Abstract
The properties of non-parametric kernel estimators for probability density function from two special classes are investigated. Each class is parametrized with distribution smoothness parameter. One of the classes was introduced by Rosenblatt, another one is introduced in this paper. For the case of the known smoothness parameter, the rates of mean square convergence of optimal (on the bandwidth) density estimators are found. For the case of unknown smoothness parameter, the estimation procedure of the parameter is developed and almost surely convergency is proved. The convergence rates in the almost sure sense of these estimators are obtained. Adaptive estimators of densities from the given class on the basis of the constructed smoothness parameter estimators are presented. It is shown in examples how parameters of the adaptive density estimation procedures can be chosen. Non-asymptotic and asymptotic properties of these estimators are investigated. Specifically, the upper bounds for the mean square error of the adaptive density estimators for a fixed sample size are found and their strong consistency is proved. The convergence of these estimators in the almost sure sense is established. Simulation results illustrate the realization of the asymptotic behavior when the sample size grows large.
Keywords:
non-parametric kernel density estimators; adaptive density estimators; mean square and almost surely convergence; rate of convergence; smoothness class PACS:
62G07; 62G20; 62F12; 62G99
1. Introduction
Let be independent identically distributed random variables (i.i.d. r.v.’s) having a probability density function f. In the typical non-parametric set-up, nothing is assumed about f except that it possesses a certain degree of smoothness, e.g., that it has r continuous derivatives.
Estimating f via kernel smoothing is a sixty year old problem; M. Rosenblatt who was one of its originators discusses the subject’s history and evolution in the monograph [1]. For some point x, the kernel smoothed estimator of is defined by
where the kernel is a bounded function satisfying and , and the positive bandwidth parameter h is a decreasing function of the sample size n.
If has finite moments up to q-th order, and moments of order up to equal to zero, then q is called the ‘order’ of the kernel . Since the unknown function f is assumed to have r continuous derivatives, it typically follows that
and
where , and are bounded functions depending on as well as f and its derivatives, cf. [1] p. 8.
The idea of choosing a kernel of order q bigger (or equal) than r in order to ensure the to be dates back to the early 1960s in work of [2,3]; recent references on higher-order kernels include the following: [4,5,6,7,8,9,10]. Note that since r is typically unknown and can be arbitrarily large, it is possible to use kernels of infinite order that achieve the minimal bias condition for any r; Ref. [11] gives many properties of kernels of infinite order. In this paper we will employ a particularly useful class of infinite order kernels namely the flat-top family; see [12] for a general definition.
It is a well-known fact that optimal bandwidth selection is perhaps the most crucial issue in such non-parametric smoothing problems; see [13], as well as the book [14]. The goal typically is minimization of the large-sample mean squared error (MSE) of . However, to perform this minimization, the practitioner needs to know the degree of smoothness r, as well as the constants and . Using an infinite order kernel and focusing just on optimizing the order of magnitude of the large-sample MSE, it is apparent that the optimal bandwidth h must be asymptotically of order ; this yields a large-sample MSE of order .
A generalization of the above scenario is possible using a degree of smoothness r that has another sense, and that is not necessarily an integer. Let denote the integer part of r, and define ; then, one may assume that f has continuous derivatives, and that the th derivative satisfies a Lipschitz condition of order . Interestingly, even in this case where f is assumed to belong to the Hölder class of degree r (the derivative of the density function of the order r satisfies the Lipschitz condition) the MSE–optimal bandwidth h is still of order and again yields a large-sample MSE of the order (see, e.g., [15,16,17,18] among others).
The problem of course is that, as previously mentioned, the underlying degree of smoothness r is typically unknown. In Section 4 of the paper at hand, we develop an estimator of r and prove its strong consistency; this is perhaps the first such result in the literature. In order to construct our estimator , we operate under a class of functions that is slightly more general than the aforementioned Hölder class; this class of functions is formally defined in Section 2 via Equation (3) or (4).
