
RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network


Abstract
1. Introduction
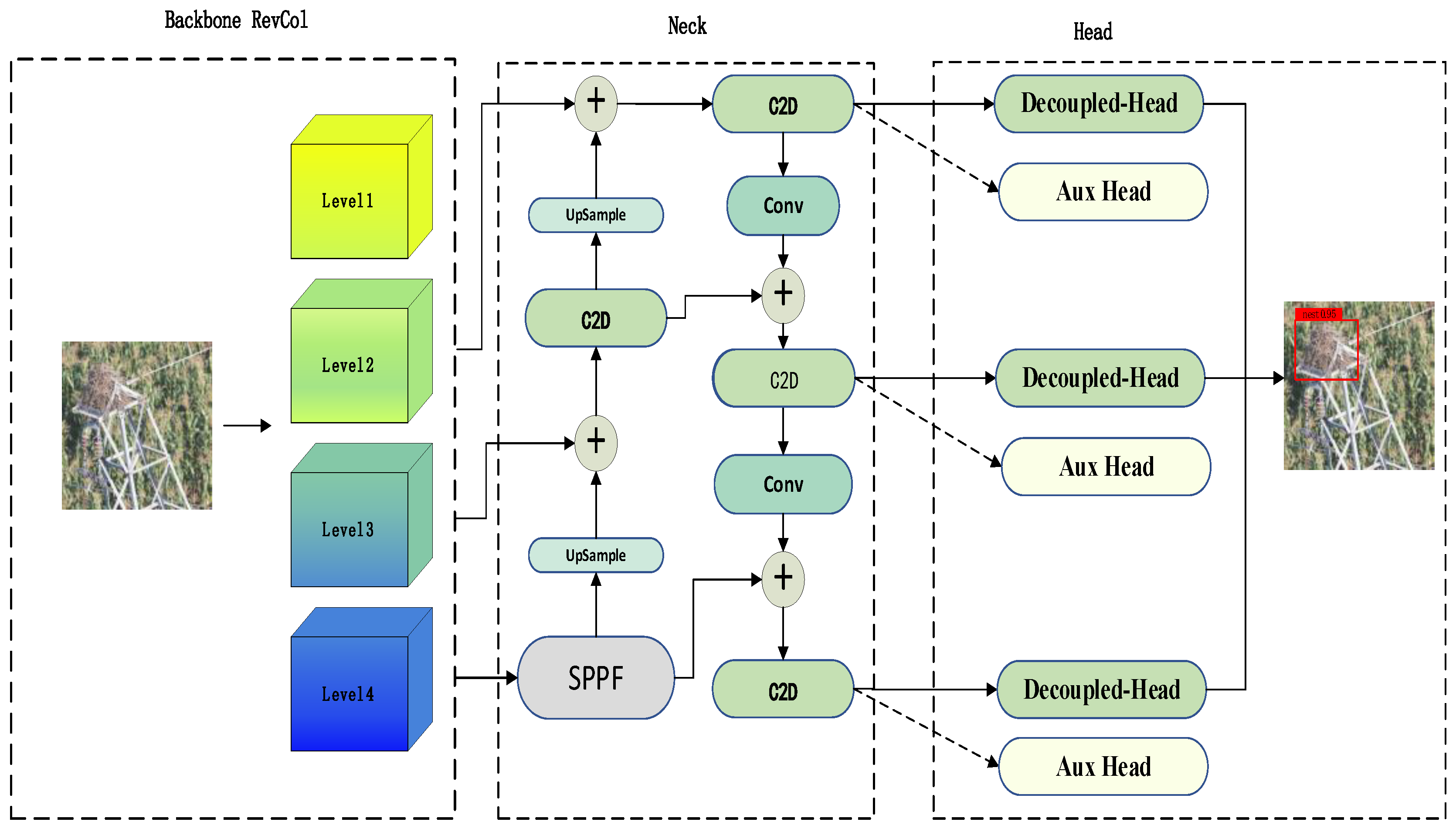
2. Model Construction
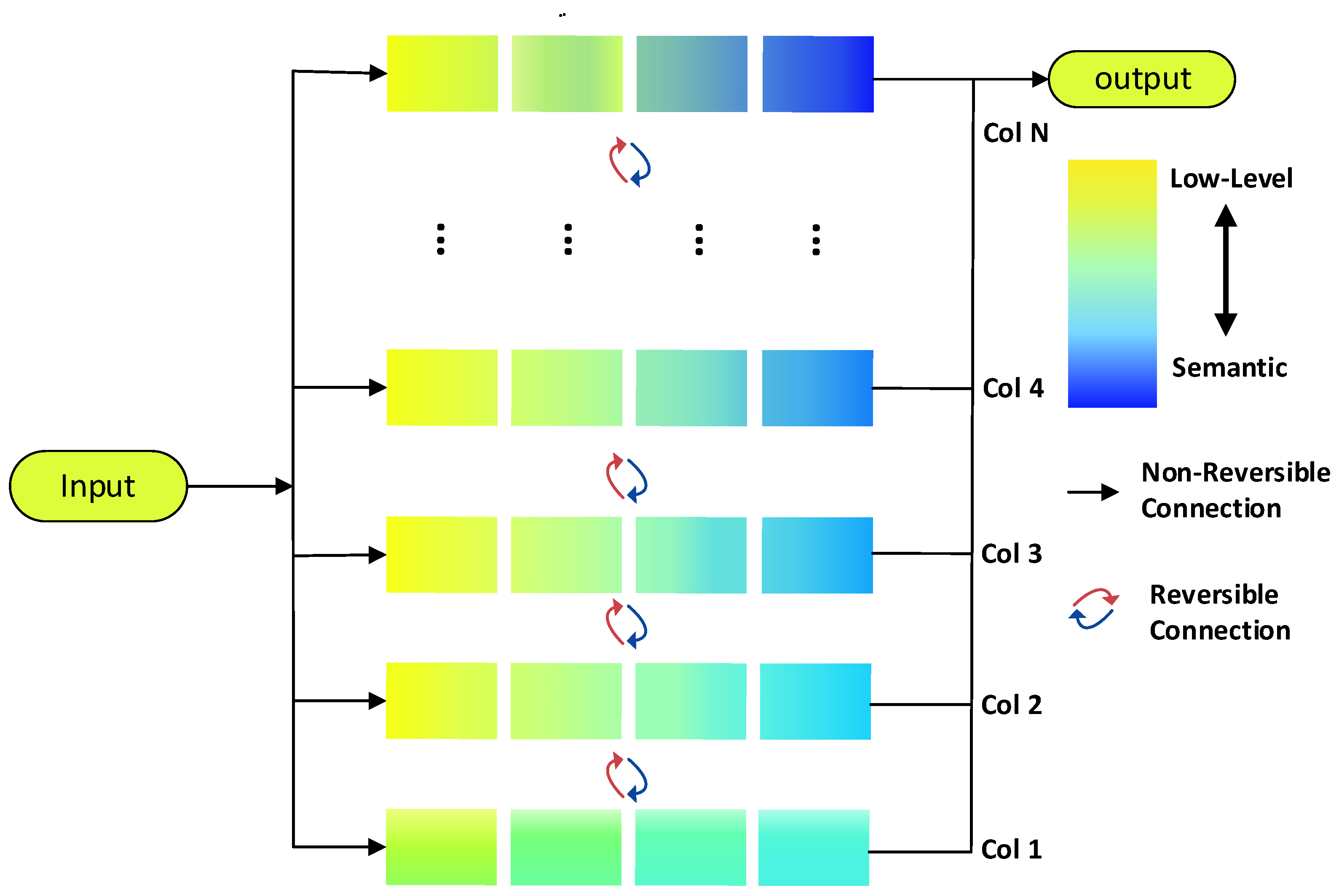
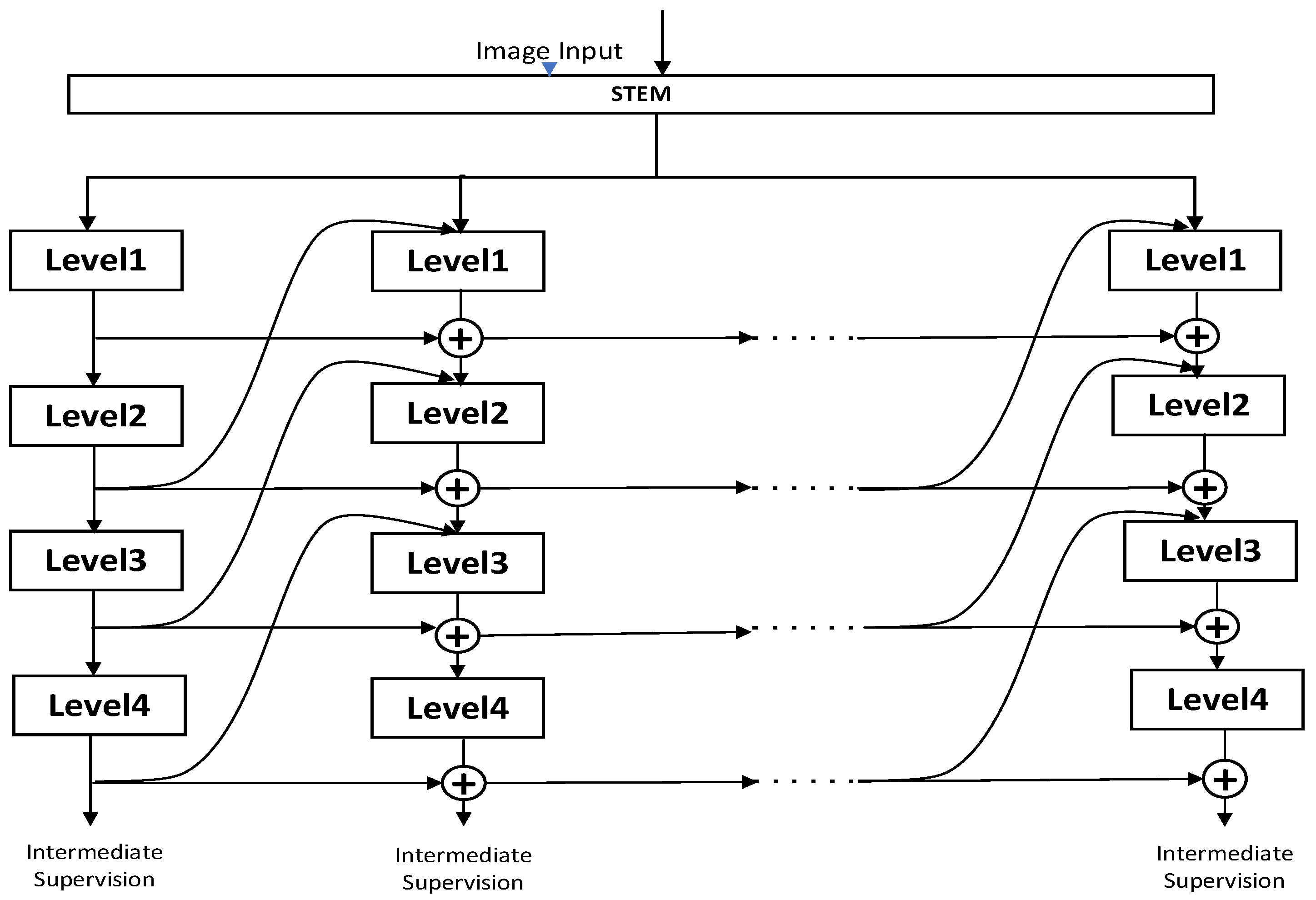
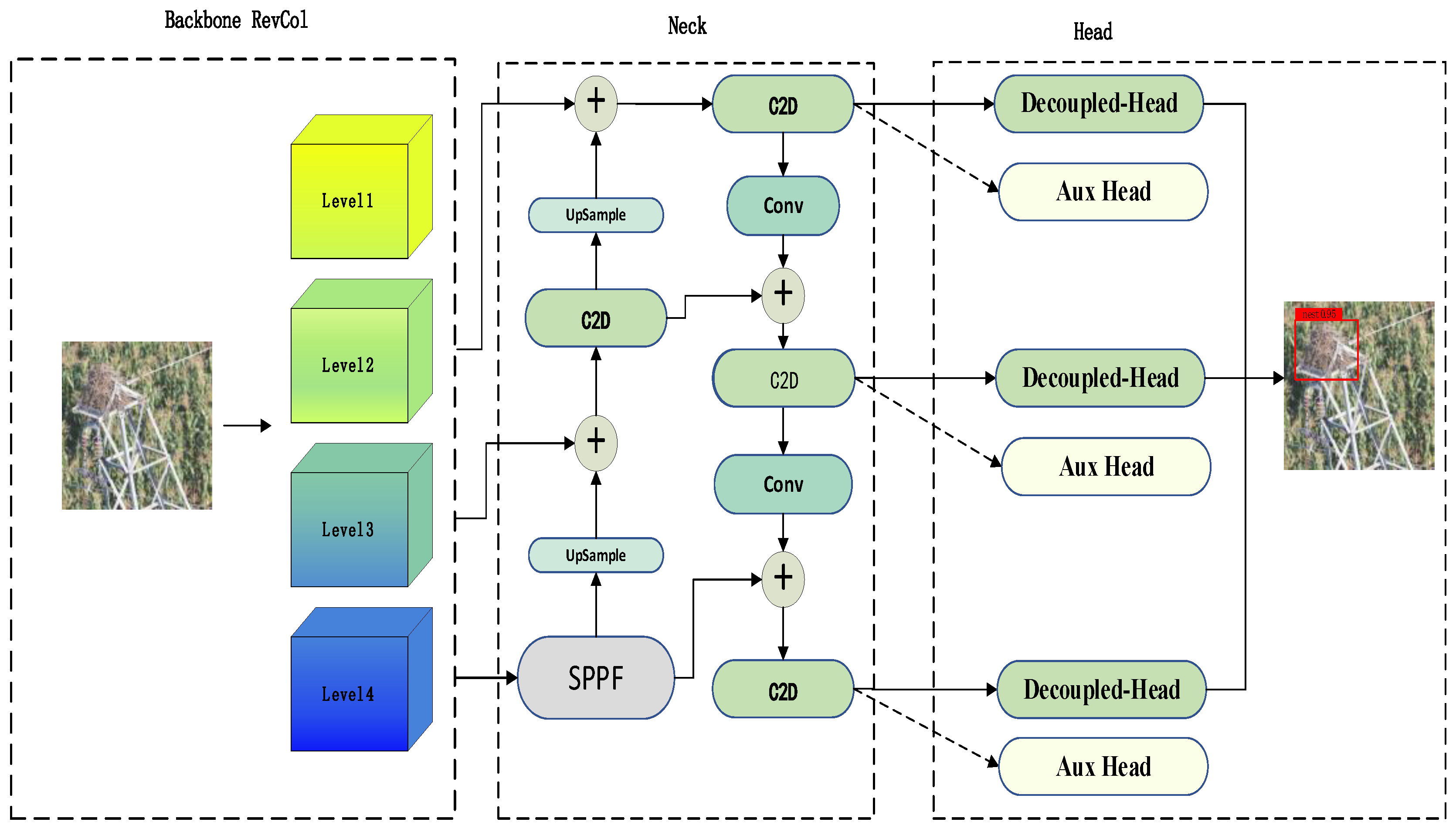
2.1. Backbone Network-RevCol
2.2. Neck-Network
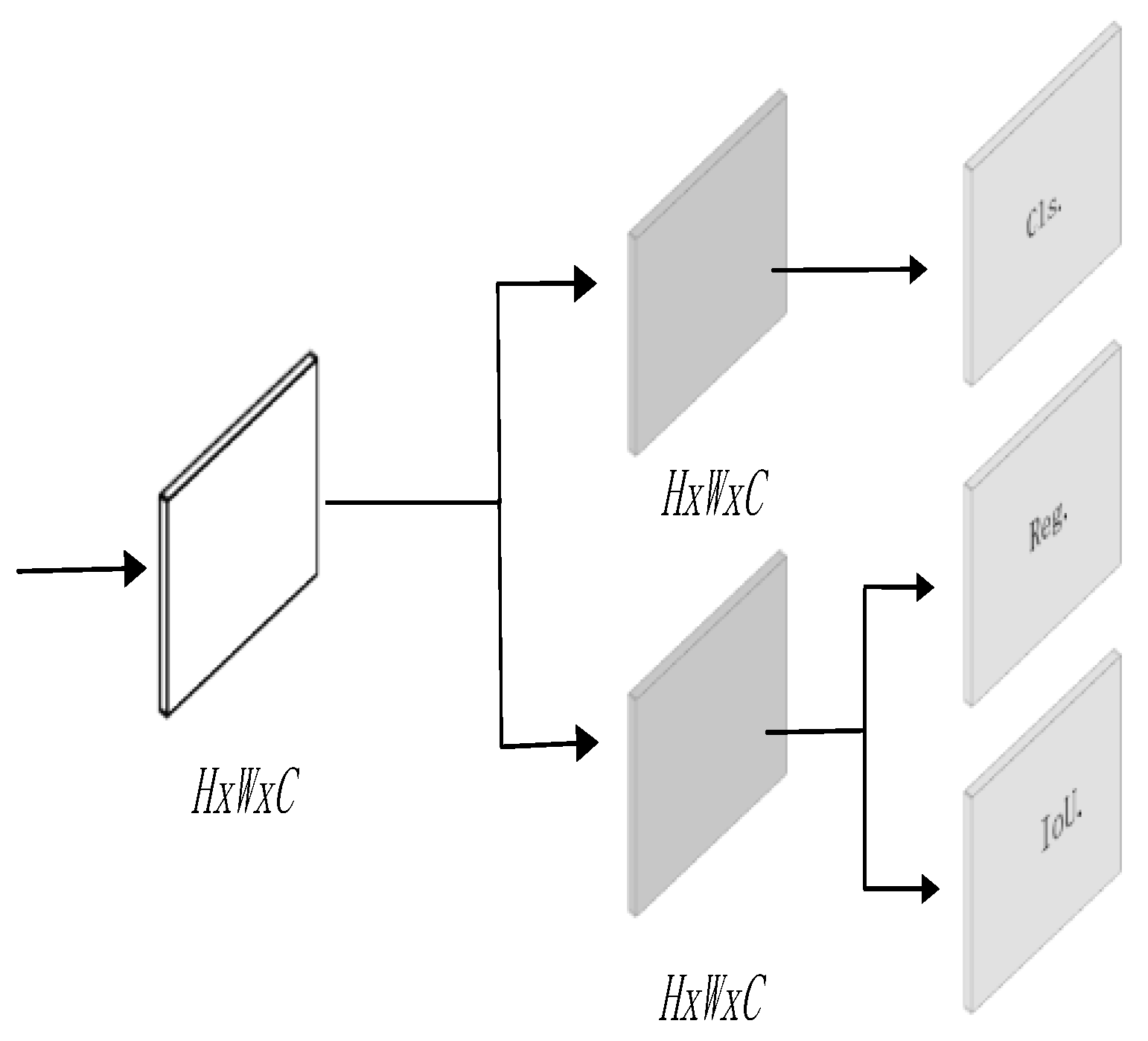
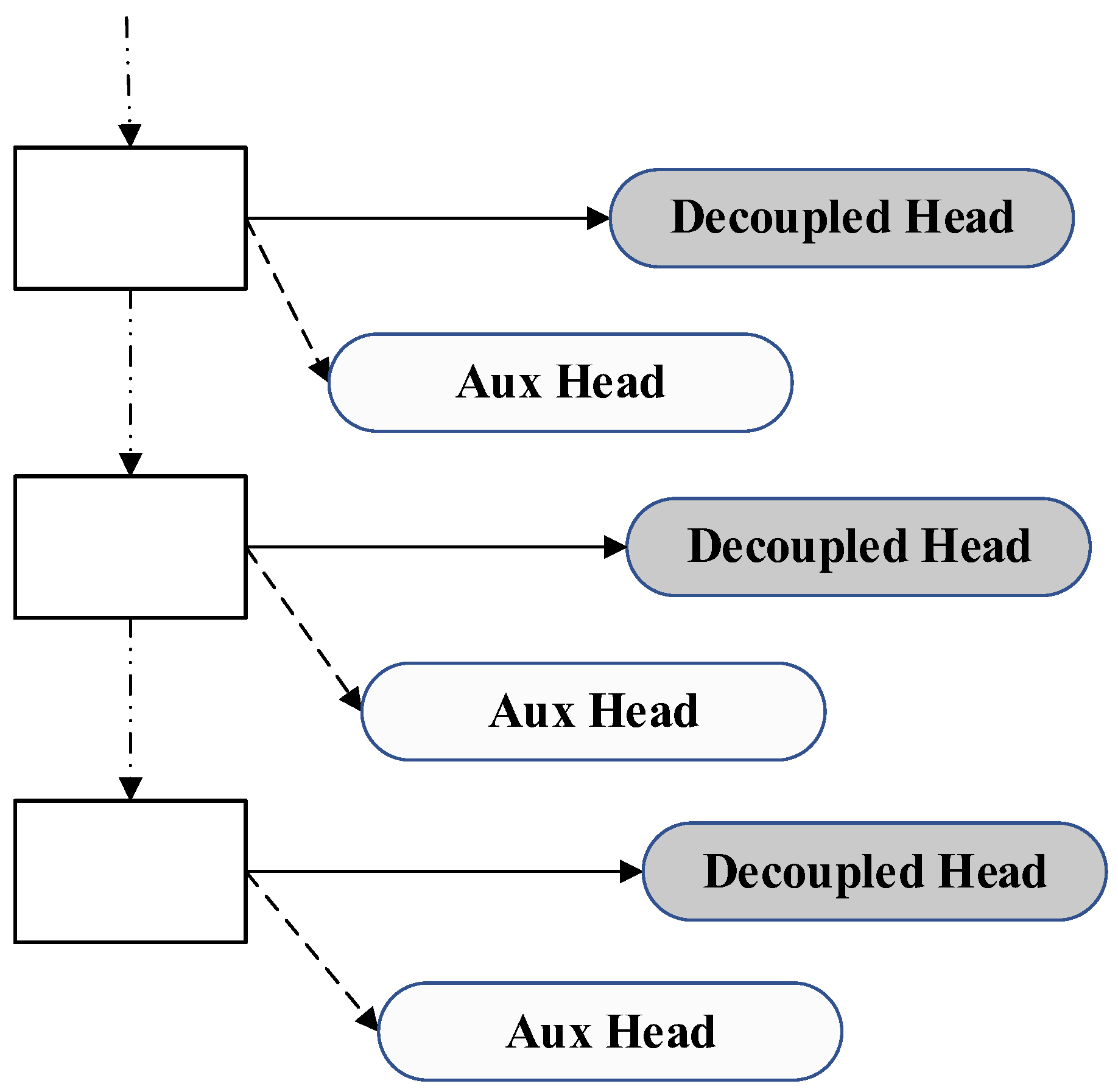
2.3. Detection Head Networks
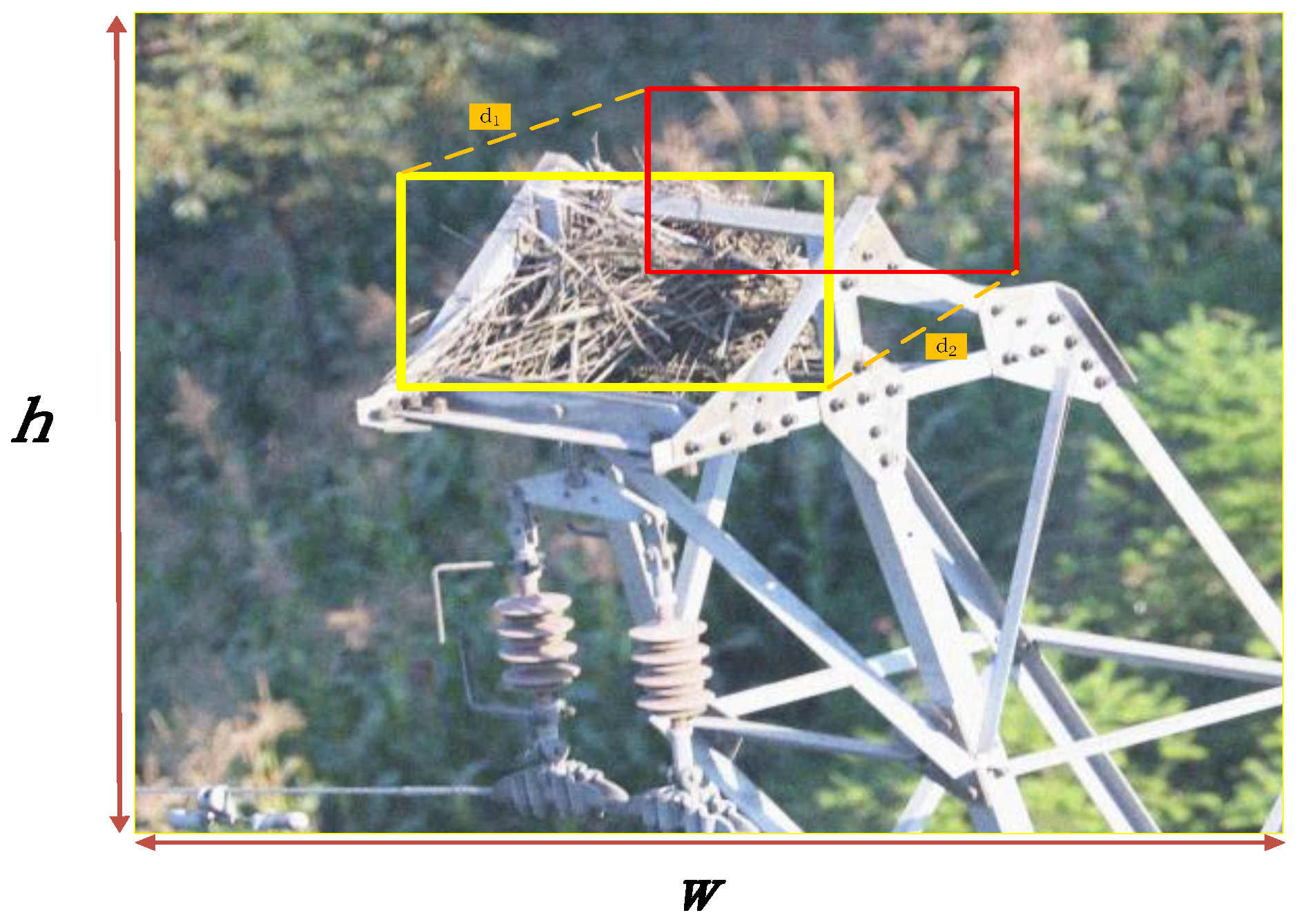
2.4. MPDIoU Loss Function
3. Experimental Results and Analysis
3.1. Experimental Environment
3.2. Evaluation Metrics
3.3. Data Processing
3.4. Experimental Result and Comparative Analysis
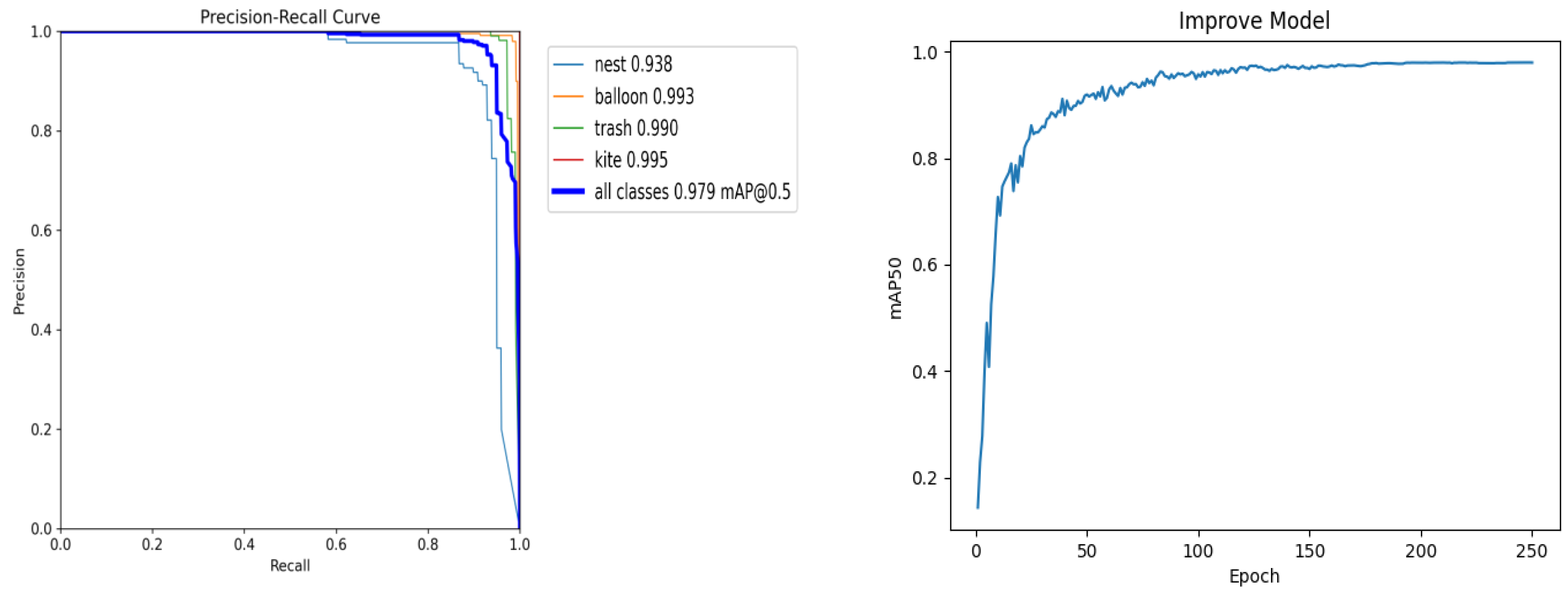
3.4.1. Comparative Experiments
3.4.2. Ablation Experiments
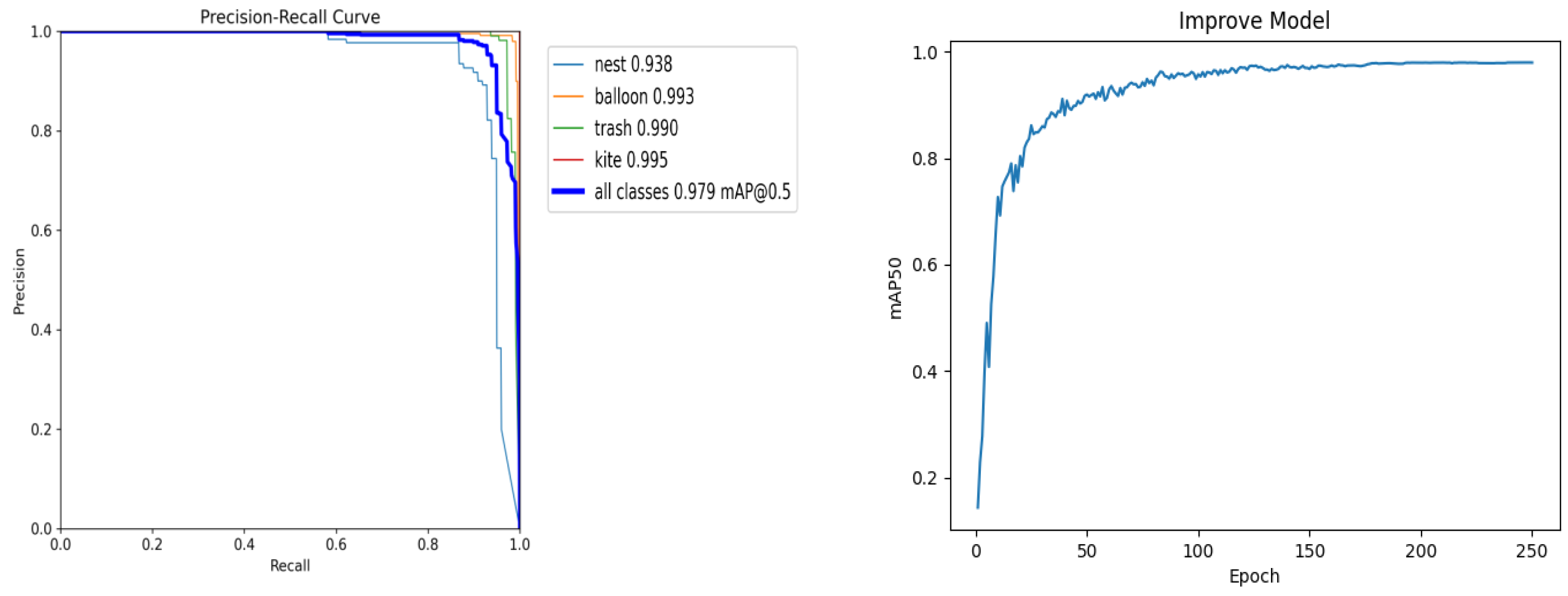
3.4.3. Detection Result
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jalil, B.; Leone, G.R.; Martinelli, M.; Moroni, D.; Berton, A. Fault Detection in Power Equipment via an Unmanned Aerial System Using Multi Modal Data. Sensors 2019, 19, 3014. [Google Scholar] [CrossRef] [PubMed]
