
Scene Text Detection Using Attention with Depthwise Separable Convolutions


Abstract
:1. Introduction
- A novel U-shaped network for scene text detection for real-time applications is presented, which applies the depthwise separable convolution operation. The network predicts a quadrilateral bounding box around text instances in scene images. The incorporation of skip connections enables the detector to efficiently capture arbitrarily shaped text instances at multiple scales. The network is incorporated with ECA-based text attention blocks for robust and efficient text feature extraction, and the training is performed using a novel multitasking formulation. Next, a novel post-processing method using non-maximal suppression is applied for final prediction, which accounts for the text expectation in candidate quadrilateral bounding boxes.
- The different components of the proposed detector have been extensively validated on ICDAR2013, ICDAR2015, COCOText, and MSRA-TD500 datasets. With thorough experiments under different settings, the results demonstrate that the proposed scene text detector presents an efficient solution for the detection of arbitrary shaped, multi-oriented text instances in different real-life settings. As shown later in the results, the proposed detector outperforms many prominent deep neural network-based methods, and it achieves on par performance in comparison with others.
2. Literature Survey
3. Proposed Methodology
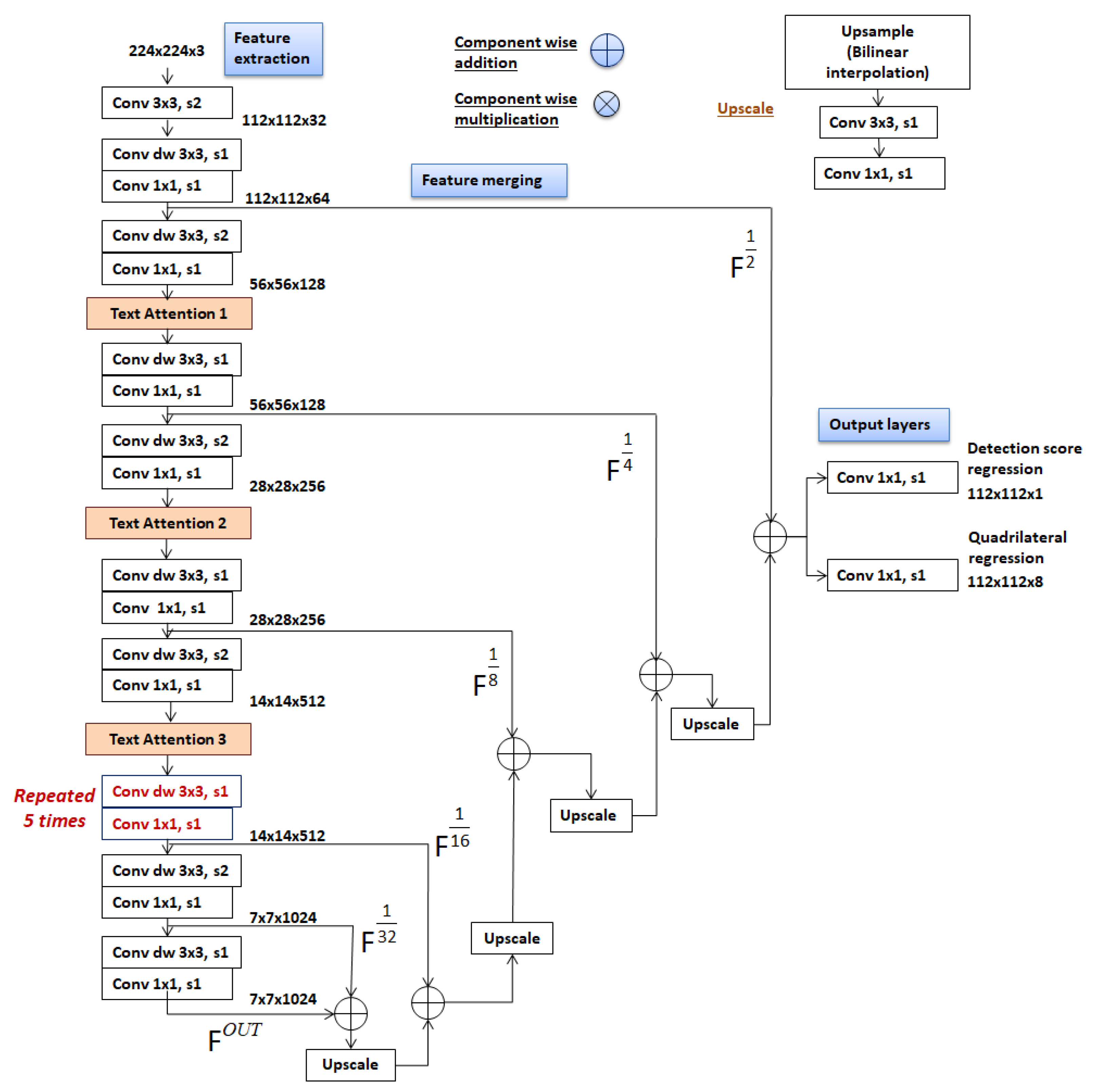
3.1. The Network Design—MobileTDNet
- First output layer: 2nd order tensor of size having single channel output, assuming the input size as . The corresponds to the text/non-text segmentation map generated at one-half the resolution of the input. The tensor values represent text confidence scores at each position.
