


J. Imaging 2026, 12(5), 217; https://doi.org/10.3390/jimaging12050217 - 20 May 2026
Abstract
Preclinical multimodal imaging is widely applied in small animal models for longitudinal studies of human diseases. Beyond murine systems, cost-effective and ethically sustainable models such as the chicken embryo and its chorioallantoic membrane are gaining increasing interest in accordance with the 3Rs principles.
[...] Read more.
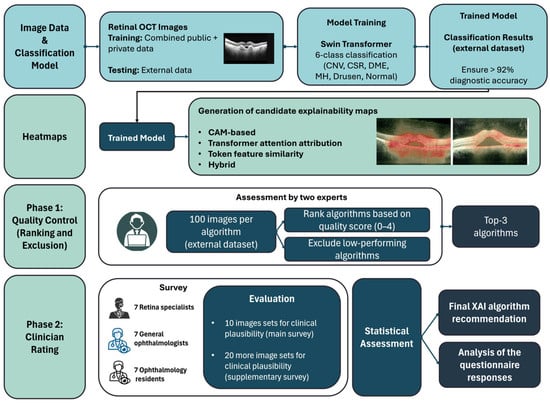
Preclinical multimodal imaging is widely applied in small animal models for longitudinal studies of human diseases. Beyond murine systems, cost-effective and ethically sustainable models such as the chicken embryo and its chorioallantoic membrane are gaining increasing interest in accordance with the 3Rs principles. This study evaluated the feasibility of using both high-frequency ultrasound and magnetic resonance imaging for the non-invasive longitudinal monitoring of chicken embryo development in ovo. Fifty fertilized eggs were incubated under controlled conditions and examined up to embryonic day 14. High-frequency ultrasound (15–71 MHz) enabled real-time imaging and quantitative assessment of superficial structures, including cranial biometry and limb growth, while magnetic resonance imaging (7T) provided high-resolution three-dimensional visualization of internal organs and extraembryonic compartments. Together, these modalities allowed the progressive identification of key anatomical structures from ED5 onward, with HFUS enabling earlier linear measurements and MRI facilitating detailed anatomical and volumetric evaluation. The integration of these techniques allowed the generation of a developmental imaging timeline and quantitative reference dataset of normal embryogenesis. This multimodal approach represents a promising strategy for in vivo developmental studies, offering a robust baseline to characterize structural alterations induced by experimental conditions. Moreover, the use of the chicken embryo model provides significant ethical and economic advantages, supporting its application in preclinical research and imaging-based studies.
Full article
(This article belongs to the Special Issue Translational Preclinical Imaging: Techniques, Applications and Perspectives)
►
Show Figures
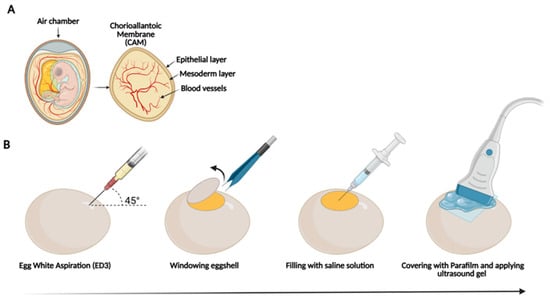
Figure 1
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}