
Wearable Impedance-Matched Noise Canceling Sensor for Voice Pickup †


Abstract
:1. Introduction
2. Materials and Methods
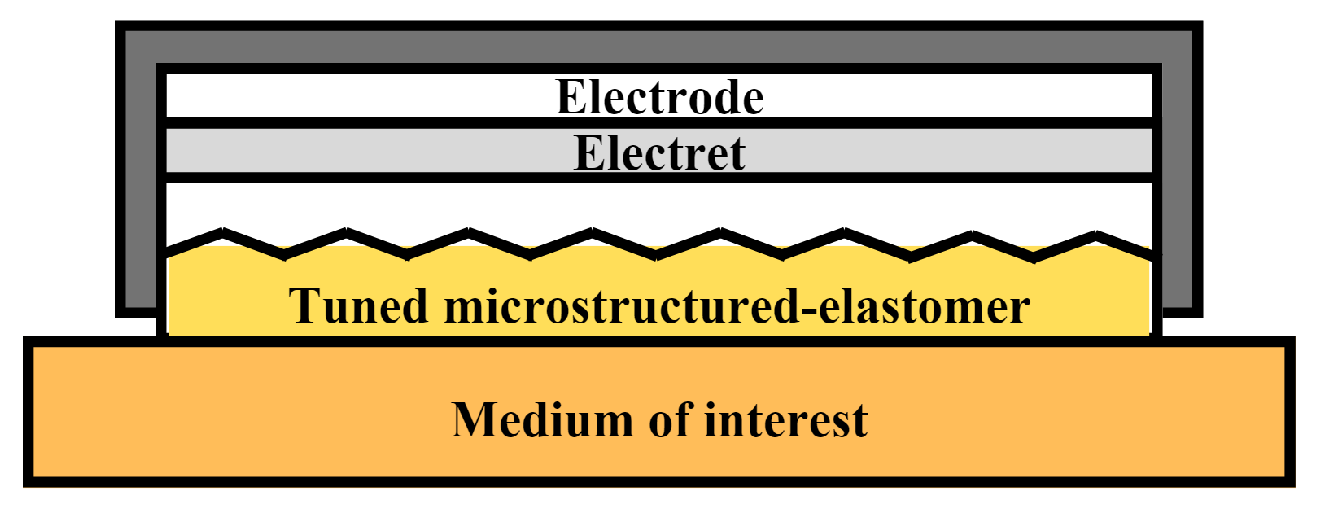
2.1. Impedance-Matched Transducer
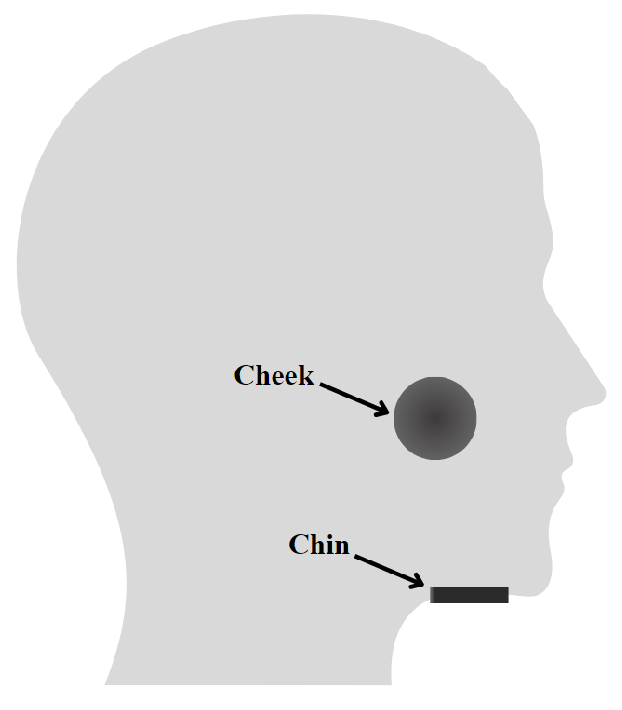
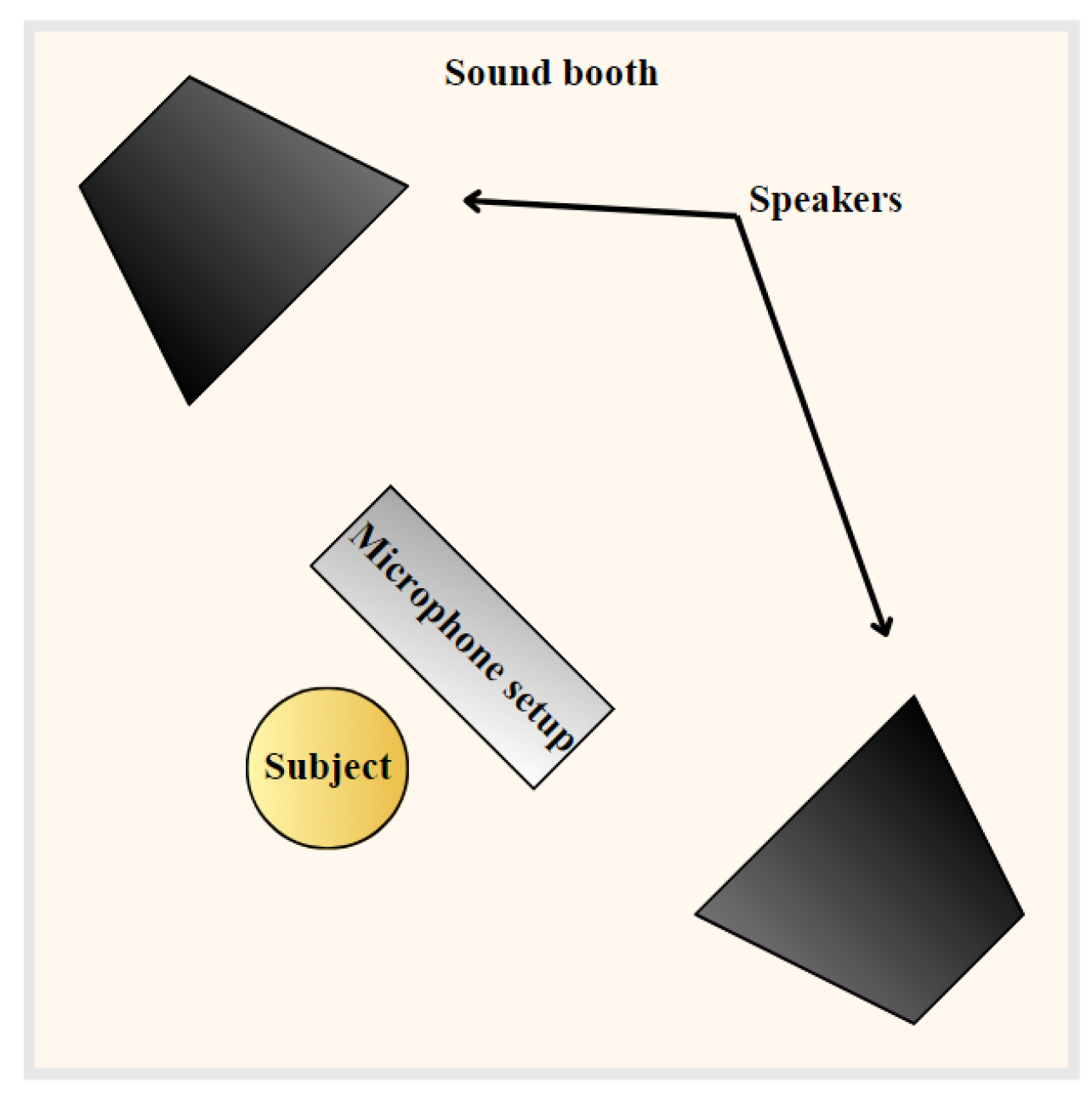
2.2. Experimental Setup
2.3. Speech Quality
2.3.1. Post-Processing
2.3.2. Speech Quality Measurement
2.4. Noise Cancellation
3. Results
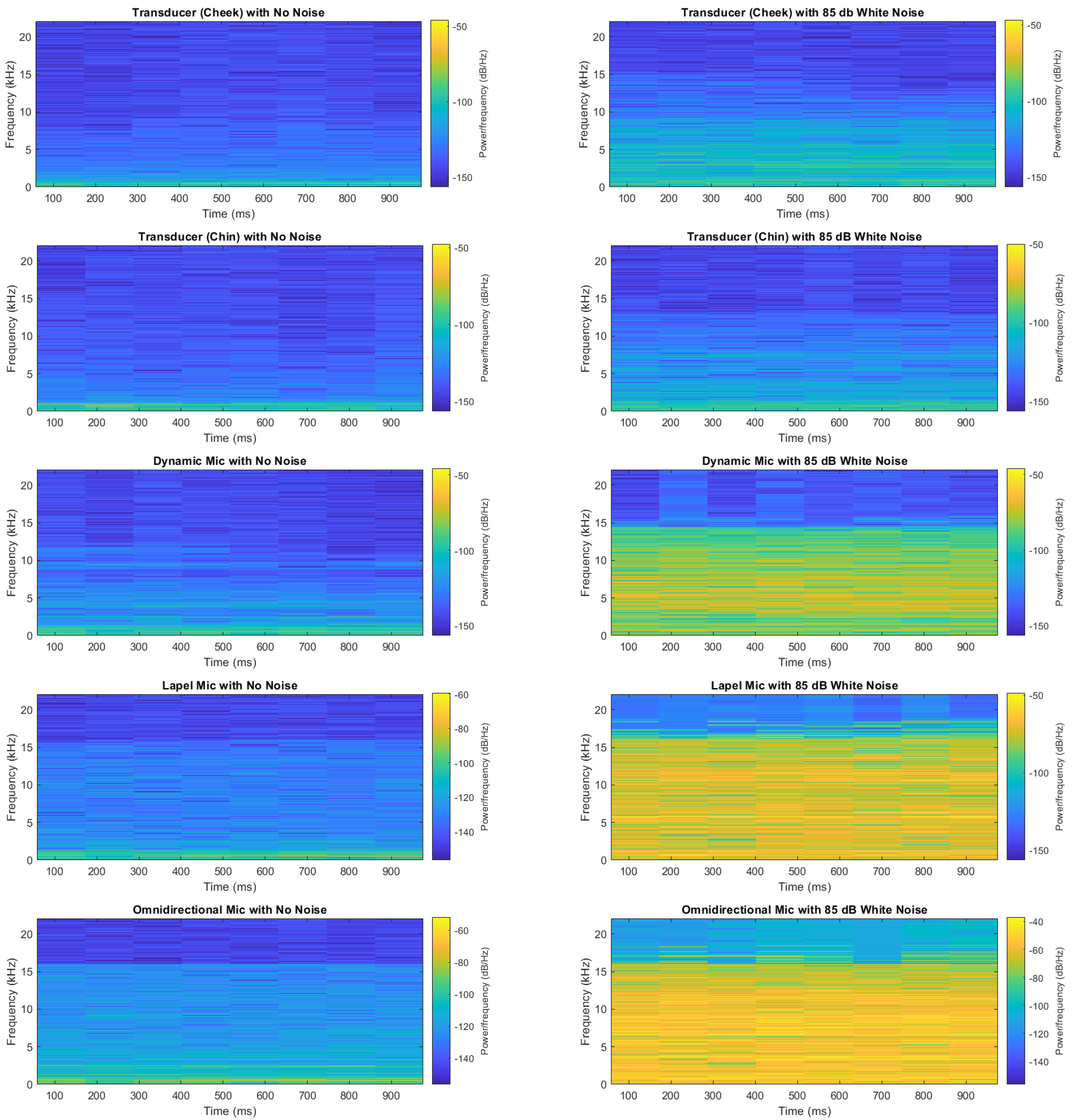
3.1. Speech Quality
3.2. Noise Cancellation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boll, S.; Pulsipher, D. Suppression of acoustic noise in speech using two microphone adaptive noise cancellation. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 752–753. [Google Scholar] [CrossRef]
- Dixit, S.; Nagaria, D. LMS Adaptive Filters for Noise Cancellation: A Review. Int. J. Electr. Comput. Eng. (IJECE) 2017, 7, 2520–2529. [Google Scholar] [CrossRef]
- De Sena, E.; Hacihabiboglu, H.; Cvetkovic, Z. On the Design and Implementation of Higher Order Differential Microphones. IEEE Trans. Audio Speech Language Process. 2012, 20, 162–174. [Google Scholar] [CrossRef]
