Abstract
Generative artificial intelligence (AI) is reshaping creative practices, yet many systems rely on traditional interfaces, limiting intuitive and embodied engagement. This study presents a qualitative observational analysis of participant interactions with a real-time generative AI installation designed to co-create Ukiyo-e-style artwork through embodied inputs. The system dynamically interprets physical presence, object manipulation, body poses, and gestures to influence AI-generated visuals displayed on a large public screen. Drawing on systematic video analysis and detailed interaction logs across 13 sessions, the research identifies core modalities of interaction, patterns of co-creation, and user responses. Tangible objects with salient visual features such as color and pattern emerged as the primary, most intuitive input method, while bodily poses and hand gestures served as compositional modifiers. The system’s immediate feedback loop enabled rapid learning and iterative exploration and enhanced the user’s feeling of control. Users engaged in collaborative discovery, turn-taking, and shared authorship, frequently expressing a positive effect. The findings highlight how embodied interaction lowers cognitive barriers, enhances engagement, and supports meaningful human–AI collaboration. This study offers design implications for future creative AI systems, emphasizing accessibility, playful exploration, and cultural resonance, with the potential to democratize artistic expression and foster deeper public engagement with digital cultural heritage.
1. Introduction
Recent advancements in generative AI, particularly large-scale diffusion models, and real-time conditional generation, are radically transforming creative processes in immersive environments [1,2]. These technologies promise new modes of interaction in spatial computing systems, where extended reality (XR) interfaces can dynamically respond to contextual cues such as bodily motion, object manipulation, and spatial proximity [3]. However, current generative interfaces are mainly limited to text prompts and graphical user interfaces (GUIs), which often impose high cognitive loads, obscure the logic of generative models, and restrict the expressive potential of users, particularly in creative or performative contexts [4]. This challenge is particularly pronounced in innovative environments where adaptivity, responsiveness, and embodied feedback loops are central to effective human–machine interactions. As immersive media becomes increasingly interactive and multimodal, new paradigms are needed to bridge the semantic and sensory gap between human intention and AI output. Tangible and gestural inputs already core to interactions in mixed-reality installations offer a promising direction by enabling users to communicate with AI systems through intuitive physical actions that mirror real-world creative behavior [5]. Despite these opportunities, the literature on context-aware generative systems in XR remains sparse. Most immersive applications employ gesture or motion sensing for navigation or selection tasks but not for real-time, high-fidelity co-creation with generative AI [6,7]. There remains a critical gap in our understanding of how embodied, real-time interfaces can facilitate collaborative authorship, intuitive learning, and affective engagement in adaptive multimedia systems. This study directly confronts these challenges by proposing that the limitations of cognitive load and restricted expression can be overcome through embodied interactions. To bridge the semantic and sensory gap between human intention and AI output, we leverage tangible and gestural inputs as a new interaction paradigm. Our system replaces abstract text prompts and complex GUIs with intuitive physical actions, allowing users to communicate with the AI through direct manipulation that mirrors real-world creative behavior. This approach is designed to lower cognitive barriers, making generative AI more accessible and expressive, particularly in performative and collaborative contexts.
Our contributions are as follows: An embodied, context-aware co-creation loop that turns physical action into generative control is designed, and a mixed-methods analysis (thematic + five-indicator framework) of 334 interaction events and design implications for accessible, playful, culturally resonant creative AI is performed. This study addresses how embodied control affects agency, learning, and affect in public settings with an observational analysis of an embodied generative art system. The system translates bodily poses, tangible object properties, and gestural expressions into live visual outputs using a real-time adaptive generative model optimized for artistic responsiveness. Through interaction episodes, this research explores how embodied inputs function as control mechanisms and creative gestures, fostering a fluid, expressive partnership between humans and generative AI. By situating this study within the domain of adaptive immersive media, we contribute to the design of next-generation extended reality interfaces that are context-aware, cognitively accessible, emotionally engaging, and socially co-creative. This embodied approach aims to reduce cognitive barriers, enhance intuitive engagement, and expand creative expression by seamlessly translating real-world physical actions into artistic output, proposing a more direct and natural dialog between humans and AI.
2. Background and Related Work
This research addresses some gaps at the intersection of embodied interaction, real-time generative artificial intelligence, and human–AI co-creation. While the existing literature extensively explores these domains individually, there remains a significant need for systems that seamlessly integrate physical, intuitive user input with dynamic AI generation in ways that enhance user agency and foster authentic co-creative experiences, particularly within public, performative contexts. To establish a logical framework for our study, this section synthesizes insights from four key domains (Table 1). For each domain, we identify the current strengths and highlight areas where our research aims to contribute new understanding or propose novel solutions, culminating in our specific research questions and hypotheses.

Table 1.
Key domains and their roles in this study.
2.1. Embodied Interaction and Tangible User Interfaces
Foundational work in tangible user interfaces (TUIs) highlights how physical objects can intuitively manipulate digital content. While TUIs successfully lower interaction barriers by leveraging natural hand–object relationships, current applications often focus on manipulating pre-defined digital assets rather than dynamically influencing the parameters of real-time generative AI. This leaves a gap in understanding how such embodied principles can be extended to foster emergent co-creation, where the physical input directly shapes AI’s creative process in an unscripted manner. Our study, by employing tangible props to control a generative Ukiyo-e model, seeks to bridge this gap, investigating how this direct manipulation enhances user agency in AI art generation. Embodied interaction posits that cognition is fundamentally shaped by bodily engagement with the physical world, an idea prominently articulated by Dourish as a shift from abstract symbol manipulation toward situated action [8]. In interactive systems, this paradigm has informed the design of tangible user interfaces (TUIs), where physical objects serve as direct handles for manipulating digital content. Ishii and Ullmer’s foundational work on “tangible bits” continues to influence current developments in sensor-augmented materials and spatially aware objects for immersive systems [9]. Recent applications have extended these concepts into mixed-reality contexts, enabling users to manipulate generative algorithms through embodied actions such as gesture-based sculpting or prop manipulation [10]. Svanæs highlights how interactive systems should be designed “for and with the lived body,” integrating motor–perceptual feedback and corporeal expressiveness into digital workflows [11]. This framework is critical for developing intuitive, adaptive systems in XR environments where physical and digital boundaries become fluid.
2.2. Context-Aware Multimedia and Immersive Media Systems
Context-aware multimedia systems leverage environmental and user-centric data such as position, posture, or proxemics to adapt content delivery and interaction modes dynamically in real time [12]. This capability in immersive media environments such as VR and AR is particularly relevant for enhancing presence, responsiveness, and user control. Pose estimation technologies like OpenPose [13] and camera-based sensing frameworks such as PoseNet [14] enable systems to track fine-grained motion and spatial configuration, forming the backbone of embodied adaptivity. Latent diffusion models with conditional control, including ControlNet [15], have advanced the ability to synthesize high-resolution visual content in real time, dynamically conditioned on multimodal inputs. This convergence of deep generative models and contextual sensor data underpins emerging forms of creative interaction in smart environments, ranging from adaptive stage visuals to personalized museum exhibits [16]. The system examined in this study exemplifies this convergence: it captures user posture, tangible inputs, and gestures to influence stylistically constrained generative outputs in a continuously updating visual display. This real-time responsiveness transforms the interaction from command-based control to an embodied, performative dialog with AI.
