
A Machine Learning-Based Risk Prediction Model During Pregnancy in Low-Resource Settings †


Abstract
1. Introduction
2. Related Studies
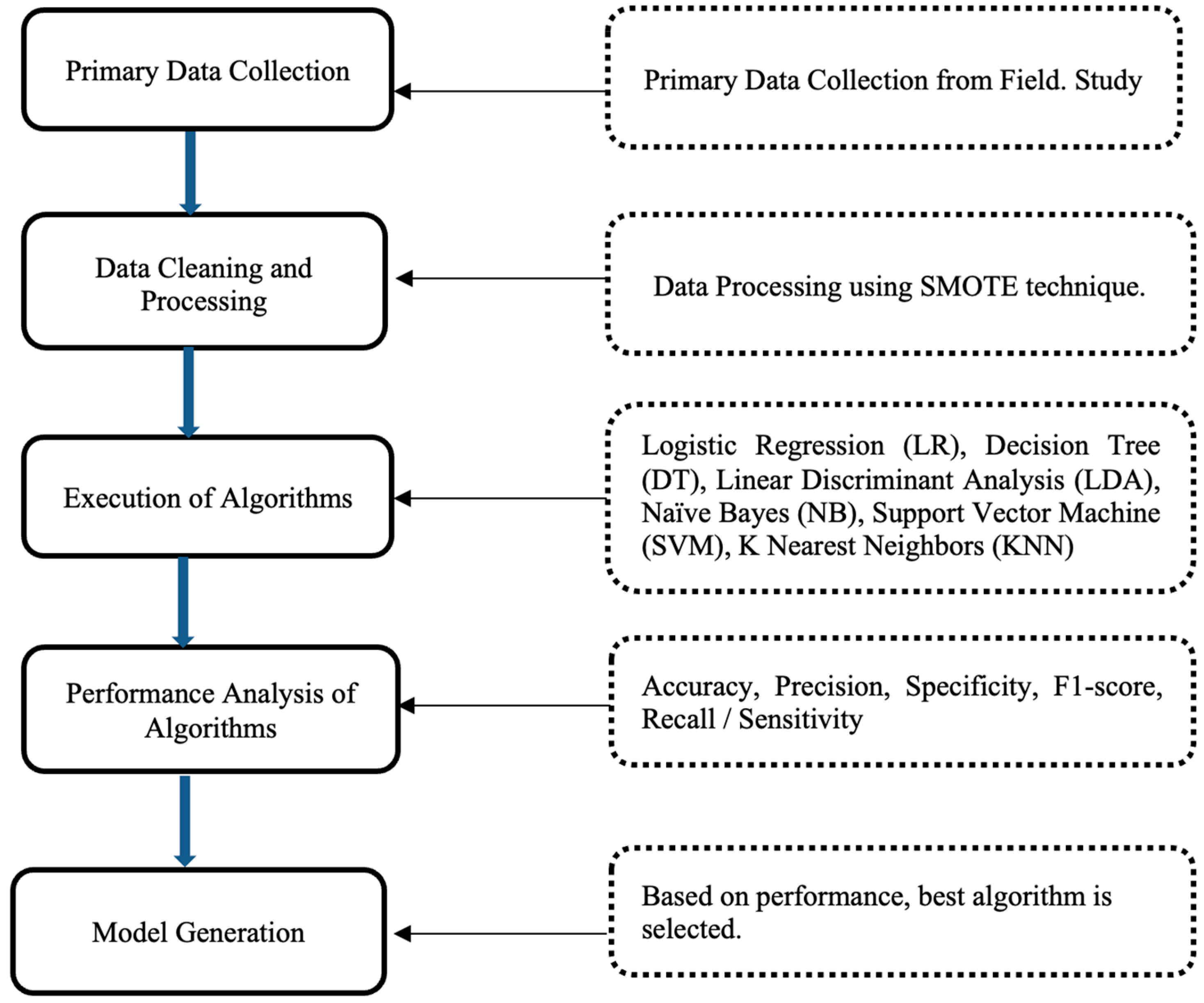
3. Methodology
3.1. Data Collection
3.2. Data Cleaning and Processing
3.3. Machine Learning Algorithms
3.4. Performance Metrics for Comparative Analysis
4. Results
Comparative Analysis of Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tomar, K.; Sharma, C.M.; Sharma, P.; Gupta, D.; Chariar, V.M. Impacts of Environmental Factors on Maternal Health in Low Resource Settings. In Proceedings of the 6th International Conference on Resources and Environment Sciences (ICRES 2024), Bangkok, Thailand, 7–9 June 2024. [Google Scholar] [CrossRef]
- Cleveland Clinic. High-Risk Pregnancy. 14 December 2021. Available online: https://my.clevelandclinic.org/health/diseases/22190-high-risk-pregnancy (accessed on 10 April 2023).
- US National Institutes of Health. What Is a High-Risk Pregnancy? 31 January 2017. Available online: https://www.nichd.nih.gov/health/topics/pregnancy/conditioninfo/high-risk (accessed on 10 April 2023).
