Abstract
A novel statistical model, the Bounded Gamma–Gompertz Distribution (BGGD), is presented alongside a full characterization of its properties. Our investigation identifies maximum-likelihood estimation (MLE) as the most effective fitting procedure, proving it to be more consistent and efficient than alternative approaches like L-moments and Bayesian estimation. Empirical validation on Tesla (TSLA) financial records—spanning open, high, low, close prices, and trading volume—showcased the BGGD’s superior performance. It delivered a better fit than several competing heavy-tailed distributions, including Student-t, Log-Normal, Lévy, and Pareto, as indicated by minimized AIC and BIC statistics. The results substantiate the distribution’s robustness in capturing extreme-value behavior, positioning it as a potent tool for financial modeling applications.
1. Introduction
The application of probability distributions to model stock prices and returns has evolved significantly. Early models like log-normal prices, and later empirical findings revealed stylized facts such as heavy tails and volatility clustering, challenging the normality assumption [1]. This led to advanced frameworks like GARCH and the Variance Gamma process [1] to model time-varying volatility and excess kurtosis [2]. The necessity for explicitly modeling skewness and heavy tails has been emphasized by [3], motivating the use of stable Paretian distributions [4] and mixture models for regime shifts. Such fat-tailed distributions provide a more realistic basis for critical financial applications like risk management. However, for financially constrained variables, bounded distributions offer a powerful alternative.
This passage contrasts fat-tailed and bounded distributions, arguing that the latter are essential for modeling financially constrained variables with inherent limits. Unlike models with infinite support, bounded distributions are suited for normalized data, specific risk measures, and default probabilities. Their application in risk management and Value at Risk is highlighted, as they avoid the problems of infinite tails. Refs. [5,6] demonstrate their use for skewed returns and nonlinear price patterns, and their finite domain offers computational advantages. In conclusion, bounded distributions provide a vital, realistic framework for data with natural boundaries, and developing flexible models that incorporate hard bounds remains a crucial research focus.
Fat-tailed distributions are essential for capturing extreme returns and heavy tails, which the normal distribution fails to model. While specific distributions offer unique advantages, they also have significant limitations:
- The Pareto can model large movements but may lack finite moments [7].
- The Laplace captures sharp changes but is symmetric [8].
- The Student’s t handles kurtosis but requires extension for skewness [1,7].
- The Inverse Gaussian models duration but has no closed-form CDF, less interpretable parameters, and an exponential tail decay that may miss power-law behavior [7,9,10,11].
- The Log-normal ensures positive values but cannot model losses, may have insufficiently heavy tails, and can be non-robust [4,12,13,14].
More flexible models like the Generalized Hyperbolic, Variance Gamma, and Lévy-stable processes integrate fat tails and skewness but increase computational complexity [1,15]. Despite these trade-offs, fat-tailed distributions remain a foundational tool for realistic financial modeling and accurate risk assessment.
Building on the need for flexible, bounded models, this study explores an exponential transformation of the Gompertz distribution. This model is noted for its ability to represent skewness and variability, making it applicable to time-varying volatility. Its particular utility in Bayesian analysis stems from its role as a conjugate prior [10,16]. Although rooted in survival analysis, the Gompertz distribution has been effectively applied to finance, including credit risk and default probability modeling [17]. Its inherently bounded, asymmetric nature is adept at capturing constrained nonlinear processes, such as those under regulatory limits. Consequently, while not typical for raw returns, the Gamma–Gompertz distribution provides significant value for modeling financial durations and outcomes with extreme bounds.
Reflecting the shift toward data-driven methods, bounded distributions are increasingly vital for quantifying uncertainty and improving financial forecasts. This class includes established models like the Beta, Kumaraswamy, and triangular distributions. We contribute to this family by introducing the Bounded Gamma–Gompertz Distribution (BGGD), with its formal derivation and properties detailed in Section 2. A key benefit of these distributions is their confinement of probabilities to realistic ranges, which directly enhances forecast accuracy and risk management. To fully leverage this, however, critical considerations include selecting appropriate bounds, integrating with other techniques, and mitigating overfitting to ensure clear communication of results to stakeholders.
This manuscript is structured as follows: Section 2 introduces the proposed model, detailing its derivation and key properties such as its probability density, hazard rate, and moment generating functions. Section 3 provides a comparative analysis of bounded models. Tail risk is evaluated in Section 4, while Section 5 outlines parameter estimation methods (maximum likelihood and Bayesian) and a simulation study. An empirical application to stock data and its risk assessment is presented in Section 6, with conclusions and future research directions in Section 7.
2. Derivation and Properties of the Proposed Model
This section details the derivation of the proposed model and investigates its fundamental mathematical and statistical properties.
2.1. Model Derivation
Consider a random variable X that follows a Gompertz distribution characterized by the parameters , , and b. Under the constraint , the cumulative distribution function (CDF) of the proposed distribution is derived as:
- The first step in this formulation involves selecting an odd link function, denoted by , which is defined aswhere represents the baseline cumulative distribution function (CDF). The function is required to satisfy the following conditions:
- is differentiable and monotonically non-decreasing;
- as , and as .
- Now, consider the CDF of the log-logistic distribution as a baseline function, with parameters , defined over the interval as
- By substituting the baseline distribution function into , we obtain
- To incorporate the growth or decay rates of returns, volatility, or prices, we consider a mixture based on the Gamma–Gompertz distribution CDF [18]. Specifically, letand define the corresponding density asUsing this formulation, we generate a new class of distributions suitable for modeling dynamic behaviors in financial or economic data.
- Finally, we propose a new class, the bounded Gamma–Gompertz family, by substituting into and applying the necessary domain constraints to ensure that the resulting function iswhich, after simplification, yieldswhich is constrained both theoretically and empirically. If , the CDF reduces to which resembles a Pareto-like distribution. For , it simplifies to a shifted Lomax distribution. Moreover, Figure 1 portrays that dissimilarities in parameters impact the height, spread, and shape of the curves. Smaller values of , , and result in taller, sharper curves that drop rapidly, whereas larger values generates flatter, wider curves with heavier tails and more dispersed data. The left graph illustrates PDFs over a smaller x-range (0–8), while the right graph outspreads the analysis to a larger scale (up to 250). Overall, the figure demonstrates the sensitive dependence of the BGGD PDF on its parameters, affecting both the peak and tail characteristics.
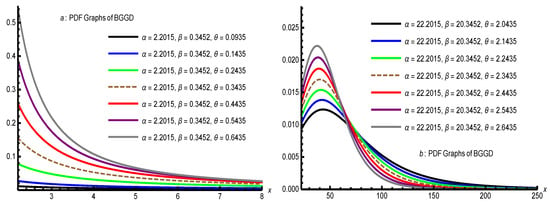 Figure 1. PDF graphs for different values of and .
Figure 1. PDF graphs for different values of and .
Theorem 1.
The probability density function (PDF) of the BGGD distribution with CDF
can be derived by solving the generalized Burr-type differential equation:
Proof.
In order to prove and derive the PDF of the above function, we start with , where and are continuous functions of y, , for any y, and is the unknown function to be determined, whose specific value is y. The solution to this differential equation will lead to the PDF of the Generalized Three-Parameter Burr XII Distribution. To generate the Generalized Three-Parameter Burr XII Distribution, from , we have or . By integrating both sides of with respect to y, we obtain where . For getting we proceed through the following steps: Let . The CDF becomes:
Differentiating the CDF with respect to y:
Since , we obtain:
Taking the natural logarithm of :
Differentiating with respect to y:
Combining terms over a common denominator to rewrite in generalized Burr form as
Expanding the numerator:
Thus, we obtain the generalized Burr-type differential equation as
on compared to the generalized Burr differential equation as expressed in Equation (4) with Equation (3)
Now integrating Equation (2) with respect to y we obtain
where C is the constant of integration. Please note that the BGGD is not a standard Burr XII distribution; however, its PDF does satisfy a generalized Burr-type differential equation with an additional offset parameter . Therefore, we call it as Bounded Gamma–Gompertz Distribution (BGGD). Its survival function (SF) and probability density function (PDF) are defined as follows:
and
where is the scale parameter, and are shape parameters. Similarly, another important measure is the hazard function which represents the instantaneous rate of failure at time t, given that the subject has survived up to time t. Mathematically, it is defined as: and for BGGD it is expressed as
□
2.2. PDF and HRF Shapes and Behavior
2.2.1. Mode of Distribution
The mode is found by solving Beginning with the logarithm of Equation (6)
Differentiating with respect to y:
Simplify:
Set the derivative to zero:
Multiply both sides by y (since ) and let :
Solving for u:
Thus,
Substituting back , we find the mode:
For to be greater than the lower bound , we require
Given and , this requires . If , this simplifies to . If , the critical point lies outside the support. In this case, the derivative can be shown to be negative for all , implying the PDF is strictly decreasing and its maximum is at the boundary .
2.2.2. Development of Formal Theorems on PDF Log-Concavity and HRF Monotonicity
Here we shall prove the log-concavity of the PDF and the monotonicity of the HRF. We will build upon the provided expressions with the requirements.
2.2.3. Log-Concavity of the PDF
A function is log-concave if its logarithm is a concave function. This is a strong property with important implications for the unimodality and reliability of a distribution.
Theorem 2.
Let Y follow the BGGD with PDF as defined in Equation (11), for . The PDF is log-concave if and only if .
Proof.
Since , we have . Thus,
Substituting t:
Differentiating with respect to y:
Calculations show that:
Denote
The sign of the second derivative depends on . Since the prefactor is negative for , the sign of is opposite to that of .
and the remaining terms are positive, so . Thus,
establishing log-concavity.
and for y close to (i.e., ), the negative term can dominate, making , and thus the second derivative positive, violating log-concavity. □
We start with the log-PDF from Equation (6):
To prove log-concavity, we need to show that the second derivative of with respect to y is non-positive.
- Define . Then . It simplifies analysis to work with t.
- First, compute the first derivative:
- - For :
- - For :
Conclusion: is log-concave if and only if .
2.3. Monotonicity of the Hazard Rate Function (HRF)
Let us define the hazard rate: , where is the survival function. The next theorem studies the change points of the distribution.
Theorem 3.
provided . In this case, is unimodal (increasing for and decreasing for ).
Let with hazard rate function
The behavior of is as follows:
- If , the hazard rate is strictly decreasing for all .
- If , the hazard rate has a unique mode (change point) at
Proof.
Take the natural logarithm:
Differentiate with respect to y:
Compute the derivative in the last term:
Substitute back:
Simplify the first two terms: . Thus,
On equating Equation (9) to zero, we obtain the mode of the hazard function as:
For this to be valid, we need , which requires . Since and , this is a condition on the parameters. If , the critical point , which is outside the support. □
We analyze the monotonicity of by examining the derivative of its logarithm.
- Start with the HRF:
Now the cumulative hazard function is defined as has derivatives related to :
Theorem 4.
The HRF is decreasing for all if . If , the HRF may be non-monotonic, potentially exhibiting an upside-down bathtub shape.