- Rennoll, V.; McLane, I.M.; Eisape, A.; Elhilali, M.; West, J. Evaluating the impact of acoustic impedance matching on the airborne noise rejection and sensitivity of an electrostatic transducer. J. Acoust. Soc. Am. 2021, 149, A23. [Google Scholar] [CrossRef]
- Rennoll, V.; McLane, I.M.; Eisape, A.; Grant, D.; Hahn, H.; Elhilali, M.; West, J. Electrostatic Acoustic Sensor with an Impedance-Matched Diaphragm Characterized for Body Sound Monitoring. ACS Appl. Bio Mater. 2023, 6, 3241–3256. [Google Scholar] [CrossRef] [PubMed]
- Rennoll, V.; McLane, I.M.; Eisape, A.; Grant, D.; Betz, C.; Chen, X.; Gebhart, M.; Hahn, H.; Kartub, S.; Lehr, B.; et al. Project-based learning through sensor characterization in a musical acoustics course. J. Acoust. Soc. Am. 2022, 152, 1932–1941. [Google Scholar] [CrossRef] [PubMed]
- Rothauser, E.H. IEEE Recommended Practice for Speech Quality Measurements. IEEE Trans. Audio Electroacoust. 1969, 17, 225–246. [Google Scholar] [CrossRef]
- Trine, A.; Monson, B.B. Extended High Frequencies Provide Both Spectral and Temporal Information to Improve Speech-in-Speech Recognition. Trends Hear. 2024, 24. [Google Scholar] [CrossRef] [PubMed]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal, Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Sentence |
|---|---|