Under such a condition on the tails of the characteristic function we are able to show in Section 3 that the optimized MSE of is again of order for possibly non-integer this is true, for example, when the characteristic function has tails of order see Example 2.
Furthermore, in Section 5 we develop an adaptive estimator that achieves the optimal MSE rate of within a logarithmic factor despite the fact that r is unknown, see Examples after Theorem 3. Similar effect arises in the adaptive estimation problem of the densities from the Hölder class; see [18,19,20]. It should pointed that problems of asymptotic adaptive optimal density estimations from another classes have also been considered in the literature; see, e.g., [14,21,22,23].
The construction of is rather technical; it uses the new estimator , and it is inspired from the construction of sequential estimates although we are in a fixed n, non-sequential setting. As the major theoretical result of our paper, we are able to prove a non-asymptotic upper bound for the MSE of that satisfies the above mentioned optimal rate. Section 6 contains some simulation results showing the performance of the new estimator in practice. All proofs are deferred to Section 7, while Section 8 contains our conclusions and suggestions for future work.
2. Problem Set-Up and Basic Assumptions
Let be i.i.d. having a probability density function f. Denote the characteristic function of f and the sample characteristic function For some finite , define two families and of bounded, i.e.,
and continuous functions f satisfying one of the following conditions, respectively:
In other words, is the family of functions (introduced by M. Rosenblatt) satisfying (2) and (3), while is the family of functions (introduced in this paper) satisfying (2) and (4). It should be noted that the new class is a little bit more wide that the classical class .
In addition, define the family (respectively, ) as the family of functions f that belong to (respectively, ) but with f being such that its characteristic function has monotonously decreasing tails.
Consider the class of non-parametric kernel smoothed estimators of as given in Equation (1). Note that we can alternatively express in terms of the Fourier transform of kernel , i.e.,
where
In this paper, we will employ the family of flat-top infinite order kernels, i.e., we will let the function be of the form
where c is a fixed number in chosen by the practitioner, and is some properly chosen continuous, real-valued function satisfying and for any with and ; see [12,24,25,26] for more details on the above flat-top family of kernels.
Define the partial derivative of the function with respect to the bandwidth We will also assume that for some
Denote for every the functions
Define the following classes and
The main aim of the paper is the estimation of the parameter r of these classes and adaptive estimation of densities from the class with the unknown parameter
3. Asymptotic Mean Square Optimal Estimation
The mean square error (MSE) of the estimators has the following form:
where is the principal term of the MSE,
Thus, in particular,
To minimize the principal term by h we set its first derivative with respect to to zero which gives the following equality for the optimal (in the mean square sense) value
From the definition of the class of kernels for cases we have
and for h small enough, according to (6)
Then, by the definition of the class as h small enough, denoting we have
Thus, for
and from (8) it follows
Define the number from the equality
It is obvious, that and
In such a way we have proved the following theorem, which gives the rates of convergence of the random quantities and We can loosely call and ‘estimators’ although it is clear that these functions can not be considered as estimators in the usual sense in view of the dependence of the bandwidths and on unknown parameters r and Nevertheless, this theorem can be used for the construction of bona fide adaptive estimators with the optimal and suboptimal converges rates; see Examples 1 and 2, as well as Section 5.3 in what follows.
Theorem 1.
Let Then, for the asymptotically optimal (with respect to bandwidth h) in the MSE sense ‘estimator’ of the function and for the ‘estimator’ of the following limit relations, as hold
Remark 1.
The definition (9) of is essentially simpler than the definition (8) of the optimal bandwidth From Theorem 1 it follows that the (slightly) suboptimal ‘estimator’ can be successfully used instead.
It should be noted that the parameter is chosen by the practitioner here and that but in which case we want to choose close to 0.
We shall write in the sequel as instead of the limit relations
Example 1.
Consider an estimation problem of the function satisfying the following additional condition
using the kernel estimator
By making use of (9) and (10) we find the rate of convergence of the MSE and To this end we calculate
Therefore, as we have
Consider the piecewise linear flat-top kernel introduced by [25] (see [26] as well):
where is the positive part function.
