Abstract
In aerial target-tracking research, complex scenarios place extremely high demands on the precision and robustness of tracking algorithms. Although the existing target-tracking algorithms have achieved good performance in general scenarios, all of them ignore the correlation between contextual information to a certain extent, and the manipulation between features exacerbates the loss of information, leading to the degradation of precision and robustness, especially in the field of UAV target tracking. In response to this, we propose a new lightweight Siamese-based tracker, SiamCTCA. Its innovative cross-temporal aggregated strategy and three feature correlation fusion networks play a key role, in which the Transformer multistage embedding achieves cross-branch information fusion with the help of the intertemporal correlation interactive vision Transformer modules to efficiently integrate different levels of features, and the feed-forward residual multidimensional fusion edge mechanism reduces information loss by introducing residuals to cope with dynamic changes in the search region; and the response significance filter aggregation network suppresses the shallow noise amplification problem of neural networks. The modules are confirmed to be effective after ablation and comparison experiments, indicating that the tracker exhibits excellent tracking performance, and with faster tracking speeds than other trackers, these can be better deployed in the field of a UAV as a platform.
1. Introduction
In recent years, there has been significant advancement in both high-resolution airborne remote sensing sensors and associated remote sensing technologies, although the development of airborne-based target-tracking systems continues to be a key focus and significant challenge in contemporary remote sensing research. The core process of the traditional target-tracking technology is to predict the position information, size, or subsequent motion state of subsequent consecutive targets based on the initial positional data and dimensions of any target in the first frame and to generate the predicted anchor frame [1]. However, distinguishing from the scenarios of target tracking in general scenes, aerial target tracking in practice often encounters complex scenarios in different video sequences that contain scale changes, occlusion, similar object interference, small targets, and low resolution [2], which requires target-tracking algorithms to have high precision and strong robustness. In order to satisfy the above objectives, ensuring the performance of target tracking in difficult challenges is an extremely challenging task. Therefore, we prefer to devise a target-tracking algorithm that can enhance remote sensing image tracking techniques in different aerial environments and extract deeper semantic information.
For existing technology, one method of target tracking involves learning the appearance model of the target, and then the generative tracking method identifies the target position in subsequent frames by locating the region that best matches the learned appearance model; the optical flow method [3] and the Kalman filter method [4] are two typical generative tracking methods. However, these generative tracking methods have disadvantages of complex structure, high computational cost, and poor tracking effect.
Another discriminative tracking approach emphasizes learning to differentiate between the target and background boundaries to improve tracking precision, and turn the tracking problem into a binary classification problem between target and non-target regions. Discriminative tracking algorithms, represented by deep learning [5], have achieved remarkable results in the field of target tracking due to their excellent adaptability and robustness. A Siamese network [6], as a special neural network architecture, contains two identical sub-networks; it extracts the target template and the candidate region features, and then compares the two features by a classification regression network to determine whether the candidate region is a target or not. Some studies show that an effective use of different levels of features can improve tracking performance. Common methods, such as context-dynamic feature fusion, achieve this function by computing target features or enhancing local feature analysis mining [7]. Nevertheless, existing methods for feature exploitation remain limited in their ability to effectively utilize contextual semantic information. Based on the above evaluation of current techniques, the balance between computational and precision performance of Siamese trackers makes these more suitable for aviation tracking performance, and the optimization method for feature exploitation is the key to improve their performance.
Therefore, we design a new lightweight aerial tracker, SiamCTCA, and our proposed innovative target-tracking framework employs a multiplexed parallel inter-temporal strategy, which improves the richness and precision of feature representation through the fusion of multi-level global information in temporal and spatial contexts, thus realizing the organic combination of multilevel features. Our method can effectively eliminate false high-confidence regions so that the tracker is able to concentrate more precisely on the target while minimizing the influence of irrelevant information. Meanwhile, by suppressing noise and removing irrelevant background information, it ensures that the information passed to the subsequent prediction stage is purer and more accurate, which not only improves the prediction precision of states such as target position and attitude, but also strengthens the tracker’s ability to perform reliably in complex and rapidly changing scenarios.
The key innovations and advantages of our approach are summarized below:
- We design a cross-temporal aggregated response fusion architecture, which adopts a multiplexed parallel cross-temporal strategy, realizes multi-level global information fusion in temporal and spatial through TME (Transformer multistage embedding) modules, organically combines high-level semantics and low-level features, and enhances the richness and precision of feature expression. This innovative architecture breaks through the traditional limitations, effectively improves the feature utilization efficiency, and provides more reliable feature support for target tracking.
- The FRMFE (feed-forward residual multidimensional fusion edge) module eliminates false high-confidence regions, allowing the tracker to focus on the target itself, reducing interference from irrelevant information, and significantly improving tracking precision and stability; the RSFA (response significance filter aggregation) network suppresses noise, removes irrelevant background information, and improves the precision of target position and attitude prediction, thus enhancing the tracker’s robustness in complex and changing environments.
- In the DTB70, UAV123 and UAVDT benchmarks, SiamCTCA delivers about 3% performance improvement over other lightweight mainstream trackers. It also performs well in difficult challenges. We employ a lightweight network architecture as the backbone for feature extraction, which enhances tracking speed without compromising tracking precision.
2. Related Work
In this part, we present a short review of recent research that is closely related to our work, including the Siamese-based trackers, attention mechanism, and lightweight network.
2.1. Siamese-Based Trackers
In the development of the target-tracking field, traditional methods have dominated for a long time, which is mainly attributed to the imperfection of the early machine learning theoretical system and the limitations of related technologies in practical applications [8,9]. Among them, correlation filtering-based methods are of interest due to their high calculation efficiency, simple deployment, and low computational resource requirements. Meanwhile, tracking algorithms based on key-point matching have been widely used due to their robustness to changes in target scales, rotations, and illumination, as well as the uniqueness of the feature descriptors and the precision of the matching. These traditional methods have driven the development of the aerial target-tracking field to a certain extent. In recent years, with the breakthroughs in deep learning theory and technological advances, a series of innovative and practical target-tracking algorithms have emerged one after another [10,11,12]. For example, MDNet [13] learns a shared feature representation across video domains through an online fine-tuning strategy, which significantly enhances the model’s adaptability to new targets and scenes, DeepSRDCF [14] innovatively combines deep learning feature extraction with a discriminative correlation filtering (DCF) framework and introduces a spatial regularization mechanism to improve tracking performance, the ECO [15] algorithm achieves efficient and accurate target tracking through the integration of convolutional neural network features, and the compact ECO algorithm achieves efficient and accurate target tracking by integrating convolutional neural network features and compact model representations. These deep-learning-based methods not only demonstrate powerful feature learning capabilities to capture complex target features, but also make significant breakthroughs in generalization capability and scene adaptation.
Today, Siamese trackers stand out among trackers with excellent tracking performance. Siamese network is a classical symmetric two-branch neural network architecture; the central concept is to learn the feature representation of the input samples through a two-branch structure with shared weights, and to judge how well the two samples match each other by using similarity metrics (e.g., mutual correlation, cosine distance). Traditional Siamese networks were first applied to tasks such as face recognition [16] and signature verification [17], with the advantage of efficient feature alignment through end-to-end training. Siamese network is a template-matching framework in the target-tracking domain: the initial frame is treated as the target template and the subsequent frames as the search region, and it determines the target location by calculating the similarity between the two. The original target-tracking algorithm applying Siamese networks was SINT [18], and an early representative work, SiamFC [6], initially applied Siamese networks to the tracking task, learning the generalized matching capability through offline training and implementing real-time tracking in the inference phase. Subsequent improvements such as SiamRPN [19] introduced the region proposal network (RPN), which significantly improved the localization precision. SiamRPN++ [20] further addresses the feature misalignment problem of deep networks (e.g., ResNet [21]) in the Siamese framework and enhances multi-scale adaptation through hierarchical feature fusion. In addition, SiamMask [22] achieves joint optimization of pixel-level target segmentation and tracking by adding a mask prediction branch, while Ocean [23] proposes an anchor-free design to simplify complex manual parameter tuning.
