
Local AI Governance: Addressing Model Safety and Policy Challenges Posed by Decentralized AI


Abstract
1. Introduction
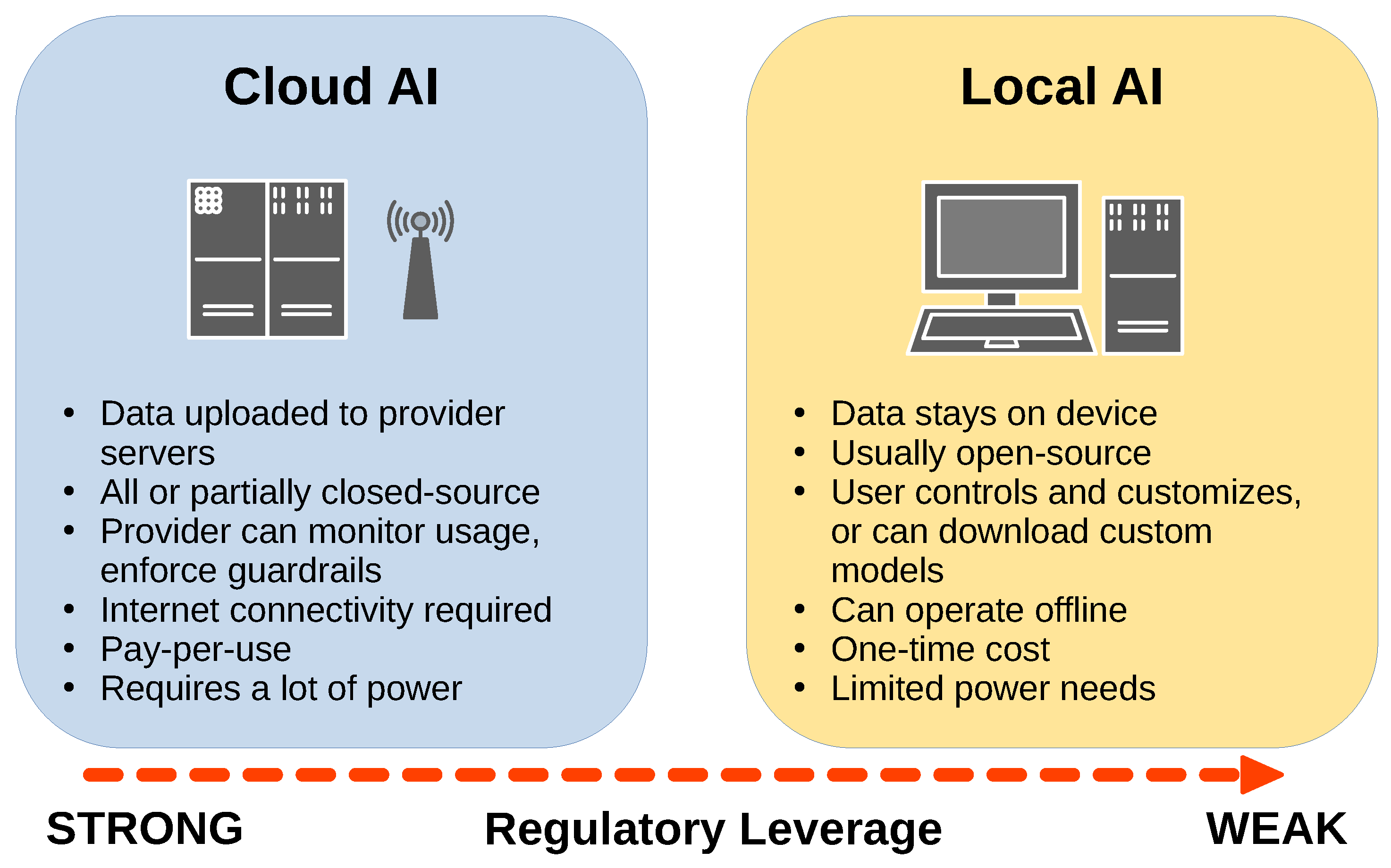
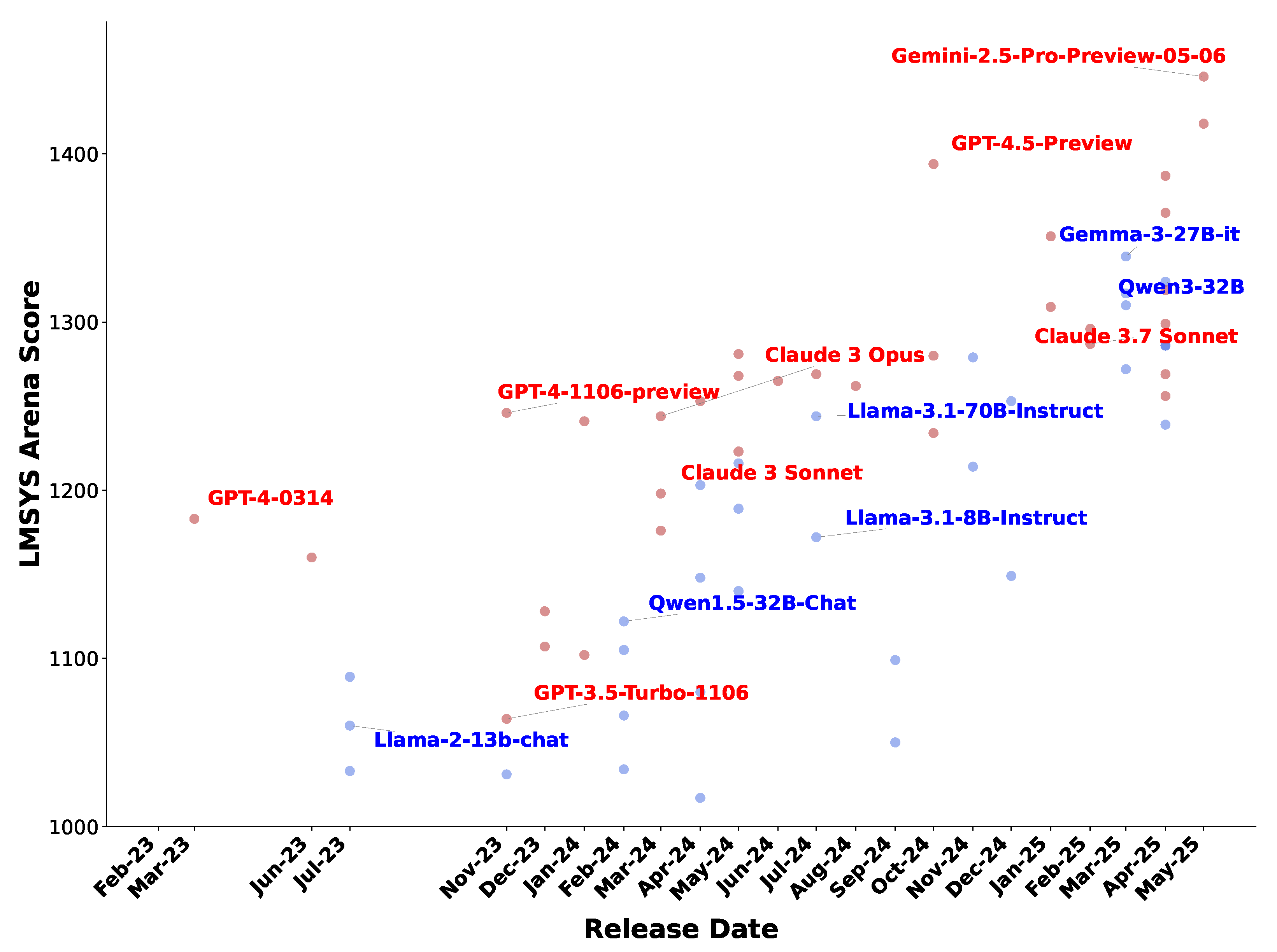
2. The Development of Local Generative AI
3. Benefits of Local AI
4. Potential Risks of Local AI
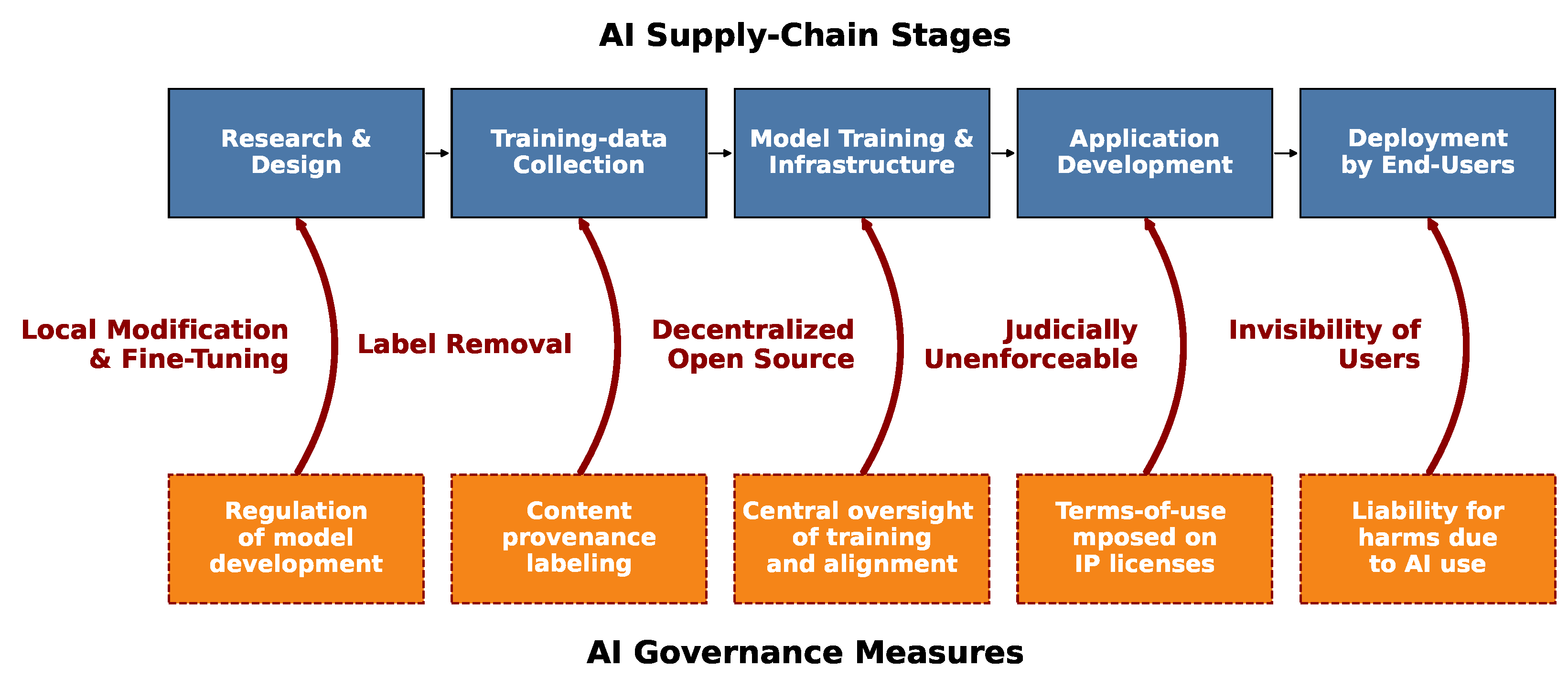
5. Local AI’s Challenges to Current AI Safety Measures
5.1. Challenges to Technical Safeguards
5.2. Challenges to Policy Frameworks
5.2.1. Governmental Regulatory Frameworks
5.2.2. Voluntary (“Self-Regulatory”) Frameworks
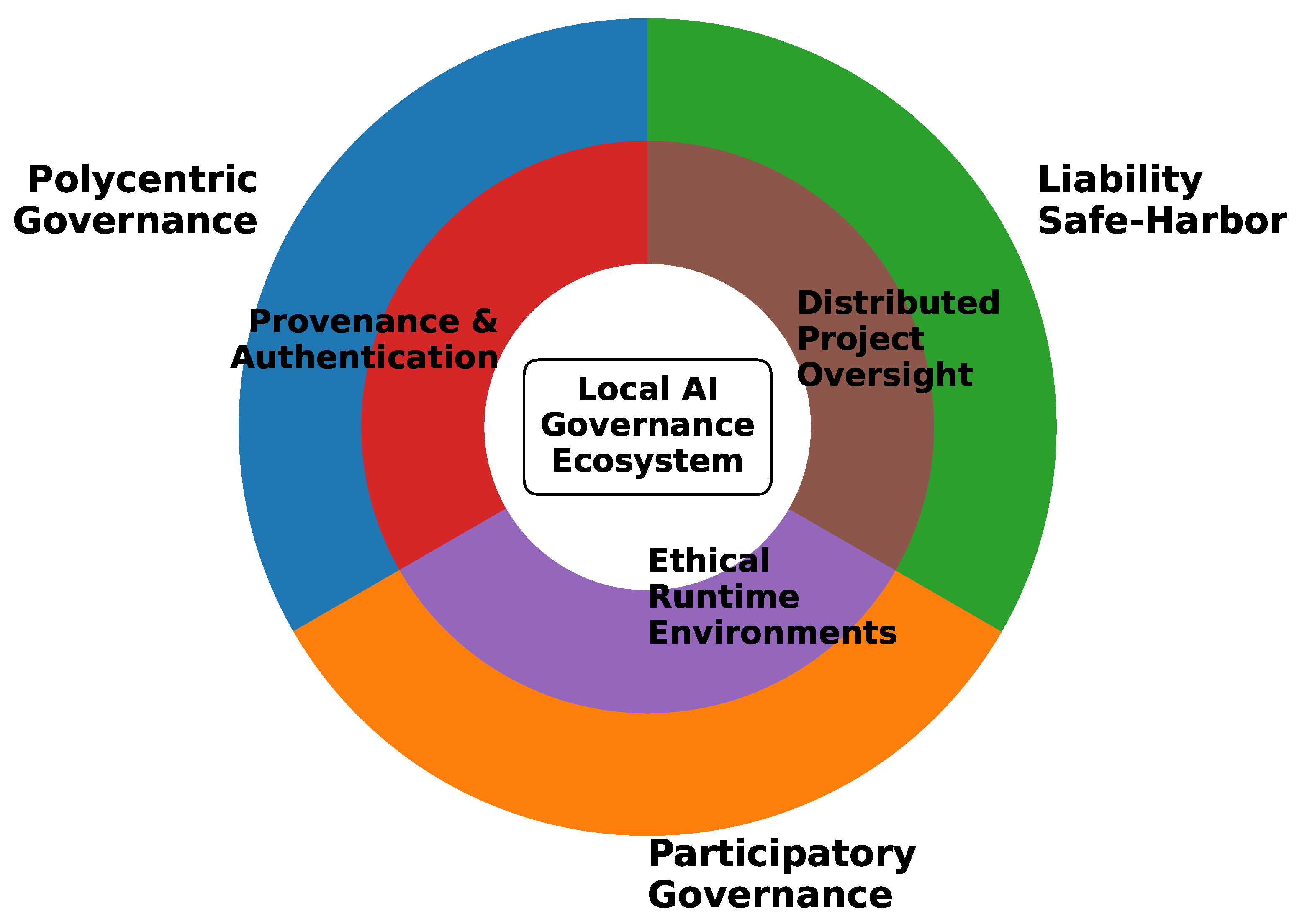
6. Reimagining Governance for Local AI
6.1. Proposed Technical Safeguards Designed for Local AI
6.1.1. Content Provenance and Authentication
6.1.2. Ethical Runtime Environments for Technical Safety
6.1.3. Distributed Oversight of Open-Source AI Projects
6.2. Proposed Policy Measures for Local AI
6.2.1. Polycentric Governance Frameworks
6.2.2. Empowering Community Governance and Participation
6.2.3. Liability “Safe Harbors” for Local AI
7. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| LLM | Large Language Model |
| VLM | Vision–Language Model |
| GPU | Graphics Processing Unit |
| API | Application Programming Interface |
| VRAM | Video Random Access Memory |
| TEE | Trusted Execution Environment |
| ERE | Ethical Runtime Environment |
| CCS | Community Citizen Science |
| AIA | Algorithmic Impact Assessment |
| NIST | National Institute of Standards and Technology |
| EO | Executive Order |
| EU | European Union |
| MRO | Multistakeholder Regulatory Organization |
| CAITE | Copyleft AI with Trust Enforcement |
| RAIL | Responsible AI License |
| IP | Intellectual Property |
| LoRA | Low-Rank Adaptation |
| DEI | Diversity, Equity, and Inclusion |
References
- Roose, K. How ChatGPT Kicked Off an A.I. Arms Race. The New York Times, 3 February 2023. [Google Scholar]
- Feuerriegel, S.; Hartmann, J.; Janiesch, C.; Zschech, P. Generative AI. Bus. Inf. Syst. Eng. 2024, 66, 111–126. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. AI Advancements: Comparison of Innovative Techniques. AI 2024, 5, 38–54. [Google Scholar] [CrossRef]
- Tomassi, A.; Falegnami, A.; Romano, E. Talking Resilience: Embedded Natural Language Cyber-Organizations by Design. Systems 2025, 13, 247. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Tihanyi, N.; Debbah, M. From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review. arXiv 2025. [Google Scholar] [CrossRef]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.; Tang, J.; Chen, X.; Lin, Y.; et al. A Survey on Large Language Model Based Autonomous Agents. Front. Comput. Sci. 2024, 18, 186345. [Google Scholar] [CrossRef]
- Lee, N.; Cai, Z.; Schwarzschild, A.; Lee, K.; Papailiopoulos, D. Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges. arXiv 2025. [Google Scholar] [CrossRef]