Proof.
where
- When : so for all . Therefore,
and the HRF is decreasing.
If , for , implying the HRF initially increases and then decreases, exhibiting a non-monotonic shape.
The survival function:
The cumulative hazard:
Differentiating:
where
- Differentiating :
- - When : is linear in t with a negative slope, possibly crossing zero at
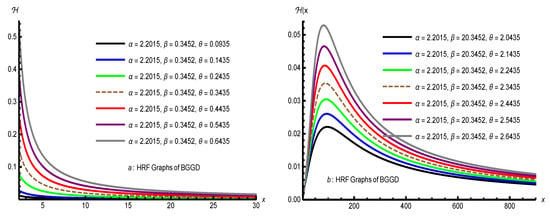
Conclusion: The HRF is decreasing for , and may be non-monotonic when . These theorems establish a rigorous foundation for the distribution’s shape properties, replacing heuristic observations with formal proofs. Moreover, the Figure 2 portrays that as parameters increase, the hazard functions tend to decrease more gradually, indicating a heavier tail and increased spread. Conversely, smaller parameters produce sharper declines, reflecting lighter tails and less dispersion. These behaviors highlight the sensitivity of the hazard functions to parameter changes. □
Figure 2.
Some HRF of BGGD for different values of parameters.
2.4. Log-Concavity and Curvature Analysis
Log-concavity plays a significant role in statistics, optimization, and economics because it ensures nice properties like unimodality, stability under convolution, and convexity of the negative log-likelihood, which facilitates efficient estimation and inference.
2.4.1. Log-Concavity of the BGGD
Let Y while its PDF ith lograthmic form is expressed in Equation (8) To test for log-concavity, we examine the second derivative of :
from we can conclude that for , the PDF is not log-concave (first term dominates), while for , log-concavity depends on the balance between terms (see Theorem 2).
2.4.2. Second Derivative of the PDF
The second derivative is complex but can be expressed as:
It implies that for , may change sign (possible inflection points) and for , the PDF is more likely to be unimodal and smooth.
2.4.3. Hazard Rate Function (HRF) Analysis
From Equation (7) we computed the second derivative of :
It is observed that (), confirming that is log-concave for all parameter values. Likewise, the second derivative of HRF i.e., is:
Its behavior for , simplifies to , which changes sign at and , for , the curvature depends on the interplay between and . We conclude that PDF is Log-Concave if (see Theorem 2) and its curvature can have inflection points. Similarly, HRF is Log-Concave for all and its curvature for depends on .
2.4.4. Rigorous Implications for Estimation and Modeling
Log-concavity has profound practical consequences:
- Maximum-Likelihood Estimation (MLE):
- -
- If PDF is log-concave (), is convex ⇒ the negative log-likelihood is convex in parameters ⇒ unique global maximum, no local optima.
- -
- Numerical optimization (Newton-Raphson, quasi-Newton) converges globally and rapidly.
- -
- Standard errors via observed Hessian are reliable.
- Shape-Constrained Inference:
- -
- Log-concave densities form a convex nonparametric class. BGGD with can serve as a parametric anchor in shape-constrained estimation.
- -
- Enables confidence bands and hypothesis tests with known asymptotic behavior.
- Stability and Robustness:
- -
- Convolution of log-concave densities is log-concave ⇒ BGGD priors lead to log-concave posteriors under suitable likelihoods.
- -
- Useful in Bayesian modeling with heavy-tailed data (e.g., insurance, finance).
- Hazard Rate Modeling (Survival Analysis):
- -
- Log-concave HRF ⇒ log-concave survival function and increasing failure rate on average (IFRA) in some cases.
- -
- Implies aging properties: systems wear out predictably.
- -
- Facilitates nonparametric monotone hazard estimation with BGGD as a parametric benchmark.
- Practical Recommendation:
- -
- Use for reliable MLE, interpretable shapes, and theoretical guarantees.
- -
- Use only with caution: expect multiple modes, optimization traps, and non-concave likelihoods.
- -
- Leverage log-concave HRF for robust survival modeling even when PDF is not log-concave.
3. Comparative Analysis of Bounded Probability Distributions
This section provides the Cumulative Distribution Functions (CDFs) for the BGGD and other competing bounded distributions. The CDF, , gives the probability that a random variable X takes a value less than or equal to x.
- Key Observations:
- -
- The BGGD and Kumaraswamy distributions possess a closed-form CDF, which is advantageous for direct probability calculations.
- -
- The Beta distribution’s CDF relies on the incomplete Beta function , which must be evaluated numerically and lacks a closed-form expression.
- -
- The Bounded Lomax has the simplest CDF form, which is a special case of the Kumaraswamy CDF when the shape parameter .
- The BGGD represents a specialized three-parameter model that occupies a unique niche within the family of bounded distributions. When compared to established models like the Beta, Kumaraswamy, and Bounded Lomax distributions, the BGGD’s distinctive characteristics become apparent across multiple dimensions, including mathematical structure, hazard behavior, and practical applicability.
3.1. Mathematical Form and Flexibility
The BGGD is a three-parameter distribution defined on , with a complex probability density function incorporating power-law behavior. This formulation offers substantial flexibility for modeling heavy-tailed phenomena, albeit at the expense of mathematical simplicity. In comparison, the Beta distribution is the standard choice for modeling variables bounded in , using its two-parameter form with Beta functions to accommodate diverse shapes, including U-shaped, J-shaped, reverse J-shaped, and unimodal densities. The Kumaraswamy distribution serves as a mathematically tractable two-parameter alternative to the Beta, providing closed-form expressions for both the CDF and quantile function while retaining similar shape versatility. Finally, the Bounded Lomax distribution is the most parsimonious option, typically using one or two parameters to model heavy tails via a simpler power-law structure derived from the Lomax distribution.
3.2. Hazard Function Characteristics
The behavior of the hazard function highlights key differences among these distributions. The BGGD exhibits a distinctive profile, starting at infinity at the lower bound and approaching a finite constant at the upper bound, making it ideal for reliability studies with stabilizing risk over time. The Beta distribution provides highly flexible hazard shapes, including increasing, decreasing, bathtub, and inverted bathtub patterns, depending on its parameters. In contrast, the Kumaraswamy distribution always yields infinite hazard at the upper bound, limiting its use for long-term risk assessment. Similarly, the Bounded Lomax distribution has a strictly increasing hazard diverging to infinity at the upper bound, suitable for simple wear-out failures but less appropriate for complex hazard dynamics.
3.3. Statistical Practicality and Implementation
From an implementation perspective, the distributions vary significantly in their practical utility. The BGGD presents considerable challenges for parameter estimation due to its three-parameter structure and complex likelihood surfaces, requiring careful implementation and substantial sample sizes. The Beta distribution, while lacking closed-form CDF and quantile functions, benefits from well-established estimation procedures and extensive software support. The Kumaraswamy distribution excels in computational efficiency with its closed-form expressions, making it ideal for simulation studies and applications requiring frequent quantile calculations. The Bounded Lomax offers the simplest implementation with straightforward parameter estimation and interpretation, though at the cost of limited shape flexibility.
3.4. Domain Applications and Selection Guidelines
The choice among these distributions depends fundamentally on the modeling context and requirements. The BGGD proves most valuable for heavy-tailed bounded data where finite long-term hazard is theoretically justified, such as in certain reliability engineering, insurance claim modeling, and income distribution applications. The Beta distribution remains the optimal choice for general proportion modeling, Bayesian analysis, and applications demanding maximum shape flexibility. The Kumaraswamy distribution serves as an excellent practical alternative when closed-form solutions and computational efficiency are priorities, particularly in hydrological studies and simulation-heavy applications. The Bounded Lomax provides the best option for simple heavy-tailed bounded phenomena where interpretability and parsimony outweigh the need for sophisticated shape flexibility.
In conclusion, while the BGGD introduces valuable specialized capabilities for heavy-tailed bounded modeling with finite hazard limits, its adoption should be justified by demonstrated superior fit compared to more established alternatives. The Beta distribution maintains its position as the most versatile general-purpose bounded model, with Kumaraswamy offering superior tractability for many practical applications, and Bounded Lomax providing a straightforward solution for simple heavy-tailed scenarios. The selection among these distributions ultimately hinges on the specific balance required between mathematical sophistication, implementation practicality, and theoretical appropriateness for the phenomenon under investigation.
3.5. Moments and Moment Generating Function (MGF)
Here, we will calculate the expressions for the moments and the moment generating function of the distribution that are important in any statistical analysis, especially in applied work. It is known that some of the most important characteristics of a distribution can be studied through its moments (for example, tendency, dispersion, skewness, and kurtosis).
Theorem 5.
Let with probability density function (PDF) given by
- 1.
- The r-th raw moment, , exists and is given byif and only if the following parameter conditions hold:
- (a)
- (b)
Here, is the incomplete Beta function. - 2.
- The Moment Generating Function (MGF), , exists and is given by the series expansionwhich converges for all under the same conditions and .
Proof.
Simplifying the powers:
We now focus on the integral , where , , and
We now use a standard integral identity, see [19]:
Matching this to our integral, we have:
Substituting , we obtain
Also,
The exponential function can be expressed as its Maclaurin series, , which converges absolutely for all t and u.
The integral inside the sum is identical in form to the one solved for the raw moments in Part 1, with r replaced by k. Therefore, applying the same result:
Thus, the MGF is given by:
Convergence of the MGF Series: For any fixed , the series converges because the k-th term is proportional to , and the factorial dominance in the denominator ensures convergence. The conditions and guarantee that each term in the series is well-defined. The condition from Part 2 is automatically satisfied for all k in the infinite sum for any fixed , because the Gamma function in the asymptotic form of the Beta function for large k is suppressed by the factorial term . □
By definition, the r-th raw moment is
Substituting the PDF :
To evaluate this integral, we employ the substitution:
The limits change as follows: when , ; when ,
- Substituting into the integral:
- -
- -
- Multiplying by gives
- -
- The constants:
- Thus, the moment simplifies elegantly to:
- Let . The limits become: , and .
- -
- -
- -
- Therefore,
- Now, substituting back and :
- Thus, the integral I becomes:
The derivation is valid only if the integral converges and the arguments of the Beta function are positive.
- 1.
- Condition : This ensures , which is crucial for the substitution and for the power to be well-defined for all real r. If , the term in the original PDF’s denominator becomes problematic for convergence near .
- 2.
- Condition : The incomplete Beta function requires its second and third arguments to be positive for the integral representation to be valid and finite.
- -
- The second argument is , which is always true since and .
- -
- The critical condition comes from the third argument: . Multiplying both sides by gives , or equivalently, .
- This condition, , reveals that the BGGD possesses power-law tails. The distribution has finite moments only up to a certain order determined by its shape parameter . Moments of order do not exist. This is a characteristic feature of heavy-tailed distributions. Now, we prove Theorem 5 (Part 2), that is, the “Derivation of the Moment Generating Function (MGF)”, as follows:
- The MGF is defined as .