- Second output layer: 3rd order tensor of size encodes the pixel-level quadrilateral bounding box predictions at the output feature map. On the depth of , each pair of values corresponds to a corner of the predicted quadrilateral.
3.2. The Loss Function
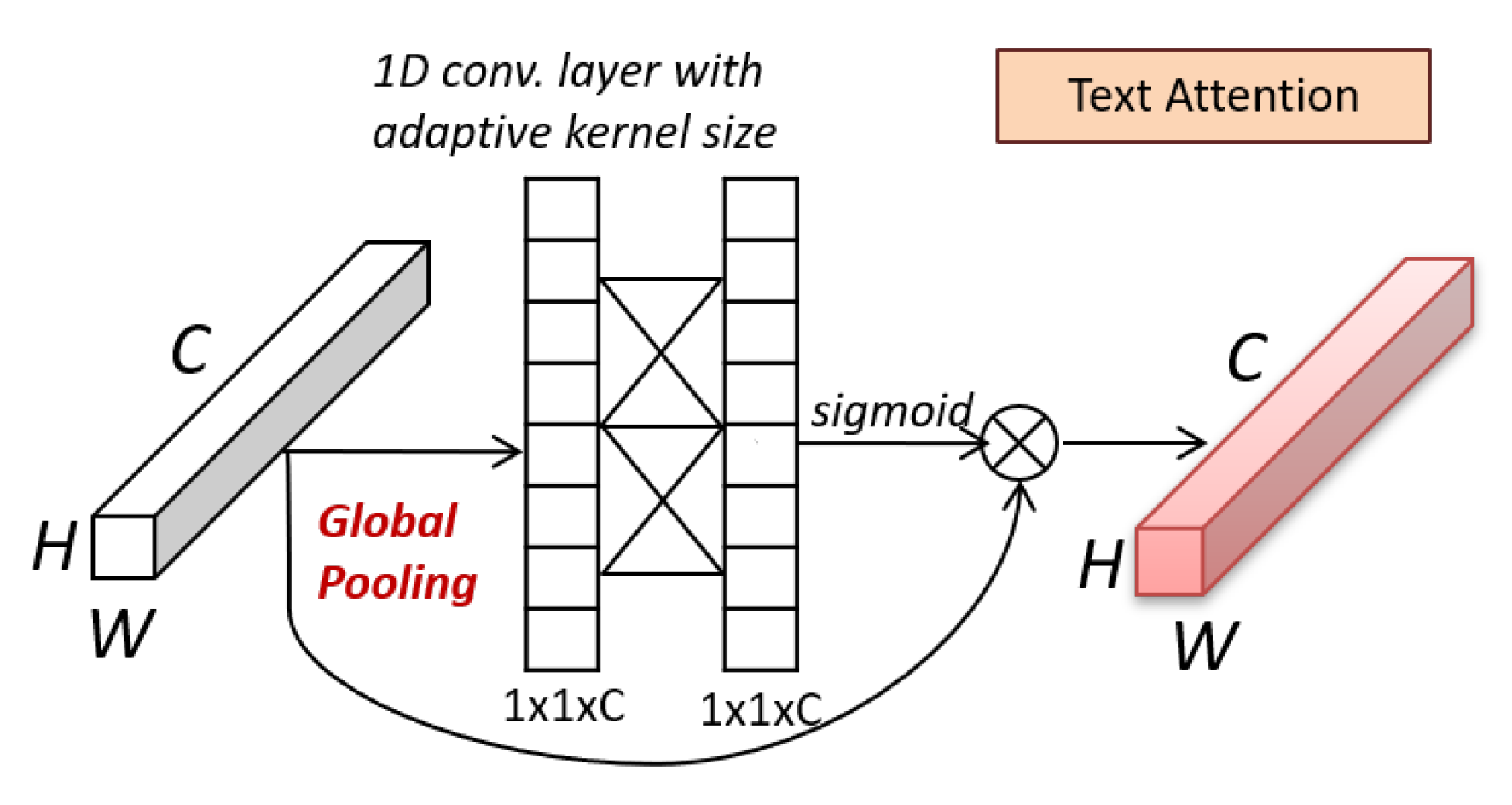
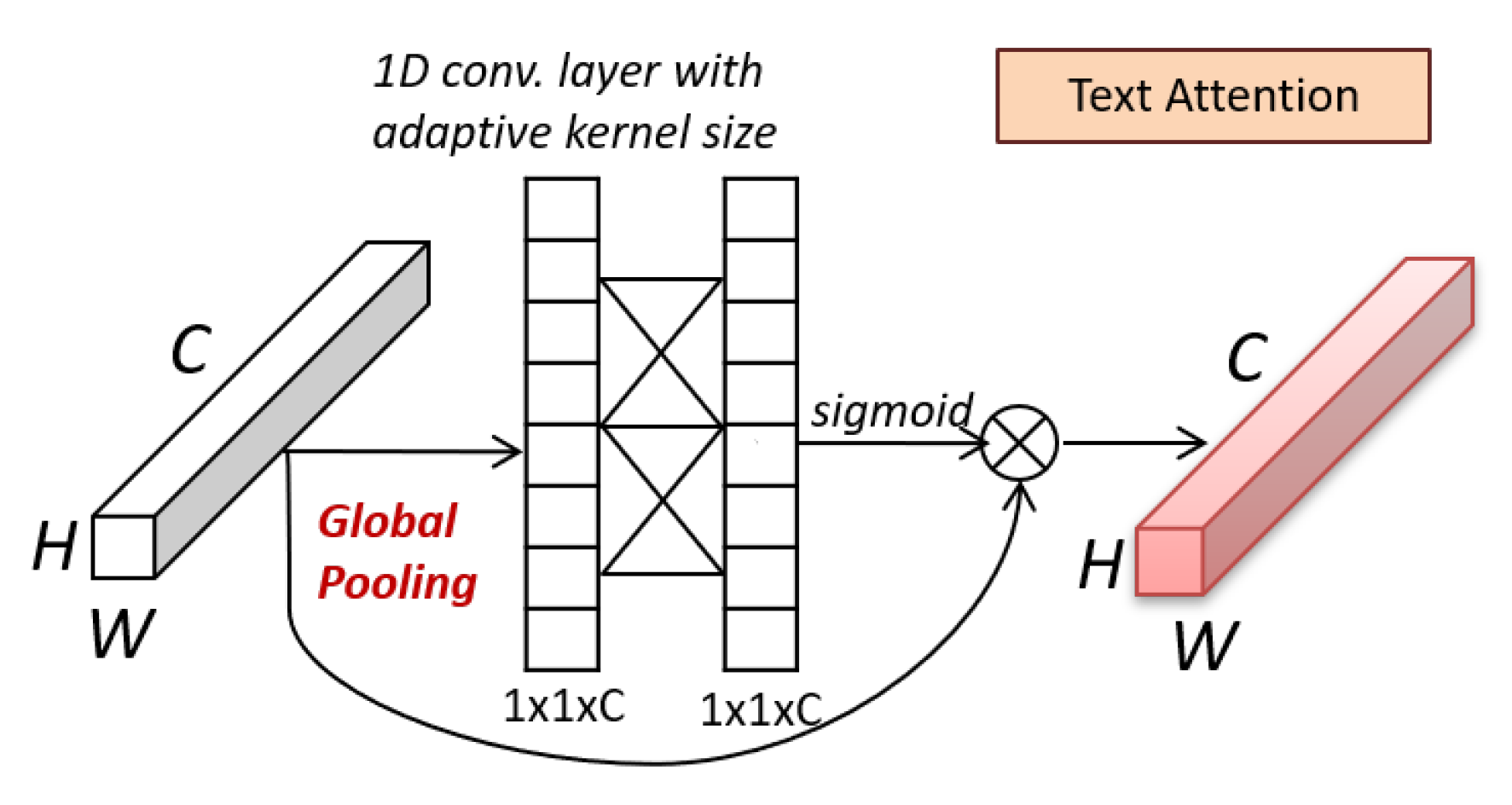
3.3. Design of Text Attention Blocks
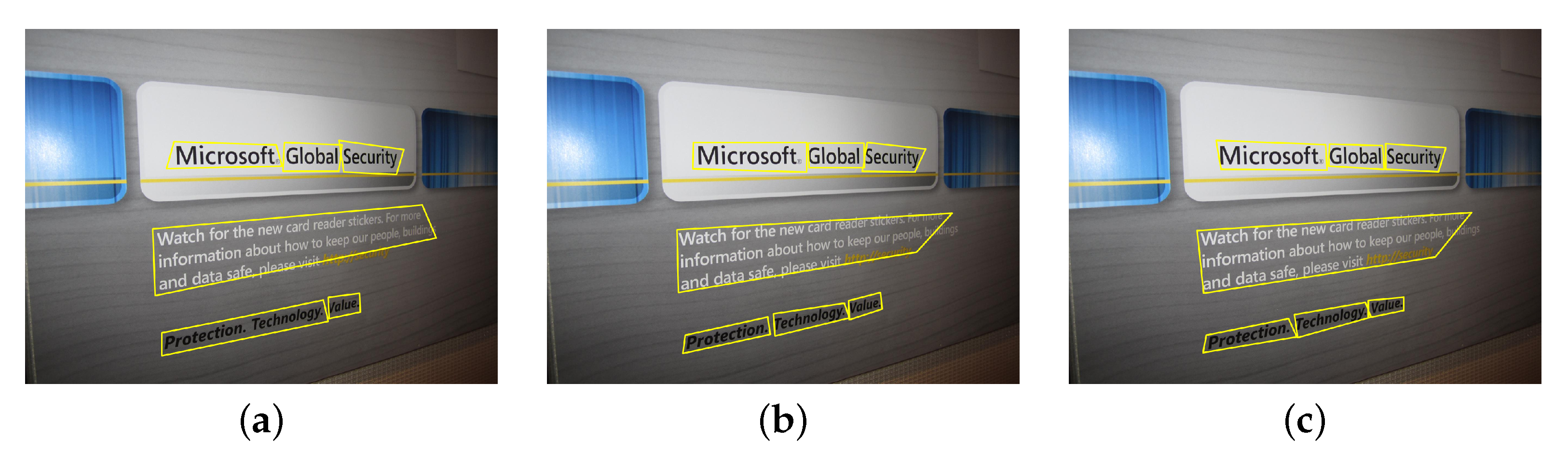
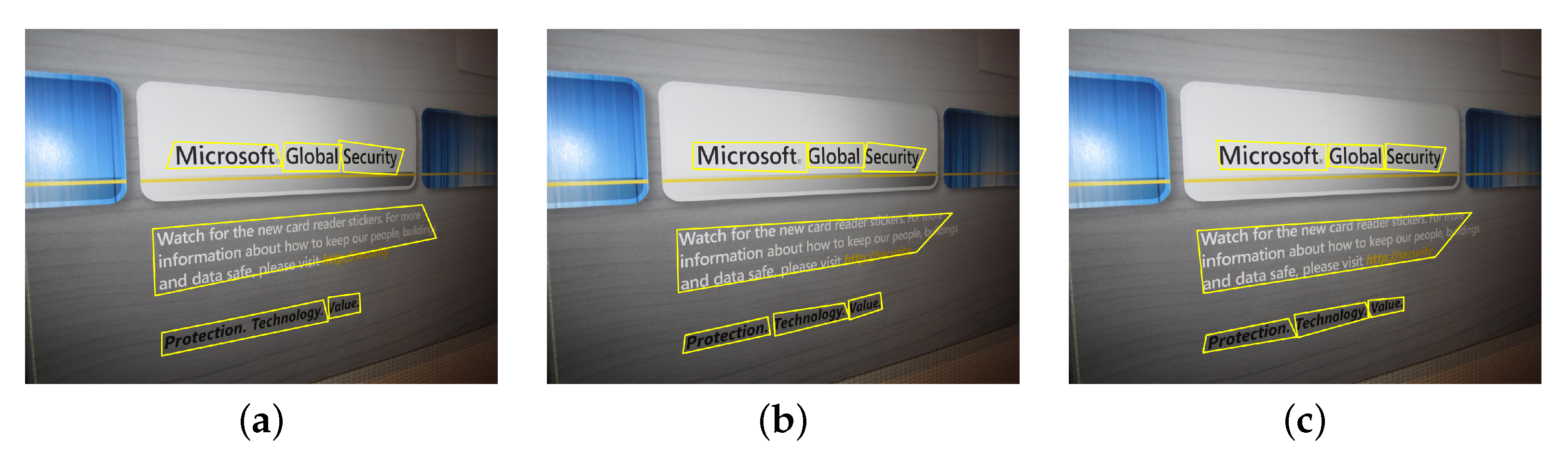
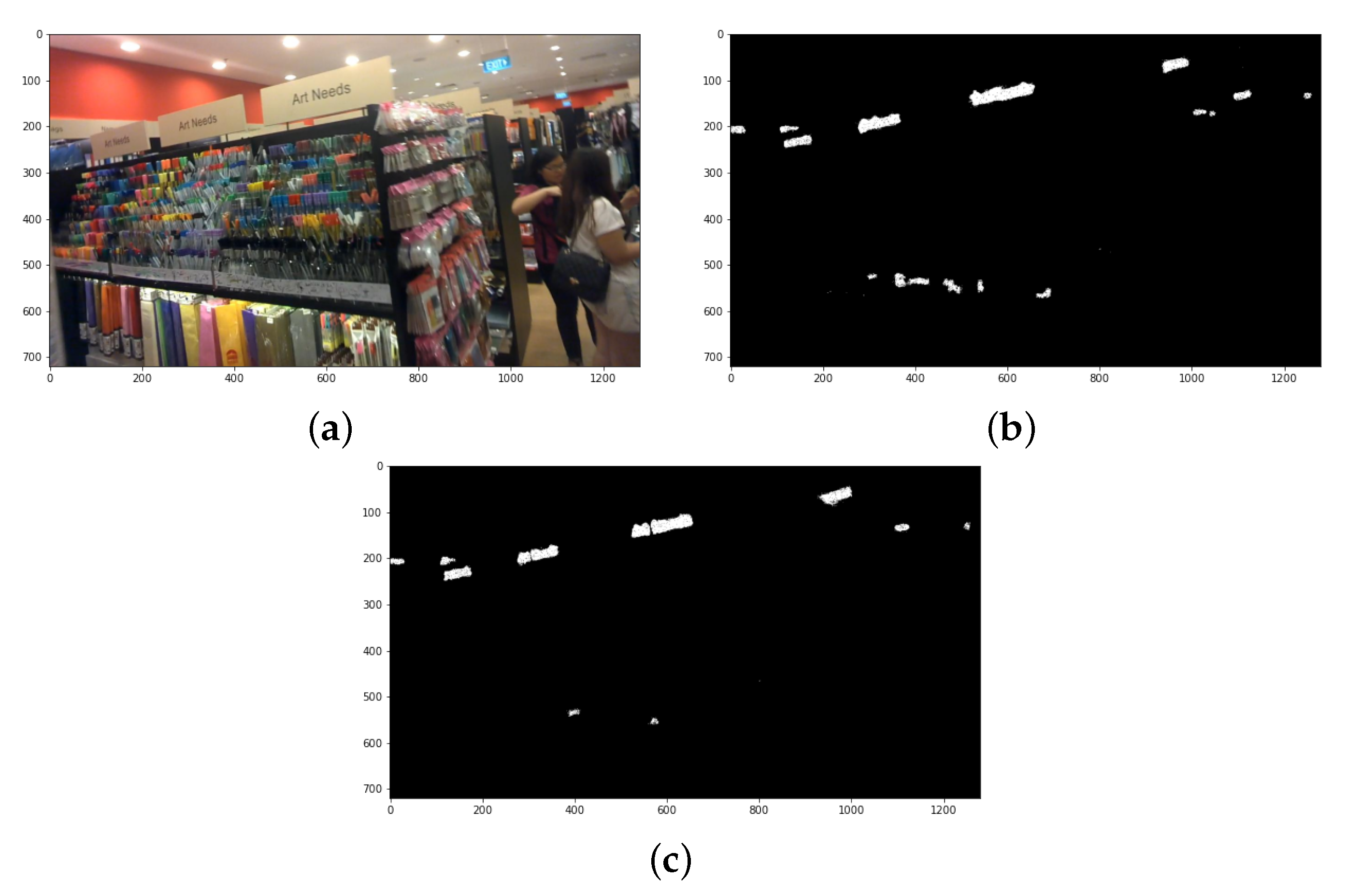
3.4. Text Aware Non-Maximal Suppression
- Text/non-text segmentation map with representing the text confidence score at the ith position with .
- Quadrilateral predictions where represents quadrilateral bounding box prediction at the ith position.
- 1.
- To identify the dominant predictions corresponding to the text segments, the text/non-text segmentation map C is filtered at 0.5. The filtering results in a reduced set of confidence score predictions , and overlapping text bounding box predictions . The NMS technique reduces the set of candidate bounding boxes by analyzing the confidence score associated with bounding box prediction and pairwise overlap between candidates. In contrast, the MobileTDNet output layer 2 prediction consists of only the geometric position of text bounding boxes without the measure of text attributes within the bounding box.