- Robeyns, M.; Szummer, M.; Aitchison, L. A Self-Improving Coding Agent. arXiv 2025. [Google Scholar] [CrossRef]
- Zhao, A.; Huang, D.; Xu, Q.; Lin, M.; Liu, Y.J.; Huang, G. ExpeL: LLM Agents Are Experiential Learners. Proc. AAAI Conf. Artif. Intell. 2024, 38, 19632–19642. [Google Scholar] [CrossRef]
- Metz, C. AI Start-Up Anthropic Challenges OpenAI and Google with New Chatbot. The New York Times, 4 March 2024. [Google Scholar]
- Ostrowski, J. Regulating Machine Learning Open-Source Software: A Primer for Policymakers; Technical Report; Abundance Institute: Salt Lake City, UT, USA, 2024. [Google Scholar]
- Mittelstadt, B. Principles Alone Cannot Guarantee Ethical AI. Nat. Mach. Intell. 2019, 1, 501–507. [Google Scholar] [CrossRef]
- Kazim, E.; Koshiyama, A.S. A High-Level Overview of AI Ethics. Patterns 2021, 2, 100314. [Google Scholar] [CrossRef] [PubMed]
- Corrêa, N.K.; Galvão, C.; Santos, J.W.; Pino, C.D.; Pinto, E.P.; Barbosa, C.; Massmann, D.; Mambrini, R.; Galvão, L.; Terem, E.; et al. Worldwide AI Ethics: A Review of 200 Guidelines and Recommendations for AI Governance. Patterns 2023, 4, 100857. [Google Scholar] [CrossRef] [PubMed]
- Prem, E. From Ethical AI Frameworks to Tools: A Review of Approaches. AI Ethics 2023, 3, 699–716. [Google Scholar] [CrossRef]
- Novelli, C.; Taddeo, M.; Floridi, L. Accountability in Artificial Intelligence: What It Is and How It Works. AI Soc. 2024, 39, 1871–1882. [Google Scholar] [CrossRef]
- Verdegem, P. Dismantling AI Capitalism: The Commons as an Alternative to the Power Concentration of Big Tech. AI Soc. 2024, 39, 727–737. [Google Scholar] [CrossRef] [PubMed]
- Sorensen, T.; Moore, J.; Fisher, J.; Gordon, M.; Mireshghallah, N.; Rytting, C.M.; Ye, A.; Jiang, L.; Lu, X.; Dziri, N.; et al. A Roadmap to Pluralistic Alignment. arXiv 2024. [Google Scholar] [CrossRef]
- Al-kfairy, M.; Mustafa, D.; Kshetri, N.; Insiew, M.; Alfandi, O. Ethical Challenges and Solutions of Generative AI: An Interdisciplinary Perspective. Informatics 2024, 11, 58. [Google Scholar] [CrossRef]
- Ribeiro, D.; Rocha, T.; Pinto, G.; Cartaxo, B.; Amaral, M.; Davila, N.; Camargo, A. Toward Effective AI Governance: A Review of Principles. arXiv 2025. [Google Scholar] [CrossRef]
- Ricciardi Celsi, L.; Zomaya, A.Y. Perspectives on Managing AI Ethics in the Digital Age. Information 2025, 16, 318. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023. [Google Scholar] [CrossRef]
- Team, G.; Kamath, A.; Ferret, J.; Pathak, S.; Vieillard, N.; Merhej, R.; Perrin, S.; Matejovicova, T.; Ramé, A.; Rivière, M.; et al. Gemma 3 Technical Report. arXiv 2025. [Google Scholar] [CrossRef]
- Abdin, M.; Jacobs, S.A.; Awan, A.A.; Aneja, J.; Awadallah, A.; Awadalla, H.; Bach, N.; Bahree, A.; Bakhtiari, A.; Behl, H.; et al. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv 2024. [Google Scholar] [CrossRef]
