Abstract
Decentralized Autonomous Organizations (DAOs) suffer from critical governance challenges, such as low voter participation, large token holders’ dominance, and inefficient proposal analysis by manual processes. We propose APOLLO (Autonomous Predictive On-Chain Learning Orchestrator), an AI-powered approach that automates the governance lifecycle in order to address these problems. The gemma-3-4b Large Language Model (LLM) in conjunction with Retrieval-Augmented Generation (RAG) powers APOLLO’s multi-agent system, which enhances contextual comprehension of proposals. The system enhances governance by merging real-time on-chain and off-chain data, ensuring adaptive decision-making. Automated proposal writing, logistic regression-based approval probability prediction, and real-time vote outcome analysis with contextual feature-based confidence scores are some of the major advancements. LLM is used to draft proposals and a feedback loop to enrich its knowledge base, reducing whale dominance and voter apathy with a transparent, bias-resistant system. This work demonstrates the revolutionary potential of AI in promoting decentralized governance, paving the way for more effective, inclusive, and dynamic DAO systems.
1. Introduction
DAO is an organizational structure that functions independently of a central authority. It is made up of people who are all committed to furthering the interests of the community and was made popular by blockchain enthusiasts. It provides accountability by being completely open and recording all decisions and acts on a distributed ledger. DAOs use a bottom–up management style in which members vote to make decisions collectively, giving everyone a say in the organization’s course [1]. This methodology involves token-weighted voting on ideas that are encoded as smart contract transactions, with approved measures running independently over blockchain infrastructure. Despite offering previously unheard-of openness, real-world DAO governance encounters structural challenges. Token-based voting creates new vulnerabilities not found in traditional corporate governance, such as power disparities and inflexible procedures [2].
The efficacy of DAO governance is threatened by a number of serious problems as we summarized in Figure 1. When a small number of token holders acquire an excessive amount of power over decision-making procedures, voter apathy is a serious problem, as poor involvement is sometimes caused by proposals’ complexity. If the voting rate is less than 15% in DAOs, it indicates a lack of interest and participation [3]. Inflexible tooling on platforms such as Tally confines proposal generation to pre-established templates, which reduces flexibility [4]. Decentralized aspirations become oligarchic realities as a result of these inefficiencies’ creation of bottlenecks [5].

Figure 1.
DAO challenges iceberg.
LLMs have become powerful tools for automating governance duties at the same time. Their ability to think contextually enables them to comprehend proposal semantics in a nuanced way [6]. Additionally, multi-step task automation enables processes to be executed sequentially starting with data retrieval, followed by analysis, and concluding with drafting proposals [7]. LLMs achieve high accuracy in classifying DAO proposals and success in synthesizing executable transactions [8], outperforming traditional rule-based systems.
To harness this potential, we introduce an end-to-end framework for AI-driven governance. This work aims to autonomously analyze, predict, and draft proposals. It also focuses on advancing transaction-centric automated governance systems such as AgentDAO [8]. The contributions of this work are as follows:
- Introduces an end-to-end LLM-based system for automating DAO governance with a multi-agent setup powered by Retrieval-Augmented Generation (RAG);
- Combines on-chain and off-chain data (transactions and forum discussions) for context-aware governance decisions;
- Addresses DAO governance issues such as whale dominance and voter apathy through neutral, data-driven analysis and proposal drafting;
- Implements a continuous feedback loop, enhancing future decisions by enriching the knowledge base with each executed proposal.
2. Preliminaries
Blockchain Governance Mechanics: On-chain governance operates through token-weighted voting systems, where stakeholders’ influence corresponds to their token holdings as seen in protocols like Uniswap [9]. The governance lifecycle unfolds in three phases: (i) the drafting phase, where proposals are encoded as technical smart contract payloads; (ii) the snapshot phase, which is an off-chain signaling period used to gauge sentiment; and (iii) the execution phase, where approved proposals deploy autonomously [10].
The voting power distribution can be quantified using the Gini Coefficient, which measures the inequality of voting power among token holders. The Gini coefficient is calculated using the following equation:
where is the voting power of token holder i, and n is the total number of voters. A higher Gini coefficient indicates more centralized voting power, often leading to whale dominance. To address such challenges, Quadratic Voting is proposed as an alternative to traditional voting systems [11].