- Substituting the PDF and using the same substitution as before, we obtain:
- Substituting the series into the integral:
Table 1 summarizes the results across 31 cases, each characterized by parameters , , and , along with their corresponding mean, standard deviation, skewness, and kurtosis. The parameter varies broadly from 0.2 to 16.0, indicating diverse distribution shapes, while ranges from 0.5 to 45.0, reflecting different scale or location parameters. The mean values span from approximately 0.1831 (Case 3) to 1.7265 (Case 31), with standard deviations indicating varying degrees of dispersion among the cases. Skewness values range from negative to positive, with some distributions exhibiting left-tailed asymmetry (e.g., Case 1 with −0.5795) and others right-tailed (e.g., Case 32 with 1.7265). Kurtosis also varies, with some cases showing lighter tails (negative kurtosis) and others heavier tails (positive kurtosis), such as Case 32 with 1.2042. Overall, the data reflect a wide diversity of distributional behaviors, from symmetric to highly skewed and heavy-tailed distributions.

Table 1.
Descriptive summary of BGGD distribution.
3.6. Quantile Function
The quantile function for the given distribution can be derived by inverting the cumulative distribution function . Starting from , we first isolate the denominator to obtain . Taking reciprocals yields . Raising both sides to the power gives . Solving for produces , which leads to the final quantile function for . This function properly recovers the boundary conditions, approaching as and diverging to infinity as . Two important special cases emerge: when , the quantile function reduces to a Pareto-type form , while for it simplifies to a shifted Lomax distribution . The derived quantile function enables Monte Carlo simulation through inverse transform sampling and facilitates risk assessment through the calculation of extreme quantiles.
4. Tail-Risk Evaluation
Tail-risk management focuses on identifying and reducing the impact of rare but severe financial losses that occur in the extreme ends (tails) of probability distributions. It uses tools like mean residual life or life expectancy (MRL), Value at Risk (VaR), Tail Value at Risk (TVaR), and Expected Shortfall (ES) to measure and assess these risks. Strategies such as stress testing, scenario analysis, diversification, and financial instruments like options and insurance help mitigate these risks. Managing tail risk is crucial to safeguarding capital and maintaining financial stability during crises or market shocks.
4.1. Mean Residual Life (MRL)
The mean residual life (MRL) or life expectancy is an important characteristic of the model. It is useful in reliability analysis of mechanical systems, survival analysis in medical studies, and risk assessment in financial modeling. It represents the expected additional lifetime given survival until time t. For a continuous random variable Y with survival function MRL is given by:
Now on incorporating the survival function of BGGD () as given in Equation (5) into Equation (12), making the substitution , and using the integral
see [19] we obtain
valid for , , . When , the expression simplifies to:
for (), and . Therefore, near the threshold , the expected remaining life is finite and proportional to , and as t grows, the expected remaining life also grows linearly. This is typical of heavy-tailed distributions, where observing a large value suggests the possibility of even larger future values.
4.2. Value at Risk (VaR)
VaR at level is simply the quantile function: . If , then .
4.3. Tail Value at Risk (TVaR)
TVaR is the expected loss given that the loss exceeds VaR is defined as . For BGGD it is expressed as
This can be expressed in terms of the quantile function and the survival function. For it is expressed as .
Table 2 presents the Mean Residual Life (MRL), Value at Risk (), and Tail Value at Risk () for the BGGD across 30 different parameter combinations. The parameters include , , , time t, and tail probability .
Table 2.
MRL, VaR, and TVaR of BGGD distribution.
- Key observations:
- -
- MRL(t) increases significantly as t increases (e.g., from Case 1 to 4 or 7), reflecting longer expected remaining lifetime at higher thresholds.
- -
- For fixed t, MRL is constant across p values within the same parameter set, as MRL is independent of p.
- -
- increases with p (moving to heavier tails) and is identical across different t values for the same , indicating scale invariance in tail quantiles.
- -
- grows rapidly with p, especially at , highlighting extreme tail-risk sensitivity.
- -
- Higher and generally reduce VaR and TVaR for the same p, suggesting lighter tails (e.g., Case 1 vs. 19).
- -
- Case 28–30 with show markedly higher risk measures, indicating heavier-tailed behavior due to increased scale.
- This numerical illustration validates the derived expressions for MRL, VaR, and TVaR in the BGGD model and demonstrates their behavior under varying parameter regimes.
4.4. Expected Shortfall (ES)
In continuous distributions, ES is the same as TVaR:. For BGGD () it is defined as
put then we obtain
where
for
4.5. Tail Variance (TV)
Tail Variance (TV)—An important measure of dispersion beyond the Value at Risk, used in risk management to capture tail risk more precisely. It is the variance of losses beyond VaR: , but . We can write it as
which simplifies to
For we have
4.6. Tail Variance Premium (TVP)
The Tail Variance Premium (TVP) — a measure of risk compensation for holding a tail-risky position. It quantifies the premium per unit variance that an investor should demand in the tail (beyond a certain quantile p. It combines TVaR and Tail Variance defined as . For BGGD () it simplifies to
which is the Tail Variance Premium under the given model, where is a risk-aversion parameter. For we have
Table 3 presents numerical results for four key risk measures—Expected Shortfall (), Tail Expected Shortfall (), Tail Variance (), and Tail Variance Premium ()—computed under the Burr-Gompertz-Geometric Distribution (BGGD) for 30 parameter configurations with tail probabilities .
Table 3.
Numerical results for ES, TES, TV, and TVP.
- Key insights include:
- -
- across all cases, suggesting that the conditional expectation beyond the p-quantile is nearly equal to the overall tail expectation, consistent with the BGGD’s continuous and smooth tail behavior.
- -
- Both and increase with p, reflecting higher average loss in extreme tails.
- -
- (tail variance) is generally small and increases slowly with p, indicating controlled dispersion in the tail conditional on exceeding .
- -
- (tail variance premium) remains modest and often decreases or stabilizes at higher p, suggesting that additional risk loading for tail variability is limited in heavy-tailed settings.
- -
- Lower or higher and reduce and (e.g., Case 13–15 vs. Case 1–3), indicating lighter tails.
- -
- Higher (e.g., Cases 16–18, 28–30) significantly increases all risk measures, confirming its role as a scale/heaviness parameter.
- -
- For fixed , risk measures are driven primarily by p, with minimal variation in and at extreme .
- These results empirically validate the closed-form expressions for , , , and derived for the BGGD, demonstrating their sensitivity to tail probability and model parameters in actuarial risk assessment.
5. Parameter Estimation, Simulation Study and Inference
This section estimates the distribution’s parameters using maximum-likelihood estimation (MLE), Bayesian estimation method (BEM), and Monte Carlo (MC) estimation. The performance of these methods is assessed via simulation studies, where synthetic data are used to measure bias and mean square error (MSE).
5.1. Maximum-Likelihood Estimation
Maximum-Likelihood Estimation (MLE) is a powerful method ideal for large samples and correctly specified models, providing efficient, unbiased estimates with a solid foundation for hypothesis testing. It works best when the likelihood function is tractable and computation is straightforward. However, MLE is not suitable for small samples, model misspecification, or heavy-tailed data, where robust or Bayesian methods are better. While MLE is the gold standard when its assumptions are met, alternatives like L-moments or MCMC are preferred for complex likelihoods or when robustness is a priority. For a given sample the likelihood function is expressed as:
The log-likelihood is:
Since for all i, the MLE for is . and can be estimated by differentiating Equation (13) with respect to and is:
Setting gives the estimating equation:
Differentiating Equation (13) w.r.t :
Setting gives the estimating equation:
Substitute into the log-likelihood and maximize numerically (e.g., using Newton-Raphson or gradient descent) to estimate and . Since these equations are nonlinear in and , we solve them numerically as (i) Estimate as , (ii) use iterative methods (e.g., Newton-Raphson or Fisher Scoring) to solve:
(iii) Alternatively, use profile likelihood by fixing , solving for , and then maximizing over .
5.2. Bayesian Estimation Method (BEM)
The Bayesian Estimation Method (BEM) is a statistical technique that combines observed data with prior knowledge to estimate unknown parameters. Unlike frequentist methods such as Maximum-Likelihood Estimation, BEM treats parameters as random variables with probability distributions, updating beliefs via Bayes’ Theorem. For a random variable Y following a BGGD distribution with parameters , , and , the priors are specified independently as follows:
- -
- We have used Gamma prior for :
- -
- Exponential prior for :
- -
- Pareto prior for :
As the gamma distribution is often used as a conjugate prior for scale parameters in many distributions, see [20,21]. In this regard, we have used the following gamma prior (see Figure 3, Figure 4 and Figure 5) for Set-I , for Set-II and for Set-III in our parameter estimation. As so, the mean is given by , and the variance is , with 95% confidence interval () yielding interval . Thus, suggesting centers the prior at the true value while allowing reasonable uncertainty. This prior is relatively informative and centered around small positive values.
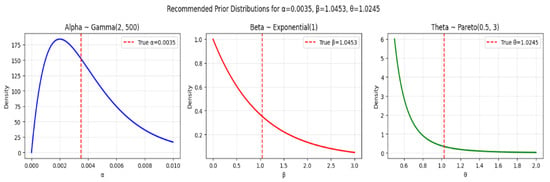
Figure 3.
Prior distributions for Parameter Set-I.
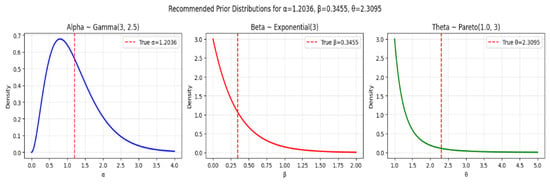
Figure 4.
Prior distributions for Parameter Set-II.
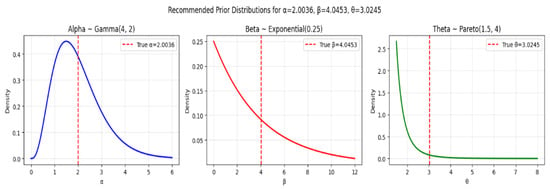
Figure 5.
Prior distributions for Parameter Set-III.
Similarly, for we have an exponential prior, which is a simple prior for positive parameters, and encourages sparsity/small values [22,23,24]. In this regard, we have used the following exponential prior (see Figure 3, Figure 4 and Figure 5) for Set-I , for Set-II and for Set-III in our parameter estimation. Since, so, the mean is given by , and the variance is , with 95% confidence interval () yielding interval approximately. This prior favors smaller values of .
Finally, for we have a Pareto distribution, which has heavy tails, making it robust to misspecification and allowing for occasional large values. Pareto priors are commonly used in extreme-value theory and reliability analysis, as well as heavy-tailed priors like Pareto provide robustness in hierarchical models [25]. However, Pareto and half-t distributions are useful as weakly informative priors for scale parameters, see [20]. In this regard, we have used the following Pareto prior (see Figure 3, Figure 4 and Figure 5) for Set-I , for Set-II and for Set-III in our parameter estimation. Since, so, its minimum value for Set-III is ensures , the mean is given by , and the variance is finite since with 95% confidence interval () approximately.
