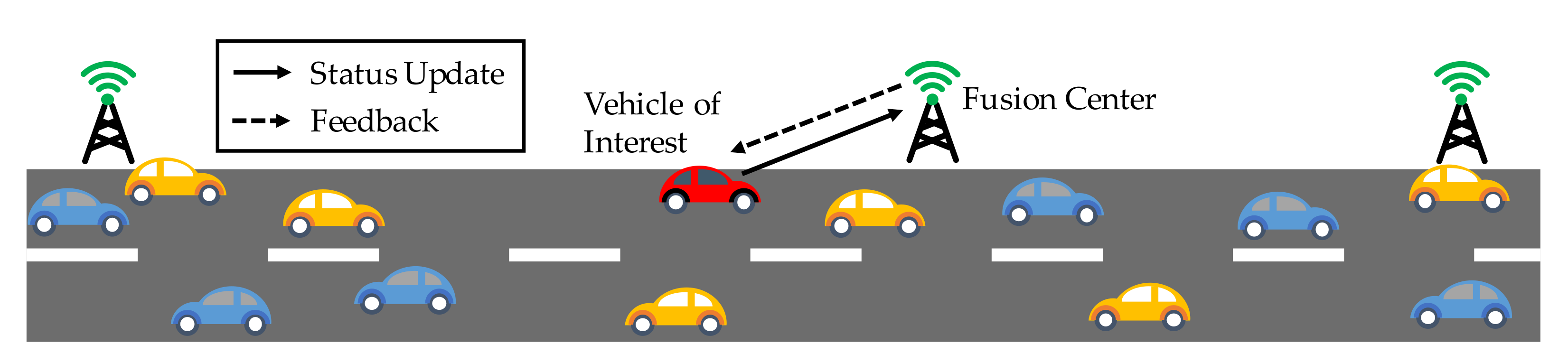
In this paper, we considered a remote monitoring system, in which a fusion center collects the status information (e.g., current location, velocity, information of surrounding) from a vehicle of interest via a wireless channel with limited resources, as shown in Figure 1. The whole system is considered as a discrete-time system and the status can be generated at will. Due to the limitations on the wireless resources and energy supply, there is a constraint on the average update frequency of the vehicle. The update decision in time slot t is denoted by , where means that the vehicle decides to transmit the current status to the center, and denotes that the vehicle decides to stay idle.
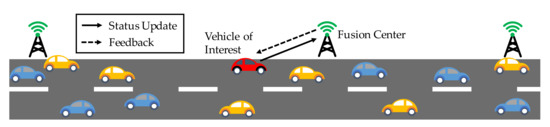
Figure 1.
Remote control and monitoring model. The vehicle of interest is shown in red.
The wireless channel is assumed as a block fading channel with successful transmission probability . Let be the state of the channel. represents that the channel is in deep fading, and no packet can be successfully transmitted. means the packets can be successfully transmitted to the center through the channel. If the center receives an update, then and an ACK will be sent to the vehicle.
Let and denote the current status of the monitored vehicle and the estimated status of the vehicle at the center, and denotes the estimation error. Similar to [26], we further assume that the time period of a packet transmission is less than a time slot and the estimation at the center equals the latest status information received by the center. This estimation scheme is easy to implement, theoretically tractable and has been proven to be an optimal policy that can minimize the average squared error of status estimation in a remote estimation system under energy constraints when the monitored process is a Wiener process [31]. Then, the recurrence relation of the estimation error is:
Equation (3) indicates that the estimation error will be the amount of variation of the monitored process from the generation time of the latest received status to the current time. The increment represents the variation of the monitored process. For example, when follows a Gaussian distribution with a mean of zero and variance of , represented by , the monitored status follows a Wiener process. When takes values from with a probability of , where , then the status of the monitored source will be a one-dimensional random walk. In this paper, we assumed that the monitored status of the vehicle is a Wiener process and is i.i.d. over time. However, the increment in estimation error during a single slot cannot be infinite in practical systems. Therefore, in contrast to [27,30], we assumed that increment obeys a truncated Gaussian distribution, i.e., the probability density function (PDF) of is:
where and are the expectation and standard deviation of increment . and are the PDF and the cumulative distribution function (CDF) of standard normal distribution. We also assumed and .
Meanwhile, the scheduling policy of information updates should also be related to the situation and environment of the system. For example, when the system is in an emergency, it should be very sensitive to the accuracy and the delay of the status information, thus the status should be updated more frequently. Therefore, our objective is to find a policy telling the vehicle whether to transmit status information or not in each slot for a minimum average UoI over time under the constraint:
where is the context-aware weight, which is independent with . is the maximum average update frequency. The cost function of the estimation error used here is , which is inspired by the squared error of status estimation.
3. Scheduling with CMDP-Based Approach
In this section, we start by formulating problem (5) into a constrained Markov decision process (CMDP) with assumptions on the distribution of the context-aware weight. We will prove the threshold structure of the UoI-optimal updating policy and derive the optimal policy through a linear programming (LP) formulation.
3.1. Constrained Markov Decision Process Formulation
In the remote monitoring system, the context may be related to the distance between adjacent vehicles/mobile devices, the unexpected maneuver of the neighboring vehicles, etc. In [32], the authors prove that whether the distance between two mobile wireless devices with Ornstein–Uhlenbeck mobility is less than a certain threshold follows a first-order Markov process. When the two devices are closer, they are more interested in each other’s status information, communication and computing resources to facilitate cooperation, share resources, and avoid collisions. At this time, the transmission of status information is more urgent than when the two devices are far apart. As for the unexpected maneuver of the neighboring vehicles, it is very challenging to find a proper formulation. Instead, we assumed that such emergencies occur independently in each slot according to a certain probability. Therefore, in contrast to [27,30], we assumed that the context-aware weight is i.i.d. over time or a first-order irreducible positive recurrent Markov process and formulated the problem (5) as a CMDP problem. The irreducible positive recurrent Markov formulation guarantees the existence of the UoI-optimal policy (see Appendix A). In this section, we will first focus on the situation where is a first-order Markov process:
- State space: The state of the vehicle in slot t, denoted by , includes the current estimation error and the context-aware weight. Then, we discretize with the step size , i.e., the estimation error . For example, when , its value will be taken as . The smaller the step size , the smaller the performance degradation caused by discretization. In addition, the value set of the context-aware weight is denoted by . Then, the state space is thus countable but infinite.
- Action space: At each slot, the vehicle can take two actions, namely , where denotes the vehicle deciding to transmit updates in slot t and denotes the vehicle deciding to wait.
- Probability transfer function: After taking action U at state , the next state is denoted by . When the vehicle decides not to transmit or the transmission fails, the probability of the estimation error transferring from Q to is written as . Due to the discretization of the estimation error, the increment , where . In addition, , where is the CDF of increment . In addition, the probability of the context-aware weight transferring from to is written as . Based on the assumption that the context-aware weight is independent with the estimation error , then the probability of the state transferring from to given action U is:
- One-step cost: The cost caused by taking action U in state is:while the one-step updating penalty only depends on the chosen action:
The average cost caused under a certain policy is the average UoI, which is defined as and the average updating penalty under is defined as . We aimed to find the UoI-optimal policy which minimizes the average cost under the resources constraint. Therefore, problem (5) can be formulated into the following CMDP problem:
3.2. Threshold Structure of the Optimal Policy
We start from some basic definitions in [33] and show the properties of problem (9).
Definition 1.
A stationary deterministic policy is a policy that takes the same action whenever in a given state , while a stationary randomized policy chooses to update or not in state s with a certain probability.
Theorem 1.
There exists an optimal stationary randomized policy for problem (9). The optimal policy is a probabilistic combination of two stationary deterministic policies. The two deterministic policies only differ on at most one state and each policy minimizes the unconstrained cost in (10) with a different Lagrange multiplier λ:
Proof of Theorem 1.
The proof is shown in Appendix A. □
We denote the optimal policy that minimizes the unconstrained cost in (10) with a given by and the cost obtained under policy by , namely . Then, there exists a differential cost function that satisfies the Bellman Equation [34]:
To solve problem (5), we first prove that with a given , the optimal stationary deterministic policy has a threshold structure. We then introduce a discounted problem with a discount factor and the discounted cost starting from state under a certain policy is:
Denote the minimum cost starting from state by . Then, we have:
Define as the difference between the value functions by taking the two different actions , meaning that:
Define as a function . Then we will prove that for , we have . To this end, we first prove the following Lemma 1.
Lemma 1.
For a given discount factor α and a fixed context-aware weight ω, the value function for Q equals the value function for , namely:
Proof of Lemma 1.
The Lemma is proven by induction. Define as the value function obtained after the iteration. Assume that for , we have: . If action U is taken in the iteration, then the expected discounted cost is defined as . Therefore, . We have:
Similarly, we can further prove that . Notice that the value function obtained in iteration is obtained by: and for any action U, . Thus, . By letting , . Hence, . □
Lemma 2.
For a given discount factor α and a fixed context-aware weight ω, function for Q increases monotonically with the absolute value of Q, namely: for .
