Machine Learning and Data Analytics for Cyber Security
Printed Edition Available!
A printed edition of this Topical Collection is available
here.
Share This Topical Collection
Editors
 Prof. Dr. Phil Legg
Prof. Dr. Phil Legg
Prof. Dr. Phil Legg
E-Mail
Website
Collection Editor
School of Computing and Creative Technologies, University of the West of England, Bristol BS16 1QY, UK
Interests: cyber security; data analytics; machine learning; visualization
 Prof. Dr. Giorgio Giacinto
Prof. Dr. Giorgio Giacinto
Prof. Dr. Giorgio Giacinto
E-Mail
Website
Collection Editor
Department of Electrical and Electronic Engineering, University of Cagliari, Piazza d’Armi, 09123 Cagliari, Italy
Interests: cybersecurity; machine learning; malware analysis; malware detection; adversarial learning; cyber threat intelligence
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
Cyber security is primarily concerned with the protection of digital systems and their respective data. Therefore, how we analyse and monitor such systems is a crucial step towards their protection. Machine learning, as a form of data analytics, has seen much use in the field of cyber security in recent years, for helping to process and analyse vast volumes of information to make for actionable intelligence for security analysts. In this Topical Collection, we invite papers that address the topics of machine learning and data analytics, and their applications to addressing challenges in cyber security.
The possible topics may include, but are not limited to:
- Network traffic analysis;
- Malware analysis;
- Behavioural analysis;
- Social media analysis;
- Wireless sensor security;
- Mobile and web application security;
- Machine learning for system security;
- The security of machine learning;
- Adversarial machine learning;
- The security of the Industrial IoT;
- The security of connected autonomous vehicles;
- The security of HealthTech;
- Machine learning for cybercrime;
- Data visualisation for cyber security;
- Analysis techniques for cyber security.
Prof. Dr. Phil Legg
Prof. Dr. Giorgio Giacinto
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Journal of Cybersecurity and Privacy is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1200 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Published Papers (21 papers)
Open AccessArticle
Beyond Semantic Noise: A Dual-Verification Framework for Thai–English Code-Mixed Malicious Script Detection via XAI-Guided Selective Integration
by
Prasert Teppap, Wirot Ponglangka, Panudech Tipauksorn and Prasert Luekhong
Viewed by 1620
Abstract
In the evolving cybersecurity landscape, detecting Thai-English code-mixed malicious scripts within high-trust domains such as governmental and academic portals presents a significant defensive challenge. While Transformer-based architectures excel in semantic parsing, they often exhibit ‘Structural Bias,’ misinterpreting the high-entropy syntax of benign legacy
[...] Read more.
In the evolving cybersecurity landscape, detecting Thai-English code-mixed malicious scripts within high-trust domains such as governmental and academic portals presents a significant defensive challenge. While Transformer-based architectures excel in semantic parsing, they often exhibit ‘Structural Bias,’ misinterpreting the high-entropy syntax of benign legacy HyperText Markup Language (HTML) as malicious obfuscation due to inherent ‘Attention Deficit’ in token-limited models. To address this, we propose an Explainable AI (XAI)-Driven Hybrid Architecture grounded in a ‘Selective Integration’ strategy. Unlike traditional hybrid models, our framework mathematically formalizes the fusion process by synergizing context-aware WangChanBERTa embeddings with orthogonal structural statistics through Dempster-Shafer Theory and Conditional Mutual Information (CMI). The proposed model was validated on a high-fidelity corpus, achieving a state-of-the-art F1-score of 0.9908, significantly outperforming standalone Transformers, Random Forest, and unsupervised baselines. XAI diagnostics revealed a ‘Dual-Validation’ mechanism where structural features act as an epistemic anchor. This mechanism effectively triggers a ‘Semantic Veto’ to filter hallucinations caused by benign complexity, achieving a remarkably low False Positive Rate (FPR) of 0.0116. Our findings demonstrate that hybridization is most effective when engineered features provide mathematical orthogonality to semantic embeddings. This work offers a robust, theoretically grounded framework for securing critical digital infrastructures in low-resource linguistic environments.
Full article
►▼
Show Figures
Open AccessArticle
Enhancing Ransomware Threat Detection: Risk-Aware Classification via Windows API Call Analysis and Hybrid ML/DL Models
by
Sarah Alhuwayshil, Sundaresan Ramachandran and Kyounggon Kim
Cited by 2 | Viewed by 2817
Abstract
Ransomware attacks pose a serious threat to computer networks, causing widespread disruption to individual, corporate, governmental, and critical national infrastructures. To mitigate their impact, extensive research has been conducted to analyze ransomware operations. However, most prior studies have focused on decryption, post-infection response,
[...] Read more.
Ransomware attacks pose a serious threat to computer networks, causing widespread disruption to individual, corporate, governmental, and critical national infrastructures. To mitigate their impact, extensive research has been conducted to analyze ransomware operations. However, most prior studies have focused on decryption, post-infection response, or general family-level classification for performance evaluation, with limited attention to linking classification accuracy to each family’s threat level and behavioral patterns. In this study, we propose a classification framework for the most dangerous ransomware families targeting Windows systems, correlating model performance with defined threat levels (high, medium, and low) based on API call patterns. Two independent datasets were used, extracted from VirusTotal and Cuckoo Sandbox, and a cross-source evaluation strategy was applied, alternating training and testing roles between datasets to assess generalization ability and minimize source bias. The results show that the proposed approach, particularly when using XGBoost and LightGBM, achieved accuracy rates ranging from 84 to 100% across datasets. These findings confirm the effectiveness of our method in accurately classifying ransomware families while accounting for their severity and behavioral characteristics.
Full article
►▼
Show Figures
Open AccessArticle
Novel Actionable Counterfactual Explanations for Intrusion Detection Using Diffusion Models
by
Vinura Galwaduge and Jagath Samarabandu
Cited by 4 | Viewed by 2783
Abstract
Modern network intrusion detection systems (NIDSs) rely on complex deep learning models. However, the “black-box” nature of deep learning methods hinders transparency and trust in predictions, preventing the timely implementation of countermeasures against intrusion attacks. Although explainable AI (XAI) methods provide a solution
[...] Read more.
Modern network intrusion detection systems (NIDSs) rely on complex deep learning models. However, the “black-box” nature of deep learning methods hinders transparency and trust in predictions, preventing the timely implementation of countermeasures against intrusion attacks. Although explainable AI (XAI) methods provide a solution to this problem by providing insights into the reasons behind the predictions, the explanations provided by the majority of them cannot be trivially converted into actionable countermeasures. In this work, we propose a novel tabular diffusion-based counterfactual explanation framework that can provide actionable explanations for network intrusion attacks. We evaluated our proposed algorithm against several other publicly available counterfactual explanation algorithms on three modern network intrusion datasets. To the best of our knowledge, this work also presents the first comparative analysis of the existing counterfactual explanation algorithms within the context of NIDSs. Our proposed method provides plausible and diverse counterfactual explanations more efficiently than the tested counterfactual algorithms, reducing the time required to generate explanations. We also demonstrate how the proposed method can provide actionable explanations for NIDSs by summarizing them into a set of actionable global counterfactual rules, which effectively filter out incoming attack queries. This ability of the rules is crucial for efficient intrusion detection and defense mechanisms. We have made our implementation publicly available on GitHub.
Full article
►▼
Show Figures
Open AccessArticle
Threat Intelligence Extraction Framework (TIEF) for TTP Extraction
by
Anooja Joy, Madhav Chandane, Yash Nagare and Faruk Kazi
Cited by 2 | Viewed by 6180
Abstract
The increasing complexity and scale of cyber threats demand advanced, automated methodologies for extracting actionable cyber threat intelligence (CTI). The automated extraction of Tactics, Techniques, and Procedures (TTPs) from unstructured threat reports remains a challenging task, constrained by the scarcity of labeled data,
[...] Read more.
The increasing complexity and scale of cyber threats demand advanced, automated methodologies for extracting actionable cyber threat intelligence (CTI). The automated extraction of Tactics, Techniques, and Procedures (TTPs) from unstructured threat reports remains a challenging task, constrained by the scarcity of labeled data, severe class imbalance, semantic variability, and the complexity of multi-class, multi-label learning for fine-grained classification. To address these challenges, this work proposes the Threat Intelligence Extraction Framework (TIEF) designed to autonomously extract Indicators of Compromise (IOCs) from heterogeneous textual threat reports and represent them by the STIX 2.1 standard for standardized sharing. TIEF employs the DistilBERT Base-Uncased model as its backbone, achieving an F1 score of 0.933 for multi-label TTP classification, while operating with 40% fewer parameters than traditional BERT-base models and preserving 97% of their predictive performance. Distinguishing itself from existing methodologies such as TTPDrill, TTPHunter, and TCENet, TIEF incorporates a multi-label classification scheme capable of covering 560 MITRE ATT&CK classes comprising techniques and sub-techniques, thus facilitating a more granular and semantically precise characterization of adversarial behaviors. BERTopic modeling integration enabled the clustering of semantically similar textual segments and captured the variations in threat report narratives. By operationalizing sub-technique-level discrimination, TIEF contributes to context-aware automated threat detection.
Full article
►▼
Show Figures
Open AccessArticle
MICRA: A Modular Intelligent Cybersecurity Response Architecture with Machine Learning Integration
by
Alessandro Carvalho Coutinho and Luciano Vieira de Araújo
Cited by 1 | Viewed by 3231
Abstract
The growing sophistication of cyber threats has posed significant challenges for organizations in terms of accurately detecting and responding to incidents in a coordinated manner. Despite advances in the application of machine learning and automation, many solutions still face limitations such as high
[...] Read more.
The growing sophistication of cyber threats has posed significant challenges for organizations in terms of accurately detecting and responding to incidents in a coordinated manner. Despite advances in the application of machine learning and automation, many solutions still face limitations such as high false positive rates, low scalability, and difficulties in interorganizational cooperation. This study presents MICRA (Modular Intelligent Cybersecurity Response Architecture), a modular conceptual proposal that integrates dynamic data acquisition, cognitive threat analysis, multi-layer validation, adaptive response orchestration, and collaborative intelligence sharing. The architecture consists of six interoperable modules and incorporates techniques such as supervised learning, heuristic analysis, and behavioral modeling. The modules are designed for operation in diverse environments, including corporate networks, educational networks, and critical infrastructures. MICRA seeks to establish a flexible and scalable foundation for proactive cyber defense, reconciling automation, collaborative intelligence, and adaptability. This proposal aims to support future implementations and research on incident response and cyber resilience in complex operational contexts.
