Abstract
We obtained a curated database based on the database published elsewhere. Chemical descriptors were introduced as characteristics of active pharmaceutical ingredients (APIs). We used H2O AutoML platform in order to develop a Deep Learning model and SHAP method to explain its predictions. Obtained results were satisfactory with NRMSE of 8.1% and R2 of 0.84. Finally, we identified critical parameters affecting the process of disintegration of directly compressed ODTs.
1. Introduction
Traditional tablets are not an ideal drug dosage form. Many groups of patients, e.g., pediatric or geriatric patients, have problems with swallowing or simply are not willing to take tablets. As a consequence, all these factors may reduce a patient’s compliance. In order to overcome the inconvenience of conventional tablet use, orally disintegrating tablets (ODTs) were introduced into the drug market. One of the methods of preparing ODTs is direct compression, which is cost efficient and simple. It involves comparatively fewer stages than compression preceded by wet or dry granulation. In brief, powders are grinded, if necessary, and blended. Then, the mixture is compressed into the tablets. Although the process is quite simple, there are many factors that influence the characteristics of the ODTs. Among the crucial factors is the disintegration time.
One of the methods used to solve problems with many factors, where the hypothesis governing the phenomenon is unknown or the whole process is complex, is machine learning (ML). Automated machine learning (AutoML) is currently in focus as a branch of ML automating the time-consuming, iterative tasks of model development. AutoML enables machine-driven building of large-scale, high-performance, and superb predictability models with minimal human intervention.
The Motivation of this study was a limited knowledge of relationships between excipients, APIs, and process parameters of direct compression and their influence on disintegration of ODTs. Knowing such behavior would enhance the design and development of novel drug dosage forms. In this work we applied a concept of AutoML-based heuristic model development for prediction of the disintegration time based on the quantitative and qualitative composition of powder mixtures.
2. Materials and Methods
Our database was built based on the database presented by Han et al. [1]. First, we curated the existing database [1], neglecting any unclear or uncertain data records. We put emphasis on the occurrence of the ODTs’ characteristic and process parameters, such as tablet hardness, thickness, and dimension of tablet press die. Moreover, we performed a literature survey in order to enhance the database. Scopus® database was searched for publications fulfilling the following criteria: the direct compression method of ODTs should be used in processing, the amount of all excipients should be present, tablet characteristics (hardness, thickness, and die dimension) should be present, and the compendial disintegration test should be applied (Ph. Eur. or USP).
After data scrapping, we calculated APIs’ two-dimensional (2D) molecular descriptors using mordred-descriptor v.1.2.1a1 Python package [2] and included them in the curated database. Excipients’ types and amounts were encoded in a topological manner. The only output was the time needed for the disintegration of tablets.
A Computational experiment was performed according to the scheme presented in Figure 1. In brief, a preprocessed database was passed to the Python script [3] performing at the first stage a feature selection. Then, the final model was built according to a 10-fold cross-validation scheme. All available algorithms in H2O implementation of AutoML were used [4]: Distributed Random Forest (DRF), Extremely Randomized Trees (XRT), Generalized Linear Model (GLM), Extreme Gradient Boosting Machine, (XGBoost), Gradient Boosting Machine (GBM), Deep Learning (fully connected multi-layer artificial neural network), and Stacked Ensemble models.
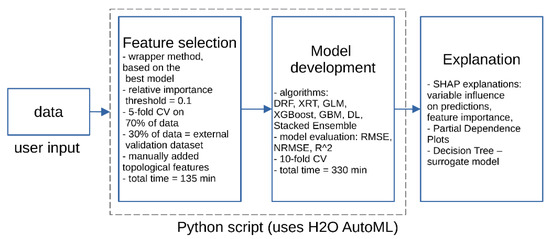
Figure 1.
Scheme of computational experiment design.