Proof of Lemma 2.
Using the induction method, we first assume that for , we have . Therefore:
Similarly, we can obtain . Meanwhile, , then we have , for . Obviously, if we want to use induction to complete the proof of Lemma 2, we have to prove that: , for . To simplify the proof, it is assumed that . The discussion will be divided into the following three situations.
- When , then , for , we can derive that:
- When , there exists an increment , such that , and . Notice that and , then is a term in the summation , namely . Similarly, is a term in the summation . We further define , since , then .Furthermore, the probability of the estimation error transferring from to , i.e., equals , the probability of the estimation error transferring from to . Since , then . According to our assumption of the increment, we can prove that for any , . Then, we can derive:where .
- When , since , we only need to consider the case when , in this case . Therefore, is a term in the summation . Similarly, we can also prove that when .
According to Lemma 1, the conclusions above can be easily generalized to the cases without the condition . Finally, by letting , , therefore: . Hence: . □
Remark 1.
Lemma 2 holds when , i.e., the PDF of increment satisfies the following conditions:
- , ;
- .
Then, with Lemmas 1 and 2, we can prove the threshold structure of the optimal stationary deterministic policy which minimizes in (10).
Theorem 2.
For a given λ, the optimal stationary deterministic policy which minimizes in (10) has a threshold structure when the context-aware weight is a first-order irreducible positive recurrent Markov process.
Proof of Theorem 2.
Let denote the optimal action which minimizes the discounted cost at state . If the optimal action , then the vehicle will transmit its status update to the center at state and . Thus, we have:
According to Lemma 2, for any , can be lower bounded by
If , then for any states with , the optimal policy is to transmit the status to the center. If , then for any states with , the optimal action is not to transmit. In addition, the optimal policy will not be choosing to wait in all the slots. Therefore, for each context-aware weight , there must be a threshold . For any state with , the optimal choice is to transmit the status update. We can then conclude that for a given weight , the optimal policy with a discount factor has a threshold structure.
Let denote a sequence of discount factors and converges to 1 when . Then, the optimal deterministic policy for will also converge to the optimal policy with a discount factor which is less than 1 [35]. Similar derivation is also applied in [12]. Therefore, we can prove the threshold structure of the optimal stationary deterministic policy which minimizes . □
Similarly, when the context-aware weight is i.i.d. over time, we can obtain the following theorem:
Theorem 3.
For a given λ, the optimal stationary deterministic policy which minimizes in (10) has a threshold structure when the context-aware weight is i.i.d. over time. The thresholds are the same for each state of the context-aware weight.
Proof of Theorem 3.
If the context-aware weight is i.i.d. over time, then we have:
where is the probability of the value of the context-aware weight being in state . Therefore, in this case, the state will be reduced to one dimension and the thresholds will be the same for all the states of the context-aware weight. □
According to Theorems 2 and 3, we proved the threshold structure of the two stationary deterministic policies that compose the UoI-optimal policy. Since the UoI-optimal policy for problem (9) is a probabilistic combination of two deterministic policies with threshold structures, we can finally draw the conclusion that the UoI-optimal policy also has a threshold structure.
3.3. Numerical Solution of Optimal Strategy
Based on Theorem 2, we only need to consider the policy that chooses to update with a probability of 1 in state , for . Let denote the probability that the state of the vehicle is . denotes the probability that the state is and the vehicle chooses to transmit an update. Therefore, we have:
Theorem 4.
When the context-aware weight is a first-order irreducible positive recurrent Markov process, the UoI-optimal policy can be derived by solving the following LP problem:
Proof of Theorem 4.
We first derive the average UoI as a function of and . The vehicle is in state and produces a cost of with a probability of . Therefore, the average UoI is:
As for the constraints, (22b) means that the sum of the probabilities of all the states should be 1. To explain (22c), we note that is the probability of the vehicle being in state and choosing to transmit the update, then the expectation of a one-step updating penalty for state in (8) is . Therefore, the constraint on average update frequency can be illustrated by
Then, we introduce to represent that the probability of the vehicle choosing to transmit updates in state and (22d) can be obtained by the fact that , while (22e) is derived by the nature of probability.
The right-hand side of (22f) can be viewed as two terms. The first term is the sum of transition probability from all the states to state when the vehicle chooses to update and the transmission of status is successful. The second term is the sum of transition probability from all the states to state when the transmission is failed or the vehicle chooses to wait. Therefore, we can prove that the optimal solution of problem (5) equals the solution of the LP problem. □
When is i.i.d. over time, we can also obtain the UoI-optimal policy through the LP problem proposed in Theorem 4 and only need to use as a replacement of .
4. Scheduling in Unknown Contexts
To make decisions, the UoI-optimal updating policy obtained in Section 3 still needs the distributions of the context-aware weight , the increment and the successful transmission probability, which may not be available in advance or may change over time in most practical systems. To solve this problem, we will assume that the distribution of the context-aware weight is not pre-determined and the vehicle has to learn it. In this section, we use the reinforcement learning (RL) algorithm to learn the dynamic of the context and the characteristic of the wireless channel.
To solve this problem, we turn to the model-based RL framework proposed in [36]. We only consider the cases when the UoI-optimal policy has a threshold structure. This assumption makes the optimal policy based on the truncated state space equal the optimal policy of the original problem.
We use the 3-tuple to formulate the proposed RL-based updating policy. The states in the current slot and next slot are denoted by s and , respectively. U denotes the action chosen in the current slot. The settings of the discretized state space and the action space are the same as the settings proposed in Section 3.1. The smaller the step size used in the discretization is, the closer our results are to those in continuous state space. In addition, the selection of the step size only affects the accuracy of the update threshold. Therefore, the performance loss caused by discretization can be reduced by choosing a smaller step size.
We display details about the proposed RL-based updating policy in Algorithm 1. At the beginning of episode k, we randomly decide whether to explore or exploit. represents the trade-off between exploration and exploitation during the following episode. A larger l means a higher frequency of exploration and vice versa. If the algorithm chooses to explore during this episode, a random policy will be used, i.e., we randomly choose to update or not in each state to find more valuable actions. If the algorithm chooses to exploit, then we have to obtain the probability transfer functions for each state transmission pair. In Algorithm 1, and represent the number of occurrences of state–action pair and state transition from s to given action U, respectively. Based on the assumption that the optimal policy has a threshold structure, the policy which can minimize the average UoI with the estimated probability transfer functions, can be directly solved through the LP problem proposed in Theorem 4. Then, the vehicle will use policy to derive state–action pairs and the state transitions in the following slots. Here, is defined to control the number of state transitions observed in each episode. At the end of each episode, the model will be updated according to the state–action pairs and the state transitions observed during the episode. Finally, after K episodes, the algorithm will output the RL-based updating policy , which is derived based on .
| Algorithm 1 RL-based Updating Policy |
Input:
Output: output the RL-based updating policy |
5. Simulation Results and Discussion
5.1. Simulation Setup
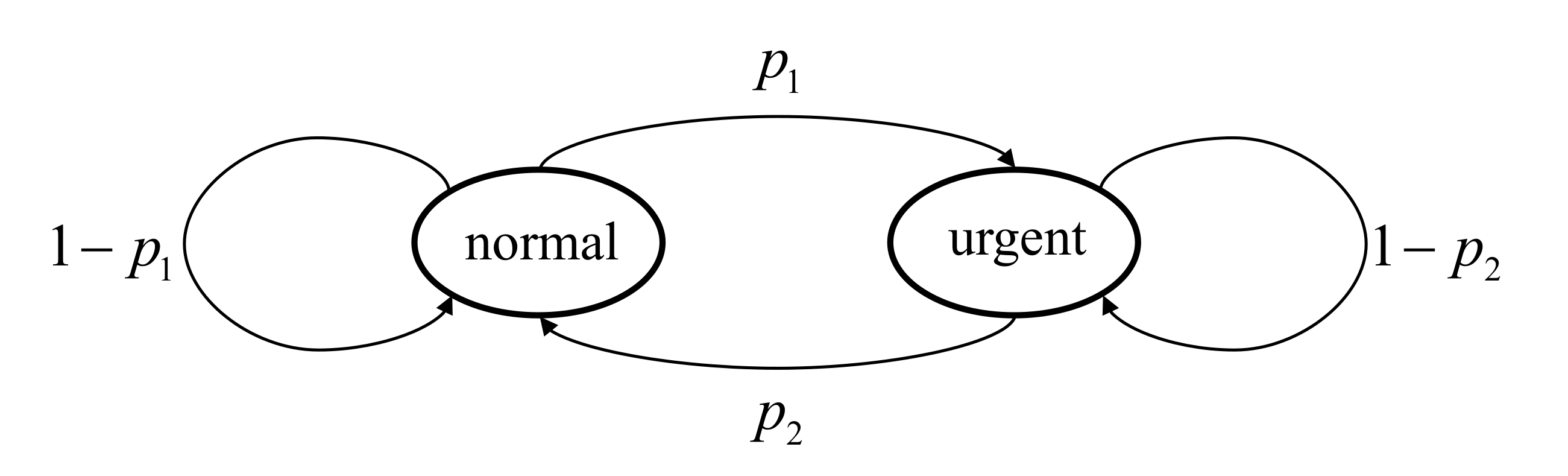
To facilitate the simulation, we consider the case where the context-aware weight of the vehicle only has two different states: the ’normal’ state and ’urgent’ state. The ’normal’ state means that the vehicle is in ordinary situations and the significance of accuracy of status information is relatively low. We set as 1 in ’normal’ state while is set as a constant much larger than 1, , in ’urgent’ state to show that the vehicle is in emergencies. Two different distributions of the context-aware weight are taken into consideration to conform to the assumptions about used in Section 3.1:
- The context-aware weight has the first-order Markov property. The state transition diagram of is shown in Figure 2 and is irreducible and positive recurrent. is the probability of the context-aware weight transferring from the normal state to the urgent state, while is the probability of the weight transferring from the urgent state to the normal state;
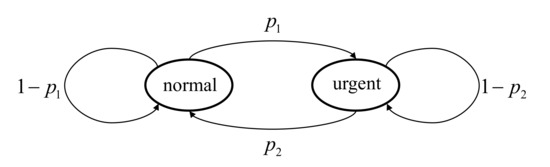 Figure 2. The state transition diagram of .
