Securing Generative AI Systems: Threat-Centric Architectures and the Impact of Divergent EU–US Governance Regimes


Abstract
1. Introduction
2. Methodology
2.1. Study Design and Scope
2.2. Review Methodology
2.2.1. The Constellation of Frameworks
2.2.2. Positioning the Structural–Configurable Distinction in the Literature
- Expanded scope of “design.” In GenAI systems, “design” encompasses not only software architecture but also training data provenance, model selection, fine-tuning procedures, alignment techniques, and emergent capabilities [29]. Structural risks, therefore, include properties that are fixed once a foundation model is chosen, even if the deployer has no visibility into or control over those properties.
- Blurred trust boundaries. Traditional security models assume clear boundaries between code and data, instructions, and inputs. GenAI systems process natural language as both data and control—a fundamental architectural property that creates structural exposure to prompt injection and related attacks.
- Probabilistic and emergent behavior. Unlike deterministic software, where design flaws produce consistent failures, GenAI systems exhibit probabilistic behavior and emergent capabilities that may only manifest under specific conditions. This complicates both the identification and remediation of structural risks.
- Provider–deployer responsibility allocation. The structural–configurable distinction has direct practical implications for allocating security responsibility: structural risks typically require intervention by AI providers or system architects (who control model training, architecture, and capability boundaries), while configurable risks can often be addressed by deploying organizations through operational controls. This allocation is essential for cross-jurisdictional compliance, where regulations may impose different obligations on providers versus deployers.
2.3. Reference Architecture for Generative AI Systems
- Training and adaptation pipeline (data acquisition and filtering, dependency models and datasets, fine-tuning, and update processes). This layer determines the system’s baseline behavior and latent risk. Errors or compromises here propagate downward and are difficult to fully correct later, echoing long-standing lessons from software supply-chain security.
- Model layer (foundation model, system prompts, safety tuning, and configuration). Here, the model is not yet acting on external data or tools. The emphasis is on intent and constraint, similar to how operating system kernels define what is possible and what is forbidden.
- Retrieval and data interface layer (RAG sources, vector stores, connectors, indexing, and access control for enterprise data). This is where many modern GenAI risks emerge, because the model’s outputs are now shaped by live, mutable data rather than solely by static training.
- Orchestration and tool layer (agents, plug-ins/tools, workflow engines, and external system calls). Traditionally, software separated computation from execution. This layer collapses that boundary, making control, permissions, and auditing essential.
- Runtime interaction layer (multi-turn conversations, context windows, output moderation, logging, and monitoring). This is where theoretical risk becomes operational risk, and where failures are visible to users, regulators, and auditors.
2.4. Threat Taxonomy Selection and Threat–Layer Mapping
2.5. Control Identification and Control–Layer Alignment
2.6. Reliability Measures and Method Limitations
3. Threat Landscape and Opportunities
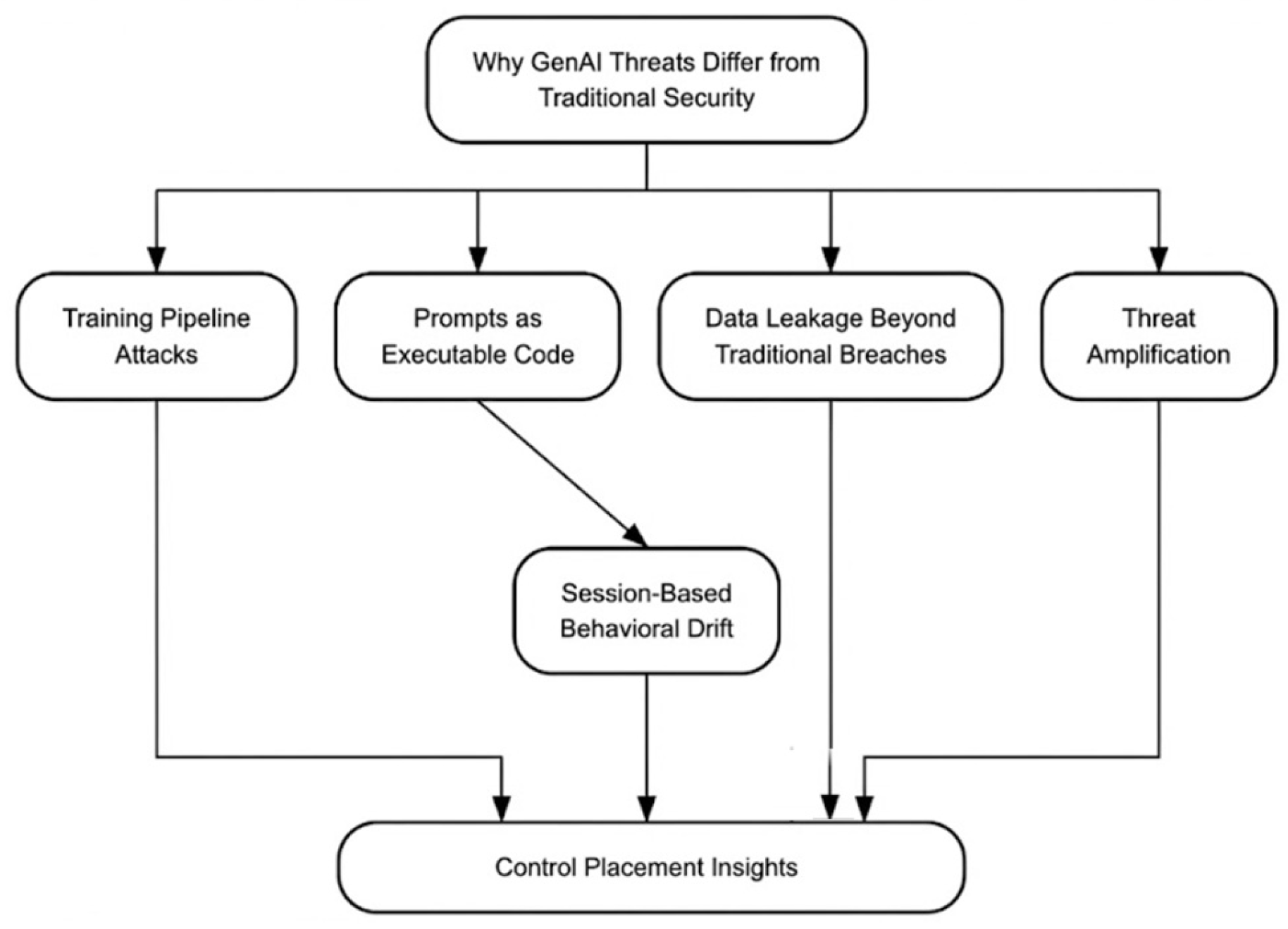
3.1. Why GenAI Threats Differ from Traditional Security
3.1.1. Training Pipeline Attacks
- Data poisoning: Malicious training samples create subtle behavioral changes
- Supply chain: Compromised models or datasets propagate downstream
- Transfer learning: Foundation model weaknesses persist after fine-tuning
- Fine-tuning manipulation: Attackers weaken safety behaviors through updated workflows
3.1.2. Prompts as Executable Code
- Direct injection: Override system instructions via crafted prompts
- Indirect injection: Embedded commands in retrieved documents
- Context manipulation: Crowd out safety instructions
- Jailbreaking: Systematic bypass of constraints.