2.3. Human-AI Co-Creation and Creative Interfaces
As generative models become more sophisticated, a growing body of research explores how users can interact with AI systems as tools and co-creative partners. Mixed-initiative systems [17] and co-creative interfaces [18] seek to balance user agency with AI autonomy, facilitating iterative cycles where both human input and machine output inform the creative trajectory. Physical co-creation with AI has emerged as a particularly rich modality in this context. Huang and Dong’s “Sand Playground” project, for example, enables users to shape generative art through bodily movement and physical media, foregrounding the role of embodied intelligence in AI collaboration [19]. Using stylized generative models trained on cultural corpora, such as Ukiyo-e, further introduces the dimension of aesthetic coherence and cultural specificity—enabling adaptive and culturally expressive systems [20]. Such interfaces demand new design principles for transparency, affective engagement, and creative empowerment. Recent design guidelines emphasize interpretability, real-time feedback, and the capacity for emergent user learning as key elements of generative AI UX [21].
2.4. Situated Cognition and Affect in Interaction
Situated cognition theory argues that knowledge emerges from contextual, embodied experience rather than abstract reasoning alone. In human–computer interactions, this translates to designing systems that respond to physical, temporal, and social use situations [8]. By reacting to bodily cues and spatial configurations, embodied AI systems align with this perspective by making the interface intelligible through sensorimotor experience rather than textual commands or symbolic representations. The cognitive benefits of embodied interfaces are increasingly documented: users more easily develop mental models of AI behavior, their cognitive load is reduced, and they engage more freely in creative exploration [19]. This effect is particularly evident in installations like the one studied here, where rapid feedback loops allow users to refine gestures and objects iteratively to influence the AI’s generative response, resulting in affectively charged moments of discovery, surprise, and delight. Affective engagement is a by-product and a central design outcome for embodied systems. By enabling playful exploration and fostering a sense of authorship, these systems facilitate flow states and positive emotional resonance core predictors of creative engagement and long-term system adoption [22]. The literature review highlights a critical need for generative AI systems to adopt embodied co-creation, moving beyond conventional text or GUI-based interactions, especially in public, engaging contexts. While the individual components of embodied interaction, real-time sensing, generative AI, and theories of situated cognition are well-established, their seamless and empirically evaluated integration to foster user agency in a specific cultural aesthetic remains underexplored. This project—an ‘Embodied Ukiyo-e’ system—directly addresses these gaps by investigating how such an integrated approach can drive co-creation.
3. Methodology
3.1. System Description
The generative Ukiyo-e art system examined in this study is an innovative embodied interaction platform designed to overcome the limitations of traditional text-prompt- and graphical user interface (GUI)-based systems. Unlike interfaces that rely on abstract commands, our installation functions as a responsive digital canvas, enabling participants to co-create Ukiyo-e-style artworks through intuitive physical interactions in real time. Within a designated interaction zone, the system translates the audience’s physical inputs, such as gestures, body poses, and the manipulation of tangible props, into a continuously evolving visual output on a large, high-resolution screen. We chose Ukiyo-e, a genre of Japanese art from the 17th to 19th centuries known for its distinctive woodblock prints [23], as the generative style. This provides a rich aesthetic framework with recognizable motifs (e.g., Mt. Fuji, cherry blossoms), against which the AI’s novel interpretations of user input can be clearly observed, allowing for an exploration of how users engage with AI within a specific cultural domain. The large, high-resolution screen displays the evolving output of a generative AI model, continuously updated in response to user actions within a designated interaction zone. The system is framed as a responsive canvas, translating the audience’s physical inputs like gestures, body poses, and the manipulation of tangible props into visual outputs that retain stylistic fidelity to traditional Japanese woodblock aesthetics (see Figure 1). The system’s primary innovation lies in its integration of real-time generative AI with a multimodal embodied interface in a public setting. This unique combination allows for the study of naturalistic, unscripted, and co-creative human–AI partnerships, moving beyond conventional command-based interaction models.
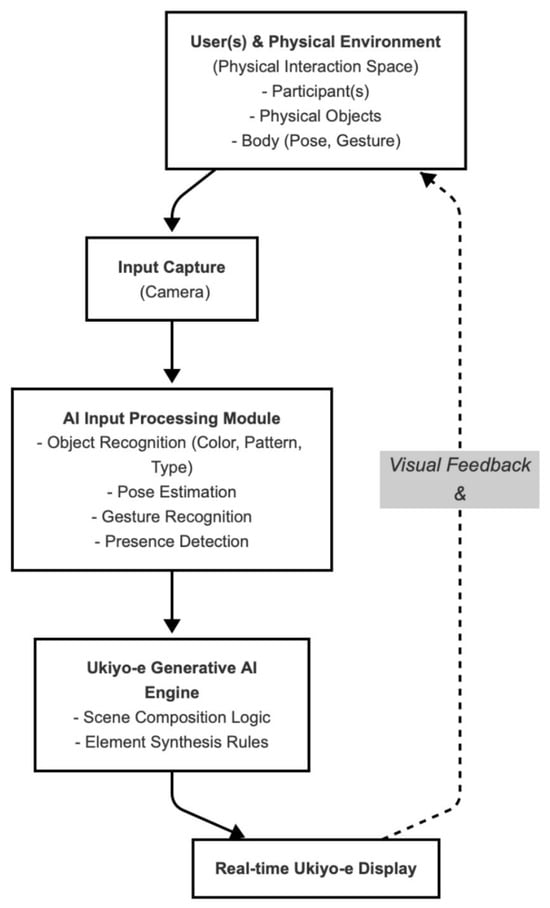
Figure 1.
System Architecture and Real-Time Interaction Loop.
3.2. Input Modalities
3.2.1. Gesture and Pose Detection
The system employs a vision pipeline based on the Intel RealSense D435i camera, designed by Intel Corporation in Santa Clara, USA, and manufactured in Shenzhen, China to interpret full-body poses and expressive hand gestures. Techniques similar to OpenPose [24] and PoseNet [25] allow for real-time tracking of posture, limb extension, and hand configurations. These embodied signals function as modifiers: wide arm spreads result in panoramic compositions, raised arms trigger vertical expansion, and specific gestures (e.g., hand-framing) consistently lead to architectural framing motifs in the AI output. The interaction between static props and dynamic gestures forms a rich co-creative input space.
3.2.2. Object-Based Input
The system incorporates tangible objects as intuitive control elements. Each prop, ranging from pillows with distinctive colors and patterns to shiny fabric sheets, is an input feature recognized through a real-time vision system. The AI maps visual properties such as hue, texture, material reflectivity, and pattern geometry to stylistic parameters of the generated scene, including color palette, environmental motifs (e.g., blossoms, cliffs), and texture composition. For instance, a polka-dot pillow reliably induces checkerboard hill patterns, while shiny blue fabric consistently generates reflective water surfaces.