All of the above methods use a deeper level of feature extraction network. Although all of the above trackers have been applied in target-tracking scenarios, they fail to fully utilize multi-level features and lack an effective fusion mechanism for combining high-level semantic information with low-level details after feature extraction, and as a result, erroneous high-confidence intervals are generated, leading to limited effectiveness in airborne environments, especially for challenges like target occlusion, out-of-view conditions, and deformation tracking. Furthermore, its heavy reliance on external code makes it difficult to implement in aviation target-tracking systems.
2.2. Attention Mechanism
2.2.1. Overview of Attention Mechanism
In the field of deep learning, the attention mechanism, as an important technical tool, can be regarded as a kind of a computational method that simulates the information-screening mechanism in the human cognitive process, and has received widespread attention in recent years [24]. The core idea of the attention mechanism is to simulate the selective attention mechanism in the human visual or cognitive process so that the model can dynamically focus on the most relevant information [25,26]. Bahdanau et al. (2015) introduced this mechanism for the first time in a machine translation task in order to solve the long-distance dependency in the traditional encoder–decoder framework problem [27].
The attention mechanism is centered on selective focusing of input information. From a computational point of view, the implementation process of the attention mechanism can be formally characterized through given n input sequences structured as key–value pairs [(k1,v1),(k2,v2),…,(kn,vn)], whose computational process consists of three key steps.
Initially, the attention score function determines the similarity between the query matrix Q and each key K (we usually use the dot-product model). Then, normalization of the attention scores is achieved through the softmax function, which transforms it into a probability distribution, i.e., attention distribution. This normalization operation not only highlights the weights of important feature elements, but also guides the neural network to dynamically allocate computational resources to the most relevant feature regions, thus achieving effective capture of key information. The third step achieves the aggregation of input information by weighted summation of the attention distribution coefficients with the value matrix to generate the final output representation. The complete attention calculation process described above can be represented in the following formulas:
In these formulas, K denotes the key matrix in a key–value pair, the exact form of which depends on the contextual situation: it can be either the original input features or a linearly transformed representation of the features. s denotes the attention score matrix, where each element si corresponds to the attention score of the i-th position in the input sequence, n represents the sequence length, and d is the attention distribution matrix, calculated by applying the softmax function to the score matrix S, which results in a normalized probability distribution, where each element dᵢ denotes the attention weight of the i-th position in the input sequence. The final attentional output A is computed by weighted summation, which is expressed as the sum of the products of all the value vectors vi and the corresponding attentional weights di in the value matrix V. This process achieves adaptive aggregation of input information, reflecting the model’s focus on essential elements. In summary, the attention mechanism’s computational process can be summarized by the following simplified formalism: where Q denotes the query variable, and K and V correspond to the keys and values in the input key–value pairs, respectively.
In the exploration of attention mechanisms within computer vision, they are commonly classified into two distinct groups, self-attention [28] and non-self-attention, determined by whether the query, key, and value triples come from the same data source. According to the dimensional features extracted from the attention distribution, the self-attention mechanism can be further subdivided into various forms: for example, spatial attention [29] focuses on the spatial location relationship of the feature map, temporal attention [30] is used to deal with the dynamic dependency in the time-series data, channel attention [31] focuses on the interaction relationship between feature channels, and contextual attention [32] is used to capture global contextual information. These multidimensional attention mechanisms are designed to provide flexible and efficient feature extraction capabilities for computer vision tasks.
2.2.2. Transformer and Multi-Head Attention
We refer to the architecture of the homologous self-attention mechanism mentioned in Section 2.2.1 as the Transformer architecture [28]. The Transformer can compute the representation of an entire sequence in parallel, greatly increasing the speed of training and inference. This parallelism allows the Transformer to process long sequence data without the limitations of the gradient vanishing or gradient explosion problems in RNNs, and attention mechanism of the Transformer can directly compute the correlation between any two positions in the sequence so as to effectively deal with long sequence data. The core innovation of this architecture is the introduction of multi-head attention [28] based on scaled dot-product attention and multi-head attention, as shown in Figure 1. The Transformer abandons the traditional recurrent neural network structure. It significantly improves model efficiency by using a parallel computing approach, built from an attention mechanism, while enhancing the ability to model distant dependencies, laying an important foundation for the subsequent development of deep learning models. The Transformer model can be expressed by the following mathematical formula:
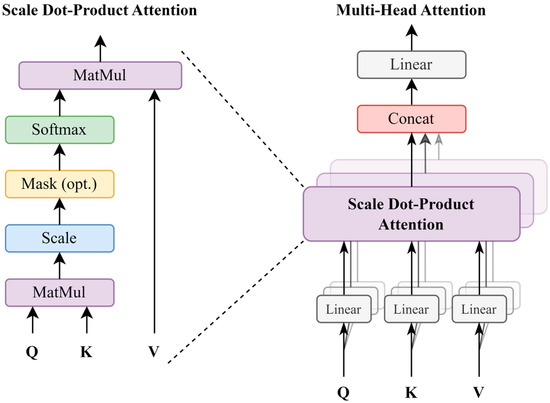
Figure 1.
The implementation processes of scaled dot-product attention and multi-head attention.
In the multi-head attention mechanism, the input data matrix X is linearly transformed to generate the query matrix Q, the key matrix K, and the value matrix V. Specifically, Q, K and V are obtained by matrix multiplication of the learnable weight matrices Wq, Wk, and Wv with the input X, respectively, where Wq, Wk, and Wv act as trainable parameters of the model, updated optimally via the stochastic gradient descent (SGD) algorithm [33] throughout the training phase. To stabilize the gradient propagation, the dot-product results are scaled using the dimension dk of the key vector when computing the attention score. Equation 4 shows the matrix operation procedure for linear transformations in this mechanism and its implementation details.
For each attention head, headi in the above equation, an independent self-attention computation process is used and a unique set of parameter matrices Wi are initialized separately. Specifically, each attention head generates the corresponding outputs through parallel computation, which are subsequently concatenated in feature dimensions and linearly transformed by the trainable parameter matrices Wo to acquire the ultimate representation of the multi-attention outputs. The core of the mechanism lies in computing the similarity among the Q and the K to generate an attention map. Subsequently, context-aware enhancement in the input features is achieved by weighted summation of the V with the softmax-normalized attention map.
2.3. Lightweight Network
Research on lightweight networks focuses on model compression, architecture design, knowledge distillation and applications. Model compression covers pruning and quantization techniques; architectural design includes MobileNets [34] and its improved version MobileNetV2, which introduces deeply separable convolution, and ShuffleNets [35], which adopts point-by-point grouped convolution and channel mixing operations; knowledge distillation can help lightweight knowledge distillation enable lightweight ‘student’ networks to learn from ‘teacher’ networks, and these networks are extensively applied to image classification, target detection and semantic segmentation.
The proposal of AlexNet [36] has had a profound influence on computer vision. The network successfully applies the ReLU activation function on large-scale image datasets, which effectively alleviates the gradient vanishing problem and significantly improves the training efficiency. By introducing data augmentation and Dropout techniques, AlexNet boosts the model’s generalization performance and decreases the risk of overfitting. It has the advantages of simple structure and easy implementation, as well as low computational resource requirements for model compression and inference acceleration, which makes it particularly well suited for deploying in computationally resource-limited environments. The pre-trained model of AlexNet shows excellent performance in migration learning tasks, particularly when the target is small and the hardware requirements are low for embedded or mobile devices. Compared with networks such as MobileNet and ShuffleNet, which are designed to be lightweight, AlexNet may be slightly less computationally efficient, but it has a simpler structure, which makes it easier to implement and debug in certain application scenarios. Compared with SqueezeNet [37], AlexNet usually achieves higher precision and performs better in specific tasks despite a slightly larger number of parameters. In conclusion, AlexNet has the advantages of simple and clear network, low computational costs, and ease of lightweight improvement, is particularly suitable as a feature extraction backbone network for lightweight models, and has important application value in scenarios with limited resources or in need of fast implementation.