| Counting | One, two, three, four, five, six, seven, eight, nine, ten. |
| Tongue-twister | She sells seashells by the seashore. |
| Harvard sentences | 1. The birch canoe slid on the smooth planks. |
| List 1 | 2. Glue the sheet to the dark blue background. |
| 3. It’s easy to tell the depth of a well. | |
| 4. These days a chicken leg is a rare dish. | |
| 5. Rice is often served in round bowls. | |
| 6. The juice of lemons makes fine punch. | |
| 7. The box was thrown beside the parked truck. | |
| 8. The hogs were fed chopped corn and garbage. | |
| 9. Four hours of steady work faced us. | |
| 10. A large size in stockings is hard to sell. |
| Sentence | Transducer (Cheek) Original | Transducer (Chin) Original | Transducer (Cheek) Post-Processed | Transducer (Chin) Post-Processed | Lapel Mic | Omnidirectional Mic |
|---|---|---|---|---|---|---|
| Counting | 1.4783 | 2.1966 | 3.0238 | 3.0599 | 3.4527 | 3.4018 |
| Tongue-Twister | 1.8844 | 2.0097 | 2.3804 | 2.2728 | 3.1010 | 2.9669 |
| 1 * | 1.6549 | 1.4344 | 2.6274 | 2.4440 | 3.1259 | 3.0640 |
| 2 | 1.4278 | 1.3410 | 2.2930 | 2.9153 | 3.2753 | 3.2726 |
| 3 | 1.8041 | 1.6775 | 2.8402 | 2.6124 | 3.0955 | 3.0113 |
| 4 | 1.6774 | 1.7726 | 2.3861 | 2.6759 | 3.1076 | 3.0472 |