- Menendez, O.; Cheein, F.A.A.; Perez, M.; Kouro, S. Robotics in Power Systems: Enabling a More Reliable and Safe Grid. IEEE Ind. Electron. Mag. 2017, 11, 22–34. [Google Scholar] [CrossRef]
- Mann, B.J.; Morrison, I.F. Digital calculation of impedance for transmission line protection. IEEE Trans. Power Appar. Syst. 1971, 270–279. [Google Scholar] [CrossRef]
- Wale, P.B. Maintenance of transmission line by using robot. In Proceedings of the 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), Pune, India, 9–10 September 2016; pp. 538–542. [Google Scholar]
- Xie, X.; Liu, Z.; Xu, C.; Zhang, Y. A multiple sensors platform method for power line inspection based on a large unmanned helicopter. Sensors 2017, 17, 1222. [Google Scholar] [CrossRef] [PubMed]
- Alhassan, A.B.; Zhang, X.; Shen, H.; Xu, H. Power transmission line inspection robots: A review, trends and challenges for future research. Int. J. Electr. Power Energy Syst. 2020, 118, 105862. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Kumar, N.S.; Shobha, G.; Balaji, S. Key frame extraction algorithm for video abstraction applications in underwater videos. In Proceedings of the 2015 IEEE Underwater Technology (UT), Chennai, India, 23–25 February 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–5. [Google Scholar]