3. Methodology
In the architecture shown in Figure 2, this method includes a search region branch combined with a target template branch. Specifically, feature extraction is first performed by AlexNet, and then after a series of convolutional operations, it is fed into the TFN. The TFN contains the Transformer multistage embedding (TME) module, and the TME module contains five intertemporal correlation interactive vision Transformer (ICIT) modules, and all of them have an adjustment layer at the front end of the TFN, which is used to reduce the amount of data for subsequent processing of features. After completing the processing flow of the similarity matching network, the feature maps are passed to prediction heads through the response significance filter aggregation network (RSFA) module. The classification network is responsible for determining the class attributes of the target, while the regression network concentrates on predicting bounding boxes of the measurement target for accurate target localization.

Figure 2.
The overall framework of this tracker consists of two different branches, the search region and the template patch, where the original image is passed through a feature abstraction backbone, a Transformer fusion neck, and a similarity match net. The response map is then input to the prediction head to predict the location of the target.
3.1. Multistage Interactive Modeling Functional Part
In this module, we adopt a novel cascade Transformer encoder design, named Transformer multistage embedding (TME), using the intertemporal correlation interactive vision Transformer (ICIT), and the operations of the ICIT module may be summarized as below:
where Q, K, and V represent the ternary inputs, MLP refers to the fully connected layer, Norm represents the normalization layer operation, AvgPool indicates the average pooling layer operation, and X is the intermediate variable of the residual structure. The multi-attention process is represented as follows:
where are all weighting matrices, and N is the number of the heads.
The TME structure is shown in Figure 3. Specifically, we utilize a pyramidal feature structures Pi, where i ∈ {3,4,5}, integrating low-level spatial details and high-level semantic information, where the latter helps to identify the class and overall features of the target, while the low-level spatial information captures details like the subtle textures and edges of the target. The configurations are P5, P4, P3 from the bottom to the top. The bottom–up path consists of the feed-forward convolution in the backbone architecture, producing the feature hierarchy {P5, P4, P3}.
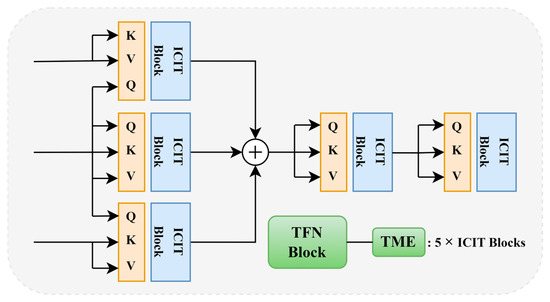
Figure 3.
Overall framework of the TME module. Inputs from top to bottom are P5, P4, P3.
Firstly, the information with pyramid features is fed to the 1×1 convolutional layer for the work of downscaling and spreading; P3, P4, P5 provide the key K and value V to their own feature hierarchy, using P4 as the query Q for the feature hierarchy of P3, P4, and P5.
Based on the above conditions, the respective features are fed to the ICIT module.
After that, we sum and fuse the results Pi, where i ∈ {3,4,5} obtained from P3, P4 and P5 features, respectively, are used to obtain R.
We fuse the R we just obtained and feed it into the ICIT module again to obtain R′.
We repeat the steps above again to fuse R′ and feed it into the ICIT module to obtain the final result R″.
Overall, our design implements inter-branch information interactive fusion, and we designed a total of three levels of structure, with the first level presenting three Transformer Encoders in parallel with additive fusion processing. The second and third levels both adopt a Transformer Encoder structure and connect them in series. At the practical application level, the processing and fusion of contextual information can be better as these were further enhanced and improved, as follows:
Firstly, we made innovative improvements to the existing Transformer encoder architecture. Specifically, we introduce the dual optimization mechanisms of average pooling and layer normalization at the input of key K and value V, which significantly improves the quality of the input information. Different from the existing Transformer encoder, which adopts the position encoding method with high computational complexity, we innovatively utilize the inherent spatial encoding information of the image and transformed it into sequential data through the flatten operation, which serves as the input to the encoder. This enhanced approach not only greatly decreases the computational complexity, but improves the module’s ability to perceive sequential information, thus achieving better sequential execution results.
Secondly, we proposed a three-way parallel multilevel feature fusion mechanism. Analyzed from the temporal relationships, the three blocks across branches achieve multilevel feature extraction at the semantic level, and feature information interaction across channel is achieved through element-by-element summing operations at the same pixel position between feature maps. Considering the spatial relationships, we adopt the multi-head attention mechanism, in which each parallel attention head can effectively capture different representation patterns of the target features, focusing on highly responsive regions in the feature map. Within a single feature map, we achieve spatial dimensional feature interactions by establishing responsive correlations between pixel locations to better characterize inter-pixel correlations. In addition, the introduction of cascade operation further enhances the characterization of high-confidence responsive regions.
The synergistic effect of the above mechanisms finally realizes the effective interaction and fusion of spatial–temporal features.
3.2. Feed-Forward Residual Multidimensional Fusion Edge (FRMFE)
Regarding the search region branch of similarity match net, we innovatively introduce the residual mechanism. From the analysis of the operation flow of the model architecture, the target template contains the key feature descriptions of the target, and using the target template as the convolution kernel can help in precisely exploring the matching feature information in the search region. The key part of the feature learning model is that the response map generated after the convolution operation contains highly responsive regions with two branching features.
The process is as shown in the equation below:
where is the output obtained after the target template is operated according to Section 3.1, and is the output obtained after the search region is operated according to Section 3.1.
The introduction of the residual mechanism is crucial for target tracking because it can dynamically adjust the target feature representation according to the changes in the search region, thus effectively capturing the feature changes in the current frame. Although the response map fuses the information of the search region and the target template, some critical information may still be lost during feature fusion due to the approximation processing during computation and the inherent limitations of deep networks.
In the image-data-processing process, the original image can obtain a feature representation with high discriminative properties after the feature extraction network. However, in the subsequent network-processing stage, adding the target template to the cross-correlation operation causes feature selection bias, i.e., the target template is selective to the features in the search region, and amplifies the specific feature responses in the cross-correlation calculation process. This feature amplification mechanism may generate bias in practical application scenarios, especially in complex scenarios, where the amplified feature response may differ significantly from the real feature distribution of the target, leading to misjudgment of the target state by the model, and affecting the robustness of tracking performance.
For these reasons, the residual edge mechanism that we introduce deeply fuses the search region with the results after the cross-correlation operation. This operation aims to prevent the high-confidence intervals of the results from deviating from the true intervals due to the amplification of certain features during the cross-correlation operation; the preference for the target template and the selectivity of the search region cause specific consequences. It also prevents the loss of information resulting from the pre-processing step. Essentially, the operation belongs to a kind of deep separation at the channel level. Spatial information is integrated into the pre-processing stage to construct a better feature representation through multilayer feature interactions across spatial and temporal, thus improving the efficiency of the model for target recognition and detection.
3.3. Response Significance Filter Aggregation Network (RSFA)
After completing the series of operations above, according to the conventional process, we usually input the response map obtained in the previous section into the prediction header in the next step in order to carry out classification, regression and location determination operations on the high-confidence intervals in the response map. However, after in-depth research and a lot of experimental observations, we found a key problem: At the shallower level of the neural network, the noise will be gradually amplified with the increasing depth of the neural network. This phenomenon seriously affects the model’s accurate identification and localization of targets, resulting in biased predictions and diminishing the model’s reliability and precision.
