Abstract
Daily data on COVID-19 infections and deaths tend to possess weekly oscillations. The purpose of this work is to forecast COVID-19 data with partially cyclical fluctuations. A partially periodic oscillating ARIMA model is suggested to enhance the predictive performance. The model, optimized for improved prediction, characterizes and forecasts COVID-19 time series data marked by weekly oscillations. Parameter estimation and out-of-sample forecasting are carried out with data on daily COVID-19 infections and deaths between January 2021 and October 2022 in the USA, Germany, and Brazil, in which the COVID-19 data exhibit the strongest weekly cycle behaviors. Prediction accuracy measures, such as RMSE, MAE, and HMAE, are evaluated, and 95% prediction intervals are constructed. It was found that predictions of daily COVID-19 data can be improved considerably: a maximum of 55–65% in RMSE, 58–70% in MAE, and 46–60% in HMAE, compared to the existing models. This study provides a useful predictive model for the COVID-19 pandemic, and can help institutions manage their healthcare systems with more accurate statistical information.
1. Introduction
The prevalence of COVID-19 has been a worldwide concern for more than three years and continues to threaten human health. The trends of COVID-19 cases display different patterns across various countries. In some countries, daily cases are decreasing due to beneficial policies, such as booster vaccine campaigns. On the other hand, some other countries have experienced surges in COVID-19 infections due to local problems. Moreover, cyclical fluctuations or waves are also observed in some countries, either long-term or short-term. For the dynamic time series patterns of COVID-19, numerous studies have been conducted on modeling and forecasting since the outbreak began in 2019–2020. For instance, see [1,2,3,4,5,6,7,8,9,10] for remarkable works on the forecasting analysis of COVID-19. They dealt with ARIMA models and machine learning for COVID-19 pandemic forecasting. Refs. [11,12] proposed exponential decay models for short-term forecasts of COVID-19, which proved to be effective in short-term forecasting. Developing accurate predictive models for dynamic data represents a significant challenge. This is because the process of modeling and forecasting such random phenomena carries academic importance. Moreover, reliable statistical analysis can play a crucial role in enhancing social policies aimed at human health. In academia and health institutions, efforts to prevent the transmission of respiratory diseases should continue until the proliferation of the virus is completely over.
Many infectious diseases, including malaria, dengue, the influenza virus, as well as COVID-19, are not maintained in a state of equilibrium but exhibit significant fluctuations in prevalence over time [13], for which mathematical modelings have been developed with gradually improved achievements in the past years. For instance, we refer to [14,15,16] for the seasonality of malaria, dengue, and influenza virus. Refs. [17,18,19] focused on the seasonal trends in COVID-19 cases. However, beyond the seasonality of COVID-19, they also observed high-frequency oscillations with a periodicity of approximately one week. In other words, one distinctive characteristic of the COVID-19 pandemic patterns is the presence of periodic oscillations with weekly cycles. This aspect was also discussed by [20], who investigated high-frequency (i.e., weekly) oscillatory patterns in COVID-19 infections and deaths.
Moreover, Ref. [20] urged the scientific community to conduct an in-depth exploration of the periodicity in COVID-19 cases, which might lead to a better understanding and forecasting of COVID-19 transmission. Refs. [21,22,23,24,25,26] discussed the weekly cycle behaviors and periodic recurrent waves of COVID-19 data. In particular, Refs. [22,24] applied the cyclical fluctuation to infer or predict the spread rate and incidence rate of the coronavirus, while [26] dealt with modeling the drivers of oscillations in COVID-19 data on college campuses by emphasizing that the oscillations of COVID-19 exist as a result of incorporating human behaviors into the systems.
Refs. [20,22,23] pointed out that periodic oscillations are associated with a testing bias. As global COVID-19 cases rose, the overwhelming tasks of managing the severe virus have led to a testing bias, resulting in varied patterns in COVID-19 data. This testing bias stems from more frequent testing on certain days of the week and less on others, contributing to the weekly cycle fluctuations in the number of COVID-19 cases. For example, in some of the most affected countries, such as the USA, Germany, and Brazil, recent COVID-19 time series data exhibit exceptionally partial-periodic oscillations with weekly cycles. These oscillations are characterized by stronger fluctuations at larger magnitudes.
Meanwhile, Refs. [27,28] handled the 7-day smoothed data of COVID-19. Their modeling/forecasting work is significant in itself, as social policies against COVID-19, such as lockdowns and travel restrictions, typically span periods longer than 7 days. Nevertheless, as claimed by [20,22,23] periodic oscillation phenomena should be explored in depth in the evolutionary history of the COVID-19 pandemic. It is important to identify the cyclical behaviors of COVID-19 time series data for the purpose of their full understanding and improved prediction.
The oscillations observed in COVID-19 time series data do not fit well into existing models, necessitating the development of a new model for improved predictive performance. This study focuses on modeling and forecasting the partially periodic oscillatory patterns of COVID-19 data. We utilize an autoregressive integrated moving average (ARIMA) model and incorporate a partially periodic oscillating (PPO) component to capture the weekly cyclical fluctuations. This model is referred to as the PPO-ARIMA model. However, unlike a seasonal ARIMA (SARIMA) model with a 7-day cycle, in our proposed model, the oscillation amplitudes are proportional to the magnitudes of the ARIMA part: stronger oscillations are reflected on larger magnitudes of the ARIMA part, whereas weaker oscillations align with smaller magnitudes. To create this feature, the PPO part is generated theoretically by indicator variables and weights, depending on the values of the ARIMA part. The oscillations occur by adopting periodic weights on the values of the ARIMA part. An additional oscillation part is the main difference from the traditional ARIMA model.
This study aims to improve the forecasting capability for the spread of the COVID-19 pandemic by adding the PPO part to existing ARIMA models. We conduct estimation and out-of-sample forecasting through empirical analysis of real data from three countries: the USA, Germany, and Brazil, which possess the strongest oscillations in their COVID-19 infection and death cases. The estimation methods are simple and easy to implement by means of average and linear regression. As the forecasting performance measures, the root mean square error (RMSE), mean absolute error (MAE), and heterogeneous MAE (HMAE) are computed and compared with other existing models. Some discussions about the superiority of the proposed model are addressed, including the evaluation of the efficiency of the model based on the forecasting performance accuracy. Finally, prediction intervals are constructed.
2. Method
To achieve the forecasting analysis on COVID-19 data, in this section, we first describe the datasets and then introduce the PPO-ARIMA model.
2.1. Data
In the empirical experiments, the daily numbers of confirmed COVID-19 cases and related deaths are considered for three countries—USA, Germany, and Brazil—are considered. These countries have strong partial periodic oscillations among others. COVID-19 time series data from 1 January 2021 to 13 October 2022, with a size of 651, were obtained from the WHO website: https://covid19.who.int/data (accessed on 12 October 2023) A summary of the statistics is given in Table 1. To achieve the purpose of estimation and forecasting, the standardized data, subtracted by the mean and then divided by the standard deviation, are applied to the PPO-ARIMA model. In other words, with is used in the proposed model, where is the (original) daily COVID-19 confirmed (or death) cases at time t, , and are its sample mean and sample standard deviation given in Table 1. The transformed data form a triangular array with . Once the estimation and prediction have been conducted using , the empirical results for the original data are then inversely transformed for the visualizations presented in the following section. The estimation results discussed below are derived from applying the proposed model to the standardized data, while the illustrations of the one-step ahead predictions and their prediction intervals are displayed using the original data.

Table 1.
Statistics of daily confirmed (C) and death (D) cases with days between 1 January 2021 and 13 October 2022; SD = standard deviation.
Oscillation modeling is needed to forecast the propagation of COVID-19 more precisely. Oscillation is due to daily differences in testing for the virus and death reporting, as mentioned by [21]. In other words, it is caused by testing bias, which means that testing for the virus is performed more often during certain days of the week and less often on other days, as mentioned by [22,23]. In order to represent the oscillation more precisely, we suggest combining periodic oscillations in the ARIMA models.
2.2. ARIMA Model with Partial Periodic Oscillation
In this work, we consider an ARIMA model with partial periodic oscillation, , given by
where is an ARIMA model, is a oscillation component, and is an i.,i.d. noise process.
Firstly, we briefly describe the ARIMA model of order . Using the back-shift operator B, let , be the difference operator, such that . The ARIMA () model satisfies the following: defining , which is the d-th order differenced series of ,
for coefficients and , and ), and for a white noise . The characteristic function has roots outside the unit circle. Then, the d-th order difference series is stationary. The ARIMA model is very popular in time series analysis and has been used by many researchers; for example, see [29,30]).
