Computer Vision and Machine Learning: Theory, Methods and Applications
Share This Topical Collection
Editors
 Prof. Dr. Andrea Prati
Prof. Dr. Andrea Prati
Prof. Dr. Andrea Prati
E-Mail
Website
Collection Editor
Department of Engineering and Architecture, University of Parma, Parco Area delle Scienze, 181/A, 43124 Parma, Italy
Interests: video surveillance; mobile vision; visual sensor networks; machine vision; multimedia and video processing; performance analysis of multimedia computer architectures
Special Issues, Collections and Topics in MDPI journals
 Prof. Dr. Yuan-Kai Wang
Prof. Dr. Yuan-Kai Wang
Prof. Dr. Yuan-Kai Wang
E-Mail
Website
Collection Editor
Electrical Engineering, Fu Jen Catholic University, New Taipei 24205, Taiwan
Interests: intelligent video surveillance; face recognition; deep learning for object detection; robotic vision; embedded computer vision; sleep healthcare; neuromorphic computing
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
Computer vision (CV) and machine learning (ML) now represent two of the most addressed topics in artificial intelligence and computer science. The field of computer vision has witnessed an incredible shift in the last decade with the advent of deep learning, by means of which new applications have emerged and new milestones have been made reachable. Deep learning represents the most noticeable point of connection between CV and ML, but there is still much to be discovered in all these fields.
This topical collection will gather papers proposing advances in theory and models in CV and ML, paving the way to new applications.
Hence, we invite the academic community and relevant industrial partners to submit papers to this collection, on relevant fields and topics including (but not limited to) the following:
- New algorithms and methods of classical computer vision.
- Architecture and applications of convolutional neural networks.
- Transformers applied to computer vision.
- Geometric deep learning and graph convolution networks.
- Generative adversarial networks (GAN).
- Generative models beyond GANs.
- Fairness, privacy, and explainability in deep learning.
- Continual, online, developmental, and federated learning.
- Zero- and few-shot learning.
- Brand new applications of computer vision and machine learning.
Prof. Dr. Andrea Prati
Prof. Dr. Yuan-Kai Wang
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-anonymized peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Applied Sciences is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- deep learning
- generative models
- computer vision
- pattern recognition
- explainable AI
Published Papers (7 papers)
Open AccessArticle
Detection of Defects on Metal Surfaces Based on Deep Learning
by
Onur Cem Han and Uğurhan Kutbay
Cited by 5 | Viewed by 5565
Abstract
Various types of defects can occur on metal surfaces during production due to various factors. Detecting these defects is of great importance for the quality and reliability of the product. Manual inspections are time-consuming and prone to errors, especially as production scales increase
[...] Read more.
Various types of defects can occur on metal surfaces during production due to various factors. Detecting these defects is of great importance for the quality and reliability of the product. Manual inspections are time-consuming and prone to errors, especially as production scales increase Although Deep Learning and Computer Vision techniques show promise, the large data sizes of datasets created for deep learning and the high training costs of deep learning models lead to negative effects in terms of storage and energy efficiency. We propose a new method to improve defect detection rates, reduce labor losses, decrease data sizes, and improve energy efficiency. For the experiments, we used the Northeastern University (NEU) surface defect database as a reference, and the MobileNetV2 architecture as the model. The deep learning model was trained separately using both the grayscale-converted NEU database and the database created with the proposed method, and the accuracies of the datasets were compared. Image preprocessing techniques such as morphological operations, Gaussian noise addition, Principal Component Analysis, and image thresholding with Otsu thresholding were used for defect detection. The model was trained using the newly created database, achieving a successful result with an average accuracy rate of 87% using the proposed algorithm.