Figure 2. The state transition diagram of . - The context-aware weight is i.i.d. over time. The probability of the weight being in the urgent state and the normal state are denoted by and , respectively.
As for the increment , is set to a large enough positive number to simplify the simulations.
5.2. Numerical Results
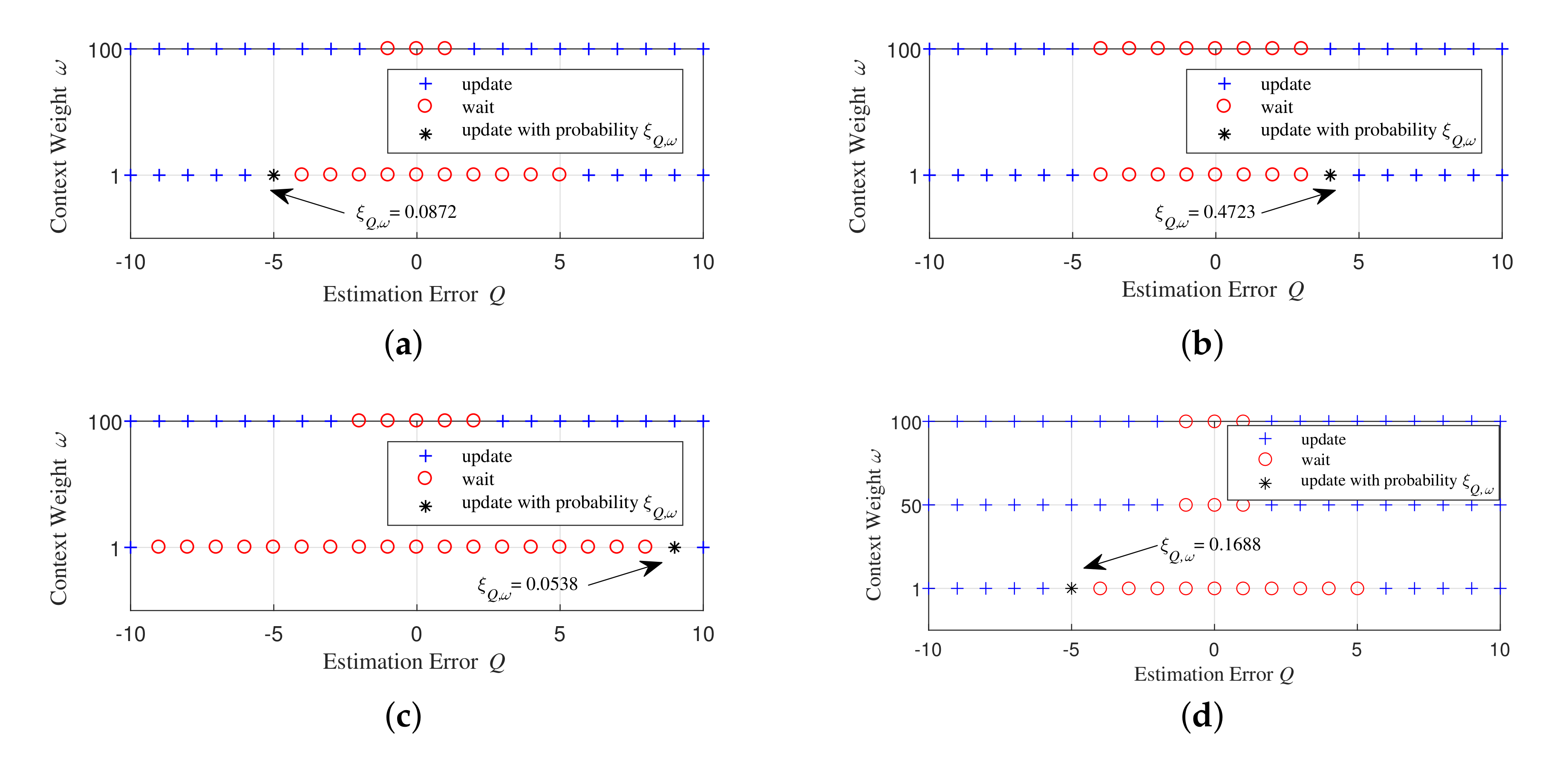
Figure 3 shows the structure of the UoI-optimal updating policy. For the discretization of the estimation error, the step size used is 1. It can be seen that under the two different distributions of the context-aware weight mentioned above, the optimal updating policies all have threshold structures. Especially when the context-aware weight is i.i.d. over time, Figure 3b shows that thresholds for all the states of the context-aware weight are the same, which matches well with theoretical analysis. From Figure 3c, we can find that the UoI-optimal policy also has threshold structure when increment obeys a uniform distribution , which verifies Remark 1. We then simulate the UoI-optimal policy under the contexts with more states to show the policy is generic. We consider a three-state context-aware weight which takes value from . The state transition matrix of the three-state context-aware weight is:
where the j-th element on the i-th row indicates the probability that the context transfers from state to state . The numerical results (Figure 3d) show that when the context-aware weight has more states, the UoI-optimal policy still has a threshold structure, which verifies our theoretical results.
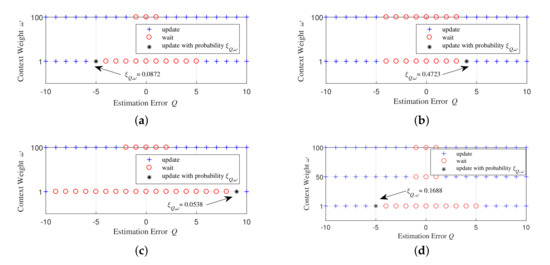
Figure 3.
Threshold structure of the UoI-optimal updating policy when: (a) the context-aware weight is a first-order Markov process, ; (b) the context-aware weight is i.i.d. over time, ; (c) the context-aware weight is a first order Markov process, , increment in the estimation error during one slot, i.e., , for ; and (d) the context-aware weight is a three-state first-order Markov process, which takes value from and evolves according to the state transition matrix , .