- 2.
- For calculating the text attribute of a quadrilateral box prediction , the text neighborhood correlation within the quadrilateral boundary is exploited. For each quadrilateral prediction , the text confidence scores from at all positions within the boundary of is averaged to a single point measure . This returns the set . Here, is referred to as the text expectation measure for the bounding box , as text appearances within the boundary can be in any shape and size, and the constricted boundary around the text segment is expected to have high text expectation. The quadrilateral boxes with low text expectation measures are filtered out, and the boxes within the top of the text expectation measures are preserved. The filtration results in the quadrilateral bounding box prediction set , with the corresponding text expectation values represented in set . The and sets are next processed using the NMS to generate final predictions.
- 3.
- The conventional NMS procedure outcomes are sensitive to the selected intersection over union (IoU) threshold; therefore, the soft-NMS procedure by Bodla et al. [64] is applied. The soft-NMS uses a fixed IoU threshold for pruning, but the confidence scores of all unfinished quadrilateral boxes are rescaled with a smooth penalty function in each pruning iteration. The idea is to gradually decrease the score of overlapping quadrilateral boxes, which is expected to reduce the contribution in the false positive rate in the detection. At the same time, the function should impose a low penalty in the case of non-overlapping quadrilateral prediction boxes. The complete algorithm steps are listed below (Algorithm 1).
| Algorithm 1: Soft-NMS for final quadrilateral box prediction |
 |
4. Experimental Results
- 1.
- ICDAR2013 [65]: The dataset is a collection of natural images having horizontal and near-horizontal text appearances. The collection consists of 229 training and 233 testing images having character and word-level bounding box annotations and corresponding annotations.
- 2.
- ICDAR2015 [66]: The dataset was released as the fourth challenge in the ICDAR 2015 robust reading competition (incidental scene text detection). The dataset consists of 1500 images, of which 1000 were for training purposes, and the remaining images were used for testing. The dataset images are real-life scenes captured in Google Glass in an incidental manner, with the annotations available as quadrangle text bounding boxes with corresponding unicode transcription.
- 3.
- COCOText [67]: This is a large dataset that consists of 63,000 images sampled from the MSCOCO image collection [68] exhibiting scene texts in all appearances. The dataset provides rich annotations, including the text bounding boxes, handwritten/printed labeling, script labeling, and transcripted text. The bounding boxes are horizontal axis aligned. The dataset comes with a standard distribution of 43,000 training images, 10,000 for validation and the remaining 10,000 for testing tasks.
- 4.
- MSRA-TD500 [69]: The dataset consists of 500 examples distributed as 300/200 for training and testing tasks. The images are indoor and outdoor natural scenes with English and Chinese texts in all orientations and complex backgrounds. The image resolution varies between and . The annotations in the dataset are available at the text line level with the orientation value of corresponding text lines.