Full article
►▼
Show Figures
Open AccessArticle
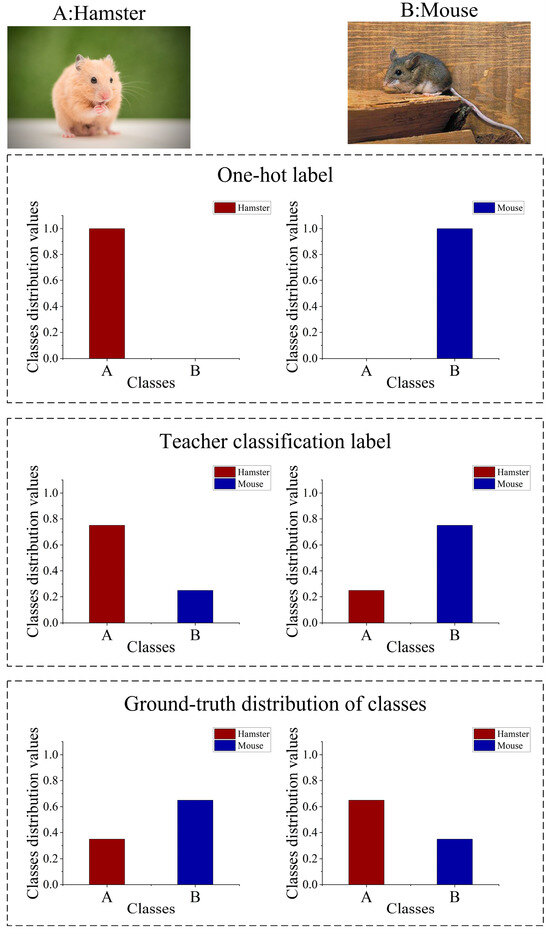
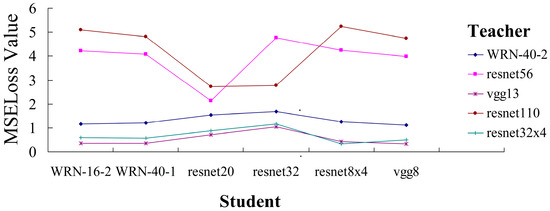
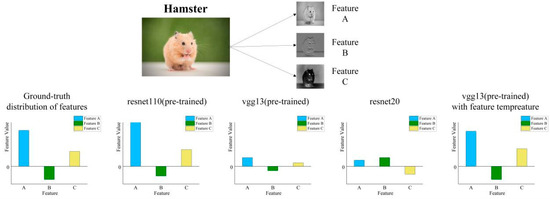
Knowledge Distillation Based on Fitting Ground-Truth Distribution of Images
by
Jianze Li, Zhenhua Tang, Kai Chen and Zhenlei Cui
Cited by 3 | Viewed by 2467
Abstract
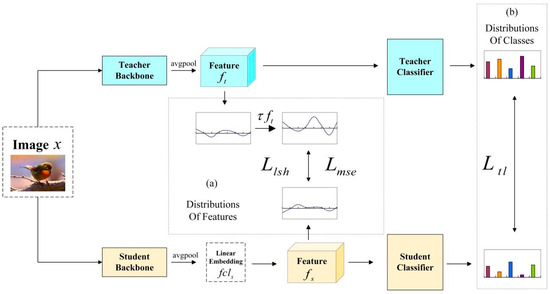
Knowledge distillation based on the features from the penultimate layer allows the student (lightweight model) to efficiently mimic the internal feature outputs of the teacher (high-capacity model). However, the training data may not conform to the ground-truth distribution of images in terms of
[...] Read more.
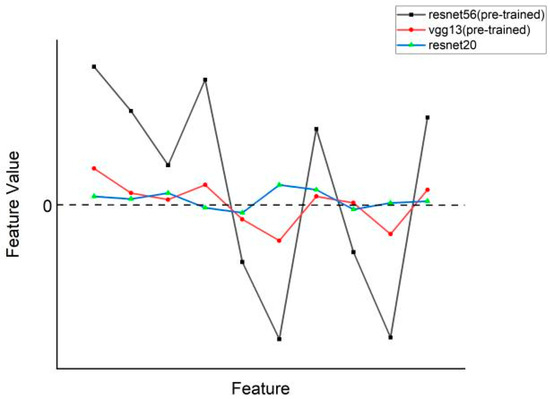
Knowledge distillation based on the features from the penultimate layer allows the student (lightweight model) to efficiently mimic the internal feature outputs of the teacher (high-capacity model). However, the training data may not conform to the ground-truth distribution of images in terms of classes and features. We propose two knowledge distillation algorithms to solve the above problem from the directions of fitting the ground-truth distribution of classes and fitting the ground-truth distribution of features, respectively. The former uses teacher labels to supervise student classification output instead of dataset labels, while the latter designs feature temperature parameters to correct teachers’ abnormal feature distribution output. We conducted knowledge distillation experiments on the ImageNet-2012 and Cifar-100 datasets using seven sets of homogeneous models and six sets of heterogeneous models. The experimental results show that our proposed algorithms improve the performance of penultimate layer feature knowledge distillation and outperform other existing knowledge distillation methods in terms of classification performance and generalization ability.