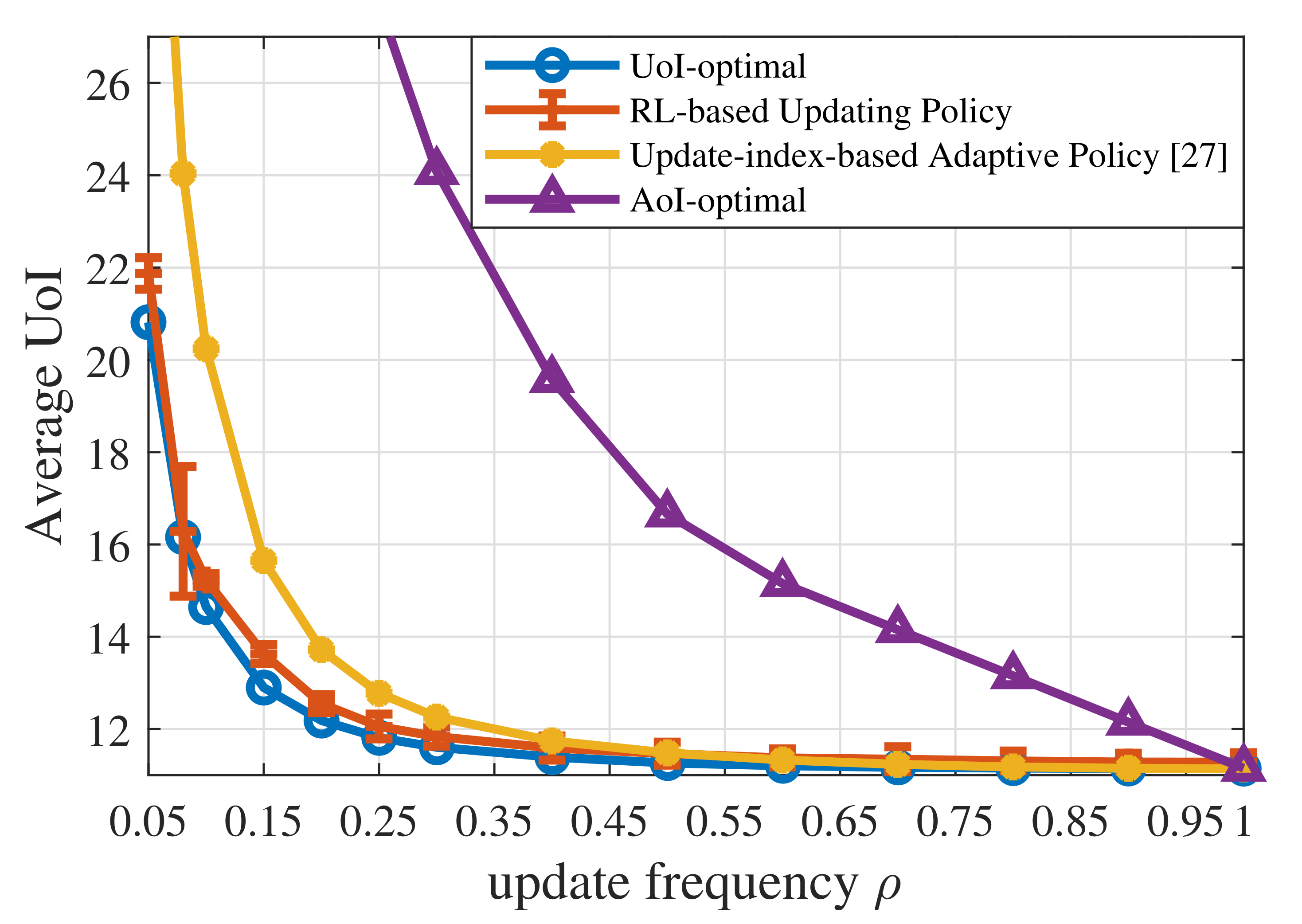
Then, we will focus on the results obtained when the context-aware weight is a first-order irreducible positive recurrent Markov process, as shown in Figure 2. Figure 4 shows the average UoI of the UoI-optimal policy, the AoI-optimal policy derived by CMDP, the RL-based updating policy, and the update-index-based adaptive scheme [27]. In the RL-based updating policy, , and . All the numerical results of the RL-based policy are averaged over 100 runs.
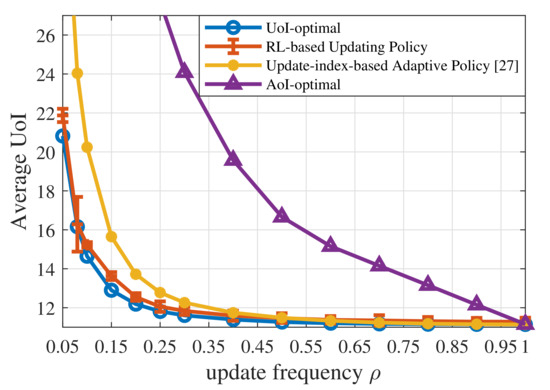
Figure 4.
Average UoI of the UoI-optimal updating policy, the RL-based updating policy, the update-index-based adaptive scheme [27], and the AoI-optimal updating policy when .
First of all, the UoI-optimal policy can only be obtained based on advanced information about the system dynamics. However, the RL-based policy achieves near-optimal without knowing the system dynamics, which indicates that Algorithm 1 learns relatively accurate probability transfer functions from the observed state–action pairs and state transitions during the training.
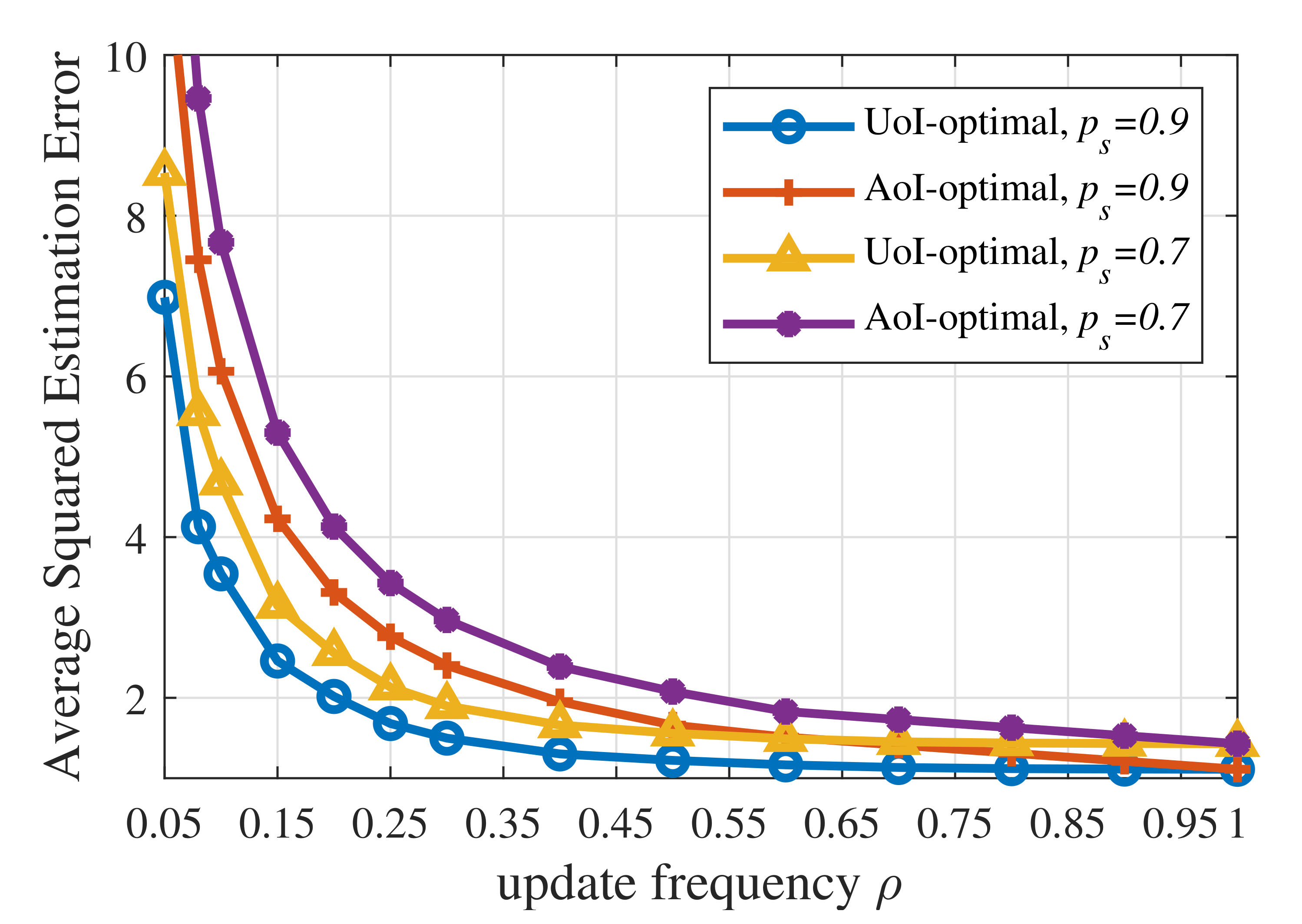
Secondly, according to Figure 4, the AoI-optimal policy yields a much higher UoI than the three UoI-based policies, namely the UoI-optimal policy, the RL-based updating policy, and the update-index-based adaptive scheme. On the one hand, AoI is one special case of UoI. When the context-aware weight , the increment , and the cost function , then UoI equals AoI. Therefore, the AoI-optimal policy ignores the fact that different contexts have different requirements for information freshness. In the proposed UoI-based updating policies, different contexts have different policies and update thresholds, while the AoI-optimal updating policies for different contexts are the same. On the other hand, Figure 5 reveals that the AoI-optimal policy leads to a much higher estimation error, which results in worse performance in terms of UoI. The AoI-optimal policy is an oblivious policy, which is independent of the monitored process. Since AoI increases linearly with time, the AoI-optimal policy can only minimize the linear performance degradation in terms of time. However, the UoI-based policies (the cost function ) considered in this paper are process-dependent, which are called non-oblivious policies, and can benefit from both age and process realization [37]. These policies can directly minimize the nonlinear impact exerted by information staleness and the gap between the actual status and the estimated status.
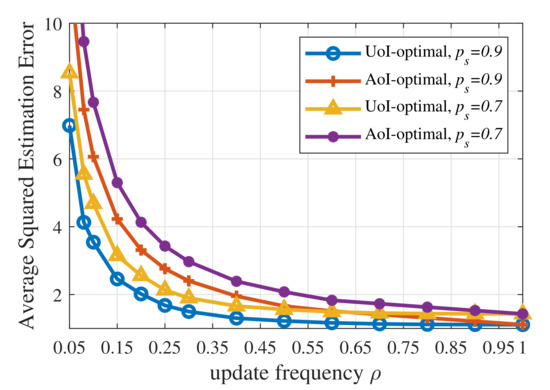
Figure 5.