LLM Integration: LLMs improve DAO governance via the self-attention mechanism by analyzing proposal details, where RAG combines real-time data and past discussions for informed decisions [8,12]. Finally, chain-of-thought prompting breaks tasks into steps for clear reasoning [13]. These features make LLMs valuable tools for enhancing decision-making in DAOs [14]. Specialized LLMs (agents) act as collaborative agents, such as analysts and forecasters, performing roles typically seen in organizational structures [15]. These agents are coordinated by orchestration systems such as LangChain, which manages task transitions and error recovery during operations [5]. Safety mechanisms, including constraint prompting, ensure responses adhere to specific rules. Additionally, transaction emulation in sandboxed environments, like Ganache, validates payloads before blockchain deployment [16].
Relevant Terminologies: Vote Escrow involves locking tokens to increase governance power, as seen in Curve’s veCRV model, promoting long-term holding and governance stability [17]. Proposal Payload is the celldata specifying on-chain actions, which is crucial for smart contract execution once a proposal is approved [18]. Vector DB stores semantic search indexes and governance documents to enable the efficient querying of complex data in decentralized governance systems, with tools like Weaviate and Pinecone providing enhanced search functionality [19].
3. Related Work
Recent work has leveraged LLMs for automating tasks within DAO governance. At early-stage tooling in DAOs was focused on static rule-based automation, which has since evolved into more advanced AI-powered systems [20]. It can achieve over 90% accuracy in classifying DAO proposals, a significant leap over traditional rule-based systems [7]. Additionally, Ref. [6] explored multi-agent systems to automate crypto management, emphasizing the role of specialized agents in governance automation. Furthermore, Ref. [21] introduced a novel approach using Graph Attention Networks for forecasting DAO vote outcomes, enhancing predictive models by analyzing relational data between voters and proposals.
In addition to LLMs, multi-agent systems have become integral to governance automation. For instance, Ref. [22] introduced an LLM-powered framework for automated proposal analysis, significantly streamlining proposal triage by autonomously categorizing and flagging proposals for further review. Similarly, a multi-modal RAG system for financial decision support underscores the versatility of RAG in dynamic, real-time environments [23]. As blockchain ecosystems expand, the need for compliance and legal reasoning becomes critical. Using LLMs for smart contract explainability is a technique that could be integrated to provide transparent legal interpretations of governance [24]. The use of RAG for dynamic compliance highlights how this approach automates legal checks and ensures that proposals adhere to governance and regulatory standards [25]. Table 1 presents a comparison between the proposed work and existing related studies, highlighting the improvements achieved by our approach.

Table 1.
Comparison of related work with proposed APOLLO.
4. Problem Statement and Motivation
One of the governance issues that DAOs deal with is whale dominance, which occurs when a small number of token owners have an excessive level of voting power. Sybil attacks use fictitious identities to influence the governance. When proposal intricacy reduces voter turnout and gives whales the upper hand, rational ignorance takes place. It is challenging to match preferences in DAOs with several blockchains due to cross-chain fragmentation, which complicates governance. The manual vetting process involves core teams spending hours verifying proposals, causing delays in decision making [26]. Tooling rigidity on platforms limits proposals to predefined templates, reducing innovation and flexibility in governance [3]. Additionally, there is a legitimacy and efficiency tradeoff, where prioritizing speed can undermine inclusivity, while thoroughness may slow down proposal execution and decision-making [27].
In order to tackle the issues mentioned, the proposed system (APOLLO) has encouraging prospects for additional improvement. By incorporating Reinforcement Learning (RL), the system can learn from previous governance outcomes to improve forecast accuracy. More coherence and smoother governance across different blockchain networks can result from support for multi-chain DAOs in the crucial domain of cross-chain governance [3,26]. Using a multi-agent system with RAG-powered decision-making to automate the whole proposal lifecycle represents a major advance in AI-driven decentralized governance [6,22]. APOLLO combines continuous learning, predictive modeling, and real-time data to improve decisions while addressing rigid tooling, voter apathy, and whale dominance. The comparative analysis in Table 1 exposes key limitations in the existing approaches, thereby justifying the problem formulation and motivating the proposed solution.