Then, from (8) we obtain
and, for n large enough
Thus, similarly to as for we find
and
Example 2.
Consider an estimation problem of the function satisfying the following additional condition:
using the kernel estimator
Using (9) and (10) we will find the rate of convergence of the MSE and To this end, we calculate
It is easy to verify that Thus, from (9), as
Therefore, we have
Similarly to Example 1 as for we find
and
4. Estimation of the Degree of Smoothness r
Define the functions
Let and be two given sequences of positive numbers chosen by the practitioner such that and as The sequence represents the ‘grid’-size in our search of the correct exponent while represents an upper bound that limits this search.
Define the following sets of non-random sequences
Remark 2.
Formally, the definition of sets and, as follows of estimators and as well of sets defined below depend on the unknown function At the same time, the set (and, as follows, the estimator and the set can be defined independently of
Indeed, denote and
– let
Then for every
Thus for appropriate chosen and because (consider for simplification the case
According to the definition of the class it is impossible to find elements of the set independently of the function to be estimated without usage of an a priori information about Consider one simple example.
– Let
Suppose, e.g., in addition that
Then for appropriate chosen and because
Another examples are in Example 3 (see also Remark 3 and Example 4).
For an arbitrary given chosen by the practitioner, define the estimators and of the parameter r in (3) and (4) as follows
Example 3.
Define
Lemma 1.
Let Then, for every and there exist positive numbers such that
and for every
Define the sets and of non-random sequences
Remark 3.
It can be directly verified that under the conditions of Remark 2 the sequences if and as well as if and
Moreover, under the conditions of Example 3.1, if we put
Example 4.
Consider the functions from Examples 1, 2 and suppose, that the smooth parameter for some known number Then the sequences if we put
5. Adaptive Estimation of the Functions
The purpose of this section is the construction and investigation of an adaptive estimator of the function with unknown which can either serve as the main estimator (since it achieves the optimal rate of convergence within or can serve as a ‘pilot’ estimator to be used in (8) and (9) for the construction of an adaptive optimal and suboptimal bandwidths and
5.1. Adaptive MSE–Optimal Estimation
We define an adaptive estimator of as follows
where is the smoothing kernel, and the required bandwidths are defined by
where if and if recall that the estimators and are defined in (11) and (12), respectively.
From the definition of it follows, that where Note, that and if the following additional condition
on the sequence defined in the beginning of Section 4 holds.
Denote
where the constant H first used in (11) and (12). Define the following sequences for
as well as the constants
and the function
Note that the summability of the series in the definitions of the constants and follows from the corresponding demand in the definition of the classes and
Main properties of constructed estimators are stated in the following theorem.
Theorem 3.
Let the sequences in the definition of the estimator belong to the set and in the definition of the estimator to the set and the condition (15) is fulfilled.
Let if and if Then, for every and the estimator (14) has the following properties:
the estimator is strongly consistent:
Example 11. (Examples 1 and 4 revisited, ) In this case
and
Thus, under the following conditions
we have, as
and, as follows,
Then, according to Theorem 2, in this case the rate of convergence of adaptive density estimators of differs from the rate of non-adaptive estimators in [26] on the extra log-factor only.
For the functions and from Examples 2 and 4, it is easy to verify, that
5.2. A Symmetric Estimator
Noting that the construction of the estimator depends on the order by which the data are employed, a simple improvement is immediately available. Let be the order statistics that are a sufficient statistic in the case of our i.i.d. sample . Hence, by the Rao–Blackwell theorem, the estimator
will have smaller (or, at least, not larger) MSE than .
Unfortunately, the estimator (16) is difficult to compute. However, it is possible to construct a simple estimator that captures the same idea. To do this, consider all distinct permutations of the data , and order them in some fashion so that is the kth permutation. For unifying presentation, the 1st permutation will be the original data . Because of the continuity of the r.v.s , the number of such permutations is with probability one.