Average squared estimation error of the UoI-optimal updating policy and the AoI-optimal updating policy when .
Thirdly, our updating policies outperform the update-index-based adaptive scheme [27] in terms of UoI. Under the adaptive scheme, the vehicle will derive an update index as a function of the current estimation error and the context-aware weight for the next slot. If the index is larger than the adaptive update threshold, then the vehicle is supposed to transmit its status information to the center. If the vehicle transmits an update in slot t, then the adaptive threshold will increase in the next slot; otherwise, the adaptive threshold will decrease. The adaptive scheme will cause an overuse of the resource in `urgent’ states and lead to the fact that the vehicles cannot receive resources in `normal’ states. However, the UoI-optimal policy and the trained RL-updating policy are fixed schemes, which can avoid the extremely unbalanced resource allocation between the two contexts and achieve better performance.
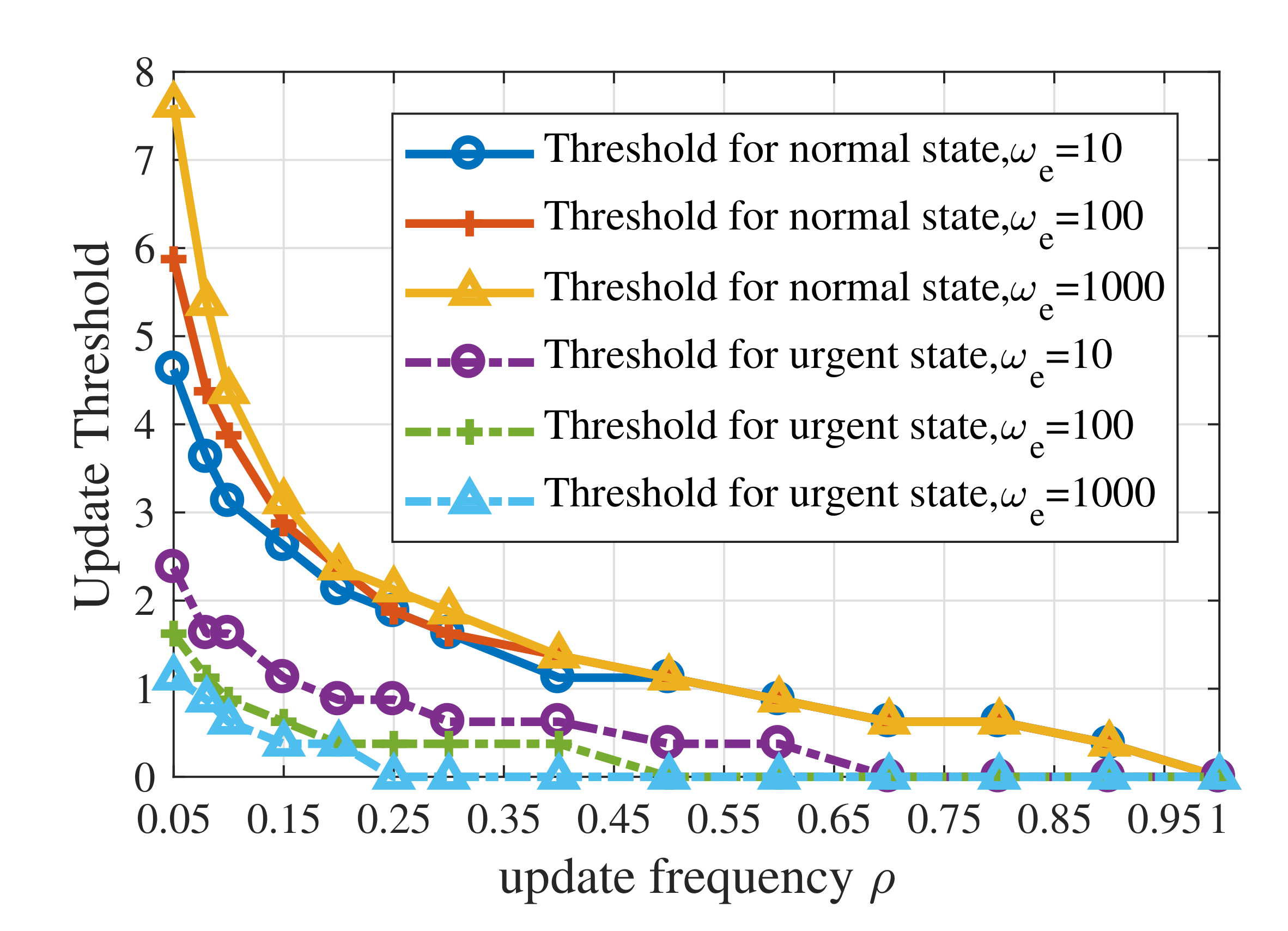
Figure 6 shows the influence of the maximum average update frequency and the context weight for emergency, , on update threshold of UoI-optimal policy. In order to obtain more accurate results, the step size used here is 0.25. The solid curves show update thresholds for the normal state while the dashed curves show update thresholds for the urgent state. When the constraint on update resources is strict, the update thresholds fall faster. Furthermore, a larger results in a lower update threshold for the urgent state and a higher threshold for the normal state. This phenomenon indicates that the value of means the tolerance of estimation error in the emergency. When , the influence of on the update threshold for the normal state is larger than the urgent state. For the cases where the maximum average update frequency is relatively large, has little effect on update thresholds for both normal state and urgent state.
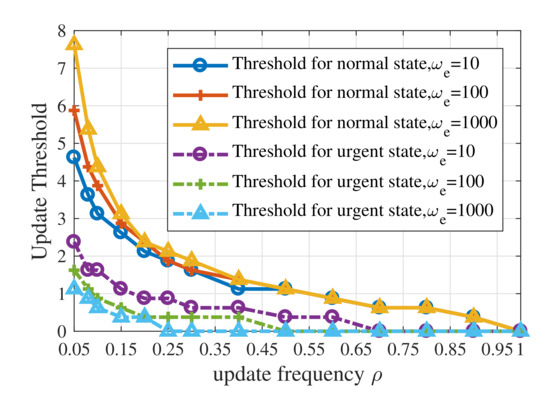
Figure 6.
Update thresholds of the UoI-optimal updating policy with different values of when .
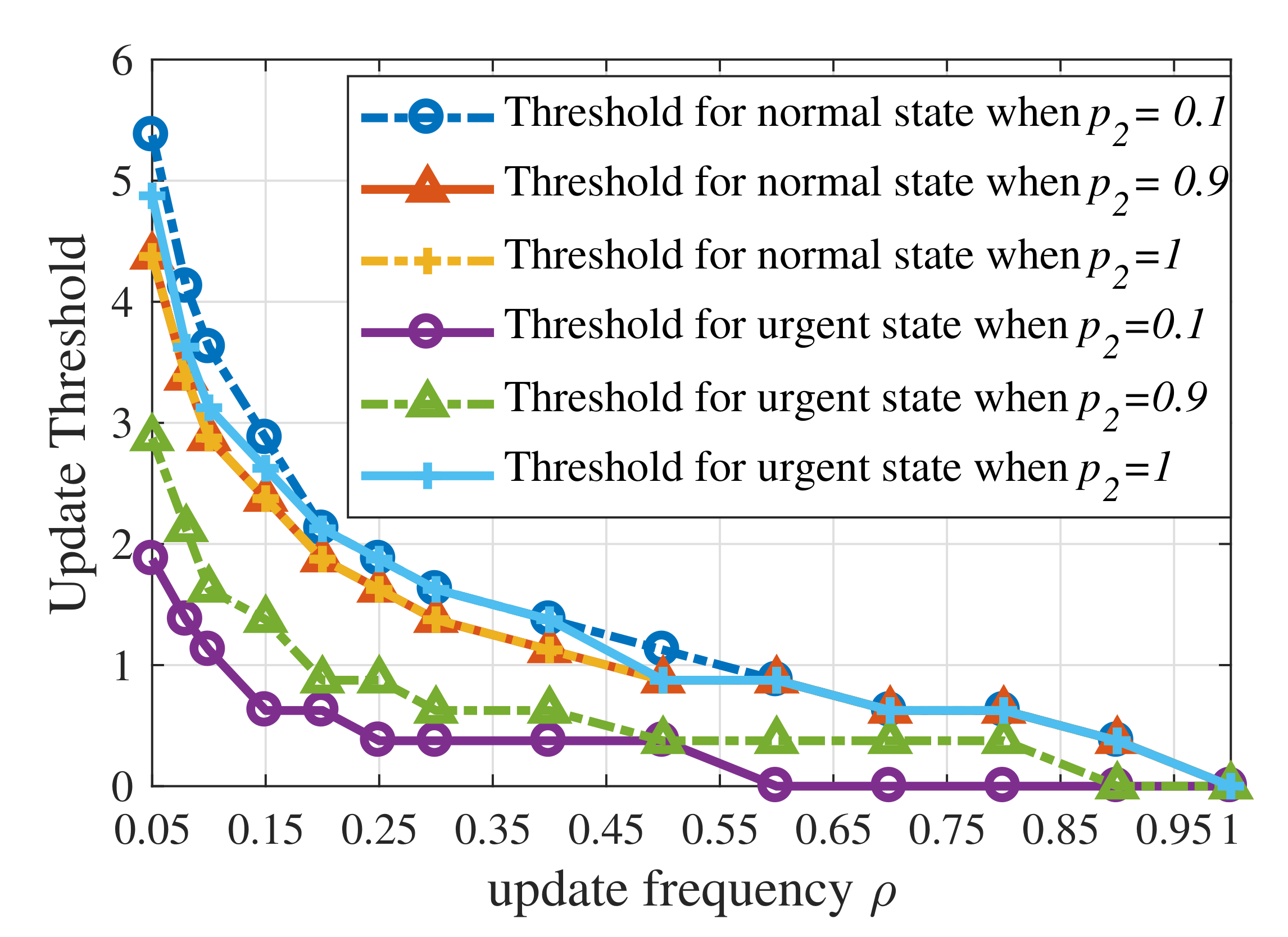
Figure 7 shows that the update thresholds also depend on the dynamic of context-aware weight when the weight has first-order Markov property. When is approaching , the gap between update thresholds for the urgent state and the normal state becomes smaller for the context-aware weight which tends to be i.i.d. over time. When , the update threshold for the urgent state exceeds the threshold for the normal state. Therefore, the update threshold for the urgent state is not necessarily lower than the update threshold for the normal state.
