Highlights
What are the main findings?
- An explainable voting ensemble machine learning framework is developed for early-warning forecasting of corporate financial distress under imbalanced and rare-event conditions.
- The proposed ensemble delivers more reliable and stable forecasting performance than classical single classifiers and maintains robustness when benchmarked against advanced ensemble models.
What are the implications of the main findings?
- The findings reframe financial distress modeling from retrospective classification accuracy toward decision-relevant early-warning forecasting reliability.
- The proposed framework supports transparent and scalable early-warning systems for audit, investment, and regulatory risk monitoring, particularly in emerging market contexts.
Abstract
Accurate early-warning forecasting of corporate financial distress remains a critical challenge due to nonlinear financial relationships, severe data imbalance, and the high operational costs of false alarms in risk-monitoring systems. This study proposes an explainable voting ensemble framework for early-warning forecasting of corporate financial distress using lagged accounting-based financial information. The proposed framework integrates heterogeneous base learners, including Decision Tree, Neural Network, and k-Nearest Neighbors models, and is evaluated using financial statement data from 752 publicly listed firms in Thailand, comprising sixteen financial ratios across six dimensions: liquidity, operating efficiency, debt management, profitability, earnings quality, and solvency. To ensure robustness under imbalanced and rare-event conditions, the study employs feature selection, data normalization, stratified cross-validation, resampling techniques, and repeated validation procedures. Empirical results demonstrate that the proposed Voting Ensemble delivers a precision-oriented and decision-relevant forecasting profile, outperforming classical classifiers and maintaining greater early-warning reliability when benchmarked against advanced tree-based ensemble models. Probability-based evaluation further confirms the robustness and calibration stability of the proposed framework under repeated cross-validation. By adopting a forward-looking, early-warning perspective and integrating ensemble learning with explainable machine learning principles, this study offers a transparent and scalable approach to financial distress forecasting. The findings offer practical implications for auditors, investors, and regulators seeking reliable early-warning tools for corporate risk assessment, particularly in emerging market environments characterized by data imbalance and heightened uncertainty.
1. Introduction
Financial distress forecasting among publicly listed firms remains a persistent challenge, constrained by limitations in predictive accuracy, data imbalance, and the contextual validity of applied models. In Thailand, prior studies have increasingly adopted machine learning (ML) techniques combined with resampling strategies to mitigate class imbalance in financial distress prediction. For example, the integration of the C5.0 classifier with the Borderline Synthetic Minority Oversampling Technique (BLSMOTE) achieved a balanced accuracy of 73.79%, highlighting the potential of ML-based approaches for early warning applications [1]. Nevertheless, forecasting distress in failing firms remains problematic, as traditional statistical models such as logistic regression have demonstrated substantially reduced predictive performance, with accuracy falling to as low as 42.9% in certain settings [2].
At the global level, financial distress forecasting models continue to face contextual and methodological constraints. While the Grover model has reported exceptionally high accuracy—reaching 96.6% in specific financial environments [3]—such results are often sensitive to market structure, accounting regimes, and institutional contexts. Similarly, evidence from Spain indicates that incorporating qualitative disclosures from audit reports into accounting-based prediction models improves forecasting accuracy, yet remains insufficient for consistently distinguishing between distressed and non-distressed firms across time [4]. These findings suggest that strong retrospective performance alone does not guarantee reliable early warning capability.
Recent advancements further demonstrate the growing role of ML in financial distress forecasting. Neural Network (NN) models have achieved strong predictive performance in Turkey’s manufacturing sector [5], while the Zmijewski and B-Sherrod models have shown effectiveness in forecasting corporate failure among publicly traded firms, emphasizing the value of forward-looking early warning mechanisms [6]. In the Indian context, logistic regression models have identified key financial drivers—such as working capital and return on assets—that significantly influence failure [7]. Collectively, these studies confirm the relevance of financial ratios for distress forecasting while also revealing persistent challenges in model stability and generalizability.
Although prior studies have reported notable improvements in predictive accuracy using both statistical and machine learning–based approaches, a substantial portion of the literature continues to conceptualize financial distress as a classification problem rather than a forward-looking forecasting task. In many cases, model performance is evaluated primarily through retrospective accuracy metrics, with limited attention to early warning reliability, temporal precedence, or the asymmetric costs associated with false alarms and missed distress signals. As a result, high in-sample or cross-sectional accuracy does not necessarily translate into effective early warning capability when models are deployed for real-time financial risk monitoring.
From a forecasting perspective, early-stage financial distress constitutes a rare-event problem rather than a conventional balanced classification task. Distress observations typically represent a small fraction of the overall firm population, particularly when pre-failure or special-problem conditions are considered. Under such conditions, forecasting models must prioritize robustness and decision reliability over aggregate accuracy, as excessive false alarms can undermine the practical usefulness of early warning systems. Ensemble learning methods—especially Voting Ensemble approaches—have therefore gained attention not solely for their ability to improve accuracy, but for their capacity to stabilize predictions by aggregating complementary model behaviors under uncertainty and data imbalance.
Despite this progress, ML-based financial distress forecasting in emerging markets—particularly Thailand—remains underexplored. The distinctive characteristics of emerging economies, including regulatory environments, capital market structures, and firm-level financial behavior, require forecasting models that remain robust under heterogeneous and imbalanced conditions [8]. Recent evidence indicates that ensemble learning approaches, especially Voting Ensemble methods, offer a promising pathway for addressing these challenges by aggregating the complementary strengths of multiple ML algorithms and improving predictive stability [9].
Despite extensive research on financial distress prediction, several critical gaps remain unresolved in the current state of the art. First, a substantial portion of prior studies conceptualize financial distress as a retrospective classification problem, emphasizing overall accuracy or balanced accuracy rather than forward-looking early-warning reliability. Models that perform well in post-event classification may fail to deliver decision-relevant signals when deployed for proactive risk monitoring, where temporal precedence and stability are essential.
Second, although ensemble learning techniques—such as weighted voting, random forests, and boosting-based frameworks—have demonstrated performance gains, most existing approaches prioritize aggregate predictive accuracy without explicitly addressing the asymmetric costs associated with false alarms and missed distress signals. In practical early-warning systems used by auditors and regulators, excessive false positives can be as costly as missed failures, yet this trade-off is rarely incorporated into model design and evaluation.
Third, explainability remains limited in many ensemble-based financial distress models. While advanced learners may improve predictive power, their black-box nature constrains interpretability and hinders adoption in high-stakes financial contexts that demand transparency, auditability, and alignment with accounting logic. This limitation is particularly pronounced in emerging-market settings, where institutional trust and regulatory scrutiny require forecasting systems that are not only accurate but also explainable and context-sensitive.
Collectively, these gaps indicate the need for a forecasting-oriented, precision-aware, and explainable ensemble framework that prioritizes decision reliability over retrospective accuracy, while remaining robust under severe class imbalance and suitable for emerging-market financial environments.
In response to these gaps, this study makes the following contributions.
First, this study reframes corporate financial distress prediction from a retrospective classification task to an early-warning forecasting problem, emphasizing decision reliability and temporal precedence rather than isolated accuracy optimization. By using lagged financial information, the proposed framework aligns predictive modeling with the real-world early-warning requirements faced by auditors, regulators, and investors.
Second, the study develops a precision-oriented voting ensemble framework that explicitly addresses class imbalance and asymmetric decision costs. Rather than maximizing detection at all costs, the ensemble design prioritizes high precision to reduce false alarms, thereby enhancing the practical usability of early-warning systems in financial surveillance and audit planning contexts.
Third, this study integrates explainable artificial intelligence into ensemble-based financial distress forecasting by employing SHAP-based interpretation. Through surrogate-model explainability, the framework links machine learning predictions to economically meaningful accounting ratios, strengthening transparency, interpretability, and regulatory relevance.
Finally, the proposed framework is empirically validated using longitudinal firm-year data from an emerging-market context (Thailand), which remains underrepresented in high-impact financial distress forecasting literature. The findings provide context-sensitive evidence on how ensemble learning can support reliable and explainable early-warning systems under imbalanced and uncertain financial conditions.
Against this backdrop, this study develops an explainable, forecasting-oriented voting ensemble framework for early warning prediction of corporate financial distress and going-concern risk. Rather than introducing a novel classifier, the proposed approach reconfigures well-established machine learning models within a precision-aware and explainable ensemble design, explicitly aligned with early-warning decision requirements under class imbalance. The framework evaluates sixteen accounting-based financial ratios across six dimensions—liquidity, operating efficiency, debt management, profitability, earnings quality, and solvency—using lagged financial information. Empirical analysis is conducted on a longitudinal firm-year dataset comprising 752 publicly listed firms across multiple industries in Thailand during 2011–2020, enabling assessment of forecasting reliability across varying economic and industry conditions. By prioritizing decision reliability over aggressive distress detection, the proposed framework aligns with the practical needs of financial risk monitoring, auditing, and regulatory early warning systems.
2. Literature Reviews
Financial distress forecasting has been extensively examined due to its critical role in early warning systems that support business continuity, financial stability, and risk management. Existing studies span multiple interconnected domains, including financial indicators, modeling methodologies, data characteristics, and contextual factors, each of which influences forecasting reliability under different economic conditions. Accordingly, this literature review is structured to synthesize prior findings across key dimensions relevant to financial distress forecasting, beginning with financial ratio–based determinants, followed by predictive modeling approaches, regional evidence, and methodological challenges related to data imbalance and ensemble learning.
2.1. Factors Influencing Financial Distress
Liquidity or short-term solvency ratios serve as crucial indicators of a firm’s ability to manage its immediate obligations while ensuring uninterrupted operations. These ratios include the Current Ratio (CA/CL), Cash Ratio (Cash/CL), and Net Working Capital to Total Asset Ratio (WC/TA). Such metrics are particularly relevant for small and medium-sized enterprises (SMEs), where financial constraints can significantly affect growth potential [10]. The relationship between liquidity risk and elevated funding costs emphasizes the necessity of effective liquidity management, as firms with pressing liquidity needs often incur higher costs [11]. Moreover, distinguishing between short-term and long-term financial ratios enhances the predictive accuracy of financial distress models by capturing the dynamic nature of liquidity [12]. Therefore, maintaining robust liquidity ratios is essential for operational resilience and long-term investment viability.