Model performance was assessed according to the 10-fold cross-validation (10-CV) and expressed by three goodness of fit metrics: root-mean-square error (RMSE), normalized root-mean-square error (NRMSE), and coefficient of determination (R2). For reference, please see Equations (1)–(3).
where obsi and predi are observed and predicted values, i is the data record number, and n is the total number of records.
where RMSE is the root-mean-square error and obsmax and obsmin are observed minimal and maximal values.
where R2 is the coefficient of determination, SSres is the sum of squares of the residual errors, SStot is the total sum of the errors, obsi and predi are observed and predicted values, and obs is the arithmetical mean of observed values.
Predictions of the best model were explained with the use of another Python wrapper [5] implementing among others, including the SHapley Additive exPlanations (SHAP) method by Lundberg et al. [6].
3. Results
Each record of the curated database represented one formulation of ODTs. It consisted of 633 chemical descriptors encoding API, 28 inputs encoding amounts of excipients, and 9 inputs characterizing drug dosage form. A single, independent variable was the disintegration time. The database consisted of 243 records (formulations), of which only 52 records (~21%) overlapped the Han et al. database [1].
In the feature selection stage, inputs’ number was reduced to 39, among which there were 28 inputs (amount of 2-hydroxypropyl-beta-cyclodextrin [%], Aerosil [%], Amberlite IRP 64-69 [%], API [%], beta-cyclodextrin [%], calcium silicate [%], camphor [%], colloidal silicon dioxide [%], croscarmellose sodium [%], crospovidone [%], cyclodextrin methacrylate [%], Eudragit EPO [%], hydroxy propyl methyl cellulose [%], lactose [%], low-substituted hydroxy propyl cellulose [%], magnesium stearate [%], mannitol [%], microcrystalline cellulose [%], Poloxamer 188 [%], polyvinyl alcohol [%], polyvinylpyrrolidone [%], pregelatinized starch [%], sodium bicarbonate [%], sodium carboxymethyl starch [%], sodium lauryl sulphate [%], sodium starch glycolate [%], sodium stearyl fumarate [%], and talc [%]) responsible for encoding the quantity of excipients and API, 8 molecular descriptors characterizing API (API Geary autocorrelation of lag 7 weighted by ionization potential, API topological charge index of order 7, API Geary autocorrelation—lag 7/weighted by polarizabilities, API modified information content index, API Moran autocorrelation of lag 4 weighted by polarizability, API negative logarithm of the partition (oil/water) coefficient, API number of 12-membered rings (includes counts from fused rings), API number of 8-membered fused rings containing heteroatoms (N, O, P, S, or halogens)), and 3 inputs characterizing the drug dosage form (diameter of die or tablet [mm], hardness of ODT [N], thickness of ODT [mm]). A list of selected features along with their type and relative importance is presented in Table 1.

Table 1.
The First 15 selected features and their relative importance.
The best results were obtained by a Deep Learning (DL) model, which had RMSE = 10.9, NRMSE = 8.1%, and R2 = 0.84. The model had two hidden layers with 100 neurons in each layer and a rectifier with dropout as an activation function. A plot of predicted versus observed disintegration values is presented in Figure 2.
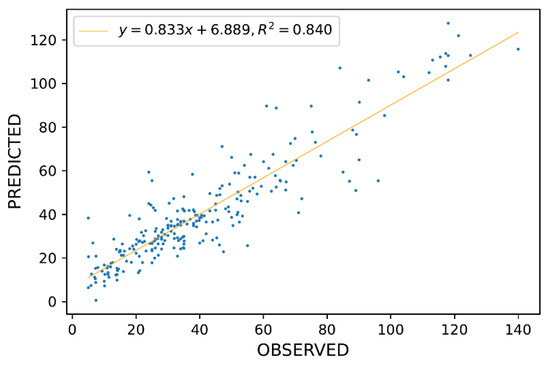
Figure 2.
Predicted vs. Observed values for disintegration time for Deep Learning model.
Following model development, a procedure of the SHAP method was applied. Then, selected plots were analyzed, and conclusions were drawn (Figure 3).
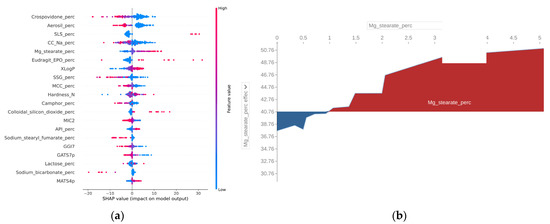
Figure 3.