Full article
►▼
Show Figures
Open AccessArticle
Detecting Malware C&C Communication Traffic Using Artificial Intelligence Techniques
by
Mohamed Ali Kazi
Cited by 7 | Viewed by 5238
Abstract
Banking malware poses a significant threat to users by infecting their computers and then attempting to perform malicious activities such as surreptitiously stealing confidential information from them. Banking malware variants are also continuing to evolve and have been increasing in numbers for many
[...] Read more.
Banking malware poses a significant threat to users by infecting their computers and then attempting to perform malicious activities such as surreptitiously stealing confidential information from them. Banking malware variants are also continuing to evolve and have been increasing in numbers for many years. Amongst these, the banking malware Zeus and its variants are the most prevalent and widespread banking malware variants discovered. This prevalence was expedited by the fact that the Zeus source code was inadvertently released to the public in 2004, allowing malware developers to reproduce the Zeus banking malware and develop variants of this malware. Examples of these include Ramnit, Citadel, and Zeus Panda. Tools such as anti-malware programs do exist and are able to detect banking malware variants, however, they have limitations. Their reliance on regular updates to incorporate new malware signatures or patterns means that they can only identify known banking malware variants. This constraint inherently restricts their capability to detect novel, previously unseen malware variants. Adding to this challenge is the growing ingenuity of malicious actors who craft malware specifically developed to bypass signature-based anti-malware systems. This paper presents an overview of the Zeus, Zeus Panda, and Ramnit banking malware variants and discusses their communication architecture. Subsequently, a methodology is proposed for detecting banking malware C&C communication traffic, and this methodology is tested using several feature selection algorithms to determine which feature selection algorithm performs the best. These feature selection algorithms are also compared with a manual feature selection approach to determine whether a manual, automated, or hybrid feature selection approach would be more suitable for this type of problem.
Full article
►▼
Show Figures
Open AccessArticle
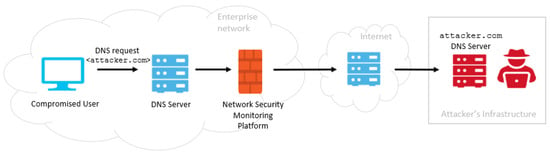
Towards a Near-Real-Time Protocol Tunneling Detector Based on Machine Learning Techniques
by
Filippo Sobrero, Beatrice Clavarezza, Daniele Ucci and Federica Bisio
Cited by 1 | Viewed by 3926
Abstract
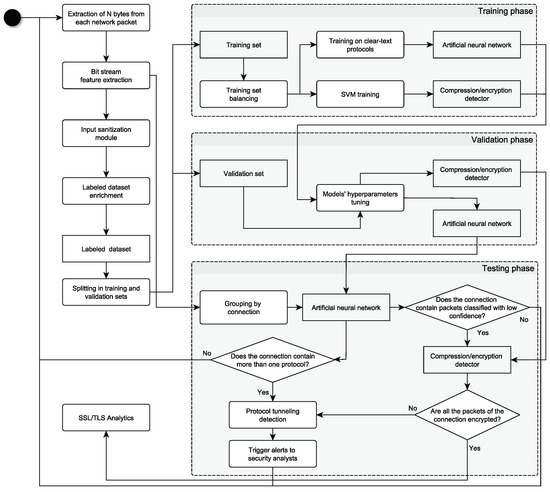
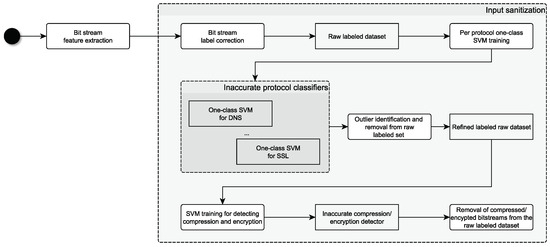
In the very recent years, cybersecurity attacks have increased at an unprecedented pace, becoming ever more sophisticated and costly. Their impact has involved both private/public companies and critical infrastructures. At the same time, due to the COVID-19 pandemic, the security perimeters of many
[...] Read more.
In the very recent years, cybersecurity attacks have increased at an unprecedented pace, becoming ever more sophisticated and costly. Their impact has involved both private/public companies and critical infrastructures. At the same time, due to the COVID-19 pandemic, the security perimeters of many organizations expanded, causing an increase in the attack surface exploitable by threat actors through malware and phishing attacks. Given these factors, it is of primary importance to monitor the security perimeter and the events occurring in the monitored network, according to a tested security strategy of detection and response. In this paper, we present a protocol tunneling detector prototype which inspects, in near real-time, a company’s network traffic using machine learning techniques. Indeed, tunneling attacks allow malicious actors to maximize the time in which their activity remains undetected. The detector monitors unencrypted network flows and extracts features to detect possible occurring attacks and anomalies by combining machine learning and deep learning. The proposed module can be embedded in any network security monitoring platform able to provide network flow information along with its metadata. The detection capabilities of the implemented prototype have been tested both on benign and malicious datasets. Results show an overall accuracy of
and an F1-score equal to
.
Full article
►▼
Show Figures
Open AccessArticle
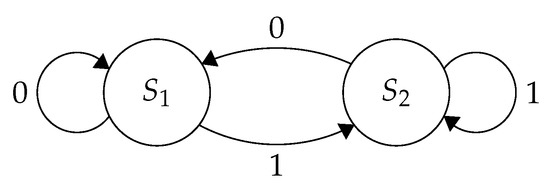
Power-Based Side-Channel Attacks on Program Control Flow with Machine Learning Models
by
Andey Robins, Stone Olguin, Jarek Brown, Clay Carper and Mike Borowczak
Cited by 1 | Viewed by 4861
Abstract
The control flow of a program represents valuable and sensitive information; in embedded systems, this information can take on even greater value as the resources, control flow, and execution of the system have more constraints and functional implications than modern desktop environments. Early
[...] Read more.
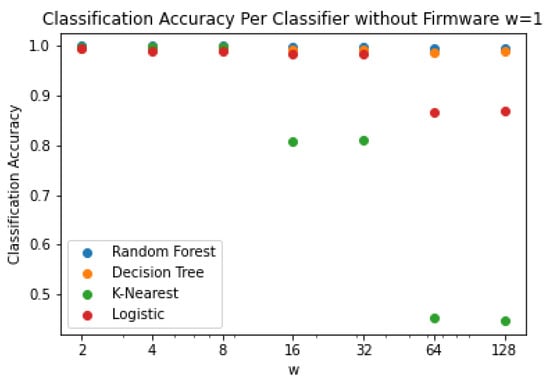
The control flow of a program represents valuable and sensitive information; in embedded systems, this information can take on even greater value as the resources, control flow, and execution of the system have more constraints and functional implications than modern desktop environments. Early works have demonstrated the possibility of recovering such control flow through power-based side-channel attacks in tightly constrained environments; however, they relied on meaningful differences in computational states or data dependency to distinguish between states in a state machine. This work applies more advanced machine learning techniques to state machines which perform identical operations in all branches of control flow. Complete control flow is recovered with 99% accuracy even in situations where 97% of work is outside of the control flow structures. This work demonstrates the efficacy of these approaches for recovering control flow information; continues developing available knowledge about power-based attacks on program control flow; and examines the applicability of multiple standard machine learning models to the problem of classification over power-based side-channel information.
Full article
►▼
Show Figures
Open AccessFeature PaperReview
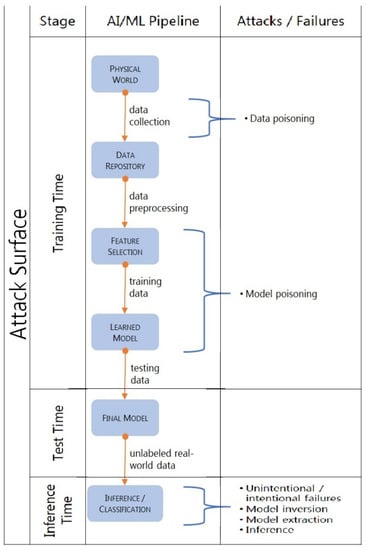
Cybersecurity for AI Systems: A Survey
by
Raghvinder S. Sangwan, Youakim Badr and Satish M. Srinivasan
Cited by 24 | Viewed by 16716
Abstract
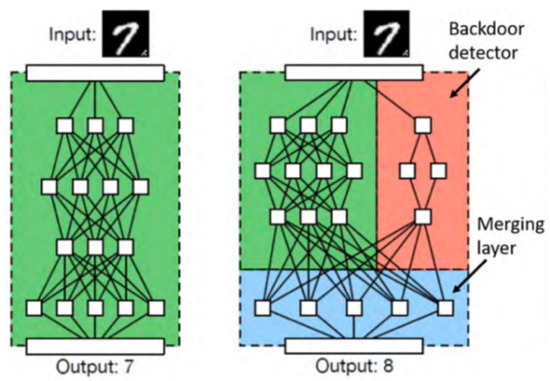
Recent advances in machine learning have created an opportunity to embed artificial intelligence in software-intensive systems. These artificial intelligence systems, however, come with a new set of vulnerabilities making them potential targets for cyberattacks. This research examines the landscape of these cyber attacks
[...] Read more.
Recent advances in machine learning have created an opportunity to embed artificial intelligence in software-intensive systems. These artificial intelligence systems, however, come with a new set of vulnerabilities making them potential targets for cyberattacks. This research examines the landscape of these cyber attacks and organizes them into a taxonomy. It further explores potential defense mechanisms to counter such attacks and the use of these mechanisms early during the development life cycle to enhance the safety and security of artificial intelligence systems.