3.3. Real-Time Adaptation Mechanism
3.3.1. Camera-Based Context Sensing
At the installation’s core is a vision system that continuously captures the state of the physical environment, including participant presence, object introduction, movement vectors, and relative proximity to the sensor (See Figure 2). The system infers which users are contributing input and the social composition of the groups, enabling it to adapt in both solo and collaborative contexts.
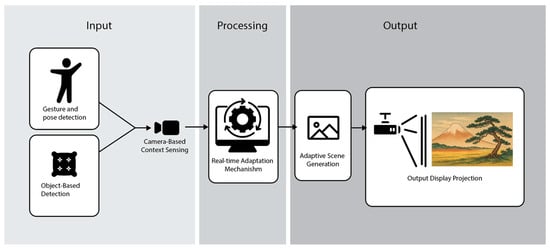
Figure 2.
Embodied real-time co-creative and generative art system installation.
3.3.2. AI Generation Loop with Style Conditioning
Extracted features are passed to a conditional generative model capable of synthesizing new images in the Ukiyo-e style. The underlying model resembles a latent diffusion architecture [26] with stylistic control inspired by ControlNet-like frameworks [15]. The training set comprises a curated corpus of historical Ukiyo-e art, allowing the AI to maintain stylistic authenticity while accommodating novel compositional inputs. Object colors, material types, and gestures are encoded as conditioning vectors influencing scene layout, brushstroke density, and thematic motifs in the output image.
3.3.3. Output Display and User Feedback Loop
Output from the generative model is displayed on a large public screen. The visual response to user input occurs within 1–2 s, establishing a rapid and intuitive feedback loop. This immediacy supports iterative exploration, as users quickly test cause-effect relationships and adjust their inputs accordingly. The installation’s responsiveness is critical for encouraging interaction, sustaining attention, and supporting mental model development [27].
3.4. Context-Aware Design Features
3.4.1. Immediate Visual Feedback
One of the system’s defining features is its ability to respond visually to even subtle changes in user input. This immediacy facilitates a sense of direct manipulation and empowers users to experiment with different combinations of props, poses, and positions without requiring instruction or technical knowledge. Such responsiveness aligns with best practices for adaptive AI UX design, emphasizing low latency and real-time interpretability [28].
3.4.2. Adaptive Scene Generation Based on Social/Multi-User Input
The system supports multi-user engagement by recognizing concurrent inputs from multiple participants. When several people present props or perform gestures simultaneously, the system blends these inputs to generate composite scenes that reflect the group’s collective influence. This social adaptivity is central to the system’s design, promoting co-creation, collaboration, and shared authorship—hallmarks of participatory AI art environments [29]. Participants often engage in coordinated acts, such as forming framing gestures in unison or combining props to layer visual themes, which the system seamlessly interprets as coherent outputs.
4. Observational Study Design and Mixed-Methods Analysis
4.1. Observational Ethnographic Protocol
To understand the human–AI co-creation behaviors within our Ukiyo-e art installation, we employed a qualitative observational ethnographic protocol. This approach allowed us to capture unscripted interactions in an authentic, uncontrolled setting, providing rich insights into user engagement, emergent social dynamics, and the nuances of embodied interaction. Our observations focused on general patterns of physical movement, prop manipulation, participant reactions, and the duration of engagement within the designated interaction zone.
4.1.1. Ethics and Limitations
Our study was conducted through passive observations within a public exhibition space, a methodological choice driven by the desire to capture naturalistic human–AI interaction without interference. A rigorous ethical protocol was implemented to safeguard participant privacy. Specifically, no personal data or identifiers were collected or stored; all video input was processed in real time, and only anonymized, abstract numerical parameters of user interaction were retained. The data collected, strictly devoid of any personally identifiable information, was used solely for non-commercial academic purposes. Despite these careful ethical considerations, the study inherently faced several methodological limitations. Primarily, the absence of direct participant feedback, such as interviews or surveys, limited our ability to triangulate findings with subjective experiences. Consequently, we could not gain deeper insights into individual user intentions, motivations, or perceived agency, relying instead on observable behaviors. Furthermore, emotional states were inferred from visual cues like facial expressions and body language recorded in the anonymized logs. While these inferences provided valuable insights, they represent the researchers’ interpretation rather than confirmed verbal accounts, thereby introducing potential for interpretive bias. Additionally, the lack of demographic information (e.g., age, cultural background, prior experience with AI) restricted any analysis of how such factors might have influenced interaction patterns or engagement levels with the system. Finally, the underlying generative AI system operated as a “black box” from a research perspective. Without direct access to its internal architecture, training data, or detailed operational logic, our interpretations of its behavior and the AI’s “contribution” to co-creation had to rely solely on observable input–output relationships and the generated artistic outputs. Despite these inherent constraints, the naturalistic setting of a public exhibition and the richness of the anonymized interaction data provided a robust empirical foundation. This allowed us to draw grounded conclusions about embodied co-creation and real-time context-aware responsiveness within adaptive AI systems, focusing on observable patterns of human–AI engagement.
4.1.2. Participants
Participants were self-selected visitors to a public exhibition. They varied widely in apparent age and group composition (e.g., individuals, families, friends), reflecting the inclusive nature of the setting. Due to the unobtrusive nature of the observation and the ethical constraints of passive video data collection, no formal demographic data was recorded. Engagements ranged from short, curious interactions to extended, highly performative co-creation sessions involving turn-taking and collaborative input. The primary data source was a high-resolution video recording capturing continuous participant interaction with the system over multiple sessions. The recording documented body movements, object usage, visible emotional reactions, and the system’s real-time output. The system was presented and used at the final exhibition of the Design Graduation Event at Chiba University, held at the Design Research Institute on the Sumida Campus.
4.1.3. Data Collection
Our data collection focused exclusively on the anonymized parameters extracted in real time from participant interactions, rather than stored raw video footage. While the system’s live operation relied on video input for real-time skeletal pose and prop recognition, this video stream was processed in real time, and no visual recordings of participants were ever saved or archived. Instead, as described in the Ethical Considerations, the system systematically generated “Detailed User–Action Interaction Logs.” These logs, saved as a structured dataset, captured discrete user events and system responses without retaining any identifiable visual data. Multiple distinct interaction sequences, which we called “documents” (identified by restarts in system activity or changes in participant groups), were collected as anonymized interaction data. This detailed CVS log, comprising the parameters outlined in Table 2, forms the primary dataset for all subsequent analysis. The detailed interaction log capturing discrete user events, including participant actions, emotional states, object usage, and AI-generated Ukiyo-e scene descriptions, facilitated analysis of user–AI interaction dynamics.
Table 2.
Detailed User-Action Interaction Log parameters.