Secondly, we describe the partial periodic oscillation component as follows:
where is the indicator function, is the threshold, is the exponent, and , ( are weights that are chosen with the relationship of mod periodically as is periodicity, in other words, ℓ is the remainder of t as divided by . In order to generate oscillations, we consider different values for weights, . If and have the same remainder, as divided by , then and have the same weight with the same remainder . Since the summation expression of implies with mod , (1) can be expressed as
This expression unifies all cases for the general time index t and, thus, it is a better expression of the mathematical analysis below.
We focus on the partial periodic oscillation (PPO) part , which is constructed by indicator variables and weights, depending on the values of the ARIMA part. From the expressions in (1) or (2), we see that the partial periodic oscillation part is generated by three parameters: threshold , exponent , and weights . Moreover, it consists of three terms: , and . The indicator variable implies the existence of the PPO part in the model; if , then , i.e., if the magnitude of the ARIMA part is less than the threshold, the PPO part does not exist. Thus, the role of threshold is to control the portion of partial oscillations in the model. The amplitude of the PPO part is proportional to the value of the ARIMA part if the value is greater than threshold : is proportional to if it does not vanish. Also, the amplitude depends on the weight, of which, the index is determined by the remainder of the time epoch, divided by , so that -period oscillations occur in the time series data. Thus, the role of weights is to control the occurrence of the pure oscillations by having increasing/decreasing patterns on the values of . The exponent plays a role in finding pure oscillation magnitudes as well as controlling the magnitudes of the oscillations depending on the values of the ARIMA part. The bigger the , the larger the PPO values. Also, makes pure oscillation weights .
The goal of this work is to model and forecast COVID-19 case data, focusing on the partial periodic oscillations with a periodicity of , by focusing on weekly oscillatory patterns in the COVID data. As observed in the COVID-19 confirmed and death case figures for the three countries, extreme values (local maximal or minimal points) exhibit a period of 7 days. Rather than other intervals, such as 28 days, 7 days are adopted for to describe the oscillation periodicity for our purpose. In the following, we first propose parameter estimation and then perform an out-of-sample forecasting analysis to present our main results.
2.3. Estimation
We now describe the estimation of parameters in (1) before providing the empirical results. Suppose that a sample is observed with periodicity . We use and for a positive integer k; that is, n is a multiple of for COVID-19 data analysis. Since the value of is small, compared to the total sample size n, if the sample size is not a multiple of , the initial finite set of data, which is smaller than may be deleted without affecting the analysis. In order to estimate parameters and , ( from the sample , we follow three steps: the first is to decompose the time series into two parts, the ARIMA part and the PPO part ; the second is to estimate the exponent parameter , and the final step is to estimate the weights by averaging.
First, to decompose into two parts, we compute the -day smoothed moving average series given by
where is the integer part of a real number a; if , is regarded as 0 and is evaluated as the average of nonzero observations, instead of dividing by . For the transformed data , an ARIMA model is fitted with the estimated ARIMA coefficients. For the PPO part , which is obtained by , the model (1) will be fitted.
Second, in order to estimate in (1): , where ℓ is the index in , such that mod , with some chosen threshold (whose selection will be discussed in the next section), we split the time period into disjoint subperiods with the ith time period , for . For each i, let and denote, respectively, the maximum and minimum of in the ith period, provided for , with some small constant . That is,