Full article
►▼
Show Figures
Open AccessArticle
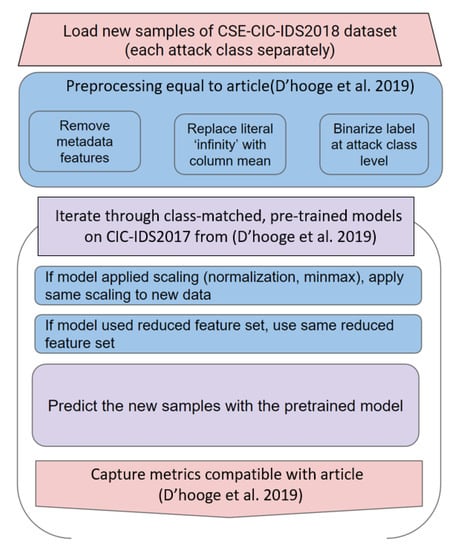
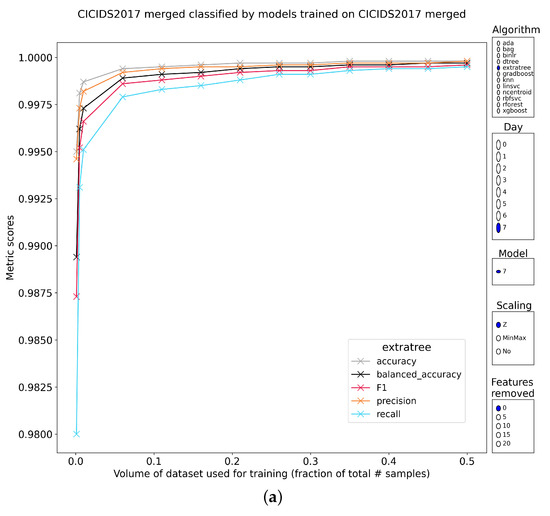
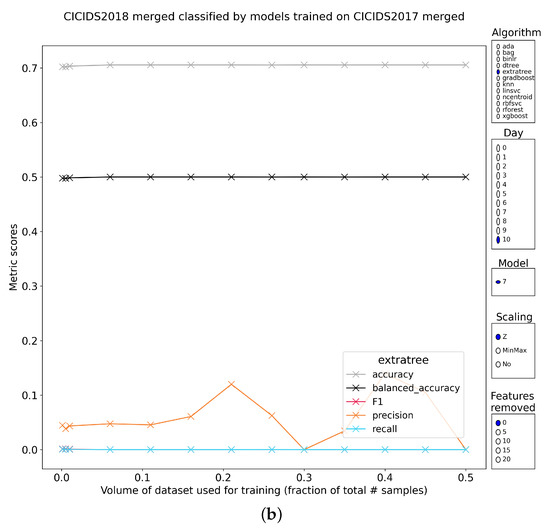
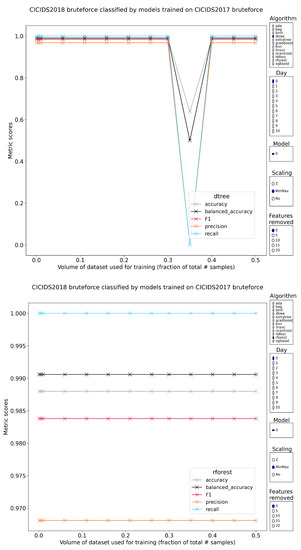
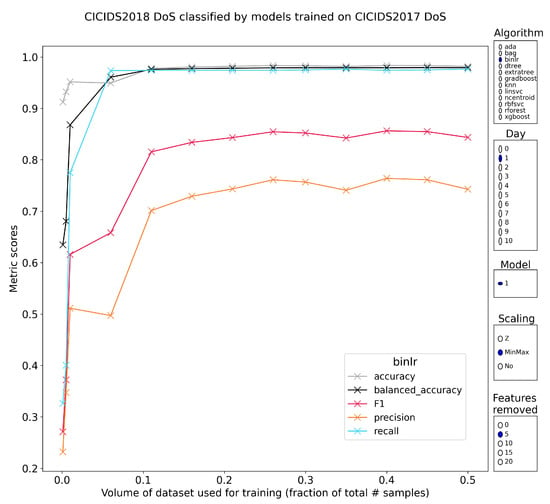
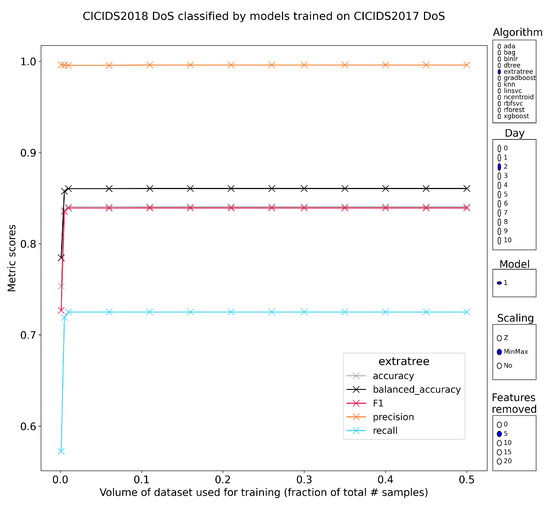
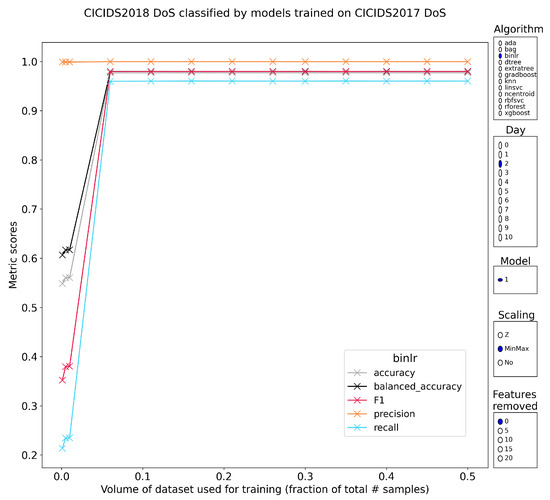
Characterizing the Impact of Data-Damaged Models on Generalization Strength in Intrusion Detection
by
Laurens D’hooge, Miel Verkerken, Tim Wauters, Filip De Turck and Bruno Volckaert
Cited by 3 | Viewed by 3842
Abstract
Generalization is a longstanding assumption in articles concerning network intrusion detection through machine learning. Novel techniques are frequently proposed and validated based on the improvement they attain when classifying one or more of the existing datasets. The necessary follow-up question of whether this
[...] Read more.
Generalization is a longstanding assumption in articles concerning network intrusion detection through machine learning. Novel techniques are frequently proposed and validated based on the improvement they attain when classifying one or more of the existing datasets. The necessary follow-up question of whether this increased performance in classification is meaningful outside of the dataset(s) is almost never investigated. This lacuna is in part due to the sparse dataset landscape in network intrusion detection and the complexity of creating new data. The introduction of two recent datasets, namely CIC-IDS2017 and CSE-CIC-IDS2018, opened up the possibility of testing generalization capability within similar academic datasets. This work investigates how well models from different algorithmic families, pretrained on CICIDS2017, are able to classify the samples in CSE-CIC-IDS2018 without retraining. Earlier work has shown how robust these models are to data reduction when classifying state-of-the-art datasets. This work experimentally demonstrates that the implicit assumption that strong generalized performance naturally follows from strong performance on a specific dataset is largely erroneous. The supervised machine learning algorithms suffered flat losses in classification performance ranging from 0 to 50% (depending on the attack class under test). For non-network-centric attack classes, this performance regression is most pronounced, but even the less affected models that classify the network-centric attack classes still show defects. Current implementations of intrusion detection systems (IDSs) with supervised machine learning (ML) as a core building block are thus very likely flawed if they have been validated on the academic datasets, without the consideration for their general performance on other academic or real-world datasets.
Full article
►▼
Show Figures
Open AccessArticle
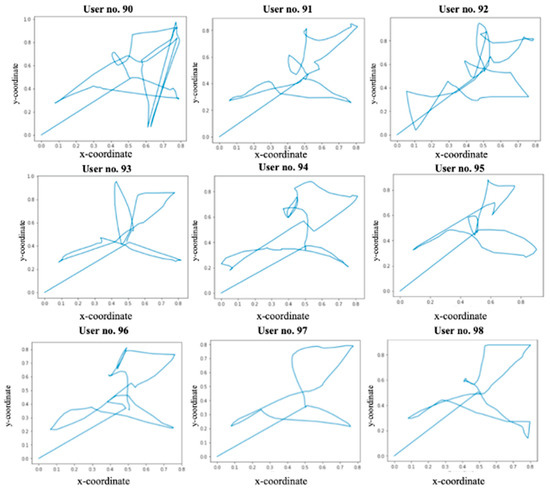
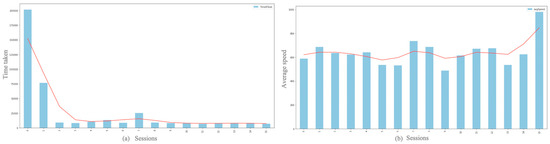
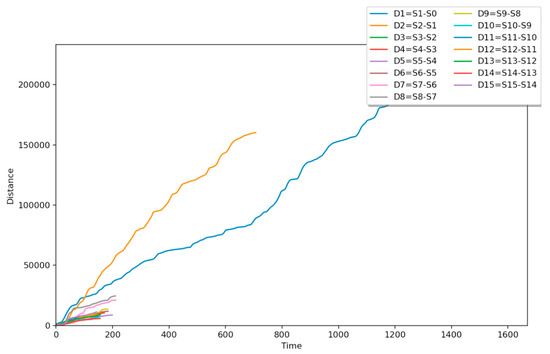
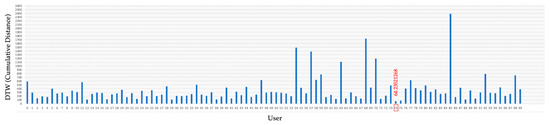
ReMouse Dataset: On the Efficacy of Measuring the Similarity of Human-Generated Trajectories for the Detection of Session-Replay Bots
by
Shadi Sadeghpour and Natalija Vlajic
Cited by 8 | Viewed by 6430
Abstract
Session-replay bots are believed to be the latest and most sophisticated generation of web bots, and they are also very difficult to defend against. Combating session-replay bots is particularly challenging in online domains that are repeatedly visited by the same genuine human user(s)
[...] Read more.
