Abstract
Although large data sets are generally viewed as advantageous for their ability to provide more precise and reliable evidence, it is often overlooked that these benefits are contingent upon certain conditions being met. The primary condition is the approximate validity (statistical adequacy) of the probabilistic assumptions comprising the statistical model applied to the data. In the case of a statistically adequate and a given significance level , as n increases, the power of a test increases, and the p-value decreases due to the inherent trade-off between type I and type II error probabilities in frequentist testing. This trade-off raises concerns about the reliability of declaring ‘statistical significance’ based on conventional significance levels when n is exceptionally large. To address this issue, the author proposes that a principled approach, in the form of post-data severity (SEV) evaluation, be employed. The SEV evaluation represents a post-data error probability that converts unduly data-specific ‘accept/reject results’ into evidence either supporting or contradicting inferential claims regarding the parameters of interest. This approach offers a more nuanced and robust perspective in navigating the challenges posed by the large n problem.
Keywords:
large n problem; Neyman–Pearson testing; p-value; post-data severity evaluation; spurious statistical significance JEL Classification:
C12; C18; C51; C52; C55
1. Introduction
The recent availability of big data with large sample sizes (n) in many scientific disciplines brought to the surface an old and largely forgotten foundational issue in frequentist testing known as the ‘large n problem’. It relates to inferring that an estimated parameter is statistically significant based on conventional thresholds, , when n is very large, say .
1.1. A Brief History of the Large n Problem
As early as 1938, Berkson [] brought up the large n problem by pointing out its effect on the p-value:
“… when the numbers in the data are quite large, the P’s [p-values] tend to come out small… if the number of observations is extremely large—for instance, on the order of 200,000—the chi-square P will be small beyond any usual limit of significance. … If, then, we know in advance the P that will result…, it is no test at all. ”(p. 527)
In 1935 Fisher [] pinpointed the effect of the large n problem on the power (he used the term sensitivity) of the test:
“By increasing the size of the experiment [n], we can render it more sensitive, meaning by this that it will allow of the detection of … quantitatively smaller departures from the null hypothesis.”(pp. 21–22)
In 1942 Berkson [] returned to the large n problem by arguing that it also affects the power of a test, rendering it relevant for a sound evidential interpretation:
“In terms of the Neyman–Pearson (N-P) formulation they have different powers for any particular alternative, and hence are likely to give different results in any particular case. ”(p. 334)
One of the examples he uses to make his case is from Fisher’s book [] which is about testing the linearity assumption of a Linear Regression (LR) model.
Unfortunately, the example allowed Fisher [] to brush aside the broader issues of misinterpreting frequentist tests as evidence for or against hypotheses. In his response, he focuses narrowly on the particular example and recasts their different perspectives on frequentist testing as a choice between ‘objective tests of significance’ and ‘subjective impressions based on eyeballing’ a scatterplot:
“He has drawn the graph. He has applied his statistical insight and his biological experience to its interpretation. He enunciates his conclusion that ‘on inspection it appears as straight a line as one can expect to find in biological material.’ The fact that an objective test had demonstrated that the departure from linearity was most decidedly significant is, in view of the confidence which Dr. Berkson places upon subjective impressions, taken to be evidence that the test of significance was misleading, and therefore worthless.”(p. 692)
In his reply, Berkson [], (p. 243), reiterated the role of the power:
“When with such specific tests one has sufficient numbers, they become sensitive tests; in the terminology of Neyman and Pearson they become ‘powerful’. ”
As a result of the exchange between Berkson and Fisher, the broader issue of ‘inference results’ vs. ‘evidence’ was put aside by the statistics literature until the late 1950s. Berkson’s example from Fisher [] was an unfortunate choice since the test in question is not a N-P type test, which probes within the boundaries of the invoked statistical model, , by framing the hypotheses of interest in terms of its unknown parameters . It is a misspecification test, which probes outside the boundaries of to evaluate the validity of its assumptions—the linearity in this case; see Spanos [].
In 1957 Lindley [] presented the large n problem as a conflict between frequentist and Bayesian testing by arguing that the p-value will reject : as n increases, whereas the Bayes factor will favor . Subsequently, this became known as the Jeffreys–Lindley paradox (Spanos []) for further discussion.
In 1958 Lehmann [] raised the issue of the sample size influencing the power of a test, and proposed decreasing as n increases to counter-balance the increase in its power:
“By habit, and because of the convenience of standardization in providing a common frame of reference, these values [] became entrenched as conventional levels to use. This is unfortunate since the choice of significance level should also take into consideration the power that the test will achieve against alternatives of interest. There is little point in carrying out an experiment that has only a small chance of detecting the effect being sought when it exists. Surveys by Cohen [] and Freiman et al. [] suggest that this is, in fact, the case for many studies. ”(Lehmann [], pp. 69–70)
Interestingly, the papers cited by Lehmann [] have been published in psychology and medical journals, respectively, indicating that practitioners in certain disciplines became aware of the small/large n problems and began exploring solutions. Cohen [,], was particularly influential in convincing psychologists to supplement, or even replace the p-value, with a statistic that is free of n, known as the ‘effect size’, to address the large n problem. For instance, Cohen’s is the recommended effect size when one is testing the difference between two means based on the test statistic in testing : vs. : see Lehmann [].