where the constant , which is added to avoid a too-small value of in the denominator, plays a role where there fraction falls within a bounded range. The choice of is not so sensitive to the estimation since the maximum and minimum are not affected by the value of , which just controls the amount of zero-nonzero portions of periodic oscillations.
Let be the true (unknown) value of the exponent in the model. Note that and are constants representing the highest weight and the lowest weight, respectively, i.e., independent of i for the true value . The following explains why and are constants for all i if for the true exponent parameter . Let Also, let be the index in with the highest extreme of oscillations; that is, for all . For each , let , if mod , then we have or equivalently, if , then and, thus, for all i. Hence, for all , for the true exponent . In the same way, let be the index with the lowest extreme . Then we have and for all , . Hence, we have that and are constants that are independent of i.
Therefore, we choose , such that
for small . To do this, for two sets of and , we consider two linear regression models of and with coefficients and , respectively, as follows:
where are error terms. From the two regression models, estimates , of slope coefficients , are computed, noticing that slopes when .
Note that if the estimated slope coefficients and are close to zero, then (3) is satisfied. Thus, we may choose , so that it minimizes :
for a compact set . We claim that converges to the true exponent in probability, as . For a given compact set of , suppose that . Let
which are continuous functions of , since and are continuous functions of . Note that is the minimizer of , whereas is the minimizer of . Moreover, for all , we have . Thus, we may write
as . Hence, the desired convergence in probability holds.
Finally, using , for each , we compute estimates of given by
where . Note that if , then for , , and since as , each of converges to and so does the average of as . On the other hand, the median of can also be chosen as an alternative to the average, which is a good alternative in the case of the presence of outliers. However, in this work, we choose the average in (4), based on a basic theory, where the sample mean converges to the population mean in probability.
The idea of estimation is simple and easy to implement because just basic statistical methods, such as regression analysis and averaging, are used to estimate the parameters of the PPO part. The statistical analysis was performed using Python statistical software version 3.8, numpy, scipy, statsmodels.tsa.arima.model, statsmodels.tsa.stattools, etc., to assess the empirical results.
3. Results
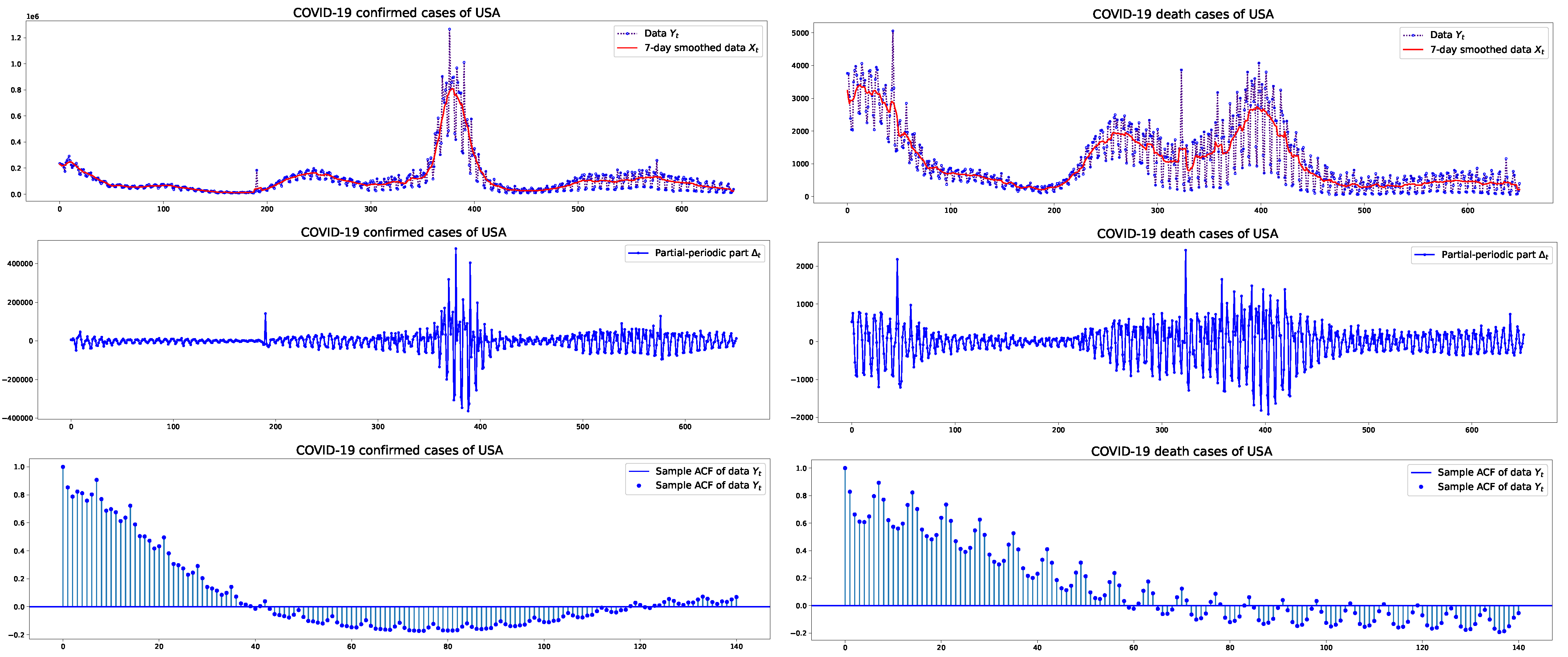
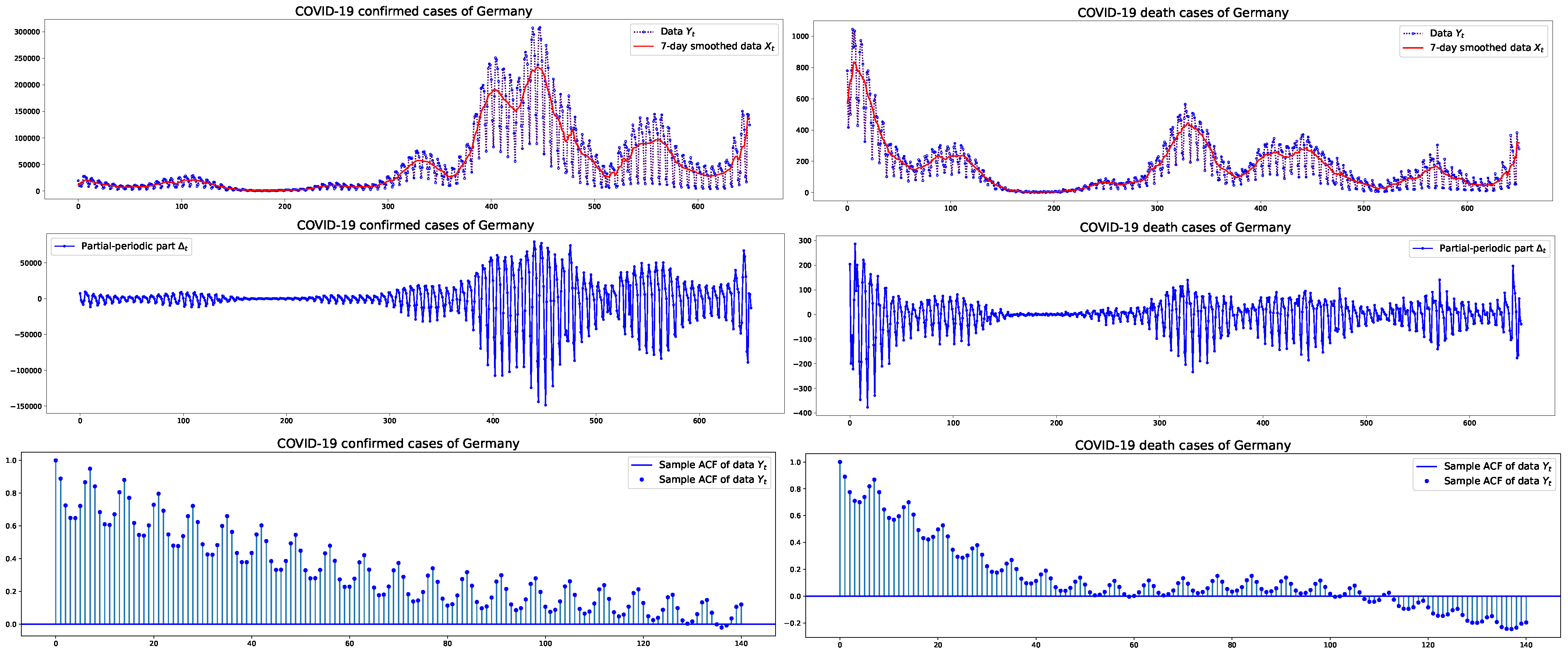
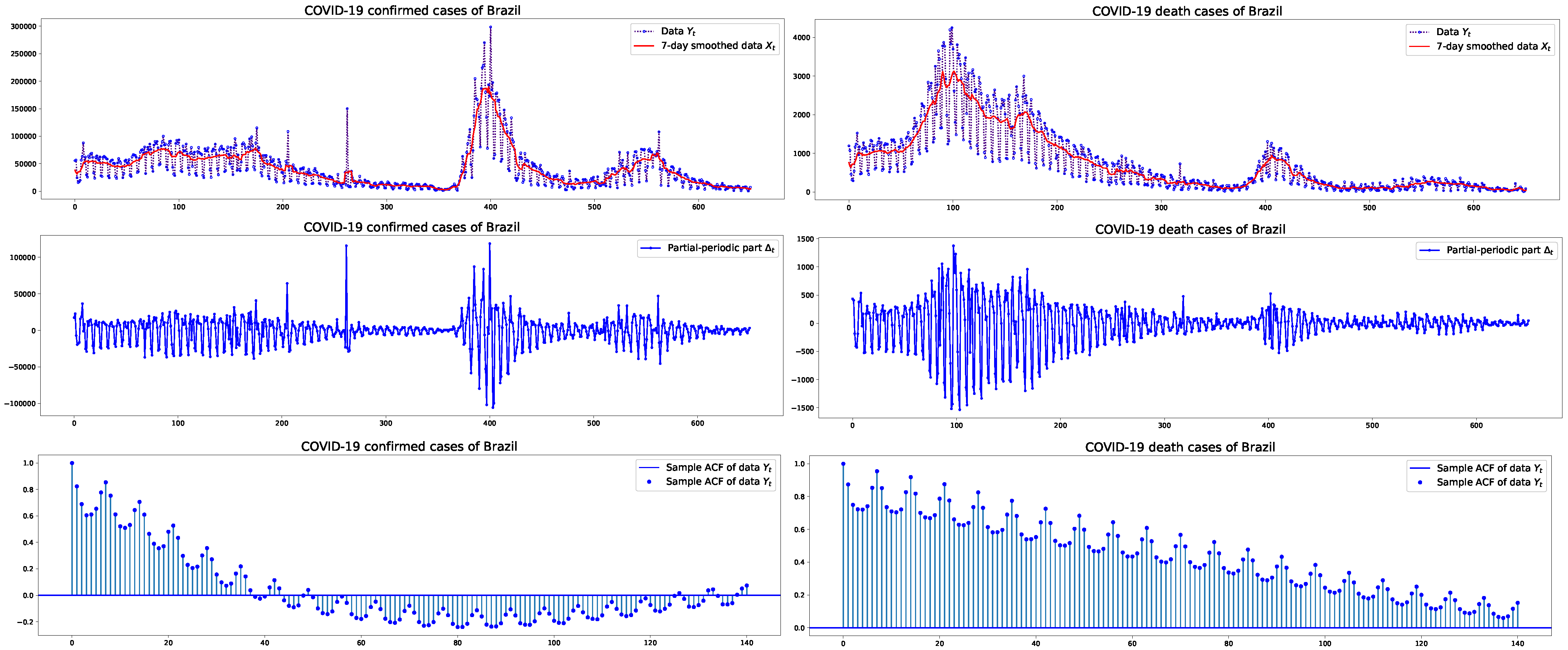
This section presents an empirical analysis of confirmed and death cases of COVID-19 in the USA, Germany, and Brazil. A primary objective of this work is to provide modeling and forecasting for pandemic data characterized by partial periodic oscillations. The dataset will be fitted to a PPO-ARIMA model. From this sample, ARIMA part and PPO part are decomposed, as detailed in Section 2.2. Figure 1, Figure 2 and Figure 3 depict the plots of the (original or unstandardized) , its ARIMA part and PPO part , as well as the sample autocorrelation function (SACF) of the original data with weekly cycles, in the three countries, respectively. The plots of the SACF are presented to show how strong the 7-day oscillations are in each dataset of the three countries. We see the strongest oscillation patterns in the confirmed cases of Germany, whereas the weakest are in the confirmed cases of the USA.
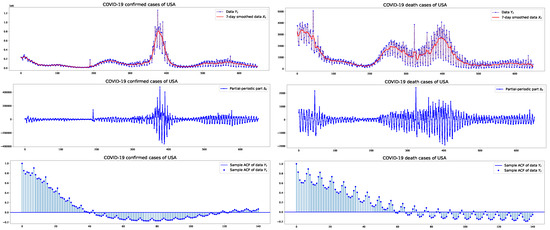
Figure 1.
USA: COVID-19 daily confirmed/death cases with their 7-day smoothed data and PPO part of size between 1 January 2021 and 13 October 2022, and the sample autocorrelation functions.
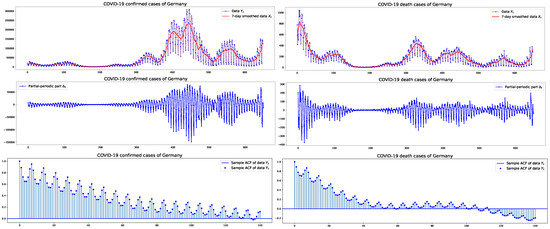
Figure 2.
Germany: COVID-19 daily confirmed/death cases with their 7-day smoothed data and PPO part of size between 1 January 2021 and 13 October 2022, and the sample autocorrelation functions.
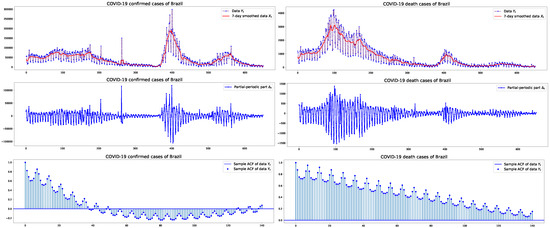
Figure 3.
