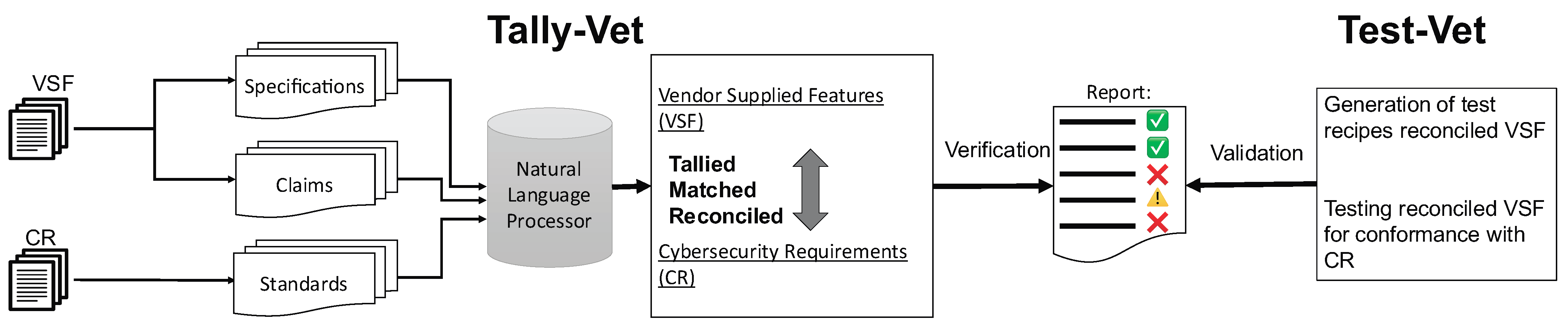
In this section, we introduce CyBERT and detail its fine-tuning strategy for BERT hyperparameters. Recall that CyBERT is a cybersecurity claim classifier to detect sequences related to device features. These claims then will be used to vet against relevant cybersecurity requirements.
There are two main steps in our framework: claim sequence database curation and fine-tuning BERT.
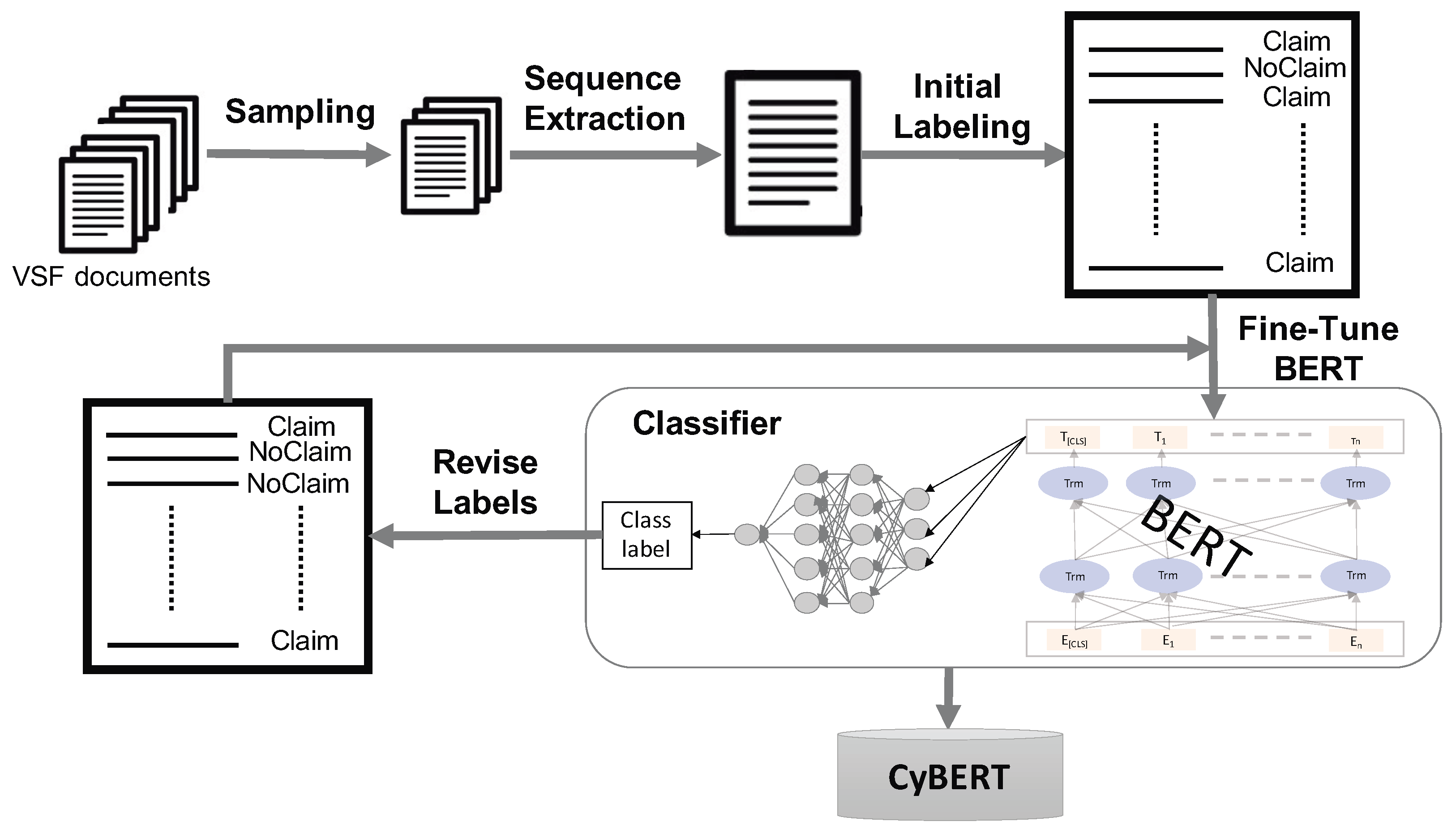
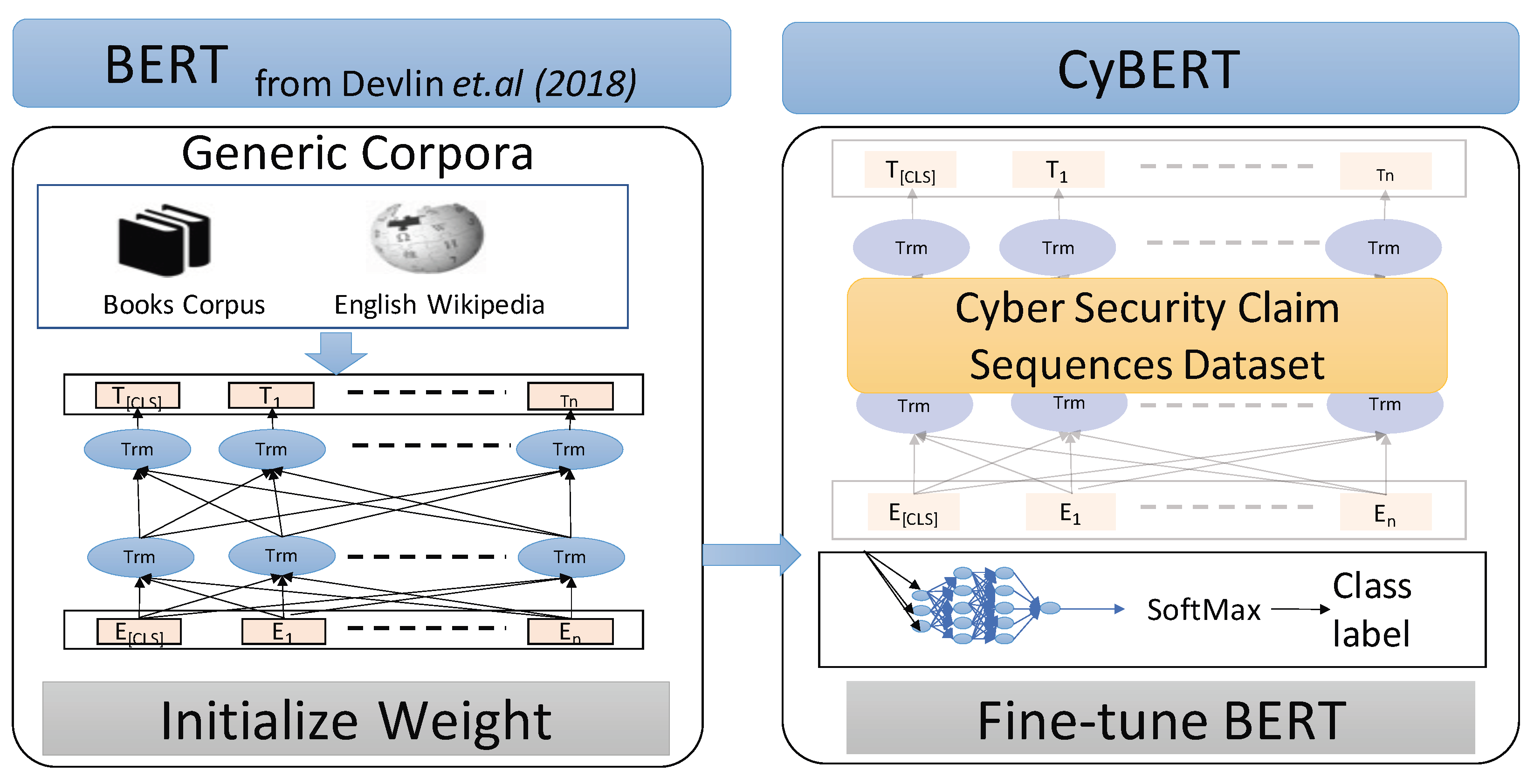
Figure 2 shows an overview of CyBERT workflow. To the best of our knowledge, there currently is no readily available dataset representing a corpus specific to cybersecurity that we could use for training CyBERT. Hence, we created a new labeled dataset that contains claim-related sequences. For fine-tuning, CyBERT is first initialized with BERT’s initial weights, adding dense layers and dropouts and subsequently tuning all layers and parameters using our labeled database and architecture.