In 1982 Good [], p. 66, went a step further than Lehmann [] to propose a rule of thumb: “p-values … should be standardized to a fixed sample size, say N = 100, by replacing P [] with ”
1.2. Large n Data and the Preconditions for More Accurate and Trustworthy Evidence
Large n data are universally considered a blessing since they can potentially give rise to more accurate and trustworthy evidence. What is often neglected, however, is that the potential for such gains requires certain ‘modeling’ and ‘inference’ stipulations to be met before any such accurate and trustworthy evidence can materialize.
[a] The most crucial modeling stipulation is for the practitioner to establish the statistical adequacy (approximate validity) of the invoked probabilistic assumptions imposed on one’s data, say = comprising the relevant statistical model ; see Spanos []. Invalid probabilistic assumptions induce sizeable discrepancies between the nominal error probabilities—derived assuming the validity of —and the actual ones based on , rendering the inferences unreliable and the ensuing evidence untrustworthy. Applying a significance level test when the actual type I error probability is closer to due to invalid probabilistic assumptions (Spanos [], p. 691) will yield spurious inference results and untrustworthy evidence; see Spanos [] for additional examples.
[b] The most crucial inference stipulation for the practitioner is to distinguish between raw ‘inference results’, such as point estimates, effect sizes, observed CIs, ‘accept/reject ’, and p-values, and ‘evidence for or against inferential claims’ relating to unknown parameters . Conflating the two often gives rise to fallacious evidential interpretations of such inference results, as well as unwarranted claims, including spurious statistical significance with a large n. The essential difference between ‘inference results’ and ‘evidence’ is that the former rely unduly on the particular data which constitutes a single realization of the sample . In contrast, sound evidence for or against inferential claims relating to needs to account for that uncertainty.
The main objective of the paper is to make a case that the large n problem can be addressed using a principled argument based on the post-data severity (SEV) evaluation of the unduly data-specific accept/reject results. This is achieved by accounting for the inference-related uncertainty to provide an evidential interpretation of such results that revolves around the discrepancy from the null value warranted by the particular test and data with high enough post-data error probability. This provides an inductive generalization of the accept/reject results that enhances learning from data.
As a prelude to the discussion that follows, Section 2 summarizes Fisher’s [] model-based frequentist statistics, with particular emphasis on Neyman–Pearson (N-P) testing. Section 3 considers the large n problem and its implications for the p-value and the power of an N-P test. Section 4 discusses examples from the empirical literature in microeconometrics where the large n problem is largely ignored. Section 5 explains how the post-data severity evaluation of the accept/reject results can address the large n problem and is illustrated using hypothetical and actual data examples.
2. Model-Based Frequentist Statistics: An Overview
2.1. Fisher’s Model-Based Statistical Induction
Model-based frequentist statistics was pioneered by Fisher [] in the form of statistical induction that revolves around a statistical model whose generic form is:
and revolves around the distribution of the sample , which encapsulates its probabilistic assumptions. denotes the sample space, and the parameter space; see Spanos [].
Unfortunately, the term ‘model’ is used to describe many different constructs across different disciplines. In the context of empirical modeling using statistics, however, the relevant models can be grouped into two broad categories: ‘substantive’ (structural, a priori postulated) and ‘statistical’ models. Although these two categories of models are often conflated, a statistical model comprises solely the probabilistic assumptions imposed (explicitly or implicitly) on the particular data ; see McCullagh []. Formally, is a stochastic mechanism framed in terms of probabilistic assumptions from three broad categories: Distribution (D), Dependence (M), and Heterogeneity (H), assigned to the observable stochastic process underlying data .
The specification (initial selection) of has a twofold objective:
- (a)
- is selected to account for all the chance regularity patterns—the systematic statistical information—in data by choosing appropriate probabilistic assumptions relating to . Equivalently, is selected to render data a ‘typical realization’ therefrom, and the ‘typicality’ can be evaluated using Mis-Specification (M-S) testing, which evaluates the approximate validity of its probabilistic assumptions.
- (b)
- is parametrized [] to enable one to shed light on the substantive questions of interest using data . When these questions are framed in terms of a substantive model, say , one needs to bring out the implicit statistical model in a way that ensures that the two sets of parameters are related via a set of restrictions colligating to the data via ; see Spanos [].
Example 1. A widely used example in practice is the simple Normal model:
where ‘’ stands for ‘Normal (D), Independent (M), and Identically Distributed (H)’.
The main objective of the model-based frequentist inference is to ‘learn from data ’ about where denotes the ‘true’ value of in ; shorthand for saying that there exists a such that could have generated data .
The cornerstone of frequentist inference is the concept of a sampling distribution, for all (∀) , of a statistic (estimator, test, predictor), derived via:
The derivation of in (3) presumes the validity of which in the case of (2) is:
In light of the crucial role of the distribution of the sample, Fisher [], p. 314, emphasized the importance of establishing the statistical adequacy (approximate validity) of the invoked statistical model :
“For empirical as the specification of the hypothetical population [] may be, this empiricism is cleared of its dangers if we can apply a rigorous and objective test of the adequacy with which the proposed population represents the whole of the available facts.”
He went on to underscore the crucial importance of Mis-Specification (M-S) testing (testing the approximate validity of the probabilistic assumptions comprising ) as the way to provide an empirical justification for statistical induction:
“The possibility of developing complete and self-contained tests of goodness of fit deserves very careful consideration, since therein lies our justification for the free use which is made of empirical frequency formulae. ”(Fisher [], (p. 314).)