3.1.3. Data Leakage Beyond Traditional Breaches
- Memorization: Models reproduce training data fragments
- Model inversion: Reconstruct training data from outputs
- Membership inference: Detect if records were in training
- Persistence: Sensitive data in parameters resists removal
3.1.4. Threat Amplification
3.1.5. Session-Based Behavioral Drift
3.1.6. Control Placement Insights
3.1.7. A Structural Vulnerability Case Study
3.2. Finding Bugs That Human Testers Miss
3.3. Operation Centers Leveraging AI
4. Security Control Model for Generative AI Systems
4.1. Controls and Fundamental Objectives
4.2. Guardrails and the Control Placement Question
4.3. Control Types Used in This Paper
- Pipeline controls (training/adaptation): dataset provenance, dependency assurance, controlled fine-tuning, and update governance.
- Interaction controls (runtime): prompt-injection defenses, context handling rules, output moderation, and session-aware monitoring.
- Retrieval and tool controls (integration boundary): least privilege for connectors and tools, retrieval isolation, provenance and trust labeling for retrieved content, and tool-call logging and approval patterns.
- Operational controls (cross-cutting): incident response playbooks, monitoring and alerting, audit trails, and governance processes aligned to risk classification and deployment context.
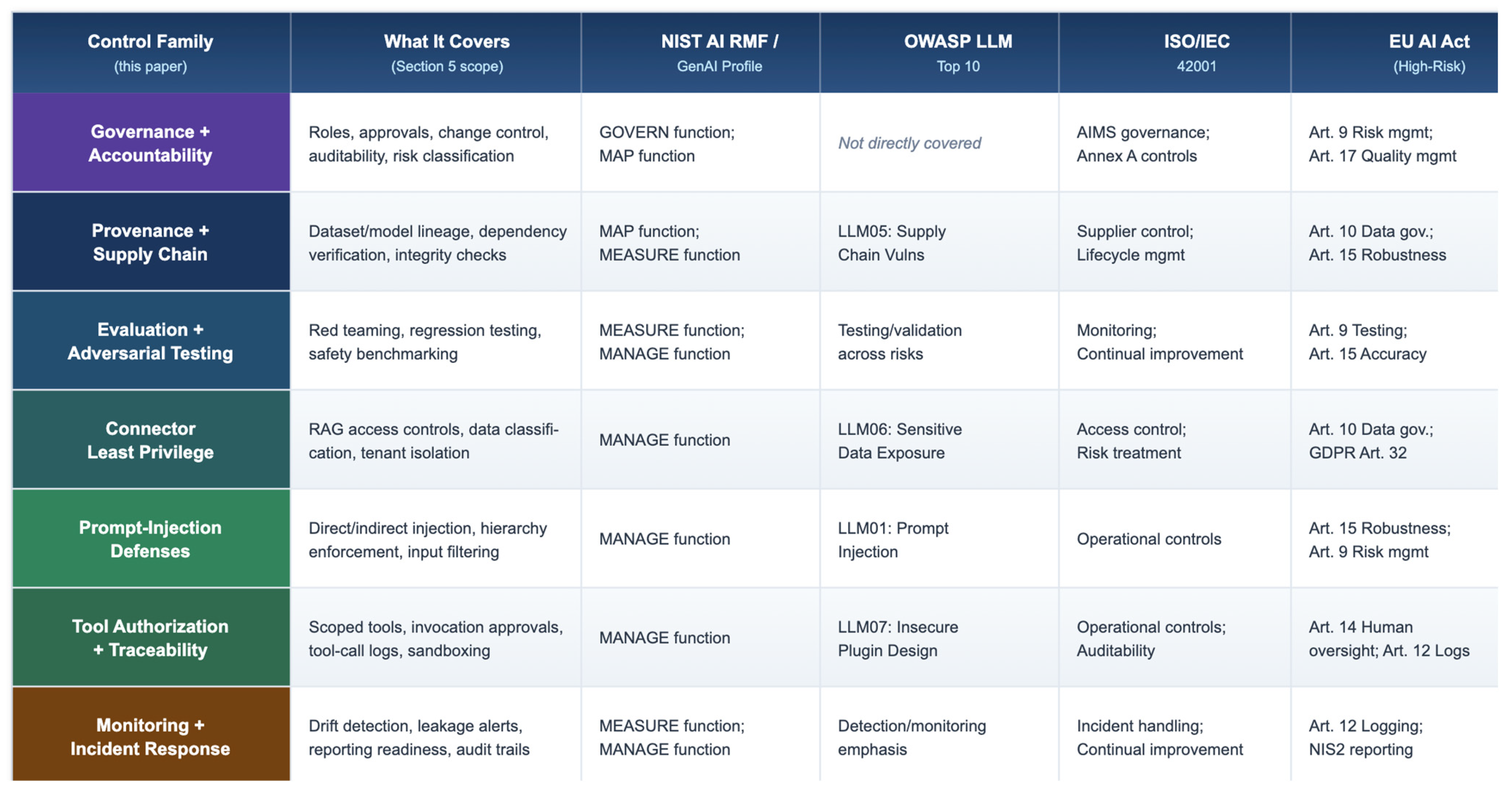
5. Control Framework Aligned to the Generative AI Stack
5.1. Overview and Design Principles
- High-risk systems (as defined by EU AI Act Article 6 or equivalent internal classification): Full implementation of all controls, third-party audits, continuous monitoring, and comprehensive documentation.