5. Proposed Method
The system is a modular framework for decentralized governance, integrating on-chain and off-chain data collection from social media, news, and blockchain nodes using specialized collectors. The data is processed into context through RAG, using LLMs (gemma-3-4b) for summarization and sentiment extraction. Cosine Similarity and embeddings are applied for context relevance. Predictions are made using the outcome forecaster agent, which utilizes statistical models such as logistic regression or a linear heuristic based on contextual data, including sentiment and historical voting trends. This model is fine-tuned on collected governance data to ensure accurate predictions aligned with community sentiment and trends. Governance proposals are generated using LLMs and broadcast across participants. The execution status is tracked, ensuring transparent and immutable outcomes. The system maintains a continuous feedback loop, improving decisions with updated data to stay responsive to community needs. The successful implementation of this work is presented in the corresponding GitHub repository [28].
5.1. APOLLO Layers
APOLLO consists of three interconnected layers as shown in Figure 2: (i) data layer, (ii) agents layer (LLM-based), and (iii) execution layer.
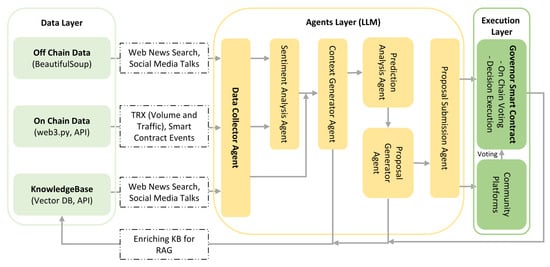
Figure 2.
APOLLO system architecture.
Data Layer: Off-chain data, on-chain data, and the knowledge base are the three main parts of the data layer. Off-chain data, which is driven by BeautifulSoup, gathers sentiment and trends in the market by extracting and preprocessing textual data from social media, news websites, and other sources. Web3.py and RPC indexer APIs are used for On-chain data such as transactions, smart contract interactions, voting patterns, and governance operations. The knowledge base acts as a central hub, using vector databases for semantic search and integrating data from APIs. It also incorporates stakeholder feedback and continuously updates insights from the agents layer to provide accurate, context-driven analytics.
Agents Layer (LLM-Based): The agents layer comprises AI-powered agents for automation and governance prediction. On-chain and off-chain data sources are gathered by the Data Collector Agent, and stakeholder sentiment is assessed by the Sentiment-Analysis Agent. Data and sentiment are combined by the Context Generator Agent, while governance outcomes are predicted by the Prediction Analysis Agent. Both the Proposal-Generator Agent and the Proposal Submission Agent generate governance proposals and automate proposal submissions.
Execution Layer: Through connections to community platforms and blockchain infrastructure, the Execution Layer makes it possible for APOLLO to automate governance. By automating governance execution, the governor smart contract guarantees that recommendations are implemented in a safe, transparent, and predictable manner. Integrating with apps like Telegram or Discord links community involvement with governance, encouraging openness, confidence, and participation.
In the proposed system, we normalize the voting weight of each token holder. The normalized voting weight for voter i is calculated using the following formula.
where is the normalized voting weight of token holder i, is the number of tokens held by voter i, and n is the total number of voters. This ensures that the voting power of each token holder is proportional to the number of tokens they hold within the system, maintaining a fair distribution of voting rights.
5.2. RAG Loop for Knowledge Base Enrichment
To ensure ongoing improvement and accuracy, APOLLO integrates a feedback loop using RAG as shown in Figure 3. Contextual insights generated by the LLM-based Context-Generator Agent are continuously fed back into the knowledge base, enhancing context precision. Each submitted proposal, along with metadata and community feedback, enriches the knowledge base, creating a growing historical context of governance decisions and their outcomes. Additionally, post-execution results from governance actions performed by the governor smart contract are systematically stored and analyzed, facilitating continuous learning and iterative improvement of predictive and proposal-generation models.