In view of this situation, in order to effectively solve the problem of noise amplification and enhance the performance of the model, we innovatively propose a response significance filter aggregation network, as shown in Figure 4. The core objective of the network is to suppress the significance of the wrongly considered correct target in the previous network processing, and, at the same time, to enhance the significance of the actually correct target to improve the model’s capacity to identify and describe the target.
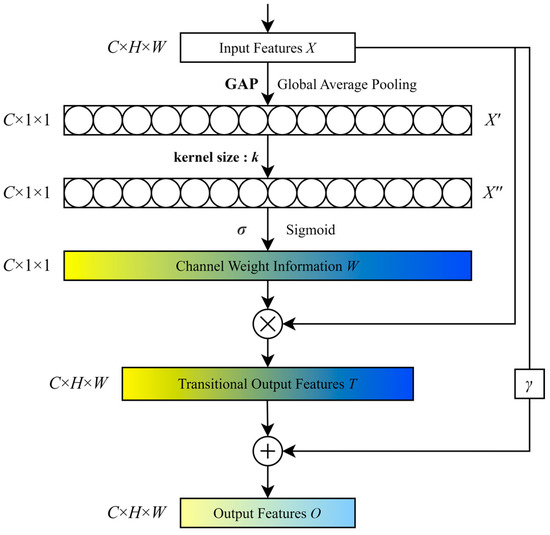
Figure 4.
Overall framework of the proposed RSFA module. The core function of the RSFA is to suppress the significance of the wrongly perceived correct target in the forward network, enhance the salience of the actual correct target, optimize the model recognition and representation ability, and solve the noise amplification problem to improve the model’s performance.
Briefly, the response map X obtained from the previous process is input into the RSFA network, and after a global average pooling operation and a special convolution operation with k as the convolution kernel, the channel weight W is obtained and then merged with the original input response X to obtain the response map T with weights, and the weighting information can intuitively and accurately suppress the saliency of the erroneous target in the previous step. Finally, we re-weight and fuse the obtained response map at the channel-wise with the original response map X from the previous step to obtain the final output O. Weighting here means multiplying the original response map X by a parameter γ, which is a learnable parameter whose value will be adjusted according to gradient descent algorithm of module to learn the weights that are most suitable for the module. The complete process is illustrated in the equation below, where ε and b are hyperparameters:
The RSFA network can effectively break through the network structure’s dependence on local information and acquire long-range and multi-dimensional interaction features. By fusing shallow details and deep semantic information, the feature aggregation process can be optimized to achieve more comprehensive information utilization, thus improving the overall performance of the model.
Compared with the traditional continuously superimposed convolution and RNN operations, the operations we propose above have significant advantages. By directly establishing the connection between spatial–temporal locations, the method is able to quickly capture remote dependencies. This high-dimensional global modeling of remote dependencies can significantly enhance the feature representation of the depth response maps, optimizing the semantic information while balancing the depth and shade information at the pixel level. In addition, the method also has a higher advantage in terms of computational efficiency, and can manage substantial amounts of data in less time, which provides strong support for practical applications.
3.4. Training Loss Function
As a key component in the target detection framework, the prediction head is primarily responsible for decoding the feature response map and accurately estimating the target parameters. The key to the precision of this module lies in the ability to accurately learn the scale and spatial distribution pattern of the target during training, which is the core of achieving accurate target estimation. In this study, after completing the optimization process of the similarity matching network, the input received by the system in the prediction header module is a feature tensor with a dimension of 25 × 25 × 256. The module performs multi-level object estimation on the input features through three sub-branches set in parallel-classification heads, regression heads, and centrality heads, and finally generates three response maps with different semantic information, corresponding to the category probability, bounding box coordinates, and centroid confidence of the target, respectively.
The classification response map generated by the classification heads has a dimensional resolution of 25×25, where each spatial location Mcls(i,j) contains a pair of feature vectors [δpos, δneg] characterizing the foreground probability scores and the background probability scores for the respective positions in the search region, respectively, because we used the softmax function as the activation function, and δpos and δneg computationally sum to 1. These probability values are encoded and stored as two-dimensional vectors, where the foreground score δpos represents the confidence that the location corresponds to the target object, while the background score δneg indicates the probability of it falling into the background region. In the supervised learning process, the true category label of each spatial location is indicated by GT(i,j), while the discrepancy between the prediction result and the true label is quantitatively evaluated by the binary cross-entropy loss function LossBCE. Its mathematical expression is shown below, where y(i,j) is the label of each pixel:
The regression heads output a regression map . Let l′, t′, r′ and b′ denote the pixel point (x,y) distances to the left, top, right and bottom edges of the ground truth box, and l, t, r and b denote the distances of the pixel points (i,j) to the four edges of the target bounding box, respectively. Where t(i,j) = (l,t,r,b), T(i,j) denote the coordinates of the ground truth box, and we mark the upper left corner of the ground truth box as (x0,y0) and the lower right corner as (x1,y1). We can express BCE loss and regression loss as in the following mathematical equation:
The LossIoU in the above equation represents the generic intersection over union loss function for calculating the IoU loss between t(i,j) and T(i,j):
I(x,y) is an indicator function; it is defined by Equation (15) as follows:
The centrality heads output a single-channel spatial feature map , where each element value Mcen(i,j) corresponds to the estimated centrality probability value C(i,j) at the image spatial location (i,j). This centrality probability value can be calculated using the following mathematical expression:
Each pixel (i,j) of the centrality map Mcen has a centrality score δcen, which is utilized to quantify the spatial correlation between the location and the target center. The centrality loss function formula is as follows:
In summary, we obtain a total loss of:
where α1, α2, and α3 represent the weights for the classification loss, centrality loss, and regression loss.
4. Experiments and Discussion
In this section, we will fully analyze and elaborate the entire experimental design process and the test results obtained. The benchmark datasets employed and their associated evaluation metrics are detailed comprehensively. Then, to comprehensively evaluate the algorithm’s performance, we choose several representative aerial image datasets and conduct comparative experiments with SOTA lightweight trackers. Finally, we validate the precision and real-time capability of SiamCTCA for aerial remote sensing target tracking through ablation experiments and tracking speed experiments.
4.1. Implementation Detail
We adopt an end-to-end training method to perform SiamCTCA. The experimental platform is configured with NVIDIA GeForce RTX4070Ti SUPER GPUs and Intel® Core™ i7 14700KF CPUs and is implemented based on the Pytorch 2.5.1 framework and the Python 3.9 environment. The training process was optimized using an SGD optimizer, with the batch size set to 32, and a total of 20 epochs were trained. The learning rate was determined using a warm-up strategy [38], with the first 5 epochs increasing linearly from 0.001 to 0.005, and then the next 15 epochs decaying linearly from 0.005 to 0.0005. The training data were obtained from the four benchmark datasets, VID, LaSOT [39], COCO [40] and GOT-10k [41]. There was a total of 60 h of training.
4.2. Comparison with the SOTA
In order to verify the tracking performance of SiamCTCA, the widely recognized benchmark datasets of DTB70 [42], UAV123 [43] and UAVDT [44] in UAV visual tracking are selected as the evaluation platform in this study. The experiment adopts the one-pass evaluation (OPE) method, with precision and success rate as the core evaluation metrics. To demonstrate the superiority of this tracker, it is compared to a variety of current lightweight SOTA that perform better. To ensure fairness and reliability of the comparisons, all trace results are obtained from the authors of the proposed models or recreated using publicly available code.