- Medium-risk systems: Core controls with periodic internal review and documented risk acceptance for any deferred measures.
- Low-risk systems: Baseline governance and monitoring, with proportionate technical controls.
5.2. Governance and Cross-Cutting Controls
5.2.1. Governance Baseline
- Risk management and classification: This involves defining the system’s purpose, assessing stakeholder impact, and establishing risk tiers; it is essential to maintain a risk register that is linked to architectural components.
- System inventory and change control: Versioning of models, prompts, connectors, tools, and datasets; formal review gates for changes affecting security posture.
- Security-by-design and roles: Establish clear ownership for model behavior, retrieval, and data interfaces, as well as tool integrations, along with defined escalation paths for safety and security incidents.
- Evidence strategy: Establish continuous logging and monitoring streams that document the complete causal chain (prompts, retrieved context, tool calls, outputs, and policy decisions) to facilitate both real-time operational insights and post-incident analysis.
5.2.2. Operational Controls
- Incident response readiness: Playbooks for GenAI-specific incidents (prompt injection, tool misuse, data leakage) with cross-border reporting paths, e.g., NIS2: 24–72 h, the mandatory incident reporting timeframe under the EU NIS2 Directive.
- Continuous monitoring: Ongoing real-time oversight of a system while it is operating, not just testing before deployment. The emphasis on vigilance after release aligns with long-standing operational security principles.
- Third-party governance: Vendor assurance for models, datasets, and tooling, supported by documented provenance and integrity checks to ensure suppliers are properly evaluated, origins are traceable, and components remain unaltered.
5.2.3. Evidence Artifacts
- Static: Risk registers, system inventories, policy documents, role assignments, and change approval records.
- Operational: Anomaly detection alerts, refusal rate dashboards, drift detection outputs, and incident response metrics.
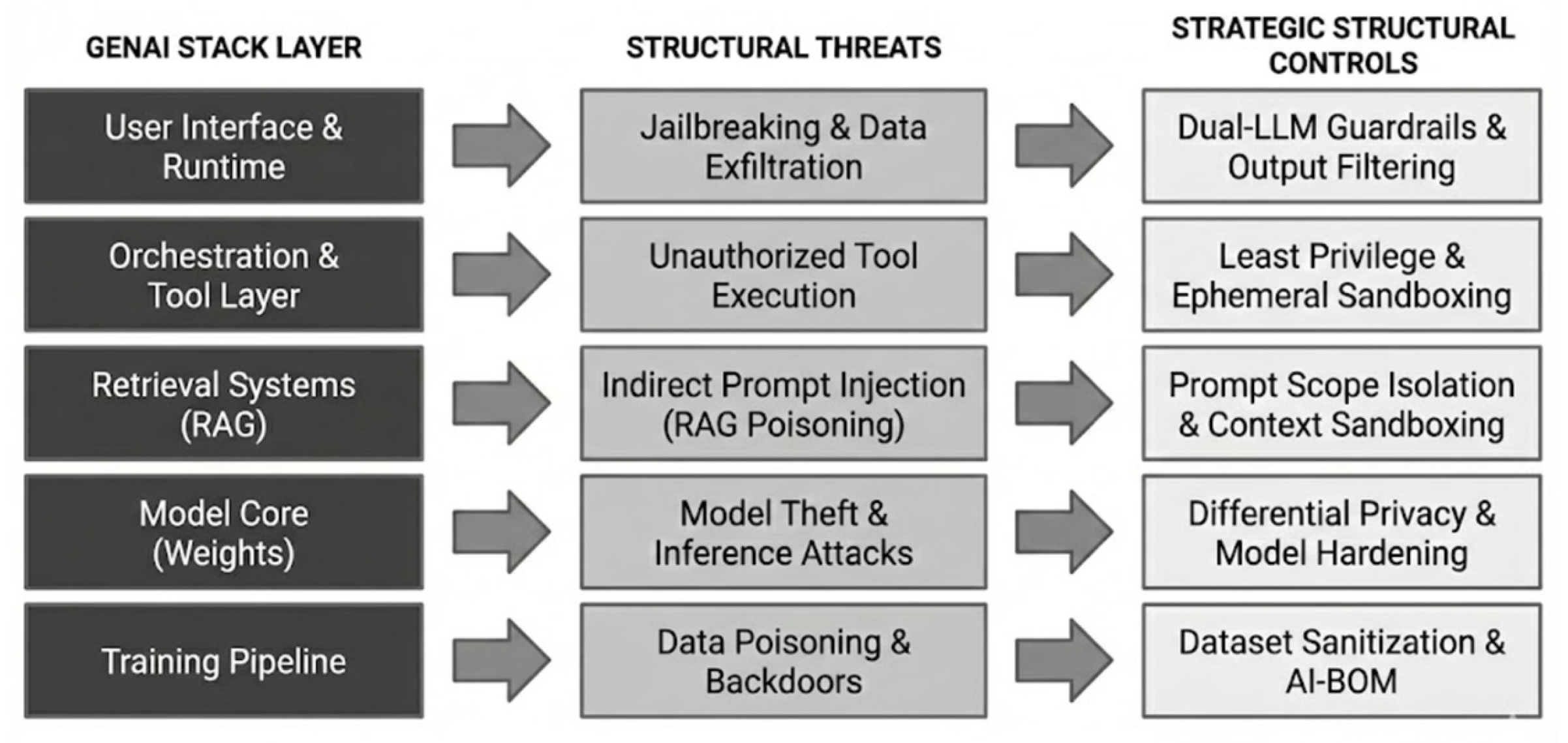
5.3. Five-Layer GenAI Threat-Control Mapping Framework
5.3.1. Layer 1: Training Data and Model Provenance
5.3.2. Layer 2: Model Behavior and Safety Tuning
5.3.3. Layer 3: Retrieval and Context Management
5.3.4. Layer 4: Orchestration and Tool Use
5.3.5. Layer 5: Runtime and Output Management
5.3.6. Orchestration and Tool Use—Detailed Controls
5.3.7. Architectural Controls (Structural)