4.1. Dataset
As previously stated, there was no available dataset specific to the cybersecurity literature for NLP tasks, in particular with an emphasis on industrial control systems (ICS). Therefore, in our previous work [
1] we proposed a framework to curate a large repository of ICS device information. This framework was designed to perform web scraping, data analytics, and natural language processing (NLP) techniques to identify ICS vendor websites, automate the collection of website-accessible documents, and automatically derive metadata from them for identification of documents relevant to this dataset.
All of the ICS device information documents that our framework curates were downloaded from vendor websites in PDF format.
Out of 19,793 documents, we scraped across the identified vendor websites; 3% were unreadable, and 5% were scanned documents. ICS product-related documents accounted for 63% of the downloaded documents. From those 12,581 product-related documents, 25% were classified as “manual,” 69% were classified as “brochure,” and 6% were “catalogs”. On average, each of the product-related documents contained 31.2 pages. Some statistics from this repository are presented in
Table 1.
The PyMuPDF python package was used to extract text from readable documents, and the Pytesseract python package was employed for optical character recognition (OCR) from any scanned PDF. These documents contain regular paragraphs, tables, lists, and images. Our system aimed to extract sequences from all of those document entities. Across the collection of ICS-related documents in our dataset, we extracted 216,0517 sequences with 41,073,376 words.
Bias in machine learning often is the result of bias present in the training data set and is a known problem for any language model [
35], including when training CyBERT. Language models such as BERT and GPT are well known to exhibit an exploitable biases, including for unethical AI behavior [
36], the irresponsible use of AI [
37], perpetuating stereotypes [
38], and negative sentiments towards specific groups [
39].
According to these articles, these issues are due to the characteristics of the training data. We therefore tried, as much as possible, during the curation of our dataset to remove any sequences that contained obvious bias towards or against vendors, devices, capabilities, etc., but we nevertheless do not presume that there is no bias present in our dataset. Hence, we are committed in our ongoing efforts to further evaluate and mitigate the bias within CyBERT’s training data set, as well as from CyBERT’s operation.
4.2. Fine-Tuning BERT
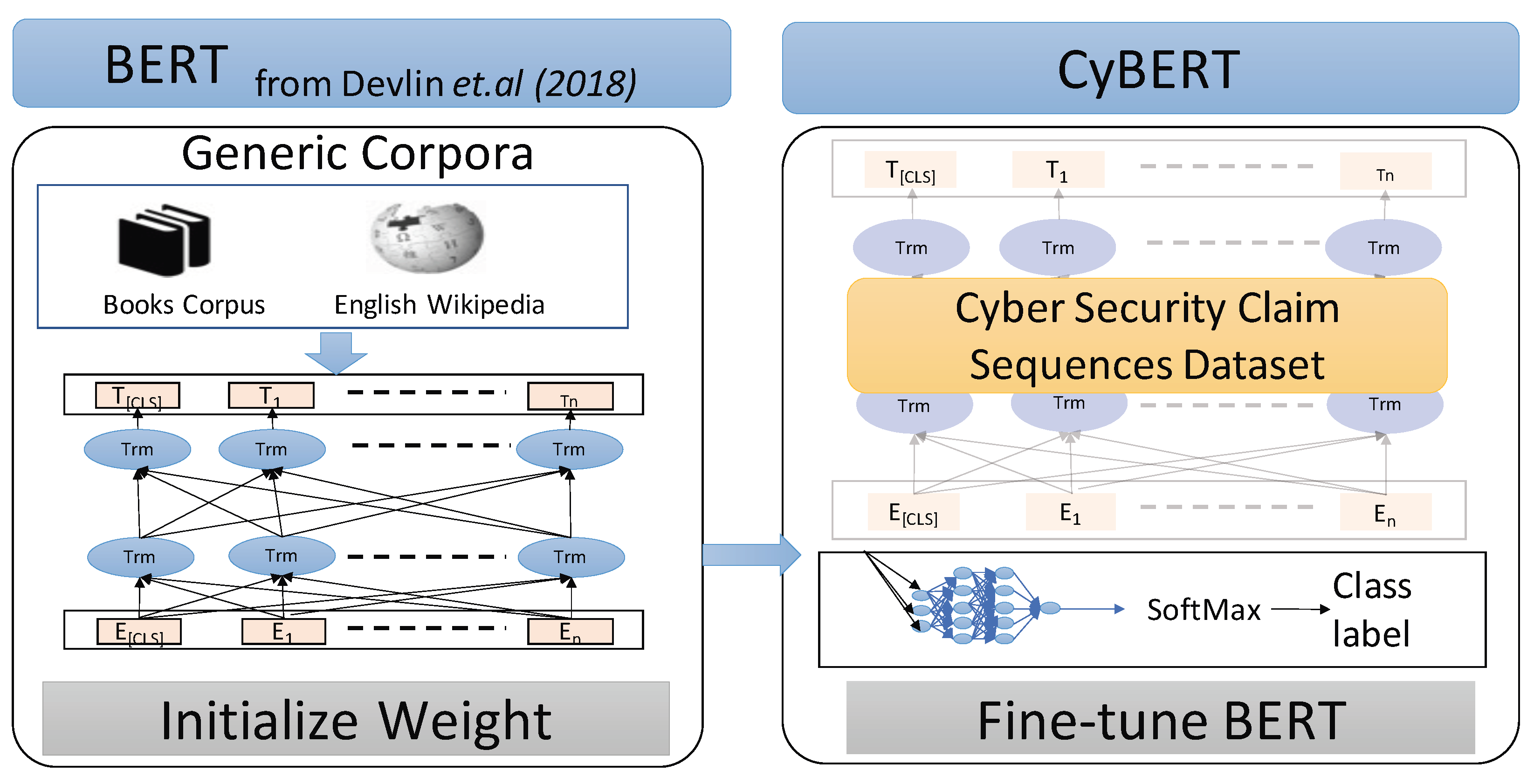
An appropriate fine-tuning strategy is needed to adapt BERT to a given downstream task in a target domain. Howard and Ruder have discussed the benefits of fine-tuning a language model on a specific dataset to improve the classification performance [
3]. An illustration of the architecture for CyBERT is in
Figure 3, where the model starts with initial weights from a general corpus and is subsequently fine-tuned based on target task-specific supervised data for text classification.