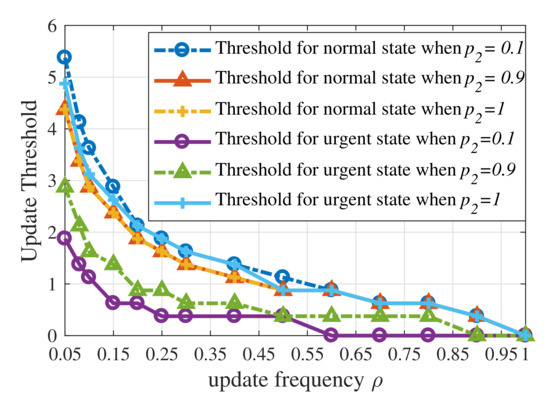
Figure 7.
Update thresholds of the UoI-optimal updating policy with different values of when .
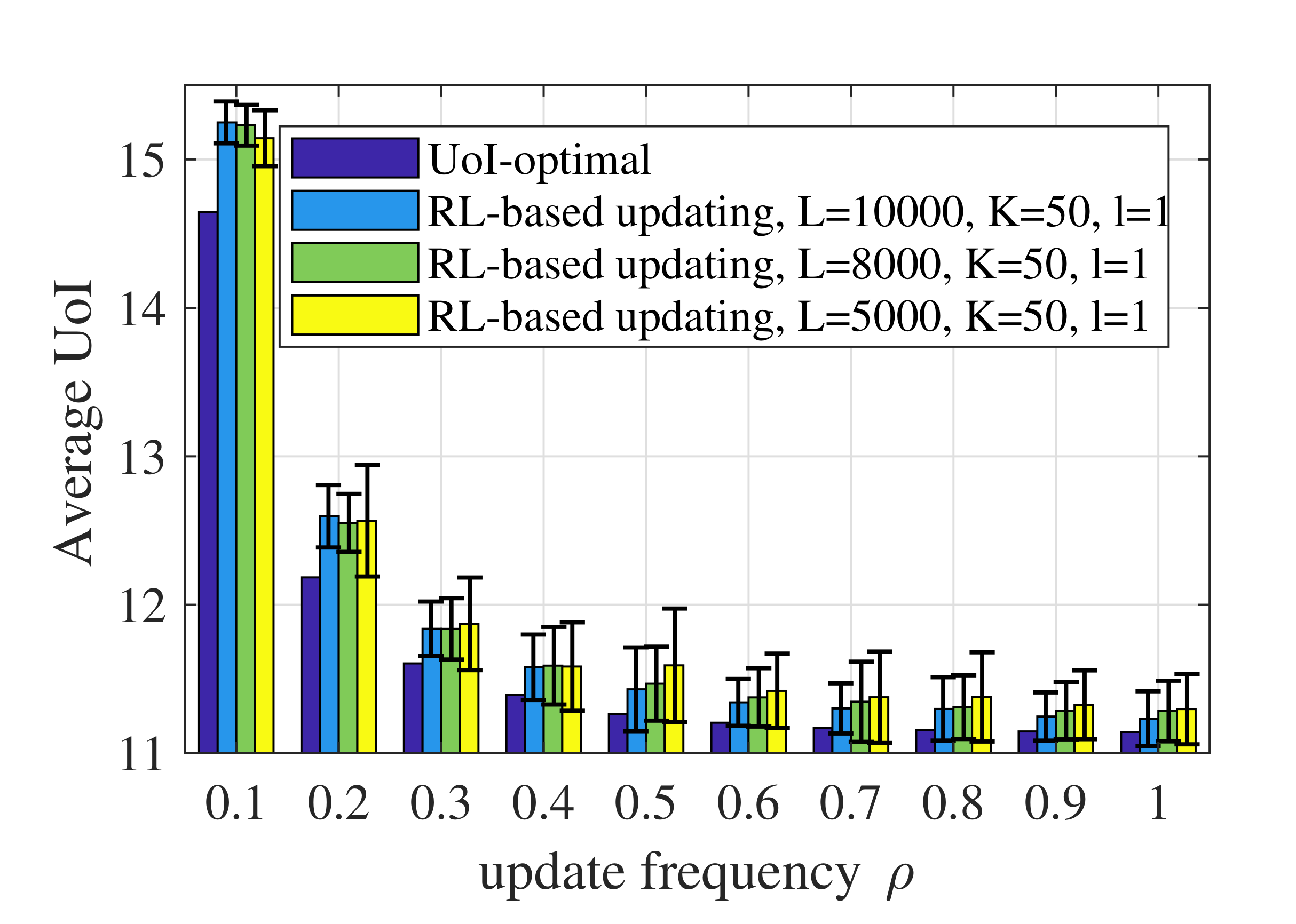
Figure 8 shows the performance of the RL-based updating policy with different values of L. According to Algorithm 1, the number of state transitions observed in episode k is . Therefore, L denotes the number of state transitions observed during the whole learning process. Generally speaking, a larger L reduces the randomness of the performance and achieves a better UoI. The performance of the RL-based updating policy depends on the accuracy of the model obtained through training, namely whether the estimated probability transfer function of the system is accurate. A larger L means that the algorithm can collect more data or state transitions and obtain a more accurate model.
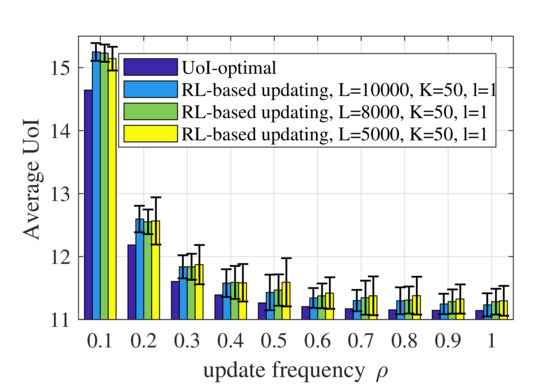
Figure 8.
Average UoI of the RL-based updating policy with different values of L when .