4.2.1. DTB70 Benchmark
- (a)
- Overall Performance
The DTB70 benchmark dataset is an essential evaluation resource in aerial target tracking, featuring 70 video sequences recorded from aerial platforms. The dataset provides a reliable testbed for comprehensive evaluation of algorithm robustness and speed by systematically integrating multiple challenging real-world challenges. In terms of the evaluation system, DTB70 adopts precision and success rate as the core quantitative metrics and establishes a standardized performance evaluation framework. Each video sequence is accompanied by precise target bounding box annotations, supplemented by detailed scene attribute annotations that can be categorized into 11 key dimensions [42]. These multi-dimensional attribute annotations not only significantly enhance the complexity of the airborne target-tracking task, but also provide a systematic evaluation dimension for the detailed analysis of the algorithm performance, which facilitates a deep understanding of the performance characteristics of the algorithm in different challenges.
In order to comprehensively evaluate the performance of the proposed SiamCTCA algorithm, this study conducts experiments comparing it with 10 SOTA trackers on the DTB70 benchmark dataset, including TCTrack [45], SGDViT [46], HiFT [47], SiamAPN [48], SiamAPN++ [49], LightTrack [50], SiamSA [51], SiamDWFC [52], SiamDWRPN [52] and Ocean [23], which are the most representative current models.
As illustrated in Figure 5, the quantitative evaluation indicates that SiamCTCA achieves the most superior performance in both key metrics of precision (81.7%) and success rate (62.4%). Specifically, compared to the suboptimal model SGDViT and to TCTrack, SiamCTCA showed a 2.2% increase in success rate and a 1.0% increase in precision, and a 0.3% increase in success rate and a 0.3% increase in precision. This significant performance improvement is mainly attributed to the cross-temporal interactive fusion network architecture proposed by SiamCTCA, which achieves better feature expression through an excellent mechanism performance: an efficient contextual information interaction mechanism is established to enable the effective fusion of multi-level features; the expression capability of positional features is strengthened in the shallow network, and the extraction capability of semantic information is enhanced in the deep network. Through the synergistic optimization of spatial–temporal features, the accurate modeling of aerial target motion characteristics is realized. The experimental results show that this multilevel feature expression mechanism can be better adapted to the special requirements of aerial target-tracking tasks and provides reliable technical support for target tracking in difficult challenges.
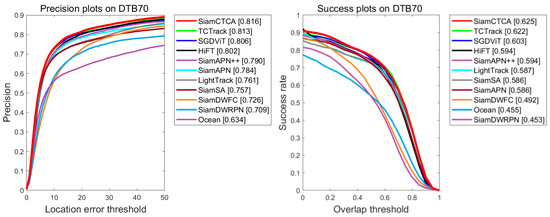
Figure 5.
The tracking results of the proposed SiamCTCA and SOTA trackers on DTB70 benchmark.
- (b)
- Difficult Challenges
As shown in Table 1, this study conducted success rate comparison experiments on nine sets of video sequences with typical challenge attributes covering the following areas: similar object around (SOA), out-of-view (OV), occlusion (OCC), fast camera motion (FCM), in-plane rotation (IPR), deformation (DEF), out-of-plane rotation (OPR), aspect ratio variation (ARV), and background clutter (BC). The experimental results indicate that, relative to existing SOTA trackers, the proposed SiamCTCA delivers a better performance in the majority of challenging scenarios. It is worth noting that TCTrack performs optimally in four of the nine difficult challenges (BC, FCM, OCC, IPR), which is mainly due to its feature extraction mechanism using temporal information enhancement. However, this temporal modeling approach significantly increases the computational complexity. In contrast, our proposed SiamCTCA tracker employs the lightweight AlexNet as the backbone feature extraction network, which has a significant advantage in terms of computational efficiency. And in these four advantageous scenarios, the performance gap between SiamCTCA and TCTrack remains small (<0.6%), while TCTrack underperforms in the OPR challenge. A comprehensive comparison shows that our method significantly improves the computational efficiency while maintaining competitive tracking precision, demonstrating a better overall performance advantage. In particular, when addressing significantly difficult difficulties, like OV, DEF, SOA and OPR, SiamCTCA achieves the highest success rates in Gull1 sequences containing DEF, BMX4 sequences with OV, BMX3 sequences with OPR, and MountainBike1 sequences with SOA. These experimental results thoroughly validate the robustness and effectiveness of SiamCTCA in difficult challenges and show that it can better cope with various challenging problems in aerial target tracking.

Table 1.
Comparison of SiamCTCA with other trackers on difficult challenges.
- (c)
- Visual Analysis
Under some difficult challenges, some of the trackers cannot fulfill the tracking task well; in order to clearly demonstrate the tracking performance of SiamCTCA in difficult challenges, we compare it with other SOTA trackers in DTB70 and discuss their performance. We select six of the seventy video sequences in DTB70, each containing various challenging difficulties, as illustrated in Figure 6. In video sequences featuring out-of-field-of-view scenes (e.g., RcCar4_1), all other trackers failed to track or tracked off target when faced with an occluded scene, while only SiamCTCA completed the tracking task, which verifies that our proposed TME module and FRMFE module can enrich the information fusion between feature maps so that the real high-confidence region is more amplified, and realize the cross-temporal multi-layer deep feature interactions, which allows features to be better utilized, thus improving tracking performance in complex scenarios. In video sequences containing low-resolution, fast-moving scenes such as ChasingDrones_1 and Surfing03_1, SiamCTCA effectively handles challenging difficulties caused by low resolution and cluttered backgrounds, achieving successful tracking, while other trackers are unable to track effectively. This further validates the robustness of SiamCTCA in addressing challenging scenarios with multiple difficulties, and highlights the RSFA network’s ability to surpass local information processing constraints to acquire long-range, multi-dimensional interaction information, which leads to better processing of semantic information and thus improves the tracking efficiency. The tracker’s precision is significantly enhanced when dealing with challenging difficulties. SiamCTCA offers a new and effective tracking method in UAV tracking.
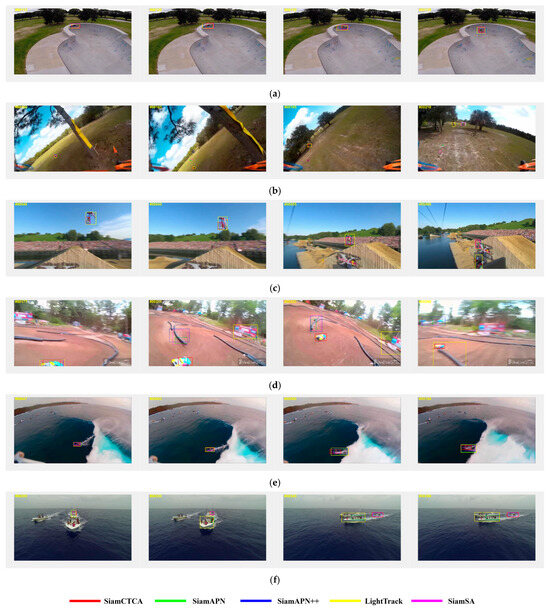
Figure 6.
Intuitive tracking results of SiamCTCA compared to other trackers for different targets in difficult scenarios; the figures illustrate the visual experiment results for the image sequences of (a) BMX5_1, (b) ChasingDrones_1, (c) Motot1_1, (d) RcCar4_1, (e) Surfing03_1, and (f) Yacht4_1.
- (d)
- Heatmap Experiments
To further validate the effectiveness of the TME module in SiamCTCA, we conducted heatmap visualization experiments on the DTB70 benchmark, and the results are shown in Figure 7. The experimental results show that compared with the baseline, the precision of target recognition is significantly improved after the introduction of the TME module. The excellent performance of the TME module is mainly attributed to its powerful feature extraction, fusion and representation capabilities. Specifically, the TME module achieves the synergistic use of target details and abstract semantics by deeply fusing different levels of semantic information: shallow features are mainly used to capture the details of the target for accurate localization, while deep features are used to extract the abstract semantic information of the target to support category discrimination. Through the pixel-by-pixel summation operation, the TME module enhances the interaction capability of global information while preserving spatial details, thus realizing efficient information exchange across channels. In addition, the multiplexed parallel feature header further enhances the inter-pixel correlation and improves the consistency and discriminate performance of the feature representation by interacting with the pixel response values at different spatial locations in the feature map.