A critical issue that must be considered when fine-tuning BERT for a target task is the problem of overfitting. It is necessary to develop a better optimization method with a suitable learning rate. In the following subsections, we describe in detail our strategies for learning rate (LR) and epoch limit selection to avoid catastrophic forgetting and overfitting, respectively. A third consideration for fine-tuning a BERT classifier is determining the most informative layer of BERT to connect to the classifier layer. The final fine-tuning step is finding best number of dense layers and dropout rate for the classifier based on the hyperparameters and the dataset.
4.2.1. Hyperparameters
4.2.1.1. Catastrophic Forgetting
During the process of learning new knowledge by unlocking weights already established from prior training, there is a risk that the pre-trained knowledge is erased. McCloskey et al. referred to this as the catastrophic forgetting effect in transfer learning [
40]. Sun et al. showed that BERT is prone to the catastrophic forgetting problem [
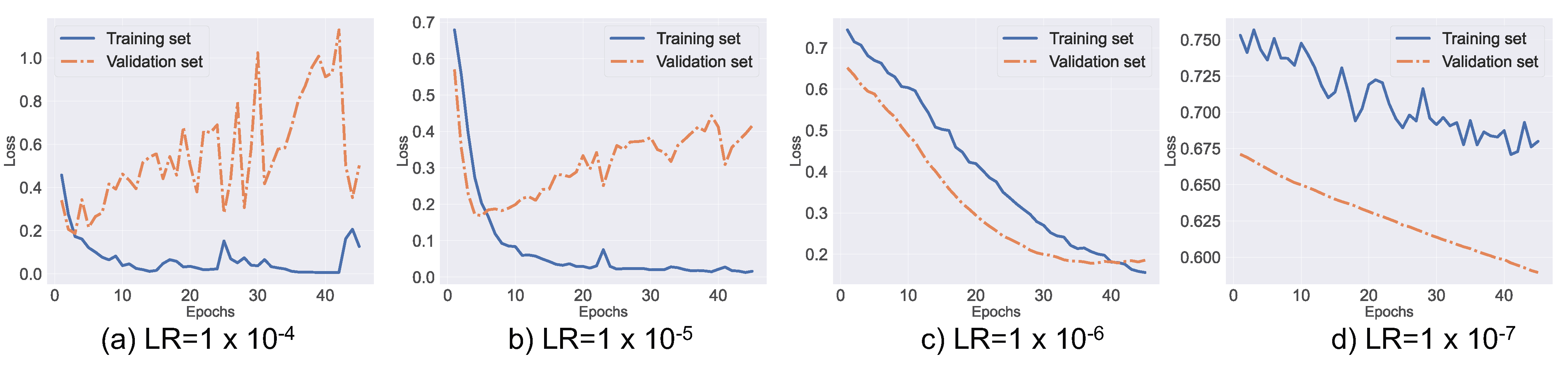
15]. We fine-tuned BERT with different learning rates (ranging from
to
) in order to investigate the catastrophic forgetting effects.
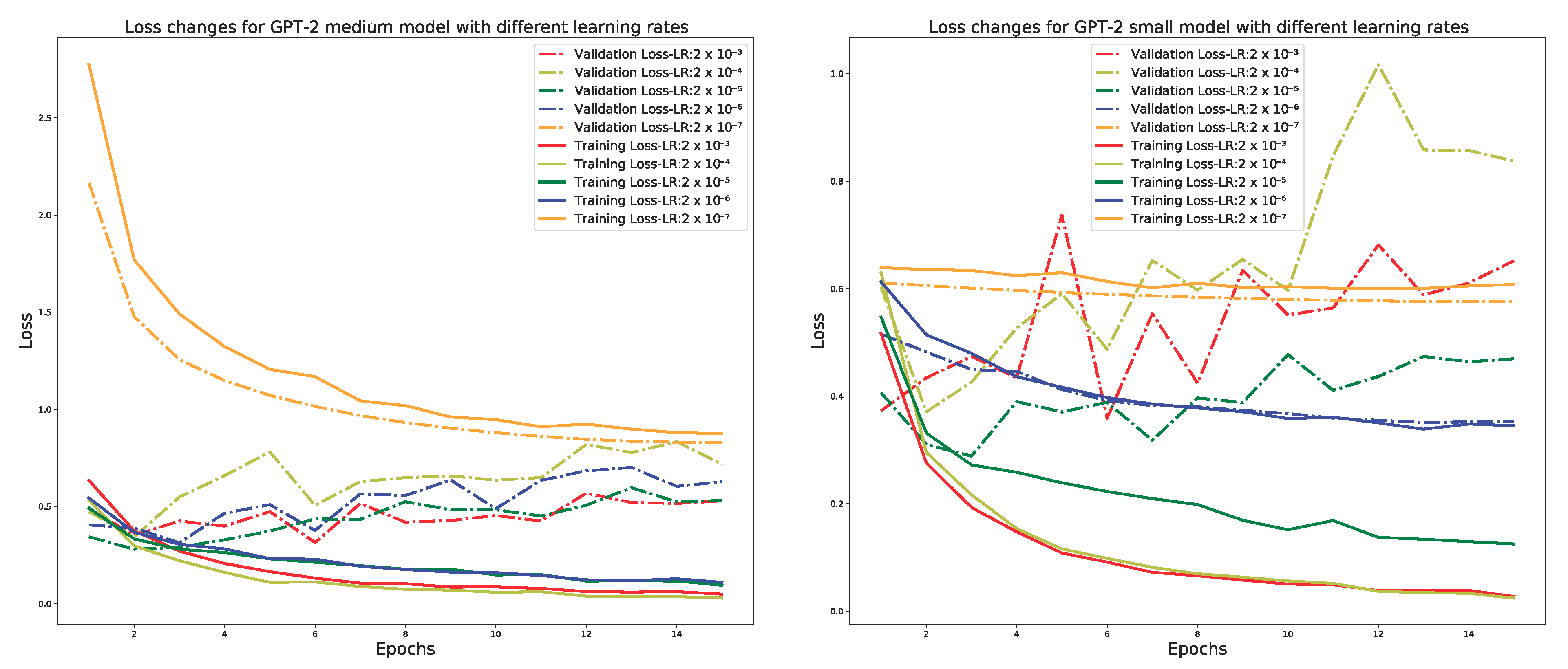
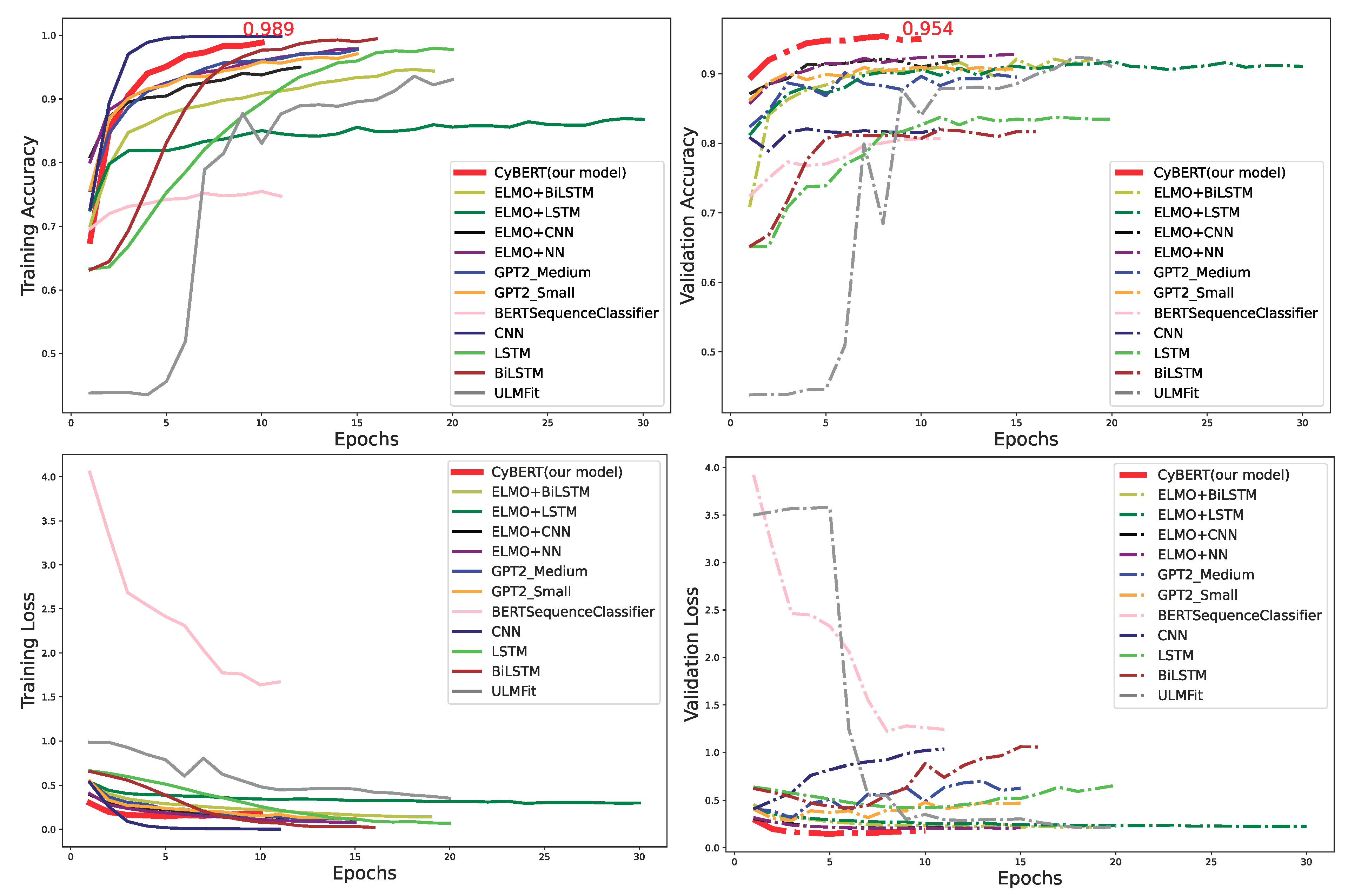
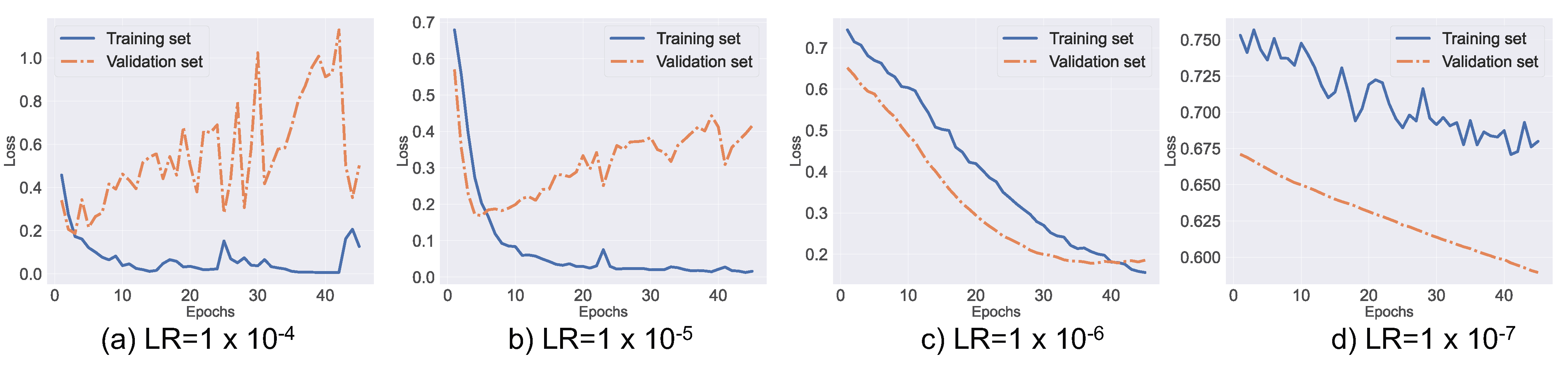
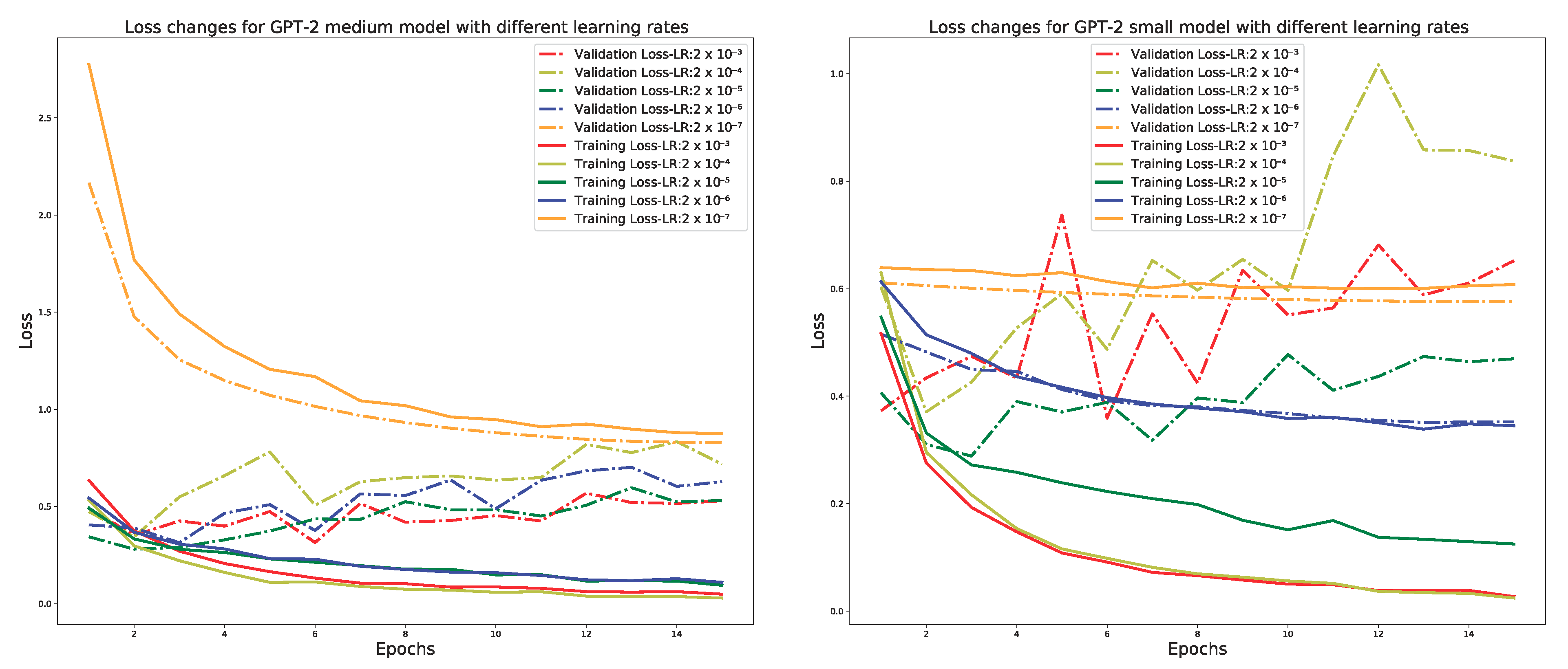
Figure 4 shows the learning curves of error rates in our training and validation sets. The validation set is a portion of the overall data set and was used to determine whether the learned patterns are extendable to unseen data.
