
Optimizable Ensemble Regression for Arousal and Valence Predictions from Visual Features †



Abstract
:1. Introduction
2. Literature Overview
3. Methods
3.1. RECOLA’s Predesigned Visual Features
3.2. Time Delay and Sequencing
3.3. Annotation Labelling
3.4. Data Shuffling and Splitting
3.5. Regression
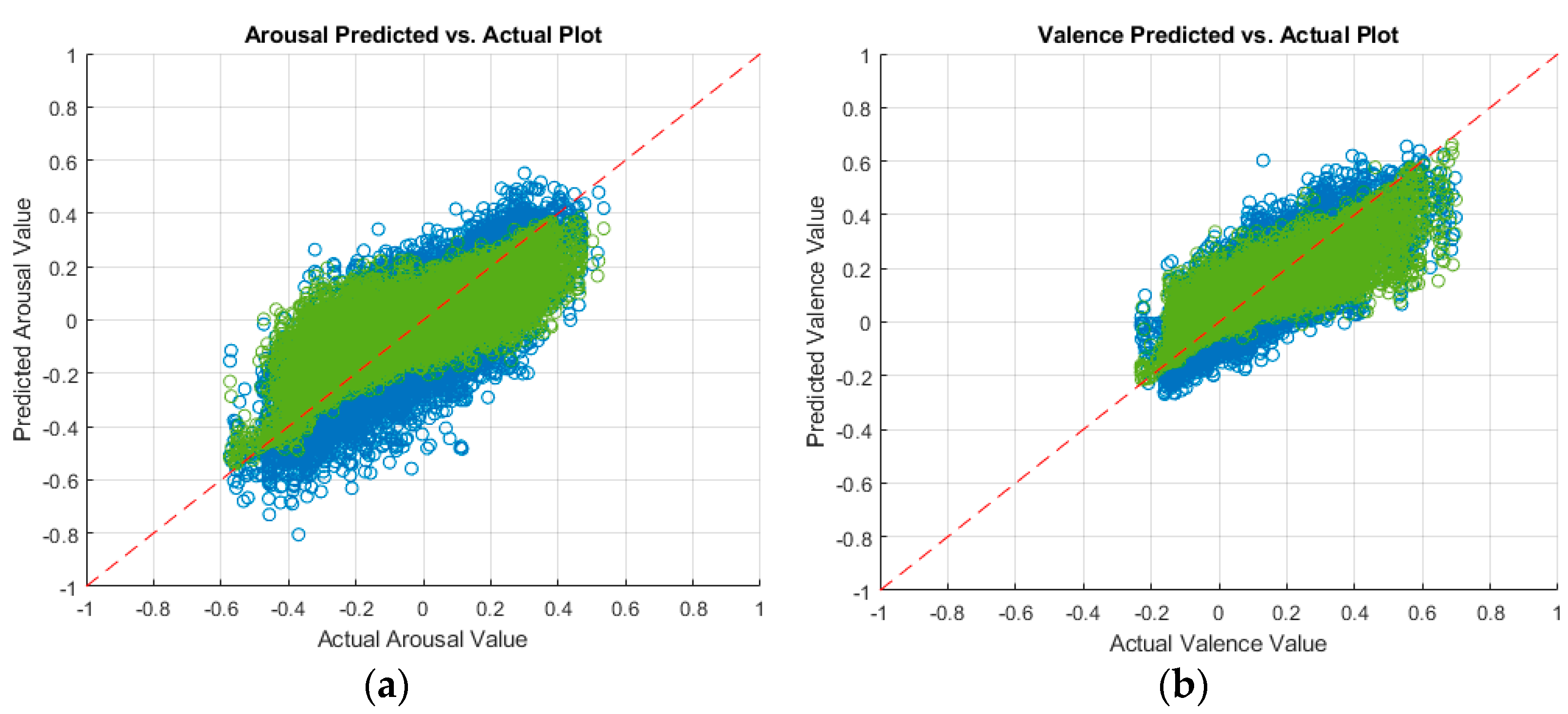
4. Discussion of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Russell, J. Affective Space Is Bipolar; American Psychological Association: Washington, DC, USA, 1979. [Google Scholar]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Joudeh, I.O.; Cretu, A.; Guimond, S.; Bouchard, S. Prediction of Emotional Measures via Electrodermal Activity (EDA) and Electrocardiogram (ECG). Eng. Proc. 2022, 27, 47. [Google Scholar]
- Joudeh, I.O.; Cretu, A.-M.; Bouchard, S.; Guimond, S. Prediction of Continuous Emotional Measures through Physiological and Visual Data. Sensors 2023, 23, 5613. [Google Scholar] [CrossRef] [PubMed]
- Joudeh, I.O.; Cretu, A.-M.; Bouchard, S.; Guimond, S. Prediction of Emotional States from Partial Facial Features for Virtual Reality Applications. In Proceedings of the 26th Annual CyberPsychology, CyberTherapy and Social Networking Conference (CYPSY26), Paris, France, 11–13 July 2023. [Google Scholar]
- Corneanu, C.A.; Simon, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-Related Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef] [PubMed]
- Al Osman, H.; Falk, T.H. Multimodal affect recognition: Current approaches and challenges. Emot. Atten. Recognit. Based Biol. Signals Images 2017, 8, 59–86. [Google Scholar]
- Almaev, T.R.; Valstar, M.F. Local Gabor Binary Patterns from Three Orthogonal Planes for Automatic Facial Expressions Recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; IEEE Computer Society: Washington, DC, USA; pp. 356–361. [Google Scholar]
- Xiong, X.; De la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Ringeval, F.; Eyben, F.; Kroupi, E.; Yuce, A.; Thiran, J.P.; Ebrahimi, T.; Lalanne, D.; Schuller, B. Prediction of Asynchronous Dimensional Emotion Ratings from Audiovisual and Physiological Data. Pattern Recognit. Lett. 2015, 66, 22–30. [Google Scholar] [CrossRef]
- Ringeval, F.; Schuller, B.; Valstar, M.; Jaiswal, S.; Marchi, E.; Lalanne, D.; Cowie, R.; Pantic, M. AV+EC 2015—The First Affect Recognition Challenge Bridging Across Audio, Video, and Physiological Data. In Proceedings of the AVEC’15, Brisbane, Australia, 26–27 October 2015; ACM: New York, NY, USA; pp. 3–8. [Google Scholar]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A.; et al. AVEC 2018 Workshop and Challenge: Bipolar Disorder and Cross-Cultural Affect Recognition. In Proceedings of the AVEC’18, Seoul, Republic of Korea, 22 October 2018; ACM: New York, NY, USA. [Google Scholar]