- Yang, A.; Li, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Gao, C.; Huang, C.; Lv, C.; et al. Qwen3 Technical Report. arXiv 2025. [Google Scholar] [CrossRef]
- Malartic, Q.; Chowdhury, N.R.; Cojocaru, R.; Farooq, M.; Campesan, G.; Djilali, Y.A.D.; Narayan, S.; Singh, A.; Velikanov, M.; Boussaha, B.E.A.; et al. Falcon2-11B Technical Report. arXiv 2024. [Google Scholar] [CrossRef]
- DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025. [Google Scholar] [CrossRef]
- Egashira, K.; Vero, M.; Staab, R.; He, J.; Vechev, M. Exploiting LLM Quantization. arXiv 2024. [Google Scholar] [CrossRef]
- Lang, J.; Guo, Z.; Huang, S. A Comprehensive Study on Quantization Techniques for Large Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Hooper, C.; Kim, S.; Mohammadzadeh, H.; Mahoney, M.W.; Shao, Y.S.; Keutzer, K.; Gholami, A. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. Adv. Neural Inf. Process. Syst. 2024, 37, 1270–1303. [Google Scholar]
- Zhao, Y.; Lin, C.Y.; Zhu, K.; Ye, Z.; Chen, L.; Zheng, S.; Ceze, L.; Krishnamurthy, A.; Chen, T.; Kasikci, B. Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving. Proc. Mach. Learn. Syst. 2024, 6, 196–209. [Google Scholar]
- Han, D.; Han, M. Run DeepSeek-R1 Dynamic 1.58-Bit. 2025. Available online: https://unsloth.ai/blog/deepseekr1-dynamic (accessed on 14 July 2025).
- Dai, D.; Deng, C.; Zhao, C.; Xu, R.X.; Gao, H.; Chen, D.; Li, J.; Zeng, W.; Yu, X.; Wu, Y.; et al. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv 2022. [Google Scholar] [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Hanna, E.B.; Bressand, F.; et al. Mixtral of Experts. arXiv 2024. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, H.; Yao, Y.; Li, Z.; Zhao, H. Keep the Cost Down: A Review on Methods to Optimize LLM’s KV-Cache Consumption. arXiv 2024. [Google Scholar] [CrossRef]
- Irugalbandara, C.; Mahendra, A.; Daynauth, R.; Arachchige, T.K.; Dantanarayana, J.; Flautner, K.; Tang, L.; Kang, Y.; Mars, J. Scaling Down to Scale Up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production. arXiv 2024. [Google Scholar] [CrossRef]
- Chiang, W.L.; Zheng, L.; Sheng, Y.; Angelopoulos, A.N.; Li, T.; Li, D.; Zhang, H.; Zhu, B.; Jordan, M.; Gonzalez, J.E.; et al. Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. arXiv 2024. [Google Scholar] [CrossRef]
- Wang, L.; Yi, D.; Jose, D.; Passarelli, J.; Gao, J.; Leventis, J.; Li, K. Enterprise Large Language Model Evaluation Benchmark. arXiv 2025. [Google Scholar] [CrossRef]
- Schroeder, S. Nvidia’s Digits Is a Tiny AI Supercomputer for Your Desk. Mashable, 7 January 2025. [Google Scholar]
- Willhoite, P. Why Apple’s M4 MacBook Air Is a Milestone for On-Device AI. 2025. Available online: https://www.webai.com/blog/why-apples-m4-macbook-air-is-a-milestone-for-on-device-ai (accessed on 14 July 2025).
