
Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies


Abstract
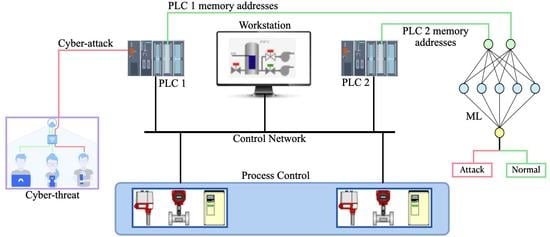
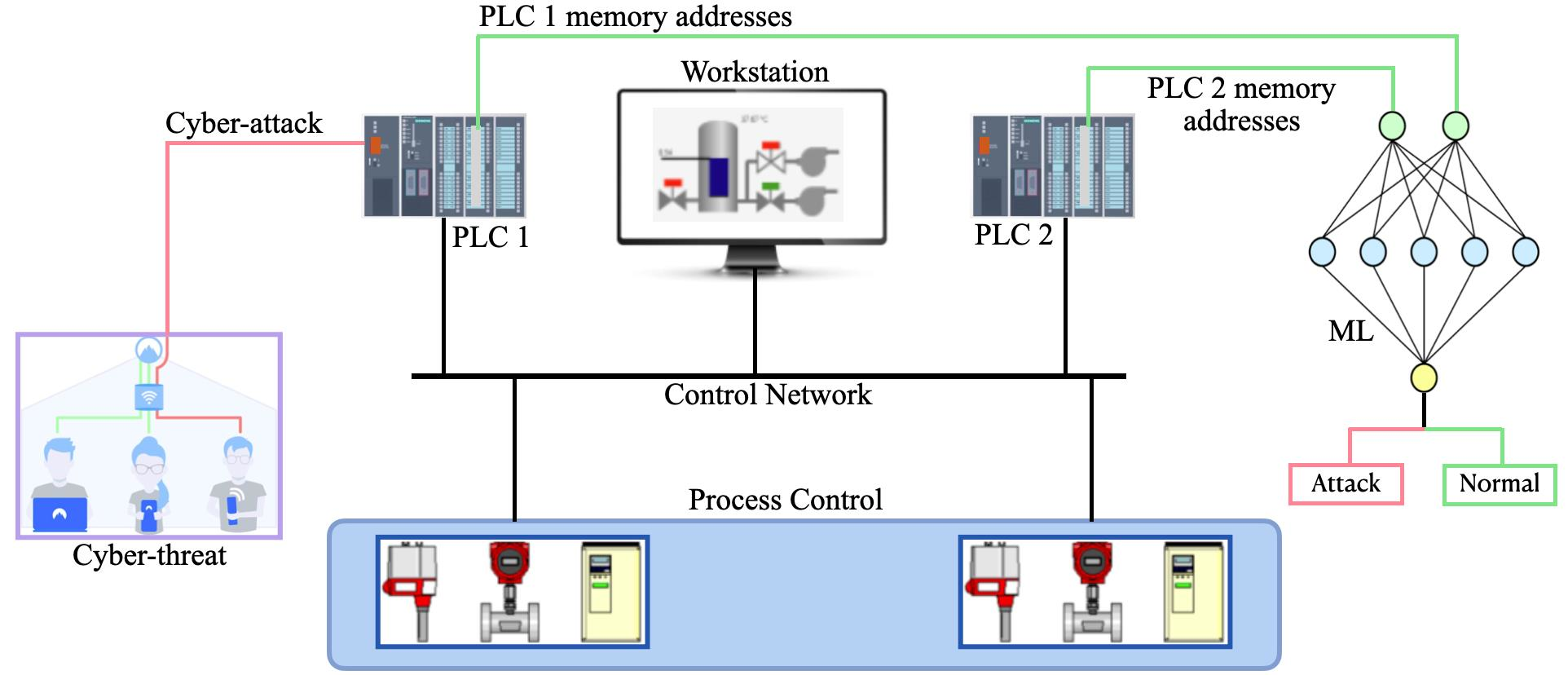
:
1. Introduction
1.1. Contributions
- Employ OCNN-based technique for detecting abnormal PLC behavior—the first known application of OCNN in the ICS domain;
- Conduct comparative performance analysis between OCSVM, OCNN, and IF based on their decision