Full article
►▼
Show Figures
Open AccessArticle
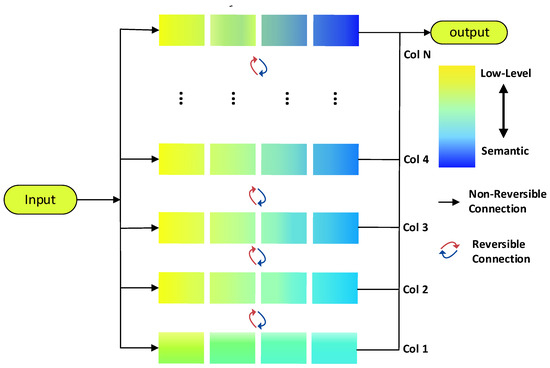
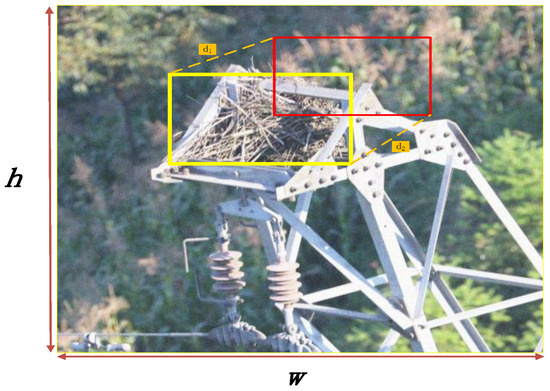
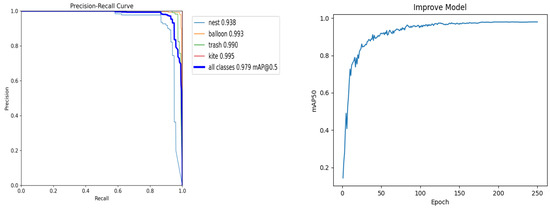
RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network
by
Wenli Zhang, Yingna Li and Ailian Liu
Cited by 9 | Viewed by 2750
Abstract
As an important part of the power system, it is necessary to ensure the safe and stable operation of transmission lines. Due to long-term exposure to the outdoors, the lines face many insecurity factors, and foreign object intrusion is one of them. Traditional
[...] Read more.
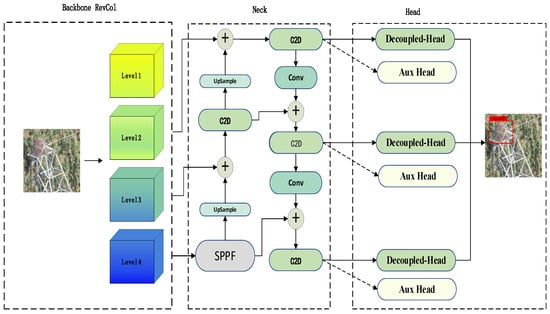
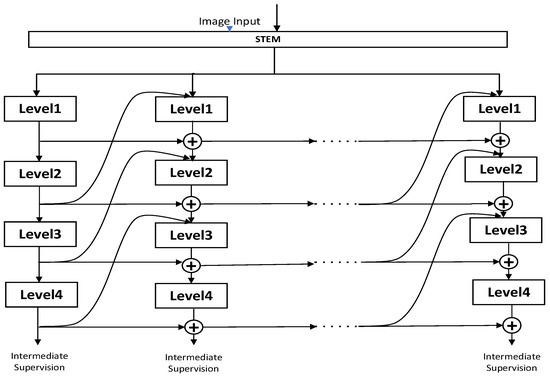
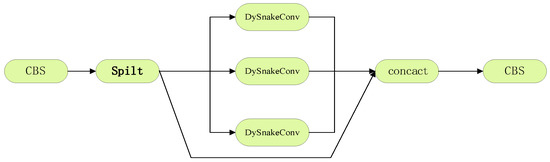
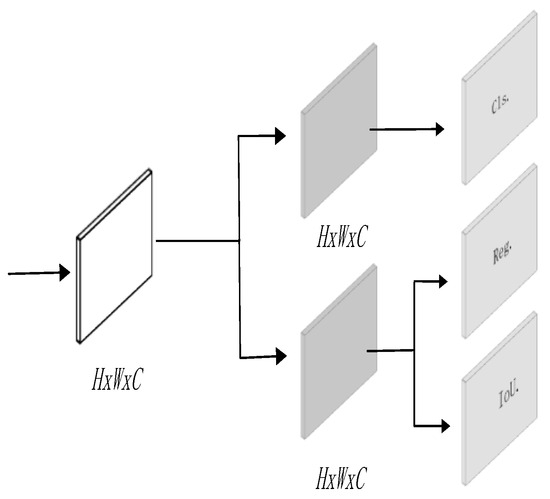
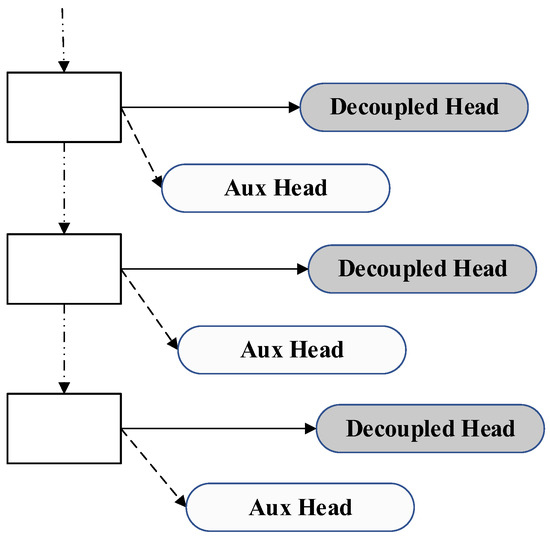
As an important part of the power system, it is necessary to ensure the safe and stable operation of transmission lines. Due to long-term exposure to the outdoors, the lines face many insecurity factors, and foreign object intrusion is one of them. Traditional foreign object (bird’s nest, kite, balloon, trash bag) detection