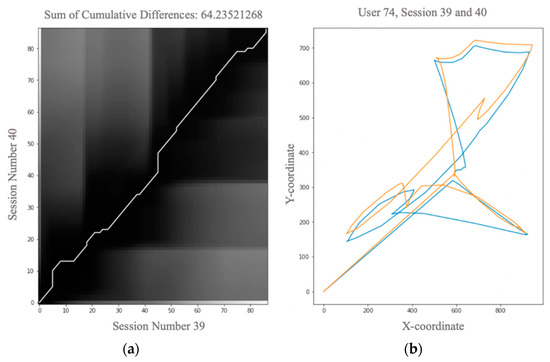
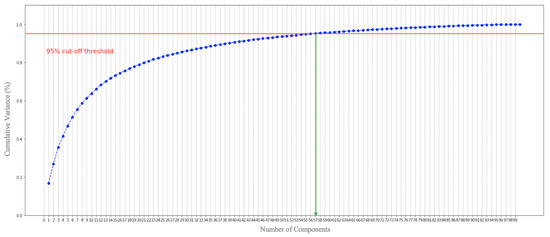
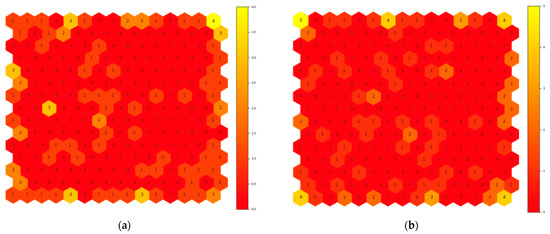
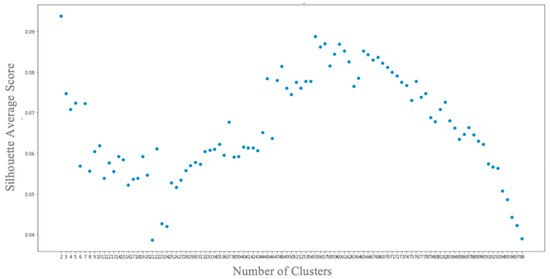
Session-replay bots are believed to be the latest and most sophisticated generation of web bots, and they are also very difficult to defend against. Combating session-replay bots is particularly challenging in online domains that are repeatedly visited by the same genuine human user(s) in the same or similar ways—such as news, banking or gaming sites. In such domains, it is difficult to determine whether two look-alike sessions are produced by the same human user or if these sessions are just bot-generated session replays. Unfortunately, to date, only a handful of research studies have looked at the problem of session-replay bots, with many related questions still waiting to be addressed. The main contributions of this paper are two-fold: (1) We introduce and provide to the public a novel real-world mouse dynamics dataset named ReMouse. The ReMouse dataset is collected in a guided environment, and, unlike other publicly available mouse dynamics datasets, it contains repeat sessions generated by the same human user(s). As such, the ReMouse dataset is the first of its kind and is of particular relevance for studies on the development of effective defenses against session-replay bots. (2) Our own analysis of ReMouse dataset using statistical and advanced ML-based methods (including deep and unsupervised neural learning) shows that two different human users cannot generate the same or similar-looking sessions when performing the same or a similar online task; furthermore, even the (repeat) sessions generated by the same human user are sufficiently distinguishable from one another.
Full article
►▼
Show Figures
Open AccessArticle
Detection of SQL Injection Attack Using Machine Learning Techniques: A Systematic Literature Review
by
Maha Alghawazi, Daniyal Alghazzawi and Suaad Alarifi
Cited by 99 | Viewed by 33953
Abstract
An SQL injection attack, usually occur when the attacker(s) modify, delete, read, and copy data from database servers and are among the most damaging of web application attacks. A successful SQL injection attack can affect all aspects of security, including confidentiality, integrity, and
[...] Read more.
An SQL injection attack, usually occur when the attacker(s) modify, delete, read, and copy data from database servers and are among the most damaging of web application attacks. A successful SQL injection attack can affect all aspects of security, including confidentiality, integrity, and data availability. SQL (structured query language) is used to represent queries to database management systems. Detection and deterrence of SQL injection attacks, for which techniques from different areas can be applied to improve the detect ability of the attack, is not a new area of research but it is still relevant. Artificial intelligence and machine learning techniques have been tested and used to control SQL injection attacks, showing promising results. The main contribution of this paper is to cover relevant work related to different machine learning and deep learning models used to detect SQL injection attacks. With this systematic review, we aims to keep researchers up-to-date and contribute to the understanding of the intersection between SQL injection attacks and the artificial intelligence field.
Full article
►▼
Show Figures
Open AccessReview
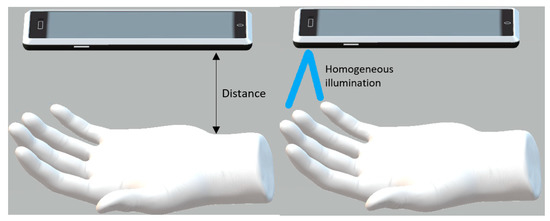
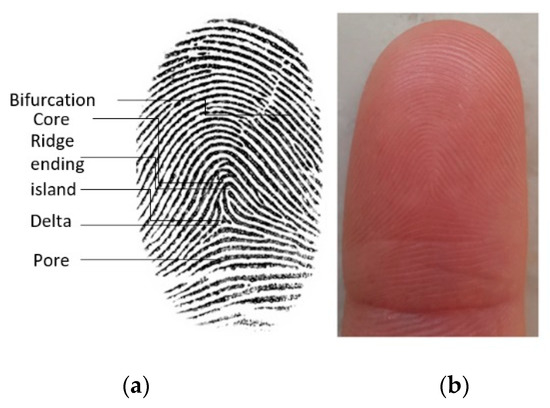
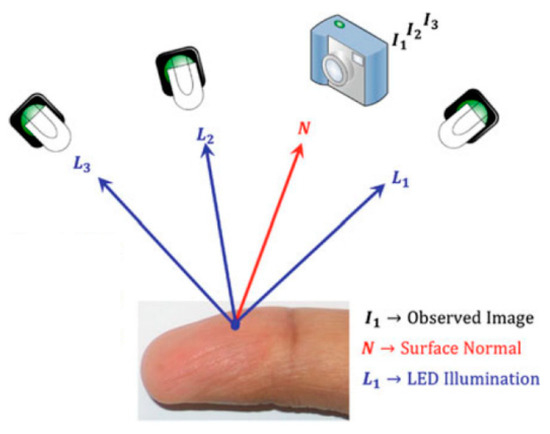
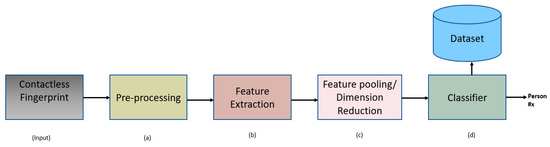
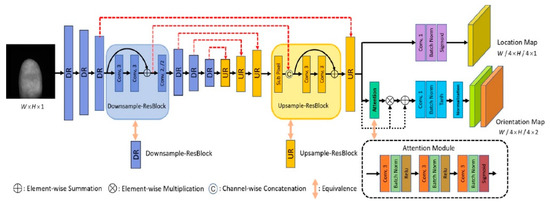
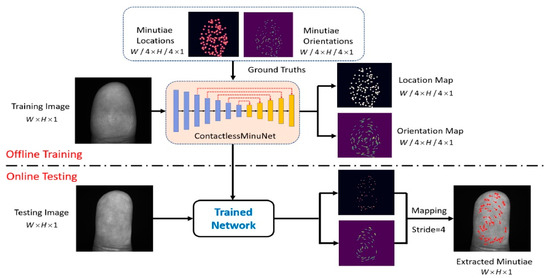
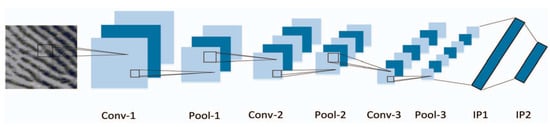
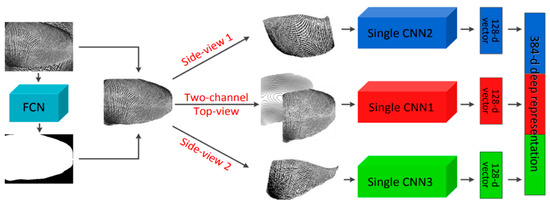
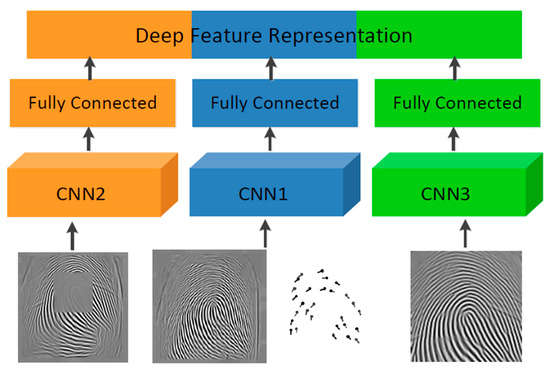
Contactless Fingerprint Recognition Using Deep Learning—A Systematic Review
by
A M Mahmud Chowdhury and Masudul Haider Imtiaz
Cited by 50 | Viewed by 19719
Abstract
Contactless fingerprint identification systems have been introduced to address the deficiencies of contact-based fingerprint systems. A number of studies have been reported regarding contactless fingerprint processing, including classical image processing, the machine-learning pipeline, and a number of deep-learning-based algorithms. The deep-learning-based methods were
[...] Read more.
Contactless fingerprint identification systems have been introduced to address the deficiencies of contact-based fingerprint systems. A number of studies have been reported regarding contactless fingerprint processing, including classical image processing, the machine-learning pipeline, and a number of deep-learning-based algorithms. The deep-learning-based methods were reported to have higher accuracies than their counterparts. This study was thus motivated to present a systematic review of these successes and the reported limitations. Three methods were researched for this review: (i) the finger photo capture method and corresponding image sensors, (ii) the classical preprocessing method to prepare a finger image for a recognition task, and (iii) the deep-learning approach for contactless fingerprint recognition. Eight scientific articles were identified that matched all inclusion and exclusion criteria. Based on inferences from this review, we have discussed how deep learning methods could benefit the field of biometrics and the potential gaps that deep-learning approaches need to address for real-world biometric applications.