- Changan, L.; Jin, S.; Hua, W.; Guotian, Y.; Chunyang, L. Research on keyframes extraction pretreatment of power-tower in flying robot inspection video. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2015, 43, 477–480. [Google Scholar] [CrossRef]
- Lijun, J.; Chunyu, Y.; Shujia, Y.; Wenhao, Z. Recognition of Extra Matterson Transmission Lines Basedon Aerial Images. J. Tongji Univ. (Nat.) 2013, 41, 277–281. [Google Scholar]
- Wanguo, W.; Jingjing, Z.; Jun, H.; Liang, L.; Mingwu, Z. Broken strand and foreign body fault detection method for power transmission line based on unmanned aerial vehicle image. J. Comput. Appl. 2015, 35, 2404–2408. [Google Scholar]
- Yongsheng, Z.; Haiqing, X.; Ligang, W.; Ruizhi, Y.; Chong, L. Application of Hough’s Linear Transform-based Foreign Object Recognition on Transmission Lines. Digit. Technol. Appl. 2017, 127–129. [Google Scholar] [CrossRef]
- Shengxi, J.; Haiyang, W. Research on foreign object recognition of transmission line based on ORB algorithm. Sci. Technol. Eng. 2016, 16, 236–240. [Google Scholar]
- Xinfu, L.; Richeng, L.; Shixuan, D.; Jing, Z.; Guanfei, Y. Research on foreign object recognition method of power line based on digital image processing. Electr. Eng. 2022, 23, 73–78. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Jinglin, H.; Xiangang, P.; Shengchao, J.; Haoliang, Y. Transmission Line Fault Classification Based on Deep Learning and Imbalanced Sample Set. Smart Power 2021, 49, 114–119. [Google Scholar]
- Xinlan, J.; Wenbo, J. Machine Vision Detection Method for Foreign Object Intrusion in High-Speed Rail Contact Net. Comput. Eng. Appl. 2019, 55, 250–257. [Google Scholar]
- Zhenmin, Z.; Liangkai, X. Detection of birds’ nest in catenary based on relative position invariance. J. Railw. Sci. Eng. 2018, 15, 1043–1049. [Google Scholar] [CrossRef]
- Wang, B.; Wu, R.; Zheng, Z.; Zhang, W.; Guo, J. Study on the method of transmission line foreign body detection based on deep learning. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017. [Google Scholar]
- Gangjun, G.; Shuai, Z.; Qiuxin, W.; Zhimin, C.; Ren, L.; Chang, S.; Alhassan, A.B. TensorFlow-based foreign object recognition for high-voltage transmission lines. Electr. Power Autom. Equip. 2019, 39, 204–209. [Google Scholar] [CrossRef]