Figure 3.
APOLLO RAG Loop.
In the Continuous RAG Loop, we first calculate the Cosine Similarity for retrieval. The cosine similarity between two vectors and is given by the following formula.
where and are the vectors, and and are the magnitudes of the vectors. Next, we apply Reciprocal Rank Fusion (RRF) [29], which combines the results of multiple retrieval systems. The RRF for document d is calculated as follows.
where is the rank of document d, and k is a constant. This formula helps in combining ranked lists from multiple sources by applying diminishing returns to the ranks. Finally, we use Mean Pooling for Embeddings. The mean pooling of the embeddings is calculated as the following equation:
where represents the hidden state of token i at layer L, and n is the total number of tokens. This approach aggregates the token representations into a single vector, representing the overall context.
5.3. Proof of Concept (PoC) Implementation
The MVP has been successfully implemented and validated across all layers. The data layer handles data efficiently and the agents layer generates accurate proposals. The execution layer automates governance with a smart contract. A continuous RAG Loop improves decision-making. In the proposed system, we first normalize the embedding for each text chunk , where each chunk consists of a maximum of 512 tokens. The normalized vector is computed using the following formula.
Here, represents the i-th text chunk, which is a sequence of tokens (words or subwords) with a maximum length of 512 tokens. Each chunk is a small portion of the input text, processed to maintain consistency and manageable size. denotes the embedding vector generated by the MiniLM-L6 encoder for the text chunk . This encoder transforms the raw text into a dense vector representation in a high-dimensional space. The term represents the L2 norm (Euclidean norm) of the vector , which normalizes the embedding to unit length, ensuring consistent scale for comparison. The normalized vector has a dimensionality of , capturing the meaning and context of the chunk.
For retrieval, we use Cosine Similarity in conjunction with IVFFlat (Inverted File with Flat Index) and HNSW (Hierarchical Navigable Small World) acceleration in Pinecone [30,31]. Empirically, recall@10 achieves 0.94 on a 5k query benchmark, indicating that the top 10 retrieved results capture 94% of the relevant data. For any artifact a (such as a tweet, transaction log, or proposal), we compute and store its embedding as follows:
Here, a represents the artifact, which is preprocessed using the function . This preprocessing step strips URLs, tags, and hex blobs to clean the text before embedding. The encoder refers to the text embedding model, where the parameters are frozen after fine-tuning. The resulting embedding vector has a dimensionality of , representing the artifact in a high-dimensional space and capturing rich semantic information.
For retrieval in the RAG process, we use Cosine Similarity to retrieve the top- chunks for RAG prompts. Additionally, for any tokenized text fragment , where each corresponds to a token, the transformer encoder maps each token to a hidden state , which represents the model’s learned features for each token. The final embedding for the entire fragment is computed by mean-pooling the hidden states over the last layer of the transformer as follows.
The resulting dimensionality of the final embedding is , representing the tokenized fragment as a 1768-dimensional vector. For enhanced retrieval, Cosine Similarity is initially applied, followed by Reciprocal Rank Fusion (RRF) for re-ranking the top-200 hits. RRF combines the strengths of sparse BM25, which is a classical retrieval model, and dense scores from the embeddings, improving retrieval quality. This technique enhances the Hits@1 score by approximately 4% in offline tests, ensuring that more relevant and contextually grounded information is retrieved.
Data Collection and Normalization: Algorithm 1 outlines the process of collecting and normalizing on-chain and off-chain data. First, blockchain RPC events are polled to capture on-chain data (RAW_ON), followed by scraping forum and social media HTML, as well as gathering off-chain API feeds (RAW_OFF). The collected data is then combined and normalized to create a canonical governance dataset (NORM_DS). Next, the current block timestamp (t) is captured to record when the data was ingested. A timestamped log of the data sources (SRC_LOG) is stored, which logs the source IDs for both on-chain and off-chain data. Finally, the normalized governance dataset (NORM_DS) is returned, ready for further processing and analysis.