- Williams, W. Return of the OG? AMD Unveils Radeon AI Pro R9700, Now a Workstation-Class GPU with 32GB GDDR6. 2025. Available online: https://www.techradar.com/pro/return-of-the-og-amd-unveils-radeon-ai-pro-r9700-now-a-workstation-class-gpu-with-32gb-gddr6 (accessed on 14 July 2025).
- Just, N.; Latzer, M. Governance by Algorithms: Reality Construction by Algorithmic Selection on the Internet. Media Cult. Soc. 2017, 39, 238–258. [Google Scholar] [CrossRef]
- Srivastava, S. Algorithmic Governance and the International Politics of Big Tech. Perspect. Politics 2023, 21, 989–1000. [Google Scholar] [CrossRef]
- Khanal, S.; Zhang, H.; Taeihagh, A. Why and How Is the Power of Big Tech Increasing in the Policy Process? The Case of Generative AI. Policy Soc. 2025, 44, 52–69. [Google Scholar] [CrossRef]
- Sætra, H.S.; Coeckelbergh, M.; Danaher, J. The AI Ethicist’s Dilemma: Fighting Big Tech by Supporting Big Tech. AI Ethics 2022, 2, 15–27. [Google Scholar] [CrossRef]
- Temsah, A.; Alhasan, K.; Altamimi, I.; Jamal, A.; Al-Eyadhy, A.; Malki, K.H.; Temsah, M.H. DeepSeek in Healthcare: Revealing Opportunities and Steering Challenges of a New Open-Source Artificial Intelligence Frontier. Cureus 2025, 17, e79221. [Google Scholar] [CrossRef] [PubMed]
- McIntosh, F.; Murina, S.; Chen, L.; Vargas, H.A.; Becker, A.S. Keeping Private Patient Data off the Cloud: A Comparison of Local LLMs for Anonymizing Radiology Reports. Eur. J. Radiol. Artif. Intell. 2025, 2, 100020. [Google Scholar] [CrossRef]
- Montagna, S.; Ferretti, S.; Klopfenstein, L.C.; Ungolo, M.; Pengo, M.F.; Aguzzi, G.; Magnini, M. Privacy-Preserving LLM-based Chatbots for Hypertensive Patient Self-Management. Smart Health 2025, 36, 100552. [Google Scholar] [CrossRef]
- Apaydin, K.; Zisgen, Y. Local Large Language Models for Business Process Modeling. In Process Mining Workshops, Proceedings of the ICPM 2024 International Workshops, Lyngby, Denmark, 14–18 October 2024; Delgado, A., Slaats, T., Eds.; Springer: Cham, Switzerland, 2025; pp. 605–609. [Google Scholar] [CrossRef]
- Pavsner, M.S. The Attorney’s Ethical Obligations When Using AI. Available online: https://perma.cc/LNN6-WNK8 (accessed on 14 July 2025).
- Tye, J.C. Exploring the Intersections of Privacy and Generative AI: A Dive into Attorney-Client Privilege and ChatGPT. Jurimetrics 2024, 64, 309. [Google Scholar]
- Sakai, K.; Uehara, Y.; Kashihara, S. Implementation and Evaluation of LLM-Based Conversational Systems on a Low-Cost Device. In Proceedings of the IEEE Global Humanitarian Technology Conference (GHTC), Radnor, PA, USA, 23–26 October 2024; pp. 392–399. [Google Scholar] [CrossRef]
- Wester, J.; Schrills, T.; Pohl, H.; van Berkel, N. “As an AI Language Model, I Cannot”: Investigating LLM Denials of User Requests. In Proceedings of the CHI ’24: CHI Conference on Human Factors in Computing Systems, New York, NY, USA, 11–16 May 2024; pp. 1–14. [Google Scholar] [CrossRef]
- Vekaria, Y.; Canino, A.L.; Levitsky, J.; Ciechonski, A.; Callejo, P.; Mandalari, A.M.; Shafiq, Z. Big Help or Big Brother? Auditing Tracking, Profiling, and Personalization in Generative AI Assistants. arXiv 2025. [Google Scholar] [CrossRef]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.M.; Chen, W.; et al. Parameter-Efficient Fine-Tuning of Large-Scale Pre-Trained Language Models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Lermen, S.; Rogers-Smith, C.; Ladish, J. LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B. arXiv 2024. [Google Scholar] [CrossRef]
- Candel, A.; McKinney, J.; Singer, P.; Pfeiffer, P.; Jeblick, M.; Lee, C.M.; Conde, M.V. H2O Open Ecosystem for State-of-the-art Large Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Zhang, D.; Feng, T.; Xue, L.; Wang, Y.; Dong, Y.; Tang, J. Parameter-Efficient Fine-Tuning for Foundation Models. arXiv 2025. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, R.; Zhang, J.; Ye, Y.; Luo, Z.; Feng, Z.; Ma, Y. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Lyu, K.; Zhao, H.; Gu, X.; Yu, D.; Goyal, A.; Arora, S. Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates. arXiv 2025. [Google Scholar] [CrossRef]
- Nguyen, M.; Baker, A.; Neo, C.; Roush, A.; Kirsch, A.; Shwartz-Ziv, R. Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs. arXiv 2025. [Google Scholar] [CrossRef]
- Peeperkorn, M.; Kouwenhoven, T.; Brown, D.; Jordanous, A. Is Temperature the Creativity Parameter of Large Language Models? arXiv 2024. [Google Scholar] [CrossRef]
- Brinkmann, L.; Cebrian, M.; Pescetelli, N. Adversarial Dynamics in Centralized Versus Decentralized Intelligent Systems. Top. Cogn. Sci. 2025, 17, 374–391. [Google Scholar] [CrossRef] [PubMed]
- Kuźmicz, M.M. Equilibrating the Scales: Balancing and Power Relations in the Age of AI. AI & Soc. 2025. [Google Scholar] [CrossRef]
- Goldstein, J.A.; Sastry, G. The Coming Age of AI-Powered Propaganda. Foreign Affairs, 7 April 2023. [Google Scholar]
- Goldstein, J.A.; Chao, J.; Grossman, S.; Stamos, A.; Tomz, M. How Persuasive Is AI-generated Propaganda? PNAS Nexus 2024, 3, pgae034. [Google Scholar] [CrossRef] [PubMed]
- Spitale, G.; Biller-Andorno, N.; Germani, F. AI Model GPT-3 (Dis)Informs Us Better than Humans. Sci. Adv. 2023, 9, eadh1850. [Google Scholar] [CrossRef] [PubMed]
- Buchanan, B.; Lohn, A.; Musser, M. Truth, Lies, and Automation; Technical Report; Center for Security and Emerging Technology: Washington, DC, USA, 2021. [Google Scholar]
- Kreps, S.; McCain, R.M.; Brundage, M. All the News That’s Fit to Fabricate: AI-Generated Text as a Tool of Media Misinformation. J. Exp. Political Sci. 2022, 9, 104–117. [Google Scholar] [CrossRef]
- Barman, D.; Guo, Z.; Conlan, O. The Dark Side of Language Models: Exploring the Potential of LLMs in Multimedia Disinformation Generation and Dissemination. Mach. Learn. Appl. 2024, 16, 100545. [Google Scholar] [CrossRef]
- Visnjic, D. Generative Models and Deepfake Technology: A Qualitative Research on the Intersection of Social Media and Political Manipulation. In Artificial Intelligence and Machine Learning, Proceedings of the 43rd IBIMA Conference, IBIMA-AI 2024, Madrid, Spain, 26–27 June 2024; Soliman, K.S., Ed.; Springer: Cham, Switzerland, 2025; pp. 75–80. [Google Scholar] [CrossRef]
- Herbold, S.; Trautsch, A.; Kikteva, Z.; Hautli-Janisz, A. Large Language Models Can Impersonate Politicians and Other Public Figures. arXiv 2024. [Google Scholar] [CrossRef]
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The Llama 3 Herd of Models. arXiv 2024. [Google Scholar] [CrossRef]
- Williams, A.R.; Burke-Moore, L.; Chan, R.S.Y.; Enock, F.E.; Nanni, F.; Sippy, T.; Chung, Y.L.; Gabasova, E.; Hackenburg, K.; Bright, J. Large Language Models Can Consistently Generate High-Quality Content for Election Disinformation Operations. PLoS ONE 2025, 20, e0317421. [Google Scholar] [CrossRef] [PubMed]
- Wack, M.; Ehrett, C.; Linvill, D.; Warren, P. Generative Propaganda: Evidence of AI’s Impact from a State-Backed Disinformation Campaign. PNAS Nexus 2025, 4, pgaf083. [Google Scholar] [CrossRef] [PubMed]
- Thomas, E. “Hey, Fellow Humans!”: What Can a ChatGPT Campaign Targeting Pro-Ukraine Americans Tell Us About the Future of Generative AI and Disinformation? Available online: https://www.isdglobal.org/digital_dispatches/hey-fellow-humans-what-can-a-chatgpt-campaign-targeting-pro-ukraine-americans-tell-us-about-the-future-of-generative-ai-and-disinformation/ (accessed on 14 July 2025).