Activity ratios are essential for evaluating a firm’s operational efficiency and resource utilization. Key ratios include Total Asset Turnover (NS/TA), Accounts Receivable Turnover (ART), and Inventory Turnover (IT), each providing unique insights into how well a company manages its assets. For instance, a high Total Asset Turnover ratio suggests effective asset deployment to generate revenue, while a strong Accounts Receivable Turnover reflects efficient collection practices, contributing to liquidity management. Similarly, the Inventory Turnover ratio evaluates how efficiently inventory is sold and replaced, balancing liquidity needs while minimizing holding costs [13,14]. These ratios are particularly critical for strategic decision-making in industries reliant on intensive resource management, as they directly impact profitability and operational performance.
Debt management ratios provide critical insights into a firm’s financial stability and its exposure to risk associated with debt obligations. Prominent ratios include the Debt-to-Total Assets Ratio (TL/TA), Cash Flow to Total Debt Ratio (CFO/TL), and Retained Earnings to Total Assets Ratio (RE/TA). A high RE/TA ratio reflects effective utilization of retained earnings to support asset growth, indicating financial resilience, whereas a low ratio may signal potential financial distress and reliance on external financing. Research highlights that firms with poor debt management ratios are more vulnerable during economic downturns, emphasizing the importance of maintaining healthy financial leverage to safeguard long-term financial health [15]. By integrating these ratios into predictive models, businesses can identify vulnerabilities early, enabling timely risk mitigation and ensuring investment sustainability.
Profitability ratios, such as Return on Assets (ROA) and Gross Margin (GM), serve as benchmarks for evaluating a firm’s financial performance and managerial efficiency. These ratios assess a company’s ability to generate profits relative to sales, assets, and equity, offering insights into both operational effectiveness and financial stability. Studies have shown that higher profitability ratios correlate with stronger financial stability and solvency. For example, PT Akasha Wira International Tbk demonstrated consistent growth in Gross Profit Margin and Net Profit Margin, averaging over 15%, as a sign of robust financial health [16]. Conversely, cases like Bank Syariah Mandiri revealed risks associated with below-industry benchmarks in profitability ratios, despite a favorable Net Profit Margin [17]. Profitability ratios thus play a pivotal role in assessing long-term solvency and guiding strategic financial decision-making [18].
Quality of earnings ratios, such as the Debt-to-Assets Ratio (D2A) and Interest Coverage Ratio (IC), are fundamental for evaluating a firm’s ability to sustain long-term obligations while ensuring financial stability. These ratios provide stakeholders, including investors and creditors, with insights into earnings reliability and the firm’s capacity to manage debt effectively [19]. Research indicates that firms with higher earnings quality often experience reduced equity financing costs, reflecting their financial strength and credibility [20]. Additionally, initiatives aimed at improving reporting quality, such as CCN programs, have been shown to mitigate information asymmetry and enhance earnings transparency, further supporting financial health [21]. These metrics are essential for predicting a firm’s solvency and ensuring sustainable operations, making them vital components of financial distress prediction models.
Long-term liabilities and solvency ratios, such as the Debt-to-Assets Ratio (D2A) and Interest Coverage Ratio (IC), play a crucial role in assessing a firm’s ability to meet long-term financial obligations. These metrics are pivotal in determining financial stability, particularly in industries with high capital requirements. Studies show that distinguishing between short-term and long-term financial ratios significantly enhances the predictive accuracy of financial distress models, as evidenced by research on Taiwanese public companies [12]. Additionally, reliance on internal cash flows for financing long-term investments underscores the strategic importance of cash flow management in maintaining solvency [22]. Comparative analyses across transition economies further reveal that economic conditions influence the prioritization of solvency ratios, highlighting the contextual nature of financial health assessments [23]. Collectively, these insights emphasize the necessity of a multifaceted approach to evaluating a firm’s long-term financial stability and resilience.
From a forecasting perspective, the predictive relevance of financial ratios extends beyond their static discriminatory power to their ability to signal early-stage deterioration prior to formal distress recognition. Prior studies suggest that liquidity, leverage, and profitability indicators often exhibit asymmetric and time-varying effects as firms transition from healthy to distressed states, implying that no single ratio category consistently dominates early warning performance across economic conditions. This temporal heterogeneity reinforces the need for forecasting frameworks capable of integrating multiple financial dimensions while maintaining stability under evolving risk patterns.
2.2. The Role of Financial Ratios in Predicting Financial Distress
Financial ratios are crucial tools for assessing a firm’s financial health and supporting early warning forecasting of financial distress. Polsiri and Sookhanaphibarn [24] emphasized the integration of governance factors with financial ratios, such as profitability and leverage, to predict corporate distress during the East Asian economic crisis. Similarly, Jaitang et al. [25] highlighted the importance of profitability and liquidity ratios in forecasting insolvency among Thai SMEs, demonstrating their relevance in emerging markets.
Abrahamsen et al. [26] further enhanced the predictive utility of financial ratios by incorporating macroeconomic indicators, significantly improving early warning systems in Nordic firms. Khan et al. [19] identified key metrics like quick ratios and gross profit margins for assessing bankruptcy risks, reflecting the global applicability of these tools. Additionally, Arefmanesh et al. [27] linked financial restatements to distress risks, highlighting the importance of accurate financial reporting.
From a forecasting standpoint, the predictive value of financial ratios lies not only in their ability to discriminate between distressed and non-distressed firms, but also in their capacity to signal deterioration at an early stage. Empirical evidence suggests that different ratio categories exhibit varying sensitivity across forecasting horizons and economic conditions, leading to unstable performance when single-model or single-ratio approaches are applied. As a result, financial distress forecasting frameworks increasingly require methods capable of integrating heterogeneous financial signals while maintaining robustness under temporal variation and data imbalance.
Despite their utility, financial ratios face inherent limitations in forecasting applications, including sensitivity to rapidly changing market conditions and reliance on historical information. These challenges are particularly pronounced in emerging economies, where structural heterogeneity and data imbalance complicate early warning reliability, underscoring the need for adaptive and integrative forecasting methodologies [28].
2.3. Review of Methods for Financial Distress Prediction
Traditional statistical methods constitute the foundational framework of financial distress prediction, providing structured and interpretable approaches for analyzing financial data. Common techniques such as logistic regression and multivariate regression have been widely applied due to their transparency and ease of implementation. For instance, Ramzan [29] compared logistic regression and decision tree models, highlighting the limitations of traditional statistical approaches when confronted with non-linear relationships. Similarly, Teymouri and Sadeghi [30] employed multivariate regression to examine the effects of accounting conservatism and financial leverage on financial distress, demonstrating that while these models yield valuable insights, they lack the adaptability required in dynamic financial environments. Mallinguh and Zéman [28] further noted that traditional methods remain predominantly validated in developed economies, leaving methodological gaps when applied to emerging markets. Collectively, these studies indicate that although statistical approaches are effective for straightforward and interpretable analyses, they struggle to capture evolving financial complexities.
From a forecasting perspective, a critical limitation of both traditional statistical models and many machine learning–based approaches lies in their predominant treatment of financial distress as a static classification problem. While such models often achieve satisfactory in-sample or cross-validation accuracy, they frequently overlook temporal dependency, early warning reliability, and the asymmetric costs associated with false alarms and missed distress events. Consequently, models optimized for retrospective discrimination may underperform when deployed for forward-looking financial risk monitoring in real-world settings, where stability and consistency over time are essential.
In response to these limitations, machine learning (ML) techniques have emerged as transformative tools capable of uncovering complex, non-linear patterns in high-dimensional financial data. Duarte and Barboza [31] emphasized the superiority of ML methods in capturing intricate financial relationships and improving predictive accuracy. Recent studies have further advanced ML-based distress prediction through explainable and hybrid approaches. Tran et al. [32] demonstrated the effectiveness of explainable ML models such as XGBoost, utilizing SHAP values to enhance transparency and interpretability. Khedr et al. [33] proposed a hybrid framework combining genetic algorithms with multi-layer perceptrons to optimize hyperparameters and improve model performance, while Elhoseny et al. [34] employed Long Short-Term Memory (LSTM) networks to capture temporal dependencies and dynamic financial patterns. Additionally, Kadkhoda and Amiri [35] integrated network analysis with ML techniques, leveraging interdependencies among financial variables to improve classification accuracy for distressed firms. Despite these advancements, challenges related to overfitting, interpretability, and data quality persist, particularly in emerging market contexts where financial information may be heterogeneous or incomplete [28].
Recent advances increasingly highlight ensemble learning as a practical response to forecasting instability in financial distress prediction. By aggregating heterogeneous learners, ensemble methods mitigate model-specific bias and variance, particularly under rare-event and imbalanced conditions. Empirical evidence suggests that voting-based ensembles enhance prediction stability and decision reliability, making them especially suitable for early warning systems where consistent performance across time is critical [35,36].
2.4. Global and Regional Perspectives
Global research provides a broad perspective on financial distress prediction models across diverse economic settings. Mallinguh and Zéman [28] reviewed 72 studies, emphasizing the concentration of research in developed markets and identifying gaps in studies targeting emerging economies. Abrahamsen et al. [26] explored the Nordic region, showing how integrating financial ratios with macroeconomic indicators enhances early detection of financial distress. Similarly, Khan et al. [19] highlighted the role of macroeconomic variables, such as trade balances and exchange rates, in predicting distress in Pakistan.
Thailand-specific studies provide insights into unique challenges and opportunities in emerging markets. Polsiri and Sookhanaphibarn [24] analyzed corporate distress during the East Asian economic crisis, linking governance and financial variables. Plypichit and Lisawadi [1] addressed class imbalance in Thai-listed companies using Borderline SMOTE, achieving higher prediction accuracy. Jaitang et al. [25] focused on SMEs, demonstrating the role of profitability and liquidity ratios in financial distress prediction, underscoring the relevance of tailored approaches for emerging economies.