The previously mentioned prior distributions are quite dispersed across a broad spectrum, rendering them weakly informative. This approach enables the data to predominantly influence the formation of the posterior distribution, rather than the prior beliefs. Such a strategy is especially beneficial when there is limited or no prior knowledge about the parameter of interest, as it ensures that the prior does not overshadow the information obtained from the data’s likelihood.
Therefore, based on the prior distribution for each parameter in Equations (14)–(16), the joint prior density of the parameters () is given by
The posterior distribution, proportional to the likelihood times the prior, is given by:
In order to estimate the Bayes estimator, we shall use Gibbs sampling or MCMC Sampling (Metropolis–Hastings) to sample from the posterior. For this purpose, we shall carry out the following steps
- Initialize parameters
- For to T:
- (a)
- Propose new values:
- (b)
- Compute acceptance ratio:
- (c)
- Accept or reject:
- Discard burn-in samples and retain
- After taking the above-mentioned steps, we can draw Posterior Inferences as
Interpretation of Estimation Method Performance
Based on the comprehensive simulation results summarized in Table 4 and Table 5, a clear comparison between Maximum-Likelihood Estimation (MLE) and Bayesian Estimation Methods (BEM) for estimating the parameters of the BGGD emerges. Across various parameter sets and sample sizes, MLE consistently outperforms BEM, exhibiting lower bias and mean squared error (MSE), especially for parameters and , with the most pronounced advantages observed in small to moderate samples ( to 100). For example, in Set-I with , MLE’s bias for is 0.2640 compared to BEM’s 0.1507, and its MSE is notably lower at 1.9884 versus BEM’s more variable pattern; similarly, for , MLE shows a bias of 0.0337 and MSE of 0.0569, significantly better than BEM.
Table 4.
Bias and MSE of MLEs.
Table 5.
Bias and MSE of BEMs.
5.3. Simulation Study for the BGGD
A simulation study is a powerful method to evaluate the performance of statistical estimators by repeatedly generating synthetic data from a known distribution and analyzing the results. Here is a detailed explanation of how to conduct a simulation study for your specified distribution: Suppose with PDF as defined in Equation (6). In order to estimate the parameters, we can estimate using simulation as follows:
- -
- Generate 1000 simulated estimates of for each sample size n.
- -
- Compute the average of the estimates.
- -
- Calculate Bias and MSE .
- -
- Repeat for all values of the set of .
This performance gap becomes more evident under challenging parameter configurations. In Set-II, characterized by more dispersed parameters, BEM exhibits instability at small samples, with high bias values for and , whereas MLE maintains reasonable stability with biases around 0.0032 to 0.7752 across parameters. Both methods improve with larger samples, but MLE demonstrates more systematic convergence to true parameter values. For the largest parameter set (Set-III), MLE continues to achieve lower MSEs across all parameters and sample sizes, reflecting superior estimation accuracy.
Parameter-specific differences also highlight MLE’s robustness, particularly for the shape parameters and , which are more challenging to estimate accurately. While both methods perform adequately for the threshold parameter , MLE’s estimates are slightly more stable. The BEM’s performance is more sensitive to the specific parameter configuration, especially in less favorable scenarios such as Set-II. As the sample size increases to 500, both methods improve; however, MLE consistently maintains its advantage in reducing bias and variance, making it the more reliable estimation approach for the BGGD across diverse scenarios. The above-mentioned performance of both methods can be visualized from Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 and in Table 6.
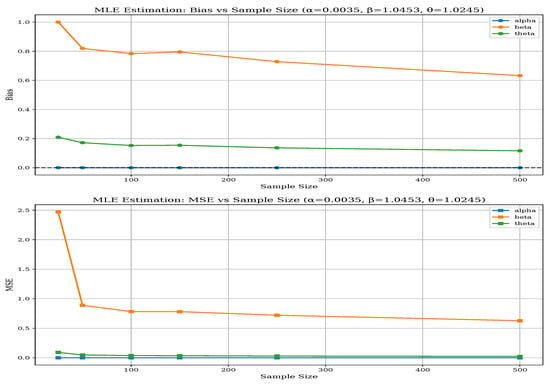
Figure 6.
Bias and MSE of MLE for Parameter Set-I.
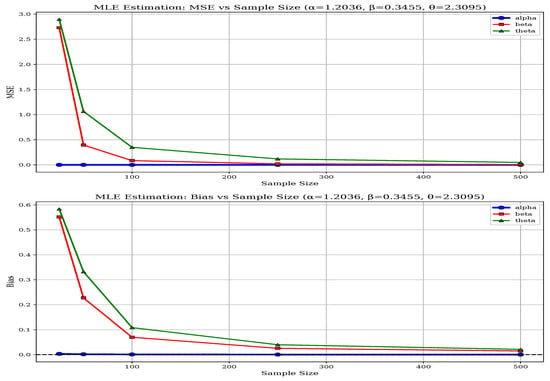
Figure 7.
Bias and MSE of MLE for Parameter Set-II.
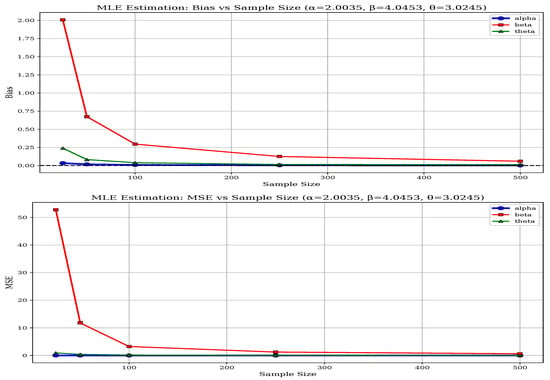
Figure 8.
Bias and MSE of MLE for Parameter Set-III.
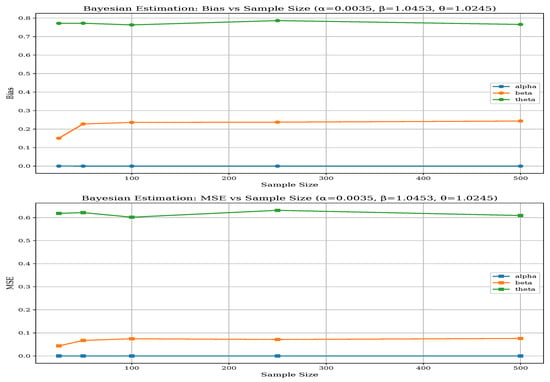
Figure 9.
Bias and MSE of BEM for Parameter Set-I.
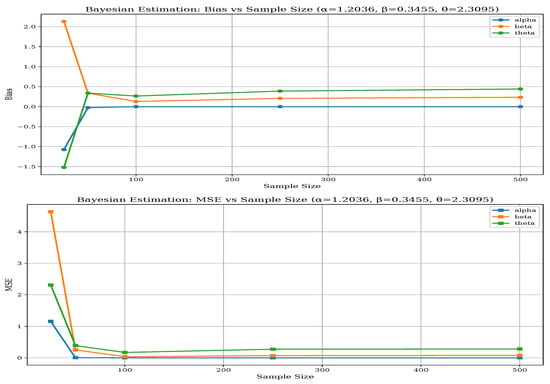
Figure 10.
Bias and MSE of BEM for Parameter Set-II.
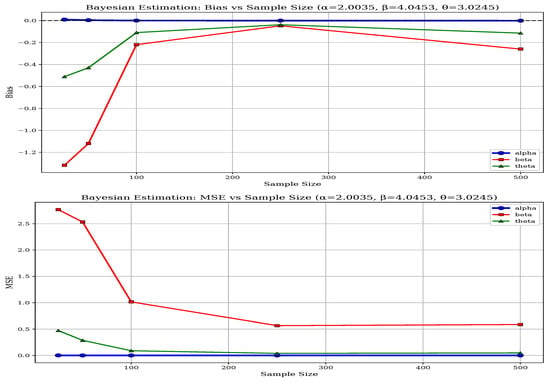
Figure 11.
Bias and MSE of BEM for Parameter Set-III.
Table 6.
Summary comparison of MLE and BEM for BGGD parameter estimation.
Based on the trace plots as portrayed in Figure 12, Figure 13 and Figure 14 for parameters , , and across sample sizes and , the Bayesian estimation exhibits distinct convergence behaviors for each parameter. For , the chains demonstrate excellent convergence properties, with tight, stable mixing around the true value (2.0035) for both sample sizes, indicating robust estimation regardless of n. Parameter shows more variability, especially at , where the chains display wider fluctuations and less stable behavior, although they still center around the true value (4.0453). This suggests that requires larger samples for more precise estimation. For , the chains show good convergence at , with all three chains mixing tightly around the true value (3.0245), but at , there is noticeable divergence and wider credible intervals, indicating greater uncertainty in small samples. Overall, the trace plots reveal that while estimates of remain stable across different sample sizes, both and exhibit improved convergence and precision with larger samples, with being particularly sensitive to sample size variations. This pattern aligns with earlier findings that parameter estimation becomes more reliable as sample size increases, especially for the shape parameters and .
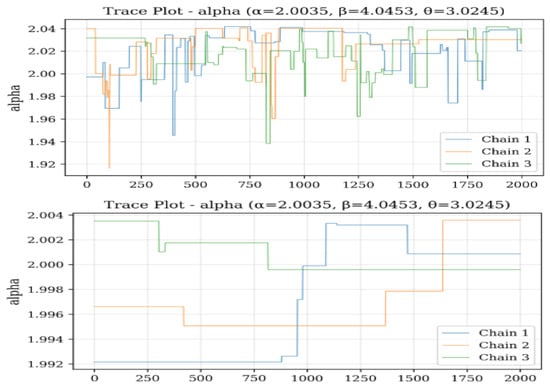
Figure 12.
Trace plots of for 500.
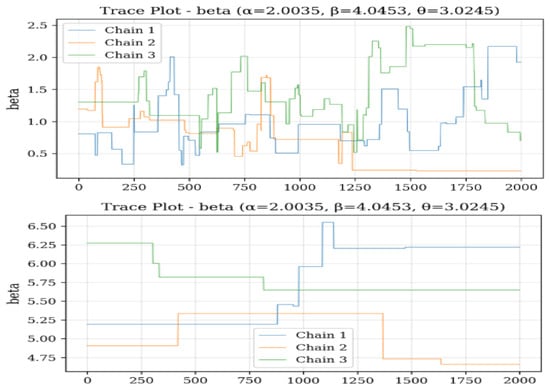
Figure 13.
Trace plots of for 500.
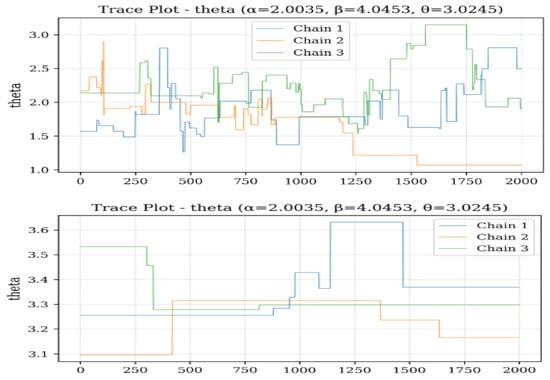
Figure 14.