Brazil: COVID-19 daily confirmed/death cases with their 7-day smoothed data and PPO part of size between 1 January 2021 and 13 October 2022, and the sample autocorrelation functions.
3.1. Estimation Results
The parameters of the model are estimated from the standardized data, as mentioned before. For the PPO-ARIMA model , the 7-day smoothed moving averaging data are fitted to an ARIMA model. To do this, we test the unit–root non-stationarity of by means of the ADF (augmented Dickey–Fuller) test. In Table 2, the results of the ADF test on the data are reported along with the p-values. The death cases of the USA and the confirmed cases in Brazil are 0.0019 and 0.0016, respectively, as the p-values of the ADF test. Since the values are less than 0.01, we reject the unit–root non-stationarity at the 1% level. Thus, they have order in the fitted ARIMA () models. Other orders are selected by the criteria, such as AIC and root mean square errors. Table 2 also presents orders of the ARIMA () models as well as coefficient estimates and their standard error (s.e).
Table 2.
Results of the ADF test, orders of the ARIMA model, coefficient estimates , and the standard error (s.e.) of the ARIMA part in the PPO-ARIMA model , where denotes the (standardized) COVID-19 confirmed (C)/death (D) case data from the USA, Germany, and Brazil, with days between 1 January 2021 and 13 October 2022.
Table 3 presents the estimates of parameters of the PPO part : Threshold is selected as the minimum of . This is because all observations appear to be oscillated, even though some small magnitudes yield slight fluctuations, as seen in Figure 1, Figure 2 and Figure 3. However, unless all observations are oscillated, one method for choosing is to minimize the mean square error. In other words, we choose , where , the mean square error. , is the fitted value derived from the coefficient estimates of the ARIMA part, and is the fitted value derived from the estimates and . In this work, we use the minimum of for the value of , because all plots of the second rows of Figure 1, Figure 2 and Figure 3 show the oscillations.
Table 3.
Estimation results of parameters for the partial-periodic part in the PPO-ARIMA model , where is the (standardized) COVID-19 confirmed (C)/death (D) case data from the USA, Germany, and Brazil, with days between 1 January 2021 and 13 October 2022.
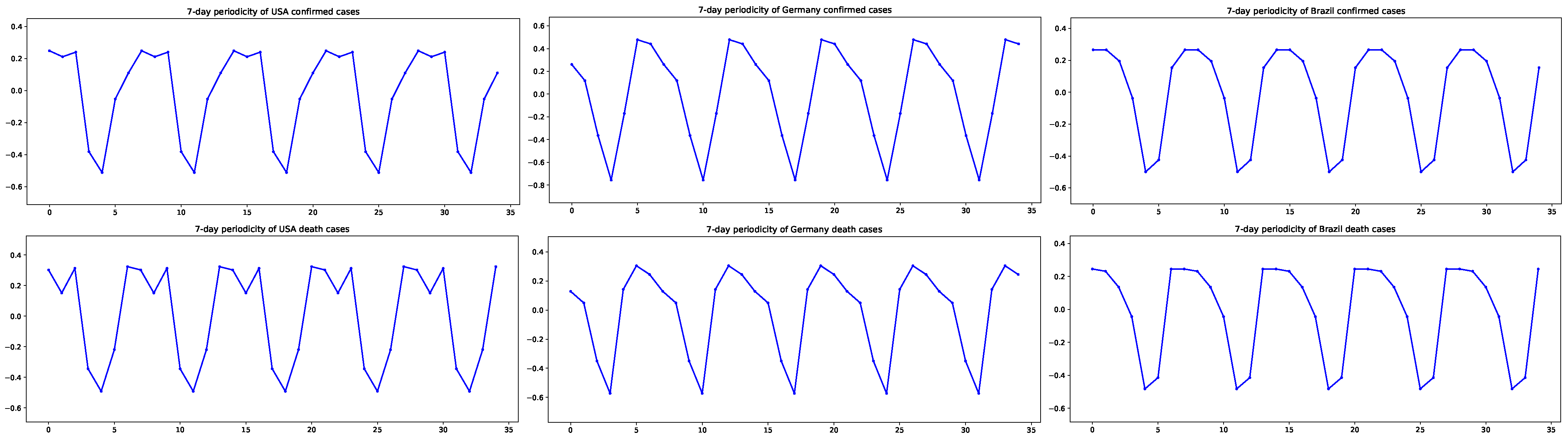
The exponent and the weights are estimated by means of arguments stated in Section 2.2. The values of the estimated weights in Table 3 indicate oscillations. In particular, in the confirmed case of Germany, stronger oscillations occur, which can be seen in the plot of the PPO part in the second row and second column of Figure 2. To highlight clear oscillations, Figure 4 depicts the periodicity of the estimates of weights, , . In the figure, weights are repeatedly plotted so that the 7-day periodicity can be seen. Note that 0 on the horizontal axis indicates Friday. In the USA and Brazil, on Friday, there are more confirmed/death cases than on other days, whereas in Germany, Wednesdays see a higher number of cases than on other days.
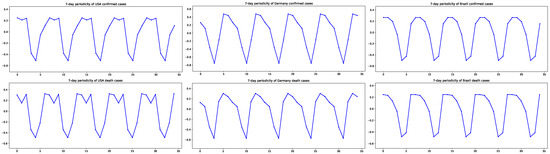
Figure 4.
The 7-day periodicity of the confirmed and death cases in the USA, Germany, and Brazil: (Repetition of ; 0 = Friday on the horizontal axis.
3.2. Prediction Results
Now, in order to see the forecasting performance, an out-of-sample forecasting analysis is conducted. We first compute k-step ahead predicted values, (), along with their accuracy measures, and secondly construct 95% prediction intervals of one-step ahead forecasts. For the out-of-sample forecasting, the total sample is divided into two subsamples. As the sample size is , the initial in-sample of size and out-of-sample of size are split into two subsamples. A rolling window technique is used to compute k-step ahead forecasts and their errors. At time t, the k-step ahead forecast of is given by
where is the k-step ahead forecast of by using the ARIMA model and mod .
From these, the root mean square error (RMSE), the mean absolute error (MAE), and heterogeneous MAE (HMAE) of the k-step ahead forecasts are evaluated as follows:
where and are standardized and unstandardized data, respectively. Because and are standardized data and their forecasts, respectively, RMSE and MAE are appropriate metrics to compare all confirmed and death case data, along with those of other existing models, such as ARIMA and SARIMA models. Also, in the expression of HMAE, the denominators are unstandardized since it is important to see the ratio of the forecast errors to the positive original data, and if the standardized data are used in the HMAE, the denominator can be too small in absolute terms, nearly zero, which would lead to too big HMAE values, rendering them nonsensical. All six instances of confirmed and death cases in the three countries are compared with each other, together with those from the other two models; thus, the formulas of the three error metrics using in RMSE, MAE, and in HMAE are appropriate.
The three accuracy measures in Table 4 are obtained by the formulas above with and . Also, Table 4 reports comparisons with the existing models: the ARIMA and SARIMA models. Model selections for the ARIMA () models are given by the criteria of the best AIC values via Python auto_arima, setting the range of orders: and . In the SARIMA models, seasonal period is taken and order is chosen by the AIC values as well. In Table 4, we see that the PPO-ARIMA models have the smallest error values in most cases, except for the HMAE on the one-step ahead forecasts of the USA and two-, three-steps of Germany. The best values are indicated by the bolded numbers in Table 4. Most of the values of RMSE, MAE, and HMAE in Table 4 are the best in the PPO-ARIMA models. In Germany’s COVID-19 data, instead of the PPO-ARIMA model, the ARIMA model gives the best values of HMAE for the two- and three-step ahead forecasts. It might be due to relatively large values of real data in the last part of the sample, as seen in Figure 2.
Table 4.
Out-of-sample forecasting results and comparison: RMSE, MAE, and HMAE of k-step ahead forecasts, (), for the last 420 days in the PPO-ARIMA models for the COVID-19 confirmed (C)/death (D) case data from the USA, Germany, and Brazil, and a comparison with those of the ARIMA and SARIMA models.