algorithms suffer from low efficiency, poor accuracy, and small coverage, etc. To address the above problems, this paper introduces the RCDAM-Net. In order to prevent feature loss or useful feature compression, the RevCol (Reversible Column Networks) is used as the backbone network to ensure that the total information remains unchanged during feature decoupling. DySnakeConv (Dynamic Snake Convolution) is adopted and embedded into the C2f structure, which is named C2D and integrates low-level features and high-level features. Compared to the original BottleNeck structure of C2f, the DySnakeConv enhances the feature extraction ability for elongated and weak targets. In addition, MPDIoU (Maximum Performance Diagonal Intersection over Union) is used to improve the regression performance of model bounding boxes, solving the problem of predicted bounding boxes having the same aspect ratio as true bounding boxes, but with different values. Further, we adopt Decoupled Head for detection and add additional auxiliary training heads to improve the detection accuracy of the model. The experimental results show that the model achieves
mAP50, Precision, and Recall of 97.98%, 98.15%, and 95.16% on the transmission tower line foreign object dataset, which is better to existing multi-target detection algorithms.
Full article
►▼
Show Figures
Open AccessArticle
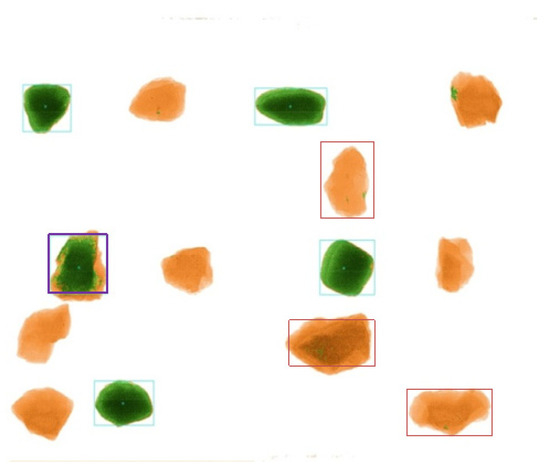
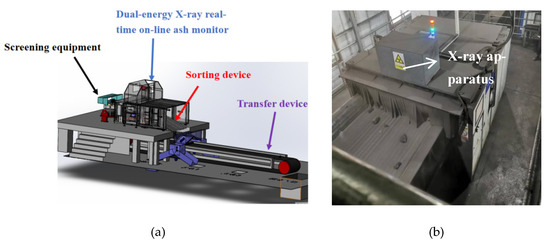
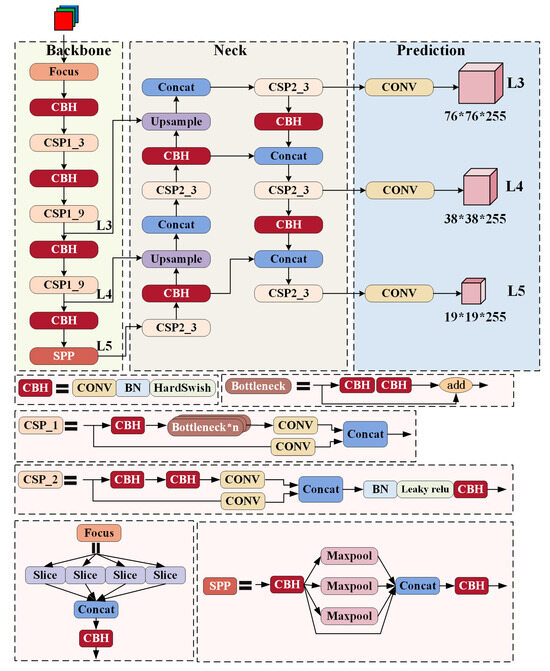
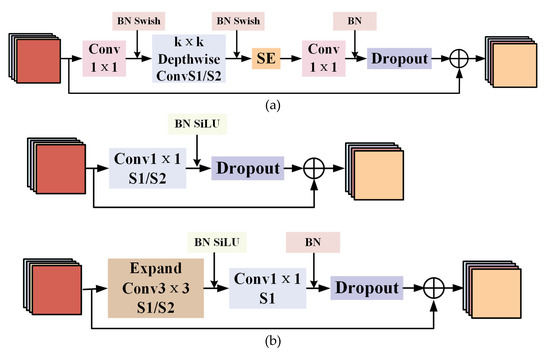
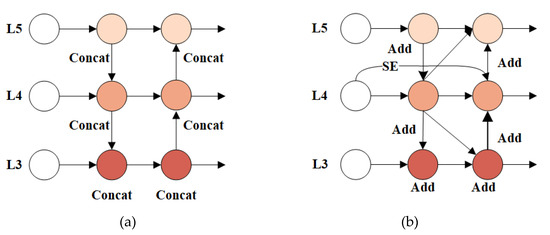
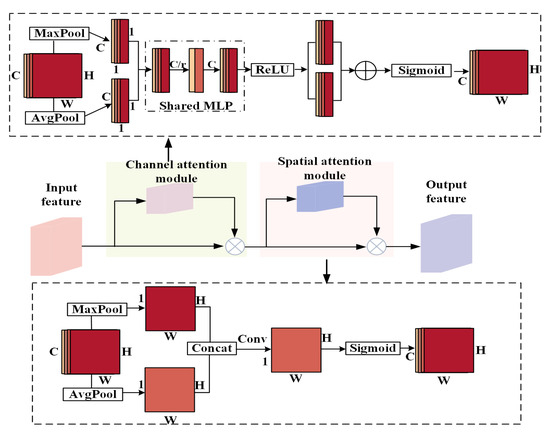
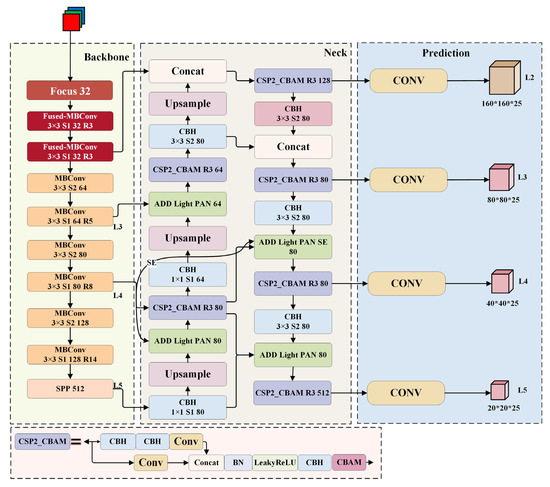
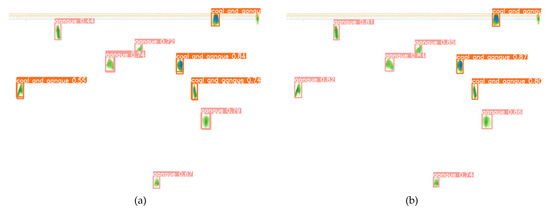
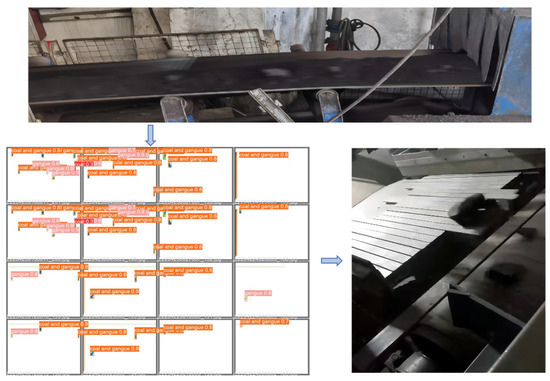
Intelligent Gangue Sorting System Based on Dual-Energy X-ray and Improved YOLOv5 Algorithm
by
Yuchen Qin, Ziming Kou, Cong Han and Yutong Wang
Cited by 13 | Viewed by 2865
Abstract
Intelligent gangue sorting with high precision is of vital importance for improving coal quality. To tackle the challenges associated with coal gangue target detection, including algorithm performance imbalance and hardware deployment difficulties, in this paper, an intelligent gangue separation system that adopts the
[...] Read more.