scores instead of using traditional binary predictions and employing analysis of variance (ANOVA) and Tukey’s range test for confirming validity of results;
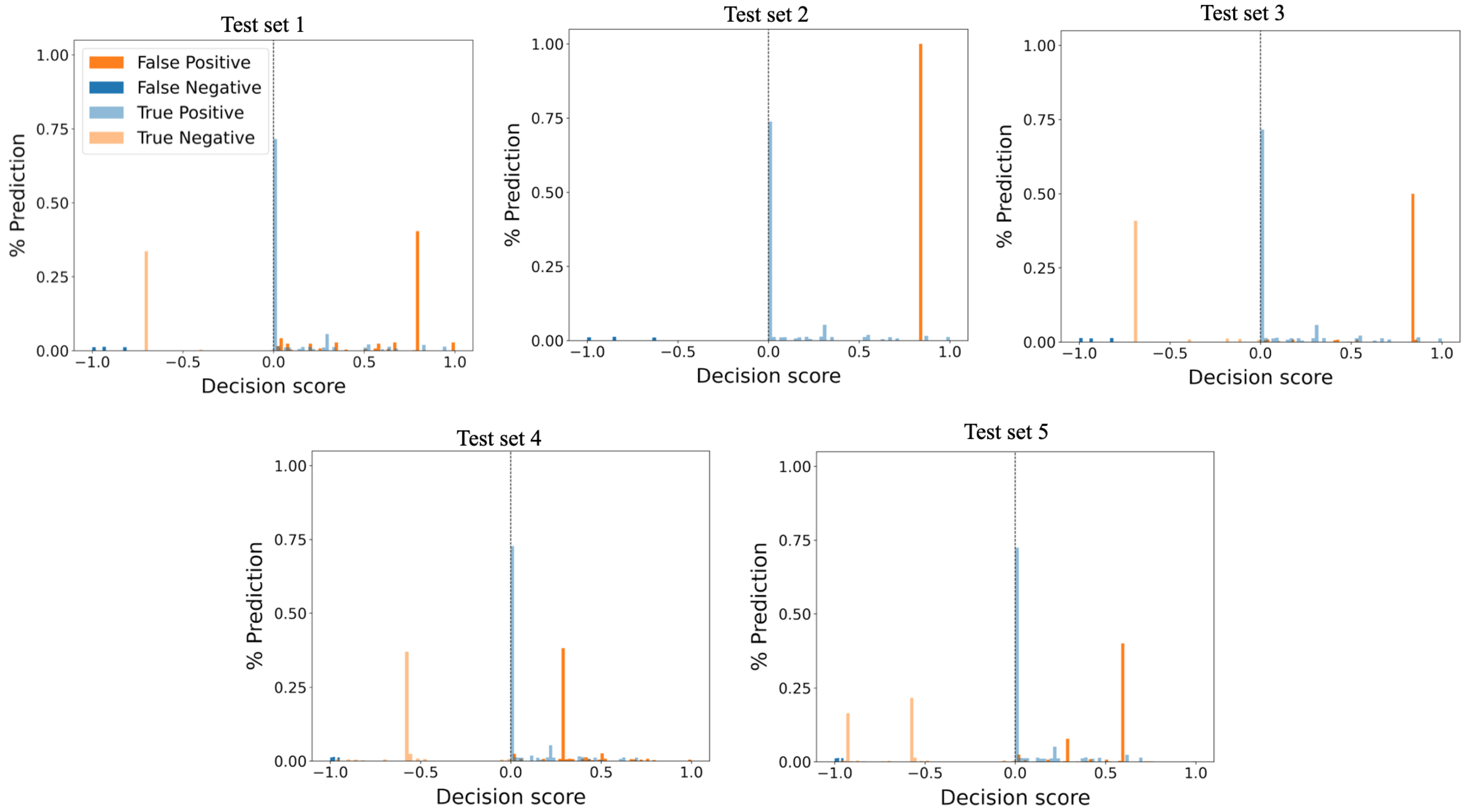
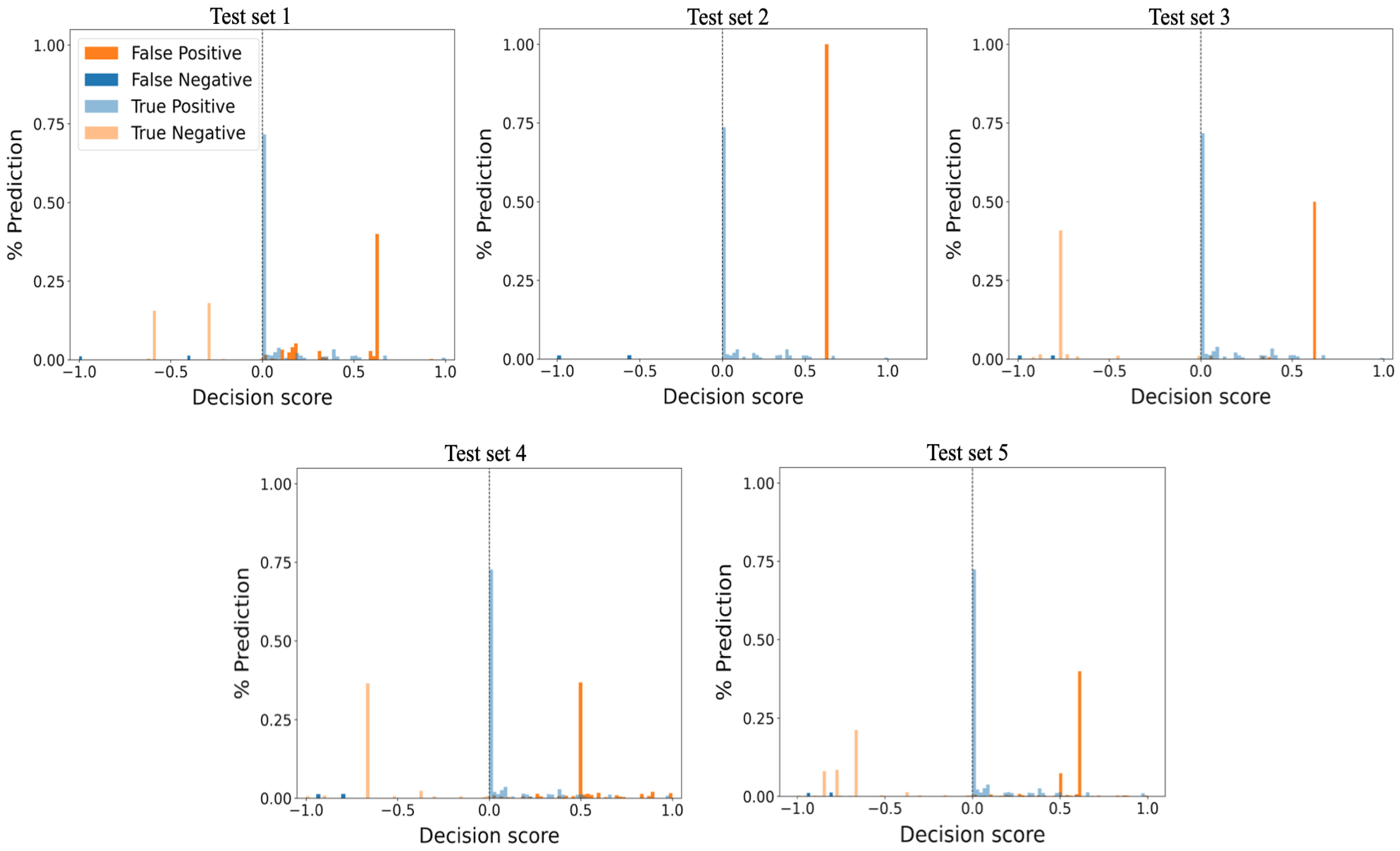
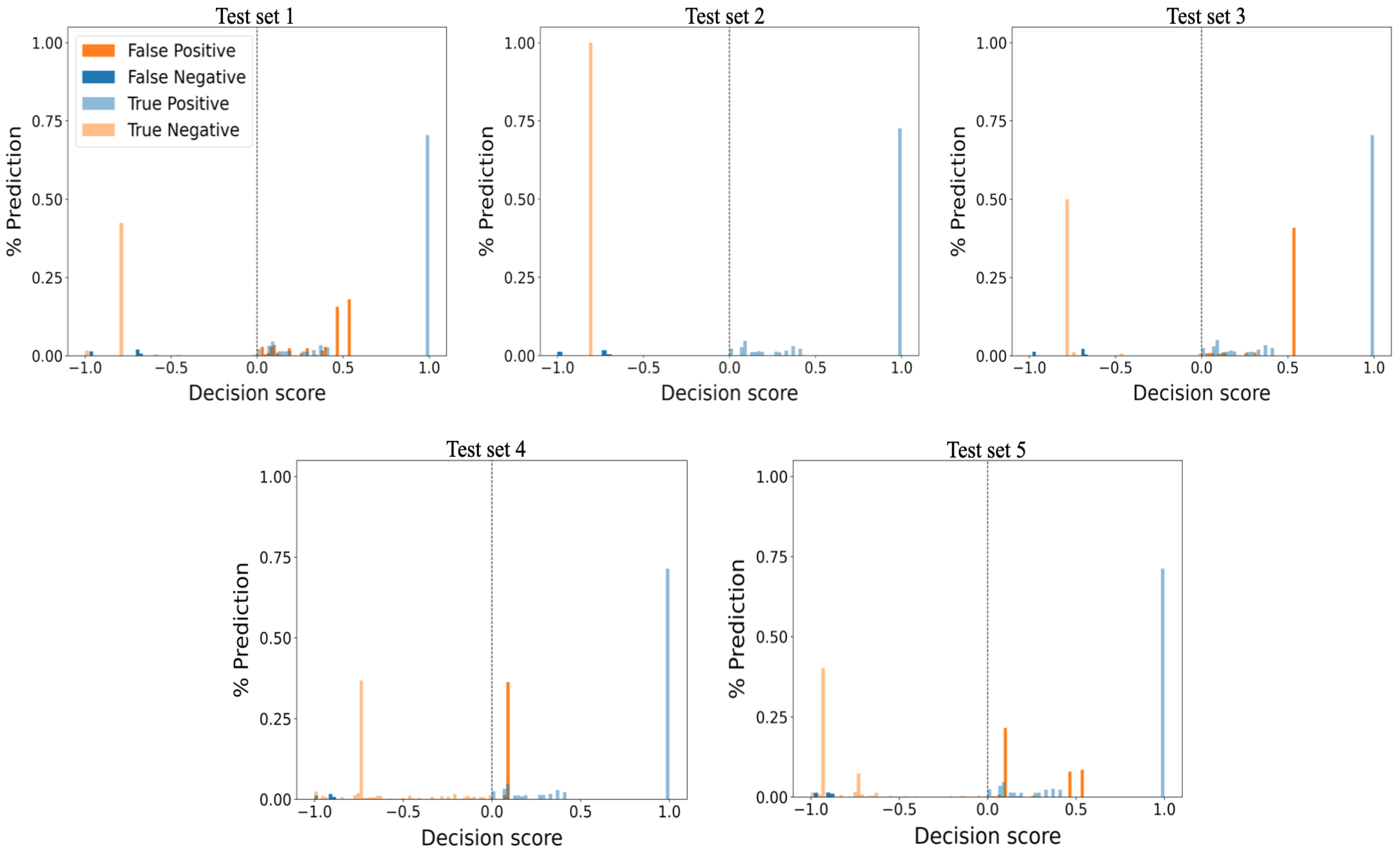
- Introduce a new histogram-based approach for visualizing anomaly-detection algorithm performance and prediction confidence.
