
Developing Conversational Agent Using Deep Learning Techniques †


Abstract
:1. Introduction
2. Related Work
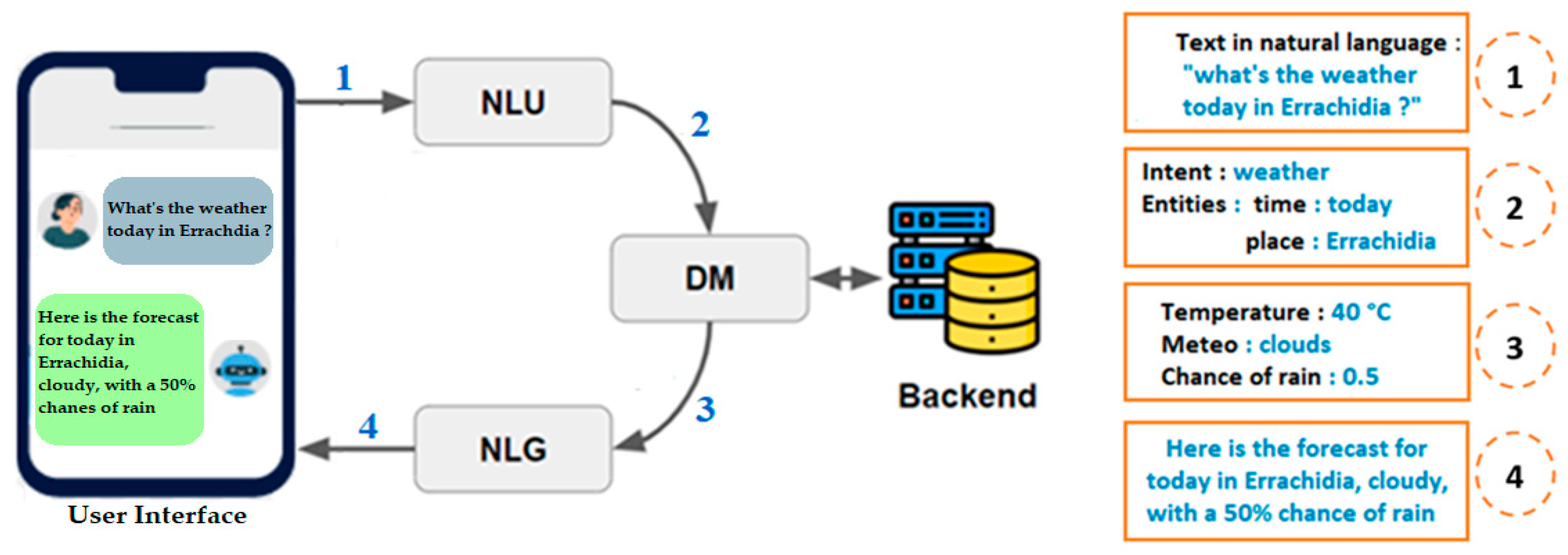
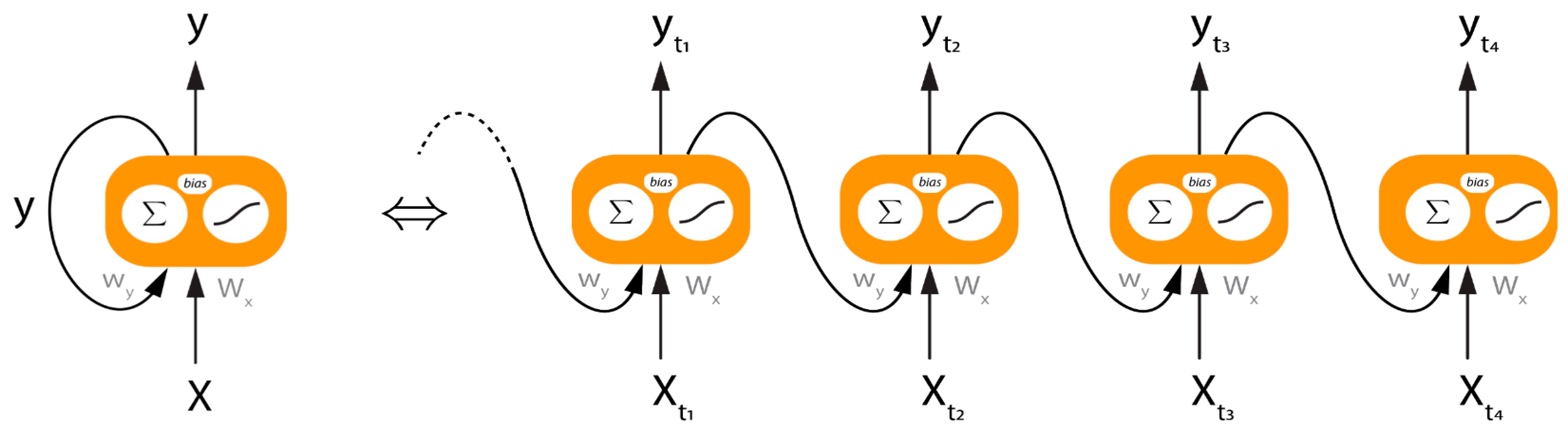
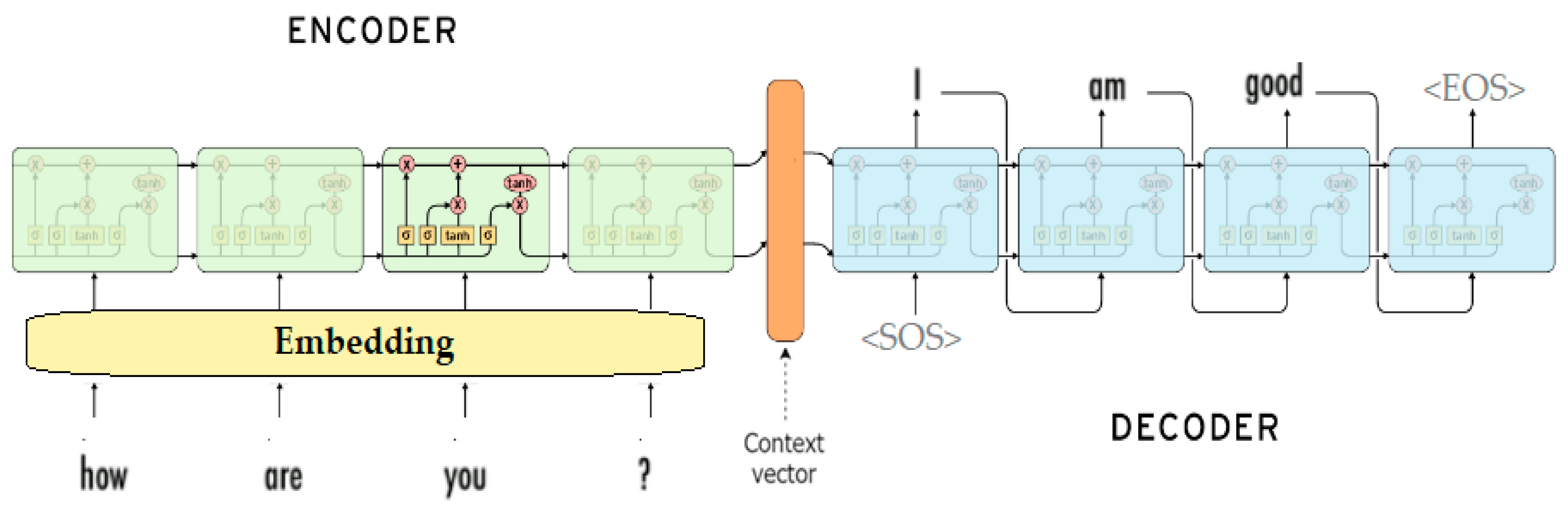
3. Approach
4. Experiment and Results
4.1. Dataset
4.2. Data Preprocessing
4.3. Splitting Data
4.4. Building the Model
4.5. Training the Model
4.6. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brandtzaeg, P.B.; Følstad, A. Why people use chatbots. In Internet Science: 4th International Conference, INSCI 2017, Thessaloniki, Greece, November 22–24, 2017, Proceedings 4; Springer: Berlin/Heidelberg, Germany, 2017; pp. 377–392. [Google Scholar]
- Lebeuf, C.; Storey, M.-A.; Zagalsky, A. Software bots. IEEE Software 2017, 35, 18–23. [Google Scholar] [CrossRef]
- Dialogflow. Available online: https://dialogflow.com/ (accessed on 10 January 2022).