Figure 7.
Heatmap comparison experiments of our proposed baseline of SiamCTCA with the addition of TME module to the baseline; the pictures show the results of heatmap comparison experiments for the following image sequences: (a) BMX4, (b) Horse1 (c) Soccer2, and (d) SpeedCar2.
From the results of the heatmap, it can be seen that after the introduction of the TME module, the tracker is able to identify and locate the high-confidence regions more accurately, and the high-confidence regions are highly consistent with the real target positions. In contrast, the tracker without the TME module has a more dispersed distribution of high-confidence regions in the heat map, and some non-target regions are also given a higher confidence level, which leads to a decrease in tracking performance. This phenomenon indicates that the TME module can effectively fuse different levels of semantic information and significantly improve the robustness of the tracker by enhancing the feature representation capability. In addition, the TME module mitigates the problem caused by feature loss during feature extraction for lightweight networks, and provides a more accurate feature representation for the subsequent networks, thus further improving the overall performance.
However, we found that in the 70th frame of the Soccer2 sequence, although the phenomenon of high confidence in the non-target region was significantly suppressed and did not significantly affect the tracking performance compared to the baseline method, there was still the problem of abnormally high confidence in the local region, which may pose a potential threat to the robustness of the system. Through in-depth analysis, we found that this phenomenon may originate from the abnormal transfer of confidence between neighboring pixels during pixel interaction, which leads to noise amplification during the weighted aggregation of pixels corresponding to coordinates. To solve this problem, we introduce the FRFME module and RSFA module into the network architecture, which effectively suppresses the noise interference through the multi-level feature optimization and spatial sensing mechanisms, thus enhancing the precision of confidence prediction in the target region.
4.2.2. UAV123 Benchmark
- (a)
- Overall performance
UAV123 is a benchmark dataset for low-altitude aerial target tracking proposed by Mueller et al. in 2016, which is widely used in related research fields. The dataset includes 123 high-quality video sequences totaling over 110,000 images covering a wide range of typical UAV photography scenarios. The target objects in the dataset have challenging difficulties, which can effectively evaluate the robustness of the tracking algorithms in difficult UAV environments. Table 2 demonstrates the performance comparison of SiamCTCA with other SOTA on the UAV123 dataset, and the comparison models include P-SiamFC++ [53], ECO-HC [54], DeconNet [55], SGDViT [46], SiamATTRPN [56], SiamAPN [48], SiamAPN++ [49], TCTrack++ [57], ARCF [58] and SiamCAR [59].
Table 2.
The tracking results of the proposed SiamCTCA and SOTA trackers on UAV123 benchmark.
The experimental results show that SiamCTCA achieves substantial enhancement in both success rate (Succ.) and precision (Pre.): the success rate is improved from 58.2% to 60.7%, and the precision is improved from 76.8% to 78.7%. Compared to trackers based on lightweight Siamese architectures such as SiamAPN++, SiamCTCA significantly outperforms other similar algorithms in success rate and precision. As regards the analysis of the results, we believe that the main reason for the improved performance is that SiamCTCA achieves deep fusion of features at different levels through multi-level relevance modeling. In addition, we designed a novel network architecture that can adaptively integrate regional features with global dependency information in difficult challenges while effectively suppressing noise interference. The feed-forward residual fusion mechanism adopted by SiamCTCA further realizes deep multi-level feature interactions across spatial and temporal boundaries, which results in higher precision in pixel-level measurements and more accurate localization of the target center position. The experimental results show that the multiphase perceptual network employed in SiamCTCA has significant advantages and achieves a significant breakthrough in performance compared to mainstream SOTA trackers.
- (b)
- Heatmap Comparison Experiments
In order to visually prove the distribution of our proposed SiamCTCA versus other Siamese-based trackers for high-confidence regions in different video sequences and further confirm the effectiveness of the cross-temporal interactive fusion approach, we chose five groups of representative cases from the UAV123 benchmark dataset and conducted a comparative analysis with SiamAPN. Figure 8 shows the heatmap comparison results of the 5 groups of cases. The experimental results reveal that, in comparison with SiamCTCA, the heatmap regions distribution of the SiamAPN tracker is more scattered, indicating that its attention mechanism is easily affected by interfering factors, which causes the tracker to misclassify the wrong pixel region as a high-confidence region. In contrast, SiamCTCA is able to effectively filter feature impairments due to cross-correlation operations and enables the model to focus more comprehensively on the multi-level features of the target by fusing the positional and semantic information between different features. This mechanism substantially boosts the tracking precision and robustness of SiamCTCA, further demonstrating the effectiveness of the proposed method.


Figure 8.
Heatmap comparison experiments between our proposed SiamCTCA tracker and the advanced tracker SiamAPN under some scenarios; the pictures show the results of heatmap comparison experiments for the following image sequences: (a) group1_1, (b) group1_2, (c) bike3, (d) boat3, and (e) car4.
4.2.3. UAVDT Benchmark
UAVDT, as a large-scale UAV detection and tracking benchmark, covers 50 video sequences of single-target tracking in real complex scenarios, which effectively simulates diverse and complex environments from the viewpoint of UAVs and provides a reliable benchmark for validating the tracking performance of the proposed method in real scenarios. The benchmark contains a variety of challenging scene attributes in the single-target-tracking task, such as background clutter (BC), camera motion (CM), object motion (OM), small object (SO), illumination variations (IV), object blur (OB), scale variations (SV), long-term tracking (LR), and large occlusion (LO). In order to comprehensively evaluate the performance of the proposed method, we selected various trackers such as HiFT, SiamAPN, AutoTrack [60], ARCF, TCTrack, SiamAPN++, RACF [61], SiamFC, SiamFC++, Aba-ViT, UpdateNet [62], Ocean, ECO, and LightTrack for the comparative experiments and performed detailed analyses for the different challenge attributes. Among them, AutoTrack, ARCF, RACF, ECO and UpdateNet belong to the correlation filtering trackers, while HiFT, SiamAPN, TCTrack, SiamAPN++, SiamFC, SiamFC++ [63], Aba-ViT [64], Ocean, and LightTrack belong to the Siamese-based trackers. The specific experimental results are shown in Table 3, and Figure 9 demonstrates the comparison of the success rates of some trackers under different challenge attributes.
Table 3.
Tracking results of SiamCTCA with other advanced trackers on the UAVDT benchmark.
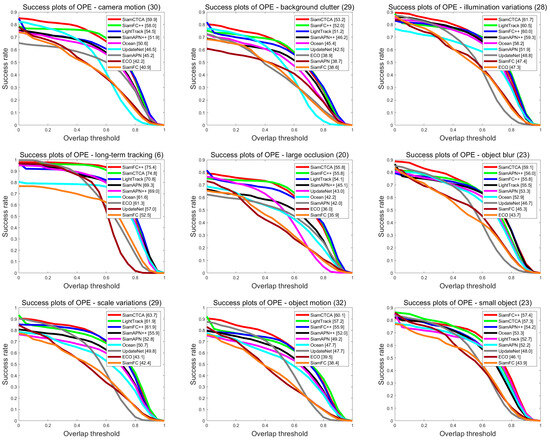
Figure 9.
Difficult challenge results of SiamCTCA with other advanced trackers on UAVDT benchmark.