Collectively, global and regional evidence underscores the importance of contextual sensitivity in financial distress forecasting. Models developed and validated in advanced economies may not generalize effectively to emerging markets, where institutional structures, regulatory regimes, and firm-level financial behavior differ substantially. These contextual variations influence not only predictive accuracy but also the stability and reliability of early warning systems over time. Consequently, forecasting frameworks for financial distress must be empirically grounded in local market conditions while maintaining methodological robustness under data imbalance and economic volatility.
2.5. Challenges and Advanced Techniques: Addressing Data Imbalance and Ensemble Methods
Imbalanced data constitute a fundamental challenge in financial distress forecasting, as distressed firms typically represent a small fraction of the overall corporate population. When learning algorithms are trained on such skewed distributions, predictive performance is often biased toward the majority class, leading to high nominal accuracy but limited early-warning effectiveness [1,37]. Although resampling strategies and imbalance-aware learning techniques have been shown to partially mitigate this issue, these approaches do not fully resolve instability in forward-looking applications where prediction reliability over time is critical [38].
Beyond class imbalance, early-warning forecasting is further complicated by temporal heterogeneity and rare-event characteristics. Financial distress mechanisms evolve across business cycles, regulatory regimes, and industry conditions, causing predictive performance to vary substantially across time periods and financial indicator subsets. Empirical evidence suggests that models optimized under static or retrospective settings often fail to deliver consistent warning signals when deployed for real-time risk monitoring, particularly in environments characterized by non-stationarity and concept drift [39]
Ensemble-based approaches have emerged as a pragmatic response to these challenges by aggregating heterogeneous learning behaviors to reduce model-specific bias and variance. Prior studies demonstrate that voting-based and hybrid ensemble frameworks can enhance robustness under imbalanced and uncertain conditions [36,40]. However, most existing ensemble designs primarily emphasize aggregate predictive accuracy rather than decision-oriented reliability, leaving limited consideration for precision-sensitive early-warning requirements.
Moreover, the increasing complexity of ensemble architectures introduces additional challenges related to interpretability and practical deployment. As multiple learners are integrated, transparency may be reduced, constraining the applicability of such models in high-stakes financial settings that demand explainable and accountable decision support. Consequently, effective early-warning frameworks must balance predictive performance with interpretability and operational relevance.
While existing studies demonstrate that ensemble learning and imbalance-handling techniques can improve predictive accuracy, relatively limited attention has been paid to forecasting reliability, precision-oriented decision design, and explainability in early-warning contexts. These unresolved challenges motivate the research questions addressed in this study.
2.6. Research Questions
Based on the reviewed literature and the identified research gaps, this study addresses the following research questions:
RQ1: Can a voting ensemble framework improve early-warning forecasting reliability for corporate financial distress under severe class imbalance compared with single classifiers?
RQ2: Does a precision-oriented ensemble design provide a more decision-relevant trade-off between false alarms and missed distress signals in early warning applications?
RQ3: Can explainable ensemble modeling, supported by SHAP-based interpretation, enhance the transparency and accounting-theoretical consistency of financial distress forecasting results?
3. Research Methodology
This study adopts a machine learning–based forecasting framework to develop an early warning system for corporate financial distress and going concern risk. Financial statement ratio data were collected and processed through a structured data preparation pipeline to ensure consistency and analytical validity. The modeling phase employs four learning techniques—Decision Tree (DT), k-Nearest Neighbors (k-NN), Neural Network (NN), and a Voting Ensemble (VOTE)—with model performance evaluated using 10-fold cross-validation to ensure robustness under imbalanced conditions.
The overall research design follows the Cross-Industry Standard Process for Data Mining (CRISP-DM), which provides a systematic and transparent structure for forecasting-oriented financial analytics. Figure 1 presents an overview of the research process adopted in this study.
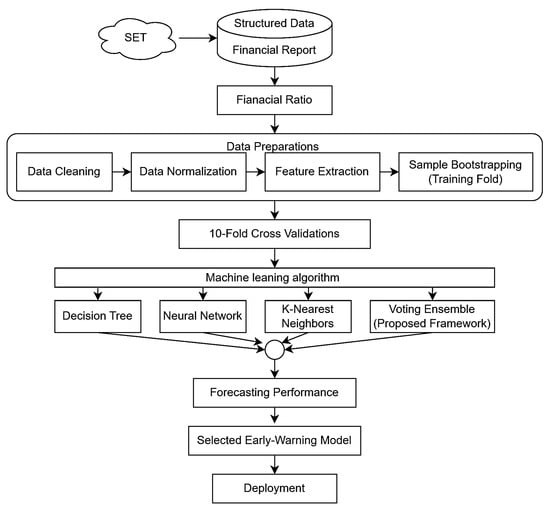
Figure 1.
Overview of the proposed early-warning forecasting framework for corporate financial distress. Financial ratios derived from structured financial reports are processed through data cleaning, normalization, feature extraction, and imbalance-aware sampling. A cross-validation strategy is applied to evaluate individual learning models and the proposed voting ensemble. Model performance is assessed using forecasting-oriented evaluation metrics to support decision-relevant early-warning applications.
3.1. Business Understanding
Financial distress arises when a firm is unable to generate sufficient cash flows to meet its financial obligations, often resulting from structural weaknesses such as excessive leverage, liquidity shortages, or persistent operating losses. If left unaddressed, financial distress can escalate into insolvency, imposing substantial costs on firms, investors, creditors, and regulators. From a forecasting perspective, the primary challenge lies not in identifying failure after it occurs, but in detecting early warning signals that precede formal financial collapse.
For publicly listed companies in Thailand, financial distress is formally signaled through regulatory classifications issued by the Stock Exchange of Thailand, including Non-Performing Group (NPG), Non-Compliance (NC), and Suspension (SP). Among these indicators, the SP classification represents a critical early warning condition, reflecting severe financial or operational deficiencies that threaten business continuity. While such classifications provide transparent and standardized distress signals, they are inherently reactive and may occur only after financial conditions have substantially deteriorated.
This limitation underscores the need for proactive forecasting mechanisms capable of identifying distress risk prior to regulatory intervention. By leveraging historical financial statement information to forecast subsequent firm status, this study aims to support earlier detection of financial distress and going concern risk, thereby enhancing decision-making for investors, auditors, and regulatory authorities.
3.2. Data Understanding
This study develops a financial distress forecasting framework based on accounting-based financial ratios derived from publicly available financial statements of firms listed on the Stock Exchange of Thailand (SET). The initial dataset consists of annual financial reports from 860 firms covering the period from 2011 to 2020, obtained from the official SET database (www.set.or.th, accessed on 15 March 2025), which represents the most authoritative and reliable source of corporate financial information in Thailand.
The unit of analysis in this study is a firm-year observation. Financial ratios derived from year t−1 are used to forecast a firm’s distress status in year t, consistent with an early-warning forecasting design rather than retrospective classification. This temporal structure ensures that all predictive information precedes the outcome of interest, thereby aligning the modeling framework with practical early-warning applications in financial risk monitoring. The final dataset comprises 752 firm-year observations, including 664 non-distressed firms (Normal) and 88 financially distressed firms (SP), reflecting a highly imbalanced early-warning forecasting environment.
To ensure data consistency and comparability, firms operating in the banking, financial services, and insurance sectors were excluded due to their distinct regulatory environments and financial reporting structures. In addition, companies involved in recent mergers or restructuring events were removed to avoid structural breaks and abnormal volatility in financial indicators. After applying these exclusion criteria, the final dataset comprised 752 non-financial Thai-listed companies.
For forecasting purposes, firms were categorized into two groups based on subsequent distress-related outcomes: distressed and non-distressed. Distress identification was aligned with regulatory and audit-based indicators, including delisting status and going-concern–related signals, resulting in 88 distressed firms and 664 non-distressed firms. This classification reflects real-world early warning conditions faced by regulators and market participants, thereby enhancing the practical relevance of the forecasting task.
Although the forecasting target is defined at a specific firm-year level, the dataset spans a longitudinal period of ten years (2011–2020), enabling the model to capture variations across different economic cycles and market conditions. This temporal coverage supports model generalizability beyond short-term fluctuations and strengthens robustness under changing financial environments. Furthermore, the dataset encompasses firms from diverse industry sectors, including manufacturing, real estate, and technology, thereby enhancing external validity.
Financial information from prior reporting periods was used to forecast subsequent firm distress status, consistent with early warning system requirements. Six categories of financial characteristics were operationalized through sixteen financial ratios reflecting liquidity, operating efficiency, debt management, profitability, earnings quality, and long-term solvency. These ratios were selected based on prior empirical evidence demonstrating their relevance in distress forecasting and early deterioration detection. Table 1 summarizes the financial ratios employed in this study.

Table 1.
Financial ratios used in the research.
3.3. Data Preparation
As described in Section 3.2, the final dataset comprises 752 Thai-listed companies across multiple industry sectors over the 2011–2020 period. Prior to model development, a structured data preparation pipeline was implemented to ensure analytical reliability, comparability, and reproducibility across forecasting experiments. These preprocessing steps were designed to transform raw financial statement data into a consistent and model-ready format while minimizing bias arising from scale differences, outliers, and class imbalance.
3.3.1. Dataset Preprocessing and Quality Assurance
To ensure data integrity and consistency, the dataset underwent a systematic preprocessing procedure before feature selection and model training. Table 2 summarizes the dataset profile and the applied preprocessing steps, including missing data handling, outlier treatment, feature scaling, and class imbalance correction. All preprocessing procedures were conducted within the cross-validation framework to prevent information leakage and to maintain robustness across folds.
Table 2.
Dataset profile and preprocessing summary.
3.3.2. Data Cleaning and Normalization
All financial variables were standardized using Z-score normalization to eliminate scale heterogeneity across financial ratios and to support convergence in distance-based and neural learning algorithms. Extreme observations were initially identified using statistical thresholds (±3 standard deviations) and subsequently controlled through winsorization at the 1st and 99th percentiles. This approach is widely adopted in financial and forecasting studies to limit the influence of extreme values while preserving the underlying distributional structure of the data [41,42].