| Algorithm 1 Data ingestion and normalization. |
|
Contextual Analysis and Prediction: Algorithm 2 processes raw data into structured context windows, enabling the extraction of insights. It calculates community sentiment and predicts voter behavior for the next 24 h, supporting informed decision-making. It derives sentiment scores from the normalized governance dataset (NORM_DS), creating a context packet (CTX_PKT), and predicting voter turnout (PRED). Using this context, the system generates a draft proposal (DRAFT) via a language model (LLM), signs it with the agent’s wallet (SIG), and returns the signed draft for community discussion and on-chain voting.
| Algorithm 2 Agents layer pipeline for governance proposal generation. |
|
Proposal Submission, Tracking, and Execution Process: Algorithm 3 outlines the process of submitting and executing a proposal in a decentralized governance system. The draft proposal (DRAFT) is first posted for community feedback, then signed (SIG) and sent to the governor for approval. After the voting period ends, the algorithm checks if the vote threshold is met. If successful, the proposal is executed, and an execution receipt (RECEIPT) is generated. If the threshold is not met or the proposal expires, the receipt is marked as “Failed or Expired”. The final status of the proposal is returned through the execution receipt (RECEIPT).
| Algorithm 3 Proposal submission and execution. |
|
Knowledge Base Update and Enrichment Process: Algorithm 4 describes how the APOLLO system updates its knowledge base (KB). It combines the context packet (CTX_PKT), draft proposal (DRAFT), and execution receipt (RECEIPT) into a single record (REC), then generates embeddings (EMB) for structured storage. These embeddings are added to the knowledge base (KB), and retrieval metrics are recalculated for accuracy. The updated KB is returned, enriched for future use in governance decisions and predictions.
| Algorithm 4 RAG_Loop_Update (REC, EMB, KB). |
|
6. Performance Evaluation and Analysis
This section evaluates APOLLO’s performance in decentralized governance, focusing on data handling, prediction accuracy, and processing efficiency. Table 2 outlines the tools and methods used for data fetching and analysis , such as BeautifulSoup (Python Software Foundation, Wilmington, DE, USA; version 4.12.2) and gemma3:4b (Google LLC, Mountain View, CA, USA; 4B parameter model) were used for sentiment analysis and forecasting. Table 3 details the components for on-chain simulation, storage, and voting tracking, implemented using Web3.py (Ethereum Foundation, Zug, Switzerland; version 6.15.1) and custom Python scripts (Python Software Foundation, Wilmington, DE, USA; version 3.10) for proposal execution and voting outcome tracking. The local server configuration supporting APOLLO includes an Intel Core i9-12900 CPU (Intel Corporation, Santa Clara, CA, USA), 64 GB DDR4 RAM, and the Ubuntu Linux operating system (Canonical Ltd., London, UK; version 22.04 LTS).
Table 2.
Data fetch and analysis.
Table 3.
Simulation, storage and voting tracking.
6.1. Benchmarking and Prediction Process
The system begins by benchmarking the margin of error (MoE) and confidence in predictions related to governance outcomes. The MoE is calculated using the Wilson score interval for binomial proportion, which blends statistical methods with a context-driven heuristic. This formula is expressed as follows:
where z is the Z-value for the confidence level, p is the estimated approval probability, and is the effective sample size. The final margin of error is determined by blending this Wilson score with a context-specific heuristic as the following equation:
where and are weighting factors based on the effective sample size , which help adjust the MoE based on the available data. Next, the confidence level is defined as the complement of the MoE as follows:
The confidence is then adjusted for stronger sentiment signals and clipped to a range of . Prediction of governance outcomes is performed using a logistic regression model as follows:
where is the logistic function, and are the features derived from context, such as sentiment scores, proposal length, historical rates, and engagement levels. The prediction model provides an estimated probability of approval, , which is used for forecasting.
Finally, forecasting is performed by combining historical approval or turnout baselines with the predictions above, computing both MoE and confidence to estimate potential outcomes. This process provides a comprehensive set of forecasts, including approval probabilities and turnout estimates, ensuring data-driven insights into governance outcomes.
