
A Systematic Implementation of Machine Learning Algorithms for Multifaceted Antimicrobial Screening of Lead Compounds †

Abstract
:1. Introduction
1.1. Background on Antibiotics and Antibiotic Resistance
1.2. Recent Advances in Computational Drug Discovery: Applications to Antimicrobial Compounds
1.3. DNA Gyrase and Dihydrofolate Reductase as Antimicrobial Targets
1.4. Purpose
2. Materials and Methods
2.1. Datasets and Dataset Preprocessing
2.2. Machine Learning Models
2.3. Bayesian Optimization
3. Results
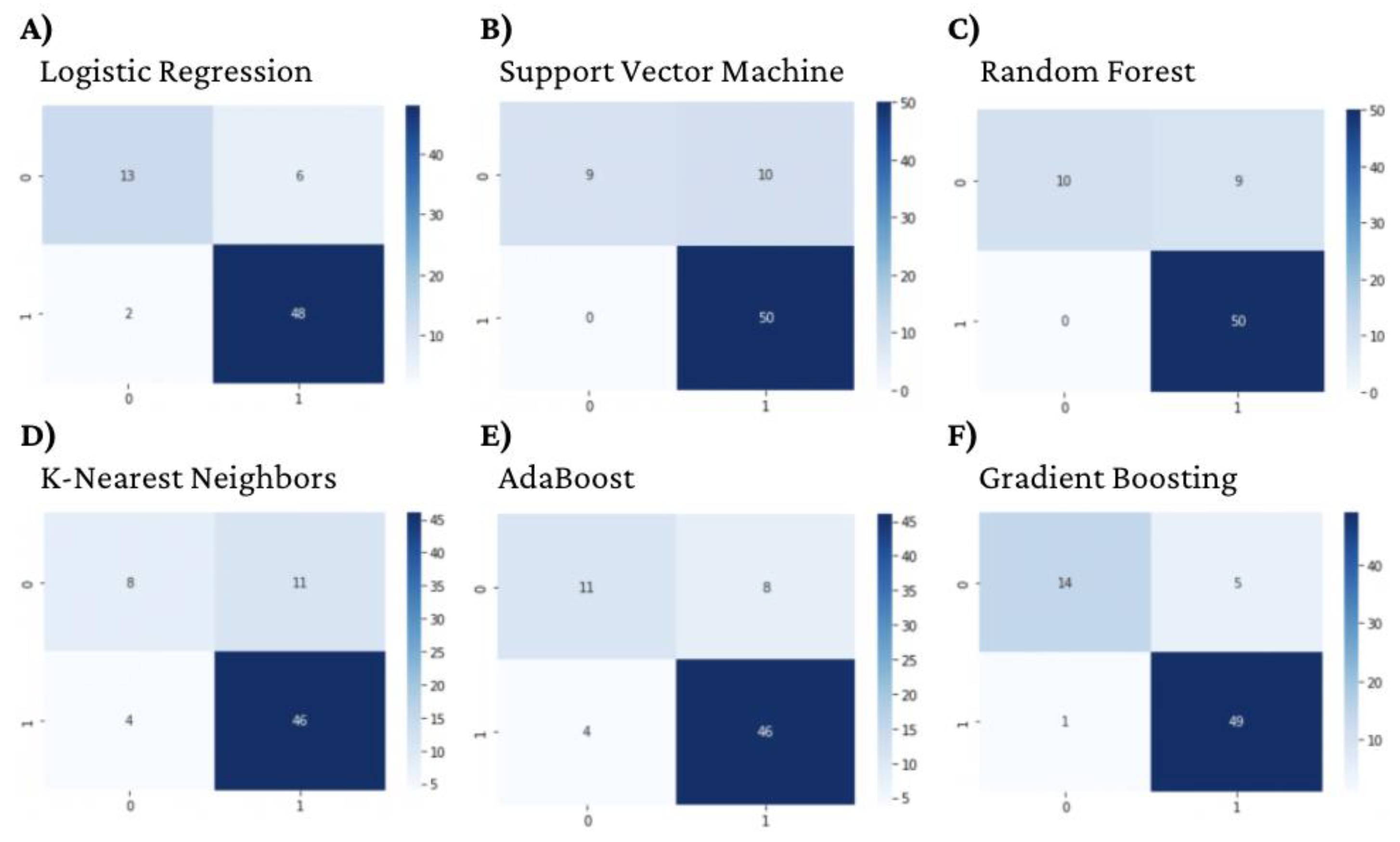
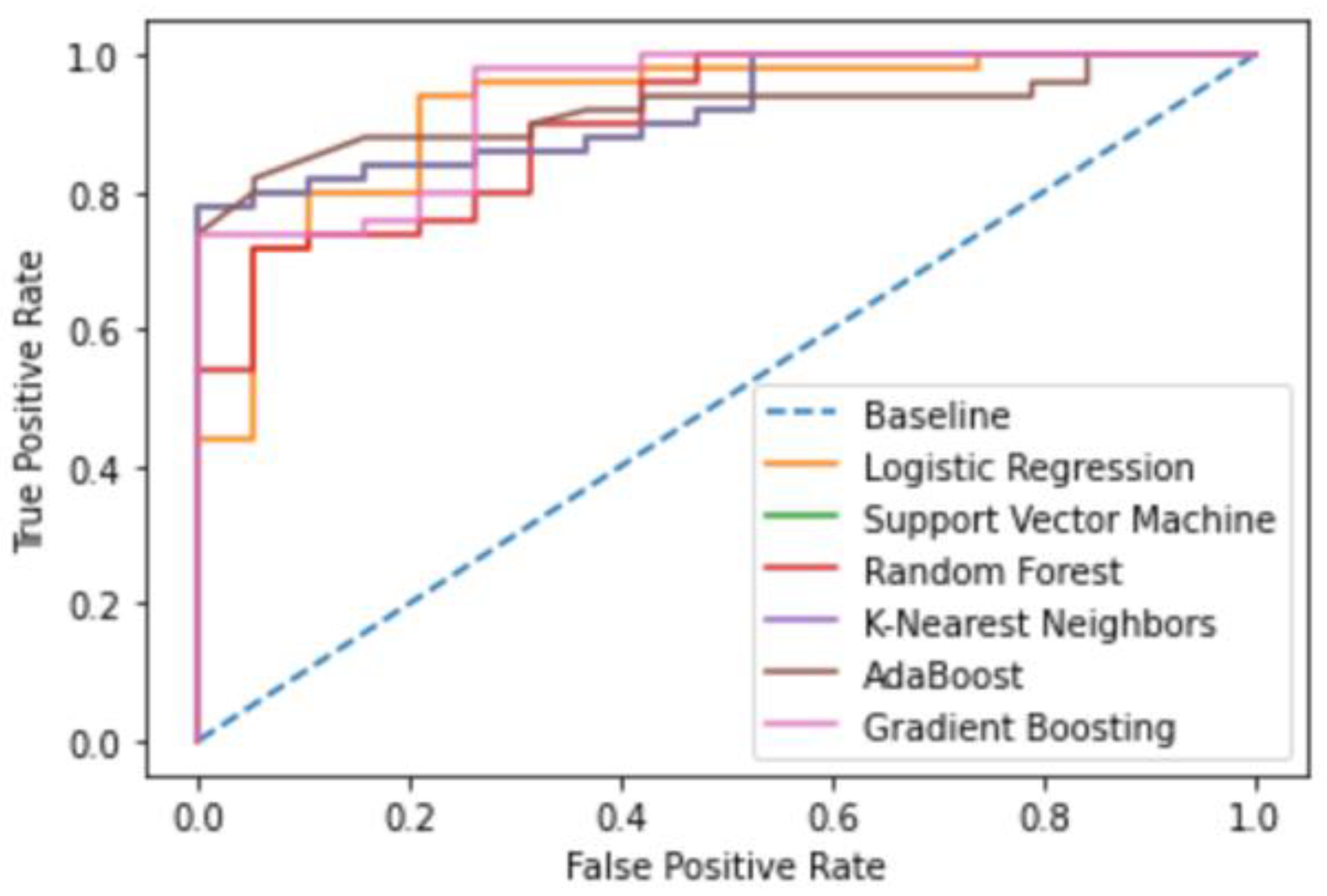
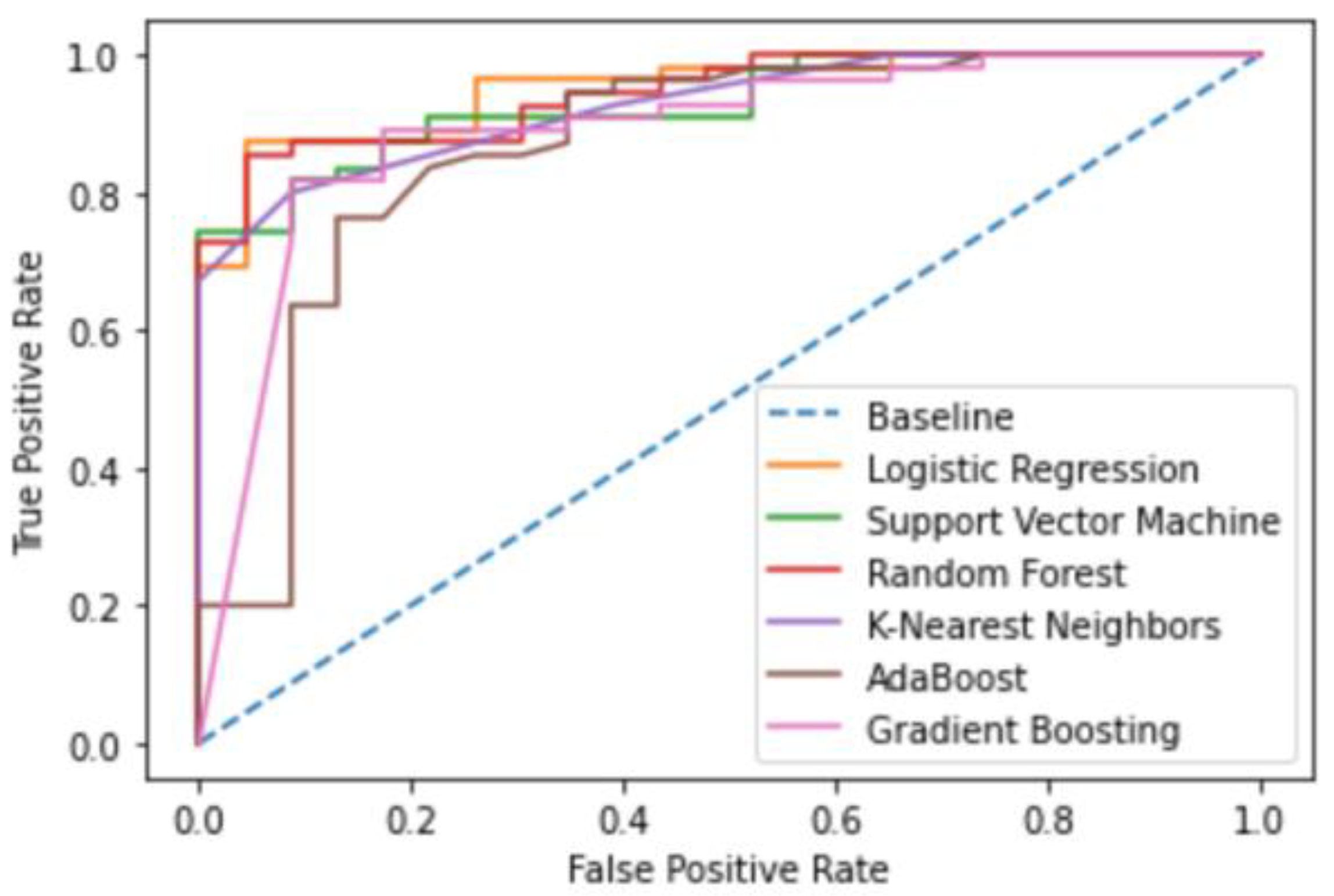
3.1. Machine Learning Model Evaluation
3.1.1. DNA gyrase Machine Learning Model Evaluation
3.1.2. Dihydrofolate reductase Machine Learning Model Evaluation
3.2. Identification and Analysis of Novel Antimicrobial Ligands
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ventola, C.L. The antibiotic resistance crisis: Part 1: Causes and threats. P T A Peer-Rev. J. Formul. Manag. 2015, 40, 277–283. [Google Scholar]
- Vamathevan, J.; Clark, D.; Czodrowski, P.; Dunham, I.; Ferran, E.; Lee, G.; Li, B.; Madabhushi, A.; Shah, P.; Spitzer, M.; et al. Applications of machine learning in drug discovery and development. Nat. Reviews. Drug Discov. 2019, 18, 463–477. [Google Scholar] [CrossRef] [PubMed]
- Dara, S.; Dhamercherla, S.; Jadav, S.S.; Babu, C.M.; Ahsan, M.J. Machine Learning in Drug Discovery: A Review. Artif. Intell. Rev. 2022, 55, 1947–1999. [Google Scholar] [CrossRef] [PubMed]