The experimental results show that SiamCTCA performs well in the tracking task with a success rate of 61.3% and a precision of 83.5%. Compared with other correlated filter trackers and Siamese-based trackers, SiamCTCA achieves a leading position in performance: the success rate is improved by 11.9% and the precision by 6.2% compared with the RACF tracker, and the success rate is improved by 1.4% and the precision by 0.1% compared with the Aba-ViT tracker. These results fully validate the effectiveness of the method in real-world tracking tasks. It is particularly noteworthy that our SiamCTCA is able to achieve better results compared to other non-Siamese-based trackers and maintains excellent tracking performance under extreme complex environments such as bad weather like haze and occlusion, low-light, motion blur, and wide-area occlusion, and successfully copes with all kinds of difficult challenges in the real world.
4.3. Ablation Experiments
To demonstrate the validity of three different modules under different conditions, TME, FRMFE, and RSFA in the SiamCTCA were proposed in this paper. We integrated each of these three modules into the baseline tracker and analyzed and discussed the validity of the proposed approach in depth. As shown in Table 4, we chose the UAV123 benchmark and the DTB70 benchmark for comprehensive and detailed ablation experiments, respectively. The baseline tracker we used consists of the AlexNet backbone network, the cross-correlation fusion network, and the prediction heads.
Table 4.
Ablation experiments of the TME, FRMFE and RSFA on DTB70 and UAV123 benchmarks.
On the DTB70 benchmark, the success rate of the TME module, the FRMFE module, and the RSFA module improved by 0.5%, 1%, and 1.3%, respectively, and the precision by 1%, 1.3%, and 1.1%, respectively, compared to the baseline tracker, and the addition of all the modules improved the tracker’s success rate and precision by 1.9% and 2.7%, respectively, to final rates of 62.4% and 81.7%. On the UAV123 benchmark, compared to the baseline tracker, the success rate improved by 1.7%, 2.3%, and 1.2%, and the precision improved by 1.6%, 2%, and 1%, respectively, and the tracker’s success rate and precision eventually improved by 3.9% and 3.8% to 60.5% and 78.6%, respectively, after adding all modules.
The improvement shows that our proposed SiamCTCA and the three modules can effectively cope with the tasks under UAV tracking by interactively fusing the information across spatial and temporal, which improves the feature-extracting efficiency of the model and further eliminates the error information.
4.4. Tracking Speed Experiments
Typically, because UAVs have limited computational resources, it is imperative to prioritize both tracking precision and tracking speed improvements. We used a lightweight AlexNet network for feature extraction, aiming to meet the needs of various aspects such as real-time, resource constraints, deployment convenience, cost control, robustness and application scenarios, and to ensure efficient and stable operation under various conditions. Therefore, this section compares the tracking speeds. We performed tracking speed tests on the DTB70 benchmark, and conducted comparison experiments by testing six SOTA trackers for UAV tracking. As shown in Table 5, the results reveal that that our proposed SiamCTCA is excellent in terms of tracking precision and speed, with a substantial advantage in tracking speed over other trackers. Moreover, according to the experimental results, our algorithm is more suitable for real-time deployment on aerial tracking platforms such as UAV platform.
Table 5.
Tracking speed comparison of different trackers on the DTB70 benchmark.
4.5. UAV Deployment and Real-Flight Tests
4.5.1. Comparison of FLOPs and Params
Typically, because UAVs have limited computational resources, it is imperative to prioritize both tracking precision and tracking speed improvements. We use a lightweight AlexNet network for feature extraction, aiming to meet the needs of various aspects such as real-time, resource constraints, deployment convenience, cost control, robustness and application scenarios, and to ensure efficient and stable operation under various conditions. Therefore, this section compares the tracking speeds. We performed tracking speed tests on the DTB70 benchmark, and conduct comparison experiments by testing six SOTA trackers for UAV tracking. As shown in Table 6, the results reveal that that our proposed SiamCTCA is excellent in terms of tracking precision and speed, with a substantial advantage in tracking speed over other trackers. Moreover, according to the experimental results, our algorithm is more suitable for real-time deployment on aerial tracking platforms such as UAV platform.
Table 6.
Comparison of FLOPs and Params of SiamCTCA with other different advanced trackers.
4.5.2. UAV Deployment and Real-World Visualization Experiments
In this study, the RK3588 developed by Rockchip is selected as the UAV on-board computing platform, which is an embedded processor that integrates a high-performance CPU, GPU, and a dedicated NPU module, and has the advantages of high computational power, high energy efficiency ratio, and compact size. Specifically, the RK3588 adopts a tri-core NPU architecture that provides 6TOPs of computing power. Regarding the supported data types, RK3588 supports INT8 integer arithmetic, while the PC-side GPU supports FP32 floating point arithmetic. Based on this hardware platform, we conducted comprehensive board-side validation experiments using video sequences captured from real scenarios (containing multiple types of targets such as vehicles, pedestrians, and non-motorized vehicles), including quantitative tests, comparative analyses, and ablation studies. The experimental data show that the average utilization rates of each computing unit when the system is running are 68.9% for GPU, 35.8% for CPU and 55.1% for NPU. The detailed performance evaluation results are shown in Table 7, which verifies the effectiveness of the algorithm in real deployment.
Table 7.
Results of SiamCTCA compared to baseline and SiamAPN++ deployments on NVIDIA GeForce RTX4070Ti SUPER GPUs and RK3588.
As shown in Table 7, we compare the performance of SiamCTCA, SiamAPN++, and SiamCTCA’s baseline under two data types, FP32 (NVIDIA GeForce RTX4070Ti SUPER GPUs) and INT8 (RK3588). The experimental results show that the tracking success rate and precision under the INT8 data type decrease by about 1% on average compared to the FP32 data type due to the presence of quantization error. Notably, SiamCTCA demonstrates significant advantages under the INT8 data type: it improves the precision by 4.6% and the success rate by 4.5% compared to the baseline, and improves the precision and the success rate by 2.5% and 2.4% compared to SiamAPN++, respectively. In terms of computational efficiency, the FPS of SiamCTCA is essentially the same as that of baseline, while it is improved by 0.2 frames per second compared with SiamAPN++. These data fully demonstrate that SiamCTCA maintains excellent tracking precision and real-time performance even under quantized deployment conditions.
As shown in Figure 10, we visualize the performance of SiamCTCA with video sequences of real scenes captured by UAVs from Changchun City, Jilin Province, People’s Republic of China, which we selected to contain four challenging sub-sequences for visualization. The experimental results show that SiamCTCA maintains a robust tracking performance even in complex realistic environments. Specifically, SiamCTCA achieves accurate tracking in a variety of difficult scenarios, including target occlusion (bike1), high-speed motion (car1), and low-light conditions (night1), etc. The TME module enhances the characterization of the target region through efficient feature fusion, while the RSFA module and the FRMFE module optimize the spatial feature aggregation to effectively suppress noise interference. The experiments verify that SiamCTCA has excellent robustness while maintaining high precision, which fully proves that the algorithm is suitable for real-time accurate tracking tasks on UAV platforms.

Figure 10.
Visualization of tracking results from the SiamCTCA tracker for video sequences filmed under real-world conditions; the image shows the results of the visual tracking of the following image sequence: (a) bike1, (b) car1, (c) girl1, (d) night1.