6.2. Prediction Accuracy and Data Source Evaluation
Table 4 outlines the different data sources, their document counts, token volumes, and update frequencies. It shows that Forum data consists of 30 documents with 47,002 tokens, updated daily, while News Blogs includes 27 documents and 13,567 tokens, updated hourly. Community Chat data has 104 documents, totaling 4290 tokens, updated in real-time, and Governance Docs comprise 1985 documents, with a significant token volume of 942,069, updated every run. On-chain data, consisting of 19 proposals, is updated every 6 s but has a low token volume of 41 tokens.
Table 4.
Data sources and scraping volume.
Table 5 summarizes sentiment analysis and knowledge base embedding for various data sources. Forum and Chat data have positive sentiment, with confidence scores of 0.50 and 0.30, respectively, and both are embedded. News and On-chain data show mixed sentiment, with confidence scores of 0.20 and 0.00, and neither are embedded.
Table 5.
Sentiment analysis and knowledge base embedding.
6.3. Governance Efficiency and Proposal Execution
Table 6 shows the predicted success of proposals across Forum, Chat, News, and On-chain data, with high confidence ranging from 93.81% to 94.87% and consistent margins of error limit ±6.30% to ±6.86%. This highlights accuracy in forecasting governance proposal outcomes. The results shows the success of decision-making in governance processes.
Table 6.
Success prediction and forecast.
Figure 4 compares the prediction times for governance proposals in two aspects. Chart (i) shows success prediction times across four data sources: Forum (404 ms), Chat (424 ms), News (309 ms), and Onchain (430 ms), with News having the shortest and Onchain the longest. Chart (ii) compares the voting result prediction times for various proposals: Proposal ID 1397 (352 ms), Proposal ID 599 (368 ms), Proposal ID 1353 (365 ms), Proposal ID 666 (309 ms), and Proposal ID 38 (314 ms), with Proposal ID 666 having the fastest and Proposal ID 599 the slowest. This figure demonstrates the prediction model’s efficiency for both success and voting results.

Figure 4.
(i) Success prediction of sources, (ii) voting result prediction of proposal ID.
Table 7 compares the predicted voting outcomes with the actual results from Polkadot DAO’s referenda, showing high accuracy (94.21% to 99.00% confidence) and low margins of error (up to ±6.02%). The predictions closely match the actual results, demonstrating APOLLO’s effectiveness in real-world scenarios.
Table 7.
Voting result prediction vs. actual outcomes in Polkadot DAO’s historical referenda.
Table 8 shows APOLLO’s processing times under different loads: 792.12 s for light load, 1768.80 s for medium load, and 42,104.58 s for high load. The processing times include ingestion, analysis and prediction, and draft and signing times. The significant rise in total time under high load highlights scalability challenges particularly in the analysis and prediction phase. These results suggest the need for optimizations in handling higher loads.
Table 8.
End-to-end timing benchmarking.
6.4. Risk Mitigation and Error Handling
Table 9 outlines common failure cases and edge conditions. These include invalid payloads, detected by the proposal_submission.py script, which ensures only properly formatted payloads are processed. Sentiment ambiguity occurs when conflicting signals are detected, leading to manual review by a human verifier. Spam proposals are flagged by the context_generator.py script, using techniques like deduplication and rate-limit enforcement. Lastly, rate-limit exceeded failures are handled by main.py and context_generator.py, employing a backoff strategy, exponential retries, and request batching to maintain functionality. These strategies ensure APOLLO’s robustness and smooth operation under various failure conditions.
Table 9.
Failure cases and edge conditions.
Finally, Figure 5 shows that APOLLO DAO has the potential to generate successful proposals. With a focus on enhancing security, community engagement, and developing vital infrastructure such as SubWallet and Snowbridge, the DAO approach emphasizes prioritizing key management and proposal accessibility. This proactive strategy addresses concerns over declining trends, positioning APOLLO to generate impactful and successful proposals that foster growth and sustainability.
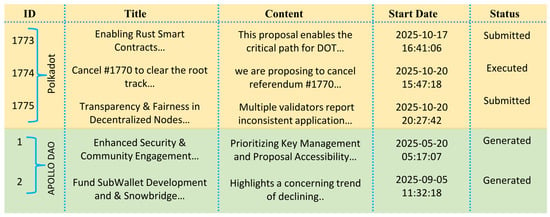
Figure 5.