5.3.8. Operational Controls (Configurable)
5.3.9. Example: Preventing Remote Code Execution via Indirect Prompt Injection
5.4. Architectural Differences: US-Style Versus EU-Compliant Deployments
5.5. Control Coverage and Residual Risk—A Policy Summary
6. Human Factors: Education and Secure Development Practices
6.1. The GenAI Security Skills Gap
6.2. Secure Development Lifecycle for GenAI
6.3. Training Curriculum Framework
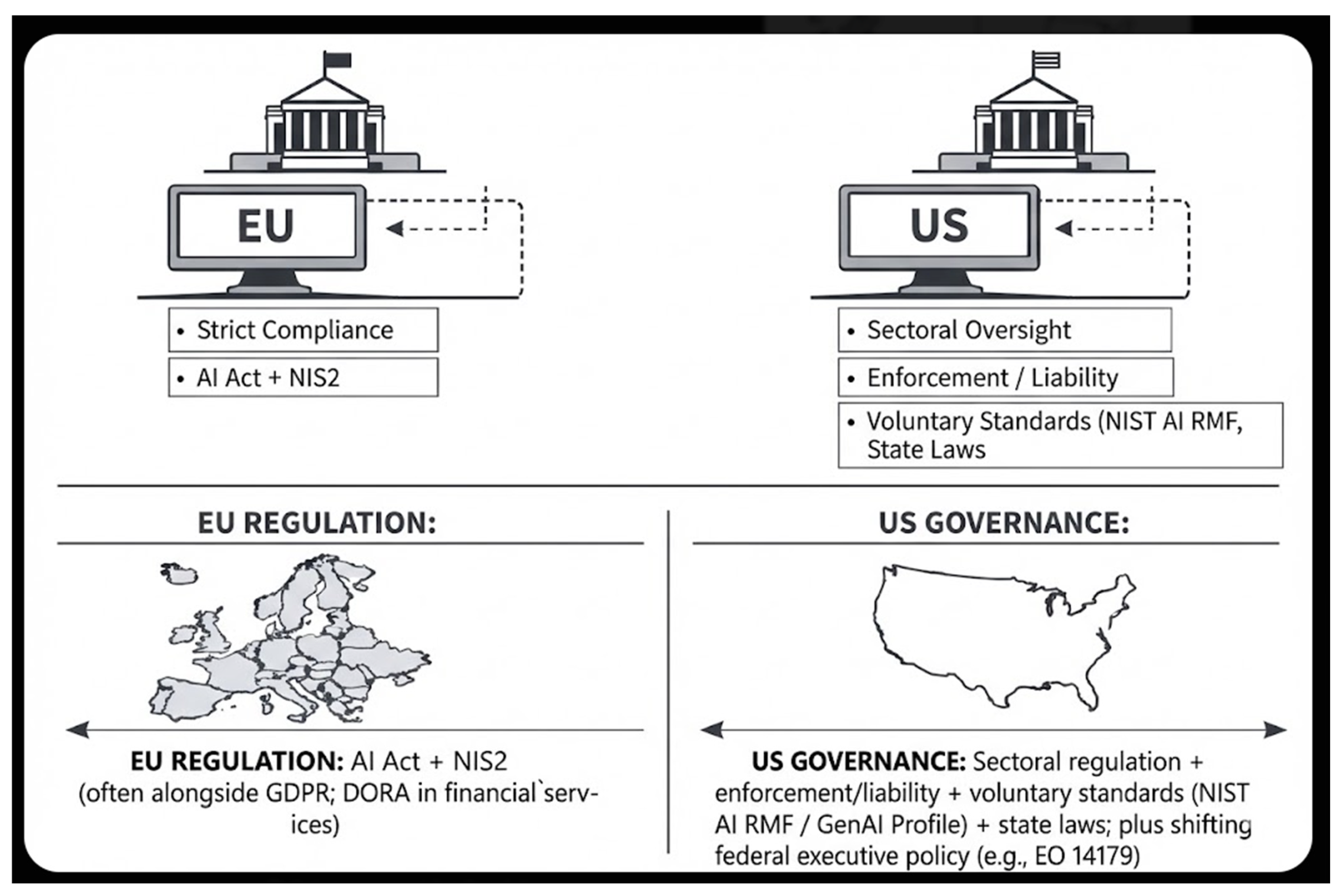
7. The Transatlantic Regulatory Divide
7.1. European Union: The Prescriptive Paradigm
7.2. United States: The Innovation-First Approach
7.3. Comparative Analysis
8. Transatlantic Divergence: Operational Implications
8.1. The Dual-Track Architecture
8.2. Compliance Strategy Options
8.3. Implementation Roadmap
9. Recommendations
9.1. For Practitioners
9.2. For Policymakers
9.2.1. European Union
9.2.2. United States
9.2.3. Transatlantic Cooperation
9.3. For the Research Community
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| AI | Artificial Intelligence |
| AIMS | Artificial Intelligence Management System |
| AML | Adversarial Machine Learning |
| ATLAS | Adversarial Threat Landscape for Artificial-Intelligence Systems |
| CC | Creative Commons |
| DLP | Data Loss Prevention |
| DORA | Digital Operational Resilience Act |
| EU | European Union |
| GenAI | Generative Artificial Intelligence |
| GDPR | General Data Protection Regulation |
| GPAI | General-Purpose Artificial Intelligence |
| IAM | Identity and Access Management |
| ISO | International Organization for Standardization |
| ISO/IEC | International Organization for Standardization/International Electrotechnical Commission |
| LLM | Large Language Model |
| MITRE | Massachusetts Institute of Technology Research and Engineering |
| NIS2 | Network and Information Security Directive (EU) 2022/2555 |
| NIST | National Institute of Standards and Technology |
| OWASP | Open Web Application Security Project |
| PII | Personally Identifiable Information |
| RAG | Retrieval-Augmented Generation |
| RLHF | Reinforcement Learning from Human Feedback |
| SIEM | Security Information and Event Management |
| SME | Small and Medium-Sized Enterprise |
| SOC | Security Operations Center |
| STRIDE | Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege |
| US | United States |
Appendix A. Empirical Literature Record-Flow Summary
A.1. Identification
- Initial candidate pool (identified): 85+ records
A.2. Screening
- Screened in (title/abstract): 52 records
A.3. Full-Text Assessment
- Full-text reviewed: 38 records.