- Watson Assistant. Available online: https://www.ibm.com/cloud/watson-assistant/ (accessed on 5 January 2022).
- Microsoft Bot Framework. Available online: https://dev.botframework.com/ (accessed on 20 April 2022).
- Amazon Lex. Available online: https://aws.amazon.com/en/lex/ (accessed on 20 February 2022).
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Sojasingarayar, A. Seq2seq ai chatbot with attention mechanism. arXiv 2020, arXiv:2006.02767. [Google Scholar]
- Sarikaya, R. The technology behind personal digital assistants: An overview of the system architecture and key components. IEEE Signal Process. Mag. 2017, 34, 67–81. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. An overview of chatbot technology. In Artificial Intelligence Applications and Innovations: 16th IFIP WG 12.5 International Conference, AIAI 2020, Neos Marmaras, Greece, June 5–7, 2020, Proceedings, Part II 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 373–383. [Google Scholar]
- Kusal, S.; Patil, S.; Choudrie, J.; Kotecha, K.; Mishra, S.; Abraham, A. AI-based Conversational Agents: A Scoping Review from Technologies to Future Directions. IEEE Access 2022, 10, 92337–92356. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Amodei, D. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Dataset. Available online: https://www.cs.cornell.edu/cristian/CornellMovieDialogsCorpus.htm (accessed on 2 January 2022).
- Keras. Available online: https://keras.io/api/ (accessed on 2 February 2023).
- Tensorflow. Available online: https://www.tensorflow.org/guide (accessed on 2 February 2023).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Configuration 1 | Configuration 2 | Configuration 3 | Configuration 4 |
|---|---|---|---|---|
| LSTM cells | 256 | 256 | 512 | 512 |
| Batch size | 32 | 32 | 32 | 64 |
| Epochs | 11 | 50 | 75 | 100 |
| Learning rate | 0.001 | 0.001 | 0.001 | 0.001 |
| Loss function | categorical_crossentropy | |||
| Metric | accuracy | |||
| Optimizer | adam | |||
| Configuration | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) |
|---|---|---|---|
| 1 | 83.80 | 83.03 | 83.50 |
| 2 | 87.08 | 82.18 | 83.40 |
| 3 | 89.87 | 81.60 | 82.12 |
| 4 | 90.65 | 81.39 | 82.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouaddi, C.; Benaddi, L.; Khriss, I.; Jakimi, A. Developing Conversational Agent Using Deep Learning Techniques. Comput. Sci. Math. Forum 2023, 6, 3. https://doi.org/10.3390/cmsf2023006003
Ouaddi C, Benaddi L, Khriss I, Jakimi A. Developing Conversational Agent Using Deep Learning Techniques. Computer Sciences & Mathematics Forum. 2023; 6(1):3. https://doi.org/10.3390/cmsf2023006003
Chicago/Turabian StyleOuaddi, Charaf, Lamya Benaddi, Ismaïl Khriss, and Abdeslam Jakimi. 2023. "Developing Conversational Agent Using Deep Learning Techniques" Computer Sciences & Mathematics Forum 6, no. 1: 3. https://doi.org/10.3390/cmsf2023006003
APA StyleOuaddi, C., Benaddi, L., Khriss, I., & Jakimi, A. (2023). Developing Conversational Agent Using Deep Learning Techniques. Computer Sciences & Mathematics Forum, 6(1), 3. https://doi.org/10.3390/cmsf2023006003