The authors would like to make the following corrections to the original publication [1].
In the original publication, there was a mistake in Figures 2 and 10 as published. Figure 2 has now been replaced with a figure from another article, and Figure 10 was replaced with the correct version. The corrected Figure 2 and Figure 10 appear below. The authors state that the scientific conclusions are unaffected. This correction was approved by the Academic Editor. The original publication has also been updated.
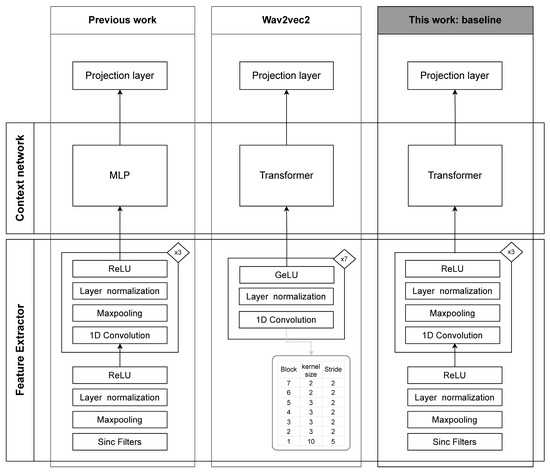
Figure 2.
A schematic overview of the original SincNet implementation model used as baseline in our previous work, the wav2vec2 fine-tuning path and the proposed fine-tuning path in this work. Based on compositionality capacity of networks, we combined the feature extractor of the original SincNet model with the pre-trained transformer of wav2vec2.

Figure 10.
Filter distribution after training.
Reference
- Coppieters de Gibson, L.; Garner, P.N. Training a Filter-Based Model of the Cochlea in the Context of Pre-Trained Acoustic Models. Acoustics 2024, 6, 470–488. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).