Intelligent gangue sorting with high precision is of vital importance for improving coal quality. To tackle the challenges associated with coal gangue target detection, including algorithm performance imbalance and hardware deployment difficulties, in this paper, an intelligent gangue separation system that adopts the elevated YOLO-v5 algorithm and dual-energy X-rays is proposed. Firstly, images of dual-energy X-ray transmission coal gangue mixture under the actual operation of a coal mine were collected, and datasets for training and validation were self-constructed. Then, in the YOLOv5 backbone network, the EfficientNetv2 was used to replace the original cross stage partial darknet (CSPDarknet) to achieve the lightweight of the backbone network; in the neck, a light path aggregation network (LPAN) was designed based on PAN, and a convolutional block attention module (CBAM) was integrated into the BottleneckCSP of the feature fusion block to raise the feature acquisition capability of the network and maximize the learning effect. Subsequently, to accelerate the rate of convergence, an efficient intersection over union (EIOU) was used instead of the complete intersection over union (CIOU) loss function. Finally, to address the problem of low resolution of small targets leading to missed detection, an L2 detection head was introduced to the head section to improve the multi-scale target detection performance of the algorithm. The experimental results indicate that in comparison with YOLOv5-S, the same version of the algorithm proposed in this paper increases by 19.2% and 32.4% on mAP @.5 and mAP @.5:.95, respectively. The number of parameters decline by 51.5%, and the calculation complexity declines by 14.7%. The algorithm suggested in this article offers new ideas for the design of identification algorithms for coal gangue sorting systems, which is expected to save energy and reduce consumption, reduce labor, improve efficiency, and be more friendly to the embedded platform.
Full article
►▼
Show Figures
Open AccessArticle
A Benchmark for the Evaluation of Corner Detectors
by
Yang Zhang, Baojiang Zhong and Xun Sun
Cited by 7 | Viewed by 5041
Abstract
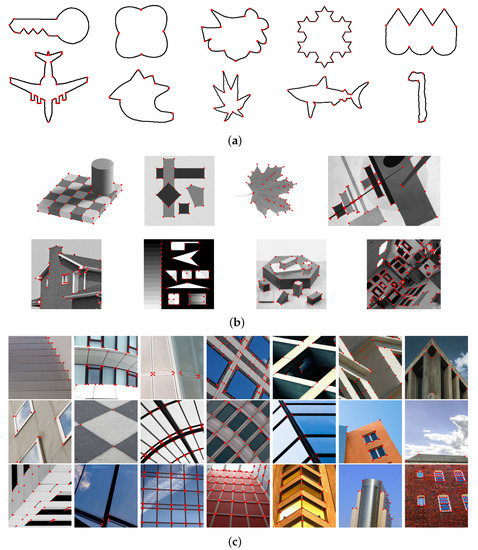
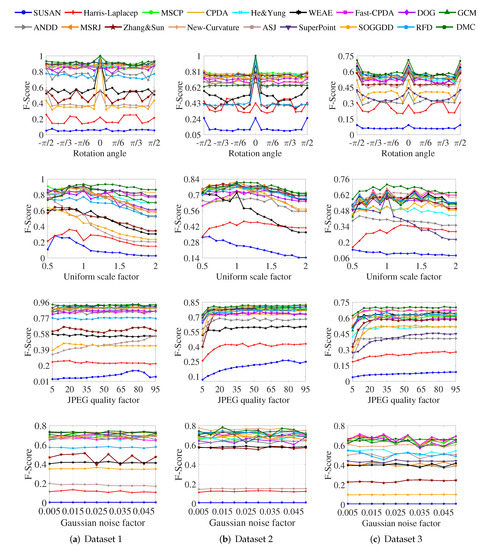
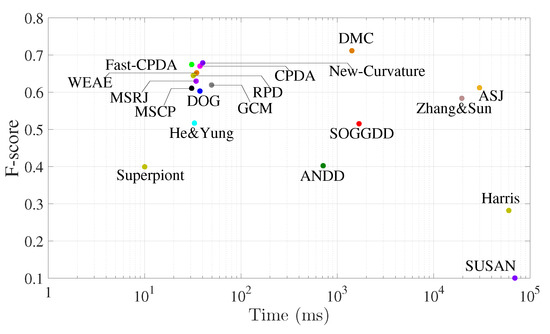
Corners are an important kind of image feature and play a crucial role in solving various tasks. Over the past few decades, a great number of corner detectors have been proposed. However, there is no benchmark dataset with labeled ground-truth corners and unified
[...] Read more.