- Out of scope on full read (LLM mentioned but not central to security/privacy contribution)
- No evaluable method (primarily conceptual commentary without measurements or threat model)
- Insufficient methodological detail to interpret results
- Redundant overlap with a later/extended version of the same study
A.4. Included Empirical Set
- Final empirical papers included: 28
A.5. Coverage Assurance
Appendix B. Representative Empirical Studies by Threat Class

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Threat Class | Representative Studies | Setting | Main Failure Mode | Mitigation (If Any) |
|---|---|---|---|---|
| Prompt Injection/Jailbreaks | [11,12,29,30,31] | Model-only | Roleplay/privilege escalation bypasses; 89–95% ASR | Adversarial training, guardrails (partial) |
| Indirect Prompt Injection + Agents | [13,14,34,38] | Tool-integrated agents | Embedded instructions in tool outputs hijack agent; 24–84% ASR | MELON, spotlighting (emerging) |
| RAG Poisoning | [48,50] | RAG systems | 5 malicious texts achieve 90% ASR in a million-doc database | Traceback forensics (post hoc) |
| Privacy Leakage | [8,9,10,51] | Model-only/fine-tuned | Training data extraction; PII exposure via prompting | Differential privacy, PAPILLON |
| Defenses and Evaluation | [14,34] | Benchmarks | Standardized testing reveals defense gaps | Multi-layer defense-in-depth |
Appendix C. Principal Frameworks
| Framework | Primary Purpose | Primary Audience | How This Review Uses It | Where It Maps in the 5-Layer Stack | Key Limitation for this Review |
|---|---|---|---|---|---|
| NIST AI RMF 1.0 + GenAI Profile (AI 600-1) | Risk management process and governance functions (Govern/Map/Measure/Manage) | Leadership, risk/compliance, program owners | Governance backbone for “what good looks like” in AI risk practice; supports the provider vs. deployer division of responsibility | Cross-cutting (all layers), with emphasis on lifecycle governance and operational management | High-level guidance; requires interpretation to translate into concrete technical controls |
| ISO/IEC 42001:2023 | Certifiable AI management system (AIMS) for organizational controls and assurance | Organizations seeking structured governance and third-party assurance | Control-system and auditability anchor (management system maturity, lifecycle management, documentation, QMS-style structure) | Cross-cutting (all layers), strongest on governance and lifecycle controls | Less specific on GenAI-native attack paths (tool misuse) than OWASP/ATLAS |
| OWASP Top 10 for LLM Applications | Practical catalog of GenAI application threats and common failure modes | Developers, app security, product engineering | Threat enumeration for application/system-level risks; provides concrete risk categories used in the threat mapping | Mostly Layers 3–5 (retrieval, orchestration/tools, runtime), with some coverage of training/supply chain | Not a governance standard; limited guidance on evidence/assurance and regulatory allocation |
| MITRE ATLAS | Adversary-centric tactics/techniques matrix for AI systems | SOC, threat intelligence, detection engineering | Threat lifecycle framing; supports mapping of real attack progression to an established “tactics/techniques” vocabulary | Cross-cutting, often operationalized in Layers 3–5 (integration boundary failures) | Describes attacker behavior more than defensive prescriptions; requires translation into controls |
| ENISA ML security guidance | EU-oriented security-by-design guidance for ML/AI and lifecycle security thinking | EU-aligned security and compliance teams, policymakers | European security perspective and regulation-adjacent framing; supports linkage to EU requirements and risk-based expectations | Lifecycle-oriented (all layers), traditionally strongest on training/inference threats and governance |
| Framework | Structural Risk Coverage (Model/Training/Architecture Properties) | Configurable Risk Coverage (Deployment/Integration/Ops) | Typical “Owner” Emphasis | How It Supports the Structural–Configurable Lens in this Paper |
|---|---|---|---|---|
| NIST AI RMF + GenAI Profile | Moderate–High (developer-managed practices: training data, model testing, upstream risk management) | High (deployer-managed practices: monitoring, oversight, incident response, deployment context) | Explicitly separates developer vs. deployer responsibilities | Provides an established responsibility split that aligns with structural (provider) vs. configurable (deployer) framing |
| ISO/IEC 42001 | Moderate (indirectly via vendor assessment, validation obligations, lifecycle controls) | High (management system controls, governance, documentation, operational processes) | Primarily deployer/organization, with vendor management requirements | Anchors the “configurable” side as auditable governance and operational control maturity |
| OWASP LLM Top 10 | Mixed (some structural issues like training data poisoning/model theft are included, but not deeply theorized) | High (prompt injection mitigation, plugin/tool security, output handling, operational safeguards) | Primarily builders/deployers, with some provider relevance | Gives concrete categories that often surface at integration boundaries; helps distinguish which items are structural vs. configurable in practice |
| MITRE ATLAS | Mixed (includes training-time and model-level attacks, but framed as attacker TTPs) | Mixed–High (many techniques exploit deployment surfaces and access patterns) | Neutral; used by SOC/defenders to describe attacks | Supports labeling threats as structural/configurable/hybrid by showing where in the lifecycle an attacker gains leverage |
| ENISA guidance | High (poisoning, evasion, privacy attacks, supply chain thinking) | Moderate–High (deployment security, monitoring, governance controls) | Balanced, EU-style lifecycle approach | Helps connect structural/configurable technical risk to EU-flavored security-by-design and compliance expectations |
References
- National Institute of Standards. Technology. In Artificial Intelligence Risk Management Framework (AI RMF 1.0); National Institute of Standards and Technology (NIST), U.S. Department of Commerce: Washington, DC, USA, 2023. [Google Scholar]
- NIST AI 600-1; Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024.