4.1.4. System Specifications
The system runs on a high-performance workstation equipped with an Intel i9-12900 K CPU and an NVIDIA GeForce RTX 4090 GPU, operating on Ubuntu 20.04. Pose and gesture tracking are managed by a custom OpenPose v1.7 implementation, optimized for real-time performance on the NVIDIA GPU. The interaction zone is a precisely defined 3 m x 2 m rectangular area directly in front of a large 4 K projection screen of 3.5 m diagonal (Figure 3). A single Intel RealSense D435i depth camera is centrally mounted 2.5 m high, facing downwards, to capture depth and RGB video for skeletal tracking and prop identification. Camera calibration was performed using a standard checkerboard pattern to minimize distortion and ensure accurate spatial mapping. The tangible props used (e.g., silk scarves, wooden blocks, colored cushions) are everyday objects, ranging from 15–50 cm in their largest dimension, chosen for their distinct visual features and ease of manipulation. They contain no embedded sensors but are visually tracked using a YOLOv5 object detection model fine-tuned on a custom dataset of these props, operating in conjunction with the OpenPose output to establish their spatial relationship to the user’s body. The generative AI at the system’s core is a latent-diffusion model fine-tuned from a Stable Diffusion v1.5 base. It was trained on a proprietary dataset of 5000 high-resolution Ukiyo-e images for 10 epochs, specifically focusing on generating diverse scenes featuring landscapes, figures, and iconic motifs. For real-time response, Latent Consistency Models (LCMs) were integrated into the diffusion pipeline, reducing inference steps to between 4 and 8, enabling near-instantaneous image generation (approximately 100 ms per frame). A critical aspect of the system’s design is the parameter mapping from embodied user inputs to the AI’s generative controls, specific changes in user pose, gesture, and prop manipulation directly modulate distinct features of the generated Ukiyo-e output. For instance, the height of the user’s hands within the interaction zone controls the scenic density, while prop rotation around its vertical axis shifts the color palette’s hue. Furthermore, specific recognized gestures (e.g., an open palm facing the screen) act as prompts to introduce or emphasize foreground elements (e.g., cherry blossoms, traditional figures), thereby allowing users direct creative agency over the AI’s output.
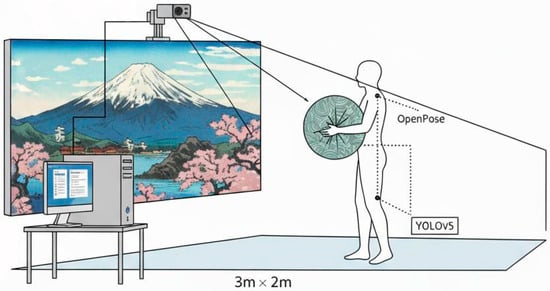
Figure 3.
Schematic side view of the “Embodied Ukiyo-e” system depicting the hardware setup.
4.1.5. Analytical Framework
Analysis followed a thematic approach informed by Braun and Clarke’s methodology [30], emphasizing inductive pattern discovery and theory-grounded interpretation.
4.1.6. Thematic Coding
Initial coding involved open-label tagging of actions, reactions, and visual outputs. These were iteratively grouped into higher-order categories such as Input modality types or core scene drivers (object-based), visual transformation patterns or significant shapers (object combinations, deliberate body, gesture-to-composition), modifiers and fine tuners (general body pose, hand gestures) and contextual elements (general movements, presence or absence) (Figure 4).
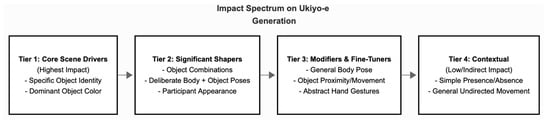
Figure 4.
Hierarchical Impact of Embodied Inputs on Ukiyo-e Output.
4.1.7. Interaction Logging with Time Stamped Behavioral Annotations
The structured CSV enabled timeline-based event analysis. Time-stamps allowed comparison of system responsiveness to input. Changes in the AI-generated scene were correlated with participant behavior in near real-time (Figure 5), revealing patterns of cause-effect perception and adaptation. This dual method, structured annotation, and interpretive coding enabled both descriptive richness and cross-case comparisons across over 300 logged events.

Figure 5.
Samples of real input and corresponding output from the interactive art system.
4.2. User Agency and Co-Creative Engagement Quantitative Analysis
This evaluation analyzes users’ interactions with a real-time Ukiyo-e generative art system to understand the dynamics of embodied co-creation. The system is driven by a latent-diffusion model, trained on a dedicated Ukiyo-e corpus and further accelerated with Latent Consistency Models (LCM) for real-time response. Drawing on detailed logs from 13 distinct interaction sessions, comprising 36 uniquely labeled participant instances and 334 actions, we quantitatively evaluate five key indicators of user agency and co-creative engagement (Table 3). These indicators include: Diversity of Inputs Used (DIU), which measures the variety of tangible objects and input modalities employed by participants, reflecting their exploration of the system’s physical interface; Intentionality and Control (IC), which assesses the user’s perceived influence over the AI based on their ability to achieve specific co-design goals or execute complex compositional blends; Iterative Refinement and Exploration (IRE), an indicator that quantifies the sequential and exploratory nature of interactions, reflecting how users build upon or evolve their creative ideas; Exploitation of the System’s Expressive Range (ESR), which gauges the extent to which participants push the AI’s capabilities by triggering a wide array of its unique Ukiyo-e output features; and User Affect and Engagement (UAE), which serves as a proxy for positive emotional experience and deep involvement, capturing observable signs of enjoyment and active participation. Together, these indicators provide a multifaceted quantitative lens through which to evaluate the effectiveness of our embodied co-creation system. Findings, reported as Weighted Engagement Scores (WES) under multiple weighting profiles, reveal distinct patterns across these indicators and clarify how different embodied actions allow users to influence the AI and experience collaboration, with implications for the design of future co-creative systems. Interaction data were logged with the following fields: Interaction-Session ID, Timestamp, Participant ID(s), Action, Object Used, Pose/Movement Description, Observed Emotion, Photo Taken (Y/N), Ukiyo-e Output Description, and contextual Notes. The resulting textual corpus was processed to identify key input parameters and output features.
Table 3.
Five key indicators for quantitative analysis.
4.2.1. Framework for Assessing User Agency and Co-Creative Engagement
Five key indicators were operationalised from the textual logs through keyword and contextual pattern detection (Table 3).
4.2.2. Weighting Profiles and Weighted Engagement Score (WES)
To examine the effect of emphasizing different facets of engagement, five weighting profiles were defined (Table 4). Each was applied to the raw indicator scores to compute a Weighted Engagement Score (WES) for every participant instance:
WES_profile = (w_diu × DIU_raw) + (w_ic × IC_raw) + (w_ire × IRE_raw) + (w_esr × ESR_raw) + (w_uae × UAE_raw)
Table 4.
Five weighting engagement profiles.
Operational definitions, calculation methods, and scale boundaries for the five raw co-creative engagement indicators: Diverse Input Use (DIU), Input Comprehension (IC), Iterative Refinement Efficiency (IRE), Exploratory Style Range (ESR), and User-Assessed Enjoyment (UAE).