- International Panel on the Information Environment (IPIE); Trauthig, I.; Valenzuela, S.; Howard, P.N.; Dommett, K.; Mahlouly, D. The Role of Generative AI Use in 2024 Elections Worldwide; Technical Report; International Panel on the Information Environment (IPIE): Zürich, Switzerland, 2025. [Google Scholar] [CrossRef]
- Myers, S.L.; Thompson, S.A. A.I. Is Starting to Wear Down Democracy. The New York Times, 27 June 2025. [Google Scholar]
- Haque, M.A. LLMs: A Game-Changer for Software Engineers? BenchCounc. Trans. Benchmarks Stand. Eval. 2025, 5, 100204. [Google Scholar] [CrossRef]
- Idrisov, B.; Schlippe, T. Program Code Generation with Generative AIs. Algorithms 2024, 17, 62. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, F.; Shen, J.; Kim, S.; Kim, S. A Survey on Large Language Models for Code Generation. arXiv 2024. [Google Scholar] [CrossRef]
- Kirova, V.D.; Ku, C.S.; Laracy, J.R.; Marlowe, T.J. Software Engineering Education Must Adapt and Evolve for an LLM Environment. In Proceedings of the SIGCSE 2024: 55th ACM Technical Symposium on Computer Science Education V.1, Portland, OR, USA, 20–23 March 2024; pp. 666–672. [Google Scholar] [CrossRef]
- Coignion, T.; Quinton, C.; Rouvoy, R. A Performance Study of LLM-Generated Code on Leetcode. In Proceedings of the EASE ’24: 28th International Conference on Evaluation and Assessment in Software Engineering, Salerno, Italy, 18–21 June 2024; pp. 79–89. [Google Scholar] [CrossRef]
- Lebed, S.V.; Namiot, D.E.; Zubareva, E.V.; Khenkin, P.V.; Vorobeva, A.A.; Svichkar, D.A. Large Language Models in Cyberattacks. Dokl. Math. 2024, 110, S510–S520. [Google Scholar] [CrossRef]
- Madani, P. Metamorphic Malware Evolution: The Potential and Peril of Large Language Models. In Proceedings of the 5th IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 1–4 November 2023; pp. 74–81. [Google Scholar] [CrossRef]
- Afane, K.; Wei, W.; Mao, Y.; Farooq, J.; Chen, J. Next-Generation Phishing: How LLM Agents Empower Cyber Attackers. In Proceedings of the IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; pp. 2558–2567. [Google Scholar] [CrossRef]
- Cerullo, M. AI Scams Mimicking Voices Are on the Rise. Here’s How to Protect Yourself. CBS News, 17 December 2024. Available online: https://www.cbsnews.com/news/elder-scams-family-safe-word/ (accessed on 14 July 2025).
- Kadali, D.K.; Narayana, K.S.S.; Haritha, P.; Mohan, R.N.V.J.; Kattula, R.; Swamy, K.S.V. Predictive Analysis of Cloned Voice to Commit Cybercrimes Using Generative AI Scammers. In Algorithms in Advanced Artificial Intelligence; CRC Press: Boca Raton, FL, USA, 2025. [Google Scholar]
- Toapanta, F.; Rivadeneira, B.; Tipantuña, C.; Guamán, D. AI-Driven Vishing Attacks: A Practical Approach. Eng. Proc. 2024, 77, 15. [Google Scholar] [CrossRef]
- Timoney, M. Gen AI Is Ramping up the Threat of Synthetic Identity Fraud. 2025. Available online: https://www.bostonfed.org/news-and-events/news/2025/04/synthetic-identity-fraud-financial-fraud-expanding-because-of-generative-artificial-intelligence.aspx (accessed on 14 July 2025).
- Microsoft Threat Intelligence. Staying Ahead of Threat Actors in the Age of AI. 2024. Available online: https://www.microsoft.com/en-us/security/blog/2024/02/14/staying-ahead-of-threat-actors-in-the-age-of-ai/ (accessed on 14 July 2025).