- Zengxiang, X.; Qifeng, X. Recognition of Foreign Objects Intrusion in Substation Based on Improved Convolutional Neural Network. Sci. Technol. Eng. 2022, 22, 1465–1471. [Google Scholar]
- Maodong, S.; Pei, J.; Xinyang, F.; Junling, Z.; Fankui, G.; Xia, L.; Alhassan. A New Transmission Line Foreign Object Detection Network Structure: TLFOD Net. Jisuanji Yu Xiandaihua 2019, 118–122. [Google Scholar]
- Yingchun, Z.; Siyu, S.; Shuai, L.; Zhiyong, L.; Yongliang, X.; Ching, H.W.; Alhassan. Recognition of Bird’s Nest on Transmission Tower in Aerial Image of High-volage Power Line by YOLOv3 Algorithm. J. Guangdong Univ. Technol. 2020, 37, 42–48. [Google Scholar]
- Qiuyan, Z.; Zhu, T.; Xiao, S.; Yang, Z.; Zeng, H.; Chi, Z.; Li, G. Foreign object detection of high voltage transmission line based on improved YOLOv4 algorithm. Appl. Sci. Technol. 2023, 50, 59–65. [Google Scholar]
- Hongmin, Z.; Hao, Z.; Shunyuan, L.; Pingping, L. Improved YOLOv3 foreign body detection method in transmission line. Laser J. 2022, 43, 82–87. [Google Scholar] [CrossRef]