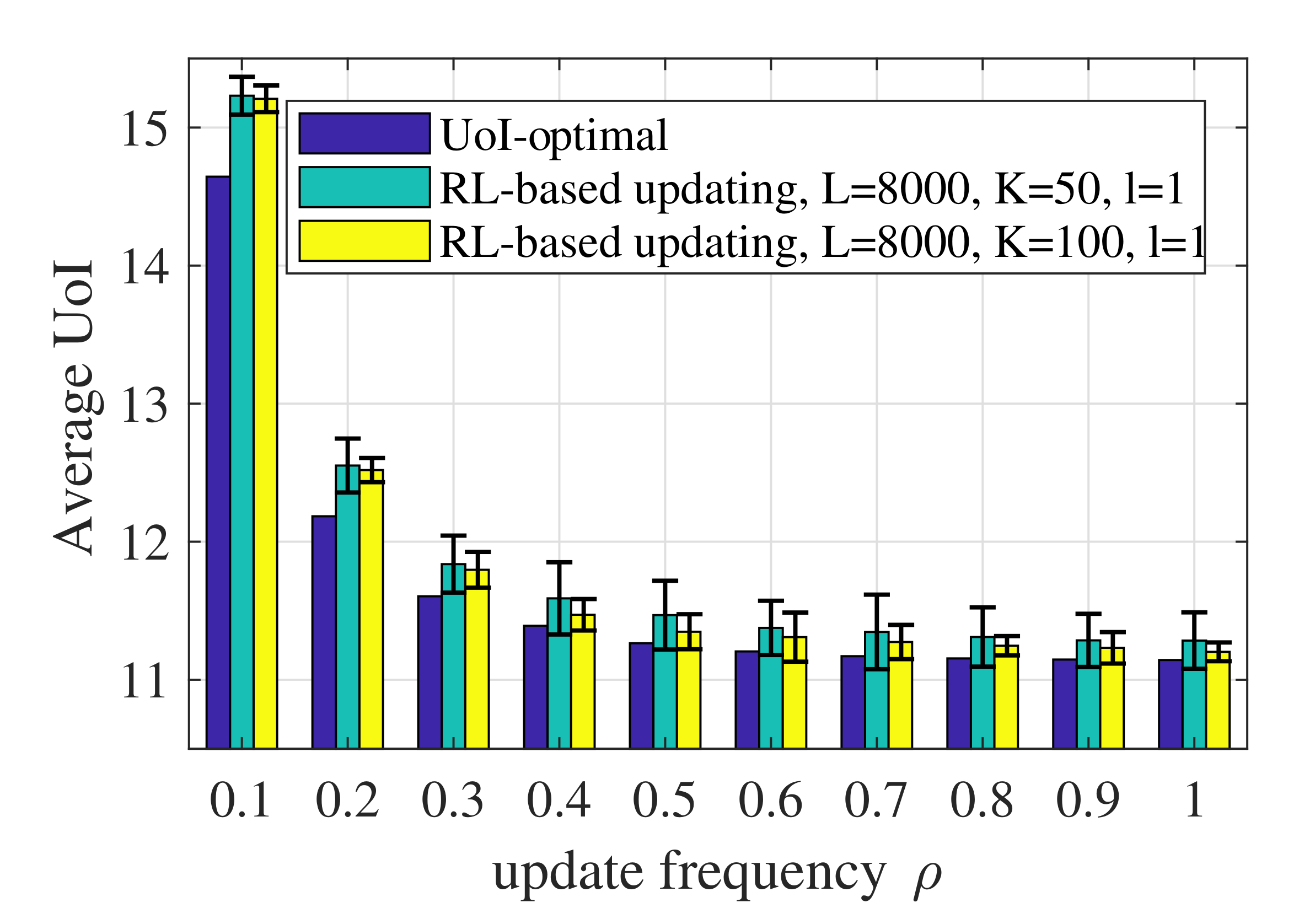
Figure 9 shows the influence of the number of episodes, i.e., K, on the performance of the RL-based updating policy. A larger K leads to a lower average UoI and smaller randomness over 100 runs. On the one hand, the more episodes and the more data the algorithm observes, the more accurate the model obtained will be and the better the performance of the updating policy will be. On the other hand, the value of K is the number of iterations for the policy obtained through the estimated CMDP. The policy used in episode k is derived based on the state–action pairs and the state transitions observed in the previous episodes. Therefore, more frequent iterations of the updating policy can obtain more valuable state–action pairs and better performance.
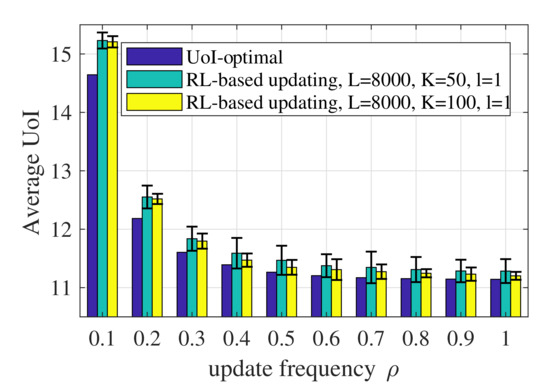
Figure 9.
Average UoI of the RL-based updating policy with different values of K when .
6. Conclusions
In this work, we studied how to minimize the performance degradation caused by outdated information in terms of UoI, which is a new metric jointly considering context and information freshness. We proved that the UoI-optimal updating policy for the considered single-user remote monitoring system has a single threshold structure. Then, the policy was obtained through linear programming by assuming that the state transition probability of the system is known in advance. In unknown contexts, we further used a reinforcement learning algorithm to learn the dynamics of the system. Simulations verified the threshold structure of the UoI-optimal policies and showed that the update thresholds decrease as the maximum average update frequency increases. In addition, a larger context-aware weight in emergencies resulted in a lower update threshold for urgent states. However, since the state transition probability also influenced the update thresholds, the update threshold for emergencies was not necessarily higher than the update threshold for normal states, especially when the probability of transferring from urgent states to normal states tended towards 1. Furthermore, the numerical results showed that the proposed RL-based updating policy achieved a near-optimal performance without advanced knowledge of the system model.
In fact, determining the context-aware weight in practical systems, where the models of the context are often very complicated and difficult to obtain in advance, remains open. As for future work, we plan to use deep RL algorithms to learn the models of the context variation. We believe that UoI can provide a new performance metric for information timeliness measurement in the future V2X scenario. In addition, we believe the proposed UoI metric and the context-aware scheduling policy can shed some light on low-latency and ultra-reliable wireless communication in the future 5G/6G systems.
Author Contributions
Conceptualization, L.W.; formal analysis, L.W.; methodology, L.W.; software, L.W.; supervision, S.Z. and Z.N.; writing—original draft, L.W.; writing—review and editing, J.S., Y.S., S.Z. and Z.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work is sponsored in part by the National Key R&D Program of China No. 2020YFB1806605, by the Nature Science Foundation of China (No. 62022049, No. 61871254, No. 61861136003), by the China Postdoctoral Science Foundation No. 2020M680558, and Hitachi Ltd.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AoI | Age of Information |
| AoII | Age of Incorrect Information |
| AoS | Age of Synchronization |
| CDF | Cumulative Distribution Function |
| CMDP | Constrained Markov Decision Process |
| CoUD | Cost of Update Delay |
| i.i.d. | Independent and Identically Distributed |
| IoT | Internet of Things |
| LP | Linear Programming |
| Probability Density Function | |
| RL | Reinforcement Learning |
| UoI | Urgency of Information |
| URLLC | Ultra-Reliable Low-Latency Communication |
| VR | Virtual Reality |
| V2X | Vehicle to Everything |
Appendix A. Proof of Theorem 1
Given a state and a nonempty subset of the state space, , let denote the class of policies such that the probability and the expected time of the first passage from s to under policy is finite. Then, let denote the class of policies such that the expected average UoI and the expected transmission cost of the first passage from s to are finite and . To prove Theorem 1, we then introduce Assumptions A1–A5 in [33]:
Assumption A1.
For all , the set is finite.
Assumption A2.
There exists a stationary deterministic policy π that induces a Markov chain with the following properties: the state space consists of a single (nonempty) positive recurrent class and a set of transient states such that , for any , and both the average UoI and the average transmission cost on are finite.
Assumption A3.
Given any two states and , there exists a policy π (a function of s and ) such that .
Assumption A4.
If a stationary deterministic policy has at least one positive recurrent state, then it has a single positive recurrent class, and this class contains the state with .
Assumption A5.
There exists a policy π such that the average UoI and average transmission cost .
Furthermore, the problem (9) has the following property:
Lemma A1.
Assumptions A1–A5 hold for problem (9).
Proof of Lemma A1.
First of all, we focus on the cases where the context-aware weight is assumed as a first-order irreducible positive recurrent Markov process:
- Assumption A1: In this problem, is the UoI at state s, namely . is 1 if the vehicle chooses to transmit its status and is 0 otherwise, namely . Therefore, Assumption A1 holds, for any , the number of states with is finite.
- Assumption A2: Due to the current high-level wireless communication technology, we reasonably assumed that the successful transmission probability is relatively close to 1. Based on the assumptions mentioned above, the Markov chain of context-aware weight obviously satisfies Assumption A2. Define the probability of the context-aware weight transferring from to in k steps for the first time as . Then, we consider the policy for all , namely this policy chooses to transmit in all the states.Since the evolution of the context-aware weight is independent with the evolution of the estimation error and the updating policy. Therefore, we first focused on the estimation error, which can be formulated as a one-dimensional irreducible Markov chain with state space . We denote the set of states which can transfer to state Q in a single step by . The probability of the estimation error transferring from state Q to state at the k-th step without an arrival to state is defined as . Obviously, . Then, the probability of the first passage from state to 0 taking steps is , where is the probability that the increment in estimation error is . Therefore, the expected time of the first passage from to 0 is finite.For state , the estimation error will stay in this state in the next step with a probability of and will first return to state in the second transition with a probability smaller than . Then, starting from state , the estimation error will first return to state in the -th () step will be smaller than . Therefore, we can prove that state is a positive recurrent state, and is a positive recurrent class of the induced Markov chain of the estimation error. Furthermore, for any states in , the expected time of the first passage from the state in to state under is finite and the probability of the states in not getting to state in k steps is smaller than .Define the probability of state Q transferring to state in k steps for the first time as . Then, the probability of state transferring to state in k steps for the first time is . Since and , then . Therefore, the set of states is a positive recurrent class. Similarly, we can prove that satisfies Assumption A2. Finally, , .