- Benegas, G.; Batra, S.S.; Song, Y.S. DNA Language Models Are Powerful Predictors of Genome-Wide Variant Effects. Proc. Natl. Acad. Sci. USA 2023, 120, e2311219120. [Google Scholar] [CrossRef] [PubMed]
- Consens, M.E.; Li, B.; Poetsch, A.R.; Gilbert, S. Genomic Language Models Could Transform Medicine but Not Yet. npj Digit. Med. 2025, 8, 212. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Zhou, Z.; Liu, H.; Davuluri, R.V. DNABERT: Pre-Trained Bidirectional Encoder Representations from Transformers Model for DNA-language in Genome. Bioinformatics 2021, 37, 2112–2120. [Google Scholar] [CrossRef] [PubMed]
- Madani, A.; Krause, B.; Greene, E.R.; Subramanian, S.; Mohr, B.P.; Holton, J.M.; Olmos, J.L.; Xiong, C.; Sun, Z.Z.; Socher, R.; et al. Large Language Models Generate Functional Protein Sequences across Diverse Families. Nat. Biotechnol. 2023, 41, 1099–1106. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, E.; Poli, M.; Durrant, M.G.; Kang, B.; Katrekar, D.; Li, D.B.; Bartie, L.J.; Thomas, A.W.; King, S.H.; Brixi, G.; et al. Sequence Modeling and Design from Molecular to Genome Scale with Evo. Science 2024, 386, eado9336. [Google Scholar] [CrossRef] [PubMed]
- James, J.S.; Dai, J.; Chew, W.L.; Cai, Y. The Design and Engineering of Synthetic Genomes. Nat. Rev. Genet. 2025, 26, 298–319. [Google Scholar] [CrossRef] [PubMed]
- Schindler, D.; Dai, J.; Cai, Y. Synthetic Genomics: A New Venture to Dissect Genome Fundamentals and Engineer New Functions. Curr. Opin. Chem. Biol. 2018, 46, 56–62. [Google Scholar] [CrossRef] [PubMed]
- Pannu, J.; Bloomfield, D.; MacKnight, R.; Hanke, M.S.; Zhu, A.; Gomes, G.; Cicero, A.; Inglesby, T.V. Dual-Use Capabilities of Concern of Biological AI Models. PLoS Comput. Biol. 2025, 21, e1012975. [Google Scholar] [CrossRef] [PubMed]
- Mackelprang, R.; Adamala, K.P.; Aurand, E.R.; Diggans, J.C.; Ellington, A.D.; Evans, S.W.; Fortman, J.L.C.; Hillson, N.J.; Hinman, A.W.; Isaacs, F.J.; et al. Making Security Viral: Shifting Engineering Biology Culture and Publishing. ACS Synth. Biol. 2022, 11, 522–527. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Lokugamage, K.G.; Zhang, X.; Vu, M.N.; Muruato, A.E.; Menachery, V.D.; Shi, P.Y. Engineering SARS-CoV-2 Using a Reverse Genetic System. Nat. Protoc. 2021, 16, 1761–1784. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhao, H.; Zheng, L.; An, W. Advances in Synthetic Biology and Biosafety Governance. Front. Bioeng. Biotechnol. 2021, 9, 598087. [Google Scholar] [CrossRef] [PubMed]
- Adam, D. Lethal AI Weapons Are Here: How Can We Control Them? Nature 2024, 629, 521–523. [Google Scholar] [CrossRef] [PubMed]
- Rees, R. Ukraine’s ‘Drone War’ Hastens Development of Autonomous Weapons. Financial Times, 26 May 2025. [Google Scholar]
- Davies, H.; Abraham, Y. Revealed: Israeli Military Creating ChatGPT-like Tool Using Vast Collection of Palestinian Surveillance Data. The Guardian, 6 March 2025. [Google Scholar]
- Zhan, Q.; Fang, R.; Bindu, R.; Gupta, A.; Hashimoto, T.; Kang, D. Removing RLHF Protections in GPT-4 via Fine-Tuning. arXiv 2024. [Google Scholar] [CrossRef]
- Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. Constitutional AI: Harmlessness from AI Feedback. arXiv 2022. [Google Scholar] [CrossRef]
- Allen, J.G.; Loo, J.; Campoverde, J.L.L. Governing Intelligence: Singapore’s Evolving AI Governance Framework. Camb. Forum AI Law Gov. 2025, 1, e12. [Google Scholar] [CrossRef]
- NIST. Artificial Intelligence Risk Management Framework (AI RMF 1.0); Technical Report NIST AI 100-1; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023. [CrossRef]
- Rauh, M.; Marchal, N.; Manzini, A.; Hendricks, L.A.; Comanescu, R.; Akbulut, C.; Stepleton, T.; Mateos-Garcia, J.; Bergman, S.; Kay, J.; et al. Gaps in the Safety Evaluation of Generative AI. Proc. AAAI/ACM Conf. AI Ethics Soc. 2024, 7, 1200–1217. [Google Scholar] [CrossRef]
- Labonne, M. Uncensor Any LLM with Abliteration. 2024. Available online: https://huggingface.co/blog/mlabonne/abliteration (accessed on 14 July 2025).
- Gault, M. AI Trained on 4Chan Becomes ‘Hate Speech Machine’. Vice, 7 June 2022. [Google Scholar]
- Castaño, J.; Martínez-Fernández, S.; Franch, X. Lessons Learned from Mining the Hugging Face Repository. In Proceedings of the WSESE ’24: 1st IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering, Lisbon, Portugal, 16 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2020. [Google Scholar] [CrossRef]
- Bondarenko, M.; Lushnei, S.; Paniv, Y.; Molchanovsky, O.; Romanyshyn, M.; Filipchuk, Y.; Kiulian, A. Sovereign Large Language Models: Advantages, Strategy and Regulations. arXiv 2025. [Google Scholar] [CrossRef]
- Pomfret, J.; Pang, J.; Pomfret, J.; Pang, J. Exclusive: Chinese Researchers Develop AI Model for Military Use on Back of Meta’s Llama. Reuters, 1 November 2024. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021. [Google Scholar] [CrossRef]
- Yang, X.; Wang, X.; Zhang, Q.; Petzold, L.; Wang, W.Y.; Zhao, X.; Lin, D. Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Yamin, M.M.; Hashmi, E.; Katt, B. Combining Uncensored and Censored LLMs for Ransomware Generation. In Web Information Systems Engineering—WISE 2024, Proceedings of the 25th International Conference, Doha, Qatar, 2–5 December 2024; Barhamgi, M., Wang, H., Wang, X., Eds.; Springer: Singapore, 2025; pp. 189–202. [Google Scholar] [CrossRef]
- Wan, A.; Wallace, E.; Shen, S.; Klein, D. Poisoning Language Models During Instruction Tuning. arXiv 2023. [Google Scholar] [CrossRef]
- Barclay, I.; Preece, A.; Taylor, I. Defining the Collective Intelligence Supply Chain. arXiv 2018. [Google Scholar] [CrossRef]
- Hopkins, A.; Cen, S.H.; Ilyas, A.; Struckman, I.; Videgaray, L.; Mądry, A. AI Supply Chains: An Emerging Ecosystem of AI Actors, Products, and Services. arXiv 2025. [Google Scholar] [CrossRef]
- Gstrein, O.J.; Haleem, N.; Zwitter, A. General-Purpose AI Regulation and the European Union AI Act. Internet Policy Rev. 2024, 13, 1–26. [Google Scholar] [CrossRef]
- Evas, T. The EU Artificial Intelligence Act. J. AI Law Regul. 2024, 1, 98–101. [Google Scholar] [CrossRef]
- El Ali, A.; Venkatraj, K.P.; Morosoli, S.; Naudts, L.; Helberger, N.; Cesar, P. Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How. In Proceedings of the CHI EA ’24: Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–11. [Google Scholar] [CrossRef]
- The White House. Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence, Executive Order 14110. 2023. Available online: https://www.federalregister.gov/documents/2023/11/01/2023-24283/safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/ (accessed on 14 July 2025).
- Lubello, V. From Biden to Trump: Divergent and Convergent Policies in The Artificial Intelligence (AI) Summer. DPCE Online 2025, 69, 1. [Google Scholar] [CrossRef]
- The White House. Removing Barriers to American Leadership in Artificial Intelligence. 2025. Available online: https://www.whitehouse.gov/presidential-actions/2025/01/removing-barriers-to-american-leadership-in-artificial-intelligence/ (accessed on 14 July 2025).
- Franks, E.; Lee, B.; Xu, H. Report: China’s New AI Regulations. Glob. Priv. Law Rev. 2024, 5, 43–49. [Google Scholar] [CrossRef]
- Diallo, K.; Smith, J.; Okolo, C.T.; Nyamwaya, D.; Kgomo, J.; Ngamita, R. Case Studies of AI Policy Development in Africa. Data Policy 2025, 7, e15. [Google Scholar] [CrossRef]
- Quan, E. Censorship Sensing: The Capabilities and Implications of China’s Great Firewall Under Xi Jinping. Sigma J. Political Int. Stud. 2022, 39, 19–31. [Google Scholar]
- Wong, H. Mapping the Open-Source AI Debate: Cybersecurity Implications and Policy Priorities. 2025. Available online: https://www.rstreet.org/research/mapping-the-open-source-ai-debate-cybersecurity-implications-and-policy-priorities/ (accessed on 14 July 2025).