Statistical adequacy plays a crucial role in securing the reliability of inference because it ensures the approximate equality between the actual and the nominal error probabilities based on assuring that one can keep track of the relevant error probabilities. In contrast, when is statistically misspecified (Spanos, []),
- (a)
- and the likelihood function are erroneous,
- (b)
- distorting the sampling distribution derived via (3), as well as
- (c)
- giving rise to ‘non-optimal’ estimators and sizeable discrepancies between the actual error probabilities and nominal—derived assuming is valid.
In light of that, the practical way to keep track of the relevant error probabilities is to establish the statistical adequacy of . When is misspecified, any attempt to adjust the relevant error probabilities is ill-fated because the actual error probabilities are unknown due to being sizeably different from the nominal ones.
Regrettably, as Rao [], p. 2, points out, validating using comprehensive M-S testing is neglected in statistics courses:
“They teach statistics as a deductive discipline of deriving consequences from given premises []. The need for examining the premises, which is important for practical applications of results of data analysis is seldom emphasized. … The current statistical methodology is mostly model-based, without any specific rules for model selection or validating a specified model. ”(p. 2)
See Spanos [] for further discussion.
2.2. Neyman–Pearson (N-P) Testing
Example 1 (continued). In the context of (2), testing the hypotheses:
an optimal (UMP) -significance level test (Neyman and Pearson, 1933 []) is:
where denotes the rejection region, and is determined by the significance level ; see Lehmann [].
The sampling distribution of evaluated under (hypothetical) is:
where ‘’ denotes the Student’s t distribution with degrees of freedom, which provides the basis for evaluating the type I error probability and the p-value:
That is, both the type I error probability and the p-value in (7) are evaluated using hypothetical reasoning, that interprets ‘ is true’ as ‘what if’ ’.
The sampling distribution of evaluated under (hypothetical) is:
where is the noncentrality parameter of St, which provides the basis for evaluating the power of test :
where in (8) indicates that the power increases monotonically with and and decreases with .
Equation (8) shows that the power increases with and and decreases with .
The optimality of N-P tests revolves around an inherent trade-off between the type I and II error probabilities. To address that trade-off, Neyman and Pearson [] proposed to construct an optimal test by prespecifying at a low value and minimizing the type II error , or maximizing the power , .
A question that is often overlooked in traditional expositions of N-P testing is:
Where does prespecifying the type I error probability at a low threshold come from?
A careful reading of Neyman and Pearson [] reveals the answer in the form of two crucial stipulations relating to the framing of : and : to ensure the effectiveness of N-P testing and the informativeness of the ensuing results:
- and should form a partition of (p. 293) to avoid
- and should be framed in such a way to ensure that the type I error is the more serious of the two, using the analogy with a criminal trial, p. 296, with : no guilty, to secure a low probability for sending an innocent person to jail.
Unveiling the intended objective of stipulation 2, suggests that the requirement for a small (prespecified) is to ensure that the test has a low probability of rejecting a true null hypothesis, i.e., when Minimizing the type II error probability implies that an optimal test should have the lowest possible probability (or equivalently, the highest power) for accepting (rejecting) when false, i.e., when . That is, an optimal test should have a high power around the potential neighborhood of This implies that when no reliable information about this potential neighborhood is available, one should use a two-sided test to avert the case where the test has no or very low power around ; see Spanos [].
For the reason that the power increases with n, it is important to take that into account in selecting an appropriate to avoid both an under-powered and an over-powered test, forefending the ‘small n’ and ‘large n problems’, respectively. First, for a given , one needs to calculate the value of n needed for to have sufficient power to detect parameter discrepancies of interest; see Spanos []. Second, for a large n one needs to adjust to avoid an ultra-sensitive test that could detect tiny discrepancies, say , and misleadingly declare them statistically significant.
The primary role of the pre-data testing error probabilities (type I, II, and power) is to operationalize the notions of ‘statistically significant/insignificant’ in terms of statistical approximations framed in terms of a test statistic and its sampling distribution. These error probabilities calibrate the capacity of the test to shed sufficient light on , giving rise to learning from data. In this sense, the reliability of the testing results ‘accept/reject ’ depends crucially on the particular testing statistical context (Spanos, [], ch. 13):
which includes, not only the adequacy of vis-a-vis data , the framing of and and as well as n; see Spanos ([,]). For instance, when , detaching the accept/reject results from their statistical context in (11), and claiming statistical significance at conventional thresholds will often be an unwarranted claim.
Let us elaborate on this assertion.
3. The Large Problem in N-P Testing
3.1. How Could One Operationalize as n Increases?
As mentioned above, for a given increasing n increases the test’s power and decreases the p-value. What is not so obvious is how to operationalize the clause ‘as n increases’ since data usually come with a specific sample size n. Assuming that one begins with large enough n to ensure that the Mis-Specification (M-S) tests have sufficient power to detect existing departures from the probabilistic assumptions of the invoked , say there are two potential scenarios one could contemplate.
Scenario 1 assumes that all different values of give rise to the same observed . This scenario has been explored by Mayo and Spanos [,].
Scenario 2 assumes that as n increases beyond the change in the estimates and are ‘relatively small’ to render the ratio approximately constant.