- Kapsiani, S.; Howlin, B.J. Random forest classification for predicting lifespan-extending chemical compounds. Sci. Rep. 2021, 11, 13812. [Google Scholar] [CrossRef] [PubMed]
- Stokes, J.M.; Yang, K.; Swanson, K.; Jin, W.; Cubillos-Ruiz, A.; Donghia, N.M.; MacNair, C.R.; French, S.; Carfrae, L.A.; Bloom-Ackermann, Z.; et al. A Deep Learning Approach to Antibiotic Discovery. Cell 2020, 180, 688–702.e13. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.; Browne, J.J.; Van Crugten, J.; Hasan, M.F.; Liu, L.; Barkla, B.J. In Silico, Molecular Docking and In Vitro Antimicrobial Activity of the Major Rapeseed Seed Storage Proteins. Front. Pharmacol. 2020, 11, 1340. [Google Scholar] [CrossRef] [PubMed]
- Reece, R.J.; Maxwell, A. DNA gyrase: Structure and function. Crit. Rev. Biochem. Mol. Biol. 1991, 26, 335–375. [Google Scholar] [CrossRef] [PubMed]
- Maxwell, A. DNA gyrase as a drug target. Trends Microbiol. 1997, 5, 102–109. [Google Scholar] [CrossRef]
- Zhang, Y.; Chowdhury, S.; Rodrigues, J.V.; Shakhnovich, E. Development of antibacterial compounds that constrain evolutionary pathways to resistance. eLife 2021, 10, e64518. [Google Scholar] [CrossRef] [PubMed]
- Gaulton, A.; Hersey, A.; Nowotka, M.; Bento, A.P.; Chambers, J.; Mendez, D.; Mutowo, P.; Atkinson, F.; Bellis, L.J.; Cibrián-Uhalte, E.; et al. The ChEMBL database in 2017. Nucleic Acids Res. 2017, 45, D945–D954. [Google Scholar] [CrossRef] [PubMed]