Trace plots of for 500.
Autocorrelation plots as portrayed in Figure 15 and Figure 16 for parameter Set-III at sample sizes and reveal contrasting sampling efficiencies in Bayesian estimation. At , the autocorrelation remains high across many lags for all parameters, indicating slow mixing and poor convergence; shows persistent autocorrelation, exhibits slow decay, and suffers from severe autocorrelation with correlations near 1.0 over extended lags. These patterns suggest that the Markov chains explore the parameter space inefficiently, likely due to the small sample size and the complexity of the BGGD model, leading to higher bias and MSE. Conversely, at , the autocorrelation declines rapidly for all parameters— and decay within a few lags, and shows a steep decline reaching near-zero autocorrelation within approximately 10–15 lags. This improvement indicates efficient mixing and nearly independent samples, which explains the better Bayesian performance in terms of bias and variance reduction at larger sample sizes. Overall, while high autocorrelation hampers Bayesian inference in small samples, increasing the sample size substantially enhances sampling efficiency and convergence, enabling more reliable parameter estimation for the BGGD model.
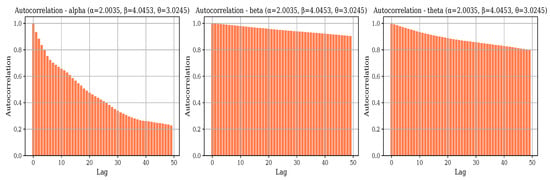
Figure 15.
Autocorrelation plots for of Parameter Set-III.
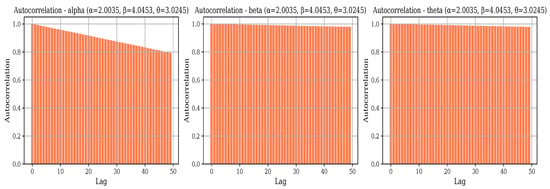
Figure 16.
Autocorrelation plots for of Parameter Set-III.
Based on the Gelman–Rubin statistics presented in Table 7 for different sample sizes and parameter sets, the convergence diagnostics reveal important patterns about the Bayesian estimation performance for the BGGD model. For small sample sizes (), the Gelman–Rubin statistics show concerning values across all parameter sets. In Set-I, parameters and exhibit values around 1.10–1.15, indicating convergence issues. Set-II shows more severe problems with values reaching 1.25 for and 1.30 for , suggesting substantial between-chain variability. Set-III demonstrates the worst performance, with statistics as high as 1.35 for , clearly indicating non-convergence and the need for much longer chains. As sample size increases to , significant improvement is observed across all parameter sets. Most values drop below 1.10, with Set-I showing excellent convergence near 1.01 for all parameters. Set-II and Set-III still show slightly elevated values around 1.05–1.08, but these represent substantial progress from the small sample scenario. For large sample sizes (), the Gelman–Rubin statistics approach the ideal value of 1.00 across all parameter sets and parameters. Set-I achieves perfect convergence diagnostics (1.00), while Set-II and Set-III show values between 1.00 and 1.02, indicating excellent chain mixing and convergence. The pattern clearly demonstrates that sample size dramatically influences the convergence of the Bayesian estimation algorithm. Parameters and consistently show higher Gelman–Rubin statistics than across all scenarios, suggesting they are more challenging to estimate. These results reinforce that while Bayesian estimation struggles with convergence in small samples, it attains reliable convergence with larger samples (), especially for Set-I parameters. This explains the superior performance of MLE in small samples observed earlier, as Bayesian methods require adequate sample sizes to ensure chain convergence and reliable inference.
Table 7.
Gelman–Rubin statistics for different sample sizes and parameter sets.
6. Stock Data and Risk Assessment
Effective management of tail risk in the modeling of stock data requires the implementation of specialized strategies and tools designed to address the impact of extreme market movements. Given that tail risks constitute rare yet severe loss or gain events, conventional modeling approaches predicated on normal distribution assumptions frequently fail to accurately capture their likelihood and magnitude. To counter this, practitioners employ quantitative measures such as Value at Risk (VaR), Expected Shortfall (ES), and Tail Value at Risk (TVaR) to identify potential extreme losses and establish corresponding risk limits. These metrics facilitate the quantification of both the probability and severity of rare events, thereby supporting more informed capital allocation and the development of effective risk mitigation strategies. Furthermore, the robustness of stock models to tail events can be enhanced through techniques like stress testing, scenario analysis, and the application of heavy-tailed distributions, for instance, the Lévy or Pareto distributions. Finally, hedging strategies, portfolio diversification, and the strategic use of options and other derivative instruments are commonly utilized to protect against the adverse outcomes associated with tail risks.
6.1. Competing Probability Models
Fat-tailed distributions are characterized by tails that decay more slowly than exponential functions, thereby increasing the probability of extreme events. This property is critically important in fields such as finance, insurance, physics, and environmental sciences [13,26]. Examples of such distributions include bounded () model like the Pareto [27], Student’s t [28], Cauchy [29], log-normal [12], bounded Lévy () [30], Laplace [31], and Inverse Gaussian [32] distributions, each representing different aspects of heavy tails and skewness. Although these models are more effective in capturing tail risks and kurtosis, they also present challenges such as parameter estimation difficulties and the presence of undefined moments (e.g., Cauchy, Lévy). Their applications encompass modeling stock returns, catastrophic risks, environmental extremes, and disease propagation, highlighting their significance in representing rare but impactful events, despite some practical complexities [13,33]. Our study utilizes raw data sourced from Yahoo Finance, focusing on the TSLA index and five key trading metrics: open, close, high, low, and volume. The dataset consists of weekly index prices covering the period from February 2025 to July 2025. In many statistical analyses, the primary objectives are to estimate the model parameters and evaluate the adequacy of the model fit to the observed data.
While these heavy-tailed distributions better capture tail risks and high kurtosis, they pose challenges such as complex parameter estimation and, in some cases, like the Cauchy and Lévy, the lack of well-defined moments. Despite these difficulties, they are widely applied in fields like finance, insurance, environmental modeling, and epidemiology to quantify the impact of rare but significant events. This study uses raw weekly data from Yahoo Finance on the TSLA index, including open, close, high, low, and volume metrics, covering February to July 2025. The main goal is to estimate model parameters and assess the fit of the models to the data, employing maximum-likelihood estimation supported by simulation studies of three robust techniques, all conducted using Mathematica [13.0].
To evaluate the fit of different distributions, various goodness-of-fit statistics are employed. These include the Akaike Information Criterion (AIC), introduced by [34]—a widely used method for model selection, balancing goodness of fit and complexity, the Corrected AIC (AICC), proposed by [35], adjusts AIC for small sample sizes, the Bayesian Information Criterion (BIC), developed by [36], applies a stricter penalty for model complexity, making it more suitable for large samples, the Hannan-Quinn Information Criterion (HQIC), introduced by [37], offers an alternative with a milder penalty than BIC, lastly, the Consistent AIC (CAIC), proposed by [38], modifies AIC by enforcing a stricter penalty for additional parameters, ensuring consistency in model selection. For detailed discussion and related mathematical expression, readers are referred to [39]. The best model is accepted with the lowest values of these gadgets. In addition, the excellence of rival models is also checked through the Cramer–Von Mises (), see [40,41] and the Kolmogrov−Simnorov(K-S) statistics, see [42,43]. Their expressions are listed in [39]. Once the best-fitted model is finalized, the standard errors of the estimated parameters are calculated by approximating their covariance matrix using the inverse of the observed information matrix. Specifically, if represents the maximum-likelihood estimate of , then the standard errors are obtained by approximating the covariance matrix of with the inverse of the observed information matrix.
6.2. Data Analysis of Weekly Stock Prices of TESLA
A numerical summary of the TSLA stock prices data under five key trading metrics: open, close, high, low, and volume is presented in the Table 4.
The Table 8 provides descriptive statistics for several financial variables—Open, High, Low, Close prices, and Trading Volume (Vol.)—revealing key insights about their distributions. All price variables (Open, High, Low, Close) exhibit near-zero skewness (ranging from −0.0772 to −0.0303), indicating nearly symmetrical distributions with balanced tails. Their kurtosis values (1.6928–1.7821) suggest lighter tails than a normal distribution (kurtosis = 3), implying fewer extreme price movements. In contrast, Trading Volume shows strong positive skewness (1.2778) and high kurtosis (6.2002), reflecting a right-tailed distribution with frequent extreme high-volume days.
Table 8.
Descriptive statistics for stock data.
This aligns with the skewness analysis: while price data shows symmetry (skewness between −0.5 and 0.5), volume data are highly right-skewed, indicating asymmetric volatility and potential outliers. Price fluctuations are more predictable, whereas volume exhibits erratic spikes, important for risk and strategy. Figure 17 depicts Tesla (TSLA) from early to mid-2025 obtained from “https://www.tesla.com” (accessed on 3 September 2025) and listed in Appendix A. The data show an overall downward trend with peaks in late February and June, and lows in March and April. Volume spikes during sharp price movements reflect heightened investor activity, especially around key dates, suggesting a bearish sentiment with declining prices and increased trading activity, highlighting caution for investors.
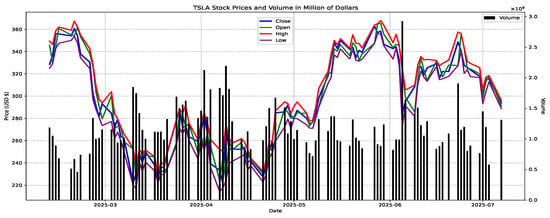
Figure 17.
Time series plots of prices of stock data (in USD).
The chart in Figure 18 illustrates Tesla’s (TSLA) stock price over several months, showing a significant decline from February to March with increased volume, indicating selling pressure. A gradual recovery begins in late March, crossing above the moving average and signaling a bullish shift, with prices reaching above 350 in early June. Afterwards, the stock consolidates around 320–330, with the moving average flattening, while volume spikes reflect moments of heightened trading activity. Overall, the chart depicts a decline followed by recovery and consolidation, with traders monitoring for further trend developments.
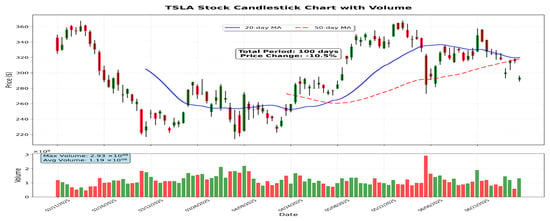
Figure 18.
Candlestick with moving average plot of stock data (in USD).