Scenario 2 seems realistic enough to shed light on the large n problem for two reasons. First, when the NIID assumptions are valid for , the changes in and from increasing n are likely to be ‘relatively small’ since is sufficiently large to provide a reliable initial estimate, and thus, increasing n is unlikely to change the ratio drastically. Second, the estimate where is a value of interest, is known as the ‘effect size’ for in psychology (Ellis, []), and is often used to infer the magnitude of the ‘scientific’ effect, irrespective of n. Let us explore the effects of increasing n using scenario 2.
3.2. The Large n Problem and the p-Value
Empirical example 1 (continued). Consider the hypotheses in (4) for in the context of (2) using the following information:
The test statistic yields: with a p-value, indicating ‘accept ’. The question of interest is how increasing n beyond will affect the result of N-P testing.
Consider the issue of how the p-value changes as n increases when is constant (scenario 2). The p-value curve in Figure 1 for indicates that one can manipulate n to obtain the desired result since (a) for the p-value will yield ‘accept ’, (b) for the p-value will yield ‘reject ’.
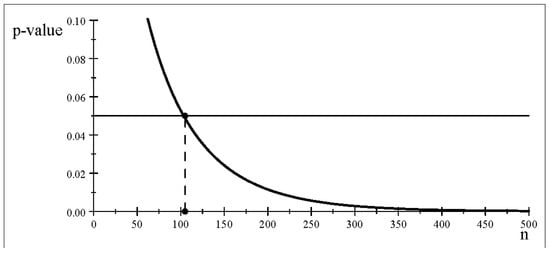
Figure 1.
The p-value curve for different sample sizes n.
Table 1 reports particular values of and from Figure 1 as n increases, showing that decreases rapidly down to tiny values for , confirming Berkson’s [], (p. 334), observation in the introduction that the p-value “… will be small beyond any usual limit of significance. ”

Table 1.
The p-value as n increases (keeping constant).
3.3. The Large n Problem and the Power of a Test
Let us consider the power of at () as n increases under scenario 2 ( held constant), and evaluate its effect on the size of the detected discrepancies
Table 2 reports several values of n showing how the test detects smaller and smaller discrepancies from confirming Fisher’s [] quotation in the introduction. This can be seen more clearly in Figure 2, where the power curves become steeper and steeper as n increases.
Table 2.
Discrepancy detected with as n increases.
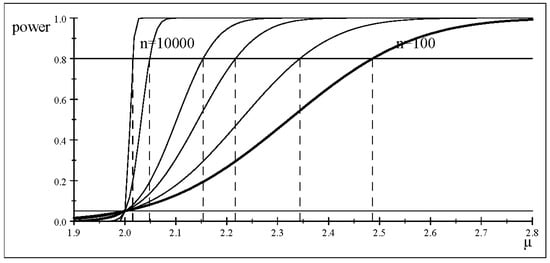
Figure 2.
The power curve for different sample sizes n.
One might object to this quote as anachronistic since Fisher [] was clearly against the use of the type II error probability and the power of a test due to his falsificationist stance where ‘accept ’ would not be an option. The response is that Fisher acknowledged the role of power using the term ‘sensitivity’ in the quotation (Section 1.1), as well as explicitly in Fisher [], p. 295. Indeed, the presence of a rejection threshold in Fisher’s significance testing brings into play the pre-data type I and II error probabilities, while his p-value is a post-data error probability; see Spanos [].
4. The Empirical Literature and the Large Problem
Examples of misuse of frequentist testing abound in all applied fields, but the large n problem is particularly serious in applied microeconometrics where very large sample sizes n are often employed to yield spurious significance results, which are then used to propose policy recommendations relating to relevant legislation; see Pesko and Warman [].
4.1. Empirical Examples in Microeconometrics
Empirical example 2A (Abouk et al. [], Appendix J: Table 1. p. 99). Based on an estimated LR model in (Table 7). with , it is inferred that the estimates , SE rendering the coefficient of a key variable statistically significant at .
Such empirical results and the claimed evidence based on the estimated models are vulnerable to three potential problems.
- (i)
- Statistical misspecification and the ensuing untrustworthy evidence since the discussion in the paper ignores the statistical adequacy of the estimated statistical models. Given that to evaluate the statistical adequacy of any published empirical study, one needs the original data to apply thorough misspecification testing (Spanos, []), that issue will be sidestepped in the discussion that follows.
- (ii)
- Large n problem. One of the many examples in the paper relates to the claimed statistical significance (with at of , ignoring its potential ‘spurious’ statistical significance results stemming from the large n problem in N-P testing.
- (iii)
- Conflating ‘testing results’ with ‘evidence’. The authors claim evidence for and proceed to infer its implications for the effectiveness of different economic policies.
Empirical example 2A (continued). Abouk et al. [] report ,
SE and implying:
The relevant sampling distribution of for the LR model is:
Focusing on just one coefficient the t-test for its significance is:
Using the information in example 2A, we can reconstruct what would have been for different n using scenario 2. The results in Table 3 indicate that the authors’ claim of statistical significance () at will be unwarranted for any .
Table 3.
The p-value with increasing n (constant estimates).