As demonstrated by Sun et al.’s [
15] method, unfreezing all transformer layers and concatenating the layer weights would reduce the error rate. Therefore, we unfroze all layers in the BERT model during CyBERT’s fine-tuning process. This allows all weights to be updated in all the layers during the training process. We conducted the training repeatedly, in order to allow us to fine-tune the selection of our starting learning rate, and then we carefully monitored the training progress, specifically to avoid the risk of catastrophic interference for the model.
Figure 4 shows that a lower learning rate, such as
, is necessary for our fine-tuned BERT model in order to overcome the catastrophic forgetting effect. Furthermore, the figure also shows that fine-tuning BERT using a higher learning rate, such as
or
, results in convergence failure.
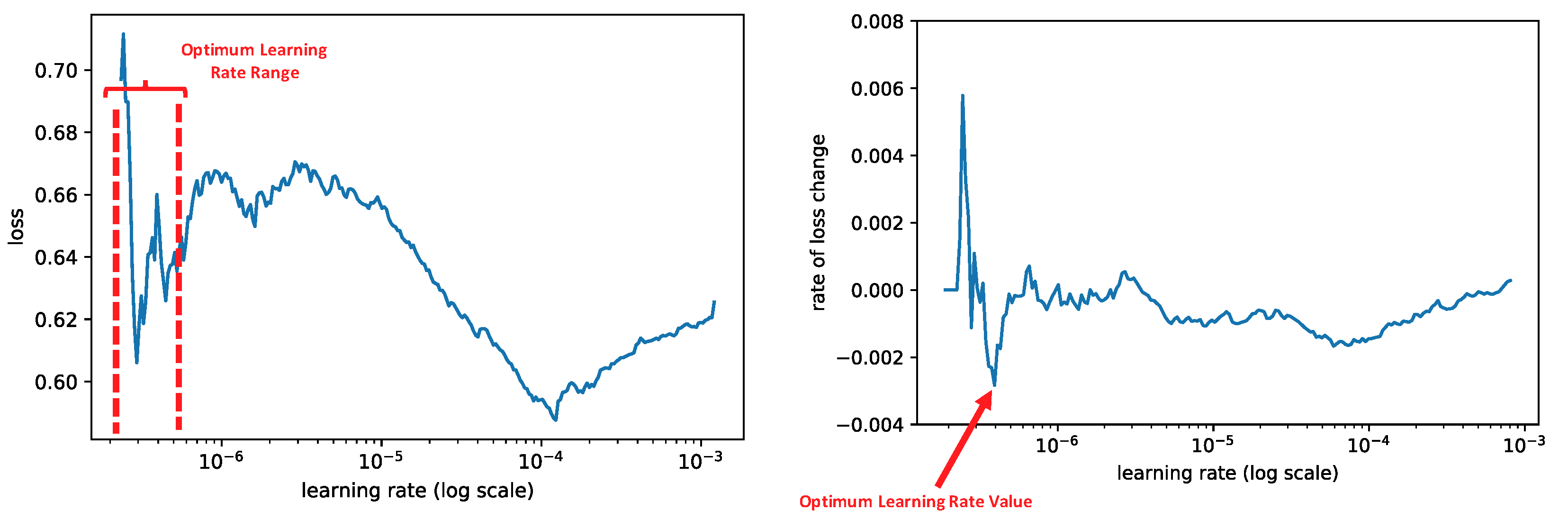
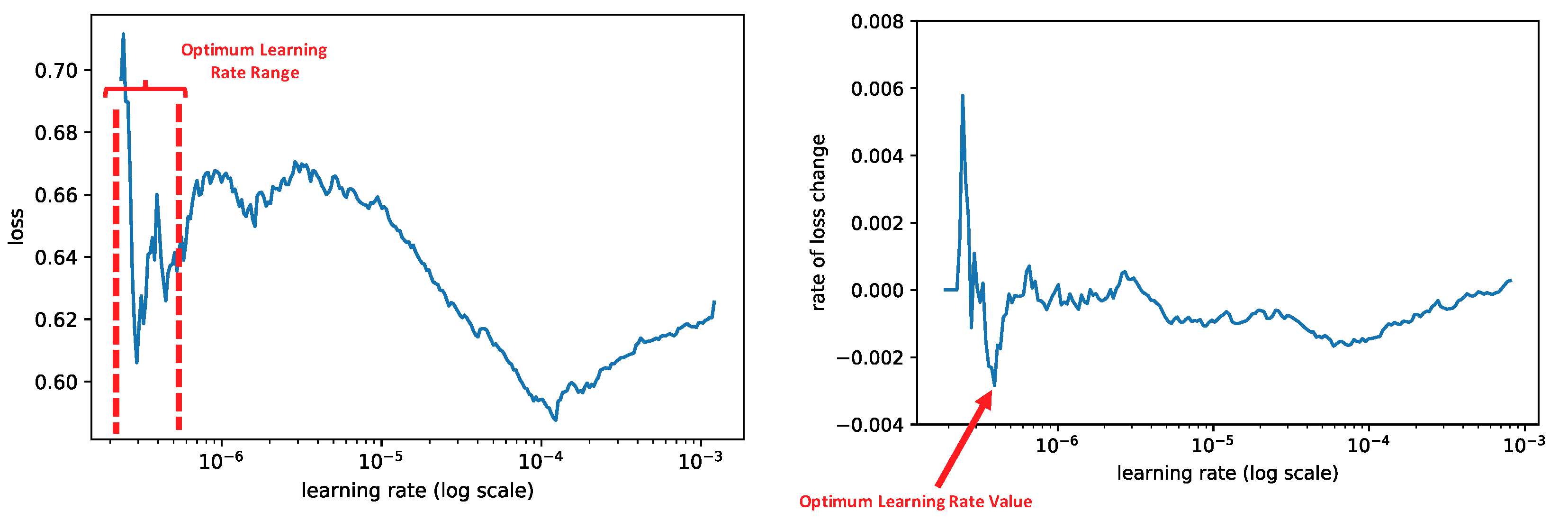
We utilized the cyclic method explained by Smith to determine the optimal learning rate range for our model [
41]. In this method, the learning rate is initially low, and then it is increased exponentially for each batch. To find the best learning rate, we plotted training loss results for each batch. The best initial value of the learning rate was somewhere around the middle of the sharpest descending loss curve (left plot) or the lowest value in the loss derivatives with respect to the learning rate (red arrow in the right plot in
Figure 5).
We analyzed different values within the optimal range shown in
Figure 5 to determine the best initial learning rate for our model. In our model, the loss function started to decrease very rapidly when the learning rate was between
and
(see
Figure 5). By choosing a value in this range, we still were able to further decrease the LR using ReduceLROnPlateau. ReduceLROnPlateau reduces learning rate by a factor of 0.5 if the validation loss does not improve after two iterations (epochs).
4.2.1.2. Overfitting
Choosing the exact number of training epochs to use is a common problem in training neural networks. Overfitting of the training dataset can be caused by too many epochs, whereas underfitting may result from too few iterations. By selecting an appropriate early-stopping method we can start with a large number of epochs and stop the training process if the monitored metric does not show any improvement. This alleviates the needs to manually select the number of epochs and instead utilize a data-driven automation approach. In our model, we monitor the validation loss value and will stop training after four epochs if it does not show any improvement.
4.2.2. Selecting Optimal Classification Layer
The BERT-base model consists of an embedding layer, a stack of 12 encoders for the base model, and a pooling layer. The input embedding layer operates on the sum of the token embeddings, the segmentation embeddings, and the position embeddings. The final hidden state from encoders is corresponding to the special classification token (CLS). For the text classification task, this token is used as the aggregate sequence representation.
The first layer after the encoders is the next sentence prediction (NSP) layer. The NSP layer is utilized to understand sentence relationships [
5]. This layer transforms the last encoder layer output (CLS token) into two vectors, each representing IsNext and NotNext, respectively. The NSP layer then is connected to a fully connected neural network for classification.