Corners are an important kind of image feature and play a crucial role in solving various tasks. Over the past few decades, a great number of corner detectors have been proposed. However, there is no benchmark dataset with labeled ground-truth corners and unified metrics to evaluate their corner detection performance. In this paper, we build three benchmark datasets for corner detection. The first two consist of those binary and gray-value images that have been commonly used in previous corner detection studies. The third one contains a set of urban images, called the Urban-Corner dataset. For each test image in these three datasets, the ground-truth corners are manually labeled as objectively as possible with the assistance of a line segment detector. Then, a set of benchmark evaluation metrics is suggested, including five conventional ones: the precision, the recall, the arithmetic mean of precision and recall (APR), the F score, the localization error (Le), and a new one proposed in this work called the
repeatability referenced to ground truth (RGT). Finally, a comprehensive evaluation of current state-of-the-art corner detectors is conducted.
Full article
►▼
Show Figures
Open AccessArticle
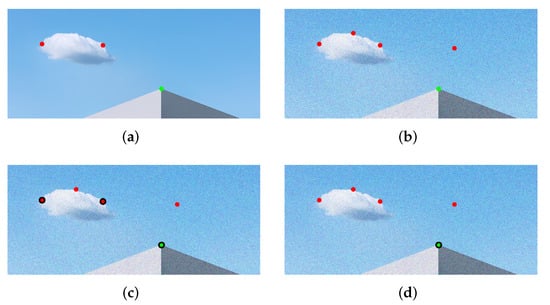
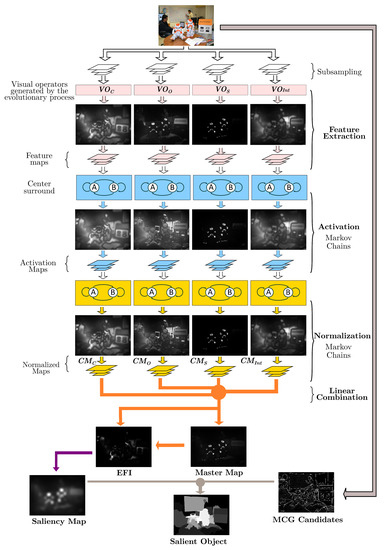
Automated Design of Salient Object Detection Algorithms with Brain Programming
by
Gustavo Olague, Jose Armando Menendez-Clavijo, Matthieu Olague, Arturo Ocampo, Gerardo Ibarra-Vazquez, Rocio Ochoa and Roberto Pineda
Cited by 5 | Viewed by 4285
Abstract
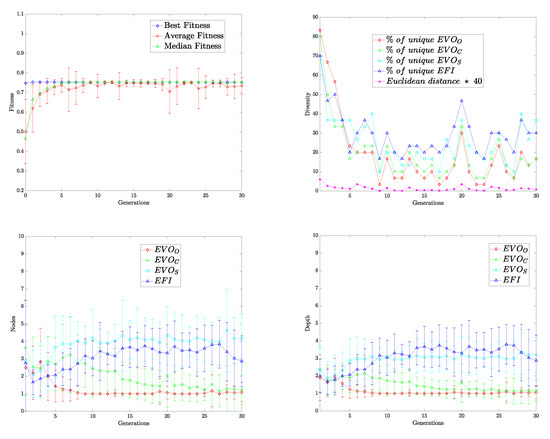
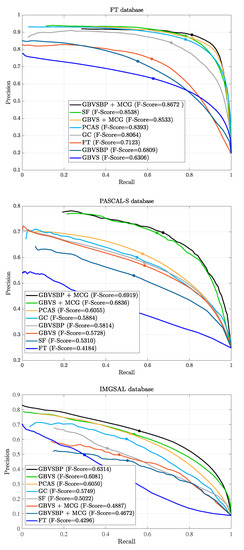
Despite recent improvements in computer vision, artificial visual systems’ design is still daunting since an explanation of visual computing algorithms remains elusive. Salient object detection is one problem that is still open due to the difficulty of understanding the brain’s inner workings. Progress
[...] Read more.