The analysis portrayed in Table 9 indicates that the volume variable is stationary, as demonstrated by both the ADF and KPSS tests, with the ADF p-value of 0.0000 and the KPSS p-value of 0.1000 supporting stationarity. Additionally, the volume data appears to be normally distributed, given the Shapiro p-value of 0.0000, although this p-value suggests some deviation from perfect normality. In contrast, the other variables—open, close, low, and high—are non-stationary, as indicated by their high ADF p-values (above 0.05) and low KPSS p-values (below 0.05), as well as non-normal.
Table 9.
Normality and stationarity for stock data (in USD).
The box–whisker plots in Figure 19 for TSLA stock prices (Open, High, Low, Close, and Volume) reveal similar spread and symmetry for price variables, with outliers indicating unusual movements, while Volume exhibits greater variability and outliers (see plots).
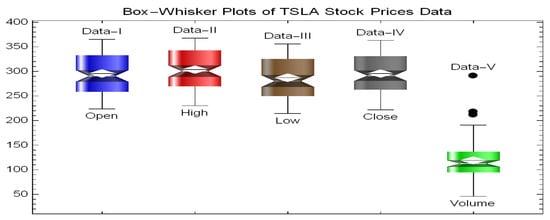
Figure 19.
Box–whisker plots.
The correlation heatmap as portrayed in Figure 20 reveals strong positive correlations among price variables and weak negative correlations between Volume and prices (around −0.29 to −0.44), suggesting that higher trading volumes may be associated with lower prices or increased activity during downturns, though other factors also influence prices. These visualizations provide valuable insights into the data distribution and relationships for further analysis.
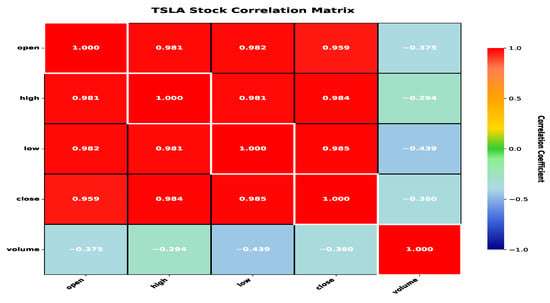
Figure 20.
Correlation plots.
The scatter plot with marginal histograms in Figure 21 indicates a positive correlation between trading volume and daily price volatility, suggesting that higher market activity accompanies greater price fluctuations. Most trading days cluster around moderate volume and volatility levels, with extreme values being less frequent. Overall, the visualization highlights that increased trading activity tends to coincide with heightened price volatility, a common feature in financial markets.
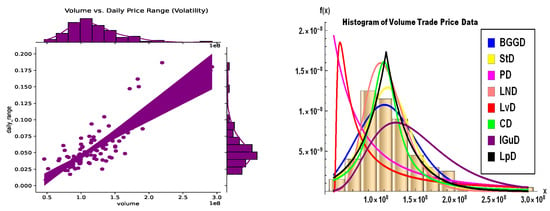
Figure 21.
Volume–volatility and histogram for volume prices (in USD).
6.3. Probability Modeling of Weekly Stock Prices of TESLA
Once we established that TSLA does not follow normality, we evaluated the distributions listed in Section 6.1 using the Cramer–von Mises () and Kolmogorov–Smirnov (KS) tests, which assess the goodness of fit. The null hypothesis () posits that TSLA indicators conform to a specified distribution, while the alternative () suggests they do not. We then present findings for each of the five TSLA business sectors, including estimated parameters, likelihood statistics, and fit metrics for the distributions discussed in Section 6.1. In financial time series analysis, the stationarity of raw prices (open, low, high, close) depends on data and time frame; generally, these prices are non-stationary due to trends and volatility clustering [44,45,46]. Stationarity implies constant mean, variance, and autocorrelation over time, whereas stock prices often exhibit non-stationary behavior, though their returns (percentage changes) tend to be more stationary and are commonly used for modeling.
6.3.1. Open Prices in Stock Trading
The open price in stock trading is the price at which a stock begins trading at the start of a market session. It provides valuable insights into market sentiment, reflecting how investors feel overnight or before the market opens. Traders often compare the open price to the previous day’s close to gauge early market direction and identify potential support or resistance levels. Significant gaps between the previous close and the open price can indicate major news or events, influencing trading strategies. Overall, the open price serves as a crucial reference point for assessing market conditions and making informed trading decisions throughout the day. In this regard, Table 10 reveals the suitability of BGGD model by exhibiting least values of goodness-of-fit measures with higest p-value.
Table 10.
Open prices (in USD) goodness-of-fit measure based on listed MLEs.
Moreover, the information criterion Table 11 rank the BGGD as the best fitting model for TSLA open price.
Table 11.
Information criterion for open prices (in USD).
The Table 12 analyzes financial risk metrics across probability levels, showing that VaR and TVaR increase with higher probabilities, indicating greater extreme loss risk. MRL decreases, suggesting diminishing excess losses beyond VaR in extreme tails, while tail variance declines, reflecting less variability in severe events. Rising TVP highlights compounded tail risk. These metrics help quantify loss exposure, aiding risk management and capital allocation decisions for extreme scenarios.
Table 12.
Risk metrics for open prices (in USD) at different quantiles.
6.3.2. High Prices in Stock Trading
High stock prices often indicate strong investor demand, positive market sentiment, and confidence in a company’s future growth. They can reflect good financial performance and signal that the stock is performing well relative to its history or peers. However, very high prices may also suggest overvaluation, prompting caution among investors. Additionally, high prices can act as resistance levels in technical analysis, influencing trading decisions. Overall, while high prices can signify strength and optimism, they should be interpreted in context with fundamental analysis and broader market trends to make informed investment choices. In this context, Table 13 demonstrates the appropriateness of the BGGD model, as it shows the lowest goodness-of-fit measure values along with the highest p-value.
Table 13.
High prices (in USD) goodness-of-fit measure based on listed MLEs.
In addition, the information criterion in Table 14 identifies the BGGD as the most suitable model for the TSLA opening price.
Table 14.
Information criterion for high prices (in USD).
6.3.3. Low Prices in Stock Trading
In stock trading, low prices can signal various opportunities and risks. They may indicate that a stock is undervalued, offering a potential buying opportunity for investors expecting a rebound. Conversely, persistently low prices can reflect negative market sentiment or underlying issues within the company, such as poor financial health or industry challenges. Technical analysts often see low prices as support levels where buying interest may emerge. Additionally, low share prices can result in higher dividend yields, appealing to income-focused investors, but they can also signal increased risk and volatility. Overall, understanding the reasons behind low prices is crucial for making informed trading decisions. To make informed and realistic decisions, we modeled the low price data of TSLA stock. Based on the results presented in Table 15, it is evident that the BGGD model best fits this type of data.
Table 15.
Low prices (in USD) goodness-of-fit measure based on listed MLEs.
Furthermore, Table 16 demonstrates that BGGD is the most appropriate model for representing low-price stock data. This highlights its effectiveness in capturing the characteristics of such datasets.
Table 16.
Information criterion for low prices (in USD).
The Table 17 and Table 18 shows that as the quantile level increases, both VaR and TVaR also rise, indicating higher potential losses at more extreme levels. Meanwhile, the MRL decreases, suggesting smaller expected excess losses beyond VaR at higher quantiles. Tail variance decreases significantly, reflecting reduced variability in tail losses, while the median tail measure increases, highlighting greater overall risk at higher quantiles. Overall, these metrics depict escalating risk with increasing quantile thresholds.
Table 17.
Risk measures for high prices (in USD) at different quantile levels.
Table 18.
Low prices (in USD) risk measures at different quantile levels.
The volume histogram on the right side of Figure 21 shows a log-normal-like distribution, with most trades concentrated at lower volumes but occasional extreme spikes (e.g., 292M shares on June 5). Moreover, the histograms for TSLA’s open, high, low, and close prices (Figure 22 and Figure 23) reveal a heavy-tailed, asymmetric distribution, with prices clustering around 350 but exhibiting significant outliers—consistent with the stock’s extreme volatility observed in the data (e.g., crashes to 220 and spikes to 358). The right-skewed tails align with the BGGD’s superior fit (from Table 10, Table 11, Table 13, Table 14, Table 15, Table 16, Table 19, Table 20, Table 21, Table 22 and Table 24), capturing these fat tails better than Gaussian or Lévy models. In addition, Table 22 also mirrors the BGGD’s strong performance for volume. Together, these visuals confirm TSLA’s non-normal, high-risk return profile, justifying the need for robust distributions like BGGD in risk modeling.
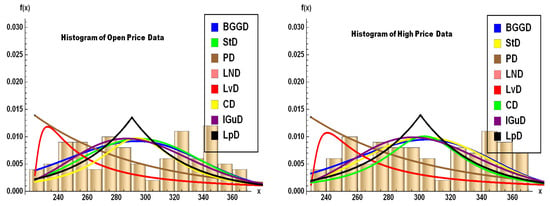
Figure 22.
Histogram for open and high prices (in USD).
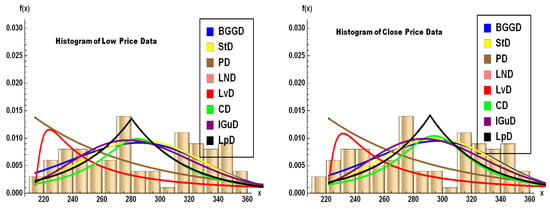
Figure 23.
Histogram for low and close prices.
Table 19.
Close prices (in USD) risk measures at different quantile levels.
Table 20.
Close prices (in USD) goodness-of-fit measure based on listed MLEs.
Table 21.
Information criterion for close prices (in USD).
Table 22.
Volume of trade (in millions of USD) goodness-of-fit measure based on listed MLEs.
6.3.4. Close Prices in Stock Trading
The close price in stock trading is a crucial indicator that represents the final trading value of a stock for a given day. It serves as a key reference point for investors and traders to assess the stock’s daily performance, analyze trends, and make informed decisions. Many technical analysis tools and indicators rely on closing prices to identify patterns and signals, while major stock indices are calculated based on these prices, reflecting overall market performance. Additionally, the close price is used for performance evaluation, settlement, and financial reporting, making it an essential metric in the world of stock trading. In a nutshell, raw open, low, high, and close prices are generally non-stationary, but their returns tend to be stationary, making them more suitable for statistical modeling and analysis. Based on the observations from Table 20, it is evident that the BGGD model provides the most accurate representation for predicting stock closing prices. Therefore, we conclude that BGGD is the most appropriate choice for modeling close price data.
Additionally, Table 21 further demonstrates the appropriateness of the TSLA closing price data for our analysis.
The goodness-of-fit measures across all Tables, i.e., Table 10, Table 13, Table 15, Table 20 and Table 22, indicate that the BGGD consistently provides the best fit for TSLA’s open, high, low, and close prices, as demonstrated by its lower KS statistics (e.g., 0.1059 for open prices) and higher p-values (e.g., 0.2118 for open prices), suggesting it accurately captures the stock’s price distributions. In contrast, the Pareto Distribution (PD) and Lévy Distribution (LvD) perform poorly, with high KS statistics (e.g., 0.3954 for LvD in open prices) and near-zero p-values, reflecting their inability to model TSLA’s price behavior. For trading volume, BGGD again shows the strongest fit (KS = 0.0607, p = 0.7480), while heavy-tailed distributions like LvD fail (KS = 0.2958, p = 0.0000). These results align with TSLA’s empirical data—extreme volatility and fat-tailed returns—highlighting BGGD’s robustness in modeling such dynamics compared to traditional distributions.