- Ebrahimzadeh, F.; Hajizadeh, E.; Vahabi, N.; Almasian, M.; Bakhteyar, K. Prediction of unwanted pregnancies using logistic regression, probit regression and discriminant analysis. Med. J. Islam. Repub. Iran 2015, 29, 828–832. [Google Scholar]
- Montella, E.; Ferraro, A.; Sperlì, G.; Triassi, M.; Santini, S.; Improta, G. Predictive Analysis of Healthcare-Associated Blood Stream Infections in the Neonatal Intensive Care Unit Using Artificial Intelligence: A Single Center Study. Int. J. Environ. Res. Public Health 2022, 19, 2498. [Google Scholar] [CrossRef] [PubMed]
- Yiu, T. Understanding Random Forest. 12 June 2019. Available online: https://towardsdatascience.com/understanding-random-forest-58381e0602d2 (accessed on 14 April 2023).
- Zhu, W.; Zeng, N.; Wang, N. Sensitivity, Specificity, Accuracy, Associated Confidence Interval and ROC Analysis with Practical SAS® Implementations; Northeast SAS Users Group 2010; Health Care and Life Sciences: Baltimore, MD, USA, 2010; pp. 1–9. [Google Scholar]
- Lakshmi, B.N.; Indumathi, T.S.; Ravi, N. A Study on C.5 Decision Tree Classification Algorithm for Risk Predictions During Pregnancy. Procedia Technol. 2016, 24, 1542–1549. [Google Scholar] [CrossRef]
- Pereira, S.; Portela, F.; Santos, M.F.; Machado, J.; Abelha, A. Predicting Type of Delivery by Identification of Obstetric Risk Factors through Data Mining. Procedia Comput. Sci. 2015, 64, 601–609. [Google Scholar] [CrossRef]
- Akbulut, A.; Ertugrul, E.; Topcu, V. Fetal health status prediction based on maternal clinical history using machine learning techniques. Comput. Methods Programs Biomed. 2018, 163, 87–100. [Google Scholar] [CrossRef] [PubMed]
- Bautista, J.M.; Quiwa, Q.A.I.; Reyes, R.S.J. Machine learning analysis for remote prenatal care. In Proceedings of the IEEE Region 10 Annual International Conference, Proceedings/TENCON, Osaka, Japan, 16–19 November 2020; pp. 397–402. [Google Scholar] [CrossRef]
- Raja, R.; Mukherjee, I.; Sarkar, B.K. A Machine Learning-Based Prediction Model for Preterm Birth in Rural India. J. Healthc. Eng. 2021, 2021, 6665573. [Google Scholar] [CrossRef] [PubMed]
- Moreira, M.W.; Rodrigues, J.J.; Kumar, N.; Al-Muhtadi, J.; Korotaev, V. Nature-Inspired Algorithm for Training Multilayer Perceptron Networks in e-health Environments for High-Risk Pregnancy Care. J. Med. Syst. 2018, 42, 51. [Google Scholar] [CrossRef] [PubMed]
- Paydar, K.; Niakan Kalhori, S.R.; Akbarian, M.; Sheikhtaheri, A. A clinical decision support system for prediction of pregnancy outcome in pregnant women with systemic lupus erythematosus. Int. J. Med. Inform. 2017, 97, 239–246. [Google Scholar] [CrossRef] [PubMed]
- Macrohon, J.J.E.; Villavicencio, C.N.; Inbaraj, X.A.; Jeng, J.-H. A Semi-Supervised Machine Learning Approach in Predicting High-Risk Pregnancies in the Philippines. Diagnostics 2022, 12, 2782. [Google Scholar] [CrossRef] [PubMed]
- Yadav, A. Support Vector Machines (SVM)—20 October 2018. Available online: https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589 (accessed on 14 April 2023).
- Antonogeorgos, G.; Panagiotakos, D.B.; Priftis, K.N.; Tzonou, A. Logistic Regression and Linear Discriminant Analyses in Evaluating Factors Associated with Asthma Prevalence among 10- to 12-Years-Old Children: Divergence and Similarity of the Two Statistical Methods. Int. J. Pediatr. 2009, 2009, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Singh, N.; Nguyen, P.H.; Jangid, M.; Singh, S.K.; Sarwal, R.; Bhatia, N.; Johnston, R.; Joe, W.; Menon, P. District Nutrition Profile: Udham Singh Nagar, Uttarakhand; International Food Policy Research Institute: New Delhi, India, 2022. [Google Scholar]
- Hernandez, M.; Epelde, G.; Beristain, A.; Ǻlvarez, R.; Molina, C.; Larrea, X.; Alberdi, A.; Timoleon, M.; Bamidis, P.; Konstantinidis, E. Incorporation of Synthetic Data Generation Techniques within a Controlled Data Processing Workflow in the Health and Wellbeing Domain. Electronics 2022, 11, 812. [Google Scholar] [CrossRef]
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Part 1: Simple Definition and Calculation of Accuracy, Sensitivity and Specificity. Emergency 2015, 3, 48–49. [Google Scholar] [PubMed]
- Villavicencio, C.N.; Macrohon, J.J.E.; Inbaraj, X.A.; Jeng, J.H.; Hsieh, J.G. COVID-19 prediction applying supervised machine learning algorithms with comparative analysis using weka. Algorithms 2021, 14, 201. [Google Scholar] [CrossRef]
- Chauhan, N.S. Decision Tree Algorithm, Explained. 9 February 2022. Available online: https://www.kdnuggets.com/2020/01/decision-tree-algorithm-explained.html (accessed on 14 April 2023).