| 5 | 1.6883 | 1.6720 | 2.3723 | 2.3198 | 3.0204 | 2.9092 |
| 6 | 1.8740 | 1.5036 | 2.8963 | 2.3081 | 3.0204 | 2.9929 |
| 7 | 1.7565 | 1.8316 | 2.6523 | 2.4899 | 3.2521 | 3.0875 |
| 8 | 1.8423 | 2.1095 | 2.9682 | 2.6612 | 3.2204 | 3.0691 |
| 9 | 1.7113 | 1.6813 | 2.5233 | 2.4539 | 3.2069 | 3.2400 |
| 10 | 1.8941 | 1.8283 | 2.5802 | 2.4474 | 3.1858 | 2.8575 |
| Average | 1.7245 | 1.7548 | 2.6286 | 2.5551 | 3.1720 | 3.0676 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suh, H.Y.; Hahn, H.; West, J. Wearable Impedance-Matched Noise Canceling Sensor for Voice Pickup. Eng. Proc. 2023, 58, 99. https://doi.org/10.3390/ecsa-10-16153
Suh HY, Hahn H, West J. Wearable Impedance-Matched Noise Canceling Sensor for Voice Pickup. Engineering Proceedings. 2023; 58(1):99. https://doi.org/10.3390/ecsa-10-16153
Chicago/Turabian StyleSuh, Hee Yun, Helena Hahn, and James West. 2023. "Wearable Impedance-Matched Noise Canceling Sensor for Voice Pickup" Engineering Proceedings 58, no. 1: 99. https://doi.org/10.3390/ecsa-10-16153
APA StyleSuh, H. Y., Hahn, H., & West, J. (2023). Wearable Impedance-Matched Noise Canceling Sensor for Voice Pickup. Engineering Proceedings, 58(1), 99. https://doi.org/10.3390/ecsa-10-16153