- Zheng, T.; Huilin, Z.; Lixin, M.; Jinzhi, L.; Hao, W. Identification of Foreign Objects on Transmission Lines Using Lightweight Network Algorithm. Electron. Sci. Technol. 2023, 36, 71–77. [Google Scholar] [CrossRef]
- Yanzhen, Y.; Zhibin, Q.; Yinbiao, Z.; Xuan, Z.; Qing, W. Foreign Body Detection for Transmission Lines Based on Convolutional Neural Network and ECOC-SVM. Smart Power 2022, 50, 87–92. [Google Scholar]
- Zamir, A.R.; Sax, A.; Shen, W.; Guibas, L.J.; Malik, J.; Savarese, S. Taskonomy: Disentangling task transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3712–3722. [Google Scholar]
- Cai, Y.; Zhou, Y.; Han, Q.; Sun, J.; Kong, X.; Li, J.; Zhang, X. Reversible Column Networks. arXiv 2023, arXiv:2212.11696. [Google Scholar]
- Hinton, G. How to represent part-whole hierarchies in a neural network. Neural Comput. 2023, 35, 413–452. [Google Scholar] [CrossRef]
- Chang, B.; Meng, L.; Haber, E.; Ruthotto, L.; Begert, D.; Holtham, E. Reversible Architectures for Arbitrarily Deep Residual Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 6070–6079. [Google Scholar]
- Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics 2023, 12, 3804. [Google Scholar] [CrossRef]