So let be the estimator as computed from the kth permutation , i.e., Equation (14) with instead of .
Finally, let be a positive integer (possibly depending on n), and let
Theorem 4.
For any choice of , we have
Ideally, the practitioner would use a high value of b—even if the latter is computationally feasible. However, even moderate values of b would give some improvement; in this case, the b permutations to be included in the construction of might be picked randomly as in resampling/subsampling methods—see e.g., [27].
5.3. Adaptive Optimal Bandwidth
Define
According to (8) the optimal bandwidth is defined from the equality
Thus, it is natural to define the adaptive (to the unknown parameter r and the function optimal bandwidth from the equality
where the adaptive estimator is defined in (17).
It is hoped that the bandwidths and have similar asymptotic properties in view of the fact that, according to Theorems 3 and 4 the function
is bounded in probability.
6. Simulation Results
In this section we provide results of a simulation study regarding the estimators introduced in Section 3.
Two flat-top kernels have been used in the simulation. The first one has the piecewise linear kernel characteristic function introduced in [26], i.e.,
The piecewise linear characteristic function and corresponding kernel are shown in Figure 1.
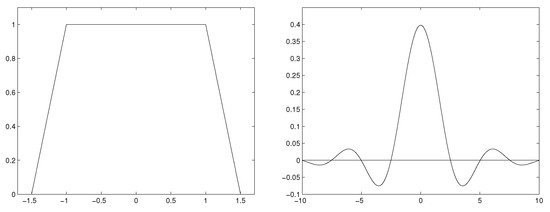
Figure 1.
Piecewise linear characteristic function (left) and corresponding kernel (right), .
The second case refers to the infinitely differentiable flat-top kernel characteristic function defined in [28], i.e.,
The characteristic function and kernel of the second case are shown in Figure 2.
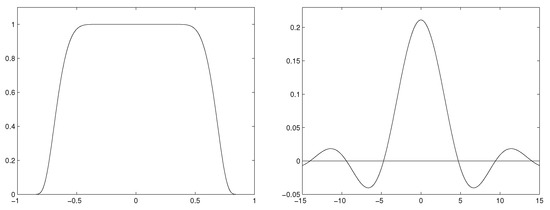
Figure 2.
Infinitely differentiable flat-top characteristic function (left) and corresponding kernel (right), , .
We examine kernel density estimators of triangular, exponential, Laplace, and gamma (with various shape parameter) distributions. Figure 3, Figure 4 and Figure 5 illustrate the estimator MSE as a function of the sample size.
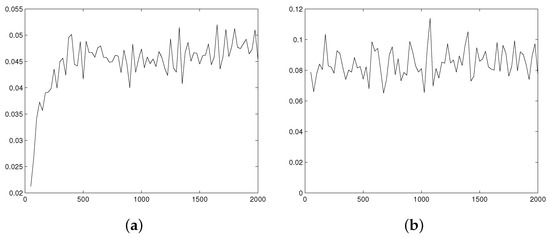
Figure 3.
MSE of kernel estimators multiplied by as a function of the sample size n for the triangle density function. (a) MSE of estimator with piecewise linear kernel characteristic function. (b) MSE of estimator with infinitely differentiable flat-top kernel characteristic function.
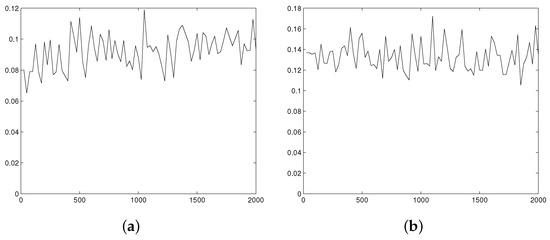
Figure 4.
MSE of kernel estimators (with piecewise linear kernel characteristic function) as a function of the sample size n. (a) Laplace density function (, MSE multiplied by ). (b) Gamma density function (, , MSE multiplied by ).