- Assumption A3: Define , . Consider the policy for all states , notably that this policy chooses not to transmit in any states. Similarly, we first focus on the Markov chain of estimation error. Starting from state Q, the probability of transferring to state in -th steps for the first time is smaller than . Then, the expected time of the first passage from state Q to state under policy is finite. Similarly, since the Markov chain of context-aware weight is irreducible positive recurrent and independent with the updating policy, we can therefore prove that the expected time of the first passage from state to state under policy is finite.
- Assumption A4: For the Markov chain of the estimation error, any state will return to state if a successful transmission occurs. For the policy without transmission, namely , state still exists in only one positive recurrent class. For each positive recurrent class containing state , we can prove that there is only one positive recurrent class. Since the Markov chain of the context-aware weight is irreducible positive recurrent, we can similarly prove Assumption A4.
- Assumption A5: The policy that updates the status with a probability of satisfies Assumption A5. Here, is a small positive number. Under this policy, and .
Similarly, we can prove that Assumptions A1–A5 also holds for problem (9) when the context-aware weight is i.i.d. over time. □
Since Assumptions A1–A5 hold for problem (9), then according to Theorem 2.5 in [33], there exists an optimal stationary randomized policy for problem (9). Meanwhile, the optimal policy is a probabilistic combination of two stationary deterministic policies which only differ on at most one state.
Furthermore, according to Lemma 3.9 in [33], the two stationary deterministic policies each optimize the unconstrained cost in (10) with a different .
References
- Talak, R.; Karaman, S.; Modiano, E. Speed limits in autonomous vehicular networks due to communication constraints. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 4998–5003. [Google Scholar]
- Hou, I.H.; Naghsh, N.Z.; Paul, S.; Hu, Y.C.; Eryilmaz, A. Predictive Scheduling for Virtual Reality. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1349–1358. [Google Scholar]
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2731–2735. [Google Scholar]
- Sun, Y.; Polyanskiy, Y.; Uysal-Biyikoglu, E. Remote estimation of the Wiener process over a channel with random delay. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 321–325. [Google Scholar]
- Sun, Y.; Polyanskiy, Y.; Uysal, E. Sampling of the wiener process for remote estimation over a channel with random delay. IEEE Trans. Inf. Theory 2019, 66, 1118–1135. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhou, S. Status from a random field: How densely should one update? In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1037–1041. [Google Scholar]
- Bedewy, A.M.; Sun, Y.; Singh, R.; Shroff, N.B. Optimizing information freshness using low-power status updates via sleep-wake scheduling. In Proceedings of the Twenty-First International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, New York, NY, USA, 11–14 October 2020; pp. 51–60. [Google Scholar]
- Ceran, E.T.; Gündüz, D.; György, A. Average age of information with hybrid ARQ under a resource constraint. IEEE Trans. Wirel. Commun. 2019, 18, 1900–1913. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Jiang, Z.; Krishnamachari, B.; Zhou, S.; Niu, Z. Closed-form Whittle’s index-enabled random access for timely status update. IEEE Trans. Commun. 2019, 68, 1538–1551. [Google Scholar] [CrossRef]
- Yates, R.D.; Kaul, S.K. Status updates over unreliable multiaccess channels. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 331–335. [Google Scholar]
- Sun, J.; Wang, L.; Jiang, Z.; Zhou, S.; Niu, Z. Age-Optimal Scheduling for Heterogeneous Traffic with Timely Throughput Constraints. IEEE J. Sel. Areas Commun. 2021, 39, 1485–1498. [Google Scholar] [CrossRef]
- Tang, H.; Wang, J.; Song, L.; Song, J. Minimizing age of information with power constraints: Multi-user opportunistic scheduling in multi-state time-varying channels. IEEE J. Sel. Areas Commun. 2020, 38, 854–868. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Aziz, M.K.; Samarakoon, S.; Liu, C.F.; Bennis, M.; Saad, W. Optimized age of information tail for ultra-reliable low-latency communications in vehicular networks. IEEE Trans. Commun. 2019, 68, 1911–1924. [Google Scholar] [CrossRef] [Green Version]
- Devassy, R.; Durisi, G.; Ferrante, G.C.; Simeone, O.; Uysal-Biyikoglu, E. Delay and peak-age violation probability in short-packet transmissions. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2471–2475. [Google Scholar]
- Inoue, Y.; Masuyama, H.; Takine, T.; Tanaka, T. A general formula for the stationary distribution of the age of information and its application to single-server queues. IEEE Trans. Inf. Theory 2019, 65, 8305–8324. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Uysal-Biyikoglu, E.; Yates, R.D.; Koksal, C.E.; Shroff, N.B. Update or wait: How to keep your data fresh. IEEE Trans. Inf. Theory 2017, 63, 7492–7508. [Google Scholar] [CrossRef]
- Zheng, X.; Zhou, S.; Jiang, Z.; Niu, Z. Closed-form analysis of non-linear age of information in status updates with an energy harvesting transmitter. IEEE Trans. Wirel. Commun. 2019, 18, 4129–4142. [Google Scholar] [CrossRef] [Green Version]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. Non-linear age of information in a discrete time queue: Stationary distribution and average performance analysis. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. The cost of delay in status updates and their value: Non-linear ageing. IEEE Trans. Commun. 2020, 68, 4905–4918. [Google Scholar] [CrossRef] [Green Version]
- Zhong, J.; Yates, R.D.; Soljanin, E. Two freshness metrics for local cache refresh. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1924–1928. [Google Scholar]
- Maatouk, A.; Kriouile, S.; Assaad, M.; Ephremides, A. The age of incorrect information: A new performance metric for status updates. IEEE/ACM Trans. Netw. 2020, 28, 2215–2228. [Google Scholar] [CrossRef]
- Kadota, I.; Sinha, A.; Uysal-Biyikoglu, E.; Singh, R.; Modiano, E. Scheduling policies for minimizing age of information in broadcast wireless networks. IEEE/ACM Trans. Netw. 2018, 26, 2637–2650. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Gunduz, D.; Choi, W. Optimal scheduling policy for minimizing age of information with a relay. arXiv 2020, arXiv:2009.02716. [Google Scholar]
- Sun, Y.; Cyr, B. Information aging through queues: A mutual information perspective. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Kam, C.; Kompella, S.; Nguyen, G.D.; Wieselthier, J.E.; Ephremides, A. Towards an effective age of information: Remote estimation of a markov source. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 367–372. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Context-aware information lapse for timely status updates in remote control systems. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Beyond age: Urgency of information for timeliness guarantee in status update systems. In Proceedings of the 2020 2nd IEEE 6G Wireless Summit (6G SUMMIT), Levi, Finland, 17–20 March 2020; pp. 1–5. [Google Scholar]
- Zheng, X.; Zhou, S.; Niu, Z. Urgency of Information for Context-Aware Timely Status Updates in Remote Control Systems. IEEE Trans. Wirel. Commun. 2020, 19, 7237–7250. [Google Scholar] [CrossRef]
- Ioannidis, S.; Chaintreau, A.; Massoulié, L. Optimal and scalable distribution of content updates over a mobile social network. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1422–1430. [Google Scholar]
- Wang, L.; Sun, J.; Zhou, S.; Niu, Z. Timely Status Update Based on Urgency of Information with Statistical Context. In Proceedings of the 2020 32nd IEEE International Teletraffic Congress (ITC 32), Osaka, Japan, 22–24 September 2020; pp. 90–96. [Google Scholar]
- Nayyar, A.; Başar, T.; Teneketzis, D.; Veeravalli, V.V. Optimal strategies for communication and remote estimation with an energy harvesting sensor. IEEE Trans. Autom. Control 2013, 58, 2246–2260. [Google Scholar] [CrossRef] [Green Version]
- Cika, A.; Badiu, M.A.; Coon, J.P. Quantifying link stability in Ad Hoc wireless networks subject to Ornstein-Uhlenbeck mobility. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Sennott, L.I. Constrained average cost Markov decision chains. Probab. Eng. Inf. Sci. 1993, 7, 69–83. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Dynamic Programming and Optimal Control; Athena Scientific: Belmont, MA, USA, 2000. [Google Scholar]
- Sennott, L.I. Average cost optimal stationary policies in infinite state Markov decision processes with unbounded costs. Oper. Res. 1989, 37, 626–633. [Google Scholar] [CrossRef]
- Liu, B.; Xie, Q.; Modiano, E. Rl-qn: A reinforcement learning framework for optimal control of queueing systems. arXiv 2020, arXiv:2011.07401. [Google Scholar]
- Chen, X.; Liao, X.; Bidokhti, S.S. Real-time Sampling and Estimation on Random Access Channels: Age of Information and Beyond. arXiv 2020, arXiv:2007.03652. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).