- Han, J.; Zhang, Z.; Ren, Z.; Schuller, B. Implicit Fusion by Joint Audiovisual Training for Emotion Recognition in Mono Modality. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 5861–5865. [Google Scholar]
- Albadawy, E.; Kim, Y. Joint Discrete and Continuous Emotion Prediction Using Ensemble and End-to-End Approaches. In Proceedings of the 20th ACM International Conference on Multimodal Interaction (ICMI ‘18), Boulder, CO, USA, 16–20 October 2018; ACM: New York, NY, USA; pp. 366–375. [Google Scholar]
- Help Center. Help Center for MATLAB, Simulink, and Other MathWorks Products. Available online: https://www.mathworks.com/help/ (accessed on 2 September 2023).

{kind=link}
| Prediction | Regression Type | Validation RMSE | Testing RMSE, PCC, CCC |
|---|---|---|---|
| Arousal | Fine Tree | 0.15389 | 0.1477, 0.6812, 0.6805 |
| Medium Tree | 0.14601 | 0.1410, 0.6902, 0.6838 | |
| Coarse Tree | 0.14477 | 0.1410, 0.6731, 0.6516 | |
| Optimizable Tree | 0.14351 | 0.1396, 0.6861, 0.6719 | |
| SVM Kernel | 0.13665 | 0.1354, 0.7018, 0.6807 | |
| Least Squares Kernel | 0.13444 | 0.1331, 0.7097, 0.6633 | |
| Boosted Trees | 0.161 | 0.1607, 0.5463, 0.3743 | |
| Bagged Trees | 0.11285 | 0.1082, 0.8304, 0.7796 | |
| Optimizable Ensemble | 0.10791 | 0.1033, 0.8498, 0.8001 | |
| MobileNet-v2 [4] | 0.12178 | 0.1220, 0.7838, 0.7770 | |
| Valence | Fine Tree | 0.10191 | 0.0981, 0.6975, 0.6967 |
| Medium Tree | 0.097111 | 0.0944, 0.7011, 0.6947 | |
| Coarse Tree | 0.097623 | 0.0948, 0.6826, 0.6610 | |
| Optimizable Tree | 0.096525 | 0.0945, 0.6922, 0.6801 | |
| SVM Kernel | 0.094882 | 0.0943, 0.6855, 0.6495 | |
| Least Squares Kernel | 0.092417 | 0.0916, 0.7030, 0.6574 | |
| Boosted Trees | 0.11142 | 0.1104, 0.5525, 0.3467 | |
| Bagged Trees | 0.074689 | 0.0714, 0.8421, 0.7962 | |
| Optimizable Ensemble | 0.073335 | 0.0702, 0.8473, 0.8053 | |
| MobileNet-v2 [4] | 0.08309 | 0.0823, 0.7789, 0.7715 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joudeh, I.O.; Cretu, A.-M.; Bouchard, S. Optimizable Ensemble Regression for Arousal and Valence Predictions from Visual Features. Eng. Proc. 2023, 58, 3. https://doi.org/10.3390/ecsa-10-16009
Joudeh IO, Cretu A-M, Bouchard S. Optimizable Ensemble Regression for Arousal and Valence Predictions from Visual Features. Engineering Proceedings. 2023; 58(1):3. https://doi.org/10.3390/ecsa-10-16009
Chicago/Turabian StyleJoudeh, Itaf Omar, Ana-Maria Cretu, and Stéphane Bouchard. 2023. "Optimizable Ensemble Regression for Arousal and Valence Predictions from Visual Features" Engineering Proceedings 58, no. 1: 3. https://doi.org/10.3390/ecsa-10-16009
APA StyleJoudeh, I. O., Cretu, A.-M., & Bouchard, S. (2023). Optimizable Ensemble Regression for Arousal and Valence Predictions from Visual Features. Engineering Proceedings, 58(1), 3. https://doi.org/10.3390/ecsa-10-16009