1.2. Outline of the Paper
2. Related Work
3. Experiment Setup
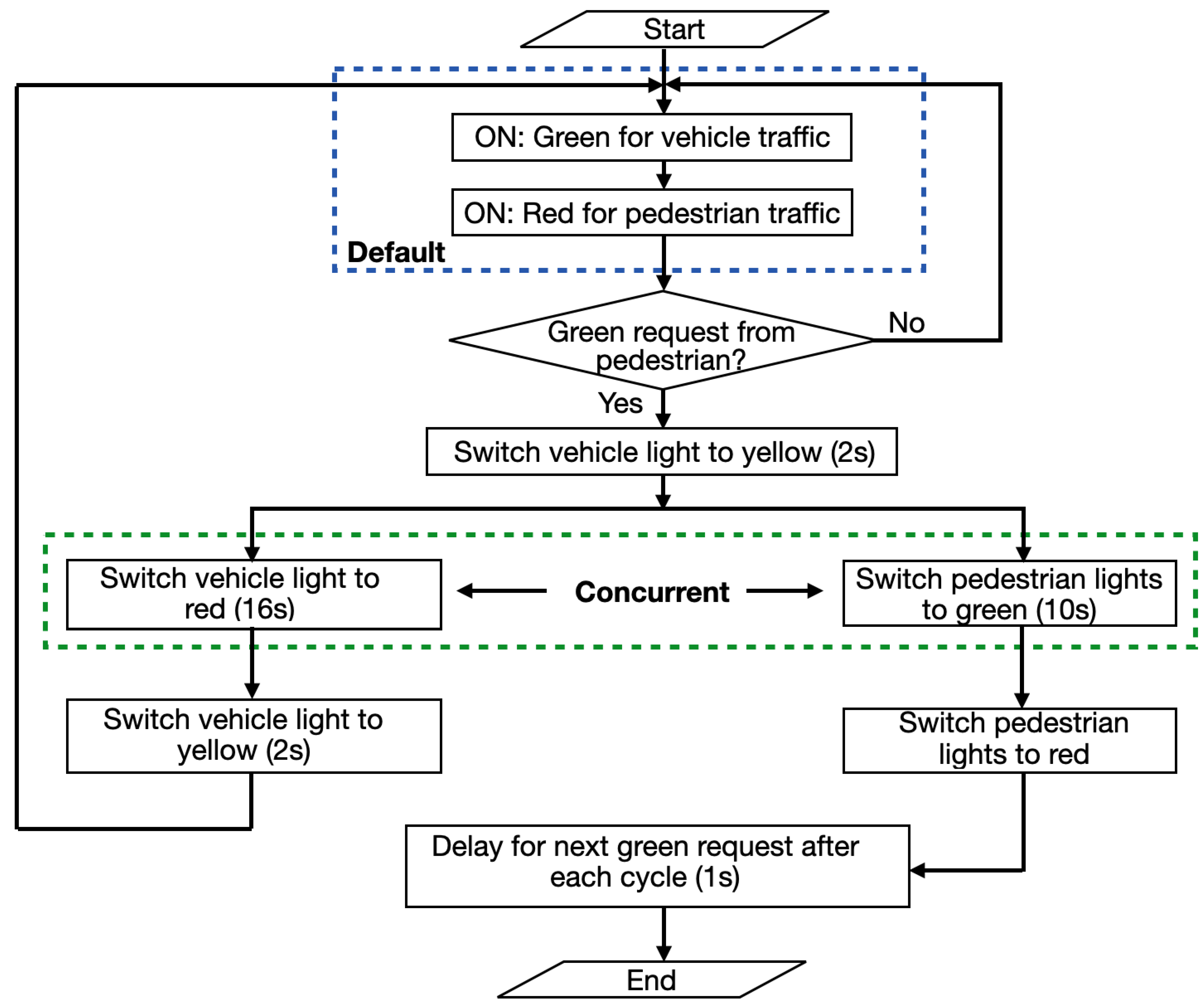
3.1. Description of Control Setup
- The control system default operation should turn ON the green and red light signals for the vehicle traffic and pedestrian traffic, respectively, to define a safe starting point;
- Whenever the program receives a green request from the pedestrian through the pushbutton, the vehicle traffic light signals must change from green to red via yellow.
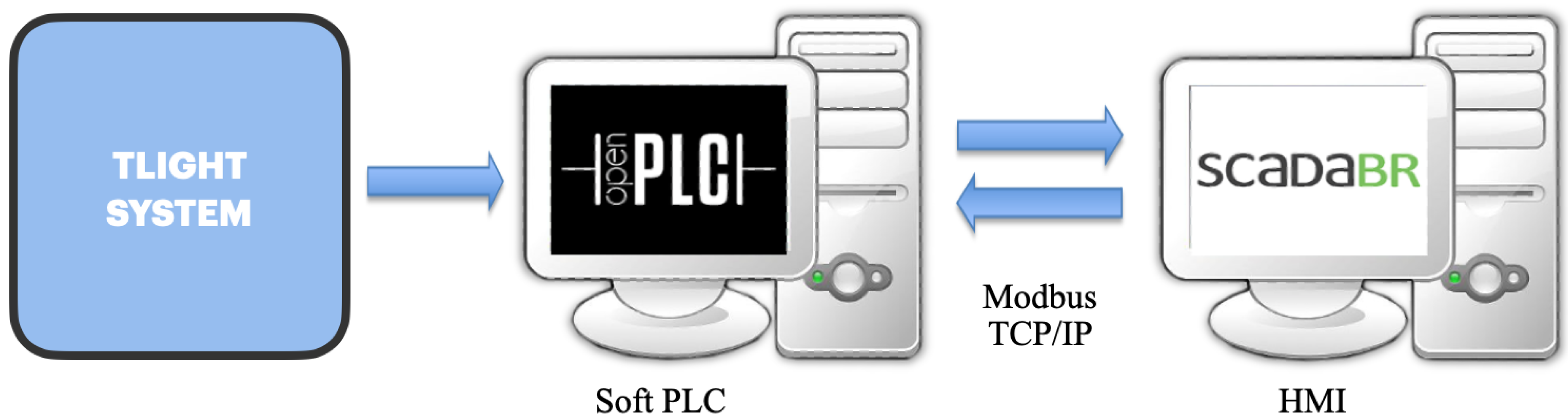
3.2. OpenPLC
| Algorithm 1: PLC runtime execution. |
 |
3.3. Human Machine Interface (HMI)
| Algorithm 2: HMI application execution. |
 |
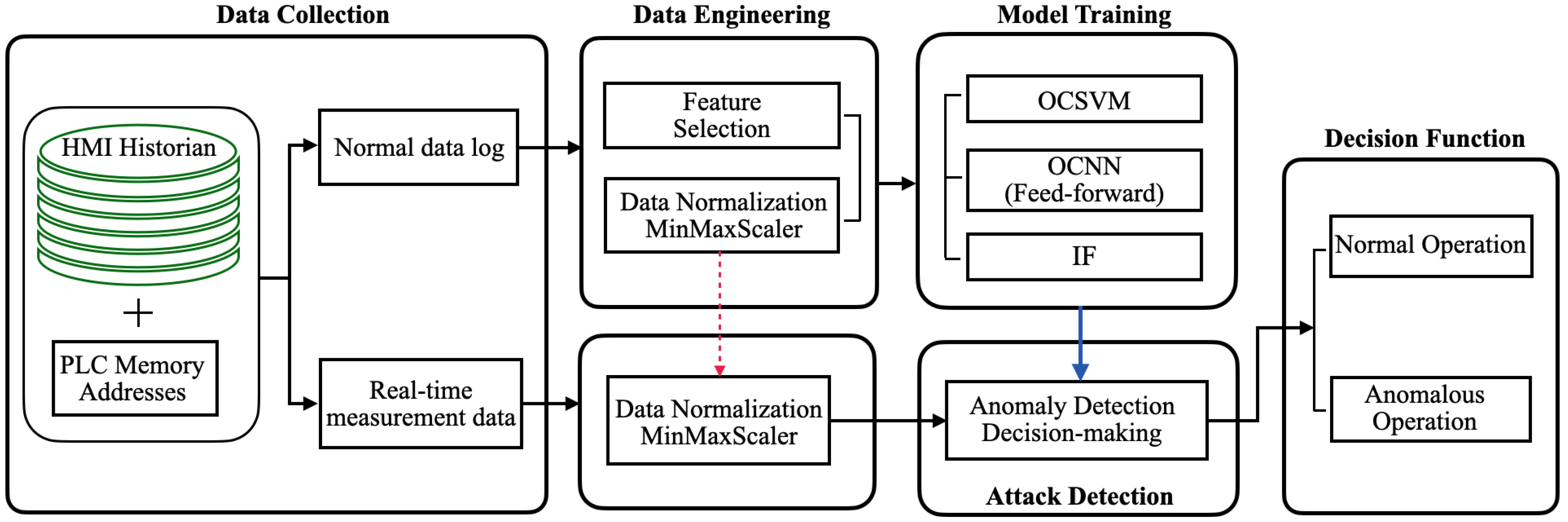
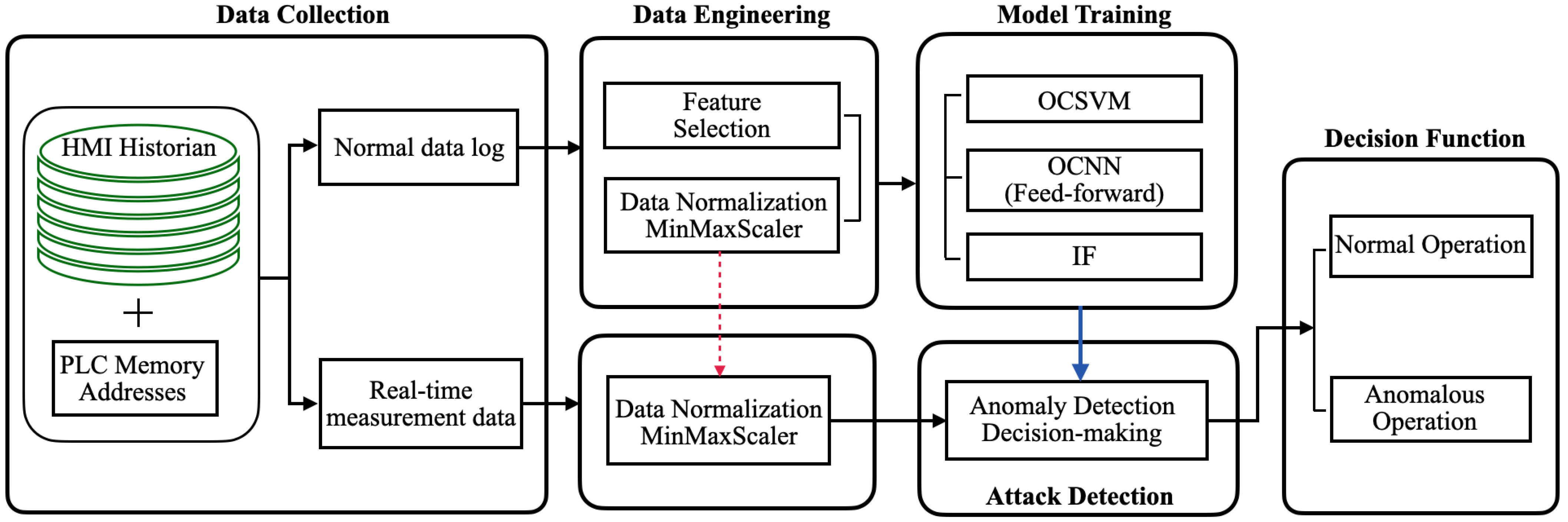
4. Proposed Method
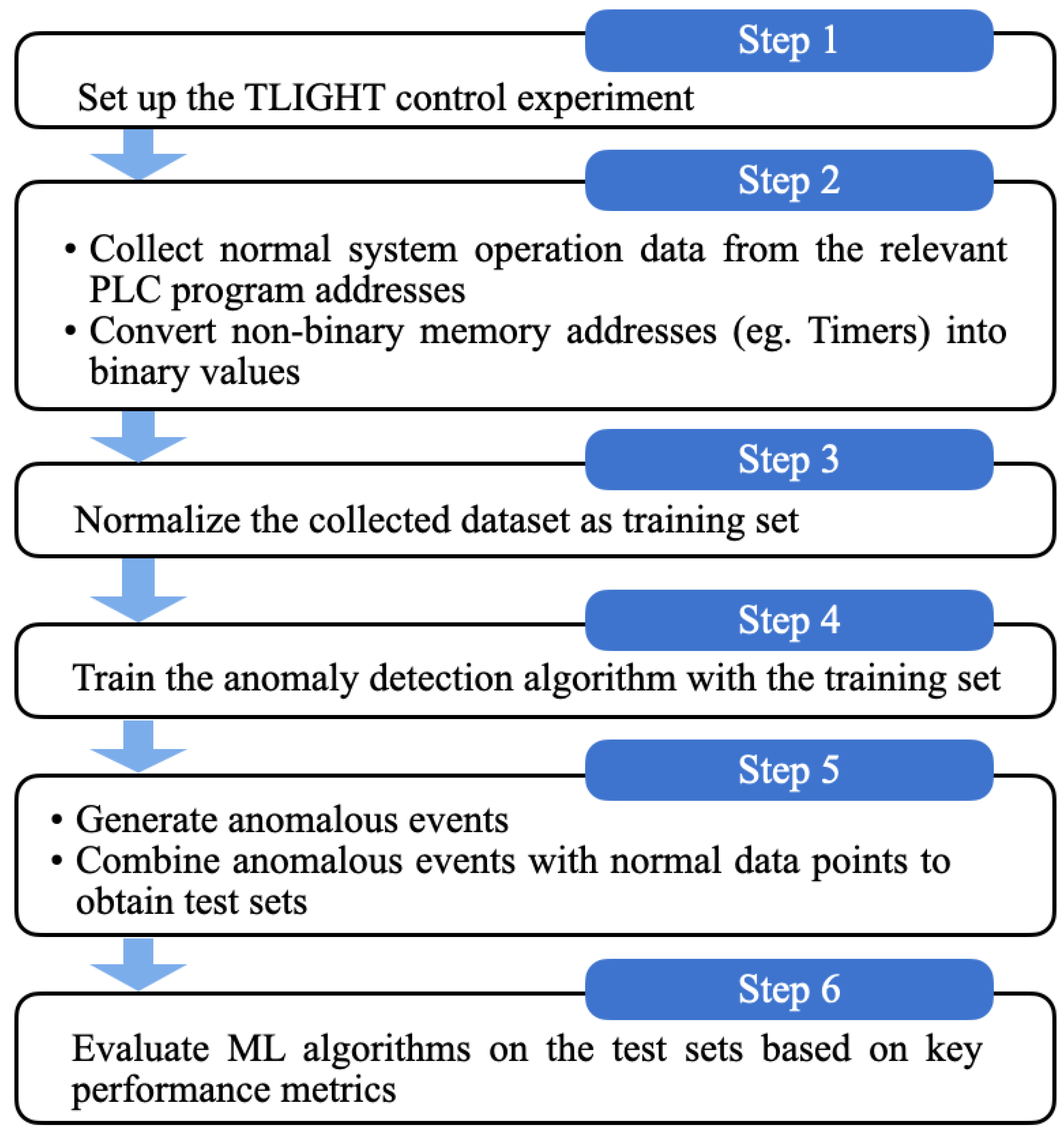
4.1. Data Collection and Preprocessing
4.1.1. Anomalous Scenarios
- Anomalous scenario 1: All the vehicles and pedestrians’ green lights are turned ON at the same time. The purpose of this anomalous event is to violate the TLIGHT system safety rules. This attack generally represents a real-world scenario in which an attacker has compromised the PLC operations through elevation of privileges attack with the aim of causing traffic collision between vehicles and pedestrians.
- Anomalous scenario 2: All the traffic lights are shut down. This attack aims to simulate an unnecessary traffic scenario for the vehicles and deny pedestrians’ green light requests. This attack represents a real-world scenario in which an attacker has introduced logic bomb attack inside the PLC ladder logic with the aim of terminating TLIGHT system operations.