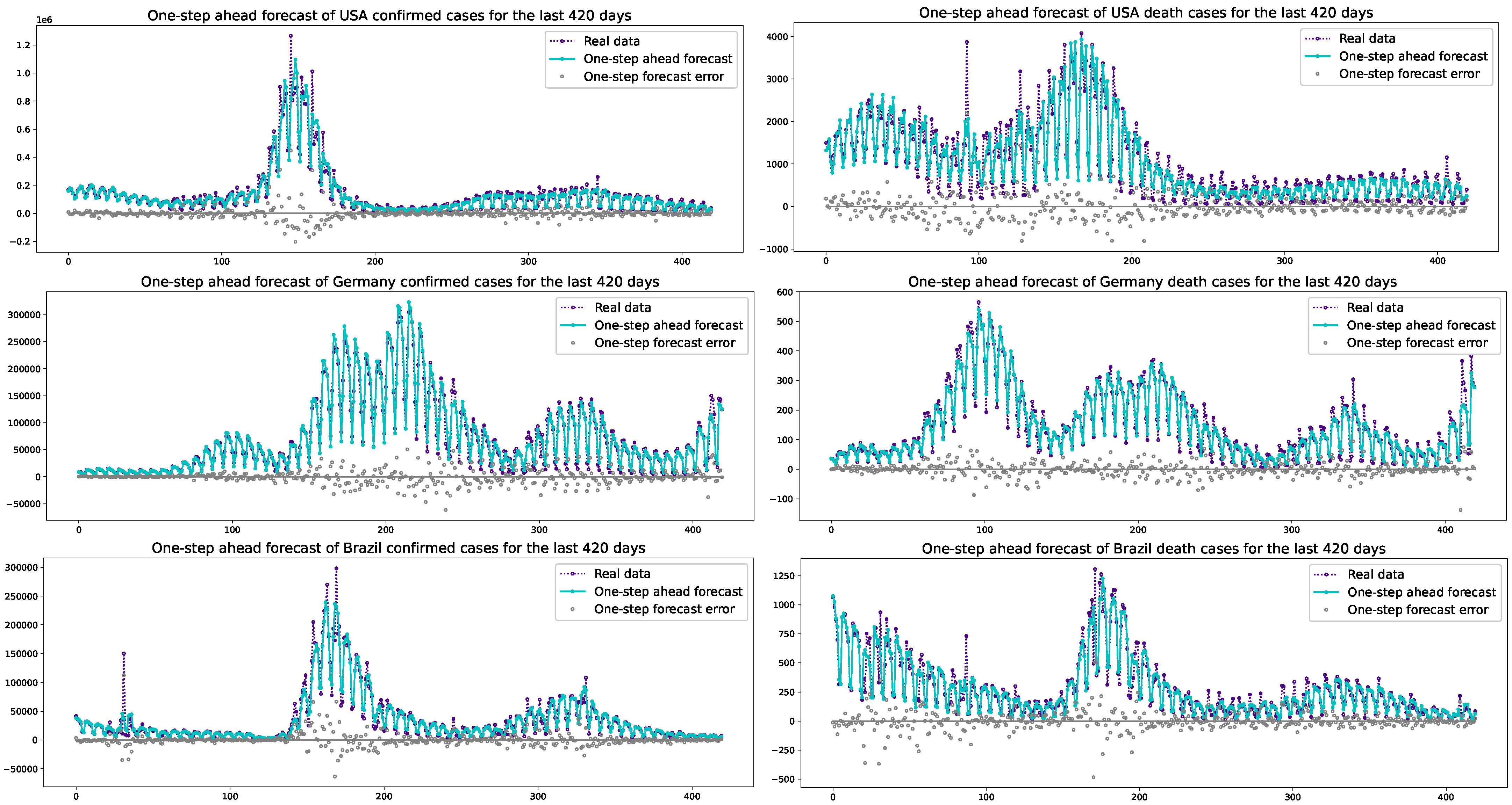
The one-step ahead forecasts by the PPO-ARIMA models for the last 420 days and their errors in the USA, Germany, and Brazil, are depicted, respectively, in Figure 5. The one-step ahead forecasted values fit well with the actual data, even though there are some errors. Also, we see that periodic oscillations of one-step ahead forecasts seem to be as strong as the actual data.
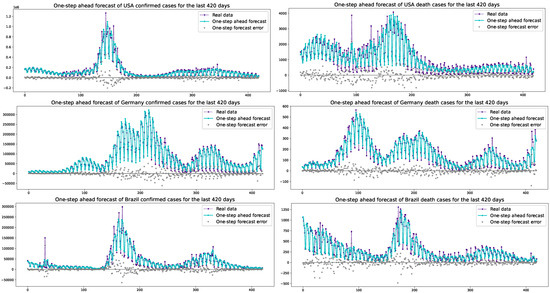
Figure 5.
One-step ahead forecasts of COVID-19 confirmed/death cases and one-step forecast errors for the last 420 days in the USA, Germany, and Brazil.
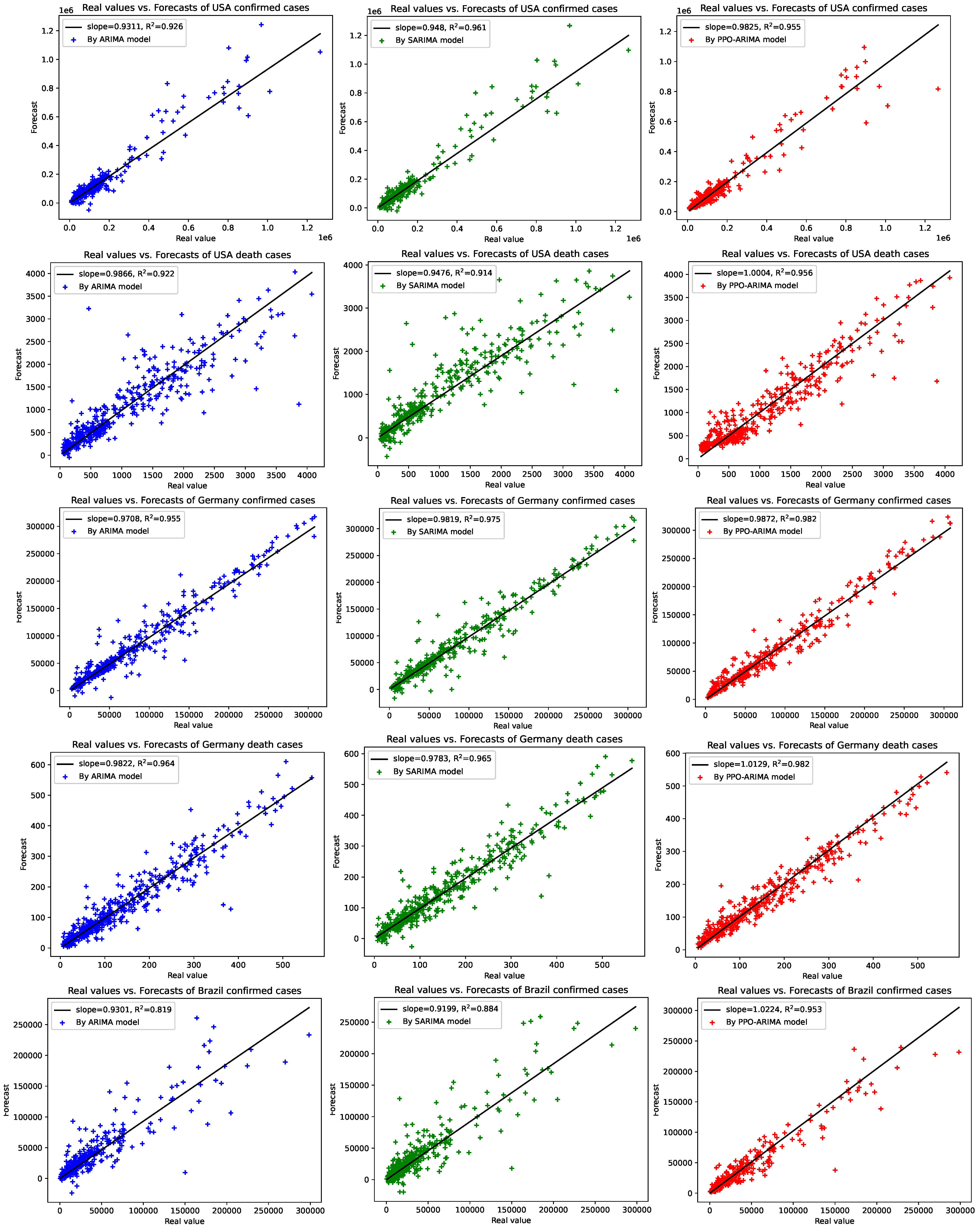
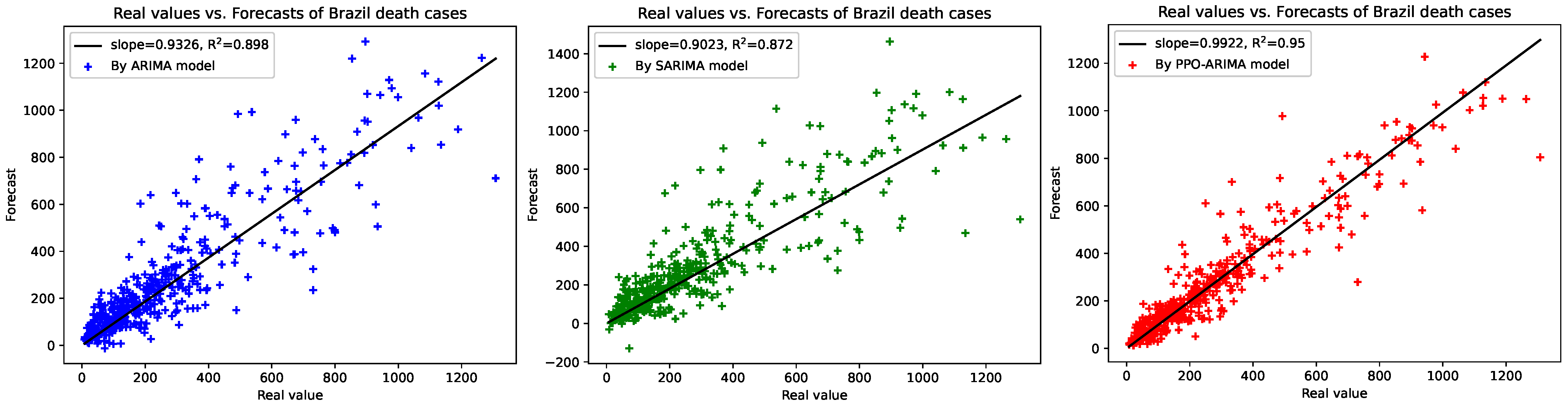
To understand how well the PPO-ARIMA model performs in prediction errors, compared to other models, we provide two results: illustrations between real values and forecasts, and efficiency evaluations. First, Figure 6 shows a straight-line relationship between real values and forecasts, along with slopes and -values of the linear regressions in the three models. In the PPO-ARIMA models, slopes are closer to one and -values are higher than the other two models. As the second measure, the efficiency of the prediction by the PPO-ARIMA model is evaluated from the error values in Table 4. For an error function , the efficiencies denoted by Effi and Effi, relative to the two benchmarks, the ARIMA and SARIMA models, are defined by
where A on the subscript stands for ARIMA, S for SARIMA, and for the PPO-ARIMA model. The results of the PPO-ARIMA prediction efficiencies, Effi and Effi, relative to the ARIMA and SARIMA models, are reported in Table 5. Because the SARIMA model is a full periodic oscillation model, SARIMA underperforms compared to the ARIMA model and, thus, efficiency relative to the SARIMA model is better than that of the ARIMA model. Note that the ARIMA models use order in their AR parts, chosen by the criteria of the best AIC values. Since the data do not have full periodic oscillation, the comparison with the SARIMA model might be somewhat unfair. To solve the unfairness, an action, such as the regime-switching Markov chain, might be required in the SARIMA model. However, this would require extensive theoretical and empirical analysis and is therefore left for future study.