Results of the model’s explanation: (a) Summary plot of impact on model output and feature value; (b) Effect of magnesium stearate amount [%] on the average model’s prediction.
4. Discussion
Based on the obtained prediction metrics (RMSE, NRMSE, R2), it was concluded that the model was satisfactory in terms of generalization. The 10-fold cross-validation technique was used as a golden standard. The mean error of the model was 10.9 (NRMSE = 8.1%); therefore it was possible to optimize a formulation with its use. Moreover, in Figure 3a, critical parameters and their impact on the disintegration time were identified. It seems that a high amount of sodium lauryl sulphate, magnesium stearate, Eudragit EPO, and colloidal silicon dioxide could increase the disintegration time of ODTs. On the other hand, a high amount of crospovidone, Aerosil, croscarmellose, sodium starch glycolate, or sodium stearyl fumarate could lead to a decreased disintegration time. Looking more closely at the variable effects, a percolation threshold could be found. For example, in Figure 3b, at a magnesium stearate value of about 1% a reverse in effects could be observed. This observation was consistent with the findings of previous studies [7]. It is believed that magnesium stearate in higher amounts than 1%, besides the usual action as a lubricant, could form a hydrophobic film around API particles and could prevent water from penetrating into the core of the tablet. Using similar reasoning, the XLogP limit was determined for the API, the value of which will increase the disintegration time of ODTs (Figure 4). The general conclusion is that a more hydrophobic API with XLogP higher than 3.5 would negatively affect the disintegration time by increasing it.
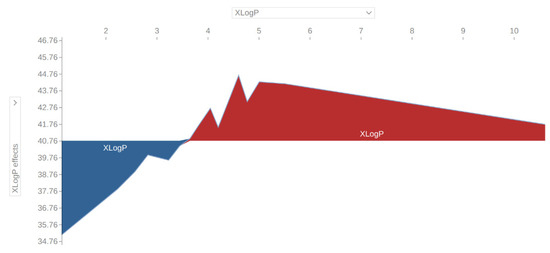
Figure 4.
Effect of XLogP (calculated partition coefficient of API) on the average model’s prediction.
Author Contributions
Conceptualization, J.S. and A.M.; methodology, J.S., A.P., N.C. and A.M.; software, J.S.; validation, J.S., A.P., N.C. and A.M.; formal analysis, J.S.; investigation, J.S.; resources, A.M.; data curation, J.S.; writing—original draft preparation, J.S., A.P., N.C. and A.M.; writing—review and editing, J.S., A.P., N.C. and A.M.; visualization, J.S.; supervision, J.S.; project administration, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Uniwersytet Jagielloński Collegium Medicum, grant number N42/DBS/000205.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available upon written request.
Acknowledgments
Not applicable.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results. The authors declare no conflict of interest.
References
- Han, R.; Yang, Y.; Li, X.; Ouyang, D. Predicting oral disintegrating tablet formulations by neural network techniques. Asian J. Pharm. Sci. 2018, 134, 336–342. [Google Scholar] [CrossRef] [PubMed]
- Moriwaki, H.; Tian, Y.-S.; Kawashita, N.; Takagi, T. Mordred: A molecular descriptor calculator. J. Cheminform. 2018, 10, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szlęk, J. h2o_AutoML_Python, Python Script for AutoML in H2O. Available online: https://github.com/jszlek/h2o_AutoML_Python (accessed on 10 August 2021).
- LeDell, E.; Poirier, S. H2O AutoML: Scalable automatic machine learning. In Proceedings of the 7th ICML Workshop on Automated Machine Learning, Vienna, Austria, 17–18 July 2020. [Google Scholar]
- Szlęk, J. Model Interpretation. 2021. Available online: https://github.com/jszlek/MODEL_INTERPRETATION (accessed on 10 August 2021).
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Wang, J.; Wen, H.; Desai, D. Lubrication in tablet formulations. Eur. J. Pharm. Biopharm. 2010, 75, 1–15. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).