3.3.3. Missing Data Handling
Missing observations were addressed using a listwise deletion strategy at the firm-year level. Firms with incomplete financial ratio information were excluded to ensure that model training relied exclusively on complete and reliable accounting data. Although this approach reduced the sample size marginally, it minimized imputation-induced bias and preserved data authenticity in line with accounting disclosure standards.
3.3.4. Class Imbalance and Resampling Strategy
The dataset exhibits a pronounced class imbalance, with distressed firms representing a minority of observations (88 out of 752 firms). To mitigate bias toward the majority class and enhance early warning sensitivity, bootstrap oversampling was applied to the minority class within each training fold at an approximate ratio of 5:1. This resampling strategy improved the model’s ability to detect financial distress while preserving the original test distributions. Future research may extend this framework by incorporating alternative resampling techniques such as SMOTE, ADASYN, or hybrid approaches to further assess robustness and generalizability.
3.3.5. Feature Scaling and Transformation
Standardization using Z-score normalization was applied to all numerical features to ensure comparability across financial ratios and compatibility with machine learning algorithms sensitive to feature scale, including k-nearest neighbors and neural networks. This transformation enhanced numerical stability and reduced dominance effects among heterogeneous financial indicators.
3.3.6. Attribute Definition and Feature Selection
The attribute Firms was treated as an identifier and excluded from model computation, while the variable Performing served as the binary forecasting label, indicating financially distressed (special-problem status) versus non-distressed firm-year observations. Initially, sixteen financial ratios were extracted to represent six dimensions of financial condition: liquidity, activity, leverage, profitability, earnings quality, and solvency.
Feature selection was subsequently conducted using the Information Gain (IG) criterion with a threshold of 0.01, reducing the feature set from 16 to 11 ratios. This method was selected for its effectiveness in quantifying the discriminatory contribution of financial indicators in imbalanced forecasting settings. By filtering weak or redundant predictors, the procedure improved computational efficiency, enhanced interpretability, and allowed the ensemble model to focus on financially meaningful signals relevant to early distress detection. The full list of financial ratios and the selected subset are presented in Table 3.
Table 3.
Financial ratio data of companies listed on the Stock Exchange of Thailand.
3.4. Modeling
This study evaluates multiple predictive models commonly applied in financial distress forecasting to assess their relative effectiveness and to establish a robust ensemble-based early warning framework. The modeling process incorporates both baseline statistical models and machine learning approaches, including Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), k-Nearest Neighbor (k-NN), Neural Network (NN), and a Voting Ensemble (VOTE). All models were implemented using RapidMiner Studio to ensure consistency in training, validation, and performance comparison.
3.4.1. Logistic Regression
Logistic Regression (LR) was employed as a baseline classifier due to its widespread adoption, computational efficiency, and interpretability in financial risk analysis. Its coefficient-based structure allows transparent assessment of the directional influence of financial ratios, which remains valuable for auditors, regulators, and practitioners engaged in going-concern evaluation [43]. In this study, LR serves as a benchmark model to evaluate whether more advanced machine learning and ensemble approaches provide incremental forecasting value beyond traditional statistical methods. Recent studies have demonstrated that LR continues to play a relevant role when combined with modern feature extraction or attention-based mechanisms [44], reinforcing its suitability as a comparative baseline.
3.4.2. Support Vector Machine (SVM)
Support Vector Machine (SVM) is a margin-based classifier recognized for its robustness in high-dimensional feature spaces and its ability to mitigate overfitting through structural risk minimization [45]. In the context of financial distress forecasting, SVM is particularly useful for capturing complex boundary structures among financial ratios when class separation is not linearly apparent. Prior research has confirmed its effectiveness across diverse classification tasks, including adversarial detection and multi-objective optimization environments [46,47]. In this study, SVM functions as a strong non-linear baseline against which the ensemble’s stability and predictive reliability are assessed.
3.4.3. Decision Tree (DT)
Decision Tree (DT) models offer rule-based learning structures that closely resemble human decision-making processes, making them highly interpretable in financial analytics. DTs partition the feature space into hierarchical decision rules, enabling clear identification of threshold-based relationships among financial ratios [48]. Although DTs may suffer from instability when applied independently, their interpretability and sensitivity to variable interactions make them valuable components within ensemble learning architectures. In this study, DT contributes transparent decision logic to the ensemble framework.
3.4.4. k-Nearest Neighbor (k-NN)
The k-Nearest Neighbor (k-NN) algorithm is an instance-based learning method that classifies observations based on proximity within the feature space. In financial distress forecasting, k-NN is particularly effective for detecting localized anomalies and neighborhood patterns among firms with similar financial profiles [49]. Its non-parametric nature complements model-based learners by capturing similarity-driven risk structures that may not be explicitly modeled through global decision boundaries.
3.4.5. Neural Network (NN)
Neural Networks (NN) are powerful non-linear learners capable of modeling complex interactions among financial indicators. By learning hierarchical representations of input features, NN models capture subtle patterns associated with early-stage financial deterioration [50]. In this study, the NN architecture was configured with a single hidden layer, balancing representational capacity and generalization under limited distressed observations. The NN component enhances the ensemble’s ability to model non-linear dependencies that are common in financial distress dynamics.
3.4.6. Voting Ensemble (VOTE)
- Concept and Design Rationale
The Voting Ensemble constitutes the core predictive framework of this study. As illustrated in Figure 2, three heterogeneous base classifiers—DT, NN, and k-NN—were independently trained and their outputs aggregated through voting mechanisms. The ensemble integrates majority voting and weighted voting strategies to enhance prediction robustness under imbalanced and rare-event conditions.
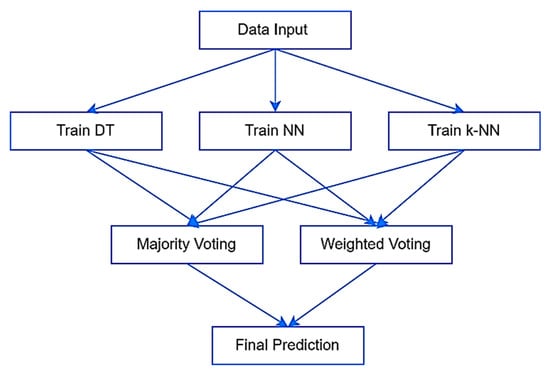
Figure 2.
Voting ensemble workflow for financial prediction.
Unlike boosting or stacking methods, which may increase model complexity or reduce transparency, the Voting Ensemble was selected for its interpretability, ease of implementation, and ability to aggregate complementary learning behaviors without introducing an additional meta-model [51,52]. These characteristics are particularly relevant in financial distress forecasting, where decision reliability and explainability are critical.
- Model Diversity and Forecasting Robustness
The ensemble design leverages structural diversity among its base learners. DT captures rule-based threshold effects, NN models non-linear interactions across financial ratios, and k-NN detects proximity-based anomalies among firms. This heterogeneity expands the hypothesis space and mitigates model-specific bias and variance, thereby improving generalization performance under uncertain and imbalanced forecasting environments.
The design logic aligns with principles observed in recent optimization and ensemble frameworks, where adaptive weighting and diversity enhance predictive stability under uncertainty [49]. Empirical evidence from related domains—including sentiment analysis and semantic retrieval—further supports the effectiveness of heterogeneous ensemble architectures in improving robustness and resilience to data irregularities [53,54,55].
- Weighted Voting and Performance Enhancement
Weighted voting was implemented to assign influence proportional to each base classifier’s cross-validated performance. This adaptive aggregation strategy enhances convergence stability and balances exploration–exploitation trade-offs, consistent with optimization principles observed in recent human-inspired weighting frameworks [56]. Theoretical support for this approach is further reinforced by the “no free lunch” principle, which emphasizes that no single classifier dominates across all data distributions [57].
To validate the ensemble strategy, hard voting, soft voting, and weighted voting configurations were systematically compared. As shown in Figure 3, the weighted voting ensemble achieved the highest overall forecasting accuracy (91.09%) and F-measure (41.99%), outperforming alternative voting schemes. These results confirm that reliability-weighted aggregation enhances early warning capability in imbalanced financial distress forecasting, consistent with recent findings in ensemble-based financial and economic prediction studies [54,58].
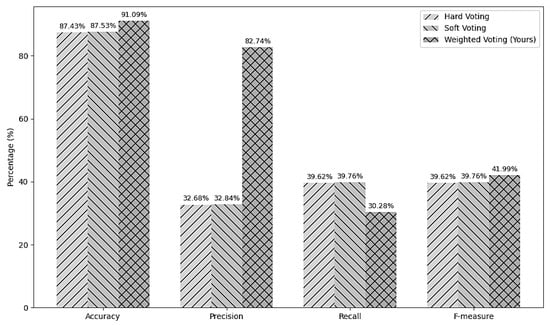
Figure 3.
Performance comparison of hard, soft, and weighted voting strategies.
To ensure fair and leakage-free aggregation under an early-warning forecasting design, the weighting mechanism in the Voting Ensemble is derived entirely from cross-validated performance within the training folds. Specifically, each base classifier’s contribution is weighted according to its predictive consistency observed during the training phase, allowing more reliable learners to exert greater influence on the final decision. This strategy eliminates the need for a separate validation set, as both weight estimation and model selection are embedded within the cross-validation procedure itself, thereby preventing information leakage and ensuring unbiased performance evaluation [59,60]. Consequently, the proposed weighted voting design aligns with the forecasting objective of decision reliability rather than retrospective classification accuracy.
- Comparative Baseline Validation
In line with best practices in forecasting research, classical models such as LR and SVM were retained as baseline comparators to assess the incremental value of the proposed ensemble framework. Prior studies in financial risk modeling and time-series forecasting consistently report superior performance for ensemble-based approaches under volatile and imbalanced conditions [54,58]. The comparative evaluation conducted in this study further substantiates the suitability of the Voting Ensemble as a reliable early warning tool for financial distress and going-concern risk assessment.
- Voting Strategy Comparison
To further validate the ensemble strategy under a forecasting and early warning perspective, three voting configurations—hard, soft, and weighted—were compared. As shown in Figure 3, the weighted voting approach achieved the highest overall accuracy (91.09%) and F-measure (41.99%), while maintaining substantially higher precision (82.74%) than alternative schemes.