Example 2B. Abouk et al. [], Table 2, p. 57, report 42 ANOVA results for the difference between two means , 40 of these tests have tiny p-values, less than even though the differences between the two means, appear to be very small. Surprisingly, two of the estimated differences are zero, (, and , ), but their reported p-values are and , respectively; one would have expected when Looking at these results, one wonders what went wrong with the reported p-values.
The hypotheses of interest take the form (Lehmann, []):
with the optimal test being the t-test where:
A close look at this t-test suggests that the most plausible explanation for the above ‘strange results’ is the statistical software using (at least) 12-digit decimal precision. Given that the authors report mostly 3-digit estimates, the software is picking up tiny discrepancies, say which, when magnified by , could yield the reported p-values. That is, the reported results have (inadvertently) exposed the effect of the large n on the p-value.
4.2. Meliorating the Large n Problem Using Rules of Thumb
In light of the inherent trade-off between the type I and type II error probabilities, some statistics textbooks advise practitioners to use ‘rules of thumb’ based on decreasing as n increases; see Lehmann [].
- Ad hoc rules for adjusting as n increases
| 100 | 200 | 500 | 1000 | 10,000 | 20,000 | 200,000 | ⋯ | |
| 0.05 | 0.025 | 0.01 | 0.001 | 0.0001 | 0.00001 | 0.00000001 | ⋯ |
- 2.
- Good [], p. 66, proposed to standardize the p-value relative toApplying his rule of thumb, to the p-value curve in Figure 1, based on yields:
| 100 | 120 | 150 | 300 | 500 | 1000 | 5000 | 10,000 | |
The above numerical examples suggest that such rules of thumb for selecting as n increases can meliorate the problem; they do not, however, address the large n problem since they are ad hoc, and their suggested thresholds decrease to nearly zero beyond .
4.3. The Large n Problem and Effect Sizes
Although there is no authoritative definition of the notion of an effect size, the one that comes closest to its motivating objective is Thompson’s []:
“An effect size is a statistic quantifying the extent to which the sample statistics diverge from the null hypothesis. ”(p. 172)
The notion is invariably related to a certain frequentist test and has a distinct resemblance to its test statistic. To shed light on its effectiveness in addressing the large n problem, consider a simpler form of the test in (13) where the sample size n is the same for both and and for The optimal t-test is based on a simple bivariate Normal distribution with parameters for : vs. : , takes the form:
The recommended effect size for this particular test is the widely used Cohen’s . As argued by Abelson [], the motivation underlying the choice of the effect size statistic:
“… is that its expected value is independent of the size of the sample used to perform the significance test. ”(p. 46)
That is, if one were to view Cohen’s as a point estimate of the unknown parameter the statistic referred to by Thompson above is confirming Abelson’s claim that is free of
The question that naturally arises at this point is to what extent deleting and using the point estimate of as the effect size result associated with addresses the large n problem. The demonstrable answer is that it does not since the claim that approximates closely for a large enough n is unwarranted; see Spanos []. The reason is that a point estimate represents a single realization relating to the relevant sampling distribution, i.e., it represents a ‘statistical result’ that ignores the relevant uncertainty. Indeed, the by itself, does not have a sampling distribution without since its relevant sampling distribution relates to:
where denotes the true value of see Spanos [] for more details.
5. The Post-Data Severity Evaluation (SEV) and the Large n Problem
The post-data severity (SEV) evaluation of the accept/reject results is a principled argument that provides an evidential account for these results. Its main objective is to transform the unduly data-specific accept/reject results into evidence. This takes the form of an inferential claim that revolves around the discrepancy warranted by data and test with a high enough probability; see Spanos [].
A hypothesis H ( or ) passes a severe test with if: (C-1) accords with H, and (C-2) with very high probability, test would have produced a result that ‘accords less well’ with H than does, if H were false; see Mayo and Spanos [].
5.1. Case 1: Accept
In the case of ‘accept ’, the SEV evaluation is seeking the smallest’ discrepancy from with a high enough probability.
Empirical example 1 (continued). For , and test in (5) for the hypotheses in (4) yields: with indicating ‘accept ’. (C-1) indicates that accords with , and since the relevant inferential claim is for Hence, (C-2) calls for evaluating the probability of the event: “outcomes that accord less well with than does”, i.e., [: :
where for a large enough , and evaluated based on:
and ; see Owen [].
That is, the central and non-central Student t sampling distributions differ not only with respect to their mean but also in terms of the variance as well as the higher moments since for a non-zero the non-central Student’s t is non-symmetric. The post-data severity curve for all in Figure 3 indicates that the discrepancy warranted by data and test with probability is
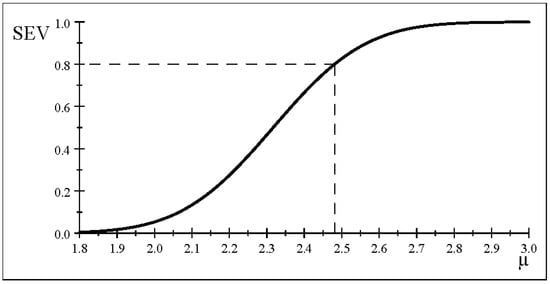
Figure 3.
The post-data severity curve (accept .
The post-data severity evaluated for typical values reported in Table 4 reveals that the probability associated with the discrepancy relating to the estimate is never high enough to be the discrepancy warranted by and test since . This calls into question any claims relating to point estimates and observed CIs more generally since they represent an uncalibrated (it ignores the relevant uncertainty) single realization () of the sample relating to the relevant sampling distribution.