Full article
►▼
Show Figures
Open AccessArticle
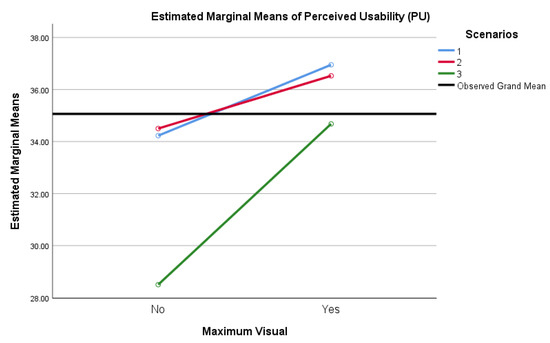
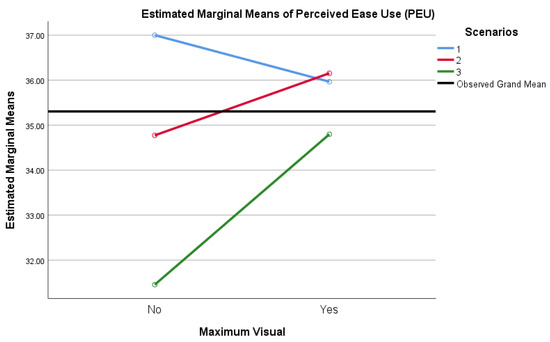
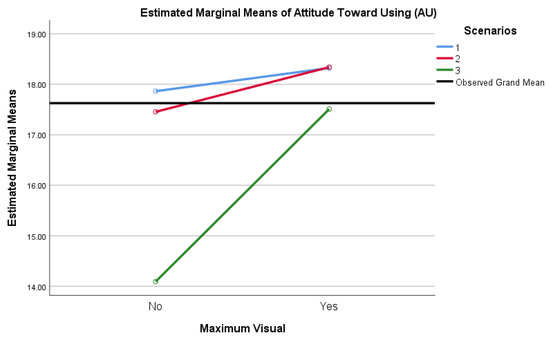
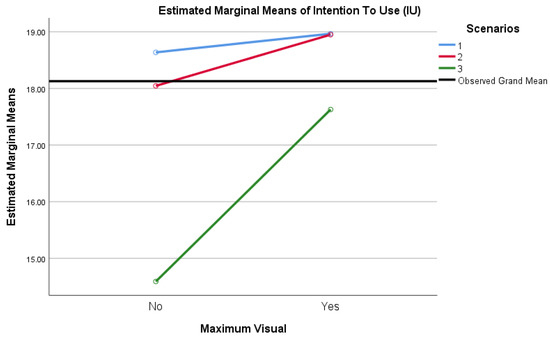
Improved Detection and Response via Optimized Alerts: Usability Study
by
Griffith Russell McRee
Cited by 6 | Viewed by 8400
Abstract
Security analysts working in the modern threat landscape face excessive events and alerts, a high volume of false-positive alerts, significant time constraints, innovative adversaries, and a staggering volume of unstructured data. Organizations thus risk data breach, loss of valuable human resources, reputational damage,
[...] Read more.
Security analysts working in the modern threat landscape face excessive events and alerts, a high volume of false-positive alerts, significant time constraints, innovative adversaries, and a staggering volume of unstructured data. Organizations thus risk data breach, loss of valuable human resources, reputational damage, and impact to revenue when excessive security alert volume and a lack of fidelity degrade detection services. This study examined tactics to reduce security data fatigue, increase detection accuracy, and enhance security analysts’ experience using security alert output generated via data science and machine learning models. The research determined if security analysts utilizing this security alert data perceive a statistically significant difference in usability between security alert output that is visualized versus that which is text-based. Security analysts benefit two-fold: the efficiency of results derived at scale via ML models, with the additional benefit of quality alert results derived from these same models. This quantitative, quasi-experimental, explanatory study conveys survey research performed to understand security analysts’ perceptions via the Technology Acceptance Model. The population studied was security analysts working in a defender capacity, analyzing security monitoring data and alerts. The more specific sample was security analysts and managers in Security Operation Center (SOC), Digital Forensic and Incident Response (DFIR), Detection and Response Team (DART), and Threat Intelligence (TI) roles. Data analysis indicated a significant difference in security analysts’ perception of usability in favor of visualized alert output over text alert output. The study’s results showed how organizations can more effectively combat external threats by emphasizing visual rather than textual alerts.
Full article
►▼
Show Figures
Open AccessArticle
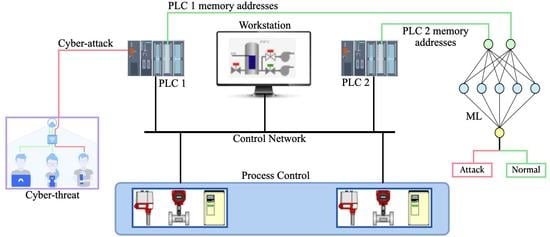
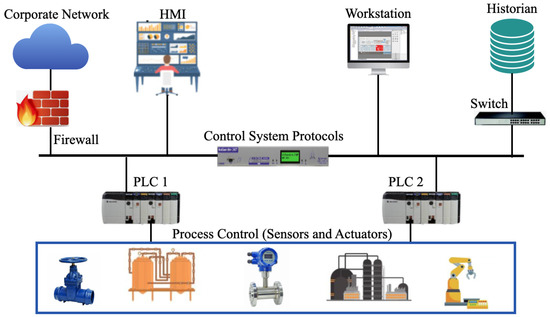
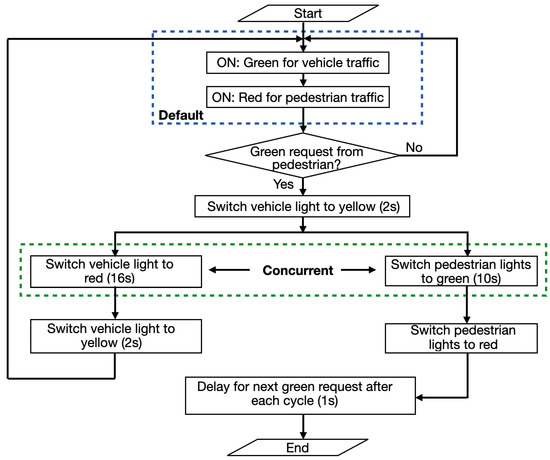
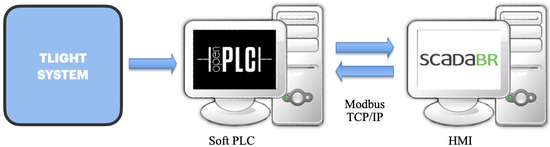
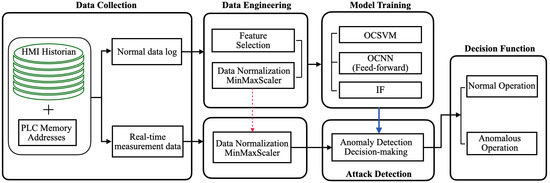
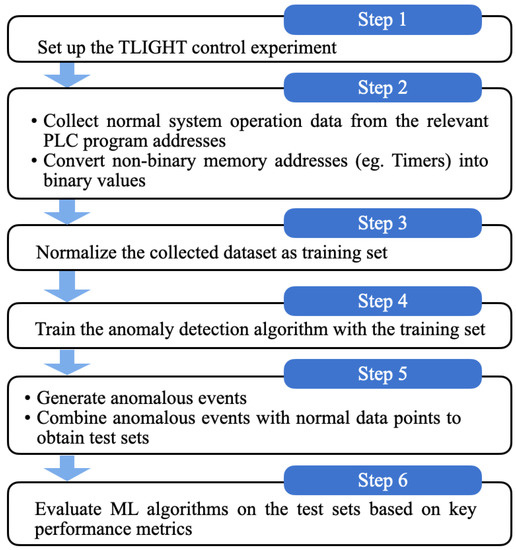
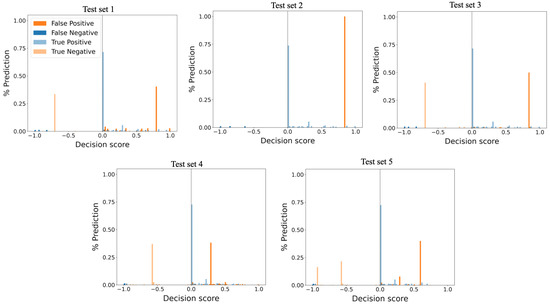
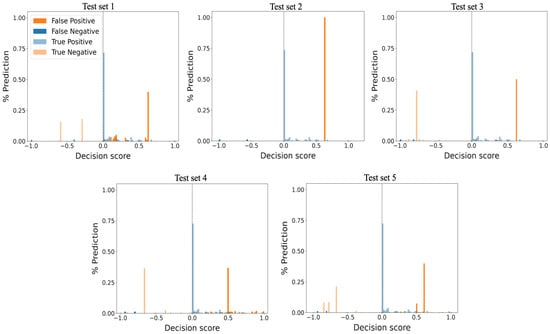
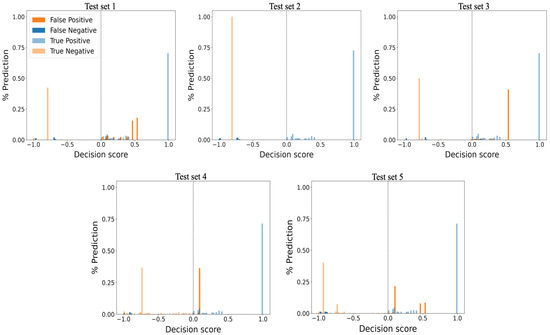
Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies
by
Emmanuel Aboah Boateng and J. W. Bruce
Cited by 14 | Viewed by 10849
Abstract
The security of programmable logic controllers (PLCs) that control industrial systems is becoming increasingly critical due to the ubiquity of the Internet of Things technologies and increasingly nefarious cyber-attack activity. Conventional techniques for safeguarding PLCs are difficult due to their unique architectures. This
[...] Read more.