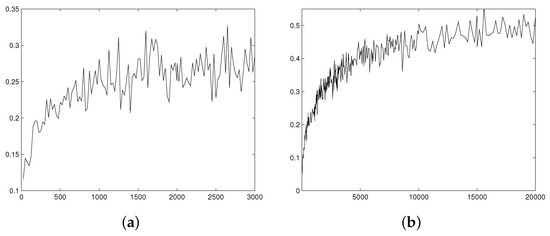
Figure 5.
MSE of kernel estimators (with piecewise linear kernel characteristic function) as a function of the sample size n. (a) Gamma distribution shape parameter , (MSE multiplied by ). (b) Gamma distribution shape parameter , (MSE multiplied by ).
Using notation for Heaviside step function, the triangular density function is defined as having characteristic function Laplace density has characteristic function , gamma density has characteristic function .
In all cases we choose scale parameter to have variation equals to 1, and consider estimation of density function at point .
All the above-mentioned characteristic functions satisfy condition (4) for (triangular and Laplace), and (gamma, ); therefore, all distributions belong to the family with corresponding value of r. In addition, all meet the requirements of Example 2. Thus, the bandwidth can be taken in the form and the expected convergence rate of the kernel estimator MSE is
The main goal of the simulation study is investigation of the MSE behavior for the kernel estimator with the growth of sample size. We generate sequences of 150 samples for sample size from 25 to 2000 with step 25, and for some distributions for sample size from 2000 to 20,000 with step 100 or 200. Then, for each sample size we calculate the estimator MSE multiplied by and expect visual stabilization of the sequence of resulting values with growth of
Typical examples of the simulation results are presented at Figure 3 (for ), Figure 4 (for and ), and Figure 5 (for and ). The expected stabilization of the scaled MSE is observed in all cases. Moreover, increasing r causes enlargement of sample size that is needed to achieve limiting asymptotic behavior. For and we can see stabilization starting from , for it starts from , while for the asymptotic behavior is observed to start from sample size 15,000.
7. Technical Proofs
7.1. Proof of Lemma 1
First we note that for every and there exist positive numbers such that
These inequalities follow from the Burkholder inequality (see, for example, [29]) for the martingale and finiteness of the function
Using this and Hölder’s inequalities we can estimate
From the Borel–Cantelli lemma and the assumed summability of the right-hand side of (13) for and follows the second assertion of Lemma 1.
7.2. Proof of Theorem 2
We prove now the statements (a) and (a) of Theorem 1. First, we show for n large enough the inequalities
To this end, according to the definition of the estimator it is enough to establish for some the limiting relation
which follows from the definition of the class and Lemma 1:
Thus,
Analogously,
From (19) and (20) it follows, that for any and for n large enough
and the assertion 1(a) of Theorem 2 is proved.
From the Borel–Cantelli lemma and the assumed summability of the right hand side in (23) for follows the assertion 2(a) of Theorem 2.
The other statements of Theorem 2 for the estimator can be proved analogically.
7.3. Proof of Theorem 3
Now we estimate second moments of and Denote For we have
Further, by the definition of the function the Cauchy–Bunyakovskii–Schwarz inequality and from (22) we have
From (24)–(26) follows the first assertion of Theorem 3.
For the proof of the second assertion we estimate first, for some integer the rate of convergence of the moment
Let be non-negative integers and denote
By the Burkholder inequality for the martingale we have
By the definition of for some and and, as follows
Thus for and by the Borel–Cantelli lemma, as
Further,
and, as follows, as
7.4. Proof of Theorem 4
Note that the distribution of is the same as that of for all . Hence, Now by the Cauchy–Schwarz inequality and the fact that . Thus,
and the theorem is proven.
8. Conclusions
Non-parametric kernel estimation crucially depends on the bandwidth choice which, in turn, depends on the smoothness of the underlying function. Focusing on estimating a probability density function, we define a smoothness class and propose a data-based estimator of the underlying degree of smoothness. The convergence rates in the almost sure sense of the proposed estimators are obtained. Adaptive estimators of densities from the given class on the basis of the constructed smoothness parameter estimators are also presented, and their consistency is established. Simulation results illustrate the realization of the asymptotic behavior when the sample size grows large.