Successful proposal generation.
7. Conclusions
APOLLO streamlines the whole proposal lifecycle with AI-driven automation, providing a revolutionary solution for decentralized governance. The key governance issues including voter apathy, strict tooling is addressed by the combination of LLMs and a multi-agent system augmented by RAG. It introduces an effective solution for DAOs and supports real-time, context-aware decision-making, which allows it to process governance proposals 3600 times faster than conventional techniques. This revolutionary potential demonstrates how AI can greatly enhance decentralized governance, promoting inclusion and flexibility in decision-making.
Some aspects of APOLLO could still be improved in spite of these advancements. Incorporating legal reasoning models is essential to improving compliance with complex and dynamic regulatory frameworks, particularly in cross-jurisdictional settings. The scalability and appropriateness for application in other blockchain ecosystems would be enhanced by expanding its capability to include multi-chain governance. Resolving cross-chain interoperability problems, improving prediction models, and improving decision-making algorithms should be the main goals of future research. With limited resources, we used gemma-3-4b; more powerful LLM models such as GPT-4o could outperform it in future deployments. A more robust, decentralized governance framework that can meet the needs of numerous blockchain platforms will be made possible by these initiatives.
Author Contributions
Conceptualization, I.A. and Z.M.Z.; methodology, I.A. and Z.M.Z.; investigation, I.A. and Z.M.Z.; formal analysis, I.A.; data curation, I.A.; writing—original draft preparation, I.A.; validation, M.S.F., T.N. and T.H.T.; supervision, M.S.F., T.N. and T.H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| vectors | |
| reciprocal-rank fusion score | |
| R | set of ranked lists |
| rank of document d | |
| k | RRF constant |
| document embedding | |
| hidden state at layer L | |
| n | token count |
| i-th text chunk | |
| artifact embedding | |
| encoder parameters | |
| d | embedding dimension |
References
- Han, J.; Lee, J.; Li, T. A review of DAO governance: Recent literature and emerging trends. J. Corp. Financ. 2025, 91, 102734. [Google Scholar] [CrossRef]
- Fritsch, R.; Müller, M.; Wattenhofer, R. Analyzing Voting Power in Decentralized Governance: Who Controls DAOs? Blockchain Res. Appl. 2024, 5, 100208. [Google Scholar] [CrossRef]
- Tally Documentation. 2025. Available online: https://docs.tally.xyz/ (accessed on 1 October 2025).
- Rikken, O.; Janssen, M.; Kwee, Z. Governance challenges of blockchain and decentralized autonomous organizations. Inf. Polity 2019, 24, 397–417. [Google Scholar] [CrossRef]
- Cronin, I. Autonomous AI Agents: Decision-Making, Data, and Algorithms. In Understanding Generative AI Business Applications: A Guide to Technical Principles and Real-World Applications; Apress: New York, NY, USA, 2024; pp. 165–180. [Google Scholar] [CrossRef]
- Luo, Y.; Feng, Y.; Xu, J.; Tasca, P.; Liu, Y. LLM-Powered Multi-Agent System for Automated Crypto Portfolio Management. arXiv 2025, arXiv:2501.00826. [Google Scholar] [CrossRef]
- Ziegler, C.; Miranda, M.; Cao, G.; Arentoft, G.; Nam, D.W. Classifying Proposals of Decentralized Autonomous Organizations Using Large Language Models. arXiv 2024, arXiv:2401.07059. [Google Scholar] [CrossRef]
- Song, Z.; Yan, B.; Liu, Y.; Fang, M.; Li, M.; Yan, R.; Chen, X. Injecting Domain-Specific Knowledge into Large Language Models: A Comprehensive Survey. arXiv 2025, arXiv:2502.10708. [Google Scholar] [CrossRef]
- Uniswap Governance. 2025. Available online: https://www.uniswapfoundation.org/governance (accessed on 1 October 2025).
- Ethereum Governance. 2025. Available online: https://ethereum.org/governance (accessed on 1 October 2025).