This performance pattern indicates that reliability-weighted aggregation improves decision stability in imbalanced and rare-event conditions, where minimizing false alarms is critical for practical early warning systems. These findings are consistent with recent ensemble optimization and decision-support studies [53,57].
3.5. Evaluation Strategy
Model performance in this study is evaluated using a cross-validation–based strategy designed to support early-warning forecasting under imbalanced and rare-event conditions. A stratified 10-fold cross-validation procedure is employed to assess model stability, mitigate overfitting, and ensure robust performance across subsets of the data. In each iteration, the model is trained on nine folds and evaluated on the remaining fold, with performance metrics averaged across all folds to produce reliable estimates.
Performance is assessed using four widely accepted evaluation metrics: accuracy, precision, recall, and F-measure. Accuracy measures the proportion of correctly predicted instances across all classes:
Precision reflects the proportion of correctly predicted positive observations to the total predicted positives:
Recall indicates the proportion of actual positive cases that are correctly identified:
F-measure is the harmonic mean of precision and recall:
where TP denotes true positives, FP false positives, FN false negatives, and TN true negatives.
From an early-warning forecasting perspective, model evaluation must reflect the asymmetric costs associated with different types of prediction errors. In practical financial risk monitoring, excessive false alarms (false positives) can impose substantial operational and supervisory burdens on auditors and regulators, while missed distress signals (false negatives) represent delayed intervention risk. Accordingly, a precision-oriented evaluation profile is practically desirable, as it emphasizes the reliability of issued warning signals rather than aggressive detection at the expense of decision stability. Under severe class imbalance, moderate recall represents a realistic and acceptable trade-off, provided that probability-based metrics such as AUC and Brier score confirm overall discriminative performance and calibration stability, as further examined in the benchmark analysis.
3.6. Model Interpretability
Direct SHAP attribution for a voting ensemble is not well-defined because the final prediction is obtained through the aggregation of heterogeneous base learners without a single differentiable structure. To provide stable and theoretically grounded explanations, this study employs a Random Forest model as a surrogate learner trained on the same feature space to approximate the dominant decision patterns of the ensemble. SHAP values are then computed using TreeExplainer, which is specifically designed for tree-based models and enables consistent global explanations of feature contributions. It should be noted that the SHAP-based analysis is intended to provide global interpretability—highlighting the relative importance and directional influence of financial ratios—rather than an exact local decomposition of each ensemble decision. This boundary of interpretation ensures transparency and accountability for early-warning forecasting applications while maintaining methodological consistency with ensemble-based prediction design.
For interpretability, SHAP values were computed using the TreeExplainer on the Random Forest component of the ensemble rather than the full voting classifier, as this approach provides stable and model-consistent feature attributions suitable for financial ratio–based forecasting tasks. The TreeExplainer method quantifies the marginal contribution of each feature by calculating its Shapley value, derived from cooperative game theory, to reflect how much each variable contributes to the final forecasting outcome.
3.6.1. Global SHAP Analysis
Figure 4 presents the SHAP summary bar plot showing the top ten features ranked by their mean absolute SHAP value (|SHAP|). Each bar represents the average contribution of a financial ratio to model predictions across all observations, where higher values indicate a stronger influence on financial distress forecasting.
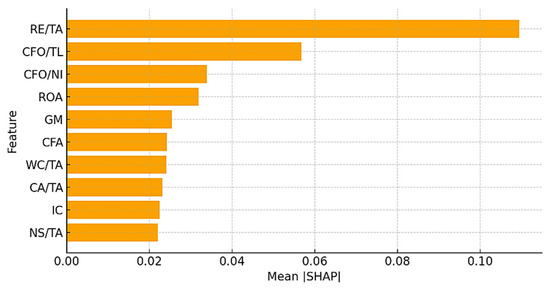
Figure 4.
SHAP Feature Importance.
The results demonstrate that Retained Earnings to Total Assets (RE/TA), Cash Flow to Total Liabilities (CFO/TL), Operating Cash Index (CFO/NI), and Return on Assets (ROA) are the most influential predictors of financial distress. These variables reflect profitability, liquidity, and long-term solvency—core dimensions consistent with accounting and financial stability theory. Firms exhibiting low retained earnings, weak cash flow coverage, and reduced profitability show significantly higher predicted probabilities of distress. Conversely, strong cash flow ratios and sustainable earnings structures reduce the likelihood of delisting, confirming the model’s theoretical and empirical validity.
3.6.2. Summary of SHAP-Derived Financial Drivers
Table 4 summarizes the top-ten financial indicators ranked by their mean |SHAP| values, together with the direction and financial interpretation of each relationship.
Table 4.
Top-10 feature importance by mean |SHAP| (Random Forest Component).
3.6.3. Accounting–Financial Perspective Context
From an accounting and financial management perspective, the top-ranked ratios—particularly RE/TA, CFO/TL, and ROA—reflect the firm’s retained earnings capacity, cash-flow adequacy, and profitability. These are core indicators routinely used in financial statement analysis [61,62], and their SHAP-derived prominence confirms that machine learning explanations remain consistent with traditional accounting logic. Thus, integrating SHAP interpretability supports not only predictive performance but also aligns with the conceptual validity of ratio-based financial diagnostics.
3.6.4. Practical Interpretation of SHAP Results
These interpretability results demonstrate how SHAP effectively decomposes ensemble-based forecasting outputs into financially meaningful attributions. By quantifying both the magnitude and direction of each variable’s contribution, SHAP bridges the gap between predictive performance and interpretive transparency, enabling users to understand how accounting-based financial indicators influence early-warning forecasting outcomes. This global interpretability is particularly important in ensemble learning contexts, where aggregated decision mechanisms may otherwise obscure the contribution of individual financial variables [44,63].
The SHAP-based analysis conducted in this study focuses on global feature importance, providing an overall explanation of dominant financial drivers associated with corporate financial distress forecasting. Such global explanations allow for systematic interpretation of ensemble behavior across the full sample, ensuring consistency with accounting theory and supporting methodological transparency. While the current analysis does not aim to deliver exact local explanations for individual firm predictions, it establishes a robust interpretability foundation for early-warning forecasting models that operate under severe class imbalance and heterogeneous financial conditions.
The interpretability achieved in this framework also provides a methodological basis for future extensions toward local SHAP analysis. Beyond global explanations, instance-level interpretations could further enhance firm-specific financial risk assessment by revealing how particular financial indicators influence distress risk at the individual firm level. Such extensions would increase the granularity of interpretability while maintaining alignment with the forecasting-oriented and decision-relevant objectives of early-warning financial distress modeling.
3.7. Deployment
The outcomes of this study provide a robust and scalable forecasting model for assessing financial distress and going concern risk, validated using firms listed on the Stock Exchange of Thailand. By employing a Voting Ensemble approach, which integrates the strengths of Decision Tree, Neural Network, and k-Nearest Neighbors, the model delivers high predictive accuracy and strong generalization—particularly in the presence of class imbalance. This enables practical applications for stakeholders including investors, auditors, regulators, and financial risk managers.
The deployment strategy focuses on integrating the proposed model into operational decision-support systems, such as enterprise risk dashboards, portfolio evaluation tools, and supervisory financial reporting platforms. These tools can support informed decision-making in areas such as investment planning, credit risk assessment, resource allocation, and crisis mitigation. By leveraging the model’s predictive insights, stakeholders can proactively address emerging financial vulnerabilities, ensuring business continuity and economic resilience.
In addition, the model holds significant potential for integration into early-warning systems operated by auditors, regulators, and stock exchange surveillance units. These entities can use the model to detect early warning signals of financial instability—particularly in sectors sensitive to economic shocks—thereby enhancing forward-looking oversight and policy responsiveness. Investors may also apply the model in evaluating firm-level creditworthiness and resilience under financial stress, improving portfolio diversification and exposure management.
The model’s design allows for future enhancements, including the integration of qualitative indicators (e.g., auditor reports, board governance, market sentiment) and macroeconomic variables to improve contextual prediction. Such extensions may further improve contextual forecasting accuracy and support deployment in more complex and data-rich financial environments.
To promote stakeholder adoption, the deployment plan includes interpretative and visualization tools such as decision-support dashboards. These will enable users to interact with model outputs, understand risk scores, and translate predictions into actionable strategies—thereby facilitating the practical translation of forecasting outputs into risk-informed financial decision-making.
4. Empirical Results
4.1. Forecasting Performance of Proposed and Baseline Models
This subsection evaluates the predictive performance of the proposed Voting Ensemble (VOTE) model in comparison with classical machine learning classifiers, including Decision Tree (DT), Neural Network (NN), k-Nearest Neighbors (k-NN), Logistic Regression (LR), and Support Vector Machine (SVM), under an early-warning forecasting framework. As summarized in Table 5, the Voting Ensemble model achieved the strongest overall forecasting performance across accuracy, precision, and F-measure. These metrics indicate the superiority of the Voting Ensemble in terms of predictive effectiveness and cross-validated stability.
Table 5.
Forecasting performance comparison of financial distress models.
The ensemble method benefits from integrating the strengths of its base models: the interpretability of DT, the capacity of NN to model nonlinearities, and the similarity-based adaptability of k-NN. Through majority voting, the ensemble mitigates overfitting and improves robustness in handling imbalanced datasets—especially relevant in this case, where the number of delisted companies is significantly lower than non-delisted ones (88 delisted companies vs. 664 non-delisted).
From an early-warning forecasting perspective, this trade-off is particularly relevant, as excessive false alarms may impose substantial costs on auditors and regulators, while moderate recall can still support proactive risk screening. Baseline comparisons were conducted using classical models such as LR and SVM to further validate the ensemble’s performance. LR achieved 90.43% accuracy, while SVM scored 88.74%, both of which were outperformed by the Voting Ensemble. Notably, although LR achieved a high precision of 75.00%, its recall was only 16.67%, yielding an F-measure of 27.27%. In contrast, the Voting Ensemble maintained a more balanced trade-off between precision and recall, highlighting its utility for real-world decision-making contexts.