Recently, there has been an increasing interest in nonparametric estimation with dependent data both in terms of theory as well as applications; see, e.g., [15,30,31,32,33]. With respect to probability density estimation, many asymptotic results remain true when moving from i.i.d. data to data that are weakly dependent. For example, the estimator variance, bias and MSE have the same asymptotic expansions as in the i.i.d. case subject to some limitations on the allowed bandwidth rate; fortunately, the optimal bandwidth rate of is in the allowed range—see [34,35].
Consequently, it is conjectured that our proposed estimator of smoothness—as well as resulting data-based bandwidth choice and probability density estimator—will retain their validity even when the data are weakly dependent. Future work may confirm this conjecture especially since working with dependent data can be quite intricate. For example, [36] extended the results of [34] from the realm of linear time series to strong-mixing process. In so doing, Remark 5 of [36] pointed to a nontrivial error in the work of [34] which is directly relevant to optimal bandwidth choice.
Author Contributions
All authors contributed equally to this project. All authors have read and agreed to the published version of the manuscript.
Funding
Partial funding by NSF grant DMS 19-14556.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are very thankful to O. Lepskii for helpful comments and remarks.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rosenblatt, M. Stochastic Curve Estimation; NSF-CBMS Regional Conference Series in Probability and Statistics, 3; Institute of Mathematical Statistics: Hayward, CA, USA, 1991. [Google Scholar]
- Bartlett, M.S. Statistical estimation of density function. Sankhya Indian J. Stat. 1963, A25, 245–254. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Devroye, L. A Course in Density Estimation; Birkhäuser: Boston, MA, USA; Basel, Switzerland; Stuttgart, Germany, 1987. [Google Scholar]
- Gasser, T.; Müller, H.-G.; Mammitzsch, V. Kernels for nonparametric curve estimation. J. R. Stat. Soc. Ser. B 1985, 60, 238–252. [Google Scholar] [CrossRef]
- Granovsky, B.L.; Müller, H.-G. Optimal kernel methods: A unifying variational principle. Int. Stat. Rev. 1991, 59, 373–388. [Google Scholar] [CrossRef]
- Jones, M.C. On higher order kernels. J. Nonparametric Stat. 1995, 5, 215–221. [Google Scholar] [CrossRef]
- Marron, J.S. Visual understanding of higher order kernels. J. Comput. Graph. Stat. 1994, 3, 447–458. [Google Scholar]
- Müller, H.-G. Nonparametric Regression Analysis of Longitudinal Data; Springer: Berlin/Heidelberg, Germany, 1988. [Google Scholar]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice and Visualization; Wiley: New York, NY, USA, 1992. [Google Scholar]
- Devroye, L. A note on the usefulness of superkernels in density estimation. Ann. Stat. 1992, 20, 2037–2056. [Google Scholar] [CrossRef]
- Politis, D.N. On nonparametric function estimation with infinite-order flat-top kernels. In Probability and Statistical Models with Applications; Charalambides, C., Ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2001; pp. 469–483. [Google Scholar]
- Jones, M.C.; Marron, J.S.; Sheather, S.J. A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 1996, 91, 401–407. [Google Scholar] [CrossRef]
- Tsybakov, A. Introduction to Nonparametric Estimation; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Dobrovidov, A.V.; Koshkin, G.M.; Vasiliev, V.A. Non-Parametric State Space Models; Kendrick Press: Heber City, UT, USA, 2012. [Google Scholar]