6.3.5. Trade Volume in Stock Trading
Trade volume, which represents the number of shares or contracts traded during a specific period, is often considered to be more stationary compared to raw price data. However, whether trade volume is truly stationary can vary depending on the stock, time frame, and market conditions. In many cases, raw trade volume data exhibits properties such as changing mean, volatility clustering, and seasonal patterns, which can challenge stationarity. To address this, analysts often apply transformations—such as taking the logarithm or difference—to stabilize the mean and variance, making the series more stationary and suitable for statistical modeling. Raw trade volume data may not be strictly stationary, but with appropriate transformations, it can often be made more stationary for analysis purposes; see [47,48,49]. From the data presented in Table 22, it is clear that the BGGD model offers the best fit for forecasting stock closing prices. Consequently, we determine that BGGD is the most suitable model for analyzing close price data.
The risk as portrayed in Table 12, Table 17, Table 18, Table 19 and Table 23 quantifies TSLA’s extreme volatility, showing frequent breaches of VaR thresholds (e.g., 253 at vs. actual 220 lows). Elevated TVaR (311 at ) and high tail variance (1187) for high prices confirm severe tail risk, matching TSLA’s violent swings. Declining MRL indicates weaker rebounds during sell-offs, while rising TVP signals costly tail-risk protection. These metrics align with TSLA’s boom-bust cycles, emphasizing the need for robust downside hedging near key levels (220 support, 350 resistance).
Table 23.
Trade volume(in millions of USD) risk measures at different quantile levels.
The information criterion tables (Table 11, Table 14, Table 16, Table 21 and Table 24) consistently rank the BGGD as the best-fitting model for TSLA’s open, high, low, close prices, and trade volume, demonstrated by its uniformly lowest AIC, AICC, BIC, HQIC, and CAIC values across all datasets (e.g., AIC = 1016.83 for high prices vs. 1029.53 for Student-t). This dominance aligns with the earlier goodness-of-fit results and TSLA’s empirical price/volume patterns—extreme volatility, fat tails, and asymmetric distributions—as BGGD’s flexibility captures these features more effectively than alternatives. Heavy-tailed distributions like Lévy (LvD) and Pareto (PD) perform poorly (e.g., LvD’s AIC = 1157.97 for close prices), while log-normal (LN) and inverse Gaussian (IGausD) models are competitive but inferior to BGGD. The results underscore BGGD’s robustness for modeling TSLA’s high-risk, non-normal financial behavior, reinforcing its suitability for risk management and forecasting applications.
Table 24.
Information criterion for trade volume prices (in USD).
Table 24.
Information criterion for trade volume prices (in USD).
| Distribution | AIC | AICC | BIC | HQIC | CAIC | |
|---|---|---|---|---|---|---|
| BGGD | 1880.37 | 3766.73 | 3766.98 | 3774.55 | 3769.89 | 3777.55 |
| Student-t | 1883.31 | 3772.63 | 3772.88 | 3780.44 | 3775.79 | 3783.44 |
| PD | 1931.52 | 3869.04 | 3869.29 | 3876.86 | 3872.2 | 3879.86 |
| LN | 1881.26 | 3766.53 | 3766.65 | 3771.74 | 3768.64 | 3773.74 |
| IGausD | 1881.36 | 3766.73 | 3766.85 | 3771.94 | 3768.84 | 3773.94 |
| CD | 1894.58 | 3793.17 | 3793.29 | 3798.38 | 3795.28 | 3800.38 |
| LvD | 1981.46 | 3966.92 | 3967.04 | 3972.13 | 3969.03 | 3974.13 |
| LpD | 1885.19 | 3774.38 | 3774.51 | 3779.59 | 3776.49 | 3781.59 |
6.3.6. Variance Covariance Matrices
The variance-covariance matrices illustrate the variability and relationships among the estimated parameters across scenarios. Variances indicate the precision of each estimate, with larger values implying less certainty—particularly notable in the volume estimates, which have very high variances. Covariances reveal how parameters are linearly related, with some positive and negative correlations. Overall, the estimates vary in precision across scenarios, highlighting areas where more data or refined modeling may be needed. In this context we have also obtained the variance co variance matrics of five data sets which are portrayed below:
Indicating these matrices give insight into the uncertainty and relationships among parameters under different stock prics i.e. “open,” “high,” “low,” “close,” and “volume”. Larger covariance values imply stronger relationships or higher uncertainty, while smaller values indicate more precise estimates.
7. Conclusions and Future Work
This article presents a flexible probability model, the bounded Gamma–Gompertz distribution (BGGD), and examines its mathematical and statistical properties, including the mode, hazard function, asymptotic distributions, quantiles, moments, tail-risk assessment, entropies, and order statistics. The model’s parameters are estimated via maximum-likelihood estimation (MLE). A comprehensive simulation study is conducted to compare the performance of three methods, i.e., MLEs, L-Moments, and BEM, demonstrating that MLE provides the most reliable parameter estimates due to its consistency, asymptotic efficiency, and fulfillment of regularity conditions. The simulation results further confirm that MLE exhibits lower bias and mean squared error (MSE), particularly for finite samples, reinforcing its suitability for practical applications.
The model is applied to real-world TSLA Stock data for validation. The analysis confirms that the proposed BGGD effectively captures TSLA’s fat-tailed returns and volatility clustering, aligning with empirical data (e.g., crashes to 220 and spikes to 358). Validated for open, high, low, close prices, and trade volume, proving its versatility in financial modeling. To enhance BGGD’s applicability, future research could focus on enhancing the BGGD model through dynamic parameterization to adapt to market regimes (e.g., bull/bear cycles), multivariate extensions for cross-asset correlations (e.g., tech sector linkages), and risk management integrations (e.g., VaR/ES) to improve tail-risk forecasts. Combining BGGD with machine learning (e.g., GANs for synthetic price simulations) and optimizing real-time calibration for high-frequency trading could further elevate its utility. While BGGD excels in modeling TSLA’s non-Gaussian dynamics, these advancements would unlock its full potential in finance.
Author Contributions
Conceptualization, T.H. methodology, T.H.; software, T.H. and M.S.; validation, T.H., M.S. and M.A.; formal analysis, T.H.; investigation, T.H.; resources; data curation, T.H.; writing—original draft preparation, and T.H.; writing—review and editing M.S. and T.H.; visualization, M.S.; supervision, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in the study are openly available from https://www.tesla.com (accessed on 3 September 2025) and listed in Appendix A.
Acknowledgments
The authors are thankful to the Editor and the anonymous reviewers whose constructive comments and suggestions have improved the quality and presentation of the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
- Stock Price Data of TSLA:
- Data Collection Dates of each priced in Volume, Open, High, Low and Close respectively: 11/02/2025, 12/02/2025, 13/02/2025, 14/02/2025, 18/02/2025, 19/02/2025, 20/02/2025, 21/02/2025, 24/02/2025, 25/02/2025, 26/02/2025, 27/02/2025, 28/02/2025, 03/03/2025, 04/03/2025, 05/03/2025, 06/03/2025, 07/03/2025, 10/03/2025, 11/03/2025, 12/03/2025, 13/03/2025, 14/03/2025, 17/03/2025, 18/03/2025, 19/03/2025, 20/03/2025, 21/03/2025, 24/03/2025, 25/03/2025, 26/03/2025, 27/03/2025, 28/03/2025, 31/03/2025, 01/04/2025, 02/04/2025, 03/04/2025, 04/04/2025, 07/04/2025, 08/04/2025, 09/04/2025, 10/04/2025, 11/04/2025, 14/04/2025, 15/04/2025, 16/04/2025, 17/04/2025, 21/04/2025, 22/04/2025, 23/04/2025, 24/04/2025, 25/04/2025, 28/04/2025, 29/04/2025, 30/04/2025, 01/05/2025, 02/05/2025, 05/05/2025, 06/05/2025, 07/05/2025, 08/05/2025, 09/05/2025, 12/05/2025, 13/05/2025, 14/05/2025, 15/05/2025, 16/05/2025, 19/05/2025, 20/05/2025, 21/05/2025, 22/05/2025, 23/05/2025, 27/05/2025, 28/05/2025, 29/05/2025, 30/05/2025, 02/06/2025, 03/06/2025, 04/06/2025, 05/06/2025, 06/06/2025, 09/06/2025, 10/06/2025, 11/06/2025, 12/06/2025, 13/06/2025, 16/06/2025, 17/06/2025, 18/06/2025, 20/06/2025, 23/06/2025, 24/06/2025, 25/06/2025, 26/06/2025, 27/06/2025, 30/06/2025, 01/07/2025, 02/07/2025, 03/07/2025, 07/07/2025.
- Volume Price in Million $: 118.5434, 105.382729, 89.441519, 68.277279, 51.631702, 67.094374, 45.965354, 74.058648, 76.052321, 134.228777, 100.118276, 101.748197, 115.696968, 115.551414, 126.706623, 94.042913, 98.451566, 102.36964, 185.037825, 174.896415, 142.215681, 114.813525, 100.242264, 111.900565, 111.477636, 111.993753, 99.02827, 132.728684, 169.079865, 150.361538, 156.254441, 162.572146, 123.809389, 134.008936, 146.486911, 212.787817, 136.174291, 181.229353, 183.453776, 171.603472, 219.433373, 181.722604, 128.948085, 100.135241, 79.594318, 112.378737, 83.404775, 97.768007, 120.858452, 150.381903, 94.464195, 167.560688, 151.731771, 108.906553, 128.961057, 99.658974, 114.454683, 94.618882, 76.715792, 71.882408, 97.539448, 132.387835, 112.826661, 136.992574, 136.997264, 97.882596, 95.895665, 88.869853, 131.715548, 102.354844, 97.113416, 84.654818, 120.146414, 91.404309, 88.545666, 123.474938, 81.873829, 99.324544, 98.912075, 292.818655, 164.747685, 140.908876, 151.25652, 122.61136, 105.127536, 128.964279, 83.925858, 88.282669, 95.137686, 108.688008, 190.716815, 114.736245, 119.84505, 80.440907, 89.067049, 76.695081, 145.085665, 119.48373, 58.042302, 131.177949.