- Foundation, O. OWASP Top 10 for Large Language Model Applications; Open Web Application Security Project (OWASP): Columbia, MD, USA, 2023. [Google Scholar]
- Corporation, M. ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems (Advmlthreatmatrix); MITRE Corporation: McLean, VA, USA, 2021. [Google Scholar]
- European Parliament and the Council of the European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act); Publications Office of the European Union: Luxembourg, 2024. [Google Scholar]
- European Parliament and the Council of the European Union. Directive (EU) 2022/2555 of the European Parliament and of the Council of 14 December 2022 on Measures for a High Common Level of Cybersecurity Across the Union (NIS2 Directive); Publications Office of the European Union: Luxembourg, 2022. [Google Scholar]
- Federal vs. State AI Rules: What the New U.S. Executive Order Really Means. Available online: https://regulatingai.org/ (accessed on 11 May 2025).
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures. In Proceedings of the ACM Conference on Computer and Communications Security (CCS), Denver, CO, USA, 12–16 October; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Carlini, N.; Tramèr, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, Ú.; et al. Extracting Training Data from Large Language Models. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 10–13 August 2021; USENIX Association: Berkeley, CA, USA, 2021; pp. 2633–2650. [Google Scholar]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Yi, J.; Xie, Y.; Zhu, B.; Kiciman, E.; Sun, G.; Xie, X.; Wu, F. Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models; USENIX Association: Berkeley, CA, USA, 2023. [Google Scholar]
- Zhan, Q.; Liang, Z.; Ying, Z.; Kang, D. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. arXiv 2024, arXiv:2403.02691. [Google Scholar]
- Zhang, H.; Huang, J.; Mei, K.; Yao, Y.; Wang, Z.; Zhan, C.; Wang, H.; Zhang, Y. Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents. arXiv 2024, arXiv:2410.02644. [Google Scholar] [CrossRef]
- European Parliament and the Council of the European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 (General Data Protection Regulation); Publications Office of the European Union: Luxembourg, 2016. [Google Scholar]
- Haro, J. Secure APIs; O’Reilly Media: Sebastopol, CA, USA, 2023. [Google Scholar]
- Santos, O.; Radanliev, P. AI-Powered Digital Cyber Resilience; O’Reilly Media: Sebastopol, CA, USA, 2024. [Google Scholar]
- Sood, A. Combating Cyberattacks Targeting the AI Ecosystem; O’Reilly Media: Sebastopol, CA, USA, 2024. [Google Scholar]
- Wendt, D.W. The Cybersecurity Trinity: Artificial Intelligence, Automation, and Active Cyber Defense; O’Reilly Media: Sebastopol, CA, USA, 2023. [Google Scholar]
- Wendt, D.W. AI Strategy and Security: A Roadmap for Secure, Responsible, and Resilient AI Adoption; O’Reilly Media: Sebastopol, CA, USA, 2024. [Google Scholar]
- ISO 42001:2023; Information Technology-Artificial Intelligence-Management System. International Electrotechnical Commission (ISO/IEC): Geneva, Switzerland, 2023.
- ISO 31000:2018; Risk Management—Guidelines. International Organization for Standardization (ISO): Geneva, Switzerland, 2018.
- PMI. Risk Management in Portfolios, Programs, and Projects; Project Management Institute: Newtown, PA, USA, 2024. [Google Scholar]
- Souppaya, M.; Scarfone, K.; Dodson, D. Secure Software Development Framework (SSDF) Version 1.1: Recommendations for Mitigating the Risk of Software Vulnerabilities; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2022. [Google Scholar]
- McGraw, G. Six Tech Trends Impacting Software Security. Computer 2017, 50, 100–102. [Google Scholar] [CrossRef]
- Manadhata, P.K.; Wing, J.M. An Attack Surface Metric. IEEE Trans. Softw. Eng. 2011, 37, 371–386. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2021, arXiv:2108.07258. [Google Scholar] [CrossRef]
- Hardy, N. The Confused Deputy: Or why capabilities might have been invented. Oper. Syst. Rev. 1988, 22, 36–38. [Google Scholar] [CrossRef]
- Reddy, P.; Gujral, A.S. EchoLeak: The First Real-World Zero-Click Prompt Injection Exploit in a Production LLM System. arXiv 2025, arXiv:2509.10540. [Google Scholar] [CrossRef]
- Hines, K.; Lopez, G.; Hall, M.; Zarfati, F.; Zunger, Y.; Kiciman, E. Defending Against Indirect Prompt Injection Attacks With Spotlighting; USENIX Association: Berkeley, CA, USA, 2024. [Google Scholar]
- Liu, Y.; Deng, G.; Li, Y.; Wang, K.; Wang, Z.; Wang, X.; Zhang, T.; Liu, Y.; Wang, H.; Zheng, Y.; et al. Prompt Injection attack against LLM-integrated Applications. arXiv 2023, arXiv:2306.05499. [Google Scholar]
- Sabin, S. 1 Big Thing: AI-Powered Malware Is on Its Way. Available online: https://www.axios.com/newsletters/axios-ai-plus-b19d2e6e-7ec2-4d99-9b36-3f95c7298354.html (accessed on 11 May 2025).