- Anomalous scenario 3: All pedestrians and vehicles’ traffic light signals are turned ON. This attack scenario aims to violate the TLIGHT system safety requirements. This attack generally represents a real-world scenario in which an attacker has compromised the wired connection between the PLC and physical components with the aim of causing a denial-of-service attack. This attack could lead to traffic jams and delays.
- Anomalous scenario 4: Refuse all green light requests from the pedestrians. This attack scenario violates the TLIGHT system logic and operation cycle. This attack generally represents a real-world scenario in which an attacker tampered with the HMI communication protocol due to unencrypted communication with the aim of causing a denial-of-service attack.
- Anomalous scenario 5: All vehicles and pedestrians’ red light signals are turned ON at the same time. The motive of this attack is to cause unnecessary traffic for both vehicles and pedestrians and violate the TLIGHT system’s default setting. This attack generally represents a real-world scenario in which an attacker has introduced a hardware trojan inside the physical components causing the red light signals to respond differently from the PLC logic.
- Anomalous scenario 6: The vehicle’s yellow signals timing bits are manipulated. This kind of anomaly is stealthy and subtle because all the traffic lights seem to be operating normally with manipulated timing bits. This attack generally represents a real-world scenario where an attacker has executed a man-in-the-middle attack by spoofing the vehicle and pedestrian timing bits signals.