- Abdelnabi, S.; Fritz, M. Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 121–140. [Google Scholar] [CrossRef]
- Uddin, M.S.; Ohidujjaman; Hasan, M.; Shimamura, T. Audio Watermarking: A Comprehensive Review. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 5. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, K.; Su, Z.; Vasan, S.; Grishchenko, I.; Kruegel, C.; Vigna, G.; Wang, Y.X.; Li, L. Invisible Image Watermarks Are Provably Removable Using Generative AI. arXiv 2024. [Google Scholar] [CrossRef]
- Han, T.A.; Lenaerts, T.; Santos, F.C.; Pereira, L.M. Voluntary Safety Commitments Provide an Escape from Over-Regulation in AI Development. Technol. Soc. 2022, 68, 101843. [Google Scholar] [CrossRef]
- Ali, S.J.; Christin, A.; Smart, A.; Katila, R. Walking the Walk of AI Ethics: Organizational Challenges and the Individualization of Risk among Ethics Entrepreneurs. In Proceedings of the ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 217–226. [Google Scholar] [CrossRef]
- Varanasi, R.A.; Goyal, N. “It Is Currently Hodgepodge”: Examining AI/ML Practitioners’ Challenges during Co-production of Responsible AI Values. In Proceedings of the CHI ’23: CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–17. [Google Scholar] [CrossRef]
- van Maanen, G. AI Ethics, Ethics Washing, and the Need to Politicize Data Ethics. Digit. Soc. 2022, 1, 9. [Google Scholar] [CrossRef] [PubMed]
- Widder, D.G.; Zhen, D.; Dabbish, L.; Herbsleb, J. It’s about Power: What Ethical Concerns Do Software Engineers Have, and What Do They (Feel They Can) Do about Them? In Proceedings of the FAccT ’23: ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 467–479. [Google Scholar] [CrossRef]
- Ferrandis, C.M.; Lizarralde, M.D. Open Sourcing AI: Intellectual Property at the Service of Platform Leadership. J. Intellect. Prop. Inf. Technol. Electron. Commer. Law 2022, 13, 224–246. [Google Scholar]
- Contractor, D.; McDuff, D.; Haines, J.K.; Lee, J.; Hines, C.; Hecht, B.; Vincent, N.; Li, H. Behavioral Use Licensing for Responsible AI. In Proceedings of the FAccT ’22: ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 778–788. [Google Scholar] [CrossRef]
- Klyman, K. Acceptable Use Policies for Foundation Models. Proc. AAAI/ACM Conf. AI Ethics Soc. 2024, 7, 752–767. [Google Scholar] [CrossRef]
- McDuff, D.; Korjakow, T.; Cambo, S.; Benjamin, J.J.; Lee, J.; Jernite, Y.; Ferrandis, C.M.; Gokaslan, A.; Tarkowski, A.; Lindley, J.; et al. On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI. arXiv 2024. [Google Scholar] [CrossRef]
- Schmit, C.D.; Doerr, M.J.; Wagner, J.K. Leveraging IP for AI Governance. Science 2023, 379, 646–648. [Google Scholar] [CrossRef] [PubMed]
- Henderson, P.; Lemley, M.A. The Mirage of Artificial Intelligence Terms of Use Restrictions. arXiv 2024. [Google Scholar] [CrossRef]
- Crouch, D. Using Intellectual Property to Regulate Artificial Intelligence. Mo. Law Rev. 2024, 89, 781. [Google Scholar] [CrossRef]
- Widder, D.G.; Nafus, D.; Dabbish, L.; Herbsleb, J. Limits and Possibilities for “Ethical AI” in Open Source: A Study of Deepfakes. In Proceedings of the FAccT ’22: ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 2035–2046. [Google Scholar] [CrossRef]
- Pawelec, M. Decent Deepfakes? Professional Deepfake Developers’ Ethical Considerations and Their Governance Potential. AI Ethics 2024, 5, 2641–2666. [Google Scholar] [CrossRef]
- Cui, J.; Araujo, D.A. Rethinking Use-Restricted Open-Source Licenses for Regulating Abuse of Generative Models. Big Data Soc. 2024, 11, 20539517241229699. [Google Scholar] [CrossRef]
- Maktabdar Oghaz, M.; Babu Saheer, L.; Dhame, K.; Singaram, G. Detection and Classification of ChatGPT-generated Content Using Deep Transformer Models. Front. Artif. Intell. 2025, 8, 1458707. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, H.H.; Fennell, B.D.; Albahra, S.; Hu, B.; Gorbett, T. The ChatGPT Conundrum: Human-generated Scientific Manuscripts Misidentified as AI Creations by AI Text Detection Tool. J. Pathol. Inform. 2023, 14, 100342. [Google Scholar] [CrossRef] [PubMed]
- Weber-Wulff, D.; Anohina-Naumeca, A.; Bjelobaba, S.; Foltýnek, T.; Guerrero-Dib, J.; Popoola, O.; Šigut, P.; Waddington, L. Testing of Detection Tools for AI-generated Text. Int. J. Educ. Integr. 2023, 19, 26. [Google Scholar] [CrossRef]
- Poireault, K. Malicious AI Models on Hugging Face Exploit Novel Attack Technique. 2025. Available online: https://www.infosecurity-magazine.com/news/malicious-ai-models-hugging-face/ (accessed on 14 July 2025).
- Sabt, M.; Achemlal, M.; Bouabdallah, A. Trusted Execution Environment: What It Is, and What It Is Not. In Proceedings of the IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 1, pp. 57–64. [Google Scholar] [CrossRef]
- AĞCA, M.A.; Faye, S.; Khadraoui, D. A Survey on Trusted Distributed Artificial Intelligence. IEEE Access 2022, 10, 55308–55337. [Google Scholar] [CrossRef]
- Geppert, T.; Deml, S.; Sturzenegger, D.; Ebert, N. Trusted Execution Environments: Applications and Organizational Challenges. Front. Comput. Sci. 2022, 4, 930741. [Google Scholar] [CrossRef]
- Jauernig, P.; Sadeghi, A.R.; Stapf, E. Trusted Execution Environments: Properties, Applications, and Challenges. IEEE Secur. Priv. 2020, 18, 56–60. [Google Scholar] [CrossRef]
- Babar, M.F.; Hasan, M. Trusted Deep Neural Execution—A Survey. IEEE Access 2023, 11, 45736–45748. [Google Scholar] [CrossRef]
- Cai, Z.; Ma, R.; Fu, Y.; Zhang, W.; Ma, R.; Guan, H. LLMaaS: Serving Large-Language Models on Trusted Serverless Computing Platforms. IEEE Trans. Artif. Intell. 2025, 6, 405–415. [Google Scholar] [CrossRef]
- Dong, B.; Wang, Q. Evaluating the Performance of the DeepSeek Model in Confidential Computing Environment. arXiv 2025. [Google Scholar] [CrossRef]
- Greamo, C.; Ghosh, A. Sandboxing and Virtualization: Modern Tools for Combating Malware. IEEE Secur. Priv. 2011, 9, 79–82. [Google Scholar] [CrossRef]
- Prevelakis, V.; Spinellis, D. Sandboxing Applications. In Proceedings of the USENIX Annual Technical Conference, FREENIX Track, Boston, MA, USA, 25–30 June 2001; pp. 119–126. [Google Scholar]
- Johnson, J. The AI Commander Problem: Ethical, Political, and Psychological Dilemmas of Human-Machine Interactions in AI-enabled Warfare. J. Mil. Ethics 2022, 21, 246–271. [Google Scholar] [CrossRef]
- Salo-Pöntinen, H. AI Ethics—Critical Reflections on Embedding Ethical Frameworks in AI Technology. In Culture and Computing. Design Thinking and Cultural Computing; Rauterberg, M., Ed.; Springer: Cham, Switzerland, 2021; pp. 311–329. [Google Scholar] [CrossRef]
- Cai, Y.; Liang, P.; Wang, Y.; Li, Z.; Shahin, M. Demystifying Issues, Causes and Solutions in LLM Open-Source Projects. J. Syst. Softw. 2025, 227, 112452. [Google Scholar] [CrossRef]
- Win, H.M.; Wang, H.; Tan, S.H. Towards Automated Detection of Unethical Behavior in Open-Source Software Projects. In Proceedings of the ESEC/FSE 2023: 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, San Francisco, CA, USA, 3–9 December 2023; pp. 644–656. [Google Scholar] [CrossRef]
- Wang, W. Rethinking AI Safety Approach in the Era of Open-Source AI. 2025. Available online: https://www.lesswrong.com/posts/dLnwRFLFmHKuurTX2/rethinking-ai-safety-approach-in-the-era-of-open-source-ai (accessed on 14 July 2025).