We did not freeze any of the layers during the fine-tuning process. In this way, the model will adjust BERT’s pre-trained weights based on our dataset, hyperparameters, and our given downstream task.
4.2.3. Selecting the Optimal Number of Dense Layers
Different layers of a neural network can capture different levels of syntactic information for text classification [
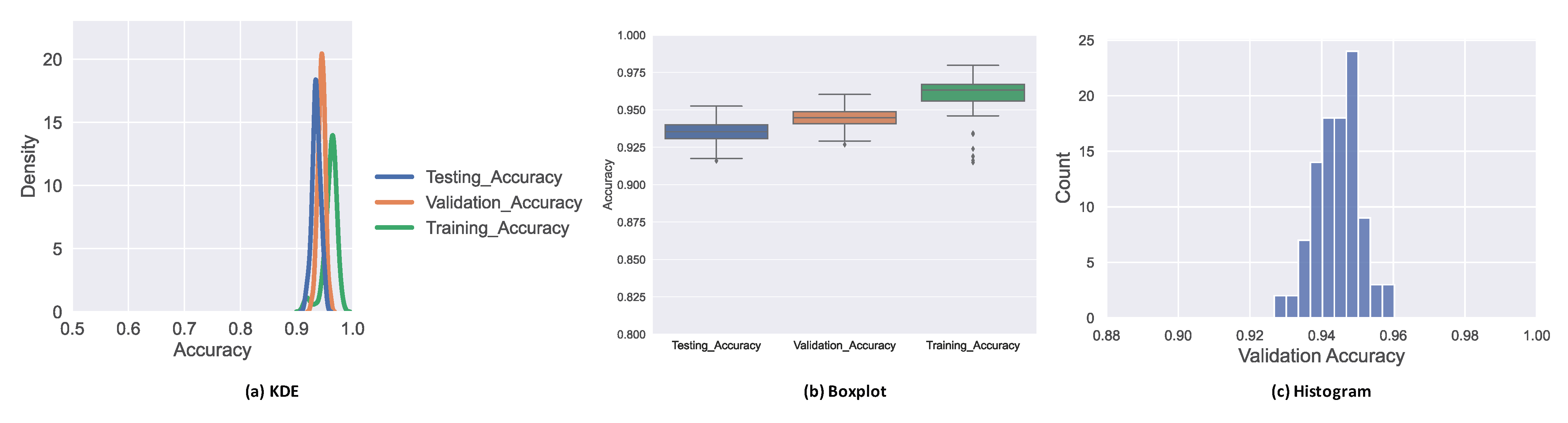
3]. We studied the impact of different numbers of fully connected dense layers on top of the stacked encoders in BERT, in order to determine the best model based on our given dataset. The hyperparameters we adapted here are the different dropouts and the number of neurons for each dense layer. We achieved the best results for two dense layers with 64 and 16 neurons and dropout rates of 0.5 and 0.3, respectively.
Table 2 shows the highest accuracy and learning rate based on the different number of dense layers.
4.2.4. Labeling Process
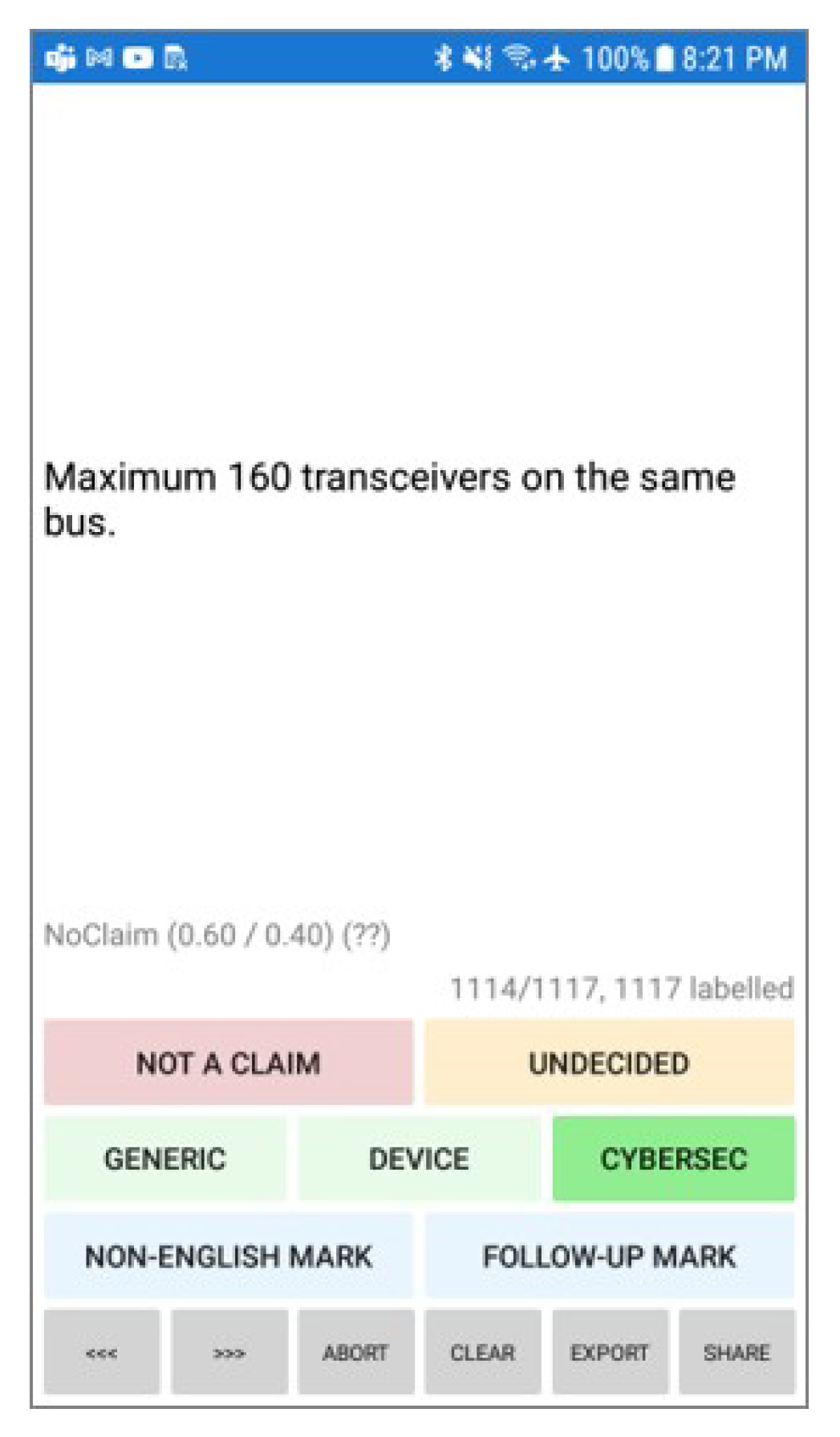
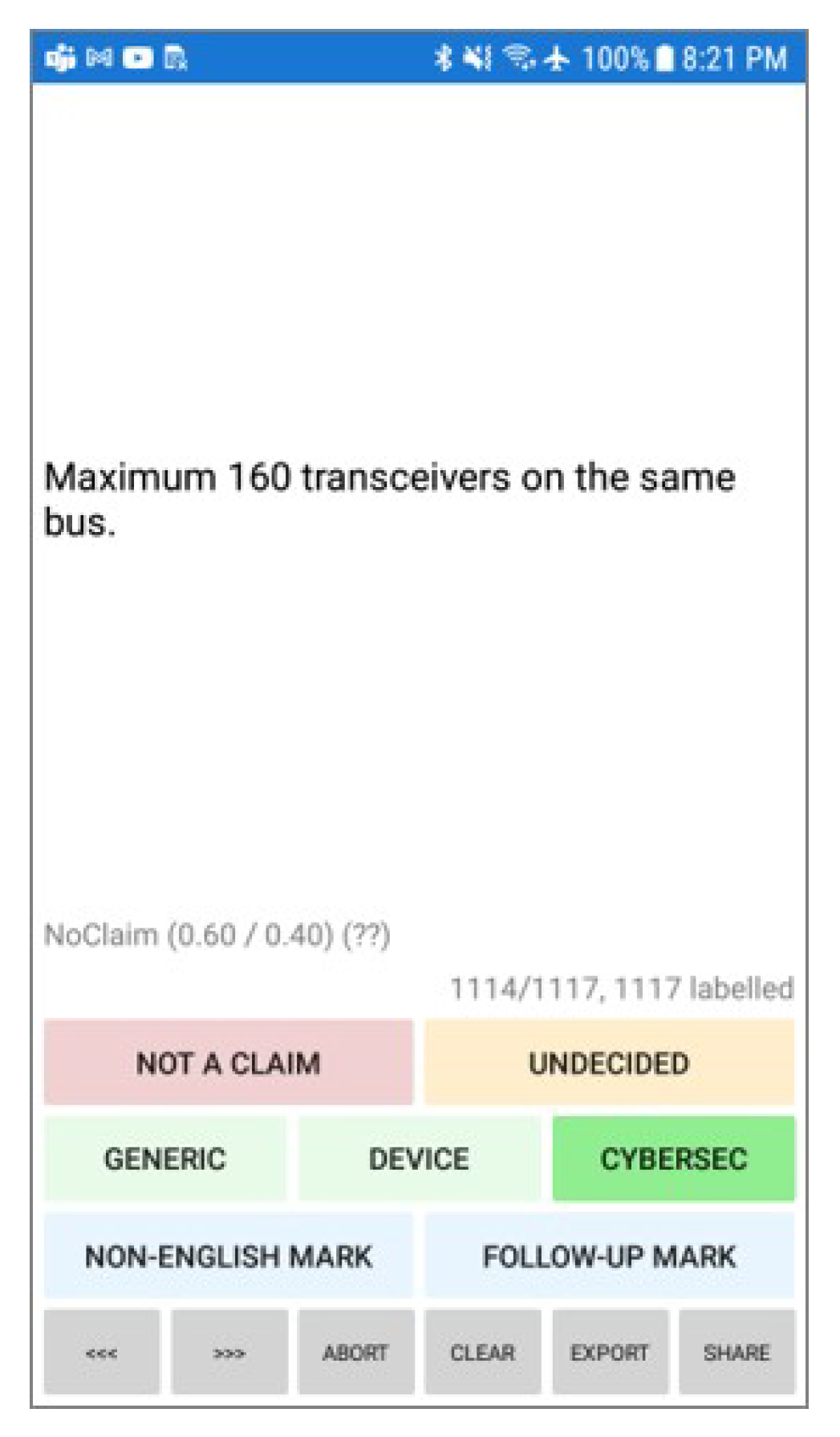
We designed and implemented a mobile application to aid in the manual labeling of extracted sequences. A snapshot of the application is provided in