- Tyagi, A.K.; Addula, S.R. Artificial Intelligence for Malware Analysis: A Systematic Study. In Artificial Intelligence-Enabled Digital Twin for Smart Manufacturing; Wiley-Scrivener: Beverly, MA, USA, 2024; pp. 359–390. [Google Scholar]
- Debenedetti, E.; Zhang, J.; Balunovic, M.; Beurer-Kellner, L.; Fischer, M.; Tramèr, F. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Adv. Neural Inf. Process. Syst. 2024, 37, 82895–82920. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Koh, P.W.; Steinhardt, J.; Liang, P. Stronger data poisoning attacks break data sanitization defenses. Mach. Learn. 2022, 111, 1–47. [Google Scholar] [CrossRef]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy (S&P), San Francisco, CA, USA, 20–22 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- De Stefano, G.; Schönherr, L.; Pellegrino, G. Rag and Roll: An End-to-End Evaluation of Indirect Prompt Manipulations in LLM-Based Application Frameworks. arXiv 2024, arXiv:2408.05025. [Google Scholar]
- Srinivas, S.; Kirk, B.; Zendejas, J.; Espino, M.; Boskovich, M.; Bari, A.; Dajani, K.; Alzahrani, N. AI-Augmented SOC: A Survey of LLMs and Agents for Security Automation. J. Cybersecur. Priv. 2025, 5, 95. [Google Scholar] [CrossRef]
- Palma, G.; Cecchi, G.; Caronna, M.; Rizzo, A. Leveraging Large Language Models for Scalable and Explainable Cybersecurity Log Analysis. J. Cybersecur. Priv. 2025, 5, 55. [Google Scholar] [CrossRef]
- EU 2024/1689; Artificial Intelligence Act. European Parliament and of the Council: Brussels, Belgium, 2024. Available online: https://artificialintelligenceact.eu/the-act/ (accessed on 21 January 2026).
- NIST AI RMF 1.0; Artificial Intelligence Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023.
- World Trade Organization. Agreement on Trade-Related Aspects of Intellectual Property Rights (TRIPS Agreement); WTO: Geneva, Switzerland, 1994. [Google Scholar]
- EU 2016/679; General Data Protection Regulation. European Parliament and Council of the European Union: Brussels, Belgium, 2016. Available online: https://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32016R0679 (accessed on 22 December 2025).
- Santos, O. Developing Cybersecurity Programs and Policies in an AI-Driven World, 4th ed.; O’Reilly Media: Sebastopol, CA, USA, 2024. [Google Scholar]
- MITRE Corporation. ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS); MITRE Corporation: McLean, VA, USA, 2021. [Google Scholar]
- OWASP Foundation. OWASP Top 10 for Large Language Model Applications; Open Worldwide Application Security Project (OWASP): Columbia, MD, USA, 2023. [Google Scholar]
- Florida Senate. Artificial Intelligence Bill of Rights; Florida Senate SB 482; Florida Senate: Tallahassee, FL, USA, 2026.
- AXIOS. Tech Group Opposes Florida AI Proposal ‘Artificial Intelligence Bill of Rights’. Available online: https://www.axios.com/newsletters/axios-tampa-bay-ea380018-35af-498f-98fb-b231af7193d0.html (accessed on 20 January 2026).
- Zhang, B.; Chen, Y.; Liu, Z.; Nie, L.; Li, T.; Liu, Z.; Fang, M. Practical poisoning attacks against retrieval-augmented generation. arXiv 2026, arXiv:2504.03957. [Google Scholar]
- Duan, M.; Suri, A.; Mireshghallah, N.; Min, S.; Shi, W.; Zettlemoyer, L.; Tsvetkov, Y.; Choi, Y.; Evans, D.; Hajishirzi, H. Do membership inference attacks work on large language models? arXiv 2024, arXiv:2402.07841. [Google Scholar] [CrossRef]





| Source Domain | Related Concept | Maps to Structural | Maps to Configurable |
|---|---|---|---|
| Risk Management (ISO 31000) | Inherent vs. Residual Risk | Inherent risk (before controls) | Residual risk (after treatment) |
| Software Security (McGraw) | Design Flaws vs. Implementation Bugs | Design flaws (require redesign) | Implementation bugs (patchable) |
| Systems Security (Hardy) | Confused Deputy Problem | Authority coupling (architectural) | Permission scoping (operational) |
| Attack Surface (Manadhata and Wing) | Design vs. Deployment Surface | Entry points fixed by design | Enabled services, exposure |
| This Paper (GenAI) | Structural vs. Configurable | Architecture, training, trust boundaries | Deployment, operational controls |
| Threat Class | RAG Chatbot Impact | Agentic System Impact |
|---|---|---|
| Indirect prompt injection | Text manipulation, misinformation | Remote code execution, data exfiltration, unauthorized actions |
| Privilege escalation | Limited to output content | Tool permissions inheritance; access to connected systems |
| Lateral movement | Not applicable | Via tool integrations to other systems |
| Persistence | None (stateless output) | Potential via file/database/credential tools |
| Attack Phase | ATLAS Tactic | ATLAS Technique (ID) | Narrative Application |
|---|---|---|---|
| 1. Seed | Initial Access | Indirect Prompt Injection (AML.T0051.001) | The attacker places a malicious payload inside an email, which is then ingested by Copilot’s RAG engine during a routine summary request. |
| 2. Bypass | ML Model Attack | Prompt Injection (AML.T0051) | The payload is semantically engineered to bypass Microsoft’s internal “Cross-Prompt Injection Attempt” (XPIA) classifiers. |
| 3. Theft | Collection | LLM Scope Violation (AML.T0051) | The AI is tricked into accessing privileged internal data (e.g., password reset links, sensitive docs) based on instructions from the untrusted external email. |
| 4. Exit | Exfiltration | Exfiltration (Not Explicit in ATLAS) | Sensitive data is encoded into a URL and rendered as a tracking pixel. The user’s browser automatically triggers the “leak” when it loads the image. |
| Threat Category | OWASP LLM |
MITRE ATLAS | Affected Layers | Primary Controls | Standards and Regulations |