- Lalley, S.P.; Weyl, E.G. Quadratic Voting: How Mechanism Design Can Radicalize Democracy. AEA Pap. Proc. 2018, 108, 33–37. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 9459–9474. Available online: https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf (accessed on 1 October 2025).
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the NIPS’22: 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Available online: https://dl.acm.org/doi/10.5555/3600270.3602070 (accessed on 1 October 2025).
- Balaji, P.G.; Srinivasan, D. An Introduction to Multi-Agent Systems. In Innovations in Multi-Agent Systems and Applications—1; Srinivasan, D., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–27. [Google Scholar] [CrossRef]
- LangChain: Multi-Agent Systems. 2025. Available online: https://docs.langchain.com/oss/python/langchain/multi-agent (accessed on 1 October 2025).
- Ganache Truffle Suite. 2025. Available online: https://archive.trufflesuite.com/ganache/ (accessed on 1 October 2025).
- Phillips, D. What Is Vote Escrow? 2025. Available online: https://coinmarketcap.com/academy/article/what-is-vote-escrow (accessed on 1 October 2025).
- Zoltu, M. EIP-2718: Typed Transaction Envelope. 2020. Available online: https://eips.ethereum.org/EIPS/eip-2718 (accessed on 1 October 2025).
- The Vector Database for Scale in Production. 2025. Available online: https://www.pinecone.io/ (accessed on 1 October 2025).
- Hung, A.H.C. DAO as Rhizome: Reimagining Rules, Governance and Organisations. Law Crit. 2025. [Google Scholar] [CrossRef]
- Vendeville, A.; Guedj, B.; Zhou, S. Forecasting elections results via the voter model with stubborn nodes. Appl. Netw. Sci. 2021, 6, 1. [Google Scholar] [CrossRef]
- Moustafa, M. Generating Proposals for DAOs Using LLM: An Experiment. 2023. Available online: https://www.linumlabs.com/articles/generating-proposals-for-daos-using-llm-an-experiment (accessed on 1 October 2025).
- Kannammal, K.E.; R K, A.; Tamizhiniyal, K.; Ganishkar, G.; Adrinath, C. Fin-RAG: A RAG System for Financial Documents. Int. J. Innov. Sci. Res. Technol. 2025, 10, 1761–1767. [Google Scholar] [CrossRef]
- David, I.; Zhou, L.; Song, D.; Gervais, A.; Qin, K. Decompiling Smart Contracts with a Large Language Model. arXiv 2025, arXiv:2506.19624. [Google Scholar] [CrossRef]
- Databricks, A. RAG Application Governance and LLMOps. 2025. Available online: https://learn.microsoft.com/en-us/azure/databricks/generative-ai/tutorials/ai-cookbook/fundamentals-governance-llmops (accessed on 1 October 2025).
- Wang, Q.; Yu, G.; Sai, Y.; Sun, C.; Nguyen, L.D.; Chen, S. Understanding DAOs: An Empirical Study on Governance Dynamics. IEEE Trans. Comput. Soc. Syst. 2025, 12, 2814–2832. [Google Scholar] [CrossRef]
- Monteiro, T.D.; Sanchez, O.P.; Moraes, G.H.S.M.d. Exploring off-chain voting and blockchain in decentralized autonomous organizations. RAUSP Manag. J. 2024, 59, 335–349. [Google Scholar] [CrossRef]
- Ahmed, I.; Zubraj, Z.M. Autonomous-Predictive-On-Chain-Learning-Orchestrator (APOLLO) for AI-Driven Blockchain Governance. 2025. Available online: https://github.com/istiaque010/Autonomous-Predictive-On-Chain-Learning-Orchestrator-APOLLO-for-AI-Driven-Blockchain-Governance.git (accessed on 1 October 2025).
- Cormack, G.V.; Clarke, C.L.A.; Buettcher, S. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the SIGIR ’09: 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 758–759. [Google Scholar] [CrossRef]
- Malkov, Y.A.; Yashunin, D.A. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 824–836. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Douze, M.; Jégou, H. Billion-Scale Similarity Search with GPUs. IEEE Trans. Big Data 2021, 7, 535–547. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.