5. Conclusions
We propose a novel lightweight tracker SiamCTCA based on Siamese architecture for UAV target tracking. In our framework design, the TME module takes into account different levels of spatial and temporal information correlation, and achieves convergence between different levels of features; the FRMFE module eliminates false high-confidence regions and focuses on the real high-confidence regions, which improves the precision and robustness of tracking. In addition, the RSFA network suppresses the noise and removes the irrelevant background information, which ensures that the information delivered to the subsequent predictor is pure, accurate and effective. We carried out numerous experiments on the DTB70 and UAV123 benchmarks, and our SiamCTCA demonstrates competitive tracking performance compared to other SOTA trackers, and SiamCTCA can also achieve excellent performance within some difficult challenges. We also performed ablation experiments, which show that our proposed modules are effective, and finally we performed tracking speed comparison experiments with some advanced trackers, and all of our tracking speeds are significantly better than those of other comparative algorithms. This shows that SiamCTCA can be able to track in real time without loss of precision and success rate. SiamCTCA is able to achieve aerial tracking efficiently and accurately, and our algorithms are more suitable for real-time deployment on aerial tracking platforms such as a UAV platform. SiamCTCA partially mitigates the above problems through cross-correlation attention modules and adaptive template updating. However, limited by the lightweight design requirements, the feature extraction module usually adopts a shallow convolutional neural network architecture, resulting in its local sense-field property reinforcing the local feature matching paradigm, which, in turn, may trigger a degradation of the tracking performance. In the future, lightweight global inference mechanisms (e.g., hybrid Transformer modules) or online meta-learning techniques need to be explored to improve the robustness of conjoined trackers in complex scenarios.
Author Contributions
Conceptualization, Q.W. and F.L.; methodology, Q.W.; project administration, J.L. and B.Z.; resources, F.X.; software, Q.W.; validation, Q.W.; investigation, Q.W., F.L., J.L., B.Z. and Y.W.; visualization, Q.W.; writing—original draft preparation, Q.W.; writing—review and editing, F.L. and F.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under Grant 62405310.
Data Availability Statement
Data are contained within this article.
Acknowledgments
The authors are grateful for the anonymous reviewers’ critical comments and constructive suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, F.; Wang, X.; Chen, Q.; Liu, J.; Liu, C. SiamMAN: Siamese Multi-Phase Aware Network for Real-Time Unmanned Aerial Vehicle Tracking. Drones 2023, 7, 707. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Wang, B.; Wang, X.; Liu, C. SiamBRF: Siamese Broad-Spectrum Relevance Fusion Network for Aerial Tracking. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Chen, Q.; Wang, X.; Liu, C. SiamHAS: Siamese Tracker with Hierarchical Attention Strategy for Aerial Tracking. Micromachines 2023, 14, 893. [Google Scholar] [CrossRef] [PubMed]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Virtual, 11–17 October 2016; pp. 850–858. [Google Scholar]
- Nai, K.; Li, Z.; Wang, H. Dynamic Feature Fusion with Spatial-Temporal Context for Robust Object Tracking. Pattern Recognit. 2022, 130, 108775. [Google Scholar] [CrossRef]
- Pulford, G.W. A Survey of Manoeuvring Target Tracking Methods. arXiv 2015, arXiv:1503.07828. [Google Scholar]
- Javed, S.; Danelljan, M.; Khan, F.S.; Khan, M.H.; Felsberg, M.; Matas, J. Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6552–6574. [Google Scholar] [CrossRef]
- Huang, Y.; Li, X.; Lu, R.; Hu, Y.; Yang, X. Infrared Maritime Target Tracking via Correlation Filter with Adaptive Context-Awareness and Spatial Regularization. Infrared Phys. Technol. 2021, 118, 103907. [Google Scholar] [CrossRef]
- Zhu, C.; Jiang, S.; Li, S.; Lan, X. Efficient and Practical Correlation Filter Tracking. Sensors 2021, 21, 790. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, T.; Liu, K.; Zhang, B.; Chen, L. Recent Advances of Single-Object Tracking Methods: A Brief Survey. Neurocomputing 2021, 455, 1–11. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Danelljan, M.; Hager, G.; Khan, F.S.; Felsberg, M. Convolutional Features for Correlation Filter Based Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 621–629. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. In Proceedings of the 7th Annual Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–2 December 1993; MIT Press: Cambridge, MA, USA, 1993; pp. 737–744. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese Instance Search for Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, W.; Wang, Q.; Zhang, L.; Bertinetto, L.; Torr, P.H.S. Siammask: A Framework for Fast Online Object Tracking and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3072–3089. [Google Scholar] [PubMed]
- Zhang, Z.; Peng, H.; Fu, J.; Li, B.; Hu, W. Ocean: Object-aware Anchor-free Tracking. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer International Publishing: Cham, Switzerland, 2020; pp. 771–787. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent Models of Visual Attention. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2204–2212. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comp. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Bahdanau, D. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation: Vancouver, BC, Canada, 2017; pp. 5998–6008. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Dux, P.E.; Marois, R. How Humans Search for Targets through Time: A Review of Data and Theory from the Attentional Blink. Atten. Percept. Psychophys. 2009, 71, 1683. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. Stochastic Estimation of the Maximum of a Regression Function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Howard, A.G. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 84–90. [Google Scholar]
- Iandola, F.N. SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Goyal, P. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings; Part V 13. Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yeung, D.Y. Visual Object Tracking for Unmanned Aerial Vehicles: A Benchmark and New Motion Models. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4140–4146. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A Benchmark and Simulator for UAV Tracking. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 445–461. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal Contexts for Aerial Tracking. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14778–14788. [Google Scholar]
- Yao, L.; Fu, C.; Li, S.; Zheng, G.; Ye, J. SGDViT: Saliency-Guided Dynamic Vision Transformer for UAV Tracking. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 3353–3359. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. HiFT: Hierarchical Feature Transformer for Aerial Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15437–15446. [Google Scholar]
- Fu, C.; Cao, Z.; Li, Y.; Ye, J.; Feng, C. Siamese Anchor Proposal Network for High-Speed Aerial Tracking. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 510–516. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15180–15189. [Google Scholar]
- Zheng, G.; Fu, C.; Ye, J.; Li, B.; Lu, G.; Pan, J. Siamese Object Tracking for Vision-Based UAM Approaching with Pairwise Scale-Channel Attention. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 10486–10492. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Wang, X.; Zeng, D.; Zhao, Q.; Li, S. Rank-Based Filter Pruning for Real-Time UAV Tracking. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Wang, Y.; Huang, H.; Huang, X.; Tian, Y. ECO-HC Based Tracking for Ground Moving Target Using Single UAV. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 6414–6419. [Google Scholar]
- Zuo, H.; Fu, C.; Li, S.; Ye, J.; Zheng, G. DeconNet: End-to-End Decontaminated Network for Vision-Based Aerial Tracking. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Cai, H.; Zhang, X.; Lan, L.; Xu, L.; Shen, W.; Chen, J.; Leung, V.C.M. SiamATTRPN: Enhance Visual Tracking with Channel and Spatial Attention. IEEE Trans. Comput. Soc. Syst. 2024, 11, 1958–1966. [Google Scholar] [CrossRef]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. Towards Real-World Visual Tracking with Temporal Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15834–15849. [Google Scholar] [CrossRef]
- Huang, Z.; Fu, C.; Li, Y.; Lin, F.; Lu, P. Learning Aberrance Repressed Correlation Filters for Real-Time UAV Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2891–2900. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6268–6276. [Google Scholar]
- Li, Y.; Fu, C.; Ding, F.; Huang, Z.; Lu, G. AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11923–11932. [Google Scholar]
- Xuan, S.; Li, S.; Zhao, Z.; Zhou, Z.; Zhang, W.; Tan, H.; Xia, G.; Gu, Y. Rotation Adaptive Correlation Filter for Moving Object Tracking in Satellite Videos. Neurocomputing 2021, 438, 94–106. [Google Scholar] [CrossRef]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.V.; Danelljan, M.; Khan, F.S. Learning the Model Update for Siamese Trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4010–4019. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; pp. 12549–12556. [Google Scholar]
- Li, S.; Yang, Y.; Zeng, D.; Wang, X. Adaptive and Background-Aware Vision Transformer for Real-Time UAV Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–8 October 2023; pp. 13989–14000. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks for Visual Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).