- Zeng, G.; Yu, W.; Wang, R.; Lin, A. Research on mosaic image data enhancement for overlapping ship targets. arXiv 2021, arXiv:2105.05090. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Category | Object Number | Object Ratio |
|---|---|---|
| bird nest | 2289 | 44.68% |
| kite | 1168 | 22.79% |
| balloon | 607 | 11.84% |
| trash bag | 1020 | 19.91% |
| Comparison of Results of Common Models | ||||
|---|---|---|---|---|
| Models | mAP50 | mAP50-95 | Recall | Precision |
| YOLOv5 | 0.9545 | 0.6836 | 0.8978 | 0.9636 |
| YOLOV6 | 0.9107 | 0.6397 | 0.8804 | 0.9110 |
| YOLOV7 | 0.9471 | 0.6457 | 0.8896 | 0.9287 |
| YOLOV8 | 0.9686 | 0.6923 | 0.9310 | 0.9580 |
| FCOS | 0.9576 | 0.6533 | 0.8897 | 0.9297 |
| SSD | 0.7570 | 0.5673 | 0.6571 | 0.7632 |
| Faster R-CNN | 0.9528 | 0.6523 | 0.8923 | 0.9312 |
| RetinaNet | 0.9253 | 0.6399 | 0.8838 | 0.9245 |
| Ours model | 0.9798 | 0.7211 | 0.9516 | 0.9815 |
| YOLOV8 | +RevCol | +C2D | +Detection Head | +MPDIoU | mAP50 | Group |
|---|---|---|---|---|---|---|
| + | - | - | - | - | 0.9686 | A |
| + | + | - | - | - | 0.9712 | B1 |