|---|---|---|---|---|---|
| Prompt Injection | LLM01 | AML.T0051 | 2, 3, 5 | Input validation, output filtering | AI Act (Art.15) [41] |
| Indirect Injection | LLM01 | AML.T0051 | 3, 5 | Injection-aware retrieval | NIST AI 600-1 [42] |
| Data Poisoning | LLM03 | AML.T0020 | 1 | Provenance, anomaly detection | AI Act (Art.10) [41] |
| Model Extraction | LLM10 | AML.T0024 | 2, 5 | Rate limiting, access controls | IP protection regulations (WTO) [43] |
| Sensitive Disclosure | LLM06 | AML.T0025 | 1, 2, 3, 5 | DLP filters, output scanning | GDPR Art.32 [44] |
| Tool Misuse | LLM07 | AML.T0040 | 4 | Least privilege, sandboxing | ISO/IEC 42001 [21] |
| Supply Chain | LLM05 | AML.T0010 | 1, 4 | Provenance, verification | NIS2 [6] |
| Jailbreaking | LLM01 | AML.T0054 | 2, 5 | Safety tuning, testing | AI Act (Art.15) [41] |
| GenAI Layer | Key Threats | Baseline Controls | Evidence to Retain | Standards Alignment |
|---|---|---|---|---|
| 1. Training and Adaptation | Data poisoning, compromised datasets or models, unsafe fine-tuning | Verify data and model provenance; control fine-tuning access; validate dependencies; stage releases with rollback | Dataset lineage records; training and fine-tuning logs; access records; release documentation | NIST AI RMF (GenAI Profile) [42]; ISO/IEC 42001; MITRE ATLAS [46] |
| 2. Model Behavior | Jailbreaks, policy evasion, unsafe outputs | Protect system prompts; enforce policy outside the model; adversarial testing; abuse rate-limiting | Prompt versions; evaluation results; red-team findings; refusal metrics | NIST AI RMF (GenAI Profile); OWASP LLM Top 10 [47] |
| 3. Retrieval and Data Interfaces | Indirect prompt injection, over-broad retrieval, and data exposure | Permission-aware retrieval; scoped data access; provenance labeling; secure vector stores | Retrieval logs; access control decisions; provenance metadata | OWASP LLM Top 10; NIST AI RMF; ISO/IEC 42001 |
| 4. Orchestration and Tools | Tool misuse, unsafe actions, and lateral movement | Least-privilege tools; explicit approval for high-risk actions; schema validation; execution isolation | Tool inventories; invocation records; approval logs; incident alerts | OWASP LLM Top 10; NIST AI RMF; MITRE ATLAS |
| 5. Runtime Interaction | Prompt injection, multi-turn escalation, output leakage | Prompt screening; context separation; output filtering; session monitoring | Prompt and context logs; moderation decisions; escalation indicators | OWASP LLM Top 10; NIST GenAI Profile; ISO/IEC 42001 |
| Element | US-Style (Framework-Led/Sectoral) | EU-Compliant (AI Act + NIS2) |
|---|---|---|
| Risk classification | Internal assessment; categorization varies by sector and organization | Mandatory classification (e.g., high-risk/GPAI categories where applicable) with corresponding obligations |
| Training data documentation | Recommended practice; often limited to internal summaries | Required documentation expectations (e.g., provenance-oriented summaries and compliance-relevant records) |
| Logging depth and traceability | Operational logs for reliability/debugging; retention driven by business need | Comprehensive traceability across prompts, retrieved context, tool calls, outputs, and key decisions; retention and audit accessibility aligned to regulatory expectations |
| Human oversight | Optional; driven by organizational risk appetite and liability | Required for high-risk use cases; defined escalation paths and documented oversight procedures |
| Incident reporting | Sectoral reporting, where applicable; timelines and thresholds vary | Rapid notification expectations under NIS2 (staged reporting) and AI Act-aligned incident handling, where applicable |
| Third-party audit/assurance | Optional; commonly customer- or procurement-driven | Conformity assessment and external assurance expectations for high-risk systems; evidence readiness for supervisory review |
| Bias testing and monitoring | Recommended; format and cadence vary | Documented testing and ongoing monitoring expectations, especially where systems are classified as high-risk |
| Role | Traditional Training Covers | GenAI Gap |
|---|---|---|
| Developers | Input validation, SQL injection, XSS | Prompt injection, context risks, tool permissions |
| Security Teams | Network attacks, malware, scanning | Model behavior analysis, adversarial ML, AI red-teaming |
| Architects | Network segmentation, access control | Context boundaries, tool sandboxing, agentic containment |
| Leadership | Compliance, risk frameworks | AI liability, probabilistic risk, regulatory divergence |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Share and Cite
Kanabar, V.; Kaloyanova, K. Securing Generative AI Systems: Threat-Centric Architectures and the Impact of Divergent EU–US Governance Regimes. J. Cybersecur. Priv. 2026, 6, 27. https://doi.org/10.3390/jcp6010027
Kanabar V, Kaloyanova K. Securing Generative AI Systems: Threat-Centric Architectures and the Impact of Divergent EU–US Governance Regimes. Journal of Cybersecurity and Privacy. 2026; 6(1):27. https://doi.org/10.3390/jcp6010027
Chicago/Turabian StyleKanabar, Vijay, and Kalinka Kaloyanova. 2026. "Securing Generative AI Systems: Threat-Centric Architectures and the Impact of Divergent EU–US Governance Regimes" Journal of Cybersecurity and Privacy 6, no. 1: 27. https://doi.org/10.3390/jcp6010027
APA StyleKanabar, V., & Kaloyanova, K. (2026). Securing Generative AI Systems: Threat-Centric Architectures and the Impact of Divergent EU–US Governance Regimes. Journal of Cybersecurity and Privacy, 6(1), 27. https://doi.org/10.3390/jcp6010027