The weights in Table 4 were defined by the authors to create five distinct analytical profiles for evaluating user engagement. This approach was not based on an empirical derivation but was a methodological choice designed to examine the data through different lenses, each emphasizing a specific facet of co-creation. For instance, the “Balanced” profile provides a general overview with relatively even weights, while the “Emphasis” profiles deliberately assign a higher weight (0.40) to a single indicator—such as Intentional Control (IC) or User Affect and Engagement (UAE), to isolate and highlight interactions that excelled in that particular dimension. This method effectively functions as a sensitivity analysis, allowing for a more nuanced interpretation of the results by revealing how the assessment of a “strong” co-creative partnership changes depending on which aspect of the user experience is prioritized.
5. Results
5.1. Qualitative Analysis Results
The systematic analysis of the extensive interaction data, meticulously logged across 13 distinct “Documents” (interaction sequences), revealed several key findings regarding how diverse users engaged with the embodied Ukiyo-e generative AI system. These findings are organized into three major thematic areas: the modalities of embodied interaction, co-creation dynamics, and cognitive/affective user engagement.
5.1.1. Modalities and Emergent Patterns of Embodied Interaction
- Dominance and Intuitiveness of Tangible Object Manipulation.
- The most consistent and impactful user interactions were mediated through tangible objects. Participants rapidly grasped that presenting physical objects to the camera would influence the generative system’s output in real time.
- Color Mapping: Object color had a direct and often immediate influence on the overall palette of the Ukiyo-e scene. Red sheets frequently triggered sunset-toned skies and reddish landscapes. Blue objects, especially the shiny blue sheet, evoked cool-toned skies and water bodies.
- Thematic Object Association: Specific objects consistently introduced thematic elements. For example, the pink rose reliably triggered cherry blossoms or floral motifs.
- Material Properties: Beyond color, material properties such as shine or texture affect the output. The shiny blue sheet often yielded more reflective water, suggesting the AI model recognized surface gloss.
- Object Hierarchy and Specificity: Some objects acted as dominant “scene keys” notably, patterned pillows like the polka dot design regularly produced checkerboard-textured terrain. These objects could override prior inputs and establish strong stylistic themes.
- Bodily Pose and Gesture as Significant Modifiers.
While objects set thematic direction, body movement, and posture were powerful compositional modifiers.
- Presence and General Appearance: Simply entering the interaction zone activated the system and changed the visual state. Clothing color also subtly influenced the visual tone.
- Compositional Poses: Expanding arms led to more expansive landscape views, while vertical gestures (e.g., arms raised or holding props high) shifted focus to clouds or mountain peaks.
- Framing Gestures: A recurring gesture was using hands to form a frame or diamond shape, often resulting in scenes centered around Mt. Fuji or moon elements.
- Pointing, Gaze, and Proximity: Though pointing was less consistent in effect, looking upward or moving objects close to the camera often intensified or zoomed specific elements.
- The Crucial Role of the Real-Time Feedback Loop.
The system’s responsiveness was critical for user learning and engagement.
- Discovering Correlations: Immediate output changes helped users intuitively grasp the input-output relationship.
- Rapid Iteration and Sustained Engagement: Participants engaged in fluid, trial-and-error interactions. The absence of “undo” features encouraged playful experimentation, with users adjusting objects or poses to shape the scene iteratively in real time.
5.1.2. Dynamics of Co-Creation and Co-Design
- User-AI Co-Creation.
AI as an Interpretive Partner: Users treated the AI as a semi-autonomous creative agent (See Figure 6). They frequently displayed surprise or delight at how their inputs were rendered.
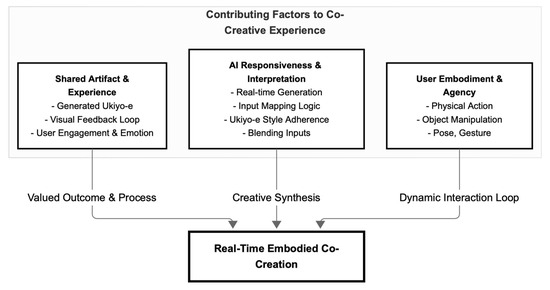
Figure 6.
Correlation Network between Physical Inputs and Generated Ukiyo-e Features.
- Learning the AI’s Language: Users progressively developed internal models of how the system responded. Repeated use of particular objects (e.g., pink rose or red sheet) illustrates a learned mapping.
- Negotiated Agency: Users directed scene themes through inputs, but the AI maintained stylistic control over composition and blending. For instance, blended outputs demonstrated an emergent, shared authorship.
- Overriding Influence: Some objects exert more control than others. Patterned pillows often overrode or reoriented the entire scene despite previous input context.
- Influence of Co-Present Social Interaction.
The public, shared setting led to rich, socially mediated co-creative dynamics.
- Collaborative Exploration: Users often engaged, suggesting inputs, reacting collectively, and co-managing object placement.
- Turn-Taking and Object Swapping: Passing and swapping objects (especially pillows) was common and often served as an informal handoff of creative control.
- Verbal and Non-Verbal Communication: While not directly recorded, visible gestures and facial expressions indicated that users engaged in active dialog and feedback loops during co-creation.
- Observational Learning: Users frequently mimicked successful strategies observed in others’ interactions, whether in their group or prior participants.
- Photo-Taking as Social Capture: Photo-taking occurred 14 times across documents. Often, sociable participants took photos of each other or the collaborative artwork, indicating a sense of shared achievement.
5.1.3. Cognitive and Affective Engagement
The embodied interface had notable cognitive and affective consequences for the users in these different aspects:
- User Agency and Sense of Control: Physical actions’ direct and immediate impact on the Ukiyo-e fostered a strong sense of user agency. Participants could see their inputs shaping the artwork, leading to feelings of control and authorship, even if the AI contributed significant stylistic interpretation. The ability to quickly change the scene by introducing new objects or poses reinforced this.
- Mental Model Formation: Users rapidly develop mental models of the system’s logic, associating specific objects or actions with predictable (or at least categorizable) outputs. This result was evident in their targeted reuse of certain objects to achieve particular effects (e.g., consistently using the “polka dot pillow” for the checkerboard landscape). The learning curve appeared relatively shallow for core object-based interactions.
- Reduced Cognitive Load: Compared to complex software with numerous menus and parameters, the embodied interface seemed to impose a lower cognitive load for basic creative control. Users could leverage their intuitive understanding of physical objects and space rather than needing to learn abstract symbolic commands.
- Positive Affective Engagement: A striking and consistent finding was the high positive effect exhibited by participants. “Smiling/Happy” was the most frequently observed emotion (noted in over 100 interaction rows). Laughter, expressions of delight, and engaged discussion were common, particularly during collaborative interactions or when the AI produced surprising or aesthetically pleasing results. These results suggest that the experience was intrinsically motivating and enjoyable.