4.1. Network Training and Hyperparameters
- The input images are randomly resized within the scale of [0.5, 3] by preserving the aspect ratio. The images for the resizing operation are selected with a probability of 0.2.
- Next, the images are randomly rotated by an angle within [−45°, 45°].
- Additionally, some images are sampled for random flip and crop within the scale of [0.5, 1]. The cropped image segments are resized to . The probability of 0.2 is used in the sampling step.
- Finally, the augmented examples having text instances smaller than half of the smallest text instances in the original dataset are filtered out.
4.2. Baseline Evaluation
4.3. Effect of Skip Connections
4.4. Incorporation of Text Attention Blocks
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Zhao, K.; Song, Y.Z.; Guo, J. Text extraction from natural scene image: A survey. Neurocomputing 2013, 122, 310–323. [Google Scholar] [CrossRef]
- Epshtein, B.; Ofek, E.; Wexler, Y. Detecting text in natural scenes with stroke width transform. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2963–2970. [Google Scholar]
- Neumann, L.; Matas, J. A Method for Text Localization and Recognition in Real-World Images. In Proceedings of the ACCV, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Lienhart, R.; Stuber, F. Automatic text recognition in digital videos. In Proceedings of the Electronic Imaging, San Jose, CA, USA, 28 January–2 February 1996. [Google Scholar]
- Cai, M.; Song, J.; Lyu, M.R. A new approach for video text detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1. [Google Scholar] [CrossRef] [Green Version]
- Agnihotri, L.; Dimitrova, N. Text detection for video analysis. In Proceedings of the IEEE Workshop on Content-Based Access of Image and Video Libraries (CBAIVL’99), Fort Collins, CO, USA, 22 June 1999; pp. 109–113. [Google Scholar] [CrossRef]
- Ezaki, N.; Bulacu, M.; Schomaker, L. Text detection from natural scene images: Towards a system for visually impaired persons. In Proceedings of the of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26 August 2004; Volume 2, pp. 683–686. [Google Scholar] [CrossRef] [Green Version]
- Neumann, L.; Matas, J.E.S. Real-time scene text localization and recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Yin, X.; Yin, X.; Huang, K. Robust Text Detection in Natural Scene Images. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 970–983. [Google Scholar] [PubMed] [Green Version]
- Cho, H.; Sung, M.; Jun, B. Canny Text Detector: Fast and Robust Scene Text Localization Algorithm. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3566–3573. [Google Scholar] [CrossRef]
- Li, Y.; Lu, H. Scene text detection via stroke width. In Proceedings of the of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 681–684. [Google Scholar]
- Gomez, L.; Karatzas, D. MSER-based real-time text detection and tracking. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3110–3115. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, X.; Meng, G.; Pan, C. Scene text detection and recognition with advances in deep learning: A survey. Int. J. Doc. Anal. Recognit. 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Long, S.; He, X.; Yao, C. Scene text detection and recognition: The deep learning era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Available online: https://rrc.cvc.uab.es/ (accessed on 8 May 2022).
- Available online: https://paperswithcode.com/sota/scene-text-detection-on-msra-td500 (accessed on 8 May 2022).
- Available online: https://paperswithcode.com/sota/scene-text-detection-on-coco-text (accessed on 8 May 2022).
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ba, J.; Mnih, V.; Kavukcuoglu, K. Multiple object recognition with visual attention. arXiv 2014, arXiv:1412.7755. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the of the 28th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 2017–2025. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2019, arXiv:1910.03151. [Google Scholar]
- Delakis, M.; Garcia, C. Text Detection with Convolutional Neural Networks. In Proceedings of the VISAPP (2), Madeira, Portugal, 22–25 January 2008; pp. 290–294. [Google Scholar]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Deep Features for Text Spotting. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, C.; Shen, W.; Yao, C.; Liu, W.; Bai, X. Multi-oriented Text Detection with Fully Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4159–4167. [Google Scholar] [CrossRef] [Green Version]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. In Proceedings of the of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- He, T.; Huang, W.; Qiao, Y.; Yao, J. Text-Attentional Convolutional Neural Network for Scene Text Detection. IEEE Trans. Image Process. 2016, 25, 2529–2541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, M.; Shi, B.; Bai, X. TextBoxes++: A Single-Shot Oriented Scene Text Detector. IEEE Trans. Image Process. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, X.; Zhou, Y.; Guo, Y.; Wu, D.; Tian, Z.; Jiang, N.; Wang, H.; Wang, W. Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 414–423. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A Fast Text eastDetector with a Single Deep Neural Network. arXiv 2016, arXiv:1611.06779. [Google Scholar]