Table 4.
Post-data severity evaluation (SEV) for .
5.2. The Post-Data Severity and the Large n Problem
5.2.1. Case 1: Accept
Empirical example 1 (continued). Consider scenario 2 where remains constant as n increases. Table 5 gives particular examples of n showing how increases and decreases for a fixed .
Table 5.
Post-data severity ).
Figure 4 presents the different SEV curves as n increases ( held constant). It confirms the results of Table 5, by showing that the curves become steeper and steeper as n increases. This reduces the warranted discrepancy monotonically (Table 5), converging to the lower bound at as That is, the warranted discrepancies indicated on the x-axis, at a constant probability 0.8 (y-axis), become smaller and smaller as n increases, with the lower bound being the value of where its optimal estimator converges to with probability one as .
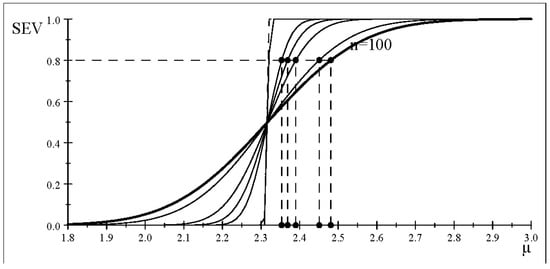
Figure 4.
The severity curve (accept for different n (same estimates).
This makes statistical sense in practice since and are strongly consistent estimators of and i.e., and thus their accuracy (precision) improves as n increases beyond a certain threshold . Recall that in the case of ‘accept ’ one is seeking the ‘smallest discrepancy’ from . Hence, as n increases SEV renders the warranted discrepancy ‘more accurate’ by reducing it, until it reaches the lower bound around [] as note that the latter is the most accurate value for only when is statistically adequate!
5.2.2. Case 2: Reject
Empirical example 3. Consider changing the estimate of to retaining , which yields: indicating ‘reject ’ in (4). In contrast to the case ‘accept ’, when the test ‘rejects ’ one is seeking the ‘largest’ discrepancy from with high probability. In light of , the relevant inferential claim is: for and its post-data probabilistic evaluation is based on:
where and the evaluation of (16) is based on (15).
Table 6 indicates that the discrepancy warranted with is (), and the discrepancy for has .
Table 6.
Post-data severity evaluation (SEV) for .
Figure 5 depicts the severity curves for , indicating that keeping the probability constant at 0.8 (y-axis), as n increases (keeping constant) renders the curves steeper and steeper, thus ‘increasing’ the warranted discrepancy monotonically (x-axis) toward approaching the upper bound, which is the value of where its optimal estimator converges to with probability one as This is analogous to the case of ‘accept ’, with the lower bound replaced by an upper bound, which is equal to in both cases. That is, the SEV evaluation increases the precision of the discrepancy warranted with high (but constant) probability as n increases.
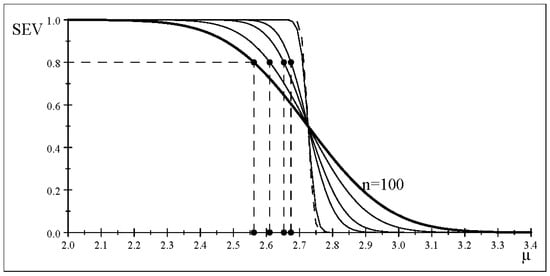
Figure 5.
The severity curve (reject for different n (same estimates).
Example 2A (Abouk et al., 2022) continued. The reported t-test result is:
What is the warranted discrepancy from with high enough severity, say (in light of The answer is which calls into question , as well as Cohen’s ; see Ellis []. This confirms the tiny discrepancies from zero due to the large n problem conjectured in Section 4.1.
One might object to the above conclusion relating to the issue of spurious significance by countering that a tiny discrepancy is still different from zero, and thus, the statistical significance is well-grounded. Regrettably, such a counter-argument is based on a serious misconstrual of statistical inference in general, where learning from data takes the form of ‘statistical approximations’ framed in terms of a statistic or a pivot and its sampling distribution. This distinguishes statistics from other sub-fields of applied mathematics. No statistical inference is evaluated in terms of a binary choice of right and wrong! Indeed, this confusion lies at the heart of misinterpreting the binary accept/reject results as evidence for or against hypotheses or claims; see Mayo and Spanos [].
Example 2B (Abouk et al. []) continued. As argued in Section 4.1, the reported results for the difference between two means exemplify the effect of the large n problem on the p-value. To be able to quantify that effect, however, one needs the exact p-values, but only two of the 42 reported p-values are given exactly, 0.8867 and 0.0056; the other 40 are reported as less than . Also, the particular sample sizes for the different reported tests are not given, and thus the overall and will be used. Focusing on the one with the p-value = 0.0056, one can retrieve the observed t-statistic, which can then be used for the SEV evaluation. For , , the observed t-statistic is , and using the SEV evaluation one can show that the warranted discrepancy from with SEV = () is which confirms that the t-test detects tiny discrepancies between the two estimated means, as conjectured in Section 4.1. That is, all but one (p-value = 0.8867) of the reported 42 test results in Table 2 (Abouk et al. [] p. 43) constitute cases of spurious rejection of the null due to the large n problem. Even if one were to reduce N by a factor of 40, the warranted discrepancies would still be tiny.