- Reduced Fear of Failure/Playful Experimentation: The ease of changing the scene and the lack of “undo” buttons (standard in digital software) did not hinder exploration. Instead, it encouraged a more playful “what if?” approach. If the output was not desired, users introduced a new object or changed their pose, iteratively sculpting the scene without apparent frustration from “mistakes.”
5.2. Quantitative Analysis Results
Quantitative analysis of the 334 interactions across 13 sessions revealed a broad spectrum of engagement styles. Figure 7 visualizes the full range and standout instances for each indicator, enabling close inspection of how different component emphases affect overall scores and relative ranking. Instance S1-P1 emerges as an “Exhaustive Explorer and Deep Interactor.” Its Balanced WES of 16.40—the study’s highest—remains high across all weighting profiles, driven by outstanding raw scores in DIU (10), IC (7), IRE (52), and ESR (9). The participant not only explored a wide range of tangible inputs but also engaged in extensive iterative refinement and produced highly varied, complex outputs, epitomizing strong co-creative partnership enabled by real-time LCM responsiveness. Group S3-G1 illustrates a “High Affective Group Engagement” profile. Its Balanced WES (8.30) is propelled by an unprecedented UAE score of 20, yielding a WES of 12.50 under the “Affective” weighting. Although its IC is low (0), the group’s primary value lay in shared experience, collective enjoyment, and the production of visually appealing artifacts they wished to keep. S9-G1 and S1-P3 exemplify “Intentional Co-design.” Despite a modest Balanced WES (2.85), S9-G1 attains its highest relative score (3.20) under “Intentional Control”, owing to an IC of 5 (the “diamond frame” gesture). Similarly, S1-P3 (Balanced 7.45) combines IC = 5 with ESR = 9, showing users can move beyond exploration to impose deliberate compositional structures. S4-P1 shows an accessible “Playful Engagement” pattern—a Balanced WES of 5.80 with UAE = 7—highlighting how intuitive interaction and immediate feedback foster engagement even in novices. Sensitivity analysis across weighting profiles confirms that while some users are robustly strong, the “strength” of co-creation may be construed differently depending on which aspect is prioritized. There is no single “best” co-creator; rather, successful and meaningful engagement manifests in multiple styles. The study points to several concrete design implications for future embodied co-creative systems: 1. A diverse palette of tangible inputs each with an immediately legible mapping to visual parameters should be offered to sustain a high Diverse Input Use (DIU) and Input Comprehension (IC). 2. Real-time system responsiveness is essential for maintaining a high Iterative Refinement Efficiency (IRE); latency must be kept to a perceptually negligible level. 3. The generative engine should support a broad aesthetic space so users can explore and extend stylistic boundaries, thereby elevating the Exploratory Style Range (ESR). 4. Every interaction should be pleasurable and yield artefacts that feel worth preserving, fostering strong User-Assessed Enjoyment (UAE). Technically, these aims are well served by a dedicated latent–diffusion backbone coupled with low-latency optimization methods such as Latent Consistency Models (LCMs), providing both stylistic fidelity and real-time performance.
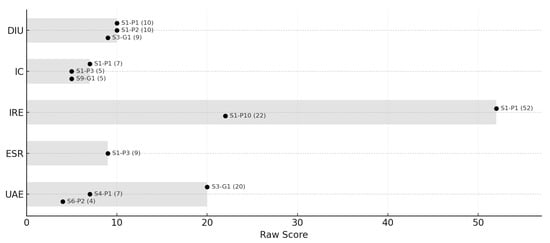
Figure 7.
Observed Ranges and Illustrative Instances for Raw Co-creative Engagement Indicators.
6. Discussion
The findings from this observational study provide compelling evidence for the efficacy of embodied interactions in fostering intuitive, engaging, and genuinely co-creative experiences with real-time generative AI. Our interpretation is grounded in principles from tangible user interface (TUI) design, situated cognition, Flow Theory, and frameworks for human–AI co-creation, aiming to connect our empirical observations and quantitative metrics to broader theoretical implications and the existing literature. The prominence of tangible objects as primary control mechanisms, quantitatively reflected in consistently high Diversity of Inputs Used (DIU) scores and qualitatively observed through rapid mental model formation, strongly affirms and extends TUI principles [9]. This demonstrates that physical objects, when directly mapped to generative parameters, significantly lower cognitive load and enhance perceived agency, going beyond the manipulation of static digital content to dynamically shape emergent AI output. Similarly, the high Generative Influence Score (GIS) further supports this strong perceived link between physical action and AI response, suggesting robust user agency. Furthermore, the emergence of user-defined interaction patterns, such as the “diamond frame” gesture, exemplifies situated cognition [31], where understanding and meaning emerge from real-time, context-dependent interactions rather than prescribed commands. This contrasts sharply with many GUI-based generative tools, where users often struggle with the ‘prompt engineering’ paradox, experiencing a disconnect between intent and outcome [relevant citation], underscoring the benefits of embedding control directly into physical actions for enhanced user agency. The system’s real-time contextual feedback loop was central to its creative usability, empowering participants to perceive a direct causal link between their inputs and generative outcomes. This responsiveness, reflected in a high Interaction Intensity and an extended Session Duration (SD), reduced the need for traditional undo mechanisms or complex interfaces, lowering cognitive load and encouraging improvisational play [32]. Quantitatively, the User Affect and Engagement (UAE) metric was measured to highlight frequent instances of positive expressions and photo-taking, qualitatively corroborated by participants reacting to the AI’s outputs with surprise, satisfaction, or humor, indicative of an almost conversational exchange. These findings strongly align with Flow Theory [22]; the immediate, perceptible feedback, coupled with a clear creative goal and balanced challenge, created conditions conducive to a deep, intrinsically motivating ‘flow’ state. This low-latency, real-time feedback loop is a crucial differentiator from batch-processing generative AI systems that can break creative flow [relevant citation] and highlights a paradigm shift for AI interaction design towards more fluid and improvisational experiences, particularly salient for XR environments. The system also fostered rich social dynamics. While Co-creative Complexity (CC) scores demonstrated varied levels of sophisticated input, qualitative observations revealed the system frequently functioned as a shared interface, promoting spontaneous turn-taking, collaborative gestures, and mutual exploration of prop effects among participants. This supports frameworks of human–AI co-creation that emphasize shared agency and mixed-initiative interaction [33], with the AI acting as a ‘third partner’ in a collaborative artistic endeavor. These findings corroborate prior work on large-screen interactive installations fostering social engagement [34], extending it by demonstrating these benefits within a generative AI context. Such insights into emergent social co-creation have significant implications for designing collaborative AI systems, particularly those intended for public or multi-user environments, suggesting that interfaces enabling observable physical actions and shared control can unlock novel forms of human–human–AI collaboration. Despite these compelling insights, our study faced several methodological limitations, including the inherent biases of inferring emotional states from visual cues, the absence of direct participant feedback (interviews/surveys), and the lack of demographic data, which constrain the generalizability and depth of individual experience analysis. Furthermore, the ‘black box’ nature of generative AI limited our ability to fully understand its internal decision-making processes, requiring interpretations to be based solely on observable input–output relationships. These limitations, alongside broader considerations, inform a number of practical challenges that arise when considering the real-world application and scalability of such embodied co-creation systems. Firstly, the system’s context-specific design for public exhibitions means generalizability to constrained or diverse settings (e.g., educational, home, professional) requires adaptable input modalities; future iterations should explore micro-gestures, haptic feedback, or mobile-controlled digital props, always retaining the core principle of mapping natural actions to AI influence. Secondly, the robustness and reliability of sensing in diverse environments present a significant hurdle. Operating in unpredictable real-world scenarios introduces complexities that impact the real-time pose and object tracking accuracy. Future developments must therefore enhance sensing pipelines through multi-sensor fusion, adaptive calibration, more resilient AI models, and robust error handling to prevent frustrating user experiences. Thirdly, the black box interpretability of the generative AI, while initially beneficial, can hinder users’ ability to intentionally refine outputs or understand input–output relationships in sustained use. To mitigate this, future systems could integrate explainable AI (XAI) components, providing subtle visual cues or progressive onboarding tutorials to reveal underlying mappings, thereby enhancing intentionality without sacrificing simplicity. Finally, accessibility and inclusivity demand careful attention, as the current system’s reliance on gross motor skills may not be universally accessible. Future designs must consider a wider range of needs, offering alternative input modes (e.g., eye-tracking, voice commands), customizable sensitivity, or a broader array of tangible interfaces, alongside research into culturally nuanced gesture libraries. These practical considerations collectively highlight critical future directions for refining embodied adaptive systems, moving beyond conceptual validation towards robust, scalable, and universally accessible co-creative AI experiences. In summary, this study provides evidence for the efficacy of embodied interactions in fostering intuitive, engaging, and genuinely co-creative experiences with real-time generative AI. By leveraging principles from tangible user interfaces and situated cognition, coupled with responsive feedback that promotes flow, our ‘Embodied Ukiyo-e’ system demonstrates a powerful paradigm for human–AI collaboration. While we acknowledge the study’s inherent limitations and practical challenges, our findings offer critical theoretical contributions regarding user agency in generative contexts and practical implications for the design of future adaptive, multimodal, and socially engaging AI systems in diverse immersive environments.
7. Implications, Future Work and Conclusions
The findings of this study have several important implications for the design of future embodied creative AI systems and for advancing our understanding of human–AI collaboration in both individual and collective contexts. Participants’ interactions with the Embodied Ukiyo-e system demonstrated that intuitive and meaningful co-creation can be made possible through tangible, embodied input modalities. The use of physical objects with clearly discernible properties, such as color, texture, and pattern, proved to be a highly effective and accessible form of input, enabling users to shape complex generative outputs without the need for technical expertise. Moreover, integrating natural body language through pose and gesture recognition allowed for more expressive and nuanced control, giving users compositional agency aligned with their innate physical understanding of space. Real-time, continuous feedback emerged as a critical design requirement, as it fostered a strong sense of user agency, supported rapid learning through iterative experimentation, and encouraged playful exploration. The system also enabled rich social interactions, facilitating co-creation through turn-taking, shared control, and visible, discussable outputs. These dynamics highlight the need for future systems to support positive social engagement, particularly in public or collaborative settings. The observed balance between user control and AI agency was particularly noteworthy: users directed thematic choices while the AI provided stylistic interpretation, resulting in co-authored visual outcomes that users found satisfying and surprising. This embodied paradigm has considerable potential for democratizing artistic expression, making generative technologies accessible to a broader range of users. For example, the successful participation of diverse users with minimal assistance suggests that embodied systems can be inclusive across age groups and levels of expertise. Moreover, systems like Embodied Ukiyo-e can catalyze collaborative creativity, allowing multiple users to influence shared digital canvases through joint physical interaction. By embedding culturally significant aesthetics—such as Ukiyo-e—into the generative output, such systems also offer novel modes of engaging with digital cultural heritage, promoting interactive reinterpretation and public appreciation of art history. However, the study’s limitations must be acknowledged. As an exploratory, observational study conducted in a public setting, participant demographics were not systematically collected, and internal cognitive processes were inferred from external behaviors rather than captured through think-aloud protocols or interviews. Additionally, audio data, which might have enriched our understanding of verbal collaboration, was not analyzed. The specific technical architecture of the AI model and its input-mapping logic were not the focus of this investigation and thus remain unexplored. Future research should address these gaps through more controlled studies incorporating structured participant sampling, qualitative interviews, and post-interaction surveys. Comparative experiments examining embodied versus traditional interfaces for generative tasks could yield insights into their strengths and trade-offs. It would also be valuable to explore how alternative tangible materials, such as malleable or multi-sensory objects, affect creative behavior and how long-term engagement influences learning curves, interaction fluency, and user satisfaction. Finally, developing AI systems capable of interpreting more nuanced embodied signals and supporting real-time dialog could further deepen the sense of partnership and enrich the co-creative experience. Such an understanding is crucial for designing future systems that foster richer, more satisfying human–AI collaborations in creative domains. In conclusion, this study demonstrates the transformative potential of embodied interaction in enabling accessible, engaging, and socially rich creative experiences with generative AI. These insights underscore the importance of designing generative AI systems that align with natural human expression to enhance usability and engagement and expand the horizons of digital creativity and cultural participation. As AI continues to shape the future of creative practice, embodied and context-aware systems will play a critical role in ensuring that these technologies remain inclusive, expressive, and human-centered.
Author Contributions
Conceptualization, J.C.C.; methodology, J.C.C.; software, J.C.C.; formal analysis, J.C.C.; investigation, M.L.; resources, J.C.C.; data curation, M.L.; writing—original draft preparation, H.N.; writing—review and editing, H.N.; visualization, H.N.; supervision, H.N., J.C.C.; project administration, M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study investigated unscripted interactions with a real-time generative AI art installation within a public exhibition space. The research was conducted via passive, naturalistic observation, with participants being self-selected visitors who engaged with the system. At no time was there any danger to the well-being of the participants. Furthermore, all data were anonymized at the point of capture; the study’s rigorous ethical protocol involved processing all video input in real-time, with “only anonymized, abstract numerical parameters” retained and no visual recordings of participants ever saved. As the data collected was “strictly devoid of any personally identifiable information”, it is not subject to Japan’s Act on the Protection of Personal Information (APPI). Thus, the research did not receive prior ethical clearance from an institutional review board (IRB). However, all efforts were made to adhere to ethical research principles, including the complete protection of participant anonymity and the minimization of potential risks. No personally identifiable information was collected or reported, and participants were not subjected to harm.