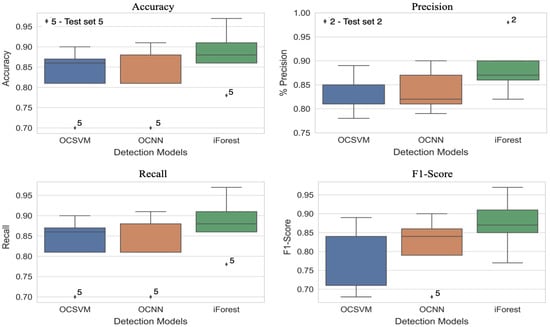
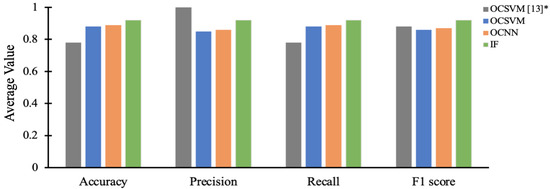
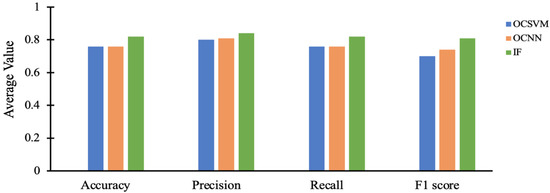
The security of programmable logic controllers (PLCs) that control industrial systems is becoming increasingly critical due to the ubiquity of the Internet of Things technologies and increasingly nefarious cyber-attack activity. Conventional techniques for safeguarding PLCs are difficult due to their unique architectures. This work proposes a one-class support vector machine, one-class neural network interconnected in a feed-forward manner, and isolation forest approaches for verifying PLC process integrity by monitoring PLC memory addresses. A comprehensive experiment is conducted using an open-source PLC subjected to multiple attack scenarios. A new histogram-based approach is introduced to visualize anomaly detection algorithm performance and prediction confidence. Comparative performance analyses of the proposed algorithms using decision scores and prediction confidence are presented. Results show that isolation forest outperforms one-class neural network, one-class support vector machine, and previous work, in terms of accuracy, precision, recall, and F1-score on seven attack scenarios considered. Statistical hypotheses tests involving analysis of variance and Tukey’s range test were used to validate the presented results.
Full article
►▼
Show Figures
Open AccessFeature PaperArticle
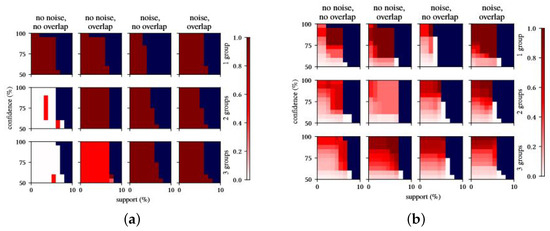
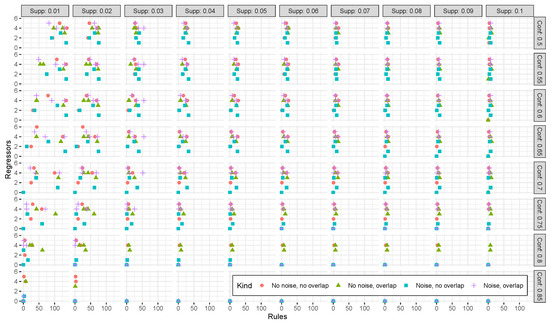
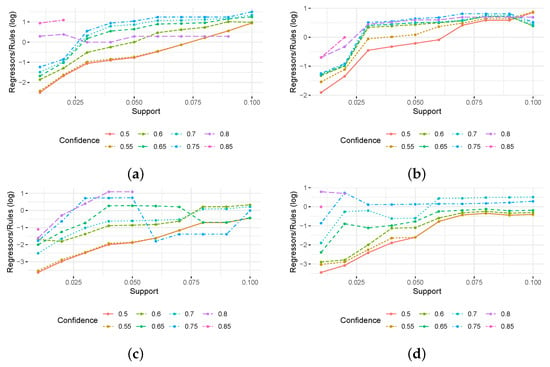
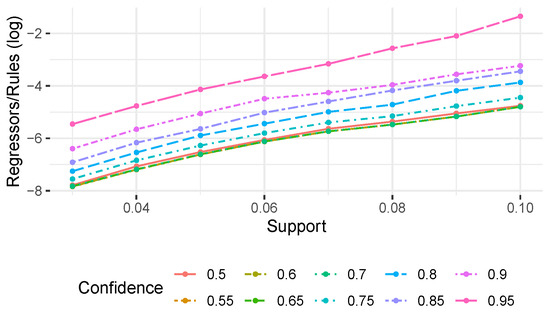
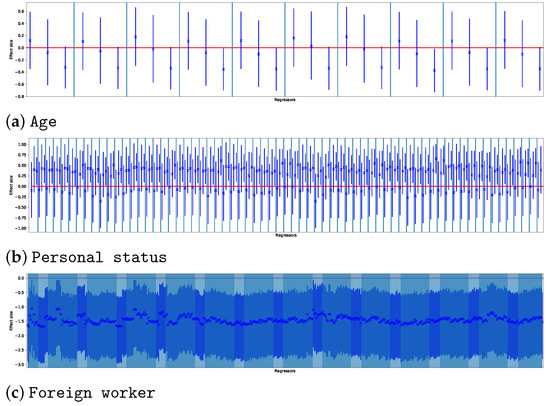
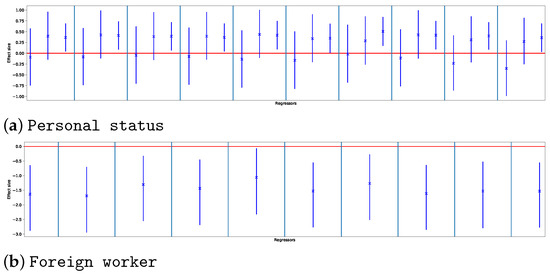
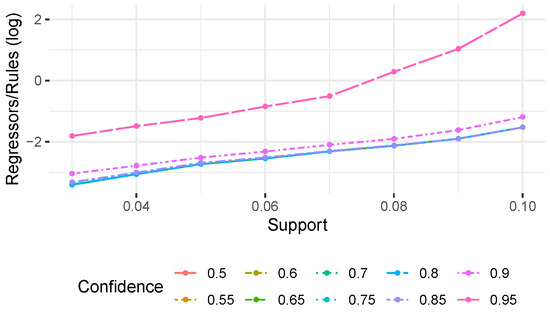
Association Rule Mining Meets Regression Analysis: An Automated Approach to Unveil Systematic Biases in Decision-Making Processes
by
Laura Genga, Luca Allodi and Nicola Zannone
Cited by 5 | Viewed by 8707
Abstract
Decisional processes are at the basis of most businesses in several application domains. However, they are often not fully transparent and can be affected by human or algorithmic biases that may lead to systematically incorrect or unfair outcomes. In this work, we propose
[...] Read more.
Decisional processes are at the basis of most businesses in several application domains. However, they are often not fully transparent and can be affected by human or algorithmic biases that may lead to systematically incorrect or unfair outcomes. In this work, we propose an approach for unveiling biases in decisional processes, which leverages association rule mining for systematic hypothesis generation and regression analysis for model selection and recommendation extraction. In particular, we use rule mining to elicit candidate hypotheses of bias from the observational data of the process. From these hypotheses, we build regression models to determine the impact of variables on the process outcome. We show how the coefficient of the (selected) model can be used to extract recommendation, upon which the decision maker can operate. We evaluated our approach using both synthetic and real-life datasets in the context of discrimination discovery. The results show that our approach provides more reliable evidence compared to the one obtained using rule mining alone, and how the obtained recommendations can be used to guide analysts in the investigation of biases affecting the decisional process at hand.
Full article
►▼
Show Figures
Open AccessArticle
Functionality-Preserving Adversarial Machine Learning for Robust Classification in Cybersecurity and Intrusion Detection Domains: A Survey
by
Andrew McCarthy, Essam Ghadafi, Panagiotis Andriotis and Phil Legg
Cited by 72 | Viewed by 14677
Abstract
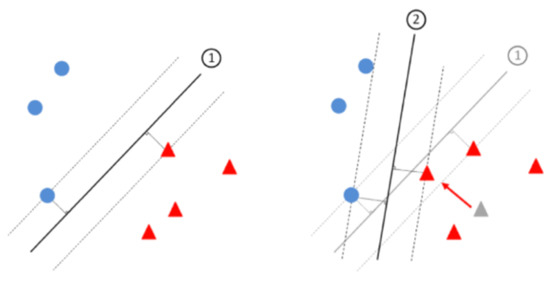
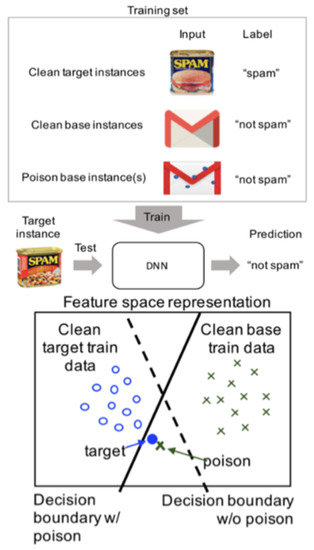
Machine learning has become widely adopted as a strategy for dealing with a variety of cybersecurity issues, ranging from insider threat detection to intrusion and malware detection. However, by their very nature, machine learning systems can introduce vulnerabilities to a security defence whereby
[...] Read more.