5.2.3. Key Features of the Post-Data SEV Evaluation
- (a)
- The is a post-data error probability, evaluated using hypothetical reasoning, that takes fully into account the testing statistical context in (11) and is guided by the sign and magnitude of as indicators of the direction of the relevant discrepancies from This is particularly important because the factual reasoning, what if , underlying point estimation and Confidence Intervals (CIs), does not apply post-data.
- (b)
- The evaluation differs from other attempts to deal with the large n problem in so far as its outputting of the discrepancy is always based on the non-central distribution (Kraemer and Paik, []):This ensures that the warranted discrepancy is evaluated using the ‘same’ sample size n, counter-balancing the effect of n on Note that ‘≈’ denotes an approximation.
- (c)
- The evaluation of the warranted with high probability accounts for the increase in n by enhancing its precision. As n increases will approach the value since for a statistically adequate approaches due to its strong consistency.
- (d)
- The SEV can be used to address other foundational problems, including distinguishing between ‘statistical’ and ‘substantive’ significance. It also provides a testing-based effect size for the magnitude of the ‘scientific’ effect by addressing the problem with estimation-based effect sizes raised in Section 4.3. Also, the SEV evaluation can shed light on several proposed alternatives to (or modifications of) N-P testing by the replication crisis literature (Wasserstein et al. []), including replacing the p-value with effect sizes and observed CIs and redefining statistical significance (Benjamin et al. []) irrespective of the sample size n; see Spanos [,].
6. Summary and Conclusions
The large n problem arises naturally in the context of N-P testing due to the in-built trade-off between the type I and II error probabilities, around which the optimality of N-P tests revolves. This renders the accept/reject results and the p-value highly vulnerable to the large n problem. Hence, for , the detection of statistical significance based on conventional significance levels will often be spurious since a consistent N-P test will detect smaller and smaller discrepancies as n increases; see Spanos [].
The post-data severity (SEV) evaluation can address the large n problem by converting the unduly data-specific accept/reject ‘results’ into ‘evidence’ for a particular inferential claim of the form . This is framed in the form of the discrepancy warranted by data and test with high enough probability. The SEV evidential account is couched in terms of a post-data error probability that accounts for the uncertainty arising from the undue data-specificity of accept/reject results. The SEV differs from other attempts to address the large n problem in so far as its evaluation is invariably based on a non-central distribution whose non-centrality parameter uses the same n as the observed test statistic to counter-balance the effect induced by n in outputting
The SEV evaluation was illustrated above using two empirical results from Abouk et al. []. Example 2A concerns an estimated coefficient, , SE, in a LR model, which is declared statistically significant at with . The SEV evaluation yields a discrepancy from warranted by data and the t-test with probability Example 2B concerns the difference between two means whose estimates are , , but the t-test outputted with . The SEV evaluation yields a discrepancy from warranted by data and the t-test with probability . Both empirical examples represent cases of spurious statistical significance results stemming from exceptionally large sample sizes, and , respectively.
Funding
This research received no external funding.
Institutional Review Board Statement
Non-applicable.
Informed Consent Statement
Non-applicable.
Data Availability Statement
All data are publicly available.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| M-S | Mis-Specification |
| N-P | Neyman–Pearson |
| UMP | Uniformly Most Powerful |
| SE | Standaard Error |
| SEV | post-data severity evaluation |
References
- Berkson, J. Some difficulties of interpretation encountered in the application of the chi-square test. J. Am. Stat. 1938, 33, 526–536. [Google Scholar] [CrossRef]
- Fisher, R.A. The Design of Experiments; Oliver and Boyd: Edinburgh, UK, 1935. [Google Scholar]
- Berkson, J. Tests of significance considered as evidence. J. Am. Assoc. 1942, 37, 325–335. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical Methods for Research Workers; Oliver and Boyd: Edinburgh, UK, 1925. [Google Scholar]
- Fisher, R.A. Note on Dr. Berkson’s criticism of tests of significance. J. Am. Stat. Assoc. 1943, 38, 103–104. [Google Scholar] [CrossRef][Green Version]
- Berkson, J. Experience with Tests of Significance: A Reply to Professor R. A. Fisher. J. Am. Assoc. 1943, 38, 242–246. [Google Scholar] [CrossRef]
- Spanos, A. Mis-Specification Testing in Retrospect. J. Econ. Surv. 2018, 32, 541–577. [Google Scholar] [CrossRef]
- Lindley, D.V. A statistical paradox. Biometrika 1957, 44, 187–192. [Google Scholar] [CrossRef]