This comparative evaluation aligns with recent research emphasizing robustness through multi-model and multi-metric validation frameworks, as demonstrated by [64], albeit in a different application domain. Our findings extend this approach into financial analytics by demonstrating that ensemble learning not only offers theoretical robustness but also practical relevance, particularly in high-risk, imbalanced domains.
Consistent with earlier studies—such as Liang et al., Pavlicko et al., and Yang and Xiao [65,66,67]—the results confirm that ensemble strategies like Voting are effective in improving prediction accuracy in financial contexts. Moreover, Sanabila and Jatmiko [68] emphasized ensemble models’ strength in managing large-scale imbalanced datasets. This study further contributes to that line of research by illustrating how ensemble learning can enhance early warning systems for financial distress prediction.
In summary, the Voting Ensemble not only excels in statistical performance but also represents a reliable and scalable tool for early risk detection, offering both methodological contribution and practical decision-support for investors, auditors, and regulators.
While the above results demonstrate the superior forecasting performance of the proposed Voting Ensemble relative to classical baseline models, additional robustness assessment against advanced ensemble benchmarks is required to further validate its effectiveness under repeated sampling conditions.
4.2. Benchmark Comparison Under Repeated Cross-Validation
To further assess the robustness of the proposed early-warning forecasting framework, additional benchmark experiments were conducted using advanced tree-based ensemble models, namely Random Forest and Gradient Boosting Decision Trees (GBDT). A repeated 10-fold cross-validation procedure with five repetitions was employed to reduce sampling variability and provide stable performance estimates. Oversampling with a 5:1 ratio was applied within the training folds only to address class imbalance, thereby avoiding information leakage.
The benchmark results are summarized in Table 6. Random Forest achieved an average accuracy of 0.9040 with a precision of 0.7117 and a recall of 0.3272, corresponding to an F1-score of 0.4296. In terms of probability-based evaluation, Random Forest yielded an average AUC of 0.8153 and a Brier score of 0.0788, indicating relatively good discriminative ability and calibration stability. GBDT demonstrated comparable overall accuracy (0.9019) but slightly lower precision (0.6683) and AUC (0.7812), with a higher Brier score (0.0870), suggesting less stable probability estimation under the same experimental setting.
Table 6.
Benchmark performance under repeated 10-fold cross-validation (5 repetitions). Oversampling with a 5:1 ratio was applied within training folds only to address class imbalance. Results are reported as mean ± standard deviation.
Overall, both advanced ensemble benchmarks exhibited moderate discriminative performance under repeated cross-validation. However, when compared with the proposed Voting Ensemble framework reported in Section 4.1, which achieved higher precision and superior early-warning reliability, the results indicate that the proposed design offers a more decision-relevant balance between false alarms and missed distress signals in highly imbalanced forecasting environments.
5. Discussion
This study advances the literature on financial distress forecasting by reframing ensemble learning from a predominantly accuracy-driven classification task toward a decision-oriented early-warning framework designed for imbalanced and rare-event conditions. While prior research has consistently demonstrated that advanced machine learning and ensemble models can achieve strong discriminative performance, the present findings emphasize that practical usefulness depends not only on predictive accuracy but also on how error trade-offs are managed, particularly in environments where false alarms and missed distress signals carry asymmetric economic and operational consequences.
Recent empirical evidence from emerging-market settings confirms the effectiveness of machine learning approaches when class imbalance is explicitly addressed. For instance, Kristanti et al. [69] demonstrate that combining SMOTE-based rebalancing with tree-based and deep learning models substantially improves minority-class detection for Indonesian firms, with performance evaluated primarily through F1-scores and recall of distressed cases. Consistent with this stream of research, our results likewise confirm that ensemble methods are well-suited to rare-event financial distress prediction. However, the present study differs fundamentally in how predictive performance is operationalized. Rather than optimizing minority recall alone through data-level resampling, the proposed Voting Ensemble explicitly prioritizes precision stability under naturally imbalanced data, preserving real-world prevalence and focusing on the reliability of issued warning signals. This distinction is critical in operational early-warning systems, where repeated false alarms may erode institutional trust, exhaust supervisory capacity, and ultimately reduce the effectiveness of financial risk monitoring.
Comparative insights can also be drawn with accuracy-driven voting frameworks. Muniappan and Subramanian [70] report exceptionally high classification accuracy through an exhaustive majority voting mechanism applied to numerous classifier combinations in the Indian automobile sector. Their findings illustrate the upper bound of predictive accuracy achievable through large-scale ensemble search. In contrast, our empirical results suggest that incremental gains in accuracy do not necessarily translate into more decision-relevant forecasting performance. Under repeated cross-validation, highly complex ensemble configurations may exhibit sensitivity to data partitions, whereas the proposed framework achieves a more stable precision-oriented trade-off, aligning more closely with early-warning contexts where the credibility of issued alerts is paramount.
From a methodological standpoint, the present findings also resonate with studies that emphasize decision support and interpretability over algorithmic complexity alone. Wu et al. [71] show that attention-based deep learning models can enhance financial distress prediction by exploiting temporal and textual information embedded in corporate reports. While such approaches expand representational capacity, they may also introduce opacity that constrains adoption in regulatory, auditing, or governance-oriented environments. By contrast, the present study integrates SHAP-based explainability to directly link ensemble predictions to economically interpretable financial indicators—such as retained earnings, cash-flow coverage, and profitability ratios—thereby enhancing transparency and supporting stakeholder trust. These drivers are consistent with established accounting-based determinants of financial distress reported in prior empirical research, reinforcing the conceptual validity of the proposed framework.
Traditional and hybrid bankruptcy prediction models, such as those examined by Vukčević et al. [72], continue to provide valuable benchmarks for early distress detection using statistical and ratio-based approaches. However, their results also highlight declining robustness when such models are applied across heterogeneous firms and evolving economic conditions. The comparative evidence from this study indicates that heterogeneous ensemble architectures, when coupled with decision-oriented evaluation criteria, are better positioned to accommodate structural variation across firms—particularly in emerging markets—by capturing complementary nonlinear, local, and threshold-based financial patterns that single-model approaches may fail to identify.
Taken together, the comparative analysis yields three central implications. First, the effectiveness of ensemble learning in financial distress prediction should be assessed relative to the decision context, not solely by aggregate accuracy metrics. Second, precision-oriented evaluation offers a meaningful alternative for early-warning systems in which the costs of false positives are substantial and asymmetric. Third, explainability is not ancillary but integral to translating predictive outputs into actionable financial risk assessments. By jointly addressing predictive robustness, evaluation alignment, and interpretability, the present study extends prior ensemble-based distress prediction research and offers a methodologically grounded framework that is more closely aligned with real-world early-warning, regulatory screening, and risk governance applications.
6. Conclusions
This study proposes and empirically validates an explainable voting ensemble framework for early-warning forecasting of corporate financial distress under severe class imbalance and rare-event conditions. Using lagged accounting-based financial information from Thai-listed firms, the framework shifts the focus of financial distress modeling from retrospective classification accuracy to decision-relevant forecasting reliability, which is essential for proactive financial risk monitoring and timely intervention.
The empirical findings demonstrate that heterogeneous ensemble learning can enhance forecasting robustness by aggregating complementary learning behaviors across rule-based, nonlinear, and similarity-driven models. Rather than pursuing aggressive detection at the expense of stability, the proposed voting ensemble exhibits a precision-oriented performance profile, thereby reducing false alarms while maintaining acceptable sensitivity to distress events. This trade-off is particularly important in real-world early-warning applications, where excessive false positives may erode institutional trust, strain supervisory resources, and diminish the practical effectiveness of risk monitoring systems.
From a methodological perspective, this study contributes by aligning model design, evaluation strategy, and interpretability with early-warning decision requirements. The use of a precision-aware evaluation framework acknowledges the asymmetric costs associated with prediction errors in financial distress forecasting, while the integration of SHAP-based explainability links ensemble predictions to economically meaningful accounting ratios. The identified drivers—such as retained earnings, cash-flow coverage, and profitability—are consistent with established financial theory, reinforcing both the conceptual validity and transparency of the proposed approach.
From a practical standpoint, the proposed framework offers a transparent and scalable decision-support tool for auditors, regulators, investors, and financial institutions operating in emerging-market environments. By providing reliable and interpretable early-warning signals, the model supports audit prioritization, regulatory surveillance, and firm-level risk screening, particularly in contexts characterized by data imbalance, institutional heterogeneity, and heightened uncertainty, such as Thailand’s capital market.
In conclusion, this study demonstrates that effective financial distress forecasting requires more than improved predictive accuracy alone. By integrating ensemble learning with precision-oriented evaluation and explainable modeling, the proposed framework advances early-warning financial risk assessment toward greater reliability, transparency, and practical relevance. These contributions offer a meaningful step forward in the development of robust and trustworthy early-warning systems for financial risk governance.
7. Limitations and Future Research Directions
Despite the contributions of this study, several limitations should be acknowledged to contextualize the findings and identify avenues for future research.
First, this study relies exclusively on accounting-based financial ratios derived from publicly available financial statements. While such information remains central to audit practice and regulatory surveillance, accounting data are inherently backward-looking and may not fully capture rapid shifts in firm conditions driven by market sentiment, macroeconomic shocks, or qualitative governance events. Future research may extend the proposed framework by integrating macroeconomic indicators, market-based variables, textual disclosures, or sentiment-based signals to enhance contextual sensitivity and early-warning responsiveness.
Second, the empirical analysis is conducted within a single-country emerging-market context, focusing on firms listed on the Stock Exchange of Thailand. Although this setting provides valuable insights into early-warning forecasting under institutional heterogeneity and data imbalance, the findings may not be directly generalizable to developed markets or jurisdictions with different regulatory regimes, accounting standards, or capital market structures. Cross-country validation and multi-market extensions would be a natural direction for future studies to assess the robustness and transferability of the proposed framework.
Third, financial distress in this study is operationalized using a binary distress proxy based on regulatory and audit-related signals, such as special-problem status and delisting indicators. While this definition aligns with practical early-warning and supervisory use cases, it may not encompass all forms or stages of financial deterioration, such as liquidity stress, covenant violations, or gradual performance decline. Future research could explore multi-state distress definitions, continuous risk scoring, or survival-based modeling approaches to capture richer distress dynamics over time.