Machine learning has become widely adopted as a strategy for dealing with a variety of cybersecurity issues, ranging from insider threat detection to intrusion and malware detection. However, by their very nature, machine learning systems can introduce vulnerabilities to a security defence whereby a learnt model is unaware of so-called adversarial examples that may intentionally result in mis-classification and therefore bypass a system. Adversarial machine learning has been a research topic for over a decade and is now an accepted but open problem. Much of the early research on adversarial examples has addressed issues related to computer vision, yet as machine learning continues to be adopted in other domains, then likewise it is important to assess the potential vulnerabilities that may occur. A key part of transferring to new domains relates to functionality-preservation, such that any crafted attack can still execute the original intended functionality when inspected by a human and/or a machine. In this literature survey, our main objective is to address the domain of adversarial machine learning attacks and examine the robustness of machine learning models in the cybersecurity and intrusion detection domains. We identify the key trends in current work observed in the literature, and explore how these relate to the research challenges that remain open for future works. Inclusion criteria were: articles related to functionality-preservation in adversarial machine learning for cybersecurity or intrusion detection with insight into robust classification. Generally, we excluded works that are not yet peer-reviewed; however, we included some significant papers that make a clear contribution to the domain. There is a risk of subjective bias in the selection of non-peer reviewed articles; however, this was mitigated by co-author review. We selected the following databases with a sizeable computer science element to search and retrieve literature: IEEE Xplore, ACM Digital Library, ScienceDirect, Scopus, SpringerLink, and Google Scholar. The literature search was conducted up to January 2022. We have striven to ensure a comprehensive coverage of the domain to the best of our knowledge. We have performed systematic searches of the literature, noting our search terms and results, and following up on all materials that appear relevant and fit within the topic domains of this review. This research was funded by the Partnership PhD scheme at the University of the West of England in collaboration with Techmodal Ltd.
Full article
►▼
Show Figures
Open AccessArticle
Comparison of Deepfake Detection Techniques through Deep Learning
by
Maryam Taeb and Hongmei Chi
Cited by 105 | Viewed by 41579
Abstract
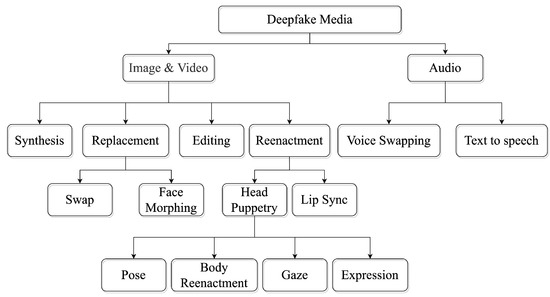
Deepfakes are realistic-looking fake media generated by deep-learning algorithms that iterate through large datasets until they have learned how to solve the given problem (i.e., swap faces or objects in video and digital content). The massive generation of such content and modification technologies
[...] Read more.
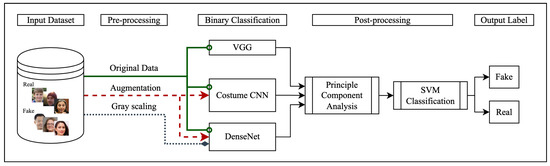
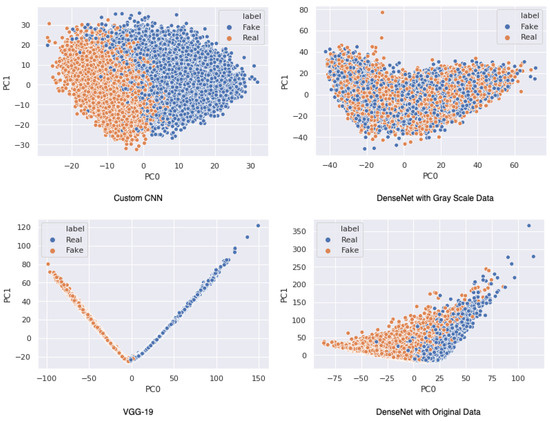
Deepfakes are realistic-looking fake media generated by deep-learning algorithms that iterate through large datasets until they have learned how to solve the given problem (i.e., swap faces or objects in video and digital content). The massive generation of such content and modification technologies is rapidly affecting the quality of public discourse and the safeguarding of human rights. Deepfakes are being widely used as a malicious source of misinformation in court that seek to sway a court’s decision. Because digital evidence is critical to the outcome of many legal cases, detecting deepfake media is extremely important and in high demand in digital forensics. As such, it is important to identify and build a classifier that can accurately distinguish between authentic and disguised media, especially in facial-recognition systems as it can be used in identity protection too. In this work, we compare the most common, state-of-the-art face-detection classifiers such as Custom CNN, VGG19, and DenseNet-121 using an augmented real and fake face-detection dataset. Data augmentation is used to boost performance and reduce computational resources. Our preliminary results indicate that VGG19 has the best performance and highest accuracy of 95% when compared with other analyzed models.
Full article
►▼
Show Figures
Open AccessArticle
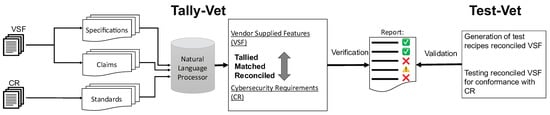
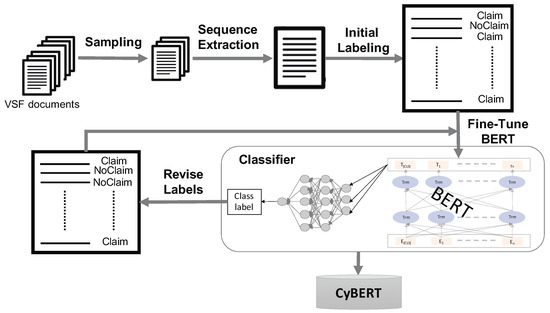
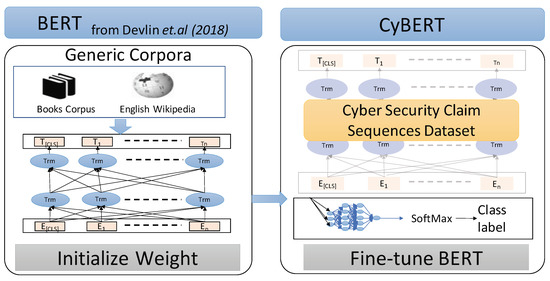
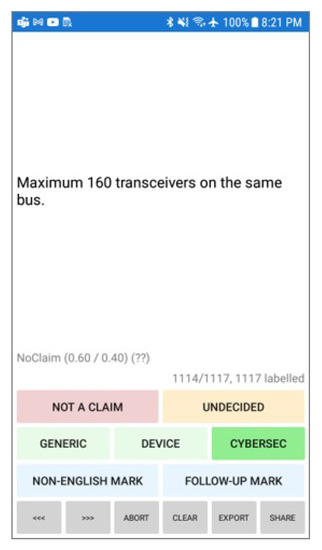
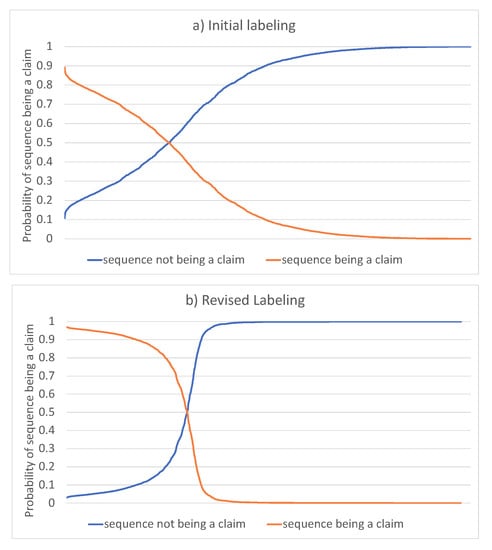
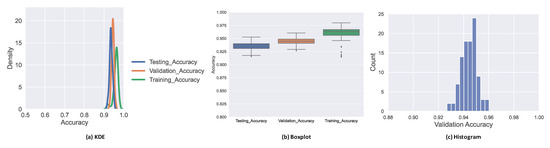
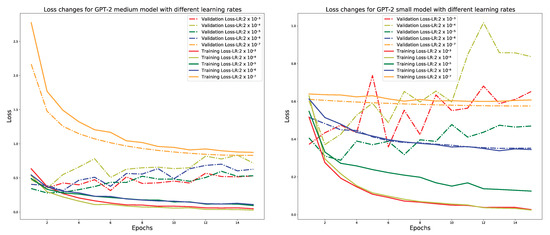
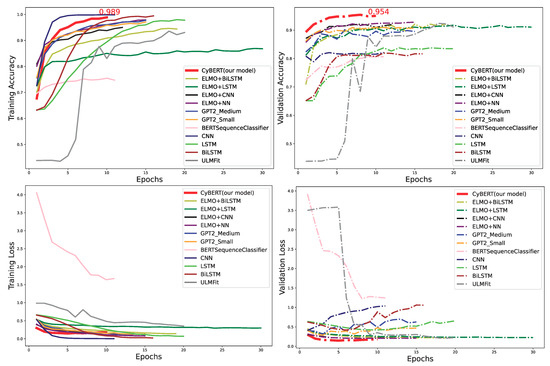
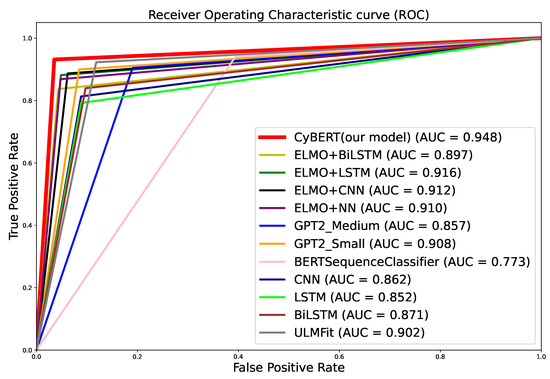
CyBERT: Cybersecurity Claim Classification by Fine-Tuning the BERT Language Model
by
Kimia Ameri, Michael Hempel, Hamid Sharif, Juan Lopez Jr. and Kalyan Perumalla
Cited by 84 | Viewed by 16903
Abstract
We introduce CyBERT, a cybersecurity feature claims classifier based on bidirectional encoder representations from transformers and a key component in our semi-automated cybersecurity vetting for industrial control systems (ICS). To train CyBERT, we created a corpus of labeled sequences from ICS device documentation
[...] Read more.