- Spanos, A. Who Should Be Afraid of the Jeffreys-Lindley Paradox? Philos. Sci. 2013, 80, 73–93. [Google Scholar] [CrossRef]
- Lehmann, E.L. Significance level and power. Ann. Math. Stat. 1958, 29, 1167–1176. [Google Scholar] [CrossRef]
- Cohen, J. The statistical power of abnormal-social psychological research: A review. J. Abnorm. Soc. Psychol. 1962, 65, 145–153. [Google Scholar] [CrossRef]
- Freiman, J.A.; Chalmers, T.C.; Smith, H.; Kuebler, R.R. The importance of beta, the type II error and sample size in the design and interpretation of the randomized control trial. N. Engl. J. Med. 1978, 299, 690–694. [Google Scholar] [CrossRef]
- Lehmann, E.L. Testing Statistical Hypotheses, 2nd ed.; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum: Hoboken, NJ, USA, 1988. [Google Scholar]
- Good, I.J. Standardized tail-area probabilities. J. Stat. Comput. Simul. 1982, 16, 65–66. [Google Scholar] [CrossRef]
- Spanos, A. Where Do Statistical Models Come From? Revisiting the Problem of Specification. In Optimality: The Second Erich L. Lehmann Symposium; Rojo, J., Ed.; Lecture Notes-Monograph Series; Institute of Mathematical Statistics: Beachwood, OH, USA, 2006; Volume 49, pp. 98–119. [Google Scholar]
- Spanos, A. Introduction to Probability Theory and Statistical Inference: Empirical Modeling with Observational Data, 2nd ed.; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Spanos, A. Statistical Misspecification and the Reliability of Inference: The simple t-test in the presence of Markov dependence. Korean Econ. Rev. 2009, 25, 165–213. [Google Scholar]
- Fisher, R.A. On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. 1922, 222, 309–368. [Google Scholar]
- McCullagh, P. What is a statistical model? Ann. Stat. 2002, 30, 1225–1267. [Google Scholar] [CrossRef]
- Spanos, A. Statistical Adequacy and the Trustworthiness of Empirical Evidence: Statistical vs. Substantive Information. Econ. Model. 2010, 27, 1436–1452. [Google Scholar] [CrossRef]
- Rao, C.R. Statistics: Reflections on the Past and Visions for the Future. Amstat. News 2004, 327, 2–3. [Google Scholar]
- Spanos, A. Frequentist Model-based Statistical Induction and the Replication crisis. J. Quant. Econ. 2022, 20, 133–159. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. 1933, 231, 289–337. [Google Scholar]
- Spanos, A. How the Post-data Severity Converts Testing Results into Evidence for or Against Pertinent Inferential Claims. Entropy 2023. under review. [Google Scholar]
- Spanos, A. Severity and Trustworthy Evidence: Foundational Problems versus Misuses of Frequentist Testing. Philos. Sci. 2022, 89, 378–397. [Google Scholar] [CrossRef]
- Mayo, G.D.; Spanos, A. Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction. Br. J. Philos. Sci. 2006, 57, 323–357. [Google Scholar] [CrossRef]
- Mayo, D.G.; Spanos, A. Error Statistics. In The Handbook of Philosophy of Science; Gabbay, D., Thagard, P., Woods, J., Eds.; Elsevier: Amsterdam, The Netherlands, 2011; Volume 7: Philosophy of Statistics, pp. 151–196. [Google Scholar]
- Ellis, P.D. The Essential Guide to Effect Sizes: Statistical Power, Meta-Analysis, and the Interpretation of Research Results; Cambirdge University Press: Cambridge, UK, 2010. [Google Scholar]
- Fisher, R.A. Statistical methods and scientific induction. J. R. Soc. Ser. Stat. Methodol. 1955, 17, 69–78. [Google Scholar] [CrossRef]
- Fisher, R.A. Two new properties of mathematical likelihood. Proc. R. Soc. Lond. Ser. 1934, 144, 285–307. [Google Scholar]
- Pesko, M.F.; Warman, C. Re-exploring the early relationship between teenage cigarette and e-cigarette use using price and tax changes. Health Econ. 2022, 31, 137–153. [Google Scholar] [CrossRef] [PubMed]
- Abouk, R.; Adams, S.; Feng, B.; Maclean, J.C.; Pesko, M. The Effects of e-cigarette taxes on pre-pregnancy and prenatal smoking. NBER Work. Pap. 2022, 26126, Revised June 2022. Available online: https://www.nber.org/system/files/workingpapers/w26126/w26126.pdf (accessed on 5 October 2023).
- Thompson, B. Foundations of Behavioral Statistics: An Insight-Based Approach; Guilford Press: New York, NY, USA, 2006. [Google Scholar]
- Abelson, R.P. Statistics as Principled Argument; Lawrence Erlbaum: Hoboken, NJ, USA, 1995. [Google Scholar]
- Spanos, A. Bernoulli’s golden theorem in retrospect: Error probabilities and trustworthy evidence. Synthese 2021, 199, 13949–13976. [Google Scholar] [CrossRef]
- Spanos, A. Revisiting noncentrality-based confidence intervals, error probabilities and estimation-based effect sizes. J. Math. 2021, 104, 102580. [Google Scholar] [CrossRef]
- Owen, D.B. Survey of Properties and Applications of the Noncentral t-Distribution. Technometrics 1968, 10, 445–478. [Google Scholar] [CrossRef]
- Kraemer, H.C.; Paik, M. A central t approximation to the noncentral t distribution. Technometrics 1979, 21, 357–360. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Schirm, A.L.; Lazar, N.A. Moving to a world beyond “p < 0.05”. Am. Stat. 2019, 73, 1–19. [Google Scholar]
- Benjamin, D.J.; Berger, J.O.; Johannesson, M.; Nosek, B.A.; Wagenmakers, E.J.; Berk, R.; Bollen, K.A.; Brembs, B.; Brown, L.; Camerer, C.; et al. Redefine statistical significance. Nat. Hum. Behav. 2017, 33, 6–10. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).