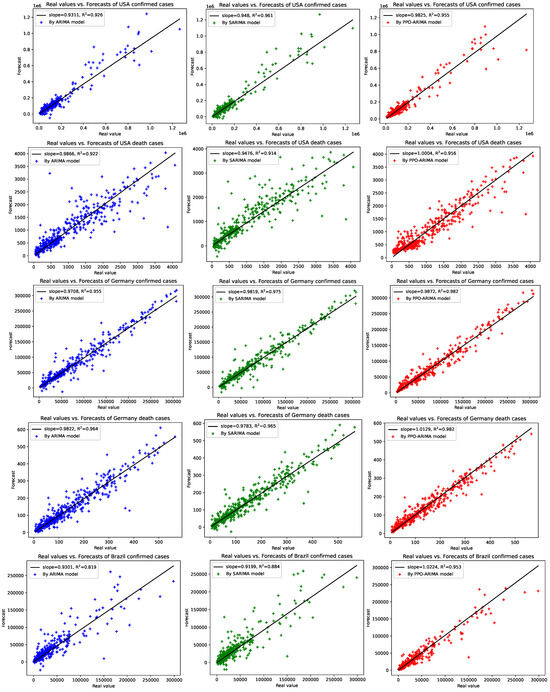
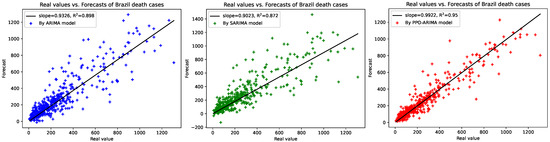
Figure 6.
Real values vs. forecasted values by ARIMA, SARIMA, and PPO-ARIMA models for the confirmed/death cases in the USA, Germany, and Brazil: Each plot gives slopes and -values of linear regressions.
Table 5.
Efficiency(%) of prediction by the PPO-ARIMA model, relative to the ARIMA and SARIMA models, respectively, defined as Effi and Effi where ; A = ARIMA, S = SARIMA, and PPO = PPO-ARIMA model.
From the efficiency results in Table 5, we conclude that our proposed PPO-ARIMA model improves the forecast errors, such as the RMSE, MAE, and HMAE for one-, two-, and three-step ahead forecasts. The superiority of the proposed model is demonstrated by large values of efficiency in Table 5. A maximum of 46–58% efficiency relative to the ARIMA model and 65–70% relative to the SARIMA model are seen in the error metrics of RMSE, MAE, and HMAE. Also, the PPO-ARIMA model achieves a maximum improvement of 55–65% in RMSE, 58–70% in MAE, and 46–60% in HMAE for the one-step forecasts, compared to the existing models.
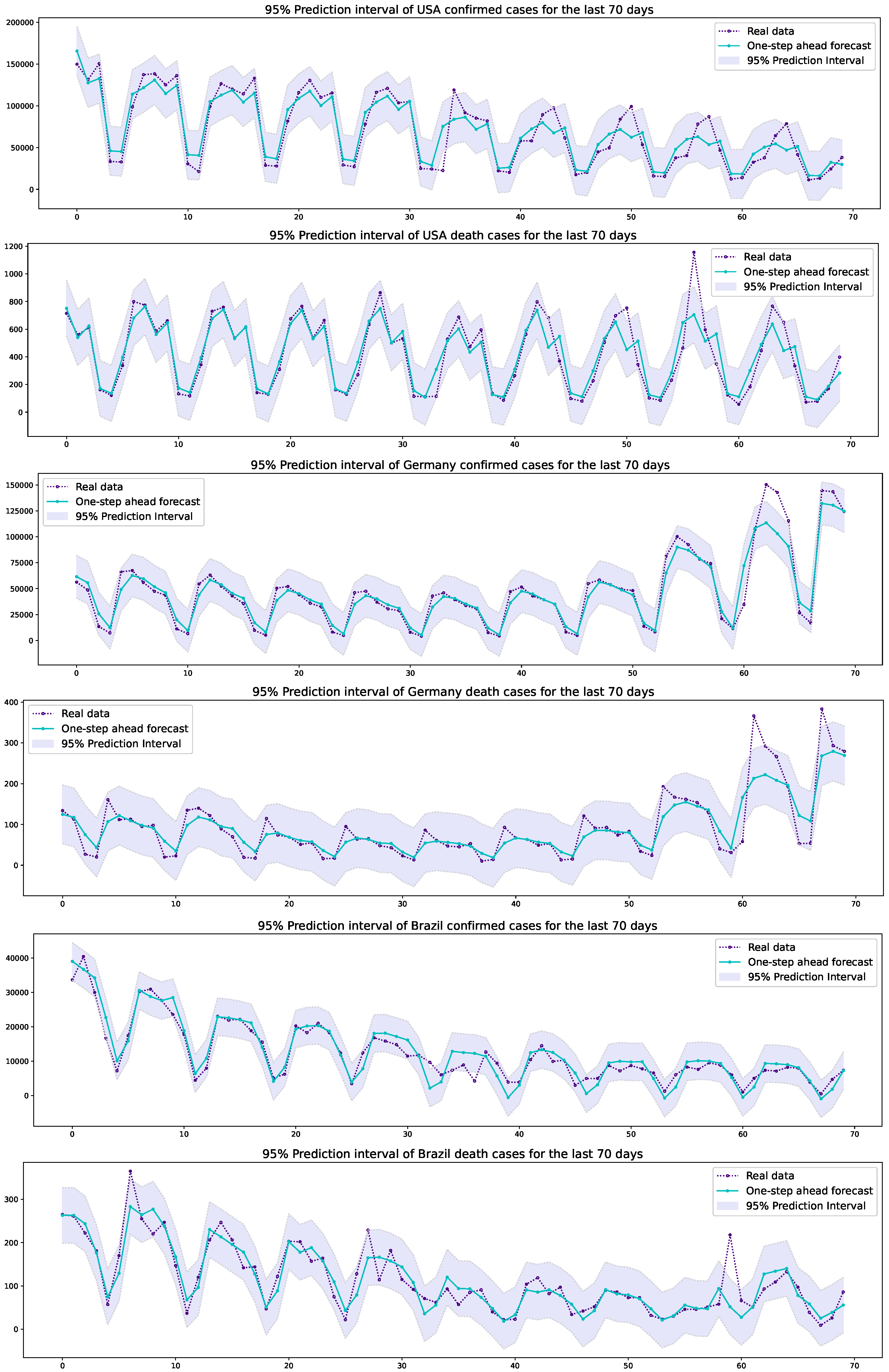
Finally, the 95% prediction intervals of the one-step forecasts are constructed by using a normal approximation. For the empirical analysis, among the 420 days forecasts in Figure 4, the last 70 days are selected to draw the prediction intervals, which are computed as follows:
where is used and is the one-step prediction variance given by The 95% prediction intervals for the last 70 days are illustrated in Figure 7. Most of the actual data belong to the prediction intervals; indeed, the 95% prediction intervals include 94.28–98.57% of actual data. These values are close to the nominal coverage of 95%. The reason for the deviation between the nominal and empirical coverage is that the sample size is 70 in the construction of the intervals and the evaluation of the prediction variance. It is well-known that the empirical coverage converges to the nominal one as the size increases. Also, we see from Figure 7 that the prediction intervals possess the features of oscillations with a periodicity of 7 as well. The prediction intervals in (5) have the same length, , and the oscillations occur, depending on the values of the one-step predicted values. In the cases of Germany, the last ten days have somewhat large extreme actual values in both confirmed and death cases (see Figure 7) and, thus, because of the large extremes, the proposed model for the cases of Germany does not give the best values in the HMAE for the two- and three-step ahead forecasts in Table 4. However, the 95% prediction intervals need to be improved because the residuals might not follow the normal distribution. As for the prediction interval improvements, Ref. [28] discussed the bootstrap improvement on the prediction intervals for COVID-19 data, along with the approach of the Laplace distribution. For the PPO-ARIMA model and its prediction in this work, the topic of prediction interval improvement will be deferred to further study.