Informed Consent Statement
Informed consent was obtained from the individual depicted in the sample images in Figure 5.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
This project was realized at the Design Research Institute on the Sumida Campus during the final exhibition of the Design Graduation Event at Chiba University. The authors gratefully acknowledge the administrative and logistical support provided by the exhibition staff and university coordinators who facilitated the setup and maintenance of the installation throughout the event. The authors also thank the anonymous participants whose spontaneous and enthusiastic interactions contributed to the richness of this study. During the preparation of this manuscript/study, the author(s) used Gemini 2.5 for the purposes of summarization and translation and ChatGPT-5 for the generation of Figure 6 The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhang, R.; Agrawala, A.; Isola, P. Adding Conditional Control to Text-to-Image Diffusion Models (ControlNet). arXiv 2023, arXiv:2302.05543. Available online: https://arxiv.org/abs/2302.05543 (accessed on 20 October 2025).
- Brewster, S.; Murray-Smith, R.; Crossan, A.; Vazquez-Alvarez, Y.; Rico, J. Multimodal Interactions for Expressive Interfaces. In Proceedings of the First International Workshop on Expressive Interactions for Sustainability and Empowerment (EISE 2009), London, UK, 29–30 October 2009. [Google Scholar] [CrossRef]
- Amin, R.M.; Kühle, O.H.; Buschek, D.; Butz, A. Composable Prompting Workspaces for Creative Writing: Exploration and Iteration Using Dynamic Widgets. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ‘25), Yokohama, Japan, 26 April–1 May 2025. [Google Scholar] [CrossRef]
- Kantosalo, A.; Toivonen, H. Modes for Creative Human–Computer Collaboration: Alternating and Task-Divided Co-Creativity. In Proceedings of the Seventh International Conference on Computational Creativity (ICCC 2016), Paris, France, 27 June–1 July 2016; Sony CSL: Paris, France, 2016; pp. 77–84. [Google Scholar]
- Bussell, C.; Ehab, A.; Hartle-Ryan, D.; Kapsalis, T. Generative AI for Immersive Experiences: Integrating Text-to-Image Models in VR-Mediated Co-Design Workflows. In Communications in Computer and Information Science; Springer Nature: Cham, Switzerland, 2023; Volume 1836, pp. 380–388. [Google Scholar]
- Li, D.; Numan, N.; Qian, X.; Chen, Y.; Zhou, Z.; Alekseev, E.; Lee, G.; Cooper, A.; Xia, M.; Chung, S.; et al. XR Blocks: Accelerating Human-Centered AI+XR Innovation. arXiv 2025, arXiv:2509.25504. Available online: https://arxiv.org/abs/2509.25504 (accessed on 29 September 2025).
- Dourish, P. Where the Action Is: The Foundations of Embodied Interaction; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Ishii, H.; Ullmer, B. Tangible Bits: Towards Seamless Interfaces Between People, Bits and Atoms. In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 22–27 March 1997; pp. 234–241. [Google Scholar]
- Andrews, C. An Embodied Approach to AI Art Collaboration. In Proceedings of the 2019 Conference on Creativity and Cognition, San Diego, CA, USA, 23–26 June 2019; pp. 13–22. [Google Scholar]
- Svanæs, D. Interaction Design for and with the Lived Body. ACM Trans. Comput.-Hum. Interact. 2013, 20, 8. [Google Scholar] [CrossRef]
- Rani, S.; Sharma, N.; Singh, R. AI and Computing Technologies in Art Museums: A Systematic Literature Review. ITM Web Conf. 2023, 53, 01004. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Real-Time Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar] [CrossRef]
- Li, M.; Yang, T.; Kuang, H.; Wu, J.; Wang, Z.; Xiao, X.; Chen, C. ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 129–147. Available online: https://github.com/liming-ai/ControlNet_Plus_Plus (accessed on 20 October 2025).
- Tiribelli, S.; Pansoni, S.; Frontoni, E.; Giovanola, B. Ethics of Artificial Intelligence for Cultural Heritage: Opportunities and Challenges. IEEE Trans. Technol. Soc. 2024, 5, 293–305. [Google Scholar] [CrossRef]
- Liapis, A.; Smith, G.; Shaker, N. Mixed-initiative content creation. In Procedural Content Generation in Games. Computational Synthesis and Creative Systems; Springer: Cham, Switzerland, 2016; pp. 195–214. [Google Scholar]
- Sundar, A.; Russell-Rose, T.; Kruschwitz, U.; Machleit, K. The AI interface: Designing for the ideal machine-human experience. Comput. Hum. Behav. 2024, 165, 108539. [Google Scholar] [CrossRef]
- Huang, Y.; Dong, Y. Sand Playground: An Embodied Human–AI Physical Interface for Co-Creation in Motion. In Proceedings of the Creativity & Cognition (C&C), Venice, Italy, 20–23 June 2022; pp. 49–55. [Google Scholar]
- Cetinic, E.; She, J. Understanding and Creating Art with AI: A Review and Outlook. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 66. [Google Scholar] [CrossRef]
- Zolfaghari, M.; Chacon, J.C.; Martinez Nimi, H.; Ono, K. A User-Guided Generative Image-Based Model Interface to Design Desired Products with Iterative Design Selection. J. Sci. Des. 2025, 9, 1_11–1_20. [Google Scholar] [CrossRef]
- Csikszentmihalyi, M. Flow: The Psychology of Optimal Experience; Harper & Row: New York, NY, USA, 1990. [Google Scholar]
- Ellis, J.W. The Floating World of Ukiyo-e Prints: Images of a Japanese Counterculture. J. Soc. Political Sci. 2019, 2, 701–718. Available online: https://www.asianinstituteofresearch.org/JSParchives/the-floating-world-of-ukiyo-e-prints%3A-images-of-a-japanese-counterculture- (accessed on 20 October 2025). [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. Research Data Supporting PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. Available online: https://www.repository.cam.ac.uk/handle/1810/251342 (accessed on 7 October 2015).
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.-H. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 2023, 56, 105. [Google Scholar] [CrossRef]
- O’Brien, H.L.; Toms, E.G. What is user engagement? A conceptual framework for defining user engagement with technology. J. Am. Soc. Inf. Sci. Tec. 2008, 59, 938–955. [Google Scholar] [CrossRef]
- Liu, Z.; Heer, J. The Effects of Interactive Latency on Exploratory Visual Analysis. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2122–2131. [Google Scholar] [CrossRef] [PubMed]
- Suh, M.; Youngblom, E.; Terry, M.; Cai, C.J. AI as social glue: Uncovering the roles of deep generative AI during social music composition. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ‘21), Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef]
- Suchman, L.A. Plans and Situated Actions: The Problem of Human–Machine Communication; Cambridge University Press: Cambridge, MA, USA, 1987. [Google Scholar]
- Norman, D.A. The Design of Everyday Things, Revised Ed.; Basic Books: New York, NY, USA, 2013. [Google Scholar]
- Weisz, J.D.; He, J.; Muller, M.; Hoefer, G.; Miles, R.; Geyer, W. Design Principles for Generative AI Applications. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ‘24), Honolulu, HI, USA, 11–16 May 2024; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Hornecker, E.; Buur, J. Getting a Grip on Tangible Interaction: A Framework on Physical Space and Social Interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006; pp. 437–446. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).