- IBM K-Nearest Neighbors Algorithm. Available online: https://www.ibm.com/topics/knn (accessed on 14 April 2023).
- Raschka, S. STAT 479: Machine Learning. 2018. Available online: https://sebastianraschka.com/pdf/lecture-notes/stat479fs18/02_knn_notes.pdf (accessed on 14 April 2023).


{kind=link}
{kind=link}
| Ref. | Used Machine Learning (ML) Algorithms | Best Performing (ML) Algorithm/s | Maximum Achieved Accuracy |
|---|---|---|---|
| [8] | C.5 DT | C.5 DT | 71.30% |
| [9] | DT, GLM, SVM, NB | DT | 83.91% |
| [10] | AP, DJ, BDT, DF, BPM, LDSVM, LR, SVM, NN | AP, BDT, DF, DJ | 89.5% |
| [11] | DT, RDT, KNN, SVM | RDT | 90% |
| [12] | DT, LR, SVM | SVM | 91% |
| [13] | MLP | MLP | 93% |
| [14] | MLP | MLP | 97% |
| [15] | DT, RF, KNN, SVM, NB, MLP | DT with self-training | 97.01% |
| Proposed Solution [16,17] | LR, LDA, KNN, DT, NB, SVM | DT | 98.82% |
| S. No | Feature ID | Feature Name |
|---|---|---|
| 1 | Age | Age of pregnant woman in years |
| 2 | G | Gravida (G)—refers to the numerical representation of the total number of times a woman has conceived, including the ongoing pregnancy. |
| 3 | P | Para (P)—refers to the delivery of a newborn after a gestational period of 20 weeks or more, irrespective of the infant’s viability at birth. |
| 4 | L | Live birth (L)—the total number of living children |
| 5 | A | Abortion (A)—the termination of pregnancies (planned or unplanned) |
| 6 | D | Death (D)—the number of children dead. |
| 7 | SBP | Systolic blood pressure |
| 8 | DSP | Diastolic blood pressure |
| 9 | RBS | Amount of glucose in blood mg/dL. |
| 10 | BT | Pregnant woman’s body temperature in Fahrenheit |
| 11 | HR | Heartbeats per minute. |
| 12 | Hb | Hemoglobin level of pregnant woman |
| 13 | RR | Normal respiration rate at rest per minute. |
| Total number of features | 13 |
| Total number of classes | 2 |
| Total number of instances | 837 |
| High Risk | 455 |
| No Risk | 382 |
| Algorithm. | Accuracy (%) | Precision (%) | Sensitivity (%) | Specificity (%) | f1-Score (%) |
|---|---|---|---|---|---|
| Support Vector Machine (SVM) | 66.67 | 80 | 66 | 100 | 62 |
| Linear Discriminant Analysis (LDA) | 83.33 | 84 | 83 | 80 | 83 |
| Naive Bayes (NB) | 88.69 | 89 | 89 | 86 | 89 |
| Logistic Regression (LR) | 91.67 | 92 | 92 | 94 | 92 |
| K-Nearest Neighbors (KNN) | 95.23 | 95 | 95 | 94 | 95 |
| Decision Tree (DT) | 98.80 | 99 | 99 | 99 | 99 |
| Decision Tree | Predicted | Predicted | Recall |
|---|---|---|---|
| High Risk | No Risk | ||
| Actual High Risk | 84 | 1 | 98.82% |
| Actual No Risk | 1 | 82 | 98.80% |
| Precision | 98.82% | 98.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tomar, K.; Sharma, C.M.; Prasad, T.; Chariar, V.M. A Machine Learning-Based Risk Prediction Model During Pregnancy in Low-Resource Settings. Med. Sci. Forum 2024, 25, 13. https://doi.org/10.3390/msf2024025013
Tomar K, Sharma CM, Prasad T, Chariar VM. A Machine Learning-Based Risk Prediction Model During Pregnancy in Low-Resource Settings. Medical Sciences Forum. 2024; 25(1):13. https://doi.org/10.3390/msf2024025013
Chicago/Turabian StyleTomar, Kapil, Chandra Mani Sharma, Tanisha Prasad, and Vijayaraghavan M. Chariar. 2024. "A Machine Learning-Based Risk Prediction Model During Pregnancy in Low-Resource Settings" Medical Sciences Forum 25, no. 1: 13. https://doi.org/10.3390/msf2024025013
APA StyleTomar, K., Sharma, C. M., Prasad, T., & Chariar, V. M. (2024). A Machine Learning-Based Risk Prediction Model During Pregnancy in Low-Resource Settings. Medical Sciences Forum, 25(1), 13. https://doi.org/10.3390/msf2024025013