Figure 6. This mobile app was written as a
Xamarin.Forms app [
42], an open-source mobile app development framework for building Android and iOS apps with .NET and C#. This application supports initial labeling and relabeling and also supports labeling using multiple people, by associating designated labels with the person providing that label. This can subsequently be used for outlier removal, computation of majority decisions on final labels, and more.
4.2.4.1. Initial Labelling
We manually labeled sequences extracted from a sample of ICS device documents. Claim sequences were initially categorized into three types, including generic claims, device claims, and cybersecurity claims. Having these individual claim types will help future investigation regarding claim type detection. For the purpose of this study, we grouped all these types of claims as claim labels and also removed the sequences with the “Not Sure” label from the classification dataset.
4.2.4.2. Prediction-Guided Relabeling Process
After obtaining our initial labeled dataset, we used it to train CyBERT. We followed the fine-tuning process we detailed earlier in this article. The trained model was then used to predict the class labels for each sequence, and we compared the results with the manual labels. From that comparison, we could find that there were a number of sequences whose class prediction probability was in the vicinity of 0.5, indicating a large uncertainty in some instances. We carefully reviewed each of those cases and adjusted the labels where necessary. The final class count and their distribution are reported in
Table 3.
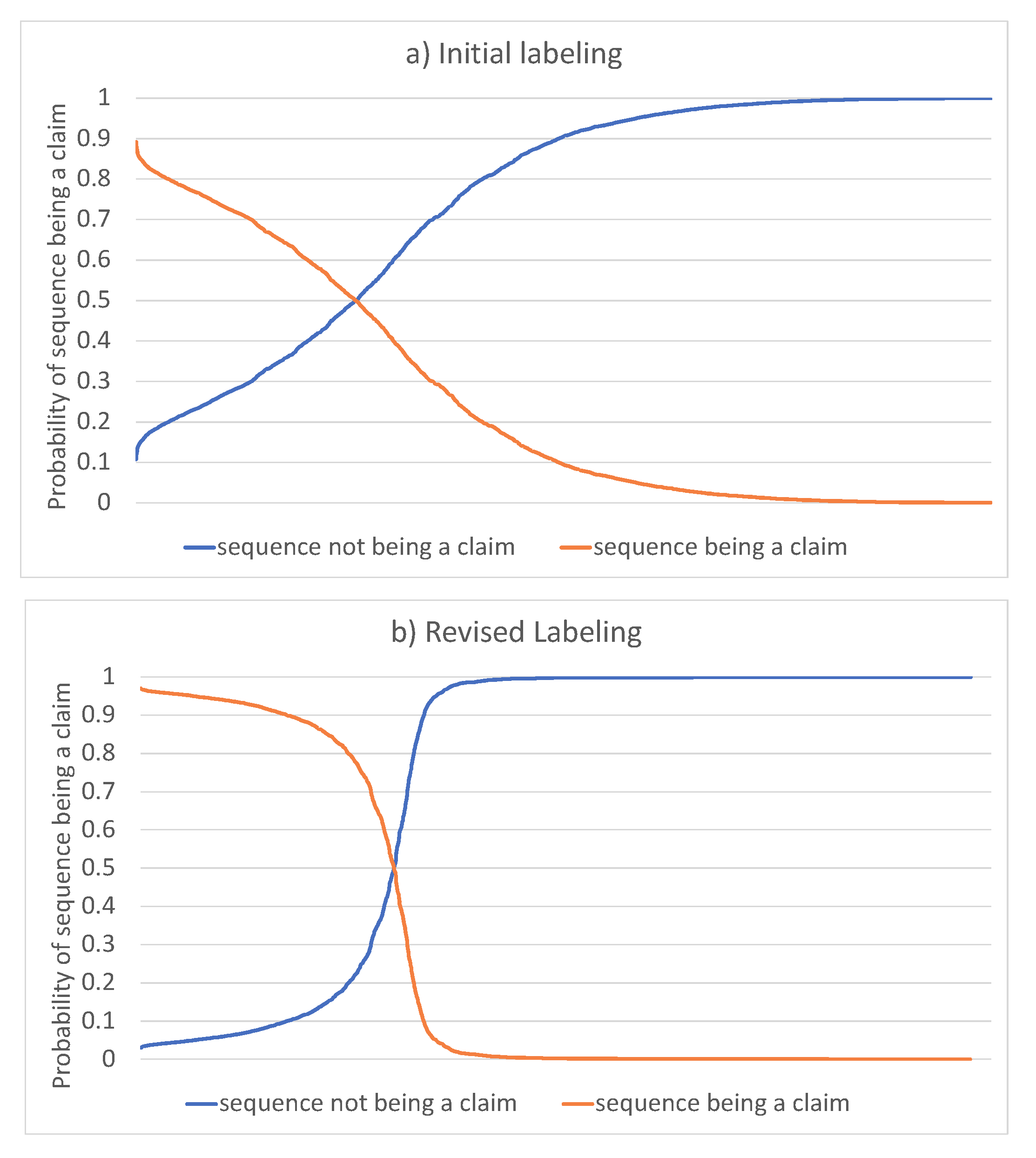
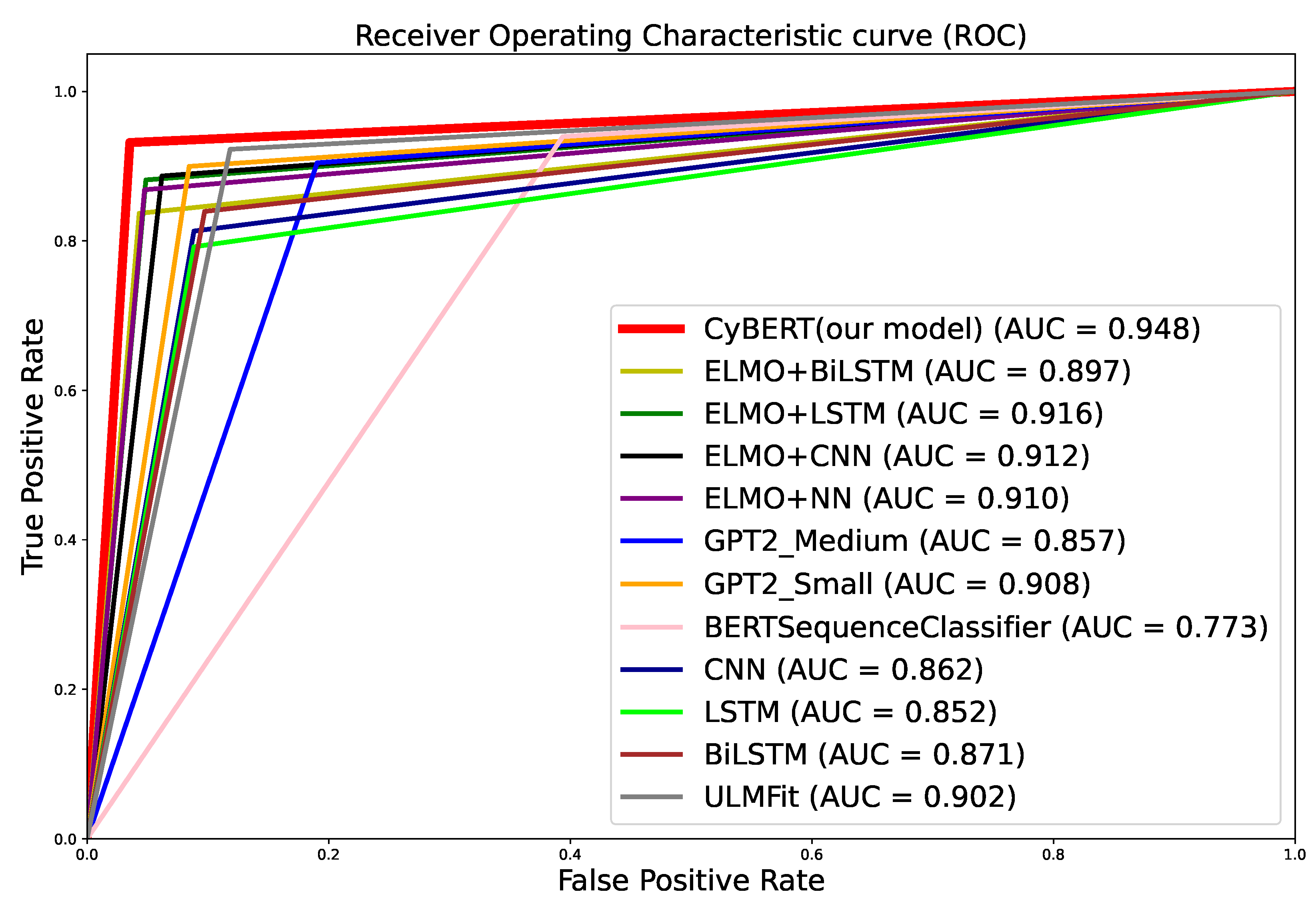
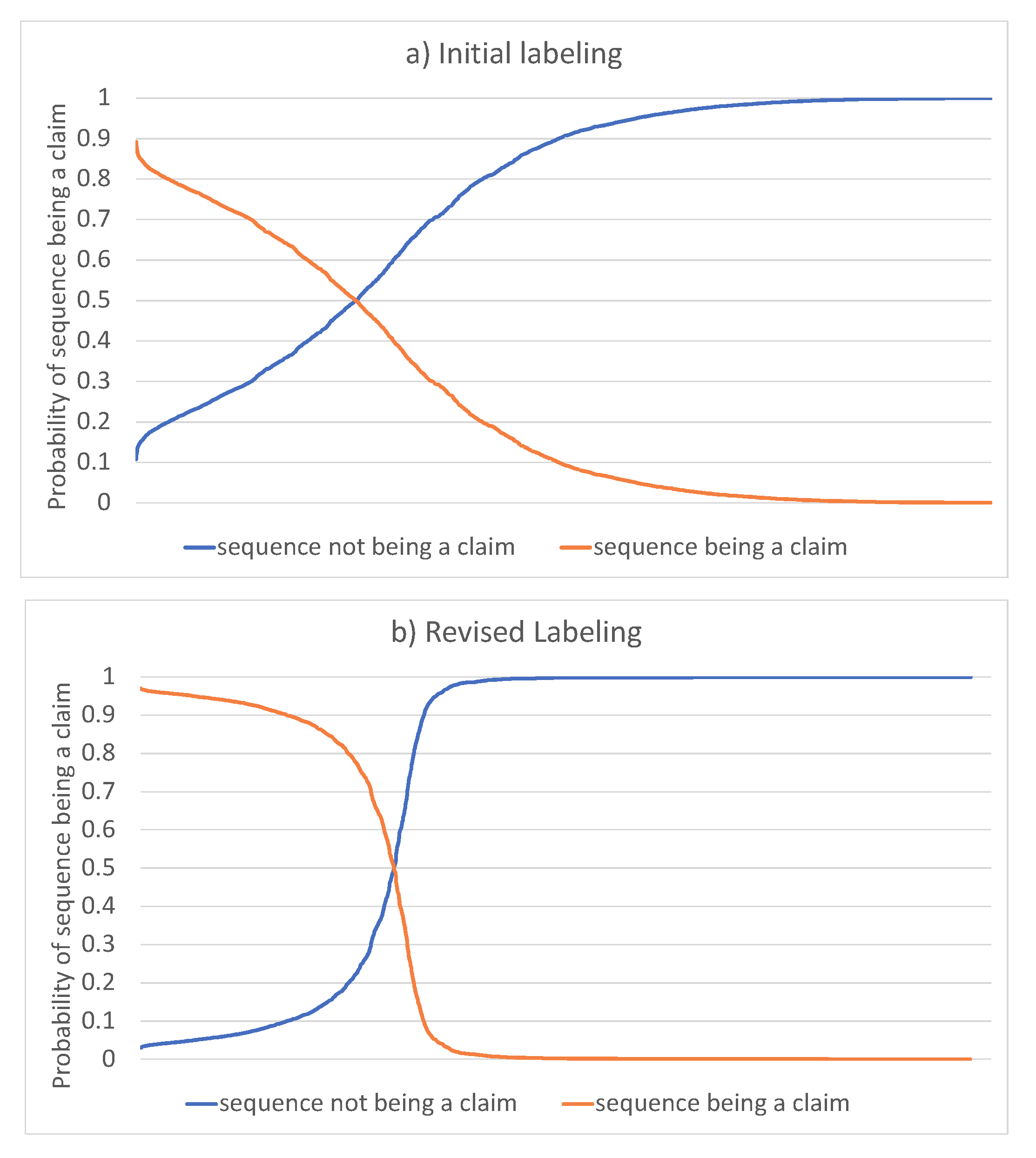
After this label review process, we repeated the fine-tuning process to obtain new model parameter values. A comparison of the obtained results pre- and post-label review demonstrate the improvement to CyBERT from this iterative refinement process. The obtained probabilities were sorted and plotted in the
Figure 7, showing that we could successfully reduce the model uncertainty.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}