- Anomalous scenario 7: Delay timing bits for subsequent pedestrian green requests, and pedestrians’ green light phase duration are manipulated. This attack scenario is similar to attack scenario six in its subtlety and difficulty of detection from a human perspective. This attack generally represents a real-world scenario in which an attacker has executed a man-in-the-middle attack by spoofing the delay timing bits for pedestrian green request signals.
4.1.2. Test Cases
- Test set 1 contains 5000 normal and anomalous events samples, of which are anomalous instances. The of anomalous instances consists of anomalous scenarios 1, 2, 3, 4, and 5;
- Test set 2 contains 7000 test samples, of which are anomalous events. These anomalous events consist solely of anomalous scenario 3;
- Test set 3 contains 13,130 normal and anomalous samples. About of the data contains anomalous instances sampled from anomalous scenarios 1 and 3. Anomalous scenarios 1 and 3 consist of each of the total anomalous events in test set 3;
- Test set 4 contains 15,000 test samples of which anomalous instances in the test sample are . These anomalous instances are sampled from anomalous scenarios 6 and 7. Moreover, anomalous scenarios 6 and 7 consist of and anomalies, respectively. This particular test set comprises only timing bits anomalies;
- Test set 5 is the most diverse and complicated test set. Test set 5 contains 18,270 normal and anomalous test samples. A total of of the test data is anomalous instances sampled from anomalous scenarios 1, 2, 3, 5, 6, and 7. This test set is the only set with a mixture of timing bits anomalies and traffic light signals anomalies. It is also the test set with the highest number of anomalies. Anomalous scenario 1 comprises of the test data, scenario 2 is , scenario 3 is , scenario 5 is , scenario 6 is , and anomalous scenario 7 is of the test data.
4.2. OCSVM-Based Detection Approach
4.3. OCNN-Based Detection Approach
| Algorithm 3: OCNN Algorithm. |
 |
4.4. Isolation Forest-Based Detection Approach
- Total number of isolation trees ;
- Sample size of training data subset used to train each isolation tree ;
- Maximum number of features representing a subset of the data features used to train each tree .
| Algorithm 4: Train . |
 |
| Algorithm 5: Train . |
 |
5. Results and Discussions
5.1. Performance Metrics
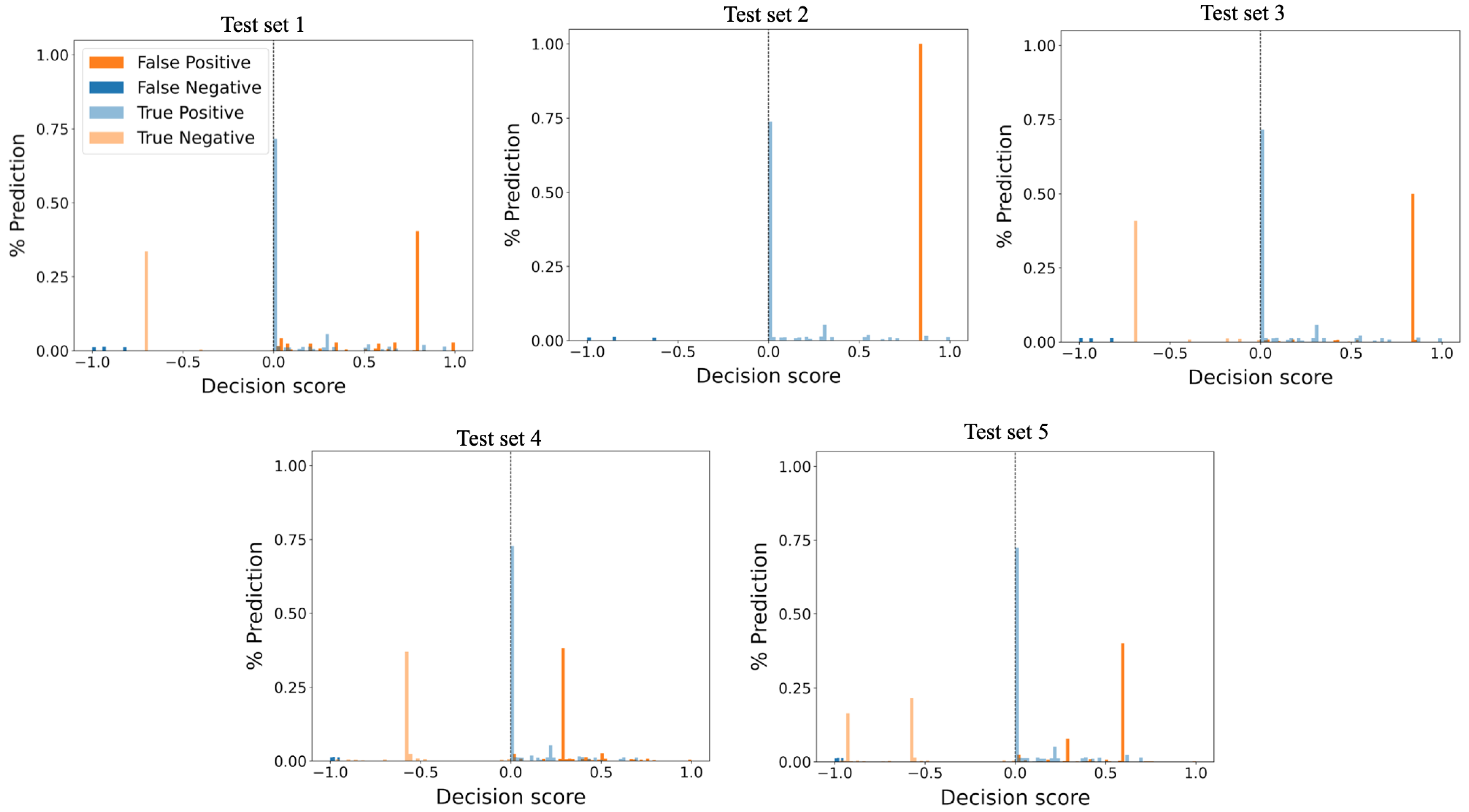
5.2. Performance Evaluation
5.2.1. Performance of OCSVM
5.2.2. Performance of OCNN
5.2.3. Performance of Isolation Forest
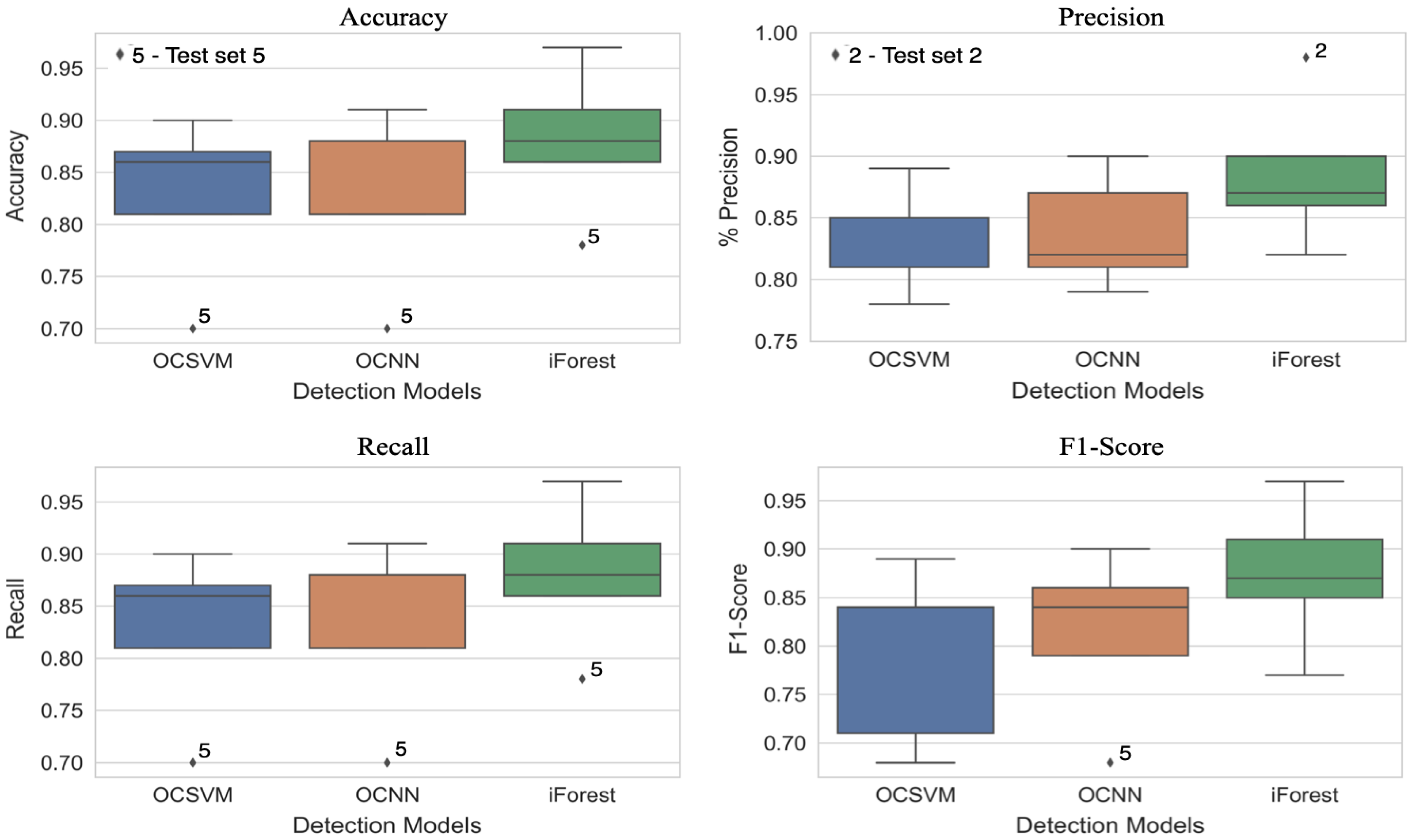
5.3. Statistical Hypothesis Test
5.3.1. Analysis of Variance Test (ANOVA)
- data points in each test sample are independent and identically distributed; and
- data points are normally distributed.