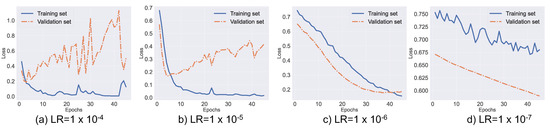
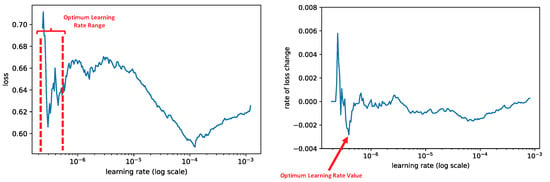
We introduce CyBERT, a cybersecurity feature claims classifier based on bidirectional encoder representations from transformers and a key component in our semi-automated cybersecurity vetting for industrial control systems (ICS). To train CyBERT, we created a corpus of labeled sequences from ICS device documentation collected across a wide range of vendors and devices. This corpus provides the foundation for fine-tuning BERT’s language model, including a prediction-guided relabeling process. We propose an approach to obtain optimal hyperparameters, including the learning rate, the number of dense layers, and their configuration, to increase the accuracy of our classifier. Fine-tuning all hyperparameters of the resulting model led to an increase in classification accuracy from 76% obtained with BertForSequenceClassification’s original architecture to 94.4% obtained with CyBERT. Furthermore, we evaluated CyBERT for the impact of randomness in the initialization, training, and data-sampling phases. CyBERT demonstrated a standard deviation of ±0.6% during validation across 100 random seed values. Finally, we also compared the performance of CyBERT to other well-established language models including GPT2, ULMFiT, and ELMo, as well as neural network models such as CNN, LSTM, and BiLSTM. The results showed that CyBERT outperforms these models on the validation accuracy and the F1 score, validating CyBERT’s robustness and accuracy as a cybersecurity feature claims classifier.
Full article
►▼
Show Figures
Open AccessArticle
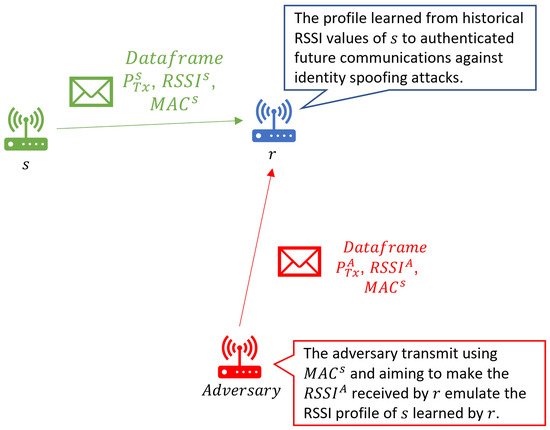
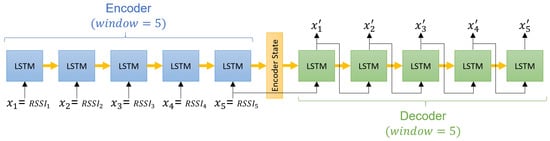
RSSI-Based MAC-Layer Spoofing Detection: Deep Learning Approach
by
Pooria Madani and Natalija Vlajic
Cited by 9 | Viewed by 8304
Abstract
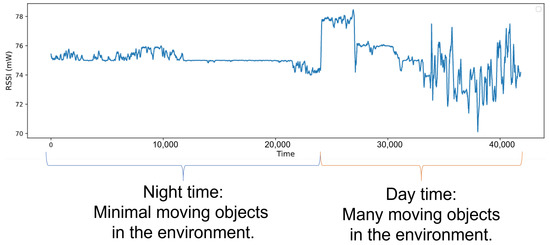
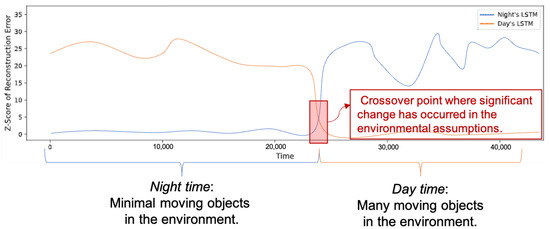
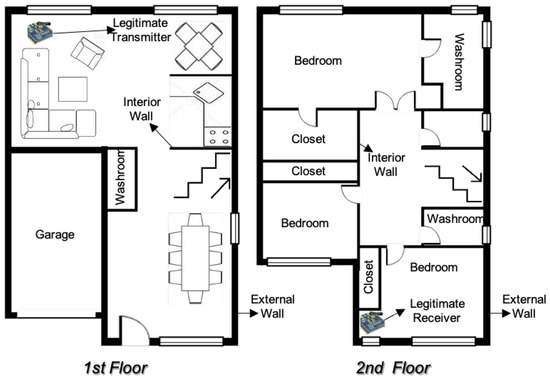
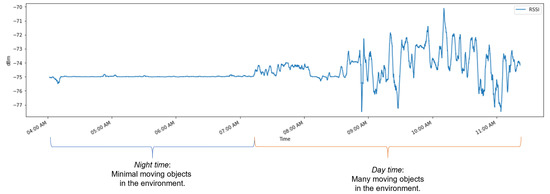
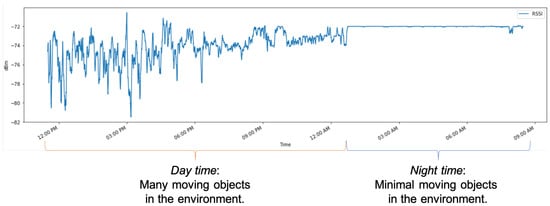
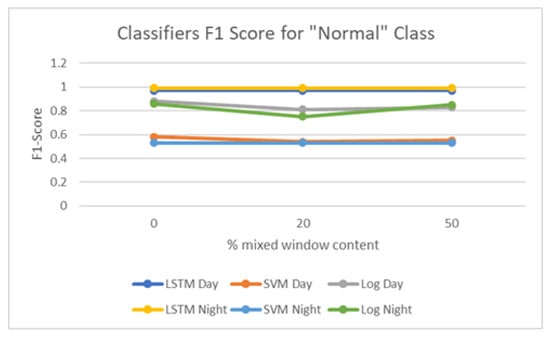
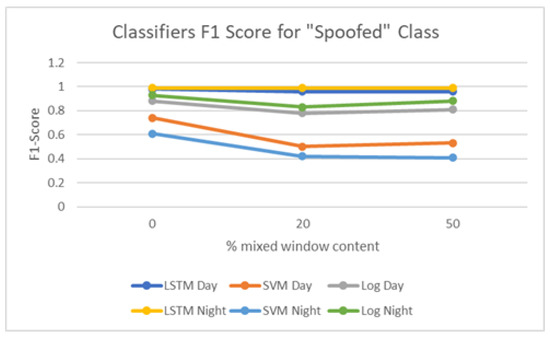
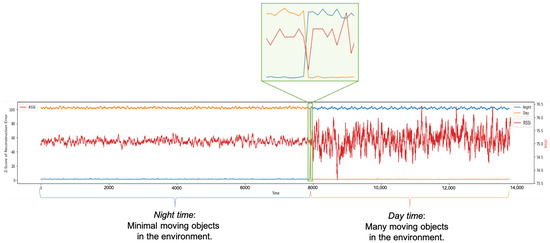
In some wireless networks Received Signal Strength Indicator (RSSI) based device profiling may be the only viable approach to combating MAC-layer spoofing attacks, while in others it can be used as a valuable complement to the existing defenses. Unfortunately, the previous research works
[...] Read more.
In some wireless networks Received Signal Strength Indicator (RSSI) based device profiling may be the only viable approach to combating MAC-layer spoofing attacks, while in others it can be used as a valuable complement to the existing defenses. Unfortunately, the previous research works on the use of RSSI-based profiling as a means of detecting MAC-layer spoofing attacks are largely theoretical and thus fall short of providing insights and result that could be applied in the real world. Our work aims to fill this gap and examine the use of RSSI-based device profiling in dynamic real-world environments/networks with moving objects. The main contributions of our work and this paper are two-fold. First, we demonstrate that in dynamic real-world networks with moving objects, RSSI readings corresponding to one fixed transmitting node are neither stationary nor i.i.d., as generally has been assumed in the previous literature. This implies that in such networks, building an RSSI-based profile of a wireless device using a single statistical/ML model is likely to yield inaccurate results and, consequently, suboptimal detection performance against adversaries. Second, we propose a novel approach to MAC-layer spoofing detection based on RSSI profiling using multi-model Long Short-Term Memory (LSTM) autoencoder—a form of deep recurrent neural network. Through real-world experimentation we prove the performance superiority of this approach over some other solutions previously proposed in the literature. Furthermore, we demonstrate that a real-world defense system using our approach has a built-in ability to self-adjust (i.e., to deal with unpredictable changes in the environment) in an automated and adaptive manner.
Full article
►▼
Show Figures
Open AccessArticle
Model for Quantifying the Quality of Secure Service
by
Paul M. Simon, Scott Graham, Christopher Talbot and Micah Hayden
Cited by 2 | Viewed by 5199
Abstract
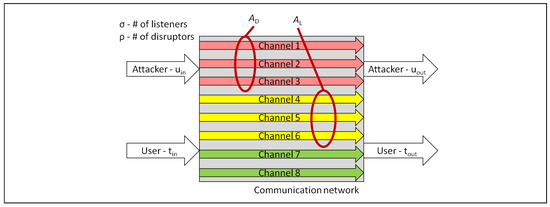
Although not common today, communications networks could adjust security postures based on changing mission security requirements, environmental conditions, or adversarial capability, through the coordinated use of multiple channels. This will require the ability to measure the security of communications networks in a meaningful
[...] Read more.
Although not common today, communications networks could adjust security postures based on changing mission security requirements, environmental conditions, or adversarial capability, through the coordinated use of multiple channels. This will require the ability to measure the security of communications networks in a meaningful way. To address this need, in this paper, we introduce the Quality of Secure Service (QoSS) model, a methodology to evaluate how well a system meets its security requirements. This construct enables a repeatable and quantifiable measure of security in a single- or multi-channel network under static configurations. In this approach, the quantification of security is based upon the probabilities that adversarial listeners and disruptors may gain access to or manipulate transmitted data. The initial model development, albeit a snap-shot of the network security, provides insights into what may affect end-to-end security and to what degree. The model was compared against the performance and expected security of several point-to-point networks, and three simplified architectures are presented as examples. Message fragmentation and duplication across the available channels provides a security performance trade-space, with an accompanying comprehensive measurement of the QoSS. The results indicate that security may be improved with message fragmentation across multiple channels when compared to the number of adversarial listeners or disruptors. This, in turn, points to the need, in future work, to build a full simulation environment with specific protocols and networks to validate the initial modeled results.
Full article
►▼
Show Figures














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}