Fourth, the explainability component of this study focuses on global interpretability using SHAP values derived from a surrogate tree-based model. This approach provides stable and theoretically grounded insights into dominant financial drivers but does not deliver exact local explanations for individual firm-level predictions. While global explanations are appropriate for regulatory screening and aggregate risk monitoring, future work may extend the framework to incorporate instance-level interpretability, counterfactual analysis, or hybrid explainable ensemble techniques to support firm-specific decision-making.
Finally, although the proposed voting ensemble demonstrates robust performance under repeated cross-validation, the framework does not explicitly model temporal dependence or concept drift beyond the lagged forecasting design. Financial distress mechanisms may evolve across business cycles, regulatory changes, and economic shocks, potentially affecting model stability over time. Future research may incorporate rolling-window validation, drift detection mechanisms, or adaptive ensemble updating strategies to enhance long-term forecasting reliability in dynamic financial environments.
By acknowledging these limitations, this study provides a transparent foundation for future methodological extensions while reinforcing the practical relevance of precision-oriented and explainable ensemble learning for early-warning financial distress forecasting.
Author Contributions
Conceptualization, L.P.; methodology, L.P. and A.S.; software, A.S. and N.S.; formal analysis, L.P.; investigation, L.P. and R.K.; data curation, L.P. and P.C.; writing—original draft preparation, L.P.; writing—review and editing, R.K., A.S., S.B. and N.S.; validation, S.B. and A.S.; visualization, L.P. and P.C.; supervision, R.K., A.S. and S.B.; project administration, L.P.; funding acquisition, L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was financially supported by Mahasarakham University, Thailand.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki and approved under an exemption category by the Institutional Review Board of Mahasarakham University (MSU IRB) (Approval No. 373–383/2025; Date of Approval: 13 June 2025).
Informed Consent Statement
Not applicable. This study did not involve human participants or the collection of personal or identifiable information.
Data Availability Statement
The data used in this study were obtained from publicly available financial statements provided by the Stock Exchange of Thailand (SET). The processed datasets generated during the analysis are available from the corresponding author upon reasonable request, subject to the data use policies of the SET.
Acknowledgments
The authors gratefully acknowledge the financial support provided by Mahasarakham University, which made this research possible. The authors would also like to thank the administrative staff and institutional units involved for facilitating access to publicly available financial data. All individuals acknowledged in this section have provided their consent to be included.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Plypichit, P.; Lisawadi, S. Predicting Thai Listed Company Financial Distress by Machine Learning and Synthetic Minority Oversampling Technique and Hybrid Resampling Techniques. Int. J. Trade Econ. Financ. 2024, 15, 93–101. [Google Scholar] [CrossRef]
- Poungsangsuk, S. Corporate Governance and Prediction of Financial Failure of Companies Listed on the Stock Exchange of Thailand; Rajamangala University of Technology Thanyaburi: Bangkok, Thailand, 2013. [Google Scholar]
- Indriyanti, M. The Accuracy of Financial Distress Prediction Models: Empirical Study on the World’s 25 Biggest Tech Companies in 2015–2016 Forbes’s Version. KnE Soc. Sci. 2019, 3, 442–450. [Google Scholar] [CrossRef]
- Muñoz-Izquierdo, N.; Laitinen, E.K.; Camacho-Miñano, M.d.M.; Pascual-Ezama, D. Does audit report information improve financial distress prediction over Altman’s traditional Z-Score model? J. Int. Financ. Manag. Account. 2019, 31, 65–97. [Google Scholar] [CrossRef]
- Kantar, L.; Ayrancı, A.E. Estimating Financial Failure in Businesses Using Artificial Neural Networks: Turkish Manufacturing Industry Model Study. J. Corp. Gov. Insur. Risk Manag. 2022, 9, 327–340. [Google Scholar] [CrossRef]
- Al-Khalili, S.S.; Kaddumi, T.A. Predicting Industrial Companies Financial Failure Using Sherrod and Zmijewski Models—Analytical Study. J. Southwest Jiaotong Univ. 2022, 57, 124–136. [Google Scholar] [CrossRef]
- Pardeshi, B. Logistic Regression Analysis for Prediction of Financial Failure: Evidence from Central Public Sector Enterprises in India. Vis. J. Bus. Perspect. 2022. ahead-of-print. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Machine learning towards intelligent systems: Applications, challenges, and opportunities. Artif. Intell. Rev. 2021, 54, 3299–3348. [Google Scholar] [CrossRef]
- Uddin, N.; Uddin Ahamed, M.K.; Uddin, M.A.; Islam, M.M.; Talukder, M.A.; Aryal, S. An ensemble machine learning based bank loan approval predictions system with a smart application. Int. J. Cogn. Comput. Eng. 2023, 4, 327–339. [Google Scholar] [CrossRef]
- Nicolas, T. Short-term financial constraints and SMEs’ investment decision: Evidence from the working capital channel. Small Bus. Econ. 2022, 58, 1885–1914. [Google Scholar] [CrossRef] [PubMed]
- Bechtel, A.; Ranaldo, A.; Wrampelmeyer, J. Liquidity Risk and Funding Cost. Rev. Financ. 2023, 27, 399–422. [Google Scholar] [CrossRef]
- Rahmi, A.; Lu, C.c.; Liang, D.; Fadilah, A.N. Splitting long-term and short-term financial ratios for improved financial distress prediction: Evidence from Taiwanese public companies. J. Forecast. 2024, 43, 2886–2903. [Google Scholar] [CrossRef]
- Masoudinejad, S.; Veitch, J.A. The effects of activity-based workplaces on contributors to organizational productivity: A systematic review. J. Environ. Psychol. 2023, 86, 101920. [Google Scholar] [CrossRef]
- Saeed, A.M.M.; Widyaningsih, A.; Khaled, A.S.D. Activity-based costing (ABC) in the manufacturing industry: A literature review. J. Dev. Econ. (JDE) 2023, 8, 261–270. [Google Scholar] [CrossRef]
- Coric, B.; Simic, V. Economic disasters and aggregate investment. Empir. Econ. 2021, 61, 3087–3124. [Google Scholar] [CrossRef] [PubMed]
- Sari, N.P.; Susanti, N.; Fitriano, Y. Profitability Ratio Analysis To Assess Financial Performance At PT Akasha Wira International Tbk. J. Ekon. Manaj. Akunt. Dan Keuang. 2023, 4, 1201–1210. [Google Scholar] [CrossRef]
- Novita, D.; Jalaludin, J.; Sucipto, M.C. Profitability Ratio Analysis in Measuring Financial Performance at Bank Syariah Mandiri (Research on Return On Assets, Return on Equity, Gross profit margin and Net Profit Margin in 2015–2019). EKSISBANK Ekon. Syariah Dan Bisnis Perbank. 2022, 6, 125–145. [Google Scholar] [CrossRef]
- Miransyah, G.G.; Dempo, S.R.S.; Sutisna, S. Profitability Ratio Analysis at PT. Medikaloka Hermina, TBK. Bina Bangsa Int. J. Bus. Manag. 2021, 1, 60–67. [Google Scholar] [CrossRef]
- Khan, A.H.; Shah, A.; Ali, A.; Shahid, R.; Zahid, Z.U.; Sharif, M.U.; Jan, T.; Zafar, M.H. A performance comparison of machine learning models for stock market prediction with novel investment strategy. PLoS ONE 2023, 18, e0286362. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.H.; Tahat, Y.; Eliwa, Y.; Burton, B. Earnings quality and the cost of equity capital: Evidence on the impact of legal background. Int. J. Account. Inf. Manag. 2021, 29, 631–650. [Google Scholar] [CrossRef]
- Ricciardi, G.; Fera, P.; Moscariello, N.; De Nuccio, E. Earnings quality among private firms: Evidence from the ELITE context. J. Appl. Account. Res. 2024, 26, 86–107. [Google Scholar] [CrossRef]
- Shivaani, M.V.; Jain, P.K.; Yadav, S.S. Development of a New Set of (Cash Flow Based) Ratios to Assess Financing of Incremental Corporate Investments: An Application in Indian Context. Glob. J. Flex. Syst. Manag. 2015, 16, 377–389. [Google Scholar] [CrossRef]
- Kliestik, T.; Valaskova, K.; Lazaroiu, G.; Kovacova, M.; Vrbka, J. Remaining Financially Healthy and Competitive: The Role of Financial Predictors. J. Compet. 2020, 12, 74–92. [Google Scholar] [CrossRef]
- Polsiri, P.; Sookhanaphibarn, K. Corporate distress prediction models using governance and financial variables: Evidence from Thai Listed firms during the East Asian economic crisis. J. Econ. Manag. 2009, 5, 273–304. [Google Scholar]
- Jaitang, C.; Li, Z.; Gan, C. An Empirical Analysis of Private SMEs’ Insolvency in Thailand Using Machine Learning. Asian J. Appl. Econ. 2024, 31, 1–30. [Google Scholar]
- Abrahamsen, N.-G.B.; Nylén-Forthun, E.; Møller, M.; de Lange, P.E.; Risstad, M. Financial Distress Prediction in the Nordics: Early Warnings from Machine Learning Models. J. Risk Financ. Manag. 2024, 17, 432. [Google Scholar] [CrossRef]
- Arefmanesh, Z.; Ghadirian-Arani, M.-H.; Ghadirian Arani, Z. Financial Distress and Restatement of Financial statements: Evidence from Tehran Stock Exchange. Empir. Stud. Financ. Account. 2020, 17, 203–227. [Google Scholar] [CrossRef]