- null hypothesis : The mean F1-score of all detection algorithms are equal; and
- alternate hypothesis : One or more of the mean F1-score are unequal.
5.3.2. Tukey’s Range Test
5.4. Summary of Results
5.5. Practical Considerations
5.6. Limitations
6. Conclusions
Recommendation
- improving the anomaly-detection rate on the TLIGHT system through ensemble techniques;
- developing dual anomaly-detection algorithms that will focus on specific subsets of the dataset; and
- extending the proposed techniques in this work to other publicly available anomaly detection datasets.
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
References
- Kello, L. The Virtual Weapon and International Order; Yale University Press: New Haven, CT, USA, 2019. [Google Scholar]
- Yaacoub, J.P.A.; Salman, O.; Noura, H.N.; Kaaniche, N.; Chehab, A.; Malli, M. Cyber-physical systems security: Limitations, issues and future trends. Microprocess. Microsyst. 2020, 77, 103201. [Google Scholar] [CrossRef] [PubMed]
- Thakur, K.; Ali, M.L.; Jiang, N.; Qiu, M. Impact of cyber-attacks on critical infrastructure. In Proceedings of the 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016; pp. 183–186. [Google Scholar]
- Plėta, T.; Tvaronavičienė, M.; Casa, S.D.; Agafonov, K. Cyber-attacks to critical energy infrastructure and management issues: Overview of selected cases. Insights Into Reg. Dev. 2020, 2, 703–715. [Google Scholar] [CrossRef]
- Wardak, H.; Zhioua, S.; Almulhem, A. PLC access control: A security analysis. In Proceedings of the 2016 World Congress on Industrial Control Systems Security (WCICSS), London, UK, 12–14 December 2016; pp. 1–6. [Google Scholar]
- Abbasi, A.; Holz, T.; Zambon, E.; Etalle, S. ECFI: Asynchronous control flow integrity for programmable logic controllers. In Proceedings of the 33rd Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2017; pp. 437–448. [Google Scholar]
- Abbasi, A. Ghost in the PLC: Stealth on-the-fly manipulation of programmable logic controllers’ I/O. In Proceedings of the Black Hat EU, London, UK, 1–4 November 2016; pp. 1–4. [Google Scholar]
- Yau, K.; Chow, K.P. PLC forensics based on control program logic change detection. J. Digit. Forensics, Secur. Law 2015, 10, 5. [Google Scholar] [CrossRef] [Green Version]
- Langmann, R.; Stiller, M. The PLC as a smart service in industry 4.0 production systems. Appl. Sci. 2019, 9, 3815. [Google Scholar] [CrossRef] [Green Version]
- Tsiknas, K.; Taketzis, D.; Demertzis, K.; Skianis, C. Cyber Threats to Industrial IoT: A Survey on Attacks and Countermeasures. IoT 2021, 2, 163–188. [Google Scholar] [CrossRef]
- Spyridopoulos, T.; Tryfonas, T.; May, J. Incident Analysis & Digital Forensics in SCADA and Industrial Control Systems. In Proceedings of the 8th IET International System Safety Conference Incorporating the Cyber Security Conference, Cardiff, UK, 16–17 October 2013. [Google Scholar]
- Boeckl, K.; Boeckl, K.; Fagan, M.; Fisher, W.; Lefkovitz, N.; Megas, K.N.; Nadeau, E.; O’Rourke, D.G.; Piccarreta, B.; Scarfone, K. Considerations for Managing Internet of Things (IoT) Cybersecurity and Privacy Risks; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- Yau, K.; Chow, K.P.; Yiu, S.M.; Chan, C.F. Detecting anomalous behavior of PLC using semi-supervised machine learning. In Proceedings of the 2017 IEEE Conference on Communications and Network Security (CNS), Las Vegas, NV, USA, 9–11 October 2017; pp. 580–585. [Google Scholar]
- Aboah, B.E.; Bruce, J.W. Anomaly Detection for Industrial Control Systems Based on Neural Networks with One-Class Objective Function. Proc. Stud. Res. Creat. Inq. Day 2021, 5, 86. [Google Scholar]
- Siemens, S. S7-300 Programmable Controller Quick Start, Primer, Preface; Technical Report; C79000-G7076-C500-01; Siemens: Nuremberg, Germany, 1996. [Google Scholar]
- Chen, Y.; Wu, W. Application of one-class support vector machine to quickly identify multivariate anomalies from geochemical exploration data. Geochem. Explor. Environ. Anal. 2017, 17, 231–238. [Google Scholar] [CrossRef]
- Welborn, T. One-Class Support Vector Machines Approach for Trust-Aware Recommendation Systems; Shareok: Norman, OK, USA, 2021. [Google Scholar]
- Hiranai, K.; Kuramoto, A.; Seo, A. Detection of Anomalies in Working Posture during Obstacle Avoidance Tasks using One-Class Support Vector Machine. J. Jpn. Ind. Manag. Assoc. 2021, 72, 125–133. [Google Scholar]
- Ahmad, I.; Shahabuddin, S.; Malik, H.; Harjula, E.; Leppänen, T.; Loven, L.; Anttonen, A.; Sodhro, A.H.; Alam, M.M.; Juntti, M.; et al. Machine learning meets communication networks: Current trends and future challenges. IEEE Access 2020, 8, 223418–223460. [Google Scholar] [CrossRef]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly detection for a water treatment system using unsupervised machine learning. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1058–1065. [Google Scholar]
- Tomlin, L.; Farnam, M.R.; Pan, S. A clustering approach to industrial network intrusion detection. In Proceedings of the 2016 Information Security Research and Education (INSuRE) Conference (INSuRECon-16), Charleston, SC, USA, 30 September 2016. [Google Scholar]
- Xiao, Y.j.; Xu, W.y.; Jia, Z.h.; Ma, Z.r.; Qi, D.l. NIPAD: A non-invasive power-based anomaly detection scheme for programmable logic controllers. Front. Inf. Technol. Electron. Eng. 2017, 18, 519–534. [Google Scholar] [CrossRef]
- Muna, A.H.; Moustafa, N.; Sitnikova, E. Identification of malicious activities in industrial internet of things based on deep learning models. J. Inf. Secur. Appl. 2018, 41, 1–11. [Google Scholar]
- Potluri, S.; Diedrich, C.; Sangala, G.K.R. Identifying false data injection attacks in industrial control systems using artificial neural networks. In Proceedings of the 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Limassol, Cyprus, 12–15 September 2017; pp. 1–8. [Google Scholar]
- Elnour, M.; Meskin, N.; Khan, K.; Jain, R. A dual-isolation-forests-based attack detection framework for industrial control systems. IEEE Access 2020, 8, 36639–36651. [Google Scholar] [CrossRef]