- Ibragimov, I.A.; Khasminskii, R.Z. Statistical Estimation: Asymptotic Theory; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Lehmann, E.L.; Romano, J.P. Testing Statistical Hypotheses, 4th ed.; Springer Texts in Statistics: New York, NY, USA, 2022. [Google Scholar]
- Lepskii, O.V.; Spokoiny, V.G. Optimal pointwise adaptive methods in nonparametric estimation. Ann. Stat. 1997, 25, 2512–2546. [Google Scholar] [CrossRef]
- Brown, L.D.; Low, M.G. Superefficiency and Lack of Adaptibility in Functional Estimation; Technical Report; Cornell University: Ithaca, NY, USA, 1992. [Google Scholar]
- Lepskii, O.V. On a problem of adaptive estimation in Gaussian white noise. Theory Probab. Its Appl. 1990, 35, 454–466. [Google Scholar] [CrossRef]
- Butucea, C. Exact adaptive pointwise estimation on Sobolev classes of densities. ESAIM Probab. Stat. 2001, 5, 1–31. [Google Scholar] [CrossRef]
- Goldenshluger, A.; Lepski, O. Bandwidth selection in kernel density estimation: Oracle inequalities and adaptive minimax optimality. Ann. Statist. 2011, 39, 1608–1632. [Google Scholar] [CrossRef]
- Lacour, C.; Massart, P.; Rivoirard, V. Estimator selection: A new method with applications to kernel density estimation. Sankhya A 2017, 79, 298–335. [Google Scholar] [CrossRef]
- Politis, D.N. Adaptive bandwidth choice. J. Nonparametric Stat. 2003, 15, 517–533. [Google Scholar] [CrossRef]
- Politis, D.N.; Romano, J.P. On a Family of Smoothing Kernels of Infinite Order. In Computing Science and Statistics, Proceedings of the 25th Symposium on the Interface, San Diego, CA, USA, 14–17 April 1993; Tarter, M., Lock, M., Eds.; The Interface Foundation of North America: San Diego, CA, USA, 1993; pp. 141–145. [Google Scholar]
- Politis, D.N.; Romano, J.P. Multivariate density estimation with general flat-top kernels of infinite order. J. Multivar. Anal. 1999, 68, 1–25. [Google Scholar] [CrossRef]
- Politis, D.N.; Romano, J.P.; Wolf, M. Subsampling; Springer: New York, NY, USA, 1999. [Google Scholar]
- McMurry, T.; Politis, D.N. Nonparametric regression with infinite order flat-top kernels. J. Nonparametric Stat. 2004, 16, 549–562. [Google Scholar] [CrossRef]
- Liptser, R.; Shiryaev, A. Theory of Martingales; Springer: New York, NY, USA, 1988. [Google Scholar]
- Bijloos, G.; Meyers, J.A. Fast-Converging Kernel Density Estimator for Dispersion in Horizontally Homogeneous Meteorological Conditions. Atmosphere 2021, 12, 1343. [Google Scholar] [CrossRef]
- Cortes Lopez, J.C.; Jornet Sanz, M. Improving Kernel Methods for Density Estimation in Random Differential Equations Problems. Math. Comput. Appl. 2020, 25, 33. [Google Scholar] [CrossRef]
- Correa-Quezada, R.; Cueva-Rodriguez, L.; Alvarez-Garcia, J.; del Rio-Rama, M.C. Application of the Kernel Density Function for the Analysis of Regional Growth and Convergence in the Service Sector through Productivity. Mathematics 2020, 8, 1234. [Google Scholar] [CrossRef]
- Vasiliev, V.A. A truncated estimation method with guaranteed accuracy. Ann. Inst. Stat. Math. 2014, 66, 141–163. [Google Scholar] [CrossRef]
- Hallin, M.; Tran, L.T. Kernel density estimation for linear processes: Asymptotic normality and bandwidth selection. Ann. Inst. Stat. Math. 1996, 48, 429–449. [Google Scholar] [CrossRef]
- Wu, W.-B.; Mielniczuk, J. Kernel density estimation for linear processes. Ann. Stat. 2002, 30, 1441–1459. [Google Scholar] [CrossRef]
- Lu, Z. Asymptotic normality of kernel density estimators under dependence. Ann. Inst. Stat. Math. 2001, 53, 447–468. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).