- Mallinguh, E.B.; Zéman, Z. Financial Distress, Prediction, and Strategies by Firms: A Systematic Review of Literature. Period. Polytech. Soc. Manag. Sci. 2020, 28, 162–176. [Google Scholar] [CrossRef]
- Ramzan, S. Comparison of Financial Distress Prediction Models Using Financial Variables. In Proceedings of the 2023 International Conference on Electrical, Computer and Energy Technologies (ICECET), Cape Town, South Africa, 16–17 November 2023; pp. 1–7. [Google Scholar]
- Teymouri, M.R.; Sadeghi, M. Investigating the effect of firm characteristics on accounting conservatism and the effect of accounting conservatism on financial governance. Arch. Pharm. Pract. 2020, 11, 124–133. [Google Scholar]
- Duarte, D.L.; Barboza, F.L.d.M. Forecasting Financial Distress With Machine Learning—A Review. Future Stud. Res. J. Trends Strateg. 2020, 12, 528–574. [Google Scholar] [CrossRef]
- Tran, K.L.; Le, H.A.; Nguyen, T.H.; Nguyen, D.T. Explainable Machine Learning for Financial Distress Prediction: Evidence from Vietnam. Data 2022, 7, 160. [Google Scholar] [CrossRef]
- Khedr, A.M.; Bannany, M.E.; Saif, A.-W.A. FDP-GAMLP: New Financial Distress Prediction Technique based on Genetic Algorithm and Multi-Layer Perceptron. In Proceedings of the 2022 19th International Multi-Conference on Systems, Signals & Devices (SSD), Sétif, Algeria, 6–10 May 2022; pp. 361–366. [Google Scholar]
- Elhoseny, M.; Metawa, N.; Sztano, G.; El-Hasnony, I.M. Deep Learning-Based Model for Financial Distress Prediction. Ann. Oper. Res. 2022, 345, 1–23. [Google Scholar] [CrossRef]
- Kadkhoda, S.T.; Amiri, B. A Hybrid Network Analysis and Machine Learning Model for Enhanced Financial Distress Prediction. IEEE Access 2024, 12, 52759–52777. [Google Scholar] [CrossRef]
- Jiang, E.P. Assessing ensemble techniques for imbalanced classification. Int. J. Bus. Intell. Data Min. 2025, 26, 66–87. [Google Scholar] [CrossRef]
- Ali, A.I.A.; Sheeja Rani, S.; Pravija Raj, P.V.; Khedr, A.M. Hierarchical cluster-based IELM for financial distress prediction with imbalanced data. Neural Comput. Appl. 2024, 37, 2925–2943. [Google Scholar] [CrossRef]
- Sun, J.; Zhao, M.; Lei, C. Class-imbalanced dynamic financial distress prediction based on random forest from the perspective of concept drift. Risk Manag. 2024, 26, 19. [Google Scholar] [CrossRef]
- Chaves, R.M.; Rossi, A.L.D.; Garcia, L.P.F. Financial Distress Prediction in an Imbalanced Data Stream Environment. In Hybrid Artificial Intelligent Systems; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNAI volume 14001; Springer: Cham, Switzerland, 2023; pp. 168–179. [Google Scholar] [CrossRef]
- Li, Z. Identification of enterprise financial risk based on logistics model. Int. J. Bus. Intell. Data Min. 2024, 25, 106–127. [Google Scholar] [CrossRef]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 8th ed.; Cengage Learning: Boston, MA, USA, 2019. [Google Scholar]
- Tukey, J.W. The Future of Data Analysis. Ann. Math. Stat. 1962, 33, 1–67. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Pradeepa, S.; Jomy, E.; Vimal, S.; Hassan, M.M.; Dhiman, G.; Karim, A.; Kang, D. HGATT_LR: Transforming review text classification with hypergraphs attention layer and logistic regression. Sci. Rep. 2024, 14, 19614. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pratap Singh, S.; Kumar, N.; Saleh Alghamdi, N.; Dhiman, G.; Viriyasitavat, W.; Sapsomboon, A. Next-Gen WSN Enabled IoT for Consumer Electronics in Smart City: Elevating Quality of Service Through Reinforcement Learning-Enhanced Multi-Objective Strategies. IEEE Trans. Consum. Electron. 2024, 70, 6507–6518. [Google Scholar] [CrossRef]
- Singh, S.P.; Kumar, N.; Dhiman, G.; Vimal, S.; Viriyasitavat, W. AI-Powered Metaheuristic Algorithms: Enhancing Detection and Defense for Consumer Technology. IEEE Consum. Electron. Mag. 2025, 14, 44–52. [Google Scholar] [CrossRef]
- Navada, A.; Ansari, A.N.; Patil, S.; Sonkamble, B.A. Overview of Use of Decision Tree ALGORITHMS in Machine Learning. In Proceedings of the 2011 IEEE Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 27–28 June 2011; pp. 37–42. [Google Scholar]
- Nadkarni, P. Core Technologies: Data Mining and “Big Data”. In Clinical Research Computing; Nadkarni, P., Ed.; Academic Press: Cambridge, MA, USA, 2016; pp. 187–204. [Google Scholar]
- Li, J.; Zhang, L. An Early Control Algorithm of Corporate Financial Risk Using Artificial Neural Networks. Mob. Inf. Syst. 2022, 2022, 4398602. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. A Weighted Majority Voting Ensemble Approach for Classification. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 1–6. [Google Scholar]
- Pintelas, P.; Livieris, I.E. Special Issue on Ensemble Learning and Applications. Algorithms 2020, 13, 140. [Google Scholar] [CrossRef]
- Bhatt, C.; Chauhan, R.; Singh, B.; Pokhariya, H.; Kumar, R.; Dhiman, G.; Singh, S.; Garg, G.K. An ensemble learning for sentiment analysis on Twitter. AIP Conf. Proc. 2025, 3185, 30003. [Google Scholar] [CrossRef]
- Dimri, S.C.; Chauhan, R.; Ansari, V.; Bhatt, C.; Negi, A.S.; Kumar, R.; Dhiman, G.; Sharma, K.; Chabra, R. A machine learning based system to detect driver’s drowsiness. AIP Conf. Proc. 2025, 3185, 30004. [Google Scholar] [CrossRef]
- Pavithra, L.K.; Subbulakshmi, P.; Paramanandham, N.; Vimal, S.; Alghamdi, N.S.; Dhiman, G. Enhanced Semantic Natural Scenery Retrieval System Through Novel Dominant Colour and Multi-Resolution Texture Feature Learning Model. Expert Syst. 2024, 42, e13805. [Google Scholar] [CrossRef]
- Hamadneh, T.; Batiha, B.; Al-Baik, O.; Montazeri, Z.; Malik, O.P.; Werner, F.; Dhiman, G.; Dehghani, M.; Eguchi, K. Spider-Tailed Horned Viper Optimization: An Effective Bio-Inspired Metaheuristic Algorithm for Solving Engineering Applications. Int. J. Intell. Eng. Syst. 2025, 18, 25–35. [Google Scholar] [CrossRef]
- Pinki; Kumar, R.; Viriyasitavat, W.; Sapsomboon, A.; Dhiman, G.; Alshahrani, R.; Solaiman, S.; Choudhary, R.; Dey, P.; Sivaranjani, R. A Symmetric and Comparative Study of Decision Making in Intuitionistic Multi-objective Optimization Environment: Past, Present and Future. Arch. Comput. Methods Eng. 2025, 32, 3375–3413. [Google Scholar] [CrossRef]
- Al-Rasheed, A.; Alsaedi, T.; Khan, R.; Rathore, B.; Dhiman, G.; Kundi, M.; Ahmad, A. Machine Learning and Device’s Neighborhood-Enabled Fusion Algorithm for the Internet of Things. IEEE Trans. Consum. Electron. 2025, 71, 467–475. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; pp. 1–15. [Google Scholar]
- Altman, E.I. Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy. J. Financ. 2012, 23, 589–609. [Google Scholar] [CrossRef]
- Ohlson, J.A. Financial Ratios and the Probabilistic Prediction of Bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef]
- Bhattacharya, P.; Prasad, V.K.; Verma, A.; Gupta, D.; Sapsomboon, A.; Viriyasitavat, W.; Dhiman, G. Demystifying ChatGPT: An In-depth Survey of OpenAI’s Robust Large Language Models. Arch. Comput. Methods Eng. 2024, 31, 4557–4600. [Google Scholar] [CrossRef]
- Singamaneni, K.K.; Yadav, K.; Aledaily, A.N.; Viriyasitavat, W.; Dhiman, G.; Kaur, A. Decoding the future: Exploring and comparing ABE standards for cloud, IoT, blockchain security applications. Multimed. Tools Appl. 2024, 84, 12299–12327. [Google Scholar] [CrossRef]
- Liang, D.; Tsai, C.-F.; Dai, A.-J.; Eberle, W. A novel classifier ensemble approach for financial distress prediction. Knowl. Inf. Syst. 2017, 54, 437–462. [Google Scholar] [CrossRef]
- Pavlicko, M.; Durica, M.; Mazanec, J. Ensemble Model of the Financial Distress Prediction in Visegrad Group Countries. Mathematics 2021, 9, 1886. [Google Scholar] [CrossRef]
- Yang, D.; Xiao, B. Feature Enhanced Ensemble Modeling With Voting Optimization for Credit Risk Assessment. IEEE Access 2024, 12, 115124–115136. [Google Scholar] [CrossRef]
- Sanabila, H.R.; Jatmiko, W. Ensemble Learning on Large Scale Financial Imbalanced Data. In Proceedings of the 2018 International Workshop on Big Data and Information Security (IWBIS), Jakarta, Indonesia, 12–13 May 2018; pp. 93–98. [Google Scholar]
- Kristanti, F.T.; Salim, D.F.; Ihsan, A.F. Financial distress prediction in emerging markets by using a machine learning approach for financial sustainability. Discov. Sustain. 2025, 6, 1296. [Google Scholar] [CrossRef]
- Muniappan, M.; Paruvachi Subramanian, N.D. A Majority Voting Mechanism-Based Ensemble Learning Approach for Financial Distress Prediction in Indian Automobile Industry. J. Risk Financ. Manag. 2025, 18, 197. [Google Scholar] [CrossRef]
- Wu, C.; Jiang, C.; Wang, Z.; Ding, Y. Predicting financial distress using current reports: A novel deep learning method based on user-response-guided attention. Decis. Support Syst. 2024, 179, 114176. [Google Scholar] [CrossRef]
- Vukčević, M.; Lakićević, M.; Melović, B.; Backović, T.; Dudić, B. Modern models for predicting bankruptcy to detect early signals of business failure: Evidence from Montenegro. PLoS ONE 2024, 19, e0303793. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.