- Ahmed, S.; Lee, Y.; Hyun, S.H.; Koo, I. Unsupervised machine learning-based detection of covert data integrity assault in smart grid networks utilizing isolation forest. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2765–2777. [Google Scholar] [CrossRef]
- Liu, B.; Chen, J.; Hu, Y. Mode division-based anomaly detection against integrity and availability attacks in industrial cyber-physical systems. Comput. Ind. 2022, 137, 103609. [Google Scholar] [CrossRef]
- Ahmed, C.M.; MR, G.R.; Mathur, A.P. Challenges in machine learning based approaches for real-time anomaly detection in industrial control systems. In Proceedings of the 6th ACM on Cyber-Physical System Security Workshop, Taipei, Taiwan, 6 October 2020; pp. 23–29. [Google Scholar]
- Priyanga, S.; Gauthama Raman, M.; Jagtap, S.S.; Aswin, N.; Kirthivasan, K.; Shankar Sriram, V. An improved rough set theory based feature selection approach for intrusion detection in SCADA systems. J. Intell. Fuzzy Syst. 2019, 36, 3993–4003. [Google Scholar] [CrossRef]
- Raman, M.G.; Somu, N.; Mathur, A.P. Anomaly detection in critical infrastructure using probabilistic neural network. In International Conference on Applications and Techniques in Information Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 129–141. [Google Scholar]
- Benkraouda, H.; Chakkantakath, M.A.; Keliris, A.; Maniatakos, M. Snifu: Secure network interception for firmware updates in legacy plcs. In Proceedings of the 2020 IEEE 38th VLSI Test Symposium (VTS), San Diego, CA, USA, 5–8 April 2020; pp. 1–6. [Google Scholar]
- Wu, T.; Nurse, J.R. Exploring the use of PLC debugging tools for digital forensic investigations on SCADA systems. J. Digit. Forensics, Secur. Law 2015, 10, 7. [Google Scholar] [CrossRef] [Green Version]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly detection using one-class neural networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Alves, T.R.; Buratto, M.; De Souza, F.M.; Rodrigues, T.V. OpenPLC: An open source alternative to automation. In Proceedings of the IEEE Global Humanitarian Technology Conference (GHTC 2014), San Jose, CA, USA, 10–13 October 2014; pp. 585–589. [Google Scholar]
- Mazurkiewicz, P. An open source SCADA application in a small automation system. Meas. Autom. Monit. 2016, 62, 199–201. [Google Scholar]
- Unipi Neuron Kernel Description. Available online: https://www.unipi.technology/products/unipi-neuron-3 (accessed on 3 March 2022).
- ZumIQ Edge Computer Kernel Description. Available online: https://www.freewave.com/products/zumiq-edge-computer/ (accessed on 3 March 2022).
- Automation without Limits Kernel Description. Available online: https://www.unipi.technology/ (accessed on 3 March 2022).
- Tiegelkamp, M.; John, K.H. IEC 61131-3: Programming Industrial Automation Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- TLIGHT SYSTEM Source Code to TLIGHT Experiment. Available online: https://github.com/emmanuelaboah/TLIGHT-SYSTEM (accessed on 17 January 2022).
- Gollapudi, S. Practical Machine Learning; Packt Publishing Ltd.: Mumbai, India, 2016. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Zhu, F.; Yang, J.; Gao, C.; Xu, S.; Ye, N.; Yin, T. A weighted one-class support vector machine. Neurocomputing 2016, 189, 1–10. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An introduction to outlier analysis. In Outlier Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–34. [Google Scholar]
- Oza, P.; Patel, V.M. One-class convolutional neural network. IEEE Signal Process. Lett. 2018, 26, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Boehm, O.; Hardoon, D.R.; Manevitz, L.M. Classifying cognitive states of brain activity via one-class neural networks with feature selection by genetic algorithms. Int. J. Mach. Learn. Cybern. 2011, 2, 125–134. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Washington, DC, USA, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended isolation forest. IEEE Trans. Knowl. Data Eng. 2019, 33, 1479–1489. [Google Scholar] [CrossRef] [Green Version]
- Staerman, G.; Mozharovskyi, P.; Clémençon, S.; d’Alché Buc, F. Functional isolation forest. In Proceedings of the Asian Conference on Machine Learning, PMLR, Nagoya, Japan, 17–19 November 2019; pp. 332–347. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. Available online: tensorflow.org (accessed on 17 February 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Goldstein, M.; Dengel, A. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In KI-2012: Poster and Demo Track; Citeseer: Princeton, NJ, USA, 2012; pp. 59–63. [Google Scholar]
- Kind, A.; Stoecklin, M.P.; Dimitropoulos, X. Histogram-based traffic anomaly detection. IEEE Trans. Netw. Serv. Manag. 2009, 6, 110–121. [Google Scholar] [CrossRef]
- Bansod, S.D.; Nandedkar, A.V. Crowd anomaly detection and localization using histogram of magnitude and momentum. Vis. Comput. 2020, 36, 609–620. [Google Scholar] [CrossRef]
- Xie, M.; Hu, J.; Tian, B. Histogram-based online anomaly detection in hierarchical wireless sensor networks. In Proceedings of the 2012 IEEE 11th International Conference on Trust, Security and Privacy in Computing and Communications, Liverpool, UK, 25–27 June 2012; pp. 751–759. [Google Scholar]
- Goldberg, D.E.; Scheiner, S.M. ANOVA and ANCOVA: Field competition experiments. Des. Anal. Ecol. Exp. 2001, 2, 69–93. [Google Scholar]
- Rutherford, A. ANOVA and ANCOVA: A GLM Approach; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Abdi, H.; Williams, L.J. Newman-Keuls test and Tukey test. In Encyclopedia of Research Design; Sage: Thousand Oaks, CA, USA, 2010; pp. 1–11. [Google Scholar]
- Alqurashi, S.; Shirazi, H.; Ray, I. On the Performance of Isolation Forest and Multi Layer Perceptron for Anomaly Detection in Industrial Control Systems Networks. In Proceedings of the 2021 8th International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Gandia, Spain, 6–9 December 2021; pp. 1–6. [Google Scholar]
- Unlu, H. Efficient neural network deployment for microcontroller. arXiv 2020, arXiv:2007.01348. [Google Scholar]
- XLA: Optimizing Compiler for Machine Learning. Available online: https://www.tensorflow.org/xla (accessed on 3 March 2022).
- NNCG: Neural Network Code Generator. Available online: https://github.com/iml130/nncg (accessed on 3 March 2022).