| + | - | + | - | - | 0.9702 | C1 |
| + | - | - | + | - | 0.9692 | D1 |
| + | - | - | - | + | 0.9689 | E1 |
| YOLOV8 | +RevCol | +C2D | +Detection Head | +MPDIoU | mAP50 | Group |
|---|---|---|---|---|---|---|
| + | - | - | - | - | 0.9686 | A |
| + | + | - | - | - | 0.9712 | B2 |
| + | + | + | - | - | 0.9755 | C2 |
| + | + | + | + | - | 0.9785 | D2 |
| + | + | + | + | + | 0.9798 | Ours model |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Li, Y.; Liu, A. RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network. Appl. Sci. 2024, 14, 1152. https://doi.org/10.3390/app14031152
Zhang W, Li Y, Liu A. RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network. Applied Sciences. 2024; 14(3):1152. https://doi.org/10.3390/app14031152
Chicago/Turabian StyleZhang, Wenli, Yingna Li, and Ailian Liu. 2024. "RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network" Applied Sciences 14, no. 3: 1152. https://doi.org/10.3390/app14031152
APA StyleZhang, W., Li, Y., & Liu, A. (2024). RCDAM-Net: A Foreign Object Detection Algorithm for Transmission Tower Lines Based on RevCol Network. Applied Sciences, 14(3), 1152. https://doi.org/10.3390/app14031152