- Carlisle, K.; Gruby, R.L. Polycentric Systems of Governance: A Theoretical Model for the Commons. Policy Stud. J. 2019, 47, 927–952. [Google Scholar] [CrossRef]
- Ostrom, E. Polycentric Systems for Coping with Collective Action and Global Environmental Change. Glob. Environ. Chang. 2010, 20, 550–557. [Google Scholar] [CrossRef]
- Huang, L.T.L.; Papyshev, G.; Wong, J.K. Democratizing Value Alignment: From Authoritarian to Democratic AI Ethics. AI Ethics 2025, 5, 11–18. [Google Scholar] [CrossRef]
- Cihon, P.; Maas, M.M.; Kemp, L. Should Artificial Intelligence Governance Be Centralised? Design Lessons from History. In Proceedings of the AIES ’20: AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 228–234. [Google Scholar] [CrossRef]
- Attard-Frost, B.; Widder, D.G. The Ethics of AI Value Chains. Big Data Soc. 2025, 12, 20539517251340603. [Google Scholar] [CrossRef]
- Muldoon, J.; Cant, C.; Graham, M.; Ustek Spilda, F. The Poverty of Ethical AI: Impact Sourcing and AI Supply Chains. AI Soc. 2025, 40, 529–543. [Google Scholar] [CrossRef]
- Widder, D.G.; Nafus, D. Dislocated Accountabilities in the “AI Supply Chain”: Modularity and Developers’ Notions of Responsibility. Big Data Soc. 2023, 10, 20539517231177620. [Google Scholar] [CrossRef]
- McKelvey, F.; MacDonald, M. Artificial Intelligence Policy Innovations at the Canadian Federal Government. Can. J. Commun. 2019, 44, 43–50. [Google Scholar] [CrossRef]
- Stahl, B.C.; Antoniou, J.; Bhalla, N.; Brooks, L.; Jansen, P.; Lindqvist, B.; Kirichenko, A.; Marchal, S.; Rodrigues, R.; Santiago, N.; et al. A Systematic Review of Artificial Intelligence Impact Assessments. Artif. Intell. Rev. 2023, 56, 12799–12831. [Google Scholar] [CrossRef] [PubMed]
- Hsu, Y.C.; Huang, T.H.K.; Verma, H.; Mauri, A.; Nourbakhsh, I.; Bozzon, A. Empowering Local Communities Using Artificial Intelligence. Patterns 2022, 3, 100449. [Google Scholar] [CrossRef] [PubMed]
- Esteves, A.M.; Daniel, F.; Vanclay, F. Social Impact Assessment: The State of the Art. Impact Assess. Proj. Apprais. 2012, 30, 34–42. [Google Scholar] [CrossRef]
- Welsh, C.; Román García, S.; Barnett, G.C.; Jena, R. Democratising Artificial Intelligence in Healthcare: Community-Driven Approaches for Ethical Solutions. Future Healthc. J. 2024, 11, 100165. [Google Scholar] [CrossRef] [PubMed]
- Buiten, M.; de Streel, A.; Peitz, M. The Law and Economics of AI Liability. Comput. Law Secur. Rev. 2023, 48, 105794. [Google Scholar] [CrossRef]
- Ramakrishnan, K.; Smith, G.; Downey, C. U.S. Tort Liability for Large-Scale Artificial Intelligence Damages: A Primer for Developers and Policymakers; Technical Report; Rand Corporation: Santa Monica, CA, USA, 2024. [Google Scholar]
- Agnese, P.; Arduino, F.R.; Prisco, D.D. The Era of Artificial Intelligence: What Implications for the Board of Directors? Corp. Gov. Int. J. Bus. Soc. 2024, 25, 272–287. [Google Scholar] [CrossRef]
- Collina, L.; Sayyadi, M.; Provitera, M. Critical Issues About A.I. Accountability Answered. Calif. Manag. Rev. Insights 2023. Available online: https://cmr.berkeley.edu/2023/11/critical-issues-about-a-i-accountability-answered/ (accessed on 14 July 2025).
- da Fonseca, A.T.; Vaz de Sequeira, E.; Barreto Xavier, L. Liability for AI Driven Systems. In Multidisciplinary Perspectives on Artificial Intelligence and the Law; Sousa Antunes, H., Freitas, P.M., Oliveira, A.L., Martins Pereira, C., Vaz de Sequeira, E., Barreto Xavier, L., Eds.; Springer International Publishing: Cham, Switzerland, 2024; pp. 299–317. [Google Scholar] [CrossRef]
- Andrews, C. European Commission Withdraws AI Liability Directive from Consideration. 2025. Available online: https://iapp.org/news/a/european-commission-withdraws-ai-liability-directive-from-consideration (accessed on 14 July 2025).
- Abbass, H.; Bender, A.; Gaidow, S.; Whitbread, P. Computational Red Teaming: Past, Present and Future. IEEE Comput. Intell. Mag. 2011, 6, 30–42. [Google Scholar] [CrossRef]
- Ahmad, L.; Agarwal, S.; Lampe, M.; Mishkin, P. OpenAI’s Approach to External Red Teaming for AI Models and Systems. arXiv 2025. [Google Scholar] [CrossRef]
- Tschider, C. Will a Cybersecurity Safe Harbor Raise All Boats? Lawfare, 20 March 2024. [Google Scholar]
- Shinkle, D. The Ohio Data Protection Act: An Analysis of the Ohio Cybersecurity Safe Harbor. Univ. Cincinnati Law Rev. 2019, 87, 1213–1235. [Google Scholar]
- Oberly, D.J. A Potential Trend in the Making? Utah Becomes the Second State to Enact Data Breach Safe Harbor Law Incentivizing Companies to Maintain Robust Data Protection Programs. ABA TIPS Cybersecur. Data Priv. Comm. Newsl. 2021. Available online: https://www.jdsupra.com/legalnews/a-potential-trend-in-the-making-utah-7390312/ (accessed on 14 July 2025).
- Lund, B.; Orhan, Z.; Mannuru, N.R.; Bevara, R.V.K.; Porter, B.; Vinaih, M.K.; Bhaskara, P. Standards, Frameworks, and Legislation for Artificial Intelligence (AI) Transparency. AI Ethics 2025, 5, 3639–3655. [Google Scholar] [CrossRef]
- McNerney, J. McNerney Introduces Bill to Establish Safety Standards for Artificial Intelligence While Fostering Innovation. 2025. Available online: https://sd05.senate.ca.gov/news/mcnerney-introduces-bill-establish-safety-standards-artificial-intelligence-while-fostering (accessed on 14 July 2025).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Key Benefit | Corresponding Risk |
|---|---|---|
| Privacy | Data remain on-device | Reduced external audit and traceability |
| Autonomy | Freedom from platform gatekeeping | Loss of centrally enforced guardrails |
| Cost and access | One-time or low cost democratizes use | Wider spread of uncensored models |
| Customizability | Easy fine-tuning for local needs | Safety alignment can be stripped |
| Innovation and equity | Broader participation in AI R&D | Malicious actors gain powerful tools |
| Governance Focus | Technical Safeguard | Policy/Process Measure |
|---|---|---|
| Content authenticity | Provenance and watermark toolkits | Voluntary community labeling norms |
| Runtime boundaries | User-configurable ethical runtime env. | Safe-harbor tied to compliance |
| Open-source oversight | Automated repo monitoring | Polycentric and participatory bodies |
| Liability and incentives | Audit logs for model releases | Multistakeholder safe-harbor schemes |
| Cross-jurisdiction coordination | Modular open tools | Distributed polycentric frameworks |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sokhansanj, B.A. Local AI Governance: Addressing Model Safety and Policy Challenges Posed by Decentralized AI. AI 2025, 6, 159. https://doi.org/10.3390/ai6070159
Sokhansanj BA. Local AI Governance: Addressing Model Safety and Policy Challenges Posed by Decentralized AI. AI. 2025; 6(7):159. https://doi.org/10.3390/ai6070159
Chicago/Turabian StyleSokhansanj, Bahrad A. 2025. "Local AI Governance: Addressing Model Safety and Policy Challenges Posed by Decentralized AI" AI 6, no. 7: 159. https://doi.org/10.3390/ai6070159
APA StyleSokhansanj, B. A. (2025). Local AI Governance: Addressing Model Safety and Policy Challenges Posed by Decentralized AI. AI, 6(7), 159. https://doi.org/10.3390/ai6070159