- Urbann, O.; Camphausen, S.; Moos, A.; Schwarz, I.; Kerner, S.; Otten, M. AC Code Generator for Fast Inference and Simple Deployment of Convolutional Neural Networks on Resource Constrained Systems. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; pp. 1–7. [Google Scholar]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Berlin/Heidelberg, Germany, 2015; Volume 1. [Google Scholar]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Kumar, V.; Minz, S. Feature selection: A literature review. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Records | % Anomalies |
|---|---|---|
| Training set | 41,580 | n/a |
| Test Set 1 | 5000 | 10 |
| Test Set 2 | 7000 | 10 |
| Test Set 3 | 13,130 | 20 |
| Test Set 4 | 15,000 | 30 |
| Test Set 5 | 18,270 | 50 |
| Parameter | Description | Choice |
|---|---|---|
| kernel | Type of kernel used in the algorithm | polynomial |
| degree | Degree of polynomial kernel function | 3 |
| coef0 | Controls how much the model is influenced by high-degree polynomials versus low-degree polynomials | 4 |
| nu() | An upper bound on the fraction of training errors and a lower bound of the fraction of support vectors | 0.1 |
| gamma | Defines the level of a single training example’s influence | 0.1 |
| Activation Function | Learning Rate | No. of Hidden Layers | |
|---|---|---|---|
| ReLU | 0.04 | 0.0001 | 32 |
| Parameter | Description | Value |
|---|---|---|
| Number of base estimators in the forest ensemble | 156 | |
| Number of training samples to draw to train each estimator | 180 | |
| Number of features to draw to train each estimator | 10 | |
| contamination | Proportion of outliers in the data set | 0.05 |
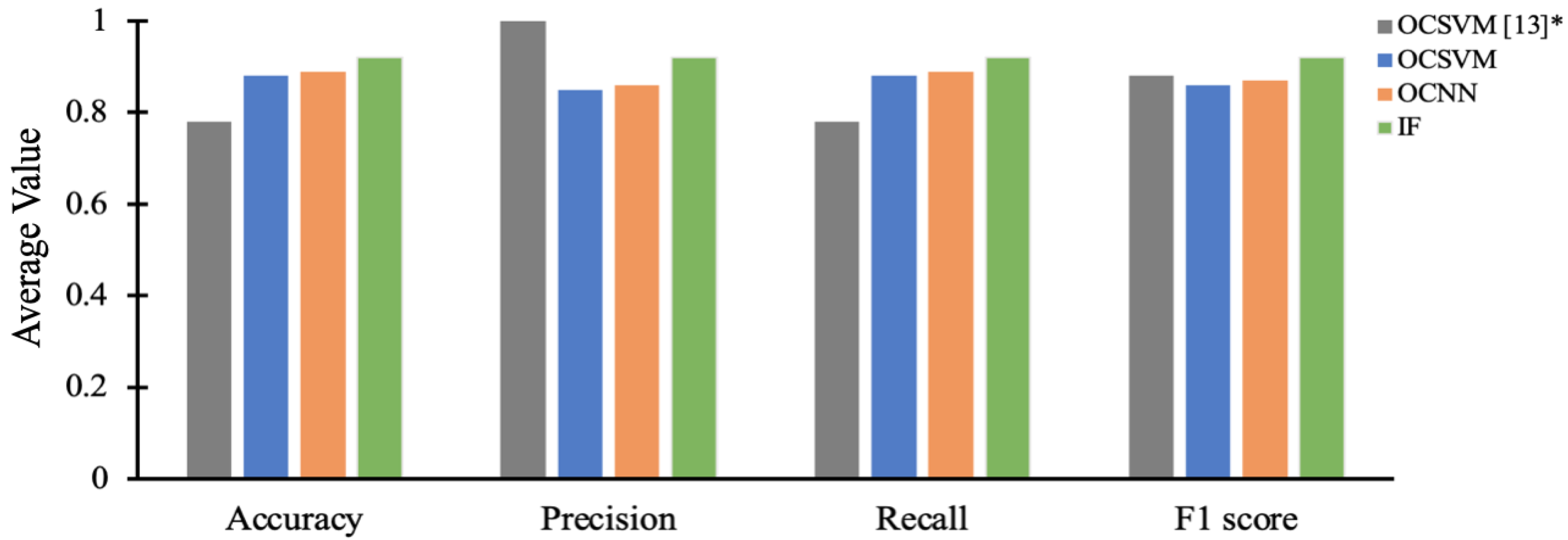
| Accuracy | Precision | Recall | F1-Score | |||||
|---|---|---|---|---|---|---|---|---|
| Dataset | OCSVM | [13] | OCSVM | [13] | OCSVM | [13] | OCSVM | [13] |
| Training set | 0.96 | 0.96 * | 1.00 | 1.00 * | 0.96 | 0.96 * | 0.98 | 0.98 * |
| Test set 1 | 0.90 | 0.78 * | 0.89 | 1.00 * | 0.90 | 0.78 * | 0.89 | 0.88 * |
| Test set 2 | 0.87 | 0.75 * | 0.81 | 1.00 * | 0.87 | 0.75 * | 0.84 | 0.86 * |
| Test set 3 | 0.86 | 0.82 * | 0.85 | 1.00 * | 0.86 | 0.82 * | 0.84 | 0.90 * |
| Test set 4 | 0.81 | - | 0.81 | - | 0.81 | - | 0.71 | - |
| Test set 5 | 0.70 | - | 0.78 | - | 0.70 | - | 0.68 | - |
| Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Training set | 0.97 | 1.00 | 0.97 | 0.99 |
| Test set 1 | 0.91 | 0.90 | 0.91 | 0.90 |
| Test set 2 | 0.88 | 0.81 | 0.88 | 0.84 |
| Test set 3 | 0.88 | 0.87 | 0.88 | 0.86 |
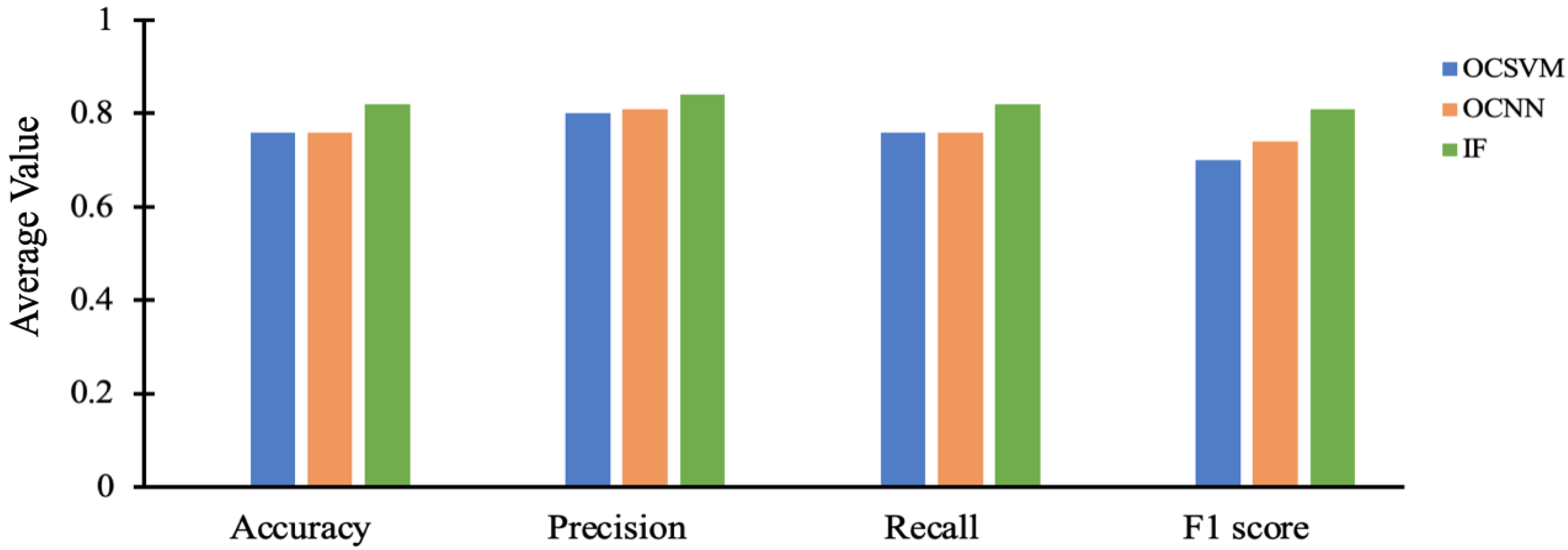
| Test set 4 | 0.81 | 0.82 | 0.81 | 0.79 |
| Test set 5 | 0.70 | 0.79 | 0.70 | 0.68 |
| Dataset | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Training set | 0.95 | 1.00 | 0.95 | 0.98 |
| Test set 1 | 0.91 | 0.90 | 0.91 | 0.91 |
| Test set 2 | 0.97 | 0.98 | 0.97 | 0.97 |
| Test set 3 | 0.88 | 0.87 | 0.88 | 0.87 |
| Test set 4 | 0.86 | 0.86 | 0.86 | 0.85 |
| Test set 5 | 0.78 | 0.82 | 0.78 | 0.77 |
| Group 1 | Group 2 | Mean Diff. | p-Adjusted | Reject |
|---|---|---|---|---|
| OCNN | IF | 5.320 | 0.001 | True |
| OCNN | OCSVM | −0.587 | 0.862 | False |
| IF | OCSVM | −5.907 | 0.001 | True |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aboah Boateng, E.; Bruce, J.W. Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies. J. Cybersecur. Priv. 2022, 2, 220-244. https://doi.org/10.3390/jcp2020012
Aboah Boateng E, Bruce JW. Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies. Journal of Cybersecurity and Privacy. 2022; 2(2):220-244. https://doi.org/10.3390/jcp2020012
Chicago/Turabian StyleAboah Boateng, Emmanuel, and J. W. Bruce. 2022. "Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies" Journal of Cybersecurity and Privacy 2, no. 2: 220-244. https://doi.org/10.3390/jcp2020012
APA StyleAboah Boateng, E., & Bruce, J. W. (2022). Unsupervised Machine Learning Techniques for Detecting PLC Process Control Anomalies. Journal of Cybersecurity and Privacy, 2(2), 220-244. https://doi.org/10.3390/jcp2020012