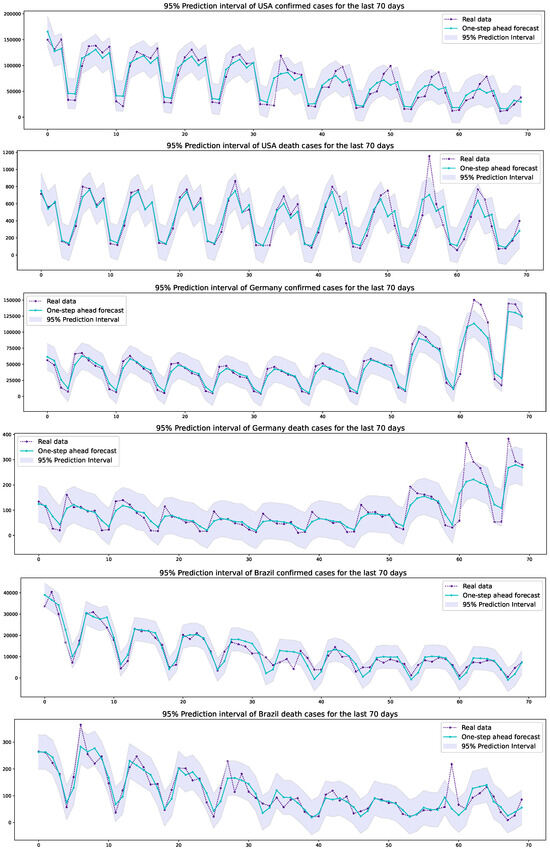
Figure 7.
The 95% prediction intervals of the USA, Germany, and Brazil confirmed/death cases for the last 70 days.
As discussed above in Section 2, the roles of threshold and exponent are important because they might incur problems of overfitting or underfitting. Even though is chosen as the minimum of the standardized data in this work, for other real-world data, some other criteria should be chosen, for instance, through MSE, as discussed in Section 3.1. As seen in the plots of weights , , in Figure 4, which shows the 7-day periodicity of COVID-19 data, most have distinct periodic oscillations with large amplitudes. However, in other datasets with somewhat small amplitudes of oscillations, we need to perform more actions like finding the standard error of the estimates, which are not given in this work. Instead of the consistency of the estimators, the asymptotic distributions should be established to find the standard errors. This generalizability problem addresses potential concerns and will be dealt with in a future study.
4. Discussion and Conclusions
The scientific community should continue to make efforts to predict and mitigate the COVID-19 pandemic using reliable scientific methods as long as the virus continues to spread globally. In particular, as discussed by [20], the high-frequency oscillatory patterns in COVID-19 infections and deaths should be incorporated into prediction analyses for a comprehensive understanding and improved forecasting. A remarkable feature, resulting from testing bias or human behaviors in health systems, is the periodic oscillations observed in the most affected countries and continents, such as North America and Europe. As [22,23] noted, identifying such cyclical oscillations in COVID-19 time series data is a significant issue. Reliable forecasting of these oscillation phenomena will mark a notable advancement in the history of the COVID-19 pandemic.
This study focused on forecasting COVID-19 data with 7-day cyclical fluctuations by combining the ARIMA model with a partial periodic oscillation model. Employing this proposed predictive model, which utilizes a straightforward mathematical approach, we predicted confirmed and death cases of COVID-19. The USA, Germany, and Brazil were selected for empirical analysis due to the strong oscillatory patterns in their COVID-19 data. New daily COVID-19 data for both confirmed and death cases in these three countries were empirically estimated. Out-of-sample forecasting experiments were conducted to evaluate prediction accuracy and construct 95% prediction intervals.
In order to see the forecasting performance, prediction accuracy measures, such as root mean square error (RMSE), mean absolute error (MAE), and heterogeneous MAE (HMAE), were evaluated. RMSE, MAE, and HMAE of the one-, two-, and three-step ahead forecasts of COVID-19 confirmed/death cases were computed and compared with other existing models. Comparisons with ARIMA models (with order of the AR part) and SARIMA models (with 7-day periodicity) were reported; model selections were determined by the optimal AIC values. The efficiencies of the PPO-ARIMA model, relative to each of the two benchmarks, were evaluated. The results showed that our model improved the ARIMA model by a maximum of 58% and the SARIMA model by 70%. More specifically, predictions of the daily COVID-19 cases can be improved by the PPO-ARIMA model: by a maximum of 55–65% in RMSE, 58–70% in MAE, and 46–60% in HMAE, compared to the existing models.
Moreover, the 95% prediction intervals of one-step ahead forecasts were constructed for the six cases; their illustrations showed that the intervals include 94.28–98.57% of actual data in the out-of-sample forecasting as well as exhibit interval–oscillation patterns, coincidentally.
The PPO-ARIMA model will be a practical tool for predicting the spread of the global COVID-19 pandemic. The results of this study can assist health institutions in medical resource allocation and emergency strategy development by providing more accurate statistical information. Hence, a contribution of this study is the identification and superior forecasting of partially weekly oscillating COVID-19 cases using the proposed model, coupled with a new mathematical approach. The PPO-ARIMA model is well-suited for data exhibiting partial oscillation, where the SARIMA model may not be appropriate. Also, our model can deliver robust results for fully oscillated data, for which the SARIMA model is suitable. This is because the values of the PPO part are proportional to the values of the ARIMA part. Therefore, the PPO-ARIMA model can offer optimal performance on data with periodicity and seasonality, whether it exhibits partial or full oscillation.
A limitation of this study is the residual analysis, from which the prediction intervals were constructed. Because this work focuses on the partial periodicity of COVID-19 data, the main concentration of the paper is not on the residual analysis. A complement to this would be the more refined construction of prediction intervals through the estimation of the distribution of residuals. This topic will be addressed in future work. Moreover, another limitation of this study is that it analyzed only three countries that have the strongest oscillations in the world. The PPO-ARIMA model could be applied to datasets from other countries with weaker oscillations. Experiments on more general datasets are needed to justify the robustness of the model.
A recent study about the exponential decay model by [11] showed its effectiveness for short-term forecasting. Our model also shows good performance in short-term forecasting by reflecting the 7-day periodicity. However, the approaches of the exponential decay model and the PPO-ARIMA model differ: the latter emphasizes oscillation, which is a critical aspect of our study. Their explicit comparison will be interesting and will need extensive experiments; therefore, it remains a topic for future study.
Three directions for further study related to the partial periodic oscillations of COVID-19 are suggested: First, in terms of time series modeling, other models such as a heterogeneous autoregression (HAR) model or nonparametric models could be adopted instead of the ARIMA model. As discussed by [28], the HAR model with lagged average regressors is suitable for the smoothed data of COVID-19, and thus, a combined model incorporating the HAR model with partial periodic oscillations might offer enhanced predictive ability. Second, some exogenous variables can be added as significant regressors in the model, as in [30]. For example, the booster vaccination rate, which influences the spread of COVID-19, could be added as an explanatory variable. Third, from the perspective of forecast error distribution, efforts to minimize errors could be made through distribution inferences. This work assumed normal approximation for the residuals to construct prediction intervals. However, for a refinement of more accurate prediction intervals, the residual distribution can be inferred by means of the bootstrap procedure or kernel method. A comparative analysis of various prediction intervals, by evaluating their average length, empirical coverage probability, and mean interval score, will be able to yield the most improved prediction for the oscillatory patterns of COVID-19, which remains an area for future research. Overall, a variety of statistical extensions will be attempted in data analysis for COVID-19 prediction. This could be a contributing role of statistics in fostering a healthy society, by providing insights into disease transmission through modeling and forecasting with reduced errors.