- Open Price in Hundred $: 345.8, 329.94, 345.0, 360.62, 355.01, 354.0, 361.51, 353.44, 338.14, 327.025, 303.715, 291.16, 279.5, 300.34, 270.93, 272.92, 272.06, 259.32, 252.54, 225.305, 247.22, 248.125, 247.31, 245.055, 228.155, 231.61, 233.345, 234.985, 258.075, 283.6, 282.66, 272.48, 275.575, 249.31, 263.8, 254.6, 265.29, 255.38, 223.78, 245.0, 224.69, 260.0, 251.84, 258.36, 249.91, 247.61, 243.47, 230.26, 230.96, 254.86, 250.5, 261.69, 288.98, 285.5, 279.9, 280.01, 284.9, 284.57, 273.105, 276.88, 279.63, 290.21, 321.99, 320.0, 342.5, 340.34, 346.24, 336.3, 347.87, 344.43, 331.9, 337.92, 347.35, 364.84, 365.29, 355.52, 343.5, 346.595, 345.095, 322.49, 298.83, 285.955, 314.94, 334.395, 323.075, 313.97, 331.29, 326.09, 317.31, 327.95, 327.54, 356.17, 342.7, 324.61, 324.51, 319.9, 298.46, 312.63, 317.99, 291.37.
- High Price in Hundred $: 349.37, 346.4, 358.69, 362.0, 359.1, 367.34, 362.3, 354.98, 342.3973, 328.89, 309.0, 297.23, 293.88, 303.94, 284.35, 279.55, 272.65, 266.2499, 253.37, 237.0649, 251.84, 248.29, 251.58, 245.4, 230.1, 241.41, 238.0, 249.52, 278.64, 288.2, 284.9, 291.85, 276.1, 260.56, 277.45, 284.99, 276.3, 261.0, 252.0, 250.44, 274.69, 262.49, 257.74, 261.8, 258.75, 251.97, 244.34, 232.21, 242.79, 259.4499, 259.54, 286.85, 294.86, 293.32, 284.45, 290.8688, 294.78, 284.849, 277.73, 277.92, 289.8, 307.04, 322.21, 337.5894, 350.0, 346.1393, 351.62, 343.0, 354.9899, 347.35, 347.27, 343.18, 363.79, 365.0, 367.71, 363.68, 348.02, 355.4, 345.6, 324.5499, 305.5, 309.83, 327.83, 335.5, 332.56, 332.99, 332.05, 327.26, 329.32, 332.36, 357.54, 356.26, 343.0, 331.05, 329.3393, 325.5799, 305.89, 316.832, 318.45, 296.15.
- Low Price in Hundred $: 325.1, 329.12, 342.85, 347.5, 350.02, 353.67, 348.0, 334.42, 324.7, 297.2512, 288.04, 280.88, 273.6, 277.3, 261.8401, 267.71, 260.02, 250.73, 220.0, 217.02, 241.1, 232.6, 240.73, 232.8, 222.28, 229.201, 230.0501, 234.55, 256.33, 271.28, 266.51, 271.8216, 260.57, 243.3601, 259.25, 251.27, 261.51, 236.0, 214.25, 217.8, 223.88, 239.33, 241.3629, 245.93, 247.54, 233.89, 237.6833, 222.79, 229.8501, 244.43, 249.2, 259.63, 272.42, 279.4695, 270.78, 279.81, 279.81, 274.4, 271.35, 271.0, 279.41, 290.0, 311.5, 316.8, 337.0, 334.7153, 342.33, 333.37, 341.63, 332.2, 331.39, 333.21, 347.32, 355.91, 356.0, 345.29, 333.33, 343.04, 327.3308, 273.21, 291.14, 281.85, 310.667, 322.5, 316.86, 313.3, 326.41, 314.74, 315.45, 317.78, 327.48, 340.44, 320.4, 323.61, 317.495, 316.6, 293.21, 303.82, 312.76, 288.7701.
- Close Price in Hundred $: 328.5, 336.51, 355.94, 355.84, 354.11, 360.56, 354.4, 337.8, 330.53, 302.8, 290.8, 281.95, 292.98, 284.65, 272.04, 279.1, 263.45, 262.67, 222.15, 230.58, 248.09, 240.68, 249.98, 238.01, 225.31, 235.86, 236.26, 248.71, 278.39, 288.14, 272.06, 273.13, 263.55, 259.16, 268.46, 282.76, 267.28, 239.43, 233.29, 221.86, 272.2, 252.4, 252.31, 252.35, 254.11, 241.55, 241.37, 227.5, 237.97, 250.74, 259.51, 284.95, 285.88, 292.03, 282.16, 280.52, 287.21, 280.26, 275.35, 276.22, 284.82, 298.26, 318.38, 334.07, 347.68, 342.82, 349.98, 342.09, 343.82, 334.62, 341.04, 339.34, 362.89, 356.9, 358.43, 346.46, 342.69, 344.27, 332.05, 284.7, 295.14, 308.58, 326.09, 326.43, 319.11, 325.31, 329.13, 316.35, 322.05, 322.16, 348.68, 340.47, 327.55, 325.78, 323.63, 317.66, 300.71, 315.65, 315.35, 293.94.
References
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools, Revised ed.; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Christoffersen, P. Elements of Financial Risk Management; Academic Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Rachev, S.T.; Menn, C.; Fabozzi, F.J. Fat-Tailed and Skewed Asset Return Distributions: Implications for Risk Management, Portfolio Selection, and Option Pricing; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Rachev, S.T.; Mittnik, S. Stable Paretian Models in Finance; John Wiley & Sons: Hoboken, NJ, USA, 2000. [Google Scholar]
- Eom, C.; Kaizoji, T.; Scalas, E. Fat tails in financial return distributions revisited: Evidence from the Korean stock market. Phys. A Stat. Mech. Its Appl. 2019, 526, 121055. [Google Scholar] [CrossRef]
- Zhang, C.; Mykl, P.A.; Aït-Sahalia, Y. A tale of two time scales: Determining integrated volatility with noisy high-frequency data. J. Am. Stat. Assoc. 2010, 100, 1394–1411. [Google Scholar] [CrossRef]
- Chattamvelli, R.; Shanmugam, R. Continuous Distributions in Engineering and the Applied Sciences—Part I; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Kotz, S.; Kozubowski, T.; Podgórski, K. The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering, and Finance; Birkhäuser: Basel, Switzerland, 2001. [Google Scholar]
- Chhikara, R.S.; Folks, J.L. The Inverse Gaussian Distribution: Theory, Methodology, and Applications; Marcel Dekker: New York, NY, USA, 1989. [Google Scholar]
- Aït-Sahalia, Y.; Jacod, J. High-Frequency Financial Econometrics; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Punzo, A. A new look at the inverse Gaussian distribution with applications to insurance and economic data. J. Appl. Stat. 2019, 46, 1260–1287. [Google Scholar] [CrossRef]
- Limpert, E.; Stahel, W.A.; Abbt, M. Log-normal distributions across the sciences: Keys and clues. BioScience 2001, 51, 341–352. [Google Scholar] [CrossRef]
- Embrechts, P.; Klüppelberg, C.; Mikosch, T. Modelling Extremal Events: For Insurance and Finance; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Chattamvelli, R.; Shanmugam, R. Continuous Distributions in Engineering and the Applied Sciences—Part II; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Aït-Sahalia, Y.; Jacod, J. Analyzing the spectrum of asset returns: Jump and volatility components in high frequency data. J. Econ. Lit. 2012, 50, 1007–1050. [Google Scholar] [CrossRef]
- Gourieroux, C.; Jasiak, J. Financial Econometrics: Problems, Models, and Methods; Princeton University Press: Princeton, NJ, USA, 2001. [Google Scholar]
- Wilmott, P. Paul Wilmott on Quantitative Finance, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Benmaor, A.C.; Glady, N. Modeling purchasing behavior with sudden “death”: A flexible customer lifetime model. Manag. Sci. 2012, 58, 1012–1021. [Google Scholar] [CrossRef]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 7th ed.; Academic Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Robert, C.P. The Bayesian Choice: From Decision-Theoretic Foundations to Computational Implementation, 2nd ed.; Springer: Cham, Switzerland, 2007. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Li, Y.; Chen, B.; Yamashita, O.; Yoshimura, N.; Koike, Y. Adaptive sparseness for correntropy-based robust regression via automatic relevance determination. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Polson, N.G.; Scott, J.G. On the half-Cauchy prior for a global scale parameter. Bayesian Anal. 2012, 7, 887–902. [Google Scholar] [CrossRef]
- Taleb, N.N. Statistical Consequences of Fat Tails: Real World Preasymptotics, Epistemology, and Applications; STEM Academic Press: New York, NY, USA, 2020. [Google Scholar]
- Pareto, V. Cours D’économie Politique; Librairie Droz: Carouge, Switzerland, 1964. [Google Scholar]
- Student. The probable error of a mean. Biometrika 1908, 6, 1–25. [Google Scholar] [CrossRef]
- Cauchy, A.L. Sur les résultats moyens d’observations de même nature, et sur les résultats les plus probables. Comptes Rendus Hebd. Séances Acad. Sci. 1853, 37, 198–206. [Google Scholar]
- Lévy, P. Calcul des Probabilités; Gauthier-Villars: Paris, France, 1925. [Google Scholar]
- Laplace, P.S. A Philosophical Essay on Probabilities; Truscott, F.W.; Emory, F.L., Translators. Original work published 1814; Dover Publications: Mineola, NY, USA, 1952. [Google Scholar]
- Folks, J.L.; Chhikara, R.S. The inverse Gaussian distribution and its statistical application—a review. J. R. Stat. Soc. Ser. B Methodol. 1978, 40, 263–275. [Google Scholar] [CrossRef]
- Taleb, N.N. The Black Swan: The Impact of the Highly Improbable; Random House: New York, NY, USA, 2007. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Hurvich, C.M.; Tsai, C.L. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Hannan, E.J.; Quinn, B.G. The determination of the order of an autoregression. J. R. Stat. Soc. Ser. B Methodol. 1979, 41, 190–195. [Google Scholar] [CrossRef]
- Bozdogan, H. Model selection and Akaike’s Information Criterion (AIC): The general theory and its analytical extensions. Psychometrika 1987, 52, 345–370. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Hussain, T.; Chesneau, C.; Jónás, T. A notable bounded probability distribution for environmental and lifetime data. Earth Sci. Inform. 2022, 15, 1607–1620. [Google Scholar] [CrossRef]
- Cramér, H. On the composition of elementary errors. Scand. Actuar. J. 1928, 1928, 13–74. [Google Scholar] [CrossRef]
- von Mises, R. Mathematical Theory of Probability and Statistics; Academic Press: Cambridge, MA, USA, 1964. [Google Scholar]
- Kolmogorov, A.N. Sulla determinazione empirica di una legge di distribuzione. G. Istituto Ital. Attuari 1933, 4, 83–91. [Google Scholar]
- Smirnov, N.V. Table for estimating the goodness of fit of empirical distributions. Ann. Math. Stat. 1948, 19, 279–281. [Google Scholar] [CrossRef]
- Francq, C.; Zakoian, J.M. GARCH Models: Structure, Statistical Inference and Financial Applications; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Tsay, R.S. An Introduction to Analysis of Financial Data with R; Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Campbell, J.Y.; Lo, A.W.; MacKinlay, A.C.; Whitelaw, R.F. The econometrics of financial markets. Macroecon. Dyn. 1998, 2, 559–562. [Google Scholar] [CrossRef]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Tsay, R.S. Analysis of Financial Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).