- Sterling, T.; Irwin, J.J. ZINC 15—Ligand Discovery for Everyone. J. Chem. Inf. Modeling 2015, 55, 2324–2337. [Google Scholar] [CrossRef] [PubMed]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | DNA Gyrase | Dihydrofolate Reductase | Unspecific |
|---|---|---|---|
| Inhibitor | 326 | 346 | 0 |
| Non-inhibitor | 132 | 176 | 0 |
| Unspecific | 0 | 0 | 18,387 |
| Model | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| Logistic Regression | 0.88 | 0.88 | 0.82 | 0.84 | 0.919 |
| Support Vector Machine | 0.86 | 0.92 | 0.74 | 0.78 | 0.921 |
| Random Forest | 0.87 | 0.92 | 0.76 | 0.80 | 0.898 |
| K-Nearest Neighbor | 0.78 | 0.74 | 0.67 | 0.69 | 0.754 |
| AdaBoost | 0.83 | 0.79 | 0.75 | 0.77 | 0.920 |
| Gradient Boosting | 0.91 | 0.92 | 0.86 | 0.88 | 0.933 |
| Model | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| Logistic Regression | 0.85 | 0.82 | 0.82 | 0.82 | 0.949 |
| Support Vector Machine | 0.85 | 0.81 | 0.83 | 0.82 | 0.929 |
| Random Forest | 0.86 | 0.83 | 0.85 | 0.84 | 0.944 |
| K-Nearest Neighbor | 0.83 | 0.81 | 0.86 | 0.82 | 0.926 |
| AdaBoost | 0.82 | 0.78 | 0.80 | 0.79 | 0.866 |
| Gradient Boosting | 0.85 | 0.82 | 0.82 | 0.82 | 0.889 |
| Compound | Predicted Probability: DNA Gyrase | Predicted Probability: Dihydrofolate Reductase | Predicted Probability: Average |
|---|---|---|---|
| CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@@H](CCC(=O)NO)C(=O)O)cc1 | 0.9988515310206159 | 0.9897304236200257 | 0.9942909773203208 |
| CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)O)C(=O)O)cc1 | 0.9910340430619817 | 0.9974326059050064 | 0.994233324483494 |
| CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@@H](CCC(=O)N[C@@H](CCC(=O)O)C(=O)O)C(=O)O)cc1 | 0.9995824679977368 | 0.9858793324775353 | 0.9927309002376361 |
| CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@H](CCC(=O)N[C@@H](CC(=O)O)C(=O)O)C(=O)O)cc1 | 0.9908400010423145 | 0.9691912708600771 | 0.9800156359511958 |
| CN(Cc1cnc2nc(N)nc(N)c2n1)c1ccc(C(=O)N[C@@H](CCC(=O)N2CCC[C@H]2C(=O)NO)C(=O)O)cc1 | 0.9993063830032061 | 0.959349593495935 | 0.9793279882495705 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, J.; Valagolam, D. A Systematic Implementation of Machine Learning Algorithms for Multifaceted Antimicrobial Screening of Lead Compounds. Med. Sci. Forum 2022, 12, 6. https://doi.org/10.3390/eca2022-12751
Shen J, Valagolam D. A Systematic Implementation of Machine Learning Algorithms for Multifaceted Antimicrobial Screening of Lead Compounds. Medical Sciences Forum. 2022; 12(1):6. https://doi.org/10.3390/eca2022-12751
Chicago/Turabian StyleShen, Justin, and Davesh Valagolam. 2022. "A Systematic Implementation of Machine Learning Algorithms for Multifaceted Antimicrobial Screening of Lead Compounds" Medical Sciences Forum 12, no. 1: 6. https://doi.org/10.3390/eca2022-12751
APA StyleShen, J., & Valagolam, D. (2022). A Systematic Implementation of Machine Learning Algorithms for Multifaceted Antimicrobial Screening of Lead Compounds. Medical Sciences Forum, 12(1), 6. https://doi.org/10.3390/eca2022-12751