Funding
This work was supported partially by the Research Fund of Gachon University (GCU-202206300001) and by the National Research Foundation of Korea (NRF-2023R1A2C1005395).
Data Availability Statement
All datasets used in this study are available in the WHO website: http://covid19.who.int/data (accessed on 12 October 2023).
Acknowledgments
The author thanks the editor and four anonymous referees for their valuable comments.
Conflicts of Interest
The author declares no conflict of interest.
References
- Ribeiro, M.H.D.M.; Silva, R.G.D.; Mariani, V.C.; Coelho, L.D.S. Short-term forecasting COVID-19 cumulative confirmed cases: Perspectives for Brazil. Chaos Solitons Fractals 2020, 135, 109853. [Google Scholar] [CrossRef] [PubMed]
- Maleki, M.; Mahmoudi, M.; Wraith, D.; Pho, K. Time series modelling to fore cast the confirmed and recovered cases of COVID-19. Travel. Med. Infect. Dis. 2020, 37, 101742. [Google Scholar] [CrossRef] [PubMed]
- Maleki, M.; Mahmoudi, M.R.; Heydari, M.H. Modeling and forecasting the spread and death rate of coronavirus (COVID-19) in the world using time series models. Chaos Solitons Fractals 2020, 140, 110151. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, K.; Khajanchi, S.; Nieto, J.J. Modeling and forecasting the COVID-19 pandemic in India. Chaos Solitons Fractals 2020, 139, 110049. [Google Scholar] [CrossRef] [PubMed]
- Balli, S. Data analysis of COVID-19 pandemic and short-term cumulative case forecasting using machine learning time series methods. Chaos Solitons Fractals 2021, 142, 110512. [Google Scholar] [CrossRef] [PubMed]
- Ala’raj, M.; Majdalawieh, M.; Nizamuddin, N. Modeling and forecasting of COVID-19 using a hybrid dynamic model based on SEIRD with ARIMA corrections. Infect. Dis. Model. 2021, 6, 98–111. [Google Scholar] [CrossRef]
- Kumar, Y.; Koul, A.; Kaur, S.; Hu, Y.C. Machine learning and deep learning based time series prediction and forecasting of ten nations’ COVID-19 pandemic. SN Comput. Sci. 2022, 4, 91. [Google Scholar] [CrossRef] [PubMed]
- Fang, L.; Wang, D.; Pan, G. Analysis and estimation of COVID-19 spreading in Russia based on ARIMA model. Sn Compr. Clin. Med. 2020, 2, 2521–2527. [Google Scholar] [CrossRef]
- Ilie, O.D.; Cojocariu, R.O.; Ciobica, A.; Timofte, S.I.; Mavroudis, I.; Doroftei, B. Fore casting the spreading of COVID-19 across Nine countries from Europe, Asia, and the American continents using the ARIMA Models. Microorganisms 2020, 8, 1158. [Google Scholar] [CrossRef]
- Toğa, G.; Atalay, B.; Toksari, M.D. COVID-19 prevalence forecasting using Autoregressive Integrated Moving Average (ARIMA) and Artifcial Neural Networks (ANN): Case of Turkey. J. Infect. Public Health 2021, 14, 811–816. [Google Scholar] [CrossRef]
- Bartolomeo, N.; Trerotoli, P.; Serio, G. Short-term forecast in the early stage of the COVID-19 outbreak in Italy. Application of a weighted and cumulative average daily growth rate to an exponential decay model. Infect. Dis. Model. 2021, 6, 212–221. [Google Scholar] [CrossRef] [PubMed]
- Petropoulos, F.; Makridakis, S.; Stylianou, N. COVID-19: Forecasting confirmed cases and deaths with a simple time series model. Int. J. Forecast. 2022, 38, 439–452. [Google Scholar] [CrossRef] [PubMed]
- Lourenco, J.; Recker, M. Natural, persistent oscillations in a spartial multi-strain disease system with application to dengue. PLoS Comput. Biol. 2013, 9, e1003308. [Google Scholar] [CrossRef] [PubMed]
- Selvaraj, P.; Wenger, E.A.; Gerardin, J. Seasonality and heterogeneity of malaria transmission determine success of interventions in high-endemic settings: A modeling study. BMC Infect. Dis. 2018, 18, 413. [Google Scholar] [CrossRef] [PubMed]
- Polwiang, S. The time series seasonal patterns of dengue fever and associated weather variables in Bangkok (2003–2017). BMC Infect. Dis. 2020, 20, 208. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Kramer, S.C.; Lau, E.H.Y.; Cowling, B.J.; Yang, W. Modeling influenza seasonality in the tropics and subtropics. PLoS Comput. Biol. 2021, 17, e1009050. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhang, T. Analysis of a COVID-19 epidemic model with seasonality. Bull. Math. Biol. 2022, 84, 146. [Google Scholar] [CrossRef]
- Ndlovu, M.; Moyo, R.; Mpofu, M. Modelling COVID-19 infection with seasonality in Zimbabwe. Phys. Chem. Earth Parts A/B/C 2022, 127, 103167. [Google Scholar] [CrossRef]
- Wiemken, T.L.; Khan, F.; Puzniak, L.; Yang, W.; Simmering, J.; Polgreen, P.; Nguyen, J.L.; Jodar, L.; McLaughlin, J.M. Seasonal trends in COVID-19 cases, hospitalizations, and mortality in the United States and Europe. Sci. Rep. 2023, 13, 3886. [Google Scholar] [CrossRef]
- Bukhari, Q.; Jameel, Y.; Massaro, J.M.; D’Agostino, R.B.; Khan, S. Periodic oscillations in daily reported infections and deaths for coronavirus disease 2019. JAMA Netw. Open 2020, 3, e2017521. [Google Scholar] [CrossRef]
- Bergman, A.; Sella, Y.; Agre, P.; Casadevall, A. Oscillations in U.S. COVID-19 incidence and mortality data reflect diagnostic and reporting factors. mSystems 2020, 5, e00544-20. [Google Scholar] [CrossRef] [PubMed]
- Dehning, J.; Zierenberg, J.; Spitzner, F.P.; Wibral, M.; Neto, J.P.; Wilczek, M.; Priesmann, V. Inferring change points in the spread of COVID-19 reveals the effectiveness of interventions. Science 2020, 369, 160. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Liu, X.; Zhang, L.; Zhao, Y.; Wang, D.; Gao, J.; Lian, X.; Liu, C. The oscillation-outbreak characteristic of the COVID-19 pandemic. Natl. Sci. Rev. 2021, 8, nwab100. [Google Scholar] [CrossRef] [PubMed]
- Soukhovolsky, V.; Kovalev, A.; Pitt, A.; Shulman, K.; Tarasova, O.; Kessel, B. The cyclicity of coronavirus cases: “Waves” and the “weekend effect”. Chaos Solitons Fractals 2021, 114, 110718. [Google Scholar] [CrossRef] [PubMed]
- Campi, G.; Bianconi, A. Periodic recurrent waves of Covid-19 epidemics and vaccination campaign. Chaos Solitons Fractals 2022, 160, 112216. [Google Scholar] [CrossRef] [PubMed]
- Simeonov, O.; Eaton, C.D. Modeling the drivers of oscillations in COVID-19 data on college campuses. Ann. Epidemiol. 2023, 82, 40–44. [Google Scholar] [CrossRef] [PubMed]
- Ekinci, A. Modeling and forecasting of growth rate of new COVID-19 cases in top nine affected countries: Considering conditional variance and asymmetric effect. Chaos Solitons Fractals 2021, 151, 111227. [Google Scholar] [CrossRef] [PubMed]
- Hwang, E. Prediction intervals of the COVID-19 cases by HAR models with growth rates and vaccination rates in top eight affected countries: Bootstrap improvement. Chaos Solitons Fractals 2022, 155, 111789. [Google Scholar] [CrossRef]
- Ceylan, Z. Estimation of COVID-19 prevalence in Italy, Spain and France. Sci. Total Environ. 2020, 729, 138817. [Google Scholar] [CrossRef]
- Selinger, C.; Choist, M.; Alison, S. Predicting COVID-19 incidence in French hospitals using human contact network analytics. Int. J. Infect. Dis. 2021, 111, 100–107. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).