Despite recent improvements in computer vision, artificial visual systems’ design is still daunting since an explanation of visual computing algorithms remains elusive. Salient object detection is one problem that is still open due to the difficulty of understanding the brain’s inner workings. Progress in this research area follows the traditional path of hand-made designs using neuroscience knowledge or, more recently, deep learning, a particular branch of machine learning. Recently, a different approach based on genetic programming appeared to enhance handcrafted techniques following two different strategies. The first method follows the idea of combining previous hand-made methods through genetic programming and fuzzy logic. The second approach improves the inner computational structures of basic hand-made models through artificial evolution. This research proposes expanding the artificial dorsal stream using a recent proposal based on symbolic learning to solve salient object detection problems following the second technique. This approach applies the fusion of visual saliency and image segmentation algorithms as a template. The proposed methodology discovers several critical structures in the template through artificial evolution. We present results on a benchmark designed by experts with outstanding results in an extensive comparison with the state of the art, including classical methods and deep learning approaches to highlight the importance of symbolic learning in visual saliency.
Full article
►▼
Show Figures
Open AccessArticle
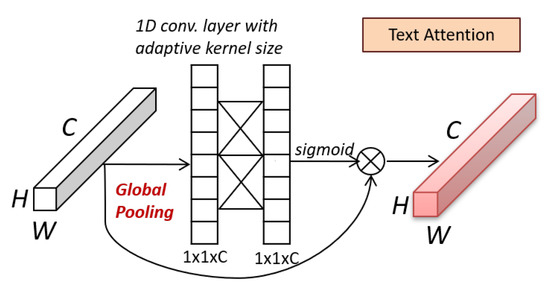
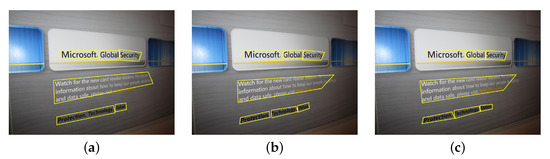
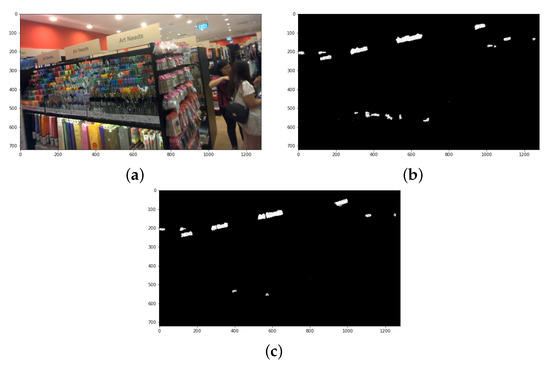
Scene Text Detection Using Attention with Depthwise Separable Convolutions
by
Ehtesham Hassan and Lekshmi V. L.
Cited by 17 | Viewed by 3467
Abstract
In spite of significant research efforts, the existing scene text detection methods fall short of the challenges and requirements posed in real-life applications. In natural scenes, text segments exhibit a wide range of shape complexities, scale, and font property variations, and they appear
[...] Read more.
In spite of significant research efforts, the existing scene text detection methods fall short of the challenges and requirements posed in real-life applications. In natural scenes, text segments exhibit a wide range of shape complexities, scale, and font property variations, and they appear mostly incidental. Furthermore, the computational requirement of the detector is an important factor for real-time operation. To address the aforementioned issues, the paper presents a novel scene text detector using a deep convolutional network which efficiently detects arbitrary oriented and complex-shaped text segments from natural scenes and predicts quadrilateral bounding boxes around text segments. The proposed network is designed in a U-shape architecture with the careful incorporation of skip connections to capture complex text attributes at multiple scales. For addressing the computational requirement of the input processing, the proposed scene text detector uses the MobileNet model as the backbone that is designed on depthwise separable convolutions. The network design is integrated with text attention blocks to enhance the learning ability of our detector, where the attention blocks are based on efficient channel attention. The network is trained in a multi-objective formulation supported by a novel text-aware non-maximal procedure to generate final text bounding box predictions. On extensive evaluations on
ICDAR2013,
ICDAR2015,
MSRA-TD500, and
COCOText datasets, the paper reports detection F-scores of 0.910, 0.879, 0.830, and 0.617, respectively.
Full article
►▼
Show Figures






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}