- Zhu, X.; Jiang, Y.; Yang, S.; Wang, X.; Li, W.; Fu, P.; Wang, H.; Luo, Z. Deep Residual Text Detection Network for Scene Text. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 807–812. [Google Scholar]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting Text in Natural Image with Connectionist Text Proposal Network. arXiv 2016, arXiv:1609.03605. [Google Scholar]
- Zhong, Z.; Jin, L.; Zhang, S.; Feng, Z. DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images. arXiv 2016, arXiv:1605.07314. [Google Scholar]
- Yao, C.; Bai, X.; Shi, B.; Liu, W. Strokelets: A learned multi-scale representation for scene text recognition. In Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4042–4049. [Google Scholar]
- Wang, X.; Jiang, Y.; Luo, Z.; Liu, C.; Choi, H.; Kim, S. Arbitrary Shape Scene Text Detection With Adaptive Text Region Representation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6442–6451. [Google Scholar]
- Xing, L.; Tian, Z.; Huang, W.; Scott, M.R. Convolutional character networks. In Proceedings of the of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9126–9136. [Google Scholar]
- Zhong, Y.; Cheng, X.; Chen, T.; Zhang, J.; Zhou, Z.; Huang, G. PRPN: Progressive region prediction network for natural scene text detection. Knowl. Based Syst. 2022, 236, 107767. [Google Scholar] [CrossRef]
- Deng, D.; Liu, H.; Li, X.; Cai, D. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Xie, E.; Zang, Y.; Shao, S.; Yu, G.; Yao, C.; Li, G. Scene text detection with supervised pyramid context network. In Proceedings of the of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9038–9045. [Google Scholar]
- Huang, Z.; Zhong, Z.; Sun, L.; Huo, Q. Mask R-CNN with pyramid attention network for scene text detection. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 764–772. [Google Scholar]
- He, W.; Zhang, X.Y.; Yin, F.; Liu, C.L. Deep Direct Regression for Multi-Oriented Scene Text Detection. arXiv 2017, arXiv:1703.08289. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting Oriented Text in Natural Images by Linking Segments. In Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-oriented scene text detection via corner localization and region segmentation. In Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Deng, L.; Gong, Y.; Lin, Y.; Shuai, J.; Tu, X.; Zhang, Y.; Ma, Z.; Xie, M. Detecting multi-oriented text with corner-based region proposals. Neurocomputing 2019, 334, 134–142. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Liang, B.; Huang, Z.; En, M.; Han, J.; Ding, E.; Ding, X. Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10544–10553. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Zhang, C.; Luo, Y.; Wang, Y.; Han, J.; Ding, E. WordSup: Exploiting Word Annotations for Character Based Text Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Fragoso, V.; Gauglitz, S.; Zamora, S.; Kleban, J.; Turk, M. TranslatAR: A mobile augmented reality translator. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 497–502. [Google Scholar]
- Petter, M.; Fragoso, V.; Turk, M.; Baur, C. Automatic text detection for mobile augmented reality translation. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 48–55. [Google Scholar]
- Yi, C.; Tian, Y. Scene text recognition in mobile applications by character descriptor and structure configuration. IEEE Trans. Image Process. 2014, 23, 2972–2982. [Google Scholar] [CrossRef]
- Shivakumara, P.; Wu, L.; Lu, T.; Tan, C.L.; Blumenstein, M.; Anami, B.S. Fractals based multi-oriented text detection system for recognition in mobile video images. Pattern Recognit. 2017, 68, 158–174. [Google Scholar] [CrossRef]
- Fu, K.; Sun, L.; Kang, X.; Ren, F. Text Detection for Natural Scene based on MobileNet V2 and U-Net. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 1560–1564. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; i Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; De Las Heras, L.P. ICDAR 2013 robust reading competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1484–1493. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Veit, A.; Matera, T.; Neumann, L.; Matas, J.; Belongie, S. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv 2016, arXiv:1601.07140. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1083–1090. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6. In COURSERA: Neural Networks for Machine Learning; Coursera: Mountain View, CA, USA, 2012. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time Scene Text Detection with Differentiable Binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zhang, S.; Liu, Y.; Jin, L.; Wei, Z.; Shen, C. OPMP: An Omnidirectional Pyramid Mask Proposal Network for Arbitrary-Shape Scene Text Detection. IEEE Trans. Multimed. 2021, 23, 454–467. [Google Scholar] [CrossRef]
- Zhu, Y.; Du, J. TextMountain: Accurate scene text detection via instance segmentation. Pattern Recognit. 2021, 110, 107336. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Initial | # of Epochs | Batch Size | # of Epochs for Decay |
|---|---|---|---|---|
| ICDAR2013 | 0.001 | 50 | 16 | 20 |
| ICDAR2015 | 0.001 | 50 | 16 | 20 |
| MSRA-TD500 | 0.0005 | 60 | 24 | 30 |
| COCO-Text | 0.0001 | 100 | 8 | 50 |
| Dataset | Precision | Recall | F-Score |
|---|---|---|---|
| ICDAR2013 | 0.930 | 0.845 | 0.885 |
| ICDAR2015 | 0.882 | 0.826 | 0.853 |
| MSRA-TD500 | 0.820 | 0.784 | 0.801 |
| COCOText | 0.622 | 0.592 | 0.606 |
| ICDAR2013 Dataset | ICDAR2015 Dataset | MSRA-TD500 Dataset | COCOText Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Pre. | Rec. | F-Score | Pre. | Rec. | F-Score | Pre. | Rec. | F-Score | Pre. | Rec. | F-Score |
| CTPN [40] | 0.930 | 0.830 | 0.877 | 0.740 | 0.520 | 0.610 | - | - | - | - | - | - |
| Text-block FCN [33] | 0.880 | 0.780 | 0.830 | 0.710 | 0.430 | 0.540 | 0.830 | 0.670 | 0.740 | - | - | - |
| RTN [39] | 0.940 | 0.890 | 0.910 | - | - | - | - | - | - | - | - | |
| Lyu et al. [51] | 0.920 | 0.840 | 0.878 | 0.895 | 0.800 | 0.844 | 0.880 | 0.760 | 0.815 | 0.620 | 0.320 | 0.425 |
| ATRR [43] | 0.937 | 0.897 | 0.917 | 0.892 | 0.860 | 0.876 | 0.852 | 0.821 | 0.836 | - | - | - |
| Mask TextSpotter [34] | 0.950 | 0.886 | 0.917 | 0.916 | 0.810 | 0.860 | - | - | - | - | - | - |
| Text-CNN [35] | 0.930 | 0.730 | 0.820 | - | - | - | 0.760 | 0.610 | 0.690 | - | - | - |
| TextBoxes++ [36] | 0.910 | 0.840 | 0.880 | 0.878 | 0.785 | 0.829 | 0.609 | 0.567 | 0.587 | |||
| PixelLink [46] | 0.886 | 0.875 | 0.881 | 0.855 | 0.820 | 0.837 | 0.830 | 0.732 | 0.778 | - | - | - |
| DB-ResNet-50 [72] | - | - | - | 0.918 | 0.832 | 0.873 | 0.915 | 0.792 | 0.849 | - | - | - |
| EAST [32] | - | - | - | 0.833 | 0.783 | 0.807 | 0.873 | 0.674 | 0.761 | 0.504 | 0.324 | 0.395 |
| Deng et al. [52] | - | - | - | - | - | - | - | - | - | 0.555 | 0.633 | 0.591 |
| SPCNET [47] | 0.938 | 0.905 | 0.921 | 0.887 | 0.858 | 0.872 | - | - | - | - | - | - |
| LOMO [53] | - | - | - | 0.878 | 0.876 | 0.877 | - | - | - | - | - | - |
| OPMP [73] | - | - | - | 0.891 | 0.855 | 0.873 | 0.860 | 0.834 | 0.847 | - | - | - |
| TextMountain [74] | - | - | - | 0.885 | 0.842 | 0.863 | - | - | - | - | - | - |
| MobileTDNet + Text Attention 1 | 0.941 | 0.853 | 0.895 | 0.903 | 0.842 | 0.871 | 0.843 | 0.802 | 0.822 | 0.627 | 0.596 | 0.611 |
| MobileTDNet + Text Attention 1, 2 and 3 | 0.947 | 0.876 | 0.910 | 0.913 | 0.847 | 0.879 | 0.854 | 0.807 | 0.830 | 0.631 | 0.603 | 0.617 |
| (a) ICDAR201 | |||||
| Skip Connection: Feature Maps | Pre. | Rec. | F-Score | F-Score Difference | Average Detection Time in Seconds |
| , , , | 0.835 | 0.814 | 0.823 | 0.062 | 0.278 |
| , , | 0.787 | 0.763 | 0.775 | 0.110 | 0.265 |
| , | 0.735 | 0.704 | 0.719 | 0.166 | 0.246 |
| 0.705 | 0.678 | 0.691 | 0.194 | 0.231 | |
| , , , | 0.842 | 0.801 | 0.821 | 0.064 | 0.267 |
| , , | 0.777 | 0.751 | 0.764 | 0.121 | 0.280 |
| (b) ICDAR2015 | |||||
| Skip Connection: Feature Maps | Pre. | Rec. | F-Score | F-Score Difference | |
| , , , | 0.825 | 0.788 | 0.806 | 0.047 | |
| , , | 0.819 | 0.778 | 0.798 | 0.055 | |
| , | 0.684 | 0.627 | 0.654 | 0.199 | |
| 0.664 | 0.581 | 0.620 | 0.233 | ||
| , , , | 0.829 | 0.796 | 0.812 | 0.041 | |
| , , | 0.736 | 0.749 | 0.742 | 0.111 | |
| W/O Attention | Text Attention 1 | Text Attention 1, 2 and 3 | |
|---|---|---|---|
| Avg. IoU | 0.772 | 0.786 | 0.793 |
| Avg. processing time in seconds | 0.385 | 0.415 | 0.486 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, E.; L., L.V. Scene Text Detection Using Attention with Depthwise Separable Convolutions. Appl. Sci. 2022, 12, 6425. https://doi.org/10.3390/app12136425
Hassan E, L. LV. Scene Text Detection Using Attention with Depthwise Separable Convolutions. Applied Sciences. 2022; 12(13):6425. https://doi.org/10.3390/app12136425
Chicago/Turabian StyleHassan, Ehtesham, and Lekshmi V. L. 2022. "Scene Text Detection Using Attention with Depthwise Separable Convolutions" Applied Sciences 12, no. 13: 6425. https://doi.org/10.3390/app12136425
APA StyleHassan, E., & L., L. V. (2022). Scene Text Detection Using Attention with Depthwise Separable Convolutions. Applied Sciences, 